如何在Agent中设置Memory
什么是LLM代理?
LLM代理可以被定义为能够对环境采取行动的大型语言模型。代理的主要组成部分包括:记忆、规划、提示、知识和工具。大型语言模型可以被视为这个架构的大脑,而其他所有组件则是代理正常工作的基础模块。
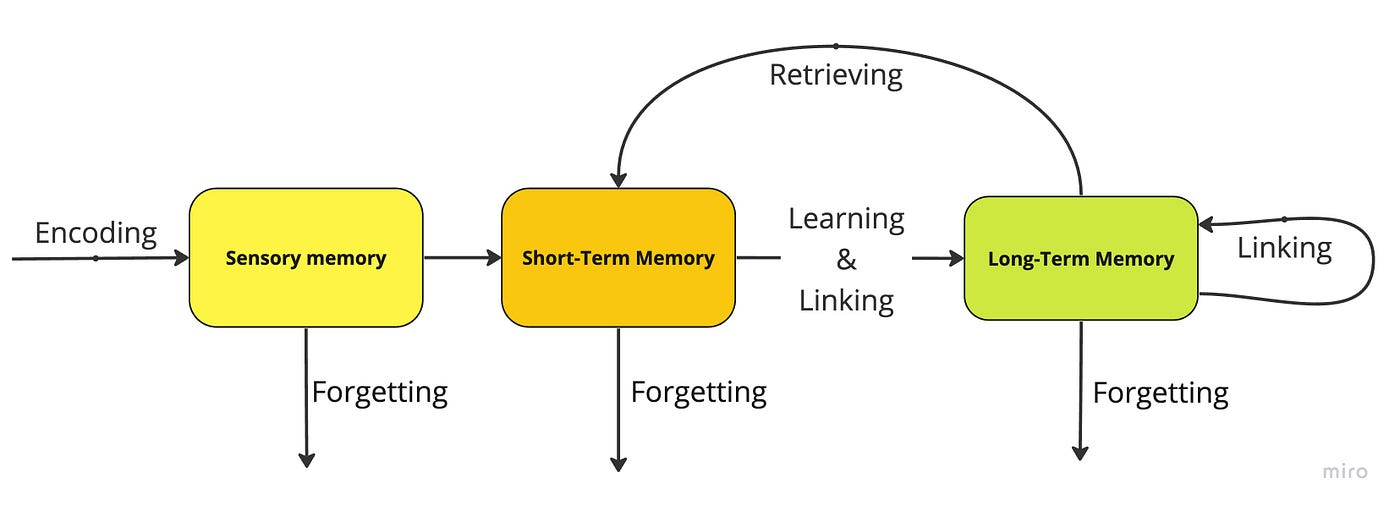
代理的组成部分
1. 提示
提示是向LLM提供其目标、行为和计划信息的指令。
2. 规划
复杂问题通常需要链式思考的方法。因此,代理必须通过其推理能力制定计划。
3. 工具
可执行的函数、API或其他服务,让代理能够完成任务并与环境交互。
4. 知识
没有领域知识,代理就无法解决甚至理解任务。所以要么对LLM进行微调以获取知识,要么创建工具从数据库中提取知识。
5. 记忆
众所周知,代理通过先将复杂任务分解为子任务,然后执行工具来完成子任务。为此,模型需要记住之前的步骤。这也是本文将重点关注的方面。
记忆分类
简单来说,记忆就是一个能记住之前互动内容的系统。这对于打造良好的代理体验至关重要。想象一下,如果你有个同事记不住过去的指示,很快就会变得无法继续工作。由于代理主要用于多阶段任务,记忆就变得尤为重要。
据《语言代理的认知架构》一文所述,语言代理使用几种类型的记忆来存储和维护与世界互动的信息:
1. 短期记忆
工作记忆维持活跃信息,作为连接语言代理各个组件的中央枢纽。它保存感知输入、来自推理或检索的活跃知识以及从前几个周期带来的其他信息。工作记忆与长期记忆和基础接口交互,并在多次LLM调用过程中持续存在。
短期记忆主要用于存储当前任务或对话的上下文信息,例如多轮对话中的用户查询和系统响应。
实现方式通常依赖大语言模型(LLM)的上下文窗口(Context Window),其容量受限于Transformer模型的架构。 例如,一些模型的上下文长度可能达到4096个令牌,但具体数值因模型而异。
短期记忆的特点是临时性,任务完成后通常会被清除,以释放资源并避免信息过载。 例如,Ali的SuperAGI通过生成交互的简洁摘要(如agent_summary.txt)来维护短期记忆,确保摘要长度不超过设定的字符限制。
三种常见的形式为:
-
上下文窗口:最基础的形式,将之前的对话历史保留在输入窗口中,但受限于模型的上下文长度限制。
-
滑动窗口:当对话超出上下文限制时,保留最近的N条交互,丢弃较早的内容。
-
消息压缩/总结:将过去的对话历史压缩或总结,以节省上下文空间。
2. 长期记忆
长期记忆用于存储需要持久保留的信息,例如用户的偏好、过去的任务经验或外部知识。
实现方式通常依赖外部存储系统,如向量数据库(Vector Database),通过将信息嵌入向量空间,支持基于相似性搜索的快速检索。
例如,千问AI agent使用一个Memory类来管理长期记忆,支持多种文件类型(如.pdf、.docx、.xlsx等),并配置参数如max_ref_token(默认4000)、parser_page_size(默认500)等,通过检索增强生成(Retrieval-Augmented Generation, RAG)技术进行高效检索。
长期记忆的另一个例子是MemoryBank,它存储完整的交互记录,以确保对话的一致性和连贯性。
总结来说两种主要形式为:
-
向量数据库存储:
- 将对话内容转换为向量嵌入
- 存储在向量数据库中(如Pinecone、Faiss、Milvus等)
- 通过相似性搜索快速检索相关信息
-
结构化知识库:
- 将信息以键值对、图结构或三元组形式存储
- 常用Neo4j、Postgres等数据库
2.1 情景记忆
情景记忆存储以前决策周期的经验。 这包括训练的输入-输出对、事件流、游戏轨迹和其他表示过去经验的内容。这些存储的内容可以在规划阶段被检索到工作记忆中以支持推理。

2.2 语义记忆
语义记忆存储代理关于世界和自身的知识。这可以从外部数据库初始化,也可以随着时间的推移通过学习积累。 语义记忆可以存储事实或通过推理获得的知识。
2.3 程序记忆:

程序记忆很有意思,比如骑车。
程序记忆存储关于如何执行操作的知识,有两种形式:
- 存储在LLM权重中通过交互学习到的隐式知识
- 写在代理代码中的显式知识。程序记忆由设计者初始化,虽然可以更新,但比更新其他类型的记忆风险更大,比如开发者为防止产品被滥用而设定的护栏。
这些不同的记忆模块让语言代理能够存储、检索和从经验中学习,并使用这些信息做出明智的决策。
简言之,程序记忆可以被定义为应用于工作记忆以确定代理行为的一套规则。
记忆的实现过程
证据倾向于支持记忆的实现包括三个主要步骤,类似于认知心理学中的记忆模型:
-
写入(Writing):
- 此步骤涉及捕获并存储新信息。例如,在对话场景中,Agent可能会提取用户输入的关键点(如饮食偏好、用餐时间)并存储到记忆中。
- 写入过程可能涉及信息提取和格式化,例如将对话记录转换为自然语言描述或向量表示。
-
管理(Management):
- 管理阶段包括更新、整合和可能遗忘信息,以保持记忆的相关性和效率。
- 一些系统使用衰减因子(如0.99)来减少旧信息的重要性,或通过抽象和合并减少冗余。例如,系统可能将多次提及的相同偏好合并为单一记录。
- 管理还可能涉及反射(Reflection)机制,将过去的经验整合为更高层次的知识。
-
读取(Reading):
- 读取阶段根据当前任务或查询检索相关信息。例如,在餐厅预订任务中,Agent可能会从长期记忆中检索用户的饮食偏好、用餐人数和时间,以确定合适的餐厅。
- 读取通常基于相似性搜索,通过将查询转换为向量并与存储的记忆向量进行比较,快速找到相关信息。
其中读取我们可以理解为记忆检索
记忆检索
-
语义搜索:基于当前查询与存储信息的语义相关性检索
-
时间衰减检索:优先考虑最近的记忆,较早的记忆权重降低
-
重要性过滤:基于预设规则或重要性评分筛选信息
其中管理我们可以理解为记忆更新,以下为记忆更新关键动作
记忆更新
-
主动总结:定期总结对话内容生成新的记忆条目
-
记忆合并与删除:合并重复信息,删除不相关或过时信息
-
分层记忆管理:
- 工作记忆:当前活跃的信息
- 短期记忆:近期但非立即需要的信息
- 长期记忆:重要但不常用的信息
以下是记忆在实际应用中的具体案例,展示了其重要性:
- 餐厅预订Agent:在“Agent 预定餐厅”案例中,记忆在第二步用于检索用户的饮食偏好、用餐人数和时间,以匹配合适的餐厅。这体现了短期记忆用于对话上下文,长期记忆用于存储用户特征。
- 对话系统:如MemoryBank,用于保存对话记录,确保多轮对话的一致性和连贯性,增强用户体验。
- 个人助理:长期记忆存储用户习惯和偏好,支持个性化推荐。
- 开放世界游戏:如Voyager,存储技能和经验,支持探索和任务执行。
如何在代理中设置记忆
现在,我们了解了各种类型的记忆以及大致实现过程,但如何在代理中设置记忆呢?
1. 暴力记忆法
我们可以将之前的消息放在一个列表中,每次运行代理时都加载这个消息列表。如果不需要长期记忆且交互不会占用太多token,这种方法是可行的。
messages = [ { "role" : "user" , "content" : "法国的首都是哪里?"}, { "role" : "assistant" , "content" : "法国的首都是巴黎。"}, { "role" : "user" , "content" : "总结这段文字:‘敏捷的棕色狐狸跳过了懒狗。’"}, { "role" : "assistant" , "content" : "这段文字描述了一只敏捷的棕色狐狸跳过了一只懒狗。"}, { "role" : "user" , "content" : "生成 Python 代码来计算数字的阶乘。"}, { "role" : "assistant" , "content" : "这是一个用于计算数字阶乘的 Python 函数:\n\n```python\nimport math\n\ndef factorial(n):\n if n < 0:\n raise ValueError(\"Factorial is not defined for negative numbers.\")\n return 1 if n == 0 else n * factorial(n - 1)\n```"}, { "role" : "user" , "content" : "用简单的术语解释神经网络是如何工作的。"}, { "role" : "assistant" , "content" : "神经网络是模仿人脑的计算机系统。它们由相互连接的节点层(如神经元)组成。数据通过这些连接传递,网络调整其内部参数以学习模式并做出预测或决策。"}, { "role" : "user" , "content" : "在此列表中找出两个最大的数字:[3, 1, 4, 1, 5, 9, 2, 6]。"}, { "role" : "assistant" , "content" : "列表中两个最大的数字是 9 和 6。"}, { "role" : "user" , "content" :"1 除以 0 的结果是多少?"}, { "role" : "assistant" , "content" : "1 除以 0 在数学上是未定义的,并且在大多数编程语言中,它会导致错误。"}, {"role" : "user" , "content" : "如何在 LangChain 中编写提示来总结文本?"}, { "role" : "assistant" , "content" : "这是一个用于总结文本的 LangChain 提示的示例:\n\n```python\nfrom langchain.prompts import PromptTemplate\n\nprompt = PromptTemplate(\n input_variables=['text'],\n template=\"\"\"\n 请总结以下文本:\n {text}\n \"\"\"\n)\n```"}
]
2. RAG或微调
我们可以使用检索增强生成(RAG)来模拟长期记忆。检索增强生成的工作原理如下:
- 首先检索与用户查询相关的内容
- 将检索内容与用户的查询结合
- 然后使用组合后的提示生成答案
这种方法的主要挑战包括开发者需要定期更新系统,这会随着时间推移变得很费力。此外,随着交互在数据库中累积,内存使用量会显著增长,最终导致难以高效管理和检索过去的交互。
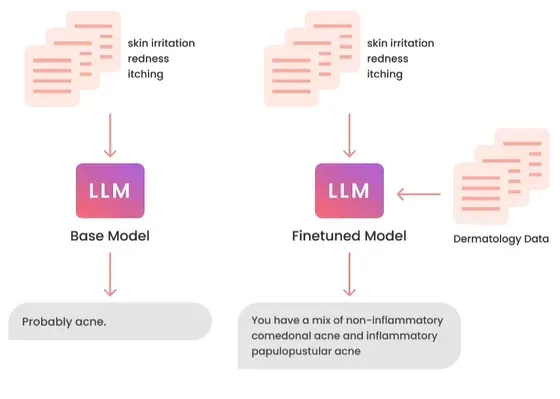
另一种方法可能是将之前的行动作为微调数据用于未来任务。微调让你能够将更多数据输入到模型中,而不仅仅是放入提示。这让模型学习数据而不只是访问数据。但这需要太多计算资源和时间,并非人人都有资源来微调大型语言模型。
3. MemGPT
还有一种完全不同的方法来完成这个任务。如果我们让LLM管理自己的记忆会怎样?论文《Memgpt: Towards llms as operating systems》回答了这个问题。
MemGPT使用受传统操作系统启发的虚拟内存系统来管理大型语言模型(LLM)的有限上下文窗口。
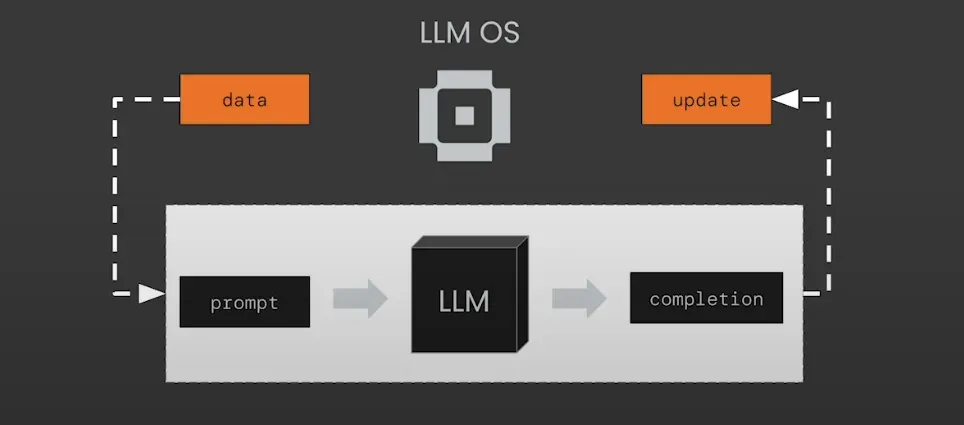
MemGPT是一个执行内存管理的LLM操作系统。在MemGPT中,这个操作系统本身也是一个LLM代理。因此,记忆管理是自动完成的。
但它是如何工作的呢?我们可以用一个类比来理解这个虚拟内存是如何工作的:
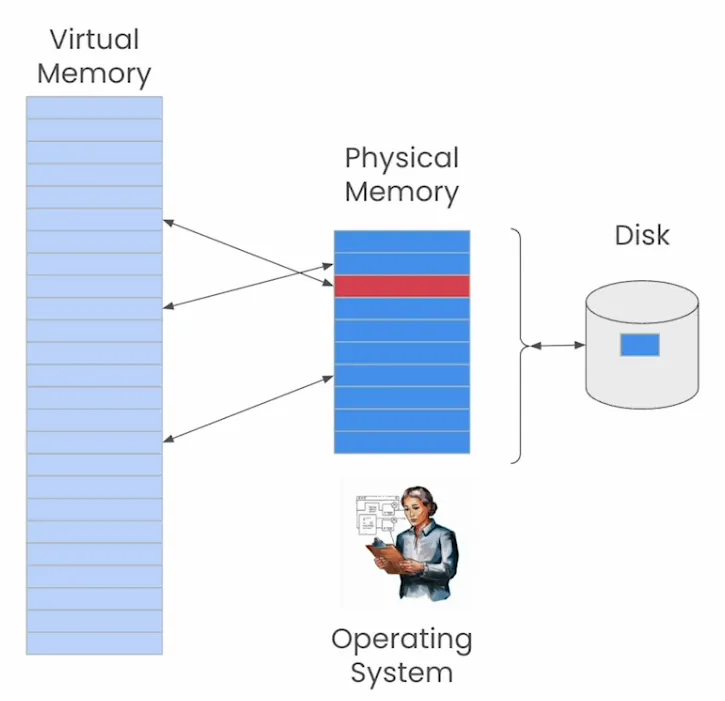
在MemGPT中,上下文窗口可以被视为计算机中的虚拟内存。你的计算机认为它有一个很大的内存,比实际拥有的物理内存大得多。具体来说,它有一个很大的虚拟内存。当它尝试引用一个不在物理内存中的虚拟位置时,操作系统会先通过将物理内存中的一块信息移出到磁盘来腾出空间,保留该块中的任何更改,然后从磁盘获取新的信息块,并将其带回物理内存。
类似地,你可以将LLM的上下文窗口视为类似于物理内存。在MemGPT系统中,LLM代理包括操作系统的角色,并决定上下文窗口中应该包含哪些信息。
MemGPT背后的关键理念
自我编辑记忆:
在MemGPT中,代理可以根据聊天中学到的内容更新自己的指令或个性化信息。它通过使用工具来实现这一点。
内心思考
在MemGPT中,代理总是进行自我思考,而回应用户只是一种工具。因此,代理不会在收到用户问题后立即回答。通常在回答前会有几步内心思考。
每个输出都是一个工具
在MemGPT中,代理总是调用工具。即使是回答用户也是一种工具。唯一不使用工具的步骤是内心思考。
通过心跳循环
在MemGPT中,代理能够通过心跳进行循环。将request_heartbeat设置为True意味着代理必须调用另一个工具。心跳可以被视为内心思考和非回答用户工具的限制器。由于LLM可能会不断创造更多内心思考,我们设置了一个叫做心跳的限制,如果不回答用户的步骤超过了心跳限制,那么LLM必须为用户形成一个答案。
基于向量数据库的记忆实现示例
# 简化的基于向量数据库的记忆实现示例
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings# 初始化嵌入模型和向量存储
embeddings = OpenAIEmbeddings()
memory_db = Chroma(embedding_function=embeddings)# 存储记忆
def store_memory(text, metadata=None):memory_db.add_texts([text], metadatas=[metadata] if metadata else None)# 检索相关记忆
def retrieve_memories(query, k=5):results = memory_db.similarity_search(query, k=k)return [doc.page_content for doc in results]# 在Agent中使用
def agent_response(user_query):# 1. 检索相关记忆relevant_memories = retrieve_memories(user_query)# 2. 构建包含记忆的提示prompt = f"""记忆:{' '.join(relevant_memories)}用户问题: {user_query}请考虑上述记忆回答问题。"""# 3. 调用LLM获取回答response = llm(prompt)# 4. 存储新记忆store_memory(f"用户: {user_query}\n助手: {response}")return response
结论
记忆是AI Agent能够学习和适应的关键:
- 学习与进化:通过积累经验,Agent可以从过去的任务中学习,支持跨任务信息的整合。
- 一致性与自然性:在对话系统中,记忆确保多轮对话的连贯性和用户参与度。
- 扩展能力:通过外部知识(如API或数据库),Agent可以超越内部知识的限制。
然而,当前研究仍面临挑战:
- 主要集中在文本形式的记忆上,而参数化记忆(Parametric Memory)研究不足。
- 多Agent记忆、终身学习(Lifelong Learning)以及模拟人类记忆的机制(如遗忘曲线)仍需进一步探索。
大模型智能体Agent的记忆通过短期记忆和长期记忆实现,前者处理临时对话信息,后者存储持久化数据。记忆的实现包括写入、管理和读取三个步骤,支持Agent在复杂任务中的学习和决策。尽管当前技术已取得进展,但仍存在挑战,未来研究将进一步提升记忆系统的效率和智能化。
相关文章:

如何在Agent中设置Memory
什么是LLM代理? LLM代理可以被定义为能够对环境采取行动的大型语言模型。代理的主要组成部分包括:记忆、规划、提示、知识和工具。大型语言模型可以被视为这个架构的大脑,而其他所有组件则是代理正常工作的基础模块。 代理的组成部分 1. 提…...

【强化学习-蘑菇书-3】马尔可夫性质,马尔可夫链,马尔可夫过程,马尔可夫奖励过程,如何计算马尔可夫奖励过程里面的价值
欢迎去各大电商平台选购纸质版蘑菇书《Easy RL:强化学习教程》 文章是根据 蘑菇书EasyRL ,网络查找资料和汇总,以及新版本的python编写的可运行代码和示例,包含了一些自己对书内容的简单理解 一、 马尔可夫性质 在随机过程中&a…...

leetcode 718 最长公共子数组
这个题目和最长公共子数组,类似于镜像题,子问题比较难想。对于 d p [ i ] [ j ] dp[i][j] dp[i][j] ,定义为分别以 i i i 和 j j j 结尾的最长公共子数组(公共后缀) 核心代码: if(nums1[i-1] nums2[j-…...

【C++】继承:万字总结
📝前言: 这篇文章我们来讲讲面向对象三大特性之一——继承 🎬个人简介:努力学习ing 📋个人专栏:C学习笔记 🎀CSDN主页 愚润求学 🌄其他专栏:C语言入门基础,py…...

java和c#的相似及区别基础对比
用过十几种语言,但是java和c#是最为重要的两门。c#发明人曾主导开发了pascal和delphi,加入微软后,参考了c和java完成了c#和net。大家用过java或c#任意一种的,可以通过本篇文章快速掌握另外一门语言。 基础语法 变量声明…...

TP8 PHP 支付宝-通用版-V3 SDK 接口加签方式为证书方式
TP8 已安装支付宝-通用版-V3 SDK 接口加签方式之前使用密钥方式,现在要使用证书 官方文档小程序文档 - 支付宝文档中心 SDK源码仓库https://github.com/alipay/alipay-sdk-php-all/tree/master/v3 第一步:生成证书 需要先下载支付宝官方工具:…...

地毯填充luogu
P1228 地毯填补问题 题目描述 相传在一个古老的阿拉伯国家里,有一座宫殿。宫殿里有个四四方方的格子迷宫,国王选择驸马的方法非常特殊,也非常简单:公主就站在其中一个方格子上,只要谁能用地毯将除公主站立的地方外的所有地方盖上,美丽漂亮聪慧的公主就是他的人了。公主…...

数据查询语言
一、DQL基础语法与执行逻辑 1.SELECT语句结构 (1)核心语法: SELECT 列名 FROM 表名 WHERE 条件 ,用于指定返回的字段和筛选行。例如, SELECT name, age FROM emp WHERE age > 25 筛选年龄大于25岁的员工姓名和年龄。 (2)执行顺序: FROM → WHERE → GROUP BY → HAV…...

【NLP】18. Encoder 和 Decoder
1. Encoder 和 Decoder 概述 在序列到序列(sequence-to-sequence,简称 seq2seq)的模型中,整个系统通常分为两大部分:Encoder(编码器)和 Decoder(解码器)。 Encoder&…...

基于Cline和OpenRouter模型进行MCP实战
大家好,我是herosunly。985院校硕士毕业,现担任算法工程师一职,获得CSDN博客之星第一名,热衷于大模型算法的研究与应用。曾担任百度千帆大模型比赛、BPAA算法大赛评委,编写微软OpenAI考试认证指导手册。曾获得多项AI顶级比赛的Top名次,其中包括阿里云、科大讯飞比赛第一名…...

Elasticsearch 故障转移及水平扩容
一、故障转移 Elasticsearch 的故障转移(Failover)机制是其高可用性的核心,通过分布式设计、自动检测和恢复策略确保集群在节点故障时持续服务。 1.1 故障转移的核心组件 组件作用Master 节点管理集群状态(分片分配、索引创建&…...

聊聊Spring AI的Prompt
序 本文主要研究一下Spring AI的Prompt Prompt org/springframework/ai/chat/prompt/Prompt.java public class Prompt implements ModelRequest<List<Message>> {private final List<Message> messages;private ChatOptions chatOptions;public Prompt(…...

centos 7:虚拟机网络配置
1、网络模式选择 桥接模式 特点:虚拟机会获得与物理机同网段的独立IP,可直接访问内网/外网适用场景:渗透测试、需要与其他设备交互的场景配置要点:需在VMware中指定桥接到物理机的真实网卡(如WiFi或有线网卡ÿ…...
)
Spring - 14 ( 5000 字 Spring 入门级教程 )
一:Spring原理 1.1 Bean 作用域的引入 在 Spring 的 IoC 和 DI 阶段,我们学习了 Spring 如何有效地管理对象。主要内容包括: 使用 Controller、Service、Repository、Component、Configuration 和 Bean 注解来声明 Bean 对象。通过 Applic…...

基于贝叶斯估计的多传感器数据融合算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.本算法原理 4.1 贝叶斯估计 4.2 多传感器数据融合 5.完整程序 1.程序功能描述 基于贝叶斯估计的多传感器数据融合算法matlab仿真,输入多个传感器的数据,通过贝叶斯估计…...

linux编辑器-vim
一、基本概念 vim有很多模式但是有三个重要的模式分别是命令模式、插入模式、低行模式。 命令模式:控制光标移动、字符、字或行的删除、移动、复制等。插入模式:只有在该模式下才可以进行文字输入。低行模式:文件的保存或退出,也…...

day27图像处理OpenCV
文章目录 一、图像预处理1 图像翻转(图像镜像旋转)2 图像仿射变换2.1 图像旋转2.2 图像平移2.3 图像缩放2.4 图像剪切 3 插值方法3.1 最近邻插值3.2 双线性插值(常用)3.3 像素区域插值--一般缩小使用3.4 双三次插值3.5 Lanczos插值 一、图像预处理 1 图像翻转(图像镜像旋转) …...

iOS开发--接入ADMob广告失败
接入ADMob的第三方广告,初始化时提示错误如下: state Not Ready;No such adapter in the application 查了各种官方文档,发现接入过程正确,查了Chatgpt和DeepSeek,它们各种分析,分析结果如下: …...

PyTorch进阶学习笔记[长期更新]
第一章 PyTorch简介和安装 PyTorch是一个很强大的深度学习库,在学术中使用占比很大。 我这里是Mac系统的安装,相比起教程中的win/linux安装感觉还是简单不少(之前就已经安好啦),有需要指导的小伙伴可以评论。 第二章…...

vue3 ts 自定义指令 app.directive
在 Vue 3 中,app.directive 是一个全局 API,用于注册或获取全局自定义指令。以下是关于 app.directive 的详细说明和使用方法 app.directive 用于定义全局指令,这些指令可以用于直接操作 DOM 元素。自定义指令在 Vue 3 中非常强大࿰…...
)
【漫话机器学习系列】199.过拟合 vs 欠拟合(Overfit vs Underfit)
机器学习核心问题:过拟合 vs 欠拟合 图示作者:Chris Albon 1. 什么是拟合(Fit)? 拟合(Fit)是指模型对数据的学习效果。 理想目标: 在训练集上效果好 在测试集上效果也好 不复杂、…...

从0到1使用C++操作MSXML
1. 引言 MSXML(Microsoft XML Core Services)是微软提供的一套用于处理XML的COM组件库,广泛应用于Windows平台的XML解析、验证、转换等操作。本文将详细介绍如何从零开始,在C中使用MSXML解析和操作XML文件,包含完整的…...

【中间件】nginx反向代理实操
一、说明 nginx用于做反向代理,其目标是将浏览器中的请求进行转发,应用场景如下: 说明: 1、用户在浏览器中发送请求 2、nginx监听到浏览器中的请求时,将该请求转发到网关 3、网关再将请求转发至对应服务 二、具体操作…...

C语言中冒泡排序和快速排序的区别
冒泡排序和快速排序都是常见的排序算法,但它们在原理、效率和应用场景等方面存在显著区别。以下是两者的详细对比: 一、算法原理 1. 冒泡排序 原理:通过重复遍历数组,比较相邻元素的大小,并在必要时交换它们的位置。…...

进程基本介绍
进程是操作系统的重要内容,都是需要了解和学习的,那么今天我们就来好好看看. 进程基本介绍 1、Linux中,每个执行的程序都称为一个进程,每一个进程都分配一个ID号(pid,进程号). 2.每个进程都可以以两种方式存在的,前台与后台,所谓前台进程就是用户目前的屏幕上可以进行操作的,…...

通过平台大数据智能引擎及工具,构建设备管理、运行工况监测、故障诊断等应用模型的智慧快消开源了
智慧快消视频监控平台是一款功能强大且简单易用的实时算法视频监控系统。它的愿景是最底层打通各大芯片厂商相互间的壁垒,省去繁琐重复的适配流程,实现芯片、算法、应用的全流程组合,从而大大减少企业级应用约95%的开发成本。 基于多年的深度…...

不同数据库的注入报错信息
不同数据库在报错注入时返回的报错信息具有显著差异,了解这些差异可以帮助快速判断数据库类型并构造针对性的注入攻击语句。以下是主流数据库的典型报错模式及对比: 目录 1. MySQL 2. Microsoft SQL Server 3. Oracle …...

tcpdump`是一个非常强大的命令行工具,用于在网络上捕获并分析数据包
通过 tcpdump,你可以抓取网络流量,诊断网络问题,或分析通信协议的细节。下面是如何在 Linux 上使用 tcpdump 进行抓包的详细步骤。 1. 安装 tcpdump 在大多数 Linux 发行版中,tcpdump 是默认安装的。如果没有安装,可…...

【漏洞复现】Vite 任意文件读取漏洞 CVE-2025-30208/CVE-2025-31125/CVE-2025-31486/CVE-2025-32395
Vite是什么,和Next.js有什么区别? 我上一篇文章刚介绍了Next.js漏洞的复现: 【漏洞复现】Next.js中间件权限绕过漏洞 CVE-2025-29927_next.js 中间件权限绕过漏洞-CSDN博客 Vite 和 Next.js 是两个不同类型的前端工具,它们各自…...
 相关控制变量传递)
Odrive源码分析(六) 相关控制变量传递
本文记录下odrive源代码中相关控制模块之间变量的传递,这对理解odrive源代码至关重要。 通过前面文字的分析,odrive有两条数据链路,一条是通过中断进行实时的控制,另外一条是OS相关的操作,主要分析下中断内部的相关变量…...

ARM架构FFmpeg极致优化交叉编译指南
ARM架构FFmpeg极致优化交叉编译指南 一、工具链科学配置 使用最新的ARM官方工具链(Linaro或ARM GNU Toolchain) 确保工具链支持目标平台特定指令集(如NEON, VFP等) 设置正确的–sysroot和–prefix参数 1. 工具链选择原则 # 32位ARM (推荐) wget https://developer.arm.com/…...

zk源码—7.ZAB协议和数据存储一
大纲 1.两阶段提交Two-Phase Commit(2PC) 2.三阶段提交Three-Phase Commit(3PC) 3.ZAB协议算法 4.ZAB协议与Paxos算法 5.zk的数据存储原理之内存数据 6.zk的数据存储原理之事务日志 7.zk的数据存储原理之数据快照 8.zk的数据存储原理之数据初始化和数据同步流程 1.两阶…...

2025蓝桥杯C++A组省赛 题解
昨天打完蓝桥杯本来想写个 p y t h o n python python A A A 组的题解,结果被队友截胡了。今天上课把 C A CA CA 组的题看了,感觉挺简单的,所以来水一篇题解。 这场 B B B 是一个爆搜, C C C 利用取余的性质比较好写&#…...

用哪个机器学习模型 依靠极少量即时静态数据来训练ai预测足球赛的结果?
目录 一、模型推荐 1.集成树模型(XGBoost/CatBoost) 2.逻辑回归(Logistic Regression) 3.贝叶斯概率模型(Naive Bayes或贝叶斯网络) 4.支持向量机(SVM) 二、模型排除 三、训练…...

讲解贪心算法
贪心算法是一种常用的算法思想,其在解决问题时每一步都做出在当前状态下看起来最优的选择,从而希望最终能够获得全局最优解。C作为一种流行的编程语言,可以很好地应用于贪心算法的实现。下面我们来讲一篇关于C贪心算法的文章。 目录 贪心算法…...

0基础 | 电动汽车的“电源翻译官” | DC/DC转换器 | 电源系统三
你有没有想过,电动汽车里那么多五花八门的电子设备,比如车灯、仪表盘、摄像头,甚至连控制马达的“大脑”(ECU),是怎么用上电的?今天就来聊聊电动车里一个默默工作的“小功臣”——DC/DC转换器&a…...

zynq7020 u-boot 速通
zynq u-boot 速通 简介 上回最小系统已经跑起来,证明串口和 ddr 正确配置.现在我们需要正确配置 网口, qspi, emmc. 网口:通过 tftp 下载 dtb,image,rootfs 在线调试.qspi:固化 boot.bin 到 qspi flash,这样 qspi 启动就可以直接运行 u-boot.emmc:存放 ubuntu_base 跟文件系统…...

C++学习之路,从0到精通的征途:string类的模拟实现
目录 一.string类的成员变量与成员函数 二.string类的接口实现 1.构造函数,析构函数,拷贝构造函数,赋值重载 (1)构造函数 (2)析构函数 (3)拷贝构造函数 &…...

网页制作中的MVC和MVT
MVC(模型-视图-控制器)和MVT(模型-模板-视图)是两种常见的软件架构模式,通常用于Web应用程序的设计。它们之间的主要区别在于各自的组件职责和工作方式。 MVC(模型-视图-控制器): 模…...

02 - spring security基于配置文件及内存的账号密码
spring security基于配置的账号密码 文档 00 - spring security框架使用01 - spring security自定义登录页面 yml文件中配置账号密码 spring:security:user:name: adminpassword: 123456yml文件中配置账号密码后,控制台将不再输出临时密码 基于内存的账号密码 …...

Firebase Studio:开启 AI 驱动的开发新纪元
Firebase Studio(前身为 Project IDX)的推出,标志着软件开发范式正经历深刻变革。它不仅是一个传统的 IDE,更是一个以 AI 为主导的、代理式 (agentic) 的云端开发环境,专注于全栈 AI 应用(包括 API、后端、…...

网络基础2
目录 跨网络传输流程 网络中的地址管理 - 认识 IP 地址 跨网络传输 报文信息的跨网络发送 IP地址的转化 认识端口号 端口号范围划分 源端口号和目的端口号 认识 TCP / UDP协议 理解 socket 网络字节序 socket 编程接口 sockaddr 结构 我们继续来学习网络基础 跨网…...
——部署项目到仓库)
Maven工具学习使用(十一)——部署项目到仓库
1、使用Maven默认方式 Maven 部署项目时默认使用的上传文件方式是通过 HTTP/HTTPS 协议。要在 Maven 项目中配置部署,您需要在项目的 pom.xml 文件中添加 部分。这个部分定义了如何部署项目的构件(如 JAR 文件)到仓库。。这个部分定义了如何…...
)
FPGA 37 ,FPGA千兆以太网设计实战:RGMII接口时序实现全解析( RGMII接口时序设计,RGMII~GMII,GMII~RGMII 接口转换 )
目录 前言 一、设计流程 1.1 需求理解 1.2 模块划分 1.3 测试验证 二、模块分工 2.1 RGMII→GMII(接收方向,rgmii_rx 模块) 2.2 GMII→RGMII(发送方向,rgmii_tx 模块) 三、代码实现 3.1 顶层模块 …...

torch.cat和torch.stack的区别
torch.cat 和 torch.stack 是 PyTorch 中用于组合张量的两个常用函数,它们的核心区别在于输入张量的维度和输出张量的维度变化。以下是详细对比: 1. torch.cat (Concatenate) 作用:沿现有维度拼接多个张量,不创建新维度 输入要求…...
)
索引下推(Index Condition Pushdown, ICP)
概念 索引下推是一种数据库查询优化技术,通过在存储引擎层面应用部分WHERE条件来减少不必要的数据读取。它特别适用于复合索引的情况,因为它可以在索引扫描阶段就排除不符合全部条件的数据行,而不是将所有可能匹配的记录加载到服务器层再进行…...

C++基础精讲-06
文章目录 1. this指针1.1 this指针的概念1.2 this指针的使用 2. 特殊的数据成员2.1 常量数据成员2.2 引用数据成员2.3 静态数据成员2.4 对象成员 3. 特殊的成员函数3.1 静态成员函数3.2 const成员函数3.3 mutable关键字 1. this指针 1.1 this指针的概念 1.c规定,t…...

Django3 - 建站基础
学习开发网站必须了解网站的组成部分、网站类型、运行原理和开发流程。使用Django开发网站必须掌握Django的基本操作,比如创建项目、使用Django的操作指令以及开发过程中的调试方法。 一、网站的定义及组成 网站(Website)是指在因特网上根据一定的规则,…...

UE5蓝图设置界面尺寸大小
UE5蓝图设置界面尺寸大小 Create widget 创建UIadd to Viewport 添加视图get Game User Settings获取游戏用户设置set Screen Resolutions 设置屏幕尺寸大小1920*1080set Fullscreen Mode 设置全屏模式为:窗口化或者全屏Apply Settings 应用设置...

无数字字母RCE
无数字字母RCE,这是一个老生常谈的问题,就是不利用数字和字母构造出webshell,从而能够执行我们的命令。 <?php highlight_file(__FILE__); $code $_GET[code]; if(preg_match("/[A-Za-z0-9]/",$code)){die("hacker!&quo…...