基于Python的LSTM、CNN中文情感分析系统
大家好,我是徐师兄,一个有着7年大厂经验的程序员,也是一名热衷于分享干货的技术爱好者。平时我在 CSDN、掘金、华为云、阿里云和 InfoQ 等平台分享我的心得体会。
🍅文末获取源码联系🍅2025年最全的计算机软件毕业设计选题大全:1000个热门选题推荐✅
Java项目精品实战案例《100套》
Python大学生实战项目《100套》
感兴趣的可以先收藏起来,还有大家在毕设选题、项目以及文档编写等相关问题都可以留言咨询,希望帮助更多的人。感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
1 简介
循环神经网络是一种特别擅长处理序列数据的深度学习模型,广泛应用于情感分类任务。咱们的系统采用了 GRU 框架来实现循环神经网络,能够自动判断用户留言的情感倾向,把留言智能地分为积极和消极两大类。这样一来,后台不仅能及时统计分析,还能为软件维护和升级提供有力支持。

2 技术栈
| 说明 | 技术栈 | 备注 |
|---|---|---|
| 后台 | Python | |
| 前端 | HTML | |
| 数据库 | MYSql | |
| 架构 | B/S 结构 |
循环神经网络通过循环结构捕获数据序列中的前后关系。RNN 模型由多个循环单元构成,每个单元中包含输入门、遗忘门、输出门以及状态变量,这套门控机制帮助模型保留必要的信息。RNN 的优势在于能处理长序列,捕捉长期依赖,但同时也容易陷入局部最优,难以应对不同长度数据。为此,LSTM 和 GRU 等改进方案应运而生,显著提升了模型的性能和泛化能力。系统的工作原理如图所示:

3 数据集处理
3.1 数据收集
数据收集是情感分类的第一步。咱们从社交媒体、在线论坛和客服平台等渠道广泛收集各类主题、风格和语气的用户留言,确保数据具备多样性。只有数据足够全面,才能提高模型的识别准确率。具体读取数据可以用如下代码实现:
python复制编辑import pandas as pd
import numpy as np# 读取数据文件
data = pd.read_csv("data.csv")
3.2 数据预处理
数据预处理环节主要包括清洗、去重、分词和停用词处理。咱们会用 Python 中的 NLTK、spaCy 等工具来删除无用的标点、特殊字符,借助 jieba 库对文本进行分词,将留言转换为词袋向量表示,保证后续特征提取的准确性。下面是处理过程的示例代码:
python复制编辑import jieba
import sklearn.feature_extraction.text as text
from sklearn.metrics import accuracy_score# 数据清洗与预处理
data = data.dropna()
data = data.astype(str)# 对文本进行分词和停用词处理
data['text'] = data['text'].apply(lambda x: ' '.join(jieba.cut(x, cut_all=True)))
data = data.dropna()# 计算文本特征向量表示
text_vectorizer = text.CountVectorizer()
data['text_vector'] = list(text_vectorizer.fit_transform(data['text']).toarray())# 将文本转化为词袋向量表示(示例转换)
data_bow = pd.DataFrame(data)
data_bow['text'] = data['text'].apply(lambda x: ' '.join(x.split()))
3.3 数据集划分
把收集到的留言数据按 80% 训练、10% 验证、10% 测试的比例进行划分。训练集用于模型训练,验证集用来调参和优化,测试集则检验模型性能。示例代码如下:
python复制编辑from sklearn.model_selection import train_test_splitX_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2, random_state=42)
3.4 特征提取
特征提取是整个流程的重要一环。咱们可以使用传统方法(词袋模型、TF-IDF、N-gram 等)来提取文本特征,也可以用深度学习的方法自动学习特征。这里主要采用 TF-IDF 方法示例:
python复制编辑from sklearn.feature_extraction.text import TfidfVectorizertfidf_vectorizer = TfidfVectorizer()
X_train_tfidf = tfidf_vectorizer.fit_transform(X_train)
X_valid_tfidf = tfidf_vectorizer.transform(X_valid)
X_test_tfidf = tfidf_vectorizer.transform(X_test)
3.5 模型训练和评估
咱们利用训练集来训练模型,采用交叉熵损失函数和准确率、召回率、F1 值等指标评估模型效果。下面是用支持向量机(SVM)做分类的示例代码:
python复制编辑from sklearn import svm
from sklearn.metrics import accuracy_score# 训练模型
clf = svm.SVC(kernel='linear', C=1, random_state=42)
clf.fit(X_train_tfidf, y_train)# 评估模型性能
y_pred = clf.predict(X_valid_tfidf)
accuracy = accuracy_score(y_valid, y_pred)
print('准确率:', accuracy)
3.6 数据集归一化
为了提升模型的鲁棒性,咱们会对数据进行归一化处理,使得均值为 0,标准差为 1。示例代码如下:
python复制编辑from sklearn.preprocessing import StandardScalerscaler = StandardScaler()
X_train_std = scaler.fit_transform(X_train_tfidf.toarray())
X_valid_std = scaler.transform(X_valid_tfidf.toarray())
X_test_std = scaler.transform(X_test_tfidf.toarray())
2 系统设计与实现
4.1 系统架构设计
本系统是一个用户留言情感分类平台,采用 GRU 模型对留言进行情感分析。前端部分主要负责页面展示和用户交互,后端则基于 Python 和 MySQL 实现数据存储及 API 接口。整个架构采用 B/S 结构,用户可以通过网页方式访问系统,利用 AJAX 技术实现实时交互。
- 前端设计:网页界面采用 Bootstrap 来打造美观大方的 UI,通过 AJAX 与后端进行数据交互。
- 后端设计:使用 Flask 和 Django 框架实现 API 接口和数据库管理,数据存储使用 MySQL。
- 模型设计:采用 GRU 模型进行情感分类,结合数据集来训练并优化模型,提升准确率。
4.2 系统功能需求分析
系统的核心功能是对用户输入的留言进行情感检测,自动将留言划分为积极或消极两类。同时,还扩展了数据管理、数据分析、公告管理和用户管理等模块,方便后台操作。系统模块设计如下图展示:

图4.2 系统功能模块
4.3 系统非功能需求分析
4.3.1 数据输入和输出
系统的输入主要是用户留言文本,输出为情感分类结果。输入数据需经过清洗、分词等预处理后,再送入模型。
4.3.2 模型超参数调整
调整模型的学习率、迭代次数等超参数对于最终性能至关重要,需要反复试验以达到最佳效果。
4.3.3 系统性能与稳定性
为提升响应速度和稳定性,系统引入了分布式计算和缓存技术,并通过日志记录和监控进行系统管理。
4.3.4 数据安全和隐私保护
在数据传输和存储过程中,系统采用加密、访问控制等手段保护用户隐私,并定期备份数据以防丢失。
4.4 系统实现
本系统采用 Python 语言和 MySQL 数据库实现,通过 Django 框架构建 Web 应用,同时利用 Flask 实现 API 接口。系统核心代码示例如下:
python复制编辑import mysql.connector
import flask
from flask import Flask, request, jsonify
import numpy as np
from tensorflow.keras.models import GRU
from tensorflow.keras.layers import Input, Denseapp = Flask(__name__)# 连接数据库
cnx = mysql.connector.connect(user="username", password="password", host="localhost", database="database_name")
cursor = cnx.cursor()# 加载训练数据
train_data = np.loadtxt("train.csv", delimiter=",", usecols=(1,), skiprows=1, dtype=float)
test_data = np.loadtxt("test.csv", delimiter=",", usecols=(1,), skiprows=1, dtype=float)# 创建模型(示例参数)
model = GRU(units=50, input_shape=(None, 1), return_sequences=False)# 定义 API 接口
@app.route("/api/情感分类", methods=["POST"])
def api_endpoint():# 获取用户输入文本text = request.json["text"]# 查询数据库cursor.execute("SELECT * FROM data WHERE text LIKE %s", (text,))result = cursor.fetchall()# 将查询结果转换为模型输入格式inputs = np.array([row[1] for row in result]).reshape(-1, 1, 1)# 前向传播outputs = model(inputs)# 这里仅为示例,实际计算方式请根据模型调整pred = np.argmax(outputs, axis=1)# 返回结果return jsonify({'prediction': int(pred[0])})if __name__ == "__main__":app.run(debug=True)
上述代码使用 mysql-connector-python 库连接 MySQL 数据库,通过 SQL 查询将留言数据转换为模型输入,利用 GRU 模型进行情感分类,并通过 API 返回分类结果。
4.5 系统展示
4.5.1 注册登录界面
系统登录页面简单明了,用户输入用户名、密码及验证码后便可登录,只有登录用户才可使用情感分类功能。效果图如下:

图4.5.1 注册登录界面
4.5.2 文本检测界面
用户在文本检测界面输入留言信息,点击开始分类按钮,即可启动情感检测功能。界面直观、操作便捷。效果图如下:

图4.5.2 文本检测界面
4.5.3 数据管理界面
此模块展示系统自动识别后的情感分类结果,用户还可对结果进行手工校对和调整。界面以列表方式呈现,便于快速查找。效果图如下:

图4.5.3 数据管理界面
4.5.4 公告管理界面
公告管理模块允许管理员发布、修改或删除系统公告,用于宣传和推广系统。界面简单大方。效果图如下:
图4.5.4 公告管理界面
4.5.5 数据分析界面
数据分析界面将系统统计的情感分类结果通过柱状图和饼状图直观展示,帮助管理员了解留言情感分布及趋势。效果图如下:

图4.5.5 数据分析界面
4.5.6 用户管理界面
用户管理模块支持新增、删除和修改用户信息。只需要填写基本信息,如用户名、密码、手机和邮箱,系统即可完成新增操作。效果图如下:

图4.5.6 用户管理界面
6 总 结
本项目开发了一款基于 Python 和 OpenCV 的疲劳检测系统,其核心在于利用 GRU 框架对用户留言进行情感分类。系统从数据收集、预处理、特征提取到模型训练与评估,全程自动化处理,并结合 MySQL 数据库实现数据存储与管理。通过网页平台,用户不仅可以在线检测情感状态,还能通过数据管理和分析模块获得直观反馈。系统既能为相关企业和检测机构提供有力支持,也能为用户提供精准的情感预警。未来系统将继续优化检测速度和稳定性,进一步提升分类准确率和用户体验。
7 源码获取
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟
2025年最全的计算机软件毕业设计选题大全:1000个热门选题推荐✅
Java项目精品实战案例《100套》
Python大学生实战项目《100套》
感兴趣的可以先收藏起来,还有大家在毕设选题、项目以及文档编写等相关问题都可以留言咨询,希望帮助更多的人。感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
相关文章:

基于Python的LSTM、CNN中文情感分析系统
大家好,我是徐师兄,一个有着7年大厂经验的程序员,也是一名热衷于分享干货的技术爱好者。平时我在 CSDN、掘金、华为云、阿里云和 InfoQ 等平台分享我的心得体会。 🍅文末获取源码联系🍅 2025年最全的计算机软件毕业设计…...

Neovim安装及lazy配置
安装neovim 官网下载 配置lazy插件总成 lazy官网 一般在C盘里会有一个nvim-data,然后用官网里的命令会生成一个nvim 安装C编译器 参考此文 插件都放在目录’C:\Users\wnlea\AppData\Local\nvim\lua\plugins’中,所以新建一个插件,起名为vi…...

什么叫“架构”
我们学硬件架构的时候常常被一些名词和概念绕晕,这篇就来讲一讲“架构”这个概念,一种“架构”指的是什么,如何去学习一种新的架构。 1.架构:硬件设计与指令集的统一体 这里放上我大二下的手写笔记: 就是说硬件设计…...

【Python浅拷贝与深拷贝详解】
目录 前言:技术背景与价值当前技术痛点解决方案概述目标读者说明 一、技术原理剖析核心概念图解关键技术模块技术选型对比 二、实战演示环境配置要求核心代码实现(10个案例)案例1:列表嵌套列表案例2:字典嵌套列表案例3…...

numpy.ma.masked_where:屏蔽满足条件的数组
1.函数功能 屏蔽满足条件的数组内容,返回值为掩码数组 2.语法结构 np.ma.masked_where(condition, a, copyTrue)3. 参数 参数含义condition屏蔽条件a要操作的数组copy布尔值,取值为True时,结果复制数组(原始数据不变),否则返回…...

力扣hot100_技巧_python版本
一、136. 只出现一次的数字 思路: 任何数和 0 做异或运算,结果仍然是原来的数,即 a⊕0a。任何数和其自身做异或运算,结果是 0,即 a⊕a0。异或运算满足交换律和结合律,即 a⊕b⊕ab⊕a⊕ab⊕(a⊕a)b⊕0b。 代…...

用队列实现栈
队列实现栈 用队列实现栈一、队列数据结构的基础定义与操作(一)队列节点与队列结构体定义(二)队列大小计算函数(三)队列初始化函数(四)队列销毁函数(五)队列元…...

Android WebView深度性能优化方案
一、启动阶段优化 预初始化策略 冷启动优化:在Application或后台线程提前初始化WebView new Thread(() -> {WebView preloadWebView new WebView(getApplicationContext());preloadWebView.loadUrl("about:blank"); }).start();WebView复用池 private…...

国标GB28181视频平台EasyCVR打造线下零售平台视频+AI全流程监管坚实防线
一、背景概述 在全球经济增长放缓、电商崛起、经营成本攀升的形势下,零售行业正经历深刻变革。数字化转型成为新零售发展的必由之路,但多数零售企业在信息化建设上困难重重,既缺乏足够重视,又因过高投入而犹豫。 随着大数据、人工…...

QML中打印Item的坐标
在 QML 中,你可以通过多种方式获取和打印 Item 的坐标信息。以下是几种常见的方法: 1. 打印相对坐标(相对于父项) qml Item {id: myItemx: 50y: 100width: 200height: 200Component.onCompleted: {// 打印相对于父项的坐标cons…...

基于【Lang Chain】构建智能问答系统的实战指南
🐇明明跟你说过:个人主页 🏅个人专栏:《深度探秘:AI界的007》 🏅 🔖行路有良友,便是天堂🔖 目录 一、引言 1、什么是Lang Chain 2、LangChain在问答系统中的核心优…...

Vue使用axios实现:上传文件、下载文件
Vue 使用 axios 框架,系列文章: 《Vue使用axios实现Ajax请求》 《Vue使用axios二次封装、解决跨域问题》 《Vue使用axios实现:上传文件、下载文件》 在实际开发过程中,浏览器通常需要和服务器端进行数据交互。而 Vue.js 并未提供与服务器端通信的接口。Axios 提供了一些方便…...

泊松分布详解:从理论基础到实际应用的全面剖析
泊松分布详解:从理论基础到实际应用的全面剖析 目录 引言:事件的罕见性与随机计数泊松分布的历史源流泊松分布的数学定义与性质 概率质量函数 (PMF)累积分布函数 (CDF)期望、方差与其他矩矩生成函数 (MGF) 与特征函数 (CF) 泊松分布的严格推导 极限推导…...

PHP爬虫教程:使用cURL和Simple HTML DOM Parser
一个关于如何使用PHP的cURL和HTML解析器来创建爬虫的教程,特别是处理代理信息的部分。首先,我需要确定用户的需求是什么。可能他们想从某个网站抓取数据,但遇到了反爬措施,需要使用代理来避免被封IP。不过用户没有提到具体的目标网…...

# 更换手机热点后secureCRT无法连接centOS7系统
更换手机热点后secureCRT无法连接centOS7系统 一、问题描述 某些情况下,我们可能使用手机共享热点而给电脑联网。本来用一个手机热点共享网络时,SecureCRT可以正常连接到CentOS 7虚拟机,当更换一个手机热点时,突然发现SecureCR…...

【集成电路版图设计学习笔记】2. 基本绘制的layer层和电路失效机制
一、基本的版图层次 1. 金属层(Metal Layers) 金属层主要起到互连的作用,完成基本电路器件的连接金属线的材质通常是铝或者铜,一般在线条比较粗的情况下,即特征尺寸比较粗的,一般是用铝制作的。在先进工艺…...

SQL学习笔记-聚合查询
非聚合查询和聚合查询的概念及差别 1. 非聚合查询 非聚合查询(Non-Aggregate Query)是指不使用聚合函数的查询。这类查询通常用于从表中检索具体的行和列数据,返回的结果是表中的原始数据。 示例 假设有一个名为 employees 的表ÿ…...

Profibus DP主站转modbusTCP网关与dp从站通讯案例
Profibus DP主站转modbusTCP网关与dp从站通讯案例 在当前工业自动化的浪潮中,不同协议之间的通讯转换成为了提升生产效率和实现设备互联的关键。Profibus DP作为一种广泛应用的现场总线技术,与Modbus TCP的结合,为工业自动化系统的集成带来了…...
)
【Linux】41.网络基础(2.3)
文章目录 2.3 TCP协议2.3.5 理解TIME_WAIT状态2.3.6 解决TIME_WAIT状态引起的bind失败的方法(作业)2.3.7 理解 CLOSE_WAIT 状态2.3.8 滑动窗口2.3.9 流量控制 2.3 TCP协议 2.3.5 理解TIME_WAIT状态 现在做一个测试,首先启动server,然后启动client,然后用Ctrl-C使server终止,这…...

C++多态知识点梳理
多态 多态的概念: 多态就是多种形态,具体点就是去完成某个行为,当不同的对象去完成时会产生出不同的状态。 比如构成多态的俩个父子类,我们调用同一个函数,可能会产生不同的行为,比如普通人买票全价&…...
)
Python批量处理PDF图片详解(插入、压缩、提取、替换、分页、旋转、删除)
目录 一、概述 二、 使用工具 三、Python 在 PDF 中插入图片 3.1 插入图片到现有PDF 3.2 插入图片到新建PDF 3.3 批量插入多张图片到PDF 四、Python 提取 PDF 图片及其元数据 五、Python 替换 PDF 图片 5.1 使用图片替换图片 5.2 使用文字替换图片 六、Python 实现 …...

计算机网络分层模型:架构与原理
前言 计算机网络通过不同的层次结构来实现通信和数据传输,这种分层设计不仅使得网络更加模块化和灵活,也使得不同类型的通信能够顺利进行。在网络协议和通信体系中,最广为人知的分层模型有 OSI模型 和 TCP/IP模型。这两种模型分别定义了计算…...

算法-mysql笔记
寻找用户推荐人 mysql判断数据是空 IS null 非空 IS NOT null 584. 寻找用户推荐人 - 力扣(LeetCode) # Write your MySQL query statement below SELECTname FROMCustomer WHEREreferee_id ! 2 OR referee_id IS null 文章概览 当查询到有多…...

销售易CRM:技术架构与安全性能的深度解析
一、技术架构:云计算与微服务的完美结合 销售易CRM基于云计算架构,采用微服务设计理念,确保系统的高可用性和扩展性。这种架构不仅提高了系统的性能和稳定性,还为企业提供了灵活的定制化能力。 云计算架构的优势 高可用性&…...
:从类设计到安全实现的完整指南)
Python用户管理系统深度解析(附源码):从类设计到安全实现的完整指南
目录 一、核心类结构全解 1.1 类定义与属性设计 代码解析: 二、注册功能代码逐行解析 2.1 用户名验证模块 功能实现: 2.2 密码设置流程 关键机制: 2.3 数据存储实现 文件操作要点: 三、登录安全机制全剖析 3.1 黑名单…...

【linux】使用LNMP环境+Discuz论坛源程序
我使用的版本是linux9.3、Discuz X3.5、nginx1.20、mariadb10.5、php8.0 整体结构 LNMP Linux Nginx mariadb PHP Nginx 最初于2004年10月4日为俄罗斯知名门户站点而开发的Nginx是一款轻量级的网站服务软件,因其稳定性和丰富的功能而深受信赖特点:…...

鸿蒙开发-动画
1. 动画-动画特效 // 定义接口 (每个列表项的数据结构) interface ImageCount {url: stringcount: number }// 需求1: 遮罩层显隐 透明度opacity 0-1 层级zIndex -1~99 // 需求2: 图片缩放 缩放scale 0-1Entry Component struct Index {// 基于接口, 准备数据State images…...

itext7 html2pdf 将html文本转为pdf
1、将html转为pdf需求分析 经常会看到爬虫有这样的需求,将某一个网站上的数据,获取到了以后,进行分析,然后将需要的数据进行存储,也有将html转为pdf进行存储,作为原始存档,当然这里看具体的需求…...

设计模式:模板模式 - 固定流程与灵活扩展的完美结合
一、为什么使用模板模式? 权限校验、数据处理、用例设计等流程虽然遵循固定步骤,但每个具体实现却总有不同。如果没有合适的设计,重复代码会堆积,导致系统复杂度增加,维护成本上升。那如何解决这个问题,让…...

Java 设计模式:组合模式详解
Java 设计模式:组合模式详解 组合模式(Composite Pattern)是一种结构型设计模式,它允许将对象组织成树形结构,以统一的方式处理单个对象和对象集合。组合模式适用于需要表示“部分-整体”层次结构的场景,例…...

使用命令打开电脑的[服务]窗口
1.首先打开[开始],找到[运行], 2.或者用快捷命令“windows键R键”命令打开运行, 3.然后输入命令“services.msc”, 4.点[确定]就可以进入电脑的[服务]窗口了...

语音识别——根据声波能量、VAD 和 频谱分析周围是否有人说话
语音活动检测(Voice Activity Detection,简称VAD)。简单来说,VAD就是用来判断一段音频里有没有人说话的技术。在实时语音识别的场景里,这个技术特别重要,因为它决定了什么时候把采集到的音频数据扔进大模型…...

C++算法优化实战:破解性能瓶颈,提升程序效率
C算法优化实战:破解性能瓶颈,提升程序效率 在现代软件开发中,算法优化是提升程序性能的关键手段之一。无论是在高频交易系统、实时游戏引擎,还是大数据处理平台,算法的高效性直接关系到整体系统的性能与响应速度。C作…...

阿里滑块 231 231纯算 水果滑块 拼图 1688滑块 某宝 大麦滑块 阿里231 验证码
声明 本文章中所有内容仅供学习交流,抓包内容、敏感网址、数据接口均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关,若有侵权,请联系我立即删除! # 欢迎交流 wjxch1004...

vs code Cline 编程接入Claude 3.7的经济方案,且保持原生接口能力
在当今快速发展的科技时代,自动化编程成为提高工作效率的重要手段。Cline AI自动编程工具,凭借其强大的智能算法,能够快速生成高质量的代码,帮助开发者节省大量的时间和精力。从简单的脚本到复杂的应用程序,Cline都能轻…...

kubectl命令补全以及oc命令补全
kubectl命令补全 1.安装bash-completion 如果你用的是Bash(默认情况下是),先安装补全功能支持包 sudo apt update sudo apt install bash-completion -y2.为kubectl 启用补全功能 会话中临时: source <(kubectl completion bash)持久化配置&#x…...

css解决边框四个角有颜色
效果 html <div class"gradient-corner">2021年</div>css background:/* 左上角横线 */linear-gradient(90deg, rgb(5, 150, 247) 9px, transparent 0) 0 0,/* 左上角竖线 */linear-gradient(0deg, rgb(5, 150, 247) 9px, transparent 0) 0 0,/* 右上…...

快速入手K8s+Docker+KubeSphere+DevOps
引用:云原生Java架构师的第一课K8sDockerKubeSphereDevOps_哔哩哔哩_bilibili 学习K8sDockerKubeSphereDevOps的可以学习该视频...

Spark-SQL核心编程
DataFrame 创建 DataFrame 在 Spark SQL 中 SparkSession 是创建 DataFrame 和执行 SQL 的入口,创建 DataFrame 有三种方式:通过 Spark 的数据源进行创建;从一个存在的 RDD 进行转换;还可以从 Hive Table 进行查询返回。 从…...

Go 1.24 新方法:编写性能测试用例方法 testing.B.Loop 介绍
Go 开发者在使用 testing包编写基准测试用例时,如果不注意,可能会遇到各种陷阱。这些陷阱,导致基准测试结果不准确。Go1.24 版本引入了一种新的基准测试编写方式,它同样易用,并且可以帮助规避编写基准测试时的一些坑。…...

【神经网络结构的组成】深入理解 转置卷积与转置卷积核
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏: 🏀《深度学习理论直觉三十讲》_十二月的猫的博客-CSDN博客 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 …...

GpuGeek:重构AI算力基础设施,赋能产业智能升级
在数字经济与实体经济深度融合的今天,人工智能已成为推动产业变革的核心驱动力。作为AI技术落地的关键支撑,算力基础设施正经历从"资源供给"向"服务赋能"的范式转变。GpuGeek凭借创新的技术架构和运营模式,重新定义了AI算…...
Chatbox多端一键配置Claude/GPT/DeepSeek-网页端配置)
(2025亲测可用)Chatbox多端一键配置Claude/GPT/DeepSeek-网页端配置
1. 资源准备 API Key:此项配置填写在一步API官网创建API令牌,一键直达API令牌创建页面创建API令牌步骤请参考API Key的获取和使用API Host:此项配置填写https://yibuapi.com/v1查看支持的模型请参考这篇教程模型在线查询 2. ChatBox网页版配…...

质变科技发布自主数据分析MCP Server
2025年4月9日,质变科技正式发布Relyt AI MCP(Model Context Protocol),结合Relyt AI 在自主数据分析领域的前沿积累与MCP的开放连接能力,我们为用户带来了一个更智能、更灵活的数据交互生态系统。这一发布不仅拓展了Re…...

【17】Strongswan bus详解2
add_listener: (1)初始化一个entry,并将要添加的listener赋值entry。 (2)添加到bus的listeners链表的尾部。 remove_listener: (1)遍历listeners,通过内存位置…...

【Windows】系统安全移除移动存储设备指南:告别「设备被占用」弹窗
Windows系统安全移除移动存储设备指南:告别「设备被占用」弹窗 解决移动硬盘和U盘正在被占用无法弹出 一、问题背景 使用Windows系统时,经常遇到移动硬盘/U盘弹出失败提示「设备正在使用中」,即使已关闭所有可见程序。本文将系统梳理已验证…...

DeepSeek 与开源:肥沃土壤孕育 AI 硕果
当 DeepSeek 以低成本推理、多模态能力惊艳全球时,人们惊叹于国产AI技术的「爆发力」,却鲜少有人追问:这份爆发力的根基何在? 答案,藏在中国开源生态二十余年的积淀中。 从倪光南院士呼吁「以开源打破垄断」…...

[从零开始学数据库] 基本SQL
注意我们的主机就是我们的Mysql数据库服务器 这里我们可以用多个库 SQL分类(核心是字段的CRUD) 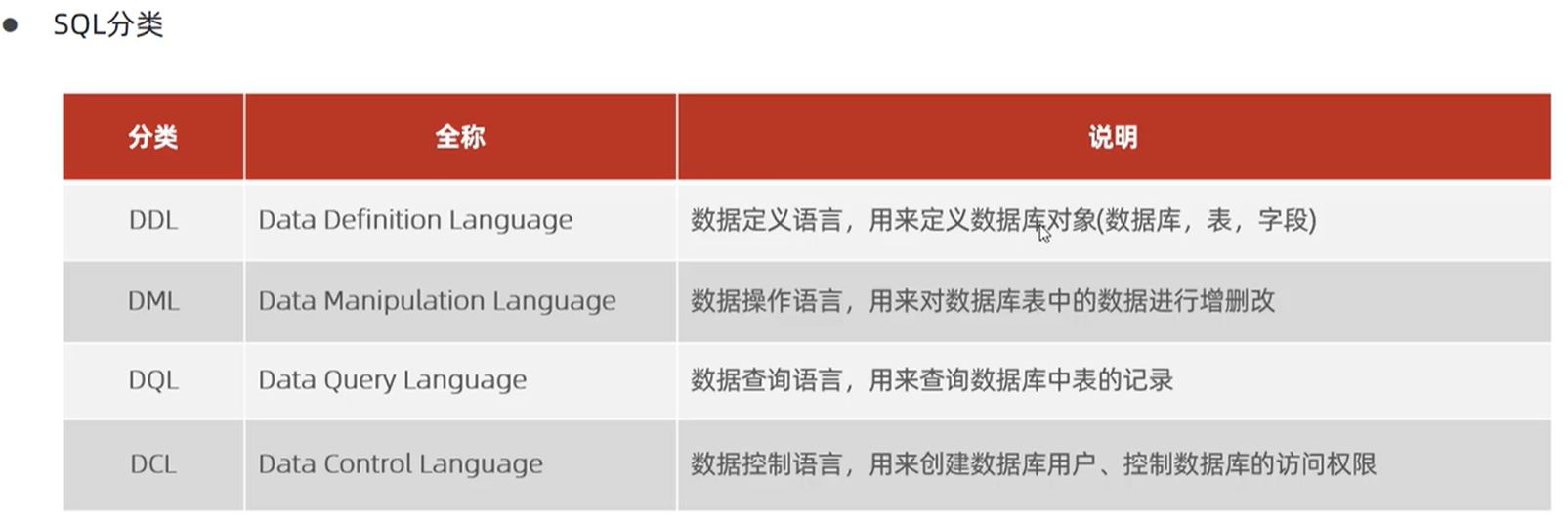 重点是我…...

uniapp开发android原生插件-java版本
一、uniapp官方文档 uni原生插件文档 二、开发流程 1、检测本地uniapp的版本号 2、根据版本号,下载uni提供的对应android的sdk对应demo 下载地址:Android 离线SDK - 正式版 | uni小程序SDK 下载文件后,复制出UniPlugin-Hello-ASÿ…...

git在IDEA中使用技巧
git在IDEA中使用技巧 merge和rebase 参考:IDEA小技巧-Git的使用 git回滚、强推、代码找回 参考:https://www.bilibili.com/video/BV1Wa411a7Ek?spm_id_from333.788.videopod.sections&vd_source2f73252e51731cad48853e9c70337d8e cherry pick …...