【MySQL】复合查询
文章目录
- 👉基本查询回顾👈
- select 子查询
- 👉多表查询👈
- 👉自连接👈
- 👉子查询👈
- 单行子查询
- 多行子查询
- 多列子查询
- 在from子句中使用子查询
- 合并查询
- 👉总结👈
👉基本查询回顾👈
- 查询工资高于 500 或岗位为 MANAGER 的雇员,同时还要满足他们的姓名首字母为大写的 J
mysql> select ename, job, sal from emp where (sal > 500 or job = 'MANAGER') and (substring(ename, 1, 1) = 'J');
+-------+---------+---------+
| ename | job | sal |
+-------+---------+---------+
| JONES | MANAGER | 2975.00 |
| JAMES | CLERK | 950.00 |
+-------+---------+---------+
2 rows in set (0.00 sec)mysql> select ename, job, sal from emp where (sal > 500 or job = 'MANAGER') and (ename like 'J%');
+-------+---------+---------+
| ename | job | sal |
+-------+---------+---------+
| JONES | MANAGER | 2975.00 |
| JAMES | CLERK | 950.00 |
+-------+---------+---------+
2 rows in set (0.00 sec)- 按照部门号升序而雇员的工资降序排序
mysql> select deptno, ename, sal from emp order by deptno asc, sal desc;
+--------+--------+---------+
| deptno | ename | sal |
+--------+--------+---------+
| 10 | KING | 5000.00 |
| 10 | CLARK | 2450.00 |
| 10 | MILLER | 1300.00 |
| 20 | SCOTT | 3000.00 |
| 20 | FORD | 3000.00 |
| 20 | JONES | 2975.00 |
| 20 | ADAMS | 1100.00 |
| 20 | SMITH | 800.00 |
| 30 | BLAKE | 2850.00 |
| 30 | ALLEN | 1600.00 |
| 30 | TURNER | 1500.00 |
| 30 | WARD | 1250.00 |
| 30 | MARTIN | 1250.00 |
| 30 | JAMES | 950.00 |
+--------+--------+---------+
14 rows in set (0.00 sec)- 使用年薪进行降序排序
-- 年薪=月薪*12+奖金
-- 如果奖金为null,则认为奖金为零
mysql> select ename, sal*12+ifnull(comm,0) as 年薪 from emp order by 年薪 desc;
+--------+----------+
| ename | 年薪 |
+--------+----------+
| KING | 60000.00 |
| SCOTT | 36000.00 |
| FORD | 36000.00 |
| JONES | 35700.00 |
| BLAKE | 34200.00 |
| CLARK | 29400.00 |
| ALLEN | 19500.00 |
| TURNER | 18000.00 |
| MARTIN | 16400.00 |
| MILLER | 15600.00 |
| WARD | 15500.00 |
| ADAMS | 13200.00 |
| JAMES | 11400.00 |
| SMITH | 9600.00 |
+--------+----------+
14 rows in set (0.00 sec)- 显示工资最高的员工的名字和工作岗位
-- select ename, max(sal) from emp; 这条SQL语句
-- 是无符合语法规范的,因为并没有按照ename进行分组
-- 只有出现在group by中的列才能出现在select中-- 这显然不是我们想要的结果
mysql> select ename, max(sal) from emp group by ename;
+--------+----------+
| ename | max(sal) |
+--------+----------+
| ADAMS | 1100.00 |
| ALLEN | 1600.00 |
| BLAKE | 2850.00 |
| CLARK | 2450.00 |
| FORD | 3000.00 |
| JAMES | 950.00 |
| JONES | 2975.00 |
| KING | 5000.00 |
| MARTIN | 1250.00 |
| MILLER | 1300.00 |
| SCOTT | 3000.00 |
| SMITH | 800.00 |
| TURNER | 1500.00 |
| WARD | 1250.00 |
+--------+----------+
14 rows in set (0.00 sec)-- 可以先找出最高工资,然后就能将拥有最高工资的人名显示出来
mysql> select max(sal) from emp;
+----------+
| max(sal) |
+----------+
| 5000.00 |
+----------+
1 row in set (0.00 sec)mysql> select ename, sal 最高工资 from emp where sal = 5000;
+-------+--------------+
| ename | 最高工资 |
+-------+--------------+
| KING | 5000.00 |
+-------+--------------+
1 row in set (0.00 sec)-- 上面用了两条SQL语句才完成需求,那么可不可以用
-- 一条SQL语句完成需求呢?当然可以
-- 通过嵌套select子查询
mysql> select ename, job from emp where sal = (select max(sal) from emp);
+-------+-----------+
| ename | job |
+-------+-----------+
| KING | PRESIDENT |
+-------+-----------+
1 row in set (0.00 sec)select 子查询

- 显示工资高于平均工资的员工信息
mysql> select ename, sal from emp where sal > (select avg(sal) from emp);
+-------+---------+
| ename | sal |
+-------+---------+
| JONES | 2975.00 |
| BLAKE | 2850.00 |
| CLARK | 2450.00 |
| SCOTT | 3000.00 |
| KING | 5000.00 |
| FORD | 3000.00 |
+-------+---------+
6 rows in set (0.00 sec)- 显示每个部门的平均工资和最高工资
mysql> select deptno, format(avg(sal), 2) 平均工资, max(sal) 最高工资 from emp group by deptno;
+--------+--------------+--------------+
| deptno | 平均工资 | 最高工资 |
+--------+--------------+--------------+
| 10 | 2,916.67 | 5000.00 |
| 20 | 2,175.00 | 3000.00 |
| 30 | 1,566.67 | 2850.00 |
+--------+--------------+--------------+
3 rows in set (0.00 sec)- 显示平均工资低于 2000 的部门号和它的平均工资
-- format会对数据进行格式化,无法再进行与原数据的比较
-- fromat会用不同的编码来呈现原始数据
mysql> select charset(format(1000, 2));
+--------------------------+
| charset(format(1000, 2)) |
+--------------------------+
| utf8 |
+--------------------------+
1 row in set (0.00 sec)mysql> select charset(1000);
+---------------+
| charset(1000) |
+---------------+
| binary |
+---------------+
1 row in set (0.00 sec)mysql> select deptno, avg(sal) 平均工资 from emp group by deptno having 平均工资<2000;
+--------+--------------+
| deptno | 平均工资 |
+--------+--------------+
| 30 | 1566.666667 |
+--------+--------------+
1 row in set (0.00 sec)- 显示每种岗位的雇员总数,平均工资
mysql> select job 岗位, count(*) 人数, format(avg(sal), 2) 平均工资 from emp group by job;
+-----------+--------+--------------+
| 岗位 | 人数 | 平均工资 |
+-----------+--------+--------------+
| ANALYST | 2 | 3,000.00 |
| CLERK | 4 | 1,037.50 |
| MANAGER | 3 | 2,758.33 |
| PRESIDENT | 1 | 5,000.00 |
| SALESMAN | 4 | 1,400.00 |
+-----------+--------+--------------+
5 rows in set (0.00 sec)👉多表查询👈
实际开发中数据往往来自不同的表,所以需要多表查询。这部分我们用一个简单的公司管理系统,有三张表 emp、dept 和 salgrade 来演示如何进行多表查询。
笛卡尔积
笛卡尔积是一种关系型数据库中的操作,用于将两个表的每一行进行组合,生成一个新的结果集。它将表之间的每个行组合,生成的结果集的行数等于两个表的行数的乘积。
假设有两个表 A 和 B,表 A 有 m 行,表 B 有 n 行,那么它们的笛卡尔积将生成一个包含 m * n 行的结果集。每个结果集的行包含来自表 A 和表 B 的一行组合。
笛卡尔积的计算方式是对两个表进行无条件的连接,即将表 A 的每一行与表 B 的每一行进行组合。结果集中的每一行都代表了表 A 和表 B 中一行的组合。
需要注意的是,笛卡尔积是对两个表进行无条件的连接的,所以新形成的表中的数据可能是一些无效的数据。因此在将两张表形成一张新表时,我们需要设置一些条件来避免数据无效的问题。
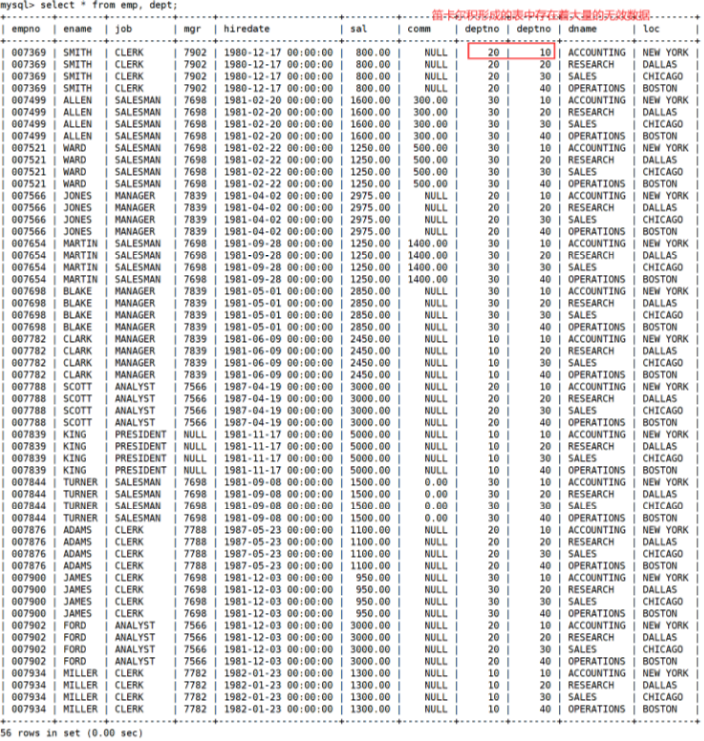
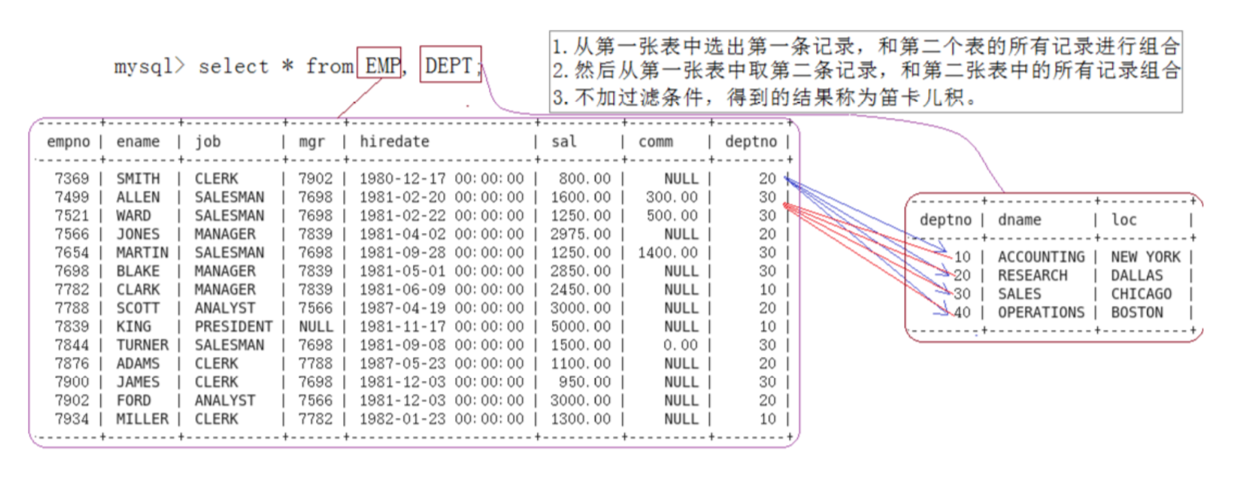
其实我们只要 emp 表中的 deptno 等于 dept 表中的 deptno 字段的记录,就能够解决数据无效的问题。
- 显示雇员名、雇员工资以及所在部门的名字
mysql> select emp.ename, emp.sal, dept.dname from emp, dept where emp.deptno = dept.deptno;
+--------+---------+------------+
| ename | sal | dname |
+--------+---------+------------+
| SMITH | 800.00 | RESEARCH |
| ALLEN | 1600.00 | SALES |
| WARD | 1250.00 | SALES |
| JONES | 2975.00 | RESEARCH |
| MARTIN | 1250.00 | SALES |
| BLAKE | 2850.00 | SALES |
| CLARK | 2450.00 | ACCOUNTING |
| SCOTT | 3000.00 | RESEARCH |
| KING | 5000.00 | ACCOUNTING |
| TURNER | 1500.00 | SALES |
| ADAMS | 1100.00 | RESEARCH |
| JAMES | 950.00 | SALES |
| FORD | 3000.00 | RESEARCH |
| MILLER | 1300.00 | ACCOUNTING |
+--------+---------+------------+
14 rows in set (0.00 sec)- 显示部门号为 10 的部门名,员工名和工资
-- 部门名只在部门表中有,而员工名和工资只有在员工表中有
-- 因此需要将这两表进行组合
mysql> select emp.deptno, emp.ename, emp.sal from emp, dept where emp.deptno = dept.deptno and dept.deptno = 10;
+--------+--------+---------+
| deptno | ename | sal |
+--------+--------+---------+
| 10 | CLARK | 2450.00 |
| 10 | KING | 5000.00 |
| 10 | MILLER | 1300.00 |
+--------+--------+---------+
3 rows in set (0.00 sec)- 显示各个员工的姓名,工资,及工资级别
mysql> select * from salgrade;
+-------+-------+-------+
| grade | losal | hisal |
+-------+-------+-------+
| 1 | 700 | 1200 |
| 2 | 1201 | 1400 |
| 3 | 1401 | 2000 |
| 4 | 2001 | 3000 |
| 5 | 3001 | 9999 |
+-------+-------+-------+
5 rows in set (0.00 sec)mysql> select ename, sal, grade from emp, salgrade where sal between losal and hisal;
+--------+---------+-------+
| ename | sal | grade |
+--------+---------+-------+
| SMITH | 800.00 | 1 |
| ALLEN | 1600.00 | 3 |
| WARD | 1250.00 | 2 |
| JONES | 2975.00 | 4 |
| MARTIN | 1250.00 | 2 |
| BLAKE | 2850.00 | 4 |
| CLARK | 2450.00 | 4 |
| SCOTT | 3000.00 | 4 |
| KING | 5000.00 | 5 |
| TURNER | 1500.00 | 3 |
| ADAMS | 1100.00 | 1 |
| JAMES | 950.00 | 1 |
| FORD | 3000.00 | 4 |
| MILLER | 1300.00 | 2 |
+--------+---------+-------+解决多表查询的思路
先明确题目和哪些表有关,然后将这些表组成成一张有效的表,那么多表查询就变成了单表查询了。
👉自连接👈
自连接是指在一个表中通过连接操作自身的过程。通常,自连接在以下场景中应用:
层级结构:当数据表中的记录之间存在层级关系时,可以使用自连接来查询父节点和子节点之间的关系。例如,组织结构表中的每个记录表示一个员工,记录中包含一个指向上级员工的外键,通过自连接可以查询员工和他们的上级。
关联关系:当表中的记录之间存在关联关系时,可以使用自连接来查找相关记录。例如,一个订单表中包含了订单的主订单号和子订单号,通过自连接可以查询主订单和对应的子订单。
数据比较:当需要比较表中的记录时,可以使用自连接来将表中的记录与其他记录进行比较。例如,可以使用自连接来比较表中不同时间段的记录,或者比较相邻行的记录。
别名使用:自连接还可以用于给表起别名,并对表进行多次引用,以便进行更复杂的查询操作。通过别名,可以在同一个查询中将表作为不同的实体进行引用,从而实现更灵活的查询需求。
-- 两张相同的表没经过重命名,无法进行笛卡尔积
mysql> select * from dept, dept;
ERROR 1066 (42000): Not unique table/alias: 'dept'-- 两张相同的表经过重命名后,可以进行笛卡尔积
mysql> select * from dept as dt1, dept as dt2;
+--------+------------+----------+--------+------------+----------+
| deptno | dname | loc | deptno | dname | loc |
+--------+------------+----------+--------+------------+----------+
| 10 | ACCOUNTING | NEW YORK | 10 | ACCOUNTING | NEW YORK |
| 20 | RESEARCH | DALLAS | 10 | ACCOUNTING | NEW YORK |
| 30 | SALES | CHICAGO | 10 | ACCOUNTING | NEW YORK |
| 40 | OPERATIONS | BOSTON | 10 | ACCOUNTING | NEW YORK |
| 10 | ACCOUNTING | NEW YORK | 20 | RESEARCH | DALLAS |
| 20 | RESEARCH | DALLAS | 20 | RESEARCH | DALLAS |
| 30 | SALES | CHICAGO | 20 | RESEARCH | DALLAS |
| 40 | OPERATIONS | BOSTON | 20 | RESEARCH | DALLAS |
| 10 | ACCOUNTING | NEW YORK | 30 | SALES | CHICAGO |
| 20 | RESEARCH | DALLAS | 30 | SALES | CHICAGO |
| 30 | SALES | CHICAGO | 30 | SALES | CHICAGO |
| 40 | OPERATIONS | BOSTON | 30 | SALES | CHICAGO |
| 10 | ACCOUNTING | NEW YORK | 40 | OPERATIONS | BOSTON |
| 20 | RESEARCH | DALLAS | 40 | OPERATIONS | BOSTON |
| 30 | SALES | CHICAGO | 40 | OPERATIONS | BOSTON |
| 40 | OPERATIONS | BOSTON | 40 | OPERATIONS | BOSTON |
+--------+------------+----------+--------+------------+----------+
16 rows in set (0.01 sec)- 显示员工 FORD 的上级领导的编号和姓名
-- mgr是员工领导的编号
-- 使用子查询mysql> select empno, ename from emp where empno = (select mgr from emp where ename = 'FORD');
+--------+-------+
| empno | ename |
+--------+-------+
| 007566 | JONES |
+--------+-------+
1 row in set (0.00 sec)-- 使用多表查询(自连接)
-- 员工领导编号等于领导的编号就能够得到一个有效的表
mysql> select leader.empno, leader.ename from emp leader, emp worker where leader.empno = worker.mgr and worker.ename = 'FORD';
+--------+-------+
| empno | ename |
+--------+-------+
| 007566 | JONES |
+--------+-------+
1 row in set (0.00 sec)👉子查询👈
子查询是指嵌入在其他 SQL 语句中的 select 语句,也叫嵌套查询。
单行子查询
单行子查询是返回一行记录的子查询。
- 显示 SMITH 同一部门的员工
mysql> select * from emp where deptno = (select deptno from emp where ename = 'SMITH');
+--------+-------+---------+------+---------------------+---------+------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+-------+---------+------+---------------------+---------+------+--------+
| 007369 | SMITH | CLERK | 7902 | 1980-12-17 00:00:00 | 800.00 | NULL | 20 |
| 007566 | JONES | MANAGER | 7839 | 1981-04-02 00:00:00 | 2975.00 | NULL | 20 |
| 007788 | SCOTT | ANALYST | 7566 | 1987-04-19 00:00:00 | 3000.00 | NULL | 20 |
| 007876 | ADAMS | CLERK | 7788 | 1987-05-23 00:00:00 | 1100.00 | NULL | 20 |
| 007902 | FORD | ANALYST | 7566 | 1981-12-03 00:00:00 | 3000.00 | NULL | 20 |
+--------+-------+---------+------+---------------------+---------+------+--------+
5 rows in set (0.00 sec)多行子查询
多行子查询是返回多行记录的子查询。
- 查询和 10 号部门的工作岗位相同的雇员的名字,岗位,工资,部门号,但是不包含 10 自己的
mysql> select ename, job, sal, deptno from emp where job in (select distinct job from emp where deptno=10) and deptno!=10;
+-------+---------+---------+--------+
| ename | job | sal | deptno |
+-------+---------+---------+--------+
| JONES | MANAGER | 2975.00 | 20 |
| BLAKE | MANAGER | 2850.00 | 30 |
| SMITH | CLERK | 800.00 | 20 |
| ADAMS | CLERK | 1100.00 | 20 |
| JAMES | CLERK | 950.00 | 30 |
+-------+---------+---------+--------+
5 rows in set (0.01 sec)-- select distinct job from emp where deptno=10 的返
-- 回结果是10号部门中所包含的岗位
-- in关键字是用来判断job是否在10号部门所包含的岗位集合中,如果在则为真- 显示工资比部门 30 的所有员工的工资高的员工的姓名、工资和部门号
-- 30号部门的员工的最高工资
mysql> select max(sal) from emp where deptno=30;
+----------+
| max(sal) |
+----------+
| 2850.00 |
+----------+
1 row in set (0.00 sec)mysql> select ename, sal, deptno from emp where sal > (select max(sal) from emp where deptno=30);
+-------+---------+--------+
| ename | sal | deptno |
+-------+---------+--------+
| JONES | 2975.00 | 20 |
| SCOTT | 3000.00 | 20 |
| KING | 5000.00 | 10 |
| FORD | 3000.00 | 20 |
+-------+---------+--------+
4 rows in set (0.00 sec)mysql> select ename, sal, deptno from emp where sal > all(select sal from emp where deptno=30);
+-------+---------+--------+
| ename | sal | deptno |
+-------+---------+--------+
| JONES | 2975.00 | 20 |
| SCOTT | 3000.00 | 20 |
| KING | 5000.00 | 10 |
| FORD | 3000.00 | 20 |
+-------+---------+--------+
4 rows in set (0.00 sec)-- select sal from emp where deptno=30 的返回结果是单列多行的数据,这些数据组成了一个集合- 显示工资比部门 30 的任意员工的工资高的员工的姓名、工资和部门号(包含自己部门的员工)
-- 30号部门的最低工资
mysql> select min(sal) from emp where deptno=30;
+----------+
| min(sal) |
+----------+
| 950.00 |
+----------+
1 row in set (0.00 sec)mysql> select ename, sal, deptno from emp where sal > (select min(sal) from emp where deptno=30);
+--------+---------+--------+
| ename | sal | deptno |
+--------+---------+--------+
| ALLEN | 1600.00 | 30 |
| WARD | 1250.00 | 30 |
| JONES | 2975.00 | 20 |
| MARTIN | 1250.00 | 30 |
| BLAKE | 2850.00 | 30 |
| CLARK | 2450.00 | 10 |
| SCOTT | 3000.00 | 20 |
| KING | 5000.00 | 10 |
| TURNER | 1500.00 | 30 |
| ADAMS | 1100.00 | 20 |
| FORD | 3000.00 | 20 |
| MILLER | 1300.00 | 10 |
+--------+---------+--------+
12 rows in set (0.00 sec)mysql> select ename, sal, deptno from emp where sal > any(select sal from emp where deptno=30);
+--------+---------+--------+
| ename | sal | deptno |
+--------+---------+--------+
| ALLEN | 1600.00 | 30 |
| WARD | 1250.00 | 30 |
| JONES | 2975.00 | 20 |
| MARTIN | 1250.00 | 30 |
| BLAKE | 2850.00 | 30 |
| CLARK | 2450.00 | 10 |
| SCOTT | 3000.00 | 20 |
| KING | 5000.00 | 10 |
| TURNER | 1500.00 | 30 |
| ADAMS | 1100.00 | 20 |
| FORD | 3000.00 | 20 |
| MILLER | 1300.00 | 10 |
+--------+---------+--------+
12 rows in set (0.00 sec)多列子查询
单行子查询是指子查询只返回单列,单行数据;多行子查询是指返回单列多行数据,都是针对单列而言的;而多列子查询则是指查询返回多个列数据的子查询语句。
- 查询和 SMITH 的部门和岗位完全相同的所有雇员,不含 SMITH 本人
-- 查看SMITH所在的部门和岗位
mysql> select job, deptno from emp where ename='SMITH';
+-------+--------+
| job | deptno |
+-------+--------+
| CLERK | 20 |
+-------+--------+
1 row in set (0.00 sec)mysql> select ename, job, deptno from emp where (job, deptno) = (select job, deptno from emp where ename='SMITH') and ename!='SMITH';
+-------+-------+--------+
| ename | job | deptno |
+-------+-------+--------+
| ADAMS | CLERK | 20 |
+-------+-------+--------+
1 row in set (0.00 sec)在from子句中使用子查询
子查询语句出现在 from 子句中。这里要用到数据查询的技巧,把一个子查询当做一个临时表使用。
-- 使用select语句形成的表也可以被看做一张表,尽管这张表
-- 并不在磁盘中真实存在,同时我们也就有对这张表进行重命名
-- 也可以其他的表进行笛卡尔积
mysql> select * from emp where deptno=20;
+--------+-------+---------+------+---------------------+---------+------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+-------+---------+------+---------------------+---------+------+--------+
| 007369 | SMITH | CLERK | 7902 | 1980-12-17 00:00:00 | 800.00 | NULL | 20 |
| 007566 | JONES | MANAGER | 7839 | 1981-04-02 00:00:00 | 2975.00 | NULL | 20 |
| 007788 | SCOTT | ANALYST | 7566 | 1987-04-19 00:00:00 | 3000.00 | NULL | 20 |
| 007876 | ADAMS | CLERK | 7788 | 1987-05-23 00:00:00 | 1100.00 | NULL | 20 |
| 007902 | FORD | ANALYST | 7566 | 1981-12-03 00:00:00 | 3000.00 | NULL | 20 |
+--------+-------+---------+------+---------------------+---------+------+--------+
5 rows in set (0.00 sec)mysql> select * from (select * from emp where deptno=20) as temp where ename='SMITH';
+--------+-------+-------+------+---------------------+--------+------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+-------+-------+------+---------------------+--------+------+--------+
| 007369 | SMITH | CLERK | 7902 | 1980-12-17 00:00:00 | 800.00 | NULL | 20 |
+--------+-------+-------+------+---------------------+--------+------+--------+
1 row in set (0.00 sec)结论:MySQL 表的大一统思想:不管我们有多少张表,所有通过 select 查出来的结果,都是一张表。
- 显示每个高于自己部门平均工资的员工的姓名、部门、工资、平均工资
-- 获取各个部门的平均工资,将其看作临时表
mysql> select deptno, format(avg(sal), 2) myavg from emp group by deptno;
+--------+----------+
| deptno | myavg |
+--------+----------+
| 10 | 2,916.67 |
| 20 | 2,175.00 |
| 30 | 1,566.67 |
+--------+----------+
3 rows in set (0.00 sec)mysql> select ename, emp.deptno, sal, format(myavg,2) from (emp, (select deptno, avg(sal) myavg from emp group by deptno) as temp)-> where emp.deptno = temp.deptno and sal > myavg;
+-------+--------+---------+-----------------+
| ename | deptno | sal | format(myavg,2) |
+-------+--------+---------+-----------------+
| ALLEN | 30 | 1600.00 | 1,566.67 |
| JONES | 20 | 2975.00 | 2,175.00 |
| BLAKE | 30 | 2850.00 | 1,566.67 |
| SCOTT | 20 | 3000.00 | 2,175.00 |
| KING | 10 | 5000.00 | 2,916.67 |
| FORD | 20 | 3000.00 | 2,175.00 |
+-------+--------+---------+-----------------+
6 rows in set (0.00 sec)-- 在上面的表的基础上,再列出这些人的薪资等级
mysql> select * from salgrade, (select ename, emp.deptno, sal, format(myavg,2) from (emp, (select deptno, avg(sal) myavg from emp group by deptno) as temp)-> where emp.deptno = temp.deptno and sal > myavg) as ret where ret.sal between losal and hisal;
+-------+-------+-------+-------+--------+---------+-----------------+
| grade | losal | hisal | ename | deptno | sal | format(myavg,2) |
+-------+-------+-------+-------+--------+---------+-----------------+
| 3 | 1401 | 2000 | ALLEN | 30 | 1600.00 | 1,566.67 |
| 4 | 2001 | 3000 | JONES | 20 | 2975.00 | 2,175.00 |
| 4 | 2001 | 3000 | BLAKE | 30 | 2850.00 | 1,566.67 |
| 4 | 2001 | 3000 | SCOTT | 20 | 3000.00 | 2,175.00 |
| 5 | 3001 | 9999 | KING | 10 | 5000.00 | 2,916.67 |
| 4 | 2001 | 3000 | FORD | 20 | 3000.00 | 2,175.00 |
+-------+-------+-------+-------+--------+---------+-----------------+
6 rows in set (0.00 sec)- 查找每个部门工资最高的人的姓名、工资、部门
mysql> select deptno, max(sal) mymax from emp group by deptno;
+--------+---------+
| deptno | mymax |
+--------+---------+
| 10 | 5000.00 |
| 20 | 3000.00 |
| 30 | 2850.00 |
+--------+---------+
3 rows in set (0.00 sec)mysql> select emp.ename, emp.sal, emp.deptno from emp, (select deptno, max(sal) mymax from emp group by deptno) as temp-> where emp.deptno=temp.deptno and emp.sal=temp.mymax;
+-------+---------+--------+
| ename | sal | deptno |
+-------+---------+--------+
| BLAKE | 2850.00 | 30 |
| SCOTT | 3000.00 | 20 |
| KING | 5000.00 | 10 |
| FORD | 3000.00 | 20 |
+-------+---------+--------+
4 rows in set (0.00 sec)-- 在上表的基础上,找出这些人的工作地点
mysql> select * from dept;
+--------+------------+----------+
| deptno | dname | loc |
+--------+------------+----------+
| 10 | ACCOUNTING | NEW YORK |
| 20 | RESEARCH | DALLAS |
| 30 | SALES | CHICAGO |
| 40 | OPERATIONS | BOSTON |
+--------+------------+----------+
4 rows in set (0.00 sec)mysql> select dept.deptno, dname, loc, ename, sal from dept, (select emp.ename, emp.sal, emp.deptno from emp, > (select deptno, max(sal) mymax from emp group by depttno) as temp where emp.deptno=temp.deptno and emp.sal=temp.mymax) as ret > where ret.deptno = dept.deptno;
+--------+------------+----------+-------+---------+
| deptno | dname | loc | ename | sal |
+--------+------------+----------+-------+---------+
| 30 | SALES | CHICAGO | BLAKE | 2850.00 |
| 20 | RESEARCH | DALLAS | SCOTT | 3000.00 |
| 10 | ACCOUNTING | NEW YORK | KING | 5000.00 |
| 20 | RESEARCH | DALLAS | FORD | 3000.00 |
+--------+------------+----------+-------+---------+
4 rows in set (0.00 sec)- 显示每个部门的信息(部门名,编号,地址)和人员数量
mysql> select dname, dept.deptno, loc, num from dept, (select deptno, count(*) num from emp group by deptno) temp-> where dept.deptno = temp.deptno;
+------------+--------+----------+-----+
| dname | deptno | loc | num |
+------------+--------+----------+-----+
| ACCOUNTING | 10 | NEW YORK | 3 |
| RESEARCH | 20 | DALLAS | 5 |
| SALES | 30 | CHICAGO | 6 |
+------------+--------+----------+-----+
3 rows in set (0.00 sec)合并查询
在实际应用中,为了合并多个 select 的执行结果,可以使用集合操作符 union,union all。
union
该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行。
- 将工资大于 2500 或职位是 MANAGER 的人找出来
-- 有些人既是MANAGER,工资也是超过2500
-- 此时就会存在重复的数据,而union会将重
-- 复的数据去重掉,只保留一条数据
mysql> select ename, sal, job from emp where sal > 2500 union-> select ename, sal, job from emp where job = 'MANAGER';
+-------+---------+-----------+
| ename | sal | job |
+-------+---------+-----------+
| JONES | 2975.00 | MANAGER |
| BLAKE | 2850.00 | MANAGER |
| SCOTT | 3000.00 | ANALYST |
| KING | 5000.00 | PRESIDENT |
| FORD | 3000.00 | ANALYST |
| CLARK | 2450.00 | MANAGER |
+-------+---------+-----------+
6 rows in set (0.00 sec)union all
该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行。
- 将工资大于 2500 或职位是 MANAGER 的人找出来
-- 可以看到JONES和BLAKE的数据是重复的
mysql> select ename, sal, job from emp where sal > 2500 union all-> select ename, sal, job from emp where job = 'MANAGER';
+-------+---------+-----------+
| ename | sal | job |
+-------+---------+-----------+
| JONES | 2975.00 | MANAGER |
| BLAKE | 2850.00 | MANAGER |
| SCOTT | 3000.00 | ANALYST |
| KING | 5000.00 | PRESIDENT |
| FORD | 3000.00 | ANALYST |
| JONES | 2975.00 | MANAGER |
| BLAKE | 2850.00 | MANAGER |
| CLARK | 2450.00 | MANAGER |
+-------+---------+-----------+
8 rows in set (0.00 sec)union 和 union all 的本质就是将多个结果合并成一个结果,也就是将多张表合并成一张表。不过需要注意的是,多张表的列属性需要是一致的。
👉总结👈
本篇博客主要讲解了多表查询、自连接和子查询等等。以上就是本篇博客的全部内容了,如果大家觉得有收获的话,可以点个三连支持一下!谢谢大家啦!💖💝❣️
相关文章:

【MySQL】复合查询
文章目录 👉基本查询回顾👈select 子查询 👉多表查询👈👉自连接👈👉子查询👈单行子查询多行子查询多列子查询在from子句中使用子查询合并查询 👉总结👈 &…...

并发编程--条件量与死锁及其解决方案
并发编程–条件量与死锁及其解决方案 文章目录 并发编程--条件量与死锁及其解决方案1.条件量1.1条件量基本概念1.2条件量的使用 2. 死锁 1.条件量 1.1条件量基本概念 在许多场合中,程序的执行通常需要满足一定的条件,条件不成熟的时候,任务…...
【NLP解析】多头注意力+掩码机制+位置编码:Transformer三大核心技术详解
目录 多头注意力:让模型化身“多面手” 技术细节:多头注意力如何计算? 实际应用:多头注意力在Transformer中的威力 为什么说多头是“非线性组合”? 实验对比:多头 vs 单头 进阶思考:如何设计更高…...

#关于数据库中的时间存储
✅ 一、是否根据“机器当前时区”得到本地时间再转 UTC? 结论:是的,但仅对 TIMESTAMP 字段生效。 数据库(如 MySQL)在插入 TIMESTAMP 类型数据时: 使用当前会话的时区(默认跟随系统时区&#…...

C# --- yield关键字 和 Lazy Execution
C# --- yield关键字 和 Lazy Execution 延迟执行(Lazy Execution)yield关键字lazy execution与yield的关系LINQ 和 lazy exectuion 延迟执行(Lazy Execution) 延迟执行指操作不会立即计算结果,而是在实际需要数据时才执…...

Qt报错dependent ‘..\..\..\..\..\..\xxxx\QMainWindow‘ 或者 QtCore\QObject not exist
Qt5.15编译项目报错如下: dependent ‘..\..\..\..\..\..\Qt\5.15.2\msvc2019_64\include\QtW...
:前端通信的基石)
彻底掌握 XMLHttpRequest(XHR):前端通信的基石
一、XHR 的起源与演进 1.1 技术背景 XHR(XMLHttpRequest)是现代 Web 应用的异步通信基石,最早由微软在 IE5 中通过 ActiveXObject 引入,后来被 Mozilla 推广并成为 W3C 的标准接口。XHR 的出现推动了 AJAX(Asynchrono…...

Bartender 5 for Mac 多功能菜单栏管理
Bartender 5 for Mac 多功能菜单栏管理 一、介绍 Bartender 5,是一款菜单栏管理软件,可以帮助用户隐藏、组织和自定义Mac菜单栏中的图标和通知。使用Bartender 5,用户可以将不常用的图标隐藏起来,使菜单栏保持整洁,并…...
Ⅰ管理人力资源Ⅳ-质量—若时间允许)
重读《人件》Peopleware -(5)Ⅰ管理人力资源Ⅳ-质量—若时间允许
20世纪的心理学理论认为,人类的性格主要由少数几个基本本能所主导:生存、自尊、繁衍、领地等。这些本能直接嵌入大脑的“固件”中。我们可以在没有强烈情感的情况下理智地考虑这些本能(就像你现在正在做的那样),但当我…...

人事招聘专员简历模板
模板信息 简历范文名称:人事招聘专员简历模板,所属行业:人力资源,模板编号:K8TG60 专业的个人简历模板,逻辑清晰,排版简洁美观,让你的个人简历显得更专业,找到好工作。…...

Java中equals与 “==” 的区别
首先我们要掌握基本数据类型和引用类型的概念 基本数据类型: byte,short,int,long,float,double,boolean,char 基本的八大数据类型都各自封装着包装类,提供了更多的方法,并且都是引言类型 引用类型: 引…...

20250412_代码笔记_CVRProblemDef
文章目录 前言一、get_random_problems 函数分析二、augment_xy_data_by_8_fold 函数分析代码 前言 该笔记分析代码的功能是生成随机VRP问题的数据,包含仓库坐标、节点坐标和节点需求。 对该代码进行改进 20250412-代码改进-拟蒙特卡洛 一、get_random_problems 函…...

《算法笔记》3.4小节——入门模拟->日期处理
日期差值 #include <iostream> using namespace std; int month[13][2]{{0,0},{31,31},{28,29},{31,31},{30,30},{31,31},{30,30},{31,31},{31,31},{30,30},{31,31},{30,30},{31,31} }; bool is_leap(int year){return (year%40&&year%100!0||year%4000); }int m…...

JetBrain/IDEA :Request for Open Source Development License
Request for Open Source Development License...

Java学习手册:Java集合框架详解
Java集合框架(Java Collections Framework)是Java语言中用于存储和操作数据集合的一组接口和类的集合。它提供了丰富的数据结构和算法,帮助开发者高效地管理和操作数据。掌握集合框架的使用是Java开发者的必备技能。 本文将深入探讨Java集合…...
数据降维(scikitlearn))
20250412 机器学习ML -(3)数据降维(scikitlearn)
1. 背景 数学小白一枚,看推理过程需要很多时间。好在有大神们源码和DS帮忙,教程里的推理过程才能勉强拼凑一二。 * 留意: 推导过程中X都是向量组表达: shape(feature, sample_n); 和numpy中的默认矩阵正好相反。 2. PCA / KPCA PCAKPCA(Li…...

深入解析系统频率响应:通过MATLAB模拟积分器对信号的稳态响应
稳态响应分析与MATLAB可视化 在控制系统中,线性时不变系统的稳态响应是描述输入与输出之间关系的关键。对于一个频率为 ω i \omega_i ωi 的正弦输入 u ( t ) M i sin ( ω i t φ i ) u(t) M_i \sin(\omega_i t \varphi_i) u(t)Misin(ωitφi)&…...

[16届蓝桥杯 2025 c++省 B] 画展布置
解题思路 理解 ( L ) 的本质 当 ( B ) 按平方值从小到大排序后,相邻项的差非负,此时 ( L ) 等于区间内最大平方值与最小平方值的差(数学公式推导) 滑动窗口找最小差值 遍历所有长度为 ( M ) 的连续…...

从代码学习深度学习 - Bahdanau注意力 PyTorch版
文章目录 1. 前言为什么选择Bahdanau注意力本文目标与预备知识2. Bahdanau注意力机制概述注意力机制简述加性注意力与乘性注意力对比Bahdanau注意力的数学原理与流程图数学原理流程图可视化与直观理解3. 数据准备与预处理数据集简介数据加载与预处理1. 读取数据集2. 预处理文本…...
:深入解析 “1D UNet”:结构、原理与实战)
具身智能零碎知识点(三):深入解析 “1D UNet”:结构、原理与实战
深入解析 “1D UNet”:结构、原理与实战 【深度学习入门】1D UNet详解:结构、原理与实战指南一、1D UNet是什么?二、核心结构与功能1. 整体架构2. 编码器(Encoder)3. 解码器(Decoder)4. 跳跃连…...
)
基于论文的大模型应用:基于SmartETL的arXiv论文数据接入与预处理(二)
上一篇 文章介绍了arXiv采集处理的任务背景、整体需求,并对数据进行了调研。 本文介绍整体方案设计。 4.整体方案设计 4.1.总体流程 基于上述调研了解的情况,针对工作需求设计处理流程如下: 下载kaggle数据集作为流程输入,出…...

Halo 设置 GitHub - OAuth2 认证指南
在当今数字化时代,用户认证的便捷性和安全性愈发重要。对于使用 Halo 搭建个人博客或网站的开发者而言,引入 GitHub - OAuth2 认证能够极大地提升用户登录体验。今天,我们就来详细探讨一下如何在 Halo 中设置 GitHub - OAuth2 认证。 一、为…...

脑影像分析软件推荐 | AIDA介绍
目录 1.软件界面 2.工具包功能简介 3.软件安装注意事项 1.软件界面 2.工具包功能简介 AIDAmri是一种新型的基于图谱的成像数据分析流程,用于处理小鼠大脑的结构和功能数据,包括解剖MRI、基于扩散张量成像(DTI)的纤维追踪以及基…...
)
SQL:Relationship(关系)
目录 🔗 什么是 Relationship? 三种基本关系类型(基于实体间的关系): 1. 一对一(One-to-One) 2. 一对多(One-to-Many) 3. 多对多(Many-to-Many…...
 / chika和蜜柑(topK) / 01背包)
【今日三题】压缩字符串(模拟) / chika和蜜柑(topK) / 01背包
⭐️个人主页:小羊 ⭐️所属专栏:每日两三题 很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~ 目录 压缩字符串 (模拟)chika和蜜柑 (topK)01背包 压缩字符串 (模拟) 压缩字符串 class Solution { public:string compressStri…...

PHP多维数组
在 PHP 中,多维数组是数组的数组,允许你存储和处理更复杂的数据结构。多维数组可以有任意数量的维度,但通常我们最常用的是二维数组(数组中的数组)。 首先来介绍一下一维数组, <?php//一维数组 $strAr…...

智能手机功耗测试
随着智能手机发展,用户体验对手机的续航功耗要求越来越高。需要对手机进行功耗测试及分解优化,将手机的性能与功耗平衡。低功耗技术推动了手机的用户体验。手机功耗测试可以采用powermonitor或者NI仪表在功耗版上进行测试与优化。作为一个多功能的智能终端,手机的功耗组成极…...

0x02.Redis 集群的实现原理是什么?
回答重点 Redis 集群(Redis cluster)是通过多个 Redis 实例组成的,每个主节点实例负责存储部分的数据,并且可以有一个或多个从节点作为备份。 具体是采用哈希槽(Hash Slot)机制来分配数据,将整…...

游戏引擎学习第219天
游戏运行时的当前状态 目前的工作基本上就是编程,带着一种预期,那就是一切都会很糟糕,而我们需要一个系统来防止它变得更糟。接下来,我们来看看目前的进展。 简要说明昨天提到的无限调试信息存储系统 昨天我们完成了内存管理的…...

二叉树深度解析:从基础概念到算法实现与应用
一、二叉树的本质定义与核心特性 (一)递归定义与逻辑结构 二叉树是一种 严格有序的树结构,其递归定义为: 空树:不含任何结点的集合,是二叉树的特殊形态。非空二叉树:由以下三部分组成&#x…...
模型上下文协议)
Model Context Protocol(MCP)模型上下文协议
Model Context Protocol(MCP)模型上下文协议 前言一、什么是MCP二、MCP的作用三、MCP与Function call对比四、构建一个简单的MCP DEMO环境准备实现MCP Server运行 ServerMCP Client端配置验证 总结 前言 在Agent时代,将Agent确立为大模型未来…...

代码随想录算法训练营第十六天
LeetCode题目: 530. 二叉搜索树的最小绝对差501. 二叉搜索树中的众数236. 二叉树的最近公共祖先3272. 统计好整数的数目(每日一题) 其他: 今日总结 往期打卡 530. 二叉搜索树的最小绝对差 跳转: 530. 二叉搜索树的最小绝对差 学习: 代码随想录公开讲解 问题: 给你一个二叉搜…...

类似东郊到家的上门按摩预约服务系统小程序APP源码全开源
🔥 为什么上门按摩正在席卷全国? 万亿蓝海市场爆发 2024年中国按摩市场规模突破8000亿,上门服务增速达65% 90后成消费主力,**72%**白领每月至少使用1次上门按摩(数据来源:艾媒咨询) 传统痛点…...

MySQL 5.7.30 Linux 二进制安装包详解及安装指南
MySQL 5.7.30 Linux 安装包详解 mysql-5.7.30-linux-glibc2.12-x86_64.tar 是 MySQL 服务器 5.7.30 版本的 Linux 二进制发行包。 mysql-5.7.30-linux-glibc2.12-x86_64.tar 安装包下载 链接:https://pan.quark.cn/s/2943cd209ca5 包信息 版本: MySQL 5.7.30 平…...
)
C语言超详细指针知识(二)
在上一篇有关指针的博客中,我们介绍了指针的基础知识,如:内存与地址,解引用操作符,野指针等,今天我们将更加深入的学习指针的其他知识。 1.指针的使用和传址调用 1.1strlen的模拟实现 库函数strlen的功能是…...

Java集合框架详解:核心类、使用场景与最佳实践
文章目录 一、Java集合框架概览二、核心集合类详解1. List接口(有序、可重复)**ArrayList****LinkedList****List对比表** 2. Set接口(无序、唯一)**HashSet****TreeSet****Set对比表** 3. Queue接口(队列)…...

模板引擎语法-标签
模板引擎语法-标签 文章目录 模板引擎语法-标签[toc]一、用于进行判断的{% if-elif-else-endif %}标签二、关于循环对象的{% for-endfor %}标签三、关于自动转义的{% autoescape-endautoescape %}标签四、关于循环对象的{% cycle %}标签五、关于检查值是否变化的{% ifchange %}…...

刘火良FreeRTOS内核实现与应用学习之7——任务延时列表
在《刘火良FreeRTOS内核实现与应用学习之6——多优先级》的基础上:关键是添加了全局变量:xNextTaskUnblockTime ,与延时列表(xDelayedTaskList1、xDelayedTaskList2)来高效率的实现延时。 以前需要在扫描就绪列表中所…...

基于红外的语音传输及通信系统设计
标题:基于红外的语音传输及通信系统设计 内容:1.摘要 本设计聚焦于基于红外的语音传输及通信系统,以解决传统通信方式在特定场景下的局限性为背景,旨在开发一种高效、稳定且具有一定抗干扰能力的语音传输系统。方法上,采用红外技术作为语音信…...

解锁AI未来,开启创新之旅——《GPTs开发详解》与《ChatGPT 4应用详解》两本书的深度解析
前言 在这个数字化时代,AI技术正在以前所未有的速度改变我们的生活和工作方式。作为一名AI爱好者和从业者,我深知了解并掌握先进技术的重要性。今天,我想向大家推荐两本极具价值的书籍:《GPTs开发详解》和《ChatGPT 4应用详解》。…...

Linux进程通信入门:匿名管道的原理、实现与应用场景
Linux系列 文章目录 Linux系列前言一、进程通信的目的二、进程通信的原理2.1 进程通信是什么2.2 匿名管道通讯的原理 三、进程通讯的使用总结 前言 Linux进程间同通讯(IPC)是多个进程之间交换数据和协调行为的重要机制,是我们学习Linux操作系…...

[SpringMVC]上手案例
创建工程 新建项目,选择maven工程,原型(Archetype)选择maven的webapp,注意名称头尾。会使用到tomcat(因为是javaWeb)。 新建的项目结构目录如下,如果没有java目录,需要自…...

kubernetes 入门篇之架构介绍
经过前段时间的学习和实践,对k8s的架构有了一个大致的理解。 1. k8s 分层架构 架构层级核心组件控制平面层etcd、API Server、Scheduler、Controller Manager工作节点层Kubelet、Kube-proxy、CRI(容器运行时接口)、CNI(网络插件&…...

说一说 Spring 中的事务
什么是事务? 事务就是用户定义的一系列执行SQL语句的操作, 这些操作要么完全地执行,要么完全地都不执行, 它是一个不可分割的工作执行单元。 Spring 中的事务是怎么实现的? Spring事务底层是基于数据库事务和AOP机制的首先对于…...

docker容器安装的可道云挂接宿主机的硬盘目录:解决群晖 威联通 飞牛云等nas的硬盘挂接问题
基于Docker部署可道云(KodCloud)时,通过挂载宿主机其他磁盘目录可实现高效、安全的数据管理。具体而言,使用绑定挂载(Bind Mounts)将宿主机目录(如/data/disk2)映射到容器内的可道云…...
)
Oracle 23ai Vector Search 系列之5 向量索引(Vector Indexes)
文章目录 Oracle 23ai Vector Search 系列之5 向量索引Oracle 23ai支持的向量索引类型内存中的邻居图向量索引 (In-Memory Neighbor Graph Vector Index)磁盘上的邻居分区矢量索引 (Neighbor Partition Vector Index) 创建向量索引HNSW索引IVF索引 向量索引示例参考 Windows 环…...

GPT模型架构与文本生成技术深度解析
核心发现概述 本文通过系统分析OpenAI的GPT系列模型架构,揭示其基于Transformer解码器的核心设计原理与文本生成机制。研究显示,GPT模型通过自回归机制实现上下文感知的序列生成,其堆叠式解码器结构配合创新的位置编码方案,可有效…...

【读者求助】如何跨行业进入招聘岗位?
文章目录 读者留言回信岗位细分1. 中介公司的招聘岗位2. 猎头专员3. 公司的招聘专员选择建议 面试建议1. 请简单介绍你过去 3 年的招聘工作经历,重点说下你负责的岗位类型和规模2. 你在招聘流程中最常用的渠道有哪些?如何评估渠道效果?3. 当你…...

2025蓝桥杯省赛C++B组解题思路
由于题面还没出来,现在先口胡一下思路 填空题直接打表找规律或者乱搞一下就能出,从大题开始说。 1,题意: 给你一个数组,这个数组里有几个数可以被一个连续递增的数字区间求和得出 思路:诈骗题,显…...

springcloud整理
问题1.服务拆分后如何进行服务之间的调用 我们该如何跨服务调用,准确的说,如何在cart-service中获取item-service服务中的提供的商品数据呢? 解决办法:Spring给我们提供了一个RestTemplate的API,可以方便的实现Http请…...