【7】深入学习Buffer缓冲区-Nodejs开发入门
深入学习Buffer缓冲区
- 前言
- ASCII码
- GBK/GB2312
- Unicode
- Javascript转换
- Buffer
- Buffer的作用
- Buffer的创建
- Buffer.alloc
- Buffer.allocUnsafe(size)
- Buffer.allocUnsafeSlow(size)
- Buffer.from(array)
- Buffer.from(arrayBuffer[, byteOffset[, length]])
- Buffer.from(buffer)
- Buffer.from(string[, encoding])
- 使用 Buffer.concat(list[, totalLength])
- Buffer的常用方法和属性
- length属性
- write(string[, offset[, length]][, encoding])
- toString([encoding[, start[, end]]])
- toJSON()
- equals(otherBuffer)
- compare(otherBuffer)
- copy(targetBuffer[, targetStart[, sourceStart[, sourceEnd]]])
- slice([start[, end]])
- fill(value[, offset[, end]][, encoding])
- indexOf(value[, byteOffset][, encoding])
- Buffer实际应用
- 参数携带方式
- 查询字符串传参
- body传参
- 从Body中提取数据
- `text/plain`
- application/x-www-form-urlencoded
- application/json
- multipart/form-data
- 在文件处理中的应用
- 其它
前言
在学习本文之前,你可能需要一些前置的知识,如进制的概念和进制转换、ASCII码、Unicode编码和UTF-8编码,如果你不太了解的话可能不太能理解本文的一些内容。
ASCII码
我们知道,计算机存储数据使用二进制0和1,但是人是=无法直接使用0和1,它们太复杂。在计算机最初发明出来的时候,并没有考虑世界各国的语言,甚至连美国自己的语言都没有统一的编码,不同的系统之间很难进行通信。
为了解决不同系统间通信障碍。,在1963年首次发布了ASCII码,1967加入小写字母和方括号(修订版ANSI X3.4-1967),成为现代ASCII基础。
ASCII码使用7位编码(128字符),覆盖英文、数字、控制字符(如换行\n)和基础符号。
我们知道,一个字节长度为8位二进制,那么一个ASCII码的长度就是一个字节。
GBK/GB2312
ASCII码的出现让世界上所有使用英文的国家都可以很好地使用计算机,但是中国不行,ASCII无法表示中文。
于是出现了GBK / GB2312(中文国家标准编码)。
GB2312:每个汉字占用 2 字节(覆盖 6763 个常用汉字)。GBK:扩展自 GB2312,仍为 2 字节(支持约 2.1 万个汉字)。
举个例子,“中国”的中编码为0xD6 0xD0,这是十六进制表示法,转换成二进制就是0b11010110和0b11010000,前缀的0b仅用来表示进制,与0x一样,我们无需考虑。
有了GBK,计算机也能显示中文了,但是这样又产生一个问题,难道世界上每一个语言都要创建一套自己的编码吗?如果日文中有个字符也使用了0xD6 0xD0这样的编码,当在中国给日本发送数据时,岂不是被翻译失败?
翻译失败就会出现我们常说的“乱码”。
Unicode
为了能够解决这个问题,Unicode出现了。
Unicode项目始于1980年代末,发起人希望解决当时存在的多种字符编码标准不兼容的问题,比如ASCII、ISO 8859系列、以及各种亚洲编码如GB2312、Shift_JIS等。这些编码互不兼容,导致跨语言文本处理困难。
Unicode编码是一种字符串,它只是一个存储了各种字符的集合,就像字典一样,我们只知道字典用拼音顺序进行排序,不同厂商的字典大小,页数都不一样,我们需要查询目录去查看某个字母从哪一页开始。
在计算机中,Unicode为了在不同场景下平衡存储效率、兼容性、处理性能和系统设计需求,同样产生了多种编码方式,它们分别是UTF-8、UTF-16和UTF-32。
这里最熟悉的可能就是UTF-8了,它是Unicode的一种实现方式,为互联网而生,兼容旧世界,空间高效。
在本节,我们只讨论UTF-8编码,不涉及UTF-16和UTF-32。
同样是汉字“中”,在Unicode中,它的码点是U+4E2D,注意,这并不代表它的长度是2个字节,这仅仅是一种表示法,它也可以写成\u4e2d。实际上Unicode 码点的长度在概念上是固定的,每个码点对应一个字符,不论其数值大小。
那么utf-8是怎么实现这个中字的呢?
我们不对转换规则做讨论,仅做分析。Unicode有一套编码规则,我们根据字符的码点\u4e2d经过规则计算之后,可以得到一个长度为1字节至6字节的utf8编码。汉字的“中”,经过转换会得到一个长度为3字节的utf8编码,而字母“a”,经过转换得到的utf8编码为01100001,也就是长度1字节。
你看懂了吗?
Javascript转换
在JavaScript中,我们可以通过TextEncoder对象将字符串转化为utf8编码,它会返回一个类数组,这个类数组就是字符串转换之后的内容,它以16进制表示。
const encoder = new TextEncoder();
const str = '你好';
const utf8Array = encoder.encode(str);
我们对utf8Array的结果并不感兴趣,因为它不是字符串,它是编码,我们看不懂十六进制。
但是你可以逆向转换回来,使用TextDecoder:
// 创建一个 TextDecoder 实例
const decoder = new TextDecoder();// UTF-8 编码的字节序列
const utf8Array = new Uint8Array([228, 184, 173]);// 将字节序列解码为字符串
const str = decoder.decode(utf8Array);console.log(str); // 输出: '中'
Buffer
Buffer的作用
对于前端开发者来说,我们接触到的基本上都是字符串,几乎不会遇到任何形式的二进制数据,所以对于很多人来说,Buffer就显得很抽象。
官方对于Buffer的解释是:
The Buffer class is a subclass of JavaScript’s class and extends it with methods that cover additional use cases. Node.js APIs accept plain s wherever Buffers are supported as well.
Buffer是Uint8Array的子类,并且Node.js API对于两者都支持。
如果你运行了上面JavaScript的转换代码,你会发现,转换之后得到的类型就是Uint8Array。

那也就是说,Buffer可能是用来接收从客户端传递过来的二进制数据的。
当然,你也会有疑问,前端传递的数据不是字符串吗?为什么会有二进制?
在Node.js中,HTTP 请求的body在底层传输时其实是以二进制形式进行传输,这是由TCP协议决定的。
Buffer的创建
我们需要先了解一下,Buffer是如何被创建出来的,有多种形式可以创建Buffer。
注意,Buffer的长度单位为字节。
Buffer.alloc
- 描述:创建一个指定大小的 Buffer,并可选地填充内容。
- 参数:
- size:Buffer 的大小(字节)。
- fill(可选):用于填充 Buffer 的值,默认是 0。
- encoding(可选):如果 fill 是字符串,则指定其编码,默认是 ‘utf8’。
const buf1 = Buffer.alloc(5); // 创建一个大小为 5 的 Buffer,默认填充 0
console.log(buf1); // 输出: <Buffer 00 00 00 00 00>const buf2 = Buffer.alloc(5, 1); // 填充 1
console.log(buf2); // 输出: <Buffer 01 01 01 01 01>const buf3 = Buffer.alloc(10, 'a', 'utf8'); // 用字符串 'a' 填充
console.log(buf3.toString()); // 输出: 'aaaaaaaaaa'
在第二个案例中,如果填充的是汉字等长度不为1的字符,在填充时,如果长度不够则会被截断,转换成字符串则会乱码。
const buf4 = Buffer.alloc(8, '中'); // 填充 1
console.log(buf4); // 输出: <Buffer e4 b8 ad e4 b8 ad e4 b8>console.log(buf2.toString()); // 输出:中中�
Buffer.allocUnsafe(size)
- 描述:创建一个指定大小的 Buffer,但内容未初始化(可能包含旧数据)。
- 参数:
- size:Buffer 的大小(字节)。
- 注意:由于内容未初始化,使用此方法时需要小心,以避免潜在的安全问题。
const buf = Buffer.allocUnsafe(5);
console.log(buf); // 输出: <Buffer xx xx xx xx xx>(内容未定义)
优点是速度快,无须初始化,但是也会造成数据泄露等问题,一般不用它。
Buffer.allocUnsafeSlow(size)
- 描述:类似于 Buffer.allocUnsafe(size),但保证分配的内存不会被池化,适用于需要确保内存未被使用的场景。
- 参数:
- size:Buffer 的大小(字节)。
const buf = Buffer.allocUnsafeSlow(5);
console.log(buf); // 输出: <Buffer xx xx xx xx xx>(内容未定义)
一般也不用它。
Buffer.from(array)
- 描述:从一个整数数组创建一个新的 Buffer。
- 参数:
- array:整数数组,每个整数的值应在 0 到 255 之间。
const buf = Buffer.from([1, 2, 3, 4, 5]);
console.log(buf); // 输出: <Buffer 01 02 03 04 05>
这个方式实际上是将十进制的列表转换成16进制,然后作为utf8编码进行使用,这个方法使用场景也比较特殊,常规情况下用不到。
Buffer.from(arrayBuffer[, byteOffset[, length]])
- 描述:从一个 ArrayBuffer 创建一个新的 Buffer。
- 参数:
- arrayBuffer:一个 ArrayBuffer 对象。
- byteOffset(可选):开始复制的字节偏移量,默认是 0。
- length(可选):要复制的字节数,默认是 arrayBuffer.byteLength - byteOffset。
const arr = new Uint8Array([1, 2, 3, 4, 5]);
const buf = Buffer.from(arr.buffer);
console.log(buf); // 输出: <Buffer 01 02 03 04 05>
如果你需要有一个较大的文件让客户端下载,那么使用这个方法可以实现分片下载。
Buffer.from(buffer)
- 描述:从一个现有的 Buffer 创建一个新的 Buffer,复制数据。
- 参数:
- buffer:一个现有的 Buffer 对象。
const original = Buffer.from([1, 2, 3]);
const copy = Buffer.from(original);
console.log(copy); // 输出: <Buffer 01 02 03>
用来复制Buffer,一般是在同一个Buffer要被多次处理的情况下使用。
Buffer.from(string[, encoding])
- 描述:从一个字符串创建一个新的 Buffer。
- 参数:
- string:要编码的字符串。
- encoding(可选):字符串的编码,默认是 ‘utf8’。
const buf = Buffer.from('hello', 'utf8');
console.log(buf); // 输出: <Buffer 68 65 6c 6c 6f>
通常用于将大文本写入文件中使用。
使用 Buffer.concat(list[, totalLength])
- 描述:将多个 Buffer 对象合并为一个新的 Buffer。
- 参数:
- list:Buffer 对象的数组。
- totalLength(可选):合并后 Buffer 的总长度,默认是计算得出的。
const buf1 = Buffer.from([1, 2]);
const buf2 = Buffer.from([3, 4]);
const buf3 = Buffer.concat([buf1, buf2]);
console.log(buf3); // 输出: <Buffer 01 02 03 04>
上面的Buffer.from(arrayBuffer[, byteOffset[, length]])用于分片下载,这里的concat可以用作断点续传使用。
Buffer的常用方法和属性
我们还需要了解一些Buffer的属性和常用的方法,以便于能够更好地操作它。
length属性
描述:获取 Buffer 的长度(以字节为单位)。
const buf = Buffer.from([1, 2, 3]);
console.log(buf.length); // 输出: 3
write(string[, offset[, length]][, encoding])
描述:将字符串写入 Buffer,支持指定偏移量和编码。
const buf = Buffer.alloc(10);
buf.write('Hello', 0, 'utf8');
console.log(buf.toString()); // 输出: 'Hello'
toString([encoding[, start[, end]]])
描述:将 Buffer 解码为字符串,支持指定编码和范围。
const buf = Buffer.from('Hello, World!');
console.log(buf.toString('utf8', 0, 5)); // 输出: 'Hello'
toJSON()
描述:将 Buffer 转换为 JSON 对象,返回包含 type 和 data 属性的对象。
const buf = Buffer.from([1, 2, 3]);
console.log(buf.toJSON()); // 输出: { type: 'Buffer', data: [1, 2, 3] }
equals(otherBuffer)
描述:比较两个 Buffer 是否相等。
const buf1 = Buffer.from('ABC');
const buf2 = Buffer.from('ABC');
console.log(buf1.equals(buf2)); // 输出: true
compare(otherBuffer)
描述:比较两个 Buffer,返回负数、零或正数,表示小于、等于或大于。
const buf1 = Buffer.from('ABC');
const buf2 = Buffer.from('ABD');
console.log(buf1.compare(buf2)); // 输出: -1
copy(targetBuffer[, targetStart[, sourceStart[, sourceEnd]]])
描述:将数据从当前 Buffer 复制到另一个 Buffer。
const buf1 = Buffer.from('Hello');
const buf2 = Buffer.alloc(5);
buf1.copy(buf2);
console.log(buf2.toString()); // 输出: 'Hello'
slice([start[, end]])
描述:返回一个新的 Buffer,包含当前 Buffer 的指定范围的数据。
const buf = Buffer.from('Hello, World!');
const slicedBuf = buf.slice(0, 5);
console.log(slicedBuf.toString()); // 输出: 'Hello'
fill(value[, offset[, end]][, encoding])
描述:用指定的值填充 Buffer。
const buf = Buffer.alloc(10);
buf.fill(0);
console.log(buf); // 输出: <Buffer 00 00 00 00 00 00 00 00 00 00>
indexOf(value[, byteOffset][, encoding])
描述:返回指定值在 Buffer 中第一次出现的索引。
const buf = Buffer.from('Hello, World!');
console.log(buf.indexOf('World')); // 输出: 7
Buffer实际应用
Buffer相关的方法很多,我们需要案例来展示如何使用Buffer。
在前一节我们并没有讲如何从请求中获取数据,原因就是Nodejs并没有直接提供相应的方法从body中解析数据,因此我们要自行解决这个问题。
参数携带方式
我们要先回顾一下,前端如何进行数据传参的。
查询字符串传参
查询字符串(Query String) 是URL(统一资源定位符)的一部分,用于向服务器传递参数或数据。它通常出现在URL的末尾,以问号(?)开头,由一组键值对组成,多个键值对之间用与号(&)分隔。
https://example.com/search?query=apple&sort=price&order=asc
由于查询字符串是url的一部分,因此任何形式的请求方式都可以使用,不限制GET还是POST。
不过由于浏览器的限制,一般url长度不会太大,因此这种方式只适合在较少的参数使用。
另外看它的名字就知道,是用来做查询参数用的,建议只用在POST中。
body传参
body是http请求的一部分,除了GET请求外,其它的请求都有这部分。
在前端中,我们可以将多种形式的数据放在body中发送。上面说了,最终发送的都是二进制,我们大胆假设一下,是不是任意形式都可以在body发送?
从事实上来说的确是的,但是你要考虑服务端能不能解析出来,毫无规则的数据是没有意义的,服务端解析方式的比较死板的,它并不能完全考虑到所有的场景,因此html为我们做了限制。
form表单的enctype为我们提供了三种形式的数据。
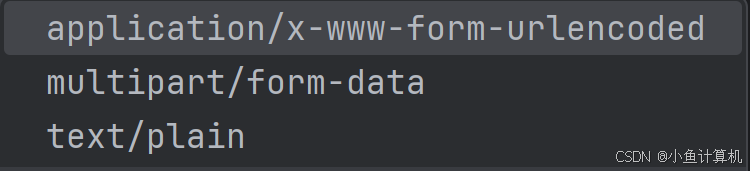
其中application/x-www-form-uriencoded是默认行为,它会将表单数据转换成查询字符串相同的k-v结构,放入body中。
username=1&password=2
multipart/form-data一般用于文件上传,表单数据被编码为多个部分,每个部分代表一个表单字段。
text/plain以纯文本发送,不进行任何编码。
username=1
password=2
在Ajax中,我们还可以使用application/json的形式发送JSON对象,这种方式其实还是将对象转换成字符串进行传递。
我们需要对这几种情况分别讨论,用实际案例来解释它们之间的区别。
从Body中提取数据
关于GET请求的传参在这里不做讨论,最简单的方式就是将请求对象的path属性以?为分割线切割,然后通过URLSearchParams将查询字符串的部分进行格式化。
我们讨论POST请求的几种情况,分别是text/plain、application/x-www-form-urlencoded、application/json和multipart/form-data。
text/plain
上面说了,这是纯文本的形式传递参数,html结构为:
<form action="http://localhost:3000/user" method="post" enctype="text/plain"><input type="text" name="username"><input type="password" name="password"><button type="submit">提交</button>
</form>
当然你也可以使用Ajax。
Nodejs的代码为:
const http = require('node:http');const hostname = '127.0.0.1';
const port = 3000;const server = http.createServer({keepAlive: true,keepAliveTimeout: 1000,
},(req, res) => {res.setHeader('Access-Control-Allow-Origin', '*');res.setHeader('Access-Control-Allow-Methods', '*');res.setHeader('access-control-allow-headers', '*');});
server.on('request', (request, response) => {const { method, url } = request;if (url === '/user'){if (method === 'POST'){console.log('创建用户');}}response.statusCode = 200;response.setHeader('Content-Type', 'text/plain');response.write('hello world!');response.end();
});server.listen(port, hostname, () => {console.log(`Server running at http://${hostname}:${port}/`);
});
后面的案例都是基于此代码运行。
我们通过request.on方法监听data事件,表示数据传递。
if (method === 'POST'){console.log('创建用户');request.on('data', (chunk) => {console.log(chunk);});
}
第二个参数表示监听data的回调,chunk就是数据,意为组块。
我们将表单填充,账号为“admin”,密码为“123456”,然后点击提交,在浏览器的网络里找到对应的请求,查看payload:

这是一个标准的字符串形式的Body,如果你用Ajax请求不一定能够得到如此标准的格式。实际上你以后不会用这个方式传参,这里就是用来做案例使用。
请求发送后,查看服务器的输出,注意,每次修改Nodejs代码都要关闭服务并重启,你可以使用nodemon插件进行热更新,具体使用方式可以自己在npm上查找。

输出的chunk为这样一个数据,我们还是能看到内容的。但是这并不是我们想要的结果,我们需要的是实际的字符串,最简单的方式就是使用.toString方法进行转换。
chunk.toString();
得到如下结果:
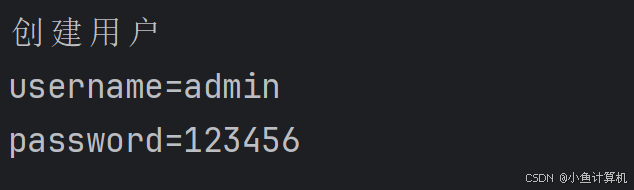
然后你就可以使用字符串的split或者其他方式进行切割裁剪, 最终得到我们想要的对象即可。
application/x-www-form-urlencoded
这种方式是用查询字符串的格式进行传递,本质上还是字符串,只是进行了格式化,上面那个文本形式切割起来很麻烦。
修改enctype属性:
<form action="http://localhost:3000/user" method="post" enctype="application/x-www-form-urlencoded">......
发送后是这样的:
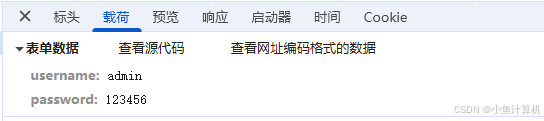
点击查看源代码得到原始格式:

服务端的响应为:

通过.toString()方法我们得到的字符串与前端的字符串一模一样,我们通过&字符进行切割,然后再根据=切割,转换成对象即可。
application/json
早期的html并没有考虑json形式的传递,因此表单的enctype属性并没有该选项,需要使用Ajax或者fetch发送,你可以这样写:
const data = {name: 'John Doe',age: 30
};
fetch(url, {method: 'POST',headers: {'Content-Type': 'application/json'},body: JSON.stringify(data)
});
注意请求方法不能是GET,设置请求头为'Content-Type': 'application/json',实际上,用fetch并不需要设置请求头,在html里面是要让html帮我们格式化数据,在fetch里面body是我们直接写入的,最终都是字符串发送出去。
提交之后,服务端得到的数据为:

这是JSON格式的字符串,通过JSON.parse可以直接转换为对象。实际上我们可以猜测一下,所谓的Content-Type请求头并不是限定格式,而是告诉服务端如何解析文本。
multipart/form-data
我们最后讨论一下multipart/form-data的传参方式,它又会有点特殊。
修改html,并加入file文件域:
<form action="http://localhost:3000/user" method="post" enctype="multipart/form-data"><input type="text" name="username"><input type="password" name="password"><input type="file" name="file"><button type="submit">提交</button>
</form>
这次我们给username填入汉字“管理员”,选择一张图片,然后提交:

这是浏览器给出参数,以6个短横线开头的是分隔符,它是随机生成的,用于分隔不同的数据,同时也会作为Content-Type的一部分传递给服务端,用于分隔数据:

注意,为了限制JavaScript的能力,防止操作客户端文件,JavaScript是不允许直接操作文件的,因此文件的部分是空。
服务端接收到的数据为:
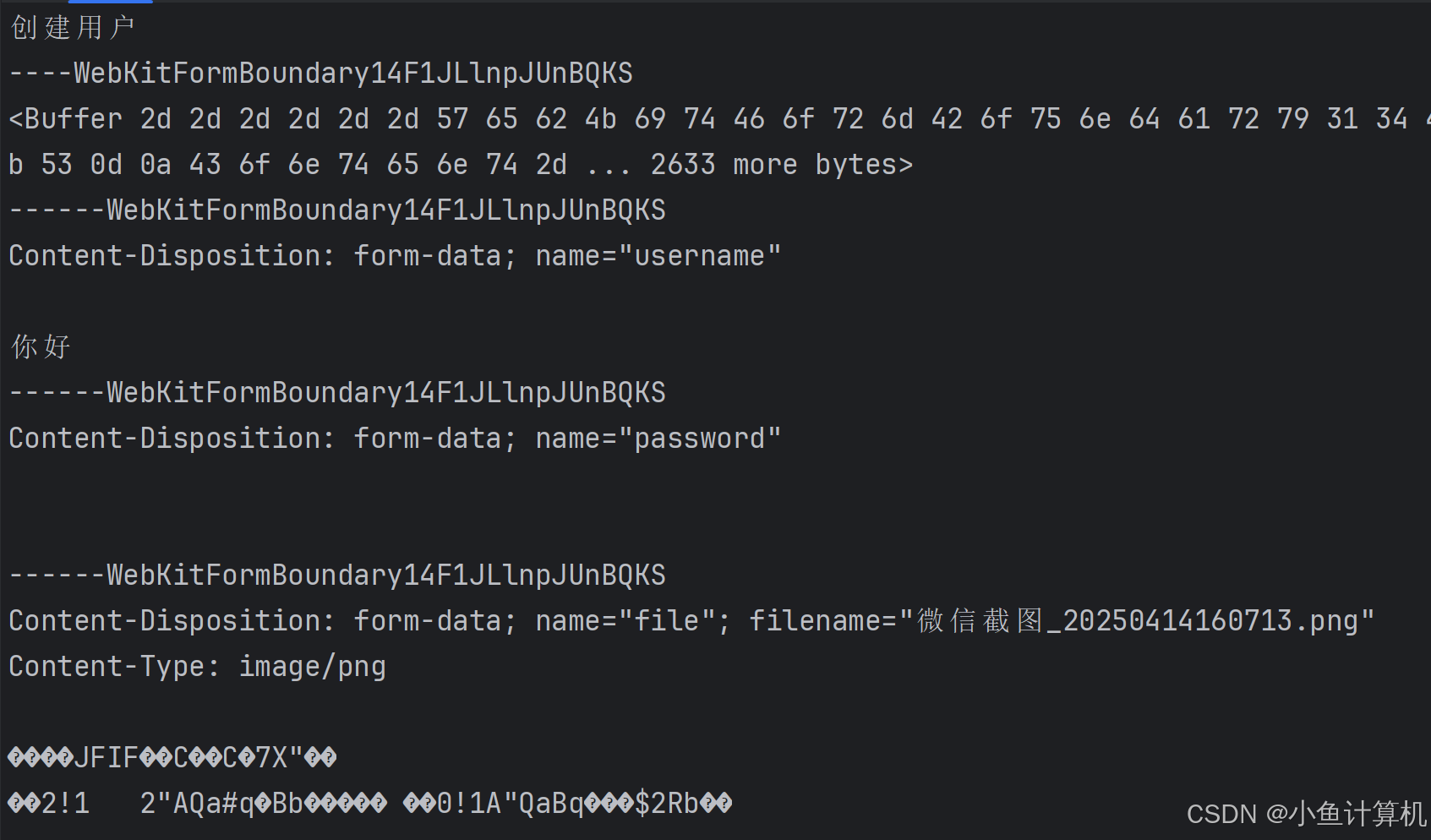
我们从请求头切割出了分隔符,方便后续使用,chunk仍然是Buffer,它的长度有点长,转换成字符串之后前面的内容都正常,但是我们上传的文件就乱码了,乱码的原因你能猜到吗?其实就是图片不是文本,它的二进制无法被正确解析为字符串。
我们可以根据分隔符进行切割,这里我们不要其它的数据,只需要文件数据,
request.on('data', (chunk) => {const content = chunk.toString();// 从请求头提取分隔符,注意短横线长度const separator = `--${request.headers['content-type'].match(/boundary=(.+)/)[1]}`const params = content.split(separator).filter(part => part.trim() !== '');// 注意,过滤掉分隔符之后,最后还有一项为'--'const fileContent = params[params.length - 2].replace('\\r\\n', '');// 再次切割,提取内容部分,去掉空格换行,得到文件被转换成字符串的部分// 提取第三个位置的数据,也就是下标为2const fileBufferString = fileContent.split('\r\n').filter(part => part.trim() !== '')[2];// 将字符串转化为Bufferconst fileBuffer = Buffer.from(fileBufferString, 'utf8');console.log(fileBuffer);
});
上面的代码仅做测试,如果要正式使用会考虑很多场景。
转换之后得到的数据为:

你可以会说,我也不知道你这个Buffer是不是我上传文件真正的内容,怎么判断呢?我们可以根据文件的类型,也就是fileContent被切割后的第二个位置的数据进行判断,Content-Type为image/png'表示这是一个png`格式的图片,我们使用文件系统给它写入到文件看一看:
let str = ''
request.on('data', (chunk) => {// 将chunk转换成‘hex’字符串,注意如果不加参数,默认使用utf8转换图片会出问题str += chunk.toString('hex');
});
request.on('end', () => {// 从content-type提取分隔符const boundary = request.headers['content-type'].match(/boundary=(.+)/)[1];// content-type提取分隔符的分隔符只有四个短横线,需要加上两个,并转换成hexconst boundaryRegex = Buffer.from(`--${boundary}`).toString('hex');// 以分隔符分隔字符串const splitList = str.split(boundaryRegex);// 通过循环获取含有name="file"的部分,这就是我们的文件let fileContent = ''splitList.forEach(item => {const s = Buffer.from(item, 'hex').toString();if (s.includes('name="file"')) {// 找到文件之后,进行去空格,然后再去除末尾的四个字符,末尾有换行和空格const trimed = item.trim();fileContent = trimed.slice(0, trimed.length - 4);}});// 再通过Content-Type: image/png进行分割,取后面的文件内容区域// 注意,上面获取的是包含了文件和其他一些信息部分,不仅仅是文件const contentSplit = Buffer.from('Content-Type: image/png').toString('hex');// 分割之后取第二个位置,并从第八位进行切割,因为文件前面还有两个空格两个换行const fileString = fileContent.split(contentSplit)[1].slice(8);// 将最后的部分转换成bufferconst finalBuffer = Buffer.from(fileString, 'hex');// 写入文件fs.writeFileSync('./upload.png', finalBuffer);
})
注意hex也是一种编码方式,使用十六进制编码,如果直接使用toString()则默认转换成utf8,这对图片类型的资源在后期切割时会出现问题,当然你转换成base64也可以。
我们花了大量的时间在切割数据上,因为数据格式较为麻烦,实际上,可以用正则表达式进行切割会更简单。
实际工作中,我们一般会使用相应的插件进行转换,避免自己转换导致问题。
在文件处理中的应用
上面的multipart/form-data实际上用到了文件系统的相关知识,buffer大部分情况下还是用在文件中比较多,我们在上面代码没有考虑断点续传的问题,也没有考虑文件大小的问题,实际上Buffer默认大小是16kb,因此在上传大于16kb的文件时,要注意Buffer的拼接。这一点我们放在文件系统中去讲解。
其它
Buffer的功能非常强大,其作用也是非常重要,但是由于Buffer在使用上较为抽象,我们无法直接感受其内容,因此学习起来比较困难,希望大家都能够理解它。
相关文章:

【7】深入学习Buffer缓冲区-Nodejs开发入门
深入学习Buffer缓冲区 前言ASCII码GBK/GB2312UnicodeJavascript转换 BufferBuffer的作用Buffer的创建Buffer.allocBuffer.allocUnsafe(size)Buffer.allocUnsafeSlow(size)Buffer.from(array)Buffer.from(arrayBuffer[, byteOffset[, length]])Buffer.from(buffer)Buffer.from(s…...

酶动力学参数预测,瓶颈识别……中科院深圳先进技术研究院罗小舟分享AI在酶领域的创新应用
蛋白质,作为生命的基石,在生命活动中发挥着关键作用,其结构和功能的研究,对创新药物研发、合成生物学、酶制剂生产等领域,有着极其重要的意义。但传统蛋白质设计面临诸多难题,蛋白质结构复杂,序…...

Dockerfile
Dockerfile Dockerfile 是一个文本文件,其内包含了一条条指令,每一条指令构建镜像的一层,因此每一条指令的内容,就是描述该层应当如何构建。 定制镜像,可以将镜像制作的每一层的修改、安装、构建、操作的命令…...
)
Redis高频面试题(含答案)
当然可以,Redis 是面试中非常常见的高频考点,尤其在后台开发、分布式系统、缓存设计等方向,面试官常常通过 Redis 来考察你的高并发处理能力、系统设计能力和对缓存一致性理解。 以下是一些典型 Redis 的面试场景题目类型和你可以如何回答的…...

#3 物联网 的标准
商业化的技术都有标准, 标准的本质就是 可以重复多次实现的方法。而这些方法都是设定物联网的那些人布局的,当然在保证按方法操作的结果是属于物联网这个基本的操作里面,藏着的是对某些利益团队的维护,这里大家知道就可以了。 除 …...

Moviepy 视频编辑的Python库,可调整视频分辨率、格式
MoviePy简介 MoviePy 是一个用于视频编辑的Python库,支持视频剪辑、和合成、转码等多种操作,主要有点: 基于 FFmpeg:能够处理几乎所有常见的视频格式。 修改视频分辨率 方法一:指定新的宽度和高度 from moviepy.editor import V…...

【LeetCode 热题 100】哈希 系列
📁1. 两数之和 本题就是将通过两层遍历优化而成的,为什么需要两层遍历,因为遍历 i 位置时,不知道i-1之前的元素是多少,如果我们知道了,就可以通过两数相加和target比较即可。 因为本题要求返回下标…...

蓝光三维扫描:汽车冲压模具与钣金件全尺寸检测的精准解决方案
随着汽车市场竞争日趋激烈,新车型开发周期缩短,安全性能要求提高,车身结构愈加复杂。白车身由多达上百个具有复杂空间型面的钣金件,通过一系列工装装配、焊接而成。 钣金件尺寸精度是白车身装配精度的基础。采用新拓三维XTOM蓝光…...

鲲鹏+昇腾部署集群管理软件GPUStack,两台服务器搭建双节点集群【实战详细踩坑篇】
前期说明 配置:2台鲲鹏32C2 2Atlas300I duo,之前看网上文档,目前GPUstack只支持910B芯片,想尝试一下能不能310P也部署试试,毕竟华为的集群软件要收费。 系统:openEuler22.03-LTS 驱动:24.1.rc…...
)
面试篇 - GPT-1(Generative Pre-Training 1)
GPT-1(Generative Pre-Training 1) ⭐模型结构 Transformer only-decoder:GPT-1模型使用了一个12层的Transformer解码器。具体细节与标准的Transformer相同,但位置编码是可训练的。 注意力机制: 原始Transformer的解…...

探索机器人创新技术基座,傅利叶开源人形机器人 Fourier N1
一.傅利叶为什么要开源? 2025年3月17日,傅利叶正式开源全尺寸人形机器人数据集Fourier ActionNet。 2025年4月11日,傅利叶正式发布首款开源人形机器人 Fourier N1。 傅利叶为什么要做这些开源工作呢?4月11日&#x…...
)
正则表达式和excel文件保存(python)
正则表达式 import re data """ <!DOCTYPE html> <html lang"en"> <head> <meta charset"UTF-8" /> <title>测试页面</title> </head> <body> <h1>《人工智能的发展趋势分析报…...
的无人艇制导算法)
无人船 | 图解基于视线引导(LOS)的无人艇制导算法
目录 1 视线引导法介绍2 LOS制导原理推导3 Lyapunov稳定性分析4 LOS制导效果 1 视线引导法介绍 视线引导法(Line of Sight, LOS)作为无人水面艇(USV)自主导航领域的核心技术,通过几何制导与动态控制深度融合的机制&am…...

大腾智能获邀出席华为云2025生态大会,携全栈工业软件助力产业智能升级
4月10日-4月11日,以“聚力共创,加速行业智能跃迁”为主题的华为云生态大会2025在安徽芜湖召开。大腾智能受邀出席此次盛会,与众多行业精英、生态伙伴齐聚一堂,深度参与前沿技术演示、生态伙伴签约及商业场景共创,与行业…...

Java基础关键_037_Java 常见新特性
目 录 一、新语法 1.JShell 2.try-with-resources (1)jdk 7 之前 (2)jdk 7 之后 (3)jdk 9 之后 3.局部变量类型判断(不推荐) 4.instanceof 的模式匹配 (1&a…...

鸿蒙公共通用组件封装实战指南:从基础到进阶
一、鸿蒙组件封装核心原则 1.1 高内聚低耦合设计 在鸿蒙应用开发中,高内聚低耦合是组件封装的关键准则,它能极大提升代码的可维护性与复用性。 从原子化拆分的角度来看,我们要把复杂的 UI 界面拆分为基础组件和复合组件。像按钮、输入框这…...
配置相关类库(2)LineMarkerProvider)
IntelliJ 配置(二)配置相关类库(2)LineMarkerProvider
一、介绍 LineMarkerProvider 是 IntelliJ 平台插件开发中的一个接口,它的作用是在编辑器左侧的“行标记区域”(就是代码行号左边那一栏)添加各种图标、标记或导航链接。比如Java 类中看到的: 小绿色三角形(可以点击运…...

红宝书第四十二讲:Angular核心特性精讲:依赖注入 RxJS整合
红宝书第四十二讲:Angular核心特性精讲:依赖注入 & RxJS整合 资料取自《JavaScript高级程序设计(第5版)》。 查看总目录:红宝书学习大纲 一、依赖注入(Dependency Injection):快…...

AD917X系列JESD204B MODE7使用
MODE7特殊在F8,M4使用2个复数通道 CH0_NCO10MHz CH1_NCO30MHZ DP_NCO50MHz DDS1偏移20MHz DDS2偏移40MHz...

软考高级系统架构设计师-第11章 系统架构设计
【本章学习建议】 根据考试大纲,本章不仅考查系统架构设计师单选题,预计考12分左右,而且案例分析和论文写作也是必考,对应第二版教材第7章,属于重点学习的章节。 软考高级系统架构设计师VIP课程https://edu.csdn.net/…...

中和农信的“三农”服务密码:科技+标准化助力乡村振兴
作为中国农村市场最大的专注服务农村小微客户的“三农”综合服务机构,中和农信凭借多年积累的农村服务经验,成功从单一小额信贷机构转型为覆盖金融、生产、生活及生态服务的综合型“三农”服务平台。近期,中和农信在由中保保险资产登记交易系…...

【Redis】布隆过滤器应对缓存穿透的go调用实现
布隆过滤器 https://pkg.go.dev/github.com/bits-and-blooms/bloom/v3 作用: 判断一个元素是不是在集合中 工作原理: 一个位数组(bit array),初始全为0。多个哈希函数,运算输入,从而映射到位数…...
)
MyBatis-Plus笔记(下)
注解 tablename注解 - 描述:表名注解,标识实体类对应的表 - 使用位置:实体类 代码举例: TableName//可以不加,使用实体类的名字作为表名!忽略大小写 //BaseMapper->User实体类-》实体类名-》表名数据…...

【项目管理】第14章 项目沟通管理-- 知识点整理
项目管理-相关文档,希望互相学习,共同进步 风123456789~-CSDN博客 (一)知识总览 项目管理知识域 知识点: (项目管理概论、立项管理、十大知识域、配置与变更管理、绩效域) 对应:第6章-第19章 第6章 项目管理概论 4分第13章 项目资源管理 3-4分第7章 项目…...

3个关键数据解密:首航上市如何重构ebay电商新能源供应链?
3个关键数据解密:首航上市如何重构eBay电商新能源供应链? 在跨境电商圈,一个新玩家的崛起往往意味着新的格局变动。2024年,伴随一家名为“首航”的新能源企业在港股成功上市,整个eBay类目的供应链悄然掀起新一轮洗牌。…...

《华为云Node.js部署:从开发环境到生产上线的完整指南》
目录 引言第一步: 重置密码第二步:连接到服务器第三步:安装必要软件第四步:创建项目目录第五步:将代码上传到服务器1、安装 FileZilla2、打开FileZilla,连接到您的服务器:3、连接后,…...

【网络原理】TCP/IP协议五层模型
目录 一. 协议的分层 二. OSI七层网络协议 三. TCP/IP五层网络协议 四. 网络设备所在分层 五. 封装 六. 分用 七. 传输中的封装和分用 八. 数据单位术语 一. 协议的分层 常见的分层为两种OSI七层模型和TCP/IP五层模型 为什么要协议分层? 在网络通信中&…...

Asp.Net Core学习随笔
学习自BLBL杨中科老师 依赖注入(Dependency Injection) 依赖注入是实现控制反转(Inversion Of Control 即IOC)的一种方式(还有一种叫服务定位器的实现,但是不如依赖注入好用),软件开发中实现解耦常用的方式. 比如吃饭 1. 传统写法(没有DI,紧耦合&a…...
,源码可白嫖!)
基于PHP的酒店网上订房系统(源码+lw+部署文档+讲解),源码可白嫖!
摘要 酒店服务是旅游行业的一个重要组成部分,它的作用已经从过去的单一的住宿、结算帐务向全面、高水平的服务型酒店转变。酒店的服务工作贯穿于整个酒店的市场营销、预定、入住、退房、结账等环节,酒店要提高整体工作水平,简化工作程序&…...

《MySQL从入门到精通》
文章目录 《MySQL从入门到精通》1. 基础-SQL通用语法及分类2. 基础-SQL-DDL-数据库操作3. 基础-SQL-DDL-表操作-创建&查询4. 基础-SQL-DDL-数据类型及案例4.1 数值类型4.2 字符串类型4.3 时间和日期类型 5. 基础-SQL-DDL-表操作-修改&删除5.1 DDL-表操作-修改5.2 DDL-表…...

MySQL聚合查询
聚合查询 group by...
:文章的方法)
生信初学者教程(三十四):文章的方法
文章目录 介绍数据收集和整理数据整合差异基因分析功能富集分析免疫浸润分析候选标记物识别诊断ROC曲线单细胞分析统计方法介绍 在数据分析进行的同时,我们可以逐步撰写方法部分,确保其与结果紧密相连。一旦结果部分完成,方法部分应根据结果的逻辑顺序进行分类和组织。在描…...

算力云平台部署—SadTalker的AI数字人视频
选择算力 部署选择 选择镜像 机器管理 控制台 通过平台工具进入服务器 认识管理系统 打开命令行 进入目录 stable-diffusion-webui# cd 增加执行权限 chmod x ./webui.sh 运行命令 bash ./webui.sh sudo apt install -y python3 python3-venv git 安装软件 Creating the …...

iPhone相册导出到电脑的完整指南
iPhone相册导出到电脑的完整指南 本文介绍通过数据线连接实现iPhone照片视频传输到电脑的标准操作方法,适用于需要备份移动设备影像资料的用户。 环境准备 使用原装Lightning或USB-C数据线连接设备与电脑需在电脑端安装设备管理工具(如克魔助手&#…...
:复杂度)
【数据结构】励志大厂版·初阶(复习+刷题):复杂度
前引:从此篇文章开始,小编带给大家的是数据结构初阶的刷题讲解 ,此类文章将简略的包含相关知识,详细的思路拆分讲解,分析每一题的难点、易错点,看见题目如何分析,以上就是小编预备的内容&#x…...
)
Nginx底层架构(非常清晰)
目录 前言: 场景带入: HTTP服务器是什么? 反向代理是什么? 模块化网关能力: 1.配置能力: 2.单线程: 3.多worker进程 4.共享内存: 5.proxy cache 6.master进程 最后&…...

Golang|Channel 相关用法理解
文章目录 用 channel 作为并发小容器channel 的遍历channel 导致的死锁问题用 channel 传递信号用 channel 并行处理文件用channel 限制接口的并发请求量用 channel 限制协程的总数量 用 channel 作为并发小容器 注意这里的 ok 如果为 false,表示此时不仅channel为空…...

智能合约安全审计平台——以太坊虚拟机安全沙箱
目录 以太坊虚拟机安全沙箱 —— 理论、设计与实战1. 引言2. 理论背景与安全原理2.1 以太坊虚拟机(EVM)概述2.2 安全沙箱的基本概念2.3 安全证明与形式化验证3. 系统架构与模块设计3.1 模块功能说明3.2 模块之间的数据流与安全性4. 安全性与密码学考量4.1 密码学保障在沙箱中…...

趣说区块链隐私智能合约Shielder 实现原理
目录 核心理念 Deposit Withdraw Shielder 是 Aleph Zero 上的智能合约,它利用 zk-SNARK 技术实现隐私支付以及与 DeFi 的隐私交互。这与常规区块链的完全透明性形成鲜明对比,常规区块链允许追踪单个用户与链上合约以及其他用户的所有交互。Shielder 通过使第三方链观察者…...

TCPIP详解 卷1协议 五 Internet协议
5.1——Internet协议 IP是TCP/IP协议族中的核心协议。所有TCP、UDP、ICMP和IGMP数据都通过IP数据报传输。IP 提供了一种尽力而为、无连接的数据报交付服务。“尽力而为”的含义是不保证 IP 数据报能成功到达目的地。任何可靠性必须由上层(例如TCP)提供。…...

基于Oracle ADG通过dblink创建物化视图同步数据到目标库
基于Oracle ADG通过dblink创建物化视图同步数据到目标库 环境说明:源端环境Oracle ADG一主一备,版本11.2.0.4,目标端版本11.2.0.4,测试通过dblink方式在目标库创建物化视图同步ADG备库的数据。 PROD --> STANDBY – > TAR…...

openGauss新特性 | 自动参数化执行计划缓存
目录 自动化参数执行计划缓存简介 SQL参数化及约束条件 一般常量参数化示例 总结 自动化参数执行计划缓存简介 执行计划缓存用于减少执行计划的生成次数。openGauss数据库会缓存之前生成的执行计划,以便在下次执行该SQL时直接使用,可…...

qt中的正则表达式
问题: 1.在文本中把dog替换成cat,但可能会把dog1替换成cat1,如果原本不想替换dog1,就会出现问题 2文本中想获取某种以.txt为结尾的多有文本,普通的不能使用 3如果需要找到在不同的系统中寻找换行符,可以…...

开源项目 | 17款云原生安全相关的扫描和平台类开源工具
“ 随着云计算技术的不断发展,越来越多的企业开始将应用程序和数据存储到云上。然而,云安全问题也随之而来,因此,开源云原生安全工具的需求也越来越大。在本文中,我们将介绍一些流行的开源云原生安全工具,以…...

力扣面试150题—旋转图像和矩阵置零
Day21 题目描述 思路 矩阵转置 在将列反转 1 2 3 4 5 6 7 8 9 转置 1 4 7 2 5 8 3 6 9 反转 7 4 1 8 5 2 9 6 3 class Solution {public void rotate(int[][] matrix) { //分为两步 矩阵转置,将列倒序 int x0; int nmatrix.length; //转…...

ScholarCopilot:“学术副驾驶“
这里写目录标题 引言:学术写作的痛点与 AI 的曙光ScholarCopilot 的核心武器库:智能生成与精准引用智能文本生成:不止于“下一句”智能引用管理:让引用恰到好处 揭秘背后机制:检索与生成的动态协同快速上手:…...

Node.js项目开启多进程的2种方案
当node项目只部署一个单进程单实例时,遇到异常发生后程序会崩溃,此时杀掉进程在重启单这段时间会导致服务不能正常使用,这显然会影响用户体验。 所以需要以多进程的模式去部署应用,这样当某一个进程发生异常重启时,此时有其他请求被接受后,其他进程依旧可以对外提供服务…...

论文导读 | 基于GPU的子图匹配算法
摘要 大规模图上的子图匹配在社交网络挖掘,生物信息学,知识图谱等领域具有关键作用。近年来随着以GPU为代表的新硬件的发展,研究人员开始尝试在GPU上实现这一NP难的任务。GPU提供了大量的计算单元和高速的显存带宽,可以显著提升算…...

中天科技旗下的中天智能装备有限公司,在立库方面有哪些优势?
中天科技旗下的中天智能装备有限公司在立库方面优势显著,主要体现在产品与方案、技术研发、项目经验和服务质量管控等多个维度,能够为客户提供全方位、高品质的立库相关服务。 产品与解决方案优势 多种立库解决方案:提供托盘式立库、料箱式立…...

HTML5+CSS前端开发【保姆级教学】+超链接标签
一、引入: Hello!,各位编程猿们!一个页面可以跳转到其他页面,去访问其他资源,使得我们的文档更加的灵动,那我们如何实现不同页面的跳转呢?本期主要介绍超链接标签 那么什么是超链接…...