【大模型系列篇】基于Ollama和GraphRAG v2.0.0快速构建知识图谱
GraphRAG是一种结合了知识图谱和大型语言模型的检索增强生成(RAG)技术。它通过引入图结构化的知识表示和处理方法,显著提升了传统RAG系统的能力,为处理复杂和多样化数据提供了强有力的支持。更多介绍可以跳转《最强检索增强技术GraphRAG基本原理详解》阅读。

本期我们将基于GraphRAG v2.0.0版本结合Ollama本地部署的大模型来快速构建知识图谱。
1、准备环境
首先我们需要安装Ollama和GraphRAG。
Ollama 是一个强大的工具,它为模型的管理和运行提供了便利。它可以简化模型的下载、配置和启动过程,让用户能够快速地将不同的模型集成到自己的工作流程中。关于Ollama的安装部署,可以跳转《本地问答系统-部署Ollama、Open WebUI》、《Ollama、Dify和RAG:企业智能问答系统的黄金配方》里面有关于Docker如何部署Ollama的内容,当然也可以选择二进制包直接本地安装部署。
安装Ollama - Linux系统
Linux 下可以使用一键安装脚本,我们打开终端,运行以下命令:
curl -fsSL https://ollama.com/install.sh | bash安装完成后,通过以下命令验证:
ollama --version如果显示版本号,则说明安装成功。
安装GraphRAG
我们创建一个Python=3.12的虚拟环境
conda create -n env_py312 python=3.12
conda activate env_py312安装 graphrag==2.0.0
pip install graphrag==2.0.0Ollama部署模型
GraphRAG需要我们部署两个类型的模型文件,我们需要选取一个聊天模型和一个嵌入模型。我们这里选择qwen2:32B作为聊天模型,nomic-embed-text:v1.5作为嵌入模型。

如果要使用的模型不在 Ollama 模型库,可以通过选择GGUF (GPT-Generated Unified Format)模型来实现部署、使用。
- Ollama现已支持modelscope上托管的GGUF格式的大模型部署推理。(需要Ollama版本不小于0.3.12)
- GGUF 是由 llama.cpp 定义的一种高效存储和交换大模型预训练结果的二进制格式。
Ollama 支持采用 Modelfile 文件中导入 GGUF 模型。
- Ollama 是一个基于开源推理引擎 llama.cpp 构建的大模型推理工具框架。借助底层引擎的高效推理能力以及对多种硬件的适配支持,Ollama 可以在包括 CPU 和 GPU 在内的多种硬件环境上运行各种精度的 GGUF 格式大模型。通过简单的命令行操作,即可快速启动 LLM 模型服务。
- ModelScope 社区托管了数千个高质量的 GGUF 格式大模型,并支持与 Ollama 框架和 ModelScope 平台的无缝对接。用户只需使用简单的 ollama run 命令,即可直接加载并运行 ModelScope 模型库中的 GGUF 模型。
所以如果需要从魔塔社区中下载GGUF模型,我们需要先安装依赖。
pip install modelscope这里举两个示例
Chat模型https://www.modelscope.cn/models/Qwen/Qwen2.5-7B-Instruct-GGUF
modelscope download --model Qwen/Qwen2.5-7B-Instruct-GGUF qwen2.5-7b-instruct-q4_k_m.gguf --local_dir /root/autodl-tmp/modelsChatModelFile
FROM ./qwen2.5-7b-instruct-q4_k_m.gguf
执行 ollama create qwen2.5-7b-instruct -f ChatModelFile
Embedding模型https://www.modelscope.cn/models/Embedding-GGUF/nomic-embed-text-v1.5-GGUF
modelscope download --model Embedding-GGUF/nomic-embed-text-v1.5-GGUF nomic-embed-text-v1.5.f16.gguf --local_dir /root/autodl-tmp/models
EmbeddingModelFileFROM ./nomic-embed-text-v1.5.f16.gguf
执行 ollama create nomic-embed-text -f EmbeddingModelFile
ollama create 之后就可以在ollama list的模型列表里找到qwen2.5-7b-instruct 和 nomic-embed-text,我们只需要ollama run模型就可以使用了。
2、初始化 GraphRAG 项目
graphrag init --root ./ragdata-
修改.env文件
GRAPHRAG_API_KEY=ollama- 修改setting.yaml文件
model: qwen2.5:32b
api_base: http://localhost:11434/v1
encoding_model: cl100k_basemodel:nomic-embed-text:latest
api_base: http://localhost:11434/v1
encoding_model: cl100k_base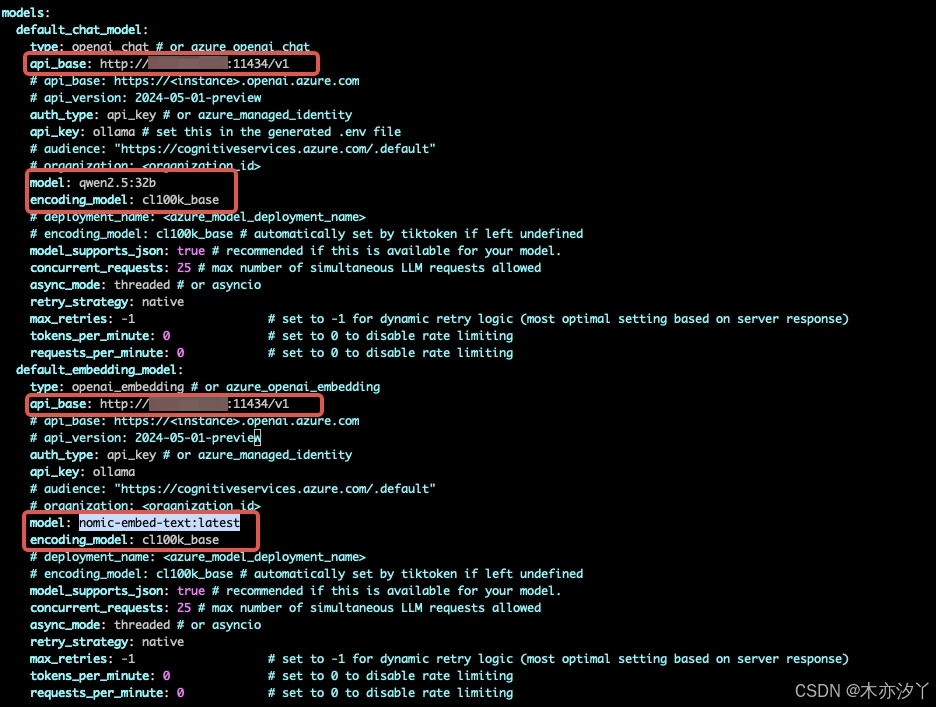
测试小文件时,建议把chunks改小:
chunks:size:200overlap: 50group_by_columns:[id]配置文件可参考:https://microsoft.github.io/graphrag/config/yaml
参考配置说明:《2025年最新更新,GraphRAG yaml配置参数详细说明》
-
添加数据集
默认在项目下创建input目录,并上传数据文件。
示例文本 input.txt
《大数据时代》是一本由维克托·迈尔-舍恩伯格与肯尼斯·库克耶合著的书籍,讨论了如何在海量数据中挖掘出有价值的信息。这本书深入探讨了数据科学的应用,并阐述了数据分析和预测在各行各业中的影响力。在书中,作者举了许多实际例子,说明大数据如何改变我们的生活,甚至如何预测未来的趋势。3、构建知识图谱
执行创建索引命令 (默认为standard模式)
graphrag index --root ./ragdata
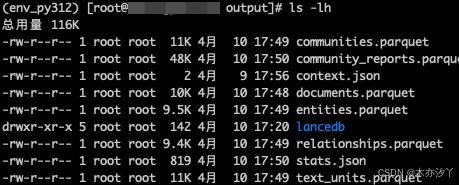
创建索引的过程包括create_base_text_units、create_final_documents、extract_graph、finalize_graph、create_communities、create_final_text_units、create_community_reports、generate_text_embeddings等过程。执行成功后,在项目output下就会存在知识图谱相关的parquet文件。
LazyGraphRAG
目前LazyGraphRAG好像还未正式发布,但是基于早期FastGraphRAG技术的NLP提取已经集成。
核心代码:graphrag/index/workflows/extract_graph_nlp.py
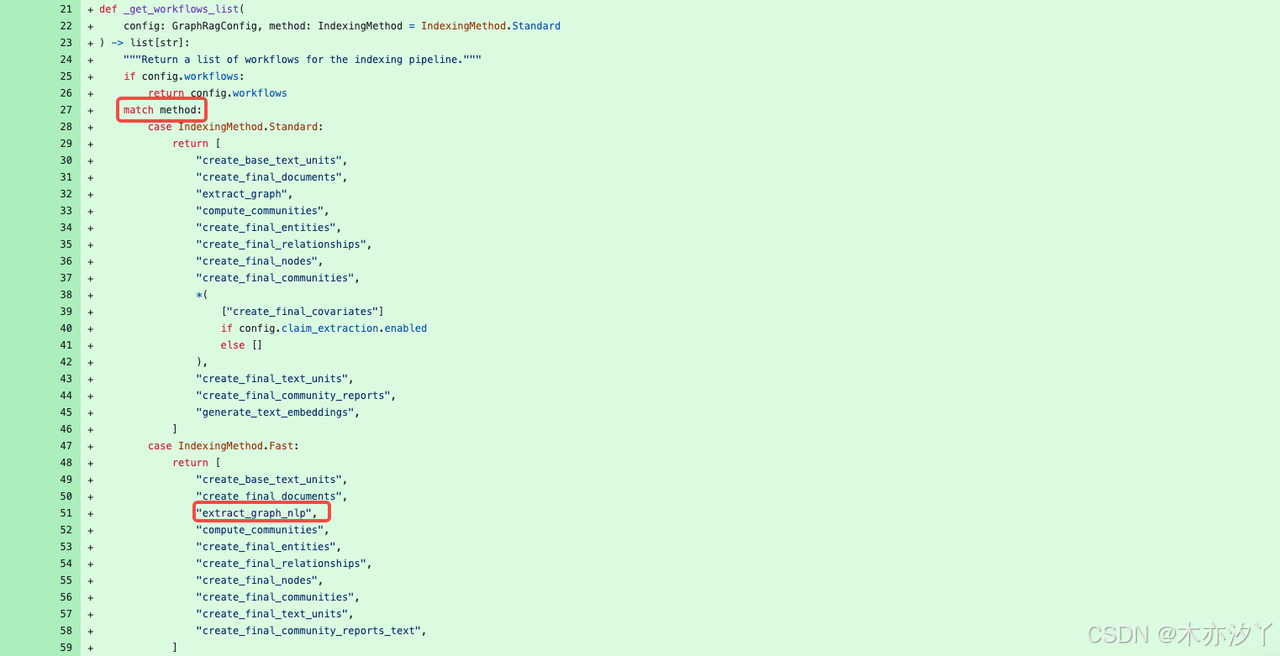
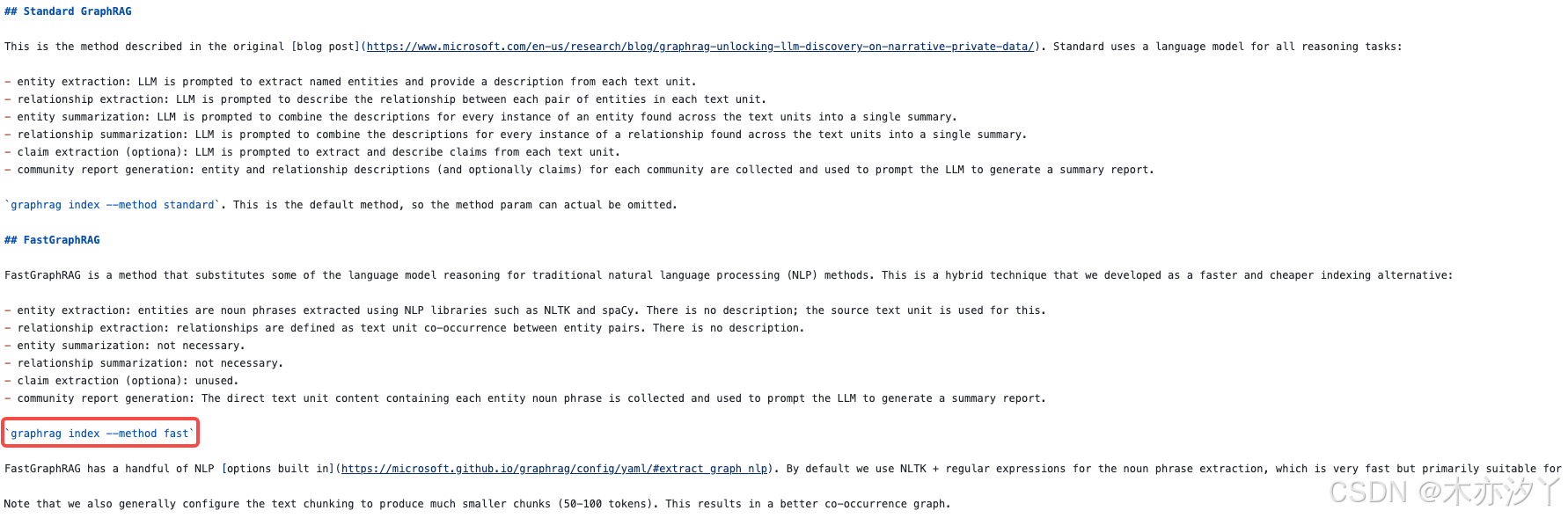

这里我们调整了chunks参数并上传了一个英文数据集来体检下fast模式的索引创建,为什么调整了成了英文数据集是因为extract_graph_nlp可能对中文支持不是很友好,作者在运行时prune_graph过程出现了报错。
graphrag index --method fast --root ./ragdata 创建索引的过程包括create_base_text_units,create_final_documents,extract_graph_nlp,prune_graph,finalize_graph,create_communities,create_final_text_units,create_community_reports_text,generate_text_embeddings等过程。我们发现除了extract_graph_nlp不同外,额外还有一个prune_graph过程。所以prune_graph的参数配置也是fast模式一个可配置调整的参数。
4、查询知识图谱
我们主要测试两种查询方式,全局搜索和本地搜索。
https://microsoft.github.io/graphrag/query/overview
Global Search(全局搜索)
Global Search很大程度上解决了传统RAG在处理数据时的局限性,Global Search更侧重于回答全文摘要总结类的场景,比如:“请帮我总结一下这篇文章讲了什么内容?”。传统RAG会因为在切分文本块时丢失信息,而回答的不够全面。以下详细介绍下Global Search的核心原理和流程。
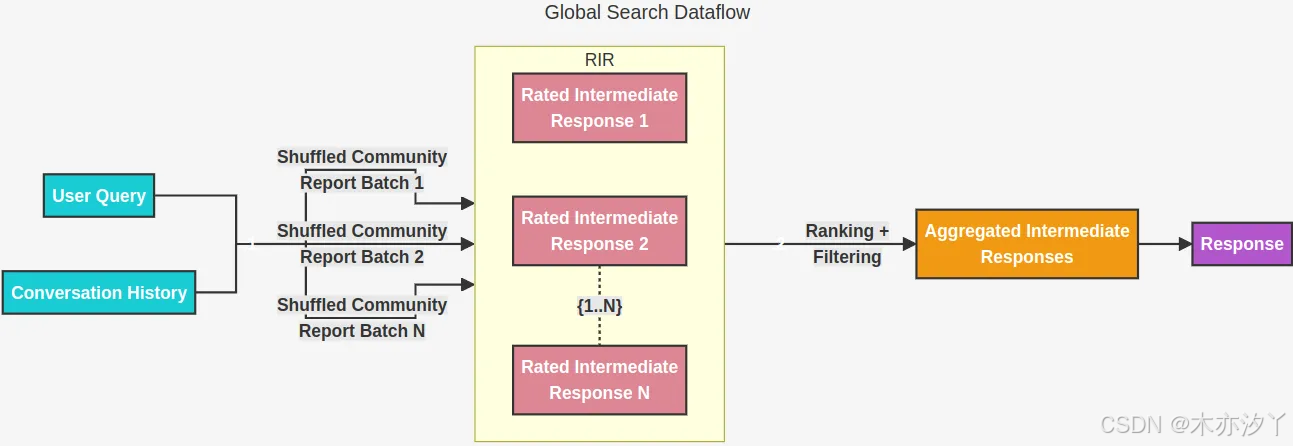
Global Search的查询分为以下两个步骤:
- Map阶段:根据用户的输入和对话历史,查询知识图谱社区结构中指定级别的社区报告集,并将其切分成预定义大小的文本块,使用这些文本块生成带有评分的中间相应。评分用来表示这些观点的重要程度,整个过程都是通过LLM来生成。(可以理解为使用LLM来总结社区报告并打分)
- Reduce阶段:在reduce阶段会对map阶段的评分进行倒排,并选出一组最重要的点汇总作为参考上下文,最后由大模型来生成最终相应结果。
特性
- 搜索范围大:Global Search会通过全文搜索的模式力争覆盖范围最广, 从而得出的结论也就更可信,所以对于一些可信度要求高的场景可以使用该模式;
- 计算成本高:因为Global Search要对整个图结构进行遍历搜索,所以中间需要大量的计算;从而会带来计算成本高、搜索时间长的问题,对于图结构规模比较大的场景会非常耗时;
graphrag query --root ./ragdata --method global --query "大数据时代"SUCCESS: Global Search Response:
Victor Mayer-Schönberger 和 Kenneth Cukier 是《Big Data Era》一书的合著者,该书强调了他们在大数据领域的重大贡献 [Data: Entities (0, 1), Relationships (0)]。他们的著作不仅在学术界产生了深远影响,还对多个行业带来了启示和应用上的指导 [Data: Entities (0, 1), Relationships (0)]。《Big Data Era》一书是该领域的重要作品之一,它探讨了大数据的含义及其广泛应用,从而深刻地改变了各个行业的运作方式和研究方法。这本书不仅为学术界提供了理论基础,还为企业在实际操作中如何利用大数据提供了宝贵的指导 [Data: Entities (0, 1), Relationships (0)]。通过这些贡献,Mayer-Schönberger 和 Cukier 在推动大数据技术的发展及其应用方面发挥了关键作用,他们的工作对于理解大数据的潜力和挑战至关重要。Local Search(本地搜索)
Local Search将用户的输入与知识图谱中的结构化数据相结合,以便在查询时使用相关实体信息来增强LLM上下文。这种方式比较适合需要了解输入文档中提到的关于某个特定实体的相关问题,例如:“小王是做什么工作的?”
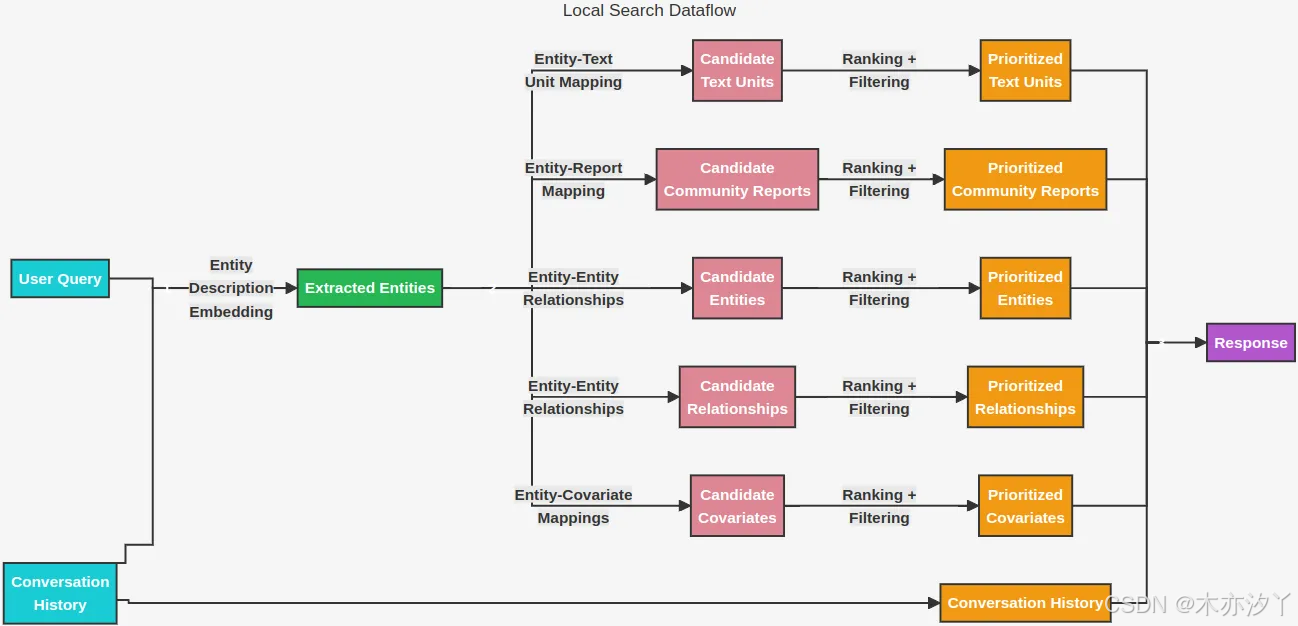
Local Search主要包含以下几个关键步骤:
- 相关实体检索:根据用户的输入和对话历史,利用向量搜索技术从知识图谱或向量数据库中识别出一组与用户输入在语义上相关的节点或文档集。
- 相关数据提取:基于上个阶段搜索的结果,在知识图谱中进一步提取更多相关的信息,包括:原始文本块、社区报告、实体描述、关系描述等信息,主要通过知识图谱检索出更大范围的相关上下文。
- 节点排序:基于图的排序算法对提取出来的数据源进行优先级排序和过滤,在一定大小的上下文窗口范围内确保最相关的信息能够被展示出来。
- 相应生成:将排序后的文档块作为上下文信息输入到LLM中,生成最终的响应结果。
特性
- 效率高:Local Search采用局部相关性搜索一定程度上提高了搜索效率和计算成本,在对于大规模的图数据场景中,Local Search可以更高效、更快的找到相关答案。
- 局限性:Local Search的局部搜索效果很大程度上取决于用户的输入,不同的输入检索到的相关节点不同,对最终的结果会有较大的局限性影响。
graphrag query --root ./ragdata --method local --query "大数据时代"INFO: Vector Store Args: {"default_vector_store": {"type": "lancedb","db_uri": "***/rag/ragdata/output/lancedb","url": null,"audience": null,"container_name": "==== REDACTED ====","database_name": null,"overwrite": true}
}SUCCESS: Local Search Response:
《大数据时代》是一本由维克托·迈尔-舍恩伯格与肯尼斯·库克耶合著的书籍,该书深入探讨了大数据的应用及其对社会的影响。这本书被认为是大数据领域的里程碑之作,它不仅在学术界产生了广泛影响,也在多个行业中被广泛应用作为理解和应用大数据的重要参考 [Data: Reports (0); Sources (0)]。维克托·迈尔-舍恩伯格是《大数据时代》的作者之一,他在大数据领域做出了显著贡献。他与肯尼斯·库克耶的合作成果——这本书,详细探讨了大数据的意义和应用场景,体现了他们在该领域的深厚专业知识 [Data: Entities (0), Relationships (0); Reports (0)]。另一位作者肯尼斯·库克耶同样在《大数据时代》中发挥了重要作用。他的合作不仅加深了对大数据的理解,还为社会如何应对大数据带来的挑战提供了洞见。这种合作关系展示了他们共同的专业知识和影响力,特别是在研究和应用大数据方面 [Data: Entities (1), Relationships (0); Reports (0)]。维克托·迈尔-舍恩伯格与肯尼斯·库克耶之间的合作是基于他们对《大数据时代》这本书的共同贡献。他们的合作关系不仅产生了重要的研究成果,还为该领域的发展做出了巨大贡献,体现了他们在大数据研究和应用方面的联合专长 [Data: Relationships (0); Reports (0)]。总的来说,《大数据时代》一书及其作者维克托·迈尔-舍恩伯格与肯尼斯·库克耶在推动大数据领域的知识传播和发展方面发挥了关键作用。这本书不仅为学术界提供了宝贵的资源,也在实际应用中产生了深远的影响 [Data: Entities (0, 1), Relationships (0); Reports (0)]。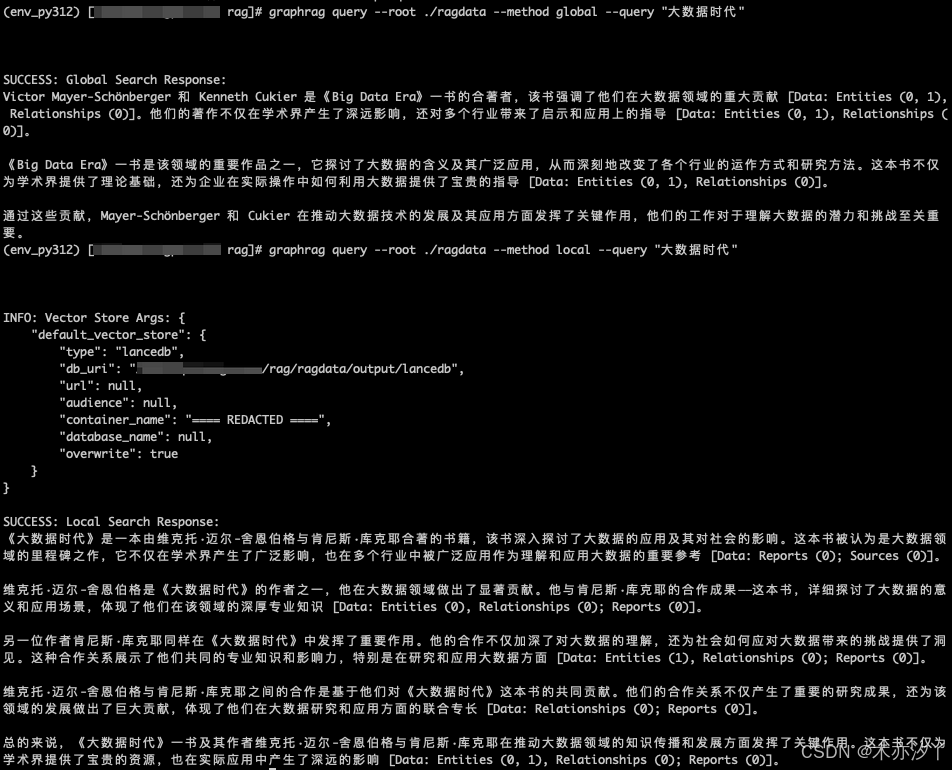
此外还有一种搜索方式:DRIFT搜索
DRIFT Search是一种结合Global Search和Local Search的方案,通过在搜索过程中纳入社区信息,为Local Search引入了新方法。该方案优化了Local Search局限性的不足,大大扩展了查询的起点,在最终答案中检索和使用更多种类的事实。同时,也扩展了GraphRAG的查询引擎,为本地搜索提供了更全面的选项,利用社区摘要将查询细化为更详细的后续问题。
整个DRIFT Search搜索层次突出了搜索过程的三个核心阶段,以下为每个阶段的详细介绍:
- 社区报告检索:DRIFT 将用户的查询与语义最相关的前K个社区报告进行比较,生成广泛的初步答案和后续问题以引导进一步的探索。
- 相关数据提取:DRIFT使用本地搜索来优化查询,生成额外的中间答案和后续问题以增强特异性,从而引导搜索引擎获取更丰富的上下文信息。
- 相关性排序:最后则是根据相关性对相关节点进行排序,并将排序后的文档作为上下文信息输入到LLM,生成最终的响应。
特性
- 平衡性:DRIFT Search方案通过融合Global Search和Local Search,反映了全局见解和局部细化之间的平衡组合,使结果更具适应性且更全面。
- 多样性:通过纳入社区报告信息,使得DRIFT Search在初步搜索就扩大了范围,也就意味着DRIFT Search能够检索到更多的相关内容,最终的检索效果就会更具多样性。
DRIFT Search是GraphRAG最新的改进版本,它既取了Globall Search的优点也补足了Local Search的缺点,但在实际工程里大家还是要结合业务场景选择最适合的方案。无论哪种搜索模式开发者都需要考虑搜索效率和LLM Tokens的资源消耗,都需要衡量召回精度、计算成本和时间成本的优先级,特别是在当前大模型应用开发领域,一定没有最优的解决方案只有最适合场景的解决方案。
5、报错回顾
配置错误引起的报错
报错一、https://github.com/microsoft/graphrag/issues/1806

和 GraghRAG 1.0系列版本不一样,这里
default_embedding_model的api_base需要配置为 http://localhost:11434/v1 。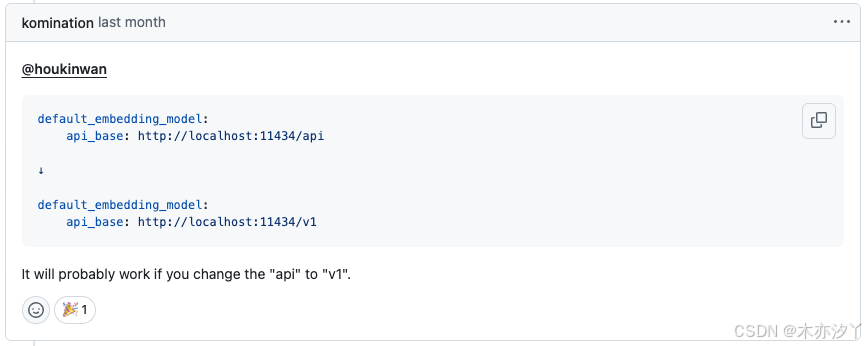
报错二、KeyError: 'Could not automatically map qwen2.5:32b tto a tokeniser. Please use tiktoken.get_encoding'to explicitly get the tokeniser you expect.
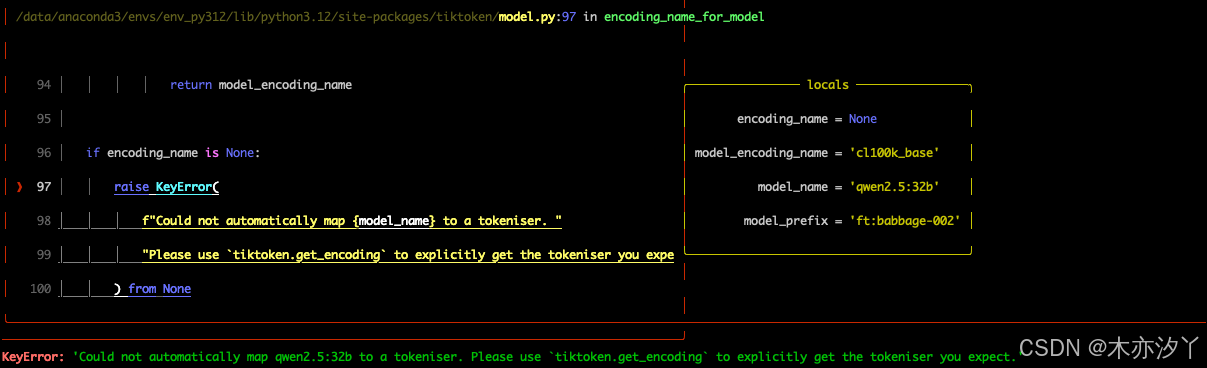
encoding_modelstr - The text encoding model to use. Default is to use the encoding model aligned with the language model (i.e., it is retrieved from tiktoken if unset).
default_chat_model和default_embedding_model都需要配置encoding_model参数。encoding_model: cl100k_base

相关文章:

【大模型系列篇】基于Ollama和GraphRAG v2.0.0快速构建知识图谱
GraphRAG是一种结合了知识图谱和大型语言模型的检索增强生成(RAG)技术。它通过引入图结构化的知识表示和处理方法,显著提升了传统RAG系统的能力,为处理复杂和多样化数据提供了强有力的支持。更多介绍可以跳转《最强检索增强技术Gr…...

Wincc管对象的使用
Wincc管对象的使用 管对象的调用多边形管T形管双T形管管弯头管道大小调整 管对象的调用 打开【图形编辑器】 多边形管 多边形管如下: 一根管子的顶点数是两个,如果修改顶点数,管子就有多少个端点。 修改顶点数为5 此时点击端点然后拖动&#…...

springboot--页面的国际化
今天来实现页面中的国际化 首先,需要创建一个新的spring boot项目,导入前端模板,在我的博客中可以找到,然后将HTML文件放在templates包下,将其他的静态资源放在statics包下,如下图结构 页面的国际化主要在首…...

记 etcd 无法在docker-compose.yml启动后无法映射数据库目录的问题
1、将etcd 单独提取 Dockerfile #镜像 FROM bitnami/etcd:3.5.11 #名称 ENV name"etcd" #重启 ENV restart"always" #运行无权限 ENV ALLOW_NONE_AUTHENTICATION"yes" #端口 EXPOSE 2379 2380 #管理员权限才能创建数据库 USER root # 设置入口点…...

c++关键字new
链接:【C】C中的new关键字用法详解...

数字内容体验的核心价值是什么?
个性化推荐提升满意度 在数字内容体验的构建中,个性化推荐已成为提升用户满意度的核心策略。通过分析用户行为数据、偏好标签及场景特征,系统能够精准匹配内容资源,减少信息过载带来的决策疲劳。例如,基于用户画像的动态推荐算法…...
来保护敏感数据)
通过实施最小权限原则(POLP)来保护敏感数据
在处理机密信息时,应始终将确保组织的敏感数据安全放在首位。无论是制定新政策还是参与项目协作,都应采取一切必要预防措施,确保对任何敏感信息进行恰当的访问控制和存储管理。 最小权限原则(POLP)是企业保护客户与员工数据、财务记录、知识…...

VBA即用型代码手册:文档Document
我给VBA下的定义:VBA是个人小型自动化处理的有效工具。可以大大提高自己的劳动效率,而且可以提高数据的准确性。我这里专注VBA,将我多年的经验汇集在VBA系列九套教程中。 作为我的学员要利用我的积木编程思想,积木编程最重要的是积木如何搭建…...
最长有效括号)
【力扣hot100题】(089)最长有效括号
这题目真是越做越难了。 但其实只是思路很难想到,一旦会了方法就很好做。 但问题就在方法太难想了…… 思路还是只要遍历一遍数组,维护动态规划数组记录截止至目前位置选取该元素的情况下有效括号的最大值。 光是知道这个还不够,看了答案…...

为什么需要「实体识别」以及 RAG如何和实体识别结合用
🤖 为什么要做「实体识别」? 实体识别(Named Entity Recognition, NER) 是自然语言处理(NLP)中的一种基础技术,它的目标是: 从文本中识别出“有意义”的实体信息,如人名…...

初级社会工作者考试精选题库
通过练习题库中的题目,考生能了解考试的题型、难度分布以及命题规律,明确备考的重点和难点,有针对性地复习知识点,避免盲目备考。 精选练习题 1、社会工作者小王在为社区孤寡老人提供服务时,总是把他们当成自己的父母来…...
Transformer 训练:AutoModelForCausalLM,AutoModelForSequenceClassification
Transformer 训练:AutoModelForCausalLM,AutoModelForSequenceClassification 目录 Transformer 训练:AutoModelForCausalLM,AutoModelForSequenceClassification`AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)`功能概述参数解释`AutoModelForSequen…...
)
图书管理系统(Python)
运行结果: 源代码: # 定义一个图书类 class Book: def __init__(self, title, author, isbn): self.title title self.author author self.isbn isbn def show_info(self): print(f"{self.title},{self.author},{self.isbn}") # 图书列表…...
任务书)
2022年全国职业院校技能大赛 高职组 “大数据技术与应用” 赛项赛卷(4卷)任务书
2022年全国职业院校技能大赛 高职组 “大数据技术与应用” 赛项赛卷(4卷)任务书 背景描述:模块A:大数据平台搭建(容器环境)(15分)任务一:Hadoop 完全分布式安装配置任务二…...

装系统的一天!镜像系统!
虚拟机可以装系统,我们都知道,但是虚拟机可以装几个系统呢? macOS: 如何在 Windows 电脑上装 macOS 系统?_windows装mac-CSDN博客 Win10: Win10镜像(官方正版)下载及虚拟机配置(保姆级教程…...

Wincc脚本全部不运行
Wincc脚本全部不运行 前言解决办法操作步骤 前言 这里主要是指旧项目移植到Wincc的高版本,移植后界面的一些功能均会失效。(例如脚本不执行,项目编辑器不可用等情况) 解决办法 Wincc的项目文件中有Dcf文件,Dcf文件包…...

第三节:React 基础篇-React组件通信方案
React 组件通信方案详解及使用场景 以下是 React 组件通信的常用方法及其适用场景,以层级结构呈现: 一、父子组件通信 1. Props 传递 • 实现方式: • 父组件通过 props 向子组件传递数据。 • 子组件通过回调函数 (onEvent) 通知父组件更…...

✨ MOS开关的非线性因素详解 ✨
MOS 开关在模拟电路、开关电源等应用中广泛使用,但其导通特性存在非线性,可能导致信号失真或系统性能下降。以下是主要非线性因素及解决思路: 🔧 1. 导通电阻(Ron)的非线性 机理: Ron 并非固定值…...

解决vcpkg使用VS2022报错问题
转自个人博客:解决vcpkg使用VS2022报错问题 最近,在把Visual Studio2019完全更新到最新Visual Studio2022后,原使用的vcpkg无法正常安装包,会报如下与Visual Studio 2022相关的错误: error: in triplet x64-windows-m…...
的空气质量预测)
基于支持向量回归(SVR)的空气质量预测
基于支持向量回归(SVR)的空气质量预测 1.作者介绍2.支持向量回归(SVR)算法介绍2.1 算法原理2.2 关键概念2.3算法特点2.4与其他回归方法对比 3.基于支持向量回归(SVR)的空气质量预测实验3.1数据集介绍3.2代码…...

【数据结构】排序
目录 1.排序的概念及其运用 1.1排序的概念 1.2常见排序算法 2插入排序 2.1直接插入排序 2.1.1基本思想 2.1.2代码实现 2.1.3特性总结 2.2 希尔排序 2.2.1基本思想 2.2.2代码实现 3.选择排序 3.1选择排序 3.1.1基本思想 3.1.2代码实现 3.1.3特性总结 3.2 堆排…...

4185 费马小定理求逆元
4185 费马小定理求逆元 ⭐️难度:简单 🌟考点:费马小定理 📖 📚 import java.util.Scanner; import java.util.Arrays;public class Main {static int[][] a;public static void main(String[] args) {Scanner sc …...

低代码控件开发平台:飞帆中粘贴富文本的控件
效果: 链接: https://fvi.cn/729...
的物化性质及其在合成中的应用)
偶氮二异丁腈(AIBN)的物化性质及其在合成中的应用
偶氮二异丁腈(AIBN)是一种常用的自由基引发剂,是一种白色结晶性粉末,不溶于水,但溶于甲醇、乙醇、丙酮、乙醚、甲苯等有机溶剂和乙烯基单体。 AIBN在60℃以上会分解形成异丁腈基,从而引发自由基反应。其分解温度区间为50ÿ…...

3.1.3.2 Spring Boot使用Servlet组件
在Spring Boot应用中使用Servlet组件,可以通过注解和配置类两种方式注册Servlet。首先,通过WebServlet注解直接在Servlet类上定义URL模式,Spring Boot会自动注册该Servlet。其次,通过创建配置类,使用ServletRegistrati…...

java——HashSet底层机制——链表扩容和树化
HashSet在Java中是基于HashMap实现的,它实际上是将所有元素作为HashMap的key存储,而value则统一使用一个静态的Object对象(Present)作为占位符。 1.举例演示 下面我们就举例说明一下,HashSet集合中,一个节点上的链表添加数据以及…...

玩转Docker | 使用Docker搭建Blog微博系统
玩转Docker | 使用Docker搭建Blog微博系统 前言一、Blog介绍项目简介主要特点二、系统要求环境要求环境检查Docker版本检查检查操作系统版本三、部署Blog服务下载镜像创建容器检查容器状态设置权限检查服务端口安全设置四、访问Blog系统访问Blog首页登录Blog五、总结前言 在数字…...

Linux中的Vim与Nano编辑器命令详解
📢 友情提示: 本文由银河易创AI(https://ai.eaigx.com)平台gpt-4-turbo模型辅助创作完成,旨在提供灵感参考与技术分享,文中代码与命令建议通过官方渠道验证。 在Linux系统中,文本编辑是最常用的…...

G1垃圾回收器介绍
G1垃圾回收器简介 全称:Garbage-First Garbage Collector。目的:G1垃圾回收器是为了替代CMS垃圾回收器而设计的,它旨在提供更好的垃圾回收性能和可预测性,特别是在处理大内存堆时。特点:G1是一种服务器端的垃圾回收器…...
)
Python学习笔记(三)
文章目录 Python函数详解基本概念定义函数函数调用参数类型1. 位置参数2. 默认参数3. 关键字参数4. 可变参数 返回值函数作用函数中的变量作用域规则 递归函数Lambda函数函数注解装饰器文档字符串其他重要概念闭包生成器函数高阶函数 Python函数详解 基本概念 函数是Python中…...

Hqst的超薄千兆变压器HM82409S在Unitree宇树Go2智能机器狗的应用
本期拆解带来的是宇树科技推出的Go2智能机器狗,这款机器狗采用狗身体形态,前端设有激光雷达,摄像头和照明灯。在腿部设有12个铝合金精密关节电机,并配有足端力传感器,通过关节运动模拟狗的运动,并可做出多种…...

TaskFlow开发日记 #1 - 原生JS实现智能Todo组件
一、项目亮点 - 📌 **零依赖实现**:纯原生JavaScript CSS3 - 📌 **数据持久化**:LocalStorage自动同步 - 📌 **交互优化**:收藏置顶 动态统计 - 📌 **响应式设计**:完美适配移动端…...

es的告警信息
Elasticsearch(ES)是一个开源的分布式搜索和分析引擎,在运行过程中可能会产生多种告警信息,以提示用户系统中存在的潜在问题或异常情况。以下是一些常见的 ES 告警信息及其含义和处理方法: 集群健康状态告警 信息示例…...

vue实现在线进制转换
vue实现在线进制转换 主要功能包括: 1.支持2-36进制之间的转换。 2.支持整数和浮点数的转换。 3.输入验证(虽然可能存在不严格的情况)。 4.错误提示。 5.结果展示,包括大写字母。 6.用户友好的界面,包括下拉菜单、输…...
)
责任链设计模式(单例+多例)
目录 1. 单例责任链 2. 多例责任链 核心区别对比 实际应用场景 单例实现 多例实现 初始化 初始化责任链 执行测试方法 欢迎关注我的博客!26届java选手,一起加油💘💦👨🎓😄😂 最近在…...

Matlab 分数阶PID控制永磁同步电机
1、内容简介 Matlab 203-分数阶PID控制永磁同步电机 可以交流、咨询、答疑 2、内容说明 略 3、仿真分析 略 4、参考论文 略...

Java中LocalDateTime类
Java中的日期类 Date类LocalDateTime类创建LocalDateTime对象1 获取当前时间2 获取自己指定时间3 字符串创建日期 获取当前日期的信息1获取当前日期的年月日 时分秒2 获取当前日期周几\当年第几天\当月第几天3 获取当前⽇期所在周的周⽇和周⼀ 日期的运算1日期加减天数2 日期加…...

【C语言】--- 文件操作
文件操作 1. 为什么要使用文件2. 什么是文件2.1 程序文件2.2 数据文件2.3 文件名 3. 二进程文件和文本文件4. 文件的打开和关闭4.1 流和标准流4.1.1流4.2.2标准流 4.2 文件指针4.3 打开和关闭操作 5. 文件的顺序读写5.1 文件顺序读写函数5.1.1 fgetc 和 fputc5.1.2 fgets 和 fg…...

操作系统 4.4-从生磁盘到文件
文件介绍 操作系统中对磁盘使用的第三层抽象——文件。这一层抽象建立在盘块(block)和文件(file)之间,使得用户可以以更直观和易于理解的方式与磁盘交互,而无需直接处理磁盘的物理细节如扇区(se…...

第六章 进阶03 外包测试亮相
因为有年度重点项目,团队缺少测试资源,所以临时招聘了一个外包测试(后文用J代指),让产品经理亮亮来带她。 到今天J差不多入职有1个月时间了,亮亮组了个会,一起评审下J做的测试用例。 J展示了其…...

如何使用通义灵码完成PHP单元测试 - AI辅助开发教程
一、引言 在软件开发过程中,测试是至关重要的一环。然而,在传统开发中,测试常常被忽略或草草处理,很多时候并非开发人员故意为之,而是缺乏相应的测试思路和方法,不知道如何设计测试用例。随着 AI 技术的飞…...

使用 nano 文本编辑器修改 ~/.bashrc 文件与一些快捷键
目录 使用 nano 编辑器保存并关闭文件使用 sed 命令直接修改文件验证更改 如果你正在使用 nano 文本编辑器来修改 ~/.bashrc 文件,以下是保存并关闭文件的具体步骤: 使用 nano 编辑器保存并关闭文件 打开 ~/.bashrc 文件 在终端中运行以下命令…...

计算机组成原理——CPU与存储器连接例题
计算机组成原理——CPU与存储器连接例题 设CPU共有16根地址线和8根数据线,并用(MREQ) ̅作为访存控制信号(低电平有效),(WR) ̅作为读/写命令信号(高电平读,低电平写)。现有下列存储芯片&#…...
详细讲解)
SQL 外键(Foreign Key)详细讲解
1. 什么是外键? 定义:外键是数据库表中的一列(或一组列),用于建立两个表之间的关联关系。外键的值必须匹配另一个表的主键(Primary Key)或唯一约束(Unique Con…...

B3647 【模板】Floyd
题目链接:点击进入 题目 思路 代码 #include <bits/stdc.h> #define inf 0x3f3f3f3f using namespace std; const int maxn 1e6 10;int n,m,g[110][5000];int main() {ios::sync_with_stdio(false);cin.tie(0);cout.tie(0);cin>>n>>m;memse…...

配置镜像端口和观察接口
top: 在G0/0/2上抓包通过其他端口ping pc4 可以看到 Wireshark 抓包没有任何反应,做个镜像端口并配置(观察接口和镜像接口) observe-port interface g0/0/2 #命令配置观察端口mirror to observe-port both …...

爬虫解决debbugger之替换文件
鼠鼠上次做一个网站的时候,遇到的debbugger问题,是通过打断点然后编辑断点解决的,现在鼠鼠又学会了一个新的技能 首先需要大家下载一个reres的插件,这里最好用谷歌浏览器 先请大家看看案例国家水质自动综合监管平台 这里我们只…...

erlang的安装-linux
1:解压 tar -zxvf 安装包 2:进入解压的目录执行: ./configure --prefix/usr/local/erlang --with-ssl --enable-threads --enable-smp-support --enable-kernel-poll --enable-hipe --without-javac 3:编译安装: m…...

Android Coil 3默认P3色域图加载/显示不出来
Android Coil 3默认P3色域图加载/显示不出来 解决,需要在Androidmanifest.xml使用Coil 3的activity配置属性: <activityandroid:colorMode"wideColorGamut"...</activity>...

【LaTeX】安装
Register - Overleaf, 在线LaTeX编辑器 注册Overleaf 安装 Latex2022 安装教程(附安装资源)_tex2022安装教程-CSDN博客 注:先安装 texlive,再安装TexStudio \documentclass{article} % 这里是导言区 \begin{document}Hello, wor…...