案例-索引对于并发Insert性能优化测试
前言
最近因业务并发量上升,开发反馈对订单表Insert性能降低。应开发要求对涉及Insert的表进行分析并提供优化方案。
一般对Insert 影响基本都在索引,涉及表已按创建日期做了分区表,索引全部为普通索引未做分区索引。
优化建议:
- 1、将UNIQUE改为HASH(64) GLOBAL INDEX,NORMAL改为Local INDEX。
优化思路:分散IO及减少维护成本,Oracle在索引分裂是当索引块空间不足时,通过分裂为新块以容纳新数据的操作,会引发性能问题。普通索引和分区索引(尤其是本地分区索引)在索引分裂时的行为存在显著差异。
- 2、RAC环境使用TAF(Transparent Application Failover)即透明应用程序故障转移技术,通过应用细化连接,减少RAC集群的内网交互,从而减少RAC集群的负载。
优化方案压力测试
表1:
- 数据量:1.5亿,需要调整的索引:唯一索引:3,普通索引:3

- 优化后:
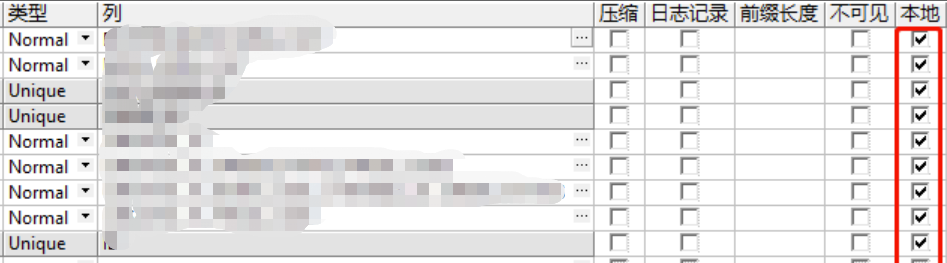
表2:
- 数据量:1.4亿,需要调整的索引:唯一索引:1,普通索引:4
- 优化后:
RAC的TAF技术测试
- 连接SCAN_IP 测试双节点插入
- 连接单节点VIP 测试单节点插入
并发测试脚本:《Oracle&Python并发Insert测试脚本.pdf》
压力测试结果:
- 并发:100,插入数据:80w
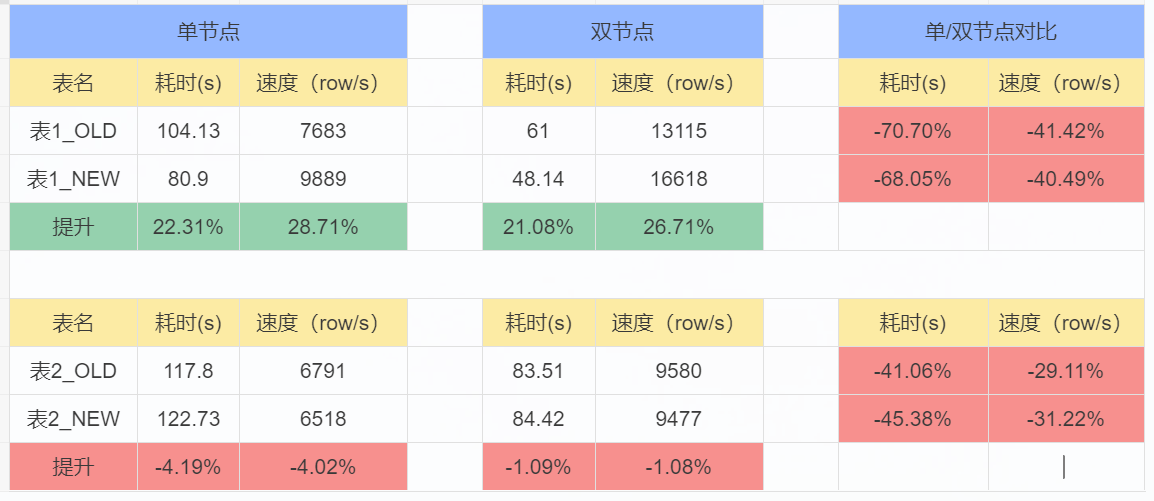
- 小结分析:
1、表1的优化效果提升20%以上,表2的优化效果差强人意(-1%至-4%之间)。
原因分析:Insert 语句导致:直接复制表中的单条记录,然后对唯一索引字段修改为UUID值,日期字段为:sysdate,其它字段为固定值。
表1:索引字段都有插入数据且值为UUID或其它索引字段均有日期字段。
表2:索引字段有3个索引值为Null(索引无操作),另一个索引插入的值为固定值(无法做到IO分散),仅唯一索引的值为UUID(有效果)。。
2、单节点比双节点插入效率-50%左右,原因为双节点分摊了并发压力,相关于单节点的:并发50,40w的数据插入,因此双节点要比单节点同样的压力要更优。
3、最终确认方案仅对表1进行索引优化,其它保持不变。
4、声明:此方案提升效果仅适用于此压测数据,而生产环境很难达到并发:100 数据量:80w 耗时:100s插入完成,并且为单条Insert语句。当并发压力未传到数据库的情况下,优化效果可能并不明显。因此生产的性能问题还需要与开发一起综合设计优化方案为最佳。
验证测试:
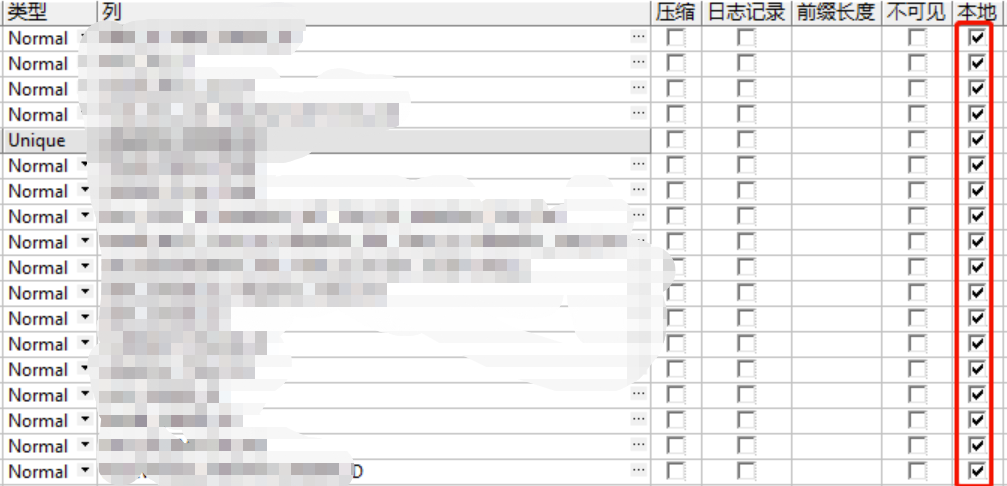
- 表说明:优化前:A_OLD、优化后:A_NEW,数据量:1.5亿
- 测试方向:对唯一索引、普通索引优化为:全局HASH分区索引(64)、本地索引提升效果。
查询索引
SELECT i.TABLE_NAME,i.index_type,p.locality ,i.UNIQUENESS,LISTAGG(ic.COLUMN_NAME, ',') WITHIN GROUP (ORDER BY ic.COLUMN_POSITION) AS INDEX_COLUMNS,i.INDEX_NAME
FROM ALL_INDEXES i
JOIN ALL_IND_COLUMNS ic ON i.INDEX_NAME = ic.INDEX_NAME
left join user_part_indexes p on i.INDEX_NAME = p.INDEX_NAME
WHERE i.TABLE_NAME in ('A_NEW','A_OLD')
GROUP BY i.TABLE_NAME,i.INDEX_NAME,i.UNIQUENESS,p.locality ,i.index_type, i.UNIQUENESS
order by 3,1;TABLE_NAME INDEX_TYPE LOCALI UNIQUENES INDEX_COLUMNS INDEX_NAME
----------- ----------- ------ --------- --------------- ------------------
A_NEW NORMAL GLOBAL UNIQUE ID IDX_UN_ID_A_NEW
A_OLD NORMAL UNIQUE ID IDX_UN_ID_A_OLD
A_NEW NORMAL LOCAL NONUNIQUE BANK_NO IDX_BANK_NO_A_NEW
A_OLD NORMAL NONUNIQUE BANK_NO IDX_BANK_NO_A_OLD并发测试脚本:<Oracle与Python并发Insert测试>
脚本输出
略......
2025-04-09 18:52:22,494 - INFO - INS:twodb1|SID:1006: A_OLD:8000: 530行/秒
2025-04-09 18:52:22,517 - INFO - INS:twodb1|SID:1923: A_OLD:8000: 523行/秒
2025-04-09 18:52:22,707 - INFO - INS:twodb1|SID:1858: A_OLD:8000: 529行/秒
2025-04-09 18:52:22,781 - INFO - INS:twodb1|SID:1925: A_OLD:8000: 527行/秒
2025-04-09 18:52:22,798 - INFO - 表 名:A_OLD
2025-04-09 18:52:22,798 - INFO - 开始时间: 2025-04-09 18:52:07
2025-04-09 18:52:22,798 - INFO - 结束时间: 2025-04-09 18:52:22
2025-04-09 18:52:22,799 - INFO - 耗 时: 15.61 seconds
2025-04-09 18:52:22,799 - INFO - 并 行: 100
2025-04-09 18:52:22,799 - INFO - 数 据 量: 800000
2025-04-09 18:52:22,799 - INFO - 速 度: 51260 行/秒
2025-04-09 18:52:22,799 - INFO - -----------------------wait 10 min------------------------------------略......
2025-04-09 19:02:40,629 - INFO - INS:twodb1|SID:1709: A_NEW:8000: 557行/秒
2025-04-09 19:02:40,655 - INFO - INS:twodb1|SID:150: A_NEW:8000: 556行/秒
2025-04-09 19:02:40,658 - INFO - INS:twodb1|SID:1217: A_NEW:8000: 555行/秒
2025-04-09 19:02:40,660 - INFO - INS:twodb1|SID:716: A_NEW:8000: 553行/秒
2025-04-09 19:02:40,677 - INFO - 表 名:A_NEW
2025-04-09 19:02:40,678 - INFO - 开始时间: 2025-04-09 19:02:26
2025-04-09 19:02:40,678 - INFO - 结束时间: 2025-04-09 19:02:40
2025-04-09 19:02:40,678 - INFO - 耗 时: 14.63 seconds
2025-04-09 19:02:40,678 - INFO - 并 行: 100
2025-04-09 19:02:40,678 - INFO - 数 据 量: 800000
2025-04-09 19:02:40,678 - INFO - 速 度: 54695 行/秒
2025-04-09 19:02:40,681 - INFO - --------------程序执行结束-----------------------------------
测试结果:
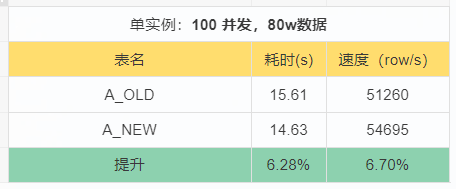
测试小结
- 从上面的测试结果来看,普通索引(UNIQU、NORMAL)优化为(HASH(64)INDEX、Local INDEX)效果提升6%以上。
分析:普通索引、本地分区索引、全局分区索引
- 1、 普通索引
结构影响:普通索引基于整个表构建,索引分裂会影响整个索引树结构。例如,频繁插入可能导致叶子块分裂(如50-50分裂或99-分裂),甚至触发分支节点分裂,增加I/O和锁争用。
维护开销:每次分裂需更新整个索引结构,高并发写入时可能成为性能瓶颈。
热点问题:所有插入操作集中在同一索引结构,可能导致块竞争(如索引块争用)。 - 2、 本地分区索引(Local Partitioned Index)
分区独立性:每个分区的索引独立维护,索引分裂仅发生在操作对应的分区内,不影响其他分区。
维护效率:分区操作(如TRUNCATE或DROP)仅影响本地索引的对应分区,维护更快且无需重建整个索引。
并发优化:不同分区的插入操作分散到各自的索引分区,减少锁争用和热点问题。
适用场景:适合数据有明显分区键(如时间范围),且频繁写入的场景。 - 3、 全局分区索引(Global Partitioned Index)
跨分区结构:索引的分区方式与表分区无关,索引分裂可能影响整个全局索引的结构,类似普通索引,优化是分散IO。
维护开销:对表分区的维护操作(如删除分区)可能导致全局索引失效,需重建或命令加:update indexes来维护索引。
灵活性:分区键可独立于表,但牺牲了本地索引的维护优势。 - 4. 索引分裂优化策略
普通索引:使用REVERSE KEY索引或调整PCTFREE减少分裂频率。
本地分区索引:合理设计分区键,确保写入均匀分布到不同分区。
全局索引:慎用,仅在查询模式需要时使用,并定期维护。 - 5、索引相关案例:数据裁剪偶遇【enq: TX - index contention】
总结
- 本地分区索引在分裂和维护效率上显著优于普通索引和全局索引,尤其适合分区表的高并发场景。
- 普通索引简单但易成瓶颈;全局索引灵活性高但维护成本大。设计时应根据数据分布和查询需求权衡选择。
- 全局分区索引也有某些局限,那就是如果查询条件跨多个索引分区,则效率就下降了,因此全局分区索引对范围查询(Between…and…、>、<、<>等)操作通常性能不好。总之,全局分区索引将索引高度降低了,能提升性能,但如果横向扩展访问多个分区索引树,性能又会下降。
- 周期性的开启Oracle 的“索引监控功能”,对不需要的索引及时清理。
相关文章:

案例-索引对于并发Insert性能优化测试
前言 最近因业务并发量上升,开发反馈对订单表Insert性能降低。应开发要求对涉及Insert的表进行分析并提供优化方案。 一般对Insert 影响基本都在索引,涉及表已按创建日期做了分区表,索引全部为普通索引未做分区索引。 优化建议ÿ…...

@Async 为什么要自定义线程池,使用默认线程池风险
为什么要自定义线程池而非使用默认线程池 使用Spring的Async注解时,如果不自定义线程池而使用默认线程池,可能会带来一些风险和问题。以下是主要原因: 默认线程池的风险 无限制的资源消耗 默认线程池使用SimpleAsyncTaskExecutor࿰…...

Spark-SQL简介与编程
1. Spark-SQL是什么 Spark SQL 是 Spark 用于结构化数据(structured data)处理的 Spark 模块。 Hadoop与Spark的对比 Hadoop的局限性 Hadoop无法处理结构化数据,导致一些项目无法推进。 例如,MySQL中的数据是结构化的,Hadoop无法直接处理。…...

如何分析 JVM OOM 内存溢出 Dump 快照日志
文章目录 1、需求背景2、OOM 触发3、Dump 日志分析 1、需求背景 企业开发过程中,如果系统服务客户量比较大,偶尔会出现OOM内存溢出问题,导致服务发生宕机,停止对外提供访问。 这种情况就需要排查定位内存溢出的原因(…...

系统监控 | 简易多个内网服务器的CPU和内存使用率监控 system_moniter
效果图 原理 一台主机A上运行mysql数据库,接收数据。 其他主机设置定时任务,每6分钟发送一次自己的CPU和内存使用百分数到主机A。 主机A上提供flask为后台的可视化网页,见上图。 源码库 https://github.com/BioMooc/system_moniterhttps:/…...
——误差反向传播的基础理论)
【神经网络】python实现神经网络(四)——误差反向传播的基础理论
一.反向传播 本章将介绍能够高效计算权重参数的梯度的方法——误差反向传播法,这里简单介绍一下什么是反向传播,加入有个函数y = f(x),那么它的反向传播为图下这个样子: 反向传播的计算顺序是,将输入信号E乘以节点的局部导数,然后将结果传递给下一个节点。这里所…...

Django 开发服务器
$ python manage.py runserver $ python manage.py runserver 666 # 用 666 端口 $ python manage.py runserver 0.0.0.0:8000 # 让局域网内其他客户端也可访问 $ python manage.py runserver --skip-checks # 跳过检查自动检查 $ python manage.py runserver --…...
ARM基础)
嵌入式基础(二)ARM基础
嵌入式基础(二)ARM基础 1.精简指令集和复杂指令集的区别⭐⭐⭐ 精简指令集 (RISC) 精简指令集 (Reduced Instruction Set Computing) 具有简洁、精简的指令集,每条指令执行的操作都很基础,使得处理器设计更简单。RISC 处理器通…...
)
RNA免疫共沉淀测序(RIP-seq)
技术简介 RNA免疫共沉淀测序(RNA Immunoprecipitation Sequencing, RIP-seq)是一种将RNA免疫共沉淀(RIP)与二代测序技术(NGS)相结合,用于研究细胞内RNA与蛋白相互作用的技术。 技术原理 利用目…...

期指跌对股市的影响是什么?
国内股指期货对大盘的影响,这种一般就是不想再买这种指数,大多数都在蓝筹股方面,题材股很少,股指期货是保证金交易,一手大概在15-18W,它的价格是根据指数(如上证指数、深证成指)来确…...

基于Python的LSTM、CNN中文情感分析系统
大家好,我是徐师兄,一个有着7年大厂经验的程序员,也是一名热衷于分享干货的技术爱好者。平时我在 CSDN、掘金、华为云、阿里云和 InfoQ 等平台分享我的心得体会。 🍅文末获取源码联系🍅 2025年最全的计算机软件毕业设计…...

Neovim安装及lazy配置
安装neovim 官网下载 配置lazy插件总成 lazy官网 一般在C盘里会有一个nvim-data,然后用官网里的命令会生成一个nvim 安装C编译器 参考此文 插件都放在目录’C:\Users\wnlea\AppData\Local\nvim\lua\plugins’中,所以新建一个插件,起名为vi…...

什么叫“架构”
我们学硬件架构的时候常常被一些名词和概念绕晕,这篇就来讲一讲“架构”这个概念,一种“架构”指的是什么,如何去学习一种新的架构。 1.架构:硬件设计与指令集的统一体 这里放上我大二下的手写笔记: 就是说硬件设计…...

【Python浅拷贝与深拷贝详解】
目录 前言:技术背景与价值当前技术痛点解决方案概述目标读者说明 一、技术原理剖析核心概念图解关键技术模块技术选型对比 二、实战演示环境配置要求核心代码实现(10个案例)案例1:列表嵌套列表案例2:字典嵌套列表案例3…...

numpy.ma.masked_where:屏蔽满足条件的数组
1.函数功能 屏蔽满足条件的数组内容,返回值为掩码数组 2.语法结构 np.ma.masked_where(condition, a, copyTrue)3. 参数 参数含义condition屏蔽条件a要操作的数组copy布尔值,取值为True时,结果复制数组(原始数据不变),否则返回…...

力扣hot100_技巧_python版本
一、136. 只出现一次的数字 思路: 任何数和 0 做异或运算,结果仍然是原来的数,即 a⊕0a。任何数和其自身做异或运算,结果是 0,即 a⊕a0。异或运算满足交换律和结合律,即 a⊕b⊕ab⊕a⊕ab⊕(a⊕a)b⊕0b。 代…...

用队列实现栈
队列实现栈 用队列实现栈一、队列数据结构的基础定义与操作(一)队列节点与队列结构体定义(二)队列大小计算函数(三)队列初始化函数(四)队列销毁函数(五)队列元…...

Android WebView深度性能优化方案
一、启动阶段优化 预初始化策略 冷启动优化:在Application或后台线程提前初始化WebView new Thread(() -> {WebView preloadWebView new WebView(getApplicationContext());preloadWebView.loadUrl("about:blank"); }).start();WebView复用池 private…...

国标GB28181视频平台EasyCVR打造线下零售平台视频+AI全流程监管坚实防线
一、背景概述 在全球经济增长放缓、电商崛起、经营成本攀升的形势下,零售行业正经历深刻变革。数字化转型成为新零售发展的必由之路,但多数零售企业在信息化建设上困难重重,既缺乏足够重视,又因过高投入而犹豫。 随着大数据、人工…...

QML中打印Item的坐标
在 QML 中,你可以通过多种方式获取和打印 Item 的坐标信息。以下是几种常见的方法: 1. 打印相对坐标(相对于父项) qml Item {id: myItemx: 50y: 100width: 200height: 200Component.onCompleted: {// 打印相对于父项的坐标cons…...

基于【Lang Chain】构建智能问答系统的实战指南
🐇明明跟你说过:个人主页 🏅个人专栏:《深度探秘:AI界的007》 🏅 🔖行路有良友,便是天堂🔖 目录 一、引言 1、什么是Lang Chain 2、LangChain在问答系统中的核心优…...

Vue使用axios实现:上传文件、下载文件
Vue 使用 axios 框架,系列文章: 《Vue使用axios实现Ajax请求》 《Vue使用axios二次封装、解决跨域问题》 《Vue使用axios实现:上传文件、下载文件》 在实际开发过程中,浏览器通常需要和服务器端进行数据交互。而 Vue.js 并未提供与服务器端通信的接口。Axios 提供了一些方便…...

泊松分布详解:从理论基础到实际应用的全面剖析
泊松分布详解:从理论基础到实际应用的全面剖析 目录 引言:事件的罕见性与随机计数泊松分布的历史源流泊松分布的数学定义与性质 概率质量函数 (PMF)累积分布函数 (CDF)期望、方差与其他矩矩生成函数 (MGF) 与特征函数 (CF) 泊松分布的严格推导 极限推导…...

PHP爬虫教程:使用cURL和Simple HTML DOM Parser
一个关于如何使用PHP的cURL和HTML解析器来创建爬虫的教程,特别是处理代理信息的部分。首先,我需要确定用户的需求是什么。可能他们想从某个网站抓取数据,但遇到了反爬措施,需要使用代理来避免被封IP。不过用户没有提到具体的目标网…...

# 更换手机热点后secureCRT无法连接centOS7系统
更换手机热点后secureCRT无法连接centOS7系统 一、问题描述 某些情况下,我们可能使用手机共享热点而给电脑联网。本来用一个手机热点共享网络时,SecureCRT可以正常连接到CentOS 7虚拟机,当更换一个手机热点时,突然发现SecureCR…...

【集成电路版图设计学习笔记】2. 基本绘制的layer层和电路失效机制
一、基本的版图层次 1. 金属层(Metal Layers) 金属层主要起到互连的作用,完成基本电路器件的连接金属线的材质通常是铝或者铜,一般在线条比较粗的情况下,即特征尺寸比较粗的,一般是用铝制作的。在先进工艺…...

SQL学习笔记-聚合查询
非聚合查询和聚合查询的概念及差别 1. 非聚合查询 非聚合查询(Non-Aggregate Query)是指不使用聚合函数的查询。这类查询通常用于从表中检索具体的行和列数据,返回的结果是表中的原始数据。 示例 假设有一个名为 employees 的表ÿ…...

Profibus DP主站转modbusTCP网关与dp从站通讯案例
Profibus DP主站转modbusTCP网关与dp从站通讯案例 在当前工业自动化的浪潮中,不同协议之间的通讯转换成为了提升生产效率和实现设备互联的关键。Profibus DP作为一种广泛应用的现场总线技术,与Modbus TCP的结合,为工业自动化系统的集成带来了…...
)
【Linux】41.网络基础(2.3)
文章目录 2.3 TCP协议2.3.5 理解TIME_WAIT状态2.3.6 解决TIME_WAIT状态引起的bind失败的方法(作业)2.3.7 理解 CLOSE_WAIT 状态2.3.8 滑动窗口2.3.9 流量控制 2.3 TCP协议 2.3.5 理解TIME_WAIT状态 现在做一个测试,首先启动server,然后启动client,然后用Ctrl-C使server终止,这…...

C++多态知识点梳理
多态 多态的概念: 多态就是多种形态,具体点就是去完成某个行为,当不同的对象去完成时会产生出不同的状态。 比如构成多态的俩个父子类,我们调用同一个函数,可能会产生不同的行为,比如普通人买票全价&…...
)
Python批量处理PDF图片详解(插入、压缩、提取、替换、分页、旋转、删除)
目录 一、概述 二、 使用工具 三、Python 在 PDF 中插入图片 3.1 插入图片到现有PDF 3.2 插入图片到新建PDF 3.3 批量插入多张图片到PDF 四、Python 提取 PDF 图片及其元数据 五、Python 替换 PDF 图片 5.1 使用图片替换图片 5.2 使用文字替换图片 六、Python 实现 …...

计算机网络分层模型:架构与原理
前言 计算机网络通过不同的层次结构来实现通信和数据传输,这种分层设计不仅使得网络更加模块化和灵活,也使得不同类型的通信能够顺利进行。在网络协议和通信体系中,最广为人知的分层模型有 OSI模型 和 TCP/IP模型。这两种模型分别定义了计算…...

算法-mysql笔记
寻找用户推荐人 mysql判断数据是空 IS null 非空 IS NOT null 584. 寻找用户推荐人 - 力扣(LeetCode) # Write your MySQL query statement below SELECTname FROMCustomer WHEREreferee_id ! 2 OR referee_id IS null 文章概览 当查询到有多…...

销售易CRM:技术架构与安全性能的深度解析
一、技术架构:云计算与微服务的完美结合 销售易CRM基于云计算架构,采用微服务设计理念,确保系统的高可用性和扩展性。这种架构不仅提高了系统的性能和稳定性,还为企业提供了灵活的定制化能力。 云计算架构的优势 高可用性&…...
:从类设计到安全实现的完整指南)
Python用户管理系统深度解析(附源码):从类设计到安全实现的完整指南
目录 一、核心类结构全解 1.1 类定义与属性设计 代码解析: 二、注册功能代码逐行解析 2.1 用户名验证模块 功能实现: 2.2 密码设置流程 关键机制: 2.3 数据存储实现 文件操作要点: 三、登录安全机制全剖析 3.1 黑名单…...

【linux】使用LNMP环境+Discuz论坛源程序
我使用的版本是linux9.3、Discuz X3.5、nginx1.20、mariadb10.5、php8.0 整体结构 LNMP Linux Nginx mariadb PHP Nginx 最初于2004年10月4日为俄罗斯知名门户站点而开发的Nginx是一款轻量级的网站服务软件,因其稳定性和丰富的功能而深受信赖特点:…...

鸿蒙开发-动画
1. 动画-动画特效 // 定义接口 (每个列表项的数据结构) interface ImageCount {url: stringcount: number }// 需求1: 遮罩层显隐 透明度opacity 0-1 层级zIndex -1~99 // 需求2: 图片缩放 缩放scale 0-1Entry Component struct Index {// 基于接口, 准备数据State images…...

itext7 html2pdf 将html文本转为pdf
1、将html转为pdf需求分析 经常会看到爬虫有这样的需求,将某一个网站上的数据,获取到了以后,进行分析,然后将需要的数据进行存储,也有将html转为pdf进行存储,作为原始存档,当然这里看具体的需求…...

设计模式:模板模式 - 固定流程与灵活扩展的完美结合
一、为什么使用模板模式? 权限校验、数据处理、用例设计等流程虽然遵循固定步骤,但每个具体实现却总有不同。如果没有合适的设计,重复代码会堆积,导致系统复杂度增加,维护成本上升。那如何解决这个问题,让…...

Java 设计模式:组合模式详解
Java 设计模式:组合模式详解 组合模式(Composite Pattern)是一种结构型设计模式,它允许将对象组织成树形结构,以统一的方式处理单个对象和对象集合。组合模式适用于需要表示“部分-整体”层次结构的场景,例…...

使用命令打开电脑的[服务]窗口
1.首先打开[开始],找到[运行], 2.或者用快捷命令“windows键R键”命令打开运行, 3.然后输入命令“services.msc”, 4.点[确定]就可以进入电脑的[服务]窗口了...

语音识别——根据声波能量、VAD 和 频谱分析周围是否有人说话
语音活动检测(Voice Activity Detection,简称VAD)。简单来说,VAD就是用来判断一段音频里有没有人说话的技术。在实时语音识别的场景里,这个技术特别重要,因为它决定了什么时候把采集到的音频数据扔进大模型…...

C++算法优化实战:破解性能瓶颈,提升程序效率
C算法优化实战:破解性能瓶颈,提升程序效率 在现代软件开发中,算法优化是提升程序性能的关键手段之一。无论是在高频交易系统、实时游戏引擎,还是大数据处理平台,算法的高效性直接关系到整体系统的性能与响应速度。C作…...

阿里滑块 231 231纯算 水果滑块 拼图 1688滑块 某宝 大麦滑块 阿里231 验证码
声明 本文章中所有内容仅供学习交流,抓包内容、敏感网址、数据接口均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关,若有侵权,请联系我立即删除! # 欢迎交流 wjxch1004...

vs code Cline 编程接入Claude 3.7的经济方案,且保持原生接口能力
在当今快速发展的科技时代,自动化编程成为提高工作效率的重要手段。Cline AI自动编程工具,凭借其强大的智能算法,能够快速生成高质量的代码,帮助开发者节省大量的时间和精力。从简单的脚本到复杂的应用程序,Cline都能轻…...

kubectl命令补全以及oc命令补全
kubectl命令补全 1.安装bash-completion 如果你用的是Bash(默认情况下是),先安装补全功能支持包 sudo apt update sudo apt install bash-completion -y2.为kubectl 启用补全功能 会话中临时: source <(kubectl completion bash)持久化配置&#x…...

css解决边框四个角有颜色
效果 html <div class"gradient-corner">2021年</div>css background:/* 左上角横线 */linear-gradient(90deg, rgb(5, 150, 247) 9px, transparent 0) 0 0,/* 左上角竖线 */linear-gradient(0deg, rgb(5, 150, 247) 9px, transparent 0) 0 0,/* 右上…...

快速入手K8s+Docker+KubeSphere+DevOps
引用:云原生Java架构师的第一课K8sDockerKubeSphereDevOps_哔哩哔哩_bilibili 学习K8sDockerKubeSphereDevOps的可以学习该视频...

Spark-SQL核心编程
DataFrame 创建 DataFrame 在 Spark SQL 中 SparkSession 是创建 DataFrame 和执行 SQL 的入口,创建 DataFrame 有三种方式:通过 Spark 的数据源进行创建;从一个存在的 RDD 进行转换;还可以从 Hive Table 进行查询返回。 从…...

Go 1.24 新方法:编写性能测试用例方法 testing.B.Loop 介绍
Go 开发者在使用 testing包编写基准测试用例时,如果不注意,可能会遇到各种陷阱。这些陷阱,导致基准测试结果不准确。Go1.24 版本引入了一种新的基准测试编写方式,它同样易用,并且可以帮助规避编写基准测试时的一些坑。…...