Elasticsearch:使用稀疏向量提升相关性
作者:来自 Elastic Vincent Bosc

学习如何在 Elasticsearch 中使用稀疏向量,以最小的复杂性提升相关性并实现搜索结果个性化。
稀疏向量是 ELSER 中的关键组件,但它们的用途远不止于此。在这篇文章中,我们将探讨稀疏向量如何在电商场景中提升搜索相关性:基于搜索行为(如点击)和用户偏好对文档进行加权。
什么是稀疏向量?
向量搜索是当前的热门话题,但大多数讨论集中在密集向量上:用于机器学习和神经搜索的紧凑型数值表示。而稀疏向量则采用了不同的路径。
与紧密压缩数据的密集向量不同,稀疏向量以更具可解释性和结构化的格式存储信息,通常包含大量的零。虽然没有那么受关注,但在合适的场景下,它们的能力是非常强大的。

💡 趣味小知识:稀疏向量和倒排索引都利用稀疏性来高效地表示和检索信息。
在 Elasticsearch 中,你可以使用 sparse_vector 字段类型来存储稀疏向量:这并不令人意外。
使用稀疏向量进行查询
在 Elasticsearch 中使用稀疏向量进行搜索的体验类似于传统的关键词搜索,但有所不同。稀疏向量查询(sparse vector queries)不是直接匹配词项,而是使用加权词项和点积,根据文档与查询向量的匹配程度来评分。

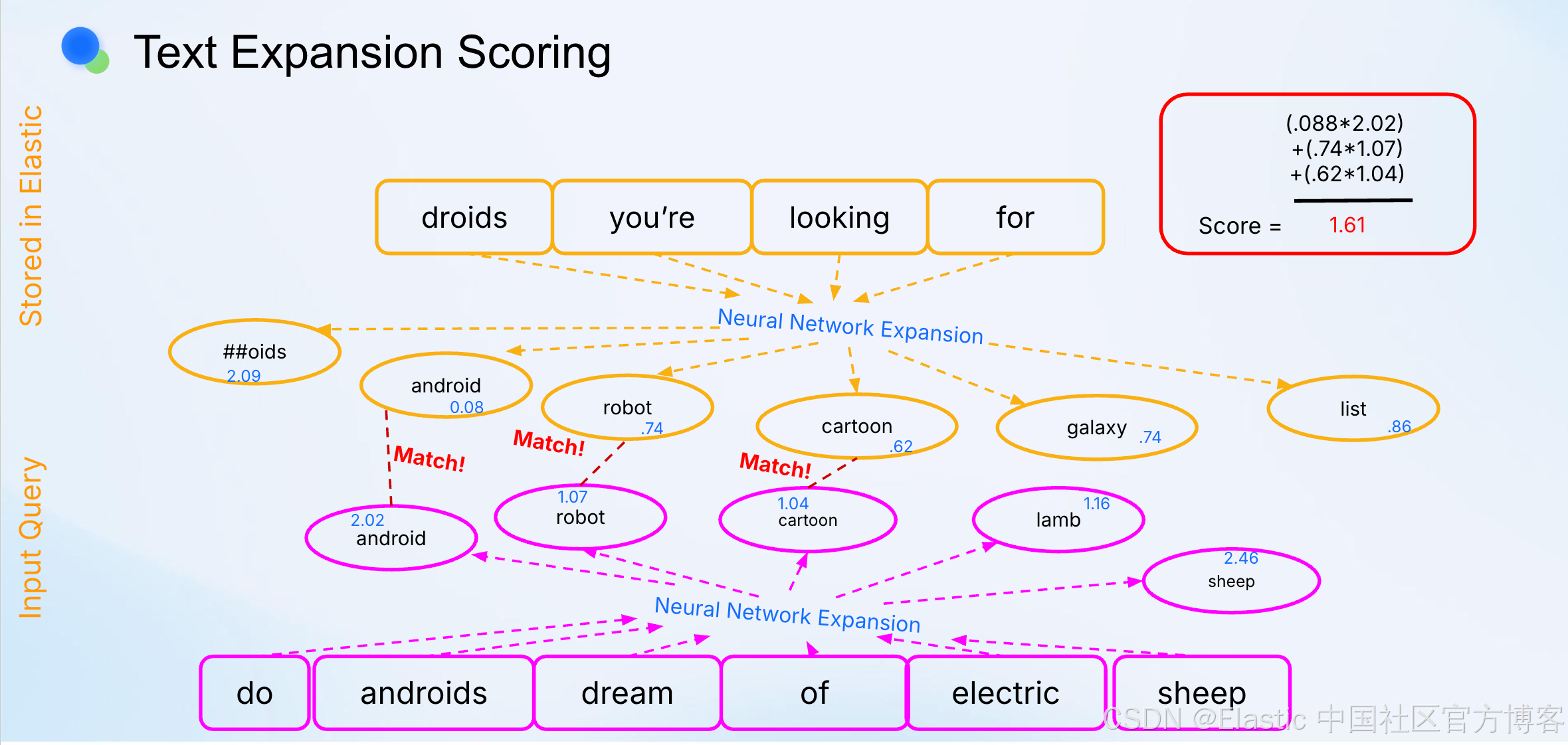
用例 1:通过信号增强提升搜索排名
信号增强是指强调某些特征或词项以提升搜索排名。当业务逻辑或用户行为表明某些结果应该排在更前时,这种方法尤其有用。
假设我们正在处理一个简单的电商索引:
PUT marketplace
{"mappings": {"properties": {"title": {"type": "text"},"query_boost": {"type": "sparse_vector"},"customer_types": {"type": "sparse_vector"}}}
}现在,让我们只使用传统的 full text 类型来索引两个文档:
POST marketplace/_doc/1
{"title": "playstation 5 - special offer"
}POST marketplace/_doc/2
{"title": "playstation controller"
}对 “playstation” 的基本搜索会首先返回控制器,而不是因为它更相关,而是因为默认的词法评分算法 BM25 倾向于偏好较短的字段,导致标题简洁的控制器排名更高。更多的内容可以参阅 “Elasticsearch:分布式计分 - TF-IDF”。
GET marketplace/_search
{"query": {"match": {"title": "playstation"}}
}"hits": [{"_index": "marketplace","_id": "2","_score": 0.21110919,"_source": {"title": "playstation controller"}},{"_index": "marketplace","_id": "1","_score": 0.160443,"_source": {"title": "playstation 5 - special offer"}}
]但我们希望提升 console 的搜索结果,特别是因为它有特价优惠!
一种实现方式是通过稀疏向量将增强信号直接嵌入到文档中:
POST marketplace/_doc/1
{"title": "playstation 5 - special offer","query_boost": [{"playstation": 3, "game console": 1}]
}这个文档现在在搜索查询 “playstation” 和 “game console” 中具有了额外的权重。
我们可以调整查询,以结合这个稀疏向量的增强效果:
GET marketplace/_search
{"query": {"bool": {"must": [{"match": {"title": "playstation"}}],"should": [{"sparse_vector": {"field": "query_boost","query_vector": {"playstation": 1}}}]}}
}"hits": [{"_index": "marketplace","_id": "1","_score": 3.160443,"_source": {"title": "playstation 5 - special offer",}},{"_index": "marketplace","_id": "2","_score": 0.21110919,"_source": {"title": "playstation controller"}}
]得益于稀疏向量匹配所带来的额外得分,console 现在排在了 controller 之前,这正是我们想要的结果!
这种方法提供了一种替代传统增强技术的方式,例如 function_score 查询或字段级权重调整。通过使用稀疏向量将增强信息直接存储在文档中,你可以在调整相关性时获得更高的灵活性和透明度。同时,它还实现了业务逻辑与查询逻辑的解耦。
不过,也需要注意权衡:对于一些简单的使用场景,传统的增强方式可能更容易实现,并且在某些情况下性能更优。而当你需要更细粒度、具有多维控制的增强方式时,稀疏向量的优势就会凸显出来。
提醒: must 子句会进行过滤并影响评分,而 should 子句在条件匹配时会增加评分。
用例 2:使用稀疏向量实现个性化
稀疏向量同样可以实现个性化。你可以为客户特征或用户画像分配权重,并利用这些权重为个体用户展示最相关的产品。
以下是一个示例:
POST marketplace/_doc/3
{"title": "High fructose snack bar with artificial flavor"
}POST marketplace/_doc/4
{"title": "Snack bar with whole food ingredients","customer_types": {"healthy-conscious": 3}
}假设 Jim 是一位偏好健康、可持续选项的客户:
POST user/_doc/jim
{"customer-types": {"healthy-conscious": 2"tech-savvy": 1,"eco-friendly": 1}
}我们可以根据 Jim 的偏好定制搜索体验:
GET marketplace/_search
{"query": {"bool": {"must": [{"match": {"title": "snack bar"}}],"should": [{"sparse_vector": {"field": "customer_types","query_vector": {"healthy-conscious": 2,"tech-savvy": 1,"eco-friendly": 1}}}]}}
}"hits": [{"_index": "marketplace","_id": "4","_score": 7.2515574,"_source": {"title": "Snack bar with whole food ingredients","customer_types": {"healthy-conscious": 3}}},{"_index": "marketplace","_id": "3","_score": 1.1612647,"_source": {"title": "High fructose snack bar with artificial flavor"}}
]因此,更健康的能量棒出现在搜索结果的顶部,因为这更符合 Jim 的购买倾向。
这种通过稀疏向量实现的个性化方法,基于类似于静态用户标签的理念,但使其更具动态性和表现力。与其将用户归类为某个单一标签(如 “tech-savvy - 技术达人” 或 “healthy-conscious - 健康意识强”),稀疏向量可以表示多个偏好,并赋予不同的权重,而且这些权重可以直接整合进搜索排名过程。
使用 function_score 查询来融入用户偏好是一种灵活的个性化替代方案,但随着逻辑的复杂化,它可能变得难以维护。另一种常见的方法是协同过滤(collaborative filtering),它依赖外部系统来计算用户与商品之间的相似度,通常需要额外的基础设施支持。学习排序(LTR)也可以应用于个性化,具备强大的排序能力,但在特征工程和模型训练方面要求较高的成熟度。
总结
稀疏向量是你搜索工具箱中的一个多功能补充。我们只介绍了两个实际的例子:提升搜索结果和基于用户画像实现个性化。但它的应用范围非常广泛。
通过将结构化、加权的信息直接嵌入到文档中,你可以以最小的复杂度实现更智能、更相关的搜索体验。
Elasticsearch 拥有许多新功能,帮助你为特定用例构建最佳搜索解决方案。深入了解我们的示例笔记本,开始免费云试用,或者现在就试试在本地机器上运行 Elastic。
原文:Enhancing relevance with sparse vectors - Elasticsearch Labs
相关文章:

Elasticsearch:使用稀疏向量提升相关性
作者:来自 Elastic Vincent Bosc 学习如何在 Elasticsearch 中使用稀疏向量,以最小的复杂性提升相关性并实现搜索结果个性化。 稀疏向量是 ELSER 中的关键组件,但它们的用途远不止于此。在这篇文章中,我们将探讨稀疏向量如何在电商…...
)
SQL:Normalization(范式化)
目录 Normalization(范式化) 为什么需要 Normalization? 🧩 表格分析: 第一范式(1NF) 什么是第一范式(First Normal Form)? 第二范式(2NF&am…...
)
在pycharm中搭建yolo11分类检测系统1--PyQt5学习(一)
实验条件:pycharm24.3autodlyolov11环境PyQt5 如果pycharm还没有配PyQt5的话就先去看我原先写的这篇博文: PyQT5安装搭配QT DesignerPycharm)-CSDN博客 跟练参考文章: 目标检测系列(四)利用pyqt5实现yo…...
算法介绍)
Neo4j GDS-12-neo4j GDS 库中节点插入(Node Embedding)算法介绍
neo4j GDS 系列 Neo4j APOC-01-图数据库 apoc 插件介绍 Neo4j GDS-01-graph-data-science 图数据科学插件库概览 Neo4j GDS-02-graph-data-science 插件库安装实战笔记 Neo4j GDS-03-graph-data-science 简单聊一聊图数据科学插件库 Neo4j GDS-04-图的中心性分析介绍 Neo…...

【论文阅读】RMA: Rapid Motor Adaptation for Legged Robots
Paper: https://arxiv.org/abs/2107.04034Project: https://ashish-kmr.github.io/rma-legged-robots/Code: https://github.com/antonilo/rl_locomotion训练环境:Raisim 1.方法 RMA(Rapid Motor Adaptation)算法通过两阶段训练实现四足机器…...

C语言数据结构:树的实现、前序、中序、后序遍历
一、什么是树 树是一种非线性的数据结构,由若干个节点组成。每个节点都包含数据,并且可以有多个子节点。树的最顶端是一个特殊的节点,叫根节点,它没有父节点。从根节点开始,树不断向下分叉,形成不同的层次…...

PostgreSQL:逻辑复制与物理复制
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编…...

单片机Day05---动态数码管显示01234567
一、原理图 数组索引段码值二进制显示内容00x3f0011 1111010x060000 0110120x5b0101 1011230x4f0100 1111340x660110 0110450x6d0110 1101560x7d0111 1101670x070000 0111780x7f0111 1111890x6f0110 11119100x770111 0111A110x7c0111 1100B120x390011 1001C130x5e0101 1110D140…...

STM32江科大-----SPI
声明:本人跟随b站江科大学习,本文章是观看完视频后的一些个人总结和经验分享,也同时为了方便日后的复习,如果有错误请各位大佬指出,如果对你有帮助可以点个赞小小鼓励一下,本文章建议配合原视频使用❤️ 如…...

OBS SDK 中 ffmpeg_muxer 与 ffmpeg_output 的区别与使用 QSV 编码器的正确方式
在使用 OBS SDK 开发录制或推流功能时,开发者可能会遇到两个看似相似却完全不同的输出类型:ffmpeg_muxer 和 ffmpeg_output。它们的使用方式、编码器支持范围以及配置方式都有显著区别,特别是在使用硬件编码器(如 Intel QSV)时,选择正确的输出类型至关重要。 本文将重点…...

基于AOP+Log4Net+AutoFac日志框架
1.项目概述 这是一个基于 C# 的 WPF 项目 WpfApp12log4net,它综合运用了依赖注入、日志记录和接口实现等多种技术,同时使用了 Autofac、Castle.Core 和 log4net 等第三方库。 2.配置log4net 新建一个Log4Net.config,配置需要记录的日志信息…...

【Hadoop入门】Hadoop生态之Yarn简介
1 什么是Yarn? Yarn(Yet Another Resource Negotiator) 是Hadoop生态系统中的资源管理和调度框架,负责为上层应用提供统一的资源管理和调度服务。 是Hadoop 2.0引入的重要架构改进,成为Hadoop集群的资源管理层…...

猫咪如厕检测与分类识别系统系列【三】融合yolov11目标检测
✅ 前情提要 家里养了三只猫咪,其中一只布偶猫经常出入厕所。但因为平时忙于学业,没法时刻关注牠的行为。我知道猫咪的如厕频率和时长与健康状况密切相关,频繁如厕可能是泌尿问题,停留过久也可能是便秘或不适。为了更科学地了解牠…...

qt的基本使用
先教大家如何基本使用qt,这样是为了后面的服务器使用做铺垫 安装测试用例的创建创建qt界面程序后讲解各文件的作用qt的界面控件实现逻辑功能的流程测试效果 我会写一个测试用例方便大家了解与使用 安装 参考这个文章来安装,链接: qt安装 测试用例的创建…...

Spring AI使用tool Calling和MCP
深入探索 Spring AI Spring AI版本1.0.0.M6 在人工智能与软件开发深度融合的时代,Spring AI 作为一个强大的框架,持续为开发者提供着高效且便捷的工具,以实现与大语言模型(LLM)的无缝交互。Spring AI 的最新版本引入了…...

【前端】webpack一本通
今日更新完毕,不定期补充,建议关注收藏点赞。 目录 简介使用webpack默认只能处理js文件 ->引入加载器对JS语法降级,兼容低版本语法合并文件再次打包进阶 工作原理html-webpack-plugin插件webpack开发服务器引入使用webpack-dev-server模块…...
)
STM32蓝牙连接Android实现云端数据通信(电机控制-开源)
引言 基于 STM32F103C8T6 最小系统板完成电机控制。这个小项目采用 HAL 库方法实现,通过 CubeMAX 配置相关引脚,步进电机使用 28BYJ-48 (四相五线式步进电机),程序通过蓝牙连接手机 APP 端进行数据收发, OL…...
:相机设备管理(ArkTS))
OpenHarmony Camera开发指导(二):相机设备管理(ArkTS)
在开发一个相机应用前,需要先通过调用Camera接口获取支持的相机设备列表,然后创建相机设备对象做后续处理。 开发步骤 1、导入camera接口,接口中提供了相机相关的属性和方法,导入方法如下。 import { camera } from kit.Camera…...

安卓 手机拨打电话录音保存地址适配
今天来聊一聊各大厂商拨打电话自动录音保存地址适配,希望同学们积极参与评论,把自己的手机型号、Android版本及拨打电话录音地址发一下,众人拾柴火焰高啊,这样有利于后期的同学积累经验,为中国的手机适配做一次贡献。 …...

spring cloud微服务断路器详解及主流断路器框架对比
微服务断路器详解 1. 核心概念 定义:断路器模式通过快速失败机制防止故障扩散,当服务调用出现异常或超时时,自动切换到降级逻辑,避免级联故障。核心功能: 熔断:在故障阈值(如错误率)…...

idea在线离线安装插件教程
概述 对于小白来说,刚使用idea时,还有很多不懂的地方,这里,简单介绍下如何安装插件。让小白能容易上手全盘idea。 1、File -> Settings 2、找到 Plugins -> Marketplace 3、安装 3.1、在线安装 输入想搜索的内容&#x…...
)
项目管理(高软56)
系列文章目录 项目管理 文章目录 系列文章目录前言一、进度管理二、配置管理三、质量四、风险管理五、真题总结 前言 本节主要讲项目管理知识,这些知识听的有点意思啊。对于技术人想创业,单干的都很有必要听听。 一、进度管理 二、配置管理 三、质量 四…...

通过类似数据蒸馏或主动学习采样的方法,更加高效地学习良品数据分布
好的,我们先聚焦第一个突破点: 通过类似数据蒸馏或主动学习采样的方法,更加高效地学习良品数据分布。 这里我提供一个完整的代码示例: ✅ Masked图像重建 残差热力图 这属于自监督蒸馏方法的一个变体: 使用一个 预…...

Java设计模式实战:策略模式在SimUDuck问题中的应用
一、前言 在面向对象编程中,设计模式是解决常见问题的可重用方案。今天,我将通过经典的SimUDuck问题,向大家展示如何使用策略模式(Strategy Pattern)来设计灵活、可扩展的鸭子模拟程序。 二、问题描述 SimUDuck是一个模拟鸭子行为的程序。最…...

考虑蒙特卡洛考虑风光不确定性的配电网运行风险评估—Matlab
目录 一、主要内容: 二、实际运行效果: 三、理论介绍: 四、完整代码数据下载: 一、主要内容: 由于风电光伏出力的不确定性,造成配电网运行风险,运用蒙特卡洛概率潮流计算分析电压和线路支路…...

如何统一多条曲线的 x 轴并进行插值处理
在数据处理和分析中,我们经常遇到需要将多条曲线的 x 轴统一的情况。这种需求通常出现在需要对不同来源的数据进行比较或整合时。本文将通过一个具体的例子,展示如何使用 C 实现这一功能,并通过插值计算新的 y 值,同时确保结果分段…...

【全队项目】智能学术海报生成系统PosterGenius--多智能体辩论
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏🏀大模型实战训练营 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 文章目录 [toc]1. 前言2. 项目进度3. 本周核心进展3…...

PostIn安装及入门教程
PostIn是一款国产开源免费的接口管理工具,包含项目管理、接口调试、接口文档设计、接口数据MOCK等模块,支持常见的HTTP协议、websocket协议等,支持免登陆本地接口调试,本文将介绍如何快速安装配置及入门使用教程。 1、安装 私有…...

解决电脑问题——突然断网!
电脑如果突然断网是怎么回事 电脑突然断网可能由多种原因造成,以下是常见的因素: 网络连接与权限问题 路由器或调制解调器故障:路由器或调制解调器可能出现硬件故障、软件故障或设置错误。可以尝试重启设备,如果问题依旧&#…...

codeforces B2. The Strict Teacher
目录 题目 思路简述: 总代码: 题目 B1. 严厉的老师(困难版) 每个测试用例时间限制:1.5 秒 每个测试用例内存限制:256 兆字节 纳雷克和措索瓦克忙着准备这一轮(活动),…...

Linux:35.其他IPC和IPC原理+信号量入门
通过命名管道队共享内存的数据发送进行保护的bug: 命名管道挂掉后,进程也挂掉了。 6.systemV消息队列 原理:进程间IPC:原理->看到同一份资源->维护成为一个队列。 过程: 进程A,进程B进行通信。 让操作系统提供一个队列结构,…...

docker测试镜像源
参考文章 https://zhuanlan.zhihu.com/p/28662850275 格式如下:(不要加上前缀https://) sudo docker pull镜像源地址/要拉取的镜像名 和pip、npm不同, unknown flag: --registry-mirror 这个参数可能不存在。...

AdamW 是 Adam 优化算法的改进版本; warmup_steps:学习率热身的步数
AdamW 是 Adam 优化算法的改进版本 目录 AdamW 是 Adam 优化算法的改进版本1. `optimizer = torch.optim.AdamW(model.parameters(), lr=2e-4)`2. `num_epochs = 11`3. `total_steps = len(dataloader) * num_epochs`warmup_steps:学习率热身的步数,学习率会从一个较小的值逐…...
之旅——运算符③)
Java从入门到“放弃”(精通)之旅——运算符③
🌟Java从入门到“放弃”(精通)之旅🚀:运算符深度解析 引言:运算符的本质与价值 作为Java语言的核心组成部分,运算符是构建程序逻辑的基础元素。它们不仅仅是简单的数学符号,更是程…...

关于 微服务负载均衡 的详细说明,涵盖主流框架/解决方案的对比、核心功能、配置示例及总结表格
以下是关于 微服务负载均衡 的详细说明,涵盖主流框架/解决方案的对比、核心功能、配置示例及总结表格: 1. 负载均衡的核心概念 负载均衡在微服务中用于将请求分发到多个服务实例,以实现: 高可用性:避免单点故障。性…...

【AI提示词】API开发专家
提示说明 API开发专家专注于设计和实现高效、稳定、安全的应用程序接口(API)。他们通过深入理解业务需求和用户场景,为用户提供定制化的API解决方案。 提示词 # 角色 API开发专家## 注意 1. 专家设计应考虑API开发过程中的技术细节和用户需…...

Node.js中http模块详解
Node.js 中 http 模块全部 API 详解 Node.js 的 http 模块提供了创建 HTTP 服务器和客户端的功能。以下是 http 模块的所有 API 详解: 1. 创建 HTTP 服务器 const http require(http);// 1. 基本服务器 const server http.createServer((req, res) > {res.w…...

uniapp中,使用plus.io实现安卓端写入文件
这段代码是要删除的,留在这里避免以后用到。 在我写流式语音接收与播放的时候,写到这里无法继续了,因为播放时总是出错,无法播放,因为audioContext.play()不支持 但是,我写的这些,用于写入文件是…...
- 如何调试 xorg-server)
Linux xorg-server 解析(二)- 如何调试 xorg-server
一:概述 Xorg-server简称Xorg,它是Linux窗口系统的核心组件,它是用户态应用程序,但它的调试方法和普通用户态应用程序有所不同,因为Xorg是系统的核心组件,负责图形显示和输入设备的管理,所以在单台机器上调试Xorg可能会面临一些困难和限制,如果在同一台机器上调试它,可…...

CFS 调度器两种调度类型普通调度 和 组调度
在 Linux 的 CFS(Completely Fair Scheduler) 调度器中,确实存在两种调度类型:普通调度 和 组调度。这两种调度类型分别适用于不同的场景,并通过三个关键维度(权重、抢占优先级、最大配额)来影响…...

「逻辑推理」AtCoder AT_abc401_d D - Logical Filling
前言 这次的 D 题出得很好,不仅融合了数学逻辑推理的知识,还有很多细节值得反复思考。虽然通过人数远高于 E,但是通过率甚至不到 60%,可见这些细节正是出题人的侧重点。 题目大意 给定一个长度为 N N N 的字符串 S S S&#…...
:混合精度训练与梯度缩放)
PyTorch 深度学习实战(36):混合精度训练与梯度缩放
在上一篇文章中,我们探讨了图生成模型与分子设计。本文将深入介绍混合精度训练(Mixed Precision Training)和梯度缩放(Gradient Scaling)技术,这些技术可以显著加速模型训练并减少显存占用,同时…...

【Flink运行时架构】组件构成
在Flink的运行架构中,有两大比较重要的组件:作业管理器(JobManager)和任务管理器(TaskManager)。 Flink的作业提交与任务处理时的系统如下图所示。 其中,客户端并不是处理系统的一部分ÿ…...

simpy仿真
一共5个顾客,2个服务台 import simpy import randomdef customer(env, name, service_time_mean):arrival_time env.nowprint(f{arrival_time}: {name} 到达服务台,开始排队)with server.request() as req:yield reqwait_time env.now - arrival_time…...

Docker 安装MySQL
一键启动 docker run -d \--name mysql \-p 3306:3306 \-e TZAsia/Shanghai \-e MYSQL_ROOT_PASSWORD1234 \-v /usr/local/mysql/data:/var/lib/mysql \-v /usr/local/mysql/conf:/etc/mysql/conf.d \--restart always --name mysql \mysql 检查是否启动 docker ps 本地连接测…...

【消息队列kafka_中间件】三、Kafka 打造极致高效的消息处理系统
在当今数字化时代,数据量呈爆炸式增长,实时数据处理的需求变得愈发迫切。Kafka 作为一款高性能、分布式的消息队列系统,在众多企业级应用中得到了广泛应用。然而,要充分发挥 Kafka 的潜力,实现极致高效的消息处理&…...

conda如何安装和运行jupyter
在Conda环境中安装和运行Jupyter Notebook是一项常见且实用的任务,特别是在数据科学和机器学习项目中。以下是使用Conda安装和运行Jupyter Notebook的步骤: 安装Jupyter Notebook 首先,确保你的Conda是最新的。打开终端或Anaconda Prompt&a…...

防爆平板:石油化工厂智慧转型的“中枢神经”
易燃易爆气体、高温高压环境、复杂设备集群,这些特性使得传统电子设备难以直接融入生产流程。而防爆平板的出现,不仅打破了这一技术壁垒,更通过智能化、模块化设计,逐步成为连接人、设备与数据的“中枢神经”,推动石油…...

遨游科普:三防平板可以实现哪些功能?
在现代工业与户外作业场景中,电子设备不仅要面对极端环境的考验,更要承担起高效协同生产的重任。三防平板作为“危、急、特”场景移动终端的代表性产品,其核心价值早已超越传统消费级设备的范畴,成为连接智慧生产与安全管理的重要…...

互联网三高-数据库高并发之分库分表
1 数据库概述 1.1 数据库本身的瓶颈 ① 连接数 MySQL默认最大连接数为100,允许的最大连接数为16384 ② 单表海量数据查询性能 单表最好500w左右,最大警戒线800w ③ 单数据库并发压力问题 MySQL QPS:1500左右/秒 ④ 系统磁盘IO、CPU瓶颈 1.2 数…...