【从0到1学Elasticsearch】Elasticsearch从入门到精通(上)
黑马商城作为一个电商项目,商品的搜索肯定是访问频率最高的页面之一。目前搜索功能是基于数据库的模糊搜索来实现的,存在很多问题。
首先,查询效率较低。
由于数据库模糊查询不走索引,在数据量较大的时候,查询性能很差。
需要注意的是,数据库模糊查询随着表数据量的增多,查询性能的下降会非常明显,而搜索引擎的性能则不会随着数据增多而下降太多。目前仅10万不到的数据量差距就如此明显,如果数据量达到百万、千万、甚至上亿级别,这个性能差距会非常夸张。
其次,功能单一,数据库的模糊搜索匹配条件非常苛刻,例如,当我们需要查询java基础课程的时候,如果按照这种查询方式,我们查询出来的就只能是(---------java基础课程--------)前后匹配,那么如果一个店铺售卖的名为,(java课程,帮助你打好java基础)那么这个店铺售卖的东西就不会被搜索出来
目前全球的搜索引擎技术排名如下:
Elasticsearch功能有很多
- 1 例如github上的代码搜索
- 2 商品信息搜索
- 3 解决方案搜搜哦
- 4 附近商铺,打车搜索
- …
初识Elasticsearch
Elasticsearch是由elastic公司开发的一套搜索引擎技术,它是elastic技术栈中的一部分。完整的技术栈包括:
- Elasticsearch:用于数据存储、计算和搜索
- Logstash/Beats:用于数据收集
- Kibana:用于数据可视化
安装Elasticsearch
我们依旧采用的是docker安装,简单方便
docker run -d \--name es \-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \ -e "discovery.type=single-node" \-v es-data:/usr/share/elasticsearch/data \-v es-plugins:/usr/share/elasticsearch/plugins \--privileged \--network hm-net \-p 9200:9200 \-p 9300:9300 \elasticsearch:7.12.1
安装完成之后访问9200端口可以看到基本信息
安装Kibana
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=hm-net \
-p 5601:5601 \
kibana:7.12.1
安装完成之后访问5601端口,可以看到控制台页面
倒排索引
elasticsearch之所以有如此高性能的搜索表现,正是得益于底层的倒排索引技术。我们首先来看看什么是正向索引。
正向索引
例如我们在mysql当中有一张goods的表
| id | title | price |
|---|---|---|
| 1 | 小米手机 | 3499 |
| 2 | 华为手机 | 4999 |
| 3 | 华为小米充电器 | 49 |
| 4 | 小米手环 | 49 |
| … | … | … |
其中的id字段已经创建了索引,由于索引底层采用了B+树结构,因此我们根据id搜索的速度会非常快。但是其他字段例如title,只在叶子节点上存在。
因此要根据title搜索的时候只能遍历树中的每一个叶子节点,判断title数据是否符合要求。
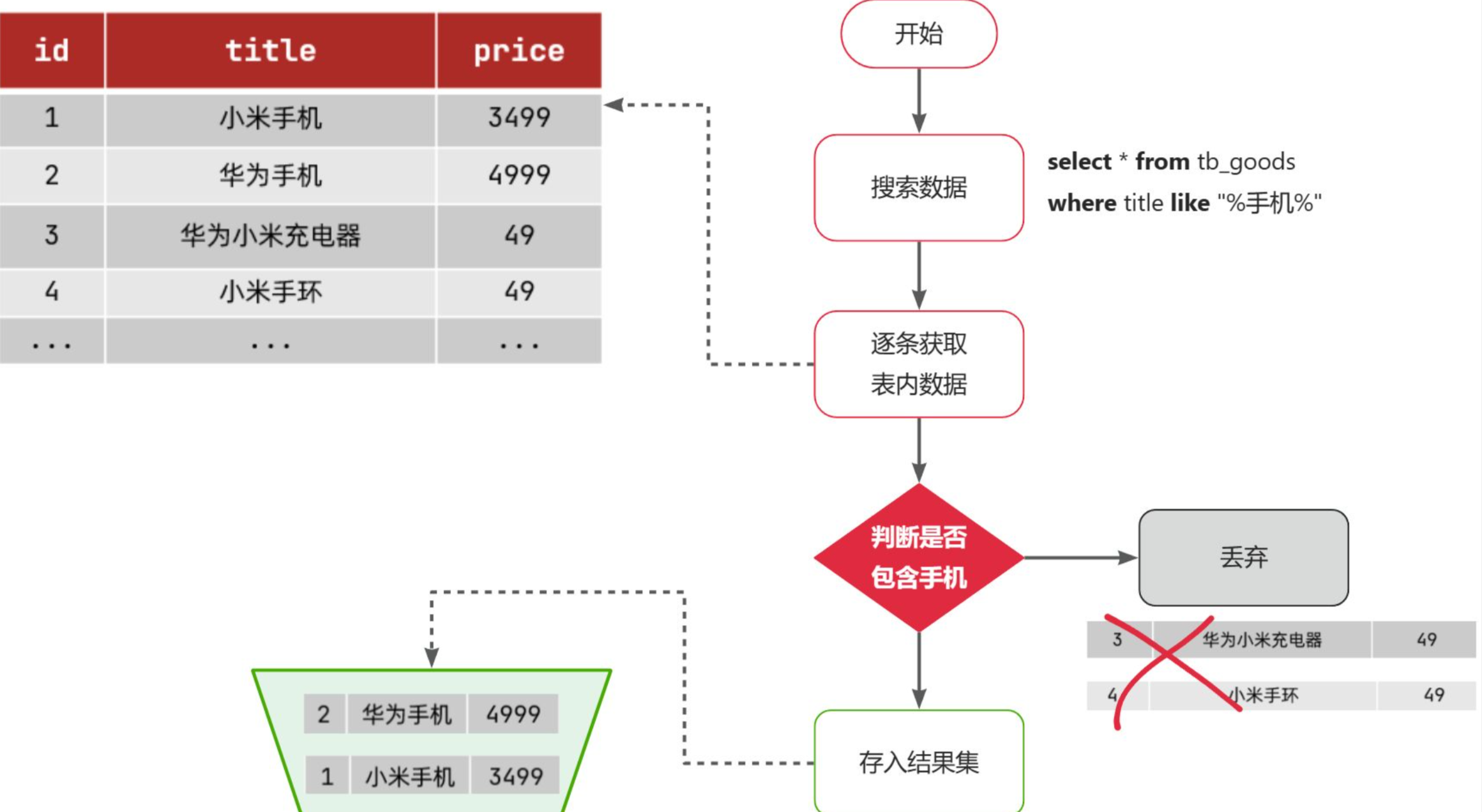
select * from tb_goods where title like '%手机%';
流程如下
说明:
- 1)检查到搜索条件为like ‘%手机%’,需要找到title中包含手机的数据
- 2)逐条遍历每行数据(每个叶子节点),比如第1次拿到id为1的数据
- 3)判断数据中的title字段值是否符合条件
- 4)如果符合则放入结果集,不符合则丢弃
- 5)回到步骤1
综上所述,如果我们根据有索引的id进行查询,那么查询效率就会非常高,但是如果搜索条件为模糊匹配时,由于索引无法生效,导致从索引查询退化为全表扫描,效率很差。
因此,正向索引适合于根据索引字段的精确搜索,不适合基于部分词条的模糊匹配。
而倒排索引恰好解决的就是根据部分词条模糊匹配的问题。
倒排索引
倒排索引中有两个非常重要的概念:
- 文档(Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息
- 词条(Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条
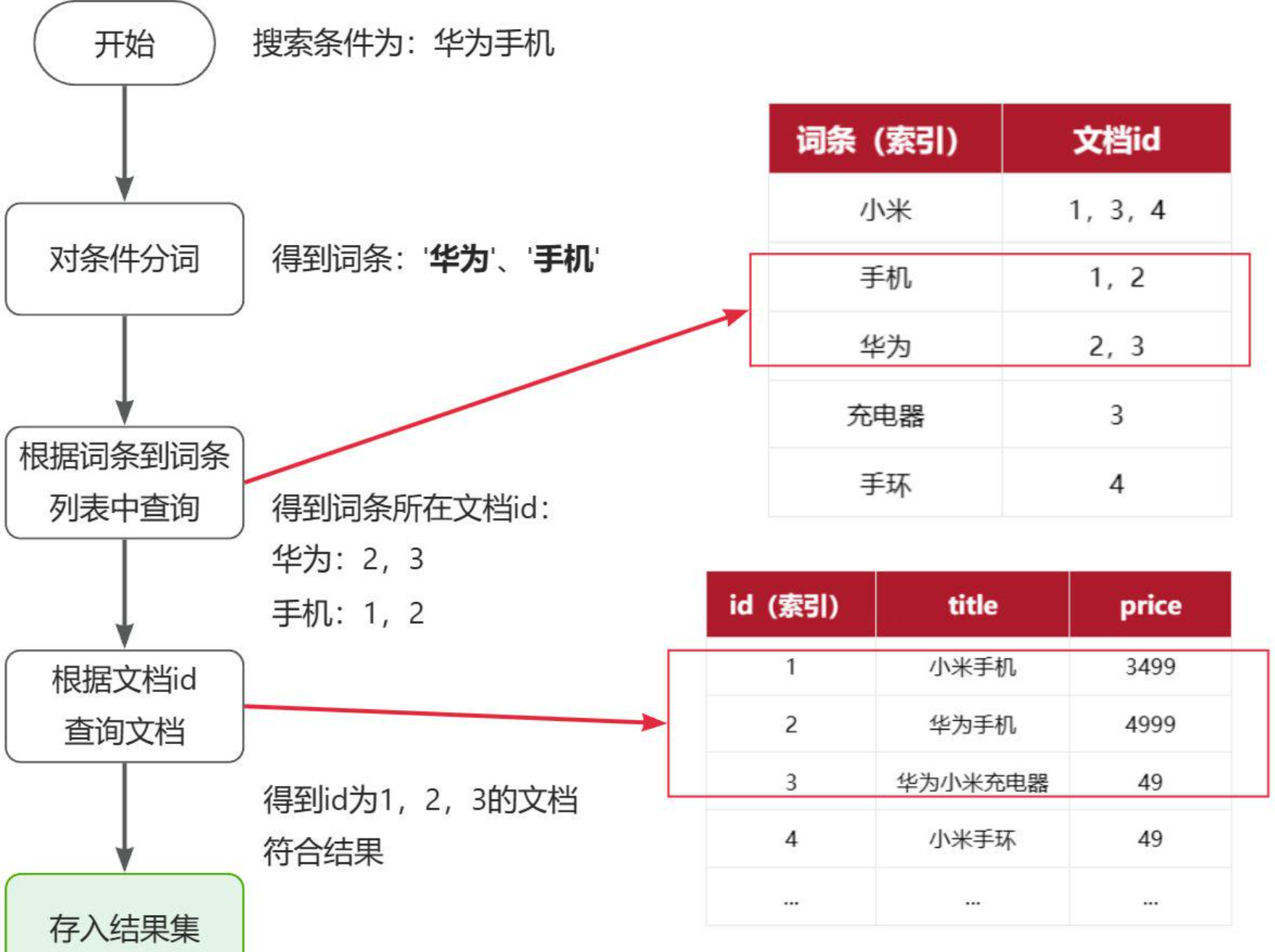
倒排索引的搜索流程如下(以搜索"华为手机"为例),如图:
流程描述:
1)用户输入条件"华为手机"进行搜索。
2)对用户输入条件分词,得到词条:华为、手机。
3)拿着词条在倒排索引中查找(由于词条有索引,查询效率很高),即可得到包含词条的文档id:1、2、3。
4)拿着文档id到正向索引中查找具体文档即可(由于id也有索引,查询效率也很高)。
虽然要先查询倒排索引,再查询倒排索引,但是无论是词条、还是文档id都建立了索引,查询速度非常快!无需全表扫描。
基础概念
elasticsearch是面向文档(Document)存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化为json格式后存储在elasticsearch中:
在mysq当中数据存储方式如下:
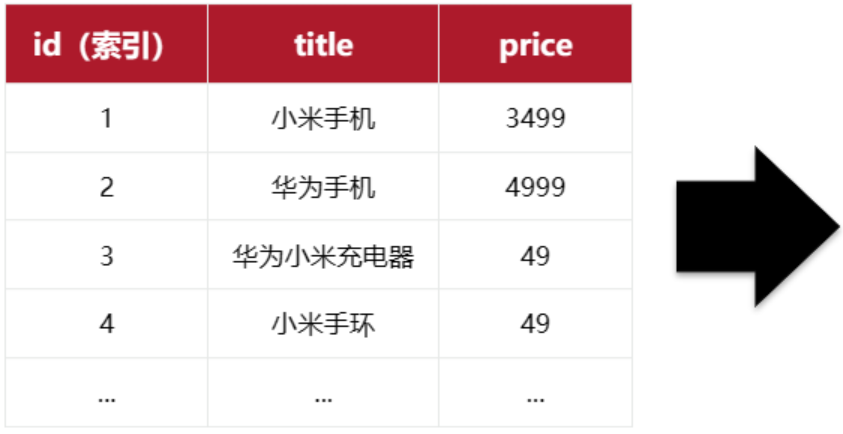
但是在es当中如下
{"id": 1,"title": "小米手机","price": 3499
}
{"id": 2,"title": "华为手机","price": 4999
}
{"id": 3,"title": "华为小米充电器","price": 49
}
{"id": 4,"title": "小米手环","price": 299
}
因此,原本数据库中的一行数据就是ES中的一个JSON文档;而数据库中每行数据都包含很多列,这些列就转换为JSON文档中的字段(Field)。
索引和映射
随着业务发展,需要在es中存储的文档也会越来越多,比如有商品的文档、用户的文档、订单文档等等:

所有文档都散乱存放显然非常混乱,也不方便管理。
因此,我们要将类型相同的文档集中在一起管理,称为索引(Index)。例如:
商品索引:
{"id": 1,"title": "小米手机","price": 3499
}{"id": 2,"title": "华为手机","price": 4999
}{"id": 3,"title": "三星手机","price": 3999
}
用户索引
{"id": 101,"name": "张三","age": 21
}{"id": 102,"name": "李四","age": 24
}{"id": 103,"name": "麻子","age": 18
}
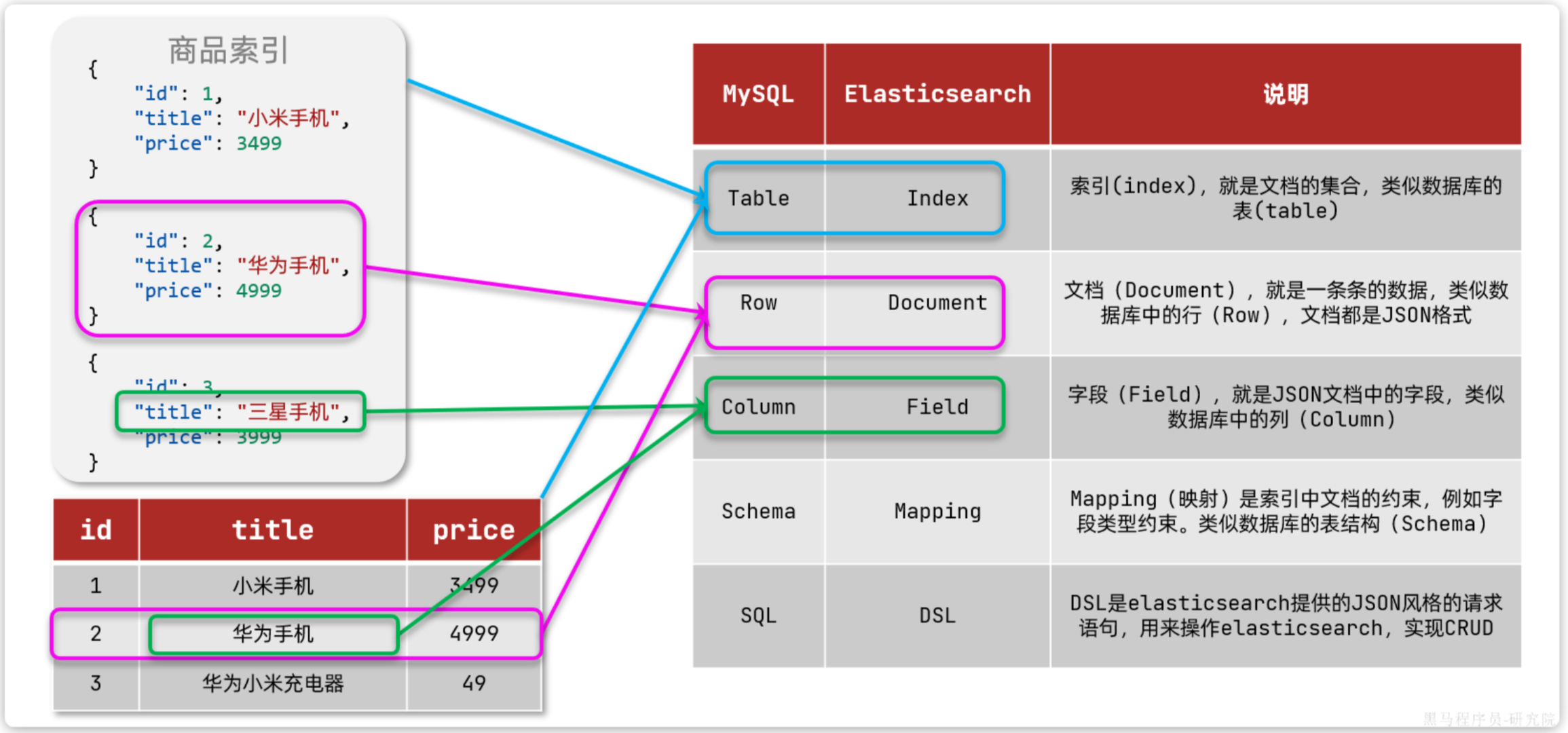
Mysql与Es
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
|---|---|---|
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
如图
那是不是说,我们学习了elasticsearch就不再需要mysql了呢?
并不是如此,两者各自有自己的擅长之处:
- Mysql:擅长事务类型操作,可以确保数据的安全和一致性
- Elasticsearch:擅长海量数据的搜索、分析、计算
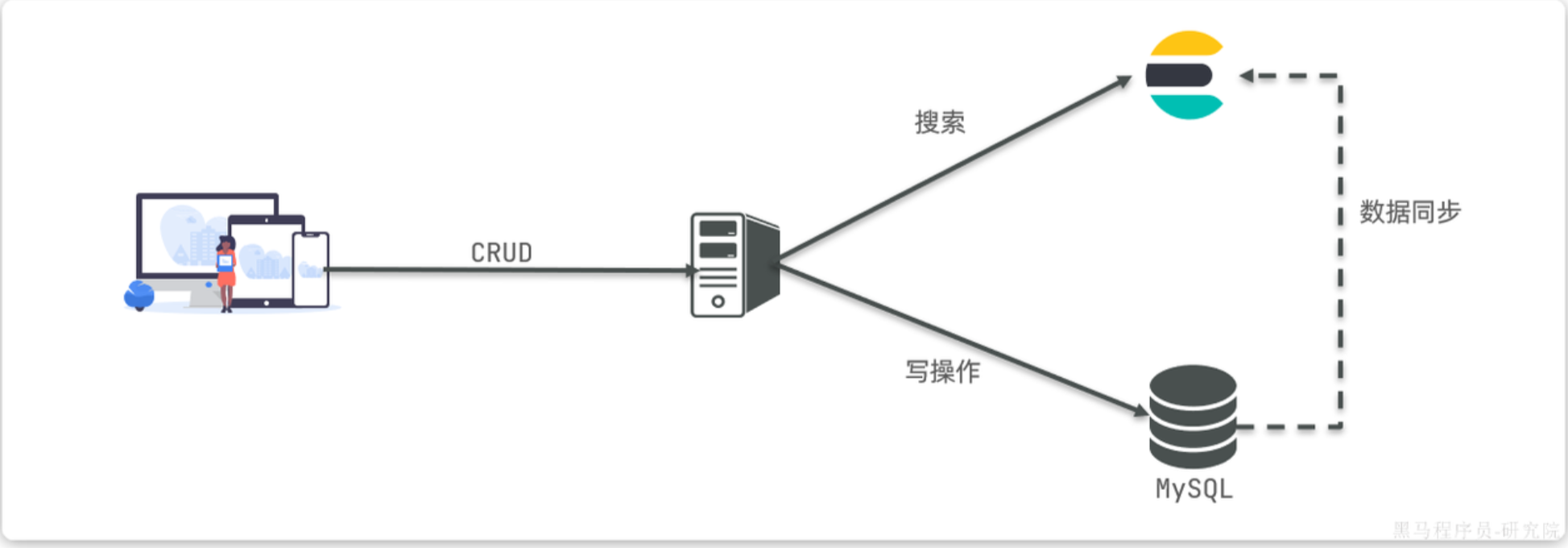
因此在企业中,往往是两者结合使用:
- 对安全性要求较高的写操作,使用mysql实现
对查询性能要求较高的搜索需求,使用elasticsearch实现- 两者再基于某种方式,实现数据的同步,保证一致性
IK分词器
爱坤分词器(露出鸡脚了),es关键的就是倒排索引,而倒排索引依赖对文档内部的词进行分词,而分词则需要高效、精准的分词算法,IK分词器就是这样一个中文分词算法。
安装IK分词器
同样是docker
方案1:在线安装
docker exec -it es ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip
安装完成之后重启es
docker restart es
方案2:离线安装
首先,查看之前安装的Elasticsearch容器的plugins数据卷目录:
docker volume inspect es-plugins
[{"CreatedAt": "2024-11-06T10:06:34+08:00","Driver": "local","Labels": null,"Mountpoint": "/var/lib/docker/volumes/es-plugins/_data","Name": "es-plugins","Options": null,"Scope": "local"}
]
可以看到elasticsearch的插件挂载到了/var/lib/docker/volumes/es-plugins/_data这个目录。我们需要把IK分词器上传至这个目录。
上传完成之后重启es容器
简单使用
IK分词器包含两种模式:
- ik_smart:智能语义切分
- ik_max_word:最细粒度切分
首先我们来看看官方提供的标准分词方式
POST /_analyze
{"analyzer": "standard","text": "黑马程序员学习java太棒了"
}
{"tokens" : [{"token" : "黑","start_offset" : 0,"end_offset" : 1,"type" : "<IDEOGRAPHIC>","position" : 0},{"token" : "马","start_offset" : 1,"end_offset" : 2,"type" : "<IDEOGRAPHIC>","position" : 1},{"token" : "程","start_offset" : 2,"end_offset" : 3,"type" : "<IDEOGRAPHIC>","position" : 2},{"token" : "序","start_offset" : 3,"end_offset" : 4,"type" : "<IDEOGRAPHIC>","position" : 3},{"token" : "员","start_offset" : 4,"end_offset" : 5,"type" : "<IDEOGRAPHIC>","position" : 4},{"token" : "学","start_offset" : 5,"end_offset" : 6,"type" : "<IDEOGRAPHIC>","position" : 5},{"token" : "习","start_offset" : 6,"end_offset" : 7,"type" : "<IDEOGRAPHIC>","position" : 6},{"token" : "java","start_offset" : 7,"end_offset" : 11,"type" : "<ALPHANUM>","position" : 7},{"token" : "太","start_offset" : 11,"end_offset" : 12,"type" : "<IDEOGRAPHIC>","position" : 8},{"token" : "棒","start_offset" : 12,"end_offset" : 13,"type" : "<IDEOGRAPHIC>","position" : 9},{"token" : "了","start_offset" : 13,"end_offset" : 14,"type" : "<IDEOGRAPHIC>","position" : 10}]
}
我们可以看到,他对中文的分词能力很差,一个字分一下,而对英文的java的分词效果很好。
我们再测试IK分词器:
POST /_analyze
{"analyzer": "ik_smart","text": "黑马程序员学习java太棒了"
}
{"tokens" : [{"token" : "黑马","start_offset" : 0,"end_offset" : 2,"type" : "CN_WORD","position" : 0},{"token" : "程序员","start_offset" : 2,"end_offset" : 5,"type" : "CN_WORD","position" : 1},{"token" : "学习","start_offset" : 5,"end_offset" : 7,"type" : "CN_WORD","position" : 2},{"token" : "java","start_offset" : 7,"end_offset" : 11,"type" : "ENGLISH","position" : 3},{"token" : "太棒了","start_offset" : 11,"end_offset" : 14,"type" : "CN_WORD","position" : 4}]
}
拓展词典
随着互联网的发展,“造词运动”也越发的频繁。出现了很多新的词语,在原有的词汇列表中并不存在。比如:“泰裤辣”,“传智播客” 等。而IK分词器无法对这些词汇分词。
所以要想正确分词,IK分词器的词库也需要不断的更新,IK分词器提供了扩展词汇的功能。
1)打开IK分词器config目录:
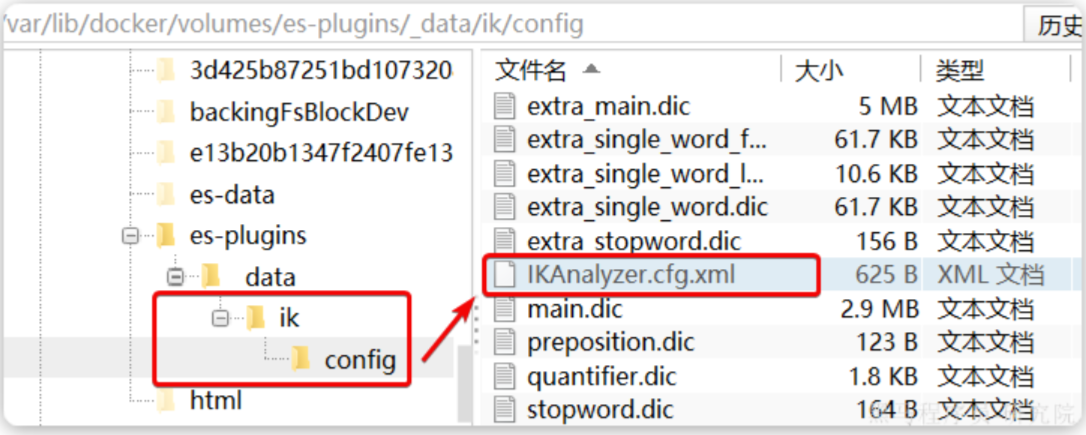
2)在IKAnalyzer.cfg.xml配置文件内容添加:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 *** 添加扩展词典--><entry key="ext_dict">ext.dic</entry>
</properties>
3)在IK分词器的config目录新建一个 ext.dic,可以参考config目录下复制一个配置文件进行修改
传智播客
泰裤辣
4)重启elasticsearch
此外我们还可以添加断分词的字段,同样是在IKAnalyzer.cfg.xml里配置,注意在线安装的话没有config目录,但是也不要手动创建config目录,具体解决方法可以在网上搜索。
索引库操作
Mapping映射属性
Mapping是对索引库中文档的约束,常见的Mapping属性包括:
- type:字段数据类型,常见的简单类型有:
- 字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float、
- 布尔:boolean
- 日期:date
- 对象:object
- index:是否创建索引,默认为true
- analyzer:使用哪种分词器
- properties:该字段的子字段
索引库的CRUD
创建索引库与映射
基本语法:
- 请求方式:
PUT - 请求路径:/索引库名,可以自定义
- 请求参数:mapping映射
PUT /索引库名称
{"mappings": {"properties": {"字段名":{"type": "text","analyzer": "ik_smart"},"字段名2":{"type": "keyword","index": "false"},"字段名3":{"properties": {"子字段": {"type": "keyword"}}},// ...略}}
}
例子
## 创建索引库并且设置mapping映射
PUT /heima
{"mappings": {"properties": {"info":{"type": "text","analyzer": "ik_smart" // 分词其类型},"age":{"type": "byte"},"email":{"type": "keyword","index": false // 不创建索引},"name":{"type": "object","properties": {"fistName":{"type": "keyword" },"lastName":{"type": "keyword"}}}}}
}
查询索引库
基本语法:
- 请求方式:GET
- 请求路径:/索引库名
- 请求参数:无
GET /索引库名
修改索引库
倒排索引结构虽然不复杂,但是一旦数据结构改变(比如改变了分词器),就需要重新创建倒排索引,这简直是灾难。因此索引库一旦创建,无法修改mapping。
虽然无法修改mapping中已有的字段,但是却允许添加新的字段到mapping中,因为不会对倒排索引产生影响。因此修改索引库能做的就是向索引库中添加新字段,或者更新索引库的基础属性。
PUT /索引库名/_mapping
{"properties": {"新字段名":{"type": "integer"}}
}
删除索引库
语法:
- 请求方式:DELETE
- 请求路径:/索引库名
- 请求参数:无
DELETE /索引库名
文档操作
新增文档
POST /索引库名/_doc/文档id
{"字段1": "值1","字段2": "值2","字段3": {"子属性1": "值3","子属性2": "值4"},
}
查询文档
根据rest风格,新增是post,查询应该是get,不过查询一般都需要条件,这里我们把文档id带上。
GET /{索引库名称}/_doc/{id}

删除文档
就不用多说了肯定是delete
DELETE /{索引库名}/_doc/id值
修改文档
修改文档由两种方式:
- 全量修改:直接覆盖原来的文档
- 局部修改:根据提供的字段进行修改
全量修改
全量修改的方法和新增文档的方法一样
全量修改是覆盖原来的文档,其本质是两步操作:
- 根据指定的id删除文档
- 新增一个相同id的文档
PUT /{索引库名}/_doc/文档id
{"字段1": "值1","字段2": "值2",// ... 略
}
这时候如果写了一个不存在的id那么就是新增
局部修改
局部修改是只修改指定id匹配的文档中的部分字段。
POST /{索引库名}/_update/文档id
{"doc": {"字段名": "新的值",}
}
批处理
批量处理的代码如下
POST _bulk
{ "index" : { "_index" : "test", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "test", "_id" : "2" } }
{ "create" : { "_index" : "test", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_index" : "test"} }
{ "doc" : {"field2" : "value2"} }
RestAPI
在elasticsearch提供的API中,与elasticsearch一切交互都封装在一个名为RestHighLevelClient的类中,必须先完成这个对象的初始化,建立与elasticsearch的连接。
初始化连接
分为三步:
1)在item-service模块中引入es的RestHighLevelClient依赖:
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
2)因为SpringBoot默认的ES版本是7.17.10,所以我们需要覆盖默认的ES版本:
<properties><maven.compiler.source>11</maven.compiler.source><maven.compiler.target>11</maven.compiler.target><elasticsearch.version>7.12.1</elasticsearch.version>
</properties>
3)初始化RestHighLevelClient:
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.150.101:9200")
));
@Configuration
public class ElasticClient {@Bean(destroyMethod = "close")@ConditionalOnMissingBeanpublic RestHighLevelClient restHighLevelClient() {return new RestHighLevelClient(RestClient.builder(new HttpHost("192.168.200.200",9200,"http")));}}
创建索引库
Mapping映射
最终我们需要改造黑马商城的搜索业务,经过我们分析,原本的增加代码如下
PUT /items
{"mappings": {"properties": {"id": {"type": "keyword"},"name":{"type": "text","analyzer": "ik_max_word"},"price":{"type": "integer"},"stock":{"type": "integer"},"image":{"type": "keyword","index": false},"category":{"type": "keyword"},"brand":{"type": "keyword"},"sold":{"type": "integer"},"commentCount":{"type": "integer","index": false},"isAD":{"type": "boolean"},"updateTime":{"type": "date"}}}
}
创建索引
创建索引的API如下
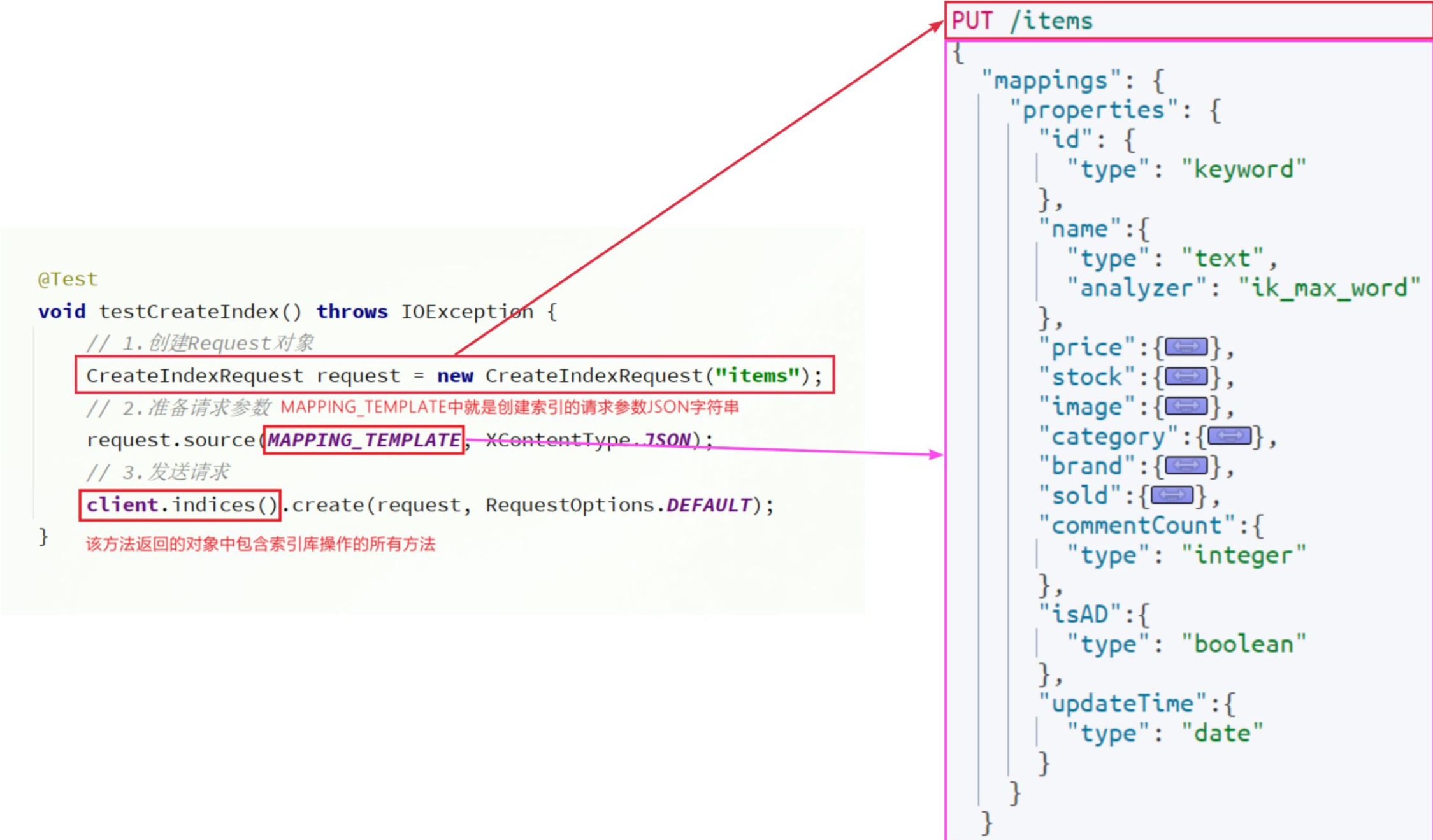
代码分为三步:
- 1)创建Request对象。
- 因为是创建索引库的操作,因此Request是CreateIndexRequest。
- 2)添加请求参数
- 其实就是Json格式的Mapping映射参数。因为json字符串很长,这里是定义了静态字符串常量MAPPING_TEMPLATE,让代码看起来更加优雅。
- 3)发送请求
- client.indices()方法的返回值是IndicesClient类型,封装了所有与索引库操作有关的方法。例如创建索引、删除索引、判断索引是否存在等
@Test
void testCreateIndex() throws IOException {// 1.创建Request对象CreateIndexRequest request = new CreateIndexRequest("items");// 2.准备请求参数request.source(MAPPING_TEMPLATE, XContentType.JSON);// 3.发送请求client.indices().create(request, RequestOptions.DEFAULT);
}static final String MAPPING_TEMPLATE = "{\n" +" \"mappings\": {\n" +" \"properties\": {\n" +" \"id\": {\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"name\":{\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\"\n" +" },\n" +" \"price\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"stock\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"image\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": false\n" +" },\n" +" \"category\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"brand\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"sold\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"commentCount\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"isAD\":{\n" +" \"type\": \"boolean\"\n" +" },\n" +" \"updateTime\":{\n" +" \"type\": \"date\"\n" +" }\n" +" }\n" +" }\n" +"}";
删除索引库
不用多说对象为DeleteIndexRequest
@Test
void testDeleteIndex() throws IOException {// 1.创建Request对象DeleteIndexRequest request = new DeleteIndexRequest("items");// 2.发送请求client.indices().delete(request, RequestOptions.DEFAULT);
}
判断索引库是否存在
不用多说对象为GetIndexRequest
@Test
void testExistsIndex() throws IOException {// 1.创建Request对象GetIndexRequest request = new GetIndexRequest("items");// 2.发送请求boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);// 3.输出System.err.println(exists ? "索引库已经存在!" : "索引库不存在!");
}
RestClient文档操作
新增文档
新增文档的API如下
POST /{索引库名}/_doc/1
{"name": "Jack","age": 21
}
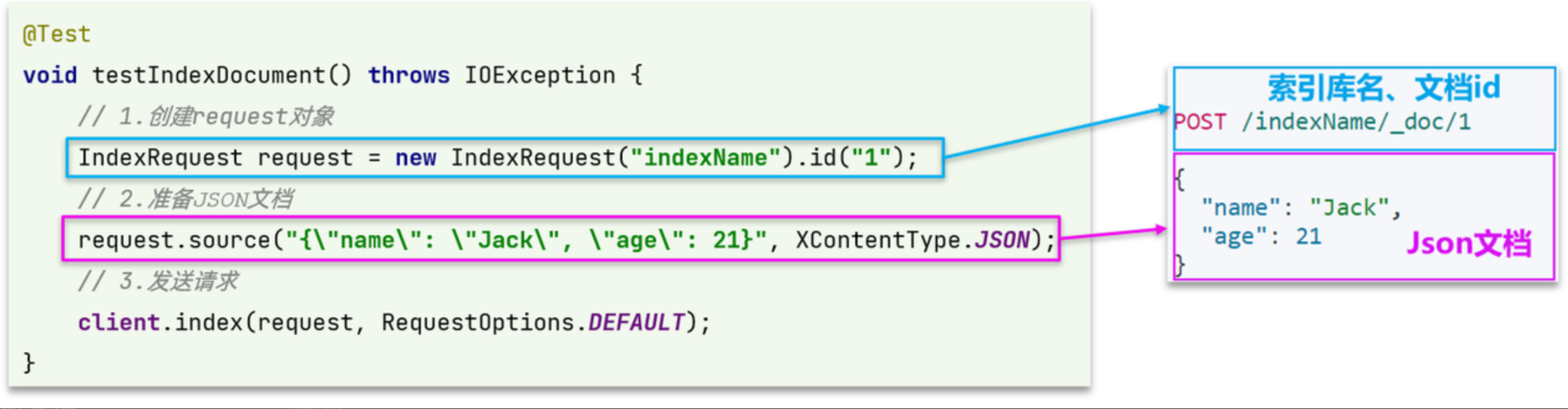
可以看到与索引库操作的API非常类似,同样是三步走:
- 1)创建Request对象,这里是IndexRequest,因为添加文档就是创建倒排索引的过程
- 2)准备请求参数,本例中就是Json文档
- 3)发送请求
变化的地方在于,这里直接使用client.xxx()的API,不再需要client.indices()了。
@Test
void testAddDocument() throws IOException {// 1.根据id查询商品数据Item item = itemService.getById(100002644680L);// 2.转换为文档类型ItemDoc itemDoc = BeanUtil.copyProperties(item, ItemDoc.class);// 3.将ItemDTO转jsonString doc = JSONUtil.toJsonStr(itemDoc);// 1.准备Request对象IndexRequest request = new IndexRequest("items").id(itemDoc.getId());// 2.准备Json文档request.source(doc, XContentType.JSON);// 3.发送请求client.index(request, RequestOptions.DEFAULT);
}
查询文档
查询的请求语句如下:
GET /{索引库名}/_doc/{id}
与之前的流程类似,代码大概分2步:
- 创建Request对象
- 准备请求参数,这里是无参,直接省略
- 发送请求
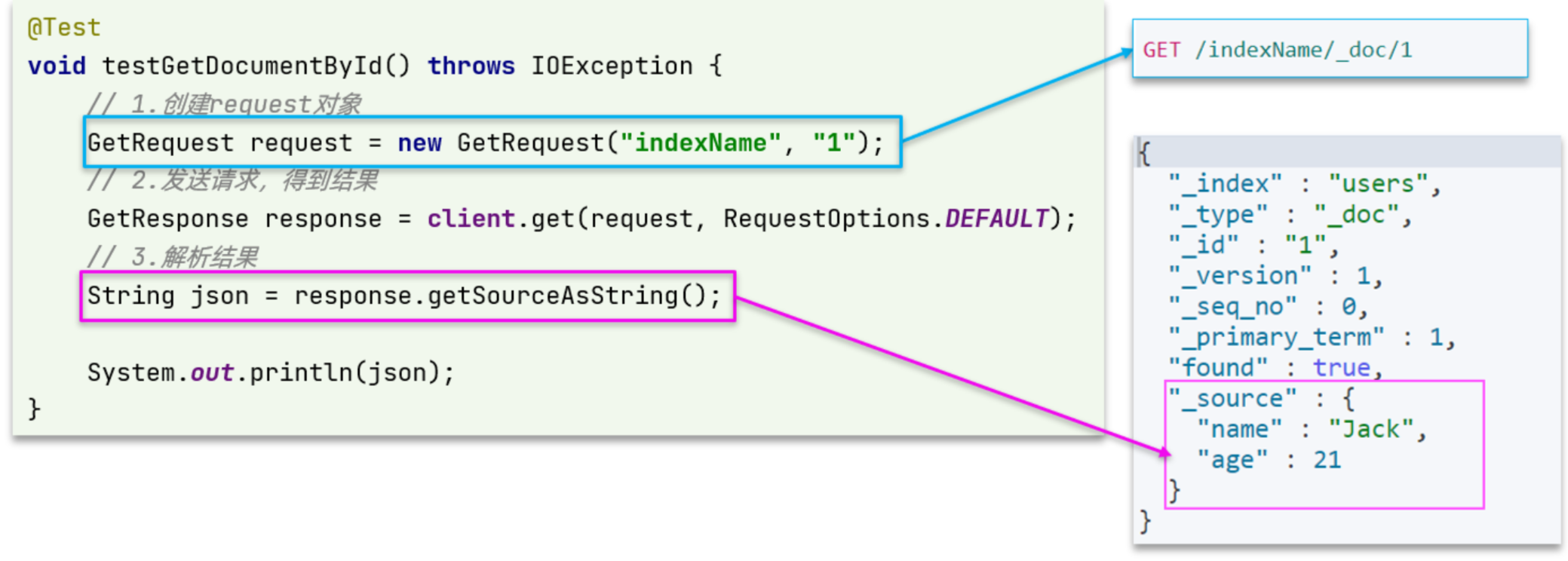
可以看到,响应结果是一个JSON,其中文档放在一个_source属性中,因此解析就是拿到_source,反序列化为Java对象即可。
其它代码与之前类似,流程如下:
- 1)准备Request对象。这次是查询,所以是GetRequest
- 2)发送请求,得到结果。因为是查询,这里调用client.get()方法
- 3)解析结果,就是对JSON做反序列化
@Test
void testGetDocumentById() throws IOException {// 1.准备Request对象GetRequest request = new GetRequest("items").id("100002644680");// 2.发送请求GetResponse response = client.get(request, RequestOptions.DEFAULT);// 3.获取响应结果中的sourceString json = response.getSourceAsString();ItemDoc itemDoc = JSONUtil.toBean(json, ItemDoc.class);System.out.println("itemDoc= " + ItemDoc);
}
删除文档
删除的请求语句如下:
DELETE /hotel/_doc/{id}
与查询相比,仅仅是请求方式从DELETE变成GET,可以想象Java代码应该依然是2步走:
- 1)准备Request对象,因为是删除,这次是DeleteRequest对象。要指定索引库名和id
- 2)准备参数,无参,直接省略
- 3)发送请求。因为是删除,所以是client.delete()方法
@Test
void testDeleteDocument() throws IOException {// 1.准备Request,两个参数,第一个是索引库名,第二个是文档idDeleteRequest request = new DeleteRequest("item", "100002644680");// 2.发送请求client.delete(request, RequestOptions.DEFAULT);
}
修改文档
我们上面说修改文档由两种方法,但是第一种方法我们肯定是不推荐的,因此这里直接看第二种方法
POST /{索引库名}/_update/{id}
{"doc": {"字段名": "字段值","字段名": "字段值"}
}
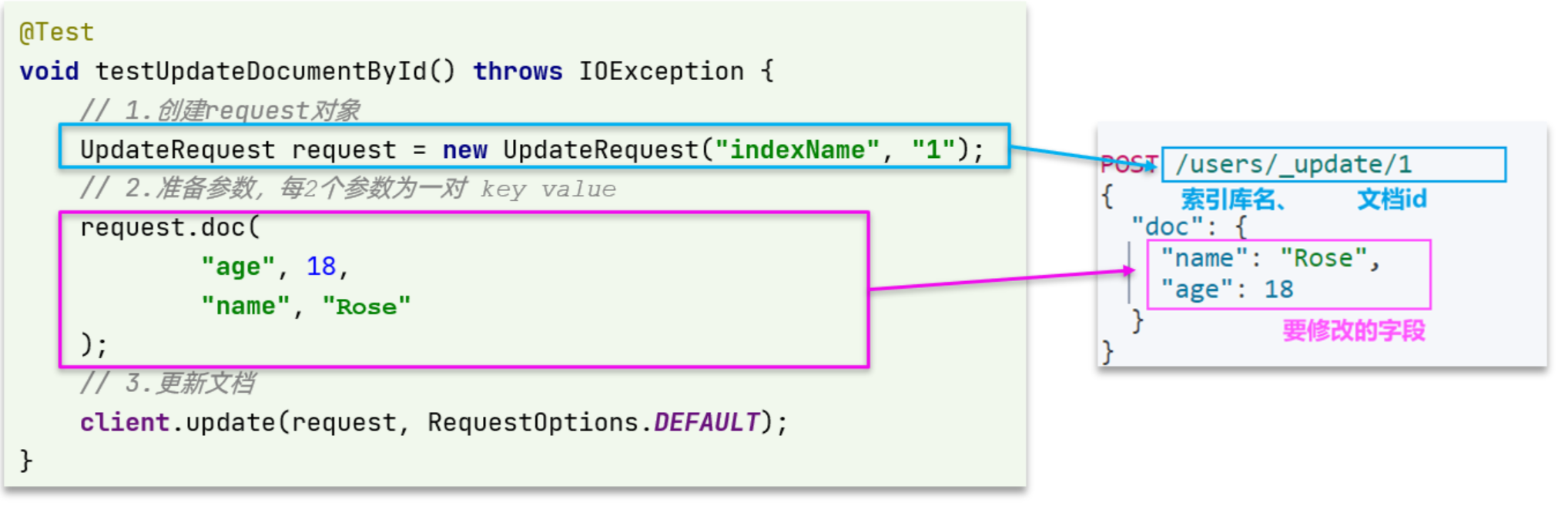
@Test
void testUpdateDocument() throws IOException {// 1.准备RequestUpdateRequest request = new UpdateRequest("items", "100002644680");// 2.准备请求参数request.doc("price", 58800,"commentCount", 1);// 3.发送请求client.update(request, RequestOptions.DEFAULT);
}
批量导入文档
在之前的案例中,我们都是操作单个文档。而数据库中的商品数据实际会达到数十万条,某些项目中可能达到数百万条。
我们如果要将这些数据导入索引库,肯定不能逐条导入,而是采用批处理方案。常见的方案有:
- 利用Logstash批量导入
- 需要安装Logstash
- 对数据的再加工能力较弱
- 无需编码,但要学习编写Logstash导入配置
- 利用JavaAPI批量导入
- 需要编码,但基于JavaAPI,学习成本低
- 更加灵活,可以任意对数据做再加工处理后写入索引库
语法说明
批处理与前面讲的文档的CRUD步骤基本一致:
- 创建Request,但这次用的是BulkRequest
- 准备请求参数
- 发送请求,这次要用到client.bulk()方法
BulkRequest本身其实并没有请求参数,其本质就是将多个普通的CRUD请求组合在一起发送。例如:
- 批量新增文档,就是给每个文档创建一个IndexRequest请求,然后封装到BulkRequest中,一起发出。
- 批量删除,就是创建N个DeleteRequest请求,然后封装到BulkRequest,一起发出
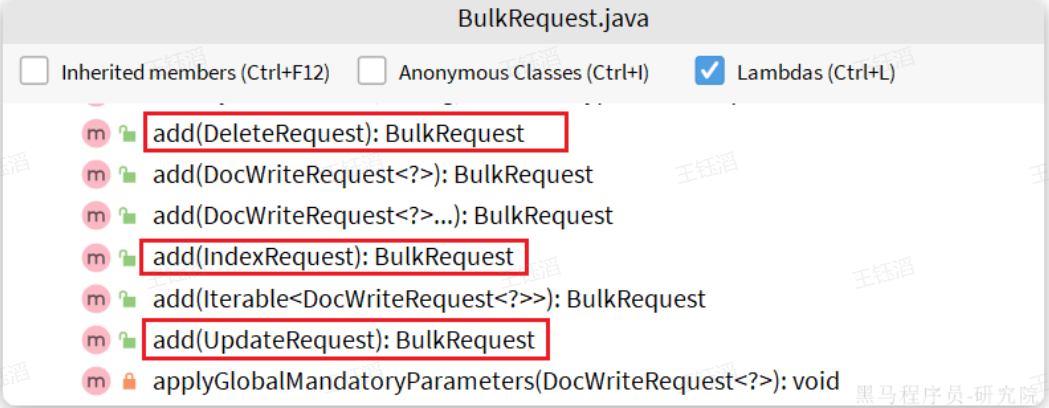
可以看到,能添加的请求有:
- IndexRequest,也就是新增
- UpdateRequest,也就是修改
- DeleteRequest,也就是删除
示例
@Test
void testBulk() throws IOException {// 1.创建RequestBulkRequest request = new BulkRequest();// 2.准备请求参数request.add(new IndexRequest("items").id("1").source("json doc1", XContentType.JSON));request.add(new IndexRequest("items").id("2").source("json doc2", XContentType.JSON));// 3.发送请求client.bulk(request, RequestOptions.DEFAULT);
}
完整代码
@Test
void testLoadItemDocs() throws IOException {// 分页查询商品数据int pageNo = 1;int size = 1000;while (true) {Page<Item> page = itemService.lambdaQuery().eq(Item::getStatus, 1).page(new Page<Item>(pageNo, size));// 非空校验List<Item> items = page.getRecords();if (CollUtils.isEmpty(items)) {return;}log.info("加载第{}页数据,共{}条", pageNo, items.size());// 1.创建RequestBulkRequest request = new BulkRequest("items");// 2.准备参数,添加多个新增的Requestfor (Item item : items) {// 2.1.转换为文档类型ItemDTOItemDoc itemDoc = BeanUtil.copyProperties(item, ItemDoc.class);// 2.2.创建新增文档的Request对象request.add(new IndexRequest().id(itemDoc.getId()).source(JSONUtil.toJsonStr(itemDoc), XContentType.JSON));}// 3.发送请求client.bulk(request, RequestOptions.DEFAULT);// 翻页pageNo++;}
}
相关文章:
)
【从0到1学Elasticsearch】Elasticsearch从入门到精通(上)
黑马商城作为一个电商项目,商品的搜索肯定是访问频率最高的页面之一。目前搜索功能是基于数据库的模糊搜索来实现的,存在很多问题。 首先,查询效率较低。 由于数据库模糊查询不走索引,在数据量较大的时候,查询性能很差…...

2.0 全栈运维管理:Linux网络基础核心概念解析、Proxmox网络组件详解、虚拟化网络模型分类
本文是Proxmox VE 全栈管理体系的系列文章之一,如果对 Proxmox VE 全栈管理感兴趣,可以关注“Proxmox VE 全栈管理”专栏,后续文章将围绕该体系,从多个维度深入展开。 摘要:Linux 网络基础借助桥接、VLAN 和 Bonding 实…...

案例驱动的 IT 团队管理:创新与突破之路: 第四章 危机应对:从风险预见到创新破局-4.1.3重构过程中的团队士气管理
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 案例驱动的 IT 团队管理:创新与突破之路 - 第四章 危机应对:从风险预见到创新破局4.1.3 重构过程中的团队士气管理1. 技术债务重构与团队士气的矛盾2…...

洛谷刷题小结
#include <iostream> using namespace std; int n, m,ans0; char s[105][105]; //深搜 void dfs(int x, int y) {//将搜索到的水坑看为干地s[x][y] .;//确定八个方向int next[8][2] {{0,1},{0,-1},{1,0},{-1,0},{1,1},{1,-1},{-1,1},{-1,-1},};//朝八个方向搜索for (in…...

Android Compose 权限申请完整指南
Android Compose 权限申请完整指南 在 Jetpack Compose 中处理运行时权限申请需要结合传统的权限 API 和 Compose 的状态管理。以下是完整的实现方案: 1. 基本权限申请流程 添加依赖 implementation "com.google.accompanist:accompanist-permissions:0.34…...

VirtualBox虚拟机转换到VMware
VirtualBox虚拟机转换到VMware **参考文章:**https://blog.csdn.net/qq_30054403/article/details/123451969 一.找到对应文件位置 Windows11系统,VirtualBox版本为6.1.50,VMware版本为17.5.2 1.首先找到自己需要转换的vdi文件位置 D:\v…...
:RedisTemplate的List类型操作)
Spring Boot(二十二):RedisTemplate的List类型操作
RedisTemplate和StringRedisTemplate的系列文章详见: Spring Boot(十七):集成和使用Redis Spring Boot(十八):RedisTemplate和StringRedisTemplate Spring Boot(十九)…...

【MySQL】关于何时使用start slave和start slave user=‘’ password=‘’
这个问题是我在配置三个服务器的复制拓扑时,一开始没有给复制用户 repl 创建密码,搭建好循环拓扑后,给server1的复制用户通过 ALTER USER USER() IDENTIFIED BY oracle 设置了密码,然后同步给了server2和server3。 这时server2突…...
第十六届蓝桥杯大赛软件赛省赛C/C++ 研究生组)
(个人题解)第十六届蓝桥杯大赛软件赛省赛C/C++ 研究生组
宇宙超级无敌声明:个人题解(好久不训练,赛中就是一个憨憨) 先放代码吧,回头写思路。 文章目录 A. 数位倍数B. IPv6C. 变换数组D. 最大数字E. 冷热数据队列F. 01串G. 甘蔗H. 原料采购 A. 数位倍数 问: 在1至…...

GitLab + Jenkins + .Net8 实现CICD部署
前提条件:需要安装好 Jenkins 和 GitLab 。 1. Jenkins配置 登录 Jenkins 找到自己的一个任务,点击配置(没有任务就新建)。 按图操作 点击高级展开后截图,点击生成Token 配置好自己的作业(我的是一个 .Ne…...

AI工具导航 快速找到喜欢的AI工具 功能使用介绍
此篇文章内容来源CTO Plus技术服务栈官网:http://www.mdrsec.com/ 在人工智能技术迅猛发展的2025年,AI工具的数量和种类呈爆炸式增长,涵盖文本生成、图像创作、视频编辑、编程辅助等多个领域。面对琳琅满目的AI工具,如何高效筛选和…...
 E - level up)
[题解] Educational Codeforces Round 168 (Rated for Div. 2) E - level up
链接 思路 1 注意到在 k ∈ [ 1 , n ] k \in [1,n] k∈[1,n] 可以得到的最高等级分别为: n , n 2 , n 3 . . . . . n n n,\frac{n}{2},\frac{n}{3}.....\frac{n}{n} n,2n,3n.....nn, 总的个数是一个调和级数, s u m n ∗ ln n sumn*\ln n sumn∗lnn, 完全可以处…...

达梦数据库-学习-19-兼容ORACLE相关参数介绍
目录 一、环境信息 二、介绍 三、参数 一、环境信息 名称值CPU12th Gen Intel(R) Core(TM) i7-12700H操作系统CentOS Linux release 7.9.2009 (Core)内存4G逻辑核数2DM版本1 DM Database Server 64 V8 2 DB Version: 0x7000c 3 03134284194-202…...

如何通过 Spring 层面进行事务回滚?
Spring 中事务可以分为声明式事务和编程式事务,那么解下来就从这两方面说一说在 Spring 层面个怎么进行回滚 声明式事务回滚: 1. 基础注解配置 通过Transactional注解实现自动回滚,默认对RuntimeException和Error生效 Transactional publ…...

学Qt笔记
使用的是Qt SDK5.14.0 根据比特汤众老师的课程学习 先叠个甲:本人正在学qt,视角还不完备,如有错误请多多包含 选了widget开始学习 1.qt creator设计提供了拖拽式的编辑ui的控件,和代码直接编辑构建的方式 2.浅浅的认识了qt的对…...

【HarmonyOS 5】鸿蒙实现手写板
【HarmonyOS 5】鸿蒙实现手写板 一、前言 实现一个手写板功能,基本思路如下: 创建一个可交互的组件,用户在屏幕上触摸并移动手指时,会根据触摸的位置动态生成路径,并使用黑色描边绘制在屏幕上。当用户按下屏幕时…...

JavaWeb 课堂笔记 —— 09 MySQL 概述 + DDL
本系列为笔者学习JavaWeb的课堂笔记,视频资源为B站黑马程序员出品的《黑马程序员JavaWeb开发教程,实现javaweb企业开发全流程(涵盖SpringMyBatisSpringMVCSpringBoot等)》,章节分布参考视频教程,为同样学习…...

设计模式 --- 访问者模式
访问者模式是一种行为设计模式,它允许在不改变对象结构的前提下,定义作用于这些对象元素的新操作。 优点: 1.符合开闭原则:新增操作只需添加新的访问者类,无需修改现有对象结构。 2.操作逻辑集中管理&am…...

【Linux C】简单bash设计
主要功能 循环提示用户输入命令(minibash$)。创建子进程(fork())执行命令(execlp)。父进程等待子进程结束(waitpid)。关键问题 参数处理缺失:scanf("%s", buf)…...

如何在Agent中设置Memory
什么是LLM代理? LLM代理可以被定义为能够对环境采取行动的大型语言模型。代理的主要组成部分包括:记忆、规划、提示、知识和工具。大型语言模型可以被视为这个架构的大脑,而其他所有组件则是代理正常工作的基础模块。 代理的组成部分 1. 提…...

【强化学习-蘑菇书-3】马尔可夫性质,马尔可夫链,马尔可夫过程,马尔可夫奖励过程,如何计算马尔可夫奖励过程里面的价值
欢迎去各大电商平台选购纸质版蘑菇书《Easy RL:强化学习教程》 文章是根据 蘑菇书EasyRL ,网络查找资料和汇总,以及新版本的python编写的可运行代码和示例,包含了一些自己对书内容的简单理解 一、 马尔可夫性质 在随机过程中&a…...

leetcode 718 最长公共子数组
这个题目和最长公共子数组,类似于镜像题,子问题比较难想。对于 d p [ i ] [ j ] dp[i][j] dp[i][j] ,定义为分别以 i i i 和 j j j 结尾的最长公共子数组(公共后缀) 核心代码: if(nums1[i-1] nums2[j-…...

【C++】继承:万字总结
📝前言: 这篇文章我们来讲讲面向对象三大特性之一——继承 🎬个人简介:努力学习ing 📋个人专栏:C学习笔记 🎀CSDN主页 愚润求学 🌄其他专栏:C语言入门基础,py…...

java和c#的相似及区别基础对比
用过十几种语言,但是java和c#是最为重要的两门。c#发明人曾主导开发了pascal和delphi,加入微软后,参考了c和java完成了c#和net。大家用过java或c#任意一种的,可以通过本篇文章快速掌握另外一门语言。 基础语法 变量声明…...

TP8 PHP 支付宝-通用版-V3 SDK 接口加签方式为证书方式
TP8 已安装支付宝-通用版-V3 SDK 接口加签方式之前使用密钥方式,现在要使用证书 官方文档小程序文档 - 支付宝文档中心 SDK源码仓库https://github.com/alipay/alipay-sdk-php-all/tree/master/v3 第一步:生成证书 需要先下载支付宝官方工具:…...

地毯填充luogu
P1228 地毯填补问题 题目描述 相传在一个古老的阿拉伯国家里,有一座宫殿。宫殿里有个四四方方的格子迷宫,国王选择驸马的方法非常特殊,也非常简单:公主就站在其中一个方格子上,只要谁能用地毯将除公主站立的地方外的所有地方盖上,美丽漂亮聪慧的公主就是他的人了。公主…...

数据查询语言
一、DQL基础语法与执行逻辑 1.SELECT语句结构 (1)核心语法: SELECT 列名 FROM 表名 WHERE 条件 ,用于指定返回的字段和筛选行。例如, SELECT name, age FROM emp WHERE age > 25 筛选年龄大于25岁的员工姓名和年龄。 (2)执行顺序: FROM → WHERE → GROUP BY → HAV…...

【NLP】18. Encoder 和 Decoder
1. Encoder 和 Decoder 概述 在序列到序列(sequence-to-sequence,简称 seq2seq)的模型中,整个系统通常分为两大部分:Encoder(编码器)和 Decoder(解码器)。 Encoder&…...

基于Cline和OpenRouter模型进行MCP实战
大家好,我是herosunly。985院校硕士毕业,现担任算法工程师一职,获得CSDN博客之星第一名,热衷于大模型算法的研究与应用。曾担任百度千帆大模型比赛、BPAA算法大赛评委,编写微软OpenAI考试认证指导手册。曾获得多项AI顶级比赛的Top名次,其中包括阿里云、科大讯飞比赛第一名…...

Elasticsearch 故障转移及水平扩容
一、故障转移 Elasticsearch 的故障转移(Failover)机制是其高可用性的核心,通过分布式设计、自动检测和恢复策略确保集群在节点故障时持续服务。 1.1 故障转移的核心组件 组件作用Master 节点管理集群状态(分片分配、索引创建&…...

聊聊Spring AI的Prompt
序 本文主要研究一下Spring AI的Prompt Prompt org/springframework/ai/chat/prompt/Prompt.java public class Prompt implements ModelRequest<List<Message>> {private final List<Message> messages;private ChatOptions chatOptions;public Prompt(…...

centos 7:虚拟机网络配置
1、网络模式选择 桥接模式 特点:虚拟机会获得与物理机同网段的独立IP,可直接访问内网/外网适用场景:渗透测试、需要与其他设备交互的场景配置要点:需在VMware中指定桥接到物理机的真实网卡(如WiFi或有线网卡ÿ…...
)
Spring - 14 ( 5000 字 Spring 入门级教程 )
一:Spring原理 1.1 Bean 作用域的引入 在 Spring 的 IoC 和 DI 阶段,我们学习了 Spring 如何有效地管理对象。主要内容包括: 使用 Controller、Service、Repository、Component、Configuration 和 Bean 注解来声明 Bean 对象。通过 Applic…...

基于贝叶斯估计的多传感器数据融合算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.本算法原理 4.1 贝叶斯估计 4.2 多传感器数据融合 5.完整程序 1.程序功能描述 基于贝叶斯估计的多传感器数据融合算法matlab仿真,输入多个传感器的数据,通过贝叶斯估计…...

linux编辑器-vim
一、基本概念 vim有很多模式但是有三个重要的模式分别是命令模式、插入模式、低行模式。 命令模式:控制光标移动、字符、字或行的删除、移动、复制等。插入模式:只有在该模式下才可以进行文字输入。低行模式:文件的保存或退出,也…...

day27图像处理OpenCV
文章目录 一、图像预处理1 图像翻转(图像镜像旋转)2 图像仿射变换2.1 图像旋转2.2 图像平移2.3 图像缩放2.4 图像剪切 3 插值方法3.1 最近邻插值3.2 双线性插值(常用)3.3 像素区域插值--一般缩小使用3.4 双三次插值3.5 Lanczos插值 一、图像预处理 1 图像翻转(图像镜像旋转) …...

iOS开发--接入ADMob广告失败
接入ADMob的第三方广告,初始化时提示错误如下: state Not Ready;No such adapter in the application 查了各种官方文档,发现接入过程正确,查了Chatgpt和DeepSeek,它们各种分析,分析结果如下: …...

PyTorch进阶学习笔记[长期更新]
第一章 PyTorch简介和安装 PyTorch是一个很强大的深度学习库,在学术中使用占比很大。 我这里是Mac系统的安装,相比起教程中的win/linux安装感觉还是简单不少(之前就已经安好啦),有需要指导的小伙伴可以评论。 第二章…...

vue3 ts 自定义指令 app.directive
在 Vue 3 中,app.directive 是一个全局 API,用于注册或获取全局自定义指令。以下是关于 app.directive 的详细说明和使用方法 app.directive 用于定义全局指令,这些指令可以用于直接操作 DOM 元素。自定义指令在 Vue 3 中非常强大࿰…...
)
【漫话机器学习系列】199.过拟合 vs 欠拟合(Overfit vs Underfit)
机器学习核心问题:过拟合 vs 欠拟合 图示作者:Chris Albon 1. 什么是拟合(Fit)? 拟合(Fit)是指模型对数据的学习效果。 理想目标: 在训练集上效果好 在测试集上效果也好 不复杂、…...

从0到1使用C++操作MSXML
1. 引言 MSXML(Microsoft XML Core Services)是微软提供的一套用于处理XML的COM组件库,广泛应用于Windows平台的XML解析、验证、转换等操作。本文将详细介绍如何从零开始,在C中使用MSXML解析和操作XML文件,包含完整的…...

【中间件】nginx反向代理实操
一、说明 nginx用于做反向代理,其目标是将浏览器中的请求进行转发,应用场景如下: 说明: 1、用户在浏览器中发送请求 2、nginx监听到浏览器中的请求时,将该请求转发到网关 3、网关再将请求转发至对应服务 二、具体操作…...

C语言中冒泡排序和快速排序的区别
冒泡排序和快速排序都是常见的排序算法,但它们在原理、效率和应用场景等方面存在显著区别。以下是两者的详细对比: 一、算法原理 1. 冒泡排序 原理:通过重复遍历数组,比较相邻元素的大小,并在必要时交换它们的位置。…...

进程基本介绍
进程是操作系统的重要内容,都是需要了解和学习的,那么今天我们就来好好看看. 进程基本介绍 1、Linux中,每个执行的程序都称为一个进程,每一个进程都分配一个ID号(pid,进程号). 2.每个进程都可以以两种方式存在的,前台与后台,所谓前台进程就是用户目前的屏幕上可以进行操作的,…...

通过平台大数据智能引擎及工具,构建设备管理、运行工况监测、故障诊断等应用模型的智慧快消开源了
智慧快消视频监控平台是一款功能强大且简单易用的实时算法视频监控系统。它的愿景是最底层打通各大芯片厂商相互间的壁垒,省去繁琐重复的适配流程,实现芯片、算法、应用的全流程组合,从而大大减少企业级应用约95%的开发成本。 基于多年的深度…...

不同数据库的注入报错信息
不同数据库在报错注入时返回的报错信息具有显著差异,了解这些差异可以帮助快速判断数据库类型并构造针对性的注入攻击语句。以下是主流数据库的典型报错模式及对比: 目录 1. MySQL 2. Microsoft SQL Server 3. Oracle …...

tcpdump`是一个非常强大的命令行工具,用于在网络上捕获并分析数据包
通过 tcpdump,你可以抓取网络流量,诊断网络问题,或分析通信协议的细节。下面是如何在 Linux 上使用 tcpdump 进行抓包的详细步骤。 1. 安装 tcpdump 在大多数 Linux 发行版中,tcpdump 是默认安装的。如果没有安装,可…...

【漏洞复现】Vite 任意文件读取漏洞 CVE-2025-30208/CVE-2025-31125/CVE-2025-31486/CVE-2025-32395
Vite是什么,和Next.js有什么区别? 我上一篇文章刚介绍了Next.js漏洞的复现: 【漏洞复现】Next.js中间件权限绕过漏洞 CVE-2025-29927_next.js 中间件权限绕过漏洞-CSDN博客 Vite 和 Next.js 是两个不同类型的前端工具,它们各自…...
 相关控制变量传递)
Odrive源码分析(六) 相关控制变量传递
本文记录下odrive源代码中相关控制模块之间变量的传递,这对理解odrive源代码至关重要。 通过前面文字的分析,odrive有两条数据链路,一条是通过中断进行实时的控制,另外一条是OS相关的操作,主要分析下中断内部的相关变量…...

ARM架构FFmpeg极致优化交叉编译指南
ARM架构FFmpeg极致优化交叉编译指南 一、工具链科学配置 使用最新的ARM官方工具链(Linaro或ARM GNU Toolchain) 确保工具链支持目标平台特定指令集(如NEON, VFP等) 设置正确的–sysroot和–prefix参数 1. 工具链选择原则 # 32位ARM (推荐) wget https://developer.arm.com/…...