从PDF中提取表格:以GB/T2260—2007为例
文章目录
- 先说结论
- 前因后果
- 思路
- 1、PDF2CSV
- 2、PDF2MD → MD2CSV
- 3、针对不同表格的两种思路
- 1) 竖形三线表
- 2)五元素为一组
- 还没结束
- 批量处理
- 1、分割markdown文档
- 2、跳过另一种格式的文档
- 总结一下
先说结论
结论就是,博主用了一天的时间去研究如何把PDF的表格内容,转换为csv文件,下面放图。
这次转换的文档是国标GB/T2260—2007,GB/T2260《中华人民共和国行政区划代码》自1980年发布以来,已广泛应用于我国计划、统计、人口普查、经济普查、农业普查、社会保障、信息化、教育、人事管理、组织机构管理等诸多领域。
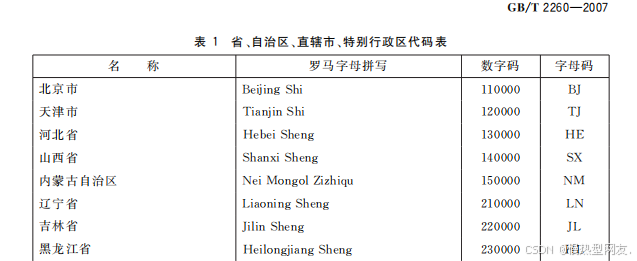
转换为👇

请注意:本篇不太赘述太多代码,主要讲解决思路。
前因后果
因为博主的课题是知识图谱方向,所以想找一些内容来测试一下图谱构建,图谱构建的第一步就是去构建实体和关系,所以我想到一个关系性很强的内容,就是今天测试的内容,我国的行政区,包含省市县区,他们中间的关系也很明确。
那么好,回到文档,起初拿到这个文档的时候,我想着要不就手动复制,反正现在各种OCR技术都这么强,结果发现正片文档整整247页,就以我需要整理的内容来说也有130页左右,这样手动构建肯定是不合适的,费时费力。
所以,我就想到能不能搞点代码来解决,其实目前大模型技术发展很迅速了,各种单模态的,多模态的,专门处理表格的,其实把这些交给大模型让它们生成结构化的文档也很方便,不过博主还是喜欢去探究一下本质,所以选择用传统方法。
思路
1、PDF2CSV
前期的思路是,直接PDF转CSV,目前有很多第三方库也都支持,Camelot、Tabula-py、pdf2csv,都不错,但是回归到根源,从文档本身出发,可以看到这是一个算是竖形的三线表格式的,这些第三方库去处理的时候都会把第一列的所有内容放在一个单元格中,等于说白干,那么我想能不能用另一种格式做一个过渡呢,这种格式还得是普遍被接收了,那么想到了一种符合当前要求的——markdown。
2、PDF2MD → MD2CSV
PDF识别表格转成markdown格式也是一种思路,再用markdown的特点,有固定的表格格式,方便分割,思路有了,开始实操。
这次选择的是pdfplumber,它有一个extract_tables()方法,可以提取PDF中的表格。
def extract_tables(self, table_settings: Optional[T_table_settings] = None) -> List[List[List[Optional[str]]]]:tset = TableSettings.resolve(table_settings)tables = self.find_tables(tset)return [table.extract(**(tset.text_settings or {})) for table in tables]def extract_table(self, table_settings: Optional[T_table_settings] = None) -> Optional[List[List[Optional[str]]]]:tset = TableSettings.resolve(table_settings)table = self.find_table(tset)if table is None:return Noneelse:return table.extract(**(tset.text_settings or {}))
提取后转为markdown格式,内容如下:
#篇幅有限取前六个元素作为示例
| 名 称 | 罗马字母拼写 | 数字码 | 字母码 |
| --- | --- | --- | --- |
| 北京市
天津市
河北省
山西省
内蒙古自治区
辽宁省| BeijingShi
TianjinShi
HebeiSheng
ShanxiSheng
NeiMongolZizhiqu
LiaoningSheng | 110000
120000
130000
140000
150000
210000| BJ
TJ
HE
SX
NM
LN|
从转换的文档看,因为markdown表格格式限制,各个元素中存在换行符,没法变为表格。
不过,博主灵机一动,那我把它们全部转为字符串,再以“|”为分割,把第一个单元格的的第一个元素作为表格里第一列的第一个,第二个单元格的第一个作为第二列的第二个,以此类推…
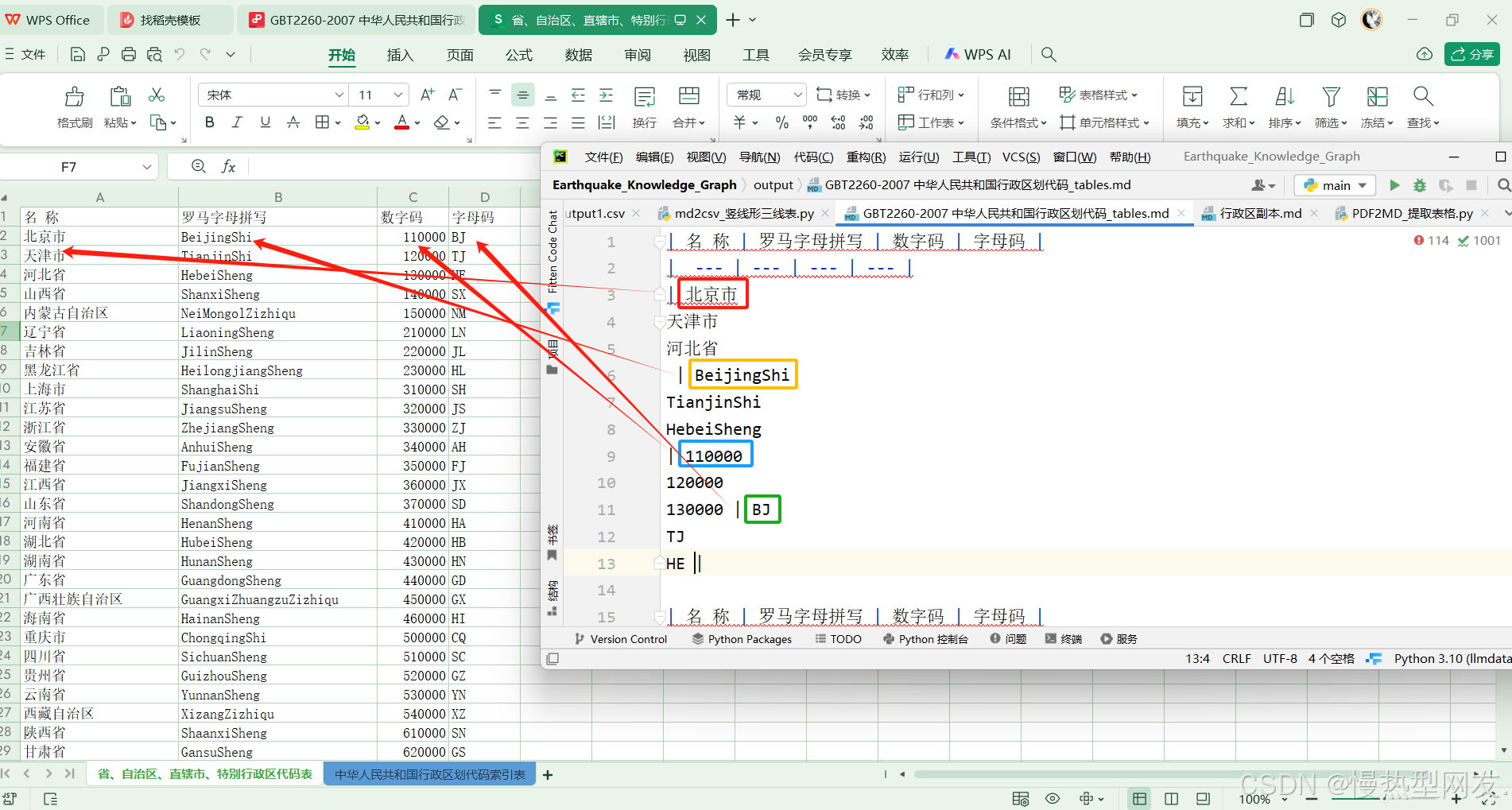
观察生成的md文件,发现总共有两种形式的md文档
第一种是刚才讲的这种,第二种是下图这样的,所有元素都在同一个单元格中,中间以空格隔开
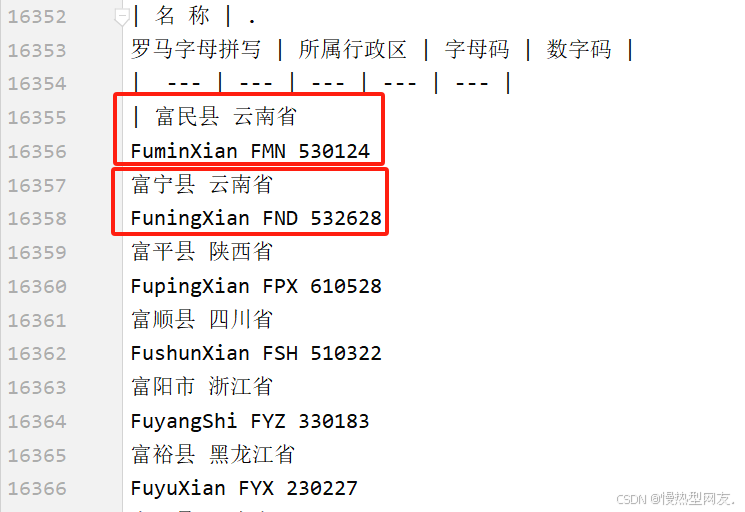
3、针对不同表格的两种思路
那么针对这两种的表格,有了下面两个思路
1) 竖形三线表
这种思路参照刚才讲的把第一个单元格的的第一个元素作为表格里第一列的第一个,第二个单元格的第一个作为第二列的第二个,讲关键步骤:
1、将数据行转换为一个长字符串,保留原始的换行符
| 北京市 天津市 河北省 山西省 内蒙古自治区 辽宁省 吉林省 黑龙江省 上海市 江苏省 浙江省 安徽省 福建省 江西省 山东省 河南省 湖北省 湖南省 广东省 广西壮族自治区 海南省 重庆市 四川省 贵州省 云南省 西藏自治区 陕西省 甘肃省 青海省 宁夏回族自治区 新疆维吾尔自治区 台湾省 香港特别行政区 澳门特别行政区 | BeijingShi TianjinShi HebeiSheng ShanxiSheng NeiMongolZizhiqu LiaoningSheng JilinSheng HeilongjiangSheng ShanghaiShi JiangsuSheng ZhejiangSheng AnhuiSheng FujianSheng JiangxiSheng ShandongSheng HenanSheng HubeiSheng HunanSheng GuangdongSheng GuangxiZhuangzuZizhiqu HainanSheng ChongqingShi SichuanSheng GuizhouSheng YunnanSheng XizangZizhiqu ShaanxiSheng GansuSheng QinghaiSheng NingxiaHuizuZizhiqu XinjiangUygurZizhiqu TaiwanSheng HongkongTebiexingzhengqu | 110000 120000 130000 140000 150000 210000 220000 230000 310000 320000 330000 340000 350000 360000 370000 410000 420000 430000 440000 450000 460000 500000 510000 520000 530000 540000 610000 620000 630000 640000 650000 710000 810000 | BJ TJ HE SX NM LN JL HL SH JS ZJ AH FJ JX SD HA HB HN GD GX HI CQ SC GZ YN XZ SN GS QH NX XJ TW HK |
2、使用正则表达式在每个 | 符号的前后都加上换行符
呈现的结果是这样的,那么可以看到每一列都被完美的隔离开,并且每个元素中间都有空格

3、按行分割清洗后的内容
['|', ' 北京市 天津市 河北省 山西省 内蒙古自治区 辽宁省 吉林省 黑龙江省 上海市 江苏省 浙江省 安徽省 福建省 江西省 山东省 河南省 湖北省 湖南省 广东省 广西壮族自治区 海南省 重庆市 四川省 贵州省 云南省 西藏自治区 陕西省 甘肃省 青海省 宁夏回族自治区 新疆维吾尔自治区 台湾省 香港特别行政区 澳门特别行政区 ', '|', ' BeijingShi TianjinShi HebeiSheng ShanxiSheng NeiMongolZizhiqu LiaoningSheng JilinSheng HeilongjiangSheng ShanghaiShi JiangsuSheng ZhejiangSheng AnhuiSheng FujianSheng JiangxiSheng ShandongSheng HenanSheng HubeiSheng HunanSheng GuangdongSheng GuangxiZhuangzuZizhiqu HainanSheng ChongqingShi SichuanSheng GuizhouSheng YunnanSheng XizangZizhiqu ShaanxiSheng GansuSheng QinghaiSheng NingxiaHuizuZizhiqu XinjiangUygurZizhiqu TaiwanSheng HongkongTebiexingzhengqu ', '|', ' 110000 120000 130000 140000 150000 210000 220000 230000 310000 320000 330000 340000 350000 360000 370000 410000 420000 430000 440000 450000 460000 500000 510000 520000 530000 540000 610000 620000 630000 640000 650000 710000 810000 ', '|', ' BJ TJ HE SX NM LN JL HL SH JS ZJ AH FJ JX SD HA HB HN GD GX HI CQ SC GZ YN XZ SN GS QH NX XJ TW HK ', '|']
4、构造两个数组,分别遍历
这里定义了两个数组,大的数组存储每一组数据,小数组放每一组数据的具体信息,遍历后结果如下:
[
['北京市', 'BeijingShi', '110000', 'BJ'],
['天津市', 'TianjinShi', '120000', 'TJ'],
['河北省', 'HebeiSheng', '130000', 'HE'],
['山西省', 'ShanxiSheng', '140000', 'SX'],
['内蒙古自治区', 'NeiMongolZizhiqu', '150000', 'NM'],
['辽宁省', 'LiaoningSheng', '210000', 'LN'],
['吉林省', 'JilinSheng', '220000', 'JL']
]
那么后面转csv就不讲了,逐行遍历逗号隔开即可。
2)五元素为一组
那么有了上一个处理的思路,这个处理思路更快的就想出来了,还是转换为字符串,但是这次就不要“|”为分割了,所以处理字符串的时候直接删掉,只留元素和空格,每五个元素为一行。
1、将数据行转换为一个长字符串,保留空格
越西县 四川省 YuexiXian YXC 513434 越秀区 广东省广州市 YuexiuQu YXU 440104 云县 云南省 YunXian YXP 530922 云安县 广东省 Yun’anXian YUA 445323 云城区 广东省云浮市 YunchengQu YYF 445302 云浮市 广东省 YunfuShi YFS 445300 云和县 浙江省 YunheXian YNH 331125 云龙区 江苏省徐州市 YunlongQu YLF 320303 云龙县 云南省 YunlongXian YLO 532929 云梦县 湖北省 YunmengXian YMX 420923 云南省 YunnanSheng YN 530000 云溪区 湖南省岳阳市 YunxiQu YXI 430603 云霄县 福建省 YunxiaoXian YXO 350622 云岩区 贵州省贵阳市 YunyanQu YYQ 520103 云阳县 重庆市 YunyangXian YNY 500235 郧县 湖北省 YunXian YUN 420321 郧西县 湖北省 YunxiXian YNX 420322 运城市 山西省 YunchengShi YCE 140800 运河区 河北省沧州市 YunheQu YHC 130903 郓城县 山东省 YunchengXian YCR 371725 杂多县 青海省 ZadoiXian ZAD 632722 赞皇县 河北省 ZanhuangXian ZHG 130129 枣强县 河北省 ZaoqiangXian ZQJ 131121 枣阳市 湖北省 ZaoyangShi ZOY 420683 枣庄市 山东省 ZaozhuangShi ZZG 370400 泽库县 青海省 ZêkogXian ZEK 632323 泽普县 新疆维吾尔自治区 Zepu(Poskam)Xian ZEP 653124 泽州县 山西省 ZezhouXian ZEZ 140525 曾都区 湖北省随州市 ZengduQu ZDU 421302 增城市 广东省 ZengchengShi ZEC 440183 扎赉特旗 内蒙古自治区 JalaidQi JAL 152223 扎兰屯市 内蒙古自治区 ZalantunShi ZLT 150783 扎鲁特旗 内蒙古自治区 JarudQi JAR 150526 扎囊县 西藏自治区 Chanang(Chatang)Xian CNG 542222 札达县 西藏自治区
2、遍历列表,按固定数量进行分组
# 初始化一个列表来存储分组后的数据groups = []current_group = []# 遍历列表,按固定数量进行分组for item in data_content.split():item = item.strip() # 去除元素前后的空格if item: # 忽略空字符串current_group.append(item)print(current_group)# 每五个元素换行if len(current_group) == 5:groups.append(current_group)current_group = []
最后的效果是这样的:

还没结束
批量处理
这两个代码固然可以提速,但我处理的md格式的文档有30929行,每一个表格大概是130行,那么我就要处理三百余次,虽然手动处理可以,但是还是觉得效率低,在处理了差不多100个的时候就觉得有点累了,所以我就在想如何可以让他批量处理
1、分割markdown文档
因为前面也讲了,我这个markdown文档里发现识别了两种表格,那么我一次处理全部的当然不合适,所以我的思路是先根据文档特点去分割markdown文档为不同的文件,再根据不同的文件结构用不同的方法。
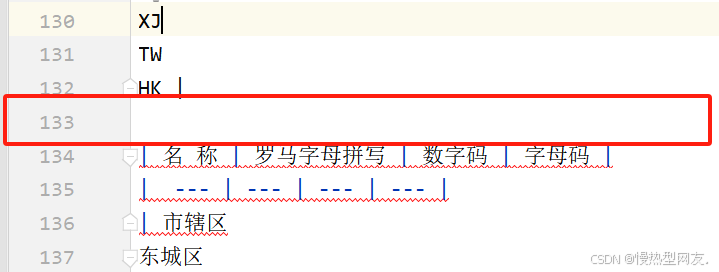
文档里每个表格之间都有一行空白行,那么就以它为标识符去分割,最后在剩余的文档里分出来了56个文档

2、跳过另一种格式的文档
经过看每个文档发现,第二种类的文档还是比较少,有以下这几个,那么我在处理的时候跳过这些即可,去批量处理。
skip_tables = {8, 11, 14, 16, 20, 21, 28, 33,37, 44, 52}
总结一下
在当今时代,AI 的强大能力确实为我们的学习和生活带来了极大的便利,但过度依赖它却可能削弱我们的思维能力。我们应将 AI 视为助力而非拐杖,在借助其高效处理数据和执行任务的同时,积极锻炼自己的思维,尤其是代码思维。这种严谨的逻辑思维不仅能帮助我们更好地与 AI 沟通协作,还能在复杂多变的现实中发挥独特价值,从而在人机合作中提升效率,实现优势互补。
相关文章:

从PDF中提取表格:以GB/T2260—2007为例
文章目录 先说结论前因后果思路1、PDF2CSV2、PDF2MD → MD2CSV3、针对不同表格的两种思路1) 竖形三线表2)五元素为一组 还没结束批量处理1、分割markdown文档2、跳过另一种格式的文档 总结一下 先说结论 结论就是,博主用了一天的时间去研究如…...

日常记录-群晖nas的docker注册表被墙,用Mac电脑的docker拉取镜像并安装到nas中
文章目录 前言一、拉取镜像二、安装到nas中总结 前言 群晖nas的docker注册表被墙,用Mac电脑的docker拉取镜像并安装到nas中 一、拉取镜像 群晖nas的架构师x86,Mac电脑的架构师arm。 在mac电脑中执行命令: # 镜像拉取 docker pull --platf…...

DeepSeek:重构办公效率的AI新范式
目录 一、效率跃迁的三重引擎 二、效率提升的量级突破 三、智能办公的范式转移 四、未来办公的效率奇点 当企业主面对堆积如山的文件审批、跨时区协作的沟通损耗、重复机械的数据整理时,是否想过这些场景正在吞噬团队的生产力?据麦肯锡研究显示&…...

AI小程序+SpringAI+管理后台+源码+支持动态添加大模型+支持动态添加AI应用
前言 今天给大家介绍一款 前端由uniapp开发的小程序,完美在小程序上运行,对话采用流式对话。后端由springbootspringai开发的应用软件源码。 功能简介 支持在管理后台动态新增“DeepSeek”,“openai”,“千帆”,“智…...

RAG的实现快速示例
RAG(Retrieval-Augmented Generation)其实就是结合了检索与生成,核心流程分为 检索(Retrieval) 和 生成(Generation) 两大阶段,通过外部知识库增强生成式模型的准确性和可靠性。 流程其实也很简单,如下图: 关于RAG的基本概念的介绍,可以参考: RAG(检索增强生成)快…...

利用 PHP 爬虫获取京东商品详情 API 返回值说明及代码示例
在电商领域,京东作为国内知名的电商平台,提供了丰富的商品信息。通过调用京东商品详情 API,我们可以获取商品的详细信息,如商品标题、价格、图片、描述等。这些信息对于数据分析、价格监控、商品推荐等场景具有重要价值。本文将详…...

PyTorch CUDA内存管理优化:深度理解GPU资源分配与缓存机制
在深度学习工程实践中,当训练大型模型或处理大规模数据集时,上述错误信息对许多开发者而言已不陌生。这是众所周知的 CUDA out of memory错误——当GPU尝试为张量分配空间而内存不足时发生。这种情况尤为令人沮丧,特别是在已投入大量时间优化…...

大模型基础知识扫盲
1 模型量化: 是什么:大模型量化是一种“压缩”技术,把模型里高精度的数字(比如32位浮点数)简化成低精度的数字(比如8位定点数)。 有什么用:它让模型占的空间更小,跑起来…...

《穿透表象,洞察分布式软总线“无形”之奥秘》
分布式系统已成为众多领域的关键支撑技术,而分布式软总线作为实现设备高效互联的核心技术,正逐渐走入大众视野。它常被描述为一条“无形”的总线,这一独特属性不仅是理解其技术内涵的关键,更是把握其在未来智能世界中重要作用的切…...

Python Cookbook-5.13 寻找子序列
任务 需要在某大序列中查找子序列。 解决方案 如果序列是字符串(普通的或者Unicode),Python 的字符串的 find 方法以及标准库的re模块是最好的工具。否则,应该使用Knuth-Morris-Pratt算法(KMP): def KnuthMorrisPratt(text,pattern): 在序列text中找…...
蓝桥杯准备(需要写的基础))
(自用)蓝桥杯准备(需要写的基础)
要写的文件 led_app lcd_app key_app adc_app usart_app scheduler LHF_SYS一、外设引脚配置 1. 按键引脚 按键引脚配置如下: B1:PB0B2:PB1B3:PB2B4:PA0 2. LCD引脚 LCD引脚配置如下: GPIO_Pin_9 /* …...
-ST和串口烧录)
STM32Cubemx-H7-14-Bootloader(上)-ST和串口烧录
前言 本文主要研究,如果把ST单片机的SWDIO和SWDCLK引脚改成推挽输出后,我们又应该怎么重新烧录,以及如何使用串口下载。 当没有设置STlink烧录为引脚或者设置成其他功能的时候 如果想恢复,那么就在烧录之前,一直按住…...

“深入浅出:Java中的Lambda表达式及其应用“
前言 Lambda表达式是Java 8引入的一项强大特性,它允许以更加简洁的方式表示匿名函数。Lambda表达式不仅让代码更加简洁、清晰,而且为函数式编程提供了有力支持,从而提升了Java语言的表达能力。 在本文中,我们将深入浅出地探讨La…...

6.1es新特性解构赋值
解构赋值是 ES6(ECMAScript 2015)引入的语法,通过模式匹配从数组或对象中提取值并赋值给变量。: 功能实现 数组解构:按位置匹配值,如 let [a, b] [1, 2]。对象解构:按属性名匹配值,…...

【从0到1学RabbitMQ】RabbitMQ高级篇
学完基础篇之后我们对用户下单这个业务进行了改造,我们可以吧用户支付这个业务抽出来,放入队列当中去执行。如下图: 但是这里我们思考一下,如果MQ通知失败了,支付服务中支付流水显示支付成功,而交易服务中…...

200 smart pid
PID整定控制面板-S7-200 SMART 跟我学/跟我做之PID功能-系列课程-西门子1847工业学习平台官网 使用西门子200SMART进行PID调节 PID自整定 PID调节技巧_哔哩哔哩_bilibili S7-200 SMART PID PID常见问题...

AI制作PPT,如何轻松打造高效演示文稿
AI制作PPT,如何轻松打造高效演示文稿!随着信息化时代的到来,PPT已经成为了几乎所有职场人士、学生、讲师的必备工具。每个人都希望自己的PPT既有创意,又能高效展示信息。而在如今的科技背景下,AI的出现彻底改变了PPT的…...

如何用postman做接口自动化测试?
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 本文适合已经掌握 Postman 基本用法的读者,即对接口相关概念有一定了解、已经会使用 Postman 进行模拟请求等基本操作。 工作环境与版本࿱…...

day29-贪心__134. 加油站__135. 分发糖果__860.柠檬水找零__406.根据身高重建队列
134. 加油站 这道题的贪心方法相当的巧妙。 首先,我们可以通过gas[i] - cost[i]得到第i个站点的净加油量(耗油量),那么如果我们现在考虑一个从某点a到某点b,那么如果a-》b范围之间的gas[i] - cost[i]存在负数,那么说明无法从a作…...

聊透多线程编程-线程基础-4.C# Thread 子线程执行完成后通知主线程执行特定动作
在多线程编程中,线程之间的同步和通信是一个常见的需求。例如,我们可能需要一个子线程完成某些任务后通知主线程,并由主线程执行特定的动作。本文将基于一个示例程序,详细讲解如何使用 AutoResetEvent 来实现这种场景。 示例代码…...

C# 组件的使用方法
类 Stopwatch 计算时间 Stopwatch sw new Stopwatch(); sw.Start(); // 要执行的代码块 Thread.Sleep(2000);sw.ElapsedMilliseconds // 消耗时间 Console.WriteLine(sw.ElapsedMilliseconds);组件 ListView 属性设置 外观 - View - Details 行为 - Columns -(…...

Python常用排序算法
1. 冒泡排序 冒泡排序是一种简单的排序算法,它重复地遍历要排序的列表,比较相邻的元素,如果他们的顺序错误就交换他们。 def bubble_sort(arr):# 遍历所有数组元素for i in range(len(arr)):# 最后i个元素是已经排序好的for j in range(0, …...
)
HTML5 服务器发送事件(Server-Sent Events)
1. 引言 HTML5 服务器发送事件(Server-Sent Events,SSE)是一种基于 HTTP 的服务器推送技术,允许服务器主动向客户端(如浏览器)发送实时更新。SSE 适用于单向通信场景,如新闻推送、实时价格更新…...

【C++游戏引擎开发】第12篇:GLSL语法与基础渲染——从管线结构到动态着色器
一、OpenGL渲染管线解密 1.1 OpenGL渲染管线流程图 #mermaid-svg-GrAgLUat95CVZKm0 {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-GrAgLUat95CVZKm0 .error-icon{fill:#552222;}#mermaid-svg-GrAgLUat95CVZKm0 .e…...

阿里云负载均衡可以抗ddos吗
本文深度解析阿里云负载均衡的DDoS防护机制,通过实测数据验证其基础防御能力边界,揭示需结合云盾高防IP实现TB级流量清洗的工程实践。结合2023年Memcached反射攻击事件,提供混合云架构下的多层级防御方案设计指南。 云原生负载均衡的基础防护…...

动手学习:路径规划原理及常用算法
一、路径规划的基本原理 路径规划(Path Planning)是机器人导航的核心任务,目标是为机器人找到一条从起点到终点的无碰撞路径,同时满足约束条件(如最短路径、最优能耗、安全性等)。在人形机器人场景中&…...

Web前端性能指标Web3D性能优化
性能指标&评估方式 在Web3D性能优化之前,先了解性能指标&评估方式 前端性能指标评估与监测工具可分为以下几类,结合不同场景和需求,开发者可选择适合的工具进行性能优化: 一、浏览器内置工具 Chrome DevTools Performance 面板:记录运行时性能,分析CPU、内存使…...

Mujoco xml <option>
xml option option总起例子timestep(一般会用到)gravity(一般会用到)windmagneticdensityviscosityo_margino_solref, o_solimpo_frictionintegrator(一般会用到)cone(一般会用到)jacobian(一般会用到)solver(一般会用到)iterations(一般会用到)tolerance(一般会用到)noslip_it…...

如何用 nvm alias default 18.20.8 实现全局 Node.js 版本管理?一篇保姆级指南!!!
📝 如何用 nvm alias default 18.20.8 实现全局 Node.js 版本管理?一篇保姆级指南 🚀 1. 核心命令解析 🔍 nvm alias default 18.20.8 是 nvm 管理工具中用于设置全局默认 Node.js 版本的核心命令。它的作用是将指定版本锁定为所…...

推荐一款Nginx图形化管理工具: NginxWebUI
Nginx Web UI是一款专为Nginx设计的图形化管理工具,旨在简化Nginx的配置与管理过程,提高开发者和系统管理的工作效率。项目地址:https://github.com/cym1102/nginxWebUI 。 一、Nginx WebUI的主要特点 简化配置:通过图形化的界…...

Pytest多环境切换实战:测试框架配置的最佳实践!
你是否也遇到过这种情况:本地测试通过,一到测试环境就翻车?环境变量错乱、接口地址混乱、数据源配置丢失……这些「环境切换」问题简直像定时炸弹,随时引爆你的测试流程! 测试人员每天都跟不同的环境打交道࿰…...

大模型在网络安全领域的七大应用
1. 高级威胁检测与防御自动化 技术路径: 数据整合:聚合网络流量、终端日志、威胁情报等多源数据,构建多维特征库。行为建模:通过大模型的上下文理解能力,建立正常行为基线,识别偏离模式。动态策略生成&am…...

SpringBoot项目部署之启动脚本
一、启动脚本方案 1. 基础启动方式 1.1 直接运行JAR java -jar your-app.jar --spring.profiles.activeprod优点:简单直接,适合快速测试缺点:终端关闭即终止进程 1.2 后台运行 nohup java -jar your-app.jar > app.log 2>&1 &…...

【spark-submit】--提交任务
Spark-submit spark-submit 是 Apache Spark 提供的用于提交 Spark 应用程序到集群的命令行工具。 基本语法 spark-submit [options] <app-jar> [app-arguments]常用参数说明 应用程序配置 --class <class-name>: 指定应用程序的主类(对于 Java/Sc…...

机器学习中的回归与分类模型:线性回归、逻辑回归与多分类
在机器学习领域,回归和分类是两类重要的任务,它们各自有着不同的应用场景和模型构建方式。本文将详细介绍线性回归、逻辑回归以及多分类任务的相关内容,包括数据预处理、模型定义、损失函数的选择以及评估指标的计算。 一、线性回归…...

spark-rdd
Spark-core RDD转换算子 RDD 根据数据处理方式的不同将算子整体上分为 Value 类型、双 Value 类型和 Key-Value 类型。 Value类型: 1.map 将处理的数据逐条进行映射转换,这里的转换可以是类型的转换,也可以是值的转换 mapPartitions map …...

Python 实现如何电商网站滚动翻页爬取
一、电商网站滚动翻页机制分析 电商网站如亚马逊和淘宝为了提升用户体验,通常采用滚动翻页加载数据的方式。当用户滚动页面到底部时,会触发新的数据加载,而不是一次性将所有数据展示在页面上。这种机制虽然对用户友好,但对爬虫来…...

pytorch TensorDataset与DataLoader类
读取数据 Dataset类 Dataset 是一个读取数据抽象类,所有自定义的数据集类需要继承该类。 该类主要实现以下三个功能 ①如何获取每一个数据及其label --> 抽象方法__getitem()__设置通过对象[索引]的方式获取每一个样本及其label ②告知一共有多少数据 -->…...

AI大模型与知识生态:重构认知的新时代引擎
📝个人主页🌹:慌ZHANG-CSDN博客 🌹🌹期待您的关注 🌹🌹 一、引言:我们如何获得知识,正在被AI彻底改写 从古代图书馆、百科全书,到搜索引擎、问答社区,人类获取知识的方式一直在进化。而随着 ChatGPT、DeepSeek、Grok 等 AI 大模型的到来,这一过程迎来了颠覆…...

Server-Sent Events一种允许服务器向客户端发送实时更新的 Web API
Server-Sent Events(SSE)是一种允许服务器向客户端发送实时更新的 Web API。它基于 HTTP 协议,提供了一种单向的、服务器到客户端的通信机制,客户端可以通过监听服务器发送的事件来接收实时数据。下面从原理、使用场景、代码示例等…...

电子电器架构 --- AI如何重构汽车产业
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 周末洗了一个澡,换了一身衣服,出了门却不知道去哪儿,不知道去找谁&am…...

操作系统CPU调度
简介 当CPU有大量任务要处理,但由于资源有限,无法同时处理。所有就需要某种规则来决定任务处理的顺序,这就是调度。 调度层次 根据调度频率与层次,共分为三种 高级调度 也称为作业调度(Long-Trem Scheduling),频次很低,它决定哪些进程从外存(硬盘)加载到内存中级调度 也…...

icoding题解排序
数组合并 假设有 n 个长度为 k 的已排好序(升序)的数组,请设计数据结构和算法,将这 n 个数组合并到一个数组,且各元素按升序排列。即实现函数: void merge_arrays(const int* arr, int n, int k, int* out…...

xHCI 上 USB 读写分析
系列文章目录 xHCI 简单分析 USB Root Hub 分析 USB Hub 检测设备 usb host 驱动之 urb xHCI那些事儿 PCIe MMIO、DMA、TLP PCIe配置空间与CPU访问机制 PCIe总线协议基础实战 文章目录 系列文章目录一、xHCI 初始化二、xHCI 驱动识别根集线器(RootHub)…...

SpringCloud Alibaba 之分布式全局事务 Seata 原理分析
1. 什么是 Seata?为什么需要它? 想象一下,你去银行转账: 操作1:从你的账户扣款 1000 元操作2:向对方账户增加 1000 元 如果 操作1 成功,但 操作2 失败了,你的钱就凭空消失了&…...

《C语言中的“魔法盒子”:自定义函数的奇妙之旅》
🚀个人主页:BabyZZの秘密日记 📖收入专栏:C语言 🌍文章目入 一、引言二、自定义函数的创建(一)基本结构(二)一个简单的例子 三、自定义函数的使用(一…...

【Spring】IoC 和 DI的关系、简单使用,从“硬编码“到“优雅解耦“:IoC与DI的Spring蜕变之旅
1.IoC 和 DI的关系 IoC(Inversion of Control,控制反转)和DI(Dependency Injection,依赖注入)是Spring框架中紧密相关但又有所区别的两个概念。理解它们的联系,可以帮助我们更深刻地掌握Spring…...

43、RESTful API 保姆教程
RESTful API 目录 RESTful API简介RESTful设计原则RESTful设计规范RESTful统一返回体JAX-RSJAX-RS与SpringBoot集成构建Restful服务实践总结一、RESTful API 简介 REST(Representational State Transfer)是一种基于HTTP的web服务架构风格,RESTful API则是遵循REST原则的网…...

ASP.NET Core 性能优化:客户端响应缓存
文章目录 前言一、什么是缓存二、客户端缓存核心机制:HTTP缓存头1)使用[ResponseCache]属性(推荐)2)预定义缓存配置(CacheProfile)3)手动设置HTTP头4)缓存验证机制&#…...
——递归)
算法导论(递归回溯)——递归
算法思路(21) 递归函数的含义: 创建一个递归函数,该函数接受两个链表的头结点作为输入,返回合并后的链表的头结点。 选择较小的节点: 在函数体内,首先比较两个链表的头结点的值,选择…...