机器学习中的距离度量与优化方法:从曼哈顿距离到梯度下降
目录
- 前言
- 一、曼哈顿距离(Manhattan Distance):
- 二、切比雪夫距离 (Chebyshev Distance):
- 三、 闵可夫斯基距离(Minkowski Distance):
- 小结
- 四、余弦距离(Cosine Distance)
- 五、杰卡德距离(Jaccard Distance)
- 六、交叉验证方法
- 6.1 HoldOut Cross-validation(Train-Test Split)(保留交叉验证)
- 6.2 K-折交叉验证(K-fold Cross Validation,记为K-CV)
- 七、前向传播与损失函数反向传播的学习率与梯度下降
- 7.1 求导法则
- 7.1.1 导数含义
- 7.1.1.1举例子理解
- 例1:速度(小车在马路上匀速的前进):
- 例2:速度(小车在马路上非匀速的前进):
- 7.2 什么是导数
- 7.3 常见的导数
- 7.3.1线性函数的导数:
- 7.3.2 其它常见的导数:
- 7.2 不可微函数
- 7.4 导数的求导法则
- 7.4.1 导数求导法则的定义:
- 7.4.2 两个函数相加的导数
- 7.4.3 两个函数乘积的导数
- 7.4.4 两个函数的比值的导数
- 7.5 复合求导运算:
- 7.6 链式求导法则:
- 7.7 偏导数
- 7.7.1 偏导数定义
- 7.8 梯度
- 八、前向传播与损失函数
- 8.1 前向传播与损失函数理论讲解
- 8.1.1 前向传播的定义
- 8.1.2 前向传播的过程
- 8.1.3 前向传播的作用
- 8.1.4 损失函数的概念:
- 8.2 基础原理讲解
- 8.2.1 案例导入
- 8.2.2 前向计算
- 8.2.3 单点误差
- 8.2.4 损失函数:均方差
- 总结
前言
书接上文
KNN算法深度解析:从决策边界可视化到鸢尾花分类实战-CSDN博客文章浏览阅读660次,点赞11次,收藏10次。本文系统讲解了KNN算法的决策边界形成机制、Scikit-learn实现细节及鸢尾花分类实战,涵盖K值选择对边界的影响、API参数解析、数据预处理(归一化/标准化)和数据集划分方法,通过代码示例和可视化分析帮助读者掌握KNN的核心应用技巧。https://blog.csdn.net/qq_58364361/article/details/147201792?spm=1011.2415.3001.10575&sharefrom=mp_manage_link
一、曼哈顿距离(Manhattan Distance):
定义:曼哈顿距离是计算两点之间水平线段或垂直线段的距离之和,也称为城市街区距离或L1距离
eg:
在曼哈顿街区要从一个十字路口开车到另一个十字路口,驾驶距离显然不是两点间的直线距离。这个实际驾驶距离就是“曼哈顿距离”。曼哈顿距离也称为“城市街区距离”(City Block distance)。
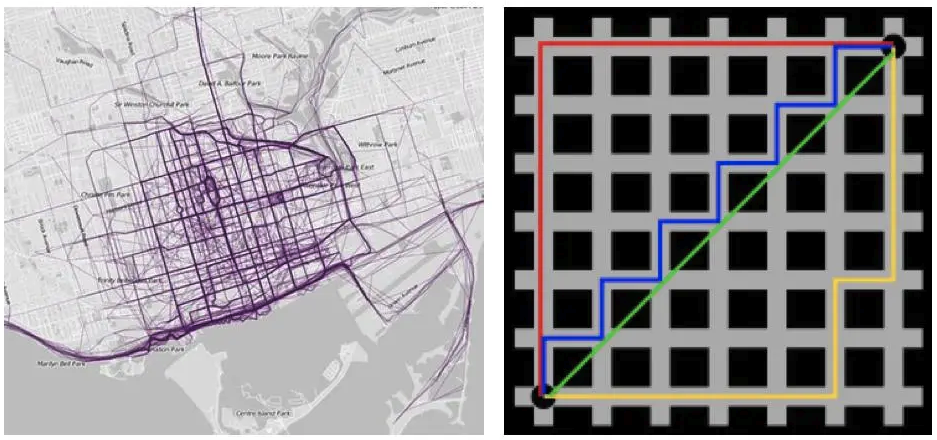
距离公式:
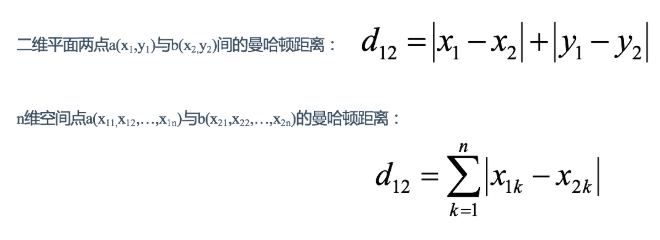
缺点:由于它不是可能的最短路径,它比欧几里得距离更有可能给出一个更高的距离值,随着数据维度的增加,曼合顿距离的用处也就越小。
#曼哈顿距离
import numpy as np#计算曼哈顿距离
x = [1, 2] # 点x的坐标
y = [3, 4] # 点y的坐标#法一:使用循环计算曼哈顿距离
def manhattan_distance(x, y):"""计算两个点之间的曼哈顿距离参数:x (list): 第一个点的坐标列表y (list): 第二个点的坐标列表返回:int/float: 两个点之间的曼哈顿距离"""sum = 0for a, b in zip(x, y):sum += abs(a - b)return summd = manhattan_distance(x, y) # 调用函数计算曼哈顿距离
print(md) # 输出结果#法二:使用numpy计算曼哈顿距离
def manhattan_distance2(x, y):"""使用numpy计算两个点之间的曼哈顿距离参数:x (list): 第一个点的坐标列表y (list): 第二个点的坐标列表返回:int/float: 两个点之间的曼哈顿距离"""x_1 = np.array(x) # 将列表转换为numpy数组y_1 = np.array(y) # 将列表转换为numpy数组return np.sum(np.abs(x_1 - y_1)) # 使用numpy函数计算绝对差的和md2 = manhattan_distance2(x, y) # 调用函数计算曼哈顿距离
print(md2) # 输出结果
D:\python_huanjing\.venv1\Scripts\python.exe C:\Users\98317\PycharmProjects\study_python\机器学习\day4_15.py
4
4进程已结束,退出代码为 0
二、切比雪夫距离 (Chebyshev Distance):
定义:切比雪夫距离是计算两点在各个坐标上的差的绝对值的最大值。
国际象棋中,国王可以直行、横行、斜行,所以国王走一步可以移动到相邻8个方格中的任意一个。国王从格子(x1,y1)走到格子(x2,y2)最少需要多少步?这个距离就叫切比雪夫距离。
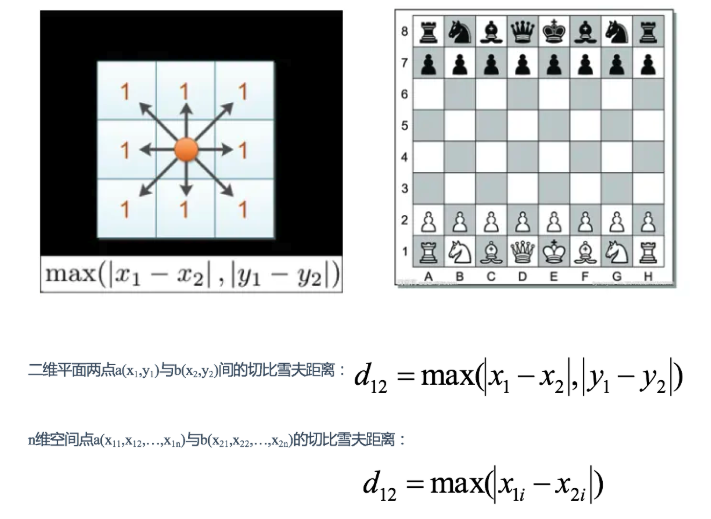
缺点:切比雪夫距离通常用于非常特定的用例,这使得它很难像欧氏距离那样作通用的距离度量
#切比雪夫距离
import numpy as np#计算切比雪夫距离
x = [1, 2] # 第一个点的坐标
y = [4, 6] # 第二个点的坐标#第一种方式计算切比雪夫距离
def chebyshev_distance(x, y):"""计算两个点之间的切比雪夫距离(使用纯Python实现)参数:x (list): 第一个点的坐标列表y (list): 第二个点的坐标列表返回:float: 两个点之间的切比雪夫距离"""max_list = []for a, b in zip(x, y):max_list.append(abs(a - b))return max(max_list)cd = chebyshev_distance(x, y)
print(f"cd:{cd}")#第2种方法
def chebyshev_distance1(x, y):"""计算两个点之间的切比雪夫距离(使用NumPy实现)参数:x (list): 第一个点的坐标列表y (list): 第二个点的坐标列表返回:float: 两个点之间的切比雪夫距离"""x_1 = np.array(x)y_1 = np.array(y)return np.max(np.abs(x_1 - y_1))cd1 = chebyshev_distance1(x, y)
print(f"cd1 :{cd1}")D:\python_huanjing\.venv1\Scripts\python.exe C:\Users\98317\PycharmProjects\study_python\机器学习\day4_15.py
cd:4
cd1 :4进程已结束,退出代码为 0三、 闵可夫斯基距离(Minkowski Distance):
两个n维变量a(x11,x12,…,x1n)与b(x21,x22,…,x2n)间的闵可夫斯基距离定义为:
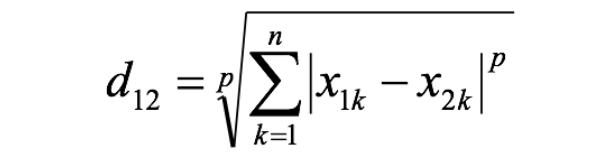
其中p是一个变参数:
当p=1时,就是曼哈顿距离;
当p=2时,就是欧氏距离;
当p→∞时,就是切比雪夫距离。
根据p的不同,闵氏距离可以表示某一类/种的距离。
import numpy as npx = [1, 2] # 第一个向量
y = [4, 6] # 第二个向量# 计算闵可夫斯基距离
def minkowski_distance(x, y, p):"""计算两个向量之间的闵可夫斯基距离参数:x -- 第一个输入向量y -- 第二个输入向量p -- 距离参数返回:两个向量之间的闵可夫斯基距离当p=1时返回曼哈顿距离当p=2时返回欧式距离当p趋近无穷时返回切比雪夫距离"""x = np.array(x) # 转换为numpy数组y = np.array(y) # 转换为numpy数组if p == 1 or p == 2: # 当p为1或2时使用标准闵可夫斯基公式test = np.power(np.sum(np.power(np.abs(x - y), p)), 1 / p)return testelse: # 其他情况返回切比雪夫距离(即最大绝对差)return np.max(np.abs(x - y))md = minkowski_distance(x, y, 1) # 计算距离
print("曼哈顿距离:", md) # 输出结果
md = minkowski_distance(x, y, 2) # 计算距离
print("欧氏距离:", md) # 输出结果
md = minkowski_distance(x, y, 3) # 计算距离
print("切比雪夫距离:", md) # 输出结果D:\python_huanjing\.venv1\Scripts\python.exe C:\Users\98317\PycharmProjects\study_python\机器学习\day4_15.py
曼哈顿距离: 7.0
欧氏距离: 5.0
切比雪夫距离: 4进程已结束,退出代码为 0小结
1 闵氏距离,包括曼哈顿距离、欧氏距离和切比雪夫距离都存在明显的缺点:
e.g. 二维样本(身高[单位:cm],体重[单位:kg]),现有三个样本:a(180,50),b(190,50),c(180,60)。
a与b的闵氏距离(无论是曼哈顿距离、欧氏距离或切比雪夫距离)等于a与c的闵氏距离。但实际上身高的10cm并不能和体重的10kg划等号。
2 闵氏距离的缺点:
(1)将各个分量的量纲(scale),也就是“单位”相同的看待了;
(2)未考虑各个分量的分布(期望,方差等)可能是不同的。
(3) 使用参数p实际上可能会很麻烦
四、余弦距离(Cosine Distance)
定义:余弦相似度是两个向量之间的夹角余弦值,表示两个向量的方向差异,而不是长度差异。
二维空间中向量A(x1,y1)与向量B(x2,y2)的夹角余弦公式:
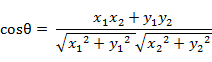
两个n维样本点a(x11,x12,…,x1n)和b(x21,x22,…,x2n)的夹角余弦为:
![]()
即:
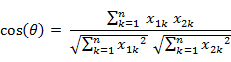
缺点:余弦相似度无法捕捉向量的幅度信息,只考虑方向。
import mathx = [1, 1]
y = [2, -2]#计算余弦距离
def cosine_distance(x, y):"""计算两个向量之间的余弦距离参数:x (list): 第一个向量y (list): 第二个向量返回:float: 余弦相似度值,范围[0,1]"""#分子为0fz = 0#分母为0fm_x = 0fm_y = 0for a, b in zip(x, y):#分子:向量点积fz = fz + a * b#分母:向量模的乘积fm_x = fm_x + a ** 2fm_y = fm_y + b ** 2fm = math.sqrt(fm_x) * math.sqrt(fm_y)if fz > 0:return fz / fmelse:return 0md = cosine_distance(x, y)
print(md)D:\python_huanjing\.venv1\Scripts\python.exe C:\Users\98317\PycharmProjects\study_python\机器学习\day4_15.py
0进程已结束,退出代码为 0五、杰卡德距离(Jaccard Distance)
杰卡德相似系数(Jaccard similarity coefficient):两个集合A和B的交集元素在A,B的并集中所占的比例,称为两个集合的杰卡德相似系数,用符号J(A,B)表示:
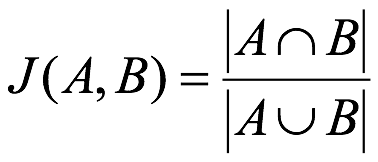
缺点:它受到数据大小的很大影响。大型数据集可能会对相似系数产生很大影响,因为数据量很大的话可能显著增加并集,同时保持交集不变。
杰卡德距离(Jaccard Distance):与杰卡德相似系数相反,用两个集合中不同元素占所有元素的比例来衡量两个集合的区分度:
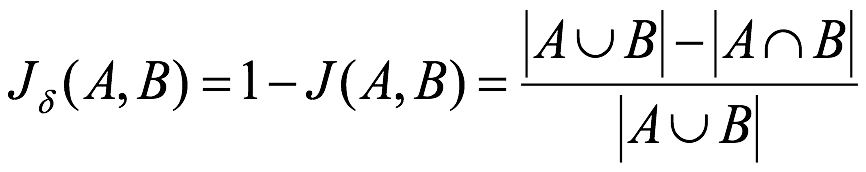
import math
import numpy as np# 定义两个集合用于计算Jaccard相似系数
x_set = {1, 2, 3}
y_set = {2, 3, 4}def jaccrd_similarity_coefficient(x_set, y_set):"""计算两个集合之间的Jaccard相似系数参数:x_set: 第一个输入集合y_set: 第二个输入集合返回:float: Jaccard相似系数值,范围[0,1]当两个集合的并集为空时返回0"""# 计算交集大小intersection = len(set(x_set) & set(y_set))# 计算并集大小union = len(set(x_set) | set(y_set))if (union > 0):return intersection / unionreturn 0# 计算并打印Jaccard距离(1-相似系数)
jsc = jaccrd_similarity_coefficient(x_set, y_set)
print(f"jsc距离 :{1 - jsc}")
D:\python_huanjing\.venv1\Scripts\python.exe C:\Users\98317\PycharmProjects\study_python\机器学习\day4_15.py
jsc距离 :0.5进程已结束,退出代码为 0
六、交叉验证方法
交叉验证是在机器学习建立模型和验证模型参数时常用的办法,一般被用于评估一个机器学习模型的表现。更多的情况下,我们也用交叉验证来进行模型选择(model selection)。
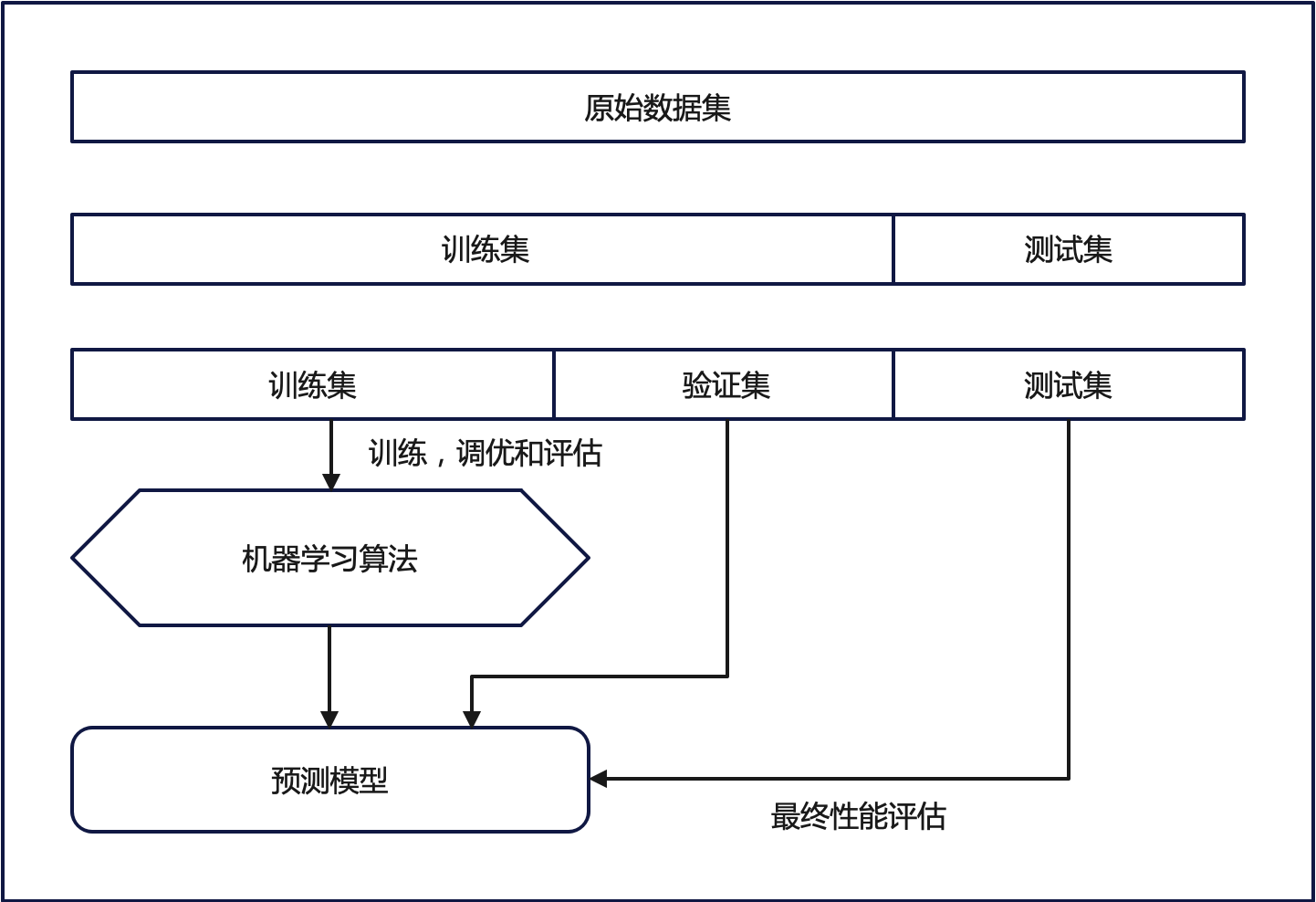
6.1 HoldOut Cross-validation(Train-Test Split)(保留交叉验证)
在这种交叉验证技术中,整个数据集被随机地划分为训练集和验证集。根据经验法则,整个数据集的近70%被用作训练集,其余30%被用作验证集。也就是我们最常使用的,直接划分数据集的方法。
6.2 K-折交叉验证(K-fold Cross Validation,记为K-CV)
模型的最终准确度是通过取k个模型验证数据的平均准确度来计算的。
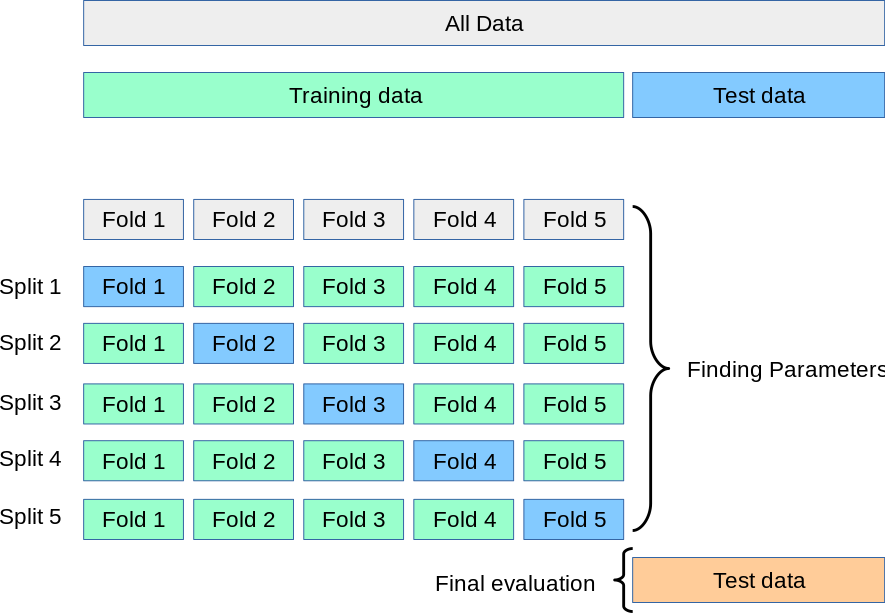
#kfold交叉验证
from sklearn.model_selection import KFold
from sklearn.datasets import load_iris#获得数据
iris = load_iris() # 加载iris数据集
# iris数据集,X是特征,Y是标签
X = iris.data # 特征数据
Y = iris.target # 目标标签
#申请一个对象
kf = KFold() # 创建KFold对象,默认n_splits=5
for i, (train_index, test_index) in enumerate(kf.split(X)):"""执行K折交叉验证参数:train_index: 训练集索引数组test_index: 测试集索引数组输出:打印每折的训练集和测试集索引"""print(f"Fold{i + 1}")print(f" Train: index={train_index}")print(f" Test: index={test_index}")七、前向传播与损失函数反向传播的学习率与梯度下降
7.1 求导法则
从以下几个方面对求导法则进行介绍
1.导数的含义
2.常见的导数
3.不可微函数
4.导数的求导法则
5.偏导数
6.梯度
上面这6个方面的内容,让大家,掌握并理解求导法则,为后续学习机器学习算法的学习奠定基础。
7.1.1 导数含义
1.导数(Derivative),也叫导函数值。又名微商,是微积分中的重要基础概念。当函数y=f(x)的自变量x在一点x0上产生一个增量Δx时,函数输出值的增量Δy与自变量增量Δx的比值在Δx趋于0时的极限a如果存在,a即为在x0处的导数,记作f'(x0)或df(x0)/dx。
2.为什么要学习微积分或者说求导?
在机器学习(或者深度学习中),绝大部分任务是构建一个损失函数,然后去最小化它,这个优化过程使用的就是微分,也可以说是求导。
7.1.1.1举例子理解
举2个非常简单、非常形象的例子,来理解一下导数为啥这样定义?
例1:速度(小车在马路上匀速的前进):
一段路程共900米,小车均速走了30s。在17.5s时,小车运动多快?

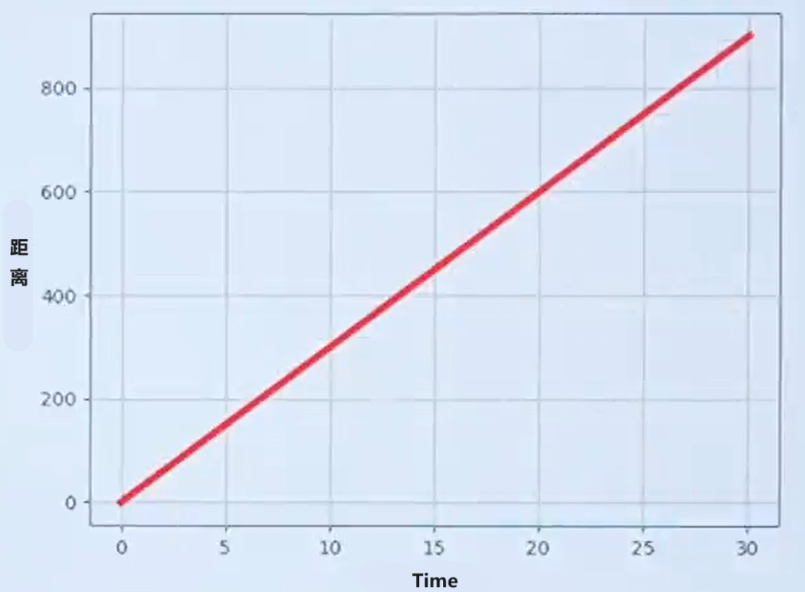
问题1:在17.5s时,小车运动多快?
小学数学就学过速度,也叫速率,表示运动物体运动的距离随时间的变化率,s=vt的公式大家都会。
高中物理开始严谨一些,会更专业地区分“位移”“速度”(向量)和“距离”“速率”(无方向的标量),公式还是s=vt,但是表示的内容不同了。
这里我们就用简单的小学数学知识:
一辆小车在水平直线上匀速运动,它运动的速率v是不变的,因此运动的距离与时间成正比,也就是s=vt,这里,速率v就是距离s随t的变化率,距离s可以看作是时间t的函数。
为了方便起见,我们用x代表时间(代替t),f(x)代表距离,就是函数:f(x)=vx。
这里v就是函数的变化率,该函数的导数就是:f'(x)=v(后面会学如何求导)。
表示在任何时刻,小车距离变化的趋势都是v,时间每增加一个小小的x,距离就增加vx。
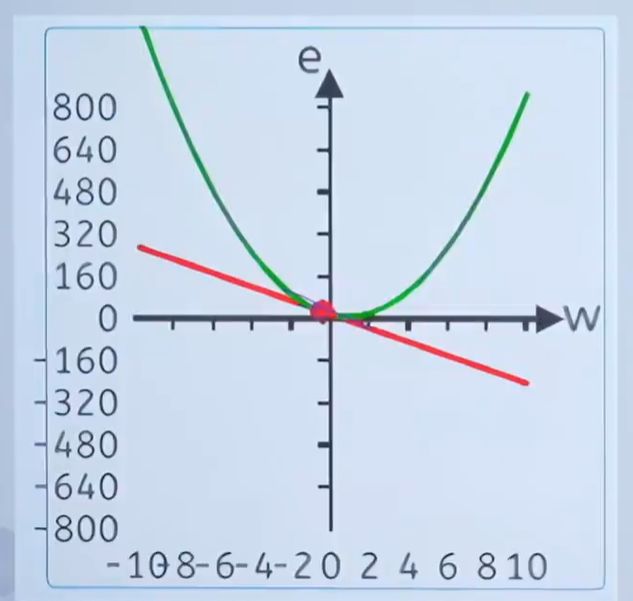
例2:速度(小车在马路上非匀速的前进):
一段路程共900米,小车不均速走了30s。在17.5s时,小车运动多快?在0~30s之间,小车的平均运动多快?
通过在不同时间内对小车进行测距离得到下图
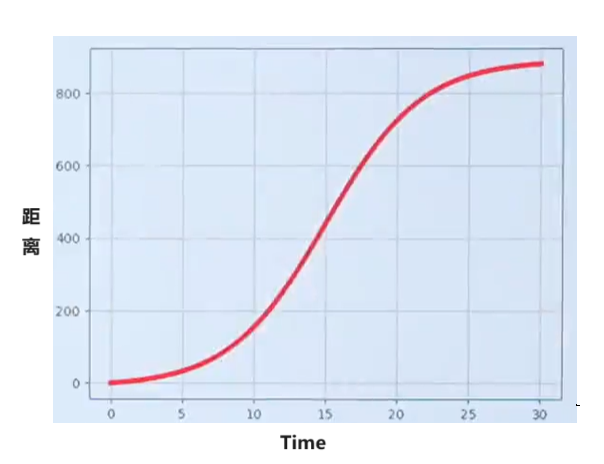
问题1:求在17.5s时,小车运动多快?
补充信息1:
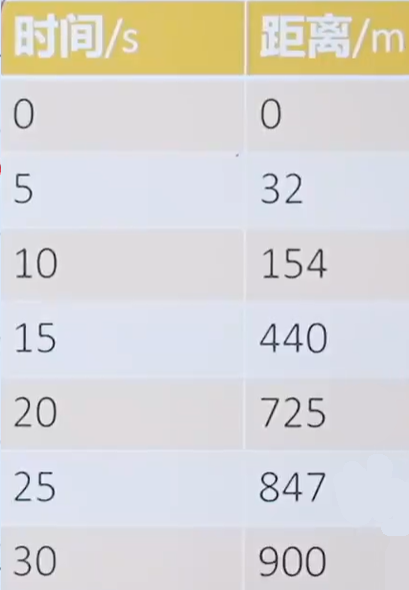
在15s~20s之间,小车的平均运动速度多快?
补充信息2 给15s到20s之间的时间和距离关系表如下所示
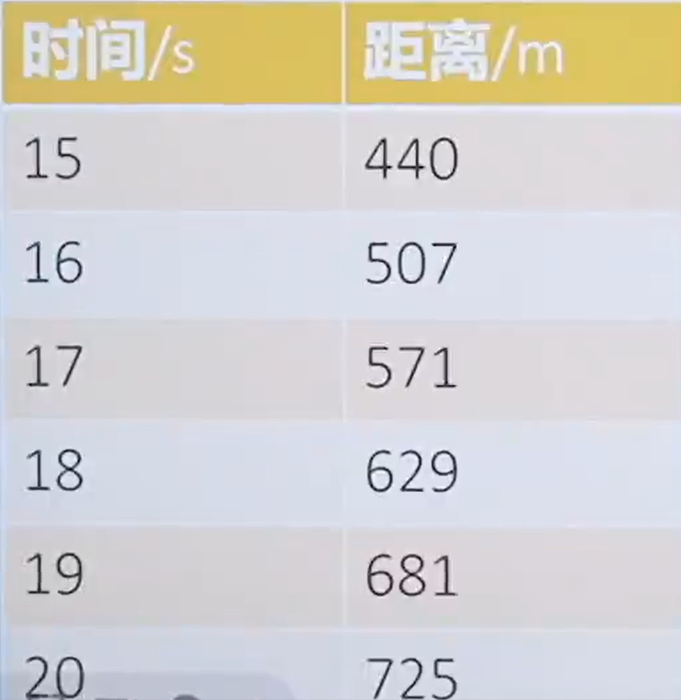
通过上面的例子是不是间隔越小计算的速度越准确,下面用更通俗的讲解一下。
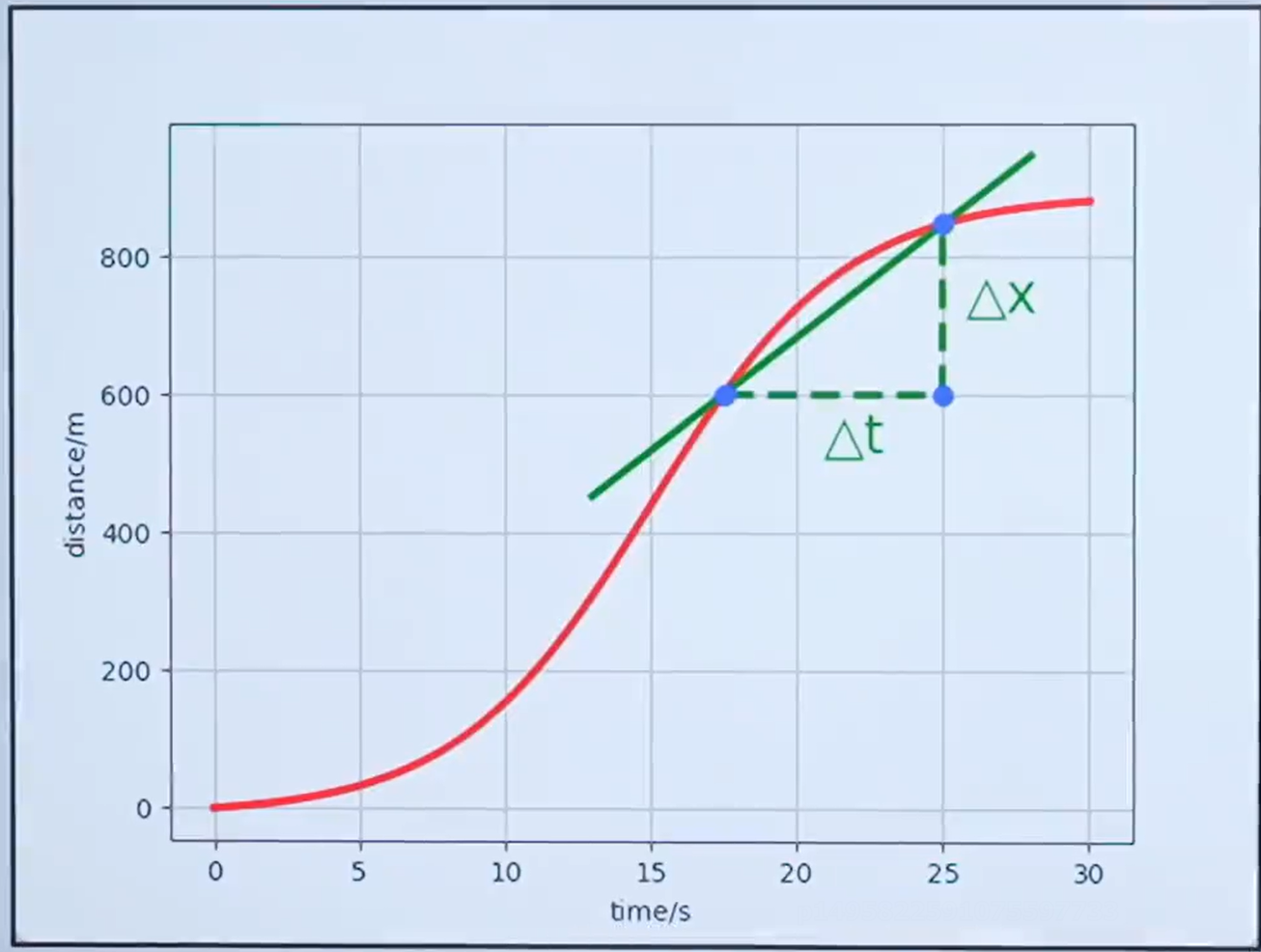
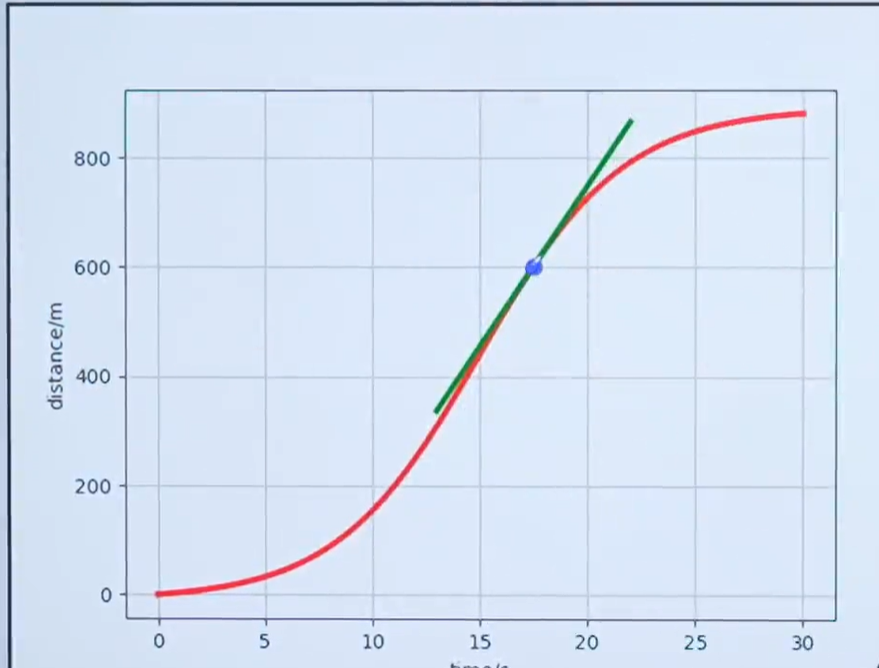
是不是用下面的公式就可以求17.5s的速度了?

两种不同的表示方法:

关于导数严谨的定义否存在的判别、计算和使用会在大学重头开始详细学习,高中只要简单地知道导数表示变化率、会求导数、会简单地用导数分析函数的性质即可。
函数f(x)的导数通常用f'(x)来表示,在f的右上角加上小撇。
当导数为正时,函数的变化率是正的,也就是递增的;
当导数为负时,函数的变化率是负的,也就是递减的;
当导数为0时,函数的变化率是0,也就是不增也不减,不变。
7.2 什么是导数
导数是函数,完整地叫应该是“导函数”,通常习惯叫“导数”,它是依附于原函数存在的函数。
导数表示函数的变化趋势:
●既可以表示函数整体的变化趋势;
●也可以表示部分的变化趋势
●还可以表示某个点的变化趋势。
导数也可以粗糙地理解为“函数在某处的切线的斜率”。
7.3 常见的导数
常数的表达式为:
![]()
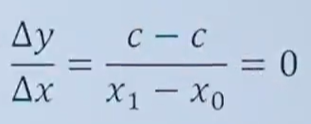
7.3.1线性函数的导数:
线性函数的表达式为:
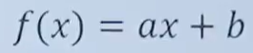
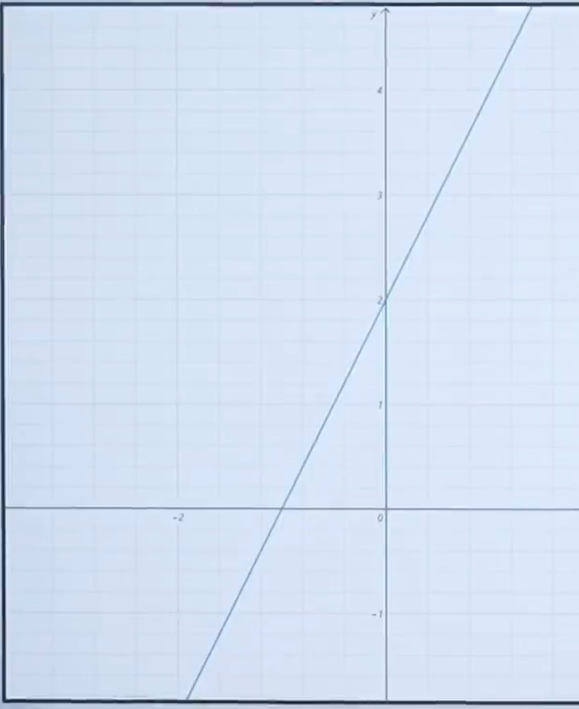
导数求解方法:
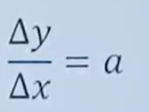
推导出:
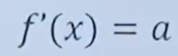
2.3二次方程函数的导数:
y=x^2
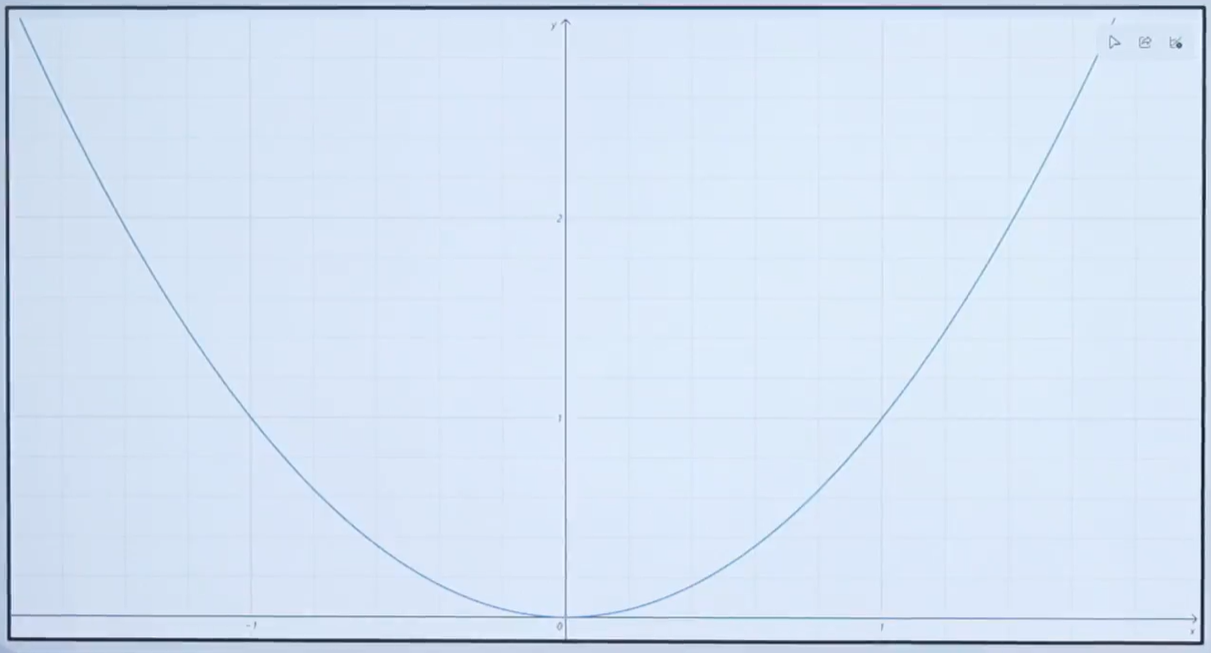
其导数求解方法:
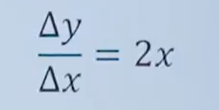
推导出:
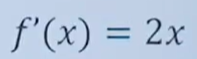
7.3.2 其它常见的导数:

7.2 不可微函数
如果一个点存在导数,那么该点的函数会在该点微分。也就是说,如果要使函数在整个区间内保持微分则该区间中的每个点,都必须存在导数。
2.实际上,并不是所有的函数在每个点上都可以找到导数,这些函数称为:不可微函数。
eg: f(x)=|x|
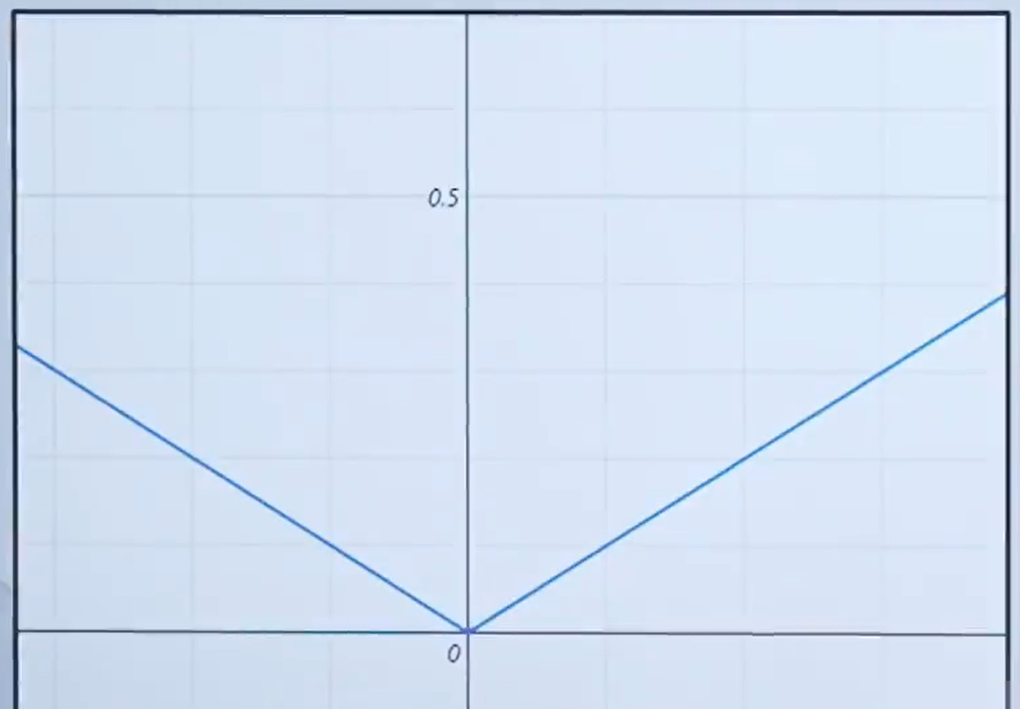
证明过程:
函数f(x)=∣x∣在x=0处不可导的原因是因为该点的左导数和右导数不相等。具体来说:
●当x<0时,f(x)=−x,因此左导数为−1(即函数值随x的减小而增大)。
●当x>0时,f(x)=x,因此右导数为1(即函数值随x的增大而增大)。 由于左导数和右导数在这点上不相等(左导数为-1,右导数为1),根据可导性的定义,函数在x=0处不可导。这是因为可导的要求是函数在该点处连续,且左右导数相等,而绝对值函数在x=0处虽然连续,但左右导数的不一致性导致了不可导的情况。
7.4 导数的求导法则
7.4.1 导数求导法则的定义:
导数是函数值相对于自变量的瞬时变化率,求导数是一个取极限的过程。对于一个连续且可导的函数,其导数的定义如下
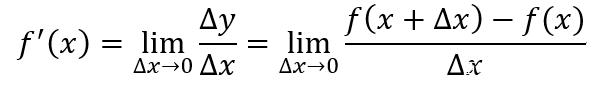
函数可导的前提是函数必须连续,对于连续函数,有下列等式成立
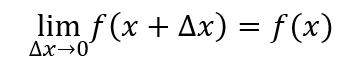
上式是函数在x处连续的定义。结合连续函数的定义和极限的运算性质,我们接下来推导导数运算法则。
7.4.2 两个函数相加的导数
设F(x)为两个可导函数的和

那么根据导数定义,F(x)的导数为
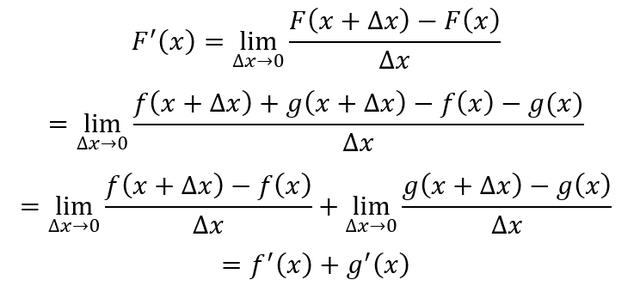
即两个可导函数的和的导数等于导数的和,导数运算减法同理。
7.4.3 两个函数乘积的导数
假设G(x)为两个可导函数的积
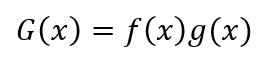
根据导数定义,G(x)的导数为
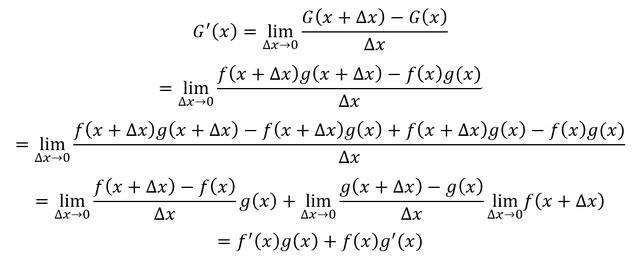
两个可导函数的乘积的导数的结果为
![]()
7.4.4 两个函数的比值的导数
设H(x)为两个可导函数的比值
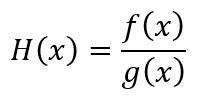
根据导数定义,那么H(x)的导数为
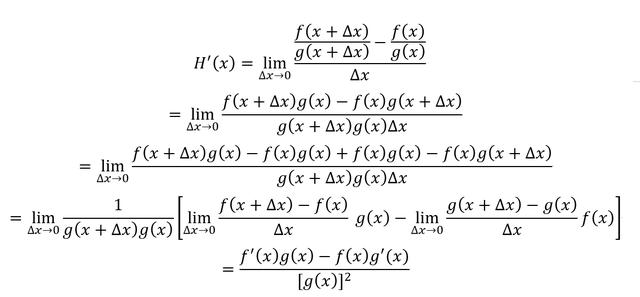
两个可导函数的比值的导数结果为
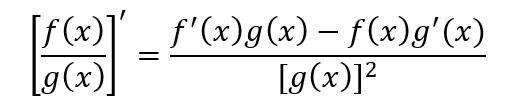
掌握推导过程可以帮助理解导数的定义和运算。
7.5 复合求导运算:

y=(sinx)^2
求导一下 y=2sinxcosx=sin2x
7.6 链式求导法则:
1)链式求导法则,也称为链式法则,是微积分中的一个基本法则,用于求解复合函数的导数。其基本公式为:如果y 是u 的函数,u 是x 的函数,即y=f(u) 且u=g(x),则 y 对 x 的导数可以表示为:
![]()
这个公式表明,复合函数的导数等于内层函数对中间变量的导数乘以中间变量对自变量的导数。
2)链式求导法则的应用非常广泛,不仅限于一元函数的情况,还可以推广到多元函数的情况。在应用链式法则时,需要明确函数的复合情况及变量的关系,通过画出链式图,然后运用公式进行求导。
7.7 偏导数
7.7.1 偏导数定义
偏导数是一个多变量函数中关于其中一个变量的导数,同时保持其他变量恒定。
偏导例子
eg1:
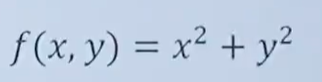
对x求偏导数,y当作常数,结果为:
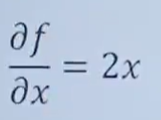
对y求偏导数,x当作常数,结果为:
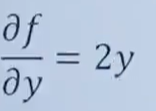
eg2:
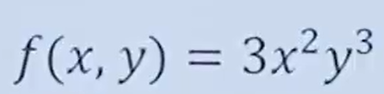
对x求偏导数,y当作常数,结果为:
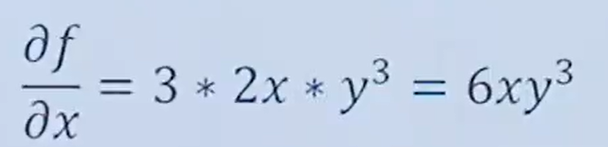
对y求偏导数,x当作常数,结果为
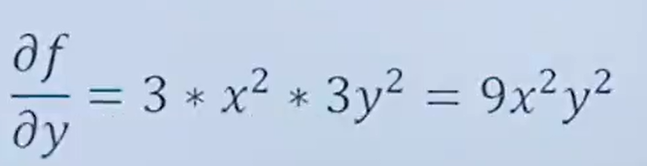
7.8 梯度
梯度通俗讲就是偏导的集合
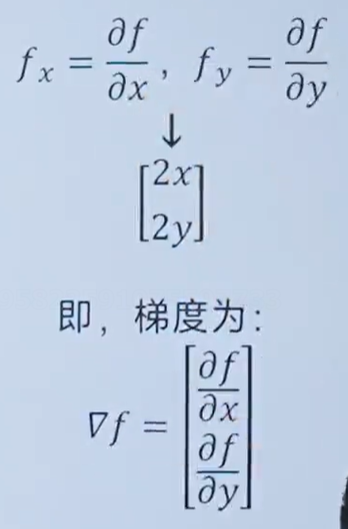
梯度的例子

八、前向传播与损失函数
以下2个方面对前向传播与损失函数进行介绍
1.前向传播与损失函数理论讲解
2.编程实例与步骤
上面这2方面的内容,让大家,掌握并理解前向传播与损失函数。
8.1 前向传播与损失函数理论讲解
8.1.1 前向传播的定义
前向传播是指在机器学习算法中,从输入到输出的信息传递过程,具体来说,就是在数据输入后,经过一系列的运算后得到结果的过程。
输入x 经过一系列计算f(x) 得到y的过程
比如y=2x+3,这个公式,前向传播就是通过给定x,根据公式2x+3得到输出结果y的值的过程就是前向传播。
8.1.2 前向传播的过程
step1:输入层,输入数据首先需要进入输入层,每一个神经元都会接收一个信号(输入值(矩阵))
step2:输入层到隐藏层,输入层的输出作为下一层的输入(通常是隐藏层),通过与权重相乘加上偏置项后进行非线性变换,使用激活函数对隐藏层的输出进行非线性变换,以引入非线性特性,增强模型的表达能力。
step3:隐藏层到输出层:将隐藏层的输出乘以隐藏层到输出层的权重矩阵,再加上偏置,计算输出层的输出。
8.1.3 前向传播的作用
对数据的输入逐步处理,提取对应的特征,并进行预测.
8.1.4 损失函数的概念:
损失函数(Loss Function)是用来衡量模型预测结果与实际结果之间的差异的一种函数。在机器学习中,损失函数通常被用来优化模型,通过最小化损失函数来提高模型的预测准确率。
8.2 基础原理讲解
8.2.1 案例导入
例子:
池塘里有7只蝌蚪,它们的体积(纵坐标)和时间(横坐标)有关,蝌蚪的体积随时间的变化。
自变量是时间x(以天为单位),因变量是蝌蚪的体积y(以毫升为单位)。
那么是否可以拟合一条线,来预测在未来的某个时间点,蝌蚪的体积可能会是多少。
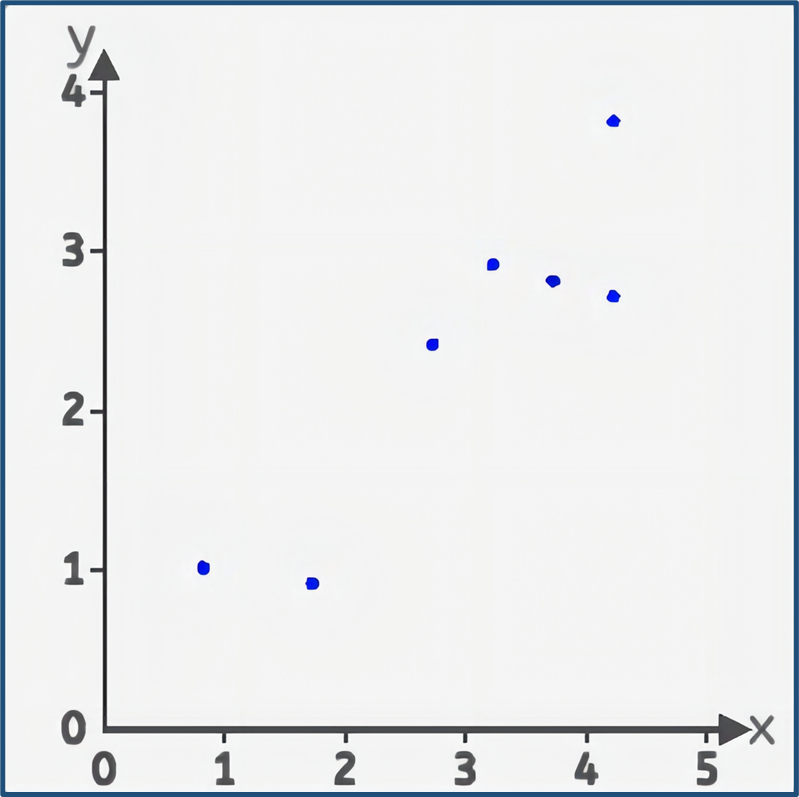
8.2.2 前向计算
前向传播是指在一个机器学习算法中,从输入到输出的信息传递过程,具体来说,就是在数据输入后,经过一系列的运算后得到结果(模型预测结果)的过程。
w表示权重 b表示偏置
在本实验中,为了使用直线来拟合上面7个散点,可以用直线的斜截式方程来进行拟合,给出直线公式:
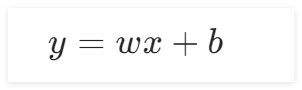
在前向计算中,为了简化运算,我们固定b的值为0,而w的值可以任意修改(范围0-2)。
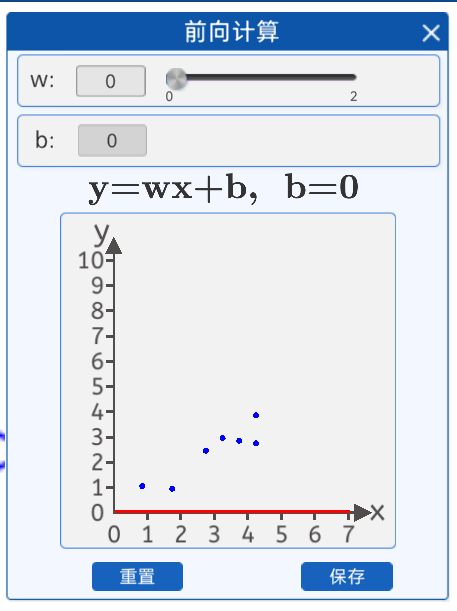
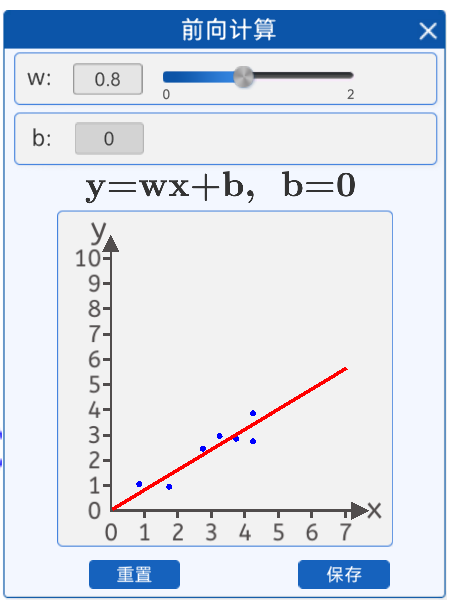
w=0 w=0.8
也就是说,我们是用一条过原点的直线来拟合这些散点,在该组件中修改w的值可以实时看到直线与散点的位置关系。
8.2.3 单点误差
由下图可知,当w等于2的时候“拟合”这些散点和实际的坐标点y轴的差距,由图上的绿色虚线表示。绿色虚线表示每一个真实的数据点和预测的数据点的差距,也就是数据点损失。
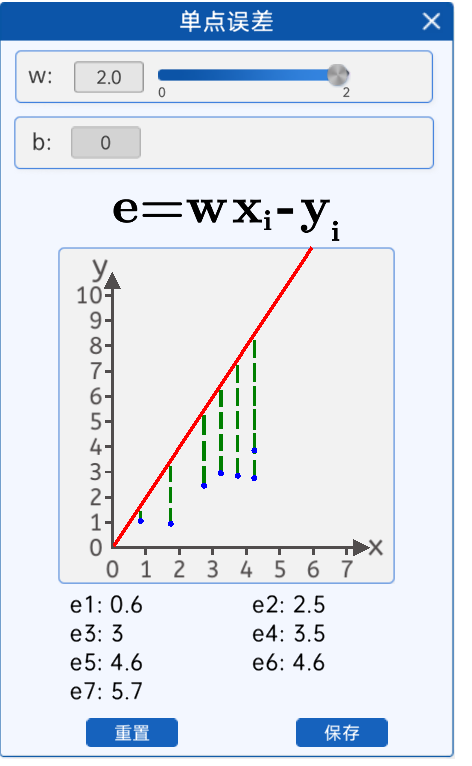
8.2.4 损失函数:均方差

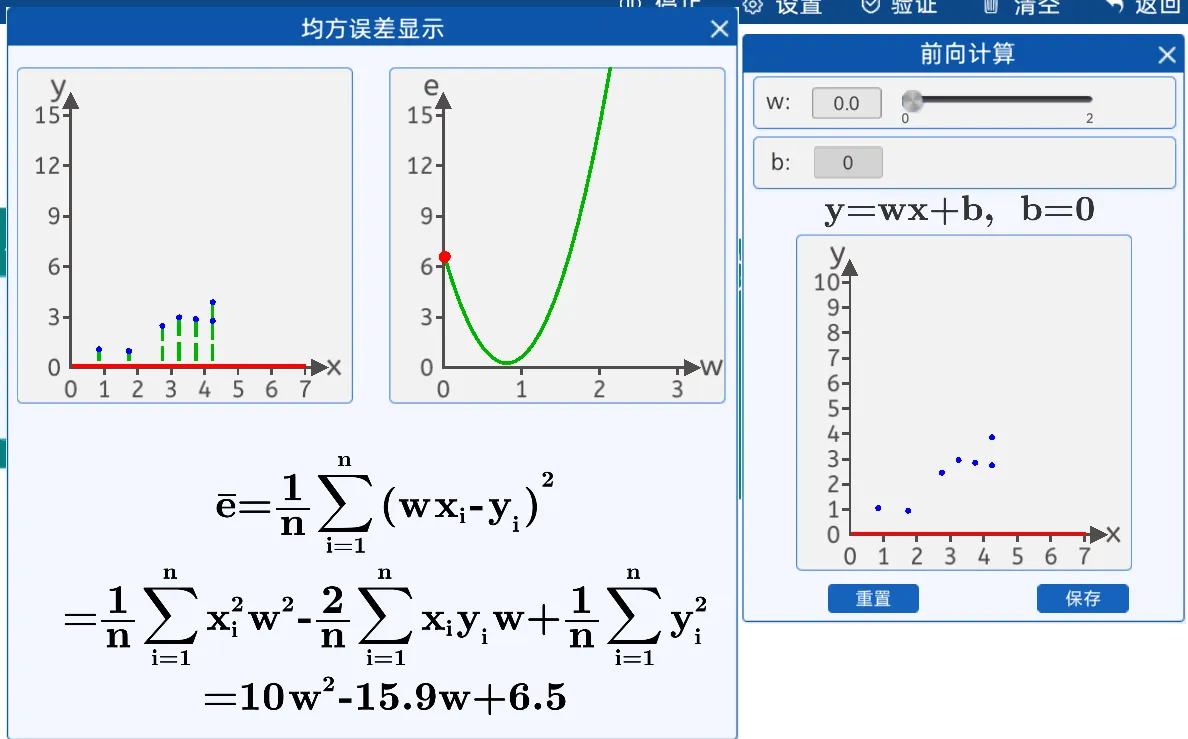
总结
本文系统介绍了机器学习中常用的距离度量方法(曼哈顿距离、切比雪夫距离、闵可夫斯基距离、余弦距离、杰卡德距离)及其数学定义、Python实现与优缺点,并探讨了交叉验证方法(HoldOut与K折)的应用场景。此外,深入解析了前向传播与损失函数的核心原理,包括导数、偏导数、梯度等数学基础,以及链式求导法则在反向传播中的作用,最后通过蝌蚪体积预测案例演示了前向计算、单点误差和均方差损失函数的实际应用,为机器学习模型优化提供了理论支撑与实践指导。
相关文章:

机器学习中的距离度量与优化方法:从曼哈顿距离到梯度下降
目录 前言一、曼哈顿距离(Manhattan Distance):二、切比雪夫距离 (Chebyshev Distance):三、 闵可夫斯基距离(Minkowski Distance):小结四、余弦距离(Cosine Distance)五、杰卡德距离(Jaccard Distance)六、交叉验证方法6.1 HoldOut Cross-v…...

在GitHub action中使用添加项目中配置文件的值为环境变量
比如我项目的根目录有一个package.json文件,但是我想在工作流中使用某个值,例如使用version的值,就需要从package.json里面取出来,然后存储到环境变量中,供后续步骤使用这个值。 读值存储 读取项目根目录中的某个jso…...

MCP认证难题破解指南
一、MCP 认证体系与核心挑战 1.1 认证体系解析 MCP(Microsoft Certified Professional)作为微软认证体系的基础,覆盖操作系统、云服务、开发工具等核心领域。2025 年最新认证体系包含以下关键方向: Azure 云服务: 覆盖 Azure 虚拟机、容器化部署、云原生应用开发等核心技…...

STM32F407实现内部FLASH的读写功能
文章目录 前言一、FLASH 简介二、读数据三、写数据四、最终效果五、完整工程 前言 我们通过仿真器下到芯片的程序一般会保存到eflash里面,在我们的STM32F407里面这里的空间挺大的,我所使用的芯片型号是STM32F407ZGT6,FLASH 容量为 1024K 字节…...

沃尔玛墨西哥30分钟极速配送:即时零售战争中的「超导革命」
当全球电商还在争夺「次日达」话语权时,沃尔玛在墨西哥城投下「时空压缩弹」——30分钟极速配送服务上线首周,订单转化率较常规渠道提升270%,生鲜品类客单价突破87美元(墨西哥财政部2024Q2数据)。这场物流革命正在改写…...

html页面打开后中文乱码
在HTML页面中遇到中文乱码通常是因为字符编码设置不正确或者不一致。要解决这个问题,你可以按照以下步骤进行: 确认HTML文件的编码 确保你的HTML文件保存时使用的是UTF-8编码。大多数现代的文本编辑器和IDE(如Visual Studio Code, Sublime Te…...

MySQL中的公用表表达式CTE实战案例应用
很多同学不会使用MySQL中的公用表表达式,今天这篇文章详细为大家介绍一下。 基础概念: 公用表表达式:MySQL中的公用表表达式(Common Table Expressions,简称CTE)是一种临时的结果集,它可以在一…...

开源TTS项目GPT-SoVITS,支持跨语言合成、支持多语言~
简介 GPT-SoVITS 是一个开源的文本转语音(TTS)项目,旨在通过少量语音数据实现高质量的语音合成。其核心理念是将基于变换器的模型(如 GPT)与语音合成技术(如 SoVITS,可能指“唱歌语音合成”&am…...
)
从零开始:Python运行环境之VSCode与Anaconda安装配置全攻略 (1)
从零开始:Python 运行环境之 VSCode 与 Anaconda 安装配置全攻略 在当今数字化时代,Python 作为一种功能强大且易于学习的编程语言,被广泛应用于数据科学、人工智能、Web 开发等众多领域。为了顺利开启 Python 编程之旅,搭建一个稳…...

3月报|DolphinScheduler项目进展一览
各位热爱 Apache DolphinScheduler 的小伙伴们,社区3月报来啦!来查看上个月项目的进展吧! 月度Merge Star 感谢以下小伙伴上个月为 Apache DolphinScheduler 所做的精彩贡献(排名不分先后): “ruanwenj…...

Flutter 应用在真机上调试的流程
在真机上调试 Flutter 应用的方法 调试 Flutter 应用有多种方式,可以使用 USB 数据线连接设备到电脑进行调试,也可以通过无线方式进行真机调试。对于 iOS 开发者,使用 appuploader 这样的工具可以更高效地管理开发流程。 1. 有线调试 设备…...

QML TableView:基础用法和自定义样式实现
目录 引言相关阅读工程结构示例一:基础TableView实现代码解析运行效果 示例二:自定义样式TableView代码解析运行效果 主界面运行效果 总结工程下载 引言 TableView作为Qt Quick中的一个核心控件,具有高性能、灵活性强的特点,能够…...

实战指南:封装Whisper为FastAPI接口并实现高并发处理-附整合包
实战指南:封装Whisper为FastAPI接口并实现高并发处理 下面给出一个详细的示例,说明如何使用 FastAPI 封装 OpenAI 的 Whisper 模型,提供一个对外的 REST API 接口,并支持一定的并发请求。 下面是主要步骤和示例代码。 1. 环境准备…...

算法——通俗讲解升幂定理
一、生活比喻:台阶与放大镜 想象你有一盏灯,光线穿过一层玻璃(基础台阶),每层玻璃会过滤掉一定颜色的光(质数 ( p ))。升幂定理就像在灯前叠加放大镜(指数 ( n ))&#…...

DeepSpeed ZeRO++:降低4倍网络通信,显著提高大模型及类ChatGPT模型训练效率
图1: DeepSpeed ZeRO 简介 大型 AI 模型正在改变数字世界。基于大型语言模型 (LLM)的 Turing-NLG、ChatGPT 和 GPT-4 等生成语言模型用途广泛,能够执行摘要、代码生成和翻译等任务。 同样,DALLE、Microsoft Designer 和 Bing Image Creator 等大型多模…...

【Audio开发四】音频audio中underrun和overrun原因详解和解决方案
一,underrun & overrun定义 我们知道,在Audio模块中数据采用的是生产者-消费者模式,生产者负责生产数据,消费者用于消费数据,针对AudioTrack和AudioRecord,其对应的角色不同; AudioTrack …...

[CMake] vcpkg的使用方法
C第三方库管理工具vcpkg使用教程。 如果要在vscode当中使用 1. 使用 CMakePresets.txt 来配置configure时的参数 2. 设置如下 即可正常编译...

光纤模块全解:深入了解XFP、SFP、QSFP28等类型
随着信息技术的快速发展,数据中心和网络的带宽需求不断提高,光纤模块的选择与应用显得尤为重要。光纤模块是实现高速网络连接的重要组件,选择合适的模块能够显著提升传输性能、降低延迟。本文将深入解析几种常见的光纤模块类型,包…...

【数据结构】之散列
一、定义与基本术语 (一)、定义 散列(Hash)是一种将键(key)通过散列函数映射到一个固定大小的数组中的技术,因为键值对的映射关系,散列表可以实现快速的插入、删除和查找操作。在这…...

利用pnpm patch命令实现依赖包热更新:精准打补丁指南
需求场景 在Element Plus的el-table组件二次开发中,需新增列显示/隐藏控件功能。直接修改node_modules源码存在两大痛点: 团队协作时修改无法同步 依赖更新导致自定义代码丢失 解决方案选型 通过patch-package工具实现: 📦 非…...

pve常用命令
pve常用命令 虚拟机管理容器管理集群管理存储与磁盘管理网络相关备份/还原手动备份计划任务备份(Web 界面常用)还原备份 快照创建快照查看快照恢复快照删除快照 其他实用命令 虚拟机管理 # 查看所有虚拟机列表 qm list# 查看虚拟机运行状态 qm status 1…...
---单向循环链表)
数据结构(三)---单向循环链表
单向循环链表(Circular Linked List) 一、基本概念 循环链表是一种特殊的链表,其末尾节点的后继指针指向头结点,形成一个闭环。 循环链表的操作与普通链表基本一致,但需注意循环特性的处理。 二、代码实现 clList…...
)
HCIP-H12-821 核心知识梳理 (3)
从EBGP邻居接受的路由发送给IBGP邻居的时候,下一跳不会自动修改。一个 Route - Policy 最多可配置 65535个节点 BFD 单跳使用UDP3784端口多跳使用UDP 4784端口。 防火墙 Local:代表防火墙自身,处理防火墙本地发起或接收的流量 。 优先级 100I…...

Vue接口平台学习七——接口调试页面请求体
一、实现效果图及简单梳理 请求体部分的左边,展示参数,分text和file类型。 右边部分一个el-upload的上传文件按钮,一个table列表展示,一个显示框,用于预览选择的文件,点击可大图展示。 二、页面内容实现 …...

STM32
GPIO 输入输出模式 GPIO 输出描述 GPIO_Mode_Out_OD 开漏输出模式: 1.对输入数据寄存器的读访问可得到I/O状态 HAL输出输出模式 GPIO输出描述GPIO_MODE_OUTPUT_PP推挽输出GPIO_MODE_OUTPUT_OD开漏输出GPIO输入GPIO_PULLUP上拉输入 寄存器 GPIOx->ODR/IDR …...

linux如何用关键字搜索日志
在 Linux 系统中搜索日志是日常运维的重要工作,以下是几种常用的关键字搜索日志方法: 1. 基础 grep 搜索 bash 复制 # 基本搜索(区分大小写) grep "keyword" /var/log/syslog# 忽略大小写搜索 grep -i "error&…...

381_C++_decrypt解密数据、encrypt加密数据,帧头和数据buffer分开
仿照.cpp中将帧头和数据分开处理的方式来修改.cpp中的加密: if (StreamCipher::self().needEncrypt()) {// 创建加密缓冲区static std::vector...

MongoDB常见语句
目录 1. 增删改 2. 评估查询运算符 3. 比较查询运算符 4. 逻辑运算符 5. 元素运算符 6. 数组查询运算符 7. 字段更新操作符 8. 数组更新操作符 10. 聚合管道 1. 增删改 增 db.getCollection("Y").insert({"age": 10,name: "ces5"});//增…...

Kotlin学习记录2
Android Studio中的注意事项 本文为个人学习记录,仅供参考,如有错误请指出。本文主要记录在Android Studio中开发时遇到的问题和回答。 Fragment有哪些特性? Fragment 是 Android 开发中的一个重要组件,具有以下特性:…...

如何通过工具实现流程自动化
通过自动化工具,企业可以显著提高工作效率、降低人为错误、节省时间和成本。现代企业的运营中,流程管理是确保工作顺畅的关键,而人工处理繁琐的流程不仅容易出错,还会消耗大量的时间和人力资源。通过使用适合的自动化工具…...

组合数哭唧唧
前言:手写一个简单的组合数,但是由于长期没写,导致一些细节没处理好 题目链接 #include<bits/stdc.h> using namespace std; #define endl "\n"#define int long longconst int N (int)2e510; const int Mod (int)1e97;int…...

LINUX基石
Vim编辑器Linux系统常用命令管理Linux实例软件源Nginx服务配置多站点Cron定时任务在Linux系统上安装图形化界面升级Linux ECS实例内核设置Linux实例的预留内存Linux系统中TCP/UDP端口测试方法进入Linux/FreeBSD系统的单用户模式 Vim编辑器 linux系统默认安装vim编辑器。终端中…...

Flowable工程化改造相关文档
本章将针对前期进行的Flowable流程引擎研究,进行相应的工程化改造,改造过程分别为对Flowable引擎流程文件远程化处理,流程过程接口化升级,等方面进行改造,以适配其他项目对流程引擎的API调用 首先对流程引擎项目主要流…...

架构设计系列
架构设计系列:什么是架构设计架构设计系列:几个常用的架构设计原则架构设计系列:高并发系统的设计目标架构设计系列:如何设计可扩展架构架构设计系列:如何设计高性能架构架构设计系列:如何设计高可用架构架…...
从算法仿真到工程源码实现-第十节-非线性波束形成)
波束形成(BF)从算法仿真到工程源码实现-第十节-非线性波束形成
一、概述 本节我们基于webrtc的非线性波束形成进行代码仿真,并对仿真结果进行展示和分析总结。更多资料和代码可以进入https://t.zsxq.com/qgmoN ,同时欢迎大家提出宝贵的建议,以共同探讨学习。 二、仿真代码 2.1 常量参数 % *author : a…...

QuickAPI 全生命周期管理:从开发到退役的闭环实践
数据 API 作为企业核心的数据资产,其生命周期管理直接影响数据服务的稳定性、安全性和复用效率。麦聪 QuickAPI 通过可视化、智能化的管理工具,构建了覆盖 API 全生命周期的闭环管理体系,实现从 "粗放式开发" 到 "精细化运营&…...

STM32 TDS+温度补偿
#define POLAR_CONSTANT (513385) /* 电导池常数,可通过与标准TDS测量仪对比计算反推 */ #define TDS_COEFFICIENT (55U) /* TDS 0.55 * 电子传导率*/void TDS_Value_Conversion() {u32 ad0;u8 i;float compensationCoefficient;float compens…...
 第 一试】)
【四川省第三届青少年C++算法设计大赛 (小低组) 第 一试】
一、单项选择题(共15题,每题2分,共计30分;每题有且仅有一个正确选项) 1、计算机中负责执行算术和逻辑运算的部件是() A. 内存 B.CPU C.硬盘 D.鼠标 2、近期备受关注的国产开源生成式人工智能大模型是() A. AlphaChat B. …...

疾控01-实验室信息管理系统需求分析
支持录入送检单位的基本信息,包括单位名称、联系方式、地址、联系人等。支持修改、删除、查询功能;支持录入检验目的的具体内容,如疾病类型(例如血液检测、癌症检测)或样本来源(如水质监测、食品安全检测&a…...

Redis之RedLock算法以及底层原理
自研redis分布式锁存在的问题以及面试切入点 lock加锁关键逻辑 unlock解锁的关键逻辑 使用Redis的分布式锁 之前手写的redis分布式锁有什么缺点?? Redis之父的RedLock算法 Redis也提供了Redlock算法,用来实现基于多个实例的分布式锁。…...

【JavaScript】二十二、通过关系查找DOM节点、新增、删除
文章目录 1、DOM节点的分类2、查找亲戚节点2.1 父节点查找2.2 子节点查找2.3 兄弟节点查找 3、新增节点3.1 创建新节点3.2 追加节点3.3 克隆节点3.4 案例:学成在线页面数据渲染 4、删除节点 1、DOM节点的分类 DOM树里每一个内容都称之为节点,节点分为三…...
)
SQL学习-关联查询(应用于多表查询)
复习 前几篇写的基础查询语法复习 以上都在单一表单内进行查询,那么我们需要用到多个表单的数据时,我们应该怎么处理呢? 关联查询 在excle文档中我们的处理方式如下 excle的这个查询虽然简单直观,但是也具有一定的局限性 比…...

在 MySQL 单表存储 500 万数据的场景下,如何设计读取
在 MySQL 单表存储 500 万数据的场景下,设计高效读取方案需要从 查询优化、架构扩展、硬件调优 三个层面综合考虑。以下是具体方案,结合实际项目经验(如标易行投标服务平台)进行分析: 一、查询优化:降低单次查询开销 1. 索引优化 核心原则:仅为高频查询条件、排序字段、…...

Python使用FastMCP开发MCP服务端
MCP简介 Model Context Protocol (MCP) 是一个专门为 LLM(大语言模型)应用设计的协议,它允许你构建服务器以安全、标准化的方式向 LLM 应用程序公开数据和功能。FastMCP 作为 Python 生态中的一款轻量级框架,利用装饰器来简化路由…...

ESLint常见错误
1、Strings must use singlequote —— 字符串必须使用单引号 2、Extra semicolon semi——额外的分号:一行语句结尾不能添加分号 3、Unexpected trailing comma —— 行尾多了一个逗号 4、Newline required at end of file but not found ——文件结尾必须要新加…...

京东硬核挑战潜规则,外卖算法要变天?
刘强东这次回归后的动作,真是越来越有看头了!最近那段内部讲话视频爆出来,直接扔了个重磅炸弹:京东外卖,净利润率永远不许超过5%,谁敢超标就得挨处分!这话一出,整个外卖圈估计都得抖…...

怎样利用 macOS 自带功能快速进行批量重命名文件教程
在日常办公或个人使用中,我们经常需要对多个文件进行重命名操作。幸运的是,macOS 提供了一套非常实用的内置工具,可以轻松完成这一任务而无需借助任何第三方应用程序。今天,我们就来详细介绍如何利用 macOS 自带的功能实现文件的批…...

Java Spring Cloud框架使用及常见问题
Spring Cloud作为基于Spring Boot的分布式微服务框架,显著简化了微服务架构的开发与管理。其核心优势包括集成Eureka、Ribbon、Hystrix等组件,提供一站式服务发现、负载均衡、熔断容错等解决方案,支持动态配置与消息总线,实现高效…...

机器视觉检测Pin针歪斜应用
在现代电子制造业中,Pin针(插针)是连接器、芯片插座、PCB板等元器件的关键部件。如果Pin针歪斜,可能导致接触不良、短路,甚至整机失效。传统的人工检测不仅效率低,还容易疲劳漏检。 MasterAlign 机器视觉对…...

抗量子算法验证工具
抗量子算法计算工具 抗量子算法验证工具ML-KEMML-DSASLH-DSA 抗量子算法验证工具 2024年末,美国NIST陆续公布了FIPS-203、FIPS-204、FIPS-205算法标准文档,抽空学习了一下,做了个算法计算工具。 ML-KEM ML-DSA SLH-DSA 需要的朋友可留言交流…...