基于【Lang Chain】构建智能问答系统的实战指南

🐇明明跟你说过:个人主页
🏅个人专栏:《深度探秘:AI界的007》 🏅
🔖行路有良友,便是天堂🔖
目录
一、引言
1、什么是Lang Chain
2、LangChain在问答系统中的核心优势
二、环境搭建与基础准备
1、开发环境配置(Python、LangChain、LLM模型选择)
2、安装FAISS数据库
3、FAISS数据库介绍
三、代码部分
1、向量化文档
2、创建问答
3、完整代码
4、运行
一、引言
1、什么是Lang Chain
什么是 LangChain?🤖📚
LangChain 是一个帮助开发者轻松构建与 语言模型(如 GPT-3 或 GPT-4)互动的工具包。它为开发者提供了一整套现成的模块和功能,使得开发者能够快速创建强大的语言模型应用,无需从零开始。
🌟 通俗比喻:
想象你有一个超级聪明的助手(就是语言模型),它能够帮助你理解和生成各种文字内容📝。但是,如果你要让这个助手处理大量的信息,比如从多个文档中提取知识、或者在海量数据中找到特定的答案,事情就变得有点复杂了。
这时,LangChain 就像是一个智能助手管理系统,它将处理这些复杂任务的各种功能模块(如文本处理、数据检索、模型生成等)都打包在一起,简化了操作,让你更轻松地与这些强大的语言模型互动。

🔧 LangChain 做了什么?
文本处理 📄
-
有大量的文本数据(例如文章、书籍、报告等),LangChain 可以帮助你将它们切割成更小、更易于处理的块。这样,语言模型就能更好地理解和分析这些文本。
信息检索 🔍
-
LangChain 能够将文本数据转化为“向量”形式,方便后续的查询和比较。就像你用 Google 搜索 查找信息一样,LangChain 会帮你找到最相关的内容。
问答系统 ❓
-
想构建一个智能问答系统吗?LangChain 可以根据你的文档和数据库内容,自动从中提取出答案。你只需提出问题,系统会帮你查找最相关的答案。
多轮对话 💬
-
如果你想要创建一个能够与人进行多轮对话的聊天机器人,LangChain 也能帮你管理对话的上下文。这样,机器人不仅能记住之前的对话,还能根据对话内容作出更智能的回答。

2、LangChain在问答系统中的核心优势
1. 强大的信息检索功能 🔍
LangChain 能够轻松整合 信息检索(IR)系统,让问答系统不仅依赖于语言模型的生成能力,还能从大量数据中检索出最相关的信息。
-
向量数据库支持:LangChain 支持集成 FAISS 等高效向量数据库,能够将文本数据转化为向量,提升查询效率。
-
精确匹配:可以根据用户的查询,快速查找到相关文档或数据,并为语言模型提供更精确的上下文。
2. 自动化文档处理和文本切割 📝✂️
在问答系统中,我们往往需要处理大量的文档和文本数据。LangChain 提供了强大的文本切割和预处理功能:
-
自动分割长文档:LangChain 提供文本切割工具(如
RecursiveCharacterTextSplitter),将长文本分割成较小的片段,便于更高效地进行处理和查询。 -
文本清洗和格式化:它帮助开发者自动处理文本数据,去除无关信息,确保模型输入的文本是干净且易于理解的。
二、环境搭建与基础准备
1、开发环境配置(Python、LangChain、LLM模型选择)
Python版本:3.12.7
安装 LangChain 工具包
pip install langchain_community langchain_openai langchain langchain_openaiLLM,这里的大模型我们使用 OpenAI 的大模型,如果还没有申请OpenAI 的KEY,可以参考:
《LangChain 安装与环境搭建,并调用OpenAI与Ollama本地大模型》这篇文章
2、安装FAISS数据库
执行以下命令:
pip install faiss-cpu3、FAISS数据库介绍
📊🔍FAISS(Facebook AI Similarity Search)是一个由 Facebook AI Research 开发的高效向量检索库,专为处理大规模高维数据集中的 相似性搜索 设计。FAISS 是一个 开源 项目,旨在提供 快速的近似最近邻(ANN) 搜索功能,广泛应用于机器学习、自然语言处理、推荐系统等领域。
FAISS 的核心优势在于它能在处理海量数据时提供 高效的检索,尤其是在计算 向量相似性 时,性能远超传统的数据库系统。
FAISS 的核心特点 🌟
高效的向量相似性搜索 🔍
-
FAISS 可以在大规模数据集中进行 高效的向量相似性搜索,帮助用户从海量数据中找到最相似的项。
-
它支持 内存中索引(例如,使用 CPU 或 GPU)以及 磁盘存储索引,即使在数据集非常庞大的情况下也能提供快速的检索。
支持多种距离度量 📏
-
FAISS 支持 欧氏距离(L2)、内积等常见的距离度量方法,能够根据不同应用场景灵活选择合适的度量方式。
-
这些距离度量对于处理 文本、图像、音频 等多模态数据非常有用。
支持高维数据 🔢
-
FAISS 能处理 高维(几百维、几千维甚至更多)的数据,尤其适用于机器学习中通过 嵌入(embedding)生成的高维向量。
-
例如,处理文本时,FAISS 能够高效地检索基于语言模型生成的 词向量 或 句向量。
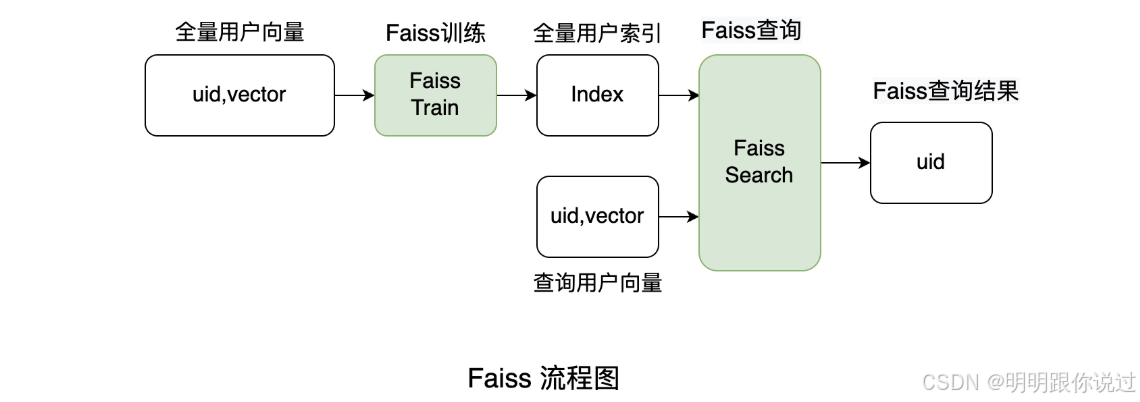
FAISS 如何工作? 🛠️
FAISS 的工作原理可以分为以下几个步骤:
数据向量化 📈
-
首先,数据(如文本、图像、音频)需要被转化为 向量,这通常通过 深度学习模型(例如,BERT、ResNet、VGG)生成。
-
这些向量是高维的,表示数据中的某些特征。
构建索引 🗄️
-
使用 FAISS 的不同索引结构(如 Flat、IVF、HNSW 等)将向量数据进行 索引。这一步骤的目的是加速查询过程。
查询和相似性搜索 🔍
-
用户提出查询,FAISS 会通过 计算查询向量与数据集中向量的相似度(如计算内积或欧氏距离)来找出最相似的项。
-
FAISS 提供近似最近邻搜索,通常在 大规模数据集 中可以显著提高检索速度。
FAISS 应用场景 🚀
FAISS 广泛应用于 自然语言处理、计算机视觉 和 推荐系统 等领域,以下是一些典型的应用:
推荐系统 🎯
-
FAISS 可以帮助根据用户历史行为或偏好从庞大的商品或内容库中找到相似的商品或内容,提供个性化推荐。
文本相似性检索 📝
-
在处理大量文本数据时(如文档、文章、问题解答等),FAISS 可以高效地查询最相关的文本,支持 问答系统、信息检索系统等应用。
图像检索 🖼️
-
在计算机视觉领域,FAISS 能够从 图像特征向量 中找到相似图像,广泛应用于 图像检索、图像分类 和 面部识别 等任务。
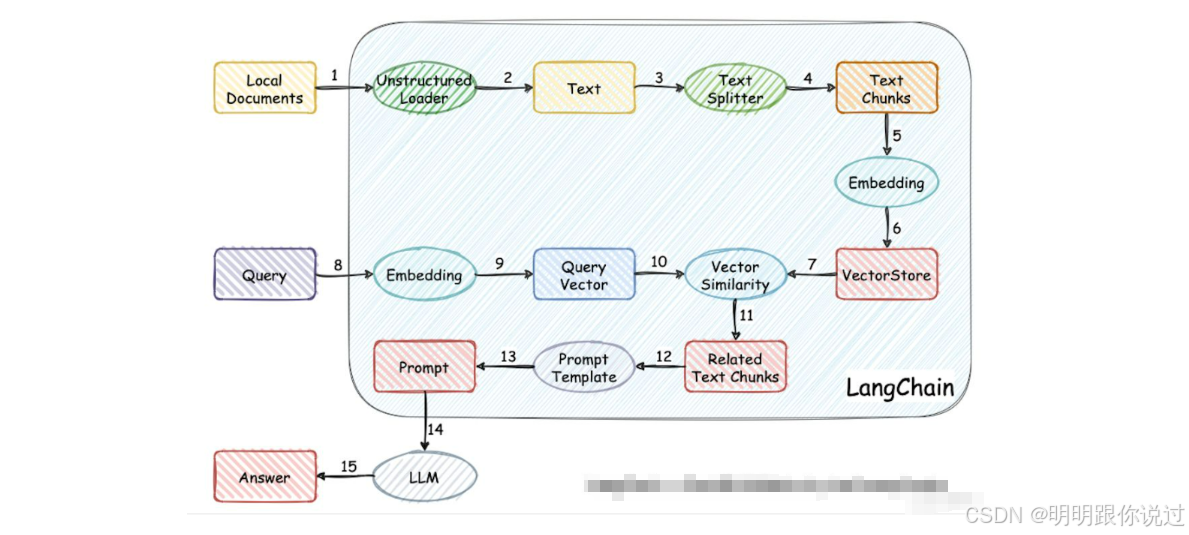
三、代码部分
1、向量化文档
代码如下:
# 加载文档
docs = ["三星 W25 手机512G价格为¥15999", "三星 W25 手机1T价格为¥17999",]# 将字符串转换为 Document 对象
documents = [Document(page_content=doc) for doc in docs]# 文本切割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
split_docs = text_splitter.split_documents(documents)# 创建Embedding
embeddings = OpenAIEmbeddings()# 使用FAISS创建向量数据库
db = FAISS.from_documents(split_docs, embeddings)# 保存数据库
db.save_local("faiss_index")1. 加载文档 📄
- 这里创建了一个简单的 文档列表(
docs),其中包含两条字符串,每条字符串描述了一个三星手机的不同存储版本和价格。
2. 将字符串转换为 Document 对象 📝
- 将每个字符串(文档内容)转换为
Document对象。Document是 LangChain 中的一个类,用于封装文本数据及其相关元数据。这里的page_content=doc将字符串作为文档的内容。
3. 文本切割(分割长文本) ✂️
- 使用
RecursiveCharacterTextSplitter来切割文档。这个工具将文档按照一定的字符数量(这里是 1000 字符)进行切割,同时允许文档切割片段之间有 200 字符的重叠。这样做的目的是确保文档在切割后,仍然能够保持上下文的连贯性。
4. 创建文档的嵌入(Embedding) 🧠
OpenAIEmbeddings是 LangChain 提供的一个工具,用于将文本转换为 向量嵌入(embedding)。嵌入是将文本表示为数字向量,这些向量能够捕捉到文本的语义信息。在此例中,使用的是 OpenAI 的嵌入模型。
5. 使用 FAISS 创建向量数据库 🔣
- 使用 FAISS 向量数据库来存储文本的嵌入。FAISS 是一个高效的相似性搜索库,可以对文本进行向量化处理后快速查询相似的内容。
split_docs是切割后的文档,embeddings是生成这些文档的嵌入的工具。from_documents方法会将文档转换为向量,并将它们存储在 FAISS 向量数据库中。这个数据库支持高效的相似性查询。
6. 保存向量数据库 💾
- 最后,将构建好的 FAISS 向量数据库保存到本地文件系统。数据库会保存在名为
faiss_index的文件夹中。我们可以将其用于后续的查询和检索操作。
2、创建问答
代码如下:
# 加载FAISS数据库
db = FAISS.load_local("C:/Users/LMT/PycharmProjects/AI/LangChain/faiss_index", embeddings, allow_dangerous_deserialization=True)# 初始化语言模型(这里用的是OpenAI)
llm = ChatOpenAI(model="gpt-4o")
# 创建问答链
qa_chain = RetrievalQA.from_chain_type(llm=llm, chain_type="map_reduce", retriever=db.as_retriever())# 查询
query = "三星 W25 手机512G价格是多少"
response = qa_chain.invoke(query)print(response)1. 加载 FAISS 数据库 📂
-
这行代码从本地路径加载已保存的 FAISS 向量数据库。路径
"C:/Users/LMT/PycharmProjects/AI/LangChain/faiss_index"指向之前存储的 FAISS 索引文件。 -
embeddings:使用的嵌入工具,用于将文本转换为向量的工具。 -
allow_dangerous_deserialization=True:这是一个安全选项,表示允许加载通过 pickle 存储的 FAISS 数据库文件。这个选项的作用是为了防止可能来自不受信任源的恶意代码执行。
2. 初始化语言模型(OpenAI GPT) 🤖
- 这里使用的是 OpenAI GPT-4 模型(
gpt-4o),作为问答系统的核心语言模型。
3. 创建问答链(QA Chain) 🔗
-
这里创建了一个 问答链(QA Chain),该链将使用 FAISS 向量数据库来检索与查询最相关的文档,并利用 GPT-4 生成回答。
-
from_chain_type:这个方法用于从指定的链类型创建问答链。-
llm=llm:将先前初始化的 GPT-4 模型作为问答链的语言模型。 -
chain_type="map_reduce":指定链的类型为 map_reduce,这意味着系统会先检索相关文档,然后将它们的内容传递给语言模型,模型再进行处理和整合最终的答案。 -
retriever=db.as_retriever():将 FAISS 向量数据库转换为检索器(retriever)。检索器负责从 FAISS 数据库中检索与查询最相似的文档。
-
4. 执行查询并获取回答 🧐💬
-
query = "三星 W25 手机512G价格是多少":这是用户输入的查询,目的是询问三星 W25 手机512G版本的价格。 -
qa_chain.invoke(query):通过问答链(QA Chain)执行查询。这个方法将根据用户的查询去 FAISS 数据库中查找相关文档,并将这些文档输入到 GPT-4 模型中,生成一个回答。
5. 打印答案 🖨️
- 最后,打印出从模型生成的回答,这个回答是针对用户查询的最佳匹配。
3、完整代码
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.docstore.document import Document
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI# 加载文档
docs = ["三星 W25 手机512G价格为¥15999", "三星 W25 手机1T价格为¥17999",]# 将字符串转换为 Document 对象
documents = [Document(page_content=doc) for doc in docs]# 文本切割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
split_docs = text_splitter.split_documents(documents)# 创建Embedding
embeddings = OpenAIEmbeddings()# 使用FAISS创建向量数据库
db = FAISS.from_documents(split_docs, embeddings)# 保存数据库
db.save_local("faiss_index")# 加载FAISS数据库
db = FAISS.load_local("C:/Users/LMT/PycharmProjects/AI/LangChain/faiss_index", embeddings, allow_dangerous_deserialization=True)# 初始化语言模型(这里用的是OpenAI)
llm = ChatOpenAI(model="gpt-4o")
# 创建问答链
qa_chain = RetrievalQA.from_chain_type(llm=llm, chain_type="map_reduce", retriever=db.as_retriever())# 查询
query = "三星 W25 手机512G价格是多少"
response = qa_chain.invoke(query)print(response)这段代码的功能是构建一个基于 FAISS 向量数据库 和 OpenAI GPT-4 的问答系统。它将文档转化为向量,存储在 FAISS 数据库中,使用 GPT-4 来生成对用户查询的答案。问答系统的主要步骤是:
-
加载文档并切割成片段。
-
创建嵌入并存储到 FAISS 向量数据库中。
-
加载 FAISS 数据库并初始化 GPT-4 模型。
-
使用检索和生成模型回答用户的查询。
这个系统可以用于各种信息检索任务,比如产品信息查询、文档检索、FAQ 自动化等。
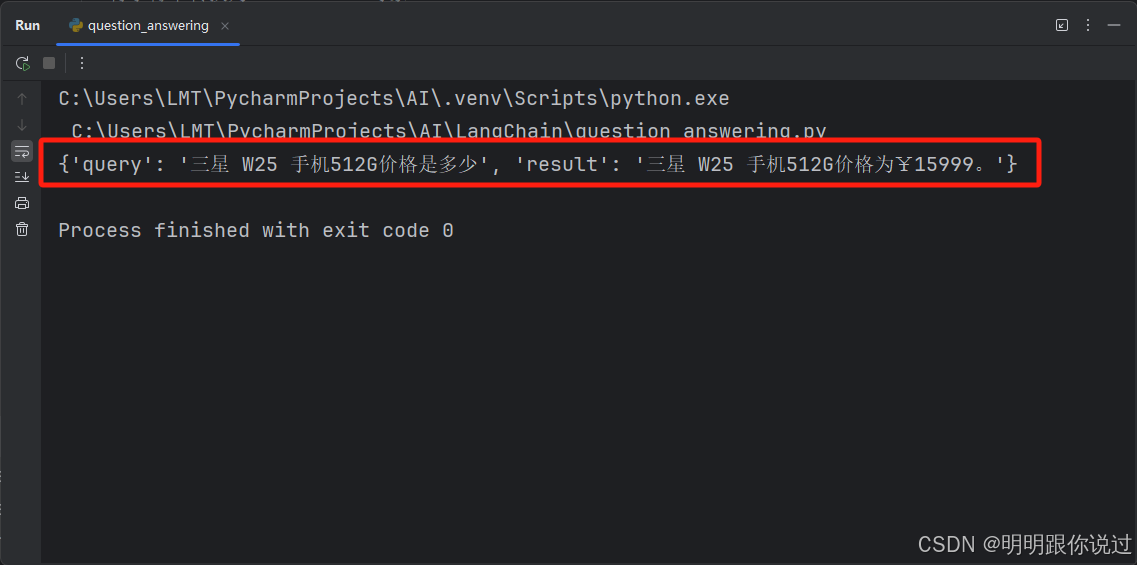
4、运行
代码执行后,结果如下:
💕💕💕每一次的分享都是一次成长的旅程,感谢您的陪伴和关注。希望这些文章能陪伴您走过技术的一段旅程,共同见证成长和进步!😺😺😺
🧨🧨🧨让我们一起在技术的海洋中探索前行,共同书写美好的未来!!!
相关文章:

基于【Lang Chain】构建智能问答系统的实战指南
🐇明明跟你说过:个人主页 🏅个人专栏:《深度探秘:AI界的007》 🏅 🔖行路有良友,便是天堂🔖 目录 一、引言 1、什么是Lang Chain 2、LangChain在问答系统中的核心优…...

Vue使用axios实现:上传文件、下载文件
Vue 使用 axios 框架,系列文章: 《Vue使用axios实现Ajax请求》 《Vue使用axios二次封装、解决跨域问题》 《Vue使用axios实现:上传文件、下载文件》 在实际开发过程中,浏览器通常需要和服务器端进行数据交互。而 Vue.js 并未提供与服务器端通信的接口。Axios 提供了一些方便…...

泊松分布详解:从理论基础到实际应用的全面剖析
泊松分布详解:从理论基础到实际应用的全面剖析 目录 引言:事件的罕见性与随机计数泊松分布的历史源流泊松分布的数学定义与性质 概率质量函数 (PMF)累积分布函数 (CDF)期望、方差与其他矩矩生成函数 (MGF) 与特征函数 (CF) 泊松分布的严格推导 极限推导…...

PHP爬虫教程:使用cURL和Simple HTML DOM Parser
一个关于如何使用PHP的cURL和HTML解析器来创建爬虫的教程,特别是处理代理信息的部分。首先,我需要确定用户的需求是什么。可能他们想从某个网站抓取数据,但遇到了反爬措施,需要使用代理来避免被封IP。不过用户没有提到具体的目标网…...

# 更换手机热点后secureCRT无法连接centOS7系统
更换手机热点后secureCRT无法连接centOS7系统 一、问题描述 某些情况下,我们可能使用手机共享热点而给电脑联网。本来用一个手机热点共享网络时,SecureCRT可以正常连接到CentOS 7虚拟机,当更换一个手机热点时,突然发现SecureCR…...

【集成电路版图设计学习笔记】2. 基本绘制的layer层和电路失效机制
一、基本的版图层次 1. 金属层(Metal Layers) 金属层主要起到互连的作用,完成基本电路器件的连接金属线的材质通常是铝或者铜,一般在线条比较粗的情况下,即特征尺寸比较粗的,一般是用铝制作的。在先进工艺…...

SQL学习笔记-聚合查询
非聚合查询和聚合查询的概念及差别 1. 非聚合查询 非聚合查询(Non-Aggregate Query)是指不使用聚合函数的查询。这类查询通常用于从表中检索具体的行和列数据,返回的结果是表中的原始数据。 示例 假设有一个名为 employees 的表ÿ…...

Profibus DP主站转modbusTCP网关与dp从站通讯案例
Profibus DP主站转modbusTCP网关与dp从站通讯案例 在当前工业自动化的浪潮中,不同协议之间的通讯转换成为了提升生产效率和实现设备互联的关键。Profibus DP作为一种广泛应用的现场总线技术,与Modbus TCP的结合,为工业自动化系统的集成带来了…...
)
【Linux】41.网络基础(2.3)
文章目录 2.3 TCP协议2.3.5 理解TIME_WAIT状态2.3.6 解决TIME_WAIT状态引起的bind失败的方法(作业)2.3.7 理解 CLOSE_WAIT 状态2.3.8 滑动窗口2.3.9 流量控制 2.3 TCP协议 2.3.5 理解TIME_WAIT状态 现在做一个测试,首先启动server,然后启动client,然后用Ctrl-C使server终止,这…...

C++多态知识点梳理
多态 多态的概念: 多态就是多种形态,具体点就是去完成某个行为,当不同的对象去完成时会产生出不同的状态。 比如构成多态的俩个父子类,我们调用同一个函数,可能会产生不同的行为,比如普通人买票全价&…...
)
Python批量处理PDF图片详解(插入、压缩、提取、替换、分页、旋转、删除)
目录 一、概述 二、 使用工具 三、Python 在 PDF 中插入图片 3.1 插入图片到现有PDF 3.2 插入图片到新建PDF 3.3 批量插入多张图片到PDF 四、Python 提取 PDF 图片及其元数据 五、Python 替换 PDF 图片 5.1 使用图片替换图片 5.2 使用文字替换图片 六、Python 实现 …...

计算机网络分层模型:架构与原理
前言 计算机网络通过不同的层次结构来实现通信和数据传输,这种分层设计不仅使得网络更加模块化和灵活,也使得不同类型的通信能够顺利进行。在网络协议和通信体系中,最广为人知的分层模型有 OSI模型 和 TCP/IP模型。这两种模型分别定义了计算…...

算法-mysql笔记
寻找用户推荐人 mysql判断数据是空 IS null 非空 IS NOT null 584. 寻找用户推荐人 - 力扣(LeetCode) # Write your MySQL query statement below SELECTname FROMCustomer WHEREreferee_id ! 2 OR referee_id IS null 文章概览 当查询到有多…...

销售易CRM:技术架构与安全性能的深度解析
一、技术架构:云计算与微服务的完美结合 销售易CRM基于云计算架构,采用微服务设计理念,确保系统的高可用性和扩展性。这种架构不仅提高了系统的性能和稳定性,还为企业提供了灵活的定制化能力。 云计算架构的优势 高可用性&…...
:从类设计到安全实现的完整指南)
Python用户管理系统深度解析(附源码):从类设计到安全实现的完整指南
目录 一、核心类结构全解 1.1 类定义与属性设计 代码解析: 二、注册功能代码逐行解析 2.1 用户名验证模块 功能实现: 2.2 密码设置流程 关键机制: 2.3 数据存储实现 文件操作要点: 三、登录安全机制全剖析 3.1 黑名单…...

【linux】使用LNMP环境+Discuz论坛源程序
我使用的版本是linux9.3、Discuz X3.5、nginx1.20、mariadb10.5、php8.0 整体结构 LNMP Linux Nginx mariadb PHP Nginx 最初于2004年10月4日为俄罗斯知名门户站点而开发的Nginx是一款轻量级的网站服务软件,因其稳定性和丰富的功能而深受信赖特点:…...

鸿蒙开发-动画
1. 动画-动画特效 // 定义接口 (每个列表项的数据结构) interface ImageCount {url: stringcount: number }// 需求1: 遮罩层显隐 透明度opacity 0-1 层级zIndex -1~99 // 需求2: 图片缩放 缩放scale 0-1Entry Component struct Index {// 基于接口, 准备数据State images…...

itext7 html2pdf 将html文本转为pdf
1、将html转为pdf需求分析 经常会看到爬虫有这样的需求,将某一个网站上的数据,获取到了以后,进行分析,然后将需要的数据进行存储,也有将html转为pdf进行存储,作为原始存档,当然这里看具体的需求…...

设计模式:模板模式 - 固定流程与灵活扩展的完美结合
一、为什么使用模板模式? 权限校验、数据处理、用例设计等流程虽然遵循固定步骤,但每个具体实现却总有不同。如果没有合适的设计,重复代码会堆积,导致系统复杂度增加,维护成本上升。那如何解决这个问题,让…...

Java 设计模式:组合模式详解
Java 设计模式:组合模式详解 组合模式(Composite Pattern)是一种结构型设计模式,它允许将对象组织成树形结构,以统一的方式处理单个对象和对象集合。组合模式适用于需要表示“部分-整体”层次结构的场景,例…...

使用命令打开电脑的[服务]窗口
1.首先打开[开始],找到[运行], 2.或者用快捷命令“windows键R键”命令打开运行, 3.然后输入命令“services.msc”, 4.点[确定]就可以进入电脑的[服务]窗口了...

语音识别——根据声波能量、VAD 和 频谱分析周围是否有人说话
语音活动检测(Voice Activity Detection,简称VAD)。简单来说,VAD就是用来判断一段音频里有没有人说话的技术。在实时语音识别的场景里,这个技术特别重要,因为它决定了什么时候把采集到的音频数据扔进大模型…...

C++算法优化实战:破解性能瓶颈,提升程序效率
C算法优化实战:破解性能瓶颈,提升程序效率 在现代软件开发中,算法优化是提升程序性能的关键手段之一。无论是在高频交易系统、实时游戏引擎,还是大数据处理平台,算法的高效性直接关系到整体系统的性能与响应速度。C作…...

阿里滑块 231 231纯算 水果滑块 拼图 1688滑块 某宝 大麦滑块 阿里231 验证码
声明 本文章中所有内容仅供学习交流,抓包内容、敏感网址、数据接口均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关,若有侵权,请联系我立即删除! # 欢迎交流 wjxch1004...

vs code Cline 编程接入Claude 3.7的经济方案,且保持原生接口能力
在当今快速发展的科技时代,自动化编程成为提高工作效率的重要手段。Cline AI自动编程工具,凭借其强大的智能算法,能够快速生成高质量的代码,帮助开发者节省大量的时间和精力。从简单的脚本到复杂的应用程序,Cline都能轻…...

kubectl命令补全以及oc命令补全
kubectl命令补全 1.安装bash-completion 如果你用的是Bash(默认情况下是),先安装补全功能支持包 sudo apt update sudo apt install bash-completion -y2.为kubectl 启用补全功能 会话中临时: source <(kubectl completion bash)持久化配置&#x…...

css解决边框四个角有颜色
效果 html <div class"gradient-corner">2021年</div>css background:/* 左上角横线 */linear-gradient(90deg, rgb(5, 150, 247) 9px, transparent 0) 0 0,/* 左上角竖线 */linear-gradient(0deg, rgb(5, 150, 247) 9px, transparent 0) 0 0,/* 右上…...

快速入手K8s+Docker+KubeSphere+DevOps
引用:云原生Java架构师的第一课K8sDockerKubeSphereDevOps_哔哩哔哩_bilibili 学习K8sDockerKubeSphereDevOps的可以学习该视频...

Spark-SQL核心编程
DataFrame 创建 DataFrame 在 Spark SQL 中 SparkSession 是创建 DataFrame 和执行 SQL 的入口,创建 DataFrame 有三种方式:通过 Spark 的数据源进行创建;从一个存在的 RDD 进行转换;还可以从 Hive Table 进行查询返回。 从…...

Go 1.24 新方法:编写性能测试用例方法 testing.B.Loop 介绍
Go 开发者在使用 testing包编写基准测试用例时,如果不注意,可能会遇到各种陷阱。这些陷阱,导致基准测试结果不准确。Go1.24 版本引入了一种新的基准测试编写方式,它同样易用,并且可以帮助规避编写基准测试时的一些坑。…...

【神经网络结构的组成】深入理解 转置卷积与转置卷积核
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏: 🏀《深度学习理论直觉三十讲》_十二月的猫的博客-CSDN博客 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 …...

GpuGeek:重构AI算力基础设施,赋能产业智能升级
在数字经济与实体经济深度融合的今天,人工智能已成为推动产业变革的核心驱动力。作为AI技术落地的关键支撑,算力基础设施正经历从"资源供给"向"服务赋能"的范式转变。GpuGeek凭借创新的技术架构和运营模式,重新定义了AI算…...
Chatbox多端一键配置Claude/GPT/DeepSeek-网页端配置)
(2025亲测可用)Chatbox多端一键配置Claude/GPT/DeepSeek-网页端配置
1. 资源准备 API Key:此项配置填写在一步API官网创建API令牌,一键直达API令牌创建页面创建API令牌步骤请参考API Key的获取和使用API Host:此项配置填写https://yibuapi.com/v1查看支持的模型请参考这篇教程模型在线查询 2. ChatBox网页版配…...

质变科技发布自主数据分析MCP Server
2025年4月9日,质变科技正式发布Relyt AI MCP(Model Context Protocol),结合Relyt AI 在自主数据分析领域的前沿积累与MCP的开放连接能力,我们为用户带来了一个更智能、更灵活的数据交互生态系统。这一发布不仅拓展了Re…...

【17】Strongswan bus详解2
add_listener: (1)初始化一个entry,并将要添加的listener赋值entry。 (2)添加到bus的listeners链表的尾部。 remove_listener: (1)遍历listeners,通过内存位置…...

【Windows】系统安全移除移动存储设备指南:告别「设备被占用」弹窗
Windows系统安全移除移动存储设备指南:告别「设备被占用」弹窗 解决移动硬盘和U盘正在被占用无法弹出 一、问题背景 使用Windows系统时,经常遇到移动硬盘/U盘弹出失败提示「设备正在使用中」,即使已关闭所有可见程序。本文将系统梳理已验证…...

DeepSeek 与开源:肥沃土壤孕育 AI 硕果
当 DeepSeek 以低成本推理、多模态能力惊艳全球时,人们惊叹于国产AI技术的「爆发力」,却鲜少有人追问:这份爆发力的根基何在? 答案,藏在中国开源生态二十余年的积淀中。 从倪光南院士呼吁「以开源打破垄断」…...

[从零开始学数据库] 基本SQL
注意我们的主机就是我们的Mysql数据库服务器 这里我们可以用多个库 SQL分类(核心是字段的CRUD) 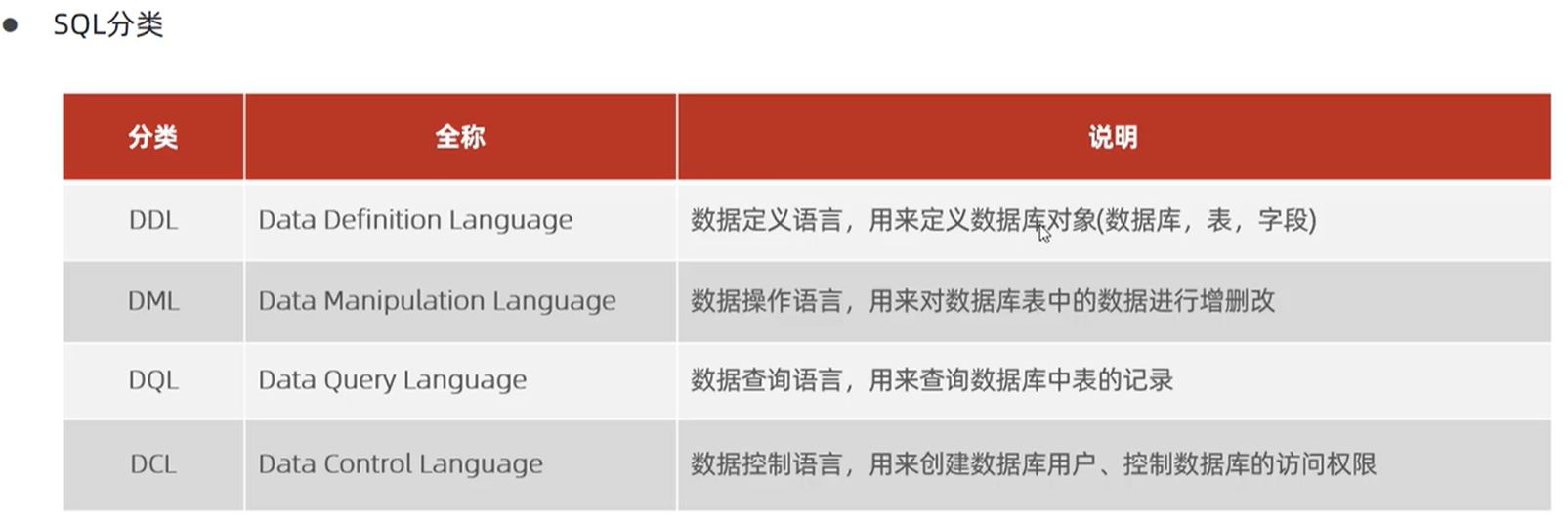 重点是我…...

uniapp开发android原生插件-java版本
一、uniapp官方文档 uni原生插件文档 二、开发流程 1、检测本地uniapp的版本号 2、根据版本号,下载uni提供的对应android的sdk对应demo 下载地址:Android 离线SDK - 正式版 | uni小程序SDK 下载文件后,复制出UniPlugin-Hello-ASÿ…...

git在IDEA中使用技巧
git在IDEA中使用技巧 merge和rebase 参考:IDEA小技巧-Git的使用 git回滚、强推、代码找回 参考:https://www.bilibili.com/video/BV1Wa411a7Ek?spm_id_from333.788.videopod.sections&vd_source2f73252e51731cad48853e9c70337d8e cherry pick …...

DeepSeek 接入 Excel 完整教程
一、前期准备 1.1 获取 DeepSeek API 密钥 注册 DeepSeek 平台 访问 DeepSeek 官方网站(或指定的 API 服务平台,如硅基流动等)。若尚未注册,按照平台指引创建新账号并完成登录。 创建 API 密钥 进入用户控制面板,找到…...

【项目管理】第15章 项目风险管理-- 知识点整理
项目管理-相关文档,希望互相学习,共同进步 风123456789~-CSDN博客 (一)知识总览 项目管理知识域 知识点: (项目管理概论、立项管理、十大知识域、配置与变更管理、绩效域) 对应:第6章-第19章 第6章 项目管理概论 4分第13章 项目资源管理 3-4分第7章 项目…...

如何将自己的项目推送到GitHub上面去
将项目推送到GitHub的流程总结 以下是将本地项目推送到GitHub仓库的完整流程: 1. 初始化Git仓库(如果尚未初始化) cd 项目目录 git init2. 配置远程仓库 # 添加远程仓库地址 git remote add origin https://github.com/用户名/仓库名.git…...

C/C++基础
C开发环境 纯语言开发要求:CIDE。 极简C/C 语法规则 仅记原始规则,把握编程的本质,不做孔乙己,要做说干就干的平头哥。 原始的规则: 各“语法单位”(组成部分)使用任意个(至少1个…...

Qt炫酷仪表盘
Qt学习优化的一款汽车仪表控件,根据github上面开源的进行优化,主要使用QPainter实现的一款炫酷仪表盘,其中的渐变效果比较有感觉 实现结果 仪表盘 实现源码 h文件 #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QPixmap> #include <QTimer&…...
)
云渗透一(云租户渗透⼊⻔)
云平台介绍 阿⾥云 阿⾥云创⽴于 2009 年,服务着制造、⾦融、政务、交通、医疗、电信、能源等众多领域的领军企业,包 括中国联通、12306 、中⽯化、中⽯油、⻜利浦、华⼤基因等⼤型企业客户,以及微博、知乎、锤⼦科技 等明星互联⽹公司。 应⽤程序访问令牌 - T1527 云实例…...
绘图保姆级模板——NMDS从原理到绘图,看师兄这篇教程就够了)
R绘图|6种NMDS(非度量多维分析)绘图保姆级模板——NMDS从原理到绘图,看师兄这篇教程就够了
感谢西农听雨同学对本文提供的大力支持! 一、引言 非度量多维尺度分析(NMDS)是一种用来简化复杂数据的工具,特别适合处理那些难以直接理解的高维数据(微生物群落数据)。它的主要目的是把数据“压缩”到更低…...

spark-SQL核心编程
1. Spark-SQL简介 起源与发展:Spark-SQL前身为Shark,因对Hive依赖制约Spark发展而被弃用。它汲取Shark优点重新开发,在数据兼容、性能优化和组件扩展方面表现出色。 特点:易整合,统一数据访问,兼容Hive&…...
)
使用MCP服务通过自然语言操作数据库(vscode+cline版本)
使用MCP服务操纵数据库(vscodecline版本) 本文主要介绍,在vscode中使用cline插件调用deepseek模型,通过MCP服务器 使用自然语言去操作指定数据库。本文使用的是以己经创建号的珠海航展数据库。 理解MCP服务: MCP(Model Context…...
的生命周期及应用场景)
.NET Core DI(依赖注入)的生命周期及应用场景
在.NET中,依赖注入(DI,Dependency Injection)是一种设计模式,它通过将依赖关系注入到类中,而不是让类自己创建依赖项,来降低类之间的耦合度。这使得代码更加模块化、灵活和易于测试。在.NET中&a…...