深度学习总结(8)
模型工作流程
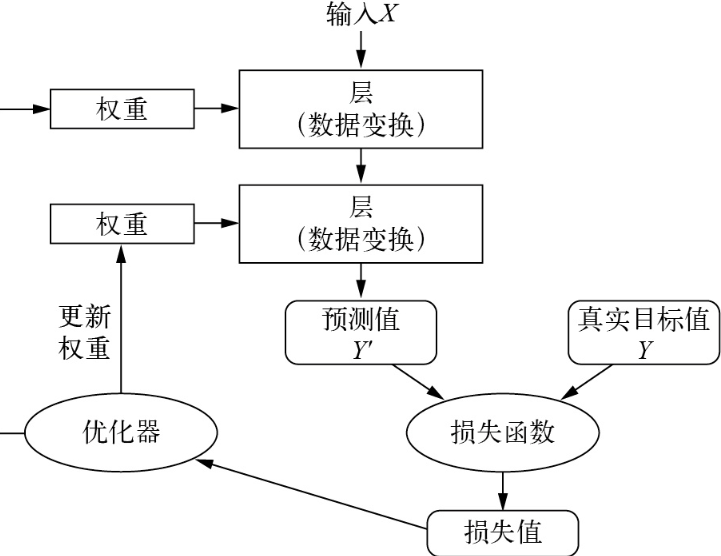
模型由许多层链接在一起组成,并将输入数据映射为预测值。随后,损失函数将这些预测值与目标值进行比较,得到一个损失值,用于衡量模型预测值与预期结果之间的匹配程度。优化器将利用这个损失值来更新模型权重。
下面是输入数据。
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype("float32") / 255
test_images = test_images.reshape((10000, 28 * 28))
test_images = test_images.astype("float32") / 255
输入图像保存在float32类型的NumPy张量中,其形状分别为(60000,784)(训练数据)和(10000, 784)(测试数据)。
下面是模型。
model = keras.Sequential([layers.Dense(512, activation="relu"),layers.Dense(10, activation="softmax")
])
这个模型包含两个链接在一起的Dense层,每层都对输入数据做一些简单的张量运算,这些运算都涉及权重张量。权重张量是该层的属性,里面保存了模型所学到的知识。
下面是模型编译。
model.compile(optimizer="rmsprop",loss="sparse_categorical_crossentropy",metrics=["accuracy"])
sparse_categorical_crossentropy是损失函数,是用于学习权重张量的反馈信号,在训练过程中应使其最小化。降低损失值是通过小批量随机梯度下降来实现的。梯度下降的具体方法由第一个参数给定,即rmsprop优化器。
下面是训练循环。
model.fit(train_images, train_labels, epochs=5, batch_size=128)
在调用fit时:模型开始在**训练数据(共60000个样本)**上进行迭代(每个小批量包含128个样本),共迭代5轮[在所有训练数据上迭代一次叫作一轮(epoch)]。对于每批数据,模型会计算损失相对于权重的梯度(利用反向传播算法,这一算法源自微积分的链式法则),并将权重沿着减小该批量对应损失值的方向移动。5轮之后,模型共执行2345次梯度更新(每轮469次),模型损失值将变得足够小,使得模型能够以很高的精度对手写数字进行分类。
用TensorFlow从头开始重新实现模型
简单的Dense类
Dense层实现了下列输入变换,其中W和b是模型参数,activation是一个逐元素的函数(通常是relu,但最后一层是softmax)。
output = activation(dot(W, input) + b)
我们实现一个简单的Python类NaiveDense,它创建了两个TensorFlow变量W和b,并定义了一个__call__()方法供外部调用,以实现上述变换。
import tensorflow as tfclass NaiveDense:#构造函数def __init__(self, input_size, output_size, activation):#模拟keras的dense层可以设置激活函数self.activation = activationw_shape = (input_size, output_size)#创建一个形状为(input_size, output_size)的矩阵W,并将其随机初始化w_initial_value = tf.random.uniform(w_shape, minval=0, maxval=1e-1)self.W = tf.Variable(w_initial_value)b_shape = (output_size,)#创建一个形状为(output_size,)的零向量bb_initial_value = tf.zeros(b_shape)self.b = tf.Variable(b_initial_value)#前向传播def __call__(self, inputs):return self.activation(tf.matmul(inputs, self.W) + self.b)#获取该层权重的便捷方法@propertydef weights(self):#以列表的形式返回本层的权重return [self.W, self.b]
我们总结一下NaiveDense实现了哪些步骤:
1.根据输入输出的形状初始化权重(kernel和bias)以实现仿射变换
2.初始化激活函数
3.实现前向传播函数(反向传播可以通过tensorflow的梯度带实现)
4.提供获取权重的方式
简单的Sequential类
我们创建一个NaiveSequential类来实现模型,将这些层链接起来。它封装了一个层列表(正如我们前面提到的模型由一系列层构成),并定义了一个__call__()方法供外部调用。这个方法将按顺序调用输入的层。它还有一个weights属性,用于记录所有层的权重。
class NaiveSequential:def __init__(self, layers):self.layers = layersdef __call__(self, inputs):x = inputsfor layer in self.layers:x = layer(x)return x@propertydef weights(self):weights = []for layer in self.layers:weights += layer.weightsreturn weights
按照惯例,总结一下这个Sequential实现了哪些行为:
1.封装层列表
2.一次调用层列表中的层进行前向传播
实例化模型
利用NaiveSequential来实例化模型
model = NaiveSequential([NaiveDense(input_size=28 * 28, output_size=512, activation=tf.nn.relu),NaiveDense(input_size=512, output_size=10, activation=tf.nn.softmax)
])
assert len(model.weights) == 4
批量生成器(batch)
对MNIST数据进行小批量迭代。
import mathclass BatchGenerator:def __init__(self, images, labels, batch_size=128):assert len(images) == len(labels)self.index = 0self.images = imagesself.labels = labelsself.batch_size = batch_sizeself.num_batches = math.ceil(len(images) / batch_size)def next(self):images = self.images[self.index : self.index + self.batch_size]labels = self.labels[self.index : self.index + self.batch_size]self.index += self.batch_sizereturn images, labels
批量生成器很简单,就是将训练数据保存下来,每次迭代产生批量大小的数据。
本文所有的代码汇总如下:
import tensorflow as tfclass NaiveDense:#构造函数def __init__(self, input_size, output_size, activation):#模拟keras的dense层可以设置激活函数self.activation = activationw_shape = (input_size, output_size)#创建一个形状为(input_size, output_size)的矩阵W,并将其随机初始化w_initial_value = tf.random.uniform(w_shape, minval=0, maxval=1e-1)self.W = tf.Variable(w_initial_value)b_shape = (output_size,)#创建一个形状为(output_size,)的零向量bb_initial_value = tf.zeros(b_shape)self.b = tf.Variable(b_initial_value)#前向传播def __call__(self, inputs):return self.activation(tf.matmul(inputs, self.W) + self.b)#获取该层权重的便捷方法@propertydef weights(self):#以列表的形式返回本层的权重return [self.W, self.b]class NaiveSequential:def __init__(self, layers):self.layers = layersdef __call__(self, inputs):x = inputsfor layer in self.layers:x = layer(x)return x@propertydef weights(self):weights = []for layer in self.layers:weights += layer.weightsreturn weightsmodel = NaiveSequential([NaiveDense(input_size=28 * 28, output_size=512, activation=tf.nn.relu),NaiveDense(input_size=512, output_size=10, activation=tf.nn.softmax)
])
assert len(model.weights) == 4import mathclass BatchGenerator:def __init__(self, images, labels, batch_size=128):assert len(images) == len(labels)self.index = 0self.images = imagesself.labels = labelsself.batch_size = batch_sizeself.num_batches = math.ceil(len(images) / batch_size)def next(self):images = self.images[self.index : self.index + self.batch_size]labels = self.labels[self.index : self.index + self.batch_size]self.index += self.batch_sizereturn images, labels相关文章:
)
深度学习总结(8)
模型工作流程 模型由许多层链接在一起组成,并将输入数据映射为预测值。随后,损失函数将这些预测值与目标值进行比较,得到一个损失值,用于衡量模型预测值与预期结果之间的匹配程度。优化器将利用这个损失值来更新模型权重。 下面是…...

[特殊字符] Hyperlane:为现代Web服务打造的高性能Rust文件上传解决方案
🚀 Hyperlane:为现代Web服务打造的高性能Rust文件上传解决方案 ▎开发者必备:为什么选择Hyperlane处理大文件上传? 在实时数据爆炸式增长的时代,开发者面临两大核心挑战: 如何实现TB级大文件的可靠传输如…...

英伟达开源253B语言模型:Llama-3.1-Nemotron-Ultra-253B-v1 模型情况
Llama-3.1-Nemotron-Ultra-253B-v1 模型情况 1. 模型概述 Llama-3.1-Nemotron-Ultra-253B-v1 是一个基于 Meta Llama-3.1-405B-Instruct 的大型语言模型 (LLM),专为推理、人类对话偏好和任务(如 RAG 和工具调用)而优化。该模型支持 128K 令…...

2025年智能合约玩法创新白皮书:九大核心模块与收益模型重构Web3经济范式
——从国库管理到动态激励的加密生态全栈解决方案 一、核心智能合约架构解析 1. 国库合约:生态财政中枢 作为协议的金库守卫者,国库合约通过多签冷钱包与跨链资产池实现资金沉淀。其创新点包括: 储备资产动态再平衡:采用预言机实…...

[250411] Meta 发布 Llama 4 系列 AI 模型 | Rust 1.86 引入重大语言特性
目录 Llama 4 家族登场:开启原生多模态 AI 创新新纪元Rust 1.86.0 版本发布亮点主要新特性与改进其他重要信息 Llama 4 家族登场:开启原生多模态 AI 创新新纪元 Meta AI 近日发布了其最新、最先进的 Llama 4 系列人工智能模型,标志着 AI 技术…...

缓存不只是加速器:深入理解 Redis 的底层机制
一、Redis 是什么?为什么我们需要它? Redis(Remote Dictionary Server)是一种高性能的内存型键值对数据库。 通俗地讲,它就像一个超快的、放在内存中的超级字典,你可以用它来存数据、查数据,而…...

windows虚拟内存
windows的虚拟内存只是 虚拟内存技术的一个拓展, 叫他分页文件更好, 真正的虚拟内存是 CPU 内存管理单元 用于调度物理内存和磁盘衍生出来的技术. 在此基础上, 虚拟内存会根据页表 去物理内存中找数据, 找不到就去磁盘找, 找到之后再登记到页表. 这里的磁盘就是window系统中所…...

Ajax------免刷新地前后端交互
本文略带PHP代码需要在PHP环境下使用 介绍 AJAX (Asynchronous JavaScript and XML) 是一种创建快速动态网页应用的开发技术,它允许网页在不重新加载整个页面的情况下,与服务器交换数据并更新部分网页内容。例如,在我们做爬虫的时候发现有些…...

python办公自动化---pdf文件的读取、添加水印
需要安装包:pdfminer、pypdf2 一、读取pdf中的内容 from pdfminer.converter import TextConverter from pdfminer.layout import LAParams from pdfminer.pdfdocument import PDFDocument from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterprete…...

下一代数据架构全景:云原生实践、行业解法与 AI 底座 | Databend Meetup 成都站回顾
3 月底,Databend 2025 开年首场 Meetup 在成都多点公司成功举办!活动特别邀请到四位重量级嘉宾:多点科技数据库架构师王春涛、多点DMALL数据平台负责人李铭、Databend联合创始人吴炳锡,以及鹏城实验室王璞博士。在春日的蓉城&…...

Kubernetes容器编排与云原生实践
第一部分:Kubernetes基础架构与核心原理 第1章 容器技术的演进与Kubernetes的诞生 1.1 虚拟化技术的三次革命 物理机时代:资源浪费严重,利用率不足15% 虚拟机突破:VMware与Hyper-V实现硬件虚拟化,利用率提升至50% …...

vue项目使用html2canvas和jspdf将页面导出成PDF文件
一、需求: 页面上某一部分内容需要生成pdf并下载 二、技术方案: 使用html2canvas和jsPDF插件 三、js代码 // 页面导出为pdf格式 import html2Canvas from "html2canvas"; import jsPDF from "jspdf"; import { uploadImg } f…...

JAVA实现在H5页面中点击链接直接进入微信小程序
在普通的Html5页面中如何实现点击URL链接直接进入微信小程序,不需要扫描小程序二维码? 网上介绍的很多方法是在小程序后台设置Schema,不过我进入我的小程序后台在开发设置里面 没有找到设置小程序Schema的地方,我是通过调用API接口…...

深入剖析 Kafka 的零拷贝原理:从操作系统到 Java 实践
Kafka 作为一款高性能的分布式消息系统,其卓越的吞吐量和低延迟特性得益于多种优化技术,其中“零拷贝”(Zero-Copy)是核心之一。零拷贝通过减少用户态与内核态之间的数据拷贝,提升了 Kafka 在消息传输中的效率。本文将…...

深度学习:AI 大模型时代的智能引擎
当 Deepspeek 以逼真到难辨真假的语音合成和视频生成技术横空出世,瞬间引发了全球对 AI 伦理与技术边界的激烈讨论。从伪造名人演讲、制造虚假新闻,到影视行业的特效革新,这项技术以惊人的速度渗透进大众视野。但在 Deepspeek 强大功能的背后…...

【Flask开发】嘿马文学web完整flask项目第4篇:4.分类,4.分类【附代码文档】
教程总体简介:2. 目标 1.1产品与开发 1.2环境配置 1.3 运行方式 1.4目录说明 1.5数据库设计 2.用户认证 Json Web Token(JWT) 3.书架 4.1分类列表 5.搜索 5.3搜索-精准&高匹配&推荐 6.小说 6.4推荐-同类热门推荐 7.浏览记录 8.1配置-阅读偏好 8.配置 9.1项目…...

【MySQL】002.MySQL数据库基础
文章目录 数据库基础1.1 什么是数据库1.2 基本使用创建数据库创建数据表表中插入数据查询表中的数据 1.3 主流数据库1.4 服务器,数据库,表关系1.5 MySQL架构1.6 SQL分类1.7 存储引擎1.7.1 存储引擎1.7.2 查看存储引擎1.7.3 存储引擎对比 前言:…...

Python爬取视频的架构方案,Python视频爬取入门教程
文章目录 前言方案概述架构设计详细实现步骤1.环境准备2. 网页请求模块3. 网页解析模块4. 视频下载模块5. 异常处理与日志模块 代码示例:性能优化注意事项 前言 以下是一个全面的使用 Python 爬取视频的架构方案,包含方案概述、架构设计、详细实现步骤、…...

ERC-20 代币标准
文章目录 一、什么是 ERC-20?核心价值:互操作性简化开发生态基石 二、ERC-20 的六大核心功能基础功能授权与代理转账事件通知 三、ERC-20 代币的典型应用场景四、ERC-20 的技术优势与局限性优势:局限性: 五、ERC-20 代币的创建步骤…...

SpringBoot实战1
SpringBoot实战1 一、开发环境,环境搭建-----创建项目 通过传统的Maven工程进行创建SpringBoot项目 (1)导入SpringBoot项目开发所需要的依赖 一个父依赖:(工件ID为:spring-boot-starter-parent…...

GSO-YOLO:基于全局稳定性优化的建筑工地目标检测算法解析
论文地址:https://arxiv.org/pdf/2407.00906 1. 论文概述 《GSO-YOLO: Global Stability Optimization YOLO for Construction Site Detection》提出了一种针对建筑工地复杂场景优化的目标检测模型。通过融合全局优化模块(GOM)、稳定捕捉模块(SCM)和创新的AIoU损失函…...

解读json.loads函数参数
json.loads()函数是解码JSON字符串为Python对象的核心工具。本文将深入探讨json.loads()函数的各个参数。 一、基本功能与输入类型 1. 功能概述 json.loads(s, *, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=N…...

2025.04.10-拼多多春招笔试第一题
📌 点击直达笔试专栏 👉《大厂笔试突围》 💻 春秋招笔试突围在线OJ 👉 笔试突围OJ 01. 神奇公园的福娃占卜 问题描述 LYA在一个神奇的公园里发现了一条特殊的小径,小径上排列着一群可爱的福娃玩偶。这条小径有 n n...

【学习笔记】CPU 的“超线程”是什么?
1. 什么是超线程? 超线程(Hyper-Threading)是Intel的技术,让一个物理CPU核心模拟出两个逻辑核心。 效果:4核CPU在系统中显示为8线程。 本质:通过复用空闲的硬件单元(如ALU、FPU)&a…...

Docker Harbor
下载Harbor安装包 wget https://github.com/goharbor/harbor/releases/download/v2.5.0/harbor-offline-installer-v2.5.0.tgz 解压安装包 tar xvf harbor-offline-installer-v2.5.0.tgz cd harbor 配置harbor vi harbor.yml hostname: registry.example.com # Harbor …...

天梯集训笔记整理
1.着色问题 直接标注哪些行和列是被标注过的,安全格子的数量就是未标注的行*列 #include <bits/stdc.h> using namespace std;const int N 1e510; int hang[N],lie[N];int main(){int n,m;cin>>n>>m;int q;cin>>q;while(q--){int x,y;ci…...
)
C语言复习笔记--指针(4)
在经过前几篇的复习后我们已经了解了大部分指针的类型,今天让我们继续复习指针的其他内容吧. 函数指针变量 函数指针变量的创建 什么是函数指针变量呢?函数指针变量应该是⽤来存放函数地址的,未来通过地址能够调⽤函数的。 那么函数是否有地址呢&#x…...

008二分答案+贪心判断——算法备赛
二分答案贪心判断 有些问题,从已知信息推出答案,细节太多,过程繁杂,不易解答。 从猜答案出发,贪心地判断该答案是否合法是个不错的思路,这要求所有可能的答案是单调的(例:x满足条件…...

Netty之内存池的原理和实战
深入理解Netty的内存池机制及其应用实践 在高性能网络编程中,内存管理对于系统的稳定性和性能至关重要。Netty作为一个高效的网络通信框架,通过引入内存池机制有效地解决了内存分配和回收频繁带来的性能瓶颈和内存碎片问题。本文将深入探讨Netty内存池的…...

Elasticsearch 向量数据库,原生支持 Google Cloud Vertex AI 平台
作者:来自 Elastic Valerio Arvizzigno Elasticsearch 将作为第一个第三方原生语义对齐引擎,支持 Google Cloud 的 Vertex AI 平台和 Google 的 Gemini 模型。这使得联合用户能够基于企业数据构建完全可定制的生成式 AI 体验,并借助 Elastics…...

《算法笔记》3.1小节——入门模拟->简单模拟
1001 害死人不偿命的(3n1)猜想 #include <iostream> using namespace std;int main() {int n,count0;cin>>n;while(n!1){if(n%20) n/2;else n(3*n1)/2;count1;}std::cout <<count;return 0; }1032 挖掘机技术哪家强 #include <iostream> using namespa…...
暴力娱乐篇24)
每日一题(小白)暴力娱乐篇24
由题已知这是一个匹配题目,题目已经说了三阶幻方是给定的,经过镜像和旋转,镜像*2旋转*4; 总共八种方案,然后接收每次的数据去匹配(跳过0),如果匹配就输出匹配的数组,如果…...

C++:函数模板类模板
程序员Amin 🙈作者简介:练习时长两年半,全栈up主 🙉个人主页:程序员Amin 🙊 P S : 点赞是免费的,却可以让写博客的作者开心好久好久😎 📚系列专栏:Java全…...
第18章:基于Global Context Vision Transformers(GCTx_unet)网络实现的oct图像中的黄斑水肿和裂孔分割
1. 网络概述 GCTx-UNET是基于传统UNet架构的改进版本,主要引入了以下几个关键创新: GCT模块:全局上下文变换器(Global Context Transformer)模块 多尺度特征融合:增强的特征提取能力 改进的跳跃连接:优化编码器与解…...

深入理解 Spring 的 MethodParameter 类
MethodParameter 是 Spring 框架中一个非常重要的类,它封装了方法参数(或返回类型)的元数据信息。这个类在 Spring MVC、AOP、数据绑定等多个模块中都有广泛应用。 核心功能 MethodParameter 主要提供以下功能: 获取参数类型信息…...

Docker部署HivisionIDPhotos1分钟生成标准尺寸证件照实操指南
文章目录 前言1. 安装Docker2. 本地部署HivisionIDPhotos3. 简单使用介绍4. 公网远程访问制作照片4.1 内网穿透工具安装4.2 创建远程连接公网地址 5. 配置固定公网地址 前言 相信大部分人办驾照、护照或者工作证时都得跑去照相馆,不仅费时还担心个人信息泄露。好消…...

python多线程+异步编程让你的程序运行更快
多线程简介 多线程是Python中实现并发编程的重要方式之一,它允许程序在同一时间内执行多个任务。在某些环境中使用多线程可以加快我们代码的执行速度,例如我们通过爬虫获得了一个图片的url数组,但是如果我们一个一个存储很明显会非常缓慢&…...
)
HDCP(五)
HDCP 2.2 测试用例设计详解 基于HDCP 2.2 CTS v1.1规范及协议核心机制,以下从正常流程与异常场景两大方向拆解测试用例设计要点,覆盖认证、密钥管理、拓扑验证等关键环节: 1. 正常流程测试 1.1 单设备认证 • 测试目标:验证源设…...

datagrip如何连接数据库
datagrip连接数据库的步骤 2025版本 想要链接数据库是需要一个jar包的,所以将上面进行删除之后,需要下载一个jar包 那么这个时候需要链接上传一个mysql链接的jar包 选择核心驱动类 上述操作完成之后,然后点击apply再点击ok即可 如下图说明my…...

Spring Boot 自动配置与启动原理全解析
下面分两部分系统讲解: 第一部分:Spring Boot 自动配置原理(核心是自动装配) 一、Spring Boot 的自动配置是干嘛的? 传统 Spring 开发时,你要写一堆 XML 或配置类,非常麻烦。Spring Boot 引入…...

python 基础:句子缩写
n int(input()) for _ in range(n):words input().split()result ""for word in words:result word[0].upper()print(result)知识点讲解 input()函数 用于从标准输入(通常是键盘)读取用户输入的内容。它返回的是字符串类型。例如在代码中…...
)
QML 中 Z 轴顺序(z 属性)
在 QML 中,z 属性用于控制元素的堆叠顺序(Z 轴顺序),决定元素在视觉上的前后层次关系。 基本概念 默认行为: 所有元素的默认 z 值为 0 同层级元素后声明的会覆盖先声明的 父元素的 z 值会影响所有子元素 核心规则…...

Redis快的原因
1、基于内存实现 Redis将所有数据存储在内存中,因此它可以非常快速地读取和写入数据,而无需像传统数据库那样将数据从磁盘读取和写入磁盘,这样也就不受I/O限制。 2、I/O多路复用 多路指的是多个socket连接;复用指的是复用一个线…...
)
蓝桥杯c ++笔记(含算法 贪心+动态规划+dp+进制转化+便利等)
蓝桥杯 #include <iostream> #include <vector> #include <algorithm> #include <string> using namespace std; //常使用的头文件动态规划 小蓝在黑板上连续写下从 11 到 20232023 之间所有的整数,得到了一个数字序列: S12345…...

每日算法-250410
今天分享两道 LeetCode 题目,它们都可以巧妙地利用二分查找来解决。 275. H 指数 II 问题描述 思路:二分查找 H 指数的定义是:一个科学家有 h 篇论文分别被引用了至少 h 次。 题目给定的 citations 数组是升序排列的。这为我们使用二分查找…...

swagger + Document
swagger 虽然有了api接口,对于复杂接口返回值说明,文档还是不能少。如果是一个人做的还简单一点,现在都搞前后端分离,谁知道你要取那个值呢...
)
线程同步与互斥(下)
线程同步与互斥(中)https://blog.csdn.net/Small_entreprene/article/details/147003513?fromshareblogdetail&sharetypeblogdetail&sharerId147003513&sharereferPC&sharesourceSmall_entreprene&sharefromfrom_link我们学习了互斥…...

MySQL 优化教程:让你的数据库飞起来
文章目录 前言一、数据库设计优化1. 合理设计表结构2. 范式化与反范式化3. 合理使用索引 二、查询优化1. 避免使用 SELECT *2. 优化 WHERE 子句3. 优化 JOIN 操作 三、服务器配置优化1. 调整内存分配2. 调整并发参数3. 优化磁盘 I/O 四、监控与分析1. 使用 EXPLAIN 分析查询语句…...

SD + Contronet,扩散模型V1.5+约束条件后续优化:保存Canny边缘图,便于视觉理解——stable diffusion项目学习笔记
目录 前言 背景与需求 代码改进方案 运行过程: 1、Run编辑 2、过程: 3、过程时间线: 4、最终效果展示: 总结与展望 前言 机器学习缺点之一:即不可解释性。最近,我在使用stable diffusion v1.5 Co…...

位掩码、哈希表、异或运算、杨辉三角、素数查找、前缀和
1、位掩码 对二进制数操作的方法,(mask1<<n),将数mask的第n位置为1,其它位置为0,即1000...2^n,当n较小时,可以用于解决类似于0/1背包的问题,要么是0,要么是1&…...