Large Language Model(LLM)的训练和微调
之前一个偏工程向的论文中了,但是当时对工程理论其实不算很了解,就来了解一下
工程流程
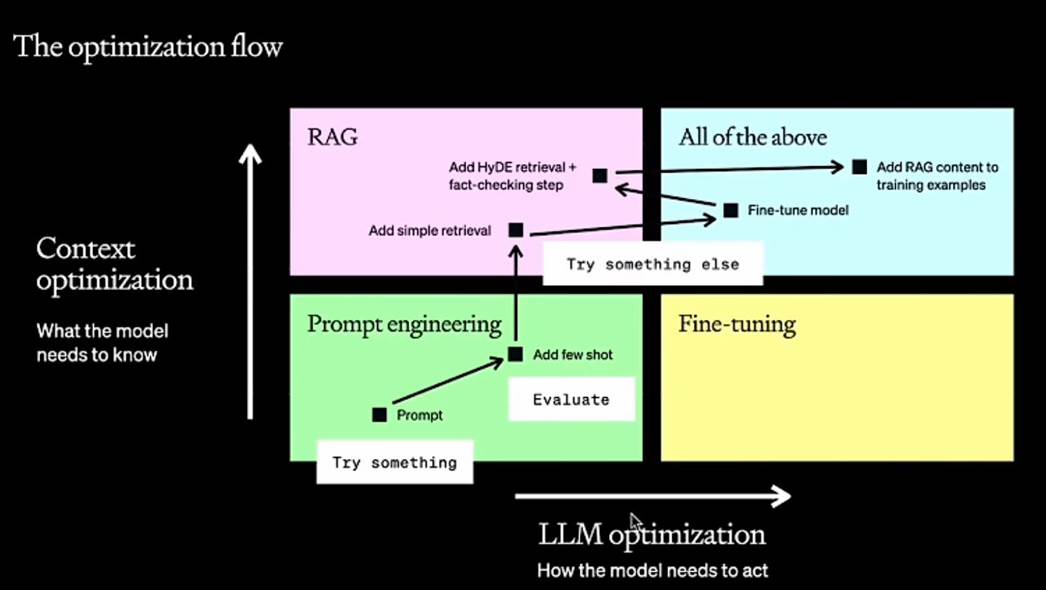
横轴叫智能追寻
竖轴上下文优化
Prompt不行的情况下加shot(提示),如果每次都要加提示,就可以试试知识库增强检索来给提示。
如果希望增强模型对知识的理解,就可以fintune微调一下
Fintune完了加更高级的检索
再最后再增加知识库
Step1:选底座
场景→列出10-50个场景问题→市面主流模型列出来→提示词+fewshot测试
Step2:增加RAG的业务知识
Step3:增加业务知识之后还不行的话那就微调
*一般情况下微调和知识库经常同时使用,时效性比较高的场景只使用微调不太合适
提示词工程使用:
给COT的Fewshot的方式


few shot 例子

如果COT测试场景效果很烂,那么需要fintuning或者换另外一个底座
RAG vs FT
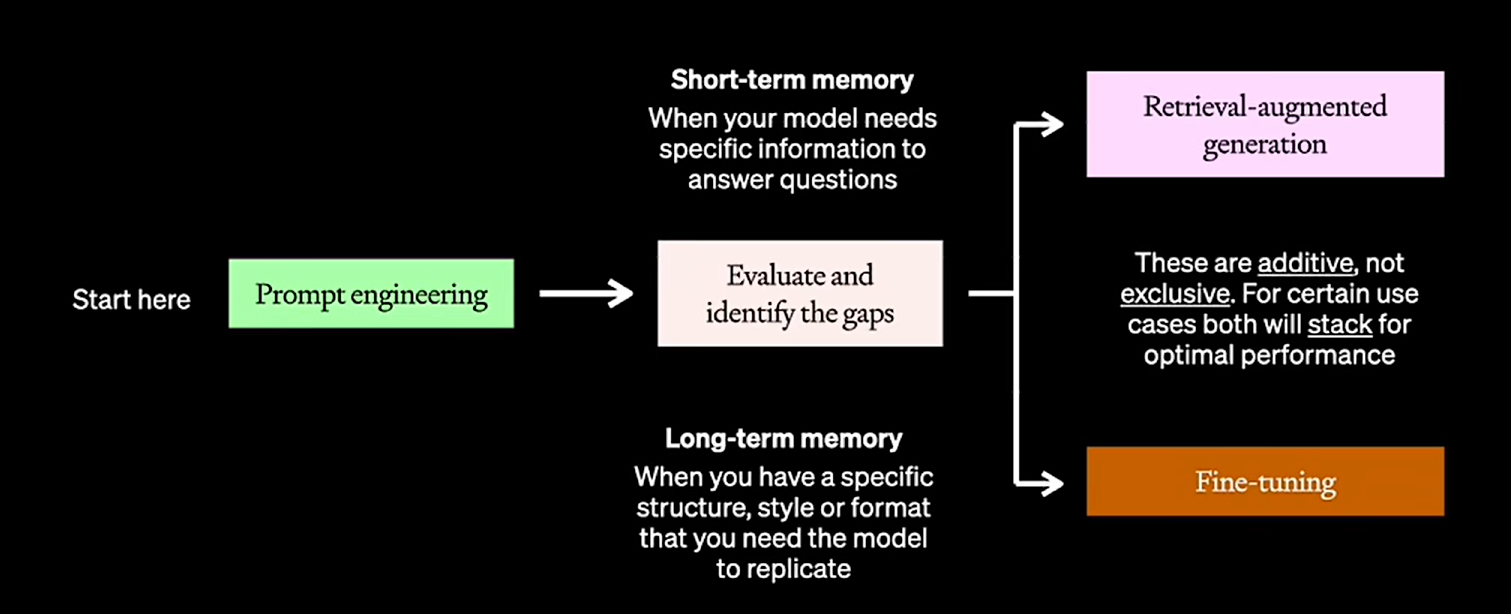
选完基座之后评估表现差多远,然后可以选择长期记忆还是短期记忆
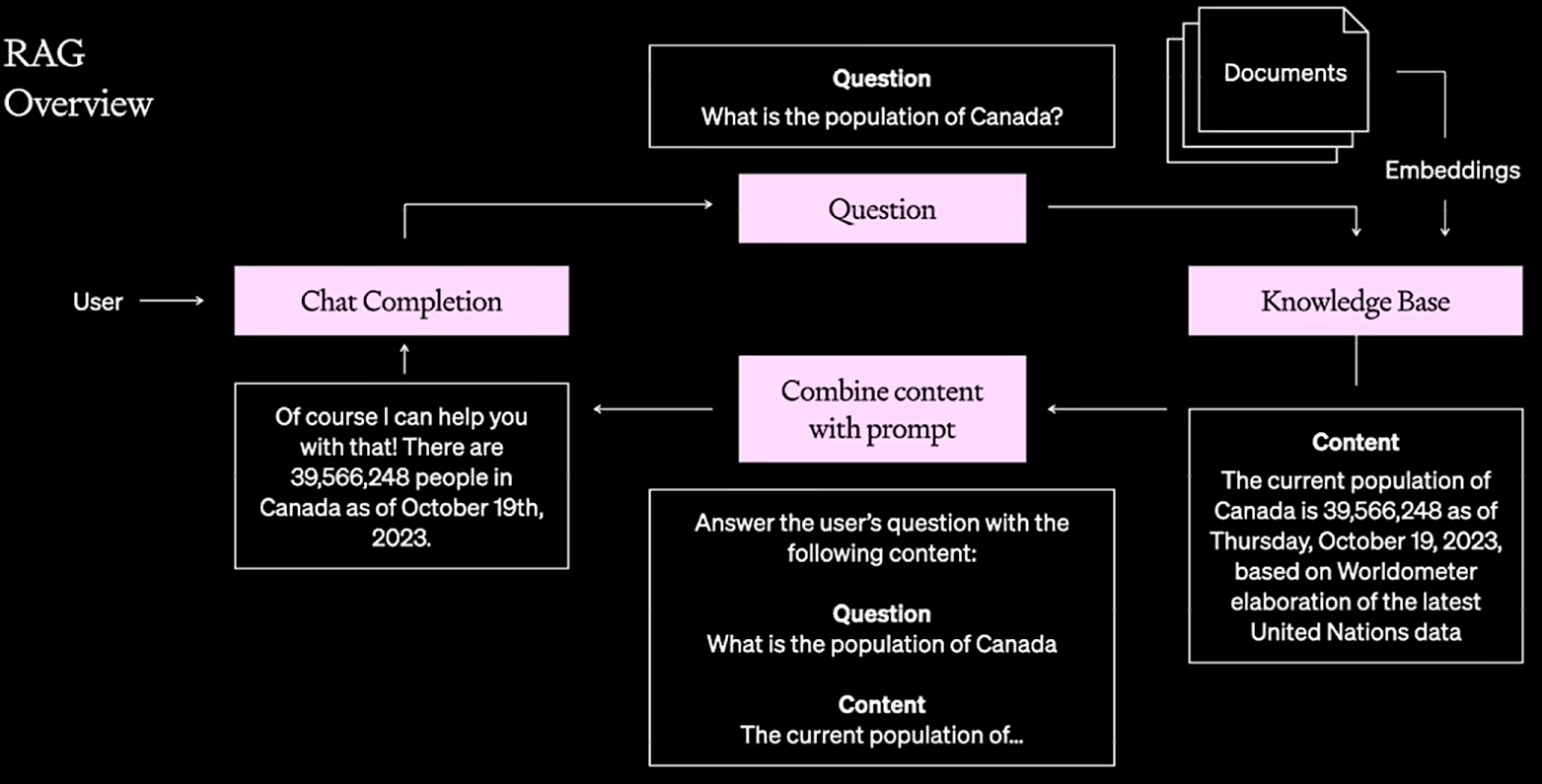
RAG框架
评估RAG框架
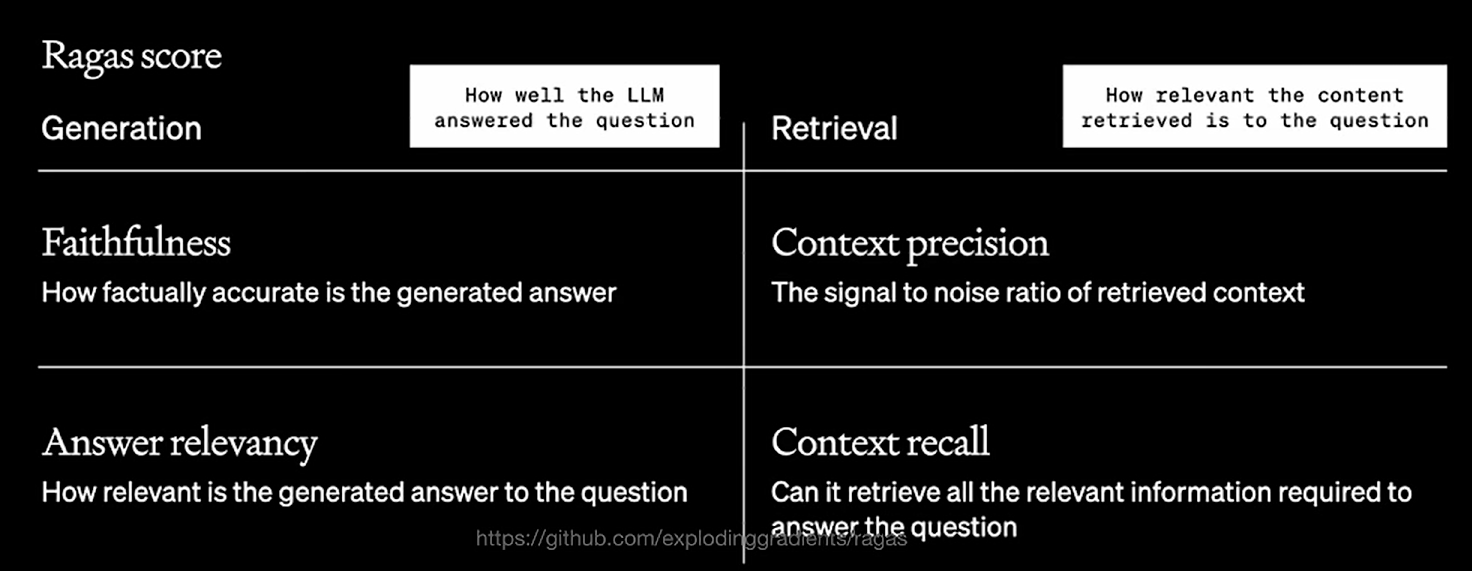
https://github.com/explodinggradients/ragas
FT前后对比
(节省不必要的token)


微调流程

agent
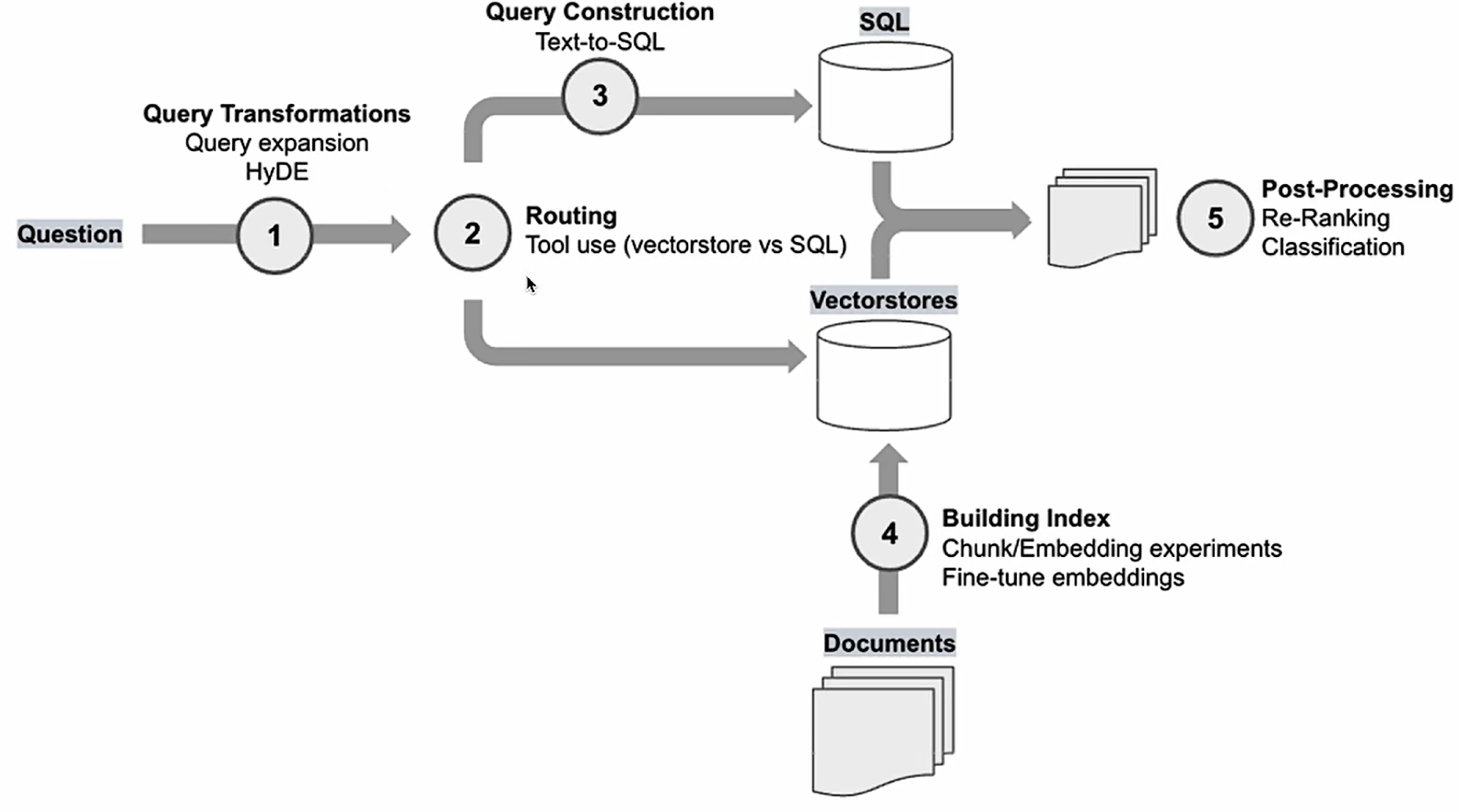
SFT(Supervised Fine-Tuning)
SFT 是最基础的微调方法,也是传统的“有监督学习”方法,尤其适用于有清晰标注数据的任务。
在预训练模型的基础上,让大模型能更好的用自己学到的知识来回答人提出的问题。 指令微调和原模型在网络结构上完全相同,loss基本相同,训练数据规模不同
SFT(任务)
├── 全参数微调(传统方式)
└── LoRA / Adapter / Prefix-Tuning / QLoRA(PEFT 方法)
基本思路:
- 在预训练的基础上,使用标注好的数据集对模型进行进一步训练。
- 目标是让模型更好地适应特定任务或领域,比如回答问题、文本分类、生成任务等。
典型流程:
- 数据集准备:准备任务特定的数据集(例如,人类写的问答对、情感分类标注数据等)。
- 微调:使用这些数据对预训练模型进行微调,通常会通过调整最后几层的权重。
- 输出优化:通过计算损失函数来优化模型输出,使其能生成更符合目标任务要求的结果。
优点:
- 适用于大多数任务,特别是需要解决特定任务的情况。
- 相对简单且有效。
缺点:
- 需要大量标注数据(这对一些任务来说可能成本很高)。
- 微调过程中,可能会丧失一些预训练过程中学到的通用知识,尤其是当训练数据和目标任务相差较大时。
| 概念 | 含义 | 作用 |
|---|---|---|
| Chat Template | 对话格式的模板,如用户和助手的标签、system指令的格式等 | 让模型识别多轮对话结构 |
| Completions Only | 只训练模型的输出部分(completion) | 提高训练效率、模拟真实生成行为 |
| NEFTune | 给词嵌入加噪声提升模型鲁棒性和泛化能力 | 增强模型稳定性、加速收敛 |
Chat Template 对话模板
在训练或推理时,如何组织多轮对话数据的模板格式、
LLMs(如ChatGPT)在处理多轮对话时,需要一个明确的格式来表示:
-
谁在说话(用户 or assistant)
-
说了什么
-
上下文是什么
对话开始的时候加上特殊的token,回答结束的时候也加上特殊的token

在SFT训练中,为了告诉模型“用户说了这些,你应该这样回答”,我们会使用chat template来把整个对话拼接成训练样本。不同模型(LLaMA、ChatGLM、Mistral等)有不同的chat格式,甚至prompt token也不同,所以需要提供“chat template”来适配模型的预训练格式。



Completions only
这个是 一种 SFT 的训练范式,指的是只用模型的 输出部分(completion) 来计算 loss
在一个完整的 prompt + answer 对里:
Human: What is 2 + 2? Assistant: 4
-
Completion only 就是只让模型学习
4这一部分的输出(即只在Assistant:之后计算loss)。 -
Prompt 部分是不需要模型拟合的。

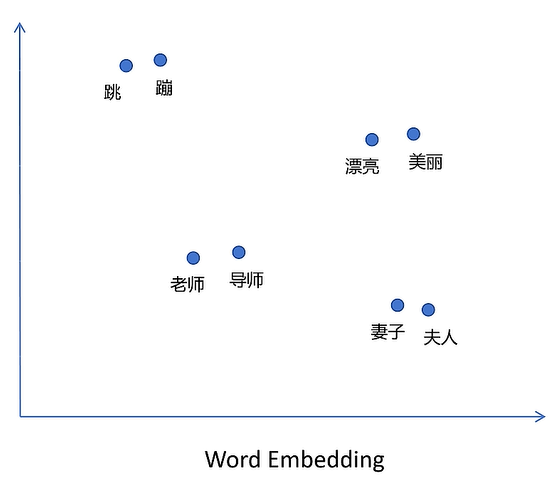
NEFTune (Noise Embedding Finetuning)
给embedding增加噪音的微调
这个是一个最近提出的 微调增强技术,主要用于增强模型鲁棒性和泛化能力。
🔬 原理:
-
在微调时,对词向量层加入一点小扰动(noise),模拟数据扰动,提升模型的泛化能力。
-
就像在图像任务里加随机噪声增强数据一样,NEFTune 给词嵌入也加“噪声”。
如果原始词嵌入是 E(x),那么训练时使用的是:
E(x) + ε
其中 ε 是一个小的高斯噪声向量。
论文:《NEFTune: Noisy Embeddings Improve Fine-tuning》
实现
调用trl库
RLHF:Reinforcement Learning with Human Feedback
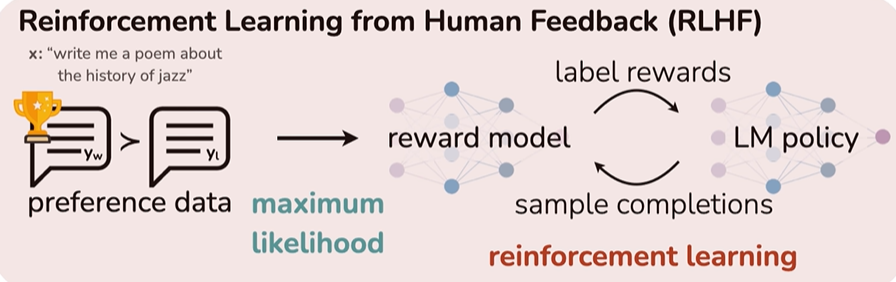
这是最早也最经典的“大模型对齐技术”。
流程可以简单理解为三步:
- SFT(Supervised Fine-Tuning):先用人类写的好回答,让模型学会基本说人话。
- Reward Model(奖励模型):训练一个模型,学会判断“哪个回答更好”。
- PPO(Proximal Policy Optimization):用强化学习方法(PPO)优化模型,鼓励它说更好的回答。虽然off-policy方法在样本效率上更有优势(可以重用历史数据),但PPO放弃这一点是为了换取训练的稳定性和可控性。在RLHF中,策略通常需要逐步适应人类反馈,而on-policy的每次更新都能直接反映当前策略的表现,更适合这种动态调整的过程。
ChatGPT(GPT-3.5)就是用RLHF训出来的
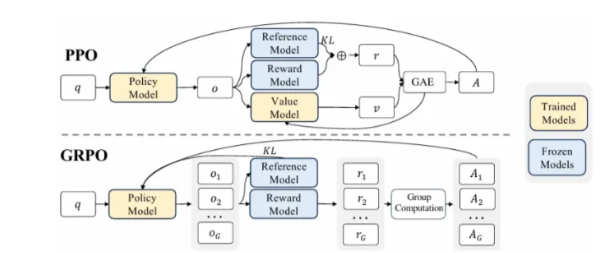
PPO(Proximal Policy Optimization)
PPO 是一种经典的强化学习算法,用于在 RLHF(Reinforcement Learning from Human Feedback) 中微调语言模型。
基本流程
预训练模型(SFT)
作为初始策略 π₀。
训练奖励模型(RM)
采样一堆回答,然后送进 奖励模型(RM)评估得分。
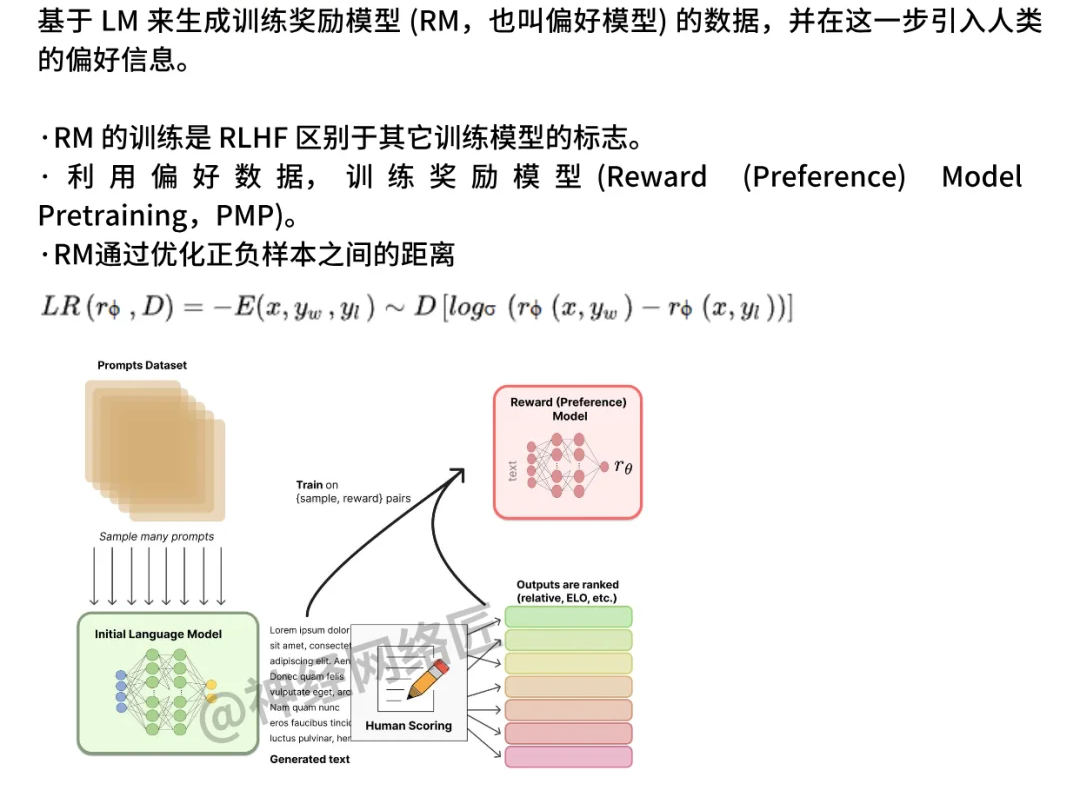
使用 RL(PPO)算法优化策略
使π在 RM 下的得分更高,同时避免偏离初始策略太远。
Loss

Advantage (A_t)优势函数:

我们无法直接知道这些值,因此:训练一个 Value Model 来估计 V(s)!
Value Model 的原理
-
输入:prompt(或者prompt + 输出的一部分)
-
输出:一个标量值 → 估计这个输入会得到多少“总回报”
-
使用的是回归目标(MSE):

本质上:Value Model 就是个评估器,让 PPO 知道“在哪些回答上继续优化”
on-policy:
-
因为你训练时必须 依赖于“当前策略 π” 采样出来的数据,不然这个比值和优势函数会不准确。
-
如果用老数据(旧策略采样的),策略更新方向会不对 → 训练不稳定甚至崩溃。
-
虽然 PPO 引入了“旧策略”的 loss function 来缓解策略变化带来的问题,但它仍然只能用刚刚采样出来的 batch 数据来更新当前策略,不能像 off-policy 那样“重用经验池里的旧数据”。
DPO:Direct Preference Optimization
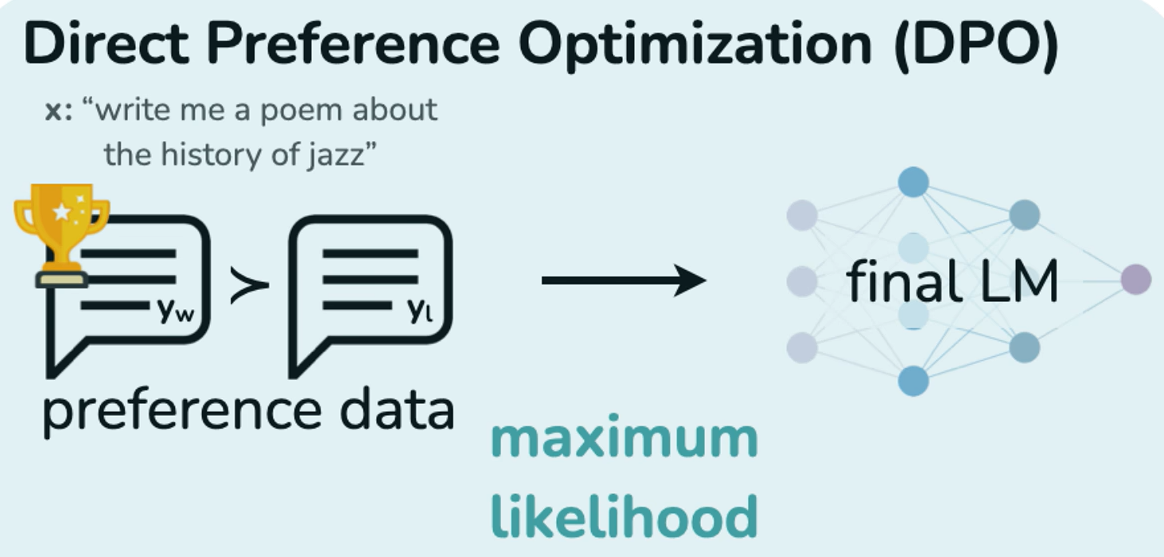
RLHF 太复杂了,reward model 和 PPO 都难搞。
于是有人提出:我们就直接优化模型让它更符合人类偏好,不用 reward model 和 RL 算法。
DPO 就是这样一个方法,直接基于“人类偏好对比数据”(哪个回答更好)来训练模型。
✅ 优点:简单,稳定,训练快,效果还挺好
🎯 所以很多新模型已经开始用 DPO 代替 PPO,比如 Anthropic 的 Claude、Mistral 的 Mixtral 都偏向这种思路。
背景知识
KL散度

Bradley-Terry 模型


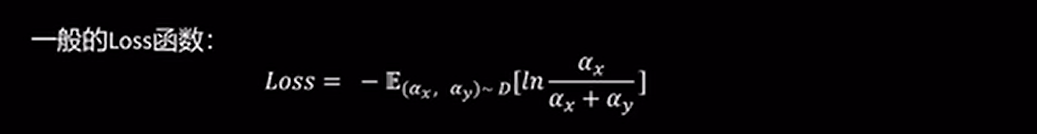
优化目标:x战胜y的概率越趋近于1越好

数据构造
DPO 依赖的是**比较数据(preference data)**而不是打分,因此构造偏好数据的关键是:选择 pair,标注偏好。
✅ 常见构造方式:
| 方法 | 描述 | 说明 |
|---|---|---|
| 人工标注 | 给定 prompt 和两个回答,让人选出更好的那个 | 最可靠但最贵 |
| GPT-4 辅助打分 | 用 GPT-4 或 Claude 给出比较意见(谁更好) | 快速、成本低、易偏差 |
| 评分转偏好 | 先对回答打分(如 1-5 分),再转化为偏好 | 可批量自动构建 |
| 多样化采样 | 从多个模型或策略中采样生成不同回答,再两两比较 | 增强数据覆盖面 |
| Pairing with ranking | 利用多个样本打分再排序 → 生成 pair | 适用于 GRPO 或 Soft-DPO |
🔧 技巧与经验:
-
尽量构建 hard pair(两个回答都还不错,差距不大)比 easy pair 更有信息量
-
数据构造建议搭配 初始模型与目标模型的策略分布采样,能更稳定收敛
-
多个偏好数据来源混合(人标、GPT辅助、评分)也能提升泛化性
-
对抗式 sample(故意制造模糊、诱导、奇葩case)可以提升鲁棒性
训练目标
虽然 DPO 不使用显式 reward model,但其实它隐含了一个 reward function

KL散度约束新旧模型的一致性
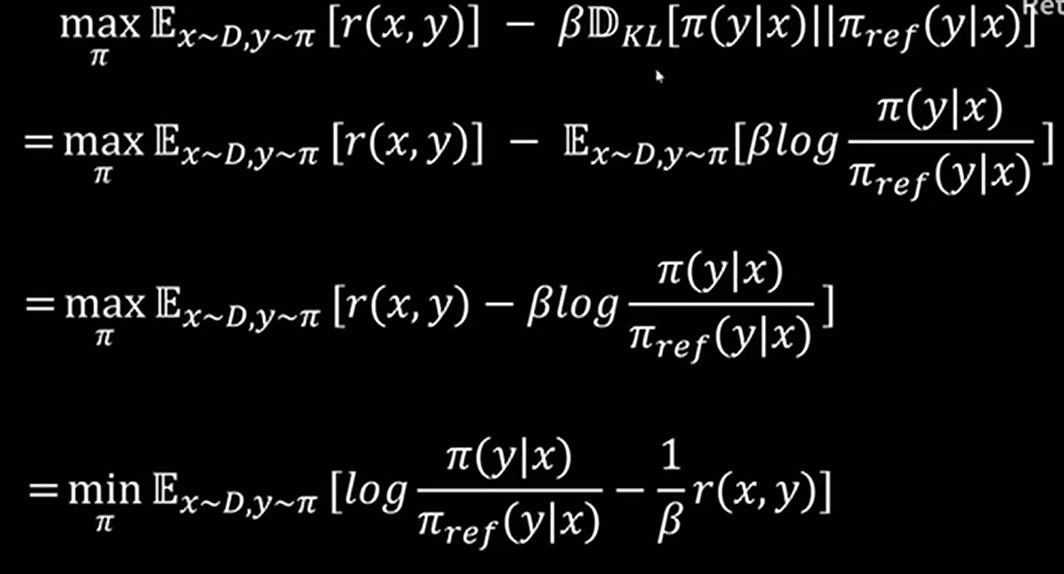
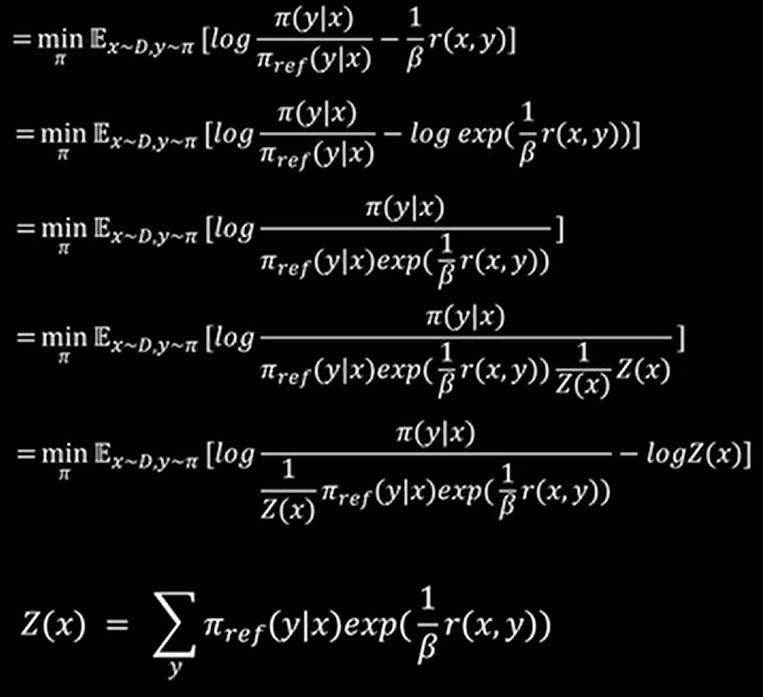
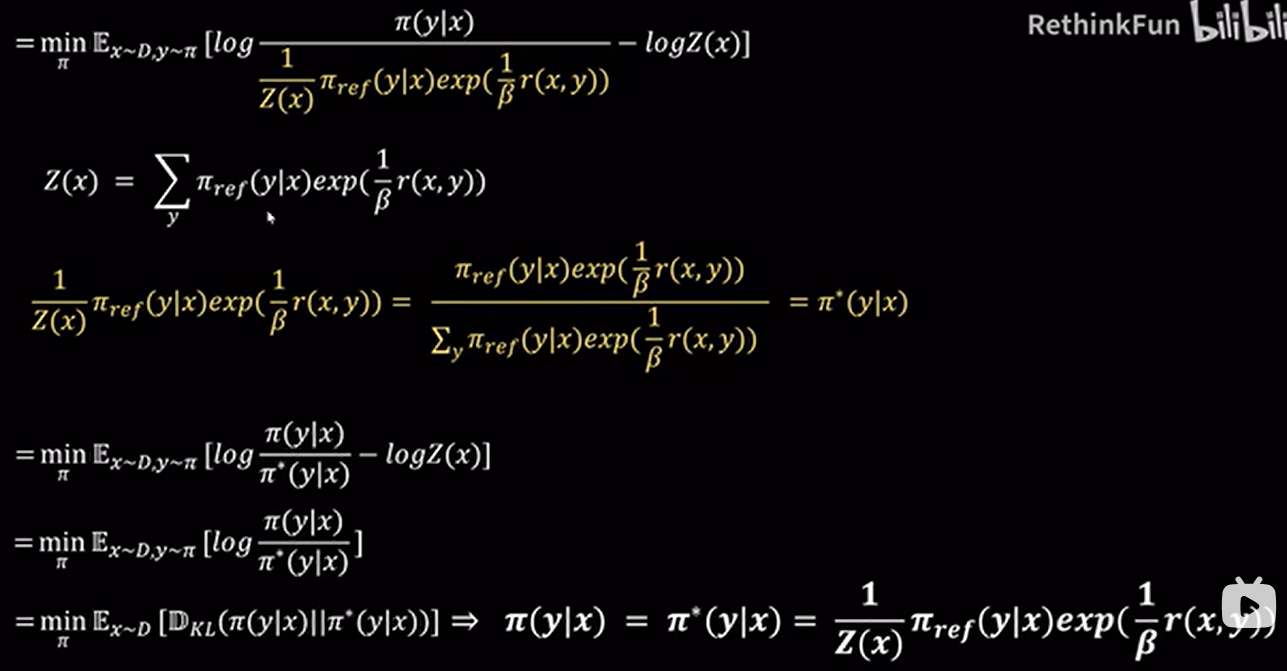
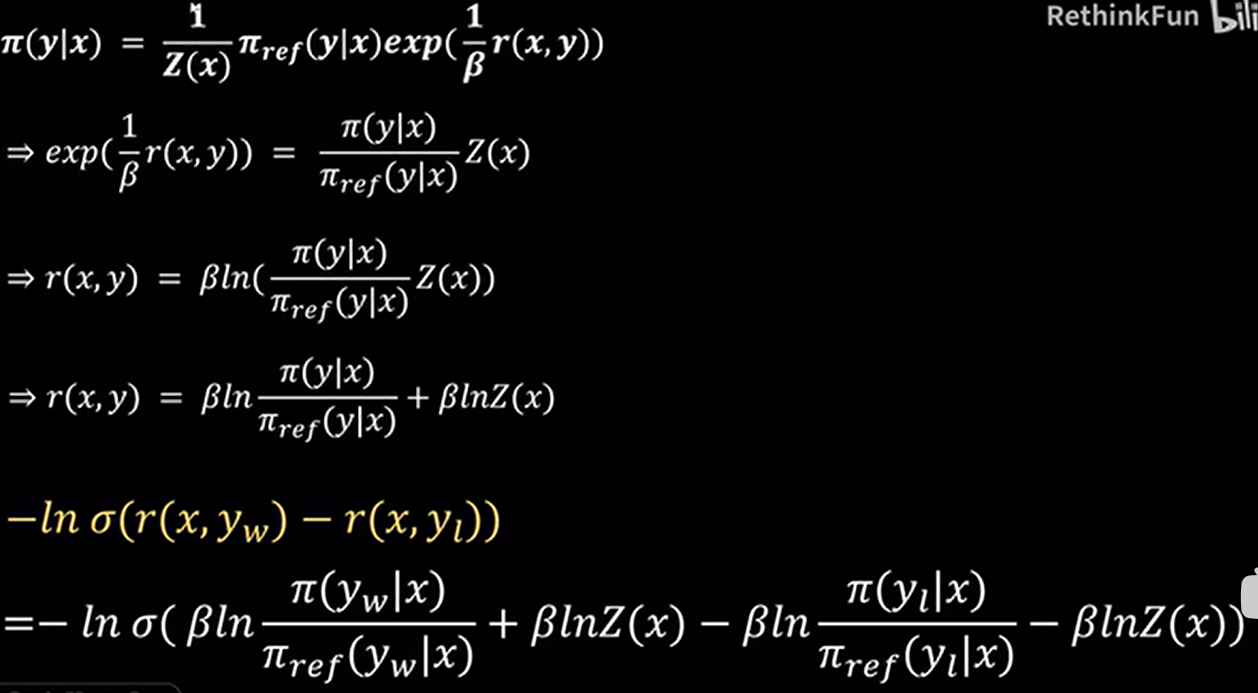
DPO Loss:
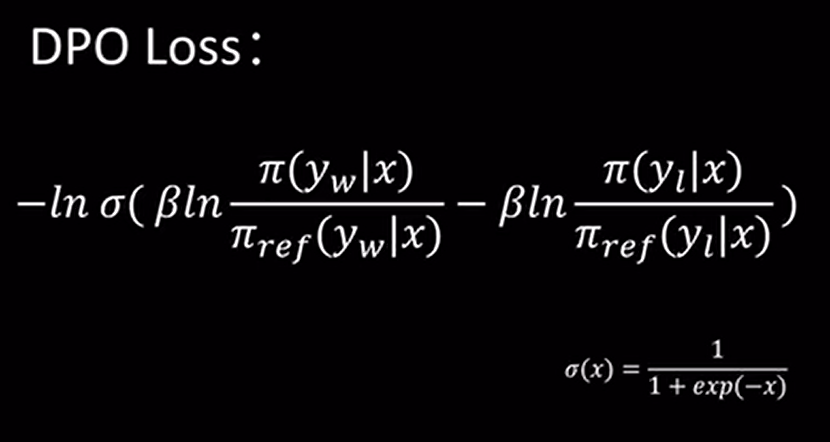

DPO vs PPO
| 项目 | PPO | DPO |
|---|---|---|
| 类别 | 强化学习(RL) | 监督学习范式(偏好对比学习) |
| 是否需要 Reward Model | ✅ 需要 | ❌ 不需要 |
| 输入形式 | prompt + 单个输出 + reward score | prompt + 两个回答(好 / 差) |
| 训练目标 | 最大化 reward,同时不偏离原策略 | 最大化好回答的 logit 分数 > 差回答 |
| 优点 | 稳定、成熟、理论支撑强 | 简单直接、无需训练 reward model、易用 |
| 缺点 | 复杂、训练成本高、reward model 容易偏 | 对偏好数据质量敏感、无显式 reward 可解释性 |
| 代表性使用场景 | ChatGPT、InstructGPT | DPO paper、一些开源RLHF项目如 TRL库 DPO 示例 |

π(target policy) π₀(reference policy)
PPO:显式构建 reward
偏好数据 y⁺ ≻ y⁻ 👉 训练 Reward Model,使其输出
r(y⁺) > r(y⁻)
这个 reward 被当作 PPO 的 r_t,再带入标准的 policy gradient:
![]()
DPO 干脆跳过显式构建 reward,直接训练策略模型:
我直接用 log π(y⁺) - log π(y⁻) 当作隐式 reward 差值
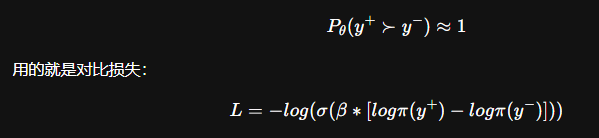
这正好就是一种:
-
近似最大化
E[r] -
同时加了对初始模型
π₀的 KL regularization
直接构建了训练目标,绕开了 reward 模型
GRPO
GRPO 是deepseek新提出的偏好优化方法,是 DPO 的升级版,它:
-
推广了 DPO:允许 reward 不再是隐式的对比形式
-
使用更加灵活的偏好概率模型:
![]()
-
可以用不同形式的 reward,甚至融合其他信号(如评分 + 比较)
如果 DPO 是二分类损失,GRPO 更像广义对比学习框架。
| 特性 | DPO | GRPO |
|---|---|---|
| 偏好方式 | 固定为“y⁺ ≻ y⁻”形式 | 可扩展为打分式、多选式、soft-preference 等 |
| reward 计算方式 | 隐式 reward(log prob 差值) | 显式 reward:r(y) 可以是任意函数或外部得分 |
| 训练方式 | 对比学习 + sigmoid loss | 更泛化的策略优化目标(支持不同形式 reward) |
| 应用场景 | 文本偏好对 | 多模态(如图文),长文本,soft ranking 等 |
DAPO
解决了GRPO会遇到熵的坍塌等问题
DAPO 是一种新型的强化学习算法,主要特点包括:
-
解耦裁剪(Decoupled Clipping):分别对高概率和低概率区域使用不同的裁剪策略,以防止策略更新过大导致的不稳定。
![]()
-
动态采样(Dynamic Sampling):在训练过程中动态选择具有信息量的样本,避免无效样本对训练的干扰。
-
Token-Level Policy Gradient Loss:在 token 级别计算策略梯度损失,提升对长序列的优化能力。传统 RL 方法对整个 output sequence 求 reward,然后算个 sequence-level advantage。而 DAPO 切到 token-level loss,这像是不再用 sequence 这个粗粒度单位训练,而是对每一个 token 做微观调节。它和 layer norm / token norm 一样,本质是“对单元粒度做独立归一”,减少梯度振荡、提高模型感知能力。
-
Overlong Reward Shaping:对过长的生成结果进行奖励塑形,减少奖励噪声,提高训练稳定性。
我感觉其实全文透露着一种normalization的思想
| DAPO 技术点 | 体现出的 Normalization 哲学 |
|---|---|
| Decoupled Clip | 对不同 token 的学习幅度进行动态归一/约束 |
| Dynamic Sampling | 对样本的信息贡献度进行归一处理,引导高效训练 |
| Token-level Gradient | 把 sequence 的整体奖励拆成 token 单元,细粒度归一 |
| Overlong Reward Shaping | 避免极长输出 reward 爆炸,类似于梯度 clipping / 激活规整 |
RLAIF:Reinforcement Learning with AI Feedback
RLHF 里人类要一直标注数据,很费钱。
那有没有可能,用另一个大模型来充当“人类”,给出偏好选择呢?
RLAIF 就是这个意思:
“用 AI 模拟人类反馈,再用 RL 方法优化模型”。
比如:拿 GPT-4 来帮你给一些小模型打分,模拟人类反馈。这样可以省下大量人力标注。
Lora
LoRA 并不直接调整模型的所有参数,而是引入了一个低秩矩阵(通过降维方式),在原有网络层之间插入适应层,更新这些适应层的权重
优点:
- 参数更新量小:不需要对整个模型进行微调,仅调整部分适配矩阵。
- 效率高:尤其适合参数量非常大的大模型,能够快速适配不同任务。
- 灵活性强:LoRA 可以与其他方法结合,尤其是在大模型的多任务学习中很有优势。
缺点:
- 相比于全模型微调,可能无法完全捕捉到复杂任务中所需的细节。
- 对任务的依赖性较强,需要根据任务特点调整 LoRA 的使用方式。
训练
预训练模型的权重更新(从通用知识到任务特定知识的转变)可以用一个低秩矩阵来近似表示。具体来说:
- 假设:权重矩阵的更新 ΔW(任务适配带来的变化)具有低秩结构,即可以用两个小矩阵的乘积来表示,而不是直接更新整个权重矩阵。
- 实现:在原始权重矩阵 W 上添加一个低秩更新矩阵 ΔW = A × B,其中 A 和 B 是两个低维矩阵,秩(rank)远小于原始矩阵的维度。

推理时:你可以选择:
-
把 LoRA 的矩阵合并到原模型上,得到一个新的权重
-
或者保留插入结构,在推理时保持低秩路径(节省内存)
在使用 LoRA 等低秩调整方法时,会优先选择调整 Query 和 Value,而不是 Key,
-
在 Self-Attention 机制中,输入的每个元素都会通过与其他元素的 Query 和 Key 计算相似度来生成注意力分数(Attention Scores)。这些分数会与 Value 相乘,得到最终的输出。
-
Query:用于与其他元素计算相似度,决定哪些信息在生成过程中更为重要。
-
Value:决定了模型最终输出的内容,是所有输入信息的加权平均。
-
Query 和 Value 直接参与注意力计算,它们的变化会直接影响模型生成的内容。通过调整这些部分,可以在保留原有模型架构的同时,优化模型对输入信息的理解和生成能力。
-
Key 更多地用于计算注意力分数,决定了哪些信息会被关注,但并不直接决定输出的内容。调整 Key 相比之下,对模型的生成效果影响较小。
LoRA 也可以配合其他训练任务使用:
-
LoRA + PPO(强化学习微调)
-
LoRA + DPO(偏好优化)
-
LoRA + 蒸馏(Distillation)
但最常见的场景是 LoRA + SFT,尤其是在训练资源有限或多个任务微调时非常高效。
相关文章:
的训练和微调)
Large Language Model(LLM)的训练和微调
之前一个偏工程向的论文中了,但是当时对工程理论其实不算很了解,就来了解一下 工程流程 横轴叫智能追寻 竖轴上下文优化 Prompt不行的情况下加shot(提示),如果每次都要加提示,就可以试试知识库增强检索来给提示。 如果希望增强…...

Windows 系统中安装 Git 并配置 GitHub 账户
由于电脑重装系统,重新配置了git. 以下是在 Windows 系统中安装 Git 并配置 GitHub 账户的详细步骤: 1. 安装 Git 访问 Git 官网下载页面下载 Windows 版本的 Git 安装程序运行安装程序,使用默认选项即可 2. 配置 Git 用户信息 打开命令…...

KWDB创作者计划—KWDB场景化创新实践:多模态数据融合与边缘智能的突破性应用
引言:AIoT时代的数据库范式重构 在工业物联网设备数量突破千亿、边缘计算节点覆盖率达75%的2025年,传统数据库面临多模态数据处理效率低下、边缘端算力利用率不足、跨域数据协同困难等核心挑战。KWDB(KaiwuDB Community Edition)通…...
从算法仿真到工程源码实现-第四节-最小方差无失真响应波束形成(MVDR))
波束形成(BF)从算法仿真到工程源码实现-第四节-最小方差无失真响应波束形成(MVDR)
一、概述 本节我们讨论最 小 方 差 无 失 真 响 应 (Minimum Variance Distortionless Response, MVDR)波束形成算法,包括原理分析及代码实现。 更多资料和代码可以进入https://t.zsxq.com/qgmoN ,同时欢迎大家提出宝贵的建议,以共同探讨学习…...

初阶数据结构--链式二叉树
二叉树(链式结构) 前面的文章首先介绍了树的相关概念,阐述了树的存储结构是分为顺序结构和链式结构。其中顺序结构存储的方式叫做堆,并且对堆这个数据结构进行了模拟实现,并进行了相关拓展,接下来会针对链…...

嵌入式硬件篇---单片机周期
文章目录 前言 前言 在单片机中,时序控制是其执行指令和协调外设的核心基础。以下是单片机中常见的各种周期及其详细说明,以层次结构展开: 时钟周期(Clock Cycle) 定义: 时钟周期是单片机的最小时间单位&a…...

嵌入式硬件篇---加法减法积分微分器
文章目录 前言 前言 在模拟电子技术中,加法器、减法器、积分器和微分器是基本的运算电路,通常基于运算放大器(运放)实现。以下是它们的核心原理、典型结构和应用场景: 加法器(Summing Amplifier࿰…...

解决使用VsCode远程ssh连接虚拟机ubuntu需要重复输入密码
1. windows打开windows powershell并输入如下命令 ssh-keygen -t ed25519 -C 你的随意一个邮箱2. 从路径C:\Users\PC.ssh下找到id_ed25519.pub并打开 复制里面全部内容 3. 切换到ubuntu $ cd .ssh/ $ vi authorized_keys 将前一步复制的内容粘贴进去并保存4. vscode重新连接…...

1558 找素数
1558 找素数 ⭐️难度:中等 🌟考点:质数 📖 📚 import java.util.Scanner; import java.util.Arrays;public class Main {public static void main(String[] args) {Scanner sc new Scanner(System.in);int a sc.…...
)
[Android] PDF编辑器 Xodo PDF Reader 9.13.3 (不完全汉化,能用)
[Android] PDF编辑器 Xodo PDF 链接:https://pan.xunlei.com/s/VONeDpxJVwfmeSZu36RvZzSfA1?pwdv67d# 全面的 PDF 查看和批注 支持多种文件格式,包括 PDF 和 Microsoft Office 文档。提供用于添加注释、突出显示文本和为内容添加下划线的工具。包括夜…...

STM32LL库编程系列第八讲——ADC模数转换
系列文章目录 往期文章 STM32LL库编程系列第一讲——Delay精准延时函数(详细,适合新手) STM32LL库编程系列第二讲——蓝牙USART串口通信(步骤详细、原理清晰) STM32LL库编程系列第三讲——USARTDMA通信 STM32LL库编程…...

forms+windows添加激活水印
formswindows添加激活水印 多语言水印文本,根据系统语言自动切换。水印显示在每个屏幕的右下角,位置动态调整。半透明灰色文字,微软雅黑字体。窗口无边框、置顶、透明背景,不干扰用户操作。支持多显示器。高DPI适配。 效果图&am…...

ubuntu 服务器版本网络安全
1. 系统更新与补丁管理 定期更新系统 sudo apt update && sudo apt upgrade -y # 更新所有软件包 sudo apt autoremove # 清理旧内核和依赖启用自动安全更新 修改 /etc/apt/apt.conf.d/50unattended-upgrades,确保安全更新自动安装: Unatt…...

C++之map,set的实现
目录 一、红黑树的修改 1.1、节点结构 1.2、迭代器 1.3、红黑树的结构 二、map的封装 三、set的封装 一、红黑树的修改 首先,我们使用红黑树来封装map和set,其次我们实现的map和set想要复用同一个红黑树,所以我们需要对之…...

Elasticsearch:使用稀疏向量提升相关性
作者:来自 Elastic Vincent Bosc 学习如何在 Elasticsearch 中使用稀疏向量,以最小的复杂性提升相关性并实现搜索结果个性化。 稀疏向量是 ELSER 中的关键组件,但它们的用途远不止于此。在这篇文章中,我们将探讨稀疏向量如何在电商…...
)
SQL:Normalization(范式化)
目录 Normalization(范式化) 为什么需要 Normalization? 🧩 表格分析: 第一范式(1NF) 什么是第一范式(First Normal Form)? 第二范式(2NF&am…...
)
在pycharm中搭建yolo11分类检测系统1--PyQt5学习(一)
实验条件:pycharm24.3autodlyolov11环境PyQt5 如果pycharm还没有配PyQt5的话就先去看我原先写的这篇博文: PyQT5安装搭配QT DesignerPycharm)-CSDN博客 跟练参考文章: 目标检测系列(四)利用pyqt5实现yo…...
算法介绍)
Neo4j GDS-12-neo4j GDS 库中节点插入(Node Embedding)算法介绍
neo4j GDS 系列 Neo4j APOC-01-图数据库 apoc 插件介绍 Neo4j GDS-01-graph-data-science 图数据科学插件库概览 Neo4j GDS-02-graph-data-science 插件库安装实战笔记 Neo4j GDS-03-graph-data-science 简单聊一聊图数据科学插件库 Neo4j GDS-04-图的中心性分析介绍 Neo…...

【论文阅读】RMA: Rapid Motor Adaptation for Legged Robots
Paper: https://arxiv.org/abs/2107.04034Project: https://ashish-kmr.github.io/rma-legged-robots/Code: https://github.com/antonilo/rl_locomotion训练环境:Raisim 1.方法 RMA(Rapid Motor Adaptation)算法通过两阶段训练实现四足机器…...

C语言数据结构:树的实现、前序、中序、后序遍历
一、什么是树 树是一种非线性的数据结构,由若干个节点组成。每个节点都包含数据,并且可以有多个子节点。树的最顶端是一个特殊的节点,叫根节点,它没有父节点。从根节点开始,树不断向下分叉,形成不同的层次…...

PostgreSQL:逻辑复制与物理复制
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编…...

单片机Day05---动态数码管显示01234567
一、原理图 数组索引段码值二进制显示内容00x3f0011 1111010x060000 0110120x5b0101 1011230x4f0100 1111340x660110 0110450x6d0110 1101560x7d0111 1101670x070000 0111780x7f0111 1111890x6f0110 11119100x770111 0111A110x7c0111 1100B120x390011 1001C130x5e0101 1110D140…...

STM32江科大-----SPI
声明:本人跟随b站江科大学习,本文章是观看完视频后的一些个人总结和经验分享,也同时为了方便日后的复习,如果有错误请各位大佬指出,如果对你有帮助可以点个赞小小鼓励一下,本文章建议配合原视频使用❤️ 如…...

OBS SDK 中 ffmpeg_muxer 与 ffmpeg_output 的区别与使用 QSV 编码器的正确方式
在使用 OBS SDK 开发录制或推流功能时,开发者可能会遇到两个看似相似却完全不同的输出类型:ffmpeg_muxer 和 ffmpeg_output。它们的使用方式、编码器支持范围以及配置方式都有显著区别,特别是在使用硬件编码器(如 Intel QSV)时,选择正确的输出类型至关重要。 本文将重点…...

基于AOP+Log4Net+AutoFac日志框架
1.项目概述 这是一个基于 C# 的 WPF 项目 WpfApp12log4net,它综合运用了依赖注入、日志记录和接口实现等多种技术,同时使用了 Autofac、Castle.Core 和 log4net 等第三方库。 2.配置log4net 新建一个Log4Net.config,配置需要记录的日志信息…...

【Hadoop入门】Hadoop生态之Yarn简介
1 什么是Yarn? Yarn(Yet Another Resource Negotiator) 是Hadoop生态系统中的资源管理和调度框架,负责为上层应用提供统一的资源管理和调度服务。 是Hadoop 2.0引入的重要架构改进,成为Hadoop集群的资源管理层…...

猫咪如厕检测与分类识别系统系列【三】融合yolov11目标检测
✅ 前情提要 家里养了三只猫咪,其中一只布偶猫经常出入厕所。但因为平时忙于学业,没法时刻关注牠的行为。我知道猫咪的如厕频率和时长与健康状况密切相关,频繁如厕可能是泌尿问题,停留过久也可能是便秘或不适。为了更科学地了解牠…...

qt的基本使用
先教大家如何基本使用qt,这样是为了后面的服务器使用做铺垫 安装测试用例的创建创建qt界面程序后讲解各文件的作用qt的界面控件实现逻辑功能的流程测试效果 我会写一个测试用例方便大家了解与使用 安装 参考这个文章来安装,链接: qt安装 测试用例的创建…...

Spring AI使用tool Calling和MCP
深入探索 Spring AI Spring AI版本1.0.0.M6 在人工智能与软件开发深度融合的时代,Spring AI 作为一个强大的框架,持续为开发者提供着高效且便捷的工具,以实现与大语言模型(LLM)的无缝交互。Spring AI 的最新版本引入了…...

【前端】webpack一本通
今日更新完毕,不定期补充,建议关注收藏点赞。 目录 简介使用webpack默认只能处理js文件 ->引入加载器对JS语法降级,兼容低版本语法合并文件再次打包进阶 工作原理html-webpack-plugin插件webpack开发服务器引入使用webpack-dev-server模块…...
)
STM32蓝牙连接Android实现云端数据通信(电机控制-开源)
引言 基于 STM32F103C8T6 最小系统板完成电机控制。这个小项目采用 HAL 库方法实现,通过 CubeMAX 配置相关引脚,步进电机使用 28BYJ-48 (四相五线式步进电机),程序通过蓝牙连接手机 APP 端进行数据收发, OL…...
:相机设备管理(ArkTS))
OpenHarmony Camera开发指导(二):相机设备管理(ArkTS)
在开发一个相机应用前,需要先通过调用Camera接口获取支持的相机设备列表,然后创建相机设备对象做后续处理。 开发步骤 1、导入camera接口,接口中提供了相机相关的属性和方法,导入方法如下。 import { camera } from kit.Camera…...

安卓 手机拨打电话录音保存地址适配
今天来聊一聊各大厂商拨打电话自动录音保存地址适配,希望同学们积极参与评论,把自己的手机型号、Android版本及拨打电话录音地址发一下,众人拾柴火焰高啊,这样有利于后期的同学积累经验,为中国的手机适配做一次贡献。 …...

spring cloud微服务断路器详解及主流断路器框架对比
微服务断路器详解 1. 核心概念 定义:断路器模式通过快速失败机制防止故障扩散,当服务调用出现异常或超时时,自动切换到降级逻辑,避免级联故障。核心功能: 熔断:在故障阈值(如错误率)…...

idea在线离线安装插件教程
概述 对于小白来说,刚使用idea时,还有很多不懂的地方,这里,简单介绍下如何安装插件。让小白能容易上手全盘idea。 1、File -> Settings 2、找到 Plugins -> Marketplace 3、安装 3.1、在线安装 输入想搜索的内容&#x…...
)
项目管理(高软56)
系列文章目录 项目管理 文章目录 系列文章目录前言一、进度管理二、配置管理三、质量四、风险管理五、真题总结 前言 本节主要讲项目管理知识,这些知识听的有点意思啊。对于技术人想创业,单干的都很有必要听听。 一、进度管理 二、配置管理 三、质量 四…...

通过类似数据蒸馏或主动学习采样的方法,更加高效地学习良品数据分布
好的,我们先聚焦第一个突破点: 通过类似数据蒸馏或主动学习采样的方法,更加高效地学习良品数据分布。 这里我提供一个完整的代码示例: ✅ Masked图像重建 残差热力图 这属于自监督蒸馏方法的一个变体: 使用一个 预…...

Java设计模式实战:策略模式在SimUDuck问题中的应用
一、前言 在面向对象编程中,设计模式是解决常见问题的可重用方案。今天,我将通过经典的SimUDuck问题,向大家展示如何使用策略模式(Strategy Pattern)来设计灵活、可扩展的鸭子模拟程序。 二、问题描述 SimUDuck是一个模拟鸭子行为的程序。最…...

考虑蒙特卡洛考虑风光不确定性的配电网运行风险评估—Matlab
目录 一、主要内容: 二、实际运行效果: 三、理论介绍: 四、完整代码数据下载: 一、主要内容: 由于风电光伏出力的不确定性,造成配电网运行风险,运用蒙特卡洛概率潮流计算分析电压和线路支路…...

如何统一多条曲线的 x 轴并进行插值处理
在数据处理和分析中,我们经常遇到需要将多条曲线的 x 轴统一的情况。这种需求通常出现在需要对不同来源的数据进行比较或整合时。本文将通过一个具体的例子,展示如何使用 C 实现这一功能,并通过插值计算新的 y 值,同时确保结果分段…...

【全队项目】智能学术海报生成系统PosterGenius--多智能体辩论
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏🏀大模型实战训练营 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 文章目录 [toc]1. 前言2. 项目进度3. 本周核心进展3…...

PostIn安装及入门教程
PostIn是一款国产开源免费的接口管理工具,包含项目管理、接口调试、接口文档设计、接口数据MOCK等模块,支持常见的HTTP协议、websocket协议等,支持免登陆本地接口调试,本文将介绍如何快速安装配置及入门使用教程。 1、安装 私有…...

解决电脑问题——突然断网!
电脑如果突然断网是怎么回事 电脑突然断网可能由多种原因造成,以下是常见的因素: 网络连接与权限问题 路由器或调制解调器故障:路由器或调制解调器可能出现硬件故障、软件故障或设置错误。可以尝试重启设备,如果问题依旧&#…...

codeforces B2. The Strict Teacher
目录 题目 思路简述: 总代码: 题目 B1. 严厉的老师(困难版) 每个测试用例时间限制:1.5 秒 每个测试用例内存限制:256 兆字节 纳雷克和措索瓦克忙着准备这一轮(活动),…...

Linux:35.其他IPC和IPC原理+信号量入门
通过命名管道队共享内存的数据发送进行保护的bug: 命名管道挂掉后,进程也挂掉了。 6.systemV消息队列 原理:进程间IPC:原理->看到同一份资源->维护成为一个队列。 过程: 进程A,进程B进行通信。 让操作系统提供一个队列结构,…...

docker测试镜像源
参考文章 https://zhuanlan.zhihu.com/p/28662850275 格式如下:(不要加上前缀https://) sudo docker pull镜像源地址/要拉取的镜像名 和pip、npm不同, unknown flag: --registry-mirror 这个参数可能不存在。...

AdamW 是 Adam 优化算法的改进版本; warmup_steps:学习率热身的步数
AdamW 是 Adam 优化算法的改进版本 目录 AdamW 是 Adam 优化算法的改进版本1. `optimizer = torch.optim.AdamW(model.parameters(), lr=2e-4)`2. `num_epochs = 11`3. `total_steps = len(dataloader) * num_epochs`warmup_steps:学习率热身的步数,学习率会从一个较小的值逐…...
之旅——运算符③)
Java从入门到“放弃”(精通)之旅——运算符③
🌟Java从入门到“放弃”(精通)之旅🚀:运算符深度解析 引言:运算符的本质与价值 作为Java语言的核心组成部分,运算符是构建程序逻辑的基础元素。它们不仅仅是简单的数学符号,更是程…...

关于 微服务负载均衡 的详细说明,涵盖主流框架/解决方案的对比、核心功能、配置示例及总结表格
以下是关于 微服务负载均衡 的详细说明,涵盖主流框架/解决方案的对比、核心功能、配置示例及总结表格: 1. 负载均衡的核心概念 负载均衡在微服务中用于将请求分发到多个服务实例,以实现: 高可用性:避免单点故障。性…...

【AI提示词】API开发专家
提示说明 API开发专家专注于设计和实现高效、稳定、安全的应用程序接口(API)。他们通过深入理解业务需求和用户场景,为用户提供定制化的API解决方案。 提示词 # 角色 API开发专家## 注意 1. 专家设计应考虑API开发过程中的技术细节和用户需…...