生成对抗网络(GAN)原理详解
生成对抗网络(GAN)原理详解
1. 背景
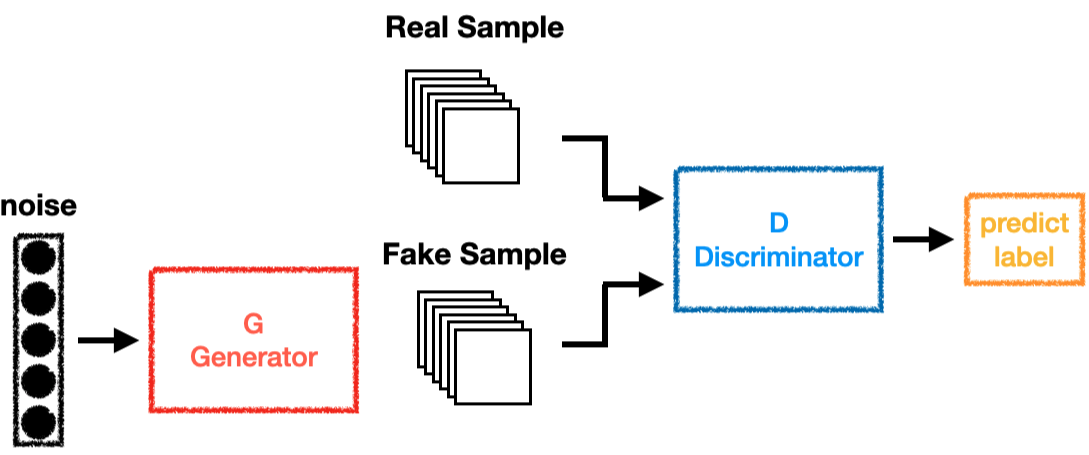
生成对抗网络(Generative Adversarial Network, GAN)由 Ian Goodfellow 等人于 2014 年提出,是一种通过对抗训练生成高质量数据的框架。其核心思想是让两个神经网络(生成器 G G G 和判别器 D D D)在博弈中共同进化:生成器试图生成逼真的假数据,而判别器试图区分真实数据与生成数据。这种对抗过程最终使生成器能够生成与真实数据分布高度接近的样本。
2. 数学推导
GAN 的目标函数是一个极小极大博弈(minimax game):
min G max D V ( D , G ) = E x ∼ p data ( x ) [ log D ( x ) ] + E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] \min_G \max_D V(D, G) = \mathbb{E}_{x \sim p_{\text{data}}(x)}[\log D(x)] + \mathbb{E}_{z \sim p_z(z)}[\log (1 - D(G(z)))] GminDmaxV(D,G)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]
- 生成器 G G G:输入噪声 z ∼ p z ( z ) z \sim p_z(z) z∼pz(z),输出生成样本 G ( z ) G(z) G(z),目标是让 D ( G ( z ) ) D(G(z)) D(G(z)) 接近 1(欺骗判别器)。
- 判别器 D D D:输入真实数据 x x x 或生成数据 G ( z ) G(z) G(z),输出概率 D ( x ) ∈ [ 0 , 1 ] D(x) \in [0,1] D(x)∈[0,1],目标是最大化对真实数据和生成数据的区分能力。
优化过程:
- 固定 G G G,优化 D D D:通过梯度上升最大化 V ( D , G ) V(D, G) V(D,G)。
- 固定 D D D,优化 G G G:通过梯度下降最小化 V ( D , G ) V(D, G) V(D,G)。
3. 与 KL 散度的关系
当判别器达到最优时(即 D ( x ) = p data ( x ) p data ( x ) + p g ( x ) D(x) = \frac{p_{\text{data}}(x)}{p_{\text{data}}(x) + p_g(x)} D(x)=pdata(x)+pg(x)pdata(x)),生成器的目标等价于最小化 JS 散度(Jensen-Shannon Divergence):
JSD ( p data ∥ p g ) = 1 2 ( KL ( p data ∥ p data + p g 2 ) + KL ( p g ∥ p data + p g 2 ) ) \text{JSD}(p_{\text{data}} \| p_g) = \frac{1}{2} \left( \text{KL}\left(p_{\text{data}} \| \frac{p_{\text{data}} + p_g}{2}\right) + \text{KL}\left(p_g \| \frac{p_{\text{data}} + p_g}{2}\right) \right) JSD(pdata∥pg)=21(KL(pdata∥2pdata+pg)+KL(pg∥2pdata+pg))
JS 散度是对称化的 KL 散度,避免了 KL 散度的不对称性。但若 p data p_{\text{data}} pdata 和 p g p_g pg 的支撑集不重叠,JS 散度为常数 log 2 \log 2 log2,导致梯度消失。
推导过程如下:
固定生成器G后,判别器D的最优解通过对每个x独立优化以下表达式得到:
f ( D ( x ) ) = p data ( x ) log D ( x ) + p g ( x ) log ( 1 − D ( x ) ) . f(D(x)) = p_{\text{data}}(x) \log D(x) + p_g(x) \log(1 - D(x)). f(D(x))=pdata(x)logD(x)+pg(x)log(1−D(x)).
对 D ( x ) D(x) D(x)求导并令导数为零:
p data ( x ) D ( x ) − p g ( x ) 1 − D ( x ) = 0 ⟹ D ∗ ( x ) = p data ( x ) p data ( x ) + p g ( x ) . \frac{p_{\text{data}}(x)}{D(x)} - \frac{p_g(x)}{1 - D(x)} = 0 \implies D^*(x) = \frac{p_{\text{data}}(x)}{p_{\text{data}}(x) + p_g(x)}. D(x)pdata(x)−1−D(x)pg(x)=0⟹D∗(x)=pdata(x)+pg(x)pdata(x).
将最优判别器 D ∗ ( x ) D^*(x) D∗(x)代入目标函数 V ( D ∗ , G ) V(D^*, G) V(D∗,G):
V ( D ∗ , G ) = E x ∼ p data [ log p data p data + p g ] + E x ∼ p g [ log p g p data + p g ] . V(D^*, G) = \mathbb{E}_{x \sim p_{\text{data}}} \left[ \log \frac{p_{\text{data}}}{p_{\text{data}} + p_g} \right] + \mathbb{E}_{x \sim p_g} \left[ \log \frac{p_g}{p_{\text{data}} + p_g} \right]. V(D∗,G)=Ex∼pdata[logpdata+pgpdata]+Ex∼pg[logpdata+pgpg].
展开后得到:
∫ p data log p data p data + p g d x + ∫ p g log p g p data + p g d x . \int p_{\text{data}} \log \frac{p_{\text{data}}}{p_{\text{data}} + p_g} dx + \int p_g \log \frac{p_g}{p_{\text{data}} + p_g} dx. ∫pdatalogpdata+pgpdatadx+∫pglogpdata+pgpgdx.
令 M = p data + p g 2 M = \frac{p_{\text{data}} + p_g}{2} M=2pdata+pg,则上式可改写为:
∫ p data ( log p data 2 M ) d x + ∫ p g ( log p g 2 M ) d x . \int p_{\text{data}} \left( \log \frac{p_{\text{data}}}{2M} \right) dx + \int p_g \left( \log \frac{p_g}{2M} \right) dx. ∫pdata(log2Mpdata)dx+∫pg(log2Mpg)dx.
进一步分解:
∫ p data log p data M d x ⏟ KL ( p data ∥ M ) − log 2 + ∫ p g log p g M d x ⏟ KL ( p g ∥ M ) − log 2. \underbrace{\int p_{\text{data}} \log \frac{p_{\text{data}}}{M} dx}_{\text{KL}(p_{\text{data}} \| M)} - \log 2 + \underbrace{\int p_g \log \frac{p_g}{M} dx}_{\text{KL}(p_g \| M)} - \log 2. KL(pdata∥M) ∫pdatalogMpdatadx−log2+KL(pg∥M) ∫pglogMpgdx−log2.
合并后得到:
KL ( p data ∥ M ) + KL ( p g ∥ M ) − 2 log 2. \text{KL}(p_{\text{data}} \| M) + \text{KL}(p_g \| M) - 2\log 2. KL(pdata∥M)+KL(pg∥M)−2log2.
根据JS散度的定义:
JSD ( p data ∥ p g ) = 1 2 ( KL ( p data ∥ M ) + KL ( p g ∥ M ) ) , \text{JSD}(p_{\text{data}} \| p_g) = \frac{1}{2} \left( \text{KL}(p_{\text{data}} \| M) + \text{KL}(p_g \| M) \right), JSD(pdata∥pg)=21(KL(pdata∥M)+KL(pg∥M)),
因此目标函数可表示为:
2 ⋅ JSD ( p data ∥ p g ) − 2 log 2. 2 \cdot \text{JSD}(p_{\text{data}} \| p_g) - 2\log 2. 2⋅JSD(pdata∥pg)−2log2.
由于常数项不影响优化方向,生成器G的最小化目标等价于最小化JS散度。
不重叠时的特性:
当 ( p ) 和 ( g ) 不重叠时,对于所有 ( x ):
- 若 ( p(x) > 0 ),则 ( g(x) = 0 ),此时 ( M(x) = \frac{p(x)}{2} );
- 若 ( g(x) > 0 ),则 ( p(x) = 0 ),此时 ( M(x) = \frac{g(x)}{2} )。
计算KL散度:
- 对于 ( \text{KL}(p \parallel M) ),在 ( p ) 的支撑集上:
[
\text{KL}(p \parallel M) = \sum p(x) \log \frac{p(x)}{M(x)} = \sum p(x) \log \frac{p(x)}{p(x)/2} = \sum p(x) \log 2 = \log 2.
] - 同理,( \text{KL}(g \parallel M) = \log 2 )。
JS散度的结果:
- 代入JS散度公式:
[
\text{JS}(p \parallel g) = \frac{1}{2} \log 2 + \frac{1}{2} \log 2 = \log 2.
]
4. 损失函数的直观理解
- 判别器损失:最大化对真实样本的置信度( log D ( x ) \log D(x) logD(x))和对生成样本的否定( log ( 1 − D ( G ( z ) ) ) \log (1 - D(G(z))) log(1−D(G(z))))。
- 生成器损失:最小化 log ( 1 − D ( G ( z ) ) ) \log (1 - D(G(z))) log(1−D(G(z))),即让生成样本被判别器判定为真实。
关键直觉:生成器和判别器在动态博弈中互相提升。生成器逐渐逼近真实分布,而判别器被迫提升鉴别能力,最终达到纳什均衡。
5. 生成高质量数据的原因
- 对抗训练的自我强化:生成器必须不断改进以欺骗判别器,而判别器的提升反过来推动生成器更精细地拟合真实分布。
- 隐式分布匹配:GAN 直接学习从噪声到数据分布的映射,避免了显式概率密度估计(如 VAE),更适合复杂分布。
6. GAN 的问题及原因
-
模型崩溃(Mode Collapse)
- 现象:生成器仅生成少数几种样本,缺乏多样性。
- 原因:生成器找到一种能欺骗当前判别器的模式后,停止探索其他区域。判别器未能提供足够梯度迫使生成器覆盖全部真实分布。
-
训练不稳定性
- 梯度消失:当判别器过于强大时,生成器的梯度 ∇ z log ( 1 − D ( G ( z ) ) ) \nabla_z \log (1 - D(G(z))) ∇zlog(1−D(G(z))) 趋近于零,导致无法更新。
- 模式不重叠:若 ( p_{\text{data}} ) 和 ( p_g ) 的支撑集不重叠,JS 散度无法提供有效梯度(理论缺陷)。
- 平衡难以维持:生成器和判别器的能力需同步提升,否则一方压倒另一方会导致训练震荡。
-
判别器过强导致梯度消失的推导**
注:模式不重叠导致的梯度消失推导在上面- 损失函数 在原始GAN中,生成器的目标是最小化以下损失函数:
L G = E z ∼ p ( z ) [ log ( 1 − D ( G ( z ) ) ) ] . \mathcal{L}_G = \mathbb{E}_{z \sim p(z)} \left[ \log(1 - D(G(z))) \right]. LG=Ez∼p(z)[log(1−D(G(z)))].
对应的梯度为:
∇ θ G L G = E z ∼ p ( z ) [ − D ′ ( G ( z ) ) 1 − D ( G ( z ) ) ⋅ ∇ θ G G ( z ) ] . \nabla_{\theta_G} \mathcal{L}_G = \mathbb{E}_{z \sim p(z)} \left[ \frac{-D'(G(z))}{1 - D(G(z))} \cdot \nabla_{\theta_G} G(z) \right]. ∇θGLG=Ez∼p(z)[1−D(G(z))−D′(G(z))⋅∇θGG(z)]. - 完美判别器 当判别器过于强大时,对生成样本的判别结果 D ( G ( z ) ) D(G(z)) D(G(z)) 会趋近于0(即判别器几乎确信生成样本是假的)。此时:
- 分子分析: D ′ ( G ( z ) ) D'(G(z)) D′(G(z)) 是判别器对生成样本的梯度,当判别器在真实样本附近饱和(例如使用Sigmoid激活函数),其梯度 D ′ ( G ( z ) ) D'(G(z)) D′(G(z)) 会趋近于0。
- 分母分析: 1 − D ( G ( z ) ) 1 - D(G(z)) 1−D(G(z)) 趋近于1,看似不影响梯度,但由于分子 D ′ ( G ( z ) ) D'(G(z)) D′(G(z)) 已趋近于0,整体梯度仍然趋近于0。 - 直观解释
- 判别器的“压倒性优势”:如果判别器完美区分真假样本( D ( G ( z ) ) → 0 D(G(z)) \to 0 D(G(z))→0),生成器的任何微小改进都无法改变判别器的判断,导致梯度缺乏方向性信息。
- 损失函数平坦化:当 log ( 1 − D ( G ( z ) ) ) \log(1 - D(G(z))) log(1−D(G(z))) 接近0时,损失函数的“地形”变得平坦,梯度消失,优化过程停滞。
- 损失函数 在原始GAN中,生成器的目标是最小化以下损失函数:
-
改进方法:
- 修改生成器损失函数:
将生成器的目标从 min log ( 1 − D ( G ( z ) ) ) \min \log(1 - D(G(z))) minlog(1−D(G(z))) 改为 max log ( D ( G ( z ) ) ) \max \log(D(G(z))) maxlog(D(G(z)))(即反转标签),避免梯度饱和。根据链式规则, ∇ θ G L G = ∇ G L G ⋅ ∇ θ G \nabla_{\theta_G}\mathcal{L}_G=\nabla_G \mathcal{L}_G \cdot \nabla_\theta G ∇θGLG=∇GLG⋅∇θG。当 D ( G ( z ) ) → 0 D(G(z))\to 0 D(G(z))→0, ∇ G l o g ( 1 − D G ( z ) ) = − D ′ G ( z ) 1 − D G ( z ) → 0 \nabla_G log(1-DG(z))=-\frac{D'G(z)}{1-DG(z)}\to 0 ∇Glog(1−DG(z))=−1−DG(z)D′G(z)→0, D ′ G ( z ) D'G(z) D′G(z)在 D G ( z ) → 0 时趋于 s i g m o i d 饱和 DG(z)\to 0时趋于sigmoid饱和 DG(z)→0时趋于sigmoid饱和,而 ∇ G l o g ( D G ( z ) ) = 1 D G ( z ) → ∞ \nabla_G log(DG(z))=\frac{1}{DG(z)}\to \infty ∇Glog(DG(z))=DG(z)1→∞ - 使用Wasserstein GAN(WGAN):
通过Wasserstein距离设计损失函数,其梯度在判别器较强时仍能保持稳定。且使用 Wasserstein 距离(Earth-Mover 距离)替代传统的 JS 散度或 KL 散度,支撑集不重叠时仍能提供有效的梯度。后续详细介绍WGAN,其数学推导也很优美 - 控制判别器的训练强度:
避免过度训练判别器(例如限制判别器的更新频率或使用梯度惩罚) - 添加噪声:向真实数据或生成数据注入噪声(如高斯噪声),扩大两者的支撑集,使其部分重叠。
- 修改生成器损失函数:
7. 总结
GAN 通过对抗训练实现了数据生成领域的突破,但其成功依赖于生成器与判别器的动态平衡。模型崩溃和训练不稳定源于目标函数的理论缺陷(如 JS 散度的局限性)及优化过程的敏感性。后续改进(如 WGAN 使用 Wasserstein 距离)通过设计更合理的距离度量缓解了这些问题,但核心挑战仍存。
以上内容由 AI 生成,仅供参考,不代表开发者的立场。
8. 代码
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np# 超参数设置
batch_size = 64
latent_dim = 100 # 潜在向量维度
img_dim = 28*28 # 图像维度(MNIST为28x28)
epochs = 200 # 训练轮数
lr = 0.0002 # 学习率
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")'''数据加载和预处理
'''
# 数据预处理:归一化到[-1, 1]范围,并转换为Tensor
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=(0.5,), std=(0.5,)) # 单通道
])# 加载MNIST数据集
dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform
)# 创建数据加载器
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True,num_workers=4 # 多线程加载
)'''生成器网络定义
'''
class Generator(nn.Module):def __init__(self):super(Generator, self).__init__()# 全连接网络结构self.model = nn.Sequential(nn.Linear(latent_dim, 256), # 输入:潜在向量 (batch, 100)nn.LeakyReLU(0.2, inplace=True), # LeakyReLU防止梯度消失nn.Linear(256, 512),nn.LeakyReLU(0.2, inplace=True),nn.Linear(512, 1024),nn.LeakyReLU(0.2, inplace=True),nn.Linear(1024, img_dim), # 输出:展平的图像 (batch, 784)nn.Tanh() # 输出范围[-1, 1],与预处理匹配)def forward(self, z):return self.model(z).view(-1, 1, 28, 28) # 重塑为图像形状 (batch, 1, 28, 28)
'''判别器网络定义
'''
class Discriminator(nn.Module):def __init__(self):super(Discriminator, self).__init__()# 全连接网络结构self.model = nn.Sequential(nn.Linear(img_dim, 1024), # 输入:展平的图像 (batch, 784)nn.LeakyReLU(0.2, inplace=True),nn.Dropout(0.3), # Dropout防止过拟合nn.Linear(1024, 512),nn.LeakyReLU(0.2, inplace=True),nn.Dropout(0.3),nn.Linear(512, 256),nn.LeakyReLU(0.2, inplace=True),nn.Dropout(0.3),nn.Linear(256, 1), # 输出:判别概率 (batch, 1)nn.Sigmoid() # 映射到[0,1])def forward(self, img):img_flat = img.view(-1, img_dim) # 展平图像return self.model(img_flat)
'''模型初始化和优化器
'''
# 初始化生成器和判别器
generator = Generator().to(device)
discriminator = Discriminator().to(device)# 定义损失函数(二元交叉熵)
criterion = nn.BCELoss()# 定义优化器(Adam优化器)
optimizer_G = optim.Adam(generator.parameters(), lr=lr)
optimizer_D = optim.Adam(discriminator.parameters(), lr=lr)'''训练循环
'''
# 固定潜在向量用于生成示例图像
fixed_z = torch.randn(16, latent_dim).to(device)for epoch in range(epochs):for i, (real_imgs, _) in enumerate(dataloader):batch_size = real_imgs.size(0)real_imgs = real_imgs.to(device)# ========================# 训练判别器(最大化对数似然)# ========================optimizer_D.zero_grad()# 真实图像的损失real_labels = torch.ones(batch_size, 1).to(device) # 真实标签为1real_output = discriminator(real_imgs)real_loss = criterion(real_output, real_labels)# 生成图像的损失,目标是最小化 log(1 - D(G(z))),但实际优化 log(D(G(z)))(更稳定)z = torch.randn(batch_size, latent_dim).to(device)fake_imgs = generator(z)fake_labels = torch.zeros(batch_size, 1).to(device) # 生成标签为0fake_output = discriminator(fake_imgs.detach()) # 阻止梯度流向生成器fake_loss = criterion(fake_output, fake_labels)# 总损失反向传播d_loss = real_loss + fake_lossd_loss.backward()optimizer_D.step()# ========================# 训练生成器(最小化判别器对生成图像的判别误差)# ========================optimizer_G.zero_grad()# 生成器的目标:让判别器认为生成图像为真gen_labels = torch.ones(batch_size, 1).to(device) # 欺骗标签为1gen_output = discriminator(fake_imgs) # 注意此处不detachg_loss = criterion(gen_output, gen_labels)g_loss.backward()optimizer_G.step()# 打印训练进度if i % 200 == 0:print(f"[Epoch {epoch}/{epochs}] [Batch {i}/{len(dataloader)}] "f"D Loss: {d_loss.item():.4f} G Loss: {g_loss.item():.4f}")# 每轮结束后生成示例图像if epoch % 10 == 0:with torch.no_grad():fake_imgs = generator(fixed_z).cpu()grid = torchvision.utils.make_grid(fake_imgs, nrow=4, normalize=True)plt.imshow(np.transpose(grid, (1, 2, 0)))plt.axis('off')plt.savefig(f'gan_generated_epoch_{epoch}.png')plt.close()相关文章:
原理详解)
生成对抗网络(GAN)原理详解
生成对抗网络(GAN)原理详解 1. 背景 生成对抗网络(Generative Adversarial Network, GAN)由 Ian Goodfellow 等人于 2014 年提出,是一种通过对抗训练生成高质量数据的框架。其核心思想是让两个神经网络(生…...

CFD中的动量方程非守恒形式详解
在计算流体力学(CFD)中,动量方程可以写成守恒形式和非守恒形式,两者在数学上等价,但推导方式和应用场景不同。以下是对非守恒形式的详细解释: 1. 动量方程的守恒形式 首先回顾守恒形式的动量方程ÿ…...

AIoT 智变浪潮演讲实录 | 刘浩然:让硬件会思考:边缘大模型网关助力硬件智能革新
4 月 2 日,由火山引擎与英特尔联合主办的 AIoT “智变浪潮”技术沙龙在深圳成功举行,活动聚焦 AI 硬件产业的技术落地与生态协同,吸引了芯片厂商、技术方案商、品牌方及投资机构代表等 700 多位嘉宾参会。 会上,火山引擎边缘智能高…...

4.B-树
一、常见的查找方式 顺序查找 O(N) 二分查找 O(logN)(要求有序和随机访问) 二叉搜索树 O(N) 平衡二叉搜索树(AVL树和红黑树) O(logN) 哈希 O(1) 考虑效率和要求而言,正常选用 平衡二叉搜索树 和 哈希 作为查找方式。 但这两种结构适合用于数据量相对不是很大,能够一次性…...

怎么看英文论文 pdf沉浸式翻译
https://arxiv.org/pdf/2105.09492 Immersive Translate Xournal打开...
)
计算机三级第一章:信息安全保障概述(以时间节点推进的总结)
淡蓝色为必背内容 第一阶段:电讯技术的发明19世纪30年代:电报电话的发明 1835年:莫尔斯(Morse)发明了电报 1837年:莫尔斯电磁式有线电报问世 1878年:人工电话交换局出现 1886年:马可尼发明了无线电报机 1876年:贝尔(Bell)发明了电话机 1892年,史瑞桥自动交换…...

车载软件架构 ---单个ECU的AUTOSAR开发流程
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 周末洗了一个澡,换了一身衣服,出了门却不知道去哪儿,不知道去找谁,漫无目的走着,大概这就是成年人最深的孤独吧! 旧人不知我近况,新人不知我过…...
【场景应用7】在TPU上使用Flax/JAX对Transformers模型进行语言模型预训练
在本笔记本中,我们将展示如何使用Flax在TPU上预训练一个🤗 Transformers模型。 这里将使用GPT2的因果语言建模目标进行预训练。 正如在这个基准测试中所看到的,使用Flax/JAX在GPU/TPU上的训练通常比使用PyTorch在GPU/TPU上的训练要快得多,而且也可以显著降低成本。 Fla…...

C++运算符重载全面总结
C运算符重载全面总结 运算符重载是C中一项强大的特性,它允许程序员为自定义类型定义运算符的行为。以下是关于C运算符重载的详细总结: 一、基本概念 1. 什么是运算符重载 运算符重载是指为自定义类型(类或结构体)重新定义或重…...

PTA | 实验室使用排期
目录 题目: 输入格式: 输出格式: 输入样例: 输出样例: 样例解释: 代码: 无注释版: 有注释版: 题目: 受新冠疫情影响,当前大家的活动都…...

3.7 字符串基础
字符串 (str):和列表用法基本一致 1.字符串的创建 -str转换(字符串,可用于将其他字符类型转换为字符串) -单引号 双引号 三引号 2.索引 3.字符串的切片 4.字符串的遍历 5.字符串的格式化 6.字符串的运算符 7.字符串的函数 #…...

《 C++ 点滴漫谈: 三十三 》当函数成为参数:解密 C++ 回调函数的全部姿势
一、前言 在现代软件开发中,“解耦” 与 “可扩展性” 已成为衡量一个系统架构优劣的重要标准。而在众多实现解耦机制的技术手段中,“回调函数” 无疑是一种高效且广泛使用的模式。你是否曾经在编写排序算法时,希望允许用户自定义排序规则&a…...
)
16bit转8bit的常见方法(图像归一化)
文章目录 16-bit转8-bit的常用方法一、数据类型转换:image.astype(np.uint8) —— 若数值 x 超出 0-255 范围,则取模运算。如:x 600 % 256 88二、截断函数:np.clip().astype(np.uint8) —— 若数值 x 超出 0-255 范围࿰…...

消息中间件kafka,rabbitMQ
在分布式系统中,消息中间件是实现不同组件之间异步通信的关键技术。Kafka 和 RabbitMQ 是两个非常流行的消息中间件系统,它们各自有着不同的特点和应用场景。下面将分别介绍 Kafka 和 RabbitMQ,并讨论它们在消息队列中的使用。 一、Kafka (Apache Kafka) 主要特点: 高吞吐…...

C语言编译预处理3
条件编译:是对源程序的一部分指定编译条件,满足条件进行编译否则不编译。 形式1 #indef 标识符 程序段1 #else 程序段2 #endif 标识符已经被定义用#ifdef #include <stdio.h>// 可以通过注释或取消注释下面这行来控制是否定义 DEBUG 宏 // …...

数据结构·树
树的特点 最小连通图 无环 有且只有 n − 1 n-1 n−1 条边 树的建立方式 顺序存储 只适用于满n叉树,完全n叉树 1<<n 表示结点 2 n 2^n 2nP4715 【深基16.例1】淘汰赛 void solve() {cin >> n;for (int i 0; i<(1<<n); i) {cin >&g…...
)
队列的各种操作实现(数据结构C语言多文件编写)
1.先创建queue.h声明文件(Linux命令:touch queue.h)。编写函数声明如下(打开文件 Linux 操作命令:vim queue.h): //头文件 #ifndef __QUEUE_H__ #define __QUEUE_H__ //队列 typedef struct queue{int* arr;int in;int out;int cap;int size; }queue_t;…...

48V/2kW储能电源纯正弦波逆变器详细设计方案-可量产
48V/2kW储能电源纯正弦波逆变器详细设计方案 1.后级驱动电路图 2.前级驱动电路图 3.功率表电路原理图 4.功率板BOM: 5.后级驱动BOM 6.前级驱动BOM...
)
[redis进阶二]分布式系统之主从复制结构(2)
目录 一 redis的拓扑结构 (1)什么是拓扑 (2)⼀主⼀从结构 (3)⼀主多从结构 (4)树形主从结构 (5)三种拓扑结构的优缺点,以及适用场景 二 redis的复制原理 (1)复制过程 (2)数据同步psync replicationid/replid (复制id)(标注同步的数据来自哪里:数据来源) offset (偏移…...

Playwright多语言生态:跨Python_Java_.NET的统一采集方案
一、问题背景:爬虫多语言割裂的旧时代 在大规模数据采集中,尤其是学术数据库如 Scopus,开发者常遇到两个经典问题: 技术语言割裂:Python开发人员使用Selenium、requests-html等库;Java阵营使用Jsoup或Htm…...

day30 第八章 贪心算法 part04
452. 用最少数量的箭引爆气球 先排序,再算重叠区间 class Solution:def findMinArrowShots(self, points: List[List[int]]) -> int:if len(points)0:return 0points.sort(keylambda x:x[0])result 1for i in range(1, len(points)):if points[i][0] > point…...

java操作redis库,开箱即用
application.yml spring:application:name: demo#Redis相关配置redis:data:# 地址host: localhost# 端口,默认为6379port: 6379# 数据库索引database: 0# 密码password:# 连接超时时间timeout: 10slettuce:pool:# 连接池中的最小空闲连接min-idle: 0# 连接池中的最…...

clickhouse中的窗口函数
窗口函数 边界核心参数 窗口边界通过 ROWS、RANGE 或 GROUPS 模式定义,语法为: ROWS BETWEEN AND 基于 物理行位置 定义窗口,与排序键的实际值无关,适用于精确控制窗口行数 – 或 RANGE BETWEEN AND 基于 排序键的数值范围 定义窗口,适用于时间序列或连续数值的场景(…...

YZ系列工具之YZ02:字典的多功能应用
我给VBA下的定义:VBA是个人小型自动化处理的有效工具。利用好了,可以大大提高自己的工作效率,而且可以提高数据的准确度。我的教程一共九套一部VBA手册,教程分为初级、中级、高级三大部分。是对VBA的系统讲解,从简单的…...

金山科技在第91届中国国际医疗器械博览会CMEF 首发新品 展现智慧装备+AI
4月8日—11日,国家会展中心(上海),第91届中国国际医疗器械(春季)博览会(以下简称“CMEF 2025”)举办。金山科技在盛会上隆重推出年度新品——全高清电子内镜光学放大镜与肛肠测压系统…...

STM32 BOOT设置,bootloader,死锁使用方法
目录 BOOT0 BOOT1的配置含义 bootloader使用方法 芯片死锁解决方法开发调试过程中,由于某种原因导致内部Flash锁死,无法连接SWD以及JTAG调试,无法读到设备,可以通过修改BOOT模式重新刷写代码。修改为BOOT01,BOOT10…...

机器学习:让数据开口说话的科技魔法
在人工智能飞速发展的今天,「机器学习」已成为推动数字化转型的核心引擎。无论是手机的人脸解锁、网购平台的推荐系统,还是自动驾驶汽车的决策能力,背后都离不开机器学习的技术支撑。那么,机器学习究竟是什么?它又有哪…...

PDF解析示例代码学习
以下是结合多种技术实现的PDF解析详细示例(Python实现),涵盖文本、表格和扫描件处理场景: 一、环境准备与依赖安装 # 核心依赖库 pip install pdfplumber tabula-py pytesseract opencv-python mysql-connector-python 二、完整…...

【云平台监控】安装应用Ansible服务
安装应用Ansible服务 文章目录 安装应用Ansible服务资源列表基础环境一、安装Ansible1.1、部署Ansible1.2、配置主机清单1.2.1、方法11.2.2、方法2 二、Ansible命令应用基础2.1、ping模块2.2、command模块2.3、user模块2.4、group模块2.5、cron模块2.6、copy模块2.7、file模块2…...

项目执行中的目标管理:从战略到落地的闭环实践
——如何让目标不“跑偏”、团队不“掉队”? 引言:为什么目标管理决定项目成败? 根据PMI研究,47%的项目失败源于目标模糊或频繁变更。在复杂多变的项目环境中,目标管理不仅是制定KPI,更是构建“方向感-执行…...

如何优雅地处理 API 版本控制?
API 会不断发展,而用户的需求也会随之变化。那么,如何确保你的 API 在升级时不会影响现有用户?答案就是:API 版本控制。就像你更新了一个应用程序,引入了新功能,但旧功能仍然保留,让老用户继续愉…...

如何通过Radius认证服务器实现虚拟云桌面安全登录认证:安当ASP身份认证系统解决方案
引言:虚拟化时代的安全挑战 随着云计算和远程办公的普及,虚拟云桌面(如VMware Horizon、Citrix)已成为企业数字化办公的核心基础设施。然而,传统的用户名密码认证方式暴露了诸多安全隐患:弱密码易被暴力破…...

自然语言处理spaCy
spaCy 是一个流行的开源 自然语言处理(NLP) 库,专注于 高效、易用和工业化应用。它由 Explosion AI 开发,广泛应用于文本处理、信息提取、机器翻译等领域。 zh_core_web_sm 是 spaCy 提供的一个小型中文预训练语言模型࿰…...
中的强化学习(Reinforcement Learning, RL))
大语言模型(LLMs)中的强化学习(Reinforcement Learning, RL)
第一部分:强化学习基础回顾 在深入探讨LLMs中的强化学习之前,我们先快速回顾一下强化学习的核心概念,确保基础扎实。 1. 强化学习是什么? 强化学习是一种机器学习范式,目标是让智能体(Agent)…...

数字后端实现Innovus DRC Violation之如何利用脚本批量解决G4:M7i DRC Violation
大家在跑完物理验证calibre DRC之后,会发现DRC里面存在一种G4:M7i的DRC违例,这种违例一般都是出现在memory的边界。今天教大家如何利用脚本来批量处理这一类DRC问题的解决。 首先,我们需要把calibre的DRC结果读取到innovus里面来,…...

Java版企业电子招标采购系统源业码Spring Cloud + Spring Boot +二次开发+ MybatisPlus + Redis
功能描述 1、门户管理:所有用户可在门户页面查看所有的公告信息及相关的通知信息。主要板块包含:招标公告、非招标公告、系统通知、政策法规。 2、立项管理:企业用户可对需要采购的项目进行立项申请,并提交审批,查看所…...

CTF web入门之文件上传
知识点 产生文件上传漏洞的原因 原因: 对于上传文件的后缀名(扩展名)没有做较为严格的限制 对于上传文件的MIMETYPE(用于描述文件的类型的一种表述方法) 没有做检查 权限上没有对于上传的文件目录设置不可执行权限,(尤其是对于shebang类型的文件) 对于web server对于上传…...

ArmSoM Sige5 CM5:RK3576 上 Ultralytics YOLOv11 边缘计算新标杆
在计算机视觉技术加速落地的今天,ArmSoM 正式宣布其基于 Rockchip RK3576 的旗舰产品 Sige5 开发板 和 CM5 核心板 全面支持 Ultralytics YOLOv11 模型的 RKNN 部署。这一突破标志着边缘计算领域迎来新一代高性能、低功耗的 AI 解决方案&am…...

游戏引擎学习第224天
回顾游戏运行并指出一个明显的图像问题。 回顾一下之前那个算法 我们今天要做一点预加载的处理。上周刚完成了游戏序章部分的所有剪辑内容。在运行这一部分时,如果观察得足够仔细,就会注意到一个问题。虽然因为视频流压缩质量较低,很难清楚…...

PN1-S25系列ProfiNet网关模组产品方案
PN1-S25系列ProfiNet网关模组是一款专为工业通信环境设计的先进设备,旨在实现ProfiNet与Modbus RTU协议之间的无缝转换,从而优化工业自动化系统中的数据传输效率。以下是对该系列ProfiNet网关模组产品的详细介绍: 一、ProfiNet网关模组功能特…...
)
提示工程指南学习记录(三)
提示词示例 文本概括 Explain the above in one sentence(用一句话解释上面的信息): 提示词工程是一种用于自然语言处理的任务,目的是通过给定的文本或语音输入来生成相应的输出。它基于预训练的大型语言模型,例如通…...

04 GE - 钳制属性,等级
1.PostGameplayEffectExecute 1.作用:在这里对生命值进行最后的钳制防止越界。 2.参数中有什么: FGameplayEffectModCallbackData //传进来的值 {EffectSpec; //GESpecTargetASC //目标ASCFGameplayModifierEvaluatedData& EvaluatedData{Magni…...

【机器学习】机器学习笔记
1 机器学习定义 计算机程序从经验E中学习,解决某一任务T,进行某一性能P,通过P测定在T上的表现因经验E而提高。 eg:跳棋程序 E: 程序自身下的上万盘棋局 T: 下跳棋 P: 与新对手下跳棋时赢的概率…...

使用SSE实现实时消息推送并语音播报:从后端到前端的完整指南
前言 在现代Web应用中,实时消息推送已成为提升用户体验的关键功能。无论是即时聊天、通知提醒还是实时数据更新,都需要一种高效的服务器到客户端的通信机制。本文将详细介绍如何使用Server-Sent Events (SSE)技术实现后端向前端的实时消息推送ÿ…...

交通运输部4项网络与数据安全标准发布
近日,交通运输部审查通过并发布《交通运输数据安全风险评估指南》《交通运输行业网络安全实战演练工作规程》《交通运输电子证照数据交换与应用要求》《冷藏集装箱智能终端技术规范》等 4 项交通运输行业标准(2025 年第 3 批)。 其中&#…...

HarmonyOS-ArkUI V2装饰器: @Monitor装饰器:状态变量修改监听
Monitor作用 Monitor的作用就是来监听状态变量的值变化的。被Monitor修饰的函数,会在其对应监听的变量发生值的变化时,回调此函数,从而可以让您知道是什么值发生变化了,变化前是什么值,变化后是什么值。 V1版本的装饰器,有个叫@Watch的装饰器,其实也有监听变化的能力,…...

在Ubuntu系统中运行Windows程序
在Ubuntu系统中运行Windows程序可通过以下方法实现,根据使用场景和需求选择最适合的方案: 一、使用Wine兼容层(推荐轻量级场景) 原理:通过模拟Windows API环境直接运行.exe文件,无需安装完整系统。 步骤&a…...

七大数据库全面对比:ClickHouse、ES、MySQL等特性、优缺点及使用场景
七大数据库全面对比:ClickHouse、ES、MySQL等特性、优缺点及使用场景 引言 在数字化时代,数据库的选择对于业务的成功至关重要。本文将通过表格形式,对ClickHouse、Elasticsearch(ES)、MySQL、SQL Server、MongoDB、HBase、Cassandra这七大数据库进行特性、优缺点及使用…...

循环神经网络 - 门控循环单元网络之参数学习
GRU(门控循环单元)的参数学习与其他循环神经网络类似,主要依赖于梯度下降和反向传播通过时间(BPTT)算法。下面我们通过一个简单例子来说明 GRU 参数是如何在训练过程中“自适应”调整的。 一、GRU参数学习 假设我们的…...
)
Java并发编程面试题:内存模型(6题)
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编…...