大数据学习(105)-大数据组件分析
🍋🍋大数据学习🍋🍋
🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。
💖如果觉得博主的文章还不错的话,请点赞👍+收藏⭐️+留言📝支持一下博主哦🤞
🍋一、CDH
CDH(Cloudera Distribution Including Apache Hadoop)是由Cloudera公司提供的一个集成了Apache Hadoop以及相关生态系统的发行版本。CDH是一个大数据平台,简化和加速了大数据处理分析的部署和管理。CDH提供Hadoop的核心元素-可伸缩存储和分布式计算-以及基于web的用户界面和重要的企业功能。CDH是Apache许可的开放源码,是唯一提供统一批处理、交互式SQL和交互式搜索以及基于角色的访问控制的Hadoop解决方案。
CDH是一个强大的商业版数据中心管理工具,提供了以下功能:
1.提供了各种能够快速稳定运行的数据计算框架,如Spark;
2.使用Apache Impala做为对HDFS、HBase的高性能SQL查询引擎;
3.使用Hive数据仓库工具帮助用户分析数据;
4.提供CM安装HBase分布式列式NoSQL数据库;
5.包含原生的Hadoop搜索引擎以及Cloudera Navigator Optimizer去对Hadoop上的计算任务进行一个可视化的协调优化,提高运行效率;
6.提供的各种软件能让用户在一个可视化的UI界面中方便地管理、配置和监控Hadoop以及其它所有相关组件,并有一定的容错容灾处理;
7.提供了基于角色的访问控制安全管理。
CDH和原生Hadoop区别
原生Hadoop的问题
1.版本管理过于混乱
2.部署过程较为繁琐,升级难度较大
3.兼容性差
4.安全性低
CDH优点
1. 提供基于web的用户界面,操作方便
2、集成的组件丰富,支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、 Hbase、Zookeeper、Sqoop
3、搭建容易,运维比原生hadoop方便。简化了大数据平台的安装和使用难度
4、版本划分清晰、更新速度快、文档清晰、支持多种安装方式、支持Kerberos安全认证等
CDH 组件
CDH作为一套开源的大数据处理平台,包含了许多不同的组件,每个组件都有各自的功能和特点。下面大概介绍下各个组件的功能和用途。
🍋二、Hadoop HDFS

Hadoop HDFS(Hadoop Distributed File System)是CDH中的一个核心组件,它是一个可扩展的分布式文件系统,用于存储大规模的数据文件。HDFS通过将文件切分为多个块,并将这些块分布在不同的计算节点上,实现了高可用性和高性能的文件存储。
HDFS文件系统维护着一个命名空间,它是一个树状结构,包含文件和目录。这个命名空间以根目录“/”开始,用户可以创建、删除文件和目录,以及修改它们的权限。
1.NameNode
负责客户端请求的响应
元数据的管理(查询,修改)
namenode是HDFS集群主节点,负责维护整个hdfs文件系统的目录树,以及每一个路径(文件)所对应的block块信息(block的id,及所在的datanode服务器)
2.JournalNode
NameNode之间共享数据(主要体现在 NameNode配置 HA)
3.DataNode
存储管理用户的文件块数据
定期向namenode汇报自身所持有的block信息(通过心跳信息上报)
🍋三、Hadoop YARN
YARN的核心思想是将资源管理和作业调度从特定的计算框架(如MapReduce)中分离出来使其成为单独的守护进程,使得Hadoop集群能够更通用地支持多种类型的应用程序和工作负载。
这个想法是拥有一个全局的 ResourceManager ( RM ) 和每个应用程序的 ApplicationMaster ( AM )。应用程序可以是单个作业,也可以是作业的 DAG。ResourceManager 和 NodeManager 构成了数据计算框架。 ResourceManager是系统中所有应用程序之间资源仲裁的最终权威。 NodeManager 是每台机器的框架代理,负责容器、监视其资源使用情况(CPU、内存、磁盘、网络)并将其报告给ResourceManager/Scheduler。每个应用程序的 ApplicationMaster 实际上是一个特定于框架的库,其任务是与 ResourceManager 协商资源并与 NodeManager 一起执行和监视任务。(ApplicationMaster 是由应用程序框架(如 MapReduce、Spark、Impala 等)提供的。每个框架都会根据自己的需求和特点来实现 ApplicationMaster。这也意味着,不同的应用程序框架会有不同的 ApplicationMaster 实现,它们负责处理与框架相关的特定逻辑。)

Hadoop YARN(Yet Another Resource Negotiator)是CDH中的另一个核心组件,它是一个资源管理器,负责对集群中的计算资源进行统一管理和调度。YARN可以根据应用程序的需求,动态分配计算资源,实现任务的高效执行。
🍋四、Hadoop MapReduce
Hadoop MapReduce是CDH中用于分布式计算的编程模型和框架,它将大规模的数据切分为多个小任务,并在集群中的计算节点上并行执行这些任务。MapReduce可以实现大规模数据的处理和分析,支持复杂的数据转换和计算操作。
一个完整的 MapReduce 程序在分布式运行时有三类实例进程:
(1)MrAppMaster:负责整个程序的过程调度及状态协调。
(2)MapTask:负责 Map 阶段的整个数据处理流程。
(3)ReduceTask:负责 Reduce 阶段的整个数据处理流程。
🍋五、HBase
HBase是CDH的一个分布式数据库,它基于Hadoop HDFS存储数据,并提高性能的随机读写能力。HBase适用于需要快速访问和查询大规模数据的场景,如日志分析、推荐系统等。
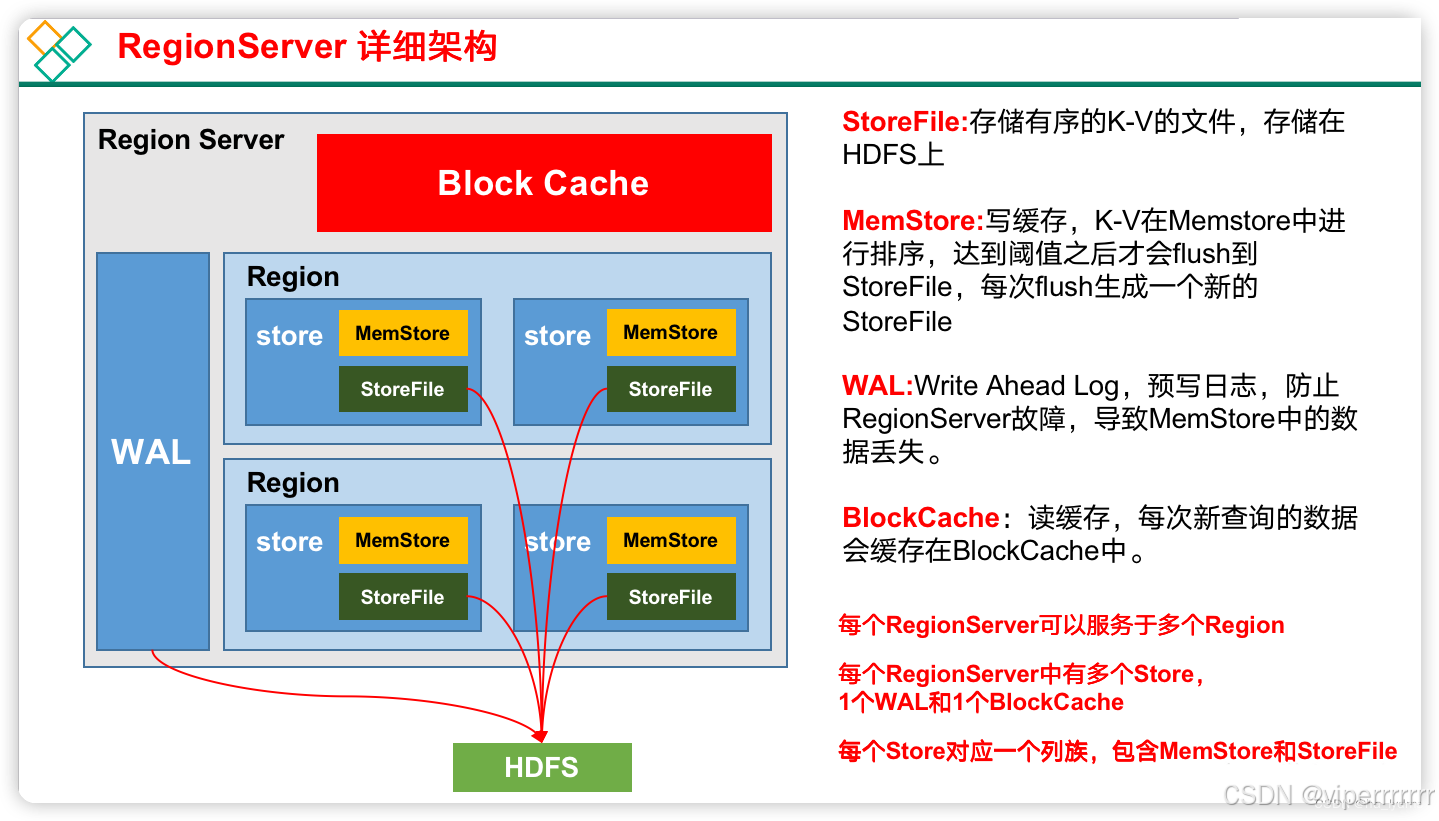
1)StoreFile
保存实际数据的物理文件,StoreFile以Hfile的形式存储在HDFS上。每个Store会有一个或多个StoreFile(HFile),数据在每个StoreFile中都是有序的。
2)MemStore
写缓存,由于HFile中的数据要求是有序的,所以数据是先存储在MemStore中,排好序后,等到达刷写时机才会刷写到HFile,每次刷写都会形成一个新的HFile。
3)HLog
由于数据要经MemStore排序后才能刷写到HFile,但把数据保存在内存中会有很高的概率导致数据丢失,为了解决这个问题,数据会先写在一个实现了Write-Ahead logfile机制的文件HLog中,然后再写入MemStore中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
4)BlockCache
读缓存,每次查询出的数据会缓存在BlockCache中,方便下次查询。
🍋六、Hive
Hive是CDH中的一个数据仓库工具,它提供了类似于SQL的查询语言(HiveSQL),它可以将结构化的数据映射到Hadoop集群中的文件,并支持高性能的数据查询和分析。Hive可以方便地进行数据的ETL(Extract、Transform、Load)操作,适用于数据分析和报表生成等任务。
Hive

基于 MapReduce 或 Tez:
Hive 最初是基于 MapReduce 的,MapReduce 是一种批处理框架,适合处理大规模数据,但延迟较高。即使后来引入了 Tez 作为执行引擎,Hive 仍然是以批处理为核心,不适合低延迟查询。
中间结果写磁盘:
MapReduce 和 Tez 在执行过程中会将中间结果写入磁盘,导致额外的 I/O 开销。
🍋七、Impala
Impala是CDH中的一个交互式查询引擎,它可以直接访问存储在Hadoop HDFS和HBase中的数据,并提供类似于SQL的查询语言。Impala通过在内存中执行查询操作,实现了低延迟的数据查询和分析,适用于实时数据处理和探索性数据分析等场景。
Impala
直接访问 HDFS:Impala 直接读取 HDFS 数据,避免了 MapReduce 的额外开销。
优化数据格式:Impala 对 Parquet 和 ORC 等列式存储格式进行了深度优化,能够快速读取和处理数据。
数据本地性:Impala 充分利用数据本地性(Data Locality),在数据所在的节点上执行计算,减少了数据传输的开销。
内存计算:Impala的计算引擎支持基于内存的计算,能够大大降低查询的延迟。与传统的基于磁盘的MapReduce计算模型相比,Impala的内存计算模型在处理大规模数据集时具有更高的性能。
分布式并行处理:Impala的计算引擎采用分布式并行处理架构,能够将查询任务拆分成多个子任务,并在多个节点上并行执行。这种架构能够充分利用集群的计算资源,提高查询的吞吐量。
与存储引擎分离:Impala的计算引擎与存储引擎是分离的,这意味着Impala可以支持多种不同的存储系统,如HDFS、HBase等。这种分离的设计使得Impala更加灵活和可扩展。
Impala 的功能相对精简,专注于 OLAP 场景,适合快速查询。Impala 的设计目标是低延迟查询,适合实时分析和交互式查询。
🍋八、Sqoop
Sqoop架构
(1) Sqoop Client
Sqoop的客户端组件,提供了命令行工具和API,用于与Sqoop Server进行通信,并提交数据导入和导出的任务。
(2) Sqoop Server
Sqoop的服务器组件,负责接收来自客户端的请求,并协调和管理数据导入和导出的任务。Sqoop Server可以在独立模式下运行,也可以与Hadoop集群中的其他组件(如HDFS、YARN)集成。
(3) Connector
Sqoop的连接器,用于与不同类型的关系型数据库进行交互。每个关系型数据库都需要一个相应的连接器来支持数据的导入和导出。Sqoop提供了一些内置的连接器,如MySQL、Oracle、SQL Server等,同时还支持自定义连接器。
(4) Metastore
Sqoop的元数据存储,用于保存与数据导入和导出相关的元数据信息,如表结构、字段映射、导入导出配置等。Metastore可以使用关系型数据库(如MySQL、PostgreSQL)或Hadoop的分布式文件系统(HDFS)来存储元数据。
(5) Hadoop/HDFS
Sqoop与Hadoop生态系统紧密集成,使用Hadoop的分布式文件系统(HDFS)来存储导入的数据。Sqoop可以将关系型数据库中的数据导入到HDFS中,也可以将HDFS中的数据导出到关系型数据库中。
Sqoop是CDH中的数据导入导出工具,它可以将关系型数据库(如Mysql、Oracle等)中的数据导入到Hadoop集群中的HDFS或HBase中,也可以将Hadoop集群中的数据导出到关系型数据库中。Sqoop支持自动化的数据传输和转换,方便进行数据的迁移和集成。
🍋九、Flume
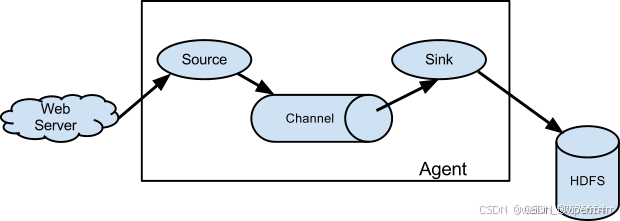
Flume 的架构设计简单但非常灵活,主要由以下几个核心组件构成:Source、Channel 和 Sink。这些组件通过配置文件进行定义和连接,形成一个数据流管道。
9.1 Source
Source 是 Flume 的数据输入组件,负责从外部数据源收集数据,并将数据转换为 Flume 的内部事件(Event)格式。常见的 Source 类型包括:
Exec Source:从命令执行的输出中读取数据,例如从 tail -F 命令读取日志文件。
Spooling Directory Source:从指定目录中读取新文件的内容。
Netcat Source:通过网络套接字接收数据。
HTTP Source:通过 HTTP POST 请求接收数据。
9.2 Channel
Channel 是 Flume 的数据缓冲组件,负责在 Source 和 Sink 之间暂存数据,确保数据传输的可靠性和高效性。常见的 Channel 类型包括:
Memory Channel:将数据存储在内存中,适用于低延迟和高吞吐量的场景。
File Channel:将数据存储在磁盘文件中,适用于需要高可靠性的场景。
Kafka Channel:使用 Apache Kafka 作为 Channel,适用于需要高可用性和持久化的场景。
9.3 Sink
Sink 是 Flume 的数据输出组件,负责将 Channel 中的数据传输到目标存储系统。常见的 Sink 类型包括:
HDFS Sink:将数据写入到 Hadoop 分布式文件系统(HDFS)。
HBase Sink:将数据写入到 HBase 数据库。
ElasticSearch Sink:将数据写入到 Elasticsearch。
Kafka Sink:将数据写入到 Apache Kafka。
Flume是CDH中的一个日志收集和传输工具,它可以实时地将分布在不同计算节点上的日志数据收集到中央存储(如HDFS)中。Flume支持灵活的数据流管道配置,可以根据需求进行数据过滤、转换和路由操作,适用于大规模分布式系统的日志管理。
🍋十、ZooKeeper
ZooKeeper是CDH中的一个分布式协调服务,它可以实现分布式系统中的数据一致性和协同操作。ZooKeeper提供了高可用性和高性能的数据存储和访问接口,可以用于分布式锁、配置管理、命名服务等场景。
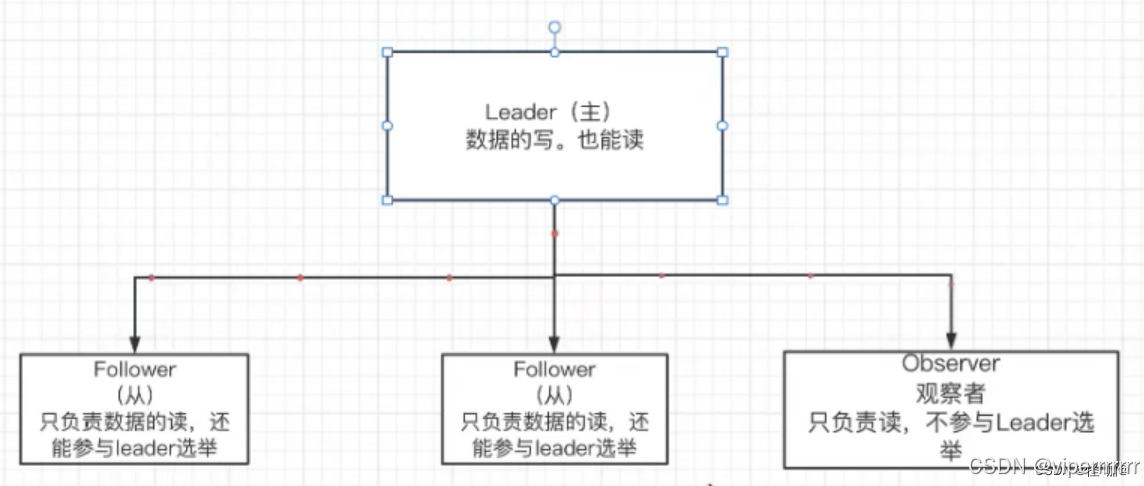
ZooKeeper的选举机制是基于ZAB(Zookeeper Atomic Broadcast)协议的,这是一种基于Paxos协议的变种,专门用于ZooKeeper的分布式协调服务。该机制确保集群中只有一个领导节点(Leader),负责处理所有的写请求和大部分的读请求,其他的节点则作为跟随者(Follower)或观察者(Observer),负责处理读请求并接收来自领导者的更新。
ZooKeeper 采用 主从架构,包含以下角色:
-
Leader
负责处理写请求和事务操作。通过选举机制产生。(ZooKeeper 的选举机制主要用于其集群管理,特别是在集群启动或领导者节点故障时,用于选出一个新的领导者节点。这个领导者节点将负责处理客户端的请求、维护集群状态以及与其他节点进行通信。) -
Follower
处理读请求,并将写请求转发给 Leader。参与 Leader 选举。 -
Observer(可选)
与 Follower 类似,但不参与选举,用于扩展读性能。 -
Client
与 ZooKeeper 集群交互的客户端。
🍋十一、Spark
Spark是一个Apache项目,它被标榜为“快如闪电的集群计算”。它拥有一个繁荣的开源社区,并且是目前最活跃的Apache项目。最早Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架。spark是一种基于内存的分布式并行计算框架,不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。Spark提供了一个更快、更通用的数据处理平台。和Hadoop相比,Spark可以让你的程序在内存中运行时速度提升100倍,或者在磁盘上运行时速度提升10倍。
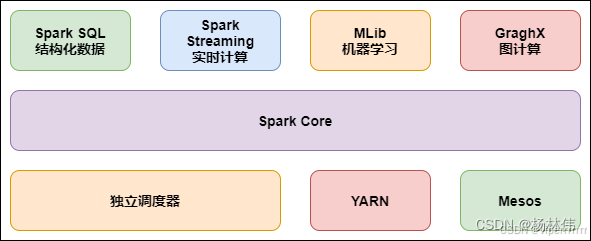
Spark有完善的生态圈,如下:
Spark Core:实现了 Spark 的基本功能,包含 RDD、任务调度、内存管理、错误恢复、与存储系统交互等模块。
Spark SQL:Spark 用来操作结构化数据的程序包。通过 Spark SQL,我们可以使用 SQL 操作数据。
Spark Streaming:Spark 提供的对实时数据进行流式计算的组件。提供了用来操作数据流的 API。
Spark MLlib:提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据导入等额外的支持功能。
GraphX(图计算):Spark 中用于图计算的 API,性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法。
集群管理器:Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。
Structured Streaming:处理结构化流,统一了离线和实时的 API。
🍋十二、Oozie
Oozie是一个工作流调度和协调工具,它可以将多个Hadoop任务组织成一个工作流,并按照指定的时间和依赖关系进行调度执行。Oozie支持复杂的任务依赖关系和条件触发,可以实现数据处理和分析的自动化流程控制。
🍋十三、CM(Cloudera Manager)
CDH分为Cloudera Manager管理平台(CM)和CDH parcel(parcel包含各种组件的安装包),需要先安装CM,再安装parcel
CM(Cloudera Manager)提供了一个管理和监控Hadoop等大数据服务的web界面,能让我们方便安装大数据生态圈的大部分服务。(至于具体CM运行见:https://blog.csdn.net/weixin_61006262/article/details/146241299?spm=1011.2124.3001.6209)
相关文章:
-大数据组件分析)
大数据学习(105)-大数据组件分析
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一…...

Spark运行
一文读懂Spark:从核心概念到实战编程 在大数据处理领域,Spark凭借其高效的计算能力和灵活的架构脱颖而出。今天,就来和大家深入聊聊Spark,帮助初学者快速入门。Spark采用经典的master - slave结构。Driver如同master,…...

在macOS的docker中如何安装及运行ROS2
1、macOS环境及版本 2、docker for macos版本 3、拉取ROS2镜像 docker pull ros:iron 4、查看容器 docker images 5、启动 ROS2 容器 docker run -it --rm ros:iron -it :以交互模式运行容器。 --rm :退出时自动删除容器(测试时推荐&am…...

FFmpeg安装和使用
1. 安装与环境配置 Windows # 方法1:官网下载预编译二进制包 https://ffmpeg.org/download.html#build-windows 解压后添加bin目录到系统PATH# 方法2:通过Chocolatey安装 choco install ffmpegmacOS # 使用Homebrew安装 brew install ffmpegLinux # …...

基于多模态大模型的ATM全周期诊疗技术方案
基于多模态大模型的ATM全周期诊疗技术方案 1. 数据预处理模块 算法1:多模态数据融合伪代码 def multimodal_fusion(data_dict):# 输入:包含MRI、EEG、实验室指标的字典# 输出:对齐后的张量序列# 模态对齐aligned_data = temporal_alignment(data_dict,sampling_rate...
)
写时复制Copy-on-Write(COW)
简单理解写时复制 读的时候,直接访问原对象。 写的时候,对复制原对象,对副本进行写操作,最后将副本替换原对象。 写时复制多用于读多写少的场景,因为写操作是用悲观锁进行的,如果写的场景多,…...

S7-1200 PLC热电偶和热电阻模拟量模块
热电偶和热电阻模拟量模块 S7-1200 PLC有专用用于对温度进行采集的热电偶模块SM1231 TC和SM 1231RTD。热电偶模块有4AI和8AI两种,下面以SM1231 TC 4AI为例看一下接线图。 该模块一共有4个通道,每个通道有两个接线端子,比如0,0-。…...
)
ffmpeg函数简介(封装格式相关)
文章目录 🌟 前置说明:FFmpeg 中 AVFormatContext 是什么?🧩 1. avformat_alloc_context功能:场景: 🧩 2. avformat_open_input功能:说明:返回值: ǹ…...

操作数组的工具类
Arrays 它里面的每一个方法基本上都是static静态修饰的,如果想要调用里面的方法,不需要创建对象,直接用类名.就可以了 操作数组的工具类 方法: public static String toString(数组) 把数组拼接成…...

小刚说C语言刷题——第19讲 循环之continue和break
在循环中,当我们得到想要的答案时,这时我们可能要提前结束循环,这个时候我们就会用到break。而我们有时需要结束某一次循环时,我们可以用continue。 1.break语句 (1)在循环中想要提前终止循环,要用break。 (2)语法格…...

FairMOT复现过程中cython_bbox库问题
cython_bbox库就该这么安装_cython-bbox库就应该-CSDN博客...

记录学习的第二十四天
还是每日一题。 题解很巧,我根本想不到。 class Solution { public: int minOperations(vector<int>& nums, int k) { int count; int mnnums[0]; //接下来查找nums数组中最小值 for(int i1;i<nums.size();i) { if(nums[i]<mn) { mnnums[i]; } } …...

Kubernetes 入门篇之网络插件 calico 部署与安装
在运行kubeadm init 和 join 命令部署好master和node节点后,kubectl get nodes 看到节点都是NotReady状态,这是因为没有安装CNI网络插件。 kubectl get nodes NAME STATUS ROLES AGE VERSION k8s-master Not…...
)
HTTP 压力测试工具autocannon(AI)
简介 autocannon 是一款基于 Node.js 的高性能 HTTP 压力测试工具,适用于评估 Web 服务的并发处理能力和性能瓶颈。 一、工具特点 高性能:利用 Node.js 异步非阻塞机制模拟高并发请求。实时监控:测试过程中动态展示请求统计和性能…...

【面试】封装、继承、多态的具象示例 模板编程的理解与应用场景 链表适用的场景
文章目录 C面试:封装、继承、多态的具象示例1. 封装 (Encapsulation)2. 继承 (Inheritance)3. 多态 (Polymorphism)综合示例:封装、继承、多态 C模板编程的理解与应用场景我对模板编程的理解C中最常用的模板编程场景1. STL (标准模板库)2. 通用容器实现3…...

机器学习02——概要
一、简介 机器学习是一门在没有明确编程的情况下让计算机学习的科学。 监督学习是有目标的,输入数据对应明确的输出;无监督学习则是“探索”型的,模型的目标是从数据中发现潜在的模式或结构,而不需要预先知道标签。 二、机器学…...

常用的网络安全靶场、工具箱
转载:https://blog.csdn.net/zjzqxzhj/article/details/137945444 打CTF很好玩。可以试一下 1.CTF在线工具 1、CTF在线工具箱:http://ctf.ssleye.com/ 包含CTF比赛中常用的编码、加解密、算法。 2、CTF加解密工具箱:http://www.atoolbox.…...
)
excel中的VBA指令示例(一)
示例注释: Sub 宏1() sub是宏开头,宏1是宏的名称,自定义,在按钮中可指定用某个宏 后面是注释 Sheets("装配材料").Select ‘选择表 装配材料 Ce…...
)
神经网络 | 基于脉冲耦合神经网络PCNN图像特征提取与匹配(附matlab代码)
内容未发表论文基于脉冲耦合神经网络(PCNN)的图像特征提取与匹配研究 摘要 本文提出一种基于脉冲耦合神经网络(Pulse-Coupled Neural Network, PCNN)的图像特征提取与匹配方法。通过模拟生物视觉皮层神经元的脉冲同步发放特性,PCNN能够有效捕捉图像纹理与边缘特征。实验表…...

Linux 内核中的 TCP 早期多路分解机制解析
一、引言 在现代高性能网络环境中,Linux 内核需要快速处理大量的 TCP 数据包,同时保持低延迟和高吞吐量。为了实现这一目标,Linux 内核引入了 早期多路分解(Early Demultiplexing) 机制。这种机制允许内核在数据包进入传输层之前,快速找到对应的套接字(socket)并关联数…...
——错误类型)
Yalmip工具箱(3)——错误类型
在yalmip中,不可避免地我们会遇到求解出问题的情况,理解和处理错误信息是至关重要的环节。在这里我们查看yalmip的所有错误类型(详细见 yalmiperror.m 函数) 函数概述 yalmiperror函数的主要作用是根据YALMIP产生的错误代码&…...

【KWDB 创作者计划】_KWDB:开源引领数据库创新变革
在数字化浪潮汹涌澎湃的当下,数据已然成为驱动各行各业发展的核心要素。数据库作为数据管理的关键工具,其性能、功能以及开放性,对企业和社会的数字化进程起着举足轻重的作用。KWDB,作为数据库领域的一颗璀璨新星,正以…...

HarmonyOS学习 实验八:显式动画与属性动画的实现
鸿蒙系统动画开发实战:显式动画与属性动画的探索 引言 在鸿蒙系统的开发过程中,动画效果是提升用户体验的重要一环。通过巧妙运用动画,可以使应用界面更加生动、交互更加流畅。鸿蒙系统提供了丰富的动画开发能力,其中显式动画和…...

高校智慧能源系统解决方案:推动绿色校园建设的智能化实践
高校智慧能源系统解决方案:推动绿色校园建设的智能化实践 一、建设背景:政策驱动与绿色发展需求 为响应国家“碳达峰、碳中和”战略目标,教育部印发《绿色低碳发展国民教育体系建设实施方案》,明确提出需完善校园能源管理体系&a…...

win日志
以第一个为例子 打开后,右上角(将所有事件另存为xx)然后一般写今天的日期,进行备份 然后选择下语言即可 日志备份时间的选择(根据实际情况选择日志时间) 点击右侧事件属性,然后xml视图即可 常见的安全事件…...
与LED灯的故事)
嵌入式开发之51单片机入门(一)与LED灯的故事
得而不惜就该死。 --小泽 继续傻冒开始,这次的傻冒之旅是关于嵌入式的51单片机开发,这个系列只讲程序开发逻辑,如需初始环境安装配置,建议移步B站江协科技大佬,本系列也是对大佬所讲内容的复刻,同时添加一…...

TCP 与 UDP
TCP 与 UDP 的区别(重要) 是否面向连接:UDP 在传送数据之前不需要先建立连接。而 TCP 提供面向连接的服务,在传送数据之前必须先建立连接,数据传送结束后要释放连接。是否是可靠传输:远地主机在收到 UDP 报…...

Linux:进程地址空间
在讲述本篇文章之前,我们先来看一段代码。 从上图输出可以看到,我们的子进程继承了父进程的全局变量val,当子进程中的val产生了修改时,父进程的val值并没有变化,但父子进程在打印val的地址时,会发现val的地…...

【Linux】Linux 操作系统 - 03 ,初步指令结尾 + shell 理解
文章目录 前言一、打包和压缩二、有关体系结构 (考)面试题 三、重要的热键四、shell 命令及运行原理初步理解五、本节命令总结总结 前言 本篇文章 , 笔者记录的笔记内容包含 : 基础指令 、重要热键 、shell 初步理解 、权限用户的部分问题 。 内容皆是重要知识点 , 需要认真理…...

华为数通不同级别的认证路径和要求是什么?
一、认证路径 HCIA:无需前置认证,通过一门考试(代码H12-811)即可拿证。 HCIP:建议先通过HCIA-Datacom,再选择子方向(如高级路由、安全)。 HCIE:最好有hcia/hcip的基础…...

电子电气架构 --- 新能源汽车电子电气系统功能需求
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 周末洗了一个澡,换了一身衣服,出了门却不知道去哪儿,不知道去找谁,漫无目的走着,大概这就是成年人最深的孤独吧! 旧人不知我近况,新人不知我过…...

《从单体到分布式:一个订单系统的架构升级》
1. 问题爆发:单体架构的极限 原来的订单系统长这样: 技术栈:SpringBoot MyBatis MySQL(主从)部署:单机跑所有模块(订单、支付、库存)痛点ÿ…...

琴键上的强化学习:让机器人在真实世界里弹钢琴!
在科技飞速发展的今天,机器人的能力边界不断拓展。想象一下,机器人坐在钢琴前,行云流水地弹奏出美妙乐章,这不再是科幻电影里的场景。近日,科研人员在机器人弹钢琴领域取得了突破性进展,让我们一同走进这个…...

【Unity网络编程知识】C#的 Http相关类学习
1、搭建HTTP服务器 使用别人做好的HTTP服务器软件,一般作为资源服务器时使用该方式(学习阶段建议使用)自己编写HTTP服务器应用程序,一般作为Web服务器或者短连接游戏服务器时使用该方式(工作后由后端程序员来做&#…...

【算法学习】链表篇:链表的常用技巧和操作总结
算法学习: https://blog.csdn.net/2301_80220607/category_12922080.html?spm1001.2014.3001.5482 前言: 在各种数据结构中,链表是最常用的几个之一,熟练使用链表和链表相关的算法,可以让我们在处理很多问题上都更加…...

【前端笔记】CSS预处理语言 LESS
官网: Less 快速入门 | Less.js 中文文档 - Less 中文网 LESS很多地方可以比CSS简写很多 安装 npm install -g less 核心优势:变量、嵌套、混合、运算功能让CSS更容易维护,比原生CSS更加简洁高效 1. 变量(Variables)…...

Oracle 查看后台正在执行的 SQL 语句
在 Oracle 数据库中,要查看后台正在执行的 SQL 语句,可以通过查询动态性能视图(Dynamic Performance Views)或使用监控工具来实现。 1. 查询动态性能视图 (1) 查看当前活跃会话及其执行的 SQL 使用 v$session 和 v$sql 视图关联…...

强化学习原理二 BasicConcepts
状态,State 状态空间,State Space 行动,Action状态转换,state transition策略,Policy 用数组或者矩阵表示这样一个策略 奖励,Reward 不确定的话,表格就不适用了。这个时候就要用数学来表示&…...

【机密计算顶会解读】13:CAGE:通过 GPU 扩展补充 Arm CCA
导读:本文介绍GAGE,利用Arm CCA中的现有硬件安全特性来确保敏感数据的安全性,支持GPU加速的机密计算,在实际平台上的平均性能开销仅为 2.45%,在保持高性能的同时,提供了良好的数据安全保护,且其…...
强制终止Native进程时,是否会生成tombstone文件)
Android 使用kill -9(SIGKILL信号)强制终止Native进程时,是否会生成tombstone文件
在Android系统中,使用kill -9(SIGKILL信号)强制终止Native进程时,不会生成tombstone文件。以下是具体原因和背景分析: 1. SIGKILL信号的特性 SIGKILL(信号9) 是Linux系统中最高优先级…...
-- 第六部分:JS集合与映射在 WPS 的应用)
WPS JS宏编程教程(从基础到进阶)-- 第六部分:JS集合与映射在 WPS 的应用
目录 第6章 JS集合与映射在 WPS 的应用6-1 集合的创建(实例:唯一值提取)示例代码详细解析Excel 环境模拟说明6-2 集合的不重复特性应用(案例:提取唯一值记录)示例代码详细解析案例说明6-3 集合成员添加与删除示例代码代码解析直观示意(Excel 模拟表格)6-4 集合成员添加…...

1.VTK 使用CMakeLists
文章目录 1.创建目录2.配置VTK编译环境3.创建main.cpp4.CMake编译 1.创建目录 选择一个空文件夹创建CMakeLists.txt 文件,注意CMakeLists不要写错 2.配置VTK编译环境 cmake_minimum_required(VERSION 3.5) # 最低要求 CMake 3.5,避免兼容性问题 proje…...

PDFtk
如果下载的pdf文件有秘钥的话,使用下面linux命令去掉秘钥: pdftk 纳税记录.pdf input_pw 261021 output 纳税记录_output.pdf将多个单页pdf合并为一个pdf的linux命令: pdftk 自然人电子税务局1.pdf 自然人电子税务局2.pdf 自然人电子税务局3.pdf 自然人…...

整理我的macos的复杂混乱的python环境
一、彻底清理现有环境(为全新配置铺路) 1. 核级清理(⚠️ 先备份重要数据) bash复制# 删除所有第三方Python安装 sudo rm -rf /Library/Frameworks/Python.framework/ rm -rf ~/Library/Python/ rm -rf ~/.local/bin/python* rm…...
)
Vue Router(1)
RouterLink 和 RouterView RouterLink 是一个导航组件,用于在不重新加载页面的情况下切换视图。 RouterView 是一个视图渲染容器组件,用于显示与当前 URL 匹配的组件。 <template><p><strong>Current route path:</strong> {{…...

AI时代如何让命令行工具快速智能化?
引言 作为开发者,我们经常会开发各种命令行工具来提升工作效率。 在AI时代我们又多了一个选择:通过AI生成代码,缺点是不可控、速度慢,优点是使用简单;而代码生成工具与AI的优缺点恰恰相反,如何结合两者的优…...

Android 回答视频边播放边下载的问题
分层次的回答突出 技术深度、架构思维 和 实战优化,从基础实现到高阶优化: 一、核心技术方案(基础回答) 如何实现视频边下边播? 1. **网络请求**:使用 HTTP Range 请求(Header: Range: bytes0…...

【HarmonyOS 5】鸿蒙中如何使用MQTT
一、MQTT是什么? MQTT(Message Queuing Telemetry Transport,消息队列遥测传输)是一种轻量级、基于发布 / 订阅(Publish/Subscribe)模式的即时通讯协议,专为资源受限的物联网(IoT&a…...

Conda与Pip:Python包管理工具的对比与选型
在当今的Python开发环境中,包管理工具的选择对于项目的顺利进行至关重要。Conda和Pip作为两种主流的Python包管理工具,各自具有独特的特点和优势。本文将详细对比Conda和Pip,帮助开发者在项目中做出更合适的选择。 一、概述 Condaÿ…...

建筑兔零基础自学记录69|爬虫Requests-2
Requests库初步尝试 #导入requests库 import requests #requests.get读取百度网页 rrequests.get(http://www.baidu.com) #输出读取网页状态 print(r.status_code) #输出网页源代码 print(r.text) HTTP 状态码是三位数字,用于表示 HTTP 请求的结果。常见的状态码有…...