乳腺癌识别:双模型融合
本文为为🔗365天深度学习训练营内部文章
原作者:K同学啊
import matplotlib.pyplot as plt
import tensorflow as tf
import warnings as w
w.filterwarnings('ignore')
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号import os,PIL,pathlib#隐藏警告
import warnings
warnings.filterwarnings('ignore')data_dir = "./J3-data"
data_dir = pathlib.Path(data_dir)image_count = len(list(data_dir.glob('*/*')))print("图片数为:",image_count)图片数为: 13403
batch_size = 64
img_height = 224
img_width = 224train_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.3,subset="training",seed=12,image_size=(img_height, img_width),batch_size=batch_size)Found 13403 files belonging to 2 classes. Using 9383 files for training.
val_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.3,subset="validation",seed=12,image_size=(img_height, img_width),batch_size=batch_size)Found 13403 files belonging to 2 classes. Using 4020 files for validation.
class_names = train_ds.class_names
print(class_names)for image_batch, labels_batch in train_ds:print(image_batch.shape)print(labels_batch.shape)breakAUTOTUNE = tf.data.AUTOTUNEdef preprocess_image(image,label):return (image/255.0,label)# 归一化处理
train_ds = train_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)
val_ds = val_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)plt.figure(figsize=(15, 10)) # 图形的宽为15高为10for images, labels in train_ds.take(1):for i in range(15):ax = plt.subplot(3, 5, i + 1) plt.imshow(images[i])plt.title(class_names[labels[i]])plt.axis("off")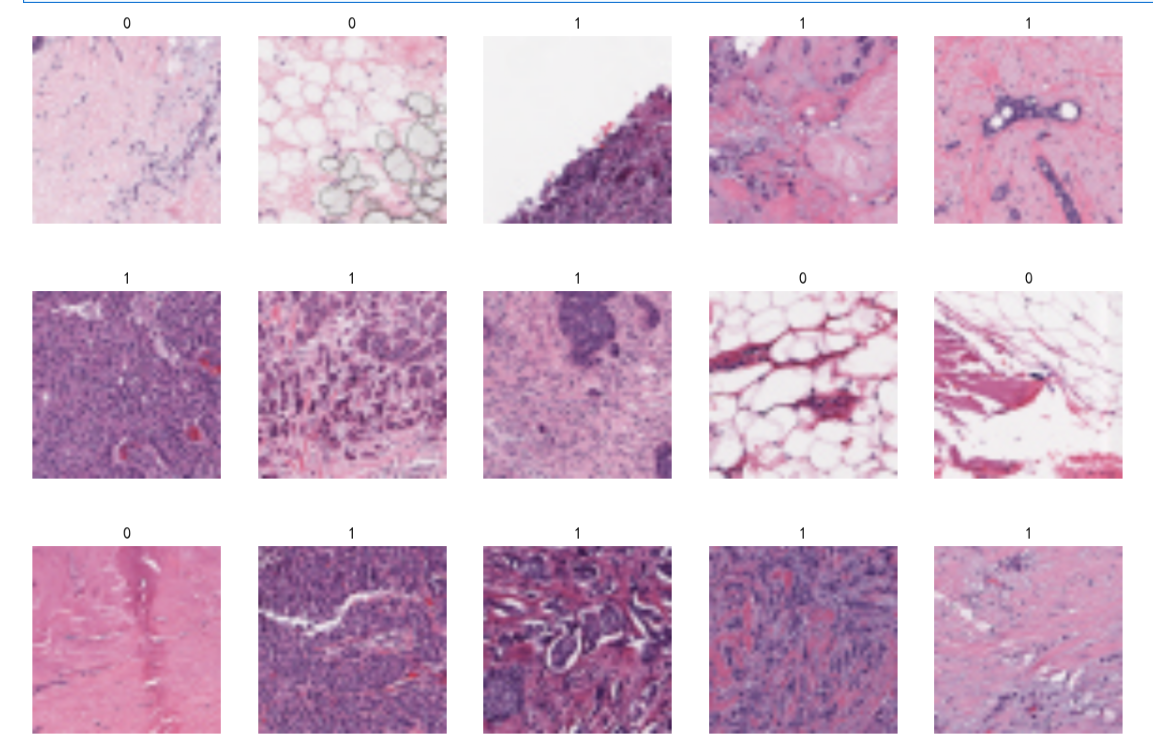
import tensorflow as tf
from tensorflow.keras import layers, models
from tensorflow.keras.applications import ResNet50, DenseNet121
from tensorflow.keras.layers import GlobalAveragePooling2D, Concatenate, Dense, Dropout, BatchNormalization, Multiply, Reshape# SE-Net 模块
def se_block(input_tensor, ratio=16):channels = input_tensor.shape[-1]se = GlobalAveragePooling2D()(input_tensor) # Squeezese = Dense(channels // ratio, activation='relu')(se)se = Dense(channels, activation='sigmoid')(se) # Excitationse = Reshape((1, 1, channels))(se)return Multiply()([input_tensor, se]) # Scale# 创建模型
def create_model(input_shape=(224, 224, 3)):# 加载预训练的 ResNet50 和 DenseNet121resnet_base = ResNet50(weights='imagenet', include_top=False, input_shape=input_shape)densenet_base = DenseNet121(weights='imagenet', include_top=False, input_shape=input_shape)# 冻结卷积层for layer in resnet_base.layers:layer.trainable = Falsefor layer in densenet_base.layers:layer.trainable = False# 输入层inputs = layers.Input(shape=input_shape)# ResNet 分支x1 = resnet_base(inputs)x1 = BatchNormalization()(x1) # 添加 BNx1 = se_block(x1) # 添加 SE-Netx1 = GlobalAveragePooling2D()(x1)# DenseNet 分支x2 = densenet_base(inputs)x2 = BatchNormalization()(x2) # 添加 BNx2 = se_block(x2) # 添加 SE-Netx2 = GlobalAveragePooling2D()(x2)# 拼接特征x = Concatenate()([x1, x2])x = Dense(256, activation='relu')(x)x = BatchNormalization()(x) # 添加 BNx = Dropout(0.5)(x)outputs = Dense(num_classes, activation='sigmoid')(x)# 构建模型model = models.Model(inputs, outputs)return model# 创建并编译模型
num_classes = 2 # 二分类
model = create_model()
model.summary()Model: "model" __________________________________________________________________________________________________Layer (type) Output Shape Param # Connected to ==================================================================================================input_3 (InputLayer) [(None, 224, 224, 3 0 [] )] resnet50 (Functional) (None, 7, 7, 2048) 23587712 ['input_3[0][0]'] densenet121 (Functional) (None, 7, 7, 1024) 7037504 ['input_3[0][0]'] batch_normalization (BatchNorm (None, 7, 7, 2048) 8192 ['resnet50[0][0]'] alization) batch_normalization_1 (BatchNo (None, 7, 7, 1024) 4096 ['densenet121[0][0]'] rmalization) global_average_pooling2d (Glob (None, 2048) 0 ['batch_normalization[0][0]'] alAveragePooling2D) global_average_pooling2d_2 (Gl (None, 1024) 0 ['batch_normalization_1[0][0]'] obalAveragePooling2D) dense (Dense) (None, 128) 262272 ['global_average_pooling2d[0][0]'] dense_2 (Dense) (None, 64) 65600 ['global_average_pooling2d_2[0][0]'] dense_1 (Dense) (None, 2048) 264192 ['dense[0][0]'] dense_3 (Dense) (None, 1024) 66560 ['dense_2[0][0]'] reshape (Reshape) (None, 1, 1, 2048) 0 ['dense_1[0][0]'] reshape_1 (Reshape) (None, 1, 1, 1024) 0 ['dense_3[0][0]'] multiply (Multiply) (None, 7, 7, 2048) 0 ['batch_normalization[0][0]', 'reshape[0][0]'] multiply_1 (Multiply) (None, 7, 7, 1024) 0 ['batch_normalization_1[0][0]', 'reshape_1[0][0]'] global_average_pooling2d_1 (Gl (None, 2048) 0 ['multiply[0][0]'] obalAveragePooling2D) global_average_pooling2d_3 (Gl (None, 1024) 0 ['multiply_1[0][0]'] obalAveragePooling2D) concatenate (Concatenate) (None, 3072) 0 ['global_average_pooling2d_1[0][0]', 'global_average_pooling2d_3[0][0]'] dense_4 (Dense) (None, 256) 786688 ['concatenate[0][0]'] batch_normalization_2 (BatchNo (None, 256) 1024 ['dense_4[0][0]'] rmalization) dropout (Dropout) (None, 256) 0 ['batch_normalization_2[0][0]'] dense_5 (Dense) (None, 2) 514 ['dropout[0][0]'] ================================================================================================== Total params: 32,084,354 Trainable params: 1,452,482 Non-trainable params: 30,631,872 __________________________________________________________________________________________________
# 设置优化器
opt = tf.keras.optimizers.Adam(learning_rate=1e-7)model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])from keras.callbacks import EarlyStopping
# 设置早停法
early_stopping = EarlyStopping(monitor='val_loss',patience=3,verbose=1,restore_best_weights=True
)
epochs = 10history = model.fit(train_ds,validation_data=val_ds,epochs=epochs,callbacks=[early_stopping]
)Epoch 1/10 147/147 [==============================] - 1032s 7s/step - loss: 0.4909 - accuracy: 0.8249 - val_loss: 0.4680 - val_accuracy: 0.8478 Epoch 2/10 147/147 [==============================] - 1031s 7s/step - loss: 0.3099 - accuracy: 0.8759 - val_loss: 0.3266 - val_accuracy: 0.8836 Epoch 3/10 147/147 [==============================] - 1040s 7s/step - loss: 0.2522 - accuracy: 0.9029 - val_loss: 0.2955 - val_accuracy: 0.8876 Epoch 4/10 147/147 [==============================] - 1048s 7s/step - loss: 0.2063 - accuracy: 0.9173 - val_loss: 0.2651 - val_accuracy: 0.8970 Epoch 5/10 147/147 [==============================] - 1048s 7s/step - loss: 0.1705 - accuracy: 0.9338 - val_loss: 0.2778 - val_accuracy: 0.9002 Epoch 6/10 147/147 [==============================] - 1026s 7s/step - loss: 0.1379 - accuracy: 0.9455 - val_loss: 0.2927 - val_accuracy: 0.8953 Epoch 7/10 147/147 [==============================] - ETA: 0s - loss: 0.1062 - accuracy: 0.9579Restoring model weights from the end of the best epoch: 4. 147/147 [==============================] - 1019s 7s/step - loss: 0.1062 - accuracy: 0.9579 - val_loss: 0.2981 - val_accuracy: 0.9045 Epoch 7: early stopping
# 获取实际训练轮数
actual_epochs = len(history.history['accuracy'])acc = history.history['accuracy']
val_acc = history.history['val_accuracy']loss = history.history['loss']
val_loss = history.history['val_loss']epochs_range = range(actual_epochs)plt.figure(figsize=(12, 4))# 绘制准确率
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')# 绘制损失
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.savefig('准确率.png')
plt.show()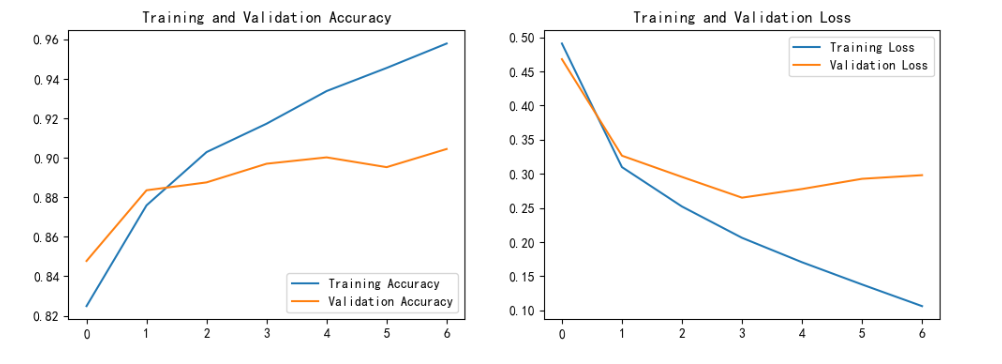
相关文章:

乳腺癌识别:双模型融合
本文为为🔗365天深度学习训练营内部文章 原作者:K同学啊 import matplotlib.pyplot as plt import tensorflow as tf import warnings as w w.filterwarnings(ignore) # 支持中文 plt.rcParams[font.sans-serif] [SimHei] # 用来正常显示中文标签 …...

ubuntu 22.04配置cuda和cudnn
cuda:12.1 wget https://developer.download.nvidia.com/compute/cuda/12.1.1/local_installers/cuda_12.1.1_530.30.02_linux.run sudo sh cuda_12.1.1_530.30.02_linux.runAbort/Continue选择Continue,不要勾选自带的driver 配置环境变量。~/.bashrc e…...

为什么Java不支持多继承?如何实现多继承?
一、前言 Java不支持多继承(一个类继承多个父类)主要出于文中设计考虑;核心目的是简化语言复杂性并避免潜在的歧义性问题。 二、直接原因:菱形继承/钻石继承问题(Diamond Problem) 假设存在如下继承关系&…...

ESP32S3 链接到 WiFi
以下是关于如何让 ESP32S3 连接到 WiFi 的完整流程和代码示例: ESP32S3 链接到 WiFi 1. 设置工作模式 ESP32 可以工作在两种模式下: Station (STA) 模式:作为无线终端连接到无线接入点(AP),类似于手机或…...

AndroidTV D贝桌面-v3.2.5-[支持文件传输]
AndroidTV D贝桌面 链接:https://pan.xunlei.com/s/VONXSBtgn8S_BsZxzjH_mHlAA1?pwdzet2# AndroidTV D贝桌面-v3.2.5[支持文件传输] 第一次使用的话,壁纸默认去掉的,不需要按遥控器上键,自己更换壁纸即可...

在spark中,窄依赖算子map和filter会组合为一个stage,这种情况下,map和filter是在一个task内进行的吗?
在 Spark 中,当 map 和 filter 这类窄依赖(Narrow Dependency)的算子连续应用时,它们会被合并到同一个 Stage 中,并且在同一个 Task 内按顺序执行。这种优化称为 流水线(Pipeline)执行ÿ…...

展讯android15源码编译之apk单编
首先找到你要单编的apk生成的路径: sys\out_system\target\product\ussi_arm64\system_ext\app\HelloDemo\HelloDemo.apk接着打开下面这个文件: sys\out_system\ussi_arm64_full-userdebug-gms.system.build.log在里面找关键字"Running command&q…...

EtherCAT 转 ModbusTCP 网关
一、功能概述 1.1 设备简介 本产品是 EtherCAT 和 Modbus TCP 网关,使用数据映射方式工作。 本产品在 EtherCAT 侧作为 EtherCAT 从站,接 TwinCAT 、 CodeSYS 、 PLC 等;在 ModbusTCP 侧做为 ModbusTCP 主站( C…...

SpringBoot集成阿里云文档格式转换实现pdf转换word,excel
一、前置条件 1.1 创建accessKey 如何申请:https://help.aliyun.com/zh/ram/user-guide/create-an-accesskey-pair 1.2 开通服务 官方地址:https://docmind.console.aliyun.com/doc-overview 未开通服务时需要点击开通按钮,然后才能调用…...

大数据-271 Spark MLib - 基础介绍 机器学习算法 线性回归 场景 定义 损失 优化
点一下关注吧!!!非常感谢!!持续更新!!! Java篇开始了! MyBatis 更新完毕目前开始更新 Spring,一起深入浅出! 目前已经更新到了: H…...

ubuntu不生成core文件的处理
1、设置unlimited ulimit -a 查看是否设置,没有设置的使用下面命令设置 ulimit -c unlimited这个设置只在当前会话有效,添加到 ~/.bashrc 中,重开终端生效 2、sysctl配置 修改 /etc/sysctl.conf 文件 ,增加以下两个配置&#…...

游戏服务器DDoS攻防实战指南——从攻击溯源到智能防护体系构建
本文深度解析游戏行业DDoS攻防技术演进路线,基于等保2.0与NIST框架,从攻击流量识别、弹性防护架构、智能调度算法三大维度,揭示游戏服务器防护体系的23个关键控制点。通过近期《永劫无间》服务器瘫痪事件复盘,结合Gartner最新混合…...

JAVA 导出 word
1、模板方式导出 1.1、引入 maven 依赖 <dependency><groupId>com.deepoove</groupId><artifactId>poi-tl</artifactId><version>1.12.2</version> </dependency>1.2、导出文档代码 public static void main(String[] args…...

OpenHarmony 5.0版本视频硬件编解码适配
一、简介 Codec HDI(Hardware Device Interface)对上层媒体服务提供视频编解码的驱动能力接口,主要功能有获取组件编解码能力,创建、销毁编解码器对象,启停编解码器操作,编解码处理等。 Codec HDI 2.0接口…...

《Python星球日记》第23天:Pandas基础
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 订阅专栏:《Python星球日记》 目录 一、Pandas 简介1. 什么是 Pandas&…...

ubuntu22.04下安装mysql以及mysql-workbench
一、mysql安装以及配置 安装之前先查看是否已将安装mysql: rpm -qa | grep mysql (一)、在线安装 保证网络正常的情况下: 1、更新软件包: sudo apt update 2、安装mysql安装包 查看可以安装的安装包: sudo apt search mysql-server 安装指定安装包: sudo apt i…...

让 Python 脚本在后台持续运行:架构级解决方案与工业级实践指南
让 Python 脚本在后台持续运行:架构级解决方案与工业级实践指南 一、生产环境需求全景分析 1.1 后台进程的工业级要求矩阵 维度开发环境要求生产环境要求容灾要求可靠性单点运行集群部署跨机房容灾可观测性控制台输出集中式日志分布式追踪资源管理无限制CPU/Memo…...
)
设计模式 四、行为设计模式(2)
五、状态模式 1、概述 状态设计模式是一种行为型设计模式,它允许对象在其内部状态发生时改变其行为,这种模式可以消除大量的条件语句,并将每个状态的行为封装到单独的类中。 状态模式的主要组成部分如下: 1)上…...

C++中作用域(public,private,protected
在C中,public、private 和 protected 是用于控制类成员(变量和函数)访问权限的关键字。它们决定了类成员在代码中的可见性和可访问性。在学习时候,对于public是最容易理解的,对于private也好理解,但是对于p…...

Spring配置方式演进:从XML到注解,构建灵活高效的开发体系
Spring配置方式演进:从XML到注解,构建灵活高效的开发体系 在Spring框架的演进长河中,配置方式始终是开发者需要掌握的核心技能。从早期XML一统天下的严谨规范,到注解驱动的敏捷开发,再到如今Java Config的优雅实践&am…...

网络4 OSI7层
OSI七层模型:数据如何传送,向下传送变成了什么样子 应用层 和用户打交道,向用户提供服务。 例如:web服务、http协议、FTP协议 1.用户接口 2.提供各种服务 通过浏览器(接口)提供Web服务 表示层 翻译 我的“…...

前端请求设置credentials: ‘include‘导致的cors问题
1.背景 前端请求设置credentials: ‘include‘其实主要是为了发送凭证,传cookie给后端 2.前端请求 fetch(http://frontend.com, { method: GET, // 或其他HTTP方法 credentials: include, // 不携带凭证 headers: { Content-Type: application/json, }, })…...

LabVIEW中VI Scripting 特定对象解析
该 LabVIEW 程序通过三条并行代码路径,借助 VI Scripting 功能,以特定方式解析程序框图对象,展示了不同方法在处理对象嵌套及特定范围对象时的差异。 上方文字:三条并行代码路径展示了解析程序框图的不同方式。第一条路径使用 …...

CISCO组建RIP V2路由网络
1.实验准备: 2.具体配置: 2.1根据分配好的IP地址配置静态IP: 2.1.1PC配置: PC0: PC1: PC2: 2.1.2路由器配置: R0: Router>en Router#conf t Enter configuration…...

性能飙升50%,react-virtualized-list如何优化大数据集滚动渲染
在处理大规模数据集渲染时,前端性能常常面临巨大的挑战。本文将探讨 react-virtualized-list 库如何通过虚拟化技术和 Intersection Observer API,实现前端渲染性能飙升 50% 的突破!除此之外,我们一同探究下该库还支持哪些新的特性…...

超低功耗MCU软件开发设计中的要点与选型推荐
前沿-超低功耗MCU应用: 超低功耗MCU(微控制器)凭借其极低的功耗和高效的能量管理能力,正在快速渗透到多个新兴领域,尤其在物联网(IoT)、可穿戴设备、智能家居和医疗电子等领域展现出巨大的应用…...

Gson、Fastjson 和 Jackson 对比解析
目录 1. Gson (Google) 基本介绍: 核心功能: 特点: 使用场景: 2. Fastjson (Alibaba) 基本介绍: 核心功能: 特点: 使用场景: 3. Jackson 基本介绍: 核心功能…...

冒泡排序与回调函数——qsort
文章核心内容总结 本文围绕数组排序展开,先介绍了冒泡排序,后引入qsort库函数进行排序,并对二者进行了对比。 1. 冒泡排序实现 在探讨冒泡排序(Bubble Sort)这一经典的排序算法时,我们首先需要了解其基本…...
机器学习---逻辑回归及其Python实现)
(四)机器学习---逻辑回归及其Python实现
之前我们提到了常见的任务和算法,本篇我们使用逻辑回归来进行分类 分类问题回归问题聚类问题各种复杂问题决策树√线性回归√K-means√神经网络√逻辑回归√岭回归密度聚类深度学习√集成学习√Lasso回归谱聚类条件随机场贝叶斯层次聚类隐马尔可夫模型支持向量机高…...

微信小程序开发:微信小程序上线发布与后续维护
微信小程序上线发布与后续维护研究 摘要 微信小程序作为移动互联网的重要组成部分,其上线发布与后续维护是确保其稳定运行和持续优化的关键环节。本文从研究学者的角度出发,详细探讨了微信小程序的上线发布流程、后续维护策略以及数据分析与用户反馈处理的方法。通过结合实…...

vue拓扑图组件
vue拓扑图组件 介绍技术栈功能特性快速开始安装依赖开发调试构建部署 使用示例演示截图组件源码 介绍 一个基于 Vue3 的拓扑图组件,具有以下特点: 1.基于 vue-flow 实现,提供流畅的拓扑图展示体验 2.支持传入 JSON 对象自动生成拓扑结构 3.自…...

Python数据分析-NumPy模块-查看数组属性
查看数组的行数和列数 from numpy import array aarray([[1,1],[2,2],[3,3]]) print(a.shape)结果: 提取数组的行数或列数 from numpy import array aarray([[1,1],[2,2],[3,3]]) print(a.shape) print(a.shape[0]) print(a.shape[1])结果: 查看数组…...

ch07课堂参考代码
DFS 的优化 1) 标记搜索过的状态 用数组标记一个状态是否被搜索过,搜索过则直接 return,不用再执行函数,用于保证每个状态只被搜索一次。 在递归调用函数之前,通过 if (vis[x]) 判断 x 是否被搜索过,搜索过则直接ret…...
,并把唯一的新闻内容保存到一个新的 JSON 文件中)
去重新闻数据中重复的正文内容(body 字段),并把唯一的新闻内容保存到一个新的 JSON 文件中
示例代码: import os import json import nltk from tqdm import tqdmdef wr_dict(filename,dic):if not os.path.isfile(filename):data []data.append(dic)with open(filename, w) as f:json.dump(data, f)else: with open(filename, r) as f:data json.l…...

centos crontab 设置定时任务访问链接
在 CentOS 系统中,使用 crontab 设置定时任务访问 URL,可以通过命令行工具(如 curl 或 wget)发送 HTTP 请求。以下是详细步骤: 1、安装必要工具(若未安装) 安装 curl 或 wget # 安装 curl su…...

oracle大师认证证书有用吗
专业能力的高度认可:OCM 是 Oracle认证的最高级别,是对数据库从业人员技术、知识和操作技能的最高级认可,也是 IT 界顶级认证之一。它表明持证者具备处理关键业务数据库系统和应用的能力,能够解决最困难的技术难题和最复杂的系统故…...

说说对 Node 中的 process 的理解?有哪些常用方法?
1. 简介 process对象是Node.js中的全局变量,它提供了有关当前Node.js进程的信息并允许对其进行控制。通过process对象,我们可以获取进程的环境变量、命令行参数,控制进程的行为以及与其他进程进行通信。 2. 常用属性 process.env process…...

maven 和 idea intej步骤记录
1 maven 安装配置 1.1 参考链接安装 maven参考链接 1.2 maven 关联本机jdk版本 配置 priofiles jdk 版本时,查看本本机jdk 版本:环境变量查看jdk 路径版本: java_home 变量路径是C:\Program Files\Java\jdk-21 # setting.xml <profile&…...

Java Socket编程从零到实战详解
摩西摩西~最近接单子用到了Java的socket编程,顺手给整理下来咯! 各个语言的socket编程除了语法之外几乎思路都是一样的。 所以这些思路都是可以直接移植到其他语言实现的! 话不多说上车! 一、Socket基础概念与工作流程…...

STM32中Hz和时间的转换
目录 一、常见的频率单位及其转换 二、计算公式 三、STM32中定时器的应用 四、例子 一、常见的频率单位及其转换 赫兹(Hz)是频率的国际单位,表示每秒钟周期性事件发生的次数。 1 kHz(千赫兹) 1,000 Hz1 MHz&#…...

Apache Hive学习教程
什么是Hive? Apache Hive是一款建立在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop文件中的结构化、半结构化 数据文件映射为一张数据库表,基于表提供了一种类似SQL的查询模型,称为Hive查询语言(HQL)&…...

学习笔记六——Rust 切片全解析
这篇文章不是告诉你“切片是啥”,而是让你真正理解并学会用切片,同时还会把你最容易卡壳的 {:?}、char_indices() 等都讲清楚! 📚 文章目录 切片到底是什么?能不能通俗一点?切片的本质:它其实…...

Apache Doris SelectDB 技术能力全面解析
Apache Doris 是一款开源的 MPP 数据库,以其优异的分析性能著称,被各行各业广泛应用在实时数据分析、湖仓融合分析、日志与可观测性分析、湖仓构建等场景。Apache Doris 目前被 5000 多家中大型的企业深度应用在生产系统中,包含互联网、金融、…...
完整讲解与实战应用)
设计模式 Day 8:策略模式(Strategy Pattern)完整讲解与实战应用
🔄 前情回顾:Day 7 重点回顾 在 Day 7 中,我们彻底讲透了观察者模式: 它是典型的行为型模式,核心理念是“一变多知”,当一个对象状态变化时,自动通知所有订阅者。 我们通过 RxCpp 实现了工业…...

HarmonyOS-ArkUI V2装饰器-@Once
前文,关于Param的使用: HarmonyOS-ArkUIV2装饰器-Param:组件外部输入-CSDN博客 Once装饰器是一个需要配合Param装饰器一块使用的的装饰器。它的特性是,仅仅在变量进行初始化的时候,接受一个外部传来的值进行初始化&am…...

前端Node.js的包管理工具npm指令
npm(Node Package Manager)是Node.js的包管理工具,主要用于安装、更新、删除和管理JavaScript包。以下是前端开发中常用的npm命令及其用途: 基本命令 npm提供了一系列命令行工具,用于执行各种包管理操作。以下是一…...

本地搭建直播录屏应用并实现使用浏览器远程控制直播间录屏详细教程
 本文主要介绍如何在 Windows 系统电脑本地部署直播录屏工具 Bililive-go,并结合 cpolar 内网穿透工具实现远程访问本地 Bililive-go 服务 web 界面管理录屏任务。 相信很多小伙伴都喜欢看直播,不过如果一旦临时有事看不了直播,…...

Hydra Columnar:一个开源的PostgreSQL列式存储引擎
Hydra Columnar 是一个 PostgreSQL 列式存储插件,专为分析型(OLAP)工作负载设计,旨在提升大规模分析查询和批量更新的效率。 Hydra Columnar 以扩展插件的方式提供,主要特点包括: 采用列式存储,…...
)
OpenGL学习笔记(assimp封装、深度测试、模板测试)
目录 模型加载Assimp网格模型及导入 深度测试深度值精度深度缓冲的可视化深度冲突 模板测试物体轮廓 GitHub主页:https://github.com/sdpyy1 OpenGL学习仓库:https://github.com/sdpyy1/CppLearn/tree/main/OpenGLtree/main/OpenGL):https://github.com/sdpyy1/CppL…...

自动化备份全网服务器数据平台
1.项目说明 1.1概述 该项目共分为2个子项目,由环境搭建和实施备份两部分组成 该项目旨在复习巩固系统服务部署使用、shell编程等知识,旨在让学生增加知识面,提高项目实习经历,充实简历 1.2项目组织方式及时间 时间:…...