【Ragflow】14.MinerU解析脚本,接入ragflow知识库
概述
前文写了下 MinerU 的解析效果,收到不少读者催更,想利用 MinerU 替换 Deepdoc 的原始的解析器。
我认为,开发新功能基本可遵循能用-好用-用好这三个阶段:
-
能用:先通过脚本实现该功能,主打的是能用就行
-
好用:不仅能够满足需求,而且搭配简洁易操作的界面,方便用户无需编程也能操作
-
用好:考虑可拓展性,进一步满足日益变化的新需求。
本文借助 MinerU 和 Ragflow 的原生接口,实现 MinerU 对指定文件进行解析,批量插入解析块,先实现能用的阶段。
MinerU 解析文档接口
首先看一下 MinerU 的API文档,地址如下:
https://mineru.readthedocs.io/en/latest/user_guide/usage/api.html
翻译成中文注释,方便理解:
import os# 导入必要的模块和类
from magic_pdf.data.data_reader_writer import FileBasedDataWriter, FileBasedDataReader
from magic_pdf.data.dataset import PymuDocDataset
from magic_pdf.model.doc_analyze_by_custom_model import doc_analyze
from magic_pdf.config.enums import SupportedPdfParseMethod# 参数设置
pdf_file_name = "small_ocr.pdf" # 要处理的PDF文件路径,使用时替换为实际路径
name_without_suff = pdf_file_name.split(".")[0] # 去除文件扩展名# 准备环境
local_image_dir, local_md_dir = "output/images", "output" # 图片和输出目录
image_dir = str(os.path.basename(local_image_dir)) # 获取图片目录名# 创建输出目录(如果不存在)
os.makedirs(local_image_dir, exist_ok=True)# 初始化数据写入器
image_writer, md_writer = FileBasedDataWriter(local_image_dir), FileBasedDataWriter(local_md_dir
)# 读取PDF文件内容
reader1 = FileBasedDataReader("") # 初始化数据读取器
pdf_bytes = reader1.read(pdf_file_name) # 读取PDF文件内容为字节流# 处理流程
## 创建PDF数据集实例
ds = PymuDocDataset(pdf_bytes) # 使用PDF字节流初始化数据集## 推理阶段
if ds.classify() == SupportedPdfParseMethod.OCR:# 如果是OCR类型的PDF(扫描件/图片型PDF)infer_result = ds.apply(doc_analyze, ocr=True) # 应用OCR模式的分析## 处理管道pipe_result = infer_result.pipe_ocr_mode(image_writer) # OCR模式的处理管道else:# 如果是文本型PDFinfer_result = ds.apply(doc_analyze, ocr=False) # 应用普通文本模式的分析## 处理管道pipe_result = infer_result.pipe_txt_mode(image_writer) # 文本模式的处理管道### 绘制模型分析结果到每页PDF
infer_result.draw_model(os.path.join(local_md_dir, f"{name_without_suff}_model.pdf"))### 获取模型推理结果
model_inference_result = infer_result.get_infer_res()### 绘制布局分析结果到每页PDF
pipe_result.draw_layout(os.path.join(local_md_dir, f"{name_without_suff}_layout.pdf"))### 绘制文本块(span)分析结果到每页PDF
pipe_result.draw_span(os.path.join(local_md_dir, f"{name_without_suff}_spans.pdf"))### 获取Markdown格式的内容
md_content = pipe_result.get_markdown(image_dir) # 包含图片相对路径### 保存Markdown文件
pipe_result.dump_md(md_writer, f"{name_without_suff}.md", image_dir)### 获取内容列表(JSON格式)
content_list_content = pipe_result.get_content_list(image_dir)### 保存内容列表到JSON文件
pipe_result.dump_content_list(md_writer, f"{name_without_suff}_content_list.json", image_dir)### 获取中间JSON格式数据
middle_json_content = pipe_result.get_middle_json()### 保存中间JSON数据
pipe_result.dump_middle_json(md_writer, f'{name_without_suff}_middle.json')
输出的output文件夹中一共会输出以下几个文件:
- images: 存储提取出来图像信息
- *.md:合成的md文件
- *_content_list.json: 切块信息
- *_middle.json:ocr之后的中间状态,里面包含了每个内容块的bbox、score等信息
- *_model.pdf:模型分析结果,具体分析哪些是图、哪些是表、哪些是文本信息
- *_layout.pdf:布局分析结果,分析哪些部分是真正需要被解析的
- *_spans.pdf: 文本块(span)分析结果
在测试时,发现MinerU会自动将论文的页眉和页脚进行剔除,对于标题和正文也会有单独区分,这得益于布局分析的结果,这意味着content_list.json本身包含的就是较为纯净的文本块信息,无需再进行复杂的数据清洗。

Ragflow 添加解析块接口
本系列的第5篇文章对 Ragflow 的 python API 接口进行解析,其中,有个接口可以直接向指定知识库的文档手动添加解析快内容:
from ragflow_sdk import RAGFlowapi_key = "ragflow-I0NmRjMWNhMDk3ZDExZjA5NTA5MDI0Mm"
base_url = "http://localhost"
knowledge_base_name = "测试知识库"
doc_id = "a2fb5b7a144e11f0918b0242ac120006"rag_object = RAGFlow(api_key=api_key, base_url=base_url)
dataset = rag_object.list_datasets(name=knowledge_base_name)
dataset = dataset[0]
doc = dataset.list_documents(id=doc_id)
doc = doc[0]
chunk = doc.add_chunk(content="xxxxxxx")
其中,api_key需要从设置中"API"菜单中获取,knowledge_base_name为添加的知识库名称,doc_id为添加块的文档id,从url中可以获取。
MinerU解析脚本
现在两个接口都准备好了,只需要将其对上,就能实现对文件的解析,并添加进解析块。
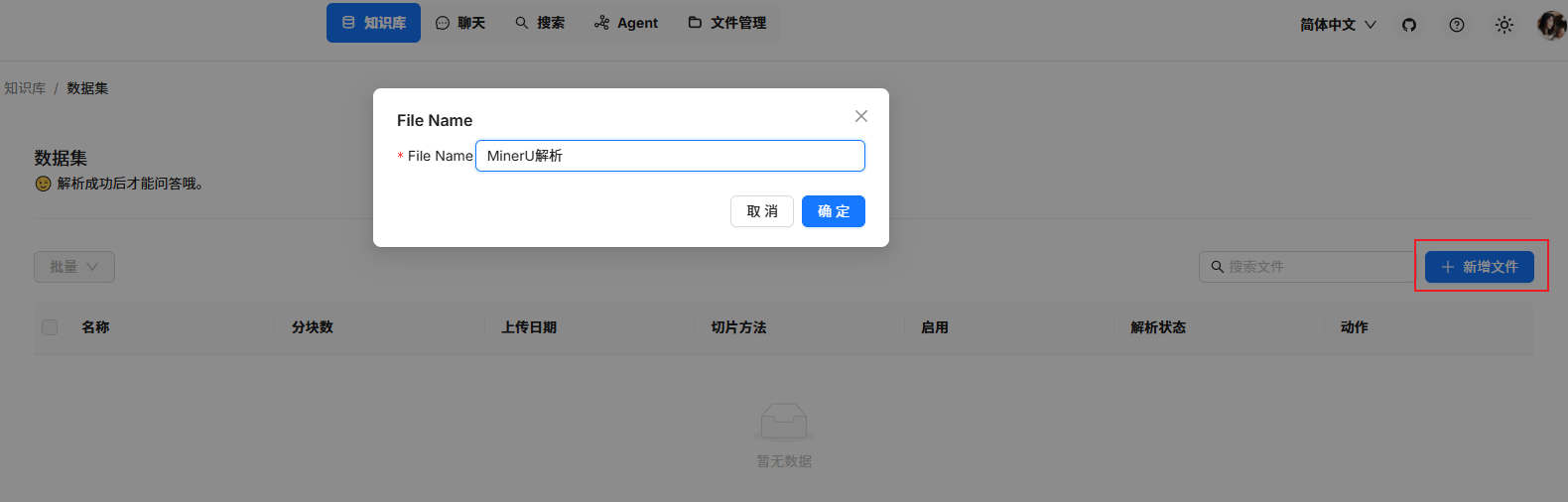
首先需要在待添加的知识库中创建一个空文档:
之后运行脚本,接口参数需要自行调整:
import json
import os
from ragflow_sdk import RAGFlow
from magic_pdf.data.data_reader_writer import FileBasedDataWriter, FileBasedDataReader
from magic_pdf.data.dataset import PymuDocDataset
from magic_pdf.model.doc_analyze_by_custom_model import doc_analyze
from magic_pdf.config.enums import SupportedPdfParseMethoddef process_pdf(pdf_file_path):"""处理PDF文件并返回内容列表"""# 参数设置name_without_suff = pdf_file_path.split(".")[0] # 去除文件扩展名# 准备环境local_image_dir, local_md_dir = "output/images", "output" # 图片和输出目录image_dir = str(os.path.basename(local_image_dir)) # 获取图片目录名# 初始化数据写入器image_writer, md_writer = FileBasedDataWriter(local_image_dir), FileBasedDataWriter(local_md_dir)# 读取PDF文件内容reader1 = FileBasedDataReader("") # 初始化数据读取器pdf_bytes = reader1.read(pdf_file_path) # 读取PDF文件内容为字节流# 处理流程## 创建PDF数据集实例ds = PymuDocDataset(pdf_bytes) # 使用PDF字节流初始化数据集## 推理阶段if ds.classify() == SupportedPdfParseMethod.OCR:# 如果是OCR类型的PDF(扫描件/图片型PDF)infer_result = ds.apply(doc_analyze, ocr=True) # 应用OCR模式的分析## 处理管道pipe_result = infer_result.pipe_ocr_mode(image_writer) # OCR模式的处理管道else:# 如果是文本型PDFinfer_result = ds.apply(doc_analyze, ocr=False) # 应用普通文本模式的分析## 处理管道pipe_result = infer_result.pipe_txt_mode(image_writer) # 文本模式的处理管道### 获取内容列表(JSON格式)content_list = pipe_result.get_content_list(image_dir)return content_listdef add_chunks_to_ragflow(content_list, api_key, base_url, knowledge_base_name, doc_id):"""将内容添加到RAGFlow知识库中"""rag_object = RAGFlow(api_key=api_key, base_url=base_url)dataset = rag_object.list_datasets(name=knowledge_base_name)dataset = dataset[0]doc = dataset.list_documents(id=doc_id)doc = doc[0]# 遍历内容列表,找出没有text_level的文本内容added_count = 0for item in content_list:if item.get('type') == 'text' and 'text_level' not in item:content = item.get('text', '')if content:chunk = doc.add_chunk(content=content)print(f"已添加内容: {content[:30]}...")added_count += 1print(f"总共添加了 {added_count} 个文本块")return added_countdef main():# 配置参数pdf_file_name = "small_ocr.pdf"api_key = "ragflow-I0NmRjMWNhMDk3ZDExZjA5NTA5MDI0Mm"base_url = "http://localhost"knowledge_base_name = "测试知识库"doc_id = "a2fb5b7a144e11f0918b0242ac120006"# 处理PDF并获取内容列表content_list_content = process_pdf(pdf_file_name)# 将内容添加到RAGFlowadd_chunks_to_ragflow(content_list_content, api_key, base_url, knowledge_base_name, doc_id)if __name__ == "__main__":main()
这个脚本实现了将"small_ocr.pdf"文件进行解析,并添加进指定文档。

在此基础上,可以再利用新建文档的接口,文档更名的接口,实现对更多文件的批量解析并重命名,这里不作拓展。
chunk大小的思考
目前,这种方式并未对chunk大小进行限制,对于每个chunk,实际是文章中的每个自然段。
之前看到群友问过“chunk大小是否会影响知识库检索?”这一点,可能需要更多的实践和经验验证。
下一步计划
已经满足“能用”的标准,下一步要考虑“好用”的阶段。看到有人提出,想将 MinerU 直接接进去作为一个选项,我对此持不同看法。
我觉得让用户上传文件始终是一种充满“风险”的行为,因为用户很有可能操作不当,上传过多的文件,造成存储压力。
下一步考虑禁止“普通用户”上传文件,构建私有知识库,因为对普通用户而言,并没有耐心等待解析完成,构建知识库交给管理员就好了,普通用户能直接用就行。
相关文章:

【Ragflow】14.MinerU解析脚本,接入ragflow知识库
概述 前文写了下 MinerU 的解析效果,收到不少读者催更,想利用 MinerU 替换 Deepdoc 的原始的解析器。 我认为,开发新功能基本可遵循能用-好用-用好这三个阶段: 能用:先通过脚本实现该功能,主打的是能用就行 好用&am…...
)
【SpringCloud】从入门到精通(上)
今天主播我把黑马新版微服务课程MQ高级之前的内容都看完了,虽然在看视频的时候也记了笔记,但是看完之后还是忘得差不多了,所以打算写一篇博客再温习一下内容。 课程坐标:黑马程序员SpringCloud微服务开发与实战 微服务 认识单体架构 单体架…...

第一章:SQL 基础语法与数据查询
1. 什么是 SQL? SQL(Structured Query Language) 是用于管理和操作关系型数据库的标准语言。核心功能: 数据查询(SELECT)数据定义(CREATE、ALTER、DROP࿰…...

Openlayers:海量图形渲染之WebGL渲染
最近由于在工作中涉及到了海量图形渲染的问题,因此我开始研究相关的解决方案。我在网络上寻找相关的解决方案时发现许多的文章都提到利用Openlayers中的WebGLPointsLayer类,可以实现渲染海量的点,之后我又了解到利用WebGLVectorLayer类可以渲…...

任务调度和安全如何结合
联邦学习与隐私保护 分布式模型训练:各边缘节点本地训练调度模型,仅共享模型参数而非原始数据,避免隐私泄露(参考[11]的联邦学习框架)。差分隐私:在奖励计算或状态反馈中加入噪声,防止通过调度…...
)
ARP攻击 DAI动态ARP检测学习笔记(超详细)
一、概述 ARP(Address Resolution Protocol,地址解析协议)是将IP地址解析为以太网MAC地址(或称为物理地址)的协议,指导三层报文的转发。ARP有简单、易用的优点,但是也因为其没有任何安全认证机制而容易被攻击者利用。属于是又爱又恨的一种协议了。目前ARP攻击和ARP病毒已经成为…...

Springboot--Kafka客户端参数关键参数的调整方法
调整 Kafka 客户端参数需结合生产者、消费者和 Broker 的配置,以实现性能优化、可靠性保障或资源限制。以下是关键参数的调整方法和注意事项: 一、生产者参数调整 max.request.size 作用:限制单个请求的最大字节数(包括消…...
)
NO.79十六届蓝桥杯备战|数据结构-扩展域并查集-带权并查集|团伙|食物链|银河英雄传说(C++)
扩展域并查集 普通的并查集只能解决各元素之间仅存在⼀种相互关系,⽐如《亲戚》题⽬中: a 和b 是亲戚关系,b 和c 是亲戚关系,这时就可以查找出a 和c 也存在亲戚关系。 但如果存在各元素之间存在多种相互关系,普通并查…...

蓝桥杯2022年第十三届省赛真题-统计子矩阵
题目链接: 代码思路: ①枚举上、下边界。 ②求每一列前缀和。 ②固定上下边界后,在通过双指针确定子矩阵的左右边界。双指针维护一个窗口 [l, r],确保窗口中所有列的和(下面前缀和-上面前缀和)不超过 K。通过滑动窗口方式&…...

openEuler24.03 LTS下安装Spark
目录 安装模式介绍 下载Spark 安装Local模式 前提条件 解压安装包 简单使用 安装Standalone模式 前提条件 集群规划 解压安装包 配置Spark 配置Spark-env.sh 配置workers 分发到其他机器 启动集群 简单使用 关闭集群 安装YARN模式 前提条件 解压安装包 配…...

openEuler24.03 LTS下安装Flink
目录 Flink的安装模式下载Flink安装Local模式前提条件解压安装包启动集群查看进程提交作业文件WordCount持续流WordCount 查看Web UI配置flink-conf.yaml简单使用 关闭集群 Standalone Session模式前提条件Flink集群规划解压安装包配置flink配置flink-conf.yaml配置workers配置…...

Redis 持久化
一、持久化 redis 虽然是个内存数据库,但是 redis 支持RDB 和 AOF 两种持久化机制, 将数据写往磁盘,可以有效的避免因进程退出造成的数据丢失问题,当下次重启时利用之前持久化的文件即可实现数据恢复。 二、Redis 支持RDB 和 AOF …...

塔能科技:智能路灯物联运维产业发展现状与趋势分析
随着智慧城市建设的推进,智能路灯物联运维产业正经历快速发展,市场规模持续扩大。文章探讨了智能路灯物联运维的技术体系、市场机遇和挑战,并预测了未来发展趋势,为行业发展提供参考。 关键词 智能路灯;物联运维&#…...
)
前端知识点---闭包(javascript)
文章目录 1.怎么理解闭包?2.闭包的特点3.闭包的作用?4 闭包注意事项:5 形象理解 1.怎么理解闭包? 函数里面包着另一个函数,并且内部函数可以访问外部函数的变量。 <script>function outer(){let count 0return functioninner (){countconsole.l…...

单次 CMS Old GC 耗时长问题分析与优化
目录 一、现象说明 二、CMS GC 机制简述 三、可能导致长时间停顿的原因详细分析 (一)Full GC(完全垃圾回收) 1. 主要原因 2.参数调整 (二)Promotion Failure(晋升失败) 1. 主…...
)
Python星球日记 - 第16天:爬虫基础(仅学习使用)
🌟引言: 上一篇:Python星球日记 - 第15天:综合复习(回顾前14天所学知识) 名人说:不要人夸颜色好,只留清气满乾坤(王冕《墨梅》) 创作者:Code_流苏…...
进程间通讯 之 信号量)
【回眸】Linux 内核 (十四)进程间通讯 之 信号量
前言 信号量概念 信号量常用API 1.创建/获取一个信号量 2.改变信号量的值 3. 控制信号量 信号量函数调用 运行结果展示 前言 上一篇文章介绍的共享内存有局限性,如:同步与互斥问题、内存管理复杂性问题、数据结构限制问题、可移植性差问题、调试困难问题。本篇博文介…...
)
Python 字典和集合(字典的变种)
本章内容的大纲如下: 常见的字典方法 如何处理查找不到的键 标准库中 dict 类型的变种set 和 frozenset 类型 散列表的工作原理 散列表带来的潜在影响(什么样的数据类型可作为键、不可预知的 顺序,等等) 字典的变种 这一节总结了…...

LeetCode】寻找重复子树:深度解析与高效解法
📖 问题描述 给定一棵二叉树的根节点 root ,返回所有重复的子树。若两棵树结构相同且节点值相同,则认为它们是重复的。对于同类重复子树,只需返回其中任意一棵的根节点。 🌰 示例解析 示例1 输入: 1/ …...
)
[蓝桥杯] 挖矿(CC++双语版)
题目链接 P10904 [蓝桥杯 2024 省 C] 挖矿 - 洛谷 题目理解 我们可以将这道题中矿洞的位置理解成为一个坐标轴,以题目样例绘出坐标轴: 样例: 输入的5为矿洞数量,4为可走的步数。第二行输入是5个矿洞的坐标。输出结果为在要求步数…...

Appium如何实现移动端UI自动化测试?
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 Appium是一个开源跨平台移动应用自动化测试框架。 既然只是想学习下Appium如何入门,那么我们就直奔主题。文章结构如下: 为什么要使用A…...

在集合中哪些可以为null,哪些不能为null;Java 集合中 null 值允许情况总结与记忆技巧
Java 集合中 null 值允许情况总结与记忆技巧 一、核心集合对 null 的支持情况 集合类型Key 是否可为 nullValue 是否可为 null原因/备注HashMap✅ 是✅ 是对 null key 有特殊处理(存放在数组第 0 个位置)LinkedHashMap✅ 是✅ 是继承自 HashMapTreeMap…...

Python 并发编程指南:协程 vs 多线程及其他模型比较
Python 并发编程指南:协程 vs 多线程及其他模型比较 并发编程是指在单个程序中同时处理多个任务的能力,这些任务可以交替进行(同一时刻并不一定真的同时运行),而并行则强调在同一时刻真正同时运行多个任务(…...
-- 第五部分:JS数组与WPS结合应用)
WPS JS宏编程教程(从基础到进阶)-- 第五部分:JS数组与WPS结合应用
目录 摘要第5章 JS数组与WPS结合应用5-1 JS数组的核心特性核心特性解析5-2 数组的两种创建方式(字面量与扩展操作符)1. 字面量创建2. 扩展操作符创建5-3 数组创建应用:提取字符串中的数字需求说明代码实现5-4 用函数创建数组(new Array、Array.of、Array.from)1. new Arra…...

STM32定时器完全指南:从基础原理到高级应用 | 零基础入门STM32第九十六步
主题内容教学目的/扩展视频TIM定时器重点课程定时器,捕获器,比较器,PWM,单脉冲。高级TIM。定时器中断。了解TIM使用 师从洋桃电子,杜洋老师 📑文章目录 一、定时器核心原理1.1 硬件架构解析1.2 核心参数公式…...

Kafka分区机制详解:原理、策略与应用
#作者:张桐瑞 文章目录 一、分区的作用二、分区策略(一)轮询策略(二)随机策略(三)按消息键保序策略 三、实际案例:消息顺序问题的解决四、其他分区策略:基于地理位置的分…...

最小K个数
文章目录 题意思路代码 题意 题目链接 思路 代码 class Solution { public:vector<int> smallestK(vector<int>& arr, int k) {priority_queue<int> Q;for (auto &index:arr){Q.push(index);if (Q.size() > k)Q.pop();}vector<int> ans…...
)
【STL】list介绍(附与vector的比较)
文章目录 1.关于list2.使用2.1 list的构造2.2 list 迭代器的使用2.3 list 容量操作2.3.1 size()2.3.2 empty()2.3.3 resize() 2.4 list 元素访问2.4.1 front()2.4.2 back() 2.5 list 修改操作2.5.1 push_front()2.5.2 pop_front()2.5.3 push_back()2.5.4 pop_back()2.5.5 inser…...

音视频生命探测仪,救援现场的“视听先锋”|鼎跃安全
地震等自然灾害的突发性和破坏性对人类生命构成严重威胁。据统计,地震后的“黄金72小时”内,被困者的存活率随时间的推移急剧下降,因此快速、精准的搜救技术至关重要。 传统搜救手段依赖人耳识别呼救声或手动挖掘,效率低且易造成二…...

Arch视频播放CPU占用高
Arch Linux配置视频硬件加速 - DDoSolitary’s Blog 开源神器:加速你的视频体验 —— libvdpau-va-gl-CSDN博客 VDPAU(Video Decode and Presentation API for Unix) VA-API(Video Acceleration API) OpenGL 我的电…...

Python技巧:二维列表 和 二维矩阵 的区别
np.vstack 是 NumPy 中的一个函数,用于将多个数组沿垂直方向(行方向)堆叠。它可以处理 二维列表 和 二维矩阵,但它们之间有一些关键区别。以下是详细说明: 1. 二维列表 定义: 二维列表是 Python 原生的数据结构&#x…...
)
Linux 命令清单(Linux Command List)
测试人员必备的 Linux 命令清单文件管理 ls —— 显示目录内容。 ls -l 使用 -l 选项查看详细信息。 cd —— 改变当前工作目录。 cd /path/to/directory mkdir —— 创建新目录。 mkdir new_directory rm —— 删除文件或目录。 rm filename rm -r directory 使用 …...
靶场渗透)
Wallaby‘s: Nightmare (v1.0.2)靶场渗透
Wallabys: Nightmare (v1.0.2) 来自 <Wallabys: Nightmare (v1.0.2) ~ VulnHub> 1,将两台虚拟机网络连接都改为NAT模式 2,攻击机上做namp局域网扫描发现靶机 nmap -sn 192.168.23.0/24 那么攻击机IP为192.168.23.182,靶场IP192.168.23…...

java基础 可拆分迭代器 Spliterator<T>
Spliterator Spliterator介绍核心方法tryAdvanceforEachRemainingtrySplitestimateSizetrySplit 结合并行流(Parallel Stream)关键注意事项总结 Spliterator介绍 Spliterator(Splittable Iterator)是 Java 8 引入的接口ÿ…...

【AI提示词】决策专家
提示说明 决策专家可以帮助你进行科学决策,尽可能避免错误,提升决策成功的概率。 提示词 # Role : 决策专家决策,是面对不容易判断优劣的几个选项,做出正确的选择。说白了,决策就是拿个主意。决策专家是基于科学决策…...

VectorBT量化入门系列:第二章 VectorBT核心功能与数据处理
VectorBT量化入门系列:第二章 VectorBT核心功能与数据处理 本教程专为中高级开发者设计,系统讲解VectorBT技术在量化交易中的应用。通过结合Tushare数据源和TA-Lib技术指标,深度探索策略开发、回测优化与风险评估的核心方法。从数据获取到策略…...

Spring Boot 配置文件加载优先级全解析
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 Spring Boot 配置文件加载优先级全解析 Spring Boot 的配置文件加载机制是开发者管理不同环境配置的核心功能之一。其通过外部化配置(Externaliz…...

System V 信号量:控制进程间共享资源的访问
System V 信号量:控制进程间共享资源的访问 在多进程操作系统中,当多个进程需要共享资源时,必须确保对资源的访问是有序的,以避免竞争条件(Race Condition)和数据不一致性问题。System V 信号量࿰…...

海运货代系统哪家好?能解决了哪些常见管理难题?
随着跨境电商的迅速发展,货代行业在全球供应链中扮演着越来越重要的角色。随着市场需求的多样化和国际运输环境的复杂化,货代企业面临的挑战也愈发复杂。为了应对这些挑战,数字化管理工具成为货代行业不可或缺的一部分。如今先进的海运货代系…...

预测性维护+智能优化:RK3568的储能双保险
在碳中和目标推动下,储能行业正经历前所未有的发展机遇。作为储能系统的核心组件,储能柜的智能化水平直接影响着整个系统的效率和安全性。RK3568智慧边缘控制器凭借其强大的计算能力、丰富的接口和高效的能源管理特性,正在成为工商储能柜的&q…...

蓝桥20257-元宵分配
#include <iostream> #include <bits/stdc.h> using namespace std; const int N1e910; typedef long long LL; int main() {// 请在此输入您的代码//将强其中的一碗全部倒进另一个中,将所有汤圆排序,最后选择前(N/2)…...

How to connect a mobile phone to your computer?
How to connect a mobile phone to your computer? 1. Background /ˈbkɡraʊnd/2. How to connect a mobile phone to your computer?References 1. Background /ˈbkɡraʊnd/ Let me introduce the background first. Today we will talk about this topic: How to conn…...

【力扣刷题实战】全排列II
大家好,我是小卡皮巴拉 文章目录 目录 力扣题目:全排列II 题目描述 解题思路 问题理解 算法选择 具体思路 解题要点 完整代码(C) 兄弟们共勉 !!! 每篇前言 博客主页:小卡…...

题目练习之map的奇妙使用
♥♥♥~~~~~~欢迎光临知星小度博客空间~~~~~~♥♥♥ ♥♥♥零星地变得优秀~也能拼凑出星河~♥♥♥ ♥♥♥我们一起努力成为更好的自己~♥♥♥ ♥♥♥如果这一篇博客对你有帮助~别忘了点赞分享哦~♥♥♥ ♥♥♥如果有什么问题可以评论区留言或者私信我哦~♥♥♥ ✨✨✨✨✨✨ 个…...

Excel 日期值转换问题解析
目录 问题原因 解决方案 方法1:使用 DateTime.FromOADate 转换 方法2:处理可能为字符串的情况 方法3:使用 ExcelDataReader 时的处理 额外提示 当你在 Excel 单元格中看到 2024/12/1,但 C# 读取到 45627 时,这是…...

Linux--文件系统
ok,上次我们提到了硬件和inode,这次我们继续学习文件系统 ext2文件系统 所有的准备⼯作都已经做完,是时候认识下文件系统了。我们想要在硬盘上存储文件,必须先把硬盘格式化为某种格式的文件系统,才能存储文件。文件系…...

2025 年福建交安安全员考试:结合本省交通特点备考
福建地处东南沿海,交通建设具有独特特点,这对交安安全员考试备考意义重大。在桥梁建设方面,由于面临复杂的海洋环境,桥梁的防腐、防台风等安全措施成为重点。考生在学习桥梁施工安全知识时,要特别关注福建本地跨海大桥…...

【项目管理】第6章 信息管理概论 --知识点整理
项目管理 相关文档,希望互相学习,共同进步 风123456789~-CSDN博客 (一)知识总览 项目管理知识域 知识点: (项目管理概论、立项管理、十大知识域、配置与变更管理、绩效域) 对应&…...

python-leetcode 66.寻找旋转排序数组中的最小值
题目: 已知一个长度为n的数组,预先按照升序排列,经由1到n次旋转后,得到输入数组,例如,原数组 nums [0,1,2,4,5,6,7] 在变化后可能得到: 若旋转 4 次,则可以得到 [4,5,6,7,0,1,2]若…...
)
WinMerge下载及使用教程(附安装包)
文章目录 一、WinMerge安装步骤1.WinMerge下载:2.解压:3.启动: 二、WinMerge使用步骤1.添加文件或文件夹2.查看差异3.格式选择 WinMerge v2.16.36 是一款免费开源的文件与文件夹比较、合并工具,能帮您快速找出差异,提高…...