下一代数据架构全景:云原生实践、行业解法与 AI 底座 | Databend Meetup 成都站回顾
3 月底,Databend 2025 开年首场 Meetup 在成都多点公司成功举办!活动特别邀请到四位重量级嘉宾:多点科技数据库架构师王春涛、多点DMALL数据平台负责人李铭、Databend联合创始人吴炳锡,以及鹏城实验室王璞博士。在春日的蓉城,嘉宾们与来自马上消费金融、多点、中国电子云等企业的用户和技术爱好者们齐聚一堂,展开了一场深度技术交流,共话云原生湖仓与 AI 基础设施的前沿趋势,拆解 Databend 在实践中的应用心得。

- 我们为什么要做冷热数据分离?多点 DMALL 冷热数据分离的架构是如何演进的?
- 游戏行业数据工作者面临着哪些严重挑战?Databend Cloud 如何为游戏行业数据分析带来 10 倍收益提升?
- 多云场景下数据湖设计原则是什么?多点 DAMLL 云原生架构的落地实践经历了怎样的历程?
- DeepSeek 火了之后,人们对大模型底层的基础设施非常感兴趣,这个基础设施是如何工作的?如何在该架构下进行编程?
以下内容就将为您带来这些话题背后的深度思考:
多点冷热数据分离架构
“为什么要做冷热数据分离?” 春涛老师在开场向现场观众提出了一个灵魂提问。
很多公司里老板经常会问,数据库为什么要花那么多钱存那么多数据?能不能把一些不用的数据删掉,或搬到其他地方去?如何能减少数据存储的开支?多点做冷热数据分离主要从三个成本考虑:首先是数据的存储成本,其次是运维管理成本,最后是前两者加起来所带来人力成本。 既然确定要做冷热数据分离,那接下来就是如何区分冷热数据。从多点的经验看,数据冷热分离可以从几个关键点思考:
1.冷热数据如何定义?
一个通用的判别是,热数据是高频访问、时效性强、性能要求高的数据;冷数据是低频访问、长期存储、对性能要求低的数据。但各个企业、各个场景、各个行业,其实对冷热数据也有着自己的一些标签,因此不能概括来说。
2.冷热数据如何分离?
- 基于时间戳: 根据数据的创建时间或最后访问时间进行分类。热数据是最近 1 天或 1 周内生成或访问的数据。
- 基于访问频率:统计数据的访问频率(如读取次数、写入次数)。热数据就是每小时或每天被访问多次的,冷数据是数月甚至数年才被访问一次的。
- 基于 数据类型 和业务: 根据数据的业务重要性和使用场景进行分类。热数据是实时监控数据、交易数据。冷数据如备份数据、审计数据。
- 基于数据生命周期: 根据数据的生成、使用和归档阶段进行分类。热数据处于生成和使用阶段的数据;冷数据是已完成归档的数据。
3.冷热数据如何存储?
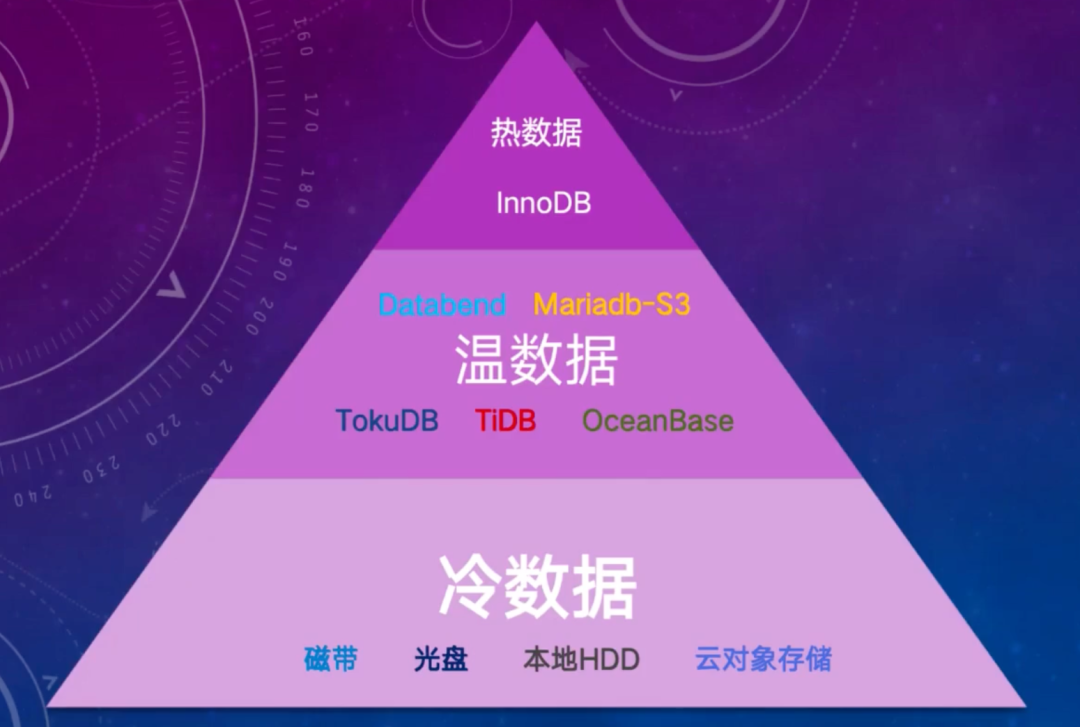
多点的热数据处理基本上都使用 MySQL 的 InnoDB,主从高可用架构。在冷热数据之间,多点增加了一层温数据。在前面的介绍中,定义了真正意义上的冷数据是基本上不会再被访问到的数据。有一些数据虽然在时间维度上是一年前或两年前的数据,但在每个月或某一天,还需要去查一下,这样的数据就叫做温数据。
温数据最开始放在 MySQL 的 TokuDB 存储引擎里,它的压缩率差不多能达到 InnoDB 的 1/ 4-1/ 5。如果有 1TB 的冷数据,存在 InnoDB 需要占用 1TB 空间,存在 TokuDB 可能只要 200G-300G。后面也开始用 TiDB、MariaDB-S3、Oceanbase、Databend 等存储引擎。这些数据库产品有一个共同的特点,都支持 SQL 直接访问。对于温数据来说,由于需要支持业务,原有的业务逻辑不能改变,业务人员无需修改语法或驱动,就能直接访问文档。
由于合规要求,冷数据主要是数据库的备份。多点的规则是每天做一次全备,保留一个月;每周做一次全备,保留半年;每月还要做一次全备,永久保存。永久保存的数据最开始放在 HDD 上,后来发现数据很大,成本还是很高,就开始放到对象存储里。对象存储的相对于磁盘它的价格,有十倍左右的缩减。
多点 DMALL 数据冷热分离的架构演进
在多点业务发展初期阶段,数据量还不大,所有数据都放在 MySQL+NVMe 架构中。由于 NVMe 存储卡成本较高, 在发展到一定阶段后,数据存储成本开始凸显。为了降低存储成本,多点开始引入 TokuDB 存储引擎。TokuDB 具有较高的存储压缩率,可以将存储缩减到 1/ 5 的磁盘空间,减少了数据存储的成本开销。跑了一段时间后,大数据团队发现 TokuDB 集群的访问要求并不高,没必要用 NVMe。所以开始将 TokuDB+NVMe 的架构改为 TokuDB+HDD ,进一步缩减存储成本。 中期时,多点发现 TiDB 的压缩率比 TokuDB 更高,所以用 TiDB 将 TokuDB 替换掉,将温数据放到 TiDB 集群上。除了存储成本降低,TiDB 带来的另一个好处是分布式架构的可扩展性好,解决了冷数据存储扩容的问题。此外,TiDB 还集成了 TiFlash,可以支持一些 OLAP 的操作。
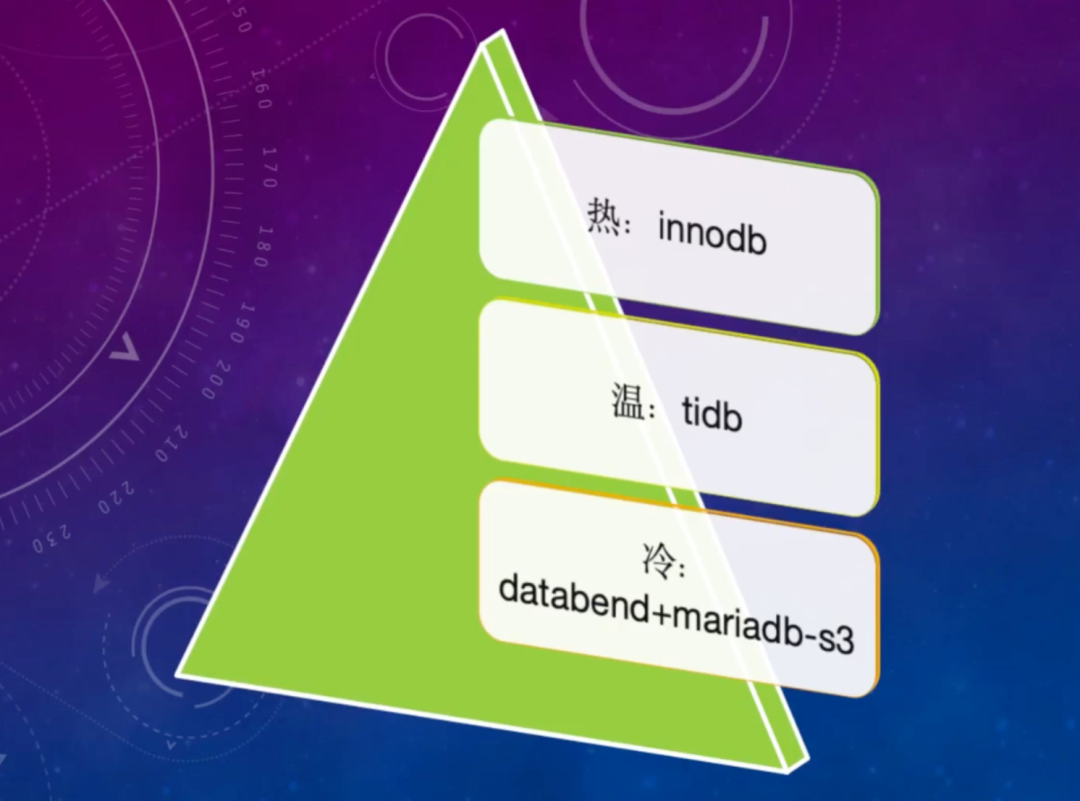
在上线了很多 TiDB 集群后,TiDB 本身也带来越来越高的存储成本。于是大数据团队开始进一步做冷热数据的区分和分离,将那些不需要长期访问、访问性能要求不高的温数据,都放到对象存储里。经过调研发现,在目前的市场中,既支持对象存储存数据,又支持 SQL 访问,就只有 Databend 和 MariaDB-S3 两个产品。经过一段时间使用后,基本温数据都存到了 Databend 里, MariaDB-S3 就可以下线了。
数据冷热分离的未来架构

未来,多点会将 MySQL InnoDB 引擎逐步迁移到 Oceanbase。Oceanbase 有着比 TiDB 更好的数据压缩,原来存在 InnoDB 里的 1TB 数据,在 OceanBase 里只有几十TB 大小。得益于这样的高压缩率,热数据的成本可以降更多。但热数据还是会不断增加,所以接下来还要将 OceanBase 里的热数据再放到 Databend 里去作为冷数据存储。OceanBase 是 SSD,Databend 是对象存储,存储成本又会进一步下降。
Databend Cloud 如何给游戏行业数据分析带来 10 倍收益提升?
吴炳锡老师对游戏行业的数据工作有着深入洞察,他认为游戏行业实际上是一个离钱特别近的行业。游戏公司很多时候上线一个游戏,要求在半年内就回本,如果半年内不能回本,这个游戏项目可能就慢慢进入冷宫了。游戏行业的这种节奏,反映到数据生产角度,每秒钟产生几十万条事件,一天产生几十 TB 数据属于常态。
游戏业务需求非常多,如运营层、玩法层、经济层等。比如四五个人组成的一个流量小组,要投放 100 万流量,这个时间段内能否赚回这 100 万?这几天如何分析数据?对于这样的数据分析需求,如果还用传统的方法做成看板展示,基本上不太现实。这种时候,团队通常会直接使用 SQL 查询,再把数据导出到 Excel 表里。一个个灵活的需求都是这样去实现分析的,需求量极大。

此外,游戏行业的数据工程师经常会面对堆积如山的需求量。很多在海外工作的朋友头衔叫“Data Engineer”(数据工程师)。最初很疑惑,他们做的是什么神奇工作?但交流后才发现,他们大部分时间都在写 SQL,做临时统计和需求导出,基本上每天要做很多个 Excel,可能有 30 多个甚至几百个的任务。
在如此庞大的需求下,游戏行业的数据治理非常复杂。数据来源方面,经常分成网页游戏、客户端游戏,而客户端游戏中又细分出不同的手机平台,比如 iPhone 和安卓,而安卓又分成不同品牌。这些不同品牌、不同渠道来的用户情况如何?用户体验怎么样?甚至具体到不同尺寸屏幕上的游戏效果如何?再比如说游戏的码率问题,通常看到的是每秒 60 帧的数据,而很多游戏会把这 60 帧里的每一帧都存下来,甚至每次交互的时延数据也都保存下来,以便做后续的优化。另外,游戏中还会有“爽感刺激”设计,比如玩家在游戏过程中砍一个怪,系统会给予什么奖励?玩家完成某个任务后,能否实时推送相应奖励?或者一局对战只有 15 分钟,结束之后如何快速匹配下一局对手,让玩家的游戏体验更好,留存更高?如何做到实时处理?一局结束之后如何快速展示玩家的荣耀时刻和游戏战绩?这些都是对实时流计算能力的巨大挑战。
曾经接触过一个团队,游戏排名在 iPhone 榜单上进入了 TOP 10,当时他们的大数据团队有 50 多人,但仍然接不完所有业务需求,一个需求通常要排两到三天才能解决。这种情况在传统的大数据团队里非常常见,成为一种标准的业务处理模式。所以,面对传统大数据方案的快速业务迭代,很多公司会陷入更狼狈的境地。在实际场景中,可以看到大量的 Flink 任务满天飞,各种任务迟到和排队现象十分严重。
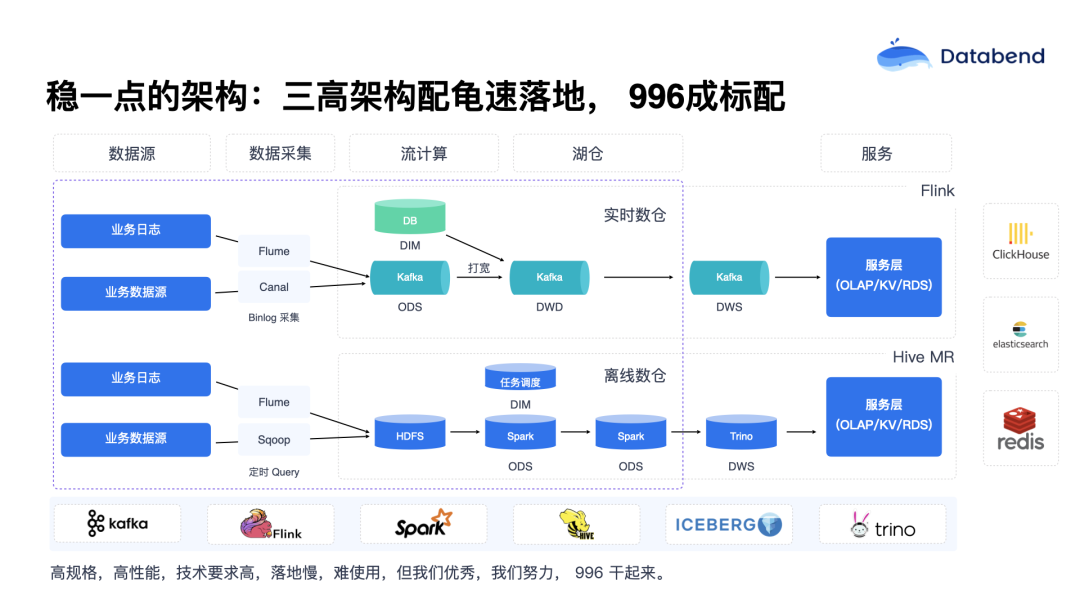
一些游戏公司早期架构都是类似情况。虽然看上去只有几个组件,但实际情况远比想象的复杂得多。比如一个 NameNode 或者目录服务背后,至少还有一个 MySQL 数据库,服务之间的可用性发现至少要依靠 ZooKeeper。这些堆积起来的组件,最终发现远比想象中多。如果环境搭建没有做到很好的自动化,就会非常难搞。游戏行业不管是哪个环节,如果没做好自动化管理,基本上都是 996 工作模式。甚至更严重的情况是“996 是起步,严重的可能高达 8 个月的高强度工作”。这里面的组件太多,出问题后的排查也特别困难。

此外,平台稳定性也是很大的挑战。数据搬运工作往往占据了 80% 的工作量。数据工程师常常自嘲是“数据搬运工”,每天最擅长的事情就是把数据从 A 搬到 B,从 B 搬到 C,进行聚合计算和数据钻取分析。平台的计算资源瓶颈明显, 平台的任务队列化非常严重。MySQL 数据库讲究的是高并发,强调一次可以处理几万个并发请求,而传统大数据团队却常常忍受任务一个个慢慢跑,实际处理起来非常麻烦。
此外,游戏平台还有一个最大问题是安全方面的挑战。平台引入了大量堆积的组件,虽然这些组件当时很好用,但一旦出安全问题,就完全不知道是哪一个组件出了故障。最后数据环节一旦掉链子,整个数据链路都会被拖累。因此在大数据平台中,网络隔离是特别需要关注的环节。还有一种严重挑战是一旦 IDC 出现故障,往往需要迁往外机房,搞同城互备,这也是一件麻烦的事。
Databend 从过去的数据仅能“存起来”,逐渐转变为切入业务场景,直接帮助业务提升效率,为游戏行业数据分析带来 10 倍收益提升。想了解 Databend 是如何解决这些严重挑战,请点击阅读《Databend Cloud 如何给游戏行业数据分析带来 10 倍收益提升?》了解详细方案。
多点 DMALL 的可演进式云原生数据架构变迁
多点DMALL 成立于 2015 年,持续深耕零售业,为企业提供一站式全渠道数字零售解决方案 DMALL OS。作为一站式全渠道数字零售解决方案服务商,多点DMALL 通过数字化解构重构零售产业,提供端到端的商业 SaaS。作为 DMALL OS 数字化能力的技术底座,大数据平台历经多次迭代平稳支撑了 DMALL 零售云 To B业务的开展。李铭老师在分享中详解了多点DMALL 大数据技术经历的从存算一体到存算分离,再到湖仓一体和 AI for Data 的架构调整变迁。
多云场景下数据湖设计原则
从 2006 年至今,大数据架构经过了一个漫长的发展历程。从最开始的 MapReduce 编程模型,到纯内存式的Spark,后来又到实时流 Flink,直至现在变成更轻量级的云原生方式。其实大数据一直在探讨的就是怎样能更轻量、更快速、更便捷地使用大数据。
传统 Hadoop 技术栈弊端
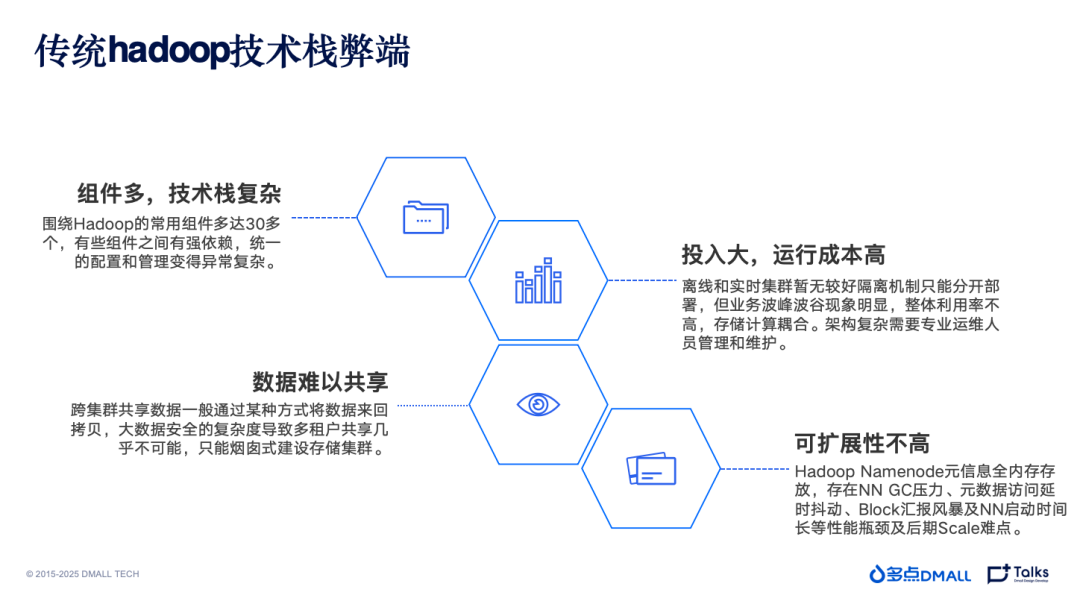
和很多企业一样,多点DMALL 的大数据体系在构建之初,也是采用传统 Hadoop存算一体的技术栈。在这个阶段,多点DMALL 大数据团队使用 CDH 发行版对组件进行统一管理 。但这一方式随着数据量的增长,暴露出越来越多的问题:
第一,组件多,技术栈复杂。 围绕 Hadoop 的常用组件多达 30 余个,有些组件技术之间存在强依赖。随着时间推移,新技术引入异常麻烦,需要考虑非常多兼容性问题
第二,投入大,运行成本高。 Hadoop 生态体系下,资源隔离无法做的很精细,导致实时和离线集群只能分开部署,加上潮汐现象严重,计算资源的整体利用率很低。另一方面,复杂的架构需要更专业的运维人员进行管理和维护,带来更大的成本开销。
第三,数据难以共享。 存算一体的数据架构下跨集群的数据共享需要面对许多现实的挑战,大数据安全的复杂度导致多租户共享几乎不可能,到最后的实现方案只能趋向于烟囱式的建设存储集群。
第四,可扩展性不高。 Hadoop ****集群扩展到一定程度后,NameNode 会暴露出 GC 压力、元数据访问延时抖动、 Block 汇报风暴等问题,这会不断加大整个集群的稳定性风险。
新一代数据架构核心逻辑
2022 年左右,多点DMALL开启全面To B转型,为越来越多的B端客户提供零售全渠道解决方案,需要具备在多云环境下提供更具性价比、可复用的大数据底层基座和平台工具链。多点DMALL 大数据团队开始结合已有经验和后续业务需求,设计搭建存算分离、轻量级、可扩展、云中立大数据集群架构。
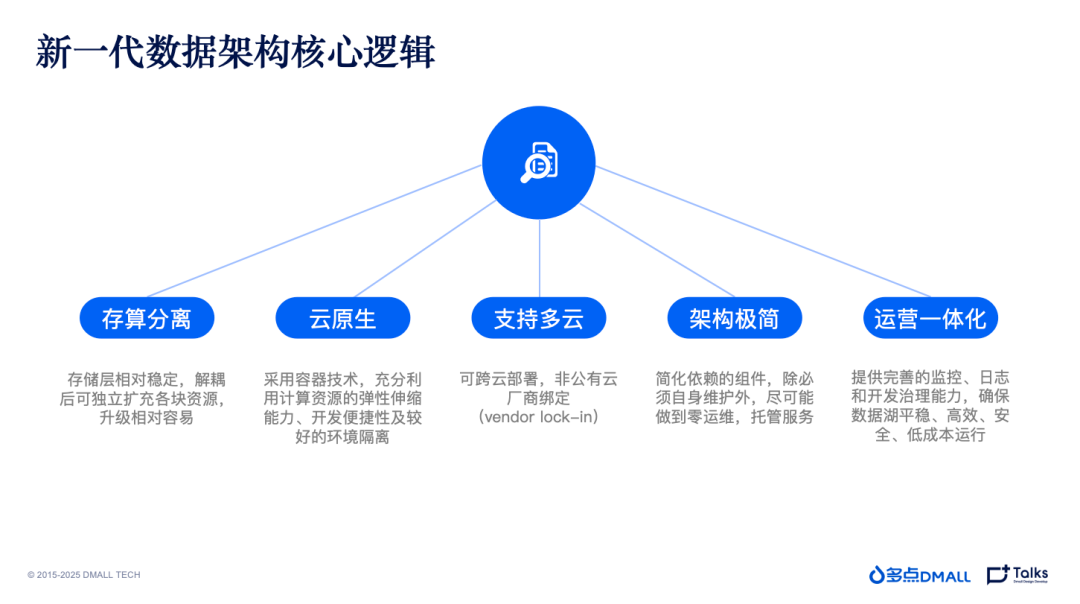
- 存算分离。 将存储和计算解耦,可独立扩充各类资源,升级相对容易。存储层可充分利用成本便宜的对象存储。
- 云原生。 采用容器技术,充分利用计算资源的弹性伸缩能力,在扩容时无需再经过层层审批,获得开发便捷性和较好的环境隔离。
- 支持多云。 B 端客户的一个显著特点是,客户对云厂商的选择是有决定权的。为此,多点DMALL 的大数据架构必须支持多云,可跨云部署。
- 架构极简。 相较于传统的 Hadoop 生态,云原生的建设需要简化所依赖的组件,除必须自身维护外,尽可能做到零运维,完全托管服务。
- 运营一体化。 在整个集群的运行中,可以提供完整的监控、日志和开发治理能力,确保数据湖平稳、高效、安全、低成本运行。
数据湖核心技术底座架构解析
基于以上设计原则,多点DMALL 开始搭建新的架构。接下来对部分组件的升级切换方案进行阐述。
弹性存储方案
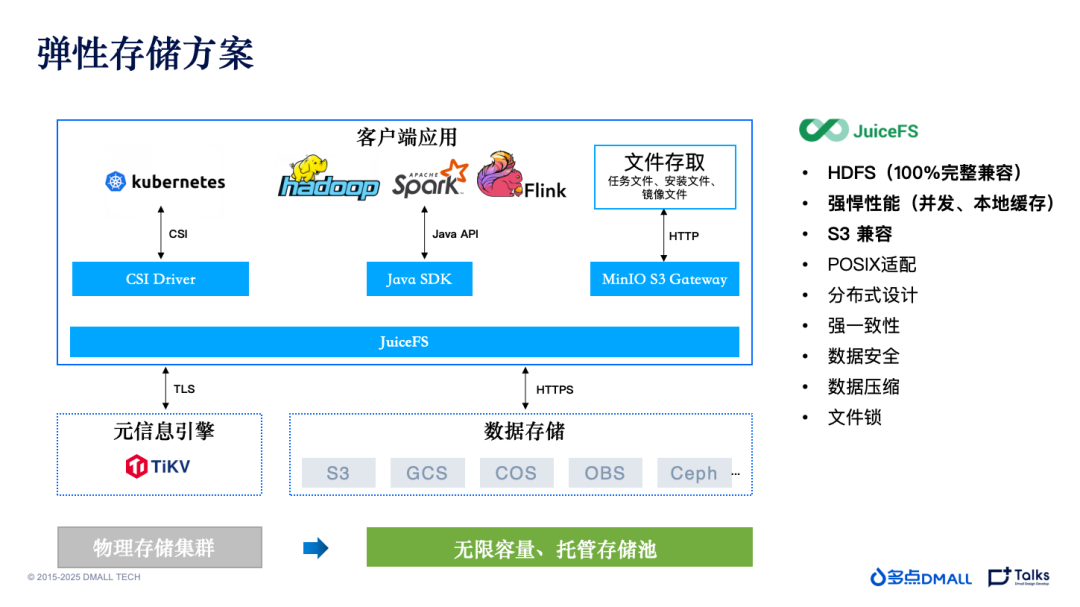
存算分离的第一步,便是要解决数据如何从 HDFS 集群上快速切换到云服务商存储服务的问题。经过多个项目的对比和选择,最后确定使用开源的 JuiceFS。它 100% 完整兼容 HDFS 协议,这意味着之前绝大部分引擎不需要做额外的兼容和操作,直接使用 JuiceFS 插件,就可以写入对象存储。
此外,JuiceFS 的性能非常强悍。对象存储速度相比 HDFS 原生上就要慢很多,但 JuiceFS 做了很多层缓存来提升性能。
第三,JuiceFS 具有 S3 兼容性。除提供了 Java SDK 外,它还提供了 S3 Gateway,有一些必须要走对象存储协议的操作,就可以直接对接。这样一来,对象存储可以完全替换之前的HDFS,包括代码层面、引擎层面全部实现统一,不用再担心底层的存储是什么。同时,JuiceFS 原生支持包括阿里云、谷歌云、AWS、腾讯云等在内的市面上几乎所有云的对接,无需做额外开发。
基于以上原因,多点DMALL大数据团队最终选用了 JuiceFS 作为与对象存储间的中介,正式将 HDFS 存储端迁移到了对象存储。
存储 容灾备份
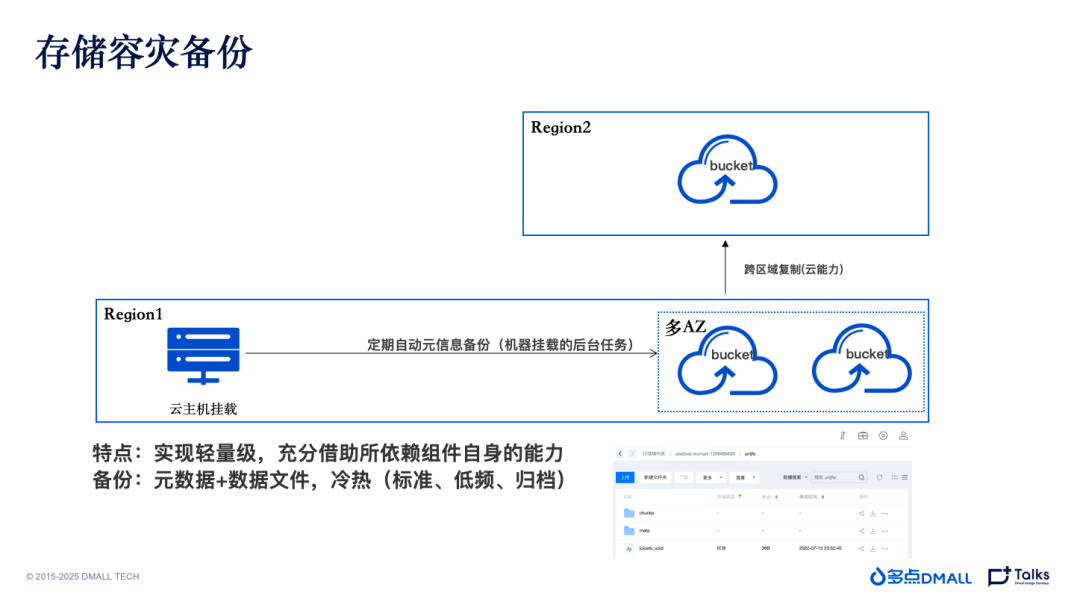
在数据容灾和备份方面,主要依靠对象存储本身的支持多云多 AZ 跨区域复制能力。JuiceFS 本身提供元数据备份同步的功能,可进行实时热数据同步功能。在这样能力的加持下,对于对象存储替换HDFS的方案可以完全放心。
权限升级设计
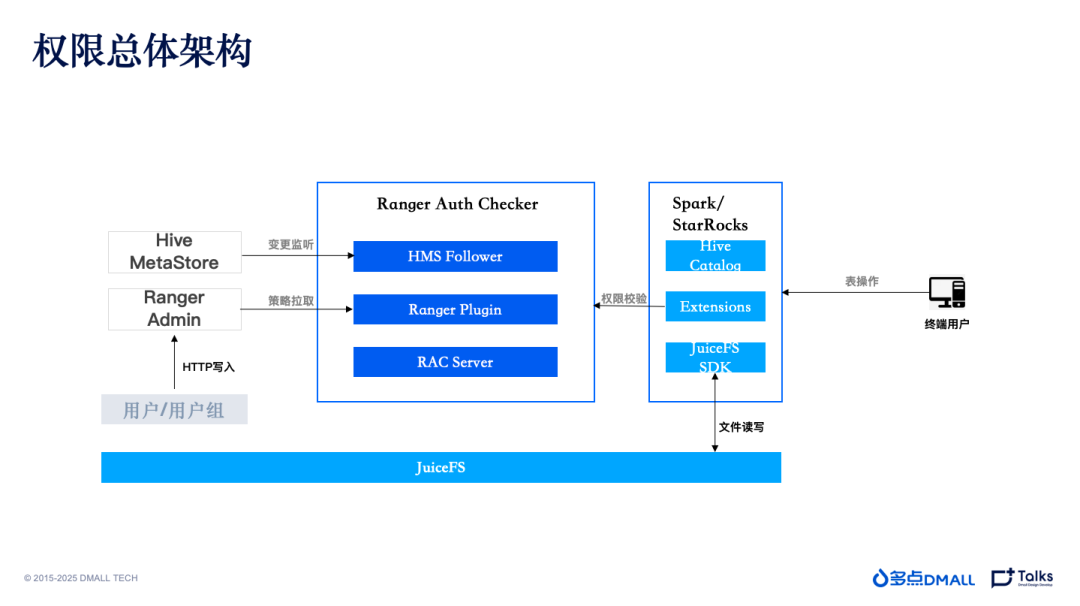
权限管控方面,多点DMALL 最开始使用 Apache Sentry,也是 CDH 发行版的默认引擎。在云原生升级中,我们直接升级到业界普遍认可的 Apache Ranger (后简称Ranger)。但是,就现有公开资料中关于 Ranger 实践文章中不难发现,Ranger 也存在不足。例如,Ranger Admin 很容易形成连接风暴,造成权限检测压力。另一方面, Ranger 的设计基于PBAC的模型,其权限底层存储会拆分为多条,简单来说如果用户申请了库表的权限,还需要单独申请(或通过服务自动生成)底层路径的权限。这就意味着在申请权限时需要做事务,维护一致性将是一个非常大的风险。
为了从根本上解决这些潜在的风险,多点DMALL 大数据团队自研了一个小组件—— Ranger Auth Checker (简称 RAC)。它的核心功能在于实现了库表和路径权限的映射。Ranger 里仅存储库表的权限,而路径权限会通过这个组件进行映射,映射成库表以确认是否有权限。此外,RAC服务统一了Ranger的权限缓存,解决了多个引擎缓存可能存在的同步不一致的问题。RAC服务仿照Ranger接口,对外暴露HTTP接口,提供多个引擎和服务的鉴权。
多点DMALL的权限进化设计,最终实现了库表和路径授权的解耦。并且在此基础上,多点DMALL很轻松的解决掉Ranger不支持的视图权限的问题,并解决了 Ranger 授权信息的冗余和膨胀的风险,避免了 Ranger Admin 的连接风暴。
弹性计算架构方案
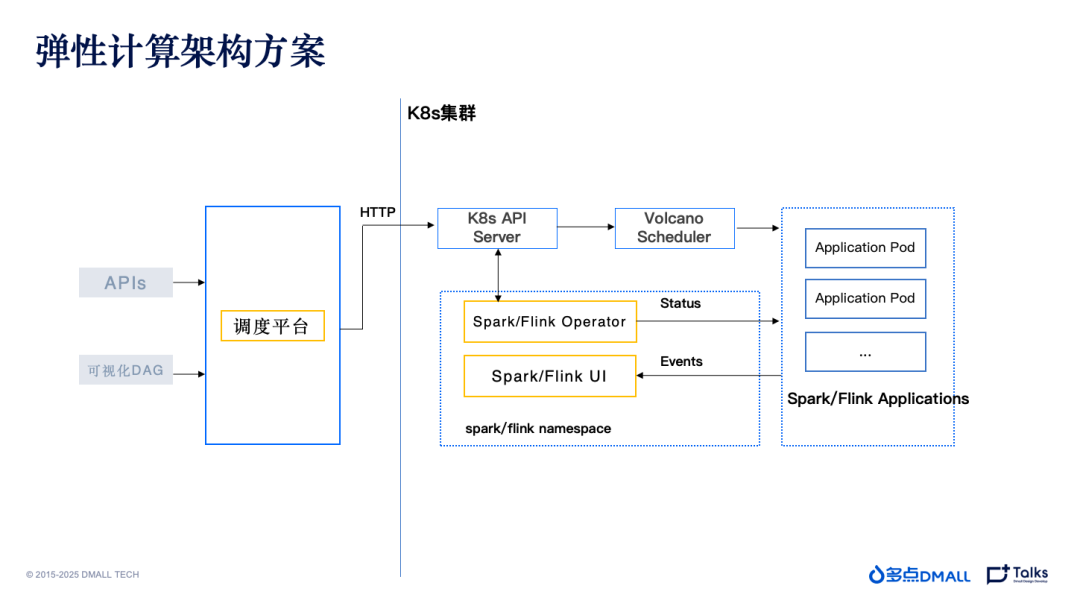
进行云原生升级后另一个需要重点关注的问题就是任务调度方案的切换。首先是调度器的选择。网上有许多开源的 Kubernetes 调度器,经过分析和对比,最终选用 volcano。作为历史“悠久”的项目,volcano 也是第一个被 Spark 和 Flink 官方社区对接的 Kubernetes 调度器,尤其在当前 Spark3.x 中有着很好的适配效果。volcano 支持多种调度算法,还提供了类似 Yarn 的队列支持业务层面的资源隔离,可以很好的辅助任务平滑迁移到新架构上。在使用中,多点DMALL意识到原生支持的 Node 亲和性和反亲和性的效果粒度较粗,为了能够更精细的控制各个任务 pod 的分布,添加了关于 pod 的亲和性配置,并已提交到开源社区。
另一个需要解决的是提交 Spark 和 Flink 任务的方式。下面以 Spark 为例。众所周知,当前提交 Spark 任务到 Kubernetes 共有两种方式:原生 Spark-Submit 和 Google Operator。
-
原生 Spark-Submit:
- 是 Spark 社区提供的最直接的方式,内部通过 Kubernetes API 在 Kubernetes 上创建 Driver Pod,然后此 Pod再创建管理其他 Executor Pod。
- 优势:简单直接,对 Spark 熟悉的开发者更容易上手。
- 劣势:Spark 与 Kubernetes 的更新频率并非同步,很多参数的处理转换并不及时,导致许多 Kubernetes 的特性无法利用。除此之外,也缺乏对 Spark 任务统一的管理组件,任务的状态、日志等处理需要额外定制。
-
Google Operator
- Google 提供的一种提交方式。Google Operator 会在 Kubernetes 上启动一个常驻服务,用户通过API将需要提交的任务信息直接传递给该服务,该服务收到后便启动对应的 Pod。
- 优势:拥有统一管理的服务,对于任务状态跟踪、日志处理等都有较为完善的方案。提交的任务是以Kubernetes YAML 的方式,支持绝大部分 Kubernetes 的参数,想要利用 Kubernetes 的特性更加便捷。
- 劣势:这种方式上手不如 Spark-Submit 的方式那么直观,需要一定学习成本。而且根据我们的经验,Google Operator 的社区维护并不活跃,使用中会发现一些问题需要自主调整代码,建议上手前充分阅读源码。
在新架构中多点DMALL针对不同的场景使用了不同的方式。就离线任务而言,自研的调度体系 TaskCenter 采用 Google Operator 的方式,支持更多 Kubernetes 特性的使用,也可以更方便的管理正在运行的 Spark Application;至于即席查询,基于所选用的 Apache Kyuubi 组件,还是采用传统的 Spark-Submit 的方式进行任务的提交。毕竟即席查询的用户仅关注查询的结果,对于执行进度、日志等更详细的信息往往并不关心。
自适应 Shuffle 存储
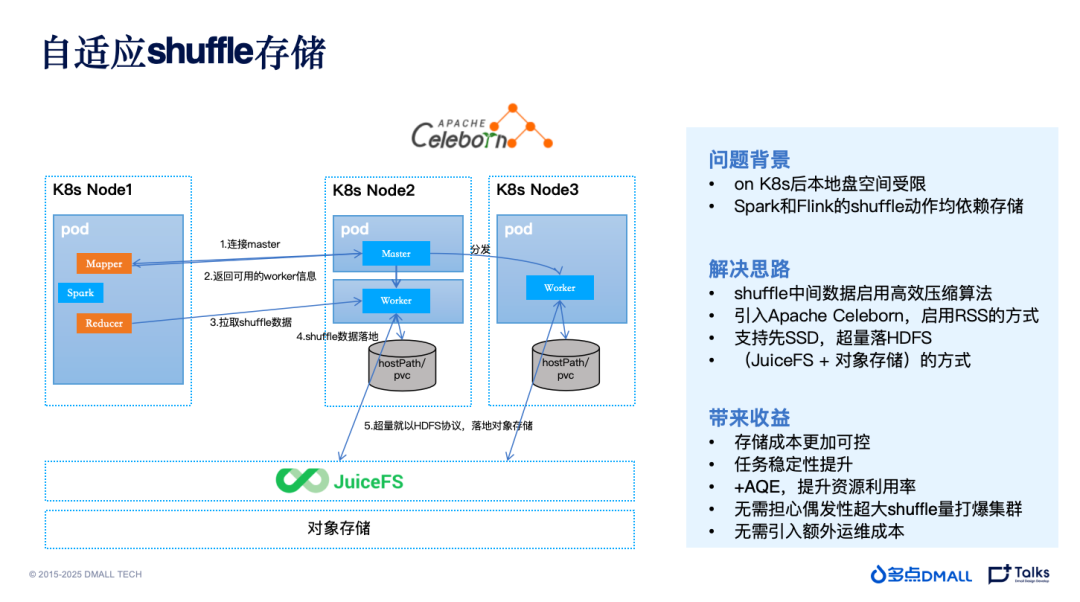
Shuffle 的处理绝对算是 Spark on Yarn 升级到 on Kubernetes 时大部分企业都会面临的问题了。传统的 on Yarn 的方式,Shuffle 可以依赖节点挂载的大容量磁盘进行处理,但如果 on Kubernetes 还是以这种方式解决,那就是视“存算分离”的目的于无物了。再加上 Spark3.x 开始支持 Dynamic Allocation,如果没有很好的处理 Shuffle 的数据,这个资源节省“利器”就无法有效利用。
经过长时间的调研测试,多点DMALL最终决定选用开源的 Apache Celeborn 组件进行处理。Celeborn 部署在大数据集群Kubernetes 中,会首先将 Shuffle 数据存储在本地磁盘中。一些集群中为了避免与其他落盘数据争抢资源,也会通过 PVC 的方式,使用云厂商提供的块存储等进行 Shuffle 数据存储。当本地磁盘或块存储的容量超过设定的阈值时,Celeborn 会将数据推到 HDFS 中。同样的,在这里多点DMALL使用 JuiceFS,将写 HDFS 转化为写对象存储。从此Shuffle 有海量对象存储做后备,不用担心其丢失的问题,Dynamic Resource Allocation 也可以充分利用起来,提升整体 Spark性能。
SQL 查询代理层
大数据即席查询 与 OLAP 面临的场景略有不同。大数据的即席查询更多是对数据的探索以及转变为定时执行任务的语法适配。传统的Hadoop生态中主要靠HiveServer2和Impala进行即席查询。在云原生升级过程中发现可以选用开源的 Apache Kyuubi (后简称Kyuubi)进行替代。Kyuubi天生能和 Spark 对接,进行多租户的Spark Thrift Server管理。并且完全兼容 HiveServer2 协议,灵活可扩展的代理适配多引擎、主流数据湖格式,高可用、多租户、高并发和可持续演进的服务架构。还有灵活的认证模式和内置 SQL 层权限校验,可以充分复用 Spark 最新版本的 DRA 和 AQE 特性。
数据湖研发与运营能力建设
研发工具链介绍
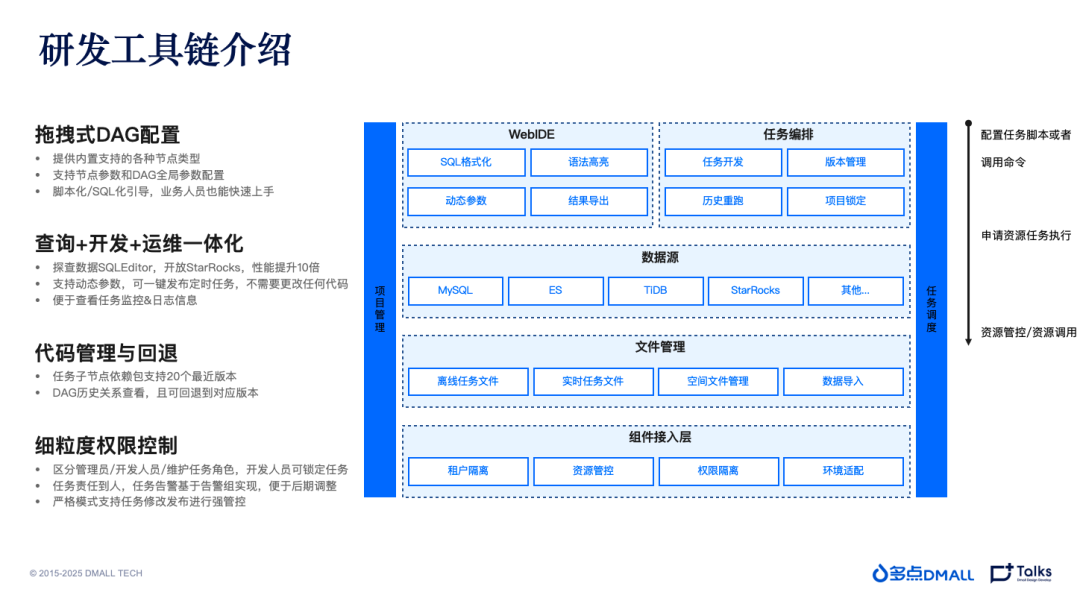
多点DMALL的研发工具链均为自研,包括数据集成、数据开发、任务调度、数据资产等功能模块,统称UniDATA大数据平台。在该平台中,不仅支持拖拽式的DAG设置、纯SQL编写开发模式,提升开发效率;还支持代码版本管理,支持任务回退和历史关系查看等。在平台中,对任务的权限管控也同样重视,区分多个角色,严格保障任务和数据的安全。
基于云原生的小时级标准化部署交付
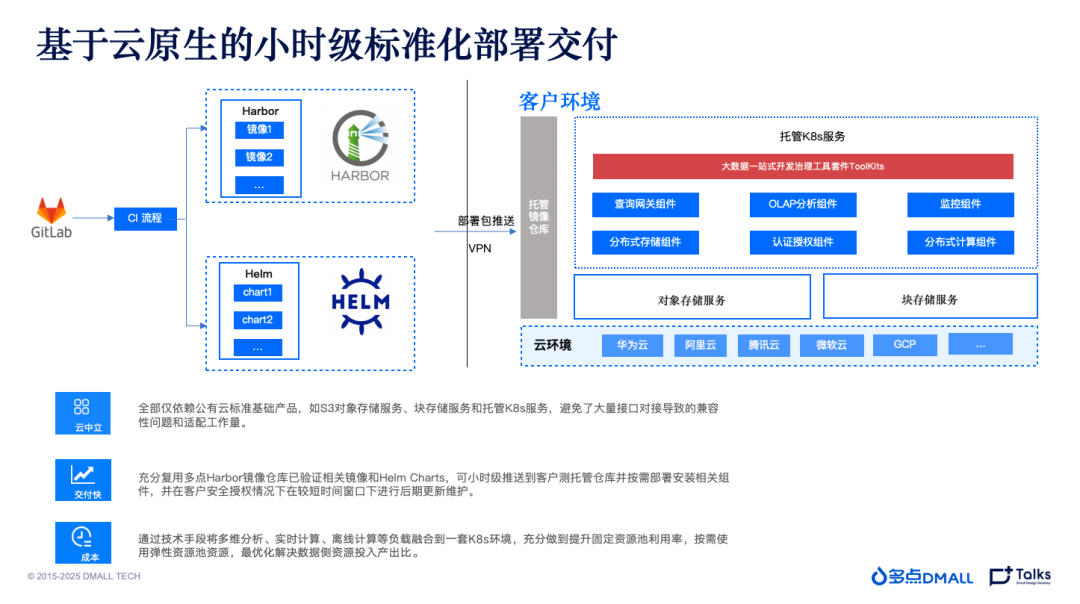
云原生升级后,多点DMALL的大数据服务就可以做到小时级标准化的部署交付。通过 GitLab 走 CI 流程,可以直接构建镜像。云原生升级后的所有数据服务代码都是中立的,无环境配置和差异,因此镜像在各个云厂商或各个环境都适用。为新客户进行交付时,将镜像推送到客户所属环境托管的云镜像仓库后,大数据团队就可以一键拉起所有服务和引擎,供客户使用。在镜像推送顺利且对象存储等资源支持完备的情况下,部署和交付操作仅需要一个人在一个小时内就可以全部完成。
这次升级带来的另一个好处是获得了极致的性价比:
混合负载,提升资源利用率。 在云端,一般而言在同等激活时间下,弹性节点的价格是包年包月的固定节点价格的 3 倍左右。多点DMALL会以两种资源配合使用。固定节点池主要用于长期存活的大数据服务、引擎、实时任务等,节点数量少,但稳定不会变动。弹性节点池用于需要更多资源的大数据任务等,例如夜间大数据数据仓库任务启动时,固定节点资源不足就会激活启动弹性节点。随用随取,不用就回收的资源逻辑可以把成本压到极致。
另一方面,多点DMALL的大数据团队将 OLAP 集群也混入了同一个Kubernetes集群内。传统的做法中,因为担心OLAP与大数据任务之间资源相互抢占相互影响,多会单独部署OLAP。但依托弹性节点池的规划,以及OLAP引擎存算分离化的发展,我们将OLAP引擎也引入Kubernetes集群内。从监控上来看,白天大数据集群任务少压力小的时间段内,正是客户查看报表、OLAP引擎开始抢占资源的时间;到了夜里,OLAP引擎释放空闲资源供大数据T+1任务和数仓构建。这样的设计大大提升了机器的资源利用率,进一步降低了成本。
削峰填谷,搭建湖仓一体化。 如上所述,先前多点DMALL夜间集群压力高峰主要来自于数仓的搭建,从 ODS 层开始,到 DWD、ADS 一层层执行构建,给集群带来不小的风险。在引入了 Apache Iceberg、搭建湖仓一体化,以前需要每天凌晨处理的数据,可以拆分到白天时间段内按小时级进行同步,大大降低了夜间集群压力和负载,转而分化到日间进行。另一方面,不论是大数据引擎Spark、Flink,还是OLAP引擎,均直接对接数据湖,读取Iceberg中的数据,减少多次数据开发和存储,避免多级数据的不一致问题,更进一步提升数据利用率、降低成本。
实践心得及展望

剪裁架构,设计 Lite 版: 针对一些体量较小、数据量不大的客户场景,提供更简单的轻量级架构设计,使用纯湖仓组件搭建(Databend/StarRocks)。如果用户后面数据量大了,需求更丰富,再无缝升级到完整版本。 持续关注批流一体方案: 当前技术发展阶段,存储侧有 Apche Paimon 等项目支持,但引擎侧依旧割裂。Spark 和 Flink 依旧难以合并,最终我们希望可以将二者合并,只留一个引擎减少使用复杂度。 轻 数仓 的设计: 现有的数仓层级比较重,多层级的设计不论是开发还是运维都很复杂。希望以后使用多层级物化视图来替代传统的数仓层级。将数仓建设变得更加简单,减少人工操作。 AI for Data : AI 是大势所趋,未来多点DMALL会全力推动 AI for Data 的实现。作为大数据底层,尽可能从被动响应演变到到主动智能方案,推动多模态湖仓建设。让 AI 支持从模型调试到应用发布的完整生命链条,全面提高大数据的价值体现。
DeepSeek 爆火的背后,高性能 AI 基础设施是如何工作的?
DeepSeek 出来之后,对于底层大模型的很多底层东西要求是很高的。如果大家对大模型了解的话,就会发现很多大模型的东西都是用 Python 程序写的,很多人开玩笑说,搞 AI 的人都是用 Python 去调用其他底层的库,俗称“调包侠”。
尤其是现在 DeepSeek 出来之后,对于很多大模型的底层架构提出了更高的要求。王璞博士介绍了自己团队在底层基础设施方面的思考:
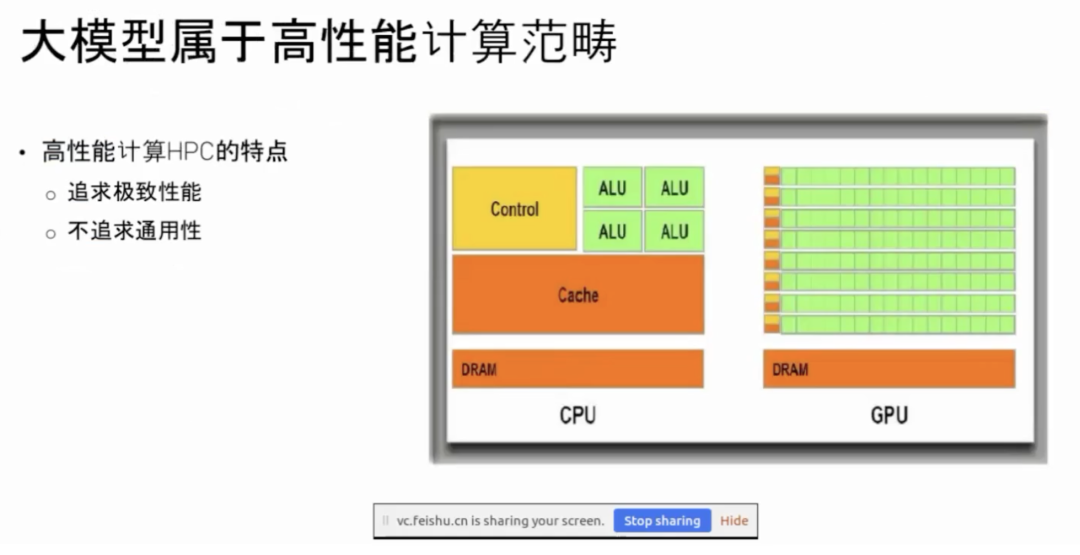
首先,这些大模型都属于高性能计算(High Performance Computing,简称 HPC)的范畴,这跟之前大家可能比较熟悉的分布式计算、云计算是不一样的。它的特点是追求极致的性能,而并不追求通用性。比如最近 DeepSeek 火了,之前国内比较常用的模型,是以“千问”为代表的,或者 LLaMA。
这些“千问”、LLaMA 这些模型属于稠密的 Transformer 架构,叫 Dense Transformer 结构,而 DeepSeek 的架构属于稀疏的 MoE 架构,也就是混合专家模型。这两种架构非常不一样。所以大家能看到,DeepSeek 火了之后,很多大模型的基础设施都得对 DeepSeek 进行重新的改造或者重构。这就是高性能计算很大的特点,它基本上没有太多的通用性。模型架构稍微改一改,比如 MoE 和之前的 Dense Transformer 架构不一样,底层很多东西都得改。为什么它不追求通用性呢?是因为高性能计算追求的是极致的性能,而极致性能和通用性本身就是天然矛盾的。
此外,高性能计算其实已经发展了几十年了,这波大模型火之前高性能计算一直是一个相对小众的领域,高性能计算发展至少有30年了甚至更久。从很早就以 GPU 为计算主力了,大概从上个世纪90年代就开始用 GPU,但当时 GPU 性能可能还不是特别强。
分布式计算基本上在 CPU 上,而高性能计算今天几乎都是用 GPU 的,大模型也都得用 GPU。所以大模型的架构首先是属于高性能计算的范畴。
GPU 的计算架构
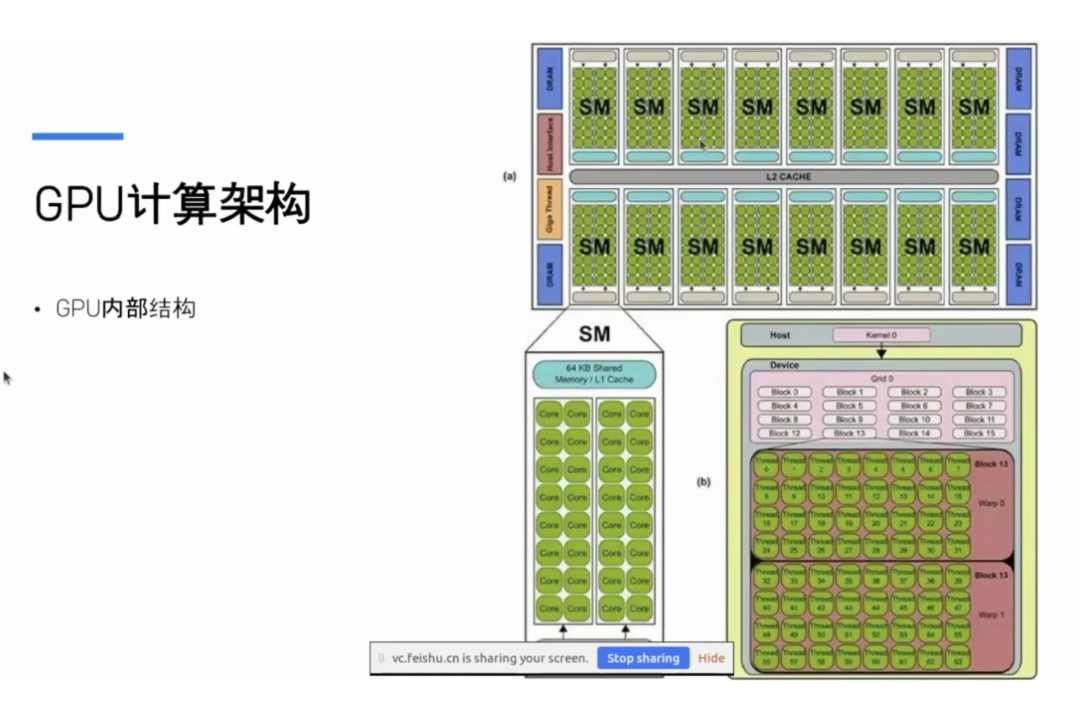
首先是 GPU 的内部结构,上图是一个典型的 GPU 结构图,以英伟达 GPU 为代表。GPU 里面有很多绿色的块,上面标着 SM,即 Streaming Multiprocessor。每个 Streaming Multiprocessor 里面有很多核(CUDA Core),每个核会跑一个线程。GPU 上写程序的时候是同时有很多线程一起运行,这些线程是按照分层的结构来组织起来的,这也是 CUDA 上的基本编程结构。
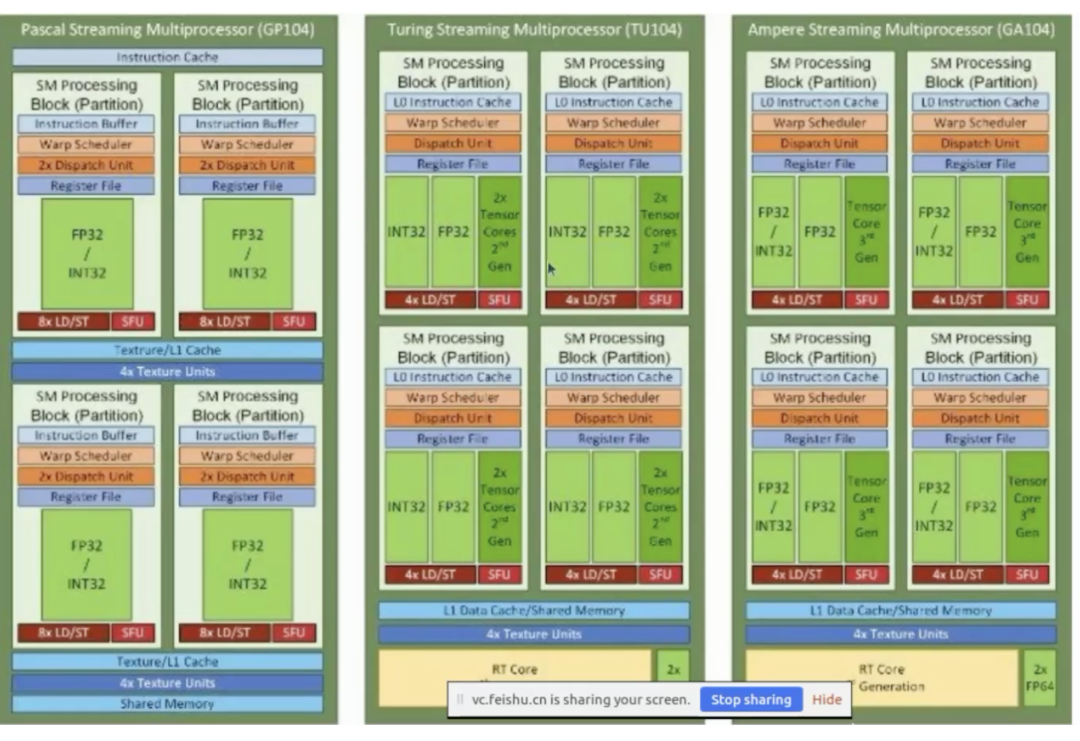
再详细看一下,这是前面几代 GPU 架构,有安培(Ampere,A100 架构),图灵(Turing),再往下是帕斯卡(Pascal)。现在的 H100 和 A100 架构差异并不大,内部细节有所区别。
以安培架构为例,右边的图画了4个 Streaming Multiprocessor。如果对标 CPU 概念,每个 Streaming Multiprocessor 相当于一颗 CPU,里面包含很多核心。有普通 CUDA 核心(浮点数、整数计算)和著名的 Tensor Core(矩阵运算)。A100 是第三代 Tensor Core,H100 是第四代 Tensor Core。
GPU 每个 Streaming Multiprocessor 里面还有 SFU(Special Function Unit),用于指数函数、对数函数等特殊函数的计算。还有指令缓存、指令分发、寄存器堆,这些跟 CPU 比较类似。GPU 特殊的是 Warp Scheduler(Warp 调度器),任务调度时不是一个线程调度,而是32个线程一起调度,即一个 Warp 一起调度。 外部是 L1 缓存或共享内存,还有用于渲染的 Texture Unit,以及用于光线追踪的 RT Core(Ray Tracing Core),这在游戏中使用较多。
GPU 编程以英伟达 CUDA 为代表,编程结构是一组线程组成一个线程块(block),一个 block 最多1024个线程,block 内的线程共享一些数据。多个 block 再组成一个 grid(网格),每个 grid 里有若干个 block,每个 block 又有若干个线程。这是 CUDA 编程线程的基本组织方式。
GPU 任务调度每次以 Warp 为单位(32个线程),CPU 每次做线程切换时有上下文切换开销,GPU Warp 切换时没有上下文切换。因为同一个 block 内线程共享上下文数据(寄存器文件、共享内存等),因此切换速度非常快。
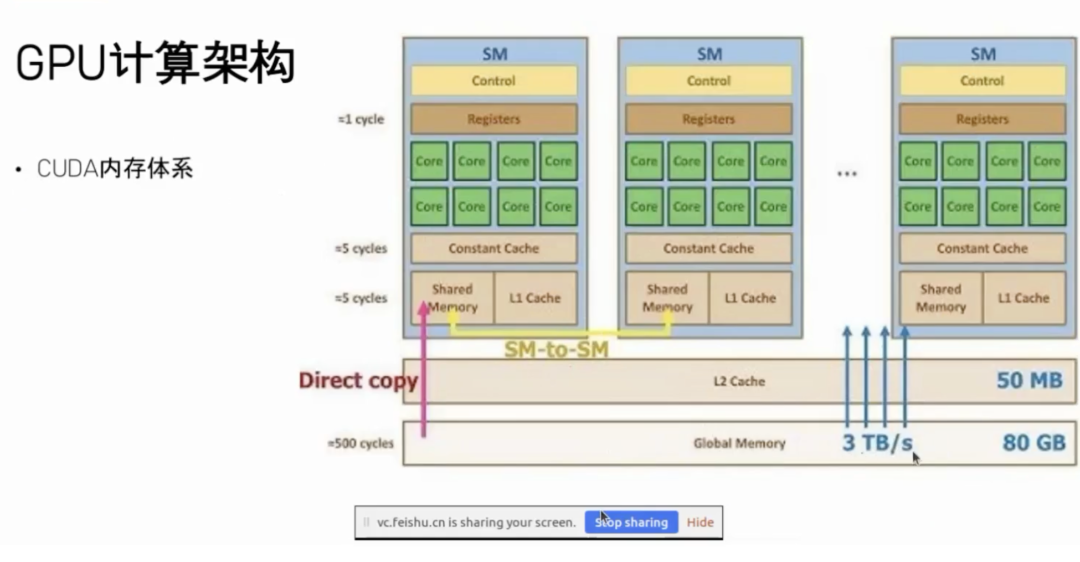
GPU 内存结构从外到内分别是 Global Memory(显存)、L2 缓存(不可编程)、共享内存(Shared Memory,本质是 L1 Cache,可编程定义大小),只读内存(Constant Cache),寄存器文件等。编程时,通常是数据从显存搬到共享内存(L1),再进行计算。
GPU 编程复杂度比 CPU 高很多,现在大部分人不会直接写 CUDA 程序,但如果想获得极致性能,必须底层手写 CUDA,而非仅靠 Python 调现有的库。
GPU 的通讯架构
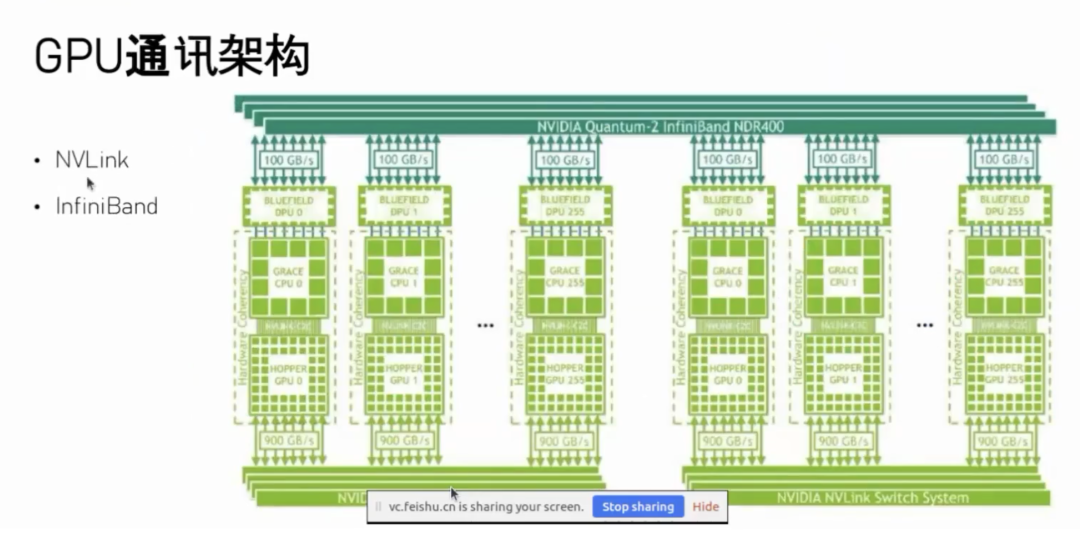
以 GH 架构(即 Grace Hopper 架构)为例,GH 架构的 GPU 里包含了一颗 CPU,每个 GPU 中都有一颗 CPU 和一颗 GPU。其中 CPU 部分叫做 Grace,本质上是基于 ARM 架构的 CPU,而 GPU 部分叫做 Hopper,就是目前 H100 或者 H200 使用的 GPU 架构。因此二者结合就称为 GH 架构。
这种 GH 架构的 GPU 通讯方式有两种: 一种是通过下方的 NVLink,即高速总线;另一种是通过上方的 InfiniBand,也就是高速网络。高速总线 NVLink 所能连接的 GPU 数量相对较少,一般是几十颗到几百颗 GPU;而高速网络 InfiniBand 所连接的 GPU 数量规模则可以更大,通常可达几千颗、上万颗,甚至是十万颗 GPU。因此 GPU 的通讯本质上是通过高速总线 NVLink 和高速网络 InfiniBand 来完成的。
在带宽方面,高速总线的带宽相对更高一些。资料标称的 NVLink 带宽为 900 GB/s,这里是双向带宽,如果换算成通常使用的单向带宽,则为 450 GB/s,这是非常高的带宽了。而高速网络 InfiniBand 标称的带宽为 100 Gb/s,这也是双向带宽,换算成单向带宽即为 50 GB/s,也就是我们常说的 400 Gb(小 b)单向网络带宽。
因此,每颗 GPU 都对应着一个高速网络接口和高速网卡,这个高速网卡名为 BlueField,即每颗 GPU 都对应一个网卡。另外,每颗 GPU 还可以通过 NVLink 总线连接其他 GPU。NVLink 和 InfiniBand 最大的区别在于速度不同:NVLink 速度更快,但所能连接的 GPU 数量有限;而 InfiniBand 虽然带宽相比 NVLink 较低,但扩展性较好,可以连接更多的 GPU,甚至可以连接更多的计算节点。
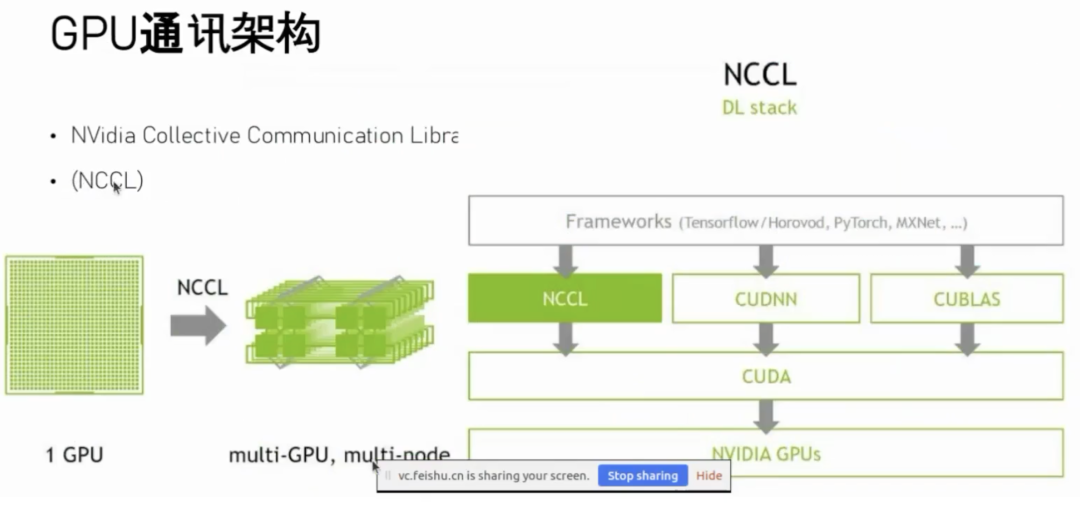
在 GPU 通讯架构的编程实现中,我们需要使用英伟达提供的集合通讯库 NCCL(NVIDIA Collective Communication Library)。该通讯库的特点在于:一颗 GPU 毕竟能计算的内容有限,那么如何使用多颗 GPU 一起来计算?特别是在大模型训练,包括推理任务中,单颗 GPU 根本无法装载大模型所有参数,因此需要将参数分布到多个 GPU 上,必然涉及跨 GPU 的通讯。
NCCL 通讯库在整个 CUDA 编程的层级结构中所处的位置大致如下:
- 底层是英伟达 GPU 硬件;
- GPU 硬件之上是 CUDA 驱动;
- CUDA 驱动之上则是 NCCL 这种集合通讯库或其他算子库,例如深度学习算子、线性代数算子、矩阵运算算子等;
- 再往上一层则是我们常见的大模型框架,例如 TensorFlow、PyTorch 等。这些框架自身并不进行具体计算,而是调用底层算子或通讯库。
GPU 的通讯模式与 CPU 通讯模式有很大区别。GPU 的通讯为什么称为“集合通讯”呢?本质原因在于 GPU 之间是对等关系,GPU 通讯中一般不使用主从(master-slave)结构,而使用对等(peer-to-peer)关系。这里有一个概念称为 rank,每个 rank 可以通俗理解为一张 GPU。例如有四张 GPU,就有四个 rank,这是高性能计算领域的术语。
我们以一种常见的 GPU 通讯模式——All Reduce 为例,All Reduce 是大模型训练中经常使用的通讯模式之一。比如,我们使用四张 GPU,每张 GPU 上分别加载了模型不同的参数。训练时计算梯度,每次计算完梯度后需要进行求和或平均,这个操作称为 All Reduce。举例来说,四张 GPU 上的数据都进行一次求和操作(sum),即 All Reduce 操作。
为什么称为 All Reduce 呢?是因为该求和操作是每张 GPU 都要执行的,即每张 GPU 都需要把其他三张 GPU 的数据读到自己 GPU 上,然后执行求和操作。所以称为 All Reduce,指的是所有 GPU 都需要进行规约操作,而求和是典型的规约操作。
经典的 All Reduce 方式是,每张 GPU 都要从其他 GPU 上读数据,这种通讯代价非常高。为此,目前常用两种优化方式:
第一种优化方式是环形规约(Ring All Reduce) ,即将所有 GPU 连接成一个环,数据通过环传递数次后,每张 GPU 就能获得其他 GPU 上的数据。例如第一颗 GPU 的数据发给第二颗 GPU,第二颗 GPU 发给第三颗 GPU,依次类推,同时第一个 GPU 再从最后一个 GPU 读数据,经过多轮传递后,每颗 GPU 都拥有其他 GPU 上的数据,最终完成求和操作。这是目前比较常用的一种优化方式。
另一种常用的优化方式是树形规约。当 GPU 数量非常多时,可以将求和操作组织成树形结构进行优化。在树形结构中,叶子节点代表 GPU,而中间节点则可以由网络交换机承担。例如英伟达的 InfiniBand 高速网络交换机,可以直接帮助 GPU 执行树形结构中的规约操作,尤其是求和操作,从而极大提升通讯效率。
GPU 的高性能编程准则
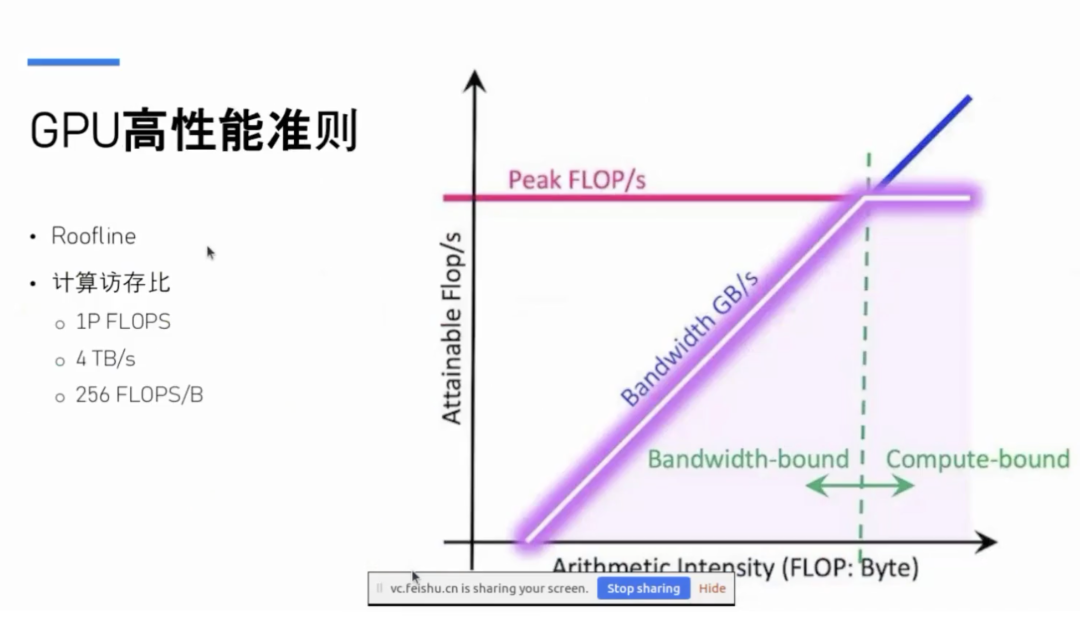
GPU 上写程序的时候,到底在追求什么?一般而言,这个准则称为 Roofline 模型,也就是“屋顶线模型”。CPU 领域也有类似的理念,不过在 CPU 中大家对 Roofline 模型的讨论相对较少。主要是在高性能计算领域,我们经常提到 Roofline 这个屋顶结构,它形象地看起来就像一个屋檐一样。那么如何理解这个模型呢?
其实 GPU 写程序的时候,追求的是极致的计算访存比(Arithmetic Intensity)。怎么理解这个概念?举个例子,比如当前比较先进的 GPU,其算力可能达到了 1 P FLOPS(每秒浮点运算次数为 1 P,即 101510^{15}1015 次浮点运算),这个 FLOPS 的意思就是浮点运算每秒次数。与此同时,假设 GPU 显存的带宽,比如现在比较新的 HBM3 或者 HBM4 显存,能够达到每秒 4 TB 的带宽。
那么,这 1 P 就代表了 GPU 的算力,而 4 TB 就代表了 GPU 显存的带宽。我们计算一下 GPU 的“计算访存比”,也就是拿这 1 P 除以 4 T,计算下来大约就是 256。那么,这个数字 256 到底意味着什么呢?它的含义是:每读取一个字节的数据之后,能不能对这个数据执行 256 次浮点运算?这个数值对应到 Roofline 图上的那条虚线,就是说,当你从显存中每读出一个字节的数据后,对这个数据执行的浮点运算次数如果超过了 256 次,就进入了所谓的“计算受限”区域,也就是说 GPU 总算力就这么多了,当每个字节需要执行的浮点操作超过 256 次之后,就落在这个区域内了。
相反,如果你每读取一个字节的数据,所需要执行的浮点运算次数少于 256 次,那么你就会落入“带宽受限”的区域。另外一种情况是,即使你每个字节所需要的浮点运算次数至少是 256 次,但如果你的显存带宽没有被充分利用,例如每秒只能加载 0.5 个字节,那么每秒最多只能做 128 次浮点运算,这种情况下同样也是处于带宽受限区域,因为此时显存带宽并没有充分发挥。
我们显然希望的是,GPU 程序尽可能不要落入带宽受限区域,而是尽可能地落入算力受限区域。也就是说,我们尽可能地将显存带宽充分利用起来。当然,倒也不一定非要将带宽用满到 4 TB/s,但每个单位字节的数据所要执行的浮点运算次数应该要远高于 256 次,尽可能地落在算力受限区域内。说得通俗一点,就是要尽量地把 GPU 内部的算力“吃满”。这就是我们追求的目标。当然,这也不可能完全实现,因为 GPU 运行时不可避免地要频繁地在显存和 GPU 内部之间进行数据搬运。因此,GPU 编程一个通俗的指导思想或者编程准则就是:
每次从显存加载一块数据到 GPU 内部之后,应该尽可能地对这块数据执行更多的计算。
这也就是 GPU 编程追求的无限提高计算访存比的理念。
另一方面,现在 GPU 编程当中还有一个现实因素,就是显存容量问题。如果大家熟悉 GPU 就会发现,现在 GPU 的显存容量已经成为制约模型训练和推理的重要因素。显存不够大,就无法放下更大的模型,因此显存容量现在已经成为性能的重要制约因素。
同时,从性能的角度出发,尤其是在训练过程中,存储设备的带宽越高,比如 L1 Cache 的带宽远高于 L2 Cache 的带宽,L2 Cache 的带宽也高于显存,显存的带宽又高于普通 DDR 内存。因此,存储设备的带宽越高,在 Roofline 模型中,这条屋顶线就会越向左上方移动,从而变相地提升计算访存比。这样,你的算力受限区域的性能上限也随之提高。
总之,我们在 GPU 上写程序时始终在追求尽可能地将 GPU 的算力“吃满”,每次从显存加载的数据,不应该在 GPU 内部仅计算一次,而应尽可能地多次利用,每块数据计算的次数越多越好。这就是 GPU 编程的高性能准则。
关于 Databend
Databend 是一款开源、弹性、低成本,基于对象存储也可以做实时分析的新式湖仓。期待您的关注,一起探索云原生数仓解决方案,打造新一代开源 Data Cloud。
👨💻 Databend Cloud:databend.cn
📖 Databend 文档:docs.databend.cn
💻 Wechat:Databend
✨ GitHub:github.com/databendlab…
相关文章:

下一代数据架构全景:云原生实践、行业解法与 AI 底座 | Databend Meetup 成都站回顾
3 月底,Databend 2025 开年首场 Meetup 在成都多点公司成功举办!活动特别邀请到四位重量级嘉宾:多点科技数据库架构师王春涛、多点DMALL数据平台负责人李铭、Databend联合创始人吴炳锡,以及鹏城实验室王璞博士。在春日的蓉城&…...

Kubernetes容器编排与云原生实践
第一部分:Kubernetes基础架构与核心原理 第1章 容器技术的演进与Kubernetes的诞生 1.1 虚拟化技术的三次革命 物理机时代:资源浪费严重,利用率不足15% 虚拟机突破:VMware与Hyper-V实现硬件虚拟化,利用率提升至50% …...

vue项目使用html2canvas和jspdf将页面导出成PDF文件
一、需求: 页面上某一部分内容需要生成pdf并下载 二、技术方案: 使用html2canvas和jsPDF插件 三、js代码 // 页面导出为pdf格式 import html2Canvas from "html2canvas"; import jsPDF from "jspdf"; import { uploadImg } f…...

JAVA实现在H5页面中点击链接直接进入微信小程序
在普通的Html5页面中如何实现点击URL链接直接进入微信小程序,不需要扫描小程序二维码? 网上介绍的很多方法是在小程序后台设置Schema,不过我进入我的小程序后台在开发设置里面 没有找到设置小程序Schema的地方,我是通过调用API接口…...

深入剖析 Kafka 的零拷贝原理:从操作系统到 Java 实践
Kafka 作为一款高性能的分布式消息系统,其卓越的吞吐量和低延迟特性得益于多种优化技术,其中“零拷贝”(Zero-Copy)是核心之一。零拷贝通过减少用户态与内核态之间的数据拷贝,提升了 Kafka 在消息传输中的效率。本文将…...

深度学习:AI 大模型时代的智能引擎
当 Deepspeek 以逼真到难辨真假的语音合成和视频生成技术横空出世,瞬间引发了全球对 AI 伦理与技术边界的激烈讨论。从伪造名人演讲、制造虚假新闻,到影视行业的特效革新,这项技术以惊人的速度渗透进大众视野。但在 Deepspeek 强大功能的背后…...

【Flask开发】嘿马文学web完整flask项目第4篇:4.分类,4.分类【附代码文档】
教程总体简介:2. 目标 1.1产品与开发 1.2环境配置 1.3 运行方式 1.4目录说明 1.5数据库设计 2.用户认证 Json Web Token(JWT) 3.书架 4.1分类列表 5.搜索 5.3搜索-精准&高匹配&推荐 6.小说 6.4推荐-同类热门推荐 7.浏览记录 8.1配置-阅读偏好 8.配置 9.1项目…...

【MySQL】002.MySQL数据库基础
文章目录 数据库基础1.1 什么是数据库1.2 基本使用创建数据库创建数据表表中插入数据查询表中的数据 1.3 主流数据库1.4 服务器,数据库,表关系1.5 MySQL架构1.6 SQL分类1.7 存储引擎1.7.1 存储引擎1.7.2 查看存储引擎1.7.3 存储引擎对比 前言:…...

Python爬取视频的架构方案,Python视频爬取入门教程
文章目录 前言方案概述架构设计详细实现步骤1.环境准备2. 网页请求模块3. 网页解析模块4. 视频下载模块5. 异常处理与日志模块 代码示例:性能优化注意事项 前言 以下是一个全面的使用 Python 爬取视频的架构方案,包含方案概述、架构设计、详细实现步骤、…...

ERC-20 代币标准
文章目录 一、什么是 ERC-20?核心价值:互操作性简化开发生态基石 二、ERC-20 的六大核心功能基础功能授权与代理转账事件通知 三、ERC-20 代币的典型应用场景四、ERC-20 的技术优势与局限性优势:局限性: 五、ERC-20 代币的创建步骤…...

SpringBoot实战1
SpringBoot实战1 一、开发环境,环境搭建-----创建项目 通过传统的Maven工程进行创建SpringBoot项目 (1)导入SpringBoot项目开发所需要的依赖 一个父依赖:(工件ID为:spring-boot-starter-parent…...

GSO-YOLO:基于全局稳定性优化的建筑工地目标检测算法解析
论文地址:https://arxiv.org/pdf/2407.00906 1. 论文概述 《GSO-YOLO: Global Stability Optimization YOLO for Construction Site Detection》提出了一种针对建筑工地复杂场景优化的目标检测模型。通过融合全局优化模块(GOM)、稳定捕捉模块(SCM)和创新的AIoU损失函…...

解读json.loads函数参数
json.loads()函数是解码JSON字符串为Python对象的核心工具。本文将深入探讨json.loads()函数的各个参数。 一、基本功能与输入类型 1. 功能概述 json.loads(s, *, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=N…...

2025.04.10-拼多多春招笔试第一题
📌 点击直达笔试专栏 👉《大厂笔试突围》 💻 春秋招笔试突围在线OJ 👉 笔试突围OJ 01. 神奇公园的福娃占卜 问题描述 LYA在一个神奇的公园里发现了一条特殊的小径,小径上排列着一群可爱的福娃玩偶。这条小径有 n n...

【学习笔记】CPU 的“超线程”是什么?
1. 什么是超线程? 超线程(Hyper-Threading)是Intel的技术,让一个物理CPU核心模拟出两个逻辑核心。 效果:4核CPU在系统中显示为8线程。 本质:通过复用空闲的硬件单元(如ALU、FPU)&a…...

Docker Harbor
下载Harbor安装包 wget https://github.com/goharbor/harbor/releases/download/v2.5.0/harbor-offline-installer-v2.5.0.tgz 解压安装包 tar xvf harbor-offline-installer-v2.5.0.tgz cd harbor 配置harbor vi harbor.yml hostname: registry.example.com # Harbor …...

天梯集训笔记整理
1.着色问题 直接标注哪些行和列是被标注过的,安全格子的数量就是未标注的行*列 #include <bits/stdc.h> using namespace std;const int N 1e510; int hang[N],lie[N];int main(){int n,m;cin>>n>>m;int q;cin>>q;while(q--){int x,y;ci…...
)
C语言复习笔记--指针(4)
在经过前几篇的复习后我们已经了解了大部分指针的类型,今天让我们继续复习指针的其他内容吧. 函数指针变量 函数指针变量的创建 什么是函数指针变量呢?函数指针变量应该是⽤来存放函数地址的,未来通过地址能够调⽤函数的。 那么函数是否有地址呢&#x…...

008二分答案+贪心判断——算法备赛
二分答案贪心判断 有些问题,从已知信息推出答案,细节太多,过程繁杂,不易解答。 从猜答案出发,贪心地判断该答案是否合法是个不错的思路,这要求所有可能的答案是单调的(例:x满足条件…...

Netty之内存池的原理和实战
深入理解Netty的内存池机制及其应用实践 在高性能网络编程中,内存管理对于系统的稳定性和性能至关重要。Netty作为一个高效的网络通信框架,通过引入内存池机制有效地解决了内存分配和回收频繁带来的性能瓶颈和内存碎片问题。本文将深入探讨Netty内存池的…...

Elasticsearch 向量数据库,原生支持 Google Cloud Vertex AI 平台
作者:来自 Elastic Valerio Arvizzigno Elasticsearch 将作为第一个第三方原生语义对齐引擎,支持 Google Cloud 的 Vertex AI 平台和 Google 的 Gemini 模型。这使得联合用户能够基于企业数据构建完全可定制的生成式 AI 体验,并借助 Elastics…...

《算法笔记》3.1小节——入门模拟->简单模拟
1001 害死人不偿命的(3n1)猜想 #include <iostream> using namespace std;int main() {int n,count0;cin>>n;while(n!1){if(n%20) n/2;else n(3*n1)/2;count1;}std::cout <<count;return 0; }1032 挖掘机技术哪家强 #include <iostream> using namespa…...
暴力娱乐篇24)
每日一题(小白)暴力娱乐篇24
由题已知这是一个匹配题目,题目已经说了三阶幻方是给定的,经过镜像和旋转,镜像*2旋转*4; 总共八种方案,然后接收每次的数据去匹配(跳过0),如果匹配就输出匹配的数组,如果…...

C++:函数模板类模板
程序员Amin 🙈作者简介:练习时长两年半,全栈up主 🙉个人主页:程序员Amin 🙊 P S : 点赞是免费的,却可以让写博客的作者开心好久好久😎 📚系列专栏:Java全…...
第18章:基于Global Context Vision Transformers(GCTx_unet)网络实现的oct图像中的黄斑水肿和裂孔分割
1. 网络概述 GCTx-UNET是基于传统UNet架构的改进版本,主要引入了以下几个关键创新: GCT模块:全局上下文变换器(Global Context Transformer)模块 多尺度特征融合:增强的特征提取能力 改进的跳跃连接:优化编码器与解…...

深入理解 Spring 的 MethodParameter 类
MethodParameter 是 Spring 框架中一个非常重要的类,它封装了方法参数(或返回类型)的元数据信息。这个类在 Spring MVC、AOP、数据绑定等多个模块中都有广泛应用。 核心功能 MethodParameter 主要提供以下功能: 获取参数类型信息…...

Docker部署HivisionIDPhotos1分钟生成标准尺寸证件照实操指南
文章目录 前言1. 安装Docker2. 本地部署HivisionIDPhotos3. 简单使用介绍4. 公网远程访问制作照片4.1 内网穿透工具安装4.2 创建远程连接公网地址 5. 配置固定公网地址 前言 相信大部分人办驾照、护照或者工作证时都得跑去照相馆,不仅费时还担心个人信息泄露。好消…...

python多线程+异步编程让你的程序运行更快
多线程简介 多线程是Python中实现并发编程的重要方式之一,它允许程序在同一时间内执行多个任务。在某些环境中使用多线程可以加快我们代码的执行速度,例如我们通过爬虫获得了一个图片的url数组,但是如果我们一个一个存储很明显会非常缓慢&…...
)
HDCP(五)
HDCP 2.2 测试用例设计详解 基于HDCP 2.2 CTS v1.1规范及协议核心机制,以下从正常流程与异常场景两大方向拆解测试用例设计要点,覆盖认证、密钥管理、拓扑验证等关键环节: 1. 正常流程测试 1.1 单设备认证 • 测试目标:验证源设…...

datagrip如何连接数据库
datagrip连接数据库的步骤 2025版本 想要链接数据库是需要一个jar包的,所以将上面进行删除之后,需要下载一个jar包 那么这个时候需要链接上传一个mysql链接的jar包 选择核心驱动类 上述操作完成之后,然后点击apply再点击ok即可 如下图说明my…...

Spring Boot 自动配置与启动原理全解析
下面分两部分系统讲解: 第一部分:Spring Boot 自动配置原理(核心是自动装配) 一、Spring Boot 的自动配置是干嘛的? 传统 Spring 开发时,你要写一堆 XML 或配置类,非常麻烦。Spring Boot 引入…...

python 基础:句子缩写
n int(input()) for _ in range(n):words input().split()result ""for word in words:result word[0].upper()print(result)知识点讲解 input()函数 用于从标准输入(通常是键盘)读取用户输入的内容。它返回的是字符串类型。例如在代码中…...
)
QML 中 Z 轴顺序(z 属性)
在 QML 中,z 属性用于控制元素的堆叠顺序(Z 轴顺序),决定元素在视觉上的前后层次关系。 基本概念 默认行为: 所有元素的默认 z 值为 0 同层级元素后声明的会覆盖先声明的 父元素的 z 值会影响所有子元素 核心规则…...

Redis快的原因
1、基于内存实现 Redis将所有数据存储在内存中,因此它可以非常快速地读取和写入数据,而无需像传统数据库那样将数据从磁盘读取和写入磁盘,这样也就不受I/O限制。 2、I/O多路复用 多路指的是多个socket连接;复用指的是复用一个线…...
)
蓝桥杯c ++笔记(含算法 贪心+动态规划+dp+进制转化+便利等)
蓝桥杯 #include <iostream> #include <vector> #include <algorithm> #include <string> using namespace std; //常使用的头文件动态规划 小蓝在黑板上连续写下从 11 到 20232023 之间所有的整数,得到了一个数字序列: S12345…...

每日算法-250410
今天分享两道 LeetCode 题目,它们都可以巧妙地利用二分查找来解决。 275. H 指数 II 问题描述 思路:二分查找 H 指数的定义是:一个科学家有 h 篇论文分别被引用了至少 h 次。 题目给定的 citations 数组是升序排列的。这为我们使用二分查找…...

swagger + Document
swagger 虽然有了api接口,对于复杂接口返回值说明,文档还是不能少。如果是一个人做的还简单一点,现在都搞前后端分离,谁知道你要取那个值呢...
)
线程同步与互斥(下)
线程同步与互斥(中)https://blog.csdn.net/Small_entreprene/article/details/147003513?fromshareblogdetail&sharetypeblogdetail&sharerId147003513&sharereferPC&sharesourceSmall_entreprene&sharefromfrom_link我们学习了互斥…...

MySQL 优化教程:让你的数据库飞起来
文章目录 前言一、数据库设计优化1. 合理设计表结构2. 范式化与反范式化3. 合理使用索引 二、查询优化1. 避免使用 SELECT *2. 优化 WHERE 子句3. 优化 JOIN 操作 三、服务器配置优化1. 调整内存分配2. 调整并发参数3. 优化磁盘 I/O 四、监控与分析1. 使用 EXPLAIN 分析查询语句…...

SD + Contronet,扩散模型V1.5+约束条件后续优化:保存Canny边缘图,便于视觉理解——stable diffusion项目学习笔记
目录 前言 背景与需求 代码改进方案 运行过程: 1、Run编辑 2、过程: 3、过程时间线: 4、最终效果展示: 总结与展望 前言 机器学习缺点之一:即不可解释性。最近,我在使用stable diffusion v1.5 Co…...

位掩码、哈希表、异或运算、杨辉三角、素数查找、前缀和
1、位掩码 对二进制数操作的方法,(mask1<<n),将数mask的第n位置为1,其它位置为0,即1000...2^n,当n较小时,可以用于解决类似于0/1背包的问题,要么是0,要么是1&…...
)
安装OpenJDK1.8 17 (macos M芯片)
安装OpenJDK 1.8 下载完后,解压,打开 环境变量的配置文件即可 vim ~/.zshrc #export JAVA_HOME/Users/xxxxx/jdk-21.jdk/Contents/Home #export JAVA_HOME/Users/xxxxx/jdk-17.jdk/Contents/Home #export JAVA_HOME/Users/xxxxx/jdk-11.jdk/Contents…...

Spring Boot 自动加载流程详解
前言 Spring Boot 是一个基于约定优于配置理念的框架,它通过自动加载机制大大简化了开发者的配置工作。本文将深入探讨 Spring Boot 的自动加载流程,并结合源码和 Mermaid 图表进行详细解析。 一、Spring Boot 自动加载的核心机制 Spring Boot 的自动加…...

2025 年“认证杯”数学中国数学建模网络挑战赛 C题 化工厂生产流程的预测和控制
流水线上也有每个位置的温度、压力、流量等诸多参数。只有参数处于正常范 围时,最终的产物才是合格的。这些参数很容易受到外部随机因素的干扰,所 以需要实时调控。但由于参数众多,测量困难,很多参数想要及时调整并不容 易&#x…...
 反卷积算法 —— 通过不断迭代更新图像估计值)
Richardson-Lucy (RL) 反卷积算法 —— 通过不断迭代更新图像估计值
文章目录 一、RL反卷积算法(1)主要特点(2)基本原理(3)关键步骤(4)优化算法 二、项目实战(1)RL 反卷积(2)优化:RL 反卷积 …...

2025.04.10-拼多多春招笔试第四题
📌 点击直达笔试专栏 👉《大厂笔试突围》 💻 春秋招笔试突围在线OJ 👉 笔试突围OJ 04. 优惠券最优分配问题 问题描述 LYA是一家电商平台的运营经理,负责促销活动的策划。现在平台上有 n n n...

------------------V2024-2信息收集完结------------------
第二部分信息收集完结撒花*★,*:.☆( ̄▽ ̄)/$:*.★* 。 进入开发部分,工具要求:phpstorm Adobe Navicat16 小皮 准备完毕 php开发起飞起飞~~~~~...

Java Lambda与方法引用:函数式编程的颠覆性实践
在Java 8引入Lambda表达式和方法引用后,函数式编程范式彻底改变了Java开发者的编码习惯。本文将通过实战案例和深度性能分析,揭示如何在新项目中优雅运用这些特性,同时提供传统代码与函数式代码的对比优化方案。 文章目录 一、Lambda表达式&a…...
)
2025年常见渗透测试面试题- PHP考察(题目+回答)
网络安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 PHP考察 php的LFI,本地包含漏洞原理是什么?写一段带有漏洞的代码。手工的话如何发掘&am…...

【在校课堂笔记】南山 - 第 10 节课 总结
- 第 92 篇 - Date: 2025 - 04 - 10 Author: 郑龙浩/仟墨 【Python 在校课堂笔记】 南山 - 第 10 节课 文章目录 南山 - 第 10 节课一 in –> 存在性测试 - 基础介绍二 in –> 例题 - 火车票 - 使用 in 优化**问题**【代码 - 以前的代码】【代码 - 使用存在性测试 in】 …...