基于LangChain的Native RAG简单样例
本文代码: Github
文章目录
- 1. 概述
- 2. Native RAG 概述
- 3. 实战:基于LangChain实现简单的Native RAG
- 概述
- 环境配置
- 文档分割
- 定义Embedding模型
- 构建向量数据库
- 与LLM交互
- 参考文献
1. 概述
众所周知, 大模型可以回答它知道的内容。但如果用户问的是它不知道的内容,它可能会瞎答,也就是幻觉(Hallucination)
要解决这个问题,只需要给大模型参考文献即可。
比如(不给参考文献):
User: Do you know what's the homework today?LLM: Sorry, I don't know.
要想让大模型可以回答上述问题,给他参考即可:
User: Do you know what's the homework today?Truly Prompt: Please answer the following question:
"""
Do you know what's the homework today?
"""You can refer to the following knowledge:
"""
The homework is to complete exercises 5.1 to 5.3 on page 87.
...
"""LLM: Yes, your homework is to complete exercises 5.1 to 5.3 on page 87.
看起来很简单,但难点在于如何从众多数据中找出与问题相关的知识,这就是 RAG (Retrieval-Augmented Generation) 要解决的核心问题。
2. Native RAG 概述
RAG可以是一个很复杂的接口,包含许多模块。每个模块都是为了提高大模型回答精准度而设计的。
但如果我们只保留RAG最基本的几个模块,那么这种RAG就被称为 Native RAG.
Native RAG的工作流可以简化成如下图:
其包含如下几个基本模块:
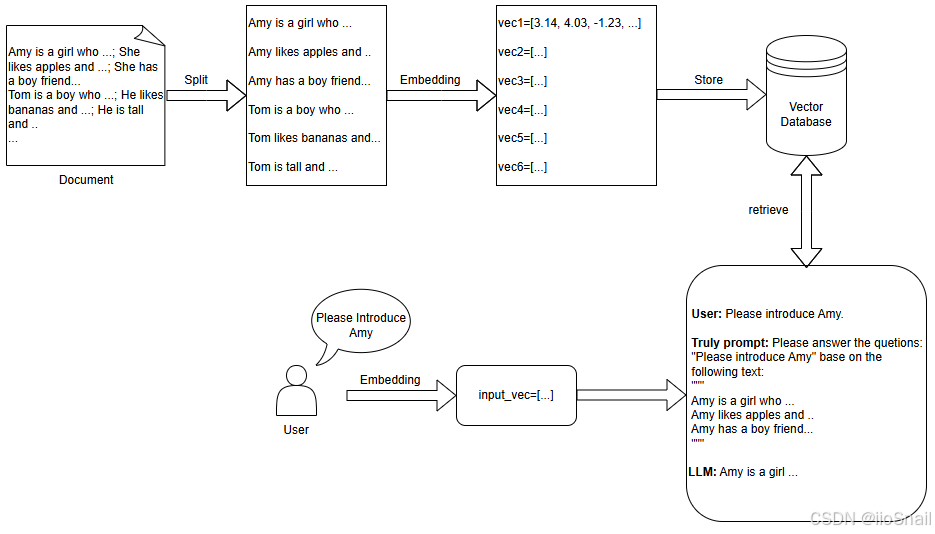
- 文档分割(Document Splitting):用户上传的文档可能是一个长文本,此时要将其分割成多个块。
- 文本编码(Text Embedding):为了计算用户输入和文档中每个块的相似度,我们需要对分割后的文本块进行编码,即将其转为向量表示(vector representations). 常用的方法包括:
- 使用embedding API(例如 OpenAI的API)
- 使用基于深度学习的模型(例如 BERT)
- 使用基于词频的方法(例如:TF-IDF)
- 向量存储(Vector Storage):生成embebdding之后,这些向量需要存到 向量数据库(vector database) 中。 向量数据库是专门用来存储和查询向量的,通过其API可以很容易的获取与查询向量相似的向量。 常用的向量数据库有Faiss和Chroma 。
- 知识获取(Knowledge Retrieval):当用户问大模型问题时,就需要从向量数据库中提取相关的知识。首先需要对用户的查询内容进行embedding,然后和向量数据库中的向量进行比较,获取前k个相似的内容即可。
- 构造Prompt(Prompt Construction):获取知识后,需要构建prompt来替换用户的问题。例如:prompt可以构造成 “请基于如下内容#{content} 回答问题 #{question}”。根据提取的数据和用户的问题替换占位符中的内容即可。
3. 实战:基于LangChain实现简单的Native RAG
概述
本章,我们将使用LangChain实现一个简单的Native RAG系统
LangChain是一个专门用来构建大模型应用的Python框架。如果你不会也没关系,它就是个各种工具的集合,可以边用边学。
简单起见,我们的文档就是一些对不同人的描述。
环境配置
安装依赖:
!pip install -U langchain langchain-community langchain-core langchain-deepseek
!pip install faiss-cpu
下载数据 (google drive 、百度网盘)
# 如果你用Colab运行的话,直接执行这个代码就会下载。
!gdown 1n8HhgQenifEBGJKMcOwh53q5JOJbv58a
文档大概长这样:
Alex is a dedicated software engineer ...Jordan is an enthusiastic ......
文档分割
首先加载文档:
from langchain.document_loaders import TextLoaderloader = TextLoader("description.txt")
document = loader.load()print(document)
[Document(metadata={'source': 'description.txt'}, page_content="Alex is a dedicated ....)]
逐句分割文档:
from langchain.text_splitter import RecursiveCharacterTextSplitter# 将文档分割成多个chunks
splitter = RecursiveCharacterTextSplitter(separators=["\n\n", "\n", ". ", "! ", "? ", "\u200b"], # 根据这些分割符分割chunk_size=1, # 每个块至少包含一个单词chunk_overlap=0, # 块之间不重叠keep_separator=False # 分割后丢弃这些分隔符
)docs = splitter.split_documents(document)
print(docs)
[
Document(page_content='Alex is a ... problems'),
Document(page_content='Alex has ... Python'),
Document(page_content='Alex thrives ... developers'),
...
]
定义Embedding模型
这里使用HugginFace上的模型进行embedding
from langchain.embeddings import HuggingFaceEmbeddingsembedding_model = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2")# 将句子进行embedding
emb = embedding_model.embed_query("Hello, I'm learning LLM.")
print(type(emb)) # list.
print(len(emb)) # 768
构建向量数据库
准备好文档和embedding模型后,就可以使用LangChain构建向量数据库了。这里使用Faiss作为我们的向量数据库
from langchain.vectorstores import FAISSvectorstore = FAISS.from_documents(docs, embedding_model)
使用similarity_search查询最相似的前3个文档:
vectorstore.similarity_search("Introduce Alex", k=3)
[
Document(page_content='Alex is a ... problems'),
Document(page_content='Alex thrives ... developers'),
Document(page_content='Alex has ... and Python')
]
与LLM交互
现在我们可以和LLM交互了。简单起见,我们不自己部署大模型,而是使用在线的大模型API。
这里我们使用比较便宜的Deepseek. 首先,你需要到DeepSeek网站上充点钱,10块就够玩很久。冲完钱后,需要获取API key.
import os
from langchain_deepseek import ChatDeepSeek# 这里填上你的API Key
os.environ["DEEPSEEK_API_KEY"] = ""llm = ChatDeepSeek(model="deepseek-chat"
)
尝试随便问点问题:
messages = [("human", "Hi, do you know Alex?"),
]
ai_msg = llm.invoke(messages)
print(ai_msg.content)
It depends! If you're referring to a specific person named Alex, I don’t have personal knowledge of individuals ...
接下来,构建Prompt
prompt_template = """You are an AI assistant. Please answer user's question based on the following content:
'''
{content}
'''Answer user's question directly. Don't need to say "Based on the information".
"""
最后,把上面功能整合起来即可。
def chat(question: str):docs = vectorstore.similarity_search(question, k=3)content = '\n'.join([doc.page_content for doc in docs])messages = [("system", prompt_template.format(content=content)),("human", question),]resp = llm.invoke(messages)return resp.content
试几个例子:
print(chat("Who is software engineer?"))
print(chat("Who can analyse data?"))
Alex is a software engineer with over five years ...
Both Casey and Sage can analyze data. Casey has strong analytica ...
效果还行,完结撒花~~
参考文献
- LangChain Tutorials : https://python.langchain.com/docs/tutorials/
相关文章:

基于LangChain的Native RAG简单样例
本文代码: Github 文章目录 1. 概述2. Native RAG 概述3. 实战:基于LangChain实现简单的Native RAG概述环境配置文档分割定义Embedding模型构建向量数据库与LLM交互 参考文献 1. 概述 众所周知, 大模型可以回答它知道的内容。但如果用户问的是它不知道…...
)
数据结构基础(2)
1.什么是算法? 算法:算法是解决特定问题求解步骤的描述,在计算机中表现为指令的有限序列,并且每条指令表示一个或多个操作。 算法定义中,提到了指令,指令能被人或机器等计算装置执行。它可以是计算机指令&a…...

慢查询解决思路
1. 复现问题 慢查询的出现是常态还是偶尔?是否在业务允许范围内? "不要过早优化,先 Make it work / right,再 Make it fast。" 建议先将查询语句及其触发条件记录下来,便于后续测试、分析和对比。 2. 定位问题 2.1 单机数据库: explain查询执行计划 数据库默…...

前端下载文件时浏览器右上角没有保存弹窗及显示进度,下载完之后才会显示保存弹窗的问题定位及解决方案
需求背景 在开发过程中会发现,有的时候下载后端返回的文件,浏览器右上角不会进行保存弹窗的弹出及下载进度,而是接口响应后文件下载完才会弹出保存并且没有进度条效果,这就导致在点击下载后用户是不知道文件下载到什么进度了&…...

Streamlit在测试领域中的应用:构建自动化测试报告生成器
引言 Streamlit 在开发大模型AI测试工具方面具有显著的重要性,尤其是在简化开发流程、增强交互性以及促进快速迭代等方面。以下是几个关键点,说明了 Streamlit 对于构建大模型AI测试工具的重要性: 1. 快速原型设计和迭代 对于大模型AI测试…...

IP组播技术与internet
1.MAC地址分为三类:广播地址;组播地址;单播地址 2.由一个源向一组主机发送信息的传输方式称为组播。 3.组播MAC地址,第一个字节的最后一位为1; 单播MAC地址,第一个字节的最后一位为0; 4.不能…...

[Java基础]StringBuilder解析
StringBuilder简单总结与源码预览。 之前写StringBuilder对象默认简写为sb,被说是骂人不让用了,现在写成strBuilder了。大家一般写什么呢 StringBuilder预留空间设计 已知Redis的String结构是通过预留空间的形式来避免频繁地分配空间。 那么Java中有没有…...

国内智能外呼系统市场概况及技术发展趋势
根据最新行业报告和用户评价,国内智能外呼系统市场呈现快速增长态势,预计2025年市场规模将达到180亿元人民币,年复合增长率约20%。主要驱动因素包括AI技术成熟、企业降本增效需求以及政策扶持(如工信部《智能语音产业发展行动计划…...

小推桌面-一款全新的第三方电视桌面-全网通桌面
你是否渴望更高效、便捷地使用机顶盒桌面?小推桌面、乐看家桌面是绝佳之选!它们的界面简洁,操作轻松上手,能快速找到所需应用,大大节省时间。 小推桌面支持个性化定制,可按个人喜好调整布局、添加组件&…...
)
SQL实战篇,数据库在Kooboo中的实际应用(一)
本文将结合实际操作与代码示例,展示SQL 在 Kooboo 中的实际应用 仅需两步:动态创建表 基础查询,无需复杂配置,快速上手! 一、动态创建表:插入数据 Kooboo 支持多种数据库,以 SQLite 为例&…...

Matlab 调制信号和fft变换
1、内容简介 Matlab 194-调制信号和fft变换 可以交流、咨询、答疑 2、内容说明 略 3、仿真分析 略 4、参考论文 略...

2025年的Android NDK 快速开发入门
十年前写过一篇介绍NDK开发的文章《Android实战技巧之二十三:Android Studio的NDK开发》,今天看来已经发生了很多变化,NDK开发变得更加容易了。下面就写一篇当下NDK开发快速入门。 **原生开发套件 (NDK) **是一套工具,使开发者能…...

opensuse Tumbleweed虚拟机上安装
值得一提的是cpu需要给多一点核,不然压力都集中在一个点上温度会比较高,然后就是可能无法正常运行这个安装界面。 前面好像是半自动的,一直到这里选择桌面界面需要手动选择 这边必然选大蜥蜴的kde,那个蜥蜴菜单还是很好看的。 …...

AI避坑:AI生成的文件格式不一定对
今天就碰到了原来正确的文件,AI生成后文件变味UTF-8 BOM文件 导致MAUI解析出错An error occured while parsing Xaml: 根级别上的数据无效。 第 1 行,位置 1 解决方案: 将文件用文本编辑器打开,另存为UTF-8格式文件...

蓝桥杯真题-危险系数DF
抗日战争时期,冀中平原的地道战曾发挥重要作用。 地道的多个站点间有通道连接,形成了庞大的网络。但也有隐患,当敌人发现了某个站点后,其它站点间可能因此会失去联系。 我们来定义一个危险系数DF(x,y): 对于两个站点x和…...

四、TorchRec的推理优化
四、TorchRec的推理优化 文章目录 四、TorchRec的推理优化前言一、TorchRec 推理优化的两个主要区别是二、TorchRec 提供了以下内容,以将 TorchRec 模型转换为可用于推理的模型总结 前言 推理环境与训练环境不同,它们对性能和模型大小非常敏感。 一、To…...

Linux 系统中从源码编译安装软件
以下是 Linux 系统中 从源码编译安装软件 的详细步骤和注意事项,帮助你掌握这一高级操作技能: 一、编译安装的核心流程 1. 下载源码包(通常为 .tar.gz/.tar.bz2/.tar.xz) 2. 解压源码包 3. 进入源码目录 4. 配置编译参数…...

【AI论文】OLMoTrace:将语言模型输出追溯到万亿个训练标记
摘要:我们提出了OLMoTrace,这是第一个将语言模型的输出实时追溯到其完整的、数万亿标记的训练数据的系统。 OLMoTrace在语言模型输出段和训练文本语料库中的文档之间找到并显示逐字匹配。 我们的系统由扩展版本的infini-gram(Liu等人…...

BeautifulSoup 踩坑笔记:SVG 显示异常的真正原因
“这图是不是糊了?”以为是样式缺了?试试手动复制差异在哪?想用对比工具一探究竟……简单到不能再简单的代码,有问题吗?最后的真相:viewBox vs viewbox,preserveAspectRatio vs preserveaspectr…...

ai-warp 开源的Platformatic Stackable 与 AI 服务交互
一、软件介绍 文末提供程序和源码下载学习 ai-warp 开源的Platformatic Stackable 与 AI 服务交互 二、用法 npx create-platformaticlatestSelect Application, then platformatic/ai-warp 选择 Application(应用程序 ),然后选择 platfor…...

AI比人脑更强,因为被植入思维模型【53】反熵增思维模型
giszz的理解:熵用来形容系统的混乱程度。熵增就是从有序到无序,反熵增就是从无序到有序。其实阴阳二级,世界总是在变化之中。保持清醒的头脑,认识到当前是有序还是无序的,如何改变,让事物向着自己希望的方式…...
)
408 计算机网络 知识点记忆(8)
前言 本文基于王道考研课程与湖科大计算机网络课程教学内容,系统梳理核心知识记忆点和框架,既为个人复习沉淀思考,亦希望能与同行者互助共进。(PS:后续将持续迭代优化细节) 往期内容 408 计算机网络 知识…...

DDR管脚违例
管脚验证,出现上述违例 上述警告是IO电平配置存在冲突,主要原因是这里配置没有显示电平特性,那么vivado工具默认是生成IP的底层的代码中自带的XDC的电平,这个就冲突了。 出现这个的主要原因还是vivado某个版本工具存在漏洞&#x…...

25年河南事业单位报名详细流程图解
1.报名时间为2025年4月11日9∶00至4月17日17∶00; 2.网上缴费:2025年4月12日9:00至4月18日17:00; 3.打印准考证:2025年5月12日9∶00至5月18日14∶30; 4.笔试时间:2025年5月18日; 5.报名方式…...

一维差分数组
2.一维差分 - 蓝桥云课 问题描述 给定一个长度为 n 的序列 a。 再给定 m 组操作,每次操作给定 3 个正整数 l, r, d,表示对 a_{l} 到 a_{r} 中的所有数增加 d。 最终输出操作结束后的序列 a。 Update: 由于评测机过快,n, m 于 20…...

Windows 录音格式为什么是 M4A?M4A 怎样转为 MP3 格式
M4A 格式凭借其高效的压缩技术和卓越的音质表现脱颖而出,成为了包括 Windows 在内的众多操作系统默认的录音格式选择。然而,尽管 M4A 格式拥有诸多优点,不同的应用场景有时需要将这些文件转换为其他格式以满足特定需求。 本文将探讨 M4A 格式…...

【KWDB 创作者计划】第一卷:基础架构篇
以下是KWDB技术白皮书第一卷:基础架构篇的完整内容展示,包含要求的三个核心章节的深度解析。我们将以技术严谨性结合可读性的方式呈现,实际交付时会进一步扩展示意图和代码示例。 目录 KWDB技术白皮书卷一:基础架构篇 1. 数…...

分享一些使用DeepSeek的实际案例
文章目录 前言职场办公领域生活领域学习教育领域商业领域技术开发领域 前言 以下是一些使用 DeepSeek 的实际案例: DeepSeek使用手册资源链接:https://pan.quark.cn/s/fa502d9eaee1 职场办公领域 行业竞品分析:刚入职的小李被领导要求一天内…...

华清远见成都中心嵌入式学习总结
一、Linux 基础入门 课程首先介绍了 Linux 系统的六大特性,包括开源、免费、可裁剪等核心优势。重点讲解了文件系统结构,强调根目录(/)作为唯一入口的树状结构。通过实操学习了 pwd、ls、cd 等基础命令,掌握了绝对路径…...

【13】数据结构之树结构篇章
目录标题 树Tree树的定义树的基本概念树的存储结构双亲表示法孩子表示法孩子兄弟表示法 二叉树二叉树与度不超过2的普通树的不同之处二叉树的基本形态二叉树的分类二叉树的性质 二叉树的顺序存储二叉树的链式存储二叉树的链式存储的结点结构树的遍历先序遍历中序遍历…...

SAP GUI 显示SAP UI5应用,并实现SSO统一登陆
想用SAP UI5 做一写界面,又不想给用户用标准的Fiori APP怎么办?我觉得可以用可配置物料标准功能的思路,在SAP GUI中显示UI5界面,而不是跳转到浏览器。 代码实现后的效果如下: 1、调用UI5应用,适用于自开发…...

Linux环境变量详解
引言 在Linux系统中,环境变量是一种非常重要的概念,它影响着系统的运行方式和应用程序的行为。无论你是Linux新手还是经验丰富的管理员,深入理解环境变量都能帮助你更高效地使用和管理Linux系统。本文将从基础概念到高级应用,全面…...

【antd + vue】Tree 树形控件:默认展开所有树节点 、点击文字可以“选中/取消选中”节点
一、defaultExpandAll 默认展开所有树节点 1、需求:默认展开所有树节点 2、问题: v-if"data.length"判断的层级不够,只判断到了物理那一层,所以只展开到那一层。 3、原因分析: 默认展开所有树节点, 如果是…...

专题三——二分查找
目录 一、二分查找 1、题目 2、解题思路 3、代码实现 4、时间复杂度 5、朴素二分法的模板总结 二、在排序数组中查找元素的第一个和最后一个位置 1、题目 2、题目解析 3、代码实现 4、 模板总结(重点) 三、x的算法平方根 1、题目 2、 题目解…...

从零实现HTTP服务器
响应: 第一部分测试代码,读取请求 Makefile binhttpserver #生成的可执行程序 ccg #编译器名称 LD_FLAGS-stdc11 -lpthread #-DDEBUG1 #链接选项 srcmain.cc$(bin):$(src)$(cc) -o $ $^ $(LD_FLAGS).PHONY:clean clean:rm -f $(bin) 1111111 main.cc…...

智能检索知识库
一、智能检索知识库作用 1. 提升信息检索效率,降低人力成本 快速获取精准答案:员工无需手动翻阅大量文档(如产品手册、合同、技术文档),直接通过自然语言提问获取答案。 减少重复性工作:HR、客服、技…...
算法学习思路总结及其算法研究:理论、实现与验证)
北斗导航 | 接收机自主完好性监测(RAIM)算法学习思路总结及其算法研究:理论、实现与验证
===================================================== github:https://github.com/MichaelBeechan CSDN:https://blog.csdn.net/u011344545 ===================================================== 接收机自主完好性监测学习思路 壹、学习思路贰、理论、实现与验证1. 引…...

无法读取库伦值文件节点解决方案
读取库伦值的目的是为了换算成电流,量化场景功耗用途 1.报错日志 /power_log/debuglogger$ adb shell dmesg | grep -Ei "avc..system_server"[ 79.942272] logd.auditd: type1400 audit(1744279324.832:7149): avc: denied { read } for comm"…...

OCR API识别对比
OCR 识别DEMO OCR识别 demo 文档由来 最开始想使用百度开源的 paddlepaddle大模型 研究了几天,发现表格识别会跨行,手写识别的也不很准确。最终还是得使用现成提供的api。。 文档说明 三个体验下来 腾讯的识别度比较高,不论是手写还是识别表…...

高速电路设计概述
1.1 低速设计和高速设计的例子 本节通过一个简单的例子,探讨高速电路设计相对于低速电路设计需要考虑哪些不同的问题。希望读者通过本例,对高速电路设计建立一个表象的认识。至于高速电路设计中各方面的设计要点,将在后续章节展开详细的讨论…...

Keil C51中32位变量赋值异常问题分析与解决
Keil C51中32位变量赋值异常问题分析与解决 问题描述 在使用Keil5对51单片机进行编程时,遇到一个32位变量赋值不正确的问题。具体代码如下: typedef unsigned long uint32;g_Flow_Time (uint32)Storage[2] << 24 | Storage[3] << 16 | S…...
)
python工程中的包管理(requirements.txt)
pip install -r requirements.txtpython工程通过requirements.txt来管理依赖库版本,上述命令,可以一把安装依赖库,类似java中maven的pom.xml文件。 参考 [](...

用Python修改字体字形与提取矢量数据:fontTools实战指南
字体设计与分析是NLP和视觉领域的交叉应用,而**fontTools** 是一款强大的Python库,可以让我们直接操作字体文件的底层结构。本文将通过两个实用函数,展示如何修改特定字形和提取所有字形的矢量数据,帮助开发者快速上手字体编辑与分…...

数据库守护神-WAL机制
什么是WAL机制? WAL(Write-Ahead Logging,预写日志)是一种保证数据库操作原子性和持久性的核心机制。其核心原则可概括为: 任何数据修改操作,必须在对应的日志记录持久化到磁盘之后,才能将实际…...

[MySQL]数据库与表创建
欢迎来到啾啾的博客🐱。 这是一个致力于构建完善 Java 程序员知识体系的博客📚。 它记录学习点滴,分享工作思考和实用技巧,偶尔也分享一些杂谈💬。 欢迎评论交流,感谢您的阅读😄。 本篇简单记录…...

工作记录 2015-05-27
工作记录 2015-05-27 序号 工作 相关人员 1 修改了指定短语的大小写的处理。 取消了一些逗号的处理。 郝 另: iCDA更新到了190的D:\Temp\CHTeam\iCDA_20150527下了 修改的文件: bin目录下是程序。 0223目录下是0223的一些设置和关键字。 更新…...

嵌入式汇编语言从小白到入门:从零开始的底层编程之旅
嵌入式汇编语言从小白到入门:从零开始的底层编程之旅 汇编语言作为最接近机器语言的编程方式,在嵌入式开发中扮演着不可替代的角色。本文将带你从零开始,逐步掌握嵌入式汇编语言的核心概念和实践技巧,最终能够独立编写简单的汇编程序并与C语言混合编程。 一、汇编语言与嵌…...

GPIO_ReadInputData和GPIO_ReadInputDataBit区别
目录 1、GPIO_ReadInputData: 2、GPIO_ReadInputDataBit: 总结 GPIO_ReadInputData 和 GPIO_ReadInputDataBit 是两个函数,通常用于读取微控制器GPIO(通用输入输出)引脚的输入状态,特别是在STM32系列微控制器中。它们之间的主要…...

不使用docker在本地安装与配置RAGFlow
RAGFlow 本地安装与配置(非docker方式) 一. 运行环境 windows10 CPU i7-12700F 2.10GHz内存 32GGPU RTX 4060 Ti 8G wsl 2 Ubuntu-22.04 1. 防火墙配置 wsl默认访问windows的本机服务需要配置防火墙,否则访问会失败。 windows10的防火墙配置: 打…...

sysfs 设备模型
介绍 Sysfs 设备文件系统与proc是同一类的文件系统,基于ramfs实现的内存文件系统。 1.1 为什么会有 sysfs?procfs 的局限性: 早期,Linux 使用 procfs 来提供内核与用户空间的交互接口。但 procfs 的设计不够层次化,设…...