【Linux】进程池bug、命名管道、systemV共享内存
一.进程池bug
我们在之前进程池的创建中是通过循环创建管道,并且让子进程与父进程关闭不要的读写段以构成通信信道。但是我们这样构建的话会存在一个很深的bug。
我们在销毁进程池时是先将所有的信道的写端关闭,让其子进程read返回值为0,并退出,此时我们在进行等待子进程,就完成了销毁的行为。
按照我们实现的逻辑图来看,我们可以对一个信道先进行关闭在进行子进程的回收,然后再对下一个信道进行关闭操作。但是因为这个bug的存在,如果我们将关闭信道和回收子进程放在一起时,就会导致进程死循环。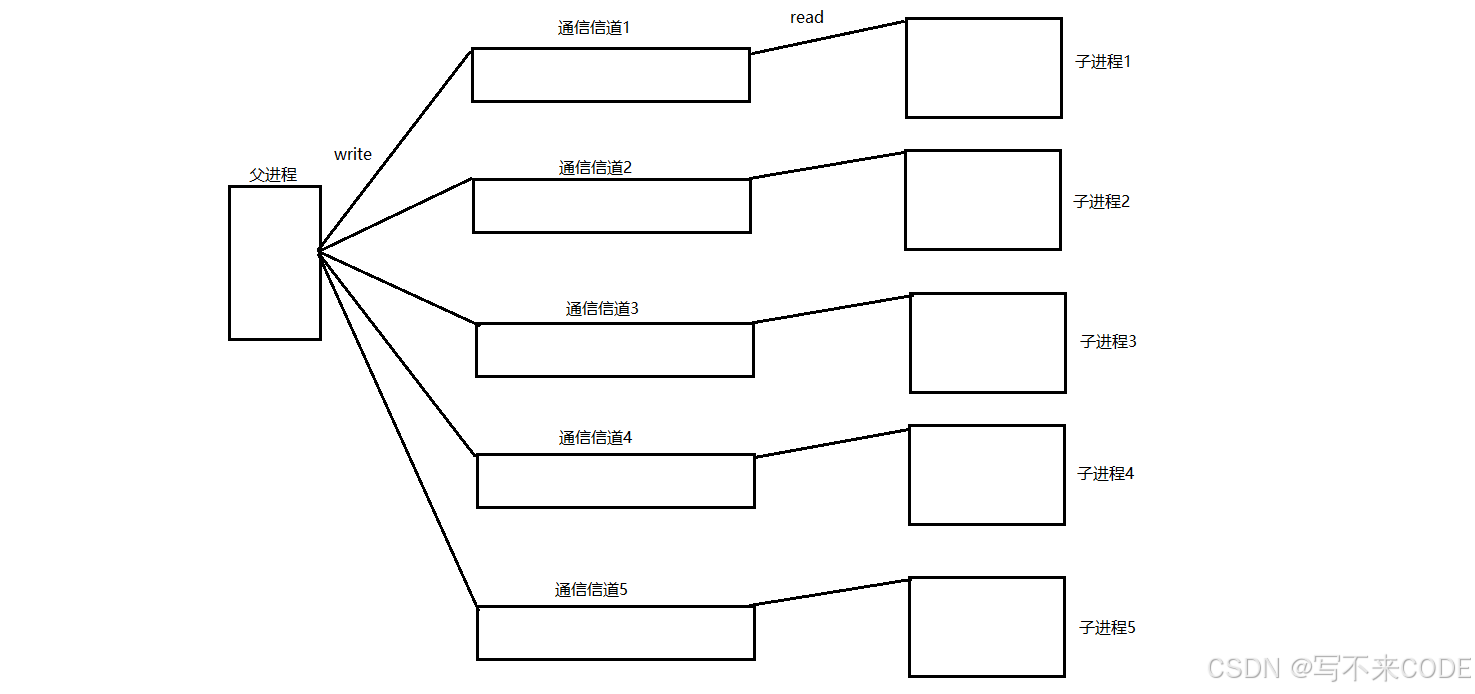
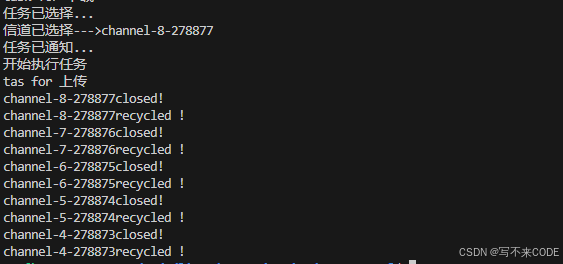
void DestoryAndRecycle(){for(auto& channel : _channels){channel.closewfd();std::cout << channel.Ref() << "closed!" << std::endl;channel.waitid();std::cout << channel.Ref() << "recycled !" << std::endl;}} // 销毁进程池void Destroy(){// 可不可以关闭一个信道就立刻回收呢?_cm.DestoryAndRecycle();}说明:此时我们便对该进程的销毁进行修改,由先关闭所有信道再回收子进程,改为关闭一个回收一个。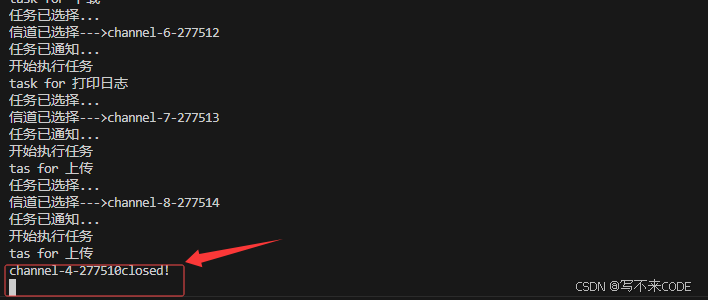
我们看上图,我们执行完10次任务之后,开始销毁进程池。但是只关闭了第一个信道,进程就进入了死循环。我们在观察该一下该进程,5个子进程以及一个父进程都还在,并没有被结束 这样的结果就是我们底层的bug导致的。那么这个bug到底是什么呢?
这样的结果就是我们底层的bug导致的。那么这个bug到底是什么呢?
我们在创建第一个子进程时,子进程的文件描述符表是拷贝自父进程的,而父进程的文件描述符表除了012外,就是管道文件的读写端了。此时父子进程各自关闭自己不需要的读写端形成单向信道,此时没有任何问题。
但是父进程循环上来再进行创建管道之后,它的文件描述符分别为3和5,此时fork创建子进程时,依旧会拷贝父进程的文件描述符表,所以此时子进程的文件描述符表除了3和5之外,还有4指向自己兄弟进程的写端!!!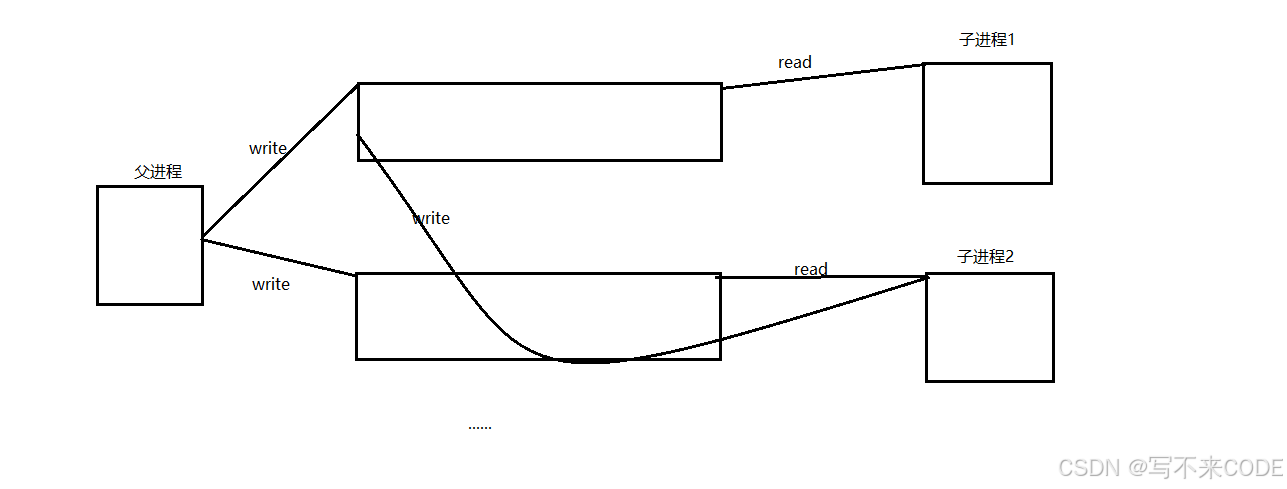
所以,对于后面创建的子进程来说,它除了自己的读端外,他还会指向前面所有的兄弟进程的写端。
现在,我们默认创建了5个子进程,那么对于第一个子进程来说,一共有5个进程指向它的写端——一个父进程四个子进程。所以,当我们销毁进程池先关闭信道的写端后,此时对于第一个进程来说它的写端并没有全部关闭,此时子进程并不会读到返回值0,而是继续再read处阻塞。所以此时我们进行wait的时候,第一个子进程并没有退出。所以就会陷入死循环。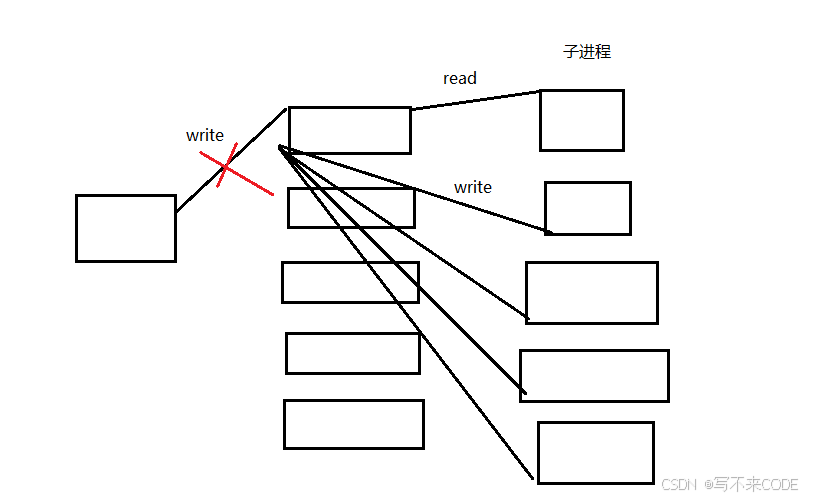
解决方案1:倒着关闭信道并回收子进程,对于最后一个子进程来说,它对应的信道只有父进程指向,所以关闭该信道,read的返回值就会为0,此时就可以退出read阻塞状态,进行等待,最后一个子进程都退出了,它的文件描述符表也就释放了,指向前面兄弟的写端也就释放了 。
for(int i = _channels.size() - 1; i >= 0; i--)
{_channels[i].closewfd();std::cout << _channels[i].Ref() << "closed!" << std::endl;_channels[i].waitid();std::cout << _channels[i].Ref() << "recycled !" << std::endl;
}

解决方案2:我们只需要在创建子进程的时候关闭指向前面兄弟进程的文件描述符即可。这里有两种方式解决:第一种,对于子进程来说,我么可以拿到读端和写端,而文件描述符表都来自父进程,读端都是3是确定的,而写端会递增。所以对于子进程来说,它的pipe[0]一定是3,而pipe[1]是它自己的写端,而这两个之前的文件描述符就是兄弟进程的写端。我们只需要关闭这些即可。
for(int i = pipefd[0] + 1; i <= pipefd[1]; ++i)
{close(i);
}第二种,子进程fork会拷贝父进程的pcb等各种信息,所以子进程也会有自己的数据和代码。而对于子进程来说,它也有自己的channelmanager,里面存储了前面兄弟进程的所有的写端。所以我们在创建子进程的时候,可以先将子进程的channelmanager给清空掉。这里并不会对父进程有所影响,因为会发生写时拷贝。
void CloseChildWrite()
{for(auto channel : _channels){close(channel.Wfd());}
}void Init()
{...else if(id == 0){_cm.CloseChildWrite();// 关闭的只是自己之前创建的子进程的写端,还需要关闭自己的写端close(pipefd[1]); // 关闭自己的写端Work(pipefd[0]); // 执行任务close(pipefd[0]);exit(0);}...
}

那么程序有这个问题,为什么我们之前先关闭所有信道,再回收子进程就没有问题呢?
按照上面的分析,关闭第一个信道,它的写端并不会全部关闭,子进程不会退出,但是我们并没有进行等待,而是直接关闭下一个信道,所以等到所有的信道关闭完成,此时就会有类似递归回退的效果,从后往前,子进程的read读到返回值0,开始退出,自此,我们才进行等待。
二.命名管道
我们已经了解过了匿名管道,但是匿名管道只能让具有血缘关系的进程进行通信。那么如果我们想让两个毫不相关的进程之间进行通信呢?
1.命名管道原理
首先我们得明确一点,两个毫不相关的进程如果同时打开同一个文件,该文件的内容和属性并不会在内存中加载两份。因为操作系统是不会允许有浪费内存资源的情况出现的。所以对于这两个进程来说,它们有各自的文件描述符表,里面都有一个struct file*指向打开的同一个文件,但是struct file指向的inode和文件内核缓冲区则只有一份。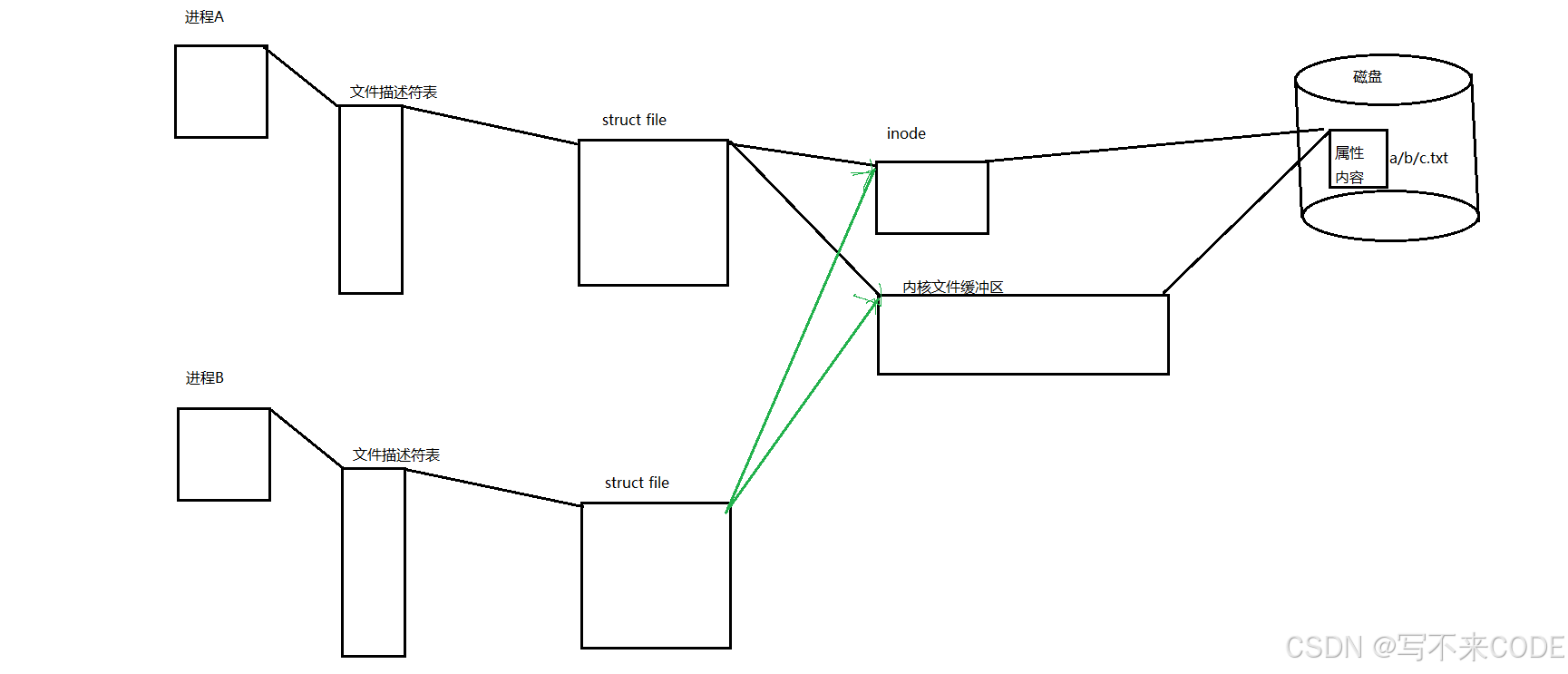
而我们说过,进程间通信的前提条件就是让进程看到同一份资源,而上面两个不同进程打开同一个文件其实就达到了我们的目的。而这个资源是我们通过路径+文件名打开的, 所以这个资源是具有唯一性的。而上述的原理就是命名管道的原理。
但是打开的普通文件会进行刷盘,会进行IO操作。但是我们进行的进程间通信是不涉及刷盘操作的。所以我们两个进行打开的同一个文件不是普通文件,而是管道文件。
2.命名管道的构建
有了命名管道,我们就可以让不相关的进程之间进行通信。而前提是我们得打开管道文件。在命令行,我们可以通过mkfifo命令创建一个管道文件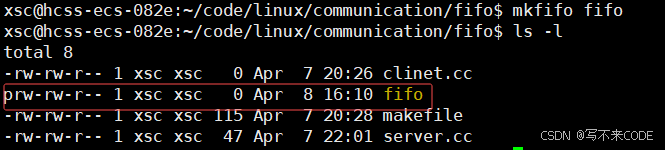
我们可以通过rm删除该管道文件或者通过unlink的方式来删除该管道文件。
但是我们想要的是利用系统调用的方式创建管道文件以运用在代码中。
#include <sys/types.h>
#include <sys/stat.h>int mkfifo(const char *pathname, mode_t mode);#include <iostream>
#include <sys/types.h>
#include <sys/stat.h>int main()
{int n = mkfifo("fifo", 0666);if(n < 0){std::cerr << "fifo error" << std::endl;return 1;}return 0;
}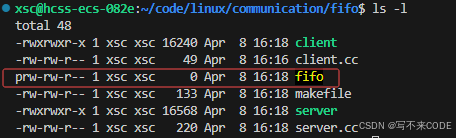
这里权限与我们设置的不同主要是因为权限掩码的存在,它会屏蔽掉一些权限。
有了上面的管道文件,我们就可以利用这个管道文件让两个毫不相关的进程进行通信。下面是demo代码:
// server.cc#include <iostream>
#include <cstdio>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include "file.hpp"int main()
{// 1.创建管道文件int n = mkfifo(FILE_FIFO, 0666);if (n < 0){perror("mkfifo");exit(1);}// 2.打开管道文件,该进程以读打开int fd = open(FILE_FIFO, O_RDONLY);if (fd < 0){perror("open");exit(2);}// 3.read进行通信char buffer[1024];while (true){n = read(fd, buffer, sizeof(buffer) - 1);if (n > 0){buffer[n] = 0;std::cout << "slient say:" << buffer << std::endl;}else if (n == 0){std::cout << "read EOF" << std::endl;break;}else{perror("read");exit(3);}}// 4.关闭管道文件close(fd);// 5.删除管道文件unlink(FILE_FIFO);return 0;
}client.cc#include <iostream>
#include <string>
#include <cstdio>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include "file.hpp"int main()
{// 1.以写方式打开管道文件int fd = open(FILE_FIFO, O_WRONLY);if(fd < 0){perror("open");exit(1);}// 2.对管道文件内写,以进行通信std::string message;while(true){std::cout << "client enter->";std::cin >> message;int n = write(fd, message.c_str(), message.size());}close(fd);return 0;
}说明:首先要进行两个进程间的通信,得看到同一份资源。而这份资源就是管道文件。我们现在有服务端和客户端。我们让服务端创建管道文件,而这个管道文件的名字定义在一个公共的文件中,两个端口都可以看到。创建好之后我们便开始构建通信信道,让服务端以读打开,客户端以写打开,这样我们就在两个进程之间构建起了一个通信信道。客户端端每写一条消息,就在服务端打印一次。最后通信完毕,都得关闭对应的文件描述符,服务端还得删除管道文件。
3.命名管道实现文件备份
我们既然已经知道了命名管道的原理,以及如何利用命令管道实现两个进程间的通信。那么就可以实现让两个毫不相关的程序进行文件的备份工作。
我们可以让一个sever进程创建管道文件,并进行读取管道文件内容,生成一个备份文件。而我们的client进程用来读已有的文件,写入到管道文件中。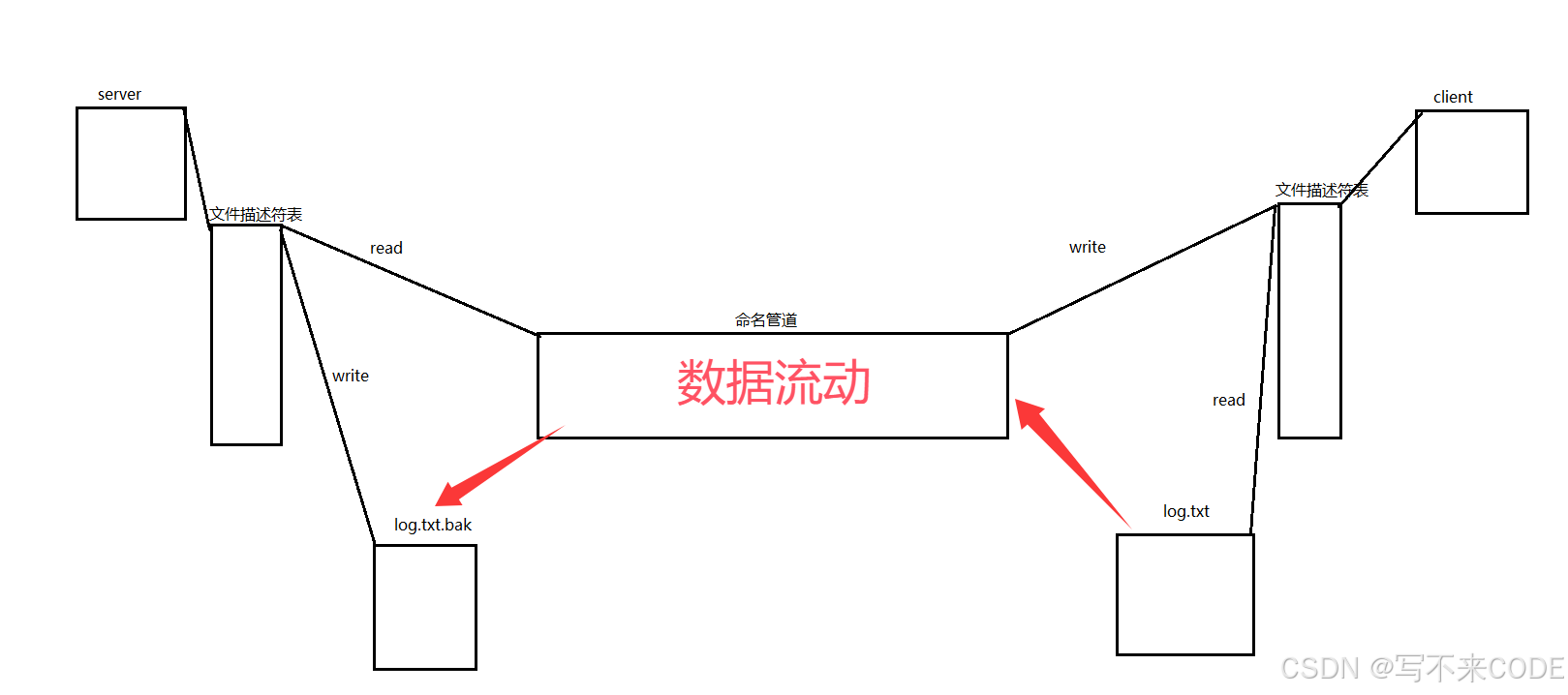
server.cc#include <iostream>
#include <string>
#include <cstdio>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>int main()
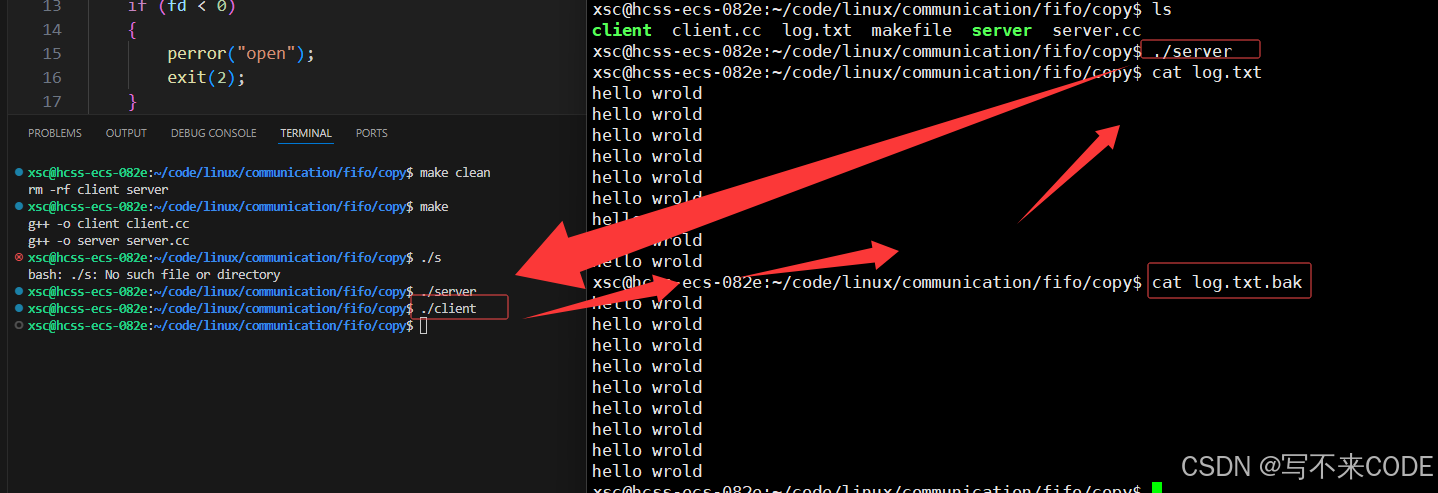
{// 1.创建管道文件int n = mkfifo("fifo_for_copy", 0666);if (n < 0){perror("mkfifo");exit(1);}// 2.以读方式打开管道文件int fd = open("fifo_for_copy", O_RDONLY);if (fd < 0){perror("open");exit(2);}// 备份文件int bak = open("log.txt.bak", O_CREAT | O_TRUNC | O_WRONLY, 0666);if (bak < 0){perror("open");exit(2);}// 从管道文件中读取文件,并做备份char text[1024];while ((n = read(fd, text, sizeof(text))) > 0){write(bak, text, n);}close(fd);close(bak);unlink("fifo_for_copy");return 0;
}client.cc#include <iostream>
#include <string>
#include <cstdio>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>int main()
{// 1.以写方式打开管道文件int fd = open("fifo_for_copy", O_WRONLY);if (fd < 0){perror("open");exit(2);}// 以读方式打开待拷贝的文件int need = open("log.txt", O_RDONLY);if (need < 0){perror("open");exit(2);}// 读need,写入管道文件中char buffer[1024];ssize_t n = 0;while ((n = read(need, buffer, sizeof(buffer))) > 0){write(fd, buffer, n);}close(fd);close(need);return 0;
}
4. 封装命名管道进程间通信
我们将命名管道的创建,以及借助管道通信的方式都封装成类的接口。这样在进行进程间通信的时候我们直接调用对应的接口即可。
#include <iostream>
#include <string>
#include <cstdio>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <fcntl.h>#define ERR(m) \do \{ \perror(m); \exit(EXIT_FAILURE); \} while (0);#define DEFAULTPATH "."
#define DEFAULTNAME "fifo"class fifo
{
public:fifo(const std::string &path = DEFAULTPATH, const std::string &name = DEFAULTNAME): _path(path), _name(name){_fifoname = path + "/" + name;}~fifo(){int n = unlink(_fifoname.c_str());if (n == 0){std::cout << "fifo deleted" << std::endl;}elseERR("unlink");}void CreatFifo(){int n = mkfifo(_fifoname.c_str(), 0666);if (n < 0)ERR("mkfifo");std::cout << "mkfifo succeess" << std::endl;}void OpenForWrite(){// 以写方式打开管道文件_fd = open(_fifoname.c_str(), O_WRONLY);if (_fd < 0)ERR("open");std::cout << "open for write succeed!" << std::endl;}void Write(){// 写内容到管道文件中std::string message;std::cout << "please enter->";std::cin >> message;write(_fd, message.c_str(), message.size());}void OpenForRead(){// 以读方式打开管道文件// 如果write方没有打开管道文件// read方就会在open处阻塞// 知道有人打开了管道文件,open才返回_fd = open(_fifoname.c_str(), O_RDONLY);if (_fd < 0)ERR("open");std::cout << "open for read succeed!" << std::endl;}void Read(){// 从管道文件中读内容char buffer[1024];int n = read(_fd, buffer, sizeof(buffer));if (n > 0){buffer[n] = 0;std::cout << "i get->" << buffer << std::endl;}else if (n == 0){std::cout << "read end of file" << std::endl;exit(0);}else{ERR("read");exit(0);}}void Close(){close(_fd);}private:std::string _path;std::string _name;std::string _fifoname;int _fd;
};说明:当我们创建好对应的管道文件后,读端此时如果要打开管道文件的话是无法打开的,它会阻塞在open处。它必须得等其他的以写方式打开管道文件的进程打开之后,才会打开。
当打开写端之后,对应的读端也会打开 
测试代码:
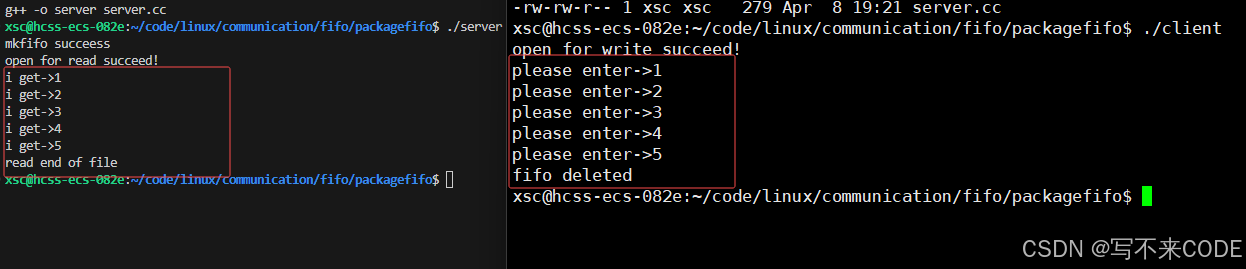
server.cc#include "fifo.hpp"// 服务端
// 用来读
int main()
{// 服务端得先创建管道fifo f;f.CreatFifo();// 以读方式打开管道文件f.OpenForRead();while(true){// 读f.Read();} f.Close();return 0;
}client.cc#include "fifo.hpp"// 客户端
// 用来写
int main()
{// 以写方式打开管道文件fifo f; f.OpenForWrite();int n = 5;while(n--){// 写f.Write();}f.Close();return 0;
}
三.systemV共享内存
我们前面基于管道文件实现进程间的通信是在已有代码的基础上如文件管理等实现的。而随着通信要求的日益增长,基于管道的通信终究是不能满足需求了。
所以Linux就专门开发出了一套通信模块,而其支持的标准就是systemV。
1.共享内存的原理
进程间通信的前提是让不同的进程看到同一个资源。而共享内存也得遵循这个前提。
共享内存在通信之前会先在物理内存开辟一块内存空间,然后通过映射到进程的虚拟地址空间上的共享区中,再借助页表进行虚拟地址与物理地址的映射,这样该进程就看到了一个资源。同样的,将该物理内存映射到另一个进程的虚拟地址空间的共享区中,并进行页表映射。此时这两个进程就看到了同一份资源,有了通信的前提要求。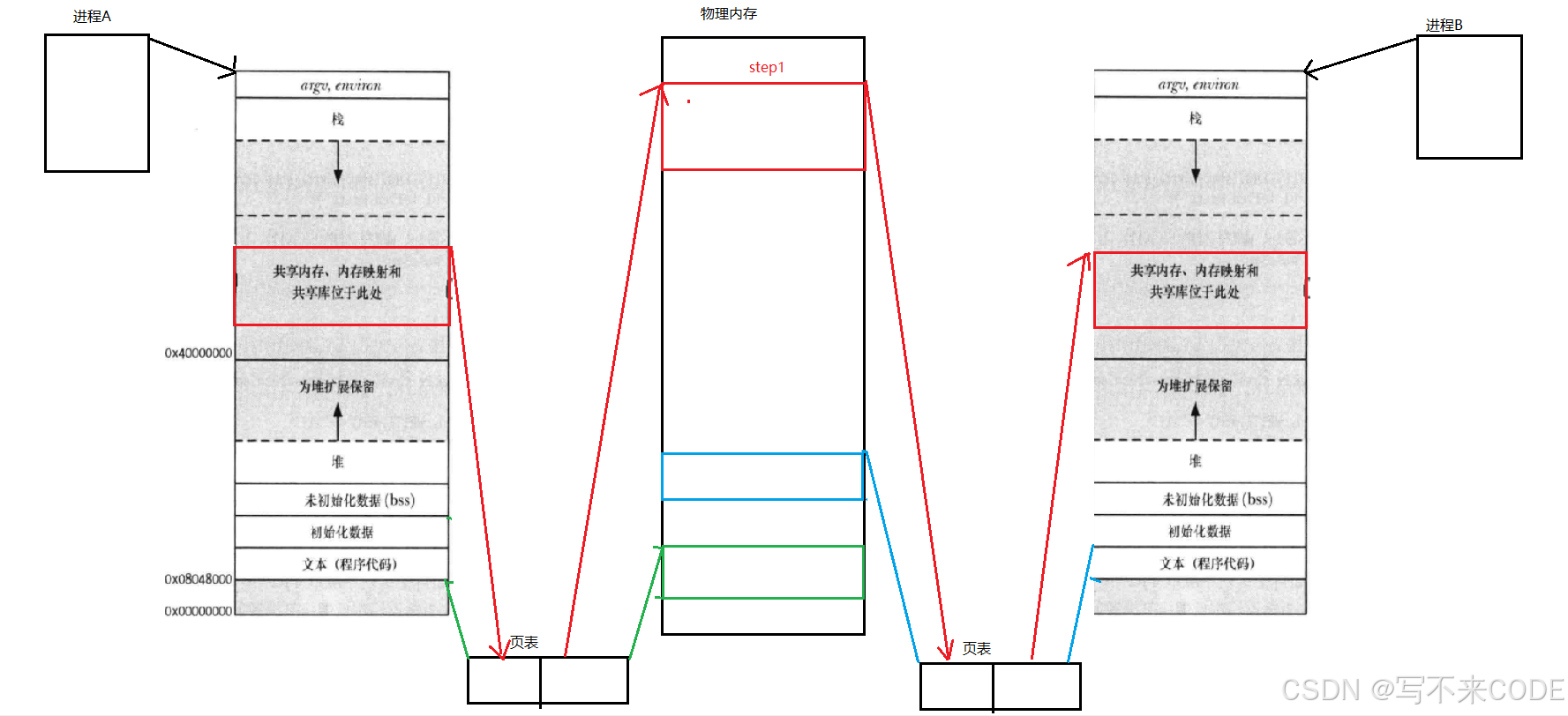
上面所说的所有动作都是由操作系统自己完成的。而我们用户想进行上面的操作需要借助操作系统提供的系统调用才可以。
当我们将共享内存与进程关联之后,就有了通信的基础,而如果取消关联关系,及没有页表的映射,此时OS就会释放这段共享内存。
在同一时间,可能同时存在多个正在进行通信的进程,而他们都有自己对应的共享内存。这些共享内存有的可能刚申请,有的正在是使用,有的则正准备释放。所以OS要对这些共享内存进行管理,先描述再组织。所以共享内存一定要有自己的内核数据结构对象。这样,共享内存与进程之间的关系就转变成了内核数据结构之间的关系!!!
2.共享内存的接口
0x1.shmget
#include <sys/ipc.h>
#include <sys/shm.h>int shmget(key_t key, size_t size, int shmflg);shmget - allocates a System V shared memory segmentsize:表明要申请的共享内存的大小
通常这个空间的大小是4kb(4096type)的整数倍,如果不够4kb就会向上取整。
shmflg:创建共享内存的选项
这里传选项的方式与当是open打开的方式类似,参数其实就宏,可以通过|的方式,同时传递多个不同的选项。
IPC_CREAT
创建共享内存,如果指定目标共享内存不存在就创建,否则就打开这个已存在的共享内存。
IPC_EXCL
该选项单独使用没有任何意义,通常与IPC_CREAT同时使用。
同时使用时表示:创建共享内存,如果指定目标共享内存不存在就创建,否则就shmget就报错返回。也就是说,只要使用这两个选项创建成功后,创建出来的共享内存一定是全新的。
那么 我们怎么评估,共享内存是否存在呢?怎么保证两个不同的进程,拿到的是同一个共享内存呢?
当我们想要创建一个共享内存时,我们怎么判断该共享内存存在与否呢?就算我们知道我们创建好了一个新的共享内存,我们怎么确定我们即将要进行通信的进程拿到的是同一个共享内存呢?
而这两个问题的答案就在shmget的第一个参数上
key:用来表示共享内存的唯一性
不同的进程,用key值来表示共享内存的唯一性。而这个key值只是用于区分不同的共享内存,这并不是OS内核直接提供的,而是由用户提供的,构建key并传递给操作系统。操作系统可以根据这个key值来进行类似于遍历的操作,如果已存在的共享内存中没有这个key值的,就创建,如果有,则根据选项的不同,进行不同而操作。
所以对于进程来说,它们在通信之前可以共同约定一个key值,一个进程通过IPC_CREAT | IPC_EXCL这两个选项,创建一个全新的共享内存,而另一个进程可以通过IPC_CREAT这个选项打开一个指定key值的共享内存。这样,它们就可以看到同一份资源了。
那么这个key值为什么不由操作系统提供,而要由待通信的进程进行约定呢?
因为对于这两个进程来说,一个是创建共享内存的,而另一个只是打开该共享内存。A进程根据操作系统给出key值创建共享内存,那么B进程怎么拿到这个key值来打开共享内存呢?
此时还没有进行通信,也无法让A给B。所以这个key值只能由用户提供。
RETURN VAL
On success, a valid shared memory identifier is returned. On error, -1 is returned, and errno is set to indicate the error.
如果创建成功,就会返回一个有效的描述符指向这个共享内存。之后用户访问该共享内存都使用这个描述符。
如果创建失败,则返回-1,并设置错误码!
0x2.ftok
而shmget函数的key值,通常使用ftok这个函数生成。
#include <sys/types.h>
#include <sys/ipc.h>key_t ftok(const char *pathname, int proj_id);convert a pathname and a project identifier to a System V IPC keypathname:传一个路径
proj_id:传一个随机的数
ftok函数会根据底层算法,结合pathname和proj_id生成一个key值。毕竟是算法生成的,所以难免有重复值的出现。但是如果只要pathname和proj_id给定,那么给出的key值也是固定的。
int main()
{// 1.生成key值key_t key = ftok(".", 0x11);if(key < 0) perror("ftok");printf("key:0x%x\n", key);// 2.创建共享内存int n = shmget(key, 4096, IPC_CREAT | IPC_EXCL);if(n < 0) perror("shmget");printf("n:%d\n", n);sleep(5);return 0;
}说明:我们根据上面所说的创建一个共享内存。我们可以使用命令ipcs -m来查看此时内核中所有的共享内存。


key就是我们创建共享内存的key值
shmid就是shmget函数返回的共享内存的描述符
owner表示这段共享内存的所有者
perms表示该共享内存的权限
bytes表示共享内存的大小,注意我们说过,大小是4096的整数倍,但是这里显示时会按照你申请的大小显式,但是实际上依旧会采取向上取整
nattch表示与该共享内存关联的进程
status表示该共享内存的状态
但是我们的进程都已经结束了,该共享内存还是没有删除,这么因为共享内存的生命周期是随内核的。如果我们的进程结束了,我们没有显式的释放该共享内存就会一直被占用。
那么我们怎么删除共享内存呢?
0x3.ipcrm -m 、shmctl
ipcrm -m
ipcrm -m是一个删除共享内存的命令,删除时需要指定要删除的shmid,也就是该共享内存的描述符。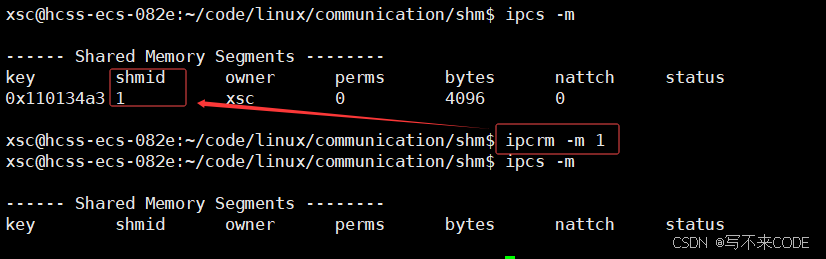
那么为什么不用key值来删除呢?
我们的key值只是用来在内核中声明共享内存的唯一性,而我们用户使用共享内存都是通过shmid来使用的。
shmctl
我们期望的是在通信结束后,由代码的方式关闭共享内存。
该接口实际上是对我们的共享内存进行控制管理的,但是我们现在不管别的,只是用该接口为我们关闭对应的共享内存。
#include <sys/ipc.h>
#include <sys/shm.h>int shmctl(int shmid, int cmd, struct shmid_ds *buf);System V shared memory controlshmid:即我们要关闭的内存空间id
cmd:即我们要如何进行共享内存管理,这里我们想要关闭共享内存,对应的选项为IPC_RMID
buf:用来获取共享内存内核数据结构,我们这里不需要直接传NULL即可。
int main()
{// 1.生成key值key_t key = ftok(".", 0x11);if(key < 0) perror("ftok");printf("key:0x%x\n", key);// 2.创建共享内存int shmid = shmget(key, 4096, IPC_CREAT | IPC_EXCL);if(shmid < 0) perror("shmget");printf("shmid:%d\n", shmid);sleep(2);// 3.关闭共享内存shmctl(shmid, IPC_RMID, NULL);sleep(2);std::cout << "shmctl done!" << std::endl;return 0;
}说明:首先我们创建共享内存,2秒过后,关闭共享内存,我们利用监控脚本来查看共享内存:
while :; do ipcs -m ; sleep(1); done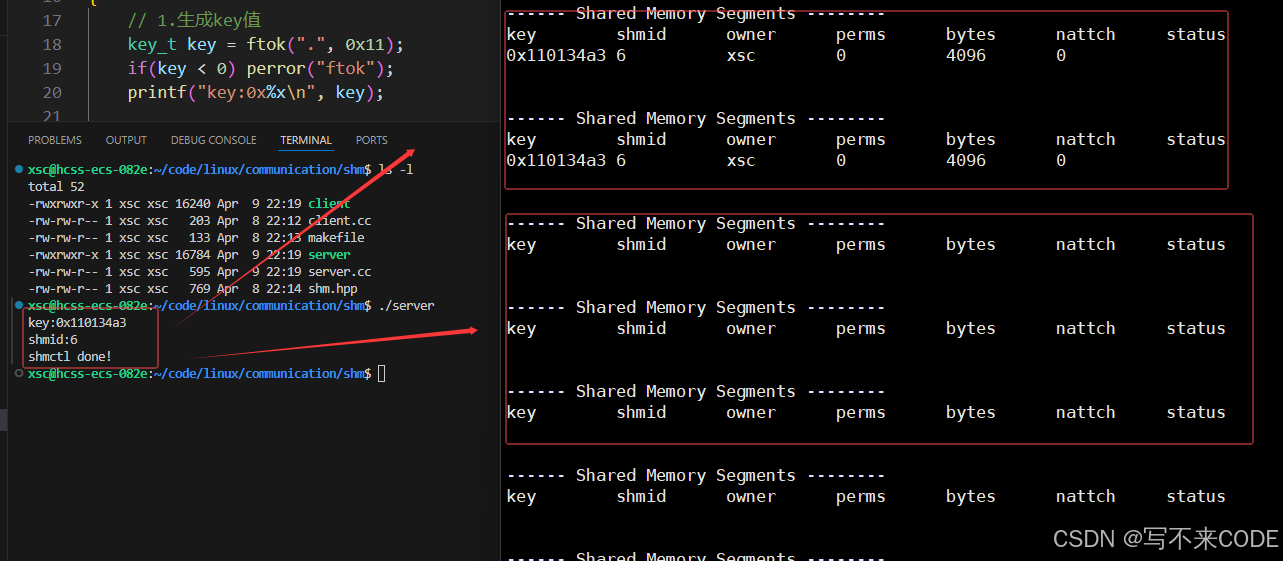
0x4.shmat
我们现在可以创建和关闭共享内存,但我们现在还无法进行通信,因为共享内存,还没有映射到任何一个进程的进程地址空间。只有让共享内存映射到不同的两个进程的地址空间中,让它们看到同一个资源,此时才有了通信的前提。
我们可以使用shmat系统调用使调用该shmat的进程挂载到该共享内存上。
#include <sys/types.h>
#include <sys/shm.h>void *shmat(int shmid, const void *shmaddr, int shmflg);
shmid:待挂载的共享内存
shmaddr:共享内存映射到该进程地址空间的固定位置,即我们可以指定共享内存映射到地址空间的位置,当然,这个不常用,容易产生冲突,这里直接给NULL即可。让其默认映射
shmflg:控制共享内存附加行为的标志。常见的标志有
- SHM_RDONLY:附加只读权限,进程对共享内存段必须有可读权限
- 0:默认的读写权限
- SHM_REMAP:替换位于
shmaddr处的任意既有映射 - SHM_EXEC:共享内存段的内存允许被执行,调用者必须对共享内存段有执行权限
我们通常传0即可。
return val
成功时,返回该共享内存映射到虚拟地址空间的起始地址。
失败时,返回(void*)-1,并设置退出码
这里为什么shmdt返回值是虚拟地址呢?
我们可以将shmat当作malloc,malloc返回的也是地址。所以当我们让进程与共享内存关联之后,我们就可以直接用该虚拟地址访问该共享内存,像malloc一样,我们想要该共享内存是什么类型就是什么类型。
...
// 与共享内存关联
void *adder = shmat(shmid, NULL, 0);
if (adder == (void *)-1)perror("shmat");
printf("adder:0x%p\n", adder);
...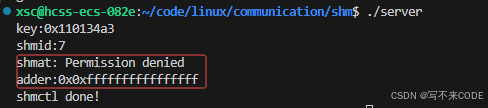
我们看到,关联时报错了,权限不允许。这是为啥呢?
我们在创建共享内存时并没有指定权限,而在Linux中一切皆文件,所以共享内存也有对应的读写可执行权限,我们需要在创建共享内存时与选项一同传给shmget
int shmid = shmget(key, 4096, IPC_CREAT | IPC_EXCL | 0666);
0x4.shmdt
我们既然能让进程与共享内存关联,我们也可以让进程与共享内存取消关联
#include <sys/types.h>
#include <sys/shm.h>int shmdt(const void *shmaddr);shmdt如果取关联成功则返回0,失败返回-1.
...
sleep(2);// 取关联
int n = shmdt(adder);
if(n < 0)perror("shmdt");
std::cout << "shmdt success!" << std::endl;
sleep(2);...说明:我们让其先关联共享内存,然后过两秒再去关联,我们观察监控脚本打印的结果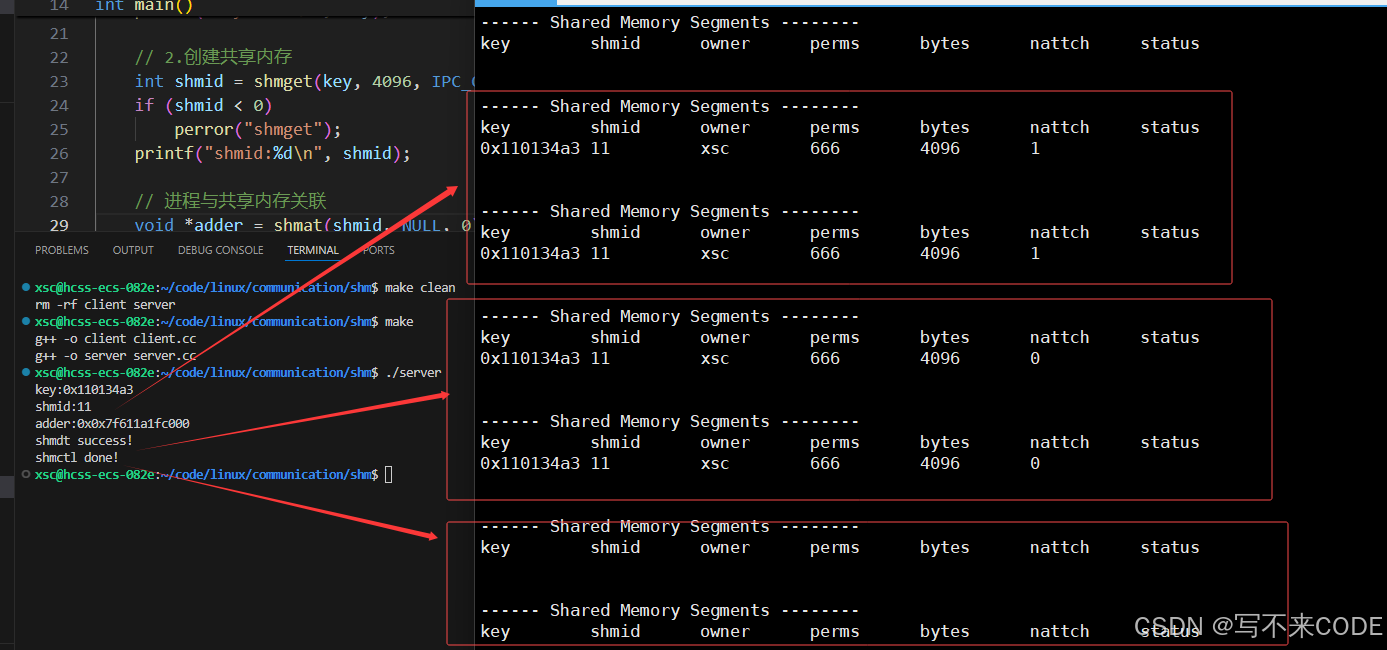
3.利用共享内存进行进程间通信
要想要两个进程间进行通信,我们就得先创建共享内存,并让共享内存与这两个进程关联。而且共享内存的使用方式与管道文件不同,它不需要使用系统调用从文件内核缓冲区中读写数据,而是像malloc创建的堆空间一样使用地址。
#include <iostream>
#include <string>
#include <cstdio>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <unistd.h>#define DEFAULT_PATHNAME "."
#define DEFAULT_PROJ_ID 0
#define DEFAULT_SIZE 4096#define CREATOR "creater"
#define USER "user"#define ERR(m) \do \{ \perror(m); \exit(EXIT_FAILURE); \} while (0);class shm
{
private:void CreatShm(){_shmid = shmget(_key, DEFAULT_SIZE, IPC_CREAT | IPC_EXCL | 0666);std::cout << "creat shm success!" << std::endl;}void Getshm(){_shmid = shmget(_key, DEFAULT_SIZE, IPC_CREAT);std::cout << "get shm success!" << std::endl;}void Attach(){// 让进程与共享内存关联void* adder = shmat(_shmid, NULL, 0);if(adder == (void*)-1)ERR("shmat");_start_mm = adder;std::cout << "attach success!" << std::endl;}void Detach(){int n = shmdt(_start_mm);if(n == -1)ERR("shmdt");std::cout << "detach success!" << std::endl;}void Destory(){shmctl(_shmid, IPC_RMID, NULL);std::cout << "delete shm sucess!" << std::endl;}public:shm(const std::string &pathname, const int proj_id, const std::string &usertype): _usertype(usertype), _start_mm(nullptr){// 获取key值_key = ftok(pathname.c_str(), proj_id);if (_key == -1)ERR("key");// 创建/获取共享内存if (usertype == CREATOR)CreatShm();else if (usertype == USER)Getshm();elsestd::cout << "usertype error!" << std::endl;// 让进程与共享内存关联Attach();}~shm() {Detach();if(_usertype == CREATOR)Destory();}void* GetAdder(){return _start_mm;}private:int _shmid;key_t _key;void *_start_mm;const std::string _usertype;
};说明:我们将创建与关联共享内存等操作定义为类。首先,因为共享内存要有一个进程创建,一个进程获取。所以我们定义使用者类型,以区别调用shmget的选项。另外就是共享内存的声明周期,它应该由创建它的进程来释放,所以我们在析构时也要进行使用者类型的判断。
下面给出server和client进程进行通信的过程:
// server.cc#include "shm.hpp"int main()
{shm shm(DEFAULT_PATHNAME, DEFAULT_PROJ_ID, CREATOR);char* buf = (char*)shm.GetAdder();int cnt = 15;while(cnt--){printf("client say->%s\n", buf);sleep(1);}return 0;
};// client.cc#include "shm.hpp"int main()
{shm shm(DEFAULT_PATHNAME, DEFAULT_PROJ_ID, USER);char *msg = (char *)shm.GetAdder();int index = 0;for (int i = 0; i <= 10; i++){msg[index++] = i + '0';sleep(1);msg[index] = 0;}return 0;
}说明:我们让server来创建共享内存,client获取共享内存。server作为读端每一秒从共享内存中读入数据,而client作为写端,每隔一秒向共享内存中写入数据。我们这里将共享内存传出的地址强制类型转换为char* ,将其像字符串一样使用。
当我们启动sever端的时候,我们此时还没有像共享内存中写入数据,他也会从中读取空白内容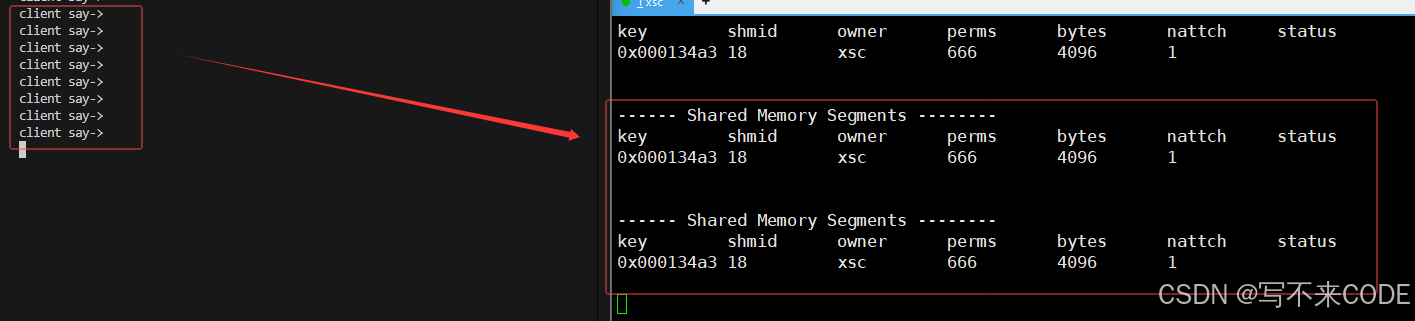
此时我们在启动client端,开始向共享内存中写入数据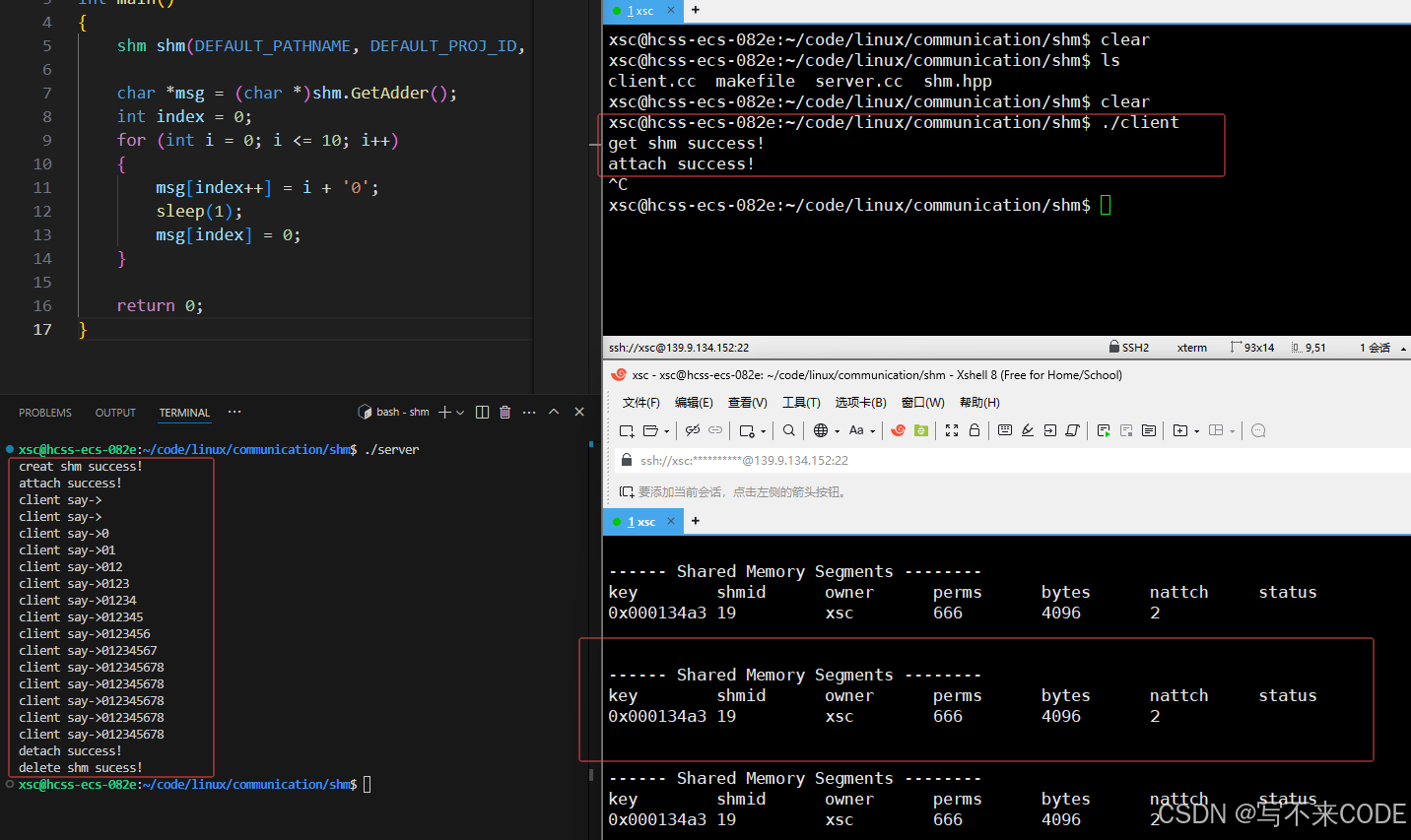
总结:利用共享内存进行进程间通信的优点就是快。数据传输速度快,一个进程写入了,另一个进程马上就可以拿到,并且共享内存的通信过程中没有使用系统调用接口哦。
但是因为读写速度很快,这就会导致数据的不一致!!!比如我们想写一个hello world,但是我才写了一个hello就被读端读取了。也就是说,共享内存没有保护机制使进程间进行同步,导致产生数据不一致的结果。
所以我们应该在写的时候不让读,读的时候不让写。我们可以利用我们之前实现的命名管道来模拟锁,以实现互斥性,即读写同一时间只有一个可以进行。
4.利用命名管道保护共享内存
管道通信时如果写端没有写内容,就会导致读端阻塞。所以我们可以让client向共享内存写的时候,写完想要写的内容之后,同时给管道文件写消息,通知server端。server端再从共享内存中读的时候,先会再命名管道处阻塞,当收到client发的消息了,这时就知道写好了,此时我们在读。
我们对命名管道的接口进行调整,因为本来就是为了充当锁,所以简单实现一下即可。
fifo.hpp//void Read()
bool wait()
{int n = 0;return read(_fd, &n, sizeof(n));
}//void Write()
void wakeup()
{int n = 1;write(_fd, &n, sizeof(n));
}我们只向管道里写一个整数,作为通知的效果。
// server.cc...char* buf = (char*)shm.GetAdder();int cnt = 15;while(cnt--){// 读的时候,先读管道文件,看看有没有内容// 有内容则表示client这一次已经写完了。if(f.wait()){printf("client say->%s\n", buf);}}...//client.cc...char *msg = (char *)shm.GetAdder();int index = 0;for(char c = 'A'; c <= 'Z'; ++c){// 向共享内存中写内容msg[index++] = c;msg[index++] = c;msg[index] = 0;// 写完了,向管道文件中写内容,通知server端可以读了f.wakeup();sleep(1);}...看下图执行过程:
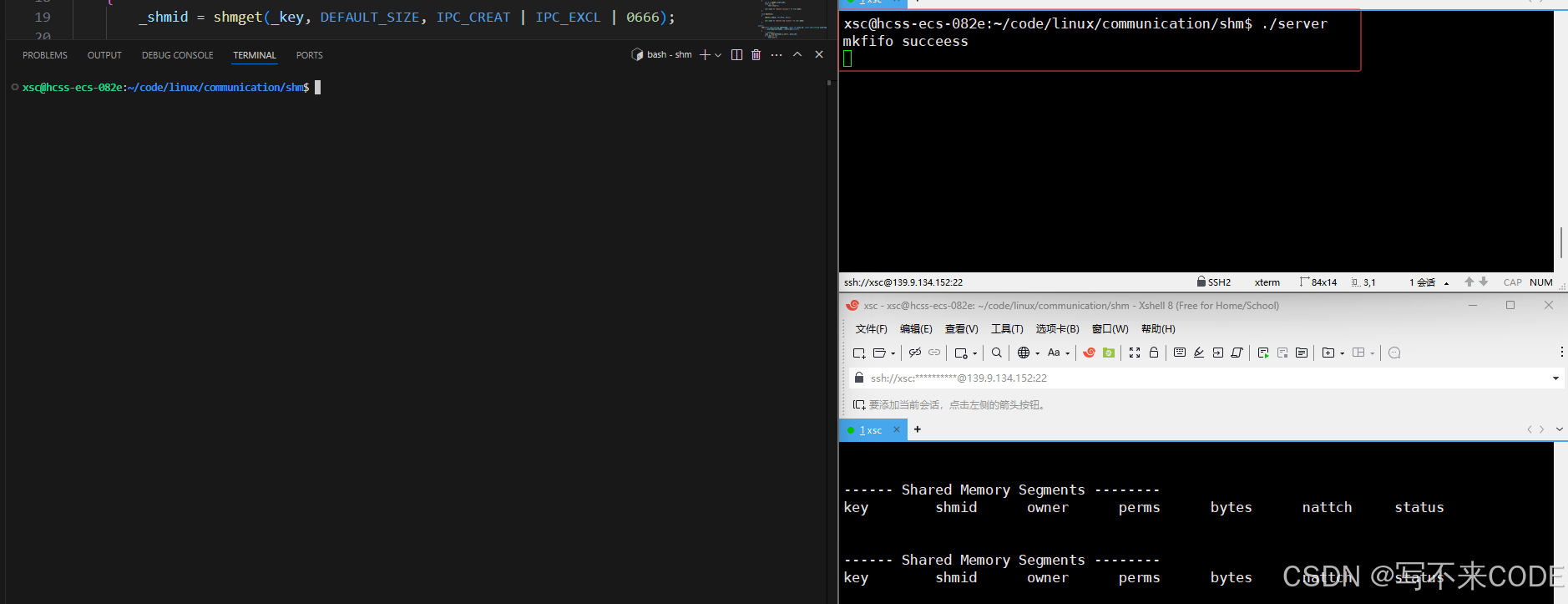
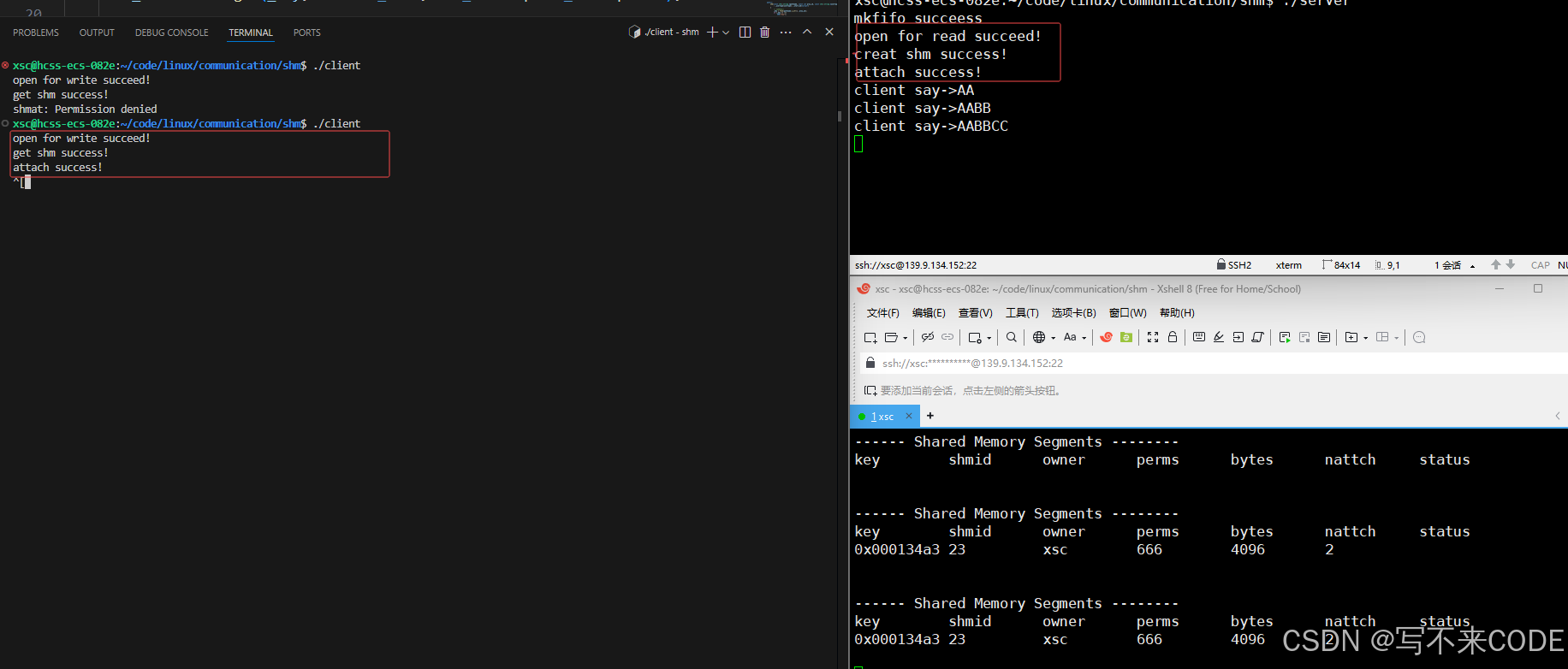
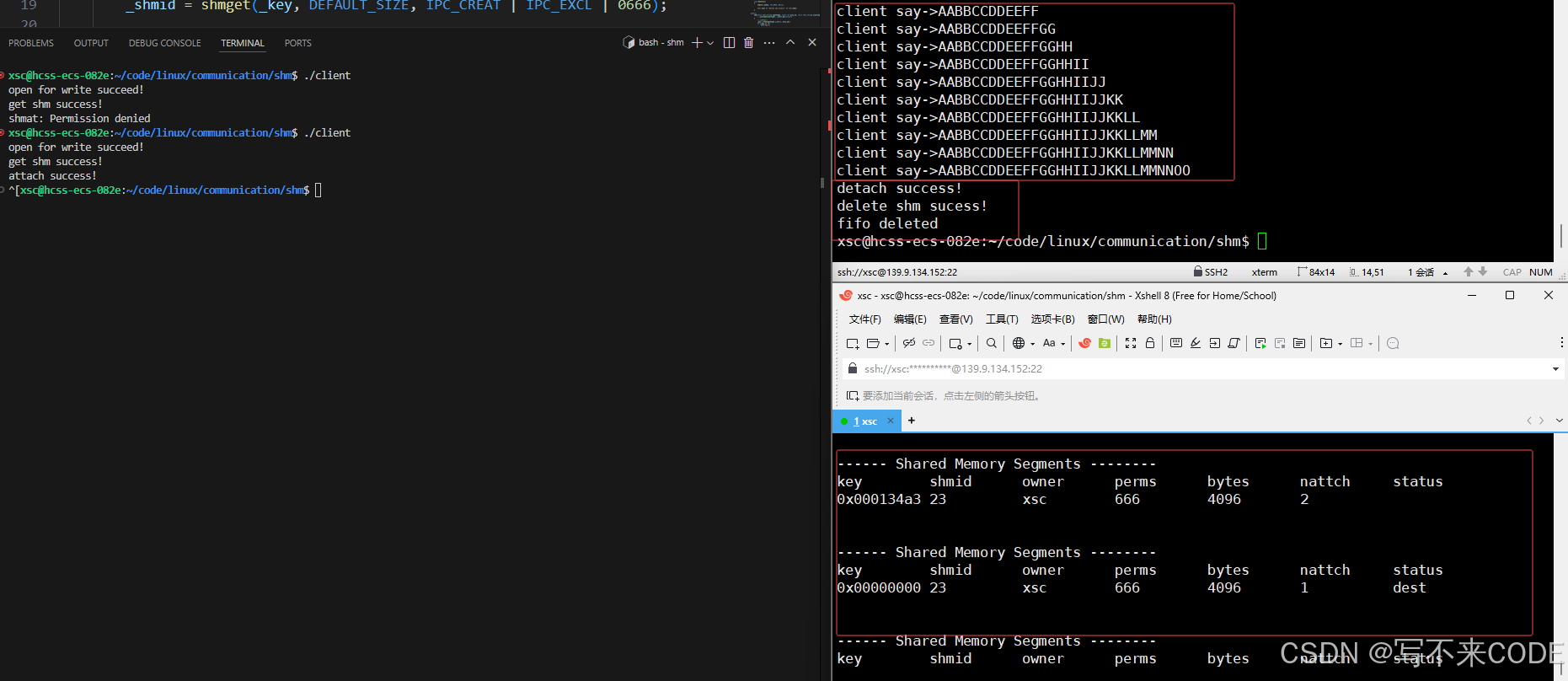
以上,我们就借助命名管道,实现了共享内存在通信过程的数据不一致问题。
5.共享内存的内核数据结构体
shmctl是用来控制共享内存的,我们除了用它来关闭共享内存,也可以用它来获取该共享内存的数据结构体。里面包含了该共享内存的一些信息。
struct shmid_ds {struct ipc_perm shm_perm; /* Ownership and permissions */size_t shm_segsz; /* Size of segment (bytes) */time_t shm_atime; /* Last attach time */time_t shm_dtime; /* Last detach time */time_t shm_ctime; /* Creation time/time of lastmodification via shmctl() */pid_t shm_cpid; /* PID of creator */pid_t shm_lpid; /* PID of last shmat(2)/shmdt(2) */shmatt_t shm_nattch; /* No. of current attaches */...
};struct ipc_perm {key_t __key; /* Key supplied to shmget(2) */uid_t uid; /* Effective UID of owner */gid_t gid; /* Effective GID of owner */uid_t cuid; /* Effective UID of creator */gid_t cgid; /* Effective GID of creator */unsigned short mode; /* Permissions + SHM_DEST andSHM_LOCKED flags */unsigned short __seq; /* Sequence number */
};int shmctl(int shmid, int cmd, struct shmid_ds *buf);我们可以定义一个shmid_ds结构体作为输出型参数拿出该共享内存的具体数据。要拿出该数据shmctl传入的cmd得是IPC_STAT.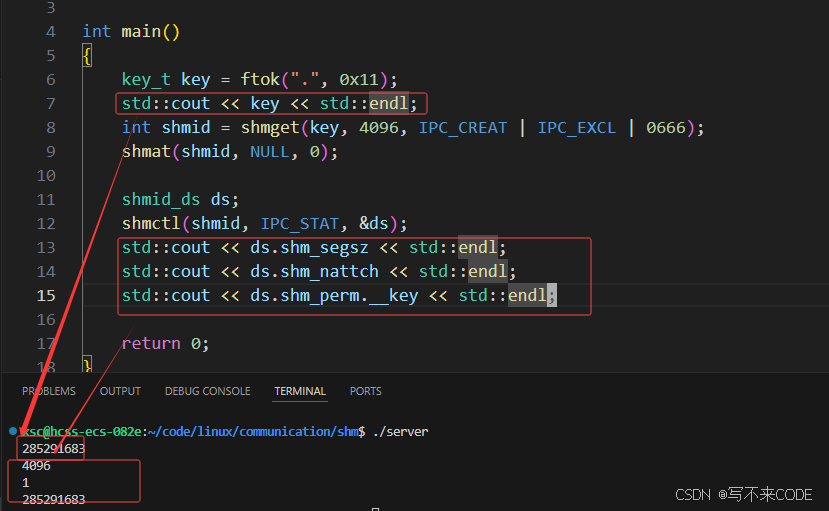
四.System V消息队列
1.消息队列理解
为了进行进程间通信,我们得让不同的进程看到同一份资源,如管道文件,共享内存。除了这两种外,我们还可以让两个进程在内存中看到同一个队列。而对于这个队列来说,通信的两个进程都可以向该队列中插入数据块。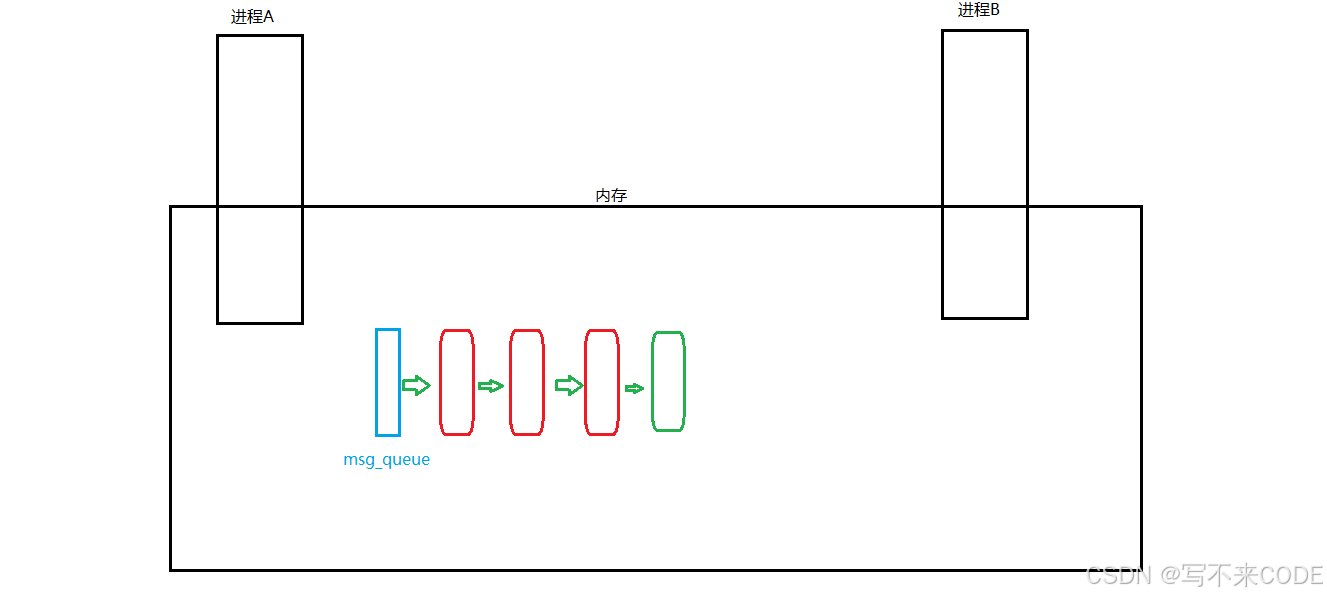
但是插入时就有一个问题产生了:A与B进程借助消息队列进行通信,都向该队列中插入数据块,那么A进程怎么确定它拿到的数据块就是B进程写的呢?B进程如何确定呢?
所以,不同的进程在插入数据块时要带有数据类型,表明该数据块是谁写的。比如在数据块中有一个整型属性type,用不同的整型值来表示不同的进程的消息。这样A与B在进程通信的时候,想要获取对方的消息时,就可以根据type来获取对方的数据块了。
进程间通信是很常见的行为,也就是说同一时间内内存中可能有多个进程都在利用该消息队列进行通信,有的正在使用,有的刚被创建,有的则准备被销毁。所以操作系统也要对消息队列进行管理——先描述,再组织。
有了上面的问题,从而就衍生出了一个新的问题:既然内存空间中同时可能会存在多个消息队列,那么A、B进程怎么确保看到的是同一个队列呢?
key值!!!与共享内存一样,我们在创建消息队列的时候,也要在用户层约定一个key值,该key值可以在内存标识消息队列的唯一性。
2.消息队列接口
因为消息队列也是遵循System V标准的,所以其接口与共享内存的接口非常相似。
0x1.msgget
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>int msgget(key_t key, int msgflg)msgget获取一个消息队列,key值表示消息队列的唯一性,借助ftok函数获取。
msgflg与shmget的选项一样IPC_CREAT和IPC_EXCL。使用方法也一致,创建全新的队列是还得指定权限。
返回值:返回一个消息队列的标识符,用户层通过该标识符来访问消息队列。
int msgid = msgget(key, IPC_CREAT | IPC_EXCL | 0666);我们可以使用ipcs -q来查看操作系统当中的所有消息队列: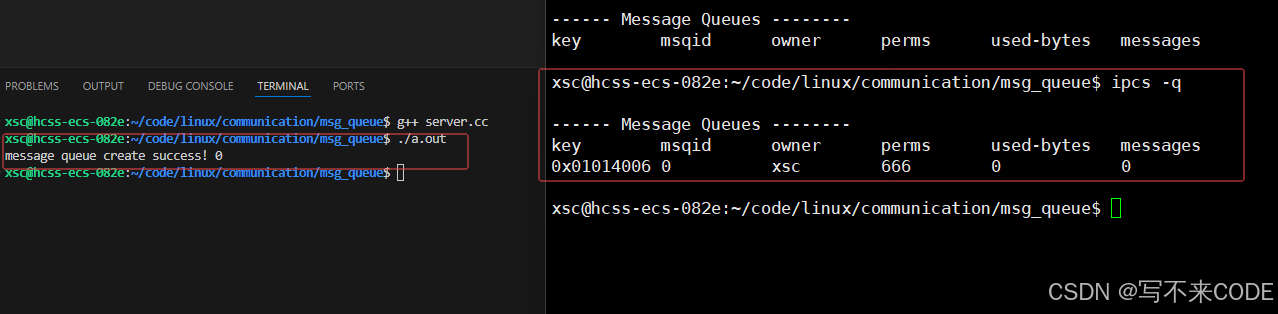
0x2.msgctl
通过msgctl来对消息队列进行管理
msgctl释放消息队列
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>int msgctl(int msqid, int cmd, struct msqid_ds *buf);// msqid 指定的消息队列
// cmd 要执行的操作,常用的有IPC_RMIN(释放消息队列), IPC_STAT(获取该消息队列的内核数据结构)
// buf 根据第二步的操作进行选择,输出型参数int n = msgctl(msgid, IPC_RMID, NULL);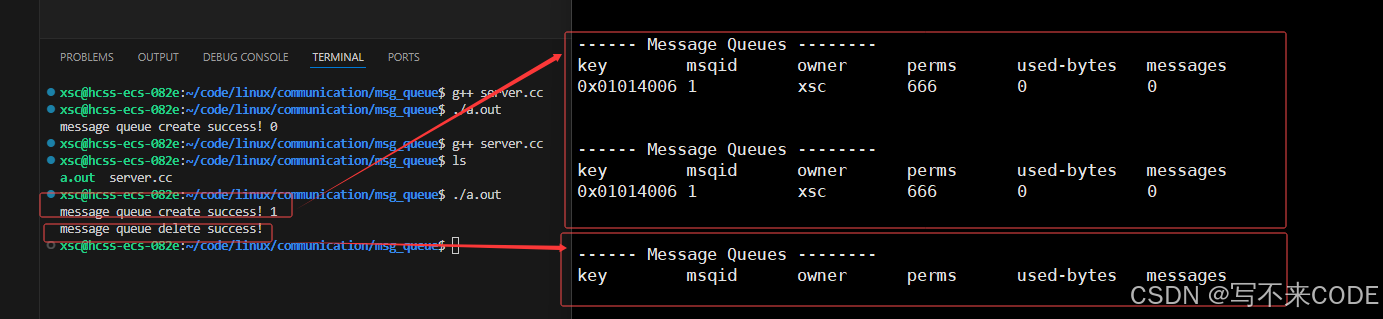
通过msgctl获取指定消息队列的内核数据结构
如下结构所示,因为消息队列和共享内存都是System V标准的,所以它们在管理上也都采取同样的方式进程管理,而他们的内核数据结构中都有ipc_perm这个结构。
struct msqid_ds
{struct ipc_perm msg_perm; /* Ownership and permissions */time_t msg_stime; /* Time of last msgsnd(2) */time_t msg_rtime; /* Time of last msgrcv(2) */time_t msg_ctime; /* Time of creation or lastmodification by msgctl() */unsigned long msg_cbytes; /* # of bytes in queue */msgqnum_t msg_qnum; /* # number of messages in queue */msglen_t msg_qbytes; /* Maximum # of bytes in queue */pid_t msg_lspid; /* PID of last msgsnd(2) */pid_t msg_lrpid; /* PID of last msgrcv(2) */
};struct ipc_perm
{key_t __key; /* Key supplied to msgget(2) */uid_t uid; /* Effective UID of owner */gid_t gid; /* Effective GID of owner */uid_t cuid; /* Effective UID of creator */gid_t cgid; /* Effective GID of creator */unsigned short mode; /* Permissions */unsigned short __seq; /* Sequence number */
};msqid_ds q;
int n = msgctl(msgid, IPC_STAT, &q);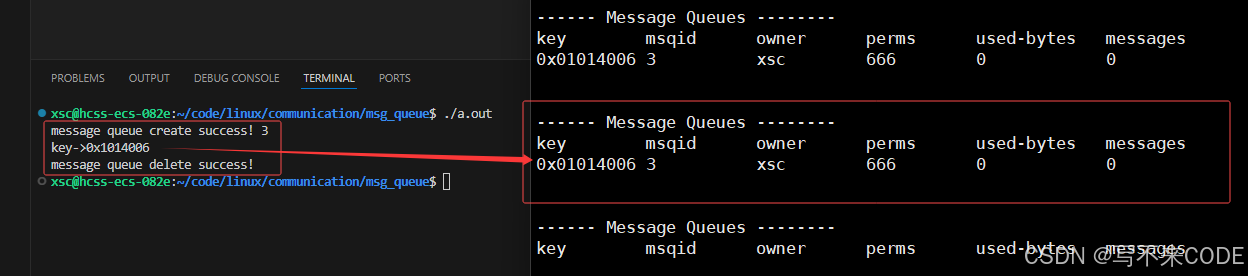
0x3.msgsnd、msgrcv
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg);ssize_t msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp, int msgflg);
msgsnd和msgrcv一个是向消息队列中写入数据块,一个则是从消息队列中读取数据块。
msqid
消息队列的标识符,向指定的消息队列中写/读内容
msgp
往消息队列中写时要写入数据块
struct msgbuf {long mtype; /* message type, must be > 0 */char mtext[1]; /* message data */
};而数据块中除了消息正文外,还要包含数据类型,用来区分不同的进程的消息。
msgsz
msgsz一般指定的正文的大小!
msgflg
写/读时的选项,我们传0即可。
消息队列与共享内存不同的就在于,消息队列读/写数据时使用的是系统调用。
五.互斥与同步
在进程间通信中,进程间看到同一份资源是前提,但是如果不对该资源进行保护,就有可能导致数据不一致。共享内存就有这样的问题。
多个进程看到的同一份资源就是共享资源。而我们需要对这些共享资源进行保护。
被保护起来的共享资源叫做临界资源。
在进程中涉及到临界资源的访问的程序段叫做临界区。说人话就是,代码中用来访问临界资源的那部分就是临界区,自然,没有访问的临界资源的就是非临界区了。
那么我们如何保证访问临界区时的数据安全呢?加锁!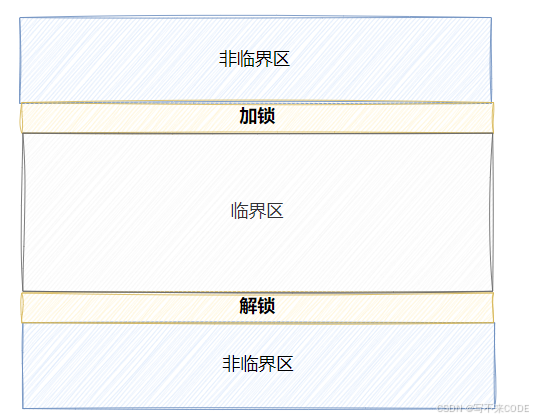
当我们需要访问临界资源时,先申请锁,只有申请成功了才可以访问临界资源,这样就保证了同一时刻只有一个进程访问临界资源。但是锁对于所有的进程来说也是共享的,也是资源。所以锁的安全也要保护。那么怎么保证锁的安全呢?申请锁必须是原子的!
而常见的保护方式分为同步和互斥。
同步:多个执行流同时访问该临界资源,但是访问的时候具有一定的顺序性,不会同时访问。这样就可以保证数据的一致性。我们之前使用管道文件进行通信的时候就具有同步性质,当我们从管道文件中read时,如果没有向管道文件中写,read是会阻塞的。
互斥:任何时刻,只允许一个执行流访问临界资源。而上面所说的临界区的保护机制就是互斥。
原子性:即做一件事,要么就做完,要么就不做。只有这两个选项。
六.System V信号量
1.理解信号量
信号量本质上就是一个计数器!用于表明临界资源中,资源数量的多少。比如电影院,就是一个临界资源。一个厅有50个座,那么该电影厅的信号量就是50.
当需要访问临界资源时,都得先访问信号量,判断是否还有临界资源剩余,本质上就是对资源的预定机制。
而对于信号量来说,它也是所有进程都可以看见的共享资源,所有信号量也要保证安全。这就要求申请信号量时是原子的。申请信号量,信号量--,P操作;使用完毕,则信号量++,V操作。
当一个资源对应的信号量只有1/0时,也就是说这个共享资源时被当作整体使用的,这个信号量就被叫做二元信号量,本质上就是互斥。
当一个资源的信号量很多时,则表明这个共享资源内部被分成了很多个小份,可以供很多进程同时访问,但不能同时访问同一个子资源。 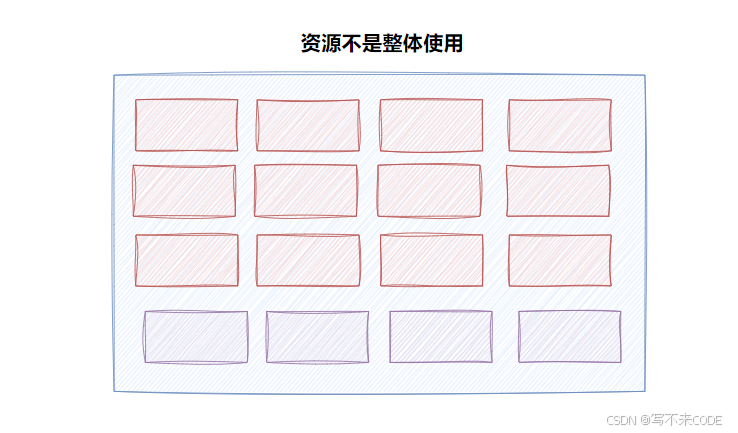
2.信号量和通信有什么关系?
上面说了这么多,好像没看出信号量和通信有什么关系。但是我们要注意通信的范畴,不是说只有进程间通信才算通信,同步与互斥也算是通信。
所以信号量其实是一个管理资源的工具,通过互斥或者同步机制来使进程可以安全的访问临界资源。
所以,信号量是用来辅助进程间通信的。我们可以先申请信号量,再申请临界资源。当有进程访问临界资源时,需要先申请信号量,申请成功了就访问;失败了,则阻塞挂起到该信号量的等待队列中,有信号量了就可以申请并访问临界资源了。
七.内核对IPC资源的管理
我们不论是在获取共享内存、消息队列还是信号量的内核数据结构的时候,它们的第一个成员都是ipc_perm。并且,在操作系统内核中,有一个全局的ipc_ids结构,该结构里面包含了一个柔性数组,该柔性数组存储的都是一个一个指向ipc_perm的指针。
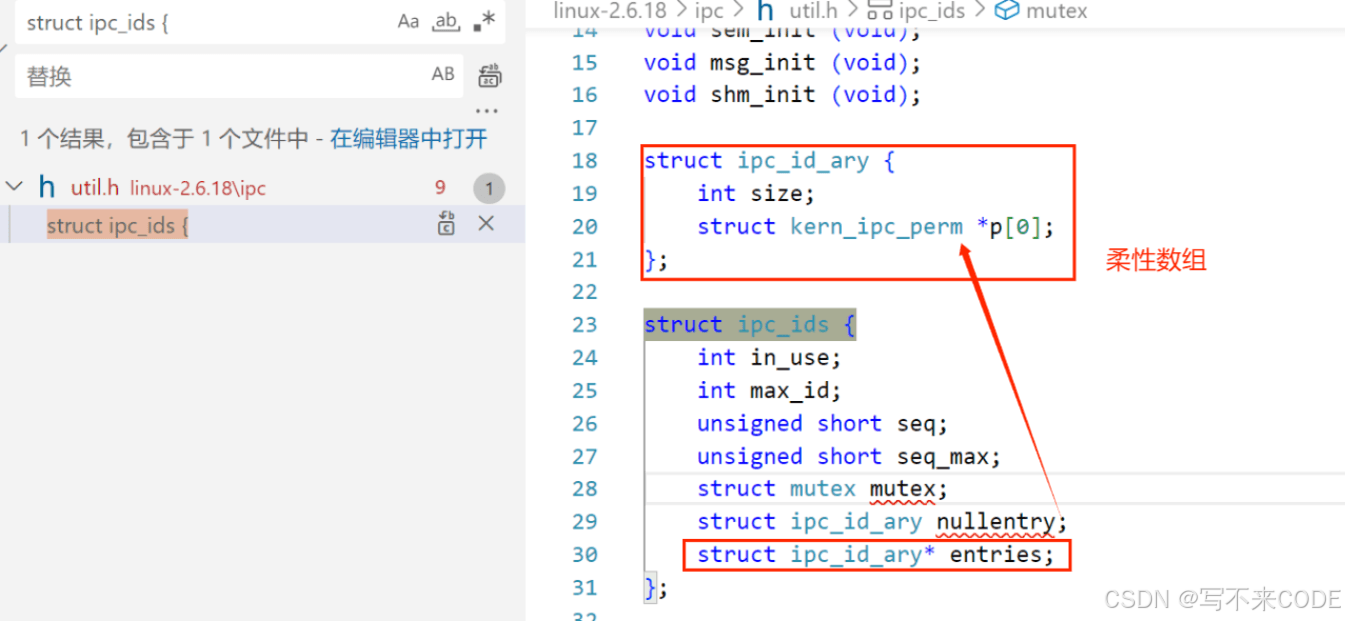
所以,对于操作系统来说,这三种资源本质上都是一样的。通过全局的ipc_ids就可以找到对应的资源。
但是我们在申请指定类型的资源的时候,操作系统内部创建的都是如下的结构体,但是我们怎么通过全局的ipc_ids找到对应的数据结构呢?


这就是因为这三个数据结构的第一个成员变量了。首先我们知道,对于一个结构体对象来说,该对象的地址和第一个成员的地址是一样的。所以在操作系统内部,我们将申请的指定资源的类型强制类型转化为ipc_perm*,这样就可以都存储在那个柔性数组中了。
所以我们在获取资源的内核数据结构的时候,本质上都是获取ipc_perm*,然后根据获取的资源的类型进行强制类型转化为指定的类型。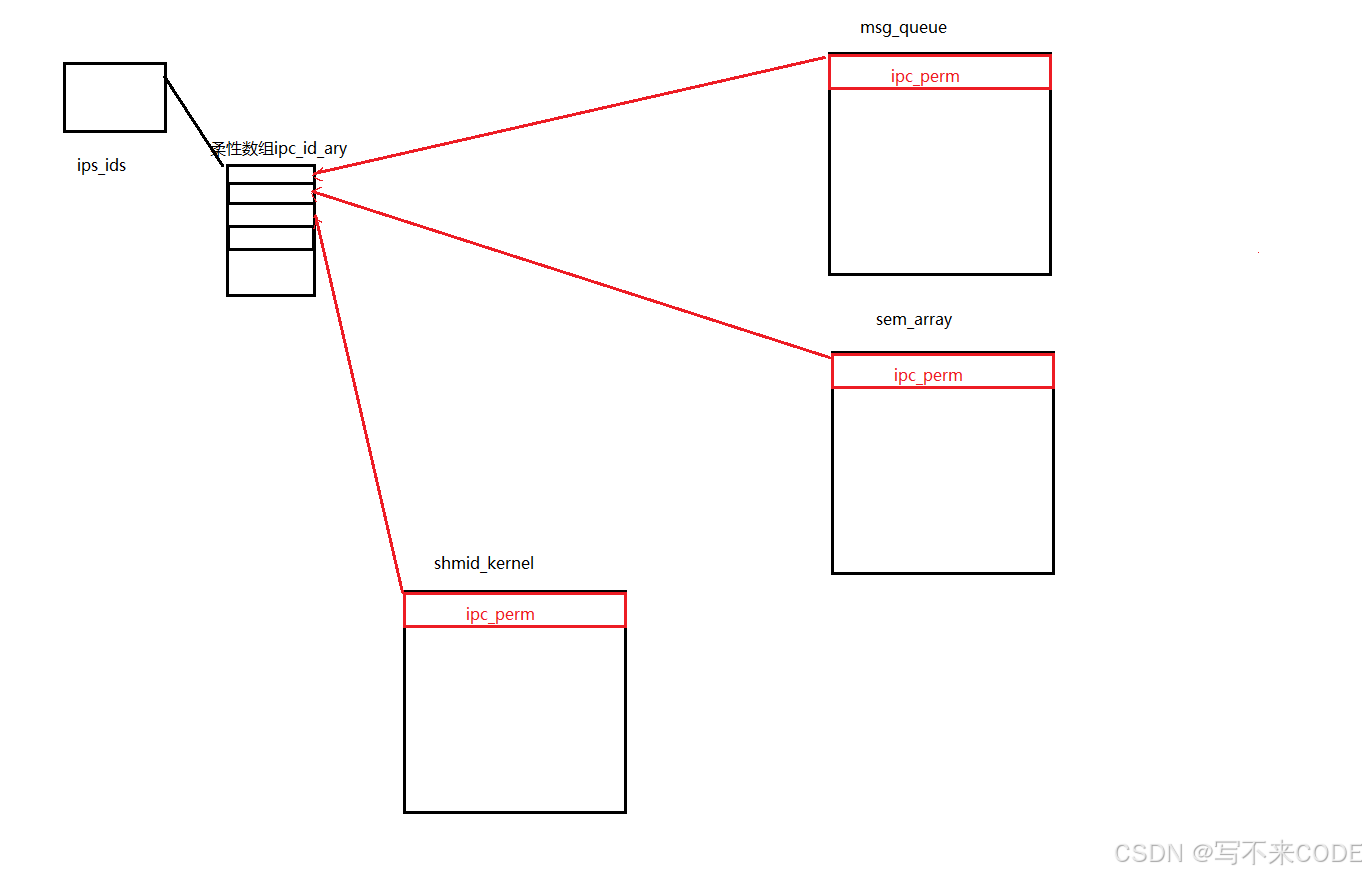
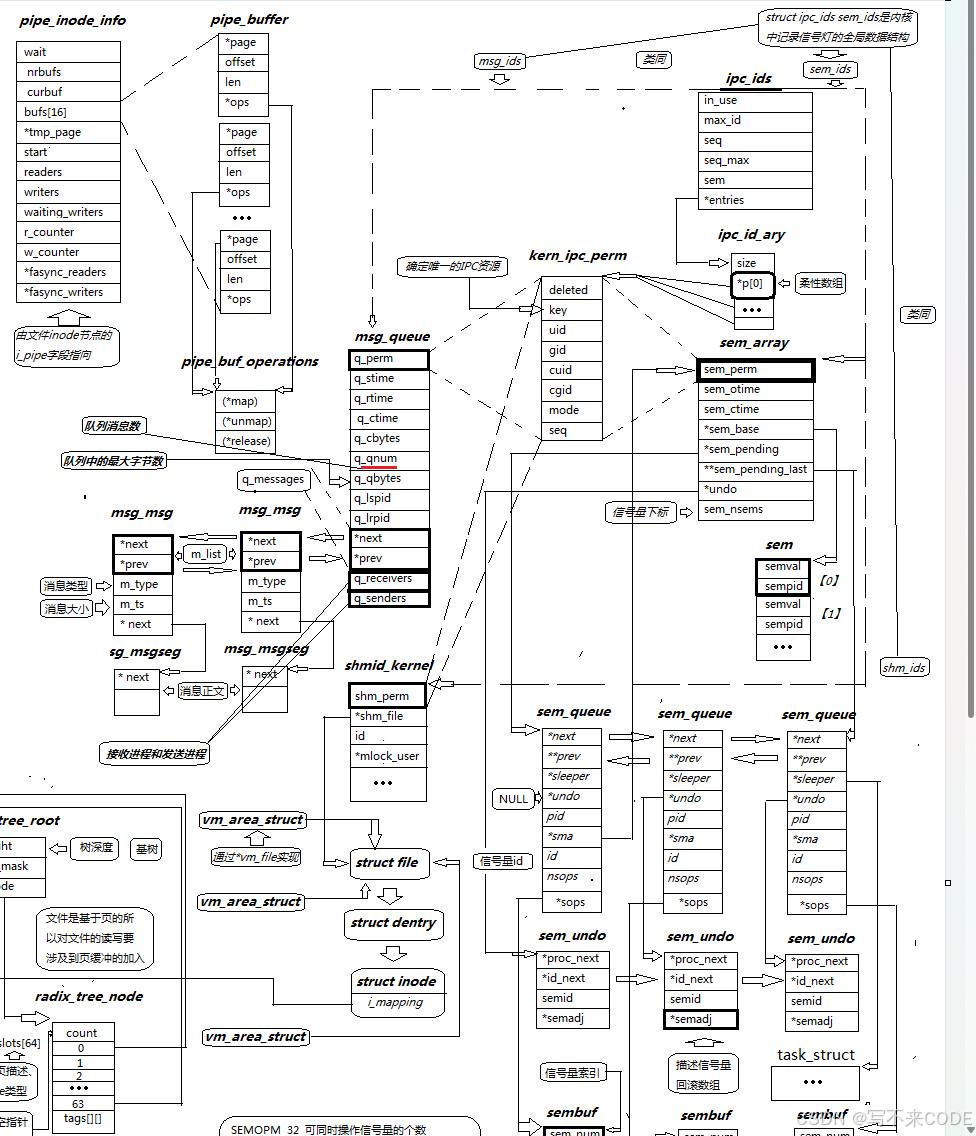
了解了内核对ipc资源的管理机制之后,我们仔细观察一下共享内存的内核数据结构中有一个file*的指针。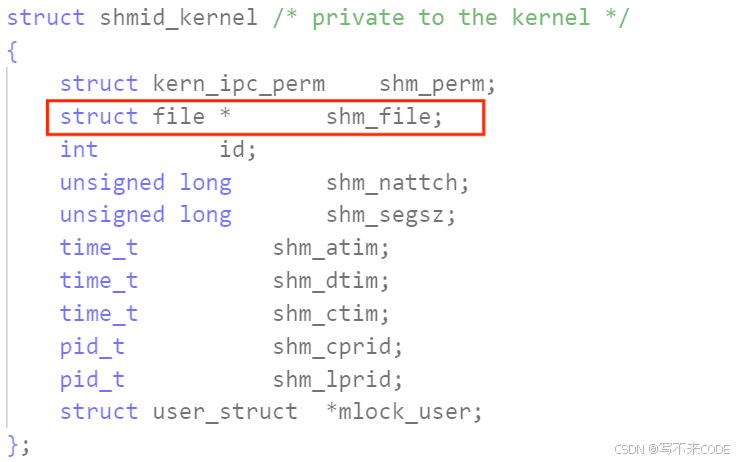
所以共享内存其实是借助文件系统实现的,那部分物理内存其实就是文件的缓冲区。 创建共享内存之后,有了struct file对象,然后进行虚拟地址和文件缓冲区之间的页表映射关系。这样我们就可以拿着虚拟地址访问对应的文件缓冲区了,也就是共享内存!
相关文章:

【Linux】进程池bug、命名管道、systemV共享内存
一.进程池bug 我们在之前进程池的创建中是通过循环创建管道,并且让子进程与父进程关闭不要的读写段以构成通信信道。但是我们这样构建的话会存在一个很深的bug。 我们在销毁进程池时是先将所有的信道的写端关闭,让其子进程read返回值为0,并…...

.Net 9 webapi使用Docker部署到Linux
参考文章连接: https://www.cnblogs.com/kong-ming/p/16278109.html .Net 6.0 WebApi 使用Docker部署到Linux系统CentOS 7 - 长白山 - 博客园 项目需要跨平台部署,所以就研究了一下菜鸟如何入门Net跨平台部署,演示使用的是Net 9 webAPi Li…...
引理1)
【差分隐私相关概念】瑞丽差分隐私(RDP)引理1
引理1的详细推导过程 引理1陈述 若分布 P P P 和 Q Q Q 满足: D ∞ ( P ∥ Q ) ≤ ϵ 且 D ∞ ( Q ∥ P ) ≤ ϵ , D_\infty(P \parallel Q) \leq \epsilon \quad \text{且} \quad D_\infty(Q \parallel P) \leq \epsilon, D∞(P∥Q)≤ϵ且D∞(Q∥P)≤ϵ, …...
)
Java练习——day1(反射)
文章目录 练习1练习2练习3思考封装原则与反射合理使用反射“破坏”封装的场景 练习1 编写代码,通过反射获取String类的所有公共方法名称,并按字母顺序打印。 示例代码: import java.lang.reflect.Method; import java.util.Arrays;public …...

【C++】二叉搜索树
目录 一、二叉搜索树 🍔二叉搜索树概念 🍟二叉搜索树的操作 🌮二叉搜索树的实现 🥪二叉搜索树的应用 🥙二叉搜索树的效率分析 二、结语 一、二叉搜索树 🍔二叉搜索树概念 二叉搜索树又称二叉排序树&…...

fastjson2 使用bug
fastjson2 版本2.0.52 转jsonString保留null值求助 有如下对象: JSONObject jsonObject {“A”:null,“B”:“value”} 当服务运行几天之后, 还是这个json格式,因为需要保留null值,如下方法: jsonObject.toJSONString…...

Redis日常维护技巧与常见问题解决方案
Redis是一个开源的内存数据存储系统,广泛应用于缓存、消息队列、实时分析等场景。由于其高性能和持久化特性,越来越多的企业开始引入Redis。然而,要使Redis高效、稳定地运行,日常的维护和问题解决显得尤其重要。本文将分享一些Red…...

【Leetcode-Hot100】最小覆盖子串
题目 解答 想到使用双指针哈希表来实现,双指针的left和right控制实现可满足字符串。 class Solution(object):def minWindow(self, s, t):""":type s: str:type t: str:rtype: str"""len_s, len_t len(s), len(t)hash_map {}for…...

【Sequelize】关联模型和孤儿记录
一、关联模型的核心机制 1. 关联类型与组合规则 • 基础四类型: • hasOne:外键存储于目标模型(如用户档案表存储用户ID) • belongsTo:外键存储于源模型(如订单表存储用户ID) • hasMany&…...

系统分析师-第三遍-章节导图
导图要求: 第一章 绪论 第二章 数学与工程基础 导图要不偏瘫...
---- 关于阶乘)
算法(ALGORITHMS)---- 关于阶乘
Everyday life is different,even with your state and mind!So if i have some new ways or logic to make a good Algorithms,I gonna post it and share with U guys! If there is anything error aboubt what I demonstrated,pls speak out on the comment,Thanks! 一.最初…...
)
电路(b站石群老师主讲,持续更新中...)
文章目录 第一章 电路模型和电路定律1.1电路和电路模型 第一章 电路模型和电路定律 第一章的重点: 1.电压、电流的参考方向 2.电阻元件和电源元件的特性 3.基尔霍夫定律(KCL,KVL,) KCL:基尔霍夫电流定律 KVL:基尔…...

Python multiprocessing模块Pool类介绍
multiprocessing.Pool 类是 Python 中用于并行处理任务的强大工具,它可以创建一个进程池,允许你在多个进程中并行执行任务,从而充分利用多核 CPU 的性能。下面为你总结 Pool 类的常用方法。 1. 创建进程池 from multiprocessing import Pool pool = Pool(processes=None)参…...
(1_移动_C++))
CCF CSP 第36次(2024.12)(1_移动_C++)
CCF CSP 第36次(2024.12)(1_移动_C) 解题思路:思路一: 代码实现代码实现(思路一): 时间限制: 1.0 秒 空间限制: 512 MiB 原题链接 解题思路&…...

【教程】PyTorch多机多卡分布式训练的参数说明 | 附通用启动脚本
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn] 如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~ 目录 torchrun 一、什么是 torchrun 二、torchrun 的核心参数讲解 三、torchrun 会自动设置的环境变量 四、torchrun 启动过程举例 机器 A&#…...

九、自动化函数02
// 进阶版本的屏幕截图 void getScreenShot(String str) throws IOException {// ./src/test/image/ 存放图片路径// 屏幕截图SimpleDateFormat sim1 new SimpleDateFormat("yyyy-MM-dd");SimpleDateFormat sim2 new SimpleDateFormat("HHmmss");Str…...

构建批量论文格式修改系统:从内容识别到自动化处理
在学术研究和论文管理中,自动化处理论文格式是一个极具挑战性但非常有价值的任务。无论是提取论文的关键信息,还是批量修改格式,都需要一个强大的内容识别系统作为基础。本文将结合两份代码(paper_parser.py 和 paper_analyzer.py),深入分析它们如何实现论文内容的识别,…...
为何总是黄色的?)
站台候车,好奇铁道旁的碎石(道砟)为何总是黄色的?
一、发现问题 同学们在站台等车时有没有发现,铁道旁的小石子很多都是黄色的,有部分为白色,像上图这样,这是为什么呢?是石头原生为黄色,还是因为其他原因变成了红黄色?是从灰白色变为了红黄色吗&…...
)
Oracle PL/SQL 中,异常(Exception)
在 Oracle PL/SQL 中,异常(Exception) 是处理运行时错误的机制,能够将错误逻辑与业务逻辑解耦,保证程序的健壮性和可维护性。以下从 原理 和 案例 两个方面详细解析 一、异常处理的核心原理 1. 异常触发机制 自动触发…...
)
OpenCV学习之获取图像所有点的坐标位置(二)
1.功能介绍 (1)使用openCV解析了.jpeg、.jpg、.png格式的图像文件,输出了图像的宽、高、通道数; (2)创建txt格式文件,保存图像中各像素点的rgba值。 2.环境介绍 操作系统:window10 开发语言:visual studio 2015 c++ 3.功能实现过程 3.1环境设置 (1)打开Vs2015…...
、Leetcode416.分割等和子集)
代码随想录算法训练营Day30 | 01背包问题(卡码网46. 携带研究材料)、Leetcode416.分割等和子集
代码随想录算法训练营Day30 | 01背包问题(卡码网46. 携带研究材料)、Leetcode416.分割等和子集 一、01背包问题 相关题目:卡码网46. 携带研究材料 文档讲解:01背包问题(二维)、01背包问题(一维…...

opencv 形态学变换
形态学变换 1. 核2.腐蚀(cv2.erode)3. 膨胀(cv2.dilate)4. 开运算(cv.MORPH_OPEN)5. 闭运算(cv2.MORPH_CLOSE)6. 礼帽运算(找出增多的白色区域)7. 黑帽运算8.…...

视频设备轨迹回放平台EasyCVR打造水库大坝智慧安防视频监控智能分析方案
一、项目背景 水库安全度汛是全国防汛抗洪工作的重点,水库监控系统对保障水库安全、及时排险意义重大。多数水库站点分散、位置偏,地形复杂,与监控中心相隔较远。 传统有线监控系统成本高、工期长,遇山河等阻碍时布线困难&…...

使用 LLaMA-Factory 对 DeepSeek R1进行微调教程
如本教程有问题,感谢大家在评论区指出。 如操作过程中遇到解决不了的问题,可以在评论区提问,作者看到了会回复。 微调简介 模型微调通过在特定任务数据集上继续训练预训练模型来进行,使得模型能够学习到与任务相关的特定领域知识…...

【Kubernetes基础--Pod深入理解】--查阅笔记2
深入理解Pod 为什么要有个Pod1. 容器协作与资源共享2. 简化调度和资源管理3. 设计模式支持 Pod 基本用法Pod 容器共享 VolumePod 的配置管理ConfigMap 概述创建 ConfigMap 资源对象在 Pod 中使用 ConfigMap使用 ConfigMap 的限制条件 为什么要有个Pod Pod 的引入并非技术冗余&…...

C语言进阶之自定义类型:结构体,枚举,联合
结构体 结构体类型的声明 结构的基础知识 结构是一些值的集合,这些值称为成员变量。结构的每个成员可以是不同类型的变量。 结构的声明 struct tag{member-list;}variable-list;例如描述一个学生: struct Stu{char name[20];//名字int age;//年龄ch…...

深入解析C++引用:安全高效的别名机制及其与指针的对比
一、引用的核心概念 1.1 引用定义 引用(Reference)是C为变量创建的别名,通过&符号声明。其核心特性: 指针适用场景: 现代C黄金法则: "引用是指针的安全马甲,而智能指针是带着安全帽的…...

【rdma通信名词概念】
rdma通信名词概念 1.在rdma网卡中,QP(SQ和RQ)、CQ、EQ和SQR的含义是什么以及功能是什么?2 PCIe中的MSI-X中断机制? 1.在rdma网卡中,QP(SQ和RQ)、CQ、EQ和SQR的含义是什么以及功能是什么? QP:queue pair&am…...

Mysql主从复制有哪些方式
MySQL 主从复制主要有以下几种方式,根据不同的分类标准(如同步机制、数据复制格式、拓扑结构等)可以分为: 一、按同步机制分类 1. 异步复制 (Asynchronous Replication) 原理:主库提交事务后,立即返回给客…...

Vue工程化开发脚手架Vue CLI
开发Vue有两种方式 核心包传统开发模式:基于html / css / js 文件,直接引入核心包,开发 Vue。工程化开发模式:基于构建工具(例如:webpack)的环境中开发Vue。 脚手架Vue CLI Vue CLl 是 Vue 官方…...

MySQL函数运算
1.日期时间函数 查询当前日期时间的函数(使用函数需要加select): curdate() 查看当前数据库的日期部分(年月日) SELECT CURDATE(); curtime() 查看当前数据库的时间部分(时分秒) SELECT CURTIME(); now() 查看当前…...

Spring如何解决项目中的循环依赖问题?
目录 什么是循环依赖? 如何解决? 采用两级缓存解决 需要AOP的Bean的循环依赖问题? 三级缓存解决 什么是循环依赖? 循环依赖就是Spring在初始化Bean时两个不同的Bean你依赖我,我依赖你的情况 例如A依赖B…...

【Pandas】pandas DataFrame itertuples
Pandas2.2 DataFrame Indexing, iteration 方法描述DataFrame.head([n])用于返回 DataFrame 的前几行DataFrame.at快速访问和修改 DataFrame 中单个值的方法DataFrame.iat快速访问和修改 DataFrame 中单个值的方法DataFrame.loc用于基于标签(行标签和列标签&#…...

正则表达式反向引用的综合应用魔法:从重复文本到简洁表达的蜕变
“我....我要....学学学学....编程 java!” —— 这类“重复唠叨”的文本是否让你在清洗数据时头疼不已? 本文将带你一步步掌握正则表达式中的反向引用技术,并结合 Java 实现一个中文文本去重与清洗的实用工具。 结合经典的结巴实例。如何高效地将这样的…...

ESP32驱动读取ADXL345三轴加速度传感器实时数据
ESP32读取ADXL345三轴加速度传感器实时数据 ADXL345三轴加速度传感器简介ADXL345模块原理图与引脚说明ESP32读取ADXL345程序实验结果 ADXL345三轴加速度传感器简介 ADXL345是一款由Analog Devices公司推出的三轴数字加速度计,分辨率高(13位),测量范围达…...

C++高级3 绑定器
绑定器 C11从Boost库中引入了bind绑定器和function函数对象机制 绑定器二元函数对象 一元函数对象 bind1st 绑定第一个 bind2nd 绑定第二个 #include <iostream> #include <memory> #include <vector> #include <functional> #include <ctime…...
)
Android 接口定义语言 (AIDL)
目录 1. 本地进程调用(同一进程内)2. 远程进程调用(跨进程)3 `oneway` 关键字用于修改远程调用的行为Android 接口定义语言 (AIDL) 与其他 IDL 类似: 你可以利用它定义客户端与服务均认可的编程接口,以便二者使用进程间通信 (IPC) 进行相互通信。 在 Android 上,一个进…...

【android bluetooth 案例分析 02】【CarLink 详解2】【Carlink无配对连接机制深度解析】
Carlink无配对连接机制深度解析(首次/二次免鉴权原理) 一、核心结论:Carlink通过SDK层协议设计完全绕过传统蓝牙配对 传统蓝牙配对(Pairing)依赖协议栈生成长期绑定密钥(LTK),而Car…...

ubuntu 2204 安装 vcs 2023
系统 : Ubuntu 22.04.1 LTS vcs 软件 : 有已经安装好的软件(位于redhat8.10),没找到安装包 . 安装好的目录文件 占用 94 G注意 : 该虚拟机(包括安装好的软件)有114G,其中安装好的目录文件占用94GB // 即 我要把 这里 已经安装好的软件(包括scl/vcs/verdi 和其他软件) 在 …...

Spring Boot循环依赖全解析:原理、解决方案与最佳实践
🚨 Spring Boot循环依赖全解析:原理、解决方案与最佳实践 #SpringBoot核心 #依赖注入 #设计模式 #性能优化 一、循环依赖的本质与危害 1.1 什么是循环依赖? 循环依赖指两个或多个Bean相互直接或间接引用,形成闭环依赖关系。 典…...

按键精灵安卓/ios脚本辅助工具开发教程:如何把界面配置保存到服务器
在使用按键精灵工具辅助的时候,多配置的情况下,如果保存现有的配置,并且读取,尤其是游戏中多种任务并行情况下,更是需要界面进行保存,简单分享来自紫猫插件的配置保存服务器写法。 界面例子: …...

【厦门大学】大模型概念、技术与应用实践
大模型概念、技术与应用实践 引言一、人工智能发展简史1.1 图灵测试的提出1.2 人工智能的诞生1.3 人工智能的发展阶段 二、大模型的核心概念2.1 大模型的定义2.2 大模型的特点 三、大模型的发展历程3.1 萌芽期(1950-2005)3.2 沉淀期(2006-201…...
 去除无效的干扰!巧妙转化)
The Strict Teacher (Hard Version) 去除无效的干扰!巧妙转化
文章目录 The Strict Teacher (Hard Version) 思考问题!那么多个人抓一个人,是否是每一个人都是对于最优策略的答案是有贡献的?答案是否定的,其实问题可以简化为三种情况: 所有的老师都在大卫的右边,…...

Linux中信号的保存
一、认识信号的其他相关概念 实际执行信号的处理动作称为信号递达 信号从产生到递达之间的状态,称为信号未决 进程可以选择阻塞某个信号 被阻塞的信号产生时将保持在未决状态,直到进程解除对该信号的阻塞,才进行递达的动作 阻塞和忽略是不同的…...

2024ICPC 南京 B 生日礼物
题目: 格莱美的生日快到了,她从朋友那里得到了一个序列 A 作为礼物。这个序列只有 0 、 1 和 2 。格莱美认为这个数列太长了,因此她决定修改 A 使其更短。 从形式上看,格莱美可以执行任意数量的运算。每次她都可以从以下三种运算…...

扫地机器人进化史:从人工智障到家政王者
1996年,瑞典伊莱克斯推出的"三叶虫"开启了扫地机器人的纪元。这款售价2000美元的"初代机"工作时像喝醉的水手,随机碰撞的清扫方式让用户直呼"买了个寂寞"。谁能想到,这个当初被戏称为"人工智障"的发…...

C 语 言 --- 数 据 类 型 的 存 储
C 语 言 --- 数 据 类 型 的 存 储 空 类 型大 小 端 存 储大 端 存 储 --- 正 着 放(从 小 到 大)小 端 存 储 --- 倒 着 放(从 大 到 小) 浮 点 型 在 内 存 中 的 存 储总结 💻作 者 简 介:曾 与 你 一 …...

3.8 字符串的常用函数
重点:字符串的常用函数 #1.测试转换大小写 lower:大写->小写 upper:小写->大写 swapcase:自动将大写转小写小写转大写 print("ABC".lower()) #abcprint("abc".upper()) #ABCprint…...

事件触发控制与响应驱动控制的定义、种类及区别
一、定义 事件触发控制(Event-Triggered Control, ETC) 事件触发控制是一种基于动态条件触发的控制策略,其核心在于通过预设的事件触发条件(如系统状态误差超过阈值、特定信号到达等)来决定何时更新控制信号或进行通信…...

Android离屏渲染
写在前面 与iOS同事聊天时聊到圆角会使用离屏渲染的方式绘制,影响性能;Android上有没有不知道,学习了一下整理了这篇文章。 Android 圆角与离屏渲染(Offscreen Rendering) 一、什么是离屏渲染? 离屏渲染…...