如何把未量化的 70B 大模型加载到笔记本电脑上运行?
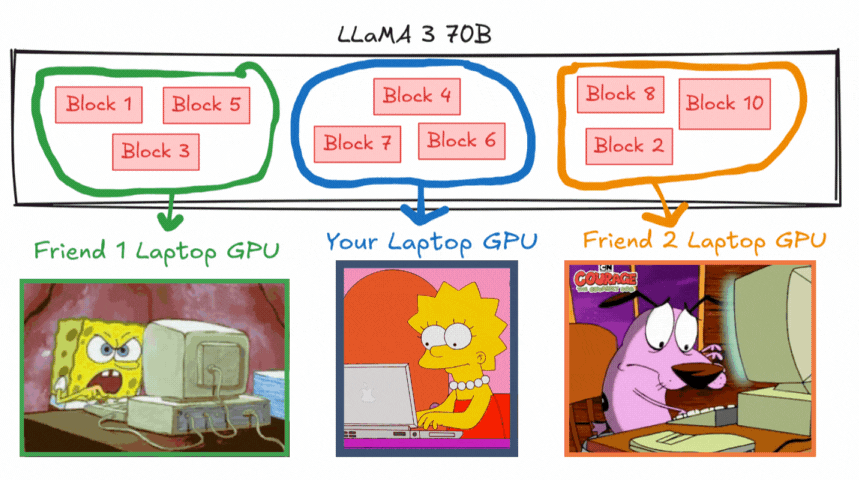
并行运行 70B 大模型
我们已经看到,量化已经成为在低端 GPU(比如 Colab、Kaggle 等)上加载大型语言模型(LLMs)的最常见方法了,但这会降低准确性并增加幻觉现象。
那如果你和你的朋友们把一个大型语言模型分着用呢?
每台笔记本的 GPU 负责一部分,这样大家一起推理和处理任务就容易多了。
我们要用 Petals 来做到这一点,把我们的大模型分布式加载到你朋友或家人那里的多个 GPU 上,它们会一起托管我们的模型。
LLMs 是怎么分布式的
在我们开始写代码之前,需要先理解一下分布是怎么进行的,要理解这个,用一张图来直观地展示是最合适的方式。
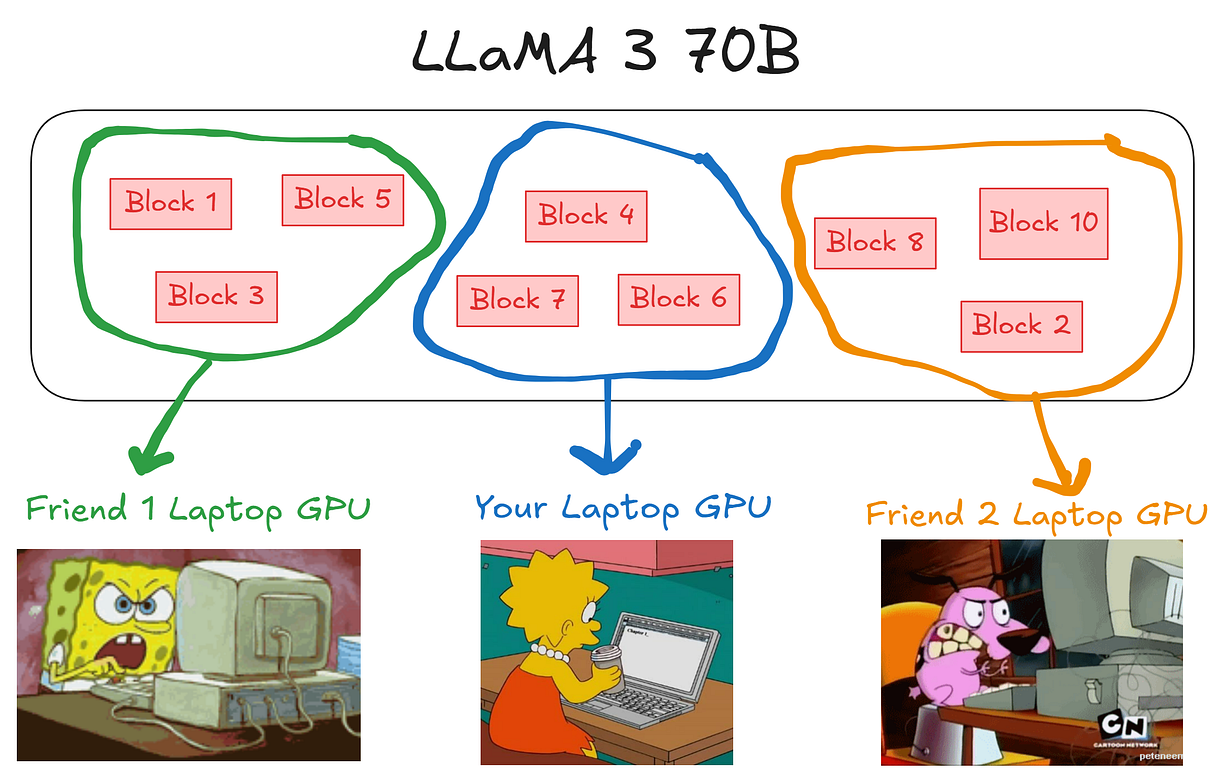
70B 大模型并行示意图(由 Fareed Khan 绘制)
每个 LLM 都是由很多 block(模块)组成的,它们彼此是独立的。
比如说 LLaMA 3 70B,它由好几个 block 组成,假设总共有 10 个 block。我们可以让一台笔记本托管其中几个 block,另一台托管另外几个,以此类推。
这样,多个 block 被分别托管了起来,就可以一起拿来推理使用了。
我们还能更进一步,比如用量化的方法来托管更大的 LLM,比如 405B 参数的 LLaMA,这样就能访问更大型的模型,而不需要付费 API 或 GPU 使用时间。
目录
• 设置环境
• 检查可用 GPU
• 创建分布式模型
• 在分布式模型上贪婪推理
• 正确地生成 Token
• 模型长什么样
• Prompt Tuning(提示词微调)
• 微调可训练的适配器
• 采样方法
• 私人 Swarm 网络
• 关键结论
设置环境
确保你的环境里安装了支持 CUDA 的 PyTorch。你可以从这里查看最新版。我们先安装带 CUDA 支持的 PyTorch。
# 安装带 CUDA 支持的 PyTorch
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
之后我们要安装 Petals。你可以从 GitHub 查看它的官方文档。我们先安装一下。
# 从源代码安装 Petals
pip install git+https://github.com/bigscience-workshop/petals
安装会花点时间,等依赖装完之后,我们就来检查一下可用的 GPU。
检查可用 GPU
为了模拟一群人一起合作的场景,我用 Colab、Kaggle 和 Lightning.ai 创建了好几个基于 GPU 的 Jupyter 笔记本,包括我本地的 GPU,用来做推理用。
来看一下我这边运行 (FP16) 70B LLM 的可用 GPU:

可用 GPU(由 Fareed Khan 绘制)
我用不同的临时账号,在同一台服务器上开了多个笔记本。所以如果把总 GPU 内存加在一起,大概有 (~170GB RAM)。
当然了,如果你目标是 8B 未量化的 LLM,肯定用不了这么多笔记本。
接下来,咱们就要开始把 LLM 的 workload(block)分布到不同的 GPU 上了。
创建分布式模型
想要把一些 block 推送到某个 GPU 上,只要在对应 GPU 的笔记本上运行这个命令,就能开始分布式加载 LLM。我们用 70B LLM 来操作:
# 把 70B LLaMA 的 block 推送到一个运行着的 GPU 上
python -m petals.cli.run_server meta-llama/Llama-3.1-70B-Instruct
执行这个命令后,它会先检查该笔记本的可用 GPU。
输出 = 检查可用 GPU
less
Mar 26 12:43:46.586 [INFO] 测量网络和计算吞吐量,大约需要一分钟,结果会缓存以供以后使用
Mar 26 12:43:52.596 [INFO] 推理吞吐量:每 block 每秒 478.6 tokens(1 tokens/batch,Tesla T4 GPU,bfloat16)
因为我用的是 Colab 的 T4 GPU 笔记本,所以它首先检测到了 GPU,还有每个 block 处理的 tokens/sec 等有用信息。
检测完 GPU 后,它会识别出我们 LLM 共有多少个 block(大约 80 个 block)。
输出 = 检查总 Blocks
less
Mar 26 12:43:58.461 [INFO] 前向传递吞吐量:每 block 每秒 5874.5 tokens(1024 tokens/batch,Tesla T4 GPU,bfloat16,量化到 nf4)
Mar 26 12:44:06.030 [INFO] 网络吞吐量:每秒 6320.9 tokens(下载 1158.43 Mbit/s,上传 414.25 Mbit/s)
Mar 26 12:44:06.031 [INFO] 汇报吞吐量:80 blocks 总体每秒 356.0 tokens
Mar 26 12:44:12.768 [INFO] 公告:blocks [14, 11, 6, 12, 14, 4, 7] 加入
它决定把 7 个 block 上传到我第一个 Colab T4 GPU 笔记本上。
所有这些都是通过 Petals Swarm 的后端管理的,自动处理了分布和内存管理,我们不需要自己手动管理。
不过 Petals 的文档非常强大,想深入了解的话可以去读(前面发过链接了)。
一旦对应的 block safetensors 下载完成,它们就会托管在 Petals 的公共 Swarm 服务器上。可以通过 health.petals.dev 监控你托管的 block 健康状况。
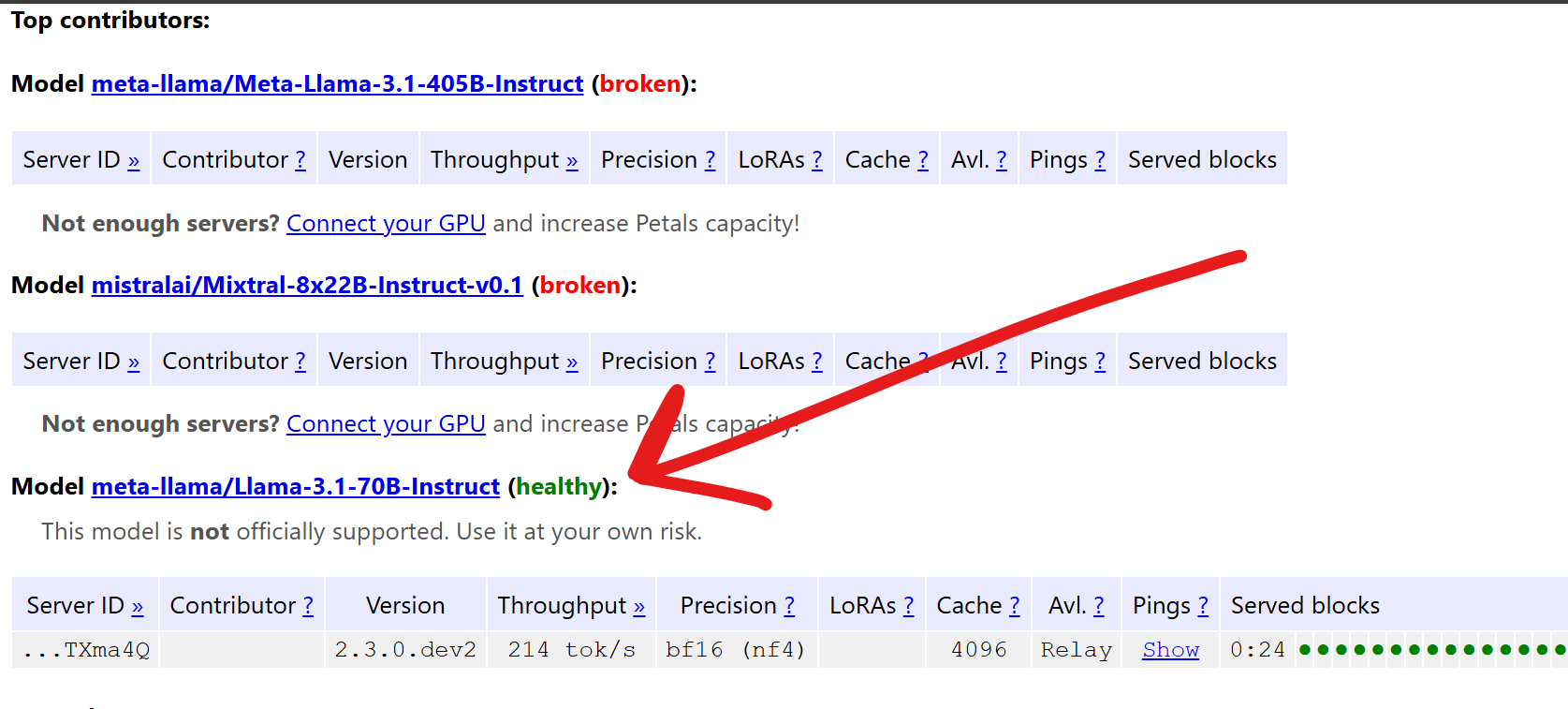
我们的 LLaMA 70B 托管的 block
可以看到,一旦那 7 个 block 成功托管在某个笔记本上,它们就出现在健康监控页面上了。
虽然单凭这一部分我们就能开始像 API 一样生成文本了,但如果托管更多的 block,生成效果肯定会更好更准。
所以,我们可以在另一个笔记本上用同样的命令继续操作,所有笔记本上流程都一样,Petals 会自动选择还没有被托管的 block。

托管 LLaMA 70B
等到所有笔记本都托管好之后,你可以看到具体托管了哪些 block,哪些 block 是在哪个服务器上。
一旦我们的 LLM 成功托管(虽然不是全部,但大部分 block 都有了),就可以像平常一样拿来推理和生成输出了。
在分布式模型上贪婪推理
我们来创建一个分布式模型,用来生成文本。这个设置下,我们本地 GPU(2GB 的机器)会下载一小部分模型权重,网络上的其他电脑负责剩下的部分。
Petals 让这一切变得很简单,它能直接和 PyTorch 还有 HF Transformers 配合使用,所以用起来就像跑本地模型一样轻松。
import torch
from transformers import AutoTokenizer
from petals import AutoDistributedModelForCausalLM
# 指定 Hugging Face Hub 上的模型名字(这里是 LLaMA 70B)
model_name = "meta-llama/Llama-3.1-70B-Instruct"
# 加载 tokenizer,并配置一些参数
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False, add_bos_token=False)
# 加载用于因果语言建模的分布式模型
model = AutoDistributedModelForCausalLM.from_pretrained(model_name)
# 把模型移动到 GPU 上,加速计算
model = model.cuda()
如果你以前在本地用过 LLM,这段代码基本不用解释了。
这里唯一的新东西就是 AutoDistributedModelForCausalLM,它负责把本地的 LLM 接到分布式托管的模型层网络上。
接下来,我们就可以用 model.generate() 方法来生成文本了。
第一次调用时可能要花几秒钟连接到 Petals,之后生成速度大约是每秒 5–6 个 token,比 CPU 或 offloading 要快。
# 将输入文本进行 token 化并移动到 GPU
inputs = tokenizer('A boy is riding "', return_tensors="pt")["input_ids"].cuda()
# 生成输出 tokens,限制最多生成 3 个新 token
outputs = model.generate(inputs, max_new_tokens=3)
# 解码并打印生成的输出
print(tokenizer.decode(outputs[0]))
输出
A boy is riding house and
如果输出看着不太对劲,不用担心。默认情况下,model.generate() 用的是贪婪生成(greedy generation)。
你可以尝试用 top-p、top-k 采样或者束搜索(beam search)等其他方法,通过调整 Transformers 的 .generate() 方法参数实现。
正确地生成 Token
如果想让模型像聊天机器人一样实时互动,我们可以用推理会话(inference session)接口。这样生成的 token 会实时显示,非常适合做聊天机器人。
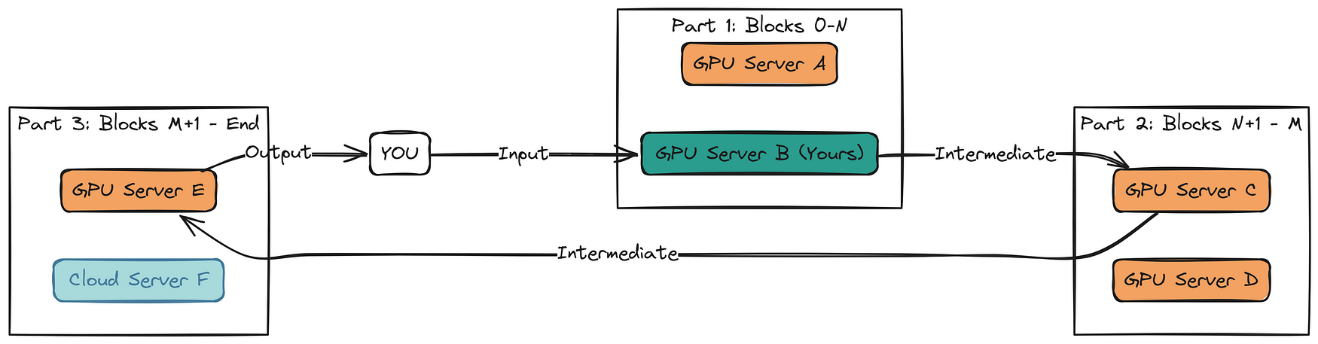
推理会话工作流(由 Fareed Khan 绘制)
这个会话会找到服务器来执行每一步,并存储注意力缓存(attention caches),所以你不需要每次都重新处理之前的 token。
如果有服务器掉线,Petals 会快速找到替代节点,只会重新生成一小部分缓存,非常高效。
来看一下,怎么一边生成一边实时显示:
# 创建一个假的 token,用来在解码时保留前导空格
fake_token = tokenizer("^")["input_ids"][0]
# 定义初始的文本提示词
text = "What is a good chatbot? Answer:"
# 把提示词 token 化并移动到 GPU
prefix = tokenizer(text, return_tensors="pt")["input_ids"].cuda()
# 开始一个推理会话,最多生成 30 个 token
with model.inference_session(max_length=30) as sess:
for i in range(20): # 迭代生成最多 20 个 token
# 只在第一次生成时提供 prefix
inputs = prefix if i == 0 else None
# 生成 1 个 token,使用采样(temperature=0.9,top-p=0.6 增加多样性)
outputs = model.generate(
inputs, max_new_tokens=1, session=sess,
do_sample=True, temperature=0.9, top_p=0.6
)
# 解码新生成的 token,并追加到文本后面
text += tokenizer.decode([fake_token, outputs[0, -1].item()])[1:]
# 每生成一个 token 就打印一次文本
print(text)
总结一下,我们刚才做了什么:
• 做了一个小技巧,确保解码时保留前导空格。
• 把提示词 token 化并移到 GPU。
• 开启推理会话,最多生成 20 个 token。
• 用采样(temperature 和 top-p)方式提高输出多样性。
• 每生成一个 token 都追加到文本,并实时打印。
接下来,我们来创建一个简单的聊天机器人!加个循环,接受用户输入,生成回复,遇到换行符(\n)就停止。
# 开启一个推理会话,最多生成 512 个 token
with model.inference_session(max_length=512) as sess:
while True:
# 获取用户输入作为聊天提示
prompt = input('Human: ')
# 如果输入为空,退出循环
if prompt == "":
break
# 格式化输入,模拟对话
prefix = f"Human: {prompt}\nFriendly AI:"
# 把输入 token 化并移动到 GPU
prefix = tokenizer(prefix, return_tensors="pt")["input_ids"].cuda()
print("Friendly AI:", end="", flush=True)
while True:
# 使用采样生成一个 token,保证回答多样性
outputs = model.generate(prefix, max_new_tokens=1, session=sess,
do_sample=True, temperature=0.9, top_p=0.6)
# 解码新生成的 token,同时保留前导空格
outputs = tokenizer.decode([fake_token, outputs[0, -1].item()])[1:]
# 立即打印新生成的 token
print(outputs, end="", flush=True)
# 如果检测到换行或结束标记,则退出
if "\n" in outputs or "</s>" in outputs:
break
# 之后不再提供 prefix,继续从会话状态生成
prefix = None
输出
Human: Hi, how are you?
Friendly AI: I am fine, thanks. And you?
你可以看到,实时推理的输出更加复杂和正式,跟我们原本的 LLM 保持一致。
如果托管的 block 更多,效果肯定会更接近原版 LLM。
我们的模型长什么样
我们用的模型其实和原版是一样的,只是部分加载到了本地 GPU 上。来看看它的结构:
# 打印模型架构
print(model)
输出
DistributedLlamaForCausalLM(
(model): DistributedLlamaModel(
(embed_tokens): Embedding(32000, 8192, padding_idx=0)
(layers): RemoteSequential(modules=llama-3-70b-intstruct.0..llama-3-70b-intstruct.79)
(norm): LlamaRMSNorm()
)
(lm_head): LMHead()
)
词嵌入(word embeddings)和一部分层是作为普通的 PyTorch 模块在本地跑的,剩下的模型部分(像 Transformer blocks)是通过 RemoteSequential 类跑在其他机器上的。
RemoteSequential 是一个特别的 PyTorch 模块,可以让模型分布式执行。
我们还能访问到单独的层,查看它们的输出,甚至能单独执行前向(forward)或反向(backward)传播。
比如提取前 5 层:
# 从模型内部的层堆栈中提取前五层
first_five_layers = model.model.layers[0:5]
# 显示提取出来的层(打印它们的细节或结构)
first_five_layers
输出
RemoteSequential(modules=llama-3-70b-intstruct.0..llama-3-70b-intstruct.4)
它打印出来了托管在其他 GPU 上的前 5 个 block,你可以直接看到。
Prompt Tuning(提示词微调)
远程托管的 transformer blocks 是冻结的(frozen),为了保证预训练模型在所有用户之间保持一致。
不过我们还是可以通过参数高效的方法(比如可训练的 prompt 或适配器 LoRA)来微调。
因为所有可训练参数和优化器都保存在本地,所以不会影响到其他用户。
在这个例子里,我们要用可训练的 prompt 来做一个简单任务:让模型学会把一句话变成它的反义句。
比如:
从 “A small white rabbit hops across the green field.”
变成
“A small white rabbit did not hop across the green field”。
首先来看一下在没有微调前,模型怎么回答:
# token 化输入文本并移动到 GPU
inputs = tokenizer("A small white rabbit ", return_tensors="pt")["input_ids"].cuda()
# 用模型生成最多 7 个新 token
outputs = model.generate(inputs, max_new_tokens=7)
# 解码并打印生成的文本
print("Generated:", tokenizer.decode(outputs[0]))
输出
A small white rabbit hop across the green field
如果你对 Prompt Tuning 不熟悉,简单说就是:在输入前面加一些可训练的“token”,这些 token 也是模型参数的一部分。
更进一步的 Deep Prompt Tuning(深度提示词微调)是在每一个 Transformer block 前都加可训练的 token,这样可以增加可训练参数数量,提高性能。
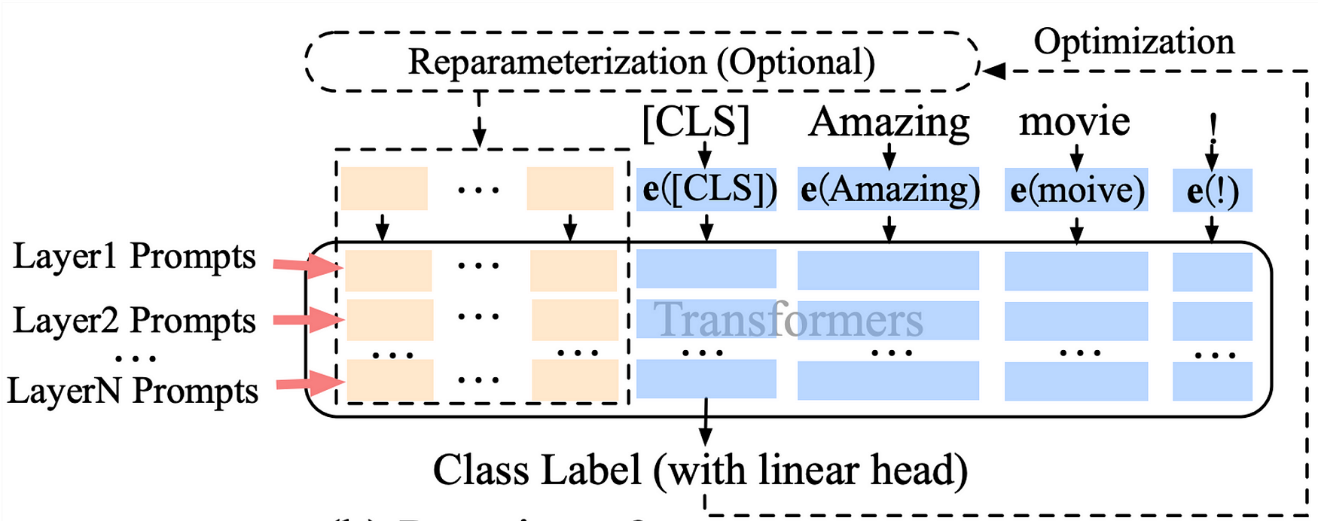
Deep Prompt Tuning(图片来自 Liu, Xiao 等人)
Petals 内置了 prompt tuning 的支持,参数 tuning_mode="ptune";也支持 deep prompt tuning,参数 tuning_mode="deep_ptune"。
我们这里用 deep prompt tuning,每层加 3 个 token(pre_seq_len=3):
# 用 deep prompt tuning 加载预训练的因果语言模型
model = AutoDistributedModelForCausalLM.from_pretrained(model_name, tuning_mode='deep_ptune', pre_seq_len=3)
# 把模型移到 GPU 上
model = model.cuda()
接下来,我们可以像本地模型一样设置 Adam 优化器,开始微调分布式模型:
# 用学习率 0.001 初始化 Adam 优化器
opt = torch.optim.Adam(model.parameters(), lr=1e-3)
# token 化目标文本并移到 GPU
the_rabbit_did_not_hop = tokenizer("A small white rabbit did not hop across the green field", return_tensors="pt")["input_ids"].cuda()
# 训练 12 步
for i in range(12):
# 前向传递,计算 loss(自监督学习)
loss = model(input_ids=the_rabbit_did_not_hop, labels=the_rabbit_did_not_hop).loss
print(f"loss[{i}] = {loss.item():.3f}")
# 清空前一次的梯度
opt.zero_grad()
# 反向传播计算梯度
loss.backward()
# 优化器更新参数
opt.step()
print("opt.step()")
输出
loss[0] = 5.324
opt.step()
loss[1] = 4.983
opt.step()
loss[2] = 4.512
opt.step()
loss[3] = 4.217
opt.step()
...
loss[11] = 0.014
opt.step()
当 loss 几乎降到 0 时,模型就学会了我们要它生成的句子。
再来测试一下:
# token 化输入 "A small white rabbit" 并移动到 GPU
inputs = tokenizer("A small white rabbit", return_tensors="pt")["input_ids"].cuda()
# 生成最多 7 个新 token
outputs = model.generate(inputs, max_new_tokens=7)
# 解码并打印生成的文本
print("Generated:", tokenizer.decode(outputs[0]))
输出
generated: A small white rabbit did not hop across the green field.
可以看到,它成功生成了反义句:“小白兔没有跳过绿色草地”。
微调可训练适配器
接下来,我们要试一下另一种微调方法,叫做可训练适配器。
适配器就是在预训练 Transformer block 之间或者旁边加的小型层。
我们会在模型里插入一个简单的可训练线性层,还会替换掉模型的头部(head),做分类任务。
像之前一样,适配器的权重和优化器状态也都是保存在本地的。
import torch.nn as nn
import torch.nn.functional as F
# 加载一个预训练的因果语言模型,并移动到 GPU
model = AutoDistributedModelForCausalLM.from_pretrained(model_name)
model = model.cuda()
# 定义一个基于 LLM 的分类器
class LLMBasedClassifier(nn.Module):
def __init__(self, model):
super().__init__()
# 提取模型的 transformer 层,用于分布式处理
self.distributed_layers = model.transformer.h
# 添加一个适配器模块:两个线性层,用来降维再升维
self.adapter = nn.Sequential(
nn.Linear(model.config.hidden_size, 32),
nn.Linear(32, model.config.hidden_size)
)
# 分类头,把隐藏状态映射成 2 个类别
self.head = nn.Linear(model.config.hidden_size, 2)
def forward(self, embeddings):
# 把模型一分为二,先通过前半部分层处理 embedding
mid_block = len(self.distributed_layers) // 2
hidden_states = self.distributed_layers[:mid_block](embeddings)
# 经过适配器进行转换
hidden_states = self.adapter(hidden_states)
# 再通过后半部分层处理
hidden_states = self.distributed_layers[mid_block:](hidden_states)
# 对序列做均值池化(mean pooling),得到固定大小的表示
pooled_states = torch.mean(hidden_states, dim=1)
# 最后通过分类头输出类别预测
return self.head(pooled_states)
然后,我们用 Adam 优化器训练这个模型,用常见的交叉熵损失(cross-entropy loss)来做分类任务:
# 初始化 LLMBasedClassifier 并移动到 GPU
classifier = LLMBasedClassifier(model).cuda()
# 用 Adam 优化器,学习率 3e-5
opt = torch.optim.Adam(classifier.parameters(), 3e-5)
# 创建虚拟输入数据(3 个样本,每个 2 个 token,隐藏层大小)
inputs = torch.randn(3, 2, model.config.hidden_size, device='cuda')
# 定义这 3 个样本的真实标签(0 和 1)
labels = torch.tensor([1, 0, 1], device='cuda')
# 训练 5 次迭代
for i in range(5):
# 计算损失:交叉熵
loss = F.cross_entropy(classifier(inputs), labels)
print(f"loss[{i}] = {loss.item():.3f}")
# 清空之前的梯度
opt.zero_grad()
# 反向传播计算梯度
loss.backward()
# 用优化器更新参数
opt.step()
# 打印预测的类别(通过 argmax 得到)
print('Predicted:', classifier(inputs).argmax(-1))
当我们开始训练时,它会在每次迭代后打印 loss:
loss[0] = 16.236
...
loss[4] = 1.254
predicted: tensor([1, 0, 1], device='cuda:0')
可以看到,loss 在不断下降,说明模型正在拟合我们的虚拟数据集!
就像 Petals 官方文档里说的那样,你还可以去看看他们的示例笔记本,在里面用 Llama 在著名的 SST2 数据集上做微调。
采样方法
之前你已经看到怎么用普通 PyTorch 代码来跟分布式模型交互了。
这种方式允许你实现更高级的微调和采样方法,很多时候是托管 API 做不到的。
现在,我们来从零开始自己写一个采样方法。
下面,我们要重新实现标准的 model.generate() 接口,手动一步步在所有层上做前向传递(forward pass):
from hivemind import get_logger
import torch
# 初始化 logger,用来在每一步打印日志
logger = get_logger()
# 小技巧,确保 tokenizer.decode() 保留前导空格
fake_token = tokenizer("^")["input_ids"][0]
# 定义输入提示词
text = "How can I improve my writing skills? Answer:"
token_ids = tokenizer(text, return_tensors="pt")["input_ids"].cuda() # 把输入文本转成 token ID 并移到 GPU
# 设置生成文本的最大长度
max_length = 100
# 禁用梯度计算,加速推理
with torch.inference_mode():
# 开启推理会话
with model.inference_session(max_length=max_length) as sess:
# 一直生成 token,直到达到最大长度
while len(text) < max_length:
# 获取 token 的词嵌入
embs = model.transformer.word_embeddings(token_ids)
embs = model.transformer.word_embeddings_layernorm(embs)
# 前向传递
h = sess.step(embs)
h_last = model.transformer.ln_f(h[:, -1]) # 取最后一个隐藏状态
logits = model.lm_head(h_last) # 计算下一步的 logits
# 贪婪地选择概率最高的 token
next_token = logits.argmax(dim=-1)
# 解码新 token,追加到输出文本里
text += tokenizer.decode([fake_token, next_token.item()])[1:]
# 更新 token_ids,准备下一步生成
token_ids = next_token.reshape(1, 1)
# 在每一步打印生成的文本
logger.info(text)
运行上面这段代码时,它会开始一边生成一边打印输出:
[INFO] How can I improve my writing skills? Answer: P
[INFO] How can I improve my writing skills? Answer: Practice
[INFO] How can I improve my writing skills? Answer: Practice writing
[INFO] How can I improve my writing skills? Answer: Practice writing regularly
[INFO] How can I improve my writing skills? Answer: Practice writing regularly and
[INFO] How can I improve my writing skills? Answer: Practice writing regularly and read
[INFO] How can I improve my writing skills? Answer: Practice writing regularly and read more
[INFO] How can I improve my writing skills? Answer: Practice writing regularly and read more books
[INFO] How can I improve my writing skills? Answer: Practice writing regularly and read more books to
[INFO] How can I improve my writing skills? Answer: Practice writing regularly and read more books to improve
[INFO] How can I improve my writing skills? Answer: Practice writing regularly and read more books to improve your
[INFO] How can I improve my writing skills? Answer: Practice writing regularly and read more books to improve your vocabulary
...
Petals 的 model.inference_session() 接口让你可以自己写定制的推理逻辑。
通过它,你可以实现任何采样算法,比如自定义的束搜索(beam search),比如避免生成脏话之类的。
私人 Swarm 网络(Private Swarm)
Petals 的公共 Swarm 允许你跟别人共享计算资源,一起跑模型。
但有时候出于隐私或者输出正确性的要求,公共网络就不太合适了。
那如果你想搭建自己的私有托管网络呢?
只让自己和朋友访问大模型的 blocks?
这个很简单,我们来搞一个私人 Swarm。
首先,你需要一台可靠的机器(或者几台)作为私有网络的“入口点”或者“地址簿”。
这个机器不需要 GPU,我们叫它 bootstrap peer。
你可以用 tmux 或 screen 把它跑在后台。命令如下:
# 启动一个 bootstrap peer,监听特定端口(比如 31337)
# 把它的唯一 ID 保存到 bootstrap1.id
python -m petals.cli.run_dht --host_maddrs /ip4/0.0.0.0/tcp/31337 --identity_path bootstrap1.id
运行后注意看输出!
它会打印出一行提示你完整的地址,比如:
输出
[INFO] 正在运行 DHT 实例。要让其他节点连接到这个节点,
请使用 --initial_peers /ip4/YOUR_PUBLIC_IP_OR_LAN_IP/tcp/31337/p2p/QmTPAIfTh1sIsMyUnique1DDontCopyThisPart...
一定要复制这个完整的 /ip4/.../p2p/... 地址!
这就是你私人 Swarm 的钥匙。(确保你的公网 IP 或局域网 IP 是其他机器能访问到的。)
然后,在你的 GPU 机器上(笔记本、Colab、其他设备上),像之前一样启动 Petals server,
但是这次要告诉它,去连接你自己的私人网络:
# 把 bootstrap peer 的地址存到变量里
export MY_INITIAL_PEERS="/ip4/YOUR_PUBLIC_IP_OR_LAN_IP/tcp/31337/p2p/QmTPAIfTh1sIsMyUnique1DDontCopyThisPart..."
# 启动 LLaMA 3.1 70B 的服务器,连接到你的私人 Swarm
python -m petals.cli.run_server meta-llama/Llama-3.1-70B-Instruct --initial_peers $MY_INITIAL_PEERS
每台你想贡献 GPU 的机器,都要这么操作。
它们会像之前那样加载 blocks,但只在你的私有网络里互相通信,不会连接到公网上。
最后,当你在 Python 脚本里推理时,也要告诉它去连接你的私人 Swarm:
import torch
from transformers import AutoTokenizer
from petals import AutoDistributedModelForCausalLM
# 你的 bootstrap peer 的地址(可以是列表)
INITIAL_PEERS = ["/ip4/YOUR_PUBLIC_IP_OR_LAN_IP/tcp/31337/p2p/QmTPAIfTh1sIsMyUnique1DDontCopyThisPart..."]
# 指定模型名
model_name = "meta-llama/Llama-3.1-70B-Instruct"
# 正常加载 tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False, add_bos_token=False)
# 加载分布式模型,指定连接你的私人 Swarm
model = AutoDistributedModelForCausalLM.from_pretrained(
model_name,
initial_peers=INITIAL_PEERS # <-- 重点就在这!
)
# 如果本地有 GPU,可以把模型移过去
model = model.cuda()
# 然后就可以像之前一样用 model.generate() 或推理会话啦!
# inputs = tokenizer('A question: "', return_tensors="pt")["input_ids"].cuda()
# outputs = model.generate(inputs, max_new_tokens=5)
# print(tokenizer.decode(outputs[0]))
就这样!
你现在就在自己的一小圈电脑里,私下运行超大 LLM 了。
不再依赖公共网络,完全自主可控。
甚至可以搭建自己的健康监控页面,实时查看你们 Swarm 的状态!
你可以通过阅读 Petals 的官方文档来进一步掌握更多高级用法哦。
关键结论
你已经看到了,prompt 模板和托管 block 的数量是影响最终效果的两个关键因素;
否则 LLM 的性能可能达不到预期水平。
你还可以用量化技术来加载更大的 LLM。
Petals 支持很多参数配置,比如指定要托管哪些 block,避免重复上传。
我个人建议你可以先托管一个 8B 的 LLM,测试一下它的表现,
肯定会让你大吃一惊的!
相关文章:

如何把未量化的 70B 大模型加载到笔记本电脑上运行?
并行运行 70B 大模型 我们已经看到,量化已经成为在低端 GPU(比如 Colab、Kaggle 等)上加载大型语言模型(LLMs)的最常见方法了,但这会降低准确性并增加幻觉现象。 那如果你和你的朋友们把一个大型语言模型分…...

xwiki的权限-页面特殊设置>用户权限>组权限
官方文档https://www.xwiki.org/xwiki/bin/view/Documentation/AdminGuide/Access%20Rights/ 他有组权限、用户权限、页面及子页面特别设置。 页面特殊设置 > 用户权限 > 组权限 XWiki提供了设置wiki范围内权限、细粒度页面级权限的能力,以及在需要更多控制的…...

Go语言比较递归和循环执行效率
一、概念 1.递归 递归是指一个函数在其定义中直接或间接调用自身的编程方法 。简单来说,就是函数自己调用自己。递归主要用于将复杂的问题分解为较小的、相同类型的子问题,通过不断缩小问题的规模,直到遇到一个最简单、最基础的情况&#x…...

Windows 图形显示驱动开发-WDDM 2.0功能_供应和回收更改
供应和回收更改 对于 Windows 显示驱动程序模型 (WDDM) v2,有关 套餐 和 回收 的要求正在放宽。 用户模式驱动程序不再需要在内部分配上使用套餐和回收。 空闲/挂起的应用程序将使用 Microsoft DirectX 11.1 中引入的 TrimAPI 删除驱动程序内部资源。 API 级别将继…...

MongoDB 新手笔记
MongoDB 新手笔记 1. MongoDB 1.1 概述 MongoDB 是一种 文档型数据库(NoSQL),数据以类似 JSON 的 BSON 格式存储,适合处理非结构化或半结构化数据。 对比 MySQL: MySQL 是关系型数据库,数据以表格形式存…...

Pytorch查看神经网络结构和参数量
基本方法 print(model) print(type(model))# 模型参数 numEl_list [p.numel() for p in model.parameters()] total_params_mb sum(numEl_list) / 1e6print(fTotal parameters: {total_params_mb:.2f} MB) # sum(numEl_list), numEl_list print(sum(numEl_list)) print(numE…...

Pytorch Dataset问题解决:数据集读取报错DatasetGenerationError或OSError
问题描述 在huggingface上下载很大的数据集,用多个parquet文件的格式下载到本地。使用load_dataset加载的时候,进度条加载到一半会报错DatasetGenerationError: An error occurred while generating the dataset;如果加载为IterableDataset&…...

学习OpenCV C++版
OpenCV C 1 数据载入、显示与保存1.1 概念1.2 Mat 类构造与赋值1.3 Mat 类的赋值1.4 Mat 类支持的运算1.5 图像的读取与显示1.6 视频加载与摄像头调用1.7 数据保存 参考:《OpenCV4快速入门》作者冯 振 郭延宁 吕跃勇 1 数据载入、显示与保存 1.1 概念 Mat 类 : Ma…...

特权FPGA之PS/2键盘解码
0 故事背景 见过这种接口的朋友们,大概都已经成家立业了吧。不过今天我们不讨论这种接口的历史,只讲讲这种接口的设计。(如果还没有成家的朋友也别生气,做自己想做的事情就对了!) 1 时序分析 数据帧格式如图…...

SpringBoot 接口限流Lua脚本接合Redis 服务熔断 自定义注解 接口保护
介绍 Spring Boot 接口限流是防止接口被频繁请求而导致服务器负载过重或服务崩溃的一种策略。通过限流,我们可以控制单位时间内允许的请求次数,确保系统的稳定性。限流可以帮助防止恶意请求、保护系统资源,并优化 API 的可用性,避…...

FPAG_BUFFER学习
在FPGA设计中,缓冲器(Buffer)是信号传输和管理的核心组件,用于处理输入/输出信号、时钟分配以及信号完整性。以下是FPGA中常见缓冲器的详细介绍,分类说明其功能、应用场景和设计注意事项: --- ### **1. 输…...

《认知觉醒》下篇·第六章第一节“清晰:一个观念,重构你的行动力” 总结
《认知觉醒》下篇第六章第一节“清晰:一个观念,重构你的行动力”的核心内容总结: 1. 清晰的力量:行动力的第一性原理 定义 清晰是对目标、路径和结果的明确认知,是破除拖延与内耗的核心前提。 模糊的代价: …...

idea手动创建resources文件夹
有时maven没有构建成功可能造成,resources文件夹不创建的现象 此时我们可以手动创建 手动创建...

Scala相关知识学习总结6
1、集合计算高级函数说明 - 过滤:遍历集合,提取满足特定条件的元素组成新集合。 - 转化/映射(map):将集合里的每个元素应用到指定函数进行转换。 - 扁平化:文档未详细阐述其具体含义和操作。 - 扁平化映射&…...

IDEA 调用 Generate 生成 Getter/Setter 快捷键
快捷键不会用? 快捷键:AltInsert 全选键:CtrlA IDEA 调用 Generate 生成 Getter/Setter 快捷键 - 爱吃西瓜的番茄酱 - 博客园...
)
【SpringCloud】从入门到精通(下)
网关与路由 什么是网关?顾明思议,网关就是网络的关口。数据在网络间传输,从一个网络传输到另一网络时就需要经过网关来做数据的路由和转发以及数据安全的校验。 现在前端不能请求各个微服务地址,只能去请求网关 网关可以做安全控…...

深入探索 C++23:特性测试与编译器支持
文章目录 一、C23 新特性概览(一)语言特性(二)标准库特性 二、特性测试程序三、主流编译器支持情况(一)GCC(二)Clang(三)MSVC 四、开发者建议(一&…...

Electron 应用太重?试试 PakePlus 轻装上阵
Electron 作为将 Web 技术带入桌面应用领域的先驱框架,让无数开发者能够使用熟悉的 HTML、CSS 和 JavaScript 构建跨平台应用。然而,随着应用规模的扩大,Electron 应用的性能问题逐渐显现——内存占用高、启动速度慢、安装包体积庞大…...
加密与 SQL Server 建立安全连接)
驱动程序无法通过使用安全套接字层(SSL)加密与 SQL Server 建立安全连接
驱动程序无法通过使用安全套接字层(SSL)加密与 SQL Server 建立安全连接 原因描述 项目中有使用到 SQL Server 数据库, 在启动项目时, 出现报错信息: 【驱动程序无法通过使用安全套接字层(SSL)加密与 SQL Server 建立安全连接。错误:“The server selected protocol version…...

Java 设计模式:原型模式详解
Java 设计模式:原型模式详解 原型模式(Prototype Pattern)是一种创建型设计模式,它通过复制现有对象来创建新对象,而无需依赖其具体类。这种模式特别适合创建复杂对象或需要频繁创建相似对象的场景。本文将详细介绍原…...
——大模型训练和推理的显存估计)
NLP高频面试题(三十七)——大模型训练和推理的显存估计
在训练和推理大型语言模型时,显存(GPU 内存)的需求是一个关键考虑因素。准确估计这些需求有助于选择合适的硬件配置,确保模型高效运行。 推理阶段的显存需求 在推理过程中,显存主要用于存储模型权重和中间激活值。模型权重的显存需求可以通过以下公式估算: 模型权重…...

PHP 阿里云oss 使用指南
1.介绍 把图片放到阿里云上的空间上,可以使用cdn加速。 可以在程序里直接调用 要使用阿里云 oss sdk ,请先到阿里云下载 或用 copmposer 安装 相关链接: 安装OSS PHP SDK_对象存储(OSS)-阿里云帮助中心 composer require aliyuncs/oss…...

leetcode_面试题 02.07. 链表相交_java
面试题 02.07. 链表相交https://leetcode.cn/problems/intersection-of-two-linked-lists-lcci/ 1、题目 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表没有交点,返回 null 。 图示两个链表在节点 c…...
空间——排序+一次遍历)
LeetCode 3375.使数组的值全部为 K 的最少操作次数:O(1)空间——排序+一次遍历
【LetMeFly】3375.使数组的值全部为 K 的最少操作次数:O(1)空间——排序一次遍历 力扣题目链接:https://leetcode.cn/problems/minimum-operations-to-make-array-values-equal-to-k/ 给你一个整数数组 nums 和一个整数 k 。 如果一个数组中所有 严格…...

紫光展锐5G SoC T8300:影像升级,「定格」美好世界
影像能力已成为当今衡量智能手机性能的重要标尺之一。随着消费者对手机摄影需求日益提升,手机厂商纷纷在影像硬件和算法上展开激烈竞争,力求为用户带来更加出色的拍摄体验。 紫光展锐专为全球主流用户打造的畅享影音和游戏体验的5G SoC——T8300&#x…...

java基础 关键字static
static static使用简介static结合类的生命周期1.加载2.链接(1) 验证(Verification)(2) 准备(Preparation)(3) 解析(Resolution) 3. 初始化4.使用5.卸载总结 staic作用总结静态变量静态代码块静态方法静态内…...
-大数据组件分析)
大数据学习(105)-大数据组件分析
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一…...

Spark运行
一文读懂Spark:从核心概念到实战编程 在大数据处理领域,Spark凭借其高效的计算能力和灵活的架构脱颖而出。今天,就来和大家深入聊聊Spark,帮助初学者快速入门。Spark采用经典的master - slave结构。Driver如同master,…...

在macOS的docker中如何安装及运行ROS2
1、macOS环境及版本 2、docker for macos版本 3、拉取ROS2镜像 docker pull ros:iron 4、查看容器 docker images 5、启动 ROS2 容器 docker run -it --rm ros:iron -it :以交互模式运行容器。 --rm :退出时自动删除容器(测试时推荐&am…...

FFmpeg安装和使用
1. 安装与环境配置 Windows # 方法1:官网下载预编译二进制包 https://ffmpeg.org/download.html#build-windows 解压后添加bin目录到系统PATH# 方法2:通过Chocolatey安装 choco install ffmpegmacOS # 使用Homebrew安装 brew install ffmpegLinux # …...

基于多模态大模型的ATM全周期诊疗技术方案
基于多模态大模型的ATM全周期诊疗技术方案 1. 数据预处理模块 算法1:多模态数据融合伪代码 def multimodal_fusion(data_dict):# 输入:包含MRI、EEG、实验室指标的字典# 输出:对齐后的张量序列# 模态对齐aligned_data = temporal_alignment(data_dict,sampling_rate...
)
写时复制Copy-on-Write(COW)
简单理解写时复制 读的时候,直接访问原对象。 写的时候,对复制原对象,对副本进行写操作,最后将副本替换原对象。 写时复制多用于读多写少的场景,因为写操作是用悲观锁进行的,如果写的场景多,…...

S7-1200 PLC热电偶和热电阻模拟量模块
热电偶和热电阻模拟量模块 S7-1200 PLC有专用用于对温度进行采集的热电偶模块SM1231 TC和SM 1231RTD。热电偶模块有4AI和8AI两种,下面以SM1231 TC 4AI为例看一下接线图。 该模块一共有4个通道,每个通道有两个接线端子,比如0,0-。…...
)
ffmpeg函数简介(封装格式相关)
文章目录 🌟 前置说明:FFmpeg 中 AVFormatContext 是什么?🧩 1. avformat_alloc_context功能:场景: 🧩 2. avformat_open_input功能:说明:返回值: ǹ…...

操作数组的工具类
Arrays 它里面的每一个方法基本上都是static静态修饰的,如果想要调用里面的方法,不需要创建对象,直接用类名.就可以了 操作数组的工具类 方法: public static String toString(数组) 把数组拼接成…...

小刚说C语言刷题——第19讲 循环之continue和break
在循环中,当我们得到想要的答案时,这时我们可能要提前结束循环,这个时候我们就会用到break。而我们有时需要结束某一次循环时,我们可以用continue。 1.break语句 (1)在循环中想要提前终止循环,要用break。 (2)语法格…...

FairMOT复现过程中cython_bbox库问题
cython_bbox库就该这么安装_cython-bbox库就应该-CSDN博客...

记录学习的第二十四天
还是每日一题。 题解很巧,我根本想不到。 class Solution { public: int minOperations(vector<int>& nums, int k) { int count; int mnnums[0]; //接下来查找nums数组中最小值 for(int i1;i<nums.size();i) { if(nums[i]<mn) { mnnums[i]; } } …...

Kubernetes 入门篇之网络插件 calico 部署与安装
在运行kubeadm init 和 join 命令部署好master和node节点后,kubectl get nodes 看到节点都是NotReady状态,这是因为没有安装CNI网络插件。 kubectl get nodes NAME STATUS ROLES AGE VERSION k8s-master Not…...
)
HTTP 压力测试工具autocannon(AI)
简介 autocannon 是一款基于 Node.js 的高性能 HTTP 压力测试工具,适用于评估 Web 服务的并发处理能力和性能瓶颈。 一、工具特点 高性能:利用 Node.js 异步非阻塞机制模拟高并发请求。实时监控:测试过程中动态展示请求统计和性能…...

【面试】封装、继承、多态的具象示例 模板编程的理解与应用场景 链表适用的场景
文章目录 C面试:封装、继承、多态的具象示例1. 封装 (Encapsulation)2. 继承 (Inheritance)3. 多态 (Polymorphism)综合示例:封装、继承、多态 C模板编程的理解与应用场景我对模板编程的理解C中最常用的模板编程场景1. STL (标准模板库)2. 通用容器实现3…...

机器学习02——概要
一、简介 机器学习是一门在没有明确编程的情况下让计算机学习的科学。 监督学习是有目标的,输入数据对应明确的输出;无监督学习则是“探索”型的,模型的目标是从数据中发现潜在的模式或结构,而不需要预先知道标签。 二、机器学…...

常用的网络安全靶场、工具箱
转载:https://blog.csdn.net/zjzqxzhj/article/details/137945444 打CTF很好玩。可以试一下 1.CTF在线工具 1、CTF在线工具箱:http://ctf.ssleye.com/ 包含CTF比赛中常用的编码、加解密、算法。 2、CTF加解密工具箱:http://www.atoolbox.…...
)
excel中的VBA指令示例(一)
示例注释: Sub 宏1() sub是宏开头,宏1是宏的名称,自定义,在按钮中可指定用某个宏 后面是注释 Sheets("装配材料").Select ‘选择表 装配材料 Ce…...
)
神经网络 | 基于脉冲耦合神经网络PCNN图像特征提取与匹配(附matlab代码)
内容未发表论文基于脉冲耦合神经网络(PCNN)的图像特征提取与匹配研究 摘要 本文提出一种基于脉冲耦合神经网络(Pulse-Coupled Neural Network, PCNN)的图像特征提取与匹配方法。通过模拟生物视觉皮层神经元的脉冲同步发放特性,PCNN能够有效捕捉图像纹理与边缘特征。实验表…...

Linux 内核中的 TCP 早期多路分解机制解析
一、引言 在现代高性能网络环境中,Linux 内核需要快速处理大量的 TCP 数据包,同时保持低延迟和高吞吐量。为了实现这一目标,Linux 内核引入了 早期多路分解(Early Demultiplexing) 机制。这种机制允许内核在数据包进入传输层之前,快速找到对应的套接字(socket)并关联数…...
——错误类型)
Yalmip工具箱(3)——错误类型
在yalmip中,不可避免地我们会遇到求解出问题的情况,理解和处理错误信息是至关重要的环节。在这里我们查看yalmip的所有错误类型(详细见 yalmiperror.m 函数) 函数概述 yalmiperror函数的主要作用是根据YALMIP产生的错误代码&…...

【KWDB 创作者计划】_KWDB:开源引领数据库创新变革
在数字化浪潮汹涌澎湃的当下,数据已然成为驱动各行各业发展的核心要素。数据库作为数据管理的关键工具,其性能、功能以及开放性,对企业和社会的数字化进程起着举足轻重的作用。KWDB,作为数据库领域的一颗璀璨新星,正以…...

HarmonyOS学习 实验八:显式动画与属性动画的实现
鸿蒙系统动画开发实战:显式动画与属性动画的探索 引言 在鸿蒙系统的开发过程中,动画效果是提升用户体验的重要一环。通过巧妙运用动画,可以使应用界面更加生动、交互更加流畅。鸿蒙系统提供了丰富的动画开发能力,其中显式动画和…...

高校智慧能源系统解决方案:推动绿色校园建设的智能化实践
高校智慧能源系统解决方案:推动绿色校园建设的智能化实践 一、建设背景:政策驱动与绿色发展需求 为响应国家“碳达峰、碳中和”战略目标,教育部印发《绿色低碳发展国民教育体系建设实施方案》,明确提出需完善校园能源管理体系&a…...