Spark-SQL核心编程
DataFrame
创建 DataFrame
在 Spark SQL 中 SparkSession 是创建 DataFrame 和执行 SQL 的入口,创建 DataFrame
有三种方式:通过 Spark 的数据源进行创建;从一个存在的 RDD 进行转换;还可以从 Hive
Table 进行查询返回。
从 Spark 数据源进行创建
Spark-SQL支持的数据类型:
➢ 在 spark 的 bin/data 目录中创建 user.json 文件
{"username":"zhangsan","age":20}
{"username":"lisi","age":17}
➢ 读取 json 文件创建 DataFrame
val df = spark.read.json("data/user.json")

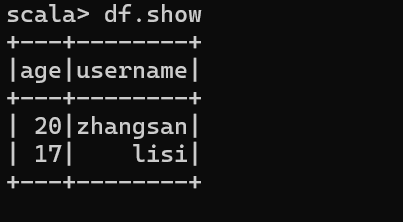
展示数据:
df.show
SQL 语法
SQL 语法风格是指我们查询数据的时候使用 SQL 语句来查询,这种风格的查询必须要
有临时视图或者全局视图来辅助
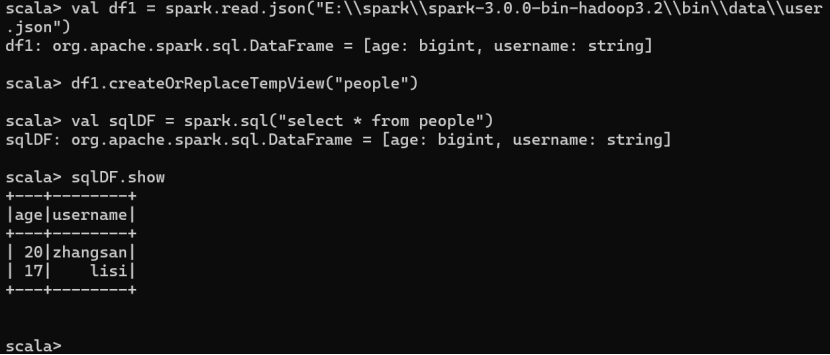
- 读取 JSON 文件创建 DataFrame
val df1 = spark.read.json("data/user.json")
- 对 DataFrame 创建一个临时表
df1.createOrReplaceTempView("people")
- 通过 SQL 语句实现查询全表
val sqlDF = spark.sql("select * from people"
- 结果展示
sqlDF.show
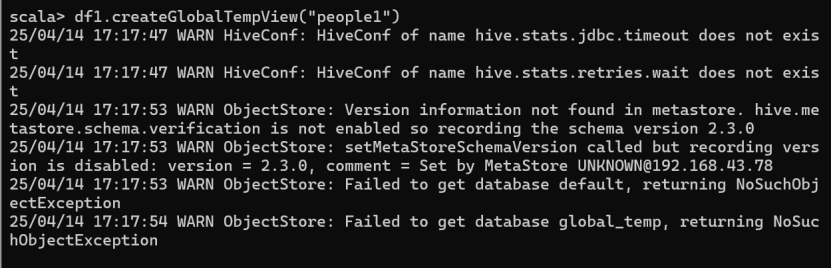
- 对于 DataFrame 创建一个全局表
df1.createGlobalTempView("people1")
Spark-SQL核心编程(二)
DataFrame
DSL 语法
DataFrame 提供一个特定领域语言(domain-specific language, DSL)去管理结构化的数据。 可以在 Scala, Java, Python 和 R 中使用 DSL,使用 DSL 语法风格不必去创建临时视图了。
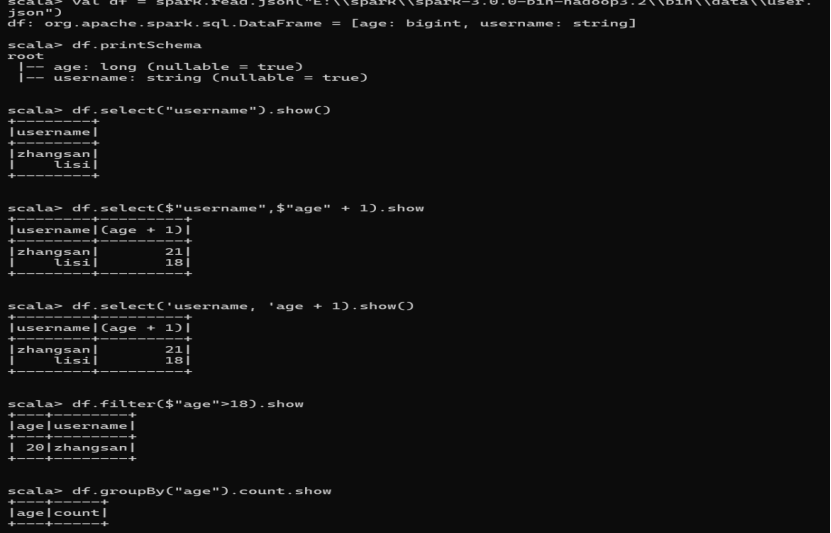
- 创建一个 DataFrame
val df = spark.read.json("data/user.json")
- 查看 DataFrame 的 Schema 信息
df.printSchema
- 只查看"username"列数据
df.select("username").show()
- 查看"username"列数据以及"age+1"数据
注意:涉及到运算的时候, 每列都必须使用$, 或者采用引号表达式:单引号+字段名
df.select($"username",$"age" + 1).show
df.select('username, 'age + 1).show()
- 查看"age"大于"18"的数据
df.filter($"age">18).show
- 按照"age"分组,查看数据条数
df.groupBy("age").count.show
RDD 转换为 DataFrame
在 IDEA 中开发程序时,如果需要 RDD 与 DF 或者 DS 之间互相操作,那么需要引入 import spark.implicits._ 这里的 spark 不是 Scala 中的包名,而是创建的 sparkSession 对象的变量名称,所以必 须先创建 SparkSession 对象再导入。这里的 spark 对象不能使用 var 声明,因为 Scala 只支持 val 修饰的对象的引入。
spark-shell 中无需导入,自动完成此操作。
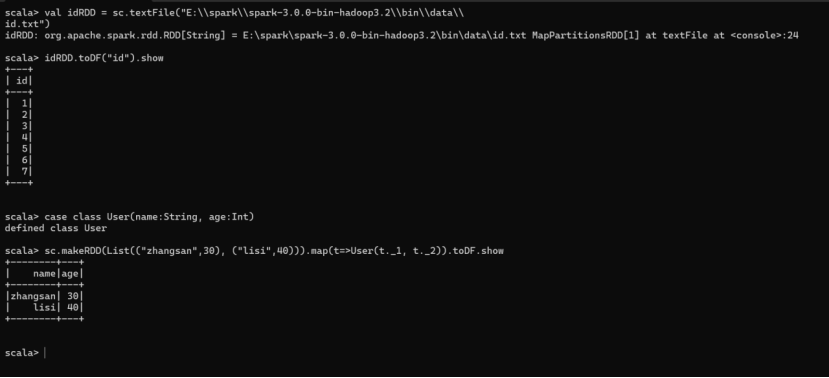
val idRDD = sc.textFile("data/id.txt")
idRDD.toDF("id").show
val df1 = spark.read.json("E:\\spark\\spark-3.0.0-bin-hadoop3.2\\bin\\data\\user
.json")
实际开发中,一般通过样例类将 RDD 转换为 DataFrame
case class User(name:String, age:Int)
sc.makeRDD(List(("zhangsan",30), ("lisi",40))).map(t=>User(t._1, t._2)).toDF.show
DataFrame 转换为 RDD
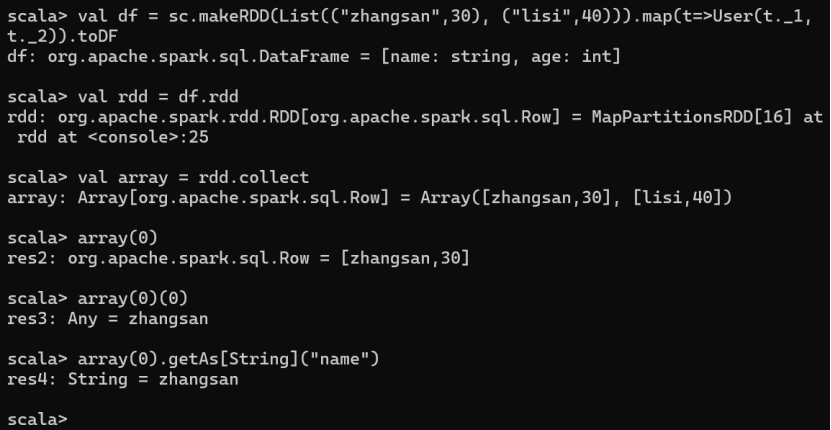
DataFrame 其实就是对 RDD 的封装,所以可以直接获取内部的 RDD
val df = sc.makeRDD(List(("zhangsan",30), ("lisi",40))).map(t=>User(t._1, t._2)).toDF
val rdd = df.rdd
val array = rdd.collect
注意:此时得到的 RDD 存储类型为 Row
array(0)
array(0)(0)
array(0).getAs[String]("name")
Spark-SQL核心编程(三)
DataSet
DataSet 是具有强类型的数据集合,需要提供对应的类型信息。
创建 DataSet
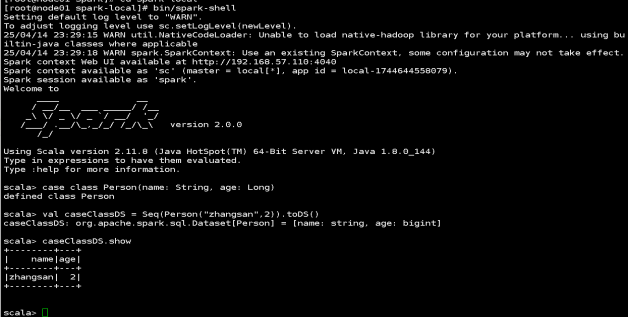
1) 使用样例类序列创建 DataSet
case class Person(name: String, age: Long)
val caseClassDS = Seq(Person("zhangsan",2)).toDS()
caseClassDS.show
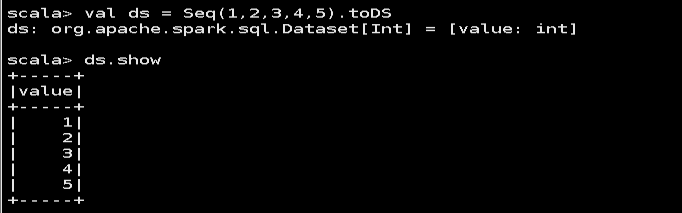
2) 使用基本类型的序列创建 DataSet
val ds = Seq(1,2,3,4,5).toDS
ds.show
RDD 转换为 DataSet
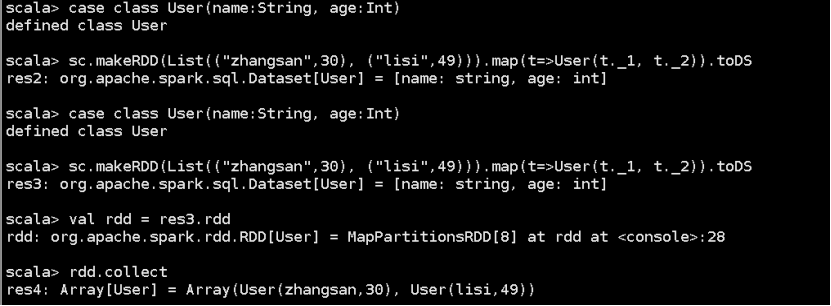
case class User(name:String, age:Int)
sc.makeRDD(List(("zhangsan",30), ("lisi",49))).map(t=>User(t._1, t._2)).toDS

DataSet 转换为 RDD
case class User(name:String, age:Int)
sc.makeRDD(List(("zhangsan",30), ("lisi",49))).map(t=>User(t._1, t._2)).toDS
val rdd = res3.rdd
rdd.collect
DataFrame 和 DataSet 转换
DataFrame 其实是 DataSet 的特例,所以它们之间是可以互相转换的。
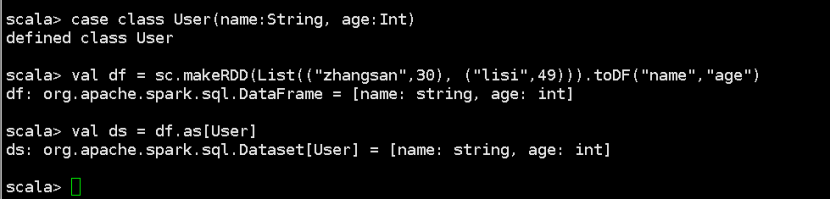
DataFrame 转换为 DataSet
case class User(name:String, age:Int)
val df = sc.makeRDD(List(("zhangsan",30), ("lisi",49))).toDF("name","age")
val ds = df.as[User]
DataSet 转换为 DataFrame
val ds = df.as[User]
val df = ds.toDF

RDD、DataFrame、DataSet 三者的关系
首先从版本的产生上来看:
➢ Spark1.0 => RDD
➢ Spark1.3 => DataFrame
➢ Spark1.6 => Dataset
如果同样的数据都给到这三个数据结构,他们分别计算之后,都会给出相同的结果。不
同是的他们的执行效率和执行方式。在后期的 Spark 版本中,DataSet 有可能会逐步取代 RDD和 DataFrame 成为唯一的 API 接口。
三者的共性
➢ RDD、DataFrame、DataSet 全都是 spark 平台下的分布式弹性数据集,为处理超大型数
据提供便利;
➢ 三者都有惰性机制,在进行创建、转换,如 map 方法时,不会立即执行,只有在遇到
Action 如 foreach 时,三者才会开始遍历运算;
➢ 三者有许多共同的函数,如 filter,排序等;
➢ 在对 DataFrame 和 Dataset 进行操作许多操作都需要这个包:
import spark.implicits._(在创建好 SparkSession 对象后尽量直接导入)
➢ 三者都会根据 Spark 的内存情况自动缓存运算,这样即使数据量很大,也不用担心会
内存溢出
➢ 三者都有分区(partition)的概念
➢ DataFrame 和 DataSet 均可使用模式匹配获取各个字段的值和类型
三者的区别
1) RDD
➢ RDD 一般和 spark mllib 同时使用
➢ RDD 不支持 sparksql 操作
2) DataFrame
➢ 与 RDD 和 Dataset 不同,DataFrame 每一行的类型固定为Row,每一列的值没法直
接访问,只有通过解析才能获取各个字段的值
➢ DataFrame 与 DataSet 一般不与 spark mllib 同时使用
➢ DataFrame 与 DataSet 均支持 SparkSQL 的操作,比如 select,groupby 之类,还能
注册临时表/视窗,进行 sql 语句操作
➢ DataFrame 与 DataSet 支持一些特别方便的保存方式,比如保存成 csv,可以带上表
头,这样每一列的字段名一目了然
3) DataSet
➢ Dataset 和 DataFrame 拥有完全相同的成员函数,区别只是每一行的数据类型不同。
DataFrame 其实就是 DataSet 的一个特例 type DataFrame = Dataset[Row]
➢ DataFrame 也可以叫 Dataset[Row],每一行的类型是 Row,不解析,每一行究竟有哪
些字段,各个字段又是什么类型都无从得知,只能用上面提到的 getAS 方法或者共性里提到的模式匹配拿出特定字段。而 Dataset 中,每一行是什么类型是不一定的,在自定义了 case class 之后可以很自由的获得每一行的信息。
三者可以通过上图的方式进行相互转换。
相关文章:

Spark-SQL核心编程
DataFrame 创建 DataFrame 在 Spark SQL 中 SparkSession 是创建 DataFrame 和执行 SQL 的入口,创建 DataFrame 有三种方式:通过 Spark 的数据源进行创建;从一个存在的 RDD 进行转换;还可以从 Hive Table 进行查询返回。 从…...

Go 1.24 新方法:编写性能测试用例方法 testing.B.Loop 介绍
Go 开发者在使用 testing包编写基准测试用例时,如果不注意,可能会遇到各种陷阱。这些陷阱,导致基准测试结果不准确。Go1.24 版本引入了一种新的基准测试编写方式,它同样易用,并且可以帮助规避编写基准测试时的一些坑。…...

【神经网络结构的组成】深入理解 转置卷积与转置卷积核
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏: 🏀《深度学习理论直觉三十讲》_十二月的猫的博客-CSDN博客 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 …...

GpuGeek:重构AI算力基础设施,赋能产业智能升级
在数字经济与实体经济深度融合的今天,人工智能已成为推动产业变革的核心驱动力。作为AI技术落地的关键支撑,算力基础设施正经历从"资源供给"向"服务赋能"的范式转变。GpuGeek凭借创新的技术架构和运营模式,重新定义了AI算…...
Chatbox多端一键配置Claude/GPT/DeepSeek-网页端配置)
(2025亲测可用)Chatbox多端一键配置Claude/GPT/DeepSeek-网页端配置
1. 资源准备 API Key:此项配置填写在一步API官网创建API令牌,一键直达API令牌创建页面创建API令牌步骤请参考API Key的获取和使用API Host:此项配置填写https://yibuapi.com/v1查看支持的模型请参考这篇教程模型在线查询 2. ChatBox网页版配…...

质变科技发布自主数据分析MCP Server
2025年4月9日,质变科技正式发布Relyt AI MCP(Model Context Protocol),结合Relyt AI 在自主数据分析领域的前沿积累与MCP的开放连接能力,我们为用户带来了一个更智能、更灵活的数据交互生态系统。这一发布不仅拓展了Re…...

【17】Strongswan bus详解2
add_listener: (1)初始化一个entry,并将要添加的listener赋值entry。 (2)添加到bus的listeners链表的尾部。 remove_listener: (1)遍历listeners,通过内存位置…...

【Windows】系统安全移除移动存储设备指南:告别「设备被占用」弹窗
Windows系统安全移除移动存储设备指南:告别「设备被占用」弹窗 解决移动硬盘和U盘正在被占用无法弹出 一、问题背景 使用Windows系统时,经常遇到移动硬盘/U盘弹出失败提示「设备正在使用中」,即使已关闭所有可见程序。本文将系统梳理已验证…...

DeepSeek 与开源:肥沃土壤孕育 AI 硕果
当 DeepSeek 以低成本推理、多模态能力惊艳全球时,人们惊叹于国产AI技术的「爆发力」,却鲜少有人追问:这份爆发力的根基何在? 答案,藏在中国开源生态二十余年的积淀中。 从倪光南院士呼吁「以开源打破垄断」…...

[从零开始学数据库] 基本SQL
注意我们的主机就是我们的Mysql数据库服务器 这里我们可以用多个库 SQL分类(核心是字段的CRUD) 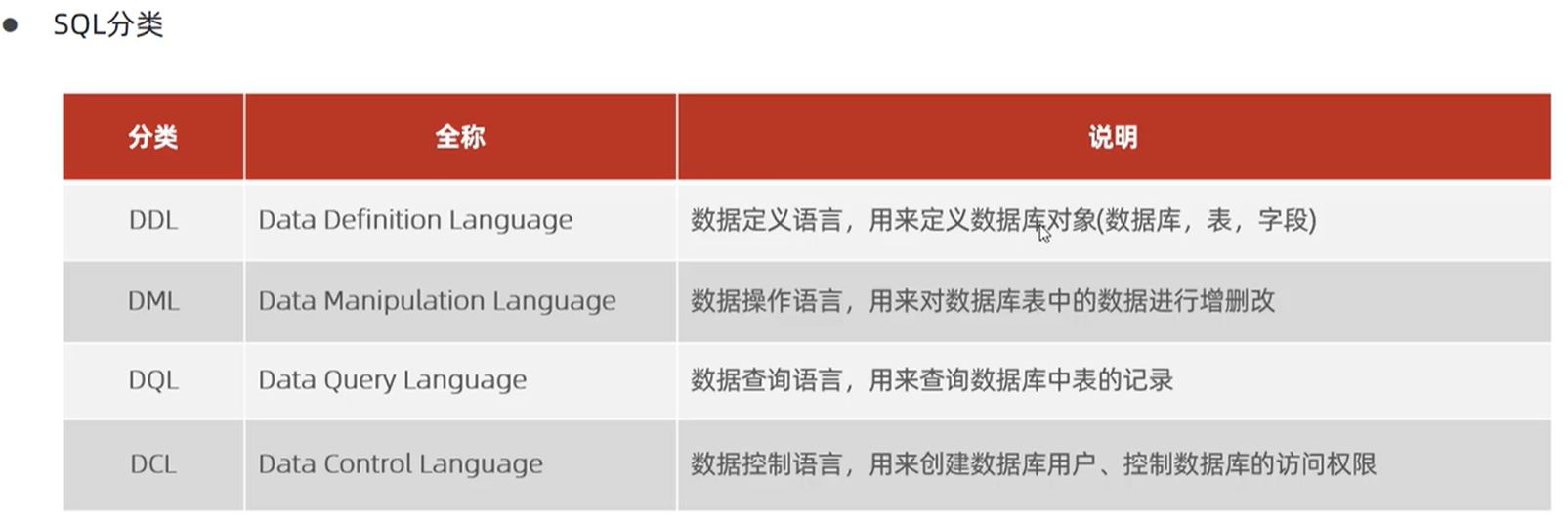 重点是我…...

uniapp开发android原生插件-java版本
一、uniapp官方文档 uni原生插件文档 二、开发流程 1、检测本地uniapp的版本号 2、根据版本号,下载uni提供的对应android的sdk对应demo 下载地址:Android 离线SDK - 正式版 | uni小程序SDK 下载文件后,复制出UniPlugin-Hello-ASÿ…...

git在IDEA中使用技巧
git在IDEA中使用技巧 merge和rebase 参考:IDEA小技巧-Git的使用 git回滚、强推、代码找回 参考:https://www.bilibili.com/video/BV1Wa411a7Ek?spm_id_from333.788.videopod.sections&vd_source2f73252e51731cad48853e9c70337d8e cherry pick …...

DeepSeek 接入 Excel 完整教程
一、前期准备 1.1 获取 DeepSeek API 密钥 注册 DeepSeek 平台 访问 DeepSeek 官方网站(或指定的 API 服务平台,如硅基流动等)。若尚未注册,按照平台指引创建新账号并完成登录。 创建 API 密钥 进入用户控制面板,找到…...

【项目管理】第15章 项目风险管理-- 知识点整理
项目管理-相关文档,希望互相学习,共同进步 风123456789~-CSDN博客 (一)知识总览 项目管理知识域 知识点: (项目管理概论、立项管理、十大知识域、配置与变更管理、绩效域) 对应:第6章-第19章 第6章 项目管理概论 4分第13章 项目资源管理 3-4分第7章 项目…...

如何将自己的项目推送到GitHub上面去
将项目推送到GitHub的流程总结 以下是将本地项目推送到GitHub仓库的完整流程: 1. 初始化Git仓库(如果尚未初始化) cd 项目目录 git init2. 配置远程仓库 # 添加远程仓库地址 git remote add origin https://github.com/用户名/仓库名.git…...

C/C++基础
C开发环境 纯语言开发要求:CIDE。 极简C/C 语法规则 仅记原始规则,把握编程的本质,不做孔乙己,要做说干就干的平头哥。 原始的规则: 各“语法单位”(组成部分)使用任意个(至少1个…...

Qt炫酷仪表盘
Qt学习优化的一款汽车仪表控件,根据github上面开源的进行优化,主要使用QPainter实现的一款炫酷仪表盘,其中的渐变效果比较有感觉 实现结果 仪表盘 实现源码 h文件 #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QPixmap> #include <QTimer&…...
)
云渗透一(云租户渗透⼊⻔)
云平台介绍 阿⾥云 阿⾥云创⽴于 2009 年,服务着制造、⾦融、政务、交通、医疗、电信、能源等众多领域的领军企业,包 括中国联通、12306 、中⽯化、中⽯油、⻜利浦、华⼤基因等⼤型企业客户,以及微博、知乎、锤⼦科技 等明星互联⽹公司。 应⽤程序访问令牌 - T1527 云实例…...
绘图保姆级模板——NMDS从原理到绘图,看师兄这篇教程就够了)
R绘图|6种NMDS(非度量多维分析)绘图保姆级模板——NMDS从原理到绘图,看师兄这篇教程就够了
感谢西农听雨同学对本文提供的大力支持! 一、引言 非度量多维尺度分析(NMDS)是一种用来简化复杂数据的工具,特别适合处理那些难以直接理解的高维数据(微生物群落数据)。它的主要目的是把数据“压缩”到更低…...

spark-SQL核心编程
1. Spark-SQL简介 起源与发展:Spark-SQL前身为Shark,因对Hive依赖制约Spark发展而被弃用。它汲取Shark优点重新开发,在数据兼容、性能优化和组件扩展方面表现出色。 特点:易整合,统一数据访问,兼容Hive&…...
)
使用MCP服务通过自然语言操作数据库(vscode+cline版本)
使用MCP服务操纵数据库(vscodecline版本) 本文主要介绍,在vscode中使用cline插件调用deepseek模型,通过MCP服务器 使用自然语言去操作指定数据库。本文使用的是以己经创建号的珠海航展数据库。 理解MCP服务: MCP(Model Context…...
的生命周期及应用场景)
.NET Core DI(依赖注入)的生命周期及应用场景
在.NET中,依赖注入(DI,Dependency Injection)是一种设计模式,它通过将依赖关系注入到类中,而不是让类自己创建依赖项,来降低类之间的耦合度。这使得代码更加模块化、灵活和易于测试。在.NET中&a…...

VSCode写java时常用的快捷键
首先得先安好java插件 1、获取返回值 这里是和idea一样的快捷键的,都是xxxx.var 比如现在我new一个对象 就输入 new MbDo().var // 点击回车即可变成下面的// MbDo mbDo new MbDo()//以此类推get方法也可获取 mbDo.getMc().var // 点击回车即可变成下面的 // St…...

Java微服务流量控制与保护技术全解析:负载均衡、线程隔离与三大限流算法
在微服务架构中,流量控制与系统保护是保障服务高可用的核心要素。本文将深入剖析负载均衡原理、线程隔离机制,并通过Java代码实例详解滑动窗口、漏桶、令牌桶三大限流算法,帮助开发者构建健壮的分布式系统。 一、负载均衡核心原理与实践 1.1 …...

Java 企业级应用:SOA 与微服务的对比与选择
企业级应用开发中,架构设计是决定系统可扩展性、可维护性和性能的关键因素。SOA(面向服务的架构)和微服务架构是两种主流的架构模式,它们各自有着独特的和设计理念适用场景。本文将深入探讨 SOA 和微服务架构的对比,并…...

Nacos深度剖析与实践应用 -1
📹 Nacos背景 在现在数字化快速发展的时代🚄,微服务架构已成为构建大型分布式系统的主流架构模式。随着微服务数量的不断增加,服务之间的通信、配置管理以及服务的高可用性等问题变得愈发复杂。Nacos 作为阿里巴巴开源的一个动态服…...
——LinkLabel 控件详解)
WinForm真入门(16)——LinkLabel 控件详解
以下是 WinForm 中 LinkLabel 控件的基本概念、核心属性、事件及典型应用案例的总结: 一、基本概念 LinkLabel 是 WinForm 中用于显示超链接文本的控件,继承自 Label,支持单链接或多链接区域。用户点击链接时可触发自定义行为࿰…...

功能丰富的PDF处理免费软件推荐
软件介绍 今天给大家介绍一款超棒的PDF工具箱,它处理PDF文档的能力超强,而且是完全免费使用的,没有任何限制。 TinyTools(PC)这款软件,下载完成后即可直接打开使用。在使用过程中,操作完毕后&a…...
)
【MySQL高级】事务,存储引擎,索引(一)
Mysql高级 DQL查询语句 反引号 模糊查询避免%出现在开头,会造成索引失效 order by排序先后 表名列名都需要用${},他们不能带’’ 去重统计数量 null的运算 分组函数会自动忽略null,不用对null进行处理 截取子串substr(字段,下标…...

React 之 Redux 第三十二节 Redux 常用API及HOOKS,以及Redux Toolkit核心API使用详解
一、4.X版本中核心 API 和用途 1. createStore(reducer, [preloadedState], [enhancer]) 用途: 创建 Redux Store(数据仓库) 参数: reducer: 状态更新函数 preloadedState: 初始状态(可选) enhancer: 中间件增强器(如…...

react tailwindcss最简单的开始
参考教程: Install Tailwind CSS with Vite - TailwindCSS中文文档 | TailwindCSS中文网https://www.tailwindcss.cn/docs/guides/vite操作过程: Microsoft Windows [版本 10.0.26100.3476] (c) Microsoft Corporation。保留所有权利。D:\gitee\tailwi…...
从算法仿真到工程源码实现-第九节-延迟相减波束形成(delay sub))
波束形成(BF)从算法仿真到工程源码实现-第九节-延迟相减波束形成(delay sub)
一、概述 本节对delay sub算法进行仿真。更多资料和代码可以进入https://t.zsxq.com/qgmoN ,同时欢迎大家提出宝贵的建议,以共同探讨学习。 二、代码仿真 import numpy as np import soundfile as sf import scipy import matplotlib.pyplot as pltfft…...

系统假死问题排查
系统假死定义 应用进程存在,但是无法正常提供服务(请求没有响应,或者响应超时)。 系统假死原因 主要分为两大类:连接无法建立、请求无法处理,如下图所示: 系统假死的原因还是比较多的&…...

图像处理有哪些核心技术?技术发展现状如何?
在数字化信息爆炸的时代,文档图像预处理技术正悄然改变着我们处理文字信息的方式。无论是手持拍摄的收据、扫描仪中的身份证,还是工业机器人采集的复杂文档,预处理技术都在背后默默提升着OCR(光学字符识别)系统的性能。…...

解决在linux下运行rust/tauri项目出现窗口有内容,但是渲染出来成纯黑问题
起因 最近折腾了一下rust/tauri程序开发,据说这玩意性能非常牛皮就玩了一下,但是我运行打包一直出现一个奇怪问题,窗口能正常打开,但是是纯黑的什么内容都没有,鼠标移上去又发现指针会变换(看起来是内容又…...

计算机网络:流量控制与可靠传输机制
目录 基本概念 流量控制:别噎着啦! 可靠传输:快递必达服务 传输差错:现实中的意外 滑动窗口 基本概念 换句话说:批量发货排队验收 停止-等待协议 SW(发1份等1份) 超时重传:…...
)
vue2改变el-message字体、图标尺寸样式(vue2,element-ui)
前言 最近接手一个项目,vue2elementui的,产品觉得message的字体太小了,展示起来看不清,所以需求就是把message的字体和图标变大,实现路径如下: 找到自己的main.scss文件,并且加上对应内容: .e…...

【笔记ing】AI大模型-05单层感知机与多层感知机
单层感知机,是一种最简单的人工神经网络 输入层input layer,输入的样本特征 输出层output layer,输出的预测结果 权值W(w0,w1,w2,...,wn)^T,感知机的权值参数,其中的w0叫做偏置,也称截距,类似…...

分布式热点网络
核心设计理念: 在自然灾害(地震、洪水、台风)、极端环境(无人区)及网络管制(欠费停机)等场景下,传统中心化网络易因核心节点失效导致全局瘫痪。本方案提出构建去中心化设备网络&…...

为 docker 拉取镜像配置代理
为 Docker 配置代理,有 两个层面 的操作:(1) Docker 守护进程(用于拉取镜像等操作),(2) Docker 容器内部(容器内应用的网络流量)。 我们这篇文章着重于前者,以下是详细步骤ÿ…...

人工智能与云计算:技术融合与实践
1. 引言 人工智能(AI)和云计算是当今科技领域最具变革性的两项技术。AI通过模拟人类智能解决问题,而云计算则提供了弹性可扩展的计算资源。两者的结合创造了前所未有的可能性,使企业能够以更低的成本部署复杂的AI解决方案。 本文将探讨AI与云计算的技术融合,包括核心概念、…...

GIT的一些操作
git仓库迁移,包括所有分支和标签 git clone --mirror http://git./test-frontend.git test-frontend 克隆项目到 test-frontend文件夹下,--mirror 表示所有分支和标签 cd test-frontend 切到目录下 git remote add bd http://git./new-frontend.git …...

大模型——Crawl4AI入门指南
大模型——Crawl4AI入门指南 本快速入门指南介绍了Crawl4AI,涵盖了基本用法、先进功能(例如分块和提取策略)以及异步编程。用户将学习如何实现各种爬虫技术,包括截图、JSON提取和动态内容爬取。 1. 什么是Crawl4AI? Crawl4AI 是一个强大的异步网络爬虫库,旨在简化信息…...
)
48、Spring Boot 详细讲义(五)
3、集成MyBatis 3.1 MyBatis 概述 3.1.1 核心功能和优势 MyBatis 是一个 Java 持久层框架,它通过 XML 或注解配置 SQL 语句,将 Java 方法与 SQL 语句映射起来,消除了大量的 JDBC 代码,简化了数据库操作。MyBatis 的核心功能和优势包括: ORM(对象关系映射):通过 XML …...

设计模式-桥接模式
例如形状和颜色,如果这么设计? 将两个具有紧耦合的设计,使用组合,为桥接模式 客户端的代码: 抽象:形状是抽象; 实现:实现颜色的代码...

3.vtkProp 和vtkProp3D
文章目录 vtkProp 和vtkProp3D使用vtkProp3D使用vtkPro vtkProp 和vtkProp3D vtkProp 和 vtkProp3D 都是VTK(Visualization Toolkit)库中的类,它们用于在渲染场景中表示可视化元素。理解这两个类的区别和用途对于有效地使用VTK进行三维数据可…...
大模型之Transformers , PyTorch和Keras
Transformers、PyTorch 和 Keras 的对比 特性TransformersPyTorchKeras主要应用自然语言处理(NLP)任务计算机视觉、NLP、强化学习等快速原型设计和深度学习模型构建架构基于 Transformer 模型,强大的自注意力机制动态计算图,灵活的模型构建和调试高层次 API,简化模型开发,…...
的详解、开发流程及同类软件对比)
云原生(Cloud Native)的详解、开发流程及同类软件对比
以下是云原生(Cloud Native)的详解、开发流程及同类软件对比: 一、云原生核心概念 定义: 云原生(Cloud Native)是基于云环境设计和运行应用程序的方法论,强调利用云平台的弹性、分布式和自动化…...
)
从文本到视频:基于扩散模型的AI生成系统全解析(附PyTorch实现)
当语言遇见动态视觉 "用文字生成电影场景"曾是科幻作品中的幻想,如今借助扩散模型(Diffusion Models)正逐步成为现实。本文将手把手带你实现一个创新的文本到视频生成系统,通过深度解析扩散模型原理,结合独…...

ES6学习04-数组扩展:扩展运算符、新增方法
一、扩展运算符 1. 2. eg: 3. 二、新增方法 1. arguments 元素组合 类似数组对象 2....