操作系统 3.4-段页结合的实际内存管理
段与页结合的初步思路
-
虚拟内存的引入:
-
为了结合段和页的优势,操作系统引入了虚拟内存的概念。虚拟内存是一段地址空间,它映射到物理内存上,但对用户程序是透明的。
-
-
段到虚拟内存的映射:
-
用户程序中的段首先映射到虚拟内存的相应区域。这一步骤通过段表(Segment Table)实现,段表记录了每个段的起始地址和长度。
-
-
虚拟内存到物理内存的映射:
-
虚拟内存中的区域再映射到物理内存的页上。这一步骤通过页表(Page Table)实现,页表记录了虚拟页到物理页框的映射关系。
-
-
地址翻译:
-
用户程序发出的地址首先被翻译成虚拟地址,然后再翻译成物理地址。这一过程通常由硬件中的内存管理单元(MMU)自动完成。
-
-
内存访问:
-
一旦地址被翻译成物理地址,CPU就可以访问物理内存中的数据,执行指令或进行数据操作。
-
用户从应用程序视角看待虚拟内存中的段和页
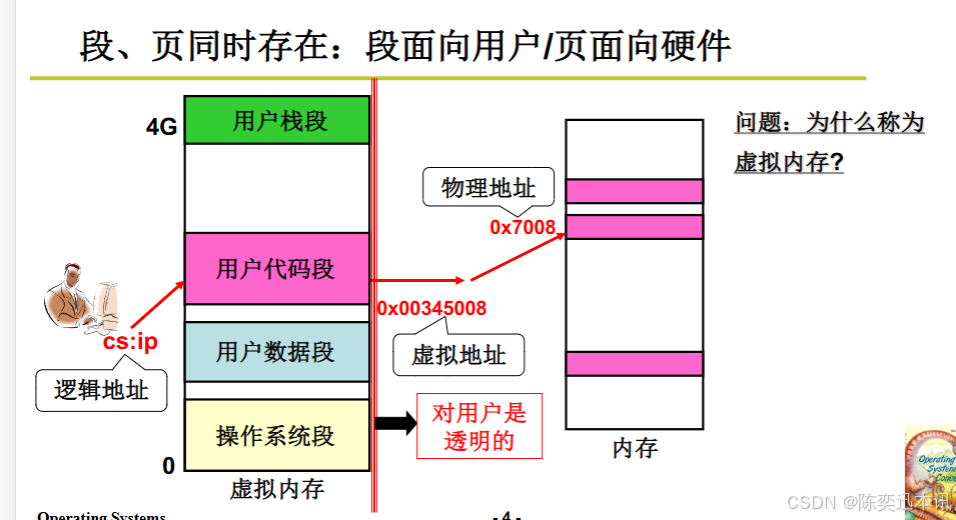
从用户程序的视角来看,虚拟内存中的段和页提供了一种抽象的内存模型,使得程序能够以一种简化和统一的方式来访问内存。以下是用户程序如何查看和与虚拟内存中的段和页交互的方式:
-
逻辑地址空间:
-
用户程序操作的是逻辑地址空间,这是一个由操作系统管理的虚拟地址空间。在这个空间中,程序可以使用段和偏移量(如
cs:ip)来访问内存,而不需要关心物理内存的实际布局。
-
-
地址翻译:
-
用户程序发出的地址(如
0x00345008)首先被翻译成虚拟地址,然后再由操作系统和硬件(如内存管理单元MMU)翻译成物理地址(如0x7008)。 -
这个过程对用户程序是透明的,用户程序不需要知道具体的物理地址。
-
-
内存保护和隔离:
-
段和页的结合允许操作系统实现内存保护和隔离。每个进程都有自己的虚拟地址空间,操作系统确保一个进程不能访问另一个进程的内存空间。
-
-
虚拟内存的优势:
-
虚拟内存提供了内存的抽象,使得程序可以假设它拥有一个连续的、大的内存空间,而实际上物理内存可能是分散的、有限的。
-
这种抽象简化了程序设计,提高了内存使用的灵活性,并允许操作系统更有效地管理内存资源。
-
重定位
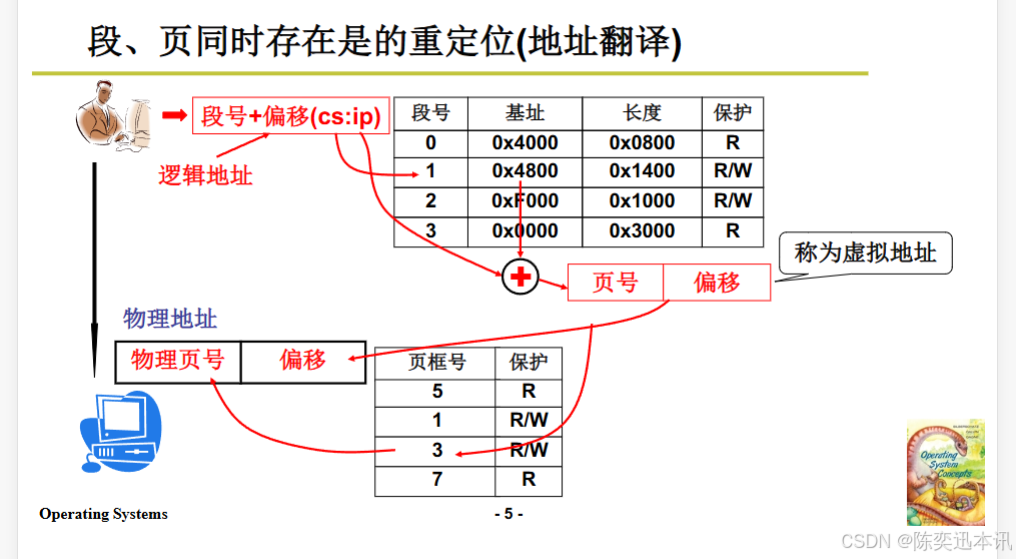
逻辑地址到物理地址的转换过程
-
逻辑地址:由段号和偏移量组成,例如
段号+偏移(cs:ip)。 -
段表:包含段号、基址、长度和保护信息。
-
段号:标识段的编号。
-
基址:段在内存中的起始地址。
-
长度:段的大小。
-
保护:段的访问权限(如只读R、读写R/W)。
-
-
页号和偏移:逻辑地址中的偏移量被进一步分解为页号和页内偏移。
-
页表:包含页框号和保护信息。
-
页框号:页在内存中的物理位置。
-
保护:页的访问权限(如只读R、读写R/W)。
-
-
物理地址:由物理页号和偏移量组成。
地址翻译过程
-
逻辑地址:由段号和偏移量组成。
-
段表查找:根据段号查找段表,获取基址和长度。
-
偏移分解:将偏移量分解为页号和页内偏移。
-
页表查找:根据页号查找页表,获取页框号。
-
物理地址计算:将页框号和页内偏移组合成物理地址。
段页同时存在的场景下,重定位过程是怎样的
在断页同时存在的场景下,用户发出的逻辑地址是CS加上段号和偏移量。
操作系统首先通过段表找到段在虚拟内存中的位置,并生成一个虚拟地址。
然而,这个虚拟地址并不是直接对应的物理内存地址,而是需要经过一次映射,根据虚拟地址计算出页号,再结合页内偏移得到物理地址。
最后,操作系统将这个物理地址发送到地址总线上,从而实现从段和页两个层次上的地址翻译,确保代码能够正确执行和获取数据。
一个实际的段页结合的例子
内存分配
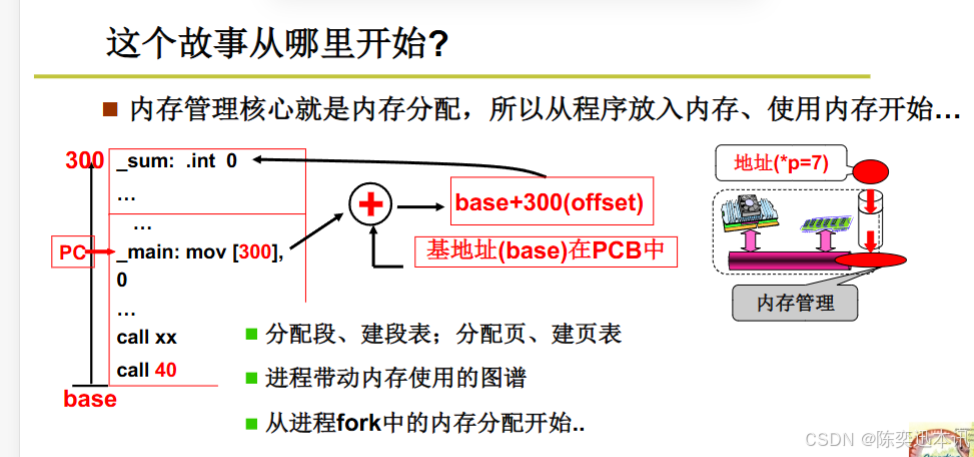
内存管理的核心
-
内存管理核心就是内存分配:强调了内存分配是内存管理的关键部分。
具体示例
-
指令:
_sum: .int 0定义了一个名为_sum的变量,初始值为0。 -
指令:
_main: mov [300], 0将0移动到偏移量为300的地址。 -
地址计算:
base + 300(offset)表示将基地址和偏移量相加得到物理地址。
内存管理过程
-
分配段、建段表:为进程分配内存段,并建立段表来管理这些段。
-
分配页、建页表:为进程分配内存页,并建立页表来管理这些页。
-
进程带动内存使用的图谱:展示了进程如何使用内存的图谱。
-
从进程fork中的内存分配开始:说明了进程创建(fork)时的内存分配过程。
载入内存
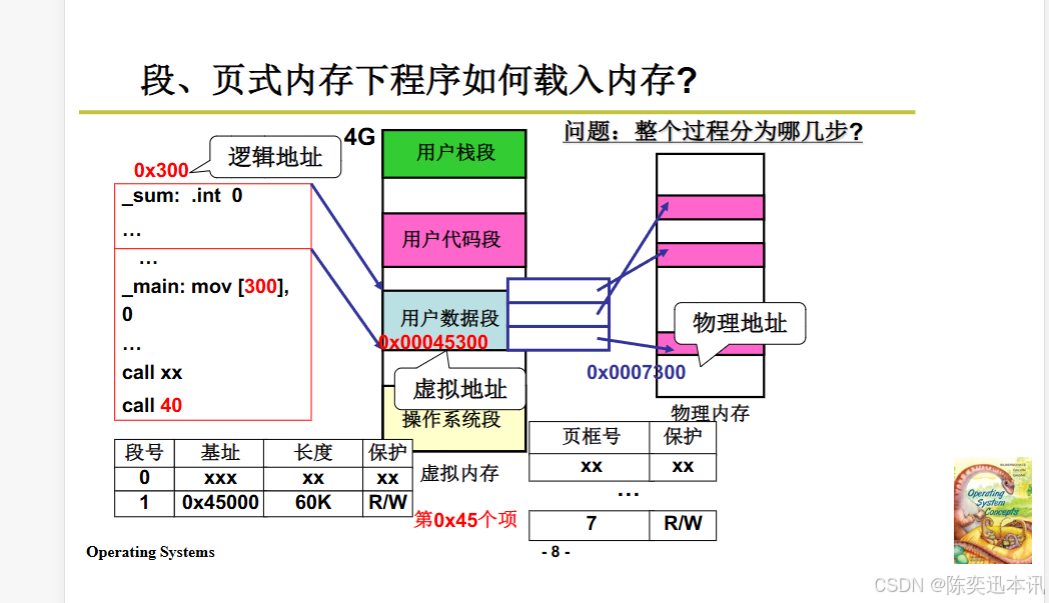
程序加载过程
-
分配段:为程序的不同部分(如代码、数据、栈)分配内存段。
-
建立段表:记录每个段的基址、长度和保护属性。
-
分配页:将每个段进一步分为页,并为每页分配物理内存。
-
建立页表:记录每个页的页框号和保护属性。
-
地址转换:将程序中的逻辑地址转换为物理地址,以便访问实际的内存。
示例
-
逻辑地址
0x300:表示用户数据段中的一个地址。 -
指令
_main: mov [300], 0:将0移动到偏移量为300的地址。 -
段表和页表:展示了如何通过段号和页号查找对应的基址和页框号,从而完成地址转换。
分配虚拟内存,建立段表
从幻灯片中提取的代码如下:
int copy_process(int nr, long ebp, ...)
{...copy_mem(nr, p); ...
}
int copy_mem(int nr, task_struct *p)
{unsigned long new_data_base;new_data_base = nr * 0x40000000; // 64M * nrset_base(p->ldt[1], new_data_base);set_base(p->ldt[2], new_data_base);
}-
计算新的数据基址:
-
在
copy_mem函数中,首先计算新的数据基址new_data_base。这个基址是通过将进程编号nr乘以0x40000000(即64MB)来得到的。这意味着每个进程将获得64MB的虚拟内存空间。
-
-
设置段表:
-
使用
set_base函数将计算出的新数据基址设置到进程的局部描述符表(LDT)中的相应段。在这个例子中,p->ldt[1]和p->ldt[2]分别代表了两个不同的段(例如,代码段和数据段)。 -
set_base函数的作用是更新段描述符中的基址字段,使其指向新的虚拟内存区域。
-
-
进程控制块(PCB):
-
task_struct *p是一个指向进程控制块(PCB)的指针,它包含了进程的所有信息,包括段表。 -
在进程创建时,操作系统会为新进程分配一个新的PCB,并复制父进程的相关信息,同时为新进程分配独立的虚拟内存空间。
-
-
内存分配:
-
在Linux中,每个进程都有独立的虚拟内存空间。通过
fork()系统调用创建的新进程会继承父进程的虚拟内存布局,但是操作系统会确保新进程的虚拟内存空间是独立的,以防止进程间的相互干扰。
-
-
进程切换:
-
在进程切换时,操作系统需要更新CPU的段寄存器,以指向新进程的段表。这样,当新进程开始执行时,它将在自己的虚拟内存空间中运行。
-
分配内存,建立页表
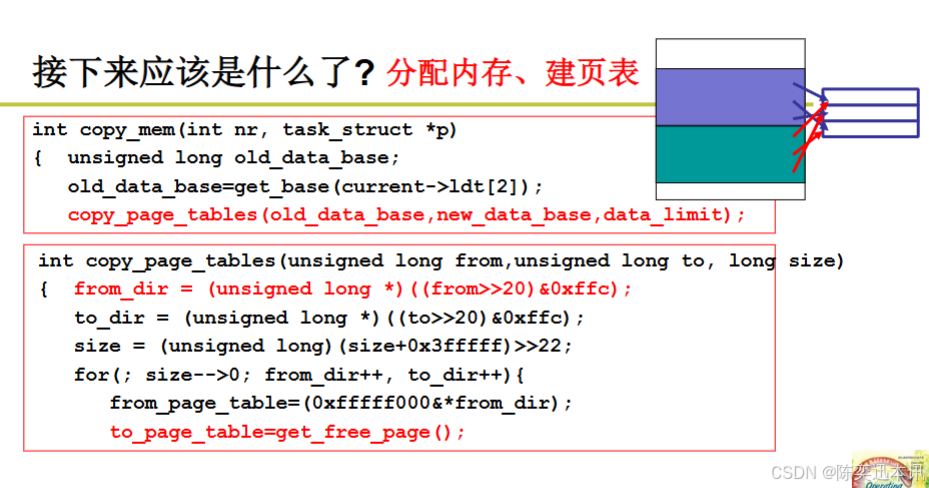
这张幻灯片展示了在Linux操作系统中,如何为新创建的进程分配内存并建立页表。以下是提取的代码和对分配内存、建立页表过程的总结:
提取的代码
int copy_mem(int nr, task_struct *p)
{unsigned long old_data_base;old_data_base = get_base(current->ldt[2]);copy_page_tables(old_data_base, new_data_base, data_limit);
}
int copy_page_tables(unsigned long from, unsigned long to, long size)
{from_dir = (unsigned long *)(((from >> 20) & 0xffc));to_dir = (unsigned long *)(((to >> 20) & 0xffc));size = (unsigned long)((size + 0x3fffff) >> 22);for (; size-- > 0; from_dir++, to_dir++) {from_page_table = (0xfffff000 & *from_dir);to_page_table = get_free_page();// 这里应该还有代码来复制页表项和设置新的页表}
}分配内存、建立页表的总结
-
获取旧数据基址:
-
在
copy_mem函数中,首先获取当前进程的数据段基址(old_data_base),这通常是通过读取当前进程的段表(LDT)来实现的。
-
-
调用复制页表函数:
-
然后调用
copy_page_tables函数,传入旧数据基址、新数据基址(new_data_base)和数据段的大小(data_limit),以复制页表。
-
-
计算目录基址:
-
在
copy_page_tables函数中,计算源目录(from_dir)和目标目录(to_dir)的基址。这是通过将虚拟地址右移20位(即页目录的索引)并取低12位(页目录项的偏移)来实现的。
-
-
计算页表项数量:
-
计算需要复制的页表项数量(
size),这是通过将数据段大小加上0x3FFFFF(即1MB-1,因为页表项是按页大小为单位的),然后右移22位(即页大小为4KB)来实现的。
-
-
复制页表项:
-
在循环中,对于每个页表项,从源目录读取页表项(
from_page_table),然后从页框(page frame)中获取一个空闲页(to_page_table = get_free_page())来存储目标页表项。 -
这里应该还有代码来复制页表项的内容,并设置新的页表项,包括页框号、保护位等。
-
-
建立页表:
-
通过上述步骤,为新进程建立了页表,将虚拟地址映射到物理内存。
-
-
更新进程控制块(PCB):
-
最后,需要更新新进程的PCB,包括新的页表基址等信息,以便新进程可以正确地访问其虚拟内存。
-
from_dir,to_dir
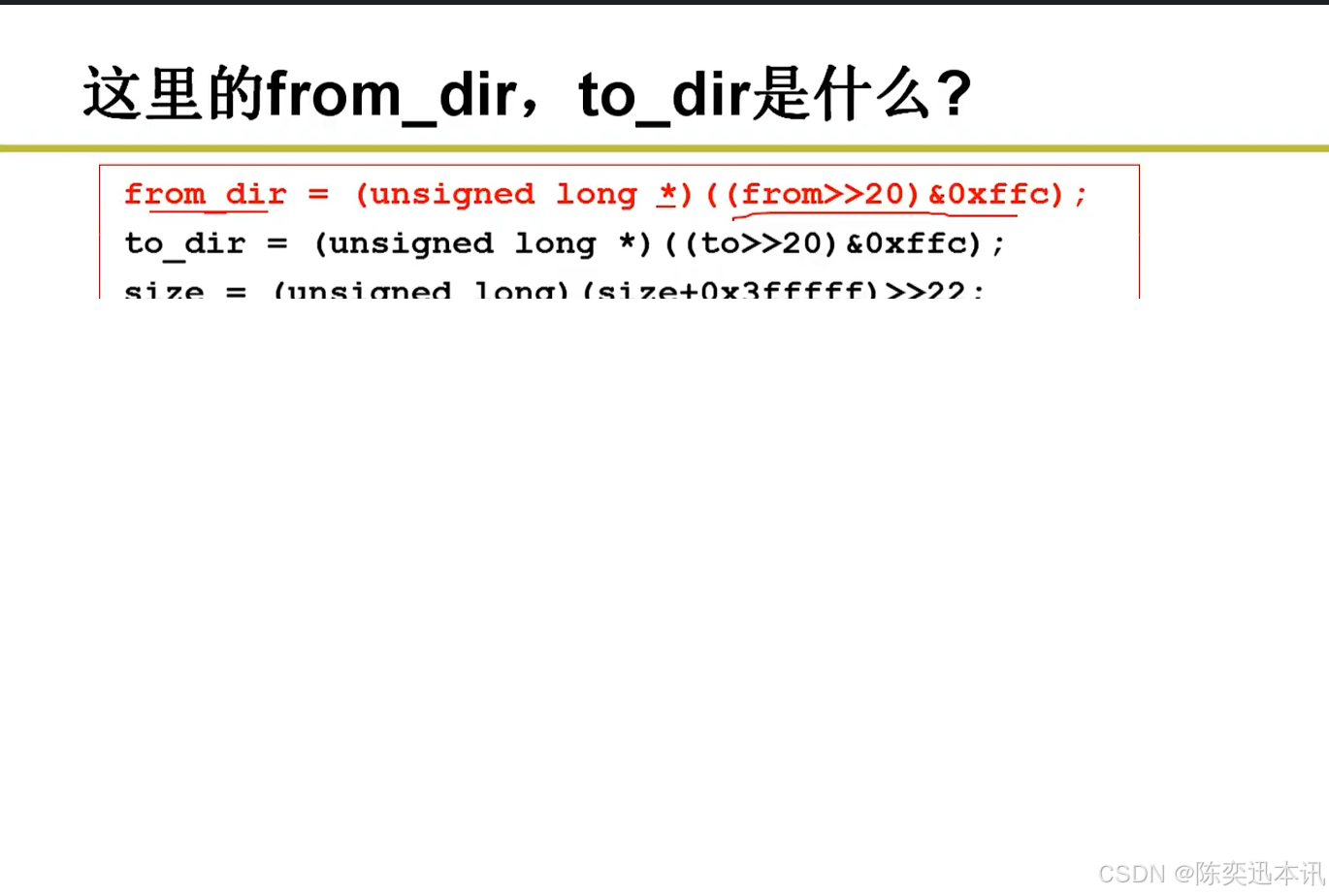
from_dir = (unsigned long *)(((from >> 20) & 0xffc));
to_dir = (unsigned long *)(((to >> 20) & 0xffc));
size = (unsigned long)((size + 0x3fffff) >> 22);
for (; size-- > 0; from_dir++, to_dir++) {from_page_table = (0xfffff000 & *from_dir);// 这里应该还有代码来复制页表项和设置新的页表
}-
计算页目录地址:
-
from_dir和to_dir是指向页目录的指针。它们是通过将虚拟地址右移20位(即页目录的索引)并取低12位(页目录项的偏移)来计算得到的。这是因为在x86架构中,页目录项是按4KB对齐的,所以需要取低12位来得到页目录项的偏移。
-
-
计算页表项数量:
-
size是需要复制的页表项数量。这是通过将数据段大小加上0x3FFFFF(即1MB-1,因为页表项是按页大小为单位的),然后右移22位(即页大小为4KB)来计算得到的。
-
-
复制页表项:
-
在循环中,对于每个页表项,从源目录读取页表项(
from_page_table),然后从页框(page frame)中获取一个空闲页(get_free_page())来存储目标页表项。 -
这里应该还有代码来复制页表项的内容,并设置新的页表项,包括页框号、保护位等。
-
-
页目录指针:
-
页目录指针(CR3)用于指向当前进程的页目录。在进程切换时,需要更新CR3寄存器以指向新进程的页目录。
-
from_page_table,to_page_table
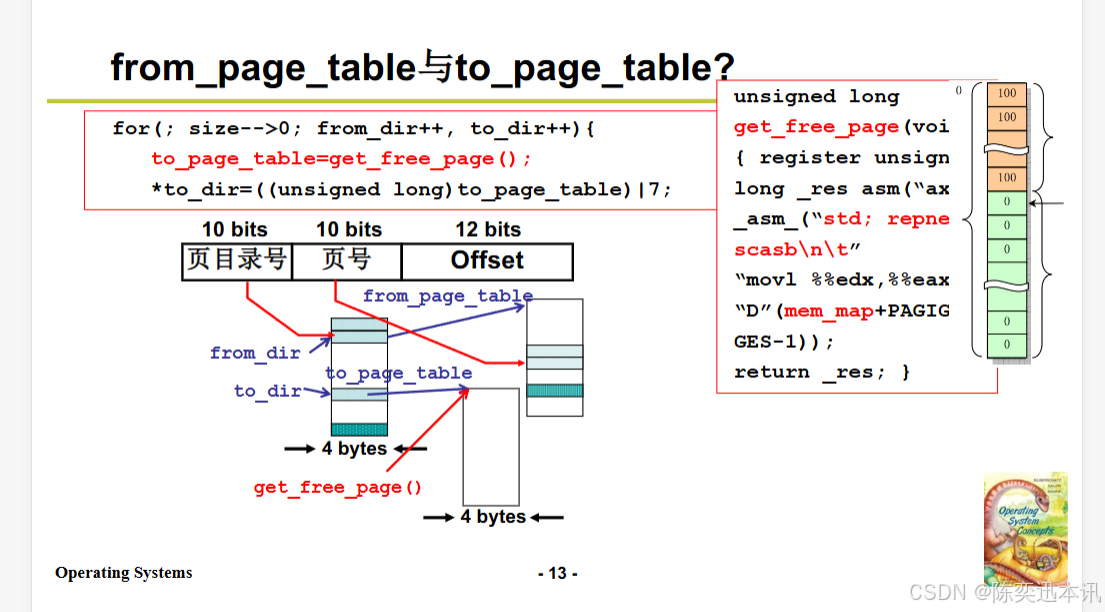
从幻灯片中提取的代码和相关信息如下:
提取的代码:
for (; size-- > 0; from_dir++, to_dir++) {to_page_table = get_free_page();*to_dir = ((unsigned long)to_page_table) | 7;
}
unsigned long get_free_page(void) {register unsigned long _res asm("ax");__asm__("std; repne; scasb\n\t""movl %%edx, %%eax\n\t""D"(mem_map+PAGING_END-1));return _res;
}总结:
-
页表复制过程:
-
在循环中,对于每个页表项,首先通过调用
get_free_page()函数为新进程分配一个空闲的页框(物理内存页)。 -
然后,将新分配的页框地址设置到目标页目录项中(
to_dir),并设置页表项的权限(这里通过或操作| 7来设置)。
-
-
页表项权限设置:
-
在x86架构中,页表项通常包含页框号和一些权限位。这里的
| 7操作可能是设置页表项的权限位,例如可读写(RW)和存在位(P)。
-
-
页表项结构:
-
幻灯片中展示了页表项的结构,包括页目录号(10 bits)、页号(10 bits)和偏移(12 bits)。这是x86架构中分页机制的基本概念。
-
-
页目录和页表:
-
from_dir和to_dir分别指向源进程和目标进程的页目录项。通过复制页目录项,可以实现页表的复制和更新。
-
-
获取空闲页框:
-
get_free_page()函数通过汇编语言实现,用于扫描内存映射(mem_map)来找到一个空闲的页框。这个过程涉及到检查内存映射中的每个条目,直到找到一个空闲的页框。
-
-
内存映射:
-
mem_map是一个内存映射数组,用于跟踪哪些页框是空闲的,哪些已经被使用。PAGING_END可能是定义了内存映射数组的结束位置。
-
复制和更新页表
这张幻灯片展示了在操作系统中,如何复制和更新页表项以实现内存管理。以下是提取的代码和对过程的总结:
提取的代码:
for (; nr-- > 0; from_page_table++, to_page_table++) {this_page = *from_page_table;this_page &= ~2; // 只读*to_page_table = this_page;*from_page_table = this_page;this_page -= LOW_MEM;this_page >>= 12;mem_map[this_page]++;
}总结:
-
页表项复制:
-
代码中的循环遍历所有的页表项,从源页表(
from_page_table)复制到目标页表(to_page_table)。
-
-
权限设置:
-
this_page &= ~2;这行代码通过位操作清除页表项中的某个权限位(通常是只读位),确保复制的页表项具有适当的权限设置。
-
-
页表项更新:
-
*to_page_table = this_page;将修改后的页表项写入目标页表。 -
*from_page_table = this_page;也将修改后的页表项写回源页表,这可能是为了确保源进程的页表项也反映了权限的更改。
-
-
页框号计算:
-
this_page -= LOW_MEM;这行代码从页框号中减去一个基址(LOW_MEM),可能是为了将页框号转换为相对于某个特定内存区域的偏移量。
-
-
页框号转换:
-
this_page >>= 12;这行代码将页框号右移12位,这通常是为了将页框号转换为页框数组中的索引。
-
-
内存映射更新:
-
mem_map[this_page]++;这行代码更新内存映射数组,增加对应页框的使用计数。这是为了跟踪每个页框的使用情况,特别是在使用写时复制(copy-on-write)技术时。
-
使用内存
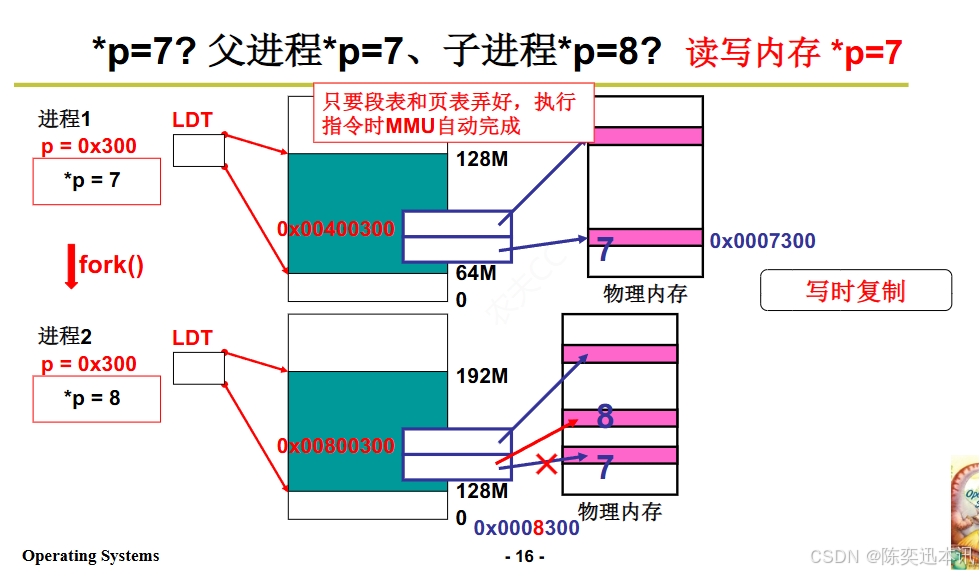
写时复制(COW)技术
写时复制是一种优化技术,用于减少复制内存的开销,特别是在创建新进程时。在写时复制中,父子进程最初共享相同的物理内存页,只有当进程实际修改内存页时,才会创建该内存页的副本。
幻灯片内容分析
-
内存共享与写时复制:
-
只要段表和页表设置正确,父子进程就可以通过MMU(内存管理单元)自动访问相同的物理内存页。
-
当父子进程中的任何一个尝试修改共享的内存页时,操作系统会触发写时复制机制,为修改内存页的进程创建一个新的物理内存页副本
-

相关文章:

操作系统 3.4-段页结合的实际内存管理
段与页结合的初步思路 虚拟内存的引入: 为了结合段和页的优势,操作系统引入了虚拟内存的概念。虚拟内存是一段地址空间,它映射到物理内存上,但对用户程序是透明的。 段到虚拟内存的映射: 用户程序中的段首先映射到虚…...

金融简单介绍及金融诈骗防范
在当今社会,金融学如同一股无形却强大的力量,深刻影响着我们生活的方方面面。无论是个人的日常收支、投资理财,还是国家的宏观经济调控,都与金融学紧密相连。 一、金融学的概念 金融学,简单来说,是研…...

基于docker搭建redis集群环境
在redis目录下创建redis-cluster目录,创建docker-compose.yml文化和generate.sh文件 【配置generate.sh文件】 for port in $(seq 1 9); \ do \ mkdir -p redis${port}/ touch redis${port}/redis.conf cat << EOF > redis${port}/redis.conf port 6379 …...

CSS 中常见的布局相关属性及其功能分类
一、块级布局(Block Layout) 1. display 作用:定义元素的显示方式。常用值: block:块级元素,默认独占一行。inline:行内元素,与其他内容在同一行显示。inline-block:兼…...

用css画一条弧线
ui里有一条弧线,现在用css实现 关键代码 border-bottom-left-radius: 100% 7px 两个参数分别代表横向和纵向的深度border-bottom-right-radius: 100% 7px...

CesiumForUnreal 本地矢量文件的加载,支持 shp/geojson 等常用格式
实现效果 Cesium for Unreal 集成 GDAL、LibPng 实现加载本地矢量文件 实现步骤 添加依赖在 cesium-unreal 中 extern -> cesium-native -> CMakeLists.txt 中的 57 行添加依赖库,代码如下: set(PACKAGES_PRIVATEabseil draco ktx modp-base64 meshoptimizer openssl …...

面向基于发布-订阅的物联网网络的匿名 MQTT 分析
中文标题: 面向基于发布-订阅的物联网网络的匿名 MQTT 分析 英文标题: An Analysis of Anonymous MQTT for Publish-Subscribe-Based IoT Networks 作者信息 Yudai Fukushima:东京都立大学电气工程与计算机科学系硕士生,研究方向…...

<C#> 详细介绍.NET 依赖注入
在 .NET 开发中,依赖注入(Dependency Injection,简称 DI)是一种设计模式,它可以增强代码的可测试性、可维护性和可扩展性。以下是对 .NET 依赖注入的详细介绍: 1. 什么是依赖注入 在软件开发里࿰…...

批量给文件编排序号,支持数字序号及时间日期序号编排文件
当我们需要对文件进行编号的时候,我们可以通过这个工具来帮我们完成,它可以支持从 001 到 100 甚至更多的数字序号编号。也可以支持按照日期、时间等方式对文件进行编号操作。这是一种操作简单,处理起来也非常的高效文件编排序号的方法。 工作…...

乳腺癌识别:双模型融合
本文为为🔗365天深度学习训练营内部文章 原作者:K同学啊 import matplotlib.pyplot as plt import tensorflow as tf import warnings as w w.filterwarnings(ignore) # 支持中文 plt.rcParams[font.sans-serif] [SimHei] # 用来正常显示中文标签 …...

ubuntu 22.04配置cuda和cudnn
cuda:12.1 wget https://developer.download.nvidia.com/compute/cuda/12.1.1/local_installers/cuda_12.1.1_530.30.02_linux.run sudo sh cuda_12.1.1_530.30.02_linux.runAbort/Continue选择Continue,不要勾选自带的driver 配置环境变量。~/.bashrc e…...

为什么Java不支持多继承?如何实现多继承?
一、前言 Java不支持多继承(一个类继承多个父类)主要出于文中设计考虑;核心目的是简化语言复杂性并避免潜在的歧义性问题。 二、直接原因:菱形继承/钻石继承问题(Diamond Problem) 假设存在如下继承关系&…...

ESP32S3 链接到 WiFi
以下是关于如何让 ESP32S3 连接到 WiFi 的完整流程和代码示例: ESP32S3 链接到 WiFi 1. 设置工作模式 ESP32 可以工作在两种模式下: Station (STA) 模式:作为无线终端连接到无线接入点(AP),类似于手机或…...

AndroidTV D贝桌面-v3.2.5-[支持文件传输]
AndroidTV D贝桌面 链接:https://pan.xunlei.com/s/VONXSBtgn8S_BsZxzjH_mHlAA1?pwdzet2# AndroidTV D贝桌面-v3.2.5[支持文件传输] 第一次使用的话,壁纸默认去掉的,不需要按遥控器上键,自己更换壁纸即可...

在spark中,窄依赖算子map和filter会组合为一个stage,这种情况下,map和filter是在一个task内进行的吗?
在 Spark 中,当 map 和 filter 这类窄依赖(Narrow Dependency)的算子连续应用时,它们会被合并到同一个 Stage 中,并且在同一个 Task 内按顺序执行。这种优化称为 流水线(Pipeline)执行ÿ…...

展讯android15源码编译之apk单编
首先找到你要单编的apk生成的路径: sys\out_system\target\product\ussi_arm64\system_ext\app\HelloDemo\HelloDemo.apk接着打开下面这个文件: sys\out_system\ussi_arm64_full-userdebug-gms.system.build.log在里面找关键字"Running command&q…...

EtherCAT 转 ModbusTCP 网关
一、功能概述 1.1 设备简介 本产品是 EtherCAT 和 Modbus TCP 网关,使用数据映射方式工作。 本产品在 EtherCAT 侧作为 EtherCAT 从站,接 TwinCAT 、 CodeSYS 、 PLC 等;在 ModbusTCP 侧做为 ModbusTCP 主站( C…...

SpringBoot集成阿里云文档格式转换实现pdf转换word,excel
一、前置条件 1.1 创建accessKey 如何申请:https://help.aliyun.com/zh/ram/user-guide/create-an-accesskey-pair 1.2 开通服务 官方地址:https://docmind.console.aliyun.com/doc-overview 未开通服务时需要点击开通按钮,然后才能调用…...

大数据-271 Spark MLib - 基础介绍 机器学习算法 线性回归 场景 定义 损失 优化
点一下关注吧!!!非常感谢!!持续更新!!! Java篇开始了! MyBatis 更新完毕目前开始更新 Spring,一起深入浅出! 目前已经更新到了: H…...

ubuntu不生成core文件的处理
1、设置unlimited ulimit -a 查看是否设置,没有设置的使用下面命令设置 ulimit -c unlimited这个设置只在当前会话有效,添加到 ~/.bashrc 中,重开终端生效 2、sysctl配置 修改 /etc/sysctl.conf 文件 ,增加以下两个配置&#…...

游戏服务器DDoS攻防实战指南——从攻击溯源到智能防护体系构建
本文深度解析游戏行业DDoS攻防技术演进路线,基于等保2.0与NIST框架,从攻击流量识别、弹性防护架构、智能调度算法三大维度,揭示游戏服务器防护体系的23个关键控制点。通过近期《永劫无间》服务器瘫痪事件复盘,结合Gartner最新混合…...

JAVA 导出 word
1、模板方式导出 1.1、引入 maven 依赖 <dependency><groupId>com.deepoove</groupId><artifactId>poi-tl</artifactId><version>1.12.2</version> </dependency>1.2、导出文档代码 public static void main(String[] args…...

OpenHarmony 5.0版本视频硬件编解码适配
一、简介 Codec HDI(Hardware Device Interface)对上层媒体服务提供视频编解码的驱动能力接口,主要功能有获取组件编解码能力,创建、销毁编解码器对象,启停编解码器操作,编解码处理等。 Codec HDI 2.0接口…...

《Python星球日记》第23天:Pandas基础
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 订阅专栏:《Python星球日记》 目录 一、Pandas 简介1. 什么是 Pandas&…...

ubuntu22.04下安装mysql以及mysql-workbench
一、mysql安装以及配置 安装之前先查看是否已将安装mysql: rpm -qa | grep mysql (一)、在线安装 保证网络正常的情况下: 1、更新软件包: sudo apt update 2、安装mysql安装包 查看可以安装的安装包: sudo apt search mysql-server 安装指定安装包: sudo apt i…...

让 Python 脚本在后台持续运行:架构级解决方案与工业级实践指南
让 Python 脚本在后台持续运行:架构级解决方案与工业级实践指南 一、生产环境需求全景分析 1.1 后台进程的工业级要求矩阵 维度开发环境要求生产环境要求容灾要求可靠性单点运行集群部署跨机房容灾可观测性控制台输出集中式日志分布式追踪资源管理无限制CPU/Memo…...
)
设计模式 四、行为设计模式(2)
五、状态模式 1、概述 状态设计模式是一种行为型设计模式,它允许对象在其内部状态发生时改变其行为,这种模式可以消除大量的条件语句,并将每个状态的行为封装到单独的类中。 状态模式的主要组成部分如下: 1)上…...

C++中作用域(public,private,protected
在C中,public、private 和 protected 是用于控制类成员(变量和函数)访问权限的关键字。它们决定了类成员在代码中的可见性和可访问性。在学习时候,对于public是最容易理解的,对于private也好理解,但是对于p…...

Spring配置方式演进:从XML到注解,构建灵活高效的开发体系
Spring配置方式演进:从XML到注解,构建灵活高效的开发体系 在Spring框架的演进长河中,配置方式始终是开发者需要掌握的核心技能。从早期XML一统天下的严谨规范,到注解驱动的敏捷开发,再到如今Java Config的优雅实践&am…...

网络4 OSI7层
OSI七层模型:数据如何传送,向下传送变成了什么样子 应用层 和用户打交道,向用户提供服务。 例如:web服务、http协议、FTP协议 1.用户接口 2.提供各种服务 通过浏览器(接口)提供Web服务 表示层 翻译 我的“…...

前端请求设置credentials: ‘include‘导致的cors问题
1.背景 前端请求设置credentials: ‘include‘其实主要是为了发送凭证,传cookie给后端 2.前端请求 fetch(http://frontend.com, { method: GET, // 或其他HTTP方法 credentials: include, // 不携带凭证 headers: { Content-Type: application/json, }, })…...

LabVIEW中VI Scripting 特定对象解析
该 LabVIEW 程序通过三条并行代码路径,借助 VI Scripting 功能,以特定方式解析程序框图对象,展示了不同方法在处理对象嵌套及特定范围对象时的差异。 上方文字:三条并行代码路径展示了解析程序框图的不同方式。第一条路径使用 …...

CISCO组建RIP V2路由网络
1.实验准备: 2.具体配置: 2.1根据分配好的IP地址配置静态IP: 2.1.1PC配置: PC0: PC1: PC2: 2.1.2路由器配置: R0: Router>en Router#conf t Enter configuration…...

性能飙升50%,react-virtualized-list如何优化大数据集滚动渲染
在处理大规模数据集渲染时,前端性能常常面临巨大的挑战。本文将探讨 react-virtualized-list 库如何通过虚拟化技术和 Intersection Observer API,实现前端渲染性能飙升 50% 的突破!除此之外,我们一同探究下该库还支持哪些新的特性…...

超低功耗MCU软件开发设计中的要点与选型推荐
前沿-超低功耗MCU应用: 超低功耗MCU(微控制器)凭借其极低的功耗和高效的能量管理能力,正在快速渗透到多个新兴领域,尤其在物联网(IoT)、可穿戴设备、智能家居和医疗电子等领域展现出巨大的应用…...

Gson、Fastjson 和 Jackson 对比解析
目录 1. Gson (Google) 基本介绍: 核心功能: 特点: 使用场景: 2. Fastjson (Alibaba) 基本介绍: 核心功能: 特点: 使用场景: 3. Jackson 基本介绍: 核心功能…...

冒泡排序与回调函数——qsort
文章核心内容总结 本文围绕数组排序展开,先介绍了冒泡排序,后引入qsort库函数进行排序,并对二者进行了对比。 1. 冒泡排序实现 在探讨冒泡排序(Bubble Sort)这一经典的排序算法时,我们首先需要了解其基本…...
机器学习---逻辑回归及其Python实现)
(四)机器学习---逻辑回归及其Python实现
之前我们提到了常见的任务和算法,本篇我们使用逻辑回归来进行分类 分类问题回归问题聚类问题各种复杂问题决策树√线性回归√K-means√神经网络√逻辑回归√岭回归密度聚类深度学习√集成学习√Lasso回归谱聚类条件随机场贝叶斯层次聚类隐马尔可夫模型支持向量机高…...

微信小程序开发:微信小程序上线发布与后续维护
微信小程序上线发布与后续维护研究 摘要 微信小程序作为移动互联网的重要组成部分,其上线发布与后续维护是确保其稳定运行和持续优化的关键环节。本文从研究学者的角度出发,详细探讨了微信小程序的上线发布流程、后续维护策略以及数据分析与用户反馈处理的方法。通过结合实…...

vue拓扑图组件
vue拓扑图组件 介绍技术栈功能特性快速开始安装依赖开发调试构建部署 使用示例演示截图组件源码 介绍 一个基于 Vue3 的拓扑图组件,具有以下特点: 1.基于 vue-flow 实现,提供流畅的拓扑图展示体验 2.支持传入 JSON 对象自动生成拓扑结构 3.自…...

Python数据分析-NumPy模块-查看数组属性
查看数组的行数和列数 from numpy import array aarray([[1,1],[2,2],[3,3]]) print(a.shape)结果: 提取数组的行数或列数 from numpy import array aarray([[1,1],[2,2],[3,3]]) print(a.shape) print(a.shape[0]) print(a.shape[1])结果: 查看数组…...

ch07课堂参考代码
DFS 的优化 1) 标记搜索过的状态 用数组标记一个状态是否被搜索过,搜索过则直接 return,不用再执行函数,用于保证每个状态只被搜索一次。 在递归调用函数之前,通过 if (vis[x]) 判断 x 是否被搜索过,搜索过则直接ret…...
,并把唯一的新闻内容保存到一个新的 JSON 文件中)
去重新闻数据中重复的正文内容(body 字段),并把唯一的新闻内容保存到一个新的 JSON 文件中
示例代码: import os import json import nltk from tqdm import tqdmdef wr_dict(filename,dic):if not os.path.isfile(filename):data []data.append(dic)with open(filename, w) as f:json.dump(data, f)else: with open(filename, r) as f:data json.l…...

centos crontab 设置定时任务访问链接
在 CentOS 系统中,使用 crontab 设置定时任务访问 URL,可以通过命令行工具(如 curl 或 wget)发送 HTTP 请求。以下是详细步骤: 1、安装必要工具(若未安装) 安装 curl 或 wget # 安装 curl su…...

oracle大师认证证书有用吗
专业能力的高度认可:OCM 是 Oracle认证的最高级别,是对数据库从业人员技术、知识和操作技能的最高级认可,也是 IT 界顶级认证之一。它表明持证者具备处理关键业务数据库系统和应用的能力,能够解决最困难的技术难题和最复杂的系统故…...

说说对 Node 中的 process 的理解?有哪些常用方法?
1. 简介 process对象是Node.js中的全局变量,它提供了有关当前Node.js进程的信息并允许对其进行控制。通过process对象,我们可以获取进程的环境变量、命令行参数,控制进程的行为以及与其他进程进行通信。 2. 常用属性 process.env process…...

maven 和 idea intej步骤记录
1 maven 安装配置 1.1 参考链接安装 maven参考链接 1.2 maven 关联本机jdk版本 配置 priofiles jdk 版本时,查看本本机jdk 版本:环境变量查看jdk 路径版本: java_home 变量路径是C:\Program Files\Java\jdk-21 # setting.xml <profile&…...

Java Socket编程从零到实战详解
摩西摩西~最近接单子用到了Java的socket编程,顺手给整理下来咯! 各个语言的socket编程除了语法之外几乎思路都是一样的。 所以这些思路都是可以直接移植到其他语言实现的! 话不多说上车! 一、Socket基础概念与工作流程…...

STM32中Hz和时间的转换
目录 一、常见的频率单位及其转换 二、计算公式 三、STM32中定时器的应用 四、例子 一、常见的频率单位及其转换 赫兹(Hz)是频率的国际单位,表示每秒钟周期性事件发生的次数。 1 kHz(千赫兹) 1,000 Hz1 MHz&#…...

Apache Hive学习教程
什么是Hive? Apache Hive是一款建立在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop文件中的结构化、半结构化 数据文件映射为一张数据库表,基于表提供了一种类似SQL的查询模型,称为Hive查询语言(HQL)&…...