《Python星球日记》第23天:Pandas基础
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
订阅专栏:《Python星球日记》
目录
- 一、Pandas 简介
- 1. 什么是 Pandas?为什么使用 Pandas?
- 2. 安装与导入
- 二、Series 和 DataFrame
- 1. Series 的创建与操作
- 2. DataFrame 的创建与基本操作
- 三、数据读取与保存
- 1. 读取 CSV 文件:`pd.read_csv()`
- 2. 保存数据到文件:`df.to_csv()`
- 四、练习:从 CSV 文件中读取数据并进行简单统计分析
- 五、总结与进阶方向
- 参考资源
👋 专栏介绍: Python星球日记专栏介绍(持续更新ing)
✅ 上一篇: Python星球日记 - 第22天:NumPy 基础
🌟引言: 欢迎来到Python星球🪐的第23天!
继昨天学习了NumPy基础后,今天我们将探索Python数据分析的另一个重要工具——Pandas。Pandas建立在NumPy的基础上,提供了更高级的数据结构和数据分析功能,是数据科学家和分析师的必备工具。
一、Pandas 简介
1. 什么是 Pandas?为什么使用 Pandas?
Pandas 是Python中用于数据分析和数据处理的强大库,它提供了灵活高效的数据结构,使处理 “关系” 或 “标签” 数据既简单又直观。Pandas的名称来源于"Panel Data"(面板数据)和"Python Data Analysis"(Python数据分析)的组合。
主要优势:
- 高效的数据结构:提供了Series(一维)和DataFrame(二维)两种主要数据结构,适合处理大多数实际数据分析需求
- 强大的数据操作功能:支持数据清洗、转换、过滤、分组、聚合等复杂操作
- 与NumPy的无缝集成:Pandas基于NumPy构建,能够利用NumPy的高性能数值计算功能
- 灵活的输入/输出支持:可以轻松读取和写入各种格式的数据,包括CSV、Excel、SQL数据库等
- 处理缺失数据:提供了丰富的工具来处理缺失或NA值
- 数据可视化支持:与Matplotlib等可视化库配合使用,可以快速创建数据图表
2. 安装与导入
在开始使用Pandas之前,我们需要先安装它。可以使用pip进行安装:
pip install pandas

安装完成后,在Python脚本中导入Pandas:
import pandas as pd # 通常使用pd作为Pandas的简写别名

💡 小贴士:使用别名
pd是数据科学社区的通用约定,这样可以减少代码量并提高可读性。
二、Series 和 DataFrame
Pandas提供了两种主要的数据结构:Series(一维)和DataFrame(二维),它们构成了Pandas的核心。

1. Series 的创建与操作
Series 是一种类似于一维数组的对象,由一组数据(各种NumPy数据类型)和一组与之相关的数据标签(索引)组成。
import pandas as pd
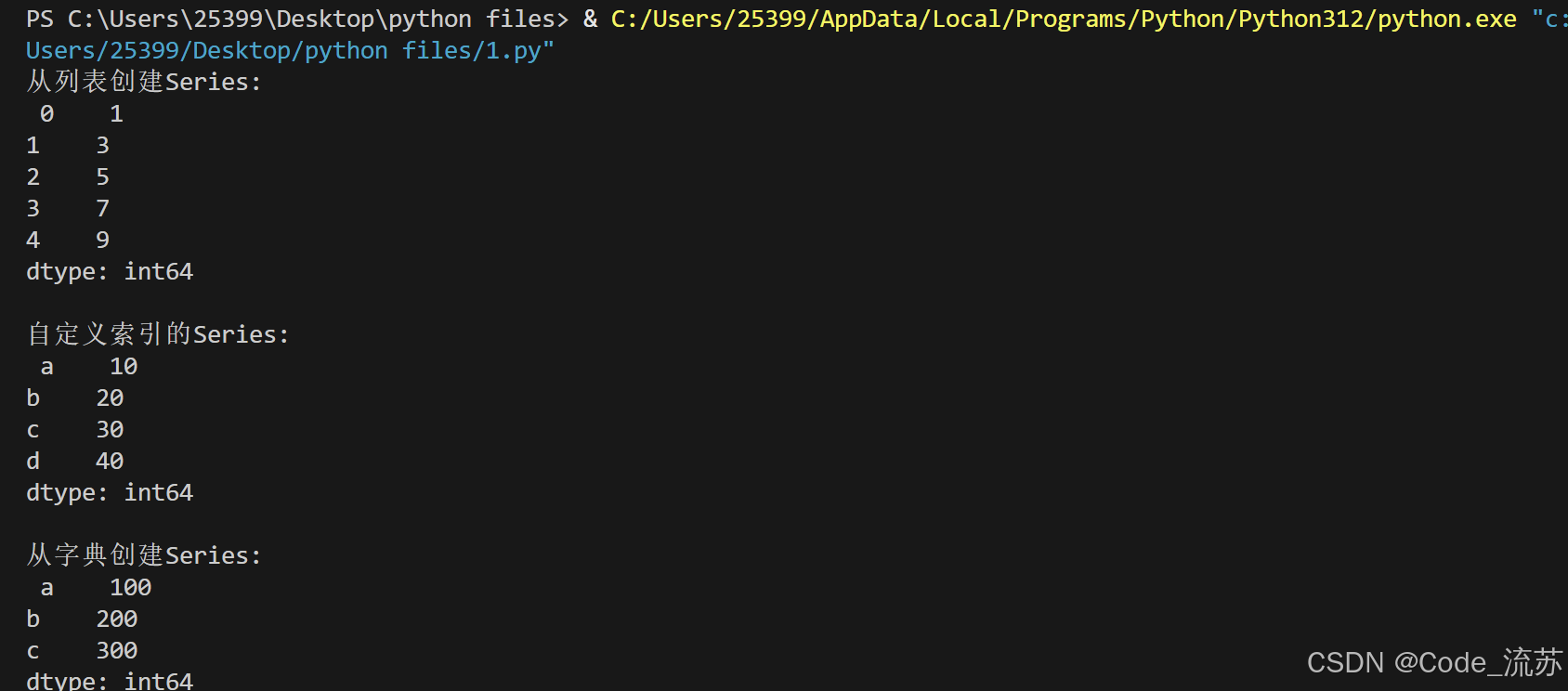
import numpy as np# 从列表创建Series
s1 = pd.Series([1, 3, 5, 7, 9])
print("从列表创建Series:\n", s1)# 自定义索引
s2 = pd.Series([10, 20, 30, 40], index=['a', 'b', 'c', 'd'])
print("\n自定义索引的Series:\n", s2)# 从字典创建Series
data_dict = {'a': 100, 'b': 200, 'c': 300}
s3 = pd.Series(data_dict)
print("\n从字典创建Series:\n", s3)# 使用标量值创建Series
s4 = pd.Series(5, index=['a', 'b', 'c'])
print("\n使用标量值创建Series:\n", s4)# 访问Series元素
print("\n访问Series元素:")
print("s2['a'] =", s2['a']) # 使用索引标签
print("s2[0] =", s2[0]) # 使用位置索引
print("s2[['a', 'c']] =\n", s2[['a', 'c']]) # 使用索引标签列表# Series的基本属性
print("\nSeries的基本属性:")
print("值:\n", s2.values)
print("索引:\n", s2.index)
print("数据类型:", s2.dtype)# Series的基本操作
print("\nSeries的基本操作:")
print("s2 * 2 =\n", s2 * 2) # 数值操作
print("np.exp(s2) =\n", np.exp(s2)) # NumPy函数操作
print("s2 > 15 =\n", s2 > 15) # 布尔操作# 缺失值处理
s5 = pd.Series([1, 2, np.nan, 4])
print("\n包含NaN的Series:\n", s5)
print("检测缺失值:\n", s5.isna()) # 或使用 isnull()
print("丢弃缺失值:\n", s5.dropna())
print("填充缺失值:\n", s5.fillna(0))
输出结果:
Series的主要特点:
- 类似NumPy数组,可以使用NumPy函数进行操作
- 类似Python字典,可以通过索引标签访问数据
- 自动对齐操作,通过索引标签进行计算
2. DataFrame 的创建与基本操作
DataFrame 是一个表格型的数据结构,包含一组有序的列,每列可以是不同的值类型。DataFrame同时具有 行索引 和 列索引 ,可以被看做由Series组成的字典。
import pandas as pd
import numpy as np# 从字典创建DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David'],'Age': [25, 30, 35, 40],'City': ['New York', 'Los Angeles', 'Chicago', 'Houston']
}
df1 = pd.DataFrame(data)
print("从字典创建DataFrame:\n", df1)# 指定列的顺序
df2 = pd.DataFrame(data, columns=['Name', 'City', 'Age'])
print("\n指定列顺序的DataFrame:\n", df2)# 自定义索引
df3 = pd.DataFrame(data, index=['p1', 'p2', 'p3', 'p4'])
print("\n自定义索引的DataFrame:\n", df3)# 从嵌套列表创建DataFrame
data_list = [['Alice', 25, 'New York'],['Bob', 30, 'Los Angeles'],['Charlie', 35, 'Chicago']
]
df4 = pd.DataFrame(data_list, columns=['Name', 'Age', 'City'])
print("\n从嵌套列表创建DataFrame:\n", df4)# 从Series字典创建DataFrame
series_dict = {'Name': pd.Series(['Alice', 'Bob', 'Charlie']),'Age': pd.Series([25, 30, 35])
}
df5 = pd.DataFrame(series_dict)
print("\n从Series字典创建DataFrame:\n", df5)# DataFrame的基本属性
print("\nDataFrame的基本属性:")
print("形状:", df1.shape)
print("维度:", df1.ndim)
print("大小:", df1.size)
print("数据类型:\n", df1.dtypes)
print("索引:\n", df1.index)
print("列名:\n", df1.columns)
print("值:\n", df1.values)# 访问DataFrame的数据
print("\n访问DataFrame的数据:")
# 访问列
print("访问'Name'列:\n", df1['Name']) # 或 df1.Name
# 访问多列
print("访问多列:\n", df1[['Name', 'Age']])
# 使用loc按标签访问
print("使用loc按标签访问:\n", df1.loc[0]) # 访问第一行
print("访问多行多列:\n", df1.loc[0:2, ['Name', 'City']])
# 使用iloc按位置访问
print("使用iloc按位置访问:\n", df1.iloc[1]) # 访问第二行
print("访问多行多列:\n", df1.iloc[0:2, 0:2])# 添加新列
df1['Salary'] = [50000, 60000, 70000, 80000]
print("\n添加新列后的DataFrame:\n", df1)# 删除列
df6 = df1.drop('Salary', axis=1) # axis=1表示列
print("\n删除'Salary'列后的DataFrame:\n", df6)# 条件过滤
print("\n条件过滤:")
print("年龄大于30的人:\n", df1[df1['Age'] > 30])# 基本统计
print("\n基本统计:")
print("年龄的平均值:", df1['Age'].mean())
print("数值列的统计摘要:\n", df1.describe())
输出结果:
从字典创建DataFrame:Name Age City
0 Alice 25 New York
1 Bob 30 Los Angeles
2 Charlie 35 Chicago
3 David 40 Houston指定列顺序的DataFrame:Name City Age
0 Alice New York 25
1 Bob Los Angeles 30
2 Charlie Chicago 35
3 David Houston 40自定义索引的DataFrame:Name Age City
p1 Alice 25 New York
p2 Bob 30 Los Angeles
p3 Charlie 35 Chicago
p4 David 40 Houston从嵌套列表创建DataFrame:Name Age City
0 Alice 25 New York
1 Bob 30 Los Angeles
2 Charlie 35 Chicago从Series字典创建DataFrame:Name Age
0 Alice 25
1 Bob 30
2 Charlie 35DataFrame的基本属性:
形状: (4, 3)
维度: 2
大小: 12
数据类型:Name object
Age int64
City object
dtype: object
索引:RangeIndex(start=0, stop=4, step=1)
列名:Index(['Name', 'Age', 'City'], dtype='object')
值:[['Alice' 25 'New York']['Bob' 30 'Los Angeles']['Charlie' 35 'Chicago']['David' 40 'Houston']]访问DataFrame的数据:
访问'Name'列:0 Alice
1 Bob
2 Charlie
3 David
Name: Name, dtype: object
访问多列:Name Age
0 Alice 25
1 Bob 30
2 Charlie 35
3 David 40
使用loc按标签访问:Name Alice
Age 25
City New York
Name: 0, dtype: object
访问多行多列:Name City
0 Alice New York
1 Bob Los Angeles
2 Charlie Chicago
使用iloc按位置访问:Name Bob
Age 30
City Los Angeles
Name: 1, dtype: object
访问多行多列:Name Age
0 Alice 25
1 Bob 30添加新列后的DataFrame:Name Age City Salary
0 Alice 25 New York 50000
1 Bob 30 Los Angeles 60000
2 Charlie 35 Chicago 70000
3 David 40 Houston 80000删除'Salary'列后的DataFrame:Name Age City
0 Alice 25 New York
1 Bob 30 Los Angeles
2 Charlie 35 Chicago
3 David 40 Houston条件过滤:
年龄大于30的人:Name Age City Salary
2 Charlie 35 Chicago 70000
3 David 40 Houston 80000基本统计:
年龄的平均值: 32.5
数值列的统计摘要:Age Salary
count 4.000000 4.000000
mean 32.500000 65000.000000
std 6.454972 12909.944487
min 25.000000 50000.000000
25% 28.750000 57500.000000
50% 32.500000 65000.000000
75% 36.250000 72500.000000
max 40.000000 80000.000000
DataFrame的主要特点:
- 可以看作是由多个Series组成的表格
- 支持灵活的数据选择、过滤和转换
- 强大的数据操作和分析功能
- 与NumPy、Matplotlib等库无缝集成
三、数据读取与保存
Pandas提供了多种方法来读取和保存各种格式的数据,如CSV、Excel、SQL数据库等。这是Pandas在数据分析中的一个重要优势。
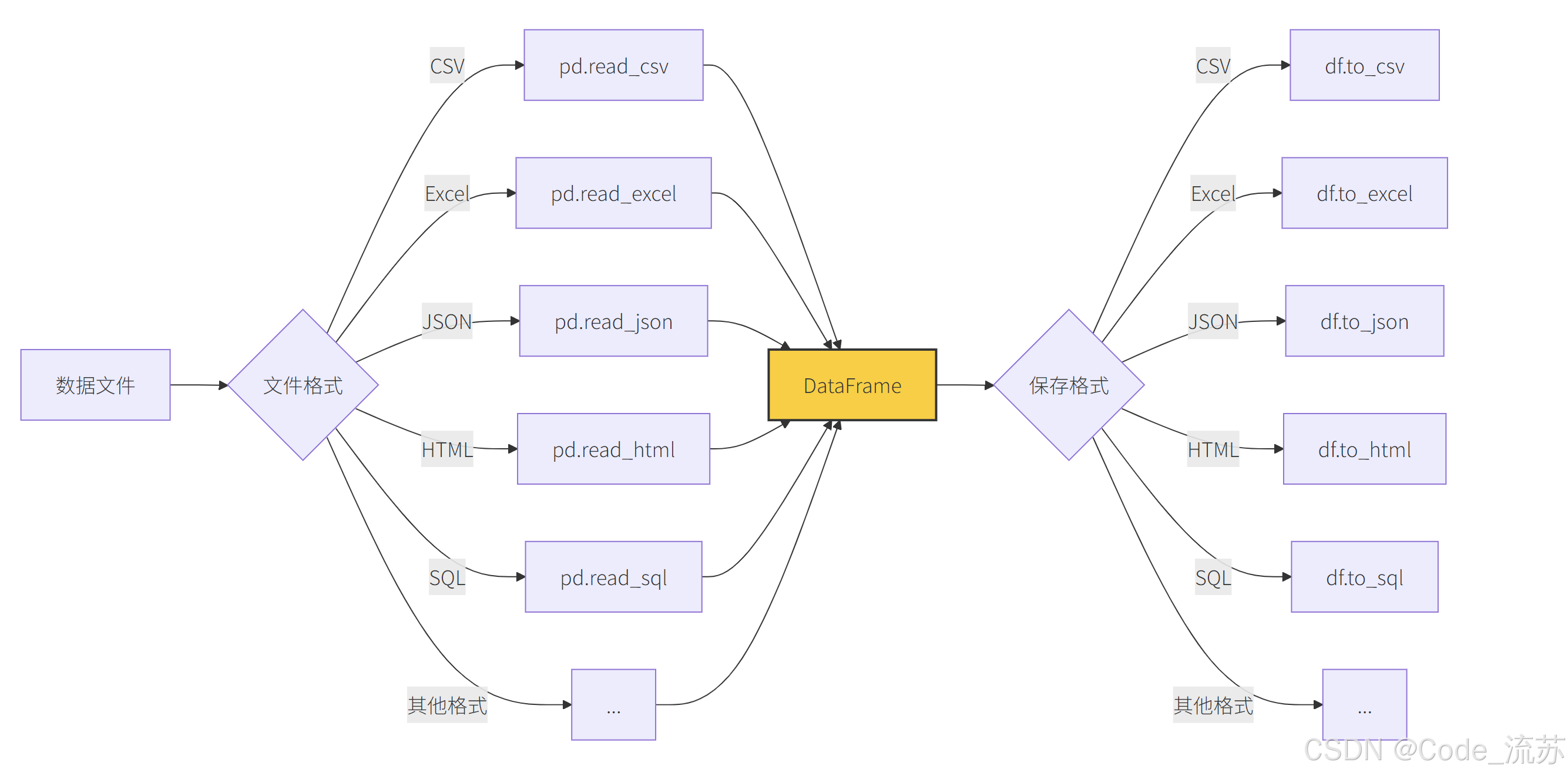
1. 读取 CSV 文件:pd.read_csv()
CSV(逗号分隔值)是最常见的数据交换格式之一。Pandas提供了read_csv()函数来读取CSV文件:
import pandas as pd# 基本用法
df = pd.read_csv('data.csv')
print("读取CSV文件的基本用法:\n", df.head()) # head()显示前5行# 高级选项
df2 = pd.read_csv('data.csv',header=0, # 将第一行作为列名index_col=0, # 将第一列作为索引sep=',', # 分隔符skiprows=1, # 跳过第一行usecols=[0, 1, 2], # 只使用指定列na_values=['NA', 'Missing'] # 自定义NA值标记)
print("\n使用高级选项读取CSV:\n", df2.head())# 处理大文件 - 只读取部分行
df3 = pd.read_csv('large_data.csv', nrows=1000)
print("\n只读取前1000行:\n", df3.head())# 读取没有列名的CSV
df4 = pd.read_csv('no_header.csv', header=None, names=['Col1', 'Col2', 'Col3'])
print("\n读取无列名的CSV:\n", df4.head())# 读取具有日期列的CSV
df5 = pd.read_csv('date_data.csv', parse_dates=['Date'])
print("\n解析日期列:\n", df5.head())
read_csv()函数的常用参数:
filepath_or_buffer:文件路径或URLsep/delimiter:分隔符,默认为’,’header:指定列名行,默认为0(第一行)index_col:指定索引列names:列名列表usecols:需要读取的列skiprows:需要跳过的行数nrows:读取的行数na_values:代表缺失值的字符串列表parse_dates:需要解析为日期的列encoding:文件编码
2. 保存数据到文件:df.to_csv()
将DataFrame保存为CSV文件同样简单:
import pandas as pd# 创建一个DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David'],'Age': [25, 30, 35, 40],'City': ['New York', 'Los Angeles', 'Chicago', 'Houston']
}
df = pd.DataFrame(data)# 基本保存
df.to_csv('output.csv')
print("已保存DataFrame到output.csv")# 高级选项
df.to_csv('output_custom.csv',index=False, # 不保存索引header=True, # 保存列名sep=',', # 分隔符columns=['Name', 'Age'], # 只保存指定列na_rep='Missing', # 缺失值表示encoding='utf-8' # 文件编码)
print("已使用自定义选项保存DataFrame")# 保存为其他格式
df.to_excel('output.xlsx', sheet_name='Sheet1')
print("已保存为Excel文件")df.to_json('output.json', orient='records')
print("已保存为JSON文件")df.to_html('output.html')
print("已保存为HTML文件")
to_csv()函数的常用参数:
path_or_buf:文件路径或类文件对象sep:分隔符,默认为’,’na_rep:缺失值表示,默认为’’columns:要写入的列header:是否写入列名,默认为Trueindex:是否写入行索引,默认为Trueencoding:文件编码date_format:日期格式
四、练习:从 CSV 文件中读取数据并进行简单统计分析
让我们通过一个实际例子来练习Pandas的基本操作。我们将从CSV文件中读取销售数据,并进行简单的统计分析。
假设我们有一个名为sales_data.csv的文件,包含以下数据:
Date,Product,Category,Price,Quantity,Region
2023-01-15,Laptop,Electronics,1200,5,North
2023-01-15,Phone,Electronics,800,10,South
2023-01-16,Desk,Furniture,350,3,East
2023-01-16,Chair,Furniture,150,8,West
2023-01-17,Tablet,Electronics,500,12,North
2023-01-17,Monitor,Electronics,300,7,South
2023-01-18,Bookshelf,Furniture,250,4,East
2023-01-18,Lamp,Home,80,15,West
2023-01-19,Keyboard,Electronics,50,20,North
2023-01-19,Mouse,Electronics,30,25,South
现在,让我们使用 Pandas 读取这个文件并进行分析:
import pandas as pd
import matplotlib.pyplot as plt# 读取CSV文件
df = pd.read_csv('sales_data.csv', parse_dates=['Date'])
print("数据概览:")
print(df.head())# 基本信息
print("\n基本信息:")
print(df.info())# 基本统计
print("\n基本统计:")
print(df.describe())# 1. 按类别分组,计算总销售额
df['Sales'] = df['Price'] * df['Quantity'] # 创建销售额列
category_sales = df.groupby('Category')['Sales'].sum().sort_values(ascending=False)
print("\n按类别的总销售额:")
print(category_sales)# 2. 按区域分组,计算平均销售额
region_avg_sales = df.groupby('Region')['Sales'].mean()
print("\n按区域的平均销售额:")
print(region_avg_sales)# 3. 按日期分组,计算销售量
date_quantity = df.groupby('Date')['Quantity'].sum()
print("\n按日期的总销售量:")
print(date_quantity)# 4. 找出销售额最高的产品
top_product = df.loc[df['Sales'].idxmax()]
print("\n销售额最高的产品:")
print(top_product['Product'])# 5. 计算每个类别的产品数量
category_count = df['Category'].value_counts()
print("\n每个类别的产品数量:")
print(category_count)# 6. 简单的数据可视化 - 按类别的总销售额
plt.figure(figsize=(10, 6))
category_sales.plot(kind='bar')
plt.title('按类别的总销售额')
plt.xlabel('类别')
plt.ylabel('总销售额(元)')
plt.xticks(rotation=0)
plt.tight_layout()
plt.savefig('category_sales.png')
print("\n已生成按类别总销售额的柱状图")# 7. 保存处理后的数据
df.to_csv('processed_sales_data.csv', index=False)
print("\n已保存处理后的数据到processed_sales_data.csv")
通过这个练习,我们完成了以下数据分析任务:
- 读取CSV文件并查看基本信息
- 计算销售额和进行基本统计分析
- 按不同维度(类别、区域、日期)分组并汇总数据
- 找出表现最佳的产品
- 进行简单的数据可视化
- 保存处理后的数据
这些是数据分析中的常见操作,Pandas使它们变得简单高效。
五、总结与进阶方向
在本篇文章中,我们学习了Pandas的基础知识,包括:
- Pandas的简介和优势
- 核心数据结构:Series和DataFrame
- 数据的读取与保存
- 使用Pandas进行简单的数据分析
Pandas 是Python数据分析的核心工具,它建立在NumPy的基础上,提供了更高级的数据结构和数据分析功能。通过掌握Pandas,你可以高效地处理各种数据分析任务,如数据清洗、转换、分析和可视化。
下一步学习方向:
- 数据清洗和预处理(处理缺失值、重复值、异常值等)
- 高级数据操作(合并、连接、重塑等)
- 时间序列数据分析
- 分组聚合运算
- Pandas与数据可视化的结合使用
练习建议:
- 尝试使用Pandas处理不同类型的数据集(可以从Kaggle等平台下载公开数据集)
- 实践不同的数据转换和分析操作
- 将Pandas与Matplotlib结合,创建数据可视化图表
- 尝试使用Pandas解决实际问题,如销售数据分析、金融数据分析等
编程提示:当处理大型数据集时,留意内存使用情况。Pandas提供了一些优化内存使用的方法,如指定数据类型、使用
chunksize参数分块读取数据等。
Pandas的学习是一个循序渐进的过程。通过实践和不断探索,你将逐渐掌握这个强大工具的各种功能,成为数据分析的专家!
参考资源
- Pandas官方文档:https://pandas.pydata.org/docs/
- Pandas用户指南:https://pandas.pydata.org/docs/user_guide/index.html
- Pandas备忘单:https://pandas.pydata.org/Pandas_Cheat_Sheet.pdf
- Python数据科学手册:https://jakevdp.github.io/PythonDataScienceHandbook/
有什么关于 Pandas 的问题,欢迎在大家评论区留言交流,在下一篇,也就是Python星球之旅的第24天,我们将探索 Pandas 数据清洗,敬请期待!
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!
相关文章:

《Python星球日记》第23天:Pandas基础
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 订阅专栏:《Python星球日记》 目录 一、Pandas 简介1. 什么是 Pandas&…...

ubuntu22.04下安装mysql以及mysql-workbench
一、mysql安装以及配置 安装之前先查看是否已将安装mysql: rpm -qa | grep mysql (一)、在线安装 保证网络正常的情况下: 1、更新软件包: sudo apt update 2、安装mysql安装包 查看可以安装的安装包: sudo apt search mysql-server 安装指定安装包: sudo apt i…...

让 Python 脚本在后台持续运行:架构级解决方案与工业级实践指南
让 Python 脚本在后台持续运行:架构级解决方案与工业级实践指南 一、生产环境需求全景分析 1.1 后台进程的工业级要求矩阵 维度开发环境要求生产环境要求容灾要求可靠性单点运行集群部署跨机房容灾可观测性控制台输出集中式日志分布式追踪资源管理无限制CPU/Memo…...
)
设计模式 四、行为设计模式(2)
五、状态模式 1、概述 状态设计模式是一种行为型设计模式,它允许对象在其内部状态发生时改变其行为,这种模式可以消除大量的条件语句,并将每个状态的行为封装到单独的类中。 状态模式的主要组成部分如下: 1)上…...

C++中作用域(public,private,protected
在C中,public、private 和 protected 是用于控制类成员(变量和函数)访问权限的关键字。它们决定了类成员在代码中的可见性和可访问性。在学习时候,对于public是最容易理解的,对于private也好理解,但是对于p…...

Spring配置方式演进:从XML到注解,构建灵活高效的开发体系
Spring配置方式演进:从XML到注解,构建灵活高效的开发体系 在Spring框架的演进长河中,配置方式始终是开发者需要掌握的核心技能。从早期XML一统天下的严谨规范,到注解驱动的敏捷开发,再到如今Java Config的优雅实践&am…...

网络4 OSI7层
OSI七层模型:数据如何传送,向下传送变成了什么样子 应用层 和用户打交道,向用户提供服务。 例如:web服务、http协议、FTP协议 1.用户接口 2.提供各种服务 通过浏览器(接口)提供Web服务 表示层 翻译 我的“…...

前端请求设置credentials: ‘include‘导致的cors问题
1.背景 前端请求设置credentials: ‘include‘其实主要是为了发送凭证,传cookie给后端 2.前端请求 fetch(http://frontend.com, { method: GET, // 或其他HTTP方法 credentials: include, // 不携带凭证 headers: { Content-Type: application/json, }, })…...

LabVIEW中VI Scripting 特定对象解析
该 LabVIEW 程序通过三条并行代码路径,借助 VI Scripting 功能,以特定方式解析程序框图对象,展示了不同方法在处理对象嵌套及特定范围对象时的差异。 上方文字:三条并行代码路径展示了解析程序框图的不同方式。第一条路径使用 …...

CISCO组建RIP V2路由网络
1.实验准备: 2.具体配置: 2.1根据分配好的IP地址配置静态IP: 2.1.1PC配置: PC0: PC1: PC2: 2.1.2路由器配置: R0: Router>en Router#conf t Enter configuration…...

性能飙升50%,react-virtualized-list如何优化大数据集滚动渲染
在处理大规模数据集渲染时,前端性能常常面临巨大的挑战。本文将探讨 react-virtualized-list 库如何通过虚拟化技术和 Intersection Observer API,实现前端渲染性能飙升 50% 的突破!除此之外,我们一同探究下该库还支持哪些新的特性…...

超低功耗MCU软件开发设计中的要点与选型推荐
前沿-超低功耗MCU应用: 超低功耗MCU(微控制器)凭借其极低的功耗和高效的能量管理能力,正在快速渗透到多个新兴领域,尤其在物联网(IoT)、可穿戴设备、智能家居和医疗电子等领域展现出巨大的应用…...

Gson、Fastjson 和 Jackson 对比解析
目录 1. Gson (Google) 基本介绍: 核心功能: 特点: 使用场景: 2. Fastjson (Alibaba) 基本介绍: 核心功能: 特点: 使用场景: 3. Jackson 基本介绍: 核心功能…...

冒泡排序与回调函数——qsort
文章核心内容总结 本文围绕数组排序展开,先介绍了冒泡排序,后引入qsort库函数进行排序,并对二者进行了对比。 1. 冒泡排序实现 在探讨冒泡排序(Bubble Sort)这一经典的排序算法时,我们首先需要了解其基本…...
机器学习---逻辑回归及其Python实现)
(四)机器学习---逻辑回归及其Python实现
之前我们提到了常见的任务和算法,本篇我们使用逻辑回归来进行分类 分类问题回归问题聚类问题各种复杂问题决策树√线性回归√K-means√神经网络√逻辑回归√岭回归密度聚类深度学习√集成学习√Lasso回归谱聚类条件随机场贝叶斯层次聚类隐马尔可夫模型支持向量机高…...

微信小程序开发:微信小程序上线发布与后续维护
微信小程序上线发布与后续维护研究 摘要 微信小程序作为移动互联网的重要组成部分,其上线发布与后续维护是确保其稳定运行和持续优化的关键环节。本文从研究学者的角度出发,详细探讨了微信小程序的上线发布流程、后续维护策略以及数据分析与用户反馈处理的方法。通过结合实…...

vue拓扑图组件
vue拓扑图组件 介绍技术栈功能特性快速开始安装依赖开发调试构建部署 使用示例演示截图组件源码 介绍 一个基于 Vue3 的拓扑图组件,具有以下特点: 1.基于 vue-flow 实现,提供流畅的拓扑图展示体验 2.支持传入 JSON 对象自动生成拓扑结构 3.自…...

Python数据分析-NumPy模块-查看数组属性
查看数组的行数和列数 from numpy import array aarray([[1,1],[2,2],[3,3]]) print(a.shape)结果: 提取数组的行数或列数 from numpy import array aarray([[1,1],[2,2],[3,3]]) print(a.shape) print(a.shape[0]) print(a.shape[1])结果: 查看数组…...

ch07课堂参考代码
DFS 的优化 1) 标记搜索过的状态 用数组标记一个状态是否被搜索过,搜索过则直接 return,不用再执行函数,用于保证每个状态只被搜索一次。 在递归调用函数之前,通过 if (vis[x]) 判断 x 是否被搜索过,搜索过则直接ret…...
,并把唯一的新闻内容保存到一个新的 JSON 文件中)
去重新闻数据中重复的正文内容(body 字段),并把唯一的新闻内容保存到一个新的 JSON 文件中
示例代码: import os import json import nltk from tqdm import tqdmdef wr_dict(filename,dic):if not os.path.isfile(filename):data []data.append(dic)with open(filename, w) as f:json.dump(data, f)else: with open(filename, r) as f:data json.l…...

centos crontab 设置定时任务访问链接
在 CentOS 系统中,使用 crontab 设置定时任务访问 URL,可以通过命令行工具(如 curl 或 wget)发送 HTTP 请求。以下是详细步骤: 1、安装必要工具(若未安装) 安装 curl 或 wget # 安装 curl su…...

oracle大师认证证书有用吗
专业能力的高度认可:OCM 是 Oracle认证的最高级别,是对数据库从业人员技术、知识和操作技能的最高级认可,也是 IT 界顶级认证之一。它表明持证者具备处理关键业务数据库系统和应用的能力,能够解决最困难的技术难题和最复杂的系统故…...

说说对 Node 中的 process 的理解?有哪些常用方法?
1. 简介 process对象是Node.js中的全局变量,它提供了有关当前Node.js进程的信息并允许对其进行控制。通过process对象,我们可以获取进程的环境变量、命令行参数,控制进程的行为以及与其他进程进行通信。 2. 常用属性 process.env process…...

maven 和 idea intej步骤记录
1 maven 安装配置 1.1 参考链接安装 maven参考链接 1.2 maven 关联本机jdk版本 配置 priofiles jdk 版本时,查看本本机jdk 版本:环境变量查看jdk 路径版本: java_home 变量路径是C:\Program Files\Java\jdk-21 # setting.xml <profile&…...

Java Socket编程从零到实战详解
摩西摩西~最近接单子用到了Java的socket编程,顺手给整理下来咯! 各个语言的socket编程除了语法之外几乎思路都是一样的。 所以这些思路都是可以直接移植到其他语言实现的! 话不多说上车! 一、Socket基础概念与工作流程…...

STM32中Hz和时间的转换
目录 一、常见的频率单位及其转换 二、计算公式 三、STM32中定时器的应用 四、例子 一、常见的频率单位及其转换 赫兹(Hz)是频率的国际单位,表示每秒钟周期性事件发生的次数。 1 kHz(千赫兹) 1,000 Hz1 MHz&#…...

Apache Hive学习教程
什么是Hive? Apache Hive是一款建立在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop文件中的结构化、半结构化 数据文件映射为一张数据库表,基于表提供了一种类似SQL的查询模型,称为Hive查询语言(HQL)&…...

学习笔记六——Rust 切片全解析
这篇文章不是告诉你“切片是啥”,而是让你真正理解并学会用切片,同时还会把你最容易卡壳的 {:?}、char_indices() 等都讲清楚! 📚 文章目录 切片到底是什么?能不能通俗一点?切片的本质:它其实…...

Apache Doris SelectDB 技术能力全面解析
Apache Doris 是一款开源的 MPP 数据库,以其优异的分析性能著称,被各行各业广泛应用在实时数据分析、湖仓融合分析、日志与可观测性分析、湖仓构建等场景。Apache Doris 目前被 5000 多家中大型的企业深度应用在生产系统中,包含互联网、金融、…...
完整讲解与实战应用)
设计模式 Day 8:策略模式(Strategy Pattern)完整讲解与实战应用
🔄 前情回顾:Day 7 重点回顾 在 Day 7 中,我们彻底讲透了观察者模式: 它是典型的行为型模式,核心理念是“一变多知”,当一个对象状态变化时,自动通知所有订阅者。 我们通过 RxCpp 实现了工业…...

HarmonyOS-ArkUI V2装饰器-@Once
前文,关于Param的使用: HarmonyOS-ArkUIV2装饰器-Param:组件外部输入-CSDN博客 Once装饰器是一个需要配合Param装饰器一块使用的的装饰器。它的特性是,仅仅在变量进行初始化的时候,接受一个外部传来的值进行初始化&am…...

前端Node.js的包管理工具npm指令
npm(Node Package Manager)是Node.js的包管理工具,主要用于安装、更新、删除和管理JavaScript包。以下是前端开发中常用的npm命令及其用途: 基本命令 npm提供了一系列命令行工具,用于执行各种包管理操作。以下是一…...

本地搭建直播录屏应用并实现使用浏览器远程控制直播间录屏详细教程
 本文主要介绍如何在 Windows 系统电脑本地部署直播录屏工具 Bililive-go,并结合 cpolar 内网穿透工具实现远程访问本地 Bililive-go 服务 web 界面管理录屏任务。 相信很多小伙伴都喜欢看直播,不过如果一旦临时有事看不了直播,…...

Hydra Columnar:一个开源的PostgreSQL列式存储引擎
Hydra Columnar 是一个 PostgreSQL 列式存储插件,专为分析型(OLAP)工作负载设计,旨在提升大规模分析查询和批量更新的效率。 Hydra Columnar 以扩展插件的方式提供,主要特点包括: 采用列式存储,…...
)
OpenGL学习笔记(assimp封装、深度测试、模板测试)
目录 模型加载Assimp网格模型及导入 深度测试深度值精度深度缓冲的可视化深度冲突 模板测试物体轮廓 GitHub主页:https://github.com/sdpyy1 OpenGL学习仓库:https://github.com/sdpyy1/CppLearn/tree/main/OpenGLtree/main/OpenGL):https://github.com/sdpyy1/CppL…...

自动化备份全网服务器数据平台
1.项目说明 1.1概述 该项目共分为2个子项目,由环境搭建和实施备份两部分组成 该项目旨在复习巩固系统服务部署使用、shell编程等知识,旨在让学生增加知识面,提高项目实习经历,充实简历 1.2项目组织方式及时间 时间:…...

Trea CN多多与主流AI编程工具万字解析
Trea CN多多与主流AI编程工具万字解析 (含数学建模、架构图、开发流程可视化) 一、数学建模:代码生成效率量化模型 1.1 全链路效率公式 T total N ⋅ ( 1 λ C S ) T check (1) T_{\text{total}} N \cdot \left( \frac{1}{\lambda} \…...

Django从零搭建卖家中心注册页面实战
在电商系统开发中,卖家中心是一个重要的组成部分,而用户注册与登陆则是卖家中心的第一步。本文将详细介绍如何使用Django框架从零开始搭建一个功能完善的卖家注册页面,包括前端界面设计和后端逻辑实现。 一、项目概述 我们将创建一个名为sel…...

如何进行预算考核
✅ 一、预算考核体系总体架构 模块内容说明考核内容1. 预算目标/指标完成情况2. 预算编制/执行情况双轮驱动,目标 + 执行双考核考核对象高层、中层、基层、后台支持分层分类考核考核周期月度(滚动)+ 季度(校验)+ 年度(决算)提高适应性和准确性考核工具指标体系、差错率评…...

django相关面试题
django相关面试题 1.django的生命周期 2.django中的orm查询如何自定义方法 3.django中的中间件的作用 4.django中间件,request进来经过哪些中间件,顺序是怎么样的 5.django中的csrf是什么 6.django每访问一次数据库都会创建一个连接吗 7.uwsgi gunicorn…...

【Java面试系列】Spring Cloud微服务架构中的分布式事务实现与性能优化详解 - 3-5年Java开发必备知识
【Java面试系列】Spring Cloud微服务架构中的分布式事务实现与性能优化详解 - 3-5年Java开发必备知识 引言 在微服务架构中,分布式事务是一个不可避免的挑战。随着业务复杂度的提升,如何保证跨服务的数据一致性成为面试中的高频问题。本文将从基础到进…...
)
PostgreSQL 17深度解析(从17.0-17.4)
PostgreSQL 17自2024年9月发布以来,持续通过小版本迭代增强功能、优化性能并修复安全漏洞。本文将从17.0到17.4的每个版本切入,深度解析其新增特性、技术原理、性能提升及实践价值,帮助开发者、DBA及架构师全面掌握PostgreSQL 17的演进脉络。 一、PostgreSQL 17.0:基石奠定…...

人物4_Japanese
Now, I start my JaPan【Tokyo】 life, 【I go out of my country{China}, the reason is I want learn more new computer technologies in foreign, also it could let me know more different culture.】I like the place and most persons in here. The JaPan culture have…...
 和main.go的使用规范)
Go 语言中的 package main、 func main() 和main.go的使用规范
本文旨在解释 Go 语言中 package main 、 func main() 和main.go的关系及其使用规则,解决如下典型问题: 是否可以在一个项目中定义多个 func main()?是否可以在非 package main 中写 func main()?多个文件中都写 func main() 会冲…...

mac 终端 code 命令打开 vscode,修改 cursor占用
rm /usr/local/bin/code vim ~/.zshrc # 定义 cursor 函数,用于打开 Cursor 应用 function cursor {open -a "/Applications/Cursor.app" "$" }# 定义 code 函数,用于打开 Visual Studio Code function code {open -a "/Appli…...

【常用功能】下载文件和复制到剪切板
前言 前端人员在开发时经常会遇到: 后端给一个地址,需要去下载的需求。将页面的内容复制到剪切板 下载文件 我们先说下载文件,通常情况下我们会自己写上一个非常简单的工具函数。 思路如下: 创建一个a元素设置a元素跳转的链接…...
】)
【ESP32-microros(vscode-Platformio)】
一、步骤 1、目前支持ESP32 2、同一个局域网 3、上位机要安装代理(电脑或者linux设备) 4、可直接通过USB下载,也可以使用官方烧录工具,具体的分区表地址要从USB烧录的时候日志查看,一共四个文件,第三个…...

如何使用AI辅助开发CSS3 - 通义灵码功能全解析
一、引言 CSS3 作为最新的 CSS 标准,引入了众多新特性,如弹性布局、网格布局等,极大地丰富了网页样式的设计能力。然而,CSS3 的样式规则繁多,记忆所有规则对于开发者来说几乎是不可能的任务。在实际开发中,…...

OpenCV图像形态学详解
文章目录 一、什么是图像形态学?二、基本概念:结构元素三、基本形态学操作1. 腐蚀(Erosion)2. 膨胀(Dilation)3. 开运算(Opening)4. 闭运算(Closing) 四、高级…...
过滤器乱码解决与监听器)
Java-servlet(完结篇)过滤器乱码解决与监听器
Java-servlet(完结篇)过滤器乱码解决与监听器 前言一、过滤器乱码解决二、监听器1. HttpSessionListener2. ServletContextListener3. ServletRequestListener 三、监听器的使用场景Java-servlet 结语 前言 在之前的 Java Servlet 学习中,我…...