OpenGL学习笔记(几何着色器、实例化、抗锯齿)
目录
- 几何着色器
- 爆破物体
- 法向量可视化
- 实例化(偏移量存在uniform中)
- 实例化数组(偏移量存在顶点属性中)
- 小行星带
- 抗锯齿
- SSAA(Super Sample Anti-aliasing)
- MSAA(Multi-Sampling Anti-aliasing)
- OpenGL中的MSAA
- 离屏MSAA
- 多重采样纹理附件
- 多重采样渲染缓冲对象
- 渲染到多重采样帧缓冲
- 自定义抗锯齿算法
GitHub主页:https://github.com/sdpyy1
OpenGL学习仓库:https://github.com/sdpyy1/CppLearn/tree/main/OpenGLtree/main/OpenGL):https://github.com/sdpyy1/CppLearn/tree/main/OpenGL
几何着色器
在顶点着色器和片段着色器中间还可以添加一个几何着色器(Geometry Shader),输入为图元,可以将顶点进行随意的变换。它能够将(这一组)顶点变换为完全不同的图元,并且还能生成比原来更多的顶点。
下面是顶点着色器的一个例子
#version 330 core
layout (points) in;
layout (line_strip, max_vertices = 2) out;void main() { gl_Position = gl_in[0].gl_Position + vec4(-0.1, 0.0, 0.0, 0.0); EmitVertex();gl_Position = gl_in[0].gl_Position + vec4( 0.1, 0.0, 0.0, 0.0);EmitVertex();EndPrimitive();
}
其中layout (points) in;用于声明图元的类型(可以是点、线、三角形等待),接下来还需要指定输出的图元类型,这里输出的是line_strip,将最大顶点数设置为2个(EmitVertex()最多执行两次)。
为了生成更有意义的结果,我们需要某种方式来获取前一着色器阶段的输出。GLSL提供给我们一个名为gl_in的内建(Built-in)变量,在内部看起来(可能)是这样的:
in gl_Vertex
{vec4 gl_Position;float gl_PointSize;float gl_ClipDistance[];
} gl_in[];
要注意的是,它被声明为一个数组,因为大多数的渲染图元包含多于1个的顶点,而几何着色器的输入是一个图元的所有顶点。
下面意思就是在输入图元是点时,输出点是把这个点左移一个单位和右移一个单位的两个点连成的线
void main() {gl_Position = gl_in[0].gl_Position + vec4(-0.1, 0.0, 0.0, 0.0); EmitVertex();gl_Position = gl_in[0].gl_Position + vec4( 0.1, 0.0, 0.0, 0.0);EmitVertex();EndPrimitive();
}
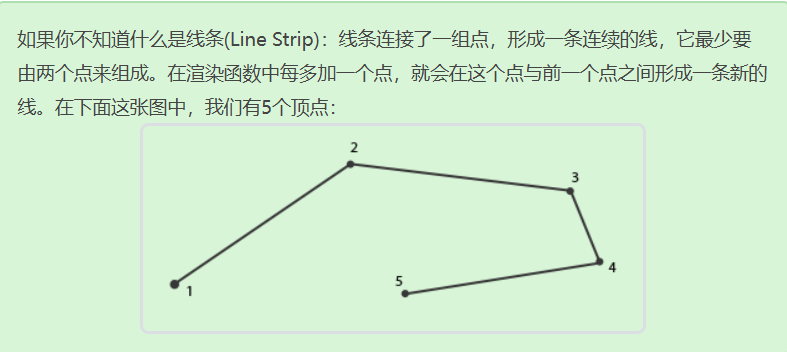
通过这个几何着色器,输入4个顶点渲染时,输出会变成四条线
下面来进行实际演示
float points[] = {-0.5f, 0.5f, // 左上0.5f, 0.5f, // 右上0.5f, -0.5f, // 右下-0.5f, -0.5f // 左下
};
shader.use();
glBindVertexArray(VAO);
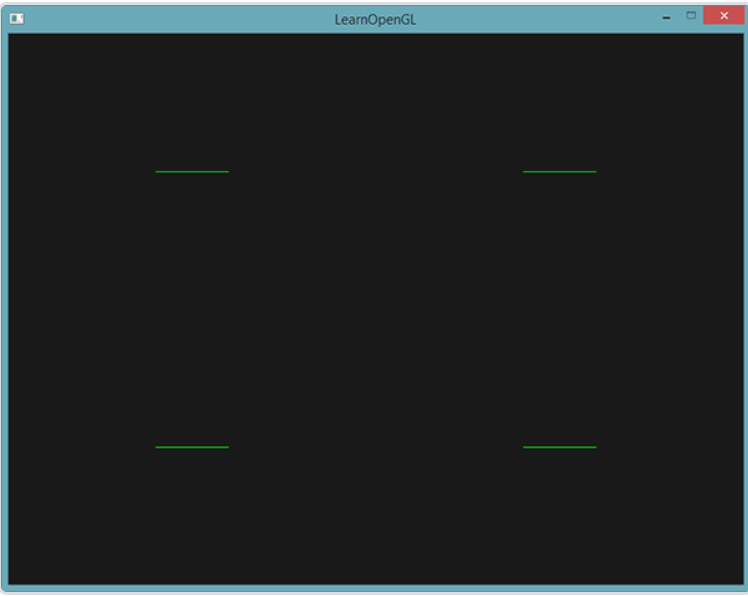
glDrawArrays(GL_POINTS, 0, 4);
先绘制出4个点

下来创建一个几何着色器,不做任何处理,直接发射
#version 330 core
layout(points) in;
layout(points, max_vertices = 1) out;
void main(){gl_Position = gl_in[0].gl_Position;EmitVertex();EndPrimitive();
}
shader编译时添加几何着色器的编译
Shader(const char* vertexPath, const char* geometryPath ,const char* fragmentPath){// 1. retrieve the vertex/fragment source code from filePathstd::string vertexCode;std::string fragmentCode;std::string geometryCode;std::ifstream vShaderFile;std::ifstream fShaderFile;std::ifstream gShaderFile;// ensure ifstream objects can throw exceptions:vShaderFile.exceptions (std::ifstream::failbit | std::ifstream::badbit);fShaderFile.exceptions (std::ifstream::failbit | std::ifstream::badbit);gShaderFile.exceptions (std::ifstream::failbit | std::ifstream::badbit);try{// open filesvShaderFile.open(vertexPath);fShaderFile.open(fragmentPath);gShaderFile.open(geometryPath);std::stringstream vShaderStream, fShaderStream, gShaderStream;// read file's buffer contents into streamsvShaderStream << vShaderFile.rdbuf();fShaderStream << fShaderFile.rdbuf();gShaderStream << gShaderFile.rdbuf();// close file handlersvShaderFile.close();fShaderFile.close();gShaderFile.close();// convert stream into stringvertexCode = vShaderStream.str();fragmentCode = fShaderStream.str();geometryCode = gShaderStream.str();}catch (std::ifstream::failure& e){std::cout << "ERROR::SHADER::FILE_NOT_SUCCESSFULLY_READ: " << e.what() << std::endl;}const char* vShaderCode = vertexCode.c_str();const char * fShaderCode = fragmentCode.c_str();const char * gShaderCode = geometryCode.c_str();// 2. compile shadersunsigned int vertex, fragment, geometry;// vertex shaderGL_CALL(vertex = glCreateShader(GL_VERTEX_SHADER));GL_CALL(glShaderSource(vertex, 1, &vShaderCode, NULL));GL_CALL(glCompileShader(vertex));GL_CALL(checkCompileErrors(vertex, "VERTEX"));// 几何着色器GL_CALL(geometry = glCreateShader(GL_GEOMETRY_SHADER));glShaderSource(geometry, 1, &gShaderCode, NULL);glCompileShader(geometry);GL_CALL(checkCompileErrors(geometry, "GEOMETRY"));// fragment ShaderGL_CALL(fragment = glCreateShader(GL_FRAGMENT_SHADER));GL_CALL(glShaderSource(fragment, 1, &fShaderCode, NULL));GL_CALL(glCompileShader(fragment));GL_CALL(checkCompileErrors(fragment, "FRAGMENT"));// shader ProgramGL_CALL(ID = glCreateProgram());GL_CALL(glAttachShader(ID, vertex));GL_CALL(glAttachShader(ID, fragment));GL_CALL(glAttachShader(ID, geometry));GL_CALL(glLinkProgram(ID));GL_CALL(checkCompileErrors(ID, "PROGRAM"));// delete the shaders as they're linked into our program now and no longer necessaryGL_CALL(glDeleteShader(vertex));GL_CALL(glDeleteShader(fragment));GL_CALL(glDeleteShader(geometry));}
这里要理解最终调用的是画点的指令glDrawArrays(GL_POINTS, 0, 4);所以几何着色器运行一次只能得到一个点。通过一个点的位移来得到不同的输出点,而不是可以一口气输入3个点。
修改几何着色器
#version 330 core
layout (points) in;
layout (triangle_strip, max_vertices = 5) out;void build_house(vec4 position)
{gl_Position = position + vec4(-0.2, -0.2, 0.0, 0.0); // 1:左下EmitVertex();gl_Position = position + vec4( 0.2, -0.2, 0.0, 0.0); // 2:右下EmitVertex();gl_Position = position + vec4(-0.2, 0.2, 0.0, 0.0); // 3:左上EmitVertex();gl_Position = position + vec4( 0.2, 0.2, 0.0, 0.0); // 4:右上EmitVertex();gl_Position = position + vec4( 0.0, 0.4, 0.0, 0.0); // 5:顶部EmitVertex();EndPrimitive();
}
void main() {build_house(gl_in[0].gl_Position);
}

进一步我们可以在几何着色器中处理颜色
首先在顶点着色器传递颜色,用接口快传递
#version 330 core
layout (location = 0) in vec2 aPos;
layout (location = 1) in vec3 aColor;out VS_OUT {vec3 color;
} vs_out;void main()
{gl_Position = vec4(aPos.x, aPos.y, 0.0, 1.0);vs_out.color = aColor;
}
注意接收接口块的时候使用数组接收(应该是为了兼容输入图元是三角形的情况),之后还要把颜色输出
#version 330 core
layout (points) in;
layout (triangle_strip, max_vertices = 5) out;
in VS_OUT {vec3 color;
} gs_in[];
out vec3 fColor;void build_house(vec4 position)
{fColor = gs_in[0].color; // gs_in[0] 因为只有一个输入顶点gl_Position = position + vec4(-0.2, -0.2, 0.0, 0.0); // 1:左下EmitVertex();gl_Position = position + vec4( 0.2, -0.2, 0.0, 0.0); // 2:右下EmitVertex();gl_Position = position + vec4(-0.2, 0.2, 0.0, 0.0); // 3:左上EmitVertex();gl_Position = position + vec4( 0.2, 0.2, 0.0, 0.0); // 4:右上EmitVertex();gl_Position = position + vec4( 0.0, 0.4, 0.0, 0.0); // 5:顶部EmitVertex();EndPrimitive();
}void main() {build_house(gl_in[0].gl_Position);
}

如果在发射某个顶点时修改了fcolor的值,那这个顶点的数据就会被修改,
gl_Position = position + vec4( 0.0, 0.4, 0.0, 0.0); // 5:顶部fColor = vec3(1.0, 1.0, 1.0);EmitVertex();
所以顶部的颜色设置为了白色,通过插值就有了下图的效果

爆破物体
我们将每个三角形在几何着色器中沿着法向量移动一小段时间。
首先把代码恢复到展示一个背包的状态。
几何着色器输入是三角形,输出也是三角形,在发射三个顶点的时候,修改顶点的位置
#version 330 core
layout (triangles) in;
layout (triangle_strip, max_vertices = 3) out;in VS_OUT {vec2 texCoords;
} gs_in[];out vec2 TexCoords; uniform float time;vec4 explode(vec4 position, vec3 normal) { ... }vec3 GetNormal() { ... }void main() { vec3 normal = GetNormal();gl_Position = explode(gl_in[0].gl_Position, normal);TexCoords = gs_in[0].texCoords;EmitVertex();gl_Position = explode(gl_in[1].gl_Position, normal);TexCoords = gs_in[1].texCoords;EmitVertex();gl_Position = explode(gl_in[2].gl_Position, normal);TexCoords = gs_in[2].texCoords;EmitVertex();EndPrimitive();
}
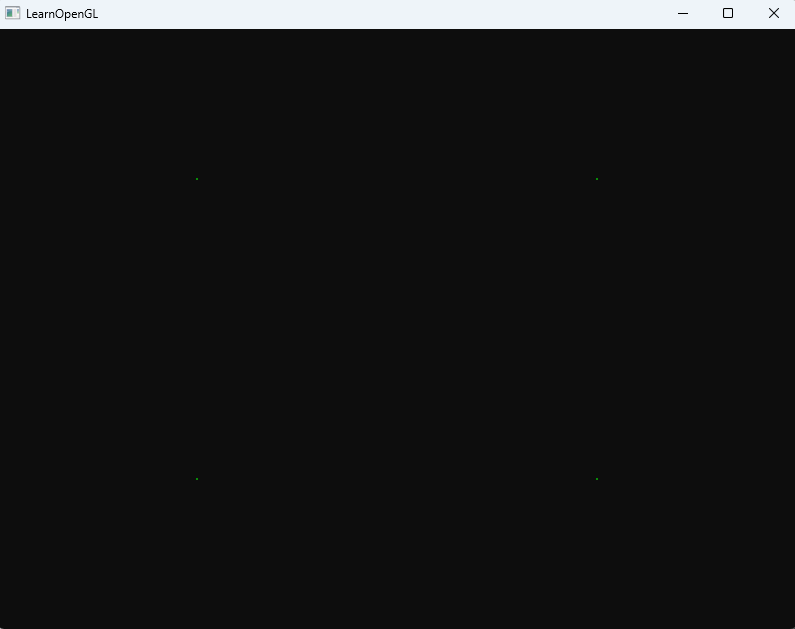
法向量可视化
三角形图元输入后额外添加3个法向量方向的点,输出图元为线图,所以会绘制出三角形+三条法线
#version 330 core
layout (triangles) in;
layout (line_strip, max_vertices = 6) out;in VS_OUT {vec3 normal;
} gs_in[];const float MAGNITUDE = 0.4;uniform mat4 projection;void GenerateLine(int index)
{gl_Position = projection * gl_in[index].gl_Position;EmitVertex();gl_Position = projection * (gl_in[index].gl_Position +vec4(gs_in[index].normal, 0.0) * MAGNITUDE);EmitVertex();EndPrimitive();
}void main()
{GenerateLine(0); // 第一个顶点法线GenerateLine(1); // 第二个顶点法线GenerateLine(2); // 第三个顶点法线
}
第一遍用正常的shader进行渲染,第二次渲染用这一套shader,就可以实现如下效果

换个模型
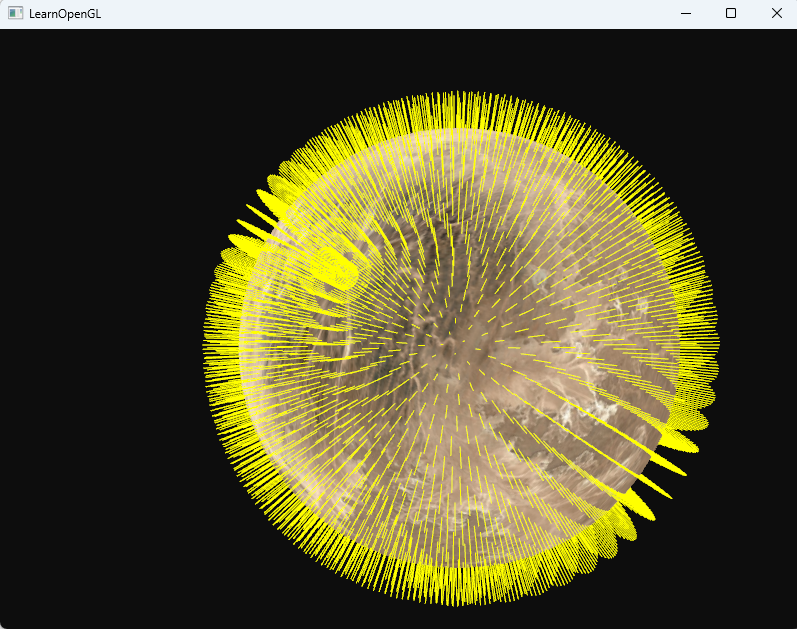
除了让我们的背包变得毛茸茸之外,它还能让我们很好地判断模型的法向量是否准确。你可以想象到,这样的几何着色器也经常用于给物体添加毛发(Fur)。
实例化(偏移量存在uniform中)
当一个模型通过修改Model变换矩阵后渲染多份(草地),如果我们需要渲染大量物体时,代码看起来会像这样:
for(unsigned int i = 0; i < amount_of_models_to_draw; i++)
{DoSomePreparations(); // 绑定VAO,绑定纹理,设置uniform等glDrawArrays(GL_TRIANGLES, 0, amount_of_vertices);
}
如果像这样绘制模型的大量实例(Instance),你很快就会因为绘制调用过多而达到性能瓶颈。【因为OpenGL在绘制顶点数据之前需要做很多准备工作(比如告诉GPU该从哪个缓冲读取数据,从哪寻找顶点属性,而且这些都是在相对缓慢的CPU到GPU总线(CPU to GPU Bus)上进行的)。所以,即便渲染顶点非常快,命令GPU去渲染却未必】。
如果我们能够将数据一次性发送给GPU,然后使用一个绘制函数让OpenGL利用这些数据绘制多个物体,就会更方便了。这就是实例化(Instancing)。
glDrawArraysInstanced和glDrawElementsInstanced就是用来实例化的,这些渲染函数需要需要一个额外的参数,叫做实例数量(Instance Count)。这样我们只需要将必须的数据发送到GPU一次,然后使用一次函数调用告诉GPU它应该如何绘制这些实例。
但我们还需要考虑是在不同的位置渲染,出于这个原因,GLSL在顶点着色器中嵌入了另一个内建变量,gl_InstanceID。
在使用实例化渲染调用时,gl_InstanceID会从0开始,在每个实例被渲染时递增1。比如说,我们正在渲染第43个实例,那么顶点着色器中它的gl_InstanceID将会是42。
具体做法就是在片段着色器中添加一个uniform,表示偏移量数组,刚好用gl_InstanceID可以来表示渲染的id
uniform vec2 offsets[100];
main中:vec2 offset = offsets[gl_InstanceID];gl_Position = vec4(aPos + offset, 0.0, 1.0);
下来就需要填充这些参数了,之后直接调glDrawArraysInstanced(GL_TRIANGLES, 0, 6, 100);来渲染一百次。这样就是一次性交给GPU100条渲染,每条渲染都有一个gl_InstanceID
调用过程就是每次渲染传入的gl_InstanceID是不一样的,所以偏移量也不同。
实例化数组(偏移量存在顶点属性中)
如果我们渲染个数特别多,偏移量将达到uniform数据上限,替代方案就是实例化数组,他被定义为一个顶点属性,只有渲染一个新的实例时才会刷新。
可以把在程序中定义的偏移量数组装在一个VBO中
unsigned int instanceVBO;
glGenBuffers(1, &instanceVBO);
glBindBuffer(GL_ARRAY_BUFFER, instanceVBO);
glBufferData(GL_ARRAY_BUFFER, sizeof(glm::vec2) * 100, &translations[0], GL_STATIC_DRAW);
glBindBuffer(GL_ARRAY_BUFFER, 0);
并设置VAO
glEnableVertexAttribArray(2);
glBindBuffer(GL_ARRAY_BUFFER, instanceVBO);
glVertexAttribPointer(2, 2, GL_FLOAT, GL_FALSE, 2 * sizeof(float), (void*)0);
glBindBuffer(GL_ARRAY_BUFFER, 0);
glVertexAttribDivisor(2, 1);
调用glVertexAttribDivisor告诉了OpenGl该什么时候更新顶点属性内容到新一组数据,第一个参数是需要的顶点属性,第二个参数是属性除数,属性除数是0,告诉OpenGL我们需要在顶点着色器的每次迭代时更新顶点属性。将它设置为1时,我们告诉OpenGL我们希望在渲染一个新实例的时候更新顶点属性。而设置为2时,我们希望每2个实例更新一次属性,以此类推。我们将属性除数设置为1,是在告诉OpenGL,处于位置值2的顶点属性是一个实例化数组。
看下边这个就懂了,设置属性位置1,2时还是正常进行,但属性3不是来自的不是quadVBO(也就是顶点数据),而是来自instanceVBO(就是偏移量数据),它存储在layout(location = 2),并通过glVertexAttribDivisor来告诉2号参数每个实例化取下一个。
unsigned int quadVAO, quadVBO;glGenVertexArrays(1, &quadVAO);glGenBuffers(1, &quadVBO);glBindVertexArray(quadVAO);glBindBuffer(GL_ARRAY_BUFFER, quadVBO);glBufferData(GL_ARRAY_BUFFER, sizeof(quadVertices), quadVertices, GL_STATIC_DRAW);glEnableVertexAttribArray(0);glVertexAttribPointer(0, 2, GL_FLOAT, GL_FALSE, 5 * sizeof(float), (void*)0);glEnableVertexAttribArray(1);glVertexAttribPointer(1, 3, GL_FLOAT, GL_FALSE, 5 * sizeof(float), (void*)(2 * sizeof(float)));// also set instance dataglEnableVertexAttribArray(2);glBindBuffer(GL_ARRAY_BUFFER, instanceVBO); // this attribute comes from a different vertex bufferglVertexAttribPointer(2, 2, GL_FLOAT, GL_FALSE, 2 * sizeof(float), (void*)0);glBindBuffer(GL_ARRAY_BUFFER, 0);glVertexAttribDivisor(2, 1); // tell OpenGL this is an instanced vertex attribute.
按照这样理解,那属性0和属性1其实事实上就是每个顶点刷新一次,也就是调用了
glVertexAttribDivisor(0,0)和glVertexAttribDivisor(1, 0)
从另外一个角度理解就是这些layout的参数是可以设置刷新时机(每个顶点或每次实例化)的,不过只有在调用实例化绘制方法glDrawArraysInstanced(GL_TRIANGLES, 0, 6, 100);时才会生效
layout (location = 0) in vec2 aPos;
layout (location = 1) in vec3 aColor;
layout (location = 2) in vec2 aOffset;
小行星带
围绕星体旋转的岩石就可以用同一个模型进行渲染。实例化很适合的场景。
如果直接渲染1000次代码如下
const unsigned int SCR_WIDTH = 800;
const unsigned int SCR_HEIGHT = 600;
// camera
Camera camera(glm::vec3(0.0f, 10.0f, 70.0f));
float lastX = SCR_WIDTH / 2.0f;
float lastY = SCR_HEIGHT / 2.0f;
bool firstMouse = true;
// timing
float deltaTime = 0.0f; // time between current frame and last frame
float lastFrame = 0.0f;int main(){// 初始化窗口GLFWwindow * window = InitWindowAndFunc();stbi_set_flip_vertically_on_load(true);// 启用深度测试glEnable(GL_DEPTH_TEST);// 加载模型Model rock("./assets/rock/rock.obj");Model planet("./assets/planet/planet.obj");// 加载shaderShader shader("./shader/rockAndPlanet.vert", "./shader/rockAndPlanet.frag");unsigned int amount = 1000;glm::mat4* modelMatrices;modelMatrices = new glm::mat4[amount];srand(static_cast<unsigned int>(glfwGetTime())); // initialize random seedfloat radius = 50.0;float offset = 2.5f;for (unsigned int i = 0; i < amount; i++){glm::mat4 model = glm::mat4(1.0f);// 1. translation: displace along circle with 'radius' in range [-offset, offset]float angle = (float)i / (float)amount * 360.0f;float displacement = (rand() % (int)(2 * offset * 100)) / 100.0f - offset;float x = sin(angle) * radius + displacement;displacement = (rand() % (int)(2 * offset * 100)) / 100.0f - offset;float y = displacement * 0.4f; // keep height of asteroid field smaller compared to width of x and zdisplacement = (rand() % (int)(2 * offset * 100)) / 100.0f - offset;float z = cos(angle) * radius + displacement;model = glm::translate(model, glm::vec3(x, y, z));// 2. scale: Scale between 0.05 and 0.25ffloat scale = static_cast<float>((rand() % 20) / 100.0 + 0.05);model = glm::scale(model, glm::vec3(scale));// 3. rotation: add random rotation around a (semi)randomly picked rotation axis vectorfloat rotAngle = static_cast<float>((rand() % 360));model = glm::rotate(model, rotAngle, glm::vec3(0.4f, 0.6f, 0.8f));// 4. now add to list of matricesmodelMatrices[i] = model;}while (!glfwWindowShouldClose(window)){// 清理窗口glClearColor(0.05f, 0.05f, 0.05f, 1.0f);glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);glm::mat4 projection = glm::perspective(glm::radians(45.0f), (float)SCR_WIDTH / (float)SCR_HEIGHT, 0.1f, 1000.0f);glm::mat4 view = camera.GetViewMatrix();;shader.use();shader.setMat4("projection", projection);shader.setMat4("view", view);// draw planetglm::mat4 model = glm::mat4(1.0f);model = glm::translate(model, glm::vec3(0.0f, -3.0f, 0.0f));model = glm::scale(model, glm::vec3(4.0f, 4.0f, 4.0f));shader.setMat4("model", model);planet.Draw(shader);// draw meteoritesfor (unsigned int i = 0; i < amount; i++){shader.setMat4("model", modelMatrices[i]);rock.Draw(shader);}// 事件处理glfwPollEvents();// 双缓冲glfwSwapBuffers(window);processFrameTimeForMove();processInput(window);}glfwTerminate();return 0;
}1000次独立渲染我的4070ts还完全hold住,
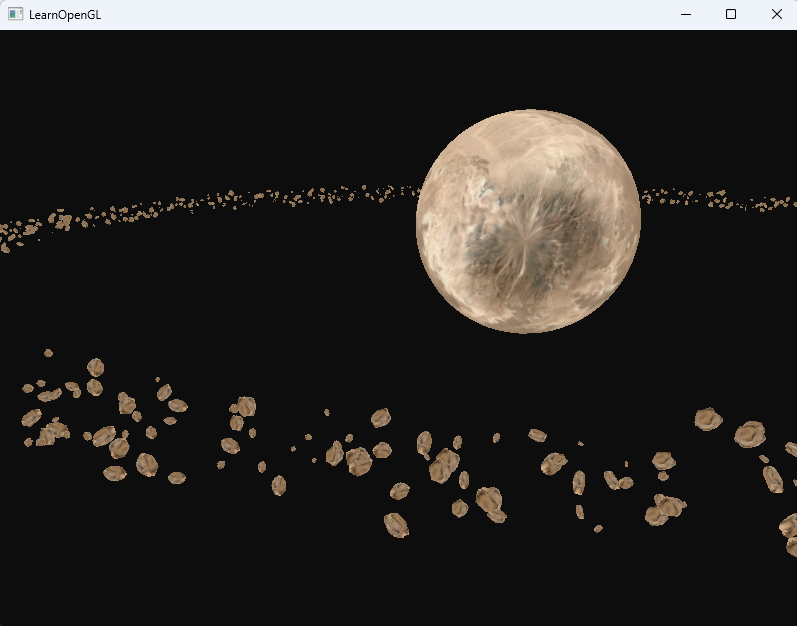
但是到了10000次就开始卡顿了,最后调整到100000次就很卡了
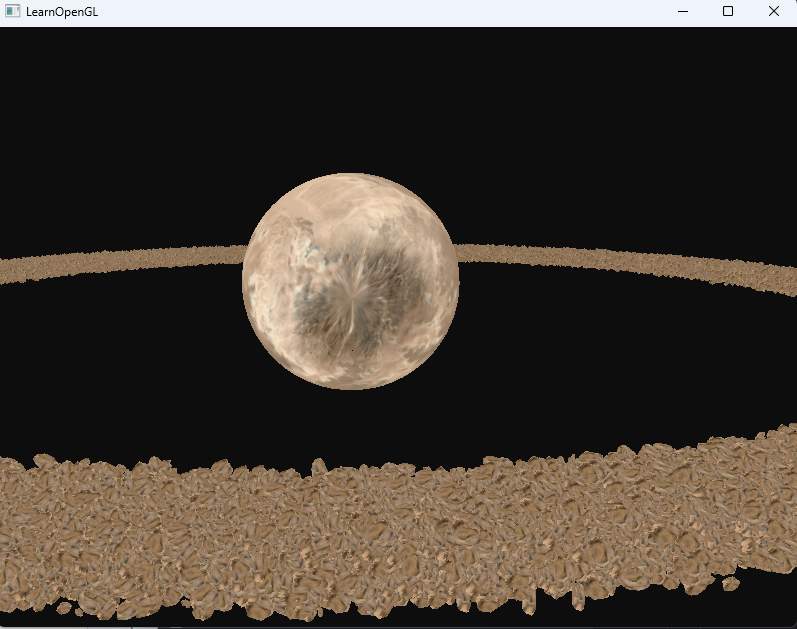
接着调整到100w次,就已经是5s一帧了
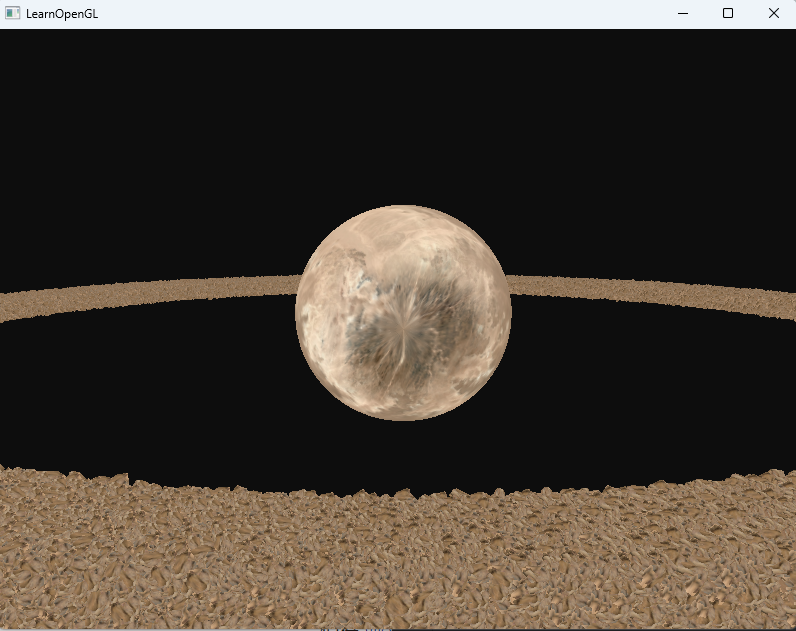
下面用实例化数组来进行优化,首先调整顶点着色器来接收数组(直接把Model变换矩阵存在数组里)
#version 330 core
layout (location = 0) in vec3 aPos;
layout (location = 2) in vec2 aTexCoords;
layout (location = 3) in mat4 instanceMatrix;out vec2 TexCoords;uniform mat4 projection;
uniform mat4 view;void main()
{gl_Position = projection * view * instanceMatrix * vec4(aPos, 1.0); TexCoords = aTexCoords;
}
把刚才存放model变换矩阵的数组存入显存中
// 数组存入VBO中待用unsigned int buffer;glGenBuffers(1, &buffer);glBindBuffer(GL_ARRAY_BUFFER, buffer);glBufferData(GL_ARRAY_BUFFER, amount * sizeof(glm::mat4), &modelMatrices[0], GL_STATIC_DRAW);
修改rock的VAO,让他接收该VBO,这里注意每个Vertex Attribute槽位最多接收4个分量,如果向存储4维矩阵,就得绑定4个属性的位置,但是接收只需要用最前边的location来接收
for (unsigned int i = 0; i < rock.meshes.size(); i++){unsigned int VAO = rock.meshes[i].VAO;glBindVertexArray(VAO);// set attribute pointers for matrix (4 times vec4)glEnableVertexAttribArray(3);glVertexAttribPointer(3, 4, GL_FLOAT, GL_FALSE, sizeof(glm::mat4), (void*)0);glEnableVertexAttribArray(4);glVertexAttribPointer(4, 4, GL_FLOAT, GL_FALSE, sizeof(glm::mat4), (void*)(sizeof(glm::vec4)));glEnableVertexAttribArray(5);glVertexAttribPointer(5, 4, GL_FLOAT, GL_FALSE, sizeof(glm::mat4), (void*)(2 * sizeof(glm::vec4)));glEnableVertexAttribArray(6);glVertexAttribPointer(6, 4, GL_FLOAT, GL_FALSE, sizeof(glm::mat4), (void*)(3 * sizeof(glm::vec4)));glVertexAttribDivisor(3, 1);glVertexAttribDivisor(4, 1);glVertexAttribDivisor(5, 1);glVertexAttribDivisor(6, 1);glBindVertexArray(0);}
最后渲染岩石的方法改为,因为rock不止一个mesh
for (unsigned int i = 0; i < rock.meshes.size(); i++){glBindVertexArray(rock.meshes[i].VAO);glDrawElementsInstanced(GL_TRIANGLES, static_cast<unsigned int>(rock.meshes[i].indices.size()), GL_UNSIGNED_INT, 0, amount);glBindVertexArray(0);}
直接上100w测试,从5s一帧变为不到1s一帧,提升还是很大的
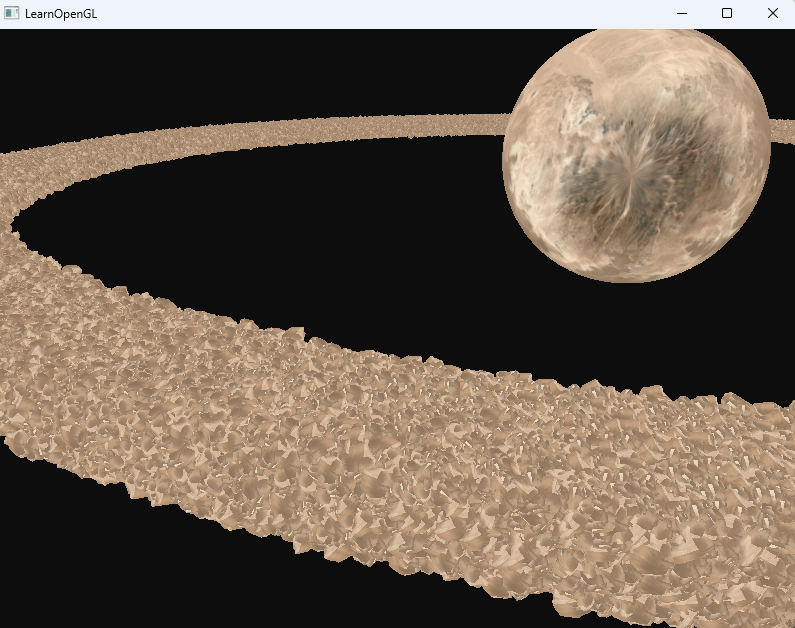
可以看到,在合适的环境下,实例化渲染能够大大增加显卡的渲染能力。正是出于这个原因,实例化渲染通常会用于渲染草、植被、粒子,以及上面这样的场景,基本上只要场景中有很多重复的形状,都能够使用实例化渲染来提高性能。
抗锯齿
这里不过多介绍抗锯齿的原因,采用一位大佬的话
锯齿的来源是因为场景的定义在三维空间中是连续的,而最终显示的像素则是一个离散的二维数组。所以判断一个点到底没有被某个像素覆盖的时候单纯是一个“有”或者“没有"问题,丢失了连续性的信息,导致锯齿。也叫做走样Aliasing,所以抗锯齿就是反走样(Anti-aliasing)

SSAA(Super Sample Anti-aliasing)
最直接的抗锯齿方法就是SSAA(Super Sampling AA)。拿4xSSAA举例子,假设最终屏幕输出的分辨率是800x600, 4xSSAA就会先渲染到一个分辨率1600x1200的buffer上,然后再直接把这个放大4倍的buffer下采样致800x600。这种做法在数学上是最完美的抗锯齿。但是劣势也很明显,光栅化和着色的计算负荷都比原来多了4倍,render target的大小也涨了4倍。
之前不是学过OpenGL的离线渲染吗,就可以先在自定义帧缓冲中渲染一个高分辨的图片加入到纹理中,在0号帧缓冲中再采样纹理,即可达到SSAA的目的
MSAA(Multi-Sampling Anti-aliasing)
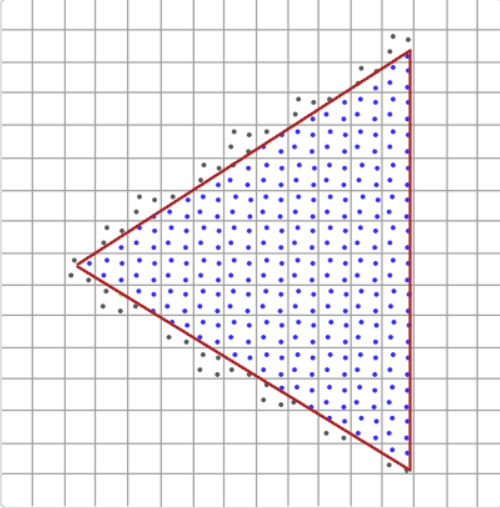
光栅器是位于最终处理过的顶点之后到片段着色器之前所经过的所有的算法与过程的总和。
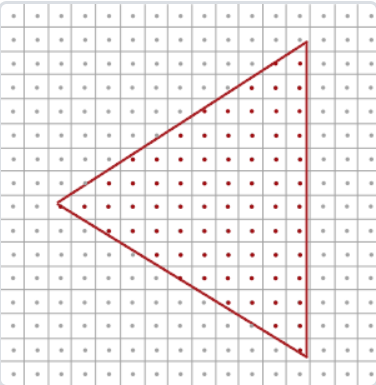
从上图到下图就有锯齿了
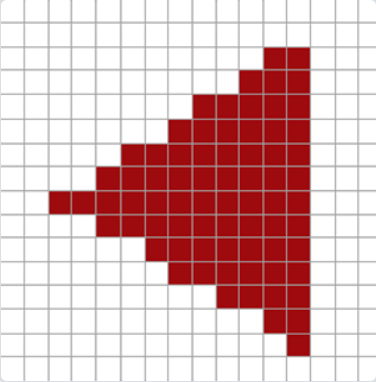
一张图就解释MSAA在干什么了。
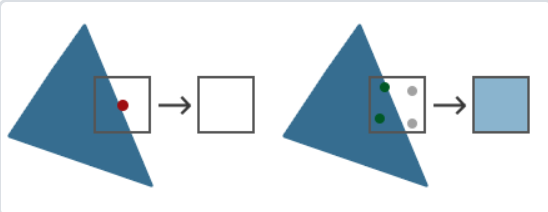
三角形的不平滑边缘被稍浅的颜色所包围后,从远处观察时就会显得更加平滑了。
OpenGL中的MSAA
走样的效果

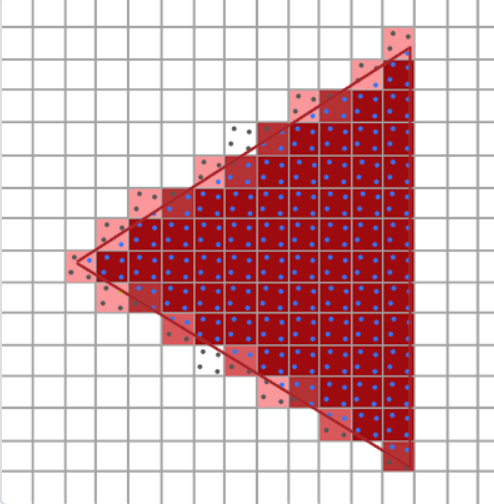
开启MSAA需要在创建窗口之前告诉OpenGL需要多重采样,每个像素有了4个颜色缓冲,4代表每个像素将会被采样4次(都cover的情况下),每次采样都会获得一个子像素值,这些值最终被平均以生成最终的像素颜色
glfwWindowHint(GLFW_SAMPLES, 4);4次采样发生在光栅化之后,片段着色器执行之前。
光栅化首先将三角形顶点通过视口变换转变到屏幕坐标上,之后对三角形求包围盒,变量包围盒中的像素,判断那些像素点在三角形内部,通过插值算出该像素对应的UV坐标,利用该坐标去纹理图片中取颜色。
4个采样点说明一个像素4个点都需要做一次判断是否在三角形内部的操作,在三角形内部的点取纹理上采样,并写入对应的子颜色缓冲,不在三角形内部的点就不改变目前子颜色缓冲中的值
开启MSAA(其实默认就是开启的)
glEnable(GL_MULTISAMPLE);
因为多重采样的算法都在OpenGL驱动的光栅器中实现了,我们不需要再多做什么。
开启后

离屏MSAA
由于GLFW负责了创建多重采样缓冲,启用MSAA非常简单。然而,如果我们想要使用我们自己的帧缓冲来进行离屏渲染,那么我们就必须要自己动手生成多重采样缓冲了。现在,我们确实需要自己创建多重采样缓冲区。
有两种方式可以创建多重采样缓冲,将其作为帧缓冲的附件:纹理附件和渲染缓冲附件
多重采样纹理附件
为了创建一个支持储存多个采样点的纹理,我们使用glTexImage2DMultisample来替代glTexImage2D,它的纹理目标是GL_TEXTURE_2D_MULTISAPLE。
glBindTexture(GL_TEXTURE_2D_MULTISAMPLE, tex);
glTexImage2DMultisample(GL_TEXTURE_2D_MULTISAMPLE, samples, GL_RGB, width, height, GL_TRUE);
glBindTexture(GL_TEXTURE_2D_MULTISAMPLE, 0);
我们使用glFramebufferTexture2D将多重采样纹理附加到帧缓冲上,但这里纹理类型使用的是GL_TEXTURE_2D_MULTISAMPLE。
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, GL_TEXTURE_2D_MULTISAMPLE, tex, 0);
多重采样渲染缓冲对象
同样也是创建RBO并绑定。在设置深度和模板缓冲时,要切换为多重采样的缓冲
glRenderbufferStorageMultisample(GL_RENDERBUFFER, 4, GL_DEPTH24_STENCIL8, width, height);
渲染到多重采样帧缓冲
因为多重采样缓冲有一点特别,我们不能直接将它们的缓冲图像用于其他运算,比如在着色器中对它们进行采样。
一个多重采样的图像包含比普通图像更多的信息,我们所要做的是缩小或者还原(Resolve)图像。多重采样帧缓冲的还原通常是通过glBlitFramebuffer来完成,它能够将一个帧缓冲中的某个区域复制到另一个帧缓冲中,并且将多重采样缓冲还原。
glBindFramebuffer(GL_READ_FRAMEBUFFER, multisampledFBO);
glBindFramebuffer(GL_DRAW_FRAMEBUFFER, 0);
glBlitFramebuffer(0, 0, width, height, 0, 0, width, height, GL_COLOR_BUFFER_BIT, GL_NEAREST);
自定义抗锯齿算法
将一个多重采样的纹理图像不进行还原直接传入着色器也是可行的。GLSL提供了这样的选项,让我们能够对纹理图像的每个子样本进行采样,所以我们可以创建我们自己的抗锯齿算法。在大型的图形应用中通常都会这么做。
要想获取每个子样本的颜色值,你需要将纹理uniform采样器设置为sampler2DMS,而不是平常使用的sampler2D:
uniform sampler2DMS screenTextureMS;
使用texelFetch函数就能够获取每个子样本的颜色值了:
vec4 colorSample = texelFetch(screenTextureMS, TexCoords, 3); // 第4个子样本
相关文章:
)
OpenGL学习笔记(几何着色器、实例化、抗锯齿)
目录 几何着色器爆破物体法向量可视化 实例化(偏移量存在uniform中)实例化数组(偏移量存在顶点属性中)小行星带 抗锯齿SSAA(Super Sample Anti-aliasing)MSAA(Multi-Sampling Anti-aliasing&…...

Git 学习笔记
这篇笔记记录了我在git学习中常常用到的指令,方便在未来进行查阅。此篇文章也会根据笔者的学习进度持续更新。 网站分享 Git 常用命令大全 Learn Git Branching 基础 $ git init //在当前位置配置一个git版本库 $ git add <file> //将文件添加至…...

浅析停车管理系统接入AI的提升
随着人工智能技术的快速发展,传统停车管理系统正在经历智能化变革。AI技术的引入不仅解决了停车管理中的诸多痛点,更为智慧城市建设提供了重要支撑。本文将从效率提升、体验优化、管理升级三个方面,详细分析AI技术为停车管理系统带来的显著提…...

PCL八叉树聚类
PCL八叉树聚类 主要流程完整代码部分代码解析关键元素解析std::for_each算法Lambda表达式等价 效果 主要流程 读取点云数据:从PCD文件中加载原始点云构建八叉树:对点云进行八叉树空间划分获取体素中心:提取八叉树中所有被占据的体素中…...

微服务最佳实践:全链路可用性保障体系
微服务最佳实践:全链路可用性保障体系 一、流量管控:分级限流与负载均衡 (一)动态限流策略 单机限流:采用令牌桶(允许突发流量,固定速率生成令牌)或漏桶算法(流量整形,固定速率处理请求),如Go的time/rate、Uber的ratelimit库,控制单节点流量峰值。分布式限流:通…...

智慧声防:构筑海滨浴场安全屏障的应急广播系
海滨浴场是夏季旅游的热门目的地,但潮汐变化、离岸流、突发天气、溺水事故等安全隐患时刻威胁着游客安全。传统的安全管理依赖人工瞭望和喊话,存在覆盖范围有限、响应速度慢等问题。“智慧声防”应急广播系统,通过智能化、网络化、多场景协同…...

linux-vi和文件操作
在 Linux 系统的世界里,有一个核心思想贯穿始终,那就是 “万物都是文件”。这一理念极大地简化了系统资源的管理和操作,为用户和开发者提供了统一且高效的交互方式。本文将深入探讨这一理念在 Linux 文件系统中的具体体现,从硬盘分…...
)
MIT6.S081 - Lab8 Locks(锁优化 | 并发安全)
本篇是 MIT6.S081 2020 操作系统课程 Lab8 的实验笔记,目标是在保证并发安全的前提下,重新设计 内存分配器 和 块缓存 这两个部分代码,提高系统并发性能。 对于有项目经验的同学来说,实验的难度不算高,重点在于找出 “…...

TMS320F28P550SJ9学习笔记15:Lin通信SCI模式结构体寄存器
今日初步认识与配置使用Lin通信SCI模式,用结构体寄存器的方式编程 文章提供完整工程下载、测试效果图 我的单片机平台是这个: LIN通信引脚: LIN通信PIE中断: 这个 PIE Vector Table 表在手册111页: 这是提到LINa的PI…...

JavaWeb 课堂笔记 —— 11 MySQL 多表设计
本系列为笔者学习JavaWeb的课堂笔记,视频资源为B站黑马程序员出品的《黑马程序员JavaWeb开发教程,实现javaweb企业开发全流程(涵盖SpringMyBatisSpringMVCSpringBoot等)》,章节分布参考视频教程,为同样学习…...
)
2025年最新总结安全基础(面试题)
活动发起人@小虚竹 想对你说: 这是一个以写作博客为目的的创作活动,旨在鼓励大学生博主们挖掘自己的创作潜能,展现自己的写作才华。如果你是一位热爱写作的、想要展现自己创作才华的小伙伴,那么,快来参加吧!我们一起发掘写作的魅力,书写出属于我们的故事。我们诚挚邀请…...

调试chili3d笔记 typescript预习
https://github.com/xiangechen/chili3d 用firefox拓展附加进程 打开开发者 工具,这个网页按f12没反应,手动打开 创建一个立方体可以看到运行了create.box方法,消息来自commandService.ts 位置 太久没写c了,3目都看不懂了 c没有…...

【北交互联-注册/登录安全分析报告】
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 暴力破解密码,造成用户信息泄露短信盗刷的安全问题,影响业务及导致用户投诉带来经济损失,尤其是后付费客户,风险巨大,造成亏损无底洞…...

YOLOv2学习笔记
YOLOv2 背景 YOLOv2是YOLO的第二个版本,其目标是显著提高准确性,同时使其更快 相关改进: 添加了BN层——Batch Norm采用更高分辨率的网络进行分类主干网络的训练 Hi-res classifier去除了全连接层,采用卷积层进行模型的输出&a…...

2025年国企社招欧治链金再生资源入职测评笔试中智赛码平台SHL测试平台Verify认知能力测试
1、欧治链金政治素质测试(中智赛码平台,电脑端作答) 10个单选题、5个多选题、1个问答题 2、欧治链金综合素质测试(SHL测试平台Verify认知能力测试,电脑端作答) 3、欧治链金职业性格测试(中智职…...

MySQL索引和事务
MySQL索引和事务 1.索引1.1概念1.2作用1.3使用场景1.4使用1.4.1查看索引1.4.2创建索引1.4.3删除索引 2.事务2.1使用2.1.1开启事务2.1.2执行多条SQL语句2.1.3回滚或提交 2.2事务的特性2.2.1回滚是怎么做到的2.2.2原子性2.2.3一致性2.2.4持久性2.2.5隔离性2.2.5.1脏读2.2.5.2不可…...

【AI News | 20250415】每日AI进展
AI News 1、字节跳动发布Seaweed-7B视频模型:70亿参数实现音视频同步生成与多镜头叙事 字节跳动推出新一代视频生成模型Seaweed-7B,该模型仅70亿参数却实现多项突破:支持音视频同步生成、多镜头叙事(保持角色连贯性)、…...

MegaTTS3: 下一代高效语音合成技术,重塑AI语音的自然与个性化
在近期的发布中,浙江大学赵洲教授团队与字节跳动联合推出了革命性的第三代语音合成模型——MegaTTS3,该模型不仅在多个专业评测中展现了卓越的性能,还为AI语音的自然性和个性化开辟了新的篇章。 MegaTTS3技术亮点 零样本语音合成 MegaTTS3采用…...

MyBatis-Plus 详解教程
文章目录 1. MyBatis-Plus 简介1.1 什么是 MyBatis-Plus?1.2 为什么要使用 MyBatis-Plus?传统 MyBatis 的痛点MyBatis-Plus 的优势 1.3 MyBatis-Plus 与 MyBatis 的关系 2. 快速开始2.1 环境要求2.2 依赖引入MavenGradle 2.3 数据库准备2.4 配置 Spring …...

Java设计模式之观察者模式:从入门到架构级实践
一、观察者模式的核心价值 观察者模式(Observer Pattern)是行为型设计模式中的经典之作,它建立了对象间的一对多依赖关系,让多个观察者对象能够自动感知被观察对象的状态变化。这种模式在事件驱动系统、实时数据推送、GUI事件处理…...

【双指针】专题:LeetCode 202题解——快乐数
快乐数 一、题目链接二、题目三、题目解析四、算法原理扩展 五、编写代码 一、题目链接 快乐数 二、题目 三、题目解析 快乐数的定义中第二点最重要,只有两种情况,分别拿示例1、示例2分析吧: 示例1中一旦出现1了,继续重复过程就…...

深度学习占用大量内存空间解决办法
应该是缓存的问题,关机重启内存多了10G,暂时没找到别的方法 重启前 关机重启后...
)
[LeetCode 1871] 跳跃游戏 7(Ⅶ)
题面: 数据范围: 2 ≤ s . l e n g t h ≤ 1 0 5 2 \le s.length \le 10^5 2≤s.length≤105 s [ i ] s[i] s[i] 要么是 ′ 0 ′ 0 ′0′ ,要么是 ′ 1 ′ 1 ′1′ s [ 0 ] 0 s[0] 0 s[0]0 1 ≤ m i n J u m p ≤ m a x J u m p <…...

同济大学轻量化低成本具身导航!COSMO:基于选择性记忆组合的低开销视觉语言导航
作者:Siqi Zhang 1 ^{1} 1, Yanyuan Qiao 3 ^{3} 3, Qunbo Wang 2 ^{2} 2, Zike Yan 4 ^{4} 4, Qi Wu 3 ^{3} 3, Zhihua Wei 1 ^{1} 1, Jing Liu 1 ^{1} 1单位: 1 ^{1} 1同济大学计算机科学与技术学院, 2 ^{2} 2中科院自动化研究所࿰…...

【Ubuntu | 网络】Vmware虚拟机里的Ubuntu开机后没有网络接口、也没有网络图标
😁博客主页😁:🚀https://blog.csdn.net/wkd_007🚀 🤑博客内容🤑:🍭嵌入式开发、Linux、C语言、C、数据结构、音视频🍭 😎金句分享😎&a…...
)
第二十一讲 XGBoost 回归建模 + SHAP 可解释性分析(利用R语言内置数据集)
下面我将使用 R 语言内置的 mtcars 数据集,模拟一个完整的 XGBoost 回归建模 SHAP 可解释性分析 实战流程。我们将以预测汽车的油耗(mpg)为目标变量,构建 XGBoost 模型,并用 SHAP 来解释模型输出。 🚗 示例…...

HP惠普打印机:解决每次打印后额外产生@PJL SET USERNAME=文档的情况
情况描述 惠普商用打印机型号:Color LaserJet Managed MFP E78223 在每次打印文档后都会出现包含我个人电脑用户名的额外文档: 这不是我希望的,因此我联系了惠普官方客服,并得到了解决 解决方案 原因 具客服所说,这些是…...

MariaDB MaxScale 的用途与实现细节
MaxScale 主要用途 MariaDB MaxScale 是一个智能数据库代理(proxy),主要用于增强 MySQL/MariaDB 数据库的高可用性、可扩展性和安全性,同时简化应用程序与数据库基础设施之间的交互。它的核心功能包括: 负载均衡&…...

CTF--eval
一、原网页: 二、步骤: 1.代码分析: <?phpinclude "flag.php"; // 引入一个文件,该文件可能定义了一些变量(例如 $flag)$a $_REQUEST[hello]; // 从用户请求中获取参数 hello 的值&#x…...
)
Android学习总结之算法篇七(图和矩阵)
有向图的深度优先搜索(DFS)和广度优先搜索(BFS)的示例,以此来模拟遍历 GC Root 引用链这种有向图结构: 一、深度优先搜索(DFS) import java.util.*;public class GraphDFS {privat…...
)
vmcore分析锁问题实例(x86-64)
问题描述:系统出现panic,dmesg有如下打印: [122061.197311] task:irq/181-ice-enp state:D stack:0 pid:3134 ppid:2 flags:0x00004000 [122061.197315] Call Trace: [122061.197317] <TASK> [122061.197318] __schedule0…...

【vue3】vue3+express实现图片/pdf等资源文件的下载
文件资源的下载,是我们业务开发中常见的需求。作为前端开发,学习下如何自己使用node的express框架来实现资源的下载操作。 实现效果 代码实现 前端 1.封装的请求后端下载接口的方法,需求配置aixos的请求参数里面的返回数据类型为blob // 下载 export…...

【BUG】Redis RDB快照持久化及写操作禁止问题排查与解决
1 问题描述 在使用Redis 的过程中,遇到如下报错,错误信息是 “MISCONF Redis is configured to save RDB snapshots, but it is currently not able to persist on disk...”,记录下问题排查过程。 2 问题排查与解决 该错误提示表明&#…...

【HD-RK3576-PI】定制用户升级固件
硬件:HD-RK3576-PI 软件:Linux6.1Ubuntu22.04 在进行 Rockchip 相关开发时,制作自定义的烧写固件是一项常见且重要的操作。这里主要介绍文件系统的修改以及打包成完整update包升级的过程。 一、修改文件系统镜像(Ubuntu环境操作&…...

【AI学习】李宏毅老师讲AI Agent摘要
在b站听了李宏毅2025最新的AI Agent教程,简单易懂,而且紧跟发展,有大量最新的研究进展。 教程中引用了大量论文,为了方便将来阅读相关论文,进一步深入理解,做了截屏纪录。 同时也做一下分享。 根据经验调整…...

狂神SQL学习笔记十:修改和删除数据表字段
1、修改与删除表 alter 修改表的名称: 增加表的字段: 修改表的字段(重命名,修改约束): 修改约束 重命名 删除表的字段 删除表...

OSPF综合实验
一、网络拓扑 二、实验要求 1,R5为ISP,其上只能配置IP地址;R4作为企业边界路由器; 2,整个0SPF环境IP基于172.16.0.8/16划分; 3,所有设备均可访问R5的环回; 4,减少LSA的更新量,加快收敛…...

2025 cs144 Lab Checkpoint 2 小白超详细版
文章目录 1 环形索引的实现1.1 wrap类wrapunwrap 2 实现tcp_receiver2.1 tcp_receiver的功能2.2 传输的报文格式TCPSenderMessageTCPReceiverMessage 2.3 如何实现函数receive()send() 1 环形索引的实现 范围是0~2^32-1 需要有SY…...

VMware虚拟机安装Ubuntu 22.04.2
一、我的虚拟机版本 二、浏览器搜索Ubuntu 三、下载Ubuntu桌面版 四、下这个 五、创建新的虚拟机 六、选择典型,然后下一步 七、选择稍后安装操作系统,然后下一步 八、选择Linux ,版本选择Ubuntu 64位 九、选择好安装位置 十、磁盘大小一般选20G就够用了…...

XSS漏洞及常见处理方案
文章背景: 在近期项目安全测试中,安全团队发现了一处潜在的 跨站脚本攻击(XSS)漏洞,该漏洞可能导致用户数据被篡改或会话劫持等安全风险。针对这一问题,项目组迅速响应,通过代码修复、输入过滤、…...

TCP标志位抓包
说明 TCP协议的Header信息,URG、ACK、PSH、RST、SYN、FIN这6个字段在14字节的位置,对应的是tcp[13],因为字节数是从[0]开始数的,14字节对应的就是tcp[13],因此在抓这几个标志位的数据包时就要明确范围在tcp[13] 示例1…...

C/C++条件判断
条件判断 if语句的三种形态 if(a<b){} 、 if(a<b){}else{} 、 if(a<b){}else if(a>b) else{} if语句的嵌套 嵌套的常见错误(配对错误),与前面最近的,而且还没有配对的if匹配 错误避免方法:严格使用 { }、先写&am…...

单位门户网站被攻击后的安全防护策略
政府网站安全现状与挑战 近年来,随着数字化进程的加速,政府门户网站已成为政务公开和服务公众的重要窗口。然而,网络安全形势却日益严峻。国家互联网应急中心的数据显示,政府网站已成为黑客攻击的重点目标,被篡改和被…...

# 工具记录
工具记录 键盘操作可视化工具openark64系统工具dufs-webui文件共享zotero文献查看cff explorerNoFencesfreeplane开源思维导图...

C/C++运算
C语言字符串的比较 #include <string.h> int strcmp( const char *str1, const char *str2 );例如: int ret; ret strcmp(str1, str2);返回值: str1 < str2时, 返回值< 0(有些编译器返回 -1) str1 > str2时…...

CloudWeGo 技术沙龙·深圳站回顾:云原生 × AI 时代的微服务架构与技术实践
2025 年 3 月 22 日,CloudWeGo “云原生 AI 时代的微服务架构与技术实践”主题沙龙在深圳圆满落幕。作为云原生与 AI 微服务融合领域的深度技术聚会,本次活动吸引了来自企业、开发者社区的百余位参与者,共同探讨如何通过开源技术应对智能时代…...

STM32移植文件系统FATFS——片外SPI FLASH
一、电路连接 主控芯片选型为:STM32F407ZGT6,SPI FLASH选型为:W25Q256JV。 采用了两片32MB的片外SPI FLASH,电路如图所示。 SPI FLASH与主控芯片的连接方式如表所示。 STM32F407GT6W25Q256JVPB3SPI1_SCKPB4SPI1_MISOPB5SPI1_MOSI…...

华为HG8546M光猫宽带密码破解
首先进光猫管理界面 将password改成text就可以看到加密后的密码了 复制密码到下面代码里 import hashlibdef sha256(todo):return hashlib.sha256(str(todo).encode()).hexdigest()def md5(todo):return hashlib.md5(str(todo).encode()).hexdigest()def find_secret(secret,…...

驱动-兼容不同设备-container_of
驱动兼容不同类型设备 在 Linux 驱动开发中,container_of 宏常被用来实现一个驱动兼容多种不同设备的架构。这种设计模式在 Linux 内核中非常常见,特别 是在设备驱动模型中。linux内核的主要开发语言是C,但是现在内核的框架使用了非常多的面向…...

UE5 检测球形范围的所有Actor
和Untiiy不同,不需要复杂的调用 首选确保角色添加了Sphere Collision 然后直接把sphere拖入蓝图,调用GetOverlappingActors来获取碰撞范围内的所有Actor...