pytorch TensorDataset与DataLoader类
读取数据 Dataset类
Dataset 是一个读取数据抽象类,所有自定义的数据集类需要继承该类。
该类主要实现以下三个功能
①如何获取每一个数据及其label --> 抽象方法__getitem()__设置通过对象[索引]的方式获取每一个样本及其label
②告知一共有多少数据 --> 抽象方法__len__()方法是返回所有样本的数量
使用
1.继承torch.utils.data.Dataset抽象类,定义从自己的数据源中创建数据集。
2.__init__用于初始化数据集,这里可以加载数据文件(定义读取的数据集地址)、初始化变量等。
3.实现__len__(self)方法,返回数据集中的样本数量
4.实现__getitem__(self, idx)方法,通过索引返回一个样本及其label
Dataset类代码实践
任意下载一个数据集(密码5suq),我下载hymenoptera_data数据集,该数据集用于蚂蚁和蜜蜂的。打开我们之前pytorch环境的pycharm,在项目目录中放入数据集。
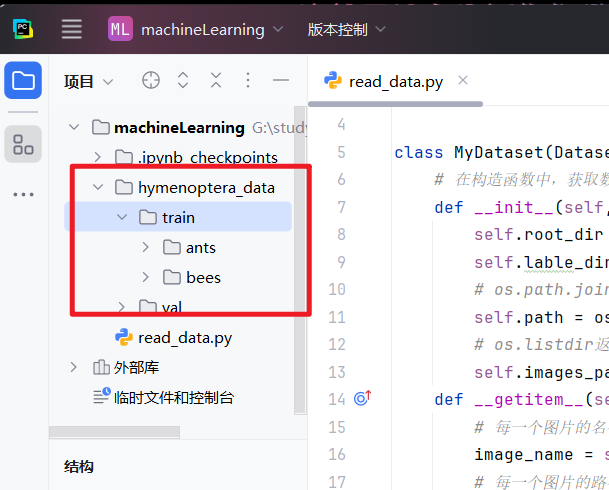
按照Datase方法的说明,我们先自定义一个数据集的类,该类需要继承torch.utils.data.Dataset,整体框架如下
from torch.utils.data import Dataset
class MyDataset(Dataset):# 在构造器中,获取数据集def __init__(self):# 获取数据集中的一个样本def __getitem__(self):# 获取数据集的样本数量def __len__(self):
__init__构造器:获取数据集所在的路径
我们把文件夹名字ants看作是蚂蚁的label,bees看作是蜜蜂的label,根地址为hymenoptera_data/train
-> 蚂蚁和蜜蜂数据集的地址分别为根地址+对应label,所以构造器方法需要根地址和label两个参数
# 需要引入 operating system 操作系统库
import osclass MyDataset(Dataset):# 在构造函数中,获取数据集def __init__(self,root_dir,lable_dir):self.root_dir = root_dirself.lable_dir = lable_dir# os.path.join()函数用于路径拼接文件路径self.path = os.path.join(self.root_dir,self.lable_dir)# os.listdir返回参数路径包含的文件或文件夹的名字的列表。这个列表以字母顺序self.images_path = os.listdir(self.path)
__getitem__方法:获取数据集中的一个样本
我们知道数据集中的路径以及数据集中所有样本名字组成的列表后,可以通过拼接路径+样本名字找到每个样本的路径,然后打开该路径获取样本。
# 需要引入Python Image Library 图像处理库
from PIL import Image def __getitem__(self, index):# 样本的名字image_name = self.images_path[index]# 样本的路径img_item_path = os.path.join(self.path, image_name)# 读取一个样本img = Image.open(img_item_path)# 样本的labellabel = self.lable_dirreturn img, label
len()方法:返回数据集中样本的数量
def __len__(self):return len(self.images_path)
完整代码
from torch.utils.data import Dataset
from PIL import Image #Python Image Library 图像处理库
import os #operating system 操作系统class MyDataset(Dataset):# 在构造函数中,获取数据集def __init__(self,root_dir,lable_dir):self.root_dir = root_dirself.lable_dir = lable_dir# os.path.join()函数用于路径拼接文件路径self.path = os.path.join(self.root_dir,self.lable_dir)# os.listdir返回参数包含的文件或文件夹的名字的列表。这个列表以字母顺序self.images_path = os.listdir(self.path)def __getitem__(self, index):# 每一个图片的名字image_name = self.images_path[index]# 每一个图片的路径img_item_path = os.path.join(self.path, image_name)# 读取一个样本img = Image.open(img_item_path)label = self.lable_dirreturn img, labeldef __len__(self):return len(self.images_path)root_dir="hymenoptera_data/train"
ants_label_dir ="ants"
bees_label_dir ="bees"
ants_dataset = MyDataset(root_dir,ants_label_dir)
bees_dataset = MyDataset(root_dir,bees_label_dir)
# 打开蚂蚁数据集中的第一张
first_img,first_label = ants_dataset[0]
first_img.show()
TensorDataset类 - 打包数据
data.TensorDataset(*tensors) 是 PyTorch 中用于将多个张量(Tensor)打包成一个数据集(Dataset)的工具。<它提供了一种方便的方法将数据封装为适合DataLoade 处理的格式。
- 数据封装:将数据的特征和标签封装到一个张量数据集中,每个元素都是一个样本。
- 简化索引:允许通过索引直接访问数据集中的任何点,简化了数据的访问和处理。
说明
*tensors:多个张量,所有张量的第一个维度(样本数)必须相同。- 通过
TensorDataset返回值<[索引],可以访问特定索引的样本,返回元组(比如(x[i],y[i])) TensorDataset是Dataset的子类,TensorDataset继承自 PyTorch 的抽象基类 torch.utils.data.Dataset,所以实例可以传入给DataLoader类。
使用案例
import torch
from torch.utils.data import DataLoader, TensorDataset# 假设我们有一些输入数据 X 和标签 Y
X = torch.randn(100, 3) # 100个样本,每个样本3个特征
Y = torch.randn(100, 1) # 100个样本的标签# 创建 TensorDataset
dataset = TensorDataset(X, Y)
# 读取第一个样本
x, y = dataset[0] # tensor([-1.1590, -0.3770, 0.3824]) tensor([-1.7849])
# 创建 DataLoader
dataloader = DataLoader(dataset, batch_size=10, shuffle=True)# 迭代 DataLoader
for i, (x, y) in enumerate(dataloader):print(f"Batch {i}:")print(f"Features: {x.size()}, Labels: {y.size()}")# 在这里,x 和 y 将是批次的特征和标签
# Batch 0:
# Features: torch.Size([10, 3]), Labels: torch.Size([10, 1])
# Batch 1:
# Features: torch.Size([10, 3]), Labels: torch.Size([10, 1])
# Batch 2:
# Features: torch.Size([10, 3]), Labels: torch.Size([10, 1])
# .....
torch.utils.data.DataLoader类 - 加载数据
函数作用: PyTorch 中用于高效加载数据的核心工具,支持批量处理、随机打乱、多进程加速等功能,适用于训练神经网络时的数据流水线构建。
参数说明
dataset(必需): 用于加载数据的数据集,通常是torch.utils.data.Dataset的子类实例。- batch_size (可选): 每个批次的数据样本数。默认值为1。
- shuffle (可选): 是否在每个周期开始时打乱数据,默认为False。训练时建议启用,验证/测试时禁用。
- sampler (可选): 定义从数据集中抽取样本的策略。如果指定,则忽略shuffle参数。
- batch_sampler (可选): 与sampler类似,但一次返回一个批次的索引。不能与batch_size、shuffle和sampler同时使用。
- num_workers (可选): 用于数据加载的子进程数量。默认为0,意味着数据将在主进程中加载。
- collate_fn (可选): 如何将多个数据样本整合成一个批次,常用于处理变长数据(如文本)。通常不需要指定。
- drop_last (可选): 如果数据集大小不能被批次大小整除,是否丢弃最后一个不完整的批次,默认为False。
返回值:可迭代的数据装载器(DataLoader)对象
from torch.utils.data import DataLoaderdataloader = DataLoader(dataset, # 数据集对象(必须继承自 torch.utils.data.Dataset)batch_size=1, # 每个批次的样本数shuffle=False, # 是否打乱数据顺序(通常训练时设为 True,验证/测试时设为 False)num_workers=0, # 加载数据的子进程数(建议设为 CPU 核心数)drop_last=False, # 是否丢弃最后一个不足 batch_size 的批次collate_fn=None # 自定义批次数据的合并逻辑(例如填充序列)
)
数据加载流程
DataLoader通过调用dataset的__len__()获取总样本数。- 根据
batch_size和shuffle参数生成批次索引。 - 对每个批次索引,调用
dataset的__getitem__()方法获取数据。 - 将多个样本的元组合并为一个批次的张量(例如,将多个
(X[i], Y[i])合并为(batch_X, batch_Y)) => 每次返回一个批次的数据
案例
*在函数调用中的解包作用,可以解包一个可迭代对象(如列表、元组),将其元素作为位置参数传递。*data_arrays这里表示将传入的元组(features, labels)解包为features、labels两个参数。
def load_array(data_arrays, batch_size, is_train=True): #@save"""构造一个PyTorch数据迭代器"""# 得到pytorch的dataseatdataset = data.TensorDataset(*data_arrays)# 每次随机挑选batch_size个样本出来return data.DataLoader(dataset, batch_size, shuffle=is_train)batch_size = 10
# (features, labels) 组合成一个list传递
data_iter = load_array((features, labels), batch_size)
print(data_iter) #<torch.utils.data.dataloader.DataLoader object at >
print(next(iter(data_iter)))
相关文章:

pytorch TensorDataset与DataLoader类
读取数据 Dataset类 Dataset 是一个读取数据抽象类,所有自定义的数据集类需要继承该类。 该类主要实现以下三个功能 ①如何获取每一个数据及其label --> 抽象方法__getitem()__设置通过对象[索引]的方式获取每一个样本及其label ②告知一共有多少数据 -->…...

AI大模型与知识生态:重构认知的新时代引擎
📝个人主页🌹:慌ZHANG-CSDN博客 🌹🌹期待您的关注 🌹🌹 一、引言:我们如何获得知识,正在被AI彻底改写 从古代图书馆、百科全书,到搜索引擎、问答社区,人类获取知识的方式一直在进化。而随着 ChatGPT、DeepSeek、Grok 等 AI 大模型的到来,这一过程迎来了颠覆…...

Server-Sent Events一种允许服务器向客户端发送实时更新的 Web API
Server-Sent Events(SSE)是一种允许服务器向客户端发送实时更新的 Web API。它基于 HTTP 协议,提供了一种单向的、服务器到客户端的通信机制,客户端可以通过监听服务器发送的事件来接收实时数据。下面从原理、使用场景、代码示例等…...

电子电器架构 --- AI如何重构汽车产业
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 周末洗了一个澡,换了一身衣服,出了门却不知道去哪儿,不知道去找谁&am…...

操作系统CPU调度
简介 当CPU有大量任务要处理,但由于资源有限,无法同时处理。所有就需要某种规则来决定任务处理的顺序,这就是调度。 调度层次 根据调度频率与层次,共分为三种 高级调度 也称为作业调度(Long-Trem Scheduling),频次很低,它决定哪些进程从外存(硬盘)加载到内存中级调度 也…...

icoding题解排序
数组合并 假设有 n 个长度为 k 的已排好序(升序)的数组,请设计数据结构和算法,将这 n 个数组合并到一个数组,且各元素按升序排列。即实现函数: void merge_arrays(const int* arr, int n, int k, int* out…...

xHCI 上 USB 读写分析
系列文章目录 xHCI 简单分析 USB Root Hub 分析 USB Hub 检测设备 usb host 驱动之 urb xHCI那些事儿 PCIe MMIO、DMA、TLP PCIe配置空间与CPU访问机制 PCIe总线协议基础实战 文章目录 系列文章目录一、xHCI 初始化二、xHCI 驱动识别根集线器(RootHub)…...

SpringCloud Alibaba 之分布式全局事务 Seata 原理分析
1. 什么是 Seata?为什么需要它? 想象一下,你去银行转账: 操作1:从你的账户扣款 1000 元操作2:向对方账户增加 1000 元 如果 操作1 成功,但 操作2 失败了,你的钱就凭空消失了&…...

《C语言中的“魔法盒子”:自定义函数的奇妙之旅》
🚀个人主页:BabyZZの秘密日记 📖收入专栏:C语言 🌍文章目入 一、引言二、自定义函数的创建(一)基本结构(二)一个简单的例子 三、自定义函数的使用(一…...

【Spring】IoC 和 DI的关系、简单使用,从“硬编码“到“优雅解耦“:IoC与DI的Spring蜕变之旅
1.IoC 和 DI的关系 IoC(Inversion of Control,控制反转)和DI(Dependency Injection,依赖注入)是Spring框架中紧密相关但又有所区别的两个概念。理解它们的联系,可以帮助我们更深刻地掌握Spring…...

43、RESTful API 保姆教程
RESTful API 目录 RESTful API简介RESTful设计原则RESTful设计规范RESTful统一返回体JAX-RSJAX-RS与SpringBoot集成构建Restful服务实践总结一、RESTful API 简介 REST(Representational State Transfer)是一种基于HTTP的web服务架构风格,RESTful API则是遵循REST原则的网…...

ASP.NET Core 性能优化:客户端响应缓存
文章目录 前言一、什么是缓存二、客户端缓存核心机制:HTTP缓存头1)使用[ResponseCache]属性(推荐)2)预定义缓存配置(CacheProfile)3)手动设置HTTP头4)缓存验证机制&#…...
——递归)
算法导论(递归回溯)——递归
算法思路(21) 递归函数的含义: 创建一个递归函数,该函数接受两个链表的头结点作为输入,返回合并后的链表的头结点。 选择较小的节点: 在函数体内,首先比较两个链表的头结点的值,选择…...

从接口400ms到20ms,记录一次JVM、MySQL、Redis的混合双打
1. 场景:促销活动的崩溃 接到报警短信,核心接口响应时间突破5秒,DB CPU飙到100%。 用Arthas抓取线上火焰图后发现: ---[ 4763ms ] com.example.service.OrderService.createOrder() |---[ 98% ] com.example.m…...

Excel通过VBA脚本去除重复数据行并保存
一、方法1:使用字典动态去重并保存 适用场景:需要灵活控制去重逻辑(如保留最后一次出现的重复项)时 Sub 动态去重保存到新表()Dim srcSheet As Worksheet, destSheet As WorksheetDim dict As Object, lastRow As Long, i As LongDim key A…...
)
Mysql表的操作(2)
1.去重 select distinct 列名 from 表名 2.查询时排序 select 列名 from 表名 order by 列名 asc/desc; 不影响数据库里面的数据 错误样例 : 但结果却有点出乎意料了~为什么会失败呢? 其实这是因为书写的形式不对,如果带了引号,…...

#Linux内存管理# 在ARM32系统中,页表是如何映射的?在ARM64系统中,页表又是如何映射的?
一、ARM32系统页表映射 1. 层级结构与地址划分 默认实现:采用两层映射(PGD→PTE),合并Linux标准三级模型中的PMD层。 虚拟地址解析(以4KB页为例): Bits[31:20]:一级页表(…...

prometheus整合jmx_exporter 使用jmx_exporter监控Kafka
docker-compose部署kafka集群;单节点单zk-CSDN博客 springboot整合kafka;docker部署kafka-CSDN博客 kafka使用SSL加密和认证--todo_ssl.truststore.location-CSDN博客 version: 3.8services:zookeeper1:image: zookeeper:3.9.1container_name: zook…...
)
深度学习实战:从零构建图像分类API(Flask/FastAPI版)
引言:AI时代的图像分类需求 在智能时代,图像分类技术已渗透到医疗影像分析、自动驾驶、工业质检等各个领域。作为开发者,掌握如何将深度学习模型封装为API服务,是实现技术落地的关键一步。本文将手把手教你使用Python生态中的Fla…...

Kafka实现延迟消息
Kafka 实现延迟消息 Kafka 本身不支持原生的延迟消息(不像 RocketMQ 内置了延迟队列),但可以通过多种方式来实现延迟消息。常见的方案如下: 1. 使用不同的 Topic 分区(最常见) 思路: 创建多…...
Kafka万亿级数据洪流下的架构优化实战:从参数调优到集群治理)
大数据(7.2)Kafka万亿级数据洪流下的架构优化实战:从参数调优到集群治理
目录 一、海量数据场景下的性能之殇1.1 互联网企业的数据增长曲线1.2 典型性能瓶颈分析 二、生产者端极致优化2.1 批量发送黄金法则2.1.1 分区选择算法对比 2.2 序列化性能突破 三、消费者端并发艺术3.1 多线程消费模式演进3.1.1 消费组Rebalance优化 3.2 位移管理高阶技巧 四、…...

要查看 FAISS 使用的 OpenMP 版本,需根据安装方式和系统环境采用不同方法。以下是具体步骤和原理分析:
要查看 FAISS 使用的 OpenMP 版本,需根据安装方式和系统环境采用不同方法。以下是具体步骤和原理分析: 方法 1:通过库文件名称直接查看(推荐) FAISS 的 OpenMP 版本通常直接体现在其依赖的动态链接库(DLL/…...
)
AI 大模型的标准化工具箱MCP (Model Context Protocol)
MCP简介 MCP (Model Context Protocol,模型上下文协议)定义了应用程序和 AI 模型之间交换上下文信息的方式。这使得开发者能够以一致的方式将各种数据源、工具和功能连接到 AI 模型(一个中间协议层),就像 …...

哈希表的封装
目录 引入 哈希表封装 修改哈希表参数 修改哈希表成员 修改%时使用的变量 修改读取时获得的变量 迭代器的实现 迭代器的定义 迭代器 迭代器*解引用 迭代器->成员访问 迭代器重载和! 封装迭代器 HashTable迭代器封装 非const版本 const版本 unordered_set迭…...

2025年认证杯数模竞赛赛题浅析-快速选题
赛题浅析 认证杯作为国内最早的数学建模论坛、唯一一个全部公开参赛论文的竞赛、国内最大的数学建模竞赛之一、唯一一个对非学生群里开放的数学建模竞赛、国内唯二的支持高中生参赛的大学生数模竞赛。在数模界一直被视为国赛之前较好的练手赛,本文将初步简略得介绍…...

【网络安全】Linux 常见命令
未经许可,不得转载。 文章目录 正文系统信息查看用户与权限管理进程管理网络配置与检测文件操作日志查看与分析权限审计与安全检测正文 在网络安全工作中,熟练掌握 Linux 系统中的常用命令,对于日常运维、日志分析、安全排查等工作至关重要。 以下为常用命令汇总,供参考。…...

电脑卡顿严重怎么办 电脑卡顿的处理指南
电脑突然卡顿比较严重,这是很多用户都曾经遇到过的问题,鼠标一直转圈圈,无法进行任何操作。电脑卡顿,电脑卡顿不仅会降低工作效率,还可能导致数据丢失,数据无法保存。很多用户解决电脑卡顿的方法就是直接一…...
之测试前后端连接)
山东大学软件学院创新项目实训开发日志(9)之测试前后端连接
在正式开始前后端功能开发前,在队友的帮助下,成功完成了前后端测试连接: 首先在后端编写一个测试相应程序: 然后在前端创建vue 并且在index.js中添加一下元素: 然后进行测试,测试成功: 后续可…...

H.264 NVMPI解码性能优化策略
H.264 NVMPI解码性能优化策略 1. 硬件与驱动配置 JetPack版本匹配:确保NVIDIA Jetson设备的JetPack SDK版本与CUDA驱动兼容,避免因驱动不匹配导致硬件解码性能下降8。显存分配优化:调整FFmpeg的-hwaccel_device参数指定GPU…...

汽车软件开发常用的需求管理工具汇总
目录 往期推荐 DOORS(IBM ) 行业应用企业: 应用背景: 主要特点: Polarion ALM(Siemens) 行业应用企业: 应用背景: 主要特点: Codebeamer ALM&#x…...

如何从零构建一个自己的 CentOS 基础镜像
如何从零构建一个自己的 CentOS 基础镜像 从零构建一个基于 CentOS 的基础镜像是一个很好的实践,可以帮助你理解 Docker 镜像的底层原理。以下是以 CentOS 为例,从零开始(不依赖现有镜像)构建基础镜像的详细步骤。我们将使用 yum…...

mongodb和clickhouse比较
好问题——MongoDB 也能处理这种高写入 定期删除的时间序列场景,尤其从 MongoDB 5.0 开始支持了专门的 Time Series Collections(时间序列集合),对你的需求其实挺对口的。 不过它有些优点和局限,需要具体分析下你场景…...

C#容器源码分析 --- List
List是一个非常常用的泛型集合类,它位于 System.Collections.Generic 命名空间下,本质上是一个动态数组,它提供了一系列方便的方法来管理和操作元素,例如添加、删除、查找等。与传统的数组相比,List可以根据需要动态调…...

以太坊区块大小的决定因素:深入解析区块 Gas 限制及其影响
以太坊(Ethereum)作为全球领先的区块链平台,其区块大小并非固定的物理尺寸,而是由区块 Gas 限制(Block Gas Limit)所决定。理解区块 Gas 限制及其影响因素,对于深入掌握以太坊网络的运行机制至…...

利用DeepFlow解决APISIX故障诊断中的方向偏差问题
概要:随着APISIX作为IT应用系统入口的普及,其故障定位能力的不足导致了在业务故障诊断中,APISIX常常成为首要的“嫌疑对象”。这不仅导致了“兴师动众”式的资源投入,还可能使诊断方向“背道而驰”,从而导致业务故障“…...

智慧养老实训基地建设方案:如何以科技赋能养老实操培训
在人口老龄化加剧的当下,智慧养老产业蓬勃发展,对专业技能型人才的需求愈发迫切。智慧养老实训基地建设意义非凡,它为培育具备实操能力与创新思维的养老人才搭建关键平台,有助于填补行业人才缺口,推动养老服务从传统模…...
实战:漏洞拦截与威胁情报集成)
基于AI的Web应用防火墙(AppWall)实战:漏洞拦截与威胁情报集成
摘要:针对Web应用面临的OWASP、CVE等漏洞攻击,本文结合群联AI云防护系统的AppWall模块,详解AI规则双引擎的防御原理,并提供漏洞拦截配置与威胁情报集成代码示例。 一、Web应用安全挑战与AppWall优势 传统WAF依赖规则库更新滞后&a…...

什么是采购管理?如何做好采购管理的持续优化?
你是不是也遇到过这种情况: 公司采购部刚换了新供应商,结果原材料质量忽高忽低,生产线上三天两头出状况;行政采购的办公用品,月初买回来月底就堆在仓库吃灰;财务部天天追着问采购成本怎么又超支了... 这些…...

Unity 设置弹窗Tips位置
根据鼠标位于屏幕的区域,设置弹窗锚点以及位置 public static void TipsPos(Transform tf) {//获取ui相机var uiCamera GetUICamera();var popup tf.GetComponent<RectTransform>();//获取鼠标位置Vector2 mousePos Input.mousePosition;float screenWidt…...

区块链知识点5-Solidity编程基础
1. 全局变量名 具体描述 msg.sender 返回当前调用函数的调用者的地址 msg.value 当前消息所附带的以太币,单位为wei 2.变量的用法 默认存储位置修饰符 函数的返回值 memory 函数内部的局…...

OLAP与OLTP架构设计原理对比
OLAP与OLTP架构设计原理对比 一、核心区别 维度OLTPOLAP设计目标支持高并发、低延迟的事务操作(增删改查)支持复杂分析查询(聚合、多维度统计)数据模型规范化模型(3NF),减少冗余维度模型&…...
)
ubuntu20.04在mid360部署direct_lidar_odometry(DLO)
editor:1034Robotics-yy time:2025.4.10 1.下载DLO,mid360需要的一些...: 1.1 在工作空间/src下 下载DLO: git clone https://github.com/vectr-ucla/direct_lidar_odometry 1.2 在工作空间/src下 下载livox_ros_driver2&…...
架构深度解析:突破大模型边界的工程实践)
检索增强生成(RAG)架构深度解析:突破大模型边界的工程实践
一、RAG技术架构设计哲学 1.1 范式演进:从静态模型到动态知识系统 graph LR A[传统LLM架构] -->|问题| B[依赖预训练参数] B --> C[知识固化风险] C --> D[领域适配困难]A -->|解决方案| E[RAG增强架构] E --> F[实时知识检索] F --> G[动态上下…...

线代第四课:行列式的性质
行列式性质 转置行列式 把行列式的第一行转置成第一列,使用表示 如果在转置一下: 性质一: 行列地位相同,对行性质,对列性质 性质二: 交换D的两行(列),D值变符号 性…...

【语音识别】vLLM 部署 Whisper 语音识别模型指南
目录 1. 模型下载 2. 环境安装 3. 部署脚本 4. 服务测试 语音识别技术在现代人工智能应用中扮演着重要角色,OpenAI开源的Whisper模型以其出色的识别准确率和多语言支持能力成为当前最先进的语音识别解决方案之一。本文将详细介绍如何使用vLLM(一个高…...

Python | kelvin波的水平空间结构
写在前面 简单记录一下之前想画的一个图: 思路 整体比较简单,两个子图,本质上就是一个带有投影,一个不带投影,通常用在EOF的空间模态和时间序列的绘制中,可以看看之前的几个详细的画法。 Python | El Ni…...

什么叫行列式
《行列式:数学中的重要概念及其应用》 行列式是数学中的一个重要概念,主要用于描述线性方程组、向量空间等方面的性质。以下是关于它的详细介绍: 定义 行列式是由排成正方形的一组数(称为元素)按照特定的规则计算得…...

构建高可用大数据平台:Hadoop与Spark分布式集群搭建指南
想象一下,你手握海量数据,却因为测试环境不稳定,频频遭遇宕机和数据丢失的噩梦。Hadoop和Spark作为大数据处理的“黄金搭档”,如何在分布式高可用(HA)环境下稳如磐石地运行?答案就在于一个精心构…...
)
[leetcode]211. 添加与搜索单词(Trie+DFS)
题目链接 题意 实现词典类 WordDictionary : WordDictionary() 初始化词典对象void addWord(word) 将 word 添加到数据结构中,之后可以对它进行匹配bool search(word) 如果数据结构中存在字符串与 word 匹配,则返回 true ;否则…...

AI | 字节跳动 AI 中文IDE编辑器 Trae 初体验
Trae 简介与安装 🔦 什么是 Trae Trae 是大厂字节跳动出品的国内首个 AI IDE,深度理解中文开发场景。AI 高度集成于 IDE 环境之中,为你带来比 AI 插件更加流畅、准确、优质的开发体验。说是能够不用写代码,全靠一张嘴跟 AI 聊天…...