Mybatis-缓存详解
什么是缓存?
-
存在内存中的临时数据
-
将用户经常查询的数据放在缓存中,用户去查询数据就不用从磁盘上(关系型数据库数据文件)查询,从缓存中查询,从而提高查询效率,解决了高并发系统的性能问题
-
经常查询且不经常改变的数据适合使用缓存
为什么使用缓存?
缓存(即cache)的作用是为了减去数据库的压力,提高数据库的性能。缓存实现的原理是从数据库中查询出来的对象在使用完后不销毁,而是存储在内存(缓存)中,当再次需要获取该对象时,直接从内存中获取,不再向数据库执行select语句,减少对数据库的查询次数,提高了数据库的性能。缓存是使用Map集合存储数据。
可用的清除策略有:
-
LRU– 最近最少使用:移除最长时间不被使用的对象。 -
FIFO– 先进先出:按对象进入缓存的顺序来移除它们。
Mybatis缓存
MyBatis有一级缓存和二级缓存之分。
一级缓存的作用域是同一个SqlSession,在同一个SqlSession中两次执行相同的sql语句,第一次执行完毕会将数据库查询的数据写到缓存(内存),第二次会从缓存中获取数据而不进行数据库查询,大大提高了查询效率。当一个SqlSession结束后该SqlSession中的一级缓存也就不存在了。MyBtais默认启动以及缓存。
二级缓存是多个SqlSession共享的,其作用域是mapper的同一个namespace,不同的sqlSession两次执行相同namespace下的sql语句且向sql中传递的参数也相同时,第一次执行完毕会将数据库中查询到的数据写到缓存(内存),第二次会直接从缓存中获取,从而提高了查询效率。MyBatis默认不开启二级缓存,需要在MyBtais全局配置文件中进行setting配置开启二级缓存。
为了提高扩展性,mybatis定义了缓存接口Cache。我们可以通过实现Cache接口来定义二级缓存
-
映射语句文件中的所有 select 语句的结果将会被缓存。
-
映射语句文件中的所有 insert、update 和 delete 语句会刷新缓存。
-
缓存会使用最近最少使用算法(LRU, Least Recently Used)算法来清除不需要的缓存。
-
缓存不会定时进行刷新(也就是说,没有刷新间隔)。
一级缓存
MyBatis默认开启一级缓存,一级缓存只是相对于同一个SqlSession而言。所以在参数个sql完全一致的情况下,我们使用同一个SqlSession对象调用一个Mapper方法,往往只执行一次sql,使用SqlSession第一次查询后,MyBatis会将其放在缓存中,之后再查询时若没有缓存失效或超时,SqlSession都会取出当前缓存的数据,不会再发送sql到数据库。
测试步骤:
1.开启日志!
2.测试在一个Session中查询两次相同的记录
3.查看日志输出
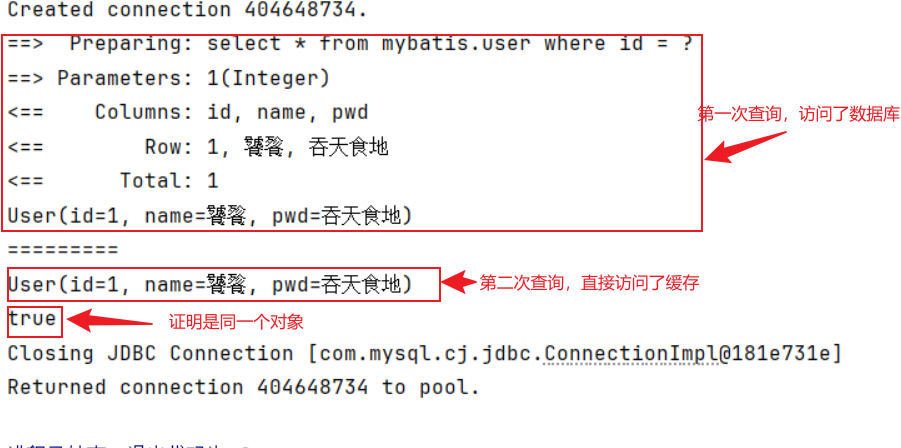
缓存失效的情况:
1.查询不同的实体
@Testpublic void testQueryUserById(){SqlSession session = MybatisUtils.getSession();SqlSession session2 = MybatisUtils.getSession();UserMapper mapper = session.getMapper(UserMapper.class);UserMapper mapper2 = session2.getMapper(UserMapper.class);User user = mapper.queryUserById(1);System.out.println(user);User user2 = mapper2.queryUserById(1);System.out.println(user2);System.out.println(user==user2);session.close();session2.close();}观察结果:发现发送了两条SQL语句!
结论:每个sqlSession中的缓存相互独立
2.增删改操作。可能会改变原来的数据,所以必定刷新缓存
增加方法
//修改用户int updateUser(Map map);编写SQL
<update id="updateUser" parameterType="map">update user set name = #{name} where id = #{id}</update>测试
@Testpublic void testQueryUserById(){SqlSession session = MybatisUtils.getSession();UserMapper mapper = session.getMapper(UserMapper.class);User user = mapper.queryUserById(1);System.out.println(user);HashMap map = new HashMap();map.put("name","kuangshen");map.put("id",4);mapper.updateUser(map);User user2 = mapper.queryUserById(1);System.out.println(user2);System.out.println(user==user2);session.close();}观察结果:查询在中间执行了增删改操作后,重新执行了
结论:因为增删改操作可能会对当前数据产生影响
3.查询不同的mapper
@Testpublic void testQueryUserById(){SqlSession session = MybatisUtils.getSession();UserMapper mapper = session.getMapper(UserMapper.class);UserMapper mapper2 = session.getMapper(UserMapper.class);User user = mapper.queryUserById(1);System.out.println(user);User user2 = mapper2.queryUserById(2);System.out.println(user2);System.out.println(user==user2);session.close();}观察结果:发现发送了两条SQL语句!很正常的理解
结论:当前缓存中,不存在这个数据
4.手动清理缓存
SqlSession sqlSession = MybatisUtils.getsqlSession();UserMapper mapper = sqlSession.getMapper(UserMapper.class);User user = mapper.queryUserById(1);System.out.println(user);sqlSession.clearCache();//手动清理缓存System.out.println("=========");User user2 = mapper.queryUserById(1);System.out.println(user2);System.out.println(user == user2);小结:
一级缓存默认开启,作用域为同一个Sqlsession,只在一次SQLsession中有效,也就是拿到连接和关闭连接之间
一级缓存就是一个map
二级缓存
二级缓存的作用域是SqlSessionFactory级别,整个应用程序只有一个。二级缓存区域是根据mapper的namespace划分的,相同的namespace的mapper查询的数据缓存在同一个区域,如果使用mapper代理方法,每一个mapper的namespace都不同,此时可以理解为二级缓存区域是根据mapper进行划分的。
每次查询都会先从缓存区域查找,如果找不到则从数据库进行查询,并将查询到的数据写入缓存。MyBtais内部缓存使用HashMap,key为hashCode+sqlid+sql语句,value为从查询出来映射生成的java对象。SqlSession执行任何一个update(修改)、delete(删除)、insert(新增)操作commit提交后都会清空缓存区域,防止脏读。
工作机制
-
一个会话查询一条数据,这个数据就会被放在当前会话的一级缓存中
-
如果当前会话关闭了,这个会话的一级缓存就没了,但是我们想要的是,会话关闭了,一级缓存的数据会被保存在二级缓存中
-
新的会话查询信息,就可以从二级缓存中获取内容
-
不同的mapper查出的数据会放在自己对应的缓存中
步骤:
1.开启全局缓存
<!-- 开启全局缓存--><setting name="cacheEnabled" value="true"/>2.在使用二级缓存的Mapper中开启
<cache/>也可以自定义一些参数
<cacheeviction="FIFO"flushInterval="60000"size="512"readOnly="true"/>//创建了一个 FIFO 缓存,每隔 60 秒刷新,最多可以存储结果对象或列表的 512 个引用,而且返回的对象被认为是只读的3.测试:
1.问题:我们要将实体类序列化!否则就会报错
org.apache.ibatis.cache.CacheException:
解决方式:在实体类实现接口: Serializable
public class User implements Serializable 小结:
-
只要开启了二级缓存,在同一个Mapper下有效
-
所有的数据都会先放在一级缓存中
-
只有当会话提交,或关闭的时候·,才会提交到二级缓存中
Mybatis缓存原理

扩充:在正式业务中,如何保证多个数据库数据一致?使用主从复制
缓存只是读,写还是数据库,为读写分离,提高数据库性能
第三方缓存实现--EhCache
Ehcache是一种广泛使用的java分布式缓存,用于通用缓存;
要在应用程序中使用Ehcache,需要引入依赖的jar包
<!-- https://mvnrepository.com/artifact/org.mybatis.caches/mybatis-ehcache --><dependency><groupId>org.mybatis.caches</groupId><artifactId>mybatis-ehcache</artifactId><version>1.2.3</version></dependency>在mapper.xml中使用对应的缓存即可
<mapper namespace = “org.acme.FooMapper” > <cache type = “org.mybatis.caches.ehcache.EhcacheCache” /> </mapper>编写ehcache.xml文件,如果在加载时未找到/ehcache.xml资源或出现问题,则将使用默认配置。
<?xml version="1.0" encoding="UTF-8"?><ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:noNamespaceSchemaLocation="http://ehcache.org/ehcache.xsd"updateCheck="false"><!--diskStore:为缓存路径,ehcache分为内存和磁盘两级,此属性定义磁盘的缓存位置。参数解释如下:user.home – 用户主目录user.dir – 用户当前工作目录java.io.tmpdir – 默认临时文件路径--><diskStore path="./tmpdir/Tmp_EhCache"/><defaultCacheeternal="false"maxElementsInMemory="10000"overflowToDisk="false"diskPersistent="false"timeToIdleSeconds="1800"timeToLiveSeconds="259200"memoryStoreEvictionPolicy="LRU"/><cachename="cloud_user"eternal="false"maxElementsInMemory="5000"overflowToDisk="false"diskPersistent="false"timeToIdleSeconds="1800"timeToLiveSeconds="1800"memoryStoreEvictionPolicy="LRU"/><!--defaultCache:默认缓存策略,当ehcache找不到定义的缓存时,则使用这个缓存策略。只能定义一个。--><!--name:缓存名称。maxElementsInMemory:缓存最大数目maxElementsOnDisk:硬盘最大缓存个数。eternal:对象是否永久有效,一但设置了,timeout将不起作用。overflowToDisk:是否保存到磁盘,当系统当机时timeToIdleSeconds:设置对象在失效前的允许闲置时间(单位:秒)。仅当eternal=false对象不是永久有效时使用,可选属性,默认值是0,也就是可闲置时间无穷大。timeToLiveSeconds:设置对象在失效前允许存活时间(单位:秒)。最大时间介于创建时间和失效时间之间。仅当eternal=false对象不是永久有效时使用,默认是0.,也就是对象存活时间无穷大。diskPersistent:是否缓存虚拟机重启期数据 Whether the disk store persists between restarts of the Virtual Machine. The default value is false.diskSpoolBufferSizeMB:这个参数设置DiskStore(磁盘缓存)的缓存区大小。默认是30MB。每个Cache都应该有自己的一个缓冲区。diskExpiryThreadIntervalSeconds:磁盘失效线程运行时间间隔,默认是120秒。memoryStoreEvictionPolicy:当达到maxElementsInMemory限制时,Ehcache将会根据指定的策略去清理内存。默认策略是LRU(最近最少使用)。你可以设置为FIFO(先进先出)或是LFU(较少使用)。clearOnFlush:内存数量最大时是否清除。memoryStoreEvictionPolicy:可选策略有:LRU(最近最少使用,默认策略)、FIFO(先进先出)、LFU(最少访问次数)。FIFO,first in first out,这个是大家最熟的,先进先出。LFU, Less Frequently Used,就是上面例子中使用的策略,直白一点就是讲一直以来最少被使用的。如上面所讲,缓存的元素有一个hit属性,hit值最小的将会被清出缓存。LRU,Least Recently Used,最近最少使用的,缓存的元素有一个时间戳,当缓存容量满了,而又需要腾出地方来缓存新的元素的时候,那么现有缓存元素中时间戳离当前时间最远的元素将被清出缓存。--></ehcache>希望对大家有所帮助!
相关文章:

Mybatis-缓存详解
什么是缓存? 存在内存中的临时数据 将用户经常查询的数据放在缓存中,用户去查询数据就不用从磁盘上(关系型数据库数据文件)查询,从缓存中查询,从而提高查询效率,解决了高并发系统的性能问题 经…...

WHAT - React useId vs uuid
目录 uuiduseId适用场景语法示例注意事项 复杂示例示例:动态表单列表 useId解读重点 useId vs uuid一句话总结对比表格示例对比useId 用于表单uuid() 用在 UI 会出问题uuid 的适合场景 总结建议 uuid 在 WHAT - Math.random?伪随机? 中我们…...
)
Leetcode 跳跃游戏 II (贪心算法)
给定一个长度为 n 的 0 索引整数数组 nums。初始位置为 nums[0]。 每个元素 nums[i] 表示从索引 i 向后跳转的最大长度。换句话说,如果你在 nums[i] 处,你可以跳转到任意 nums[i j] 处: 0 < j < nums[i] i j < n 返回到达 nums[n - 1] 的最…...

银河麒麟V10 Ollama+ShellGPT打造Shell AI助手——筑梦之路
环境说明 1. 操作系统版本: 银河麒麟V10 2. CPU架构:X86 3. Python版本:3.12.9 4. 大模型:mistral:7b-instruct 准备工作 1. 编译安装python 3.12 # 下载python 源码wget https://www.python.org/ftp/python/3.12.9/Python-3.12.9.tg…...

【物联网】GPT延时
文章目录 前言一、GPT实现延时1. 定时器介绍2. I.MX6ull GPT定时器介绍1)GPT定时器工作原理2)GPT的输入捕获3)GPT的输出比较 3. 高精度延时实现1)实现思路 前言 使用 GPT 实现延时控制以及基于 PWM 实现蜂鸣器发声与频率调节这两…...

【套题】大沥2019年真题——第4题
04.数字圈 题目描述 当我们写数字时会发现有些数字有封闭区域,有的数字没有封闭区域。 数字 0 有一个封闭区域,数字 1、2、 3 都没有封闭区域,数字 4 有一个封闭区域,数字 5 没有封闭区域,数字 6 有一个封闭区域&#…...

idea 安装 proxyai 后的使用方法
1. 可以默认使用ProxyAi 安装后使用如下配置可以进行代码提示 配置 使用示例 2. 这里有必要说一下,这里要选择提供服务的ai 选择后才可以使用ProxyAI或者Custom openAI 3. 可以使用custom openAi, 要自行配置 1)配置 code completions 这是header …...

构建实时、融合的湖仓一体数据分析平台:基于 Delta Lake 与 Apache Iceberg
1. 执行摘要 挑战: 传统数据仓库在处理现代数据需求时面临诸多限制,包括高昂的存储和计算成本、处理海量多样化数据的能力不足、以及数据从产生到可供分析的端到端延迟过高。同时,虽然数据湖提供了低成本、灵活的存储,但往往缺乏…...

数据库的MVCC机制详解
MVCC(Multi-Version Concurrency Control,多版本并发控制)是数据库系统中常用的并发控制机制,它允许数据库在同一时间点保存数据的多个版本,从而实现非阻塞的读操作,提高并发性能。 MVCC的核心思想是&…...

未来与自然的交响:蓉城生态诗篇
故事背景 故事发生在中国四川成都,描绘了未来城市中科技与自然共生的奇迹。通过六个极具创意的生态场景,展现人类如何以诗意的方式重构与自然的连接,在竹海保育、文化传承、能源循环等维度编织出震撼心灵的未来图景。 故事内容 当晨雾在竹纤维…...

【愚公系列】《高效使用DeepSeek》062-图书库存管理
🌟【技术大咖愚公搬代码:全栈专家的成长之路,你关注的宝藏博主在这里!】🌟 📣开发者圈持续输出高质量干货的"愚公精神"践行者——全网百万开发者都在追更的顶级技术博主! 👉 江湖人称"愚公搬代码",用七年如一日的精神深耕技术领域,以"…...

汽车软件开发常用的建模工具汇总
目录 往期推荐 1.Enterprise Architect(EA) 2.MATLAB/Simulink 3.TargetLink 4.Rational Rhapsody 5.AUTOSAR Builder 6.PREEvision 总结 往期推荐 2025汽车行业新宠:欧企都在用的工具软件ETAS工具链自动化实战指南<一&am…...
)
六、继承(二)
1 继承与友元 如果一个基类中存在友元关系,那么这个友元关系能不能继承呢? 例: #include <iostream> using namespace std; class Student; class Person { public:friend void Display(const Person& p, const Student& s)…...
连接达梦数据库并写入读取数据)
flink部署使用(flink-connector-jdbc)连接达梦数据库并写入读取数据
flink介绍 1)Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink 被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。 2)在实时计算或离线任务中,往往需要…...

【Rust开发】Rust快速入门,开发出Rust的第一个Hello World
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

Flink框架:批处理和流式处理与有界数据和无界数据之间的关系
本文重点 从数据集的类型来看,数据集可以分为有界数据和无界数据两种,从处理方式来看,有批处理和流处理两种。一般而言有界数据常常使用批处理方式,无界数据往往使用流处理方式。 有界数据和无界数据 有界数据有一个明确的开始和…...
)
基于 Spring Boot 瑞吉外卖系统开发(四)
基于 Spring Boot 瑞吉外卖系统开发(四) 新增分类 新增分类UI界面,两个按钮分别对应两个UI界面 两个页面所需的接口都一样,请求参数type值不一样,type1为菜品分类,type2为套餐分类。 请求方法都为POST。…...

患者根据医生编号完成绑定和解绑接口
医疗系统接口文档 一、Controller 层 1. InstitutionDoctorController 医疗机构和医生相关的控制器,提供机构查询、医生查询、绑定解绑医生等功能。 RestController RequestMapping("/institution-doctor") public class InstitutionDoctorController…...

Flutter性能优化终极指南:从JIT到AOT的深度调优
一、Impeller渲染引擎调优策略 1.1 JIT预热智能预编译 // 配置Impeller预编译策略 void configureImpeller() {ImpellerEngine.precacheShaders(shaders: [lib/shaders/skinned_mesh.vert,lib/shaders/particle_system.frag],warmupFrames: 30, // 首屏渲染前预编译帧数cach…...
英特尔 RealSense T265(三))
(1)英特尔 RealSense T265(三)
文章目录 前言 4.4 地面测试 4.5 飞行测试 4.6 室内外实验 4.7 数据闪存记录 4.8 启动时自动运行 4.9 使用 OpticalFlow 进行 EKF3 光源转换 前言 Realsense T265 通过 librealsense 支持 Windows 和 Linux 系统。不同系统的安装过程差异很大,因此请参阅 gi…...
(列表初始化、右值引用和移动语义、类的新默认成员函数、lambda表达式))
【c++11】c++11新特性(上)(列表初始化、右值引用和移动语义、类的新默认成员函数、lambda表达式)
🌟🌟作者主页:ephemerals__ 🌟🌟所属专栏:C 目录 前言 一、列表初始化 1. 大括号初始化 2. initializer_list 二、右值引用和移动语义 1. 左值和右值 2. 左值引用和右值引用 引用延长生命周期 左…...

ArcGIS 给大面内小面字段赋值
文章目录 引言:地理数据处理中的自动化赋值为何重要?实现思路模型实现关键点效果实现步骤1、准备数据2、执行3、完成4、效果引言:地理数据处理中的自动化赋值为何重要? 在地理信息系统(GIS)的日常工作中,空间数据的属性字段赋值是高频且关键的操作,例如在土地利用规划…...
)
计算机网络——传输层(Udp)
udp UDP(User Datagram Protocol,用户数据报协议 )是一种无连接的传输层协议,它在IP协议(互联网协议)之上工作,为应用程序提供了一种发送和接收数据报的基本方式。以下是UDP原理的详细解释&…...
】——生产者消费者同步互斥模型)
【操作系统(Linux)】——生产者消费者同步互斥模型
✅ 一、程序功能概述 我们将做的:实现一个经典的「生产者-消费者问题」多线程同步模型的案例,主要用到 循环缓冲区 POSIX 信号量 sem_t pthread 多线程库,非常适合理解并发控制、线程通信和缓冲区管理。 案例目标:通过多个生产…...

从数据到洞察:探索数据分析与可视化的高级方法
从数据到洞察:探索数据分析与可视化的高级方法 引言 在今天这个数据驱动的时代,海量的数据只有通过科学分析和清晰可视化,才能转化为商业价值和决策依据。然而,数据分析与可视化远不只是制作几个图表,它需要高级技术、深度洞察力以及良好的工具支持。随着大数据领域的快…...

计算机视觉中的数学:几何变换与矩阵运算详解
计算机视觉中的数学:几何变换与矩阵运算详解 一、前言二、基础数学概念回顾2.1 向量与向量运算2.1.1 向量的定义2.1.2 向量运算 2.2 矩阵基础2.2.1 矩阵的定义与表示2.2.2 矩阵运算 三、几何变换基础3.1 平移变换3.1.1 原理3.1.2 代码示例&…...

华为数字芯片机考2025合集3已校正
1. 题目内容 下列说法正确的是()。 1. 解题步骤 1.1 选项分析 选项描述正误依据A异步 FIFO 采用格雷码是为了省功耗✗格雷码用于消除多比特信号跨时钟域的位跳变风险,与功耗无关B单比特信号打两拍可以完全避免亚稳态✗双触发器同步仅降低…...

启山智软的营销方法有哪些优势?
启山智软作为一家科技或软件企业,其营销方法的优势可能体现在以下几个方面,这些优势结合了行业特点与创新策略,帮助其在竞争激烈的市场中占据有利位置: 1. 技术驱动的精准营销 数据挖掘与AI应用: 通…...

openpyxl合并连续相同元素的单元格
文章目录 前言一、openpyxl是什么?二、基础用法1.读取和写入文件2.合并单元格 三、合并单元格实战1.连续相同元素的索引范围2.转换3.获取列合并索引4.整体 总结 前言 python可以很方便的操作各种文档,比如docx,xlsx等。本文主要介绍在xlsx文…...
)
从零开始学java--泛型(二)
泛型 目录 泛型 泛型与多态 泛型方法 泛型的界限 泛型与多态 不只是类,包括接口、抽象类都可以支持泛型: public static void main(String[] args) {Score<String> scorenew Score<>("数学","aa","优秀"…...
)
设计模式 Day 6:深入讲透观察者模式(真实场景 + 回调机制 + 高级理解)
观察者模式(Observer Pattern)是一种设计结构中最实用、最常见的行为模式之一。它的魅力不仅在于简洁的“一对多”事件推送能力,更在于它的解耦能力、模块协作设计、实时响应能力。 本篇作为 Day 6,将带你从理论、底层机制到真实…...

深入理解 Shell:从原理到实战的全方位解析
1. 引言:什么是 Shell? Shell 是操作系统中最基础却最强大的工具之一。它是用户与操作系统之间的接口,一个命令行解释器,它接收用户输入的命令并调用操作系统内核完成相应的操作。 Shell 的含义包括两层: 交互式命令…...

图灵逆向——题六-倚天剑
从第六题开始就要有个先看看请求头的习惯了[doge]。 别问博主为什么要你养成这个习惯,问就是博主被坑过。。。 headers里面有一个加密参数S,然后你就去逆向这个S对吧。 然后一看响应: 好家伙返回的还是个密文,所以要两次逆向咯。…...
)
【WRF理论第十七期】单向/双向嵌套机制(含namelist.input详细介绍)
WRF运行的单向/双向嵌套机制 准备工作:WRF运行的基本流程namelist.input的详细设置&time_control 设置&domain 嵌套结构&bdy_control 配置部分 namelist 其他注意事项 嵌套说明双向嵌套(two-way nesting)单向嵌套(one…...

【Springboot知识】Springboot进阶-Micrometer指标监控深入解析
文章目录 Micrometer 核心概念与标准指标详解**Micrometer 核心概念与标准指标详解****一、Micrometer 核心概念****二、Micrometer 标准指标****1. JVM 监控指标****2. 系统资源监控****3. HTTP 请求监控****4. 数据库监控****5. 缓存监控** **三、配置与自定义指标****1.…...

Linux 的准备工作
1.root用户登录 首先讲一下root账户怎么登陆 直接 ssh root 公ip地址就可以了 比如我的是腾讯云的 这个就是公ip 下面所有普通用户的操作都是在root账户下进行的 2.普通用户创建 创建用户指令 adduser 用户名 比如说这个指令 我创建了一个ly_centos的普通用户 3.普通用…...
LLM实现模型并行训练:deepspeed 是什么; transformers` 怎么实现模型并行训练吗?
LLM实现模型并行训练:deepspeed 是什么 DeepSpeed是一个由微软开发的深度学习优化库,旨在帮助研究人员和工程师更高效地训练大规模神经网络。它提供了一系列的优化技术,包括混合精度训练、模型并行、数据并行、ZeRO优化等,以提高训练速度、减少内存占用,并支持在多个GPU或…...

STM32 HAL库之EXTI示例代码
外部中断按键控制LED灯 在main.c中 HAL_Init(); 初始化Flash,中断优先级以及HAL_MspInit函数,也就是 stm32f1xx_hal.c 中 HAL_StatusTypeDef HAL_Init(void) {/* Configure Flash prefetch */ #if (PREFETCH_ENABLE ! 0) #if defined(STM32F101x6) || …...

数字人情感表达突破:微表情自动生成的算法革新
——从量子化建模到联邦学习的全链路技术革命 一、行业痛点:传统数字人微表情的“三重困境” 2025年数据显示,83%的虚拟角色因微表情失真导致用户留存率下降(头部游戏公司实测数据)。传统方案面临核心矛盾: 制作成本…...

Django软删除功能完整指南:构建图书馆项目
Django软删除功能完整指南:构建图书馆项目 推荐超级课程: 本地离线DeepSeek AI方案部署实战教程【完全版】Docker快速入门到精通Kubernetes入门到大师通关课AWS云服务快速入门实战目录 Django软删除功能完整指南:构建图书馆项目第 1 步:安装所需包第 2 步:设置您的 Django…...

联邦学习:AI 与大数据融合的创新力量
在当今数字化时代,人工智能(AI)和大数据无疑是推动各行业发展的两大核心技术。AI 凭借其强大的数据分析和预测能力,为企业提供了智能化决策支持;大数据则通过海量数据的收集与存储,为 AI 模型的训练提供了丰…...

idea解决tomcat项目页面中文乱码
概述 解决tomcat项目页面中文乱码问题-Dfile.encodingUTF-8 设置...

Android Coil 3 Fetcher大批量Bitmap拼接成1张扁平宽图,Kotlin
Android Coil 3 Fetcher大批量Bitmap拼接成1张扁平宽图,Kotlin <uses-permission android:name"android.permission.WRITE_EXTERNAL_STORAGE" /><uses-permission android:name"android.permission.READ_EXTERNAL_STORAGE" /><u…...
分类指南)
解锁Midjourney创作潜能:超详细提示词(Prompts)分类指南
AI生图自由!就来 ChatTools (https://chat.chattools.cn),畅享Midjourney免费无限绘画。同时体验GPT-4o、Claude 3.7 Sonnet、DeepSeek等强大模型。 为了帮助大家更好地驾驭Midjourney,我们精心整理并分类了大量常用且效果出众的提示词。无论…...

HBuilder运行uni-app程序报错【Error: listen EACCES: permission denied 0.0.0.0:5173】
一、错误提示: 当使用HBuilder运行uni-app项目的时候提示了如下错误❌ 15:11:03.089 项目 project 开始编译 15:11:04.404 请注意运行模式下,因日志输出、sourcemap 以及未压缩源码等原因,性能和包体积,均不及发行模式。 15:11:04…...

k8s node inode被耗尽如何处理?
当 Kubernetes 节点因 inode 被耗尽导致 Pod 无法调度或运行异常时,需结合 Kubernetes 特性和 Linux 系统管理方法处理。以下是详细步骤: 1. 确认 inode 耗尽 首先登录问题节点,检查 inode 使用率: # 查看全局 inode 使用情况 …...

机器学习之PCA主成分分析详解
文章目录 引言一、PCA的概念二、PCA的基本数学原理2.1 内积与投影2.2 基2.3 基变换2.4 关键问题及优化目标2.5 方差2.6 协方差2.7 协方差矩阵2.8 协方差矩阵对角化 三、PCA执行步骤总结四、PCA参数解释五、代码实现六、PCA的优缺点七、总结 引言 在机器学习领域,我…...

leetcode797图论-对邻接矩阵和邻接表不同形式进行dfs与bfs遍历方法
给你一个有 n 个节点的 有向无环图(DAG),请你找出所有从节点 0 到节点 n-1 的路径并输出(不要求按特定顺序) graph[i] 是一个从节点 i 可以访问的所有节点的列表(即从节点 i 到节点 graph[i][j]存在一条有向…...

Spark核心架构与RDD:大数据处理的基石
Apache Spark作为新一代分布式计算引擎,其高效性和灵活性源于独特的运行架构与核心数据结构RDD。本文简要解析Spark的核心组件及RDD的核心特性,帮助开发者快速理解其设计思想。 一、Spark运行架构 Spark采用标准的**Master-Slave架构,核心组…...

Python Orange:托拉拽玩转机器学习、数据挖掘!
相比写代码做数据挖掘,Python Orange简直是懒人和新手的救星!传统编程得敲一行行代码,调库、debug 累得要死,而Orange靠拖拽就能搞定数据导入、清洗、可视化、建模、评估和无监督学习,支持跨Windows、Mac、Linux平台随…...