PyTorch进阶学习笔记[长期更新]
第一章 PyTorch简介和安装
PyTorch是一个很强大的深度学习库,在学术中使用占比很大。
我这里是Mac系统的安装,相比起教程中的win/linux安装感觉还是简单不少(之前就已经安好啦),有需要指导的小伙伴可以评论。
第二章 基础知识
这里划重点!
- 张量的创建/随机初始化
a = torch.tensor(1.0, dtype=torch.float)
d = torch.FloatTensor(2,3)
f = torch.IntTensor([1,2,3,4])
k = torch.rand(2, 3)
l = torch.ones(2, 3)
m = torch.zeros(2, 3)
n = torch.arange(0, 10, 2) #arrange用于创造等差数列 interval is 2
-
查看/修改维度
.shape or .size()
.view(row,column)
.unsqeeze(1)#加一维度
.squeeze(1) -
tensor&numpy.array
1.array->tensor
h = torch.tensor(g) #g = np.array([[1,2,3],[4,5,6]])
i = torch.from_numpy(g)2.tensor->array
j = h.numpy()
共享内存的情况
torch.from_numpy()和torch.as_tensor()从numpy array创建得到的张量和原数据是共享内存的,张量对应的变量不是独立变量,修改numpy array会导致对应tensor的改变。
如代码例中所示,修改g改变i
- tensor运算
o = torch.add(k,l)#o=k+l
#broadcast is two different size of tensors adding.
print(p + q)
- 灵活运用索引 [:]
- 自动求导
x1 = torch.tensor(1.0, requires_grad=True)
x1.grad.data是在有requires_grad=True即要求求导数的该数字的结果。
y.backward()反向传播于梯度,不清0会累积。
x1.grad #可尝试查看导数
第三章 组成模块
-
设计及解决学习任务
步骤如下:
1.数据预处理(格式统一、数据变换、划分训练集/测试集的)
2.选择模型,损失函数,优化函数,超参(常用:batch_size,learning rate ,max_epochs,configuration of gpu)
3.训练并计算得到表现-深度学习&机器学习 1.深度学习样本多,有批batch训练。 2.层多,需要按顺序逐层搭建。 3.损失函数,优化器使得其更灵活 -
gpu配置:略
-
数据读入:Dataset+DataLoader
Dataset定义数据格式和变换形式,DataLoader用iterative的方式不断读入批次数据
自定义Dataset类需要继承PyTorch自身的Dataset类。- 主要包含三个函数:
init: 用于向类中传入外部参数,同时定义样本集
getitem: 用于逐个读取样本集合中的元素,可以进行一定的变换,并将返回训练/验证所需的数据
len: 用于返回数据集的样本数 - 涉及到的API
1.PyTorch自带的ImageFolder类的用于读取按一定结构存储的图片数据(path对应图片存放的目录,目录下包含若干子目录,每个子目录对应属于同一个类的图片),其中“data_transform”可以对图像进行一定的变换,如翻转、裁剪等操作,可自己定义。
- 主要包含三个函数:
-
用cifar10数据集(识别普适物体的小型数据集)构建Dataset类实例:图片存放在一个文件夹,另外有一个csv文件给出了图片名称对应的标签。这种情况下需要自己来定义Dataset类
利用ImageFolder,
train_data = datasets.ImageFolder(root, transform=None, target_transform=None, loader=default_loader)- 关于ImageFolder,展开如下:(细节部分转自https://blog.csdn.net/weixin_40123108/article/details/85099449,有改动)
root:在root指定的路径下寻找图片
transform:对PIL Image进行的转换操作,transform的输入是使用loader读取图片的返回对象
target_transform:对label的转换
loader:给定路径后如何读取图片,默认读取为RGB格式的PIL Image对象 - label是按照文件夹名顺序排序后存成字典,即{类名:类序号(从0开始)},一般来说最好直接将文件夹命名为从0开始的数字,这样会和ImageFolder实际的label一致,如果不是这种命名规范,建议看看self.class_to_idx属性以了解label和文件夹名的映射关系。

- 关于ImageFolder,展开如下:(细节部分转自https://blog.csdn.net/weixin_40123108/article/details/85099449,有改动)
from torchvision import transforms as T
import matplotlib.pyplot as plt
from torchvision.datasets import ImageFolder
# cat文件夹的图片对应label 0,dog对应1
print(dataset.class_to_idx)
# 所有图片的路径和对应的label
print(dataset.imgs)
print(dataset[0][1])# 第一维是第几张图,第二维为1返回label
print(dataset[0][0]) # 为0返回图片数据
#transform配置
normalize = T.Normalize(mean=[0.4, 0.4, 0.4], std=[0.2, 0.2, 0.2])
transform = T.Compose([T.RandomResizedCrop(224),#即先随机采集,然后对裁剪得到的图像缩放为同一大小T.RandomHorizontalFlip(),#水平翻转T.ToTensor(),normalize,
])
dataset = ImageFolder('data1/dogcat_2/', transform=transform)
# 深度学习中图片数据一般保存成CxHxW,即通道数x图片高x图片宽
#print(dataset[0][0].size())
to_img = T.ToPILImage()
- 另一种读入方式,自定义构建数据集
class MyDataset(Dataset):#to build dataset we needdef __init__(self, data_dir, info_csv, image_list, transform=None):"""Args:data_dir: path to image directory.info_csv: path to the csv file containing image indexeswith corresponding labels.image_list: path to the txt file contains image names to training/validation settransform: optional transform to be applied on a sample."""label_info = pd.read_csv(info_csv)image_file = open(image_list).readlines()#distinguish among read()/readline()/readlines()#link:https://zhuanlan.zhihu.com/p/26573496self.data_dir = data_dirself.image_file = image_file #custom/user-definedself.label_info = label_infoself.transform = transformdef __getitem__(self, index):#return image and label."""Args:index: the index of itemReturns:image and its labels"""image_name = self.image_file[index].strip('\n')#只要头尾包含有指定字符序列中的字符就删除,中间的删不掉,若'12'则字符串中的'21'也能删掉 raw_label = self.label_info.loc[self.label_info['Image_index'] == image_name]#显示索引:.loc,第一个参数为 index切片,第二个为 columns列名label = raw_label.iloc[:,0]#隐式索引:.iloc(integer_location), 只能传入整数。image_name = os.path.join(self.data_dir, image_name)#path.join拼接规则https://www.jianshu.com/p/3090f7875f9bimage = Image.open(image_name).convert('RGB')if self.transform is not None:image = self.transform(image)return image, labeldef __len__(self):return len(self.image_file)
#Finishing dataset,we can use DataLoader to load batch data.
train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, num_workers=4, shuffle=True, drop_last=True)
val_loader = torch.utils.data.DataLoader(val_data, batch_size=batch_size, num_workers=4, shuffle=False)
#batch_size:样本是按“批”读入的,batch_size就是每次读入的样本数
#num_workers:有多少个进程用于读取数据
#shuffle:是否将读入的数据打乱
#drop_last:对于样本最后一部分没有达到批次数的样本,使其不再参与训练
#PyTorch中的DataLoader的读取可以使用next和iter来完成,next(iterable[, default])
#next() 返回迭代器的下一个项目。next() 函数要和生成迭代器的iter() 函数一起使用。
#iter()函数获取这些可迭代对象的迭代器。对获取到的迭代器不断使⽤next()函数来获取下⼀条数据,调⽤了可迭代对象的 iter ⽅法.
#iterable – 可迭代对象,default – 可选,用于设置在没有下一个元素时返回该默认值,如果不设置,又没有下一个元素则会触发 StopIteration 异常。images, labels = next(iter(val_loader))
print(images.shape)
plt.imshow(images[0].transpose(1,2,0))
plt.show()
- 模型构建
基于 Module 类的模型来完成,Module 类是 nn 模块里提供的一个模型构造类,是所有神经⽹网络模块的基类,我们可以继承它来定义我们想要的模型。 Module 类它的子类既可以是⼀个层(如PyTorch提供的 Linear 类),⼜可以是一个模型(如这里定义的 MLP 类),或者是模型的⼀个部分。- 继承 Module 类构造多层感知机。代码中定义的 MLP (Multilayer Perceptron)类重载了 Module 类的 init 函数和 forward 函数。它们分别用于创建模型参数和定义前向计算。前向计算也即正向传播。

- 继承 Module 类构造多层感知机。代码中定义的 MLP (Multilayer Perceptron)类重载了 Module 类的 init 函数和 forward 函数。它们分别用于创建模型参数和定义前向计算。前向计算也即正向传播。
import torch
from torch import nnclass MLP(nn.Module):# 声明带有模型参数的层,这里声明了两个全连接层def __init__(self, **kwargs):# 调用MLP父类Block的构造函数来进行必要的初始化。这样在构造实例时还可以指定其他函数super(MLP, self).__init__(**kwargs)self.hidden = nn.Linear(784, 256)#set fully connected layer#[in_features,out_features]#从输入输出的张量的shape角度来理解,相当于一个输入为[batch_size, in_features]的张量变换成了[batch_size, out_features]的输出张量。self.act = nn.ReLU()self.output = nn.Linear(256,10)# 定义模型的前向计算,即如何根据输入x计算返回所需要的模型输出def forward(self, x):o = self.act(self.hidden(x))return self.output(o) #实例化
X = torch.rand(2,784)
net = MLP()
print(net)
net(X)
以上的 MLP 类中⽆须定义反向传播函数。系统将通过⾃动求梯度⽽自动⽣成反向传播所需的 backward 函数。
我们可以实例化 MLP 类得到模型变量 net 。下⾯的代码初始化 net 并传入输⼊数据 X 做一次前向计算。其中, net(X) 会调用 MLP 继承⾃自 Module 类的 call 函数,这个函数将调⽤用 MLP 类定义的forward 函数来完成前向计算。
#Parameter 类其实是 Tensor 的子类,如果一 个 Tensor 是 Parameter ,那么它会⾃动被添加到模型的参数列表里。所以在⾃定义含模型参数的层时,我们应该将参数定义成 Parameter ,除了直接定义成 Parameter 类外,还可以使⽤ ParameterList 和 ParameterDict 分别定义参数的列表和字典。#torch.mul()对应位相乘
#torch.mm()矩阵乘法
class MyListDense(nn.Module):def __init__(self):super(MyListDense, self).__init__()self.params = nn.ParameterList([nn.Parameter(torch.randn(4, 4)) for i in range(3)])self.params.append(nn.Parameter(torch.randn(4, 1)))def forward(self, x):for i in range(len(self.params)):x = torch.mm(x, self.params[i])return x
net = MyListDense()
print(net)class MyDictDense(nn.Module):def __init__(self):super(MyDictDense, self).__init__()self.params = nn.ParameterDict({'linear1': nn.Parameter(torch.randn(4, 4)),'linear2': nn.Parameter(torch.randn(4, 1))})self.params.update({'linear3': nn.Parameter(torch.randn(4, 2))}) # 新增def forward(self, x, choice='linear1'):return torch.mm(x, self.params[choice])net = MyDictDense()
print(net)
- 卷积层

#卷积运算(二维互相关)
def corr2d(X, K): h, w = K.shapeX, K = X.float(), K.float()Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))for i in range(Y.shape[0]):for j in range(Y.shape[1]):Y[i, j] = (X[i: i + h, j: j + w] * K).sum()return Y
#Y[i, j] = (X[i: i + h, j: j + w] * K).sum()
# 二维卷积层
class Conv2D(nn.Module):def __init__(self, kernel_size):super(Conv2D, self).__init__()self.weight = nn.Parameter(torch.randn(kernel_size))self.bias = nn.Parameter(torch.randn(1))def forward(self, x):return corr2d(x, self.weight) + self.bias #corr2d 上面的二维卷积运算
#padding
X = X.view((1, 1) + X.shape)#原shape前加两个维度
# 在⾼和宽两侧的填充数分别为2和1,将每次滑动的行数和列数称为步幅(stride)
conv2d = nn.Conv2d(..., padding=(2, 1), stride=(3, 4))
#pooling最大池化或平均池化if mode == 'max':Y[i, j] = X[i: i + p_h, j: j + p_w].max()elif mode == 'avg':Y[i, j] = X[i: i + p_h, j: j + p_w].mean()
#一个nn.Module包含各个层和一个forward(input)方法,该方法返回output
#instance:
#前馈神经网络 (feed-forward network)(LeNet)
#步骤:
#定义包含一些可学习参数(或者叫权重)的神经网络
#在输入数据集上迭代
#通过网络处理输入
#计算 loss (输出和正确答案的距离)
#将梯度反向传播给网络的参数
#更新网络的权重,一般使用一个简单的规则:weight = weight - learning_rate * gradient
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
#n包则依赖于autograd包来定义模型并对它们求导。一个nn.Module包含各个层和一个forward(input)方法,该方法返回output。
#backward函数会在使用autograd时自动定义,backward函数用来计算导数。def __init__(self):super(Net, self).__init__()#Net找其父类,将父类init东西给self# 输入图像channel:1;输出channel:6;5x5卷积核self.conv1 = nn.Conv2d(1, 6, 5)self.conv2 = nn.Conv2d(6, 16, 5)# an affine operation: y = Wx + bself.fc1 = nn.Linear(16 * 5 * 5, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self, x):# 2x2 Max poolingx = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))# 如果是方阵,则可以只使用一个数字进行定义x = F.max_pool2d(F.relu(self.conv2(x)), 2)x = x.view(-1, self.num_flat_features(x))#把特征拍扁x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return xdef num_flat_features(self, x):#计算特征数用于拍扁size = x.size()[1:] # 除去批处理维度的其他所有维度num_features = 1for s in size:num_features *= sreturn num_features
net = Net()
print(net)#print the net's structure.#返回可学习参数
print(net.parameters())
params = list(net.parameters())
#print(params)
print(len(params))
print(params[0].size()) # conv1的权重#to use my model
#注意:这个网络 (LeNet)的期待输入是 32x32 的张量。如果使用 MNIST 数据集来训练这个网络,要把图片大小重新调整到 32x32。
input = torch.randn(1, 1, 32, 32)
out = net(input)
print(out)
net.zero_grad()#梯度清零
out.backward(torch.randn(1, 10))#随机梯度的反向传播
#torch.nn supports mini-batches rather than only one sample.
#nn.Conv2d 接受一个4维的张量,即nSamples x nChannels x Height x Width,如果是一个单独的样本,只需要使用input.unsqueeze(0) 来添加一个“假的”批大小维度。
-
涉及到的模块总结
- torch.Tensor - 一个多维数组,支持诸如backward()等的自动求导操作,同时也保存了张量的梯度。
- nn.Module- 神经网络模块。是一种方便封装参数的方式,具有将参数移动到GPU、导出、加载等功能。
- nn.Parameter- 张量的一种,当它作为一个属性分配给一个Module时,它会被自动注册为一个参数。
- autograd.Function - 实现了自动求导前向和反向传播的定义,每个Tensor至少创建一个Function节点,该节点连接到创建Tensor的函数并对其历史进行编码。
-
AlexNet

5个卷积层和3个全连接层组成的,深度总共8层。
class AlexNet(nn.Module):def __init__(self):super(AlexNet, self).__init__()self.conv = nn.Sequential(#convolution layersnn.Conv2d(1, 96, 11, 4), # in_channels, out_channels, kernel_size, stride, paddingnn.ReLU(),nn.MaxPool2d(3, 2), # kernel_size, stride# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数nn.Conv2d(96, 256, 5, 1, 2),nn.ReLU(),nn.MaxPool2d(3, 2),# 连续3个卷积层,且使用更小的卷积窗口。除了最后的卷积层外,进一步增大了输出通道数。# 前两个卷积层后不使用池化层来减小输入的高和宽nn.Conv2d(256, 384, 3, 1, 1),nn.ReLU(),nn.Conv2d(384, 384, 3, 1, 1),nn.ReLU(),nn.Conv2d(384, 256, 3, 1, 1),nn.ReLU(),nn.MaxPool2d(3, 2))# 这里全连接层的输出个数比LeNet中的大数倍。使用丢弃层来缓解过拟合self.fc = nn.Sequential(#fully connected layersnn.Linear(256*5*5, 4096),nn.ReLU(),nn.Dropout(0.5),nn.Linear(4096, 4096),nn.ReLU(),nn.Dropout(0.5),# 输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000nn.Linear(4096, 10),)def forward(self, img):feature = self.conv(img)output = self.fc(feature.view(img.shape[0], -1))return output

- 损失函数
#二分类交叉熵损失函数Cross Entropy
torch.nn.BCELoss(weight=None, size_average=None, reduce=None, reduction='mean')
#在二分类中,label是{0,1}。对于进入交叉熵函数的input为概率分布的形式。一般来说,input为sigmoid激活层的输出,或者softmax的输出。
#size_average:数据为bool,为True时,返回的loss为平均值;为False时,返回的各样本的loss之和。
#reduce:数据类型为bool,为True时,loss的返回是标量。
#(2) 默认情况下 nn.BCELoss(),reduce = True,size_average = True。
#(3) 如果reduce为False,size_average不起作用,返回向量形式的loss。
#(4) 如果reduce为True,size_average为True,返回loss的均值,即loss.mean()。
#(5) 如果reduce为True,size_average为False,返回loss的和,即loss.sum()。m = nn.Sigmoid()
loss = nn.BCELoss()
input = torch.randn(3, requires_grad=True)
target = torch.empty(3).random_(2)
output = loss(m(input), target)
output.backward()#交叉熵损失函数
torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean')
#ignore_index:忽略某个类的损失函数。
loss = nn.CrossEntropyLoss()
input = torch.randn(3, 5, requires_grad=True)
target = torch.empty(3, dtype=torch.long).random_(5)
output = loss(input, target)
output.backward()#L1损失函数:计算输出y和真实标签target之间的差值的绝对值。
torch.nn.L1Loss(size_average=None, reduce=None, reduction='mean')
#reduction参数决定了计算模式。有三种计算模式可选:none:逐个元素计算。 sum:所有元素求和,返回标量。 mean:加权平均,返回标量。 如果选择none,那么返回的结果是和输入元素相同尺寸的。默认计算方式是求平均。
loss = nn.L1Loss()
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5)
output = loss(input, target)
output.backward()#MSE损失函数:计算输出y和真实标签target之差的平方。
torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean')
loss = nn.MSELoss()
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5)
output = loss(input, target)
output.backward()#平滑L1 (Smooth L1)损失函数:L1的平滑输出,其功能是减轻离群点带来的影响
torch.nn.SmoothL1Loss(size_average=None, reduce=None, reduction='mean', beta=1.0)
#过程同理,略#可视化:平滑l1与l1对比
import matplotlib.pyplot as plt
inputs = torch.linspace(-10, 10, steps=5000)
target = torch.zeros_like(inputs)loss_f_smooth = nn.SmoothL1Loss(reduction='none')
loss_smooth = loss_f_smooth(inputs, target)
loss_f_l1 = nn.L1Loss(reduction='none')
loss_l1 = loss_f_l1(inputs,target)plt.plot(inputs.numpy(), loss_smooth.numpy(), label='Smooth L1 Loss')#画图
plt.plot(inputs.numpy(), loss_l1, label='L1 loss')
plt.xlabel('x_i - y_i')
plt.ylabel('loss value')
plt.legend()#图例
plt.grid()#网格线
plt.show()#目标泊松分布的负对数似然损失
torch.nn.PoissonNLLLoss(log_input=True, full=False, size_average=None, eps=1e-08, reduce=None, reduction='mean')
#log_input:输入是否为对数形式,决定计算公式。如果log_input=False:输入数据还不是对数形式,计算中还需要对input取对数,取对数时有可能遇到input=0,这样就无法正常进行取对数运算,因此在input后加入修正项eps。其中修正项很小,它的加入并不会影响到对input对数数值的,即便有影响也可忽略不计。
#full:计算所有 loss,默认为 False。
#eps:修正项,避免 input 为 0 时,log(input) 为 nan 的情况。
Smooth L1:
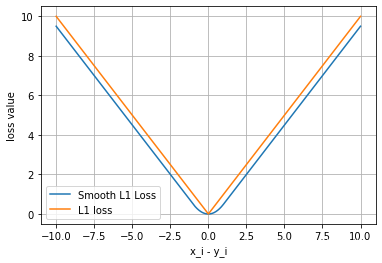
由图可见,smoothL1处x=0尖端更平滑
PoissonNLLLoss:
当参数log_input=True: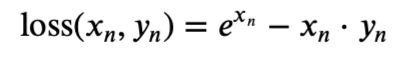
当参数log_input=False:
KLDivLoss

#kl散度
torch.nn.KLDivLoss(size_average=None, reduce=None, reduction='mean', log_target=False)
#功能:计算KL散度,也就是计算相对熵。用于连续分布的距离度量,并且对离散采用的连续输出空间分布进行回归通常很有用。
#reduction:计算模式,可为 none/sum/mean/batchmean。
inputs = torch.tensor([[0.5, 0.3, 0.2], [0.2, 0.3, 0.5]])
target = torch.tensor([[0.9, 0.05, 0.05], [0.1, 0.7, 0.2]], dtype=torch.float)
loss = nn.KLDivLoss()
output = loss(inputs,target)#排序损失函数MarginRankingLoss
#计算两个向量之间的相似度,用于排序任务。该方法用于计算两组数据之间的差异。
torch.nn.MarginRankingLoss(margin=0.0, size_average=None, reduce=None, reduction='mean')
#margin:边界值,x1 and x2之间的差异值
loss = nn.MarginRankingLoss()
input1 = torch.randn(3, requires_grad=True)
input2 = torch.randn(3, requires_grad=True)
target = torch.randn(3).sign()
output = loss(input1, input2, target)
output.backward()
MarginRankingLoss:

相关文章:

PyTorch进阶学习笔记[长期更新]
第一章 PyTorch简介和安装 PyTorch是一个很强大的深度学习库,在学术中使用占比很大。 我这里是Mac系统的安装,相比起教程中的win/linux安装感觉还是简单不少(之前就已经安好啦),有需要指导的小伙伴可以评论。 第二章…...

vue3 ts 自定义指令 app.directive
在 Vue 3 中,app.directive 是一个全局 API,用于注册或获取全局自定义指令。以下是关于 app.directive 的详细说明和使用方法 app.directive 用于定义全局指令,这些指令可以用于直接操作 DOM 元素。自定义指令在 Vue 3 中非常强大࿰…...
)
【漫话机器学习系列】199.过拟合 vs 欠拟合(Overfit vs Underfit)
机器学习核心问题:过拟合 vs 欠拟合 图示作者:Chris Albon 1. 什么是拟合(Fit)? 拟合(Fit)是指模型对数据的学习效果。 理想目标: 在训练集上效果好 在测试集上效果也好 不复杂、…...

从0到1使用C++操作MSXML
1. 引言 MSXML(Microsoft XML Core Services)是微软提供的一套用于处理XML的COM组件库,广泛应用于Windows平台的XML解析、验证、转换等操作。本文将详细介绍如何从零开始,在C中使用MSXML解析和操作XML文件,包含完整的…...

【中间件】nginx反向代理实操
一、说明 nginx用于做反向代理,其目标是将浏览器中的请求进行转发,应用场景如下: 说明: 1、用户在浏览器中发送请求 2、nginx监听到浏览器中的请求时,将该请求转发到网关 3、网关再将请求转发至对应服务 二、具体操作…...

C语言中冒泡排序和快速排序的区别
冒泡排序和快速排序都是常见的排序算法,但它们在原理、效率和应用场景等方面存在显著区别。以下是两者的详细对比: 一、算法原理 1. 冒泡排序 原理:通过重复遍历数组,比较相邻元素的大小,并在必要时交换它们的位置。…...

进程基本介绍
进程是操作系统的重要内容,都是需要了解和学习的,那么今天我们就来好好看看. 进程基本介绍 1、Linux中,每个执行的程序都称为一个进程,每一个进程都分配一个ID号(pid,进程号). 2.每个进程都可以以两种方式存在的,前台与后台,所谓前台进程就是用户目前的屏幕上可以进行操作的,…...

通过平台大数据智能引擎及工具,构建设备管理、运行工况监测、故障诊断等应用模型的智慧快消开源了
智慧快消视频监控平台是一款功能强大且简单易用的实时算法视频监控系统。它的愿景是最底层打通各大芯片厂商相互间的壁垒,省去繁琐重复的适配流程,实现芯片、算法、应用的全流程组合,从而大大减少企业级应用约95%的开发成本。 基于多年的深度…...

不同数据库的注入报错信息
不同数据库在报错注入时返回的报错信息具有显著差异,了解这些差异可以帮助快速判断数据库类型并构造针对性的注入攻击语句。以下是主流数据库的典型报错模式及对比: 目录 1. MySQL 2. Microsoft SQL Server 3. Oracle …...

tcpdump`是一个非常强大的命令行工具,用于在网络上捕获并分析数据包
通过 tcpdump,你可以抓取网络流量,诊断网络问题,或分析通信协议的细节。下面是如何在 Linux 上使用 tcpdump 进行抓包的详细步骤。 1. 安装 tcpdump 在大多数 Linux 发行版中,tcpdump 是默认安装的。如果没有安装,可…...

【漏洞复现】Vite 任意文件读取漏洞 CVE-2025-30208/CVE-2025-31125/CVE-2025-31486/CVE-2025-32395
Vite是什么,和Next.js有什么区别? 我上一篇文章刚介绍了Next.js漏洞的复现: 【漏洞复现】Next.js中间件权限绕过漏洞 CVE-2025-29927_next.js 中间件权限绕过漏洞-CSDN博客 Vite 和 Next.js 是两个不同类型的前端工具,它们各自…...
 相关控制变量传递)
Odrive源码分析(六) 相关控制变量传递
本文记录下odrive源代码中相关控制模块之间变量的传递,这对理解odrive源代码至关重要。 通过前面文字的分析,odrive有两条数据链路,一条是通过中断进行实时的控制,另外一条是OS相关的操作,主要分析下中断内部的相关变量…...

ARM架构FFmpeg极致优化交叉编译指南
ARM架构FFmpeg极致优化交叉编译指南 一、工具链科学配置 使用最新的ARM官方工具链(Linaro或ARM GNU Toolchain) 确保工具链支持目标平台特定指令集(如NEON, VFP等) 设置正确的–sysroot和–prefix参数 1. 工具链选择原则 # 32位ARM (推荐) wget https://developer.arm.com/…...

zk源码—7.ZAB协议和数据存储一
大纲 1.两阶段提交Two-Phase Commit(2PC) 2.三阶段提交Three-Phase Commit(3PC) 3.ZAB协议算法 4.ZAB协议与Paxos算法 5.zk的数据存储原理之内存数据 6.zk的数据存储原理之事务日志 7.zk的数据存储原理之数据快照 8.zk的数据存储原理之数据初始化和数据同步流程 1.两阶…...

2025蓝桥杯C++A组省赛 题解
昨天打完蓝桥杯本来想写个 p y t h o n python python A A A 组的题解,结果被队友截胡了。今天上课把 C A CA CA 组的题看了,感觉挺简单的,所以来水一篇题解。 这场 B B B 是一个爆搜, C C C 利用取余的性质比较好写&#…...

用哪个机器学习模型 依靠极少量即时静态数据来训练ai预测足球赛的结果?
目录 一、模型推荐 1.集成树模型(XGBoost/CatBoost) 2.逻辑回归(Logistic Regression) 3.贝叶斯概率模型(Naive Bayes或贝叶斯网络) 4.支持向量机(SVM) 二、模型排除 三、训练…...

讲解贪心算法
贪心算法是一种常用的算法思想,其在解决问题时每一步都做出在当前状态下看起来最优的选择,从而希望最终能够获得全局最优解。C作为一种流行的编程语言,可以很好地应用于贪心算法的实现。下面我们来讲一篇关于C贪心算法的文章。 目录 贪心算法…...

0基础 | 电动汽车的“电源翻译官” | DC/DC转换器 | 电源系统三
你有没有想过,电动汽车里那么多五花八门的电子设备,比如车灯、仪表盘、摄像头,甚至连控制马达的“大脑”(ECU),是怎么用上电的?今天就来聊聊电动车里一个默默工作的“小功臣”——DC/DC转换器&a…...

zynq7020 u-boot 速通
zynq u-boot 速通 简介 上回最小系统已经跑起来,证明串口和 ddr 正确配置.现在我们需要正确配置 网口, qspi, emmc. 网口:通过 tftp 下载 dtb,image,rootfs 在线调试.qspi:固化 boot.bin 到 qspi flash,这样 qspi 启动就可以直接运行 u-boot.emmc:存放 ubuntu_base 跟文件系统…...

C++学习之路,从0到精通的征途:string类的模拟实现
目录 一.string类的成员变量与成员函数 二.string类的接口实现 1.构造函数,析构函数,拷贝构造函数,赋值重载 (1)构造函数 (2)析构函数 (3)拷贝构造函数 &…...

网页制作中的MVC和MVT
MVC(模型-视图-控制器)和MVT(模型-模板-视图)是两种常见的软件架构模式,通常用于Web应用程序的设计。它们之间的主要区别在于各自的组件职责和工作方式。 MVC(模型-视图-控制器): 模…...

02 - spring security基于配置文件及内存的账号密码
spring security基于配置的账号密码 文档 00 - spring security框架使用01 - spring security自定义登录页面 yml文件中配置账号密码 spring:security:user:name: adminpassword: 123456yml文件中配置账号密码后,控制台将不再输出临时密码 基于内存的账号密码 …...

Firebase Studio:开启 AI 驱动的开发新纪元
Firebase Studio(前身为 Project IDX)的推出,标志着软件开发范式正经历深刻变革。它不仅是一个传统的 IDE,更是一个以 AI 为主导的、代理式 (agentic) 的云端开发环境,专注于全栈 AI 应用(包括 API、后端、…...

网络基础2
目录 跨网络传输流程 网络中的地址管理 - 认识 IP 地址 跨网络传输 报文信息的跨网络发送 IP地址的转化 认识端口号 端口号范围划分 源端口号和目的端口号 认识 TCP / UDP协议 理解 socket 网络字节序 socket 编程接口 sockaddr 结构 我们继续来学习网络基础 跨网…...
——部署项目到仓库)
Maven工具学习使用(十一)——部署项目到仓库
1、使用Maven默认方式 Maven 部署项目时默认使用的上传文件方式是通过 HTTP/HTTPS 协议。要在 Maven 项目中配置部署,您需要在项目的 pom.xml 文件中添加 部分。这个部分定义了如何部署项目的构件(如 JAR 文件)到仓库。。这个部分定义了如何…...
)
FPGA 37 ,FPGA千兆以太网设计实战:RGMII接口时序实现全解析( RGMII接口时序设计,RGMII~GMII,GMII~RGMII 接口转换 )
目录 前言 一、设计流程 1.1 需求理解 1.2 模块划分 1.3 测试验证 二、模块分工 2.1 RGMII→GMII(接收方向,rgmii_rx 模块) 2.2 GMII→RGMII(发送方向,rgmii_tx 模块) 三、代码实现 3.1 顶层模块 …...

torch.cat和torch.stack的区别
torch.cat 和 torch.stack 是 PyTorch 中用于组合张量的两个常用函数,它们的核心区别在于输入张量的维度和输出张量的维度变化。以下是详细对比: 1. torch.cat (Concatenate) 作用:沿现有维度拼接多个张量,不创建新维度 输入要求…...
)
索引下推(Index Condition Pushdown, ICP)
概念 索引下推是一种数据库查询优化技术,通过在存储引擎层面应用部分WHERE条件来减少不必要的数据读取。它特别适用于复合索引的情况,因为它可以在索引扫描阶段就排除不符合全部条件的数据行,而不是将所有可能匹配的记录加载到服务器层再进行…...

C++基础精讲-06
文章目录 1. this指针1.1 this指针的概念1.2 this指针的使用 2. 特殊的数据成员2.1 常量数据成员2.2 引用数据成员2.3 静态数据成员2.4 对象成员 3. 特殊的成员函数3.1 静态成员函数3.2 const成员函数3.3 mutable关键字 1. this指针 1.1 this指针的概念 1.c规定,t…...

Django3 - 建站基础
学习开发网站必须了解网站的组成部分、网站类型、运行原理和开发流程。使用Django开发网站必须掌握Django的基本操作,比如创建项目、使用Django的操作指令以及开发过程中的调试方法。 一、网站的定义及组成 网站(Website)是指在因特网上根据一定的规则,…...

UE5蓝图设置界面尺寸大小
UE5蓝图设置界面尺寸大小 Create widget 创建UIadd to Viewport 添加视图get Game User Settings获取游戏用户设置set Screen Resolutions 设置屏幕尺寸大小1920*1080set Fullscreen Mode 设置全屏模式为:窗口化或者全屏Apply Settings 应用设置...

无数字字母RCE
无数字字母RCE,这是一个老生常谈的问题,就是不利用数字和字母构造出webshell,从而能够执行我们的命令。 <?php highlight_file(__FILE__); $code $_GET[code]; if(preg_match("/[A-Za-z0-9]/",$code)){die("hacker!&quo…...

AutoGen参数说明
UserProxyAgent用户 user_proxy = UserProxyAgent配置说明: # 构造参数 def __init__(self,name: str,is_termination_msg: Optional[Callable[[Dict], bool]] = None,max_consecutive_auto_reply: Optional[int] = None,human_input_mode: Literal["ALWAYS", &qu…...

6.2 GitHub API接口设计实战:突破限流+智能缓存实现10K+仓库同步
GitHub Sentinel 定期更新 API 接口设计 关键词:GitHub API 集成、异步爬虫开发、RESTful 接口设计、请求限流策略、数据增量更新 1. 接口架构设计原则 采用 分层隔离架构 实现数据采集与业务逻辑解耦: #mermaid-svg-WihvC78J0F5oGDbs {font-family:"trebuchet ms&quo…...

用java代码如何存取数据库的blob字段
一.业务 在业务中我们被要求将文件或图片等转成 byte[] 或 InputStream存到数据库的Blob类型的字段中. 二.Blob类型介绍 在 MySQL 中,Blob 数据类型用于存储二进制数据。MySQL 提供了四种不同的 Blob 类型: TINYBLOB: 最大存储长度为 255 个字节。BL…...

2025蓝桥杯C++研究生组真题-上海市省赛
2025蓝桥杯C研究生组真题 A:数位倍数(5分) 问题描述:请问在 1 至 202504(含)中,有多少个数的各个数位之和是 5 的整数倍。例如:5、19、8025 都是这样的数。 A是填空题,…...
和锁)
原子操作CAS(Compare-And-Swap)和锁
目录 原子操作 优缺点 锁 互斥锁(Mutex) 自旋锁(Spin Lock) 原子性 单核单CPU 多核多CPU 存储体系结构 缓存一致性 写传播(Write Propagation) 事务串行化(Transaction Serialization&#…...

Aspose.Words导出word,服务器用内存流处理,不生成磁盘文件
框架集:.NET8 public async Task<IActionResult> ExportPDF(long? id) {var infoawait form_Dahui_ReportDao.GetAsync(id);if (info null){return Content("没找到数据");}//读取word模板string fileTemp Path.Combine(AppContext.BaseDirect…...

攻防世界——Web题ez_curl
目录 Express PHP和Node.js的解析差异 Python代码 这道题最终得不到flag,用了很多师傅的代码也不成功。但还是需要学习 下载的附件: const express require(express);const app express();const port 3000; const flag process.env.flag;app.ge…...

力扣面试150题--螺旋矩阵
Day 20 题目描述 思路 根据题目描述,我们需要顺时针输出矩阵元素,顺时针说明有四种输出状态,横向从左到右和从右到左,纵向从上到下和从下到上,唯一的难点在于,输出完成一层后,如何进入内层&am…...

智能指针之设计模式2
前面介绍了工厂模式控制了智能指针和资源对象的创建过程,现在介绍一下智能指针是如何利用代理模式来实现“类指针(like-pointer)”的功能,并控制资源对象的销毁过程的。 2、代理模式 代理模式是为其它对象提供一种代理以控制对这…...

【Redis】redis持久化
Redis 持久化 Redis:非关系型的内存数据库 持久化:将数据永久写入磁盘(内存→磁盘) Redis 默认开启了持久化,默认模式为 RDB 为什么需要持久化? Redis 是内存数据库,宕机或关机后数据会丢失。…...

AtCoder Beginner Contest 401 E题 题解
E - Reachable Sethttp://E - Reachable Set 题意概述 : 给定一个无向图, 对于每个 ,解决以下问题: -选择最少的一些顶点,使得删除这些顶点及其关联的所有边后 点1只能到达以内的所有点 牵制芝士 :头文…...

Kubernetes控制平面组件:API Server Webhook 授权机制 详解
云原生学习路线导航页(持续更新中) kubernetes学习系列快捷链接 Kubernetes架构原则和对象设计(一)Kubernetes架构原则和对象设计(二)Kubernetes架构原则和对象设计(三)Kubernetes控…...
官网示例(六)自动补全、边栏)
【CodeMirror】系列(二)官网示例(六)自动补全、边栏
一、自动补全 codemirror/autocomplete 包提供了在编辑器中显示输入建议的功能。这个示例展示了如何启用该功能以及如何编写自己的补全来源。 自动补全是通过在编辑器的配置项中加入 autocompletion 扩展实现的。有些语言包支持内置的自动补全功能,比如HTML包。 默…...

CSS 表格样式学习笔记
CSS 提供了强大的工具来美化和定制 HTML 表格的外观。通过合理使用 CSS 属性,可以使表格更加美观、易读且功能强大。以下是对 CSS 表格样式的详细学习笔记。 一、表格边框 1. 单独边框 默认情况下,表格的 <table>、<th> 和 <td> 元…...

简单记录一下Android四大组件
1、Android Layout 1.1、LinearLayout 线性布局,子控件按照水平或垂直的方向依次排列,排列方向通过属性android:orientation控制,horizontal为水平排列,vertical为垂直排列。对于同一水平线上的控件,可以调整它的lay…...

在线地图支持天地图和腾讯地图,仪表板和数据大屏支持发布功能,DataEase开源BI工具v2.10.7 LTS版本发布
2025年4月11日,人人可用的开源BI工具DataEase正式发布v2.10.7 LTS版本。 这一版本的功能变动包括:数据源方面,Oracle数据源支持获取和查询物化视图;图表方面,在线地图支持天地图、腾讯地图;新增子弹图&…...

【图像处理基石】什么是通透感?
一、画面的通透感定义 画面的通透感指图像在色彩鲜明度、空间层次感、物体轮廓清晰度三方面的综合表现,具体表现为: 色彩鲜明:颜色纯净且饱和度适中,无灰暗或浑浊感;层次分明:明暗过渡自然,光…...

猫咪如厕检测与分类识别系统系列【六】分类模型训练+混合检测分类+未知目标自动更新
前情提要 家里养了三只猫咪,其中一只布偶猫经常出入厕所。但因为平时忙于学业,没法时刻关注牠的行为。我知道猫咪的如厕频率和时长与健康状况密切相关,频繁如厕可能是泌尿问题,停留过久也可能是便秘或不适。为了更科学地了解牠的如…...