SpringAI-ollama
SpringAi主要依赖
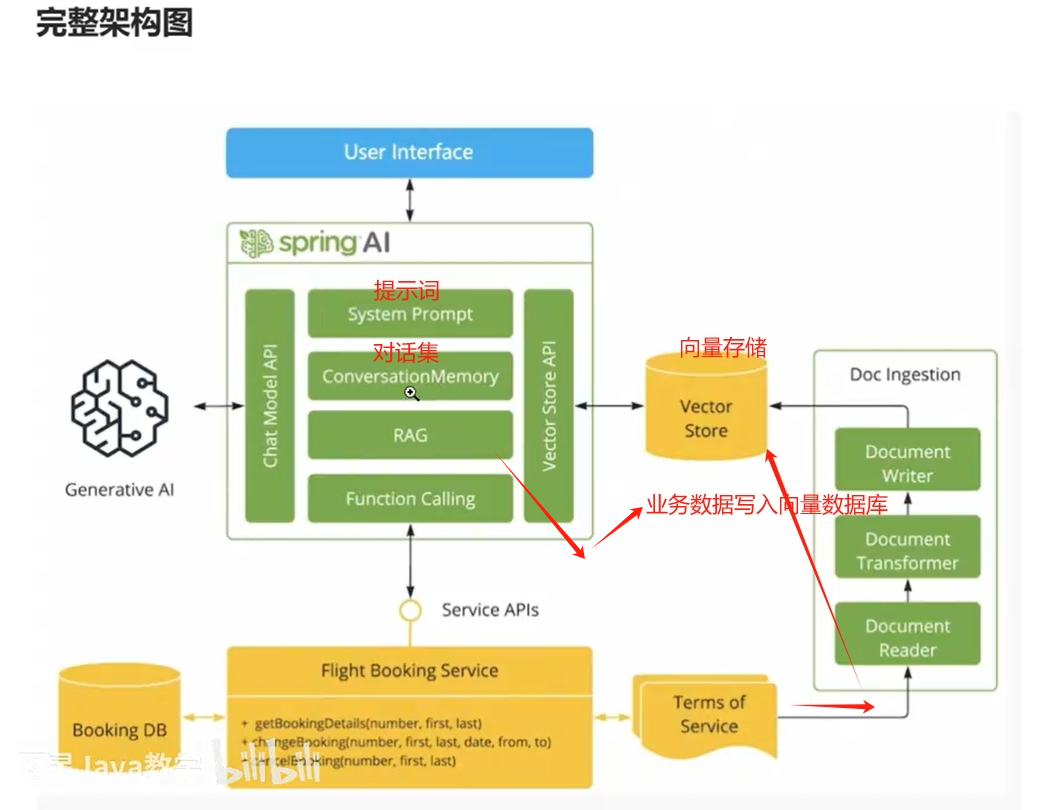
System Prompt :设置提示词 用来预设角色
ConversationMemory: 对话集
RAG: 检索增强生成 将业务数据存储在向量数据库中(做相似性检索)通过RAG进行链接
Function Calling 用来调用自己的api
<dependencyManagement><dependencies><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-bom</artifactId><version>1.0.0-M6</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement>
<dependencies><!--Springai依赖--><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-ollama-spring-boot-starter</artifactId></dependency><!--pgVector向量数据库--><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-pgvector-store-spring-boot-starter</artifactId></dependency><!--doc解析器--><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-tika-document-reader</artifactId></dependency><!--分词器--><dependency><groupId>com.knuddels</groupId><artifactId>jtokkit</artifactId><version>1.1.0</version></dependency></dependencies>
yml配置
ai:ollama:language: zhresponse-language: zhchat:options:model: qwen2:7bembedding:enabled: truemodel: bge-m3base-url: http://172.21.198.208:11434/vectorstore:pgvector:index-type: HNSWdistance-type: COSINE_DISTANCEdimension: 1024batching-strategy: TOKEN_COUNTmax-document-batch-size: 10000
chat.options.model: qwen2:7b 这个是默认的模型(但是后期不需要了我们从数据库中拿)
embedding.model: bge-m3 这个模型是用来进行向量化的模型
base-url: http://172.21.198.208:11434/ 这个是ollama模型访问地址
我这里用的是pgvector来作为向量库 vectorstore.pgvector:
dimension: 1024 这个至关重要 这里写多少创建向量库的时候就要写多少 如果两边不一致的话向向量库向量会失败
创建向量库
-- 增加扩展
create extension if not exists vector;
create extension if not exists hstore;
create extension if not exists "uuid-ossp";create table if not exists vector_store
(id uuid primary key default uuid_generate_v4(),content text,metadata json,embedding vector(1024) //这个的参数要和配置文件的一样,要不插入不进去 这个就是向量数据库的维度
);create index on vector_store using hnsw(embedding vector_cosine_ops);
ollama对话模型
/*** Ollama模型配置类* 负责配置和管理不同的Ollama模型实例*/
@Slf4j
@Configuration
public class OllamaModelConfig {/*** 创建OllamaChatModel的通用方法* @param baseUrl Ollama服务地址* @param modelName 模型名称* @param temperature 温度参数* @return 配置好的OllamaChatModel实例*/public OllamaChatModel createOllamaModel(String baseUrl, String modelName, double temperature) {Assert.hasText(baseUrl, "Ollama服务地址不能为空");Assert.hasText(modelName, "模型名称不能为空");Assert.isTrue(temperature >= 0 && temperature <= 1, "温度参数必须在0-1之间");try {log.debug("开始创建Ollama模型: {}, 温度参数: {}, 服务地址: {}", modelName, temperature, baseUrl);OllamaApi ollamaApi = new OllamaApi(baseUrl);OllamaOptions options = OllamaOptions.builder().model(modelName).temperature(temperature).build();OllamaChatModel model = OllamaChatModel.builder().ollamaApi(ollamaApi).defaultOptions(options).observationRegistry(ObservationRegistry.NOOP).build();log.debug("Ollama模型创建成功: {}", modelName);return model;} catch (Exception e) {log.error("创建Ollama模型失败: {}", modelName, e);throw new RuntimeException("创建Ollama模型失败: " + modelName, e);}}
}
temperature温度的值越小回答的越准确
调用实例
// 使用模型配置创建OllamaChatModelOllamaChatModel chatModel = ollamaModelConfig.createOllamaModel(aiModel.getAimodelAccessAddress(),aiModel.getAimodelName(),aiModel.getAimodelTemperature());ChatClient chatClient = ChatClient.builder(chatModel).build();// 使用响应式流处理对话return chatClient.prompt().user(message).stream().content().onErrorResume(e -> {log.error("聊天过程发生错误: ", e);return Flux.just("抱歉,处理您的请求时出现了错误,请稍后重试。");});
接下来介绍上面提到的主要的四个属性
1.System Prompt :设置提示词 用来预设角色
systemPrompt="你是一位专业的室内设计顾问,精通各种装修风格、材料选择和空间布局。请基于提供的参考资料,为用户提供专业、详细且实用的建议。在回答时,请注意:\n" +"1. 准确理解用户的具体需求\n" +"2. 结合参考资料中的实际案例\n" +"3. 提供专业的设计理念和原理解释\n" +"4. 考虑实用性、美观性和成本效益\n" +"5. 如有需要,可以提供替代方案";// 创建聊天客户端ChatClient chatClient = ChatClient.builder(ollamaChatModel).defaultSystem(systemPrompt).build();
将预设词放入defaultSystem中之后ai就会根据我们的提示词进行工作
2.ConversationMemory: 对话集
package com.system.ai.config;import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.messages.AssistantMessage;
import org.springframework.ai.chat.messages.Message;
import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.core.JdbcTemplate;
import java.util.List;//持久化对话
@Slf4j
@Configuration
public class AiChatMemory implements ChatMemory {//这个是存储在内存中Map<String, List<Message>> conversationHistory = new ConcurrentHashMap<>();//新增持久化 (现在没有做持久化所以都存在了内存中 重启后会丢失对话记忆)@Overridepublic void add(String conversationId, List<Message> messages) {log.error("对话id: {}", conversationId);this.conversationHistory.putIfAbsent(conversationId, new ArrayList<>());this.conversationHistory.get(conversationId).addAll(messages);}//获取@Overridepublic List<Message> get(String conversationId, int lastN) {List<Message> all = this.conversationHistory.get(conversationId);return all != null ? all.stream().skip(Math.max(0, all.size() - lastN)).toList() : List.of();}//清除@Overridepublic void clear(String conversationId) {this.conversationHistory.remove(conversationId);}
}这个是我们创建的自己的AiChatMemory他继承了ChatMemory类,可以看到他其实就是将消息存储到List内 保存到内存中 当我们程序重启之后就会从内存删除
使用我们自己的AiChatMemory
@Autowiredprivate AiChatMemory aiChatMemory ;ChatClient chatClient = ChatClient.builder(ollamaChatModel).defaultAdvisors(new PromptChatMemoryAdvisor(aiChatMemory))//设置上下文 .build();Flux<String> content = chatClient.prompt().user(message).advisors(advisorSpec -> //设置持久化对话的查询的联通上下文//设置聊天记忆检索的大小为100advisorSpec.param(AbstractChatMemoryAdvisor.CHAT_MEMORY_RETRIEVE_SIZE_KEY, 100)// 设置对话ID 在聊天应用中,不同用户或不同会话的对话历史应该是相互独立的。// 通过设置对话ID,可以让聊天记忆顾问根据不同的对话ID来管理和检索相应的对话历史记录。// 这样,当用户发起新的对话时,系统可以根据对话ID准确地获取该用户之前的对话内容,从而提供更连贯和个性化的服务。.param(AbstractChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY, "测试固定id")).stream().content();//聊天交互的场景中, content 流会不断地发出聊天响应的文本片段,// 而 [complete] 这个字符串可以作为一个特殊的标识,用来表示聊天响应已经结束。// 当客户端接收到这个 "[complete]" 标识时,就可以知道整个聊天响应已经全部接收完毕,// 从而可以进行相应的处理,例如关闭连接、更新 UI 状态等。
设置上下文有两个点
第一个点就是创建ChatClient的时候的:
.defaultAdvisors(new PromptChatMemoryAdvisor(aiChatMemory))//设置上下文
这里指定的是在哪里取上下文
.advisors(advisorSpec -> //设置持久化对话的查询的联通上下文//设置聊天记忆检索的大小为100advisorSpec.param(AbstractChatMemoryAdvisor.CHAT_MEMORY_RETRIEVE_SIZE_KEY, 100)// 设置对话ID 在聊天应用中,不同用户或不同会话的对话历史应该是相互独立的。// 通过设置对话ID,可以让聊天记忆顾问根据不同的对话ID来管理和检索相应的对话历史记录。// 这样,当用户发起新的对话时,系统可以根据对话ID准确地获取该用户之前的对话内容,从而提供更连贯和个性化的服务。.param(AbstractChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY, "测试固定id"))
这里指定的是会话的key和取出的上下文条数
AbstractChatMemoryAdvisor.CHAT_MEMORY_RETRIEVE_SIZE_KEY= 取出的上下文条数
AbstractChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY = 会话id
也可以通过向量库存储对话上下文上下文
//对话历史向量库AbstractChatMemoryAdvisor chatMemoryAdvisor = VectorStoreChatMemoryAdvisor.builder(历史对话向量库).protectFromBlocking(true).chatMemoryRetrieveSize(取出多少条).conversationId(会话id).build();ChatClient chatClient = ChatClient.builder(chatModel).defaultAdvisors(chatMemoryAdvisor) //向量库版的历史对话.build();
3.RAG: 检索增强生成 将业务数据存储在向量数据库中(做相似性检索)通过RAG进行链接
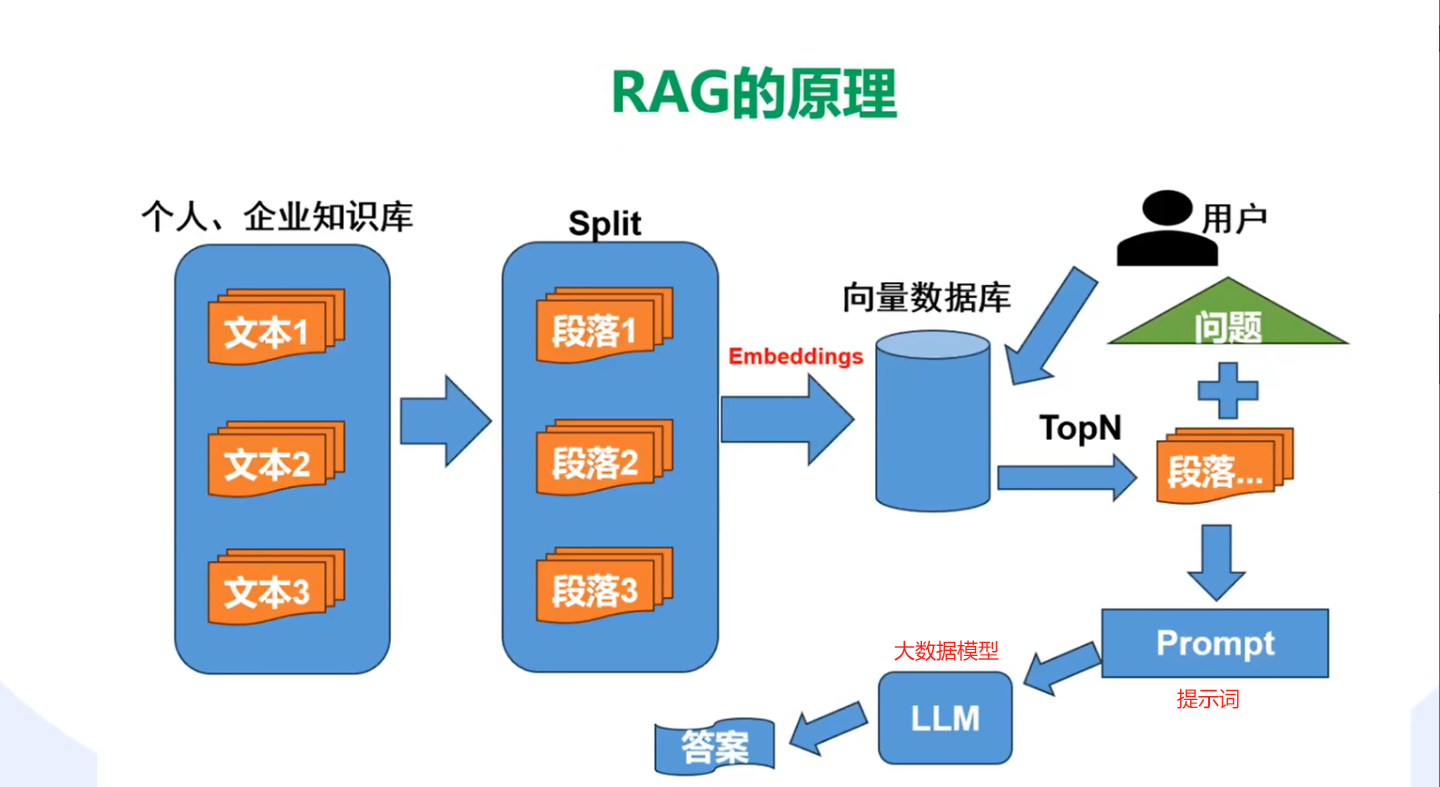
对文件进行向量化
@Autowired@Qualifier("secondaryJdbcTemplate")private JdbcTemplate jdbcTemplate;//引入嵌入模型@Autowired@Qualifier("ollamaEmbeddingModel")private EmbeddingModel embeddingModel;/*** 创建向量存储的通用方法*/private PgVectorStore.Builder createVectorStoreBuilder(JdbcTemplate jdbcTemplate, EmbeddingModel embeddingModel,String tableName) {Assert.notNull(jdbcTemplate, "JdbcTemplate 不能为空");Assert.notNull(embeddingModel, "EmbeddingModel 不能为空");Assert.hasText(tableName, "表名不能为空");return PgVectorStore.builder(jdbcTemplate, embeddingModel).dimensions(dimensions).vectorTableName(tableName);}public Result saveVectorStoreByType(String filePath, String dfileFid) {try {// 检查文件是否存在File file = new File(filePath);if (!file.exists()) {return Result.error("文件不存在: " + filePath);}Resource resource = new FileSystemResource(filePath);TikaDocumentReader reader = new TikaDocumentReader(resource);List<Document> documentList = reader.read();// 创建文本分割器并配置智能参数TextSplitter textSplitter = TokenTextSplitter.builder().withChunkSize(300) // 适中的块大小.withMinChunkSizeChars(100) // 最小块字符数.withKeepSeparator(true) // 保留分隔符.withMaxNumChunks(1000) // 最大块数量限制.build();// 应用智能分块List<Document> splitDocuments = textSplitter.apply(documentList);// 对分块结果进行后处理,确保质量List<Document> processedDocuments = new ArrayList<>();for (Document doc : splitDocuments) {String text = doc.getText().trim();// 跳过过短的块/*if (text.length() < 50) {continue;}*/// 处理过长的块if (text.length() > 1000) {// 在适当的位置进行二次分割List<String> subChunks = splitLongText(text);for (String subChunk : subChunks) {if (subChunk.trim().length() >= 50) {Map<String, Object> metadata = new HashMap<>(doc.getMetadata());metadata.put("knowledgeId", dfileFid);//知识库idprocessedDocuments.add(new Document(subChunk.trim(), metadata));}}} else {// 添加元数据Map<String, Object> metadata = new HashMap<>(doc.getMetadata());metadata.put("knowledgeId", dfileFid);//知识库idprocessedDocuments.add(new Document(text, metadata));}}VectorStore vectorStore = vectorStoreFactory.createVectorStoreByTableName(jdbcTemplate, embeddingModel, "vector_store");vectorStore.add(processedDocuments);log.info("成功将文件加载到向量数据库,共 {} 个文档片段", processedDocuments.size());return Result.ok("成功将文件 " + file.getName() + " 加载到向量数据库,共 " + processedDocuments.size() + " 个文档片段");} catch (Exception e) {log.error("保存向量存储失败", e);throw new RuntimeException("保存向量存储失败: " + e.getMessage());}}
ollamaEmbeddingModel 注入的是 ai.ollama.embedding.model: bge-m3 模型
当将数据向量化后,创建获取
/*** 创建向量存储的通用方法*/private PgVectorStore.Builder createVectorStoreBuilder(JdbcTemplate jdbcTemplate, EmbeddingModel embeddingModel,String tableName) {Assert.notNull(jdbcTemplate, "JdbcTemplate 不能为空");Assert.notNull(embeddingModel, "EmbeddingModel 不能为空");Assert.hasText(tableName, "表名不能为空");`在这里插入代码片`return PgVectorStore.builder(jdbcTemplate, embeddingModel).dimensions(dimensions).vectorTableName(tableName);}@Bean@Qualifier("VectorStore ")public VectorStore enterpriseVectorStore(@Qualifier("secondaryJdbcTemplate") JdbcTemplate jdbcTemplate,@Qualifier("ollamaEmbeddingModel") EmbeddingModel embeddingModel) {try {return createVectorStoreBuilder(jdbcTemplate, embeddingModel, "vector_store").build();} catch (Exception e) {throw new RuntimeException("创建向量库失败", e);}}
- 从向量库中查询相关信息 转为提示词给ai
// 从向量库中查询相关信息private String getVectorStoreStr(String message) {List<String> relevantInfo = new ArrayList<>();try {List<Document> similarDocs = enterpriseVectorStore.similaritySearch(message);for (Document doc : similarDocs) {relevantInfo.add(doc.getText());}log.error("从向量库获取到{}条相关信息", relevantInfo.size());} catch (Exception e) {log.error("向量库查询失败,将继续使用原始对话: {}", e.getMessage());}// 如果找到相关信息,添加到系统提示中StringBuilder context = new StringBuilder();String systemPrompt="";if (!relevantInfo.isEmpty()) {context.append("以下是一些相关的背景信息,请参考这些信息来回答问题:\n\n");for (String info : relevantInfo) {context.append("- ").append(info).append("\n");}context.append("\n请基于以上信息,结合自己的知识来回答用户的问题。如果上述信息不足以完整回答问题,可以使用自己的知识进行补充。");systemPrompt=context.toString();}return systemPrompt;}//放入预设角色中ChatClient chatClient = ChatClient.builder(ollamaChatModel).defaultSystem(getVectorStoreStr(message)).build();- 创建检索增强顾问
private Advisor getSearchEnhancementConsultant(VectorStore vectorStore,List<String> knowledge) {// 1. 构建复杂的文档过滤条件var b = new FilterExpressionBuilder();Object[] array = knowledge.toArray();// 使用in条件,匹配指定的知识库ID列表var filterExpression = b.in("knowledgeId", array);// 2. 配置文档检索器// 设置相似度阈值和返回文档数量,同时应用过滤条件DocumentRetriever retriever = VectorStoreDocumentRetriever.builder().vectorStore(vectorStore).similarityThreshold(0.5) // 设置相似度阈值,大于0.5的文档才会被返回.topK(3) // 返回相似度最高的前3个文档.filterExpression(filterExpression.build()).build();// 3. 创建并配置检索增强顾问// allowEmptyContext设置为true,确保在没有找到相关文档时也能回答问题Advisor advisor = RetrievalAugmentationAdvisor.builder().queryAugmenter(ContextualQueryAugmenter.builder().allowEmptyContext(true) // 允许空上下文,当没有找到相关文档时也会回答.build()).documentRetriever(retriever).build();return advisor;}chatClient.prompt().user(message).advisors(advisor) // 只有在开启向量库时才添加检索增强顾问 // 添加检索增强顾问 .stream().content().onErrorResume(e -> {log.error("聊天过程发生错误: ", e);return Flux.just("抱歉,处理您的请求时出现了错误,请稍后重试。");});
- 使用ai重写查询后再去向量库查询
private Advisor getSearchEnhancementConsultant2(ChatClient chatClient, VectorStore vectorStore) {Advisor retrievalAdvisor = RetrievalAugmentationAdvisor.builder().queryTransformers(RewriteQueryTransformer.builder().chatClientBuilder(chatClient.mutate())//使用ai优化查询.build()).documentRetriever(VectorStoreDocumentRetriever.builder().similarityThreshold(0.50).vectorStore(vectorStore).build()).build();return retrievalAdvisor;}chatClient.prompt().user(message).advisors(advisor) // 只有在开启向量库时才添加检索增强顾问 // 添加检索增强顾问 .stream().content().onErrorResume(e -> {log.error("聊天过程发生错误: ", e);return Flux.just("抱歉,处理您的请求时出现了错误,请稍后重试。");});
4.Function Calling 用来调用自己的api (这个官网上淘汰了)
@Bean@Description("处理机票退订")//告诉ai什么时候调用这个方法public Function<CancelBookingRequest, String> cancelBooking() {return cancelBookingRequest -> {//在这调用方法flightBookingService.cancelBooking(cancelBookingRequest.bookingId(),cancelBookingRequest.name() );return "退订成功";};}ChatClient chatClient = ChatClient.builder(chatModel).defaultFunctions("cancelBooking") //这指定的是调用那些方法的bean的名称 多个用逗号分割.build();
5.Tools (这个有个问题调用工具后返回就不是流式的了)
public class ToolsFactory {@Tool(description = "获取用户的数量")void getUserCount() {System.out.println("ai获取用户的数量");}}chatClient.prompt().user(message).tools(new ToolsFactory()) 加上这个工具后 流式返回就失效了.stream().content().onErrorResume(e -> {log.error("聊天过程发生错误: ", e);return Flux.just("抱歉,处理您的请求时出现了错误,请稍后重试。");});
相关文章:

SpringAI-ollama
SpringAi主要依赖 System Prompt :设置提示词 用来预设角色 ConversationMemory: 对话集 RAG: 检索增强生成 将业务数据存储在向量数据库中(做相似性检索)通过RAG进行链接 Function Calling 用来调用自己的api <dependencyManagement>&…...

如何在Windows 10系统中查看已连接WiFi密码-亲测可用-优雅草卓伊凡
如何在Windows 10系统中查看已连接WiFi密码-亲测可用-优雅草卓伊凡 通过系统设置查看 点击屏幕左下角的“开始”按钮,打开“设置”应用。在“设置”应用中,点击“网络和 Internet”。在“网络和 Internet”页面中,点击“WLAN”,…...

蓝耘赋能通义万相 2.1:用 C++ 构建高效 AI 视频生成生态
开篇:AI 视频生成新时代的号角 通义万相 2.1:AI 视频生成的领军者 核心技术揭秘 功能特点展示 与其他模型的全面对比 C:高效编程的基石 C 的发展历程与特性 C 在 AI 领域的广泛应用 通义万相 2.1 与 C 的完美融合 融合的意义与价值 …...

tmpfs的监控筛选/dev/shm下的shmem创建
一、背景 在一个比较注重性能的系统上,共享内存的使用肯定非常普遍。为了能更好的了解系统里共享内存的使用,比如创建、删除等操作,我们是可以对其进行监控的。 这篇博客以共享内存的创建监控为例来介绍如何监控共享内存。 这里有一个概念…...

如果你在使用 Ubuntu/Debian:使用 apt 安装 OpenSSH
情况 1:如果你在使用 Ubuntu/Debian: 使用 apt 安装 OpenSSH: bash 复制 sudo apt update sudo apt install openssh-server 完成后检查 SSH 服务状态: bash 复制 sudo systemctl status ssh 情况 2:如果你在使用 Ce…...
完整讲解与实战应用)
设计模式每日硬核训练 Day 11:适配器模式(Adapter Pattern)完整讲解与实战应用
🔄 回顾 Day 10:模板方法模式小结 在 Day 10 中,我们学习了模板方法模式: 它用于定义流程的“骨架”,将固定步骤放在父类,具体实现交给子类完成。实现了“统一流程 差异化行为”的复用范式。 而今天&am…...

xAI Elasticsearch 集群架构解析:索引数据规模与分片优化实践
Elasticsearch(ES)作为分布式搜索和分析引擎,是 xAI 构建高性能数据处理系统的基石。xAI 的业务场景,如实时日志分析、模型训练数据检索和用户行为分析,要求 Elasticsearch 集群兼顾高吞吐写入、低延迟查询和动态扩展能…...

[c语言日寄]时间复杂度
【作者主页】siy2333 【专栏介绍】⌈c语言日寄⌋:这是一个专注于C语言刷题的专栏,精选题目,搭配详细题解、拓展算法。从基础语法到复杂算法,题目涉及的知识点全面覆盖,助力你系统提升。无论你是初学者,还是…...
)
快速幂(蓝桥杯)
1. 递归实现 递归方法通过将问题分解为更小的子问题来实现。具体步骤如下: 如果指数 b 为 0,返回 1。 如果 b 是偶数,则递归计算 (a^2)b/2。 如果 b 是奇数,则递归计算 a⋅(a^2)(b−1)/2。 伪代码: function fas…...

[Python基础速成]2-模块与包与OOP
上篇➡️[Python基础速成]1-Python规范与核心语法 目录 Python模块创建模块与导入属性__name__dir()函数标准模块 Python包类类的专有方法 对象继承多态 Python模块 Python 中的模块(Module)是一个包含 Python 定义和语句的文件,文件名就是模…...

Spring AOP 学习笔记 之 常用注解
0 引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-aop</artifactId><version>3.4.2</version></dependency> 要在springboot中启用AOP,需要引入spring-boot-…...

JVM——运行时数据区
目录 Class装载到JVM的过程 装载(load)——查找和导入class文件 正文------------------- Run-time Data Areas 运行时数据区 Method Area 方法区 Heap 堆 Java Virtual Machine Stacks(Java虚拟机栈) The PC Register 程…...

Conda 入门指令教程
Conda 入门指令教程 Conda 是一个强大的包和环境管理工具,广泛应用于数据科学和机器学习项目中。本文将介绍 Conda 的常用指令,帮助你快速上手。 1. Conda 基础操作 查看 Conda 版本 conda --version显示当前安装的 Conda 版本。 更新 Conda conda…...

基于STM32、HAL库的MAX14830总线转UART驱动程序设计
一、简介: MAX14830是一款四通道UART扩展器,通过SPI或I2C接口与微控制器通信。主要特性包括: 4个独立的全双工UART通道 可编程波特率(最高达12Mbps) 每个通道有128字节的发送和接收FIFO 支持硬件和软件流控制 可配置的GPIO引脚 工作电压:1.7V至5.5V 低功耗模式 二、硬件…...

x-cmd install | jellex - 用 Python 语法在终端里玩转 JSON 数据!
目录 核心功能与特点安装优势亮点适用场景 还在为命令行下处理 JSON 数据烦恼吗?jellex 来了!它是一款基于终端的交互式 JSON 和 JSON Lines 数据处理工具,让你用熟悉的 Python 语法,轻松过滤、转换和探索 JSON 数据。 核心功能与…...

2025天梯赛 L2专项训练
L2-049 鱼与熊掌 - 团体程序设计天梯赛-练习集 思路就是模拟,正常写就完事 #include<bits/stdc.h> using namespace std; int main() {int a, b;cin >> a >> b;vector<vector<int>>arr(a, vector<int>(0));for (int i 0; i &…...
)
214、【数组】下一个排列(Python)
题目描述 原题链接:31. 下一个排列 思路 从后往前,找到第一个小于右侧集合的数,从右侧集合中找到一个比该数大的最小的数替换上去。 然后,将右侧集合从小到排列,就为当前排列中,下一个排列的数。 代码实…...
 in String use 31 as a multiplier?)
Why does Java‘s hashCode() in String use 31 as a multiplier?
HashCode 为什么使用 31 作为乘数? 1. 固定乘积 31 在这用到了2. 来自 stackoverflow 的回答3. Hash 值碰撞概率统计3.1 读取单词字典表3.2 Hash 计算函数3.3 Hash 碰撞概率计算封装碰撞统计信息的类3.4 针对一组乘数,分别计算碰撞率3.5 碰撞结果可视化3…...

如何将一个8s的接口优化到500ms以下
最近换了个工作,刚入职就接了个活--优化公司自营app的接口性能,提升用户体验。 刚开始还以为是1s优化到500ms这种,或者500ms优化到200ms的接口,感觉还挺有挑战的。下好app体验了一下。好家伙,那个慢已经超过了我的忍耐…...

如何保证本地缓存和redis的一致性
1. Cache Aside Pattern(旁路缓存模式) 核心思想:应用代码直接管理缓存与数据的同步,分为读写两个流程: 读取数据: 先查本地缓存(如 Guava Cache)。若本地未命中&…...

30天学Java第十天——反射机制
反射机制 反射机制是 Java 语言中的一个重要特性,它允许程序在运行时动态地获取类的信息(如类的属性、方法和构造器等),并且可以操作这些信息。 反射机制在某些情况下非常有用,例如开发框架、库,或者需要进…...

Nodejs Express框架
参考:Node.js Express 框架 | 菜鸟教程 第一个 Express 框架实例 接下来我们使用 Express 框架来输出 "Hello World"。 以下实例中我们引入了 express 模块,并在客户端发起请求后,响应 "Hello World" 字符串。 创建 e…...

视频设备轨迹回放平台EasyCVR打造货运汽车安全互联网视频监控与管理方案
一、背景介绍 随着互联网发展,货运中介平台大量涌现,行业纠纷也随之增多。尽管当前平台APP具备录音和定位功能,但货物交易流程的全方位监控仍无法实现。主流跟踪定位服务大部分聚焦货物轨迹与车辆定位,尚未实现货物全程可视化监控…...

玩转Docker | 使用Docker部署Docmost文档管理系统
玩转Docker | 使用Docker部署Docmost文档管理系统 前言一、Docmost介绍Docmost 简介Docmost 特点二、系统要求环境要求环境检查Docker版本检查检查操作系统版本三、部署Docmost服务下载镜像编辑部署文件创建容器检查容器状态检查服务端口安全设置四、访问Docmost服务访问Docmos…...
)
docker方式项目部署(安装容器组件+配置文件导入Nacos+dockerCompose文件创建管理多个容器+私有镜像仓库Harbor)
基于docker的部署 服务器主机ip 192.168.6.131 安装组件 安装redis docker pull redis:7.0.10#在宿主机上/var/lib/docker/volumes/redis-config/_data/目录下创建一个redis配置文件 vim redis.conf#内容如下 appendonly yes #开启持久化 port 6379 #requirepass 1234 #密码…...

基于OpenCV与PyTorch的智能相册分类器全栈实现教程
引言:为什么需要智能相册分类器? 在数字影像爆炸的时代,每个人的相册都存储着数千张未整理的照片。手动分类不仅耗时,还容易遗漏重要瞬间。本文将手把手教你构建一个基于深度学习的智能相册分类系统,实现:…...

C++中string库常用函数超详细解析与深度实践
目录 一、引言 二、基础准备:头文件与命名空间 三、string对象的创建与初始化(基础) 3.1 直接初始化 3.2 动态初始化(空字符串) 3.3 基于字符数组初始化 3.4 重复字符初始化 四、核心函数详解 4.1 字符串长度相关 4.1.1 …...
)
数据结构(3)
实验步骤: 任务:要求使用自定义函数来实现 输入一段文本,统计每个字符出现的次数,按照字符出现次数从多到少,依次输出,格式如下: 字符1-个数 字符2-个数 ...... 解题思路: 构建结构体…...

【C++教程】使用printf语句实现进制转换
在C语言中,printf 函数可以直接实现部分进制转换功能,通过格式说明符(format specifier)快速输出不同进制的数值。以下是详细使用方法及示例代码: 一、printf 原生支持的进制转换 1. 十进制、八进制、十六进制转换 #…...

el-dialog设置append-to不生效;el-dialog设置挂载层级
文章目录 一、场景二、注意点1. append-to-body何时为true2.设置层级,遮罩层大小不生效3.相关代码 三、ElMessageBox遮罩层 效果: 一、场景 正常情况下,el-dialog的弹框是挂载在body下的,导致我们会有修改样式或者修改弹框的遮罩…...

互联网软件开发自动化平台 的多维度对比分析,涵盖架构、功能、适用场景、成本等关键指标
以下是关于 互联网软件开发自动化平台 的详细解析,涵盖其核心概念、主流平台的功能、架构设计、适用场景及对比分析: 一、自动化平台的定义与核心目标 自动化平台(如CI/CD平台)是用于 持续集成(CI) 和 持续…...

UE5 制作方块边缘渐变边框效果
该效果基于之前做的(https://blog.csdn.net/grayrail/article/details/144546427)进行修改得到,思路也很简单: 1.打开实时预览 1.为了制作时每个细节调整方便,勾选Live Update中的三个选项,开启实时预览。…...

深入探究 GRU 模型:梯度爆炸问题剖析
在深度学习领域,循环神经网络(RNN)及其变体在处理序列数据时展现出了强大的威力。其中,门控循环单元(GRU)作为 RNN 的一种进阶架构,备受关注。今天,咱们就来深入聊聊 GRU 模型&#…...
原理详解)
生成对抗网络(GAN)原理详解
生成对抗网络(GAN)原理详解 1. 背景 生成对抗网络(Generative Adversarial Network, GAN)由 Ian Goodfellow 等人于 2014 年提出,是一种通过对抗训练生成高质量数据的框架。其核心思想是让两个神经网络(生…...

CFD中的动量方程非守恒形式详解
在计算流体力学(CFD)中,动量方程可以写成守恒形式和非守恒形式,两者在数学上等价,但推导方式和应用场景不同。以下是对非守恒形式的详细解释: 1. 动量方程的守恒形式 首先回顾守恒形式的动量方程ÿ…...

AIoT 智变浪潮演讲实录 | 刘浩然:让硬件会思考:边缘大模型网关助力硬件智能革新
4 月 2 日,由火山引擎与英特尔联合主办的 AIoT “智变浪潮”技术沙龙在深圳成功举行,活动聚焦 AI 硬件产业的技术落地与生态协同,吸引了芯片厂商、技术方案商、品牌方及投资机构代表等 700 多位嘉宾参会。 会上,火山引擎边缘智能高…...

4.B-树
一、常见的查找方式 顺序查找 O(N) 二分查找 O(logN)(要求有序和随机访问) 二叉搜索树 O(N) 平衡二叉搜索树(AVL树和红黑树) O(logN) 哈希 O(1) 考虑效率和要求而言,正常选用 平衡二叉搜索树 和 哈希 作为查找方式。 但这两种结构适合用于数据量相对不是很大,能够一次性…...

怎么看英文论文 pdf沉浸式翻译
https://arxiv.org/pdf/2105.09492 Immersive Translate Xournal打开...
)
计算机三级第一章:信息安全保障概述(以时间节点推进的总结)
淡蓝色为必背内容 第一阶段:电讯技术的发明19世纪30年代:电报电话的发明 1835年:莫尔斯(Morse)发明了电报 1837年:莫尔斯电磁式有线电报问世 1878年:人工电话交换局出现 1886年:马可尼发明了无线电报机 1876年:贝尔(Bell)发明了电话机 1892年,史瑞桥自动交换…...

车载软件架构 ---单个ECU的AUTOSAR开发流程
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 周末洗了一个澡,换了一身衣服,出了门却不知道去哪儿,不知道去找谁,漫无目的走着,大概这就是成年人最深的孤独吧! 旧人不知我近况,新人不知我过…...
【场景应用7】在TPU上使用Flax/JAX对Transformers模型进行语言模型预训练
在本笔记本中,我们将展示如何使用Flax在TPU上预训练一个🤗 Transformers模型。 这里将使用GPT2的因果语言建模目标进行预训练。 正如在这个基准测试中所看到的,使用Flax/JAX在GPU/TPU上的训练通常比使用PyTorch在GPU/TPU上的训练要快得多,而且也可以显著降低成本。 Fla…...

C++运算符重载全面总结
C运算符重载全面总结 运算符重载是C中一项强大的特性,它允许程序员为自定义类型定义运算符的行为。以下是关于C运算符重载的详细总结: 一、基本概念 1. 什么是运算符重载 运算符重载是指为自定义类型(类或结构体)重新定义或重…...

PTA | 实验室使用排期
目录 题目: 输入格式: 输出格式: 输入样例: 输出样例: 样例解释: 代码: 无注释版: 有注释版: 题目: 受新冠疫情影响,当前大家的活动都…...

3.7 字符串基础
字符串 (str):和列表用法基本一致 1.字符串的创建 -str转换(字符串,可用于将其他字符类型转换为字符串) -单引号 双引号 三引号 2.索引 3.字符串的切片 4.字符串的遍历 5.字符串的格式化 6.字符串的运算符 7.字符串的函数 #…...

《 C++ 点滴漫谈: 三十三 》当函数成为参数:解密 C++ 回调函数的全部姿势
一、前言 在现代软件开发中,“解耦” 与 “可扩展性” 已成为衡量一个系统架构优劣的重要标准。而在众多实现解耦机制的技术手段中,“回调函数” 无疑是一种高效且广泛使用的模式。你是否曾经在编写排序算法时,希望允许用户自定义排序规则&a…...
)
16bit转8bit的常见方法(图像归一化)
文章目录 16-bit转8-bit的常用方法一、数据类型转换:image.astype(np.uint8) —— 若数值 x 超出 0-255 范围,则取模运算。如:x 600 % 256 88二、截断函数:np.clip().astype(np.uint8) —— 若数值 x 超出 0-255 范围࿰…...

消息中间件kafka,rabbitMQ
在分布式系统中,消息中间件是实现不同组件之间异步通信的关键技术。Kafka 和 RabbitMQ 是两个非常流行的消息中间件系统,它们各自有着不同的特点和应用场景。下面将分别介绍 Kafka 和 RabbitMQ,并讨论它们在消息队列中的使用。 一、Kafka (Apache Kafka) 主要特点: 高吞吐…...

C语言编译预处理3
条件编译:是对源程序的一部分指定编译条件,满足条件进行编译否则不编译。 形式1 #indef 标识符 程序段1 #else 程序段2 #endif 标识符已经被定义用#ifdef #include <stdio.h>// 可以通过注释或取消注释下面这行来控制是否定义 DEBUG 宏 // …...

数据结构·树
树的特点 最小连通图 无环 有且只有 n − 1 n-1 n−1 条边 树的建立方式 顺序存储 只适用于满n叉树,完全n叉树 1<<n 表示结点 2 n 2^n 2nP4715 【深基16.例1】淘汰赛 void solve() {cin >> n;for (int i 0; i<(1<<n); i) {cin >&g…...
)
队列的各种操作实现(数据结构C语言多文件编写)
1.先创建queue.h声明文件(Linux命令:touch queue.h)。编写函数声明如下(打开文件 Linux 操作命令:vim queue.h): //头文件 #ifndef __QUEUE_H__ #define __QUEUE_H__ //队列 typedef struct queue{int* arr;int in;int out;int cap;int size; }queue_t;…...