zk源码—7.ZAB协议和数据存储一
大纲
1.两阶段提交Two-Phase Commit(2PC)
2.三阶段提交Three-Phase Commit(3PC)
3.ZAB协议算法
4.ZAB协议与Paxos算法
5.zk的数据存储原理之内存数据
6.zk的数据存储原理之事务日志
7.zk的数据存储原理之数据快照
8.zk的数据存储原理之数据初始化和数据同步流程
1.两阶段提交Two-Phase Commit(2PC)
(1)数据库事务通过undo和redo保证数据强一致性
(2)分布式事务通过2PC保证数据强一致性
(3)2PC的优点和缺点
(1)数据库事务通过undo和redo保证数据强一致性
2PC即二阶段提交算法,是强一致性算法。它是数据库领域内,为了使基于分布式系统架构下的所有节点,在进行事务处理过程中能够保持原子性和一致性而设计的算法。所以很适合用作数据库的分布式事务,其实数据库经常用到的TCC本身就是一种2PC。
在InnoDB存储引擎中,对数据库的事务修改都会写undo日志和redo日志。其实不只是数据库,很多需要事务支持的都会用到undo和redo思路。
一.对一条数据的修改操作首先写undo日志,记录数据原来的样子
二.然后执行事务修改操作,把数据写到redo日志里
三.万一事务失败了,可以从undo日志恢复数据
数据库通过undo和redo能保证数据强一致性。
(2)分布式事务通过2PC保证数据强一致性
解决分布式事务的前提就是节点是支持事务的。在这个前提下,2PC把整个分布式事务分两个阶段:投票阶段(Prepare)和执行阶段(Commit)。
阶段一:投票阶段
在阶段一中,各参与者投票表明是否要继续执行接下来的事务提交操作。
步骤一:协调者向参与者发起事务询问。协调者向所有的参与者发送事务内容,询问是否可以执行事务操作,并开始等待各参与者的响应。
步骤二:参与者收到协调者的询问后执行事务。各参与者节点执行事务操作,并将undo和redo信息记入事务日志中。
步骤三:参与者向协调者反馈事务询问的响应。如果参与者成功执行事务操作,就反馈协调者Yes响应,表示事务可执行。如果参与者没成功执行事务,就反馈协调者No响应,表示事务不可执行。
阶段二:执行阶段
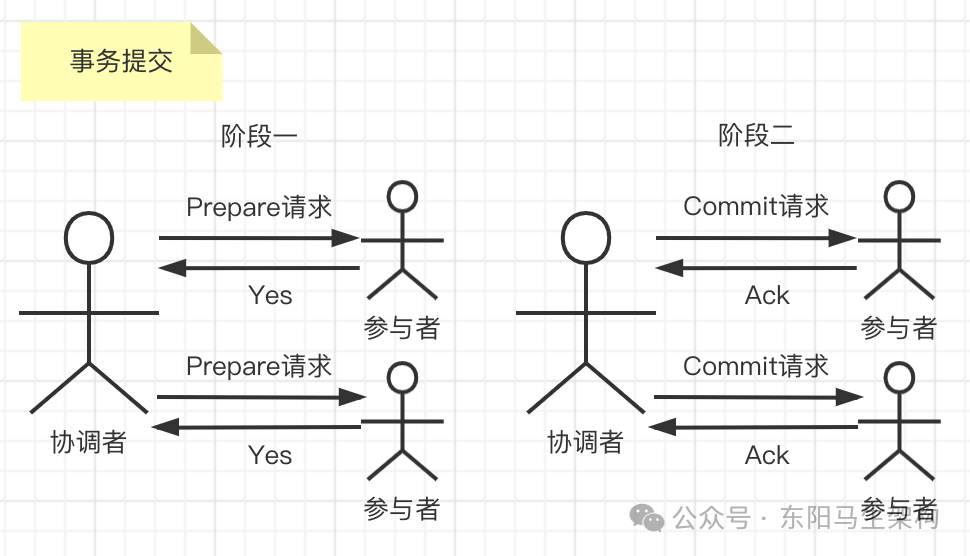
在阶段二中,协调者会根据各参与者的反馈来决定是否可以进行事务提交。有两种提交可能:执行事务提交和中断事务。
可能一:执行事务提交
假如协调者从所有参与者获得的反馈都是Yes响应,那么就会执行事务提交。
步骤一:协调者向参与者发送提交请求,协调者向所有参与者节点发出commit请求。
步骤二:参与者收到协调者的commit请求后进行事务提交。参与者接收到commit请求后,会正式执行事务提交操作,并在完成提交之后释放在整个事务执行期间占用的事务资源。
步骤三:参与者向协调者反馈事务提交结果(Ack消息)。参与者在完成事务提交之后,向协调者发送Ack消息。
步骤四:协调者收到所有参与者反馈(Ack)后完成事务。协调者接收到所有参与者反馈的Ack消息后,完成事务。
可能二:中断事务
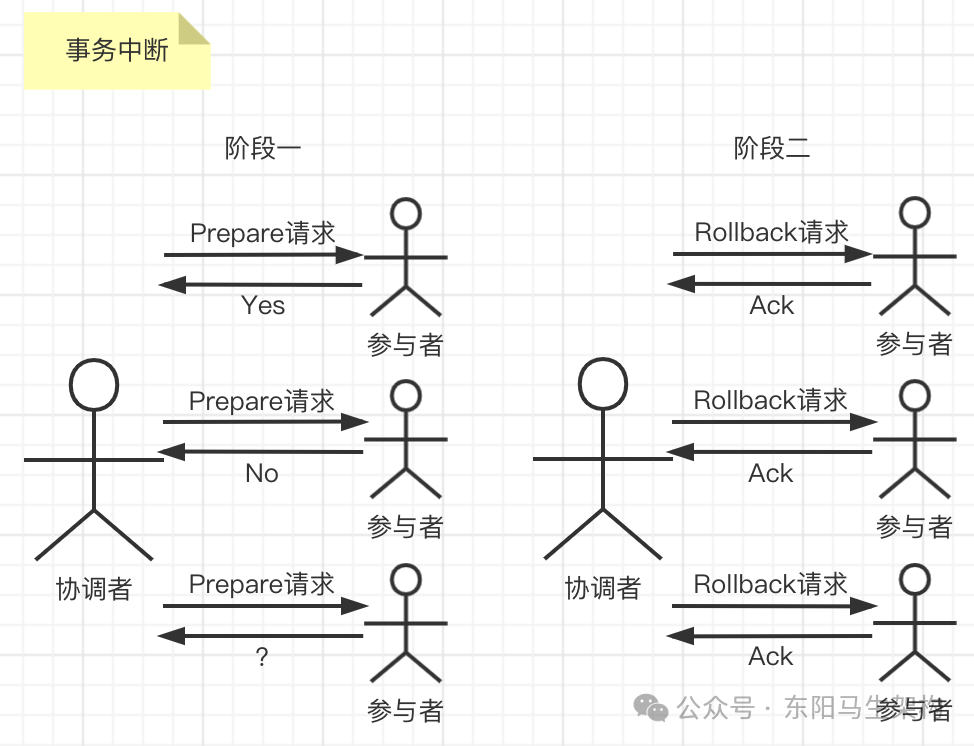
假如任何一个参与者向协调者反馈了No响应或者等待超时,那么协调者无法接收到所有参与者的反馈响应,就会中断事务。
步骤一:协调者向参与者发送回滚请求,协调者向所有参与者节点发出rollback请求。
步骤二:参与者收到协调者的rollback请求后进行事务回滚。参与者接收到rollback请求后,会利用undo信息来执行事务回滚操作,并在完成回滚之后释放占用的事务资源。
步骤三:参与者向协调者反馈事务回滚结果(Ack消息)。参与者在完成事务回滚之后,向协调者发送Ack消息。
步骤四:协调者收到所有参与者反馈(Ack)后中断事务。协调者接收到所有参与者反馈的Ack消息后,完成事务中断。
(3)2PC的优点和缺点
一.2PC优点
优点一:原理简单
优点二:实现方便
二.2PC缺点
总结来说有四个缺点:同步阻塞、单点故障、数据不一致、容错机制不完善。
缺点一:同步阻塞
在二阶段提交过程中,所有节点都在等其他节点响应,无法进行其他操作,这种同步阻塞极大的限制了分布式系统的性能。
缺点二:单点问题
协调者在整个二阶段提交过程中很重要。如果协调者在提交阶段出现问题,那么整个流程将无法运转。而且其他参与者会处于一直锁定事务资源的状态中,无法完成事务操作。
缺点三:数据不一致
假设当协调者向所有参与者发送commit请求后,发生了局部网络异常。或者是协调者在尚未发送完所有commit请求之前自身发生了崩溃,导致最终只有部分参与者收到了commit请求,这将导致数据不一致问题。
缺点四:容错性不好
二阶段提交协议没有较为完善的容错机制,任意一个参与者或协调者故障都会导致整个事务的失败。
2.三阶段提交Three-Phase Commit(3PC)
(1)第一阶段canCommit
(2)第二阶段preCommit
(3)第三阶段doCommit
(4)3PC的优缺点
(5)3PC与2PC区别
(1)第一阶段canCommit
步骤一:协调者向参与者发起事务询问。协调者向所有参与者发送一个包含事务内容的canCommit请求。询问是否可以执行事务提交操作,并开始等待各参与者响应。
步骤二:参与者收到协调者的询问后反馈响应。参与者在接收到协调者的canCommit请求后,如果认为可以顺利执行事务,会反馈Yes响应并进入预备状态,否则反馈No响应。
这一阶段其实就是确认所有的资源是否都是健康、在线的。因为有了这一阶段,大大的减少了2PC提交的阻塞时间。
因为这一阶段优化了以下这种情况:2PC提交时,如果有两个参与者1和2而恰好参与者2出现问题,参与者1执行了耗时的事务操作,最后却发现参与者2连接不上。
(2)第二阶段preCommit
包含两种可能:执行事务预提交和中断事务。
可能一:执行事务预提交
假如协调者从所有参与者获得的反馈都是Yes响应,则执行事务预提交。
步骤一:协调者向参与者发送预提交请求。协调者向所有参与者发出preCommit请求,然后协调者会进入预提交状态。
步骤二:参与者收到协调者的preCommit请求后执行事务。参与者接收到协调者发出的preCommit请求后,会执行事务操作,并将undo和redo信息记录到事务日志中。
步骤三:参与者向协调者反馈事务执行的响应(Ack)。如果参与者成功执行了事务操作,那么就会反馈给协调者Ack响应。
可能二:中断事务
假如任何一个参与者向协调者反馈了No响应,或者等待超时。协调者无法接收到所有参与者的反馈响应,那么就会中断事务。
步骤一:协调者向参与者发送中断请求,协调者向所有参与者节点发出abort请求。
步骤二:参与者收到协调者abort请求则中断事务。无论是收到来自协调者的abort请求,或者在等待协调者请求过程中出现超时,参与者都会中断事务。
(3)第三阶段doCommit
包含两种可能:执行提交和中断事务。
可能一:执行提交
接收到来自所有参与者的Ack响应。
步骤一:协调者向参与者发送提交请求。协调者向所有参与者发出doCommit请求,由预提交状态进入提交状态。
步骤二:参与者收到协调者的doCommit请求后提交事务。参与者接收到doCommit请求后,会正式执行事务提交操作,并在完成提交之后释放整个事务执行期间占用的事务资源。
步骤三:参与者向协调者反馈事务提交结果。参与者在完成事务提交之后,向协调者发送Ack消息。
步骤四:协调者收到所有参与者反馈(Ack)完成事务。协调者接收到所有参与者反馈的Ack消息后,完成事务。
可能二:中断事务
假如任何一个参与者向协调者反馈了No响应,或者等待超时。协调者无法接收到所有参与者的反馈响应,那么就会中断事务。
步骤一:协调者向参与者发送回滚请求,协调者向所有参与者节点发出abort请求。
步骤二:参与者收到协调者的abort请求后进行事务回滚。参与者接收到协调者的abort请求后,会利用undo信息执行事务回滚操作,并在完成回滚之后释放占用的事务资源。
步骤三:参与者向协调者反馈事务回滚结果(Ack消息)。参与者在完成事务回滚之后,会向协调者发送Ack消息。
步骤四:协调者收到所有参与者反馈(Ack)后中断事务。协调者接收到所有参与者反馈的Ack消息后,完成事务中断。
注意:一旦进入阶段三doCommit,无论出现哪一种故障:协调者出现了问题、协调者和参与者之间网络故障,最终都会导致参与者无法及时接收来自协调者的doCommit或abort请求。参与者都会在等待超时后,继续进行事务提交。
(4)3PC的优缺点
三阶段提交协议的优点
优点一:改善同步阻塞
与2PC相比,降低了参与者的阻塞范围。
优点二:改善单点故障
与2PC相比,出现单点故障后能继续达成一致。
三阶段提交协议的缺点
缺点一:同步阻塞
相比2PC虽然降低阻塞范围,但依然存在阻塞。
缺点二:单点故障
虽然单点故障后能继续提交,但单点故障依然存在。
缺点三:数据不一致
正因出现单点故障后能继续提交,所以数据不一致。
缺点四:容错机制不完善
参与者或协调者节点失败会导致事务失败,所以数据库的分布式事务一般都是采用2PC,而3PC更多是被借鉴扩散成其他的算法。
(5)3PC与2PC区别
区别一:3PC第二阶段才写undo和redo事务日志。
区别二:3PC第三阶段协调者出现异常或网络超时参与者也会Commit。
3.ZAB协议算法
(1)ZAB协议介绍
(2)ZAB协议的消息广播模式
(3)ZAB协议的崩溃恢复模式
(4)崩溃恢复模式中完成Leader选举后的数据同步
(1)ZAB协议介绍
一.ZAB协议的一主多从模式
二.ZAB协议的三个保证
三.Leader和非Leader对事务请求的处理
四.ZAB协议的由三个主要步骤
五.ZAB协议的两种基本模式
ZAB协议是为分布式协调服务zk设计的一种支持崩溃恢复的原子广播协议。它在设计之初并没有要求具有很好的扩展性,最初只是为了应对高吞吐量、低延迟、健壮、简单的分布式场景。ZAB协议并不像Paxos算法那样是一种通用的分布式一致性算法,它是特别为zk设计的支持崩溃恢复的原子广播算法。
一.ZAB协议的一主多从模式
zk主要依赖ZAB协议来实现分布式数据一致性。ZAB协议采用主从模式的系统架构来保证集群间各副本数据的一致性。具体如下:
ZAB协议会使用一个单一的主进程来接收并处理客户端的所有事务请求,然后该主进程会将请求的处理结果以Proposal形式广播到所有副本进程中。
二.ZAB协议的三个保证
保证同一时刻集群中只有一个主进程来广播数据变更,保证一个全局的变更序列被顺序应用,保证当主进程崩溃或重启时集群能自动恢复正常工作。
三.Leader和非Leader对事务请求的处理
ZAB协议只允许唯一一个Leader来处理事务请求。Leader接收到客户端事务请求后,会生成对应的Proposal提议并发起广播。非Leader接收到客户端事务请求后,会将事务请求转发给Leader。
四.ZAB协议的由三个主要步骤
步骤一:Leader发送Proposal提议给集群中的所有节点,包括它自己。
步骤二:节点收到Proposal提议后把Proposal提议落盘,然后发送一个ACK给Leader。
步骤三:Leader收到过半节点的ACK后,发送Commit给集群中的所有节点。
五.ZAB协议的两种基本模式
分别是崩溃恢复模式和消息广播模式。ZAB协议中的状态同步是指,集群中过半机器和Leader的数据状态一致。当集群启动或Leader出现崩溃推出等异常时,就会进入恢复模式进行选举。当集群已有过半Follower完成和Leader的状态同步,就会进入广播模式。如果集群已存在Leader进行消息广播,新加入的服务器就会进入恢复模式。
ZAB协议进入崩溃恢复模式后,只要集群中存在过半服务器能相互通信,那么就可以产生一个新的Leader并再次进入消息广播模式。比如一个由3台机器组成的ZAB服务 = 1个Leader + 2个Follower。当其中一个Follower挂掉时,整个ZAB集群是不会中断服务的,因为Leader服务器依然能够获得过半机器(包括自己)的支持。
(2)ZAB协议的消息广播模式
一.ZAB协议的消息广播过程
二.ZAB协议的消息广播过程与2PC的区别
三.ZAB协议的消息广播过程能保证消息接收和发送的顺序性
一.ZAB协议的消息广播过程
ZAB协议的消息广播过程使用的是一个原子广播协议,类似于2PC过程。首先,Leader会为客户端的事务请求生成对应的事务Proposal并进行广播。然后,Leader会收集Follower返回的ACK是否已过半。若已过半,Leader则会发送Commit消息到所有Follower去提交事务。
二.ZAB协议的消息广播过程与2PC的区别
区别一:移除了中断逻辑
在ZAB协议的消息广播(二阶段提交)过程中,移除了中断逻辑。所有的Follower要么正常反馈Leader提出的事务Proposal,要么不反馈。
区别二:无需等所有Follower都反馈响应
移除了中断逻辑,意味着可以在过半Follower反馈ACK后就可以提交事务,不需要等待集群中的所有Follower都反馈ACK响应。
区别三:添加崩溃恢复模式解决Leader崩溃退出导致的数据不一致问题
由于移除了中断逻辑 + 过半Follower反馈就可以提交事务,所以这时是无法处理Leader崩溃退出而带来的数据不一致问题的,因此ZAB协议添加了崩溃恢复模式来解决这个问题。
三.ZAB协议的消息广播过程能保证消息接收和发送的顺序性
另外,整个消息广播过程是基于FIFO特性的TCP协议来进行网络通信的,所以能够很容易保证消息广播过程中消息接收和发送的顺序性。广播时是由一个主进程Leader去通过FIFO的TCP协议进行发送,所以某Follower接收的多个Proposal和Commit请求都能按顺序入队和响应。
(3)ZAB协议的崩溃恢复模式
一.崩溃恢复过程可能出现数据不一致的两种情况
二.ZAB需要设计这样一个Leader选举算法
ZAB协议的这个基于原子广播协议的消息广播过程,正常情况下运行良好。但一旦Leader出现崩溃,或者由于网络Leader失去与过半Follower的联系。那么就会进入崩溃恢复模式,选举出一个新的Leader。
一.崩溃恢复过程可能出现数据不一致的两种情况
情况一:假设一个事务在Leader上被提交了,并且已有过半Follower反馈ACK响应。但是在Leader将Commit消息发送给所有Follower前Leader挂了。所以ZAB协议需要确保已在Leader提交的Proposal提议也能被所有Follower提交。
情况二:如果在崩溃恢复过程中出现一个需要被丢弃的Proposal提议,那么在崩溃恢复结束后需要跳过该Proposal提议,所以ZAB协议需要确保丢弃那些只在Leader上处理过的事务Proposal提议。
二.ZAB需要设计这样一个Leader选举算法
算法要求:能够确保提交已经被Leader提交的事务Proposal提议,同时丢弃已经被跳过的事务Proposal提议。
算法设计:让新选举出来的Leader拥有集群中ZXID最大的事务Proposal提议,那么就可以保证新Leader一定拥有所有已经提交的Proposal提议,同时也省去Leader去检查Proposal提议的提交和丢弃操作。
对于出现不一致的情况一:如果Leader将Commit消息发送给所有Follower前,Leader崩溃了。那么Leader崩溃后,就会选举一个拥有最大ZXID的Follower作为Leader。这个Leader会检查事务日志:如果发现自己事务日志里有一个还没进行提交的Proposal提议,那么就说明旧Leader没来得及发送Commit消息就崩溃了,此时它作为新Leader会为这个Proposal提议向Follower发送Commit消息,从而保证旧Leader提交的事务最终可以被提交到所有Follower中。
对于不一致的情况二:如果一个Leader刚把一个Proposal提议写入本地磁盘日志,还没来得及广播Proposal提议给全部Follower就崩溃了。那么当新Leader选举出来后,事务的epoch会自增长一位。然后当旧Leader重启后重新加入集群成为Follower时,会发现自己比新Leader多出一条Proposal提议,但该Proposal提议的epoch比新Leader的epoch低,所以会丢弃这条数据。
(4)崩溃恢复模式中完成Leader选举后的数据同步
一.ZAB协议在正常情况下的数据同步逻辑
二.ZAB协议如何处理需要丢弃的事务Proposal
一.ZAB协议在正常情况下的数据同步逻辑
完成Leader选举后,Leader会首先确认Follower是否完成数据同步,也就是Leader事务日志中的Proposal提议是否已被过半Follower提交。
Leader需要确保所有Follower能接收到每一条事务Proposal,并且能正确将所有已提交了的事务Proposal应用到内存数据库中。
Leader会为每个Follower都准备一个队列,并将那些没有被Follower同步的事务以Proposal提议的形式逐个发送给Follower,并在发送完每个Proposal提议消息后紧接着再发送一个Commit消息表示事务已提交。
等Follower将所有未同步的事务Proposal提议都同步并应用到内存数据库后,Leader就会将该Follower加入到真正的可用Follower列表中。
二.ZAB协议如何处理需要丢弃的事务Proposal
ZXID是一个64位的数字。低32位是一个递增计数器,Leader产生一个新Proposal都会对其+1。高32位是选举轮次的编号,每当选举产生一个新Leader都会对其+1。
4.ZAB协议与Paxos算法
(1)Paxos算法介绍
(2)联系和区别
(1)Paxos算法介绍
一.Paxos的三种角色
二.Paxos算法类似2PC的执行流程
三.Paxos的Learner如何学习被选定的value
四.Paxos算法如何保证活性
一.Paxos的三种角色
角色一:提案者(Proposer)
提出提案(Proposal),Proposal信息包括提案编号(ID)和提案的值(Value)。
角色二:决策者(Acceptor)
参与决策,回应Proposer的提案,收到提案后可以接受提案。若提案获得超半数Acceptor的接受,则称该提案被选定(批准)。
角色三:学习者(Learner)
不参与决策,从Proposer和Acceptor学习被选定的提案的值(Value)。
二.Paxos算法类似2PC的执行流程
下面是Paxos算法的概述:
与ZAB协议不同,Paxos算法处理来自客户端的事务请求时:
步骤一:首先会触发一个或多个服务器进程,向其他服务器发起提案
步骤二:然后其他服务器会向发起提案的服务器反馈提案的执行情况
步骤三:接着发起提案的服务器会对接收到的反馈信息进行统计
步骤四:当过半服务器批准该事务请求操作后,则可在本地执行提交
可见,Paxos算法对事务请求的投票过程与ZAB协议十分相似。但ZAB协议中发起投票的机器,是集群中运行的一台Leader服务器,而Paxos算法则是采用多副本的处理方式。也就是存在多个副本,每个副本分别包含提案者、决策者以及学习者。
下面是详细的Paxos两阶段提交算法:
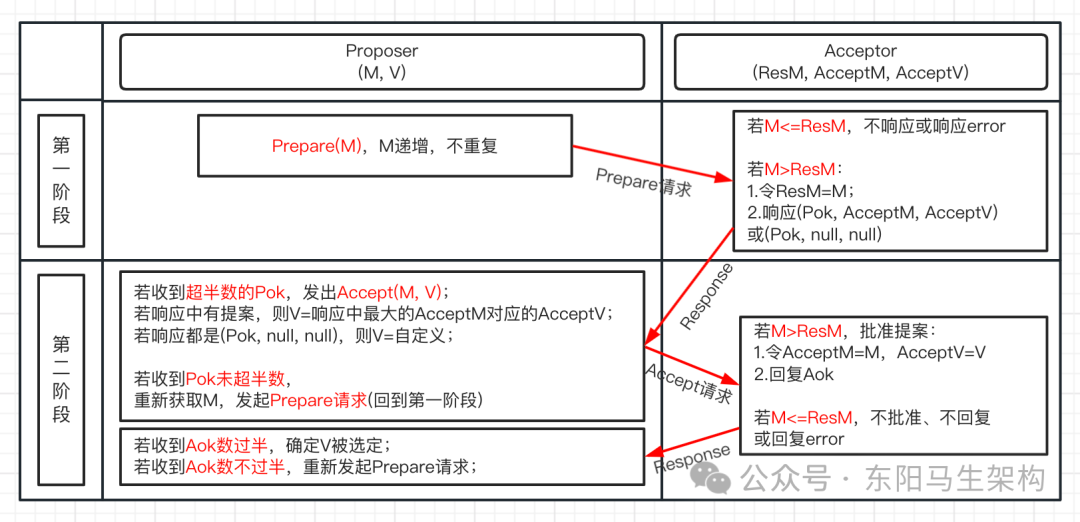
阶段一.Prepare请求
步骤一:Proposer选择一个提案编号M,然后向半数以上的Acceptor发送编号为M的Prepare请求。
步骤二:如果一个Acceptor收到一个编号为M的Prepare请求,且M大于该Acceptor已经响应过的所有Prepare请求的编号,那么它就会将它已经批准过的编号最大的提案作为响应反馈给Proposer,同时该Acceptor承诺不再批准任何编号小于M的提案。
阶段二.Accept请求
步骤一:如果Proposer收到半数以上Acceptor,对其发出的编号为M的Prepare请求的响应,那么它就会发送一个针对[M, V]提案的Accept请求给半数以上的Acceptor。注意:V就是收到的响应中编号最大的提案的value。如果响应中不包含任何提案,那么V就由Proposer自己决定。
步骤二:如果Acceptor收到一个针对[M, V]提案的Accept请求,只要该Acceptor没有对编号大于M的Prepare请求做出过响应,它就批准该提案。
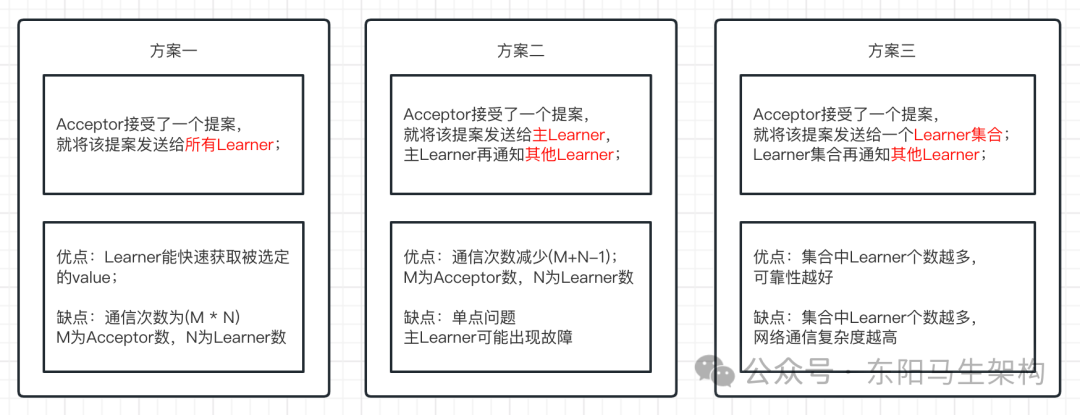
三.Paxos的Learner如何学习被选定的value
Learner获取提案,有三种方案:
四.Paxos算法如何保证活性
一个极端的活锁场景:

(2)Paxos与ZAB的联系和区别
相同之处:
一.两者都存在一个类似于Leader进程的角色,由Leader角色负责协调多个Follower进程的运行。
二.Leader进程都会等待超过半数的Follower做出正确的反馈,之后才会将一个提案进行提交。
三.都存在一个标识表示当前的Leader周期,比如ZAB是epoch、Paxos是Ballot。
不同之处:
一.ZAB协议中发起投票的机器是集群中运行的一台Leader服务器,Paxos算法则是采用多副本的处理方式。即存在多个副本,每个副本分别包含提案者、决策者以及学习者。
二.两者的设计目标不一样。ZAB协议主要用于构建一个高可用的分布式数据主从系统,Paxos算法主要用于构建一个分布式的一致性状态机系统。
5.zk的数据存储原理之内存数据
(1)DataNode
(2)DataTree和nodes
(3)ZKDatabase
从数据存储位置角度看,zk产生的数据可以分为内存数据和磁盘数据。从数据的种类和作用看,又可以分为事务日志数据和全量数据快照。
zk的数据模型是一棵树。zk存储了整棵树的内容,包括所有的节点路径、节点数据及ACL信息等。zk会定时将整棵树的数据存储到磁盘上。
(1)DataNode
DataNode是数据存储的最小单元,DataNode会保存:节点的数据内容、ACL列表、节点状态和子节点列表。
public class DataNode implements Record {byte data[];//节点的数据内容Long acl;//ACL列表public StatPersisted stat;//节点状态private Set<String> children = null;//子节点列表...
}(2)DataTree和nodes
DataTree是zk内存数据存储的核心,代表了内存中的一份完整数据,它不包含任何与网络、客户端连接以及请求处理相关的逻辑。DataTree用于存储所有zk节点的路径、内容及其ACL信息,它的核心存储结构是一个ConcurrentHashMap类型的nodes。
在DataTree.nodes这个Map中,存放了zk上所有的数据节点。对zk数据的所有操作,都是对DataTree.nodes这个Map进行操作的。DataTree.nodes的key是节点路径path,value是节点内容DataNode。DataTree.ephemerals专门存储了zk的临时节点,以便实时访问和及时清理。
public class DataTree {//在DataTree.nodes这个Map中,存放了zk上所有的数据节点,包括节点路径、内容及ACL信息private final ConcurrentHashMap<String, DataNode> nodes = new ConcurrentHashMap<String, DataNode>();//存储监听节点的WatchManagerprivate final WatchManager dataWatches = new WatchManager();//存储监听子节点的WatchManagerprivate final WatchManager childWatches = new WatchManager();//存储了zk的临时节点private final Map<Long, HashSet<String>> ephemerals = new ConcurrentHashMap<Long, HashSet<String>>();...public void createNode(final String path, byte data[], List<ACL> acl, long ephemeralOwner, int parentCVersion, long zxid, long time, Stat outputStat) {...String parentName = path.substring(0, lastSlash);...DataNode parent = nodes.get(parentName);...synchronized (parent) {...nodes.put(path, child);...HashSet<String> list = ephemerals.get(ephemeralOwner);if (list == null) {list = new HashSet<String>();ephemerals.put(ephemeralOwner, list);}synchronized (list) {list.add(path);}}...dataWatches.triggerWatch(path, Event.EventType.NodeCreated);childWatches.triggerWatch(parentName.equals("") ? "/" : parentName, Event.EventType.NodeChildrenChanged);}public Set<String> getEphemerals(long sessionId) {HashSet<String> retv = ephemerals.get(sessionId);if (retv == null) {return new HashSet<String>();}HashSet<String> cloned = null;synchronized (retv) {cloned = (HashSet<String>) retv.clone();}return cloned;}...
}(3)ZKDatabase
ZKDatabase是zk的内存数据库,它负责管理zk的所有会话、DataTree存储和事务日志,它会定时向磁盘dump数据快照。在zk服务器启动时会通过磁盘上的事务日志和快照文件恢复ZKDatabase。
public class ZKDatabase {protected DataTree dataTree;//zk的内存数据protected FileTxnSnapLog snapLog;//数据文件管理器...public ZKDatabase(FileTxnSnapLog snapLog) {dataTree = createDataTree();sessionsWithTimeouts = new ConcurrentHashMap<Long, Integer>();this.snapLog = snapLog;...}...
}6.zk的数据存储原理之事务日志
(1)事务日志的存储
(2)事务日志的写入之FileTxnLog的创建
(3)事务日志的写入之FileTxnLog写入日志的步骤
(4)事务日志截断
(1)事务日志的存储
部署zk集群时需要默认配置一个目录dataDir,用于存储事务日志文件。zk中也可以为事务日志单独分配一个文件存储目录dataLogDir。
zk的事务日志文件都具有两个特点:
一.文件大小都是64M
二.文件名后缀都是一个十六进制的、写入文件的第一条事务记录的ZXID
使用ZXID作为后缀,可迅速定位某一个事务操作所在的事务日志文件。由于ZXID的高32位当表当前Leader周期,低32位代表事务操作的计数器。所以将ZXID作为文件后缀,可以清楚看出当前运行的zk的Leader周期。
(2)事务日志的写入之FileTxnLog的创建
zk会通过FileTxnLog类来实现事务日志的写入操作。zk服务端启动时会先创建数据管理器FileTxnSnapLog,在FileTxnSnapLog的构造方法中便会创建FileTxnLog实例。
public class QuorumPeerMain {protected QuorumPeer quorumPeer;...//1.启动程序入口public static void main(String[] args) {QuorumPeerMain main = new QuorumPeerMain();try {//启动程序main.initializeAndRun(args);} catch (IllegalArgumentException e) {...}LOG.info("Exiting normally");System.exit(0);}protected void initializeAndRun(String[] args) {QuorumPeerConfig config = new QuorumPeerConfig();if (args.length == 1) {//2.解析配置文件config.parse(args[0]);}//3.创建和启动历史文件清理器DatadirCleanupManager purgeMgr = new DatadirCleanupManager(config.getDataDir(), config.getDataLogDir(), config.getSnapRetainCount(), config.getPurgeInterval());purgeMgr.start();//4.根据配置判断是集群模式还是单机模式if (args.length == 1 && config.isDistributed()) {//集群模式runFromConfig(config);} else {//单机模式ZooKeeperServerMain.main(args);}}public void runFromConfig(QuorumPeerConfig config) {...ServerCnxnFactory cnxnFactory = null;if (config.getClientPortAddress() != null) {//1.创建网络连接工厂实例ServerCnxnFactorycnxnFactory = ServerCnxnFactory.createFactory();//2.初始化网络连接工厂实例ServerCnxnFactorycnxnFactory.configure(config.getClientPortAddress(), config.getMaxClientCnxns(), false);}//接下来就是初始化集群版服务器实例QuorumPeer//3.创建集群版服务器实例QuorumPeerquorumPeer = getQuorumPeer();//4.创建zk数据管理器FileTxnSnapLogquorumPeer.setTxnFactory(new FileTxnSnapLog(config.getDataLogDir(), config.getDataDir()));...//5.创建并初始化内存数据库ZKDatabasequorumPeer.setZKDatabase(new ZKDatabase(quorumPeer.getTxnFactory()));...quorumPeer.initialize();//6.初始化集群版服务器实例QuorumPeerquorumPeer.start();//join方法会将当前线程挂起,等待QuorumPeer线程结束后再执行当前线程quorumPeer.join();}protected QuorumPeer getQuorumPeer() throws SaslException {return new QuorumPeer();}
}public class FileTxnSnapLog {private final File dataDir;//事务日志文件private final File snapDir;//数据快照文件private TxnLog txnLog;//事务日志实例private SnapShot snapLog;//快照日志实例...public FileTxnSnapLog(File dataDir, File snapDir) throws IOException {...this.dataDir = new File(dataDir, version + VERSION);this.snapDir = new File(snapDir, version + VERSION);...//创建FileTxnLog事务日志管理器的实例txnLog = new FileTxnLog(this.dataDir);//创建FileSnap数据快照管理器的实例snapLog = new FileSnap(this.snapDir);}...
}(3)事务日志的写入之FileTxnLog写入日志的步骤
一.确定是否有事务日志文件可写,如果没有就创建一个事务日志文件
二.确定事务日志文件是否需要扩容--即预分配
三.对事务头和事务体进行序列化生成一个字节数组
四.生成Checksum来保证事务日志文件的完整性和数据的准确性
五.将序列化后的事务头、事务体和Checksum写入到文件流中
六.SyncRequestProcessor处理器会触发将事务日志刷入磁盘
FileTxnLog中进行事务日志的写入操作是由append()方法来负责的。
一.确定是否有事务日志文件可写,如果没有就创建一个事务日志文件
当zk服务器启动完需要进行第一次事务日志写入或上一个事务日志写满时,zk服务器都不会和任意一个事务日志文件进行关联。所以在进行事务日志写入前,FileTxnLog会先判断logStream是否为空,来判断FileTxnLog实例是否已经关联上一个可写的事务日志文件。
如果为空则根据该事务操作相关的ZXID作为后缀来创建一个事务日志文件,然后构建事务日志文件头信息:魔数 + 版本号 + dbid,接着将事务日志文件头信息写入到事务日志文件流中,最后将事务日志文件流fos添加到streamsToFlush。
二.确定事务日志文件是否需要扩容--即预分配
当检测到当前事务日志文件剩余空间不足4096字节时,就会开始进行扩容。扩容过程就是在现有文件大小的基础上,将文件增加64M+使用0进行填充。由于事务日志的写入过程可以看成是一个磁盘IO过程,所以文件的写入操作会触发磁盘IO为文件开辟新的磁盘块,即磁盘Seek。为了避免磁盘Seek频繁出现,zk在创建文件初就预分配一个64M磁盘块。一旦已分配的文件空间不足4K时,那么将会再次预分配,从而避免每次事务日志写入时由于文件大小的增长而带来的Seek开销。
三.对事务头和事务体进行序列化生成一个字节数组
事务序列化包括对事务头TxnHeader和事务体Record的序列化。
四.生成Checksum来保证事务日志文件的完整性和数据的准确性
为了保证事务日志文件的完整性和数据的准确性,在写入事务日志到文件前,会根据序列化的字节数组来计算Checksum。
五.将序列化后的事务头、事务体和Checksum写入到文件流中
由于zk使用BufferedOutputStream,此时写入的数据并非写入到文件。
六.SyncRequestProcessor处理器会触发将事务日志刷入磁盘
前面的步骤已经将事务操作日志写入了文件流中,但由于缓存的原因,这些事务操作日志还无法实时地写入磁盘文件中。因此zk会通过SyncRequestProcessor处理器发起事务日志刷盘操作,最终会调用到FileTxnLog的commit()方法来将事务日志刷入磁盘。也就是当需要刷盘的事务请求达到1000个时,才发起强制刷盘操作。FileTxnLog的commit()方法会从streamsToFlush中提取出文件流,然后调用FileChannel的force()方法强制将数据刷入磁盘文件中,而FileChannel的force()方法会调用到底层的fsync接口。
public class SyncRequestProcessor extends ZooKeeperCriticalThread implements RequestProcessor {private final ZooKeeperServer zks;private final LinkedBlockingQueue<Request> queuedRequests = new LinkedBlockingQueue<Request>();private final LinkedList<Request> toFlush = new LinkedList<Request>();private final Random r = new Random();private static int snapCount = ZooKeeperServer.getSnapCount();...@Overridepublic void run() {int logCount = 0;int randRoll = r.nextInt(snapCount/2);while (true) {Request si = null;if (toFlush.isEmpty()) {si = queuedRequests.take();} else {si = queuedRequests.poll();if (si == null) {flush(toFlush);continue;}}...if (si != null) {//将事务请求写入到事务日志文件if (zks.getZKDatabase().append(si)) {logCount++;if (logCount > (snapCount / 2 + randRoll)) {randRoll = r.nextInt(snapCount/2);//切换事务日志文件zks.getZKDatabase().rollLog();//每切换一个事务日志文件就尝试启动一个线程进行数据快照if (snapInProcess != null && snapInProcess.isAlive()) {LOG.warn("Too busy to snap, skipping");} else {snapInProcess = new ZooKeeperThread("Snapshot Thread") {public void run() {zks.takeSnapshot();}};snapInProcess.start();}logCount = 0;}}...toFlush.add(si);//当需要强制刷盘的请求达到1000个时,就发起批量刷盘操作if (toFlush.size() > 1000) {flush(toFlush);}}}}private void flush(LinkedList<Request> toFlush) {//将事务日志刷入磁盘zks.getZKDatabase().commit();while (!toFlush.isEmpty()) {Request i = toFlush.remove();if (nextProcessor != null) {nextProcessor.processRequest(i);}}if (nextProcessor != null && nextProcessor instanceof Flushable) {((Flushable)nextProcessor).flush();}}...
}public class ZKDatabase {protected FileTxnSnapLog snapLog;...//将事务请求写入到事务日志中public boolean append(Request si) throws IOException {return this.snapLog.append(si);}//切换事务日志文件public void rollLog() throws IOException {this.snapLog.rollLog();}//将事务日志刷入磁盘public void commit() throws IOException {this.snapLog.commit();}...
}public class FileTxnSnapLog {private TxnLog txnLog;...public boolean append(Request si) throws IOException {return txnLog.append(si.getHdr(), si.getTxn());}public void commit() throws IOException {txnLog.commit();}public void rollLog() throws IOException {txnLog.rollLog();}...
}public class FileTxnLog implements TxnLog, Closeable {//和一个事务日志文件相关联的输出流volatile BufferedOutputStream logStream = null;//用来记录当前需要强制进行数据落盘的文件流private LinkedList<FileOutputStream> streamsToFlush = new LinkedList<FileOutputStream>();...//传入的hdr是事务头,传入的txn是事务体public synchronized boolean append(TxnHeader hdr, Record txn) throws IOException {if (hdr == null) {return false;}if (hdr.getZxid() <= lastZxidSeen) {LOG.warn("Current zxid " + hdr.getZxid() + " is <= " + lastZxidSeen + " for " + hdr.getType());} else {lastZxidSeen = hdr.getZxid();}//1.确定是否有事务日志文件可写,如果没有就创建一个事务日志文件if (logStream == null) {if (LOG.isInfoEnabled()) {LOG.info("Creating new log file: " + Util.makeLogName(hdr.getZxid()));}//使用ZXID作为后缀创建一个事务日志文件logFileWrite = new File(logDir, Util.makeLogName(hdr.getZxid()));fos = new FileOutputStream(logFileWrite);//将创建的事务日志文件和logStream进行关联logStream = new BufferedOutputStream(fos);oa = BinaryOutputArchive.getArchive(logStream);//构建事务日志文件头:魔数 + 版本号 + dbidFileHeader fhdr = new FileHeader(TXNLOG_MAGIC, VERSION, dbId);//将事务日志文件头写入到事务日志文件流中fhdr.serialize(oa, "fileheader");// Make sure that the magic number is written before padding.logStream.flush();//设置当前文件写入大小filePadding.setCurrentSize(fos.getChannel().position());//将事务日志文件流fos放入streamsToFlush集合,以便后续进行强制数据落盘streamsToFlush.add(fos);}//2.确定事务日志文件是否需要扩容--即预分配filePadding.padFile(fos.getChannel());//3.对事务头hdr和事务体txn进行序列化生成一个字节数组byte[] buf = Util.marshallTxnEntry(hdr, txn);if (buf == null || buf.length == 0) {throw new IOException("Faulty serialization for header " + "and txn");}//4.生成Checksum来保证事务日志文件的完整性和数据的准确性Checksum crc = makeChecksumAlgorithm();crc.update(buf, 0, buf.length);//5.写入事务日志文件流oa.writeLong(crc.getValue(), "txnEntryCRC");Util.writeTxnBytes(oa, buf);return true;}//切换事务日志文件public synchronized void rollLog() throws IOException {if (logStream != null) {this.logStream.flush();this.logStream = null;oa = null;}}//将事务日志刷入磁盘public synchronized void commit() throws IOException {if (logStream != null) {logStream.flush();}for (FileOutputStream log : streamsToFlush) {log.flush();if (forceSync) {long startSyncNS = System.nanoTime();FileChannel channel = log.getChannel();channel.force(false);syncElapsedMS = TimeUnit.NANOSECONDS.toMillis(System.nanoTime() - startSyncNS);if (syncElapsedMS > fsyncWarningThresholdMS) {if(serverStats != null) {serverStats.incrementFsyncThresholdExceedCount();}}}}while (streamsToFlush.size() > 1) {streamsToFlush.removeFirst().close();}}...
}public class FilePadding {private static long preAllocSize = 65536 * 1024;private long currentSize;//当前文件写入大小private static final ByteBuffer fill = ByteBuffer.allocateDirect(1);...long padFile(FileChannel fileChannel) throws IOException {long newFileSize = calculateFileSizeWithPadding(fileChannel.position(), currentSize, preAllocSize);if (currentSize != newFileSize) {fileChannel.write((ByteBuffer) fill.position(0), newFileSize - fill.remaining());currentSize = newFileSize;}return currentSize;}public static long calculateFileSizeWithPadding(long position, long fileSize, long preAllocSize) {// If preAllocSize is positive and we are within 4KB of the known end of the file calculate a new file size//如果当前事务日志文件的剩余空间不足4096字节if (preAllocSize > 0 && position + 4096 >= fileSize) {// If we have written more than we have previously preallocated we need to make sure the new file size is larger than what we already haveif (position > fileSize) {fileSize = position + preAllocSize;fileSize -= fileSize % preAllocSize;} else {fileSize += preAllocSize;}}return fileSize;}...
}(4)事务日志截断
为了避免某Learner机器上的事务ID比Leader的还要大(peerLastZxid),只要集群中存在Leader,所有机器都必须与该Leader数据保持同步。
因此,只要发现一台Learner机器出现这样的情况,Leader就会发送TRUNC命令给该Learner,要求进行事务日志截断。该Learner收到命令后,就会删除所有大于peerLastZxid的事务日志文件。
相关文章:

zk源码—7.ZAB协议和数据存储一
大纲 1.两阶段提交Two-Phase Commit(2PC) 2.三阶段提交Three-Phase Commit(3PC) 3.ZAB协议算法 4.ZAB协议与Paxos算法 5.zk的数据存储原理之内存数据 6.zk的数据存储原理之事务日志 7.zk的数据存储原理之数据快照 8.zk的数据存储原理之数据初始化和数据同步流程 1.两阶…...

2025蓝桥杯C++A组省赛 题解
昨天打完蓝桥杯本来想写个 p y t h o n python python A A A 组的题解,结果被队友截胡了。今天上课把 C A CA CA 组的题看了,感觉挺简单的,所以来水一篇题解。 这场 B B B 是一个爆搜, C C C 利用取余的性质比较好写&#…...

用哪个机器学习模型 依靠极少量即时静态数据来训练ai预测足球赛的结果?
目录 一、模型推荐 1.集成树模型(XGBoost/CatBoost) 2.逻辑回归(Logistic Regression) 3.贝叶斯概率模型(Naive Bayes或贝叶斯网络) 4.支持向量机(SVM) 二、模型排除 三、训练…...

讲解贪心算法
贪心算法是一种常用的算法思想,其在解决问题时每一步都做出在当前状态下看起来最优的选择,从而希望最终能够获得全局最优解。C作为一种流行的编程语言,可以很好地应用于贪心算法的实现。下面我们来讲一篇关于C贪心算法的文章。 目录 贪心算法…...

0基础 | 电动汽车的“电源翻译官” | DC/DC转换器 | 电源系统三
你有没有想过,电动汽车里那么多五花八门的电子设备,比如车灯、仪表盘、摄像头,甚至连控制马达的“大脑”(ECU),是怎么用上电的?今天就来聊聊电动车里一个默默工作的“小功臣”——DC/DC转换器&a…...

zynq7020 u-boot 速通
zynq u-boot 速通 简介 上回最小系统已经跑起来,证明串口和 ddr 正确配置.现在我们需要正确配置 网口, qspi, emmc. 网口:通过 tftp 下载 dtb,image,rootfs 在线调试.qspi:固化 boot.bin 到 qspi flash,这样 qspi 启动就可以直接运行 u-boot.emmc:存放 ubuntu_base 跟文件系统…...

C++学习之路,从0到精通的征途:string类的模拟实现
目录 一.string类的成员变量与成员函数 二.string类的接口实现 1.构造函数,析构函数,拷贝构造函数,赋值重载 (1)构造函数 (2)析构函数 (3)拷贝构造函数 &…...

网页制作中的MVC和MVT
MVC(模型-视图-控制器)和MVT(模型-模板-视图)是两种常见的软件架构模式,通常用于Web应用程序的设计。它们之间的主要区别在于各自的组件职责和工作方式。 MVC(模型-视图-控制器): 模…...

02 - spring security基于配置文件及内存的账号密码
spring security基于配置的账号密码 文档 00 - spring security框架使用01 - spring security自定义登录页面 yml文件中配置账号密码 spring:security:user:name: adminpassword: 123456yml文件中配置账号密码后,控制台将不再输出临时密码 基于内存的账号密码 …...

Firebase Studio:开启 AI 驱动的开发新纪元
Firebase Studio(前身为 Project IDX)的推出,标志着软件开发范式正经历深刻变革。它不仅是一个传统的 IDE,更是一个以 AI 为主导的、代理式 (agentic) 的云端开发环境,专注于全栈 AI 应用(包括 API、后端、…...

网络基础2
目录 跨网络传输流程 网络中的地址管理 - 认识 IP 地址 跨网络传输 报文信息的跨网络发送 IP地址的转化 认识端口号 端口号范围划分 源端口号和目的端口号 认识 TCP / UDP协议 理解 socket 网络字节序 socket 编程接口 sockaddr 结构 我们继续来学习网络基础 跨网…...
——部署项目到仓库)
Maven工具学习使用(十一)——部署项目到仓库
1、使用Maven默认方式 Maven 部署项目时默认使用的上传文件方式是通过 HTTP/HTTPS 协议。要在 Maven 项目中配置部署,您需要在项目的 pom.xml 文件中添加 部分。这个部分定义了如何部署项目的构件(如 JAR 文件)到仓库。。这个部分定义了如何…...
)
FPGA 37 ,FPGA千兆以太网设计实战:RGMII接口时序实现全解析( RGMII接口时序设计,RGMII~GMII,GMII~RGMII 接口转换 )
目录 前言 一、设计流程 1.1 需求理解 1.2 模块划分 1.3 测试验证 二、模块分工 2.1 RGMII→GMII(接收方向,rgmii_rx 模块) 2.2 GMII→RGMII(发送方向,rgmii_tx 模块) 三、代码实现 3.1 顶层模块 …...

torch.cat和torch.stack的区别
torch.cat 和 torch.stack 是 PyTorch 中用于组合张量的两个常用函数,它们的核心区别在于输入张量的维度和输出张量的维度变化。以下是详细对比: 1. torch.cat (Concatenate) 作用:沿现有维度拼接多个张量,不创建新维度 输入要求…...
)
索引下推(Index Condition Pushdown, ICP)
概念 索引下推是一种数据库查询优化技术,通过在存储引擎层面应用部分WHERE条件来减少不必要的数据读取。它特别适用于复合索引的情况,因为它可以在索引扫描阶段就排除不符合全部条件的数据行,而不是将所有可能匹配的记录加载到服务器层再进行…...

C++基础精讲-06
文章目录 1. this指针1.1 this指针的概念1.2 this指针的使用 2. 特殊的数据成员2.1 常量数据成员2.2 引用数据成员2.3 静态数据成员2.4 对象成员 3. 特殊的成员函数3.1 静态成员函数3.2 const成员函数3.3 mutable关键字 1. this指针 1.1 this指针的概念 1.c规定,t…...

Django3 - 建站基础
学习开发网站必须了解网站的组成部分、网站类型、运行原理和开发流程。使用Django开发网站必须掌握Django的基本操作,比如创建项目、使用Django的操作指令以及开发过程中的调试方法。 一、网站的定义及组成 网站(Website)是指在因特网上根据一定的规则,…...

UE5蓝图设置界面尺寸大小
UE5蓝图设置界面尺寸大小 Create widget 创建UIadd to Viewport 添加视图get Game User Settings获取游戏用户设置set Screen Resolutions 设置屏幕尺寸大小1920*1080set Fullscreen Mode 设置全屏模式为:窗口化或者全屏Apply Settings 应用设置...

无数字字母RCE
无数字字母RCE,这是一个老生常谈的问题,就是不利用数字和字母构造出webshell,从而能够执行我们的命令。 <?php highlight_file(__FILE__); $code $_GET[code]; if(preg_match("/[A-Za-z0-9]/",$code)){die("hacker!&quo…...

AutoGen参数说明
UserProxyAgent用户 user_proxy = UserProxyAgent配置说明: # 构造参数 def __init__(self,name: str,is_termination_msg: Optional[Callable[[Dict], bool]] = None,max_consecutive_auto_reply: Optional[int] = None,human_input_mode: Literal["ALWAYS", &qu…...

6.2 GitHub API接口设计实战:突破限流+智能缓存实现10K+仓库同步
GitHub Sentinel 定期更新 API 接口设计 关键词:GitHub API 集成、异步爬虫开发、RESTful 接口设计、请求限流策略、数据增量更新 1. 接口架构设计原则 采用 分层隔离架构 实现数据采集与业务逻辑解耦: #mermaid-svg-WihvC78J0F5oGDbs {font-family:"trebuchet ms&quo…...

用java代码如何存取数据库的blob字段
一.业务 在业务中我们被要求将文件或图片等转成 byte[] 或 InputStream存到数据库的Blob类型的字段中. 二.Blob类型介绍 在 MySQL 中,Blob 数据类型用于存储二进制数据。MySQL 提供了四种不同的 Blob 类型: TINYBLOB: 最大存储长度为 255 个字节。BL…...

2025蓝桥杯C++研究生组真题-上海市省赛
2025蓝桥杯C研究生组真题 A:数位倍数(5分) 问题描述:请问在 1 至 202504(含)中,有多少个数的各个数位之和是 5 的整数倍。例如:5、19、8025 都是这样的数。 A是填空题,…...
和锁)
原子操作CAS(Compare-And-Swap)和锁
目录 原子操作 优缺点 锁 互斥锁(Mutex) 自旋锁(Spin Lock) 原子性 单核单CPU 多核多CPU 存储体系结构 缓存一致性 写传播(Write Propagation) 事务串行化(Transaction Serialization&#…...

Aspose.Words导出word,服务器用内存流处理,不生成磁盘文件
框架集:.NET8 public async Task<IActionResult> ExportPDF(long? id) {var infoawait form_Dahui_ReportDao.GetAsync(id);if (info null){return Content("没找到数据");}//读取word模板string fileTemp Path.Combine(AppContext.BaseDirect…...

攻防世界——Web题ez_curl
目录 Express PHP和Node.js的解析差异 Python代码 这道题最终得不到flag,用了很多师傅的代码也不成功。但还是需要学习 下载的附件: const express require(express);const app express();const port 3000; const flag process.env.flag;app.ge…...

力扣面试150题--螺旋矩阵
Day 20 题目描述 思路 根据题目描述,我们需要顺时针输出矩阵元素,顺时针说明有四种输出状态,横向从左到右和从右到左,纵向从上到下和从下到上,唯一的难点在于,输出完成一层后,如何进入内层&am…...

智能指针之设计模式2
前面介绍了工厂模式控制了智能指针和资源对象的创建过程,现在介绍一下智能指针是如何利用代理模式来实现“类指针(like-pointer)”的功能,并控制资源对象的销毁过程的。 2、代理模式 代理模式是为其它对象提供一种代理以控制对这…...

【Redis】redis持久化
Redis 持久化 Redis:非关系型的内存数据库 持久化:将数据永久写入磁盘(内存→磁盘) Redis 默认开启了持久化,默认模式为 RDB 为什么需要持久化? Redis 是内存数据库,宕机或关机后数据会丢失。…...

AtCoder Beginner Contest 401 E题 题解
E - Reachable Sethttp://E - Reachable Set 题意概述 : 给定一个无向图, 对于每个 ,解决以下问题: -选择最少的一些顶点,使得删除这些顶点及其关联的所有边后 点1只能到达以内的所有点 牵制芝士 :头文…...

Kubernetes控制平面组件:API Server Webhook 授权机制 详解
云原生学习路线导航页(持续更新中) kubernetes学习系列快捷链接 Kubernetes架构原则和对象设计(一)Kubernetes架构原则和对象设计(二)Kubernetes架构原则和对象设计(三)Kubernetes控…...
官网示例(六)自动补全、边栏)
【CodeMirror】系列(二)官网示例(六)自动补全、边栏
一、自动补全 codemirror/autocomplete 包提供了在编辑器中显示输入建议的功能。这个示例展示了如何启用该功能以及如何编写自己的补全来源。 自动补全是通过在编辑器的配置项中加入 autocompletion 扩展实现的。有些语言包支持内置的自动补全功能,比如HTML包。 默…...

CSS 表格样式学习笔记
CSS 提供了强大的工具来美化和定制 HTML 表格的外观。通过合理使用 CSS 属性,可以使表格更加美观、易读且功能强大。以下是对 CSS 表格样式的详细学习笔记。 一、表格边框 1. 单独边框 默认情况下,表格的 <table>、<th> 和 <td> 元…...

简单记录一下Android四大组件
1、Android Layout 1.1、LinearLayout 线性布局,子控件按照水平或垂直的方向依次排列,排列方向通过属性android:orientation控制,horizontal为水平排列,vertical为垂直排列。对于同一水平线上的控件,可以调整它的lay…...

在线地图支持天地图和腾讯地图,仪表板和数据大屏支持发布功能,DataEase开源BI工具v2.10.7 LTS版本发布
2025年4月11日,人人可用的开源BI工具DataEase正式发布v2.10.7 LTS版本。 这一版本的功能变动包括:数据源方面,Oracle数据源支持获取和查询物化视图;图表方面,在线地图支持天地图、腾讯地图;新增子弹图&…...

【图像处理基石】什么是通透感?
一、画面的通透感定义 画面的通透感指图像在色彩鲜明度、空间层次感、物体轮廓清晰度三方面的综合表现,具体表现为: 色彩鲜明:颜色纯净且饱和度适中,无灰暗或浑浊感;层次分明:明暗过渡自然,光…...

猫咪如厕检测与分类识别系统系列【六】分类模型训练+混合检测分类+未知目标自动更新
前情提要 家里养了三只猫咪,其中一只布偶猫经常出入厕所。但因为平时忙于学业,没法时刻关注牠的行为。我知道猫咪的如厕频率和时长与健康状况密切相关,频繁如厕可能是泌尿问题,停留过久也可能是便秘或不适。为了更科学地了解牠的如…...

NoSQL入门指南:Redis与MongoDB的Java实战
一、为什么需要NoSQL? 在传统SQL数据库中,数据必须严格遵循预定义的表结构,就像把所有物品整齐摆放在固定尺寸的货架上。而NoSQL(Not Only SQL)数据库则像一个灵活的储物间,允许存储各种类型的数据&#x…...

游戏引擎学习第223天
回顾 今天我们正在进行过场动画序列的制作,因此我想深入探讨这个部分。昨天,我们暂时停止了过场动画的制作,距离最终结局还有一些内容没有完成。今天的目标是继续完成这些内容。 我们已经制作了一个过场动画的系列,并把它们集中…...
)
【redis进阶二】分布式系统之主从复制结构(1)
目录 一 为什么要有分布式系统? 二 分布式系统涉及到的非常关键的问题:单点问题 三 学习部署主从结构的redis (1)创建一个目录 (2)进入目录拷贝两份原有redis (3)使用vim修改几个选项 (4)启动两个从节点服务器 (5)建立复制,要想配…...
若依生成左树右表)
(自用)若依生成左树右表
第一步: 在数据库创建树表和单表: SQL命令: 商品表 CREATE TABLE products (product_id INT AUTO_INCREMENT PRIMARY KEY,product_name VARCHAR(255) , price DECIMAL(10, 2) , stock INT NOT NULL, category_id INT NOT NULL); 商品分类…...

VectorBT量化入门系列:第六章 VectorBT实战案例:机器学习预测策略
VectorBT量化入门系列:第六章 VectorBT实战案例:机器学习预测策略 本教程专为中高级开发者设计,系统讲解VectorBT技术在量化交易中的应用。通过结合Tushare数据源和TA-Lib技术指标,深度探索策略开发、回测优化与风险评估的核心方法…...

5G网络下客户端数据业务掉线频繁
MCPTT(Mission Critical Push-to-Talk)客户端的日志,和界面在待机状态下(即没有做通话等业务操作),会频繁提示“离线”。 主要先看有没有丢网,UL BLER有没有问题。确认没有问题。看到业务信道释…...
)
CPU(中央处理器)
一、CPU的定义与核心作用 CPU 是计算机的核心部件,负责 解释并执行指令、协调各硬件资源 以及 完成数据处理,其性能直接影响计算机的整体效率。 核心功能: 从内存中读取指令并译码。执行算术逻辑运算。控制数据在寄存器、内存和I/O设备间的…...
之旅——程序逻辑控制④)
Java从入门到“放弃”(精通)之旅——程序逻辑控制④
Java从入门到“放弃”(精通)之旅🚀:程序逻辑的完美理解 一、开篇:程序员的"人生选择" 曾经的我,生活就像一段顺序执行的代码: System.out.println("早上8:00起床"); Syste…...

[Dify] 基于明道云实现金融业务中的Confirmation生成功能
在金融业务的日常流程中,交易记录的处理不仅涉及数据录入、流程审批,更重要的是其最终输出形式——交易确认函(Confirmation)。本文将介绍如何通过明道云的打印模板功能,快速、准确地生成符合业务需求的交易Confirmation,提升工作效率与合规性。 为什么需要Confirmation?…...

Qt安卓设备上怎么安装两个不同的Qt应用?
在安卓设备上安装两个不同的Qt应用时,需要确保这两个应用在安卓系统中被视为独立的应用程序。以下是详细的步骤和注意事项,帮助你实现这一目标: 一、修改应用的包名 安卓系统通过应用的包名(package属性)来区分不同的…...
)
Prompt工程提示词(1-6章)
White graces:个人主页 🐹今日诗词:怅望千秋一洒泪,萧条异代不同时🐹 ⛳️点赞 ☀️收藏⭐️关注💬卑微小博主🙏 ⛳️点赞 ☀️收藏⭐️关注💬卑微小博主🙏 目录 🚀 第…...

0基础 | 硬件滤波 C、RC、LC、π型
一、滤波概念 (一)滤波定义 滤波是将信号中特定波段频率滤除的操作,是抑制和防止干扰的重要措施。通过滤波器实现对特定频率成分的筛选,确保目标信号的纯净度,提升系统稳定性。 (二)滤波器分…...

C++ 编程指南34 - C++ 中 ABI 不兼容的典型情形
一:概述 ABI(Application Binary Interface)是二进制层面的接口规范。如果一个库的 ABI 发生了变化,那么基于旧 ABI 编译的代码可能在运行时与新库不兼容(即使接口名字都一样也不行)。那么在C++中编程中,哪些情形会导致ABI不兼容呢?下面逐一列举一下。 二:C++ 中 ABI…...