MIT6.S081 - Lab8 Locks(锁优化 | 并发安全)
本篇是 MIT6.S081 2020 操作系统课程 Lab8 的实验笔记,目标是在保证并发安全的前提下,重新设计 内存分配器 和 块缓存 这两个部分代码,提高系统并发性能。
对于有项目经验的同学来说,实验的难度不算高,重点在于找出 “哪些操作有并发安全问题” 需要加锁,实验也没有涉及到新的知识点,直接动手做就行了。
- Lab8 地址:https://pdos.csail.mit.edu/6.828/2020/labs/lock.html
- 我的实验记录:https://github.com/yibaoshan/xv6-labs-2020/tree/lock
在开始实验之前,你需要(上一节看过就不用看了):
- 观看 Lecture 10 课程录播视频:Multiprocessors and Locks(多处理器和锁)
- YouTube 原版:https://www.youtube.com/watch?v=NGXu3vN7yAk
- 哔哩哔哩中译版:https://www.bilibili.com/video/BV19k4y1C7kA?vd_source=6bce9c6d7d453b39efb8a96f5c8ebb7f&p=9
- 中译文字版:https://mit-public-courses-cn-translatio.gitbook.io/mit6-s081/lec10-multiprocessors-and-locking
- 阅读 《xv6 book》 第六章: Lock
- 英文原版:https://pdos.csail.mit.edu/6.828/2020/xv6/book-riscv-rev1.pdf
- 中译版:https://xv6.dgs.zone/tranlate_books/book-riscv-rev1/c6/s0.html
Memory allocator (moderate)
The program user/kalloctest stresses xv6’s memory allocator: three processes grow and shrink their address spaces, resulting in many calls to kalloc and kfree. kalloc and kfree obtain kmem.lock. kalloctest prints (as “#fetch-and-add”) the number of loop iterations in acquire due to attempts to acquire a lock that another core already holds, for the kmem lock and a few other locks. The number of loop iterations in acquire is a rough measure of lock contention. The output of kalloctest looks similar to this before you complete the lab:
$ kalloctest
start test1
test1 results:
--- lock kmem/bcache stats
lock: kmem: #fetch-and-add 83375 #acquire() 433015
lock: bcache: #fetch-and-add 0 #acquire() 1260
--- top 5 contended locks:
lock: kmem: #fetch-and-add 83375 #acquire() 433015
lock: proc: #fetch-and-add 23737 #acquire() 130718
lock: virtio_disk: #fetch-and-add 11159 #acquire() 114
lock: proc: #fetch-and-add 5937 #acquire() 130786
lock: proc: #fetch-and-add 4080 #acquire() 130786
tot= 83375
test1 FAIL
重新设计 内存分配器 这部分的代码,测试程序 user/kalloctest 会使用 3 个进程,分别执行 申请 和 释放 内存的操作,从而测试 内存分配器的 并发安全。
实验思路
原先操作内存用到的是 kmem 结构体,里面维护一个 自旋锁 和一个 空闲内存链表
kernel/kalloc.c
struct {struct spinlock lock; // 内存分配锁struct run *freelist; // 维护空闲内存的链表
} kmem;
申请/释放 内存实际是对 freelist 链表的读写操作,大家都在一口锅里面吃饭,所以,为了并发安全,多 CPU 操作链表时需要加锁。
void
kfree(void *pa)
{struct run *r = (struct run*)pa;acquire(&kmem.lock); // 加锁r->next = kmem.freelist; // 释放页 next 指针指向链表kmem.freelist = r; // 释放的空页重新加到链表的头部release(&kmem.lock); // 解锁
}void *
kalloc(void)
{struct run *r;acquire(&kmem.lock); // 加锁r = kmem.freelist; // 从链表头取一个空闲页if(r)kmem.freelist = r->next; // 从链表头移除这个空闲页release(&kmem.lock);return (void*)r;
}
同一时间只能有一个 CPU 操作内存,效率太低,实验要求对这块代码进行优化:
- 让每个 CPU 维护一个属于自己的 空闲内存列表,申请 和 释放 都只操作自己的 空闲内存列表 ,从而提高并发性能。
- 系统默认由 CPU0 执行初始化内存,因此,刚启动时 可用内存 全部在 CPU0 的链表上。其他 CPU 执行到
kalloc()时,会按顺序从其他 CPU 的 空闲内存列表 中拉取(刚开始往往会会从 CPU0 的链表中取,因为只有它有空闲)。
- 系统默认由 CPU0 执行初始化内存,因此,刚启动时 可用内存 全部在 CPU0 的链表上。其他 CPU 执行到
- 如果自个儿的 空闲内存列表 空了,没有可用内存了,去其他 CPU 的空闲内存列表中去 “抢”。
- 操作自己的链表也需要加锁,因为其他 CPU 没内存了可能会过来抢我们的。
代码实现
第一步,把 kmem 结构体改为数组形式,让每个 CPU 维护自己的 空闲内存列表
kernel/kalloc.c
struct {struct spinlock lock;struct run *freelist;
} kmem[NPROC]; // 每个 CPU 都拥有自个儿的可用内存链表
原先初始化锁的地方改为:
void
kinit() {
// initlock(&kmem.lock, "kmem");for (int i = 0; i < NPROC; i++)initlock(&kmem[i].lock, "kmem"); // 初始化每个 CPU 的锁freerange(end, (void *) PHYSTOP);
}
然后是 申请 和 释放 内存操作,按照代码顺序,先改 释放 kfree()
void
kfree(void *pa) {struct run *r;int id = cpuid();if (((uint64) pa % PGSIZE) != 0 || (char *) pa < end || (uint64) pa >= PHYSTOP)panic("kfree");// Fill with junk to catch dangling refs.memset(pa, 1, PGSIZE);r = (struct run *) pa;// 原来的逻辑,加锁,然后把空闲页加到链表的头部,释放锁,搞定
// acquire(&kmem.lock);
// r->next = kmem.freelist;
// kmem.freelist = r;
// release(&kmem.lock);// 改为,把空闲页加入到正在执行的 CPU 的链表中acquire(&kmem[id].lock);r->next = kmem[id].freelist;kmem[id].freelist = r;
// printf("cpu %d free 1 page\n", id);release(&kmem[id].lock);
}
把已经释放的空闲页,随机加入某个 CPU 的链表中(取决于哪个 CPU 执行的释放)
接着是 申请内存 kalloc()
void *
kalloc(void) {struct run *r = 0;// 原来的逻辑,加锁,然后从链表头取一个空闲页,释放锁
// acquire(&kmem.lock);
// r = kmem.freelist;
// if(r)
// kmem.freelist = r->next;
// release(&kmem.lock);// 改为,优先从当前 CPU(curid)中获取一个空闲页,如果失败,从当前 CPU 右手边开始遍历,直到找到一页或者都没有可用内存for (int i = 0, curid = cpuid(); i < NPROC && !r; i++, curid++) {if (curid == NPROC)curid = 0; // 环形遍历acquire(&kmem[curid].lock);r = kmem[curid].freelist;if (r) {kmem[curid].freelist = r->next;
// printf("cpu %d steal 1 page from cpu %d\n", cpuid(), curid);}release(&kmem[curid].lock);}if (r)memset((char *) r, 5, PGSIZE); // fill with junkreturn (void *) r;
}
- 优先尝试从
curid(当前 CPU)中获取一个空闲页。 - 如果成功,把该页从链表头移除,不满足循环条件,退出循环。
- 如果失败,从当前 CPU 右手边继续向下遍历,直到找到一页空闲内存,或者全部 CPU 都没有可用内存,退出循环。
代码写完了,make qemu 编译,执行 kalloctest 查看结果
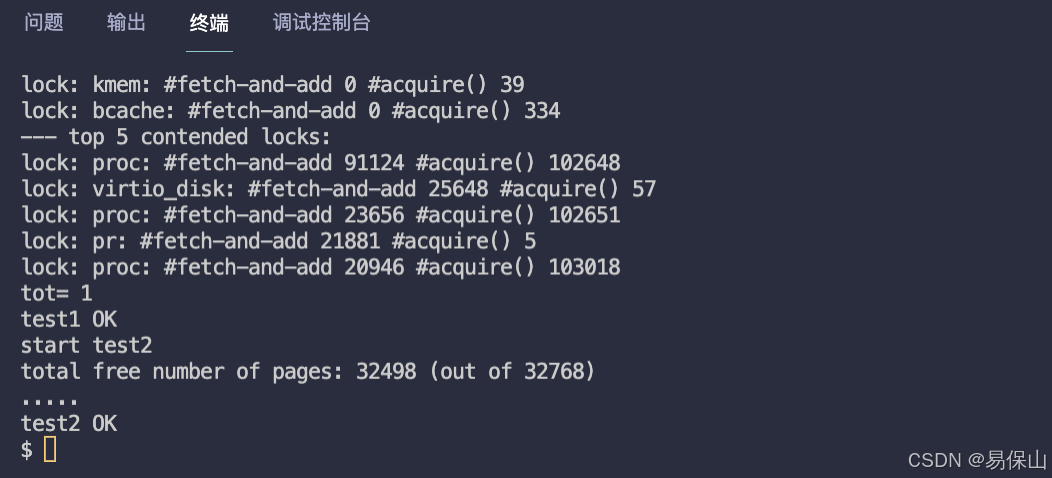
测试通过,完整代码在:https://github.com/yibaoshan/xv6-labs-2020/commit/bef38c1a26bfa3a668ccadcc3afa8bdc876c0917
Buffer cache (hard)
If multiple processes use the file system intensively, they will likely contend for bcache.lock, which protects the disk block cache in kernel/bio.c. bcachetest creates several processes that repeatedly read different files in order to generate contention on bcache.lock; its output looks like this (before you complete this lab):
$ bcachetest
start test0
test0 results:
--- lock kmem/bcache stats
lock: kmem: #fetch-and-add 0 #acquire() 33035
lock: bcache: #fetch-and-add 16142 #acquire() 65978
--- top 5 contended locks:
lock: virtio_disk: #fetch-and-add 162870 #acquire() 1188
lock: proc: #fetch-and-add 51936 #acquire() 73732
lock: bcache: #fetch-and-add 16142 #acquire() 65978
lock: uart: #fetch-and-add 7505 #acquire() 117
lock: proc: #fetch-and-add 6937 #acquire() 73420
tot= 16142
test0: FAIL
start test1
test1 OK
You will likely see different output, but the number of acquire loop iterations for the bcache lock will be high. If you look at the code in kernel/bio.c, you’ll see that bcache.lock protects the list of cached block buffers, the reference count (b->refcnt) in each block buffer, and the identities of the cached blocks (b->dev and b->blockno).
$ bcachetest
start test0
test0 results:
--- lock kmem/bcache stats
lock: kmem: #fetch-and-add 0 #acquire() 32954
lock: kmem: #fetch-and-add 0 #acquire() 75
lock: kmem: #fetch-and-add 0 #acquire() 73
lock: bcache: #fetch-and-add 0 #acquire() 85
lock: bcache.bucket: #fetch-and-add 0 #acquire() 4159
lock: bcache.bucket: #fetch-and-add 0 #acquire() 2118
lock: bcache.bucket: #fetch-and-add 0 #acquire() 4274
lock: bcache.bucket: #fetch-and-add 0 #acquire() 4326
lock: bcache.bucket: #fetch-and-add 0 #acquire() 6334
lock: bcache.bucket: #fetch-and-add 0 #acquire() 6321
lock: bcache.bucket: #fetch-and-add 0 #acquire() 6704
lock: bcache.bucket: #fetch-and-add 0 #acquire() 6696
lock: bcache.bucket: #fetch-and-add 0 #acquire() 7757
lock: bcache.bucket: #fetch-and-add 0 #acquire() 6199
lock: bcache.bucket: #fetch-and-add 0 #acquire() 4136
lock: bcache.bucket: #fetch-and-add 0 #acquire() 4136
lock: bcache.bucket: #fetch-and-add 0 #acquire() 2123
--- top 5 contended locks:
lock: virtio_disk: #fetch-and-add 158235 #acquire() 1193
lock: proc: #fetch-and-add 117563 #acquire() 3708493
lock: proc: #fetch-and-add 65921 #acquire() 3710254
lock: proc: #fetch-and-add 44090 #acquire() 3708607
lock: proc: #fetch-and-add 43252 #acquire() 3708521
tot= 128
test0: OK
start test1
test1 OK
$ usertests...
ALL TESTS PASSED
$
Please give all of your locks names that start with “bcache”. That is, you should call initlock for each of your locks, and pass a name that starts with “bcache”.
本实验涉及到一个新的模块:Buffer cache(磁盘 I/O 缓存)
代码实现在 kernel/bio.c 文件中,Buffer cache 是为了减少磁盘的 I/O 操作,提高性能:
- 读文件的时候,先检查读的部分是否已经在缓存中,如果是则直接返回,如果不在缓存中,则分配一个新的缓冲区,从磁盘读取数据。
- 写的时候,也是先修改缓冲区中的数据(如果有的话),然后等待某个时机调用
bwrite()函数将缓冲区的内容真正写到磁盘。
xv6 现存的 读(bget)、释放(brelse)、加减引用(bpin、bunpin)缓冲块的操作,用的都是同一把锁 bcache.lock
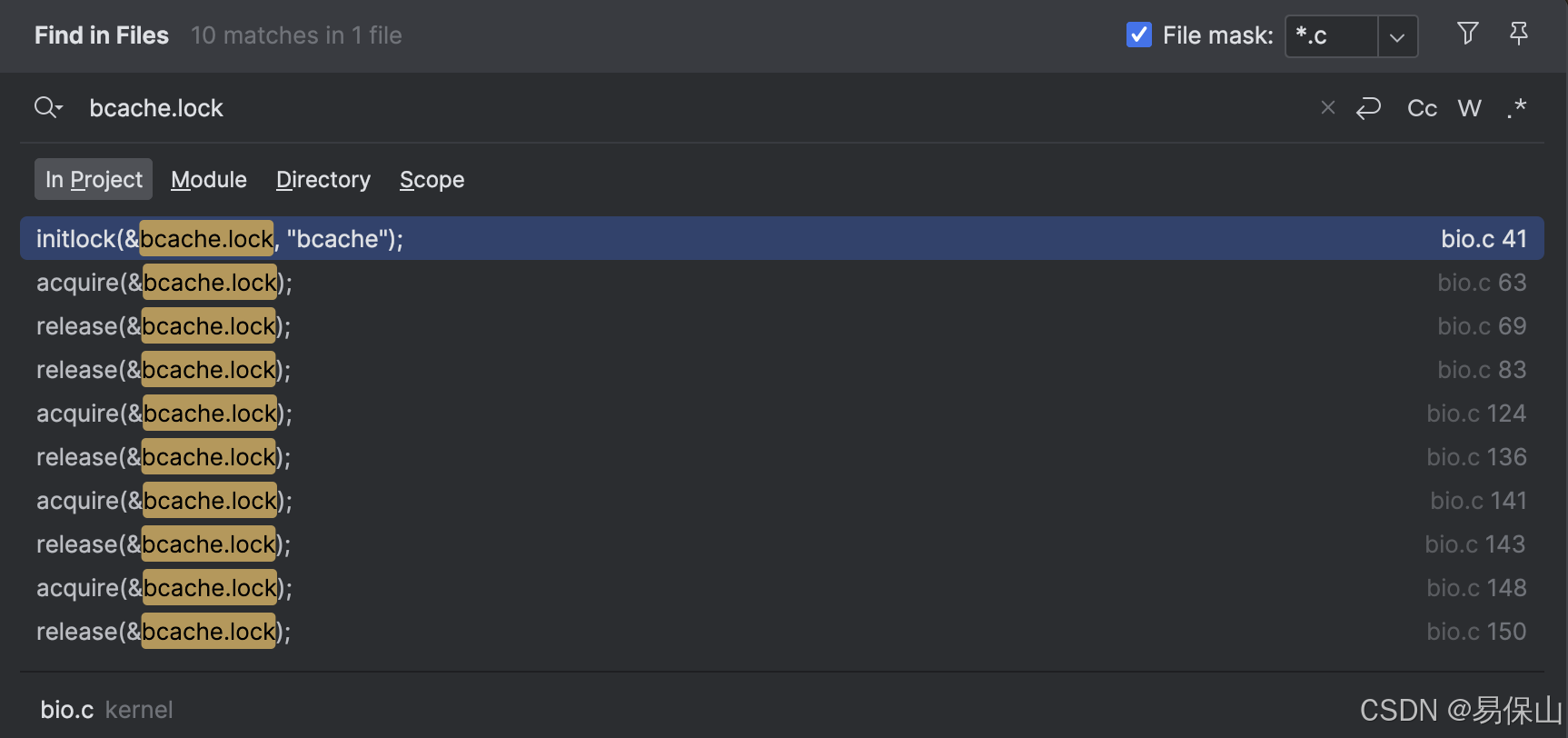
如果有多个 I/O 密集型程序在执行,竞争同一把锁将会成为 OS 的性能瓶颈,实验要求我们对这部分代码进行优化。
实验思路
xv6 用 数组 + 链表 的方式来维护缓冲区,结构如下:
struct buf {int valid; // has data been read from disk?int disk; // does disk "own" buf?uint dev;uint blockno;struct sleeplock lock;uint refcnt;struct buf *prev; // LRU cache liststruct buf *next;uchar data[BSIZE]; // BSIZE=1024
};struct {struct spinlock lock;struct buf buf[NBUF]; // NBUF=30,长度为 30 的 buf 数组// Linked list of all buffers, through prev/next.// Sorted by how recently the buffer was used.// head.next is most recent, head.prev is least.struct buf head; // 双向链表实现的 LRU,head.next 表示最近使用的,head.prev 是最久未使用的
} bcache;
buf 结构体里面的 data 字段存储的是磁盘块的内容,大小是 1024 个字节,也就是 1KB。
bcache 结构体中的 buf[] 数组长度是 30,也就是说 xv6 最多可以缓存 30 * 1KB = 30KB 的数据,当需要缓存第 31 个块时,需要通过 LRU 算法淘汰一个最近最少使用的块。
这种 数组 + 链表 的设计在 OS 中很常见,Linux 的 page cache 也是类似这种设计,好处是:
- 预分配的数组空间,可以避免动态内存分配的开销。
- 数组是连续存储,能提高缓存命中率。
[数组视角]
buf[0] buf[1] buf[2] ... buf[NBUF-1]↓ ↓ ↓ ↓
[实际内存中的固定位置][链表视角]
head ↔ 最近使用 ↔ 次近使用 ↔ ... ↔ 最久未使用buf[5] buf[2] buf[7]
扯远了,回到实验,,,
本小节的目标很明确,把 bcache.lock 这把大锁 拆分 成多个小锁,降低锁竞争,我们要面临的问题:
- 小锁怎么拆?按什么颗粒度来拆?
- 原有的全局 LRU 怎么维护?
a. 如果还是放全局,操作链表的时候肯定要加锁,那就又回退到一把锁了。
b. 如果跟小锁结构走,那通信怎么解决?怎么才能知道哪块 buffer 是最少使用的?
小锁怎么拆?
我们可以参照上一小节的 kalloc 的实现,为每一个 buffer 分配一个锁(xv6 一共才 30 个 buffer,代价也不是很高)。
不过,实验 tips 中建议我们使用哈希桶来实现,所以这部分我们就按照实验要求来,使用 hash bucket 。
原有的全局 LRU 怎么维护?
我的方案是废除原链表实现的 LRU 方案,改为使用时间戳 LRU,为 buffer 结构体增加一个时间戳字段
- 每读一次 buffer,更新 时间戳
- 时间戳 值越大,说明是最近使用
- 在查找可用 buffer 时,如果所有的 buffer 都在使用,根据时间戳,复用最久未使用的 buffer
思路讲完了,接下来上代码。
代码实现
首先,为 buf 结构体增加一个 时间戳 字段,用来记录 buffer 的使用情况
kernel/buf.h
struct buf {...uint refcnt;// 废弃掉原链表节点
// struct buf *prev; // LRU cache list
// struct buf *next;uchar data[BSIZE];uint timestamp; // 新增时间戳字段
};
然后把原来的 bcache 结构体改为数组,长度为质数 13
kernel/bio.c
#define NBUCKET 13 // 哈希桶数量,一般用质数
#define NBUFFER CEIL(NBUF, NBUCKET) // 每个桶的 buf 数量, NBUF 默认为 30,这里向上取整后结果应该是 3,即每个桶里面有 3 个 buf#define CEIL(num, divisor) (((num) + (divisor) - 1) / (divisor)) // 向上取整的宏struct {struct spinlock lock;struct buf buf[NBUFFER];
// struct buf head; 废弃
} bcache[NBUCKET]; // 哈希桶数组,长度为 13static uint global_timestamp; // 全局时间戳计数器
按照实验要求,NBUCKET 的长度为质数 13,NBUFFER 表示每个桶里面有多少个 buffer,它调用了自定义宏 CEIL,30/13 向上取整,得出每个桶里面有 3 个 buffer。
第二步是初始化锁
void
binit(void)
{for (int i = 0; i < NBUCKET; i++) {initlock(&bcache[i].lock, "bcache");for (int j = 0; j < NBUFFER; j++) {bcache[i].buf[j].timestamp = 0; // 初始化时间戳为 0initsleeplock(&bcache[i].buf[j].lock, "buffer");}}
}
第三步是对使用 bcache.lock 的地方做修改,bio.c 里面有四个函数用到了 bcache.lock,分别是 bget()、brelse()、bpin()、bunpin()
其中,bget() 有点复杂,我们放到后面讲,先把 brelse()、bpin()、bunpin() 这 3 个函数改完:
void
brelse(struct buf *b)
{if(!holdingsleep(&b->lock))panic("brelse");int bucket_id = hash(b->blockno);acquire(&bcache[bucket_id].lock);b->refcnt--;release(&bcache[bucket_id].lock);releasesleep(&b->lock);
}void
bpin(struct buf *b) {int bucket_id = hash(b->blockno);acquire(&bcache[bucket_id].lock);b->refcnt++;release(&bcache[bucket_id].lock);
}void
bunpin(struct buf *b) {int bucket_id = hash(b->blockno);acquire(&bcache[bucket_id].lock);b->refcnt--;release(&bcache[bucket_id].lock);
}
这三个函数步骤都一样,先根据 b->blockno 计算出哈希桶的索引,然后加锁,修改 refcnt,再释放锁。
最后是改动最大的 bget() 函数:
static struct buf*
bget(uint dev, uint blockno)
{struct buf *b;uint bucket_id = hash(blockno);// 优先在当前哈希桶中,查找已缓存的块acquire(&bcache[bucket_id].lock);for(int i = 0; i < NBUFFER; i++) {b = &bcache[bucket_id].buf[i];if(b->dev == dev && b->blockno == blockno) {b->refcnt++;// 增加引用的同时,更新时间戳update_timestamp(b);release(&bcache[bucket_id].lock);acquiresleep(&b->lock);return b;}}release(&bcache[bucket_id].lock);uint min_timestamp = 0xffffffff;struct buf *least_used_buf = 0;// 没有找到缓存块,和上一小节的 kalloc 一样,环形遍历所有桶,查找其他桶中未使用的空闲块// 遍历所有桶的过程中,记录最少使用并且最久未使用的块// 如果没有空闲块,那么就直接使用 最少使用并且最久未使用的块for(int i = 0, cur_bucket = bucket_id; i < NBUCKET; i++, cur_bucket++) {if(cur_bucket == NBUCKET)cur_bucket = 0; // 环形遍历acquire(&bcache[cur_bucket].lock);for(int j = 0; j < NBUFFER; j++) {b = &bcache[cur_bucket].buf[j];if(b->refcnt == 0) { // 找到未使用的块b->dev = dev;b->blockno = blockno;b->valid = 0;b->refcnt = 1;update_timestamp(b);release(&bcache[cur_bucket].lock);acquiresleep(&b->lock);return b;}//更新 最久未使用的 bufferif(b->timestamp < min_timestamp) {min_timestamp = b->timestamp;least_used_buf = b;}}release(&bcache[cur_bucket].lock);}// 其他桶里面也没有空闲块,那就只能使用 最久未使用的 bufferif(least_used_buf) {acquire(&bcache[bucket_id].lock);// 一大堆赋值和初始化操作least_used_buf->dev = dev;least_used_buf->blockno = blockno;least_used_buf->valid = 0;least_used_buf->refcnt = 1;update_timestamp(least_used_buf);release(&bcache[bucket_id].lock);acquiresleep(&least_used_buf->lock);return least_used_buf;}panic("bget: no buffers");
}
bget() 函数逻辑几乎全部推翻重写,它一共干了三件事:
- 在当前哈希桶中,查找已缓存的块,如果命中,就直接返回该块,并更新时间戳。
- 没有命中缓存块,则尝试分配一个空闲 buffer
- 环形遍历所有桶,包括自身,查找桶中是否有未使用的 buffer。
- 有空闲 buffer,增加引用并更新时间戳并返回该 buffer。
- 遍历过程中,记录并更新 最久未使用的块,
- 所有哈希桶中,都找不到空闲 buffer,那么,复用记录的最久未使用的 buffer。
补充剩余的工具函数
kernel/defs.h
// bio.c
...
void bunpin(struct buf*);
uint hash(uint);
void update_timestamp(struct buf*);
kernel/bio.c
uint
hash(uint blockno)
{return blockno % NBUCKET;
}void
update_timestamp(struct buf *b)
{// 这里 global_timestamp 会有溢出问题,暂不考虑优化b->timestamp = __sync_fetch_and_add(&global_timestamp, 1);
// printf("time %d\n",b->timestamp);
}
代码写完了,make qemu 编译,执行 bcachetest 查看结果
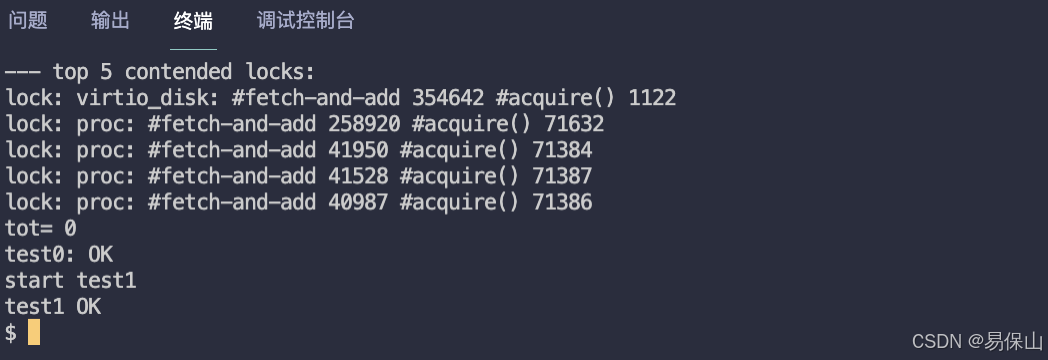
测试通过,完整代码在:https://github.com/yibaoshan/xv6-labs-2020/commit/12ea059da0cc8853c365b491190a01bd56d78550
参考资料
- CS自学指南:https://csdiy.wiki/%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F/MIT6.S081/
- Wings:https://blog.wingszeng.top/series/learning-mit-6-s081/
- Miigon:https://blog.miigon.net/categories/mit6-s081/
- 知乎专栏《28天速通MIT 6.S081操作系统》:https://zhuanlan.zhihu.com/p/632281381
相关文章:
)
MIT6.S081 - Lab8 Locks(锁优化 | 并发安全)
本篇是 MIT6.S081 2020 操作系统课程 Lab8 的实验笔记,目标是在保证并发安全的前提下,重新设计 内存分配器 和 块缓存 这两个部分代码,提高系统并发性能。 对于有项目经验的同学来说,实验的难度不算高,重点在于找出 “…...

TMS320F28P550SJ9学习笔记15:Lin通信SCI模式结构体寄存器
今日初步认识与配置使用Lin通信SCI模式,用结构体寄存器的方式编程 文章提供完整工程下载、测试效果图 我的单片机平台是这个: LIN通信引脚: LIN通信PIE中断: 这个 PIE Vector Table 表在手册111页: 这是提到LINa的PI…...

JavaWeb 课堂笔记 —— 11 MySQL 多表设计
本系列为笔者学习JavaWeb的课堂笔记,视频资源为B站黑马程序员出品的《黑马程序员JavaWeb开发教程,实现javaweb企业开发全流程(涵盖SpringMyBatisSpringMVCSpringBoot等)》,章节分布参考视频教程,为同样学习…...
)
2025年最新总结安全基础(面试题)
活动发起人@小虚竹 想对你说: 这是一个以写作博客为目的的创作活动,旨在鼓励大学生博主们挖掘自己的创作潜能,展现自己的写作才华。如果你是一位热爱写作的、想要展现自己创作才华的小伙伴,那么,快来参加吧!我们一起发掘写作的魅力,书写出属于我们的故事。我们诚挚邀请…...

调试chili3d笔记 typescript预习
https://github.com/xiangechen/chili3d 用firefox拓展附加进程 打开开发者 工具,这个网页按f12没反应,手动打开 创建一个立方体可以看到运行了create.box方法,消息来自commandService.ts 位置 太久没写c了,3目都看不懂了 c没有…...

【北交互联-注册/登录安全分析报告】
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 暴力破解密码,造成用户信息泄露短信盗刷的安全问题,影响业务及导致用户投诉带来经济损失,尤其是后付费客户,风险巨大,造成亏损无底洞…...

YOLOv2学习笔记
YOLOv2 背景 YOLOv2是YOLO的第二个版本,其目标是显著提高准确性,同时使其更快 相关改进: 添加了BN层——Batch Norm采用更高分辨率的网络进行分类主干网络的训练 Hi-res classifier去除了全连接层,采用卷积层进行模型的输出&a…...

2025年国企社招欧治链金再生资源入职测评笔试中智赛码平台SHL测试平台Verify认知能力测试
1、欧治链金政治素质测试(中智赛码平台,电脑端作答) 10个单选题、5个多选题、1个问答题 2、欧治链金综合素质测试(SHL测试平台Verify认知能力测试,电脑端作答) 3、欧治链金职业性格测试(中智职…...

MySQL索引和事务
MySQL索引和事务 1.索引1.1概念1.2作用1.3使用场景1.4使用1.4.1查看索引1.4.2创建索引1.4.3删除索引 2.事务2.1使用2.1.1开启事务2.1.2执行多条SQL语句2.1.3回滚或提交 2.2事务的特性2.2.1回滚是怎么做到的2.2.2原子性2.2.3一致性2.2.4持久性2.2.5隔离性2.2.5.1脏读2.2.5.2不可…...

【AI News | 20250415】每日AI进展
AI News 1、字节跳动发布Seaweed-7B视频模型:70亿参数实现音视频同步生成与多镜头叙事 字节跳动推出新一代视频生成模型Seaweed-7B,该模型仅70亿参数却实现多项突破:支持音视频同步生成、多镜头叙事(保持角色连贯性)、…...

MegaTTS3: 下一代高效语音合成技术,重塑AI语音的自然与个性化
在近期的发布中,浙江大学赵洲教授团队与字节跳动联合推出了革命性的第三代语音合成模型——MegaTTS3,该模型不仅在多个专业评测中展现了卓越的性能,还为AI语音的自然性和个性化开辟了新的篇章。 MegaTTS3技术亮点 零样本语音合成 MegaTTS3采用…...

MyBatis-Plus 详解教程
文章目录 1. MyBatis-Plus 简介1.1 什么是 MyBatis-Plus?1.2 为什么要使用 MyBatis-Plus?传统 MyBatis 的痛点MyBatis-Plus 的优势 1.3 MyBatis-Plus 与 MyBatis 的关系 2. 快速开始2.1 环境要求2.2 依赖引入MavenGradle 2.3 数据库准备2.4 配置 Spring …...

Java设计模式之观察者模式:从入门到架构级实践
一、观察者模式的核心价值 观察者模式(Observer Pattern)是行为型设计模式中的经典之作,它建立了对象间的一对多依赖关系,让多个观察者对象能够自动感知被观察对象的状态变化。这种模式在事件驱动系统、实时数据推送、GUI事件处理…...

【双指针】专题:LeetCode 202题解——快乐数
快乐数 一、题目链接二、题目三、题目解析四、算法原理扩展 五、编写代码 一、题目链接 快乐数 二、题目 三、题目解析 快乐数的定义中第二点最重要,只有两种情况,分别拿示例1、示例2分析吧: 示例1中一旦出现1了,继续重复过程就…...

深度学习占用大量内存空间解决办法
应该是缓存的问题,关机重启内存多了10G,暂时没找到别的方法 重启前 关机重启后...
)
[LeetCode 1871] 跳跃游戏 7(Ⅶ)
题面: 数据范围: 2 ≤ s . l e n g t h ≤ 1 0 5 2 \le s.length \le 10^5 2≤s.length≤105 s [ i ] s[i] s[i] 要么是 ′ 0 ′ 0 ′0′ ,要么是 ′ 1 ′ 1 ′1′ s [ 0 ] 0 s[0] 0 s[0]0 1 ≤ m i n J u m p ≤ m a x J u m p <…...

同济大学轻量化低成本具身导航!COSMO:基于选择性记忆组合的低开销视觉语言导航
作者:Siqi Zhang 1 ^{1} 1, Yanyuan Qiao 3 ^{3} 3, Qunbo Wang 2 ^{2} 2, Zike Yan 4 ^{4} 4, Qi Wu 3 ^{3} 3, Zhihua Wei 1 ^{1} 1, Jing Liu 1 ^{1} 1单位: 1 ^{1} 1同济大学计算机科学与技术学院, 2 ^{2} 2中科院自动化研究所࿰…...

【Ubuntu | 网络】Vmware虚拟机里的Ubuntu开机后没有网络接口、也没有网络图标
😁博客主页😁:🚀https://blog.csdn.net/wkd_007🚀 🤑博客内容🤑:🍭嵌入式开发、Linux、C语言、C、数据结构、音视频🍭 😎金句分享😎&a…...
)
第二十一讲 XGBoost 回归建模 + SHAP 可解释性分析(利用R语言内置数据集)
下面我将使用 R 语言内置的 mtcars 数据集,模拟一个完整的 XGBoost 回归建模 SHAP 可解释性分析 实战流程。我们将以预测汽车的油耗(mpg)为目标变量,构建 XGBoost 模型,并用 SHAP 来解释模型输出。 🚗 示例…...

HP惠普打印机:解决每次打印后额外产生@PJL SET USERNAME=文档的情况
情况描述 惠普商用打印机型号:Color LaserJet Managed MFP E78223 在每次打印文档后都会出现包含我个人电脑用户名的额外文档: 这不是我希望的,因此我联系了惠普官方客服,并得到了解决 解决方案 原因 具客服所说,这些是…...

MariaDB MaxScale 的用途与实现细节
MaxScale 主要用途 MariaDB MaxScale 是一个智能数据库代理(proxy),主要用于增强 MySQL/MariaDB 数据库的高可用性、可扩展性和安全性,同时简化应用程序与数据库基础设施之间的交互。它的核心功能包括: 负载均衡&…...

CTF--eval
一、原网页: 二、步骤: 1.代码分析: <?phpinclude "flag.php"; // 引入一个文件,该文件可能定义了一些变量(例如 $flag)$a $_REQUEST[hello]; // 从用户请求中获取参数 hello 的值&#x…...
)
Android学习总结之算法篇七(图和矩阵)
有向图的深度优先搜索(DFS)和广度优先搜索(BFS)的示例,以此来模拟遍历 GC Root 引用链这种有向图结构: 一、深度优先搜索(DFS) import java.util.*;public class GraphDFS {privat…...
)
vmcore分析锁问题实例(x86-64)
问题描述:系统出现panic,dmesg有如下打印: [122061.197311] task:irq/181-ice-enp state:D stack:0 pid:3134 ppid:2 flags:0x00004000 [122061.197315] Call Trace: [122061.197317] <TASK> [122061.197318] __schedule0…...

【vue3】vue3+express实现图片/pdf等资源文件的下载
文件资源的下载,是我们业务开发中常见的需求。作为前端开发,学习下如何自己使用node的express框架来实现资源的下载操作。 实现效果 代码实现 前端 1.封装的请求后端下载接口的方法,需求配置aixos的请求参数里面的返回数据类型为blob // 下载 export…...

【BUG】Redis RDB快照持久化及写操作禁止问题排查与解决
1 问题描述 在使用Redis 的过程中,遇到如下报错,错误信息是 “MISCONF Redis is configured to save RDB snapshots, but it is currently not able to persist on disk...”,记录下问题排查过程。 2 问题排查与解决 该错误提示表明&#…...

【HD-RK3576-PI】定制用户升级固件
硬件:HD-RK3576-PI 软件:Linux6.1Ubuntu22.04 在进行 Rockchip 相关开发时,制作自定义的烧写固件是一项常见且重要的操作。这里主要介绍文件系统的修改以及打包成完整update包升级的过程。 一、修改文件系统镜像(Ubuntu环境操作&…...

【AI学习】李宏毅老师讲AI Agent摘要
在b站听了李宏毅2025最新的AI Agent教程,简单易懂,而且紧跟发展,有大量最新的研究进展。 教程中引用了大量论文,为了方便将来阅读相关论文,进一步深入理解,做了截屏纪录。 同时也做一下分享。 根据经验调整…...

狂神SQL学习笔记十:修改和删除数据表字段
1、修改与删除表 alter 修改表的名称: 增加表的字段: 修改表的字段(重命名,修改约束): 修改约束 重命名 删除表的字段 删除表...

OSPF综合实验
一、网络拓扑 二、实验要求 1,R5为ISP,其上只能配置IP地址;R4作为企业边界路由器; 2,整个0SPF环境IP基于172.16.0.8/16划分; 3,所有设备均可访问R5的环回; 4,减少LSA的更新量,加快收敛…...

2025 cs144 Lab Checkpoint 2 小白超详细版
文章目录 1 环形索引的实现1.1 wrap类wrapunwrap 2 实现tcp_receiver2.1 tcp_receiver的功能2.2 传输的报文格式TCPSenderMessageTCPReceiverMessage 2.3 如何实现函数receive()send() 1 环形索引的实现 范围是0~2^32-1 需要有SY…...

VMware虚拟机安装Ubuntu 22.04.2
一、我的虚拟机版本 二、浏览器搜索Ubuntu 三、下载Ubuntu桌面版 四、下这个 五、创建新的虚拟机 六、选择典型,然后下一步 七、选择稍后安装操作系统,然后下一步 八、选择Linux ,版本选择Ubuntu 64位 九、选择好安装位置 十、磁盘大小一般选20G就够用了…...

XSS漏洞及常见处理方案
文章背景: 在近期项目安全测试中,安全团队发现了一处潜在的 跨站脚本攻击(XSS)漏洞,该漏洞可能导致用户数据被篡改或会话劫持等安全风险。针对这一问题,项目组迅速响应,通过代码修复、输入过滤、…...

TCP标志位抓包
说明 TCP协议的Header信息,URG、ACK、PSH、RST、SYN、FIN这6个字段在14字节的位置,对应的是tcp[13],因为字节数是从[0]开始数的,14字节对应的就是tcp[13],因此在抓这几个标志位的数据包时就要明确范围在tcp[13] 示例1…...

C/C++条件判断
条件判断 if语句的三种形态 if(a<b){} 、 if(a<b){}else{} 、 if(a<b){}else if(a>b) else{} if语句的嵌套 嵌套的常见错误(配对错误),与前面最近的,而且还没有配对的if匹配 错误避免方法:严格使用 { }、先写&am…...

单位门户网站被攻击后的安全防护策略
政府网站安全现状与挑战 近年来,随着数字化进程的加速,政府门户网站已成为政务公开和服务公众的重要窗口。然而,网络安全形势却日益严峻。国家互联网应急中心的数据显示,政府网站已成为黑客攻击的重点目标,被篡改和被…...

# 工具记录
工具记录 键盘操作可视化工具openark64系统工具dufs-webui文件共享zotero文献查看cff explorerNoFencesfreeplane开源思维导图...

C/C++运算
C语言字符串的比较 #include <string.h> int strcmp( const char *str1, const char *str2 );例如: int ret; ret strcmp(str1, str2);返回值: str1 < str2时, 返回值< 0(有些编译器返回 -1) str1 > str2时…...

CloudWeGo 技术沙龙·深圳站回顾:云原生 × AI 时代的微服务架构与技术实践
2025 年 3 月 22 日,CloudWeGo “云原生 AI 时代的微服务架构与技术实践”主题沙龙在深圳圆满落幕。作为云原生与 AI 微服务融合领域的深度技术聚会,本次活动吸引了来自企业、开发者社区的百余位参与者,共同探讨如何通过开源技术应对智能时代…...

STM32移植文件系统FATFS——片外SPI FLASH
一、电路连接 主控芯片选型为:STM32F407ZGT6,SPI FLASH选型为:W25Q256JV。 采用了两片32MB的片外SPI FLASH,电路如图所示。 SPI FLASH与主控芯片的连接方式如表所示。 STM32F407GT6W25Q256JVPB3SPI1_SCKPB4SPI1_MISOPB5SPI1_MOSI…...

华为HG8546M光猫宽带密码破解
首先进光猫管理界面 将password改成text就可以看到加密后的密码了 复制密码到下面代码里 import hashlibdef sha256(todo):return hashlib.sha256(str(todo).encode()).hexdigest()def md5(todo):return hashlib.md5(str(todo).encode()).hexdigest()def find_secret(secret,…...

驱动-兼容不同设备-container_of
驱动兼容不同类型设备 在 Linux 驱动开发中,container_of 宏常被用来实现一个驱动兼容多种不同设备的架构。这种设计模式在 Linux 内核中非常常见,特别 是在设备驱动模型中。linux内核的主要开发语言是C,但是现在内核的框架使用了非常多的面向…...

UE5 检测球形范围的所有Actor
和Untiiy不同,不需要复杂的调用 首选确保角色添加了Sphere Collision 然后直接把sphere拖入蓝图,调用GetOverlappingActors来获取碰撞范围内的所有Actor...

AI大模型学习十:Ubuntu 22.04.5 调整根目录大小,解决根目录磁盘不够问题
一、说明 由于默认安装时导致home和根目录大小一样,导致根目录不够,所以我们调整下 二、调整 # 确认/home和/是否为独立逻辑卷,并属于同一卷组(VG) rootnode1:~# lsblk NAME MAJ:MIN RM SIZE…...

在ros2上使用opencv显示一张图片
1.先将图片放到桌面上 2.打开终端ctrlaltT,查看自己是否已安装opencv 3.创建工作环境 4.进入工作目录并创建ROS2包添加OpenCV依赖项 5.进入/home/kong/opencv_ws/opencv_use/src目录创建.cpp文件并编辑 6.代码如下 my_opencv.cpp #include <cstdio> #include…...
)
训练神经网络的原理(前向传播、反向传播、优化、迭代)
训练神经网络的原理 通过前向传播计算预测值和损失,利用反向传播计算梯度,然后通过优化算法更新参数,最终使模型在给定任务上表现更好。 核心:通过计算损失函数(通常是模型预测与真实值之间的差距)对模型参…...
暴力娱乐篇30)
每日一题(小白)暴力娱乐篇30
顺时针旋转,从上图中不难看出行列进行了变换。因为这是一道暴力可以解决的问题,我们直接尝试使用行列转换看能不能得到想要的结果。 public static void main(String[] args) {Scanner scan new Scanner(System.in);int nscan.nextInt();int mscan.next…...

【HTTPS】免费SSL证书配置Let‘s Encrypt自动续期
【HTTPS】免费SSL证书配置Lets Encrypt自动续期 1. 安装Certbot1.1 snapd1.2 certbot2. 申请泛域名证书使用 DNS 验证申请泛域名证书3.配置nginx申请的 SSL 证书文件所在目录nginx配置证书示例查看证书信息和剩余时间4.自动续期手动自动5.不同服务器使用1. 安装Certbot 1.1 sn…...

企业应如何防范 AI 驱动的网络安全威胁?
互联网技术和 AI 科技为世界开启了一个新的发展篇章。同时,网络攻击也呈现出愈发强势的发展势头:高级持续性威胁 (APT:Advanced Persistent Threat)组织采用新的战术、技术和程序 (TTP)、AI 驱动下攻击数量和速度的提高…...

决策树简介
【理解】决策树例子 决策树算法是一种监督学习算法,英文是Decision tree。 决策树思想的来源非常朴素,试想每个人的大脑都有类似于if-else这样的逻辑判断,这其中的if表示的是条件,if之后的else就是一种选择或决策。程序设计中的…...