openEuler24.03 LTS下安装Spark
目录
安装模式介绍
下载Spark
安装Local模式
前提条件
解压安装包
简单使用
安装Standalone模式
前提条件
集群规划
解压安装包
配置Spark
配置Spark-env.sh
配置workers
分发到其他机器
启动集群
简单使用
关闭集群
安装YARN模式
前提条件
解压安装包
配置Spark
配置spark-env.sh
配置历史服务器
配置spark-env.sh
启动服务
简单使用
关闭服务
安装模式介绍
Spark常见的部署模式
(1)Local模式:在本地部署单个Spark服务,使用本地资源调度。(测试用)
(2)Standalone模式:构建一个由Master + Worker构成的Spark集群,使用Spark自带的资源调度执行任务,不需要借助Yarn或Mesos等其他框架资源。(不常用)
(3)YARN模式:Spark作为客户端,Spark直接使用Hadoop的YARN组件进行资源与任务调度。(常用)
(4)Mesos模式:和YARN模式类似。Spark直接使用Mesos进行资源与任务调度。
(5)K8S模式:和YARN模式类似。Spark直接使用K8S进行资源与任务调度。
这里介绍前面三种模式,安装模式对比如下
| 模式 | Spark安装机器数 | 需启动的进程 |
|---|---|---|
| Local模式 | 1 | 无 |
| Standalone模式 | 3 | Master、Worker |
| YARN模式 | 1 | YARN、HDFS |
下载Spark
下载Spark
https://archive.apache.org/dist/spark/spark-3.3.1/spark-3.3.1-bin-hadoop3.tgz
上传安装包到Linux /opt/software目录下
安装Local模式
解压安装包就完成Local模式安装,不需要任何配置,也不需要启动任何进程。
在node2机器操作。
前提条件
Linux机器安装好Java,可参考:openEuler24.03 LTS下安装Hadoop3完全分布式-安装Java
解压安装包
[liang@node2 ~]$ cd /opt/software
[liang@node2 sorfware]$ tar -zxvf spark-3.3.1-bin-hadoop3.tgz -C /opt/module
[liang@node2 sorfware]$ cd /opt/module
[liang@node2 sorfware]$ mv spark-3.3.1-bin-hadoop3 spark-local简单使用
使用Local模式计算pi
$ cd spark-local$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.12-3.3.1.jar \
10命令参数介绍
--class 表示要执行程序的主类 --master 表示使用本地的多少核线程来计算 xxx.jar 表示程序所在的jar包 10 表示程序计算的次数
命令行查看结果
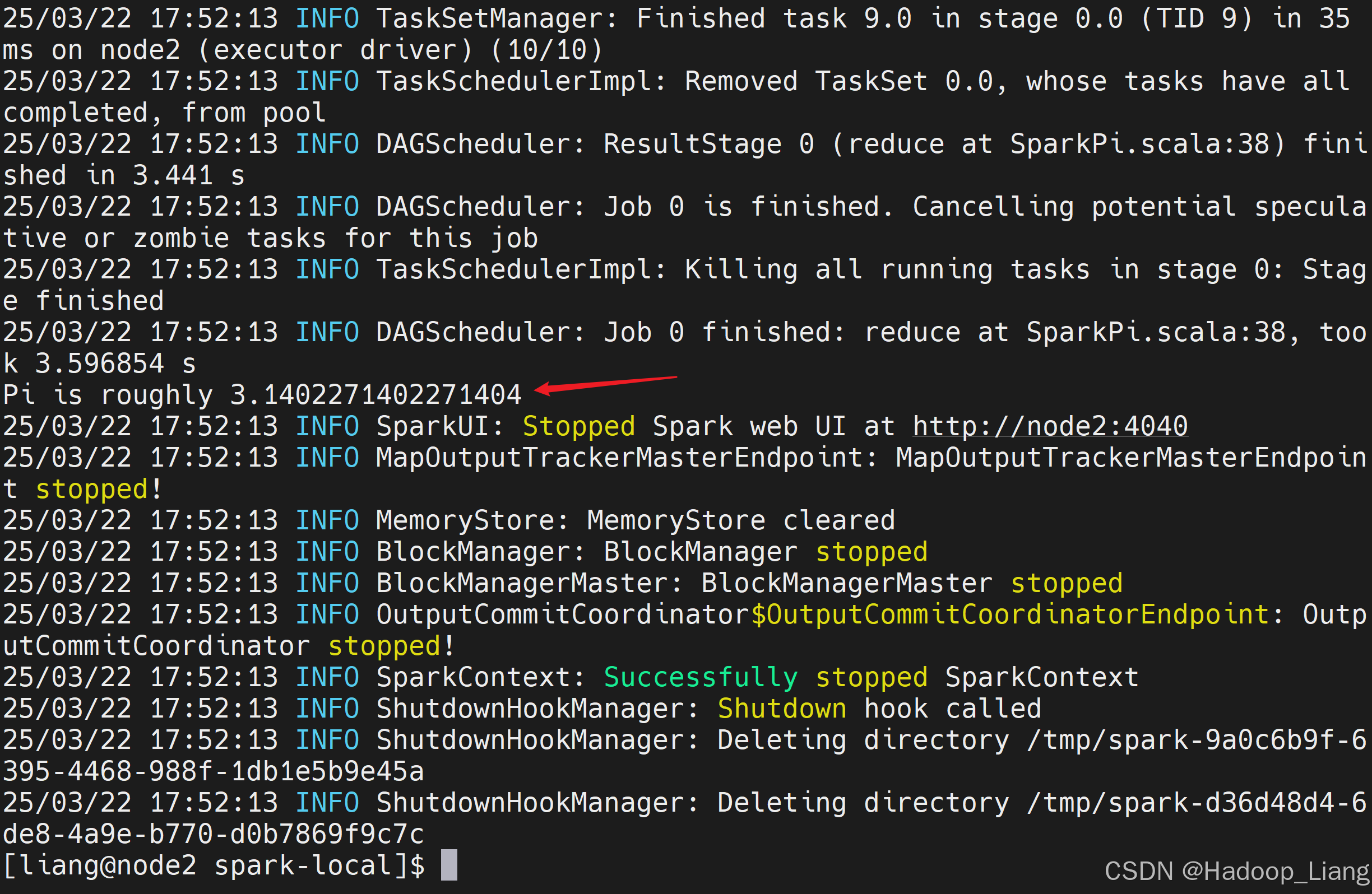
Web UI监控执行过程,浏览器访问如下地址
node2:4040
如果Web UI看不到,调大计算次数,再次查看Web UI
$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.12-3.3.1.jar \
100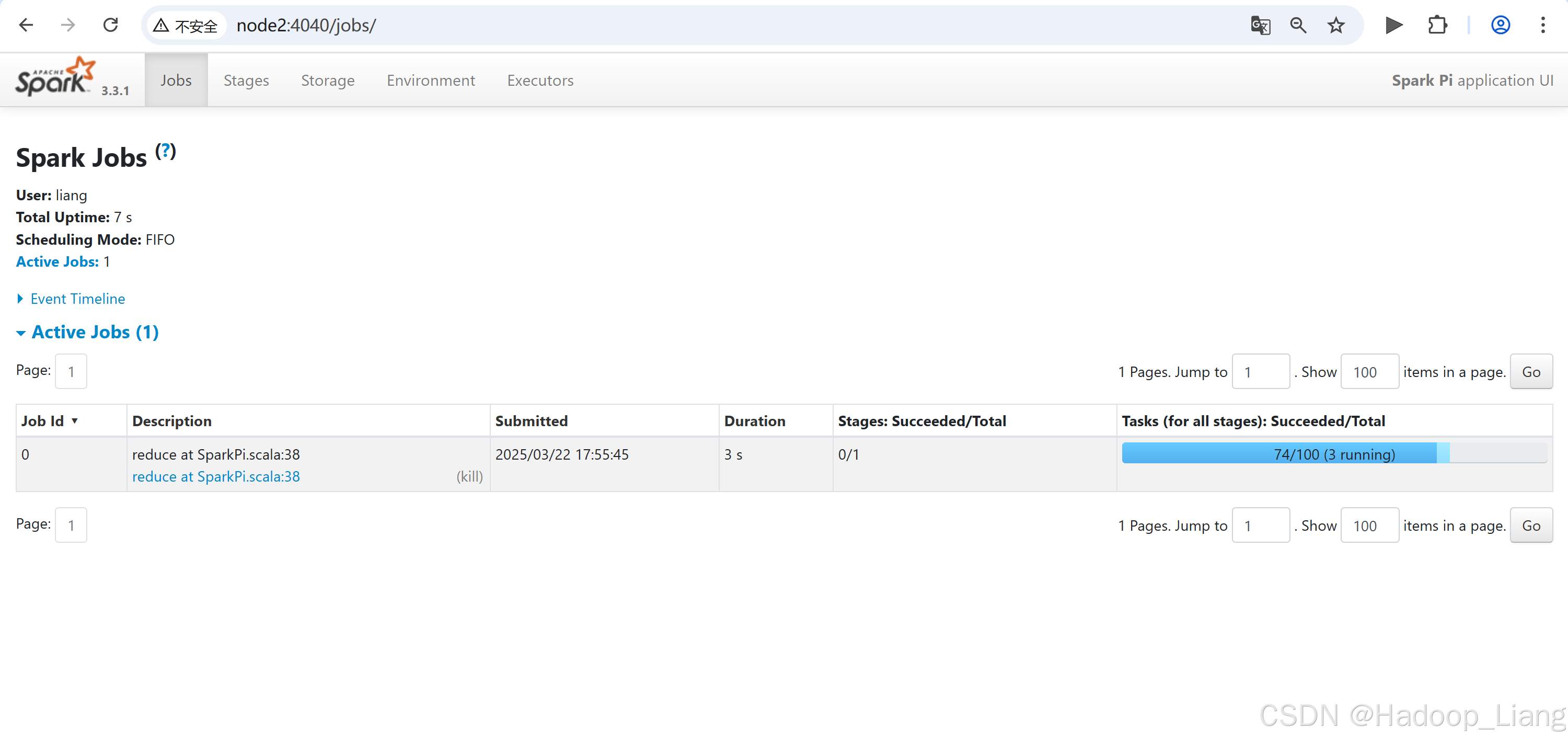
安装Standalone模式
前提条件
有三台Linux机器,都安装好Java,可参考:openEuler24.03 LTS下安装Hadoop3完全分布式-安装Java
集群规划
Spark Standalone集群规划
| node2 | node3 | node4 |
|---|---|---|
| Master | ||
| Woker | Worker | Worker |
解压安装包
解压安装包及重命名
[liang@node2 sorfware]$ cd /opt/software
[liang@node2 sorfware]$ tar -zxvf spark-3.3.1-bin-hadoop3.tgz -C /opt/module
[liang@node2 sorfware]$ cd /opt/module
[liang@node2 sorfware]$ mv spark-3.3.1-bin-hadoop3 spark-standalone配置Spark
进入Spark配置目录
[liang@node2 conf]$ cd spark-standalone/conf
[liang@node2 conf]$ ls
fairscheduler.xml.template metrics.properties.template spark-env.sh.template
log4j2.properties.template spark-defaults.conf.template workers.template配置Spark-env.sh
$ mv spark-env.sh.template spark-env.sh
$ vim spark-env.sh添加以下内容
export SPARK_MASTER_HOST=node2配置workers
[liang@node2 conf]$ mv workers.template workers
[liang@node2 conf]$ vim workers删除原有localhost,添加如下内容
node2
node3
node4分发到其他机器
$ xsync /opt/module/spark-standalone启动集群
启动集群
[liang@node2 conf]$ cd /opt/module/spark-standalone
[liang@node2 spark-standalone]$ sbin/start-all.sh执行输出
[liang@node2 spark-standalone]$ sbin/start-all.sh starting org.apache.spark.deploy.master.Master, logging to /opt/module/spark-standalone/logs/spark-liang-org.apache.spark.deploy.master.Master-1-node2.out node2: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-standalone/logs/spark-liang-org.apache.spark.deploy.worker.Worker-1-node2.out node3: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-standalone/logs/spark-liang-org.apache.spark.deploy.worker.Worker-1-node3.out node4: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-standalone/logs/spark-liang-org.apache.spark.deploy.worker.Worker-1-node4.out
jps查看进程
$ jpsall执行输出
[liang@node2 spark-standalone]$ jpsall =============== node2 =============== 2839 Worker 2921 Jps 2701 Master =============== node3 =============== 2092 Jps 2030 Worker =============== node4 =============== 2096 Jps 2034 Worker
简单使用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://node2:7077 \
--deploy-mode client \
--driver-memory 1G \
--executor-memory 1G \
--total-executor-cores 2 \
--executor-cores 1 \
./examples/jars/spark-examples_2.12-3.3.1.jar \
10查看Web UI
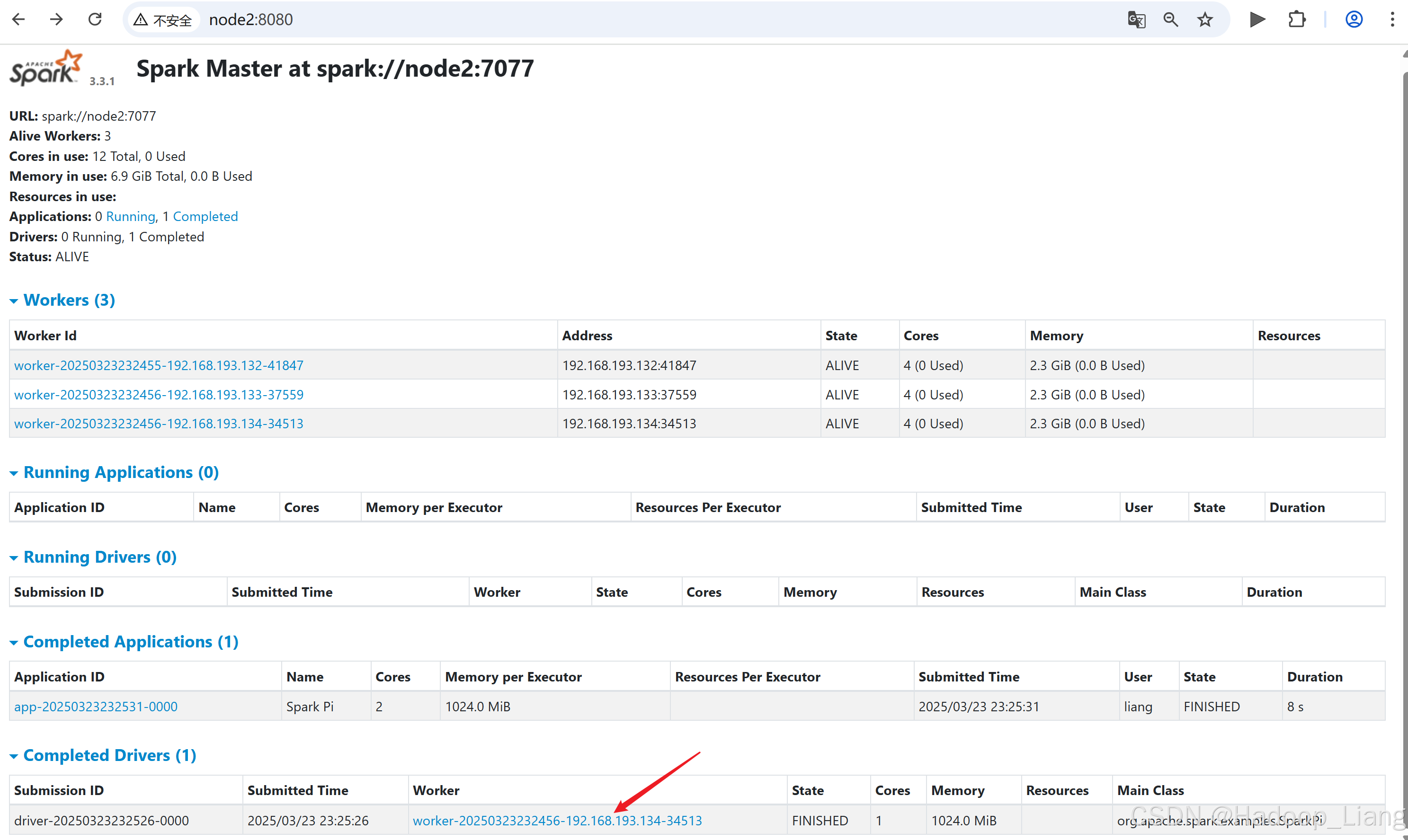
node2:8080
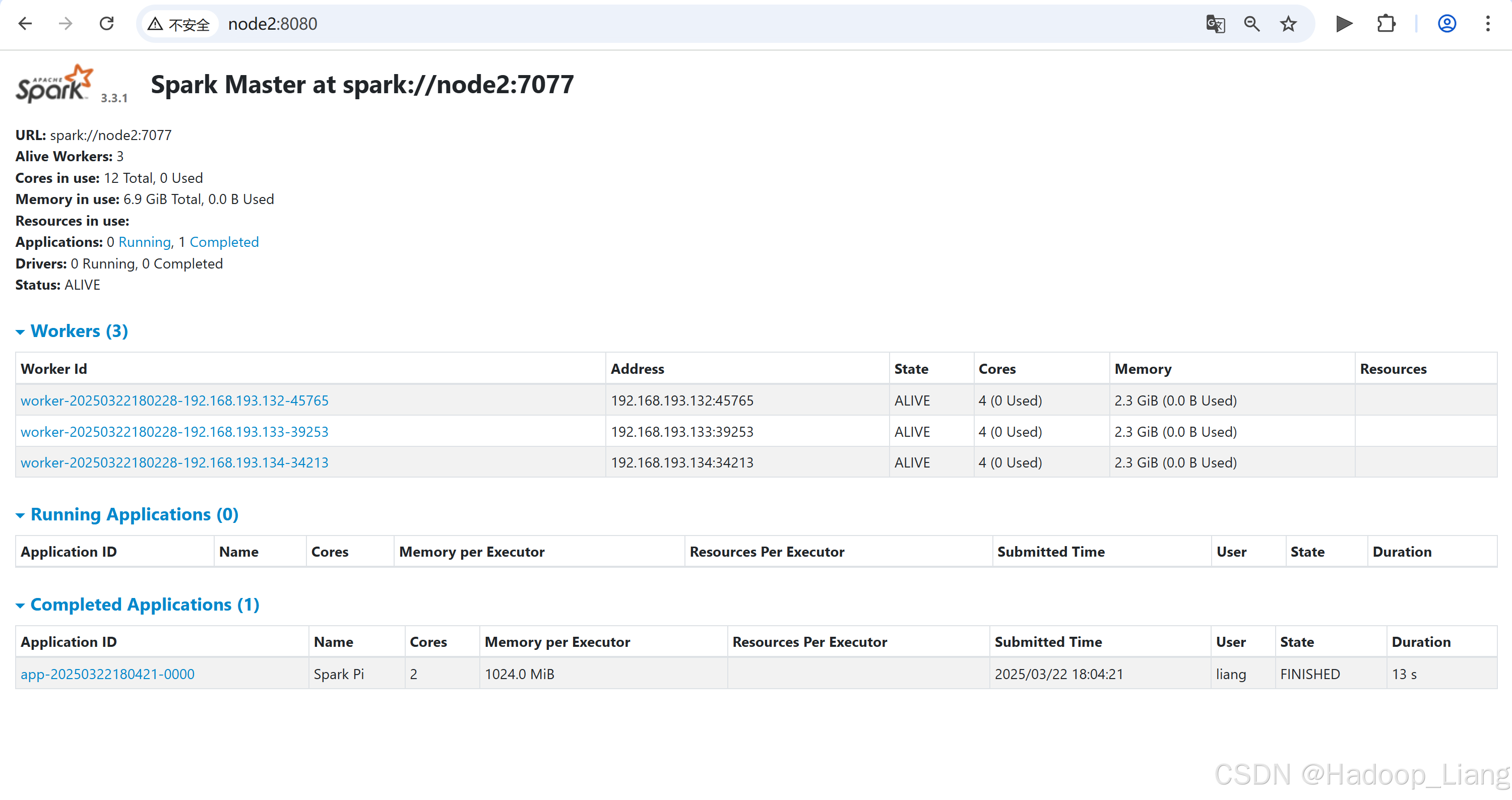
delploy-mode 为client运行,结果直接在客户端显示

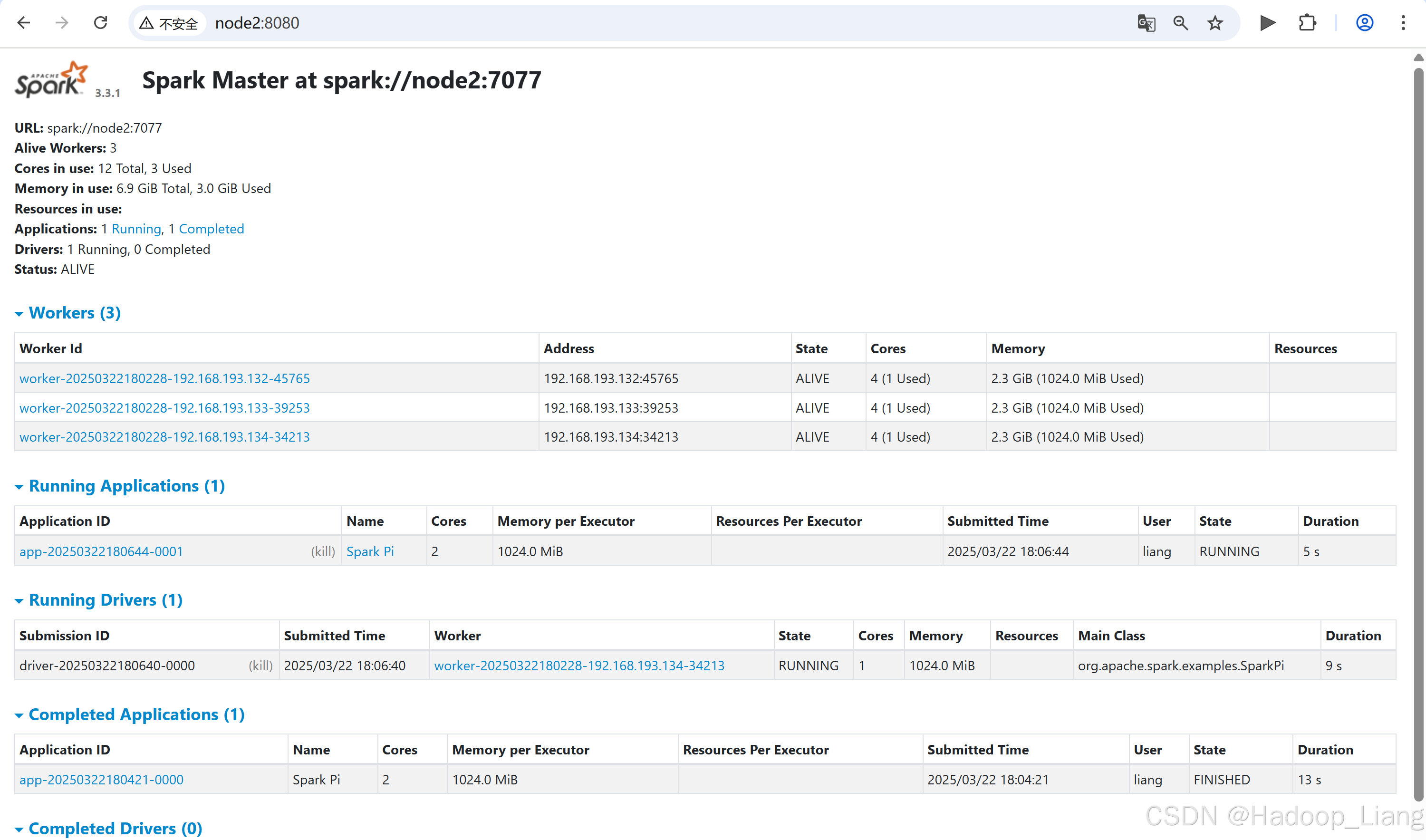
deploy-mode 可以改为 cluster ,测试看看效果,运行结果需要登录Web页面的driver 日志查看。
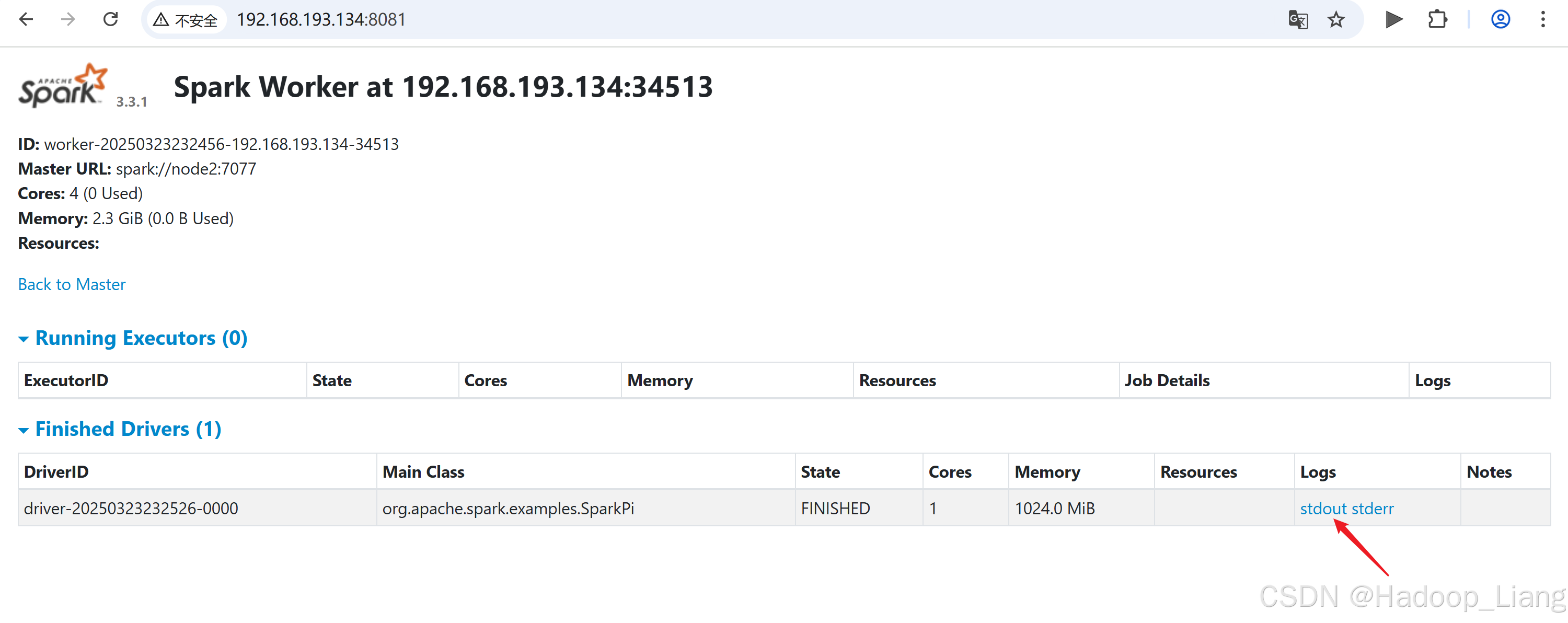
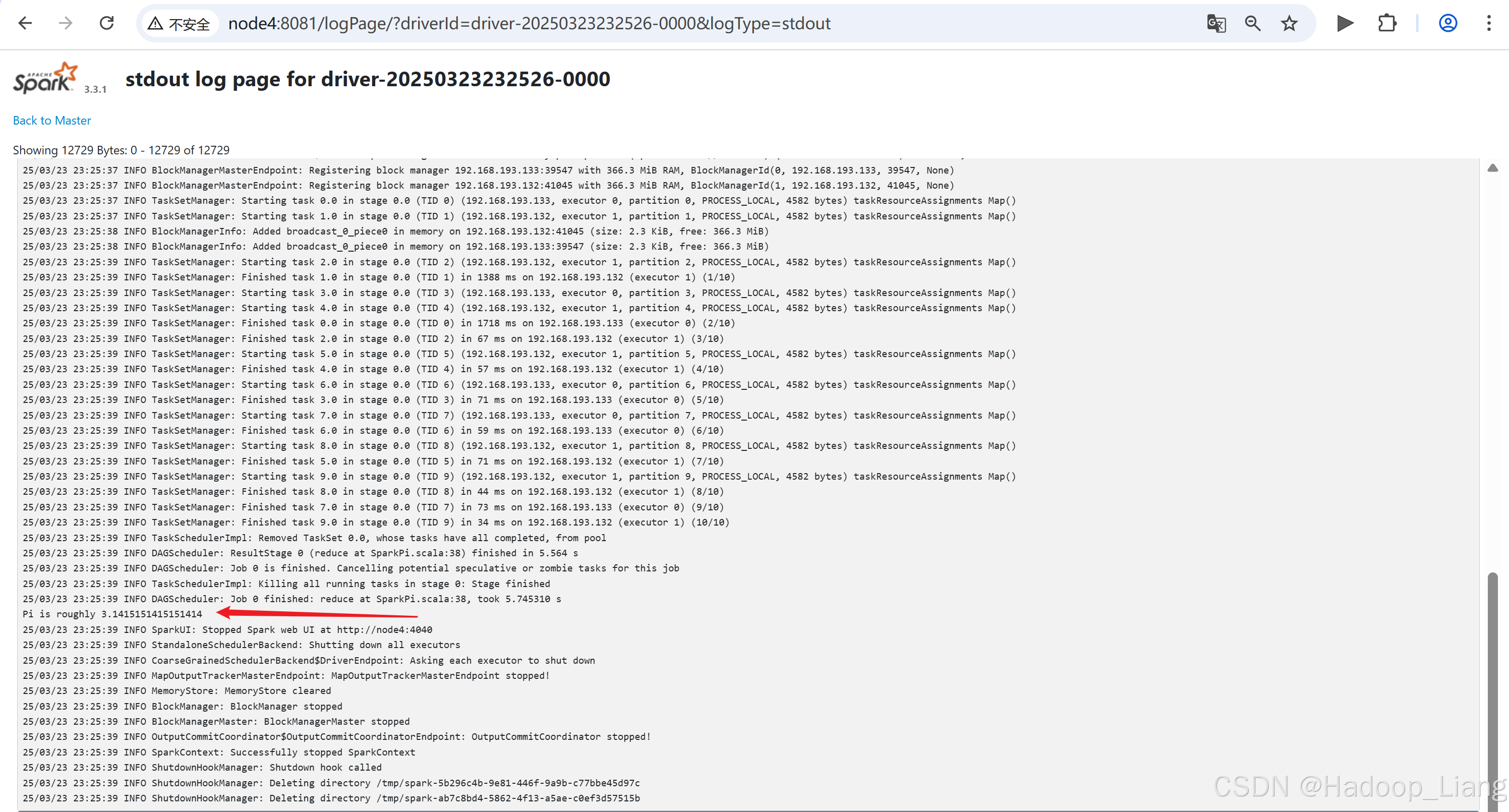
[liang@node2 spark-standalone]$ bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://node2:7077 --deploy-mode cluster --driver-memory 1G --executor-memory 1G --total-executor-cores 2 --executor-cores 1 ./examples/jars/spark-examples_2.12-3.3.1.jar 10如果访问速度较块,可以看到并点击Running Drivers下Worker的超链接


如果运行完成,过一定的时间后,可以在Completed Drivers的Worker去找结果
关闭集群
关闭集群
./sbin/stop-all.shjps查看进程
jpsall操作过程
[liang@node2 spark-standalone]$ sbin/stop-all.sh node3: stopping org.apache.spark.deploy.worker.Worker node2: stopping org.apache.spark.deploy.worker.Worker node4: stopping org.apache.spark.deploy.worker.Worker stopping org.apache.spark.deploy.master.Master [liang@node2 spark-standalone]$ jpsall =============== node2 =============== 3404 Jps =============== node3 =============== 2365 Jps =============== node4 =============== 2371 Jps
安装YARN模式
在node2机器操作
前提条件
安装好Hadoop完全分布式集群, 可参考:openEuler24.03 LTS下安装Hadoop3完全分布式
解压安装包
[liang@node2 ~]$ cd /opt/software
[liang@node2 sorfware]$ tar -zxvf spark-3.3.1-bin-hadoop3.tgz -C /opt/module
[liang@node2 sorfware]$ cd /opt/module
[liang@node2 sorfware]$ mv spark-3.3.1-bin-hadoop3 spark-yarn配置Spark
进入Spark配置目录
[liang@node2 conf]$ cd spark-yarn/conf
[liang@node2 conf]$ ls
fairscheduler.xml.template metrics.properties.template spark-env.sh.template
log4j2.properties.template spark-defaults.conf.template workers.template配置spark-env.sh
$ mv spark-env.sh.template spark-env.sh
$ vim spark-env.sh添加如下内容
YARN_CONF_DIR=/opt/module/hadoop-3.3.4/etc/hadoop配置含义:告诉Spark yarn的配置哪里,yarn-site.xml配置了yarn相关信息。
配置历史服务器
配置spark-defaults.conf
$ mv spark-defaults.conf.template spark-defaults.conf
$ vim spark-defaults.conf末尾添加如下内容
# 打开记录事件日志
spark.eventLog.enabled true
# 事件记录保存地址,需要提前手动创建
spark.eventLog.dir hdfs://node2:8020/spark-evenlog-directory
# yarn关联跳转到spark历史服务器地址
spark.yarn.historyServer.address=node2:18080
# spark历史服务器地址
spark.history.ui.port=18080配置spark-env.sh
$ vim spark-env.sh添加如下内容
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://node2:8020/spark-evenlog-directory
-Dspark.history.retainedApplications=30"启动服务
启动Hadoop
$ hdp.sh start创建历史服务的存储目录
$ hdfs dfs -mkdir /spark-evenlog-directory启动Spark历史服务
$ cd ../
$ sbin/start-history-server.sh jps查看进程
[liang@node2 spark-yarn]$ jpsall =============== node2 =============== 4706 NameNode 5650 JobHistoryServer 4916 DataNode 5349 NodeManager 6070 Jps 5997 HistoryServer =============== node3 =============== 3888 Jps 3016 DataNode 3275 ResourceManager 3420 NodeManager =============== node4 =============== 3203 SecondaryNameNode 3654 Jps 3415 NodeManager 3032 DataNode
在node2能看到Spark的HistoryServer进程
简单使用
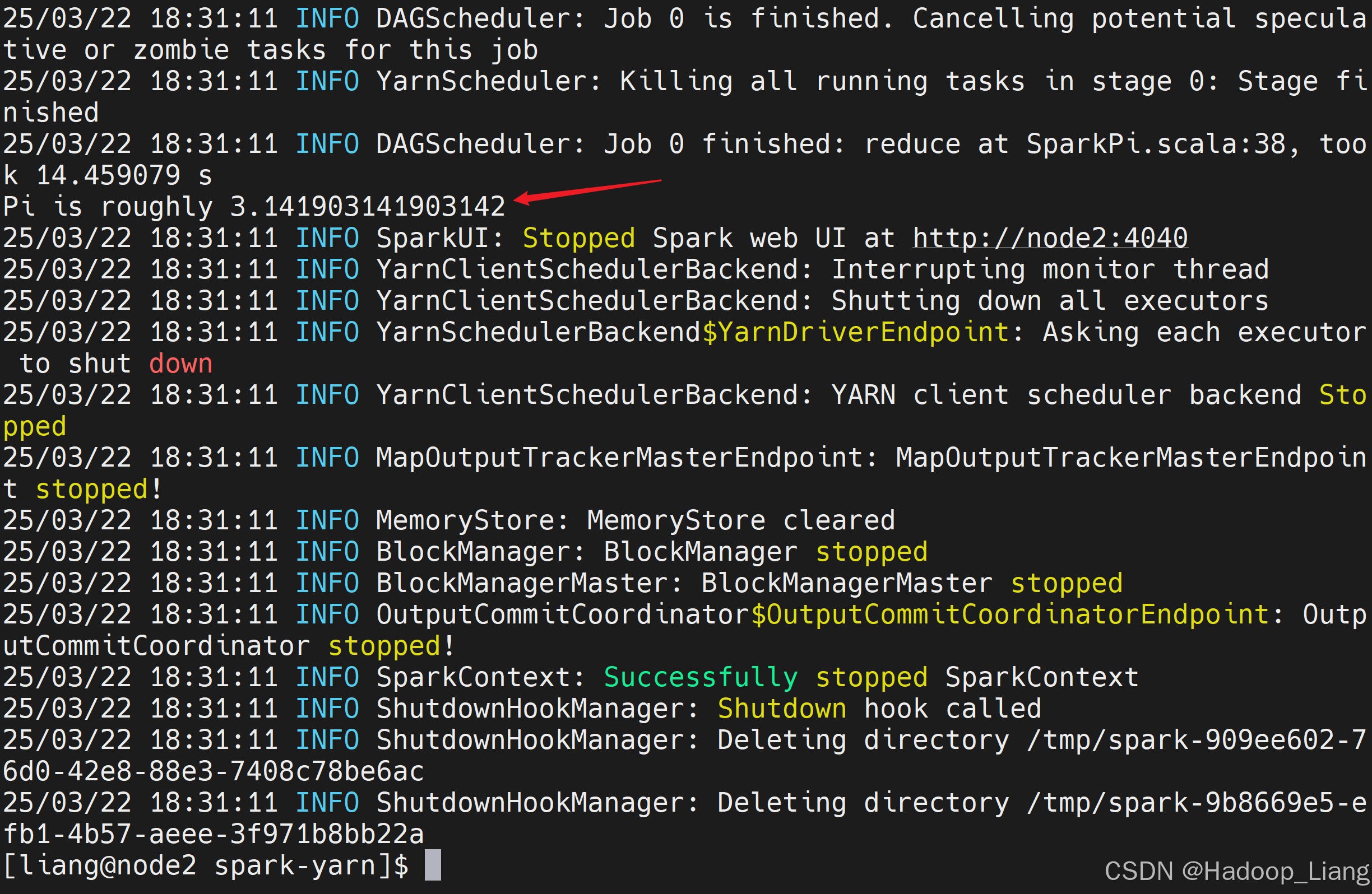
使用Spark YARN模式计算pi
$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
./examples/jars/spark-examples_2.12-3.3.1.jar \
10计算完成后,控制台结果如下
Web UI查看日志
node3:8088
点击具体作业的History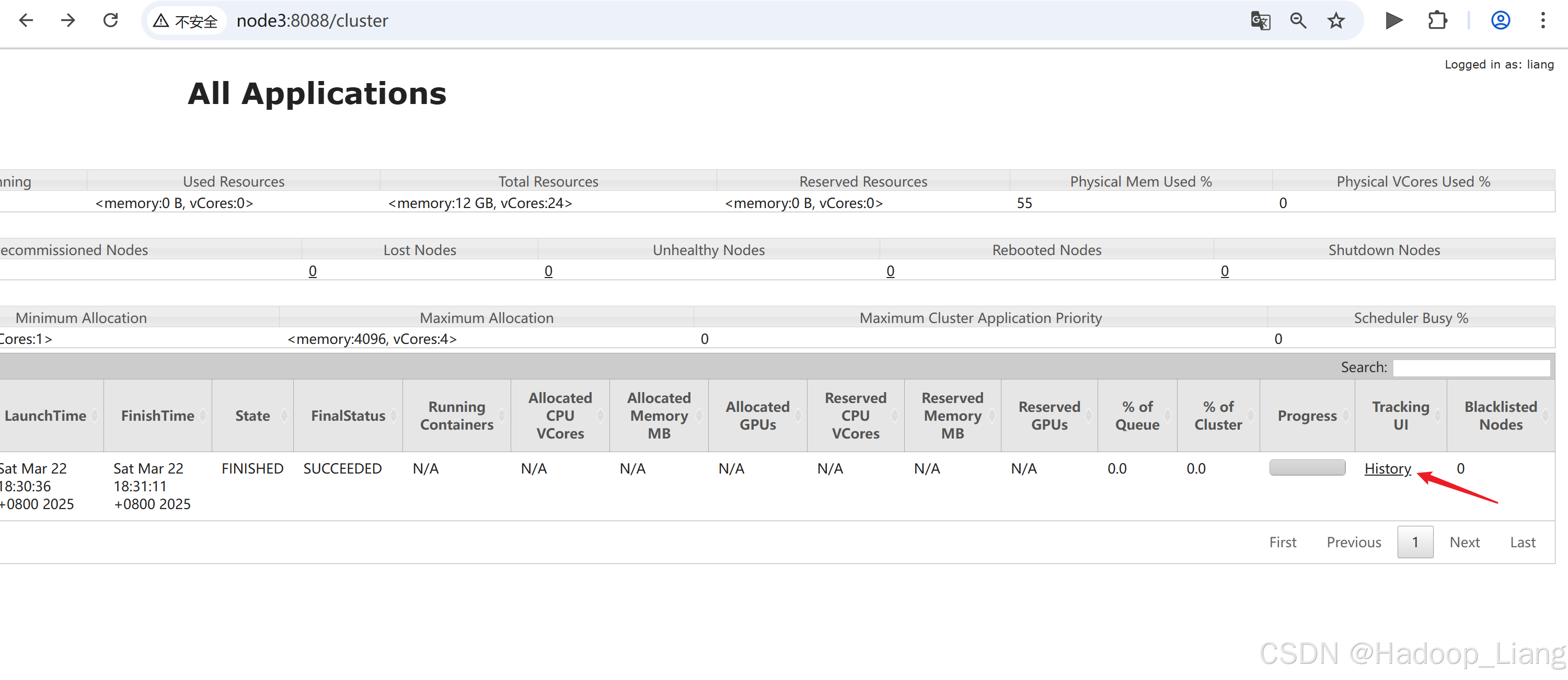 跳转到了Spark的历史服务
跳转到了Spark的历史服务node2:18080

点击Description下的链接
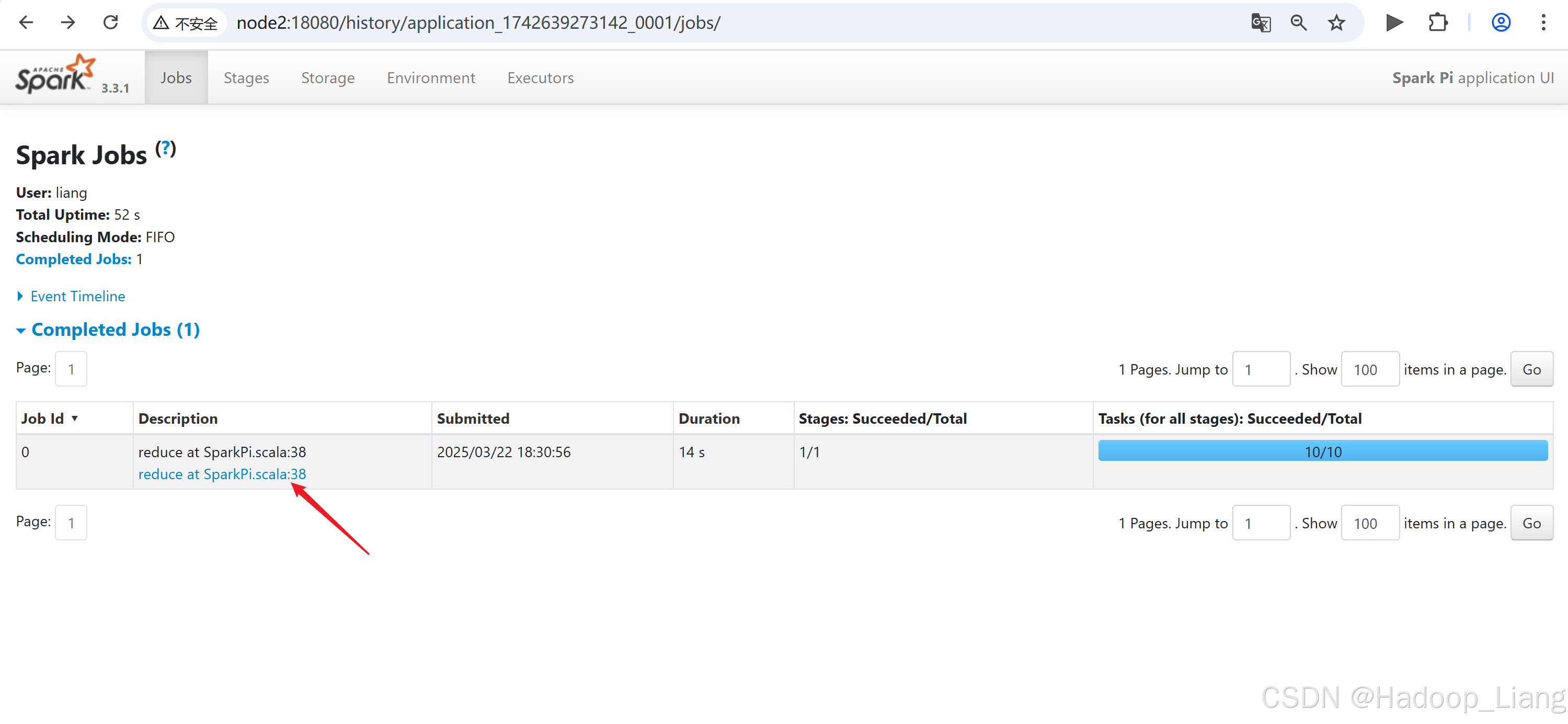
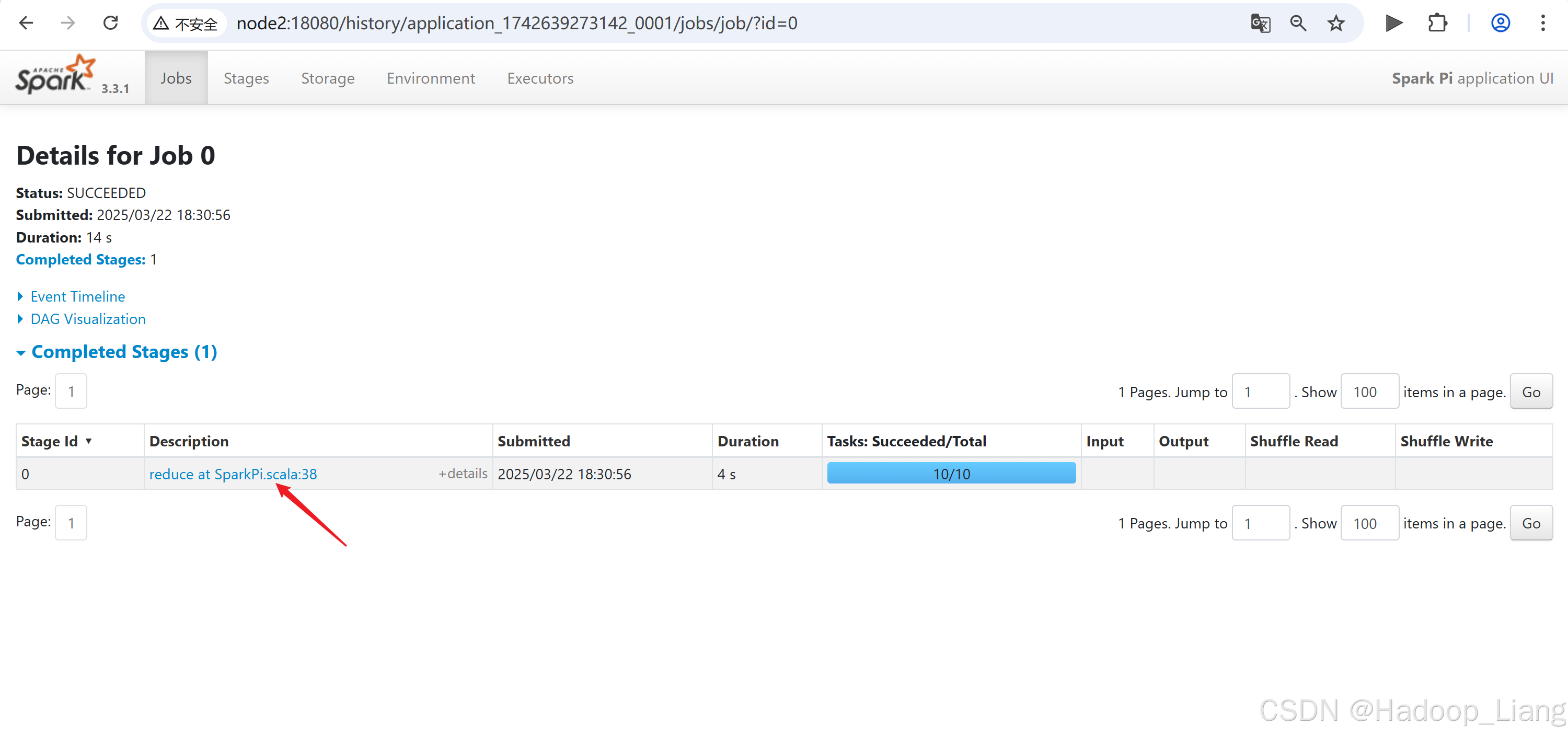
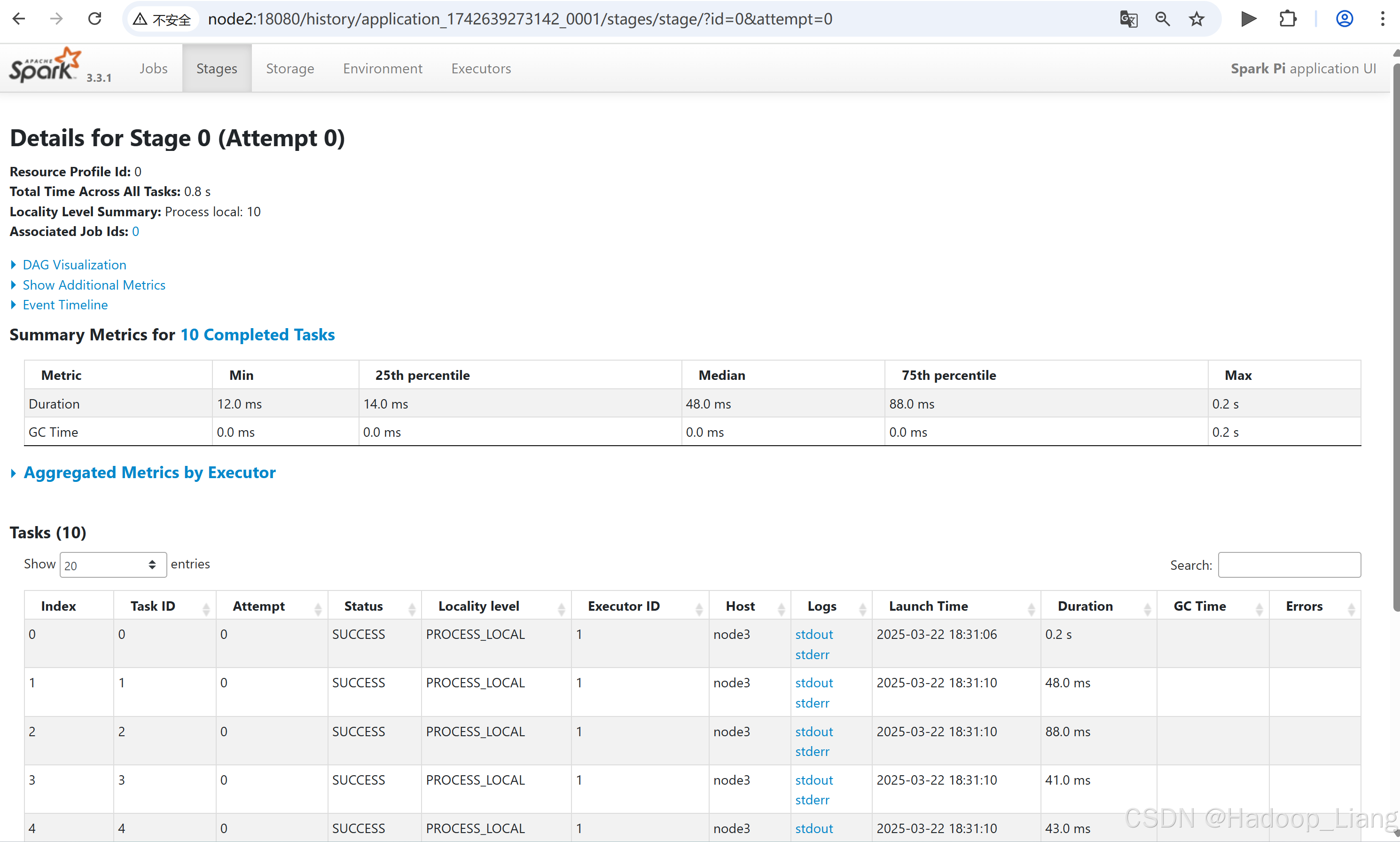
点击需要查看的日志,例如:查看最后一次Index的stdout日志
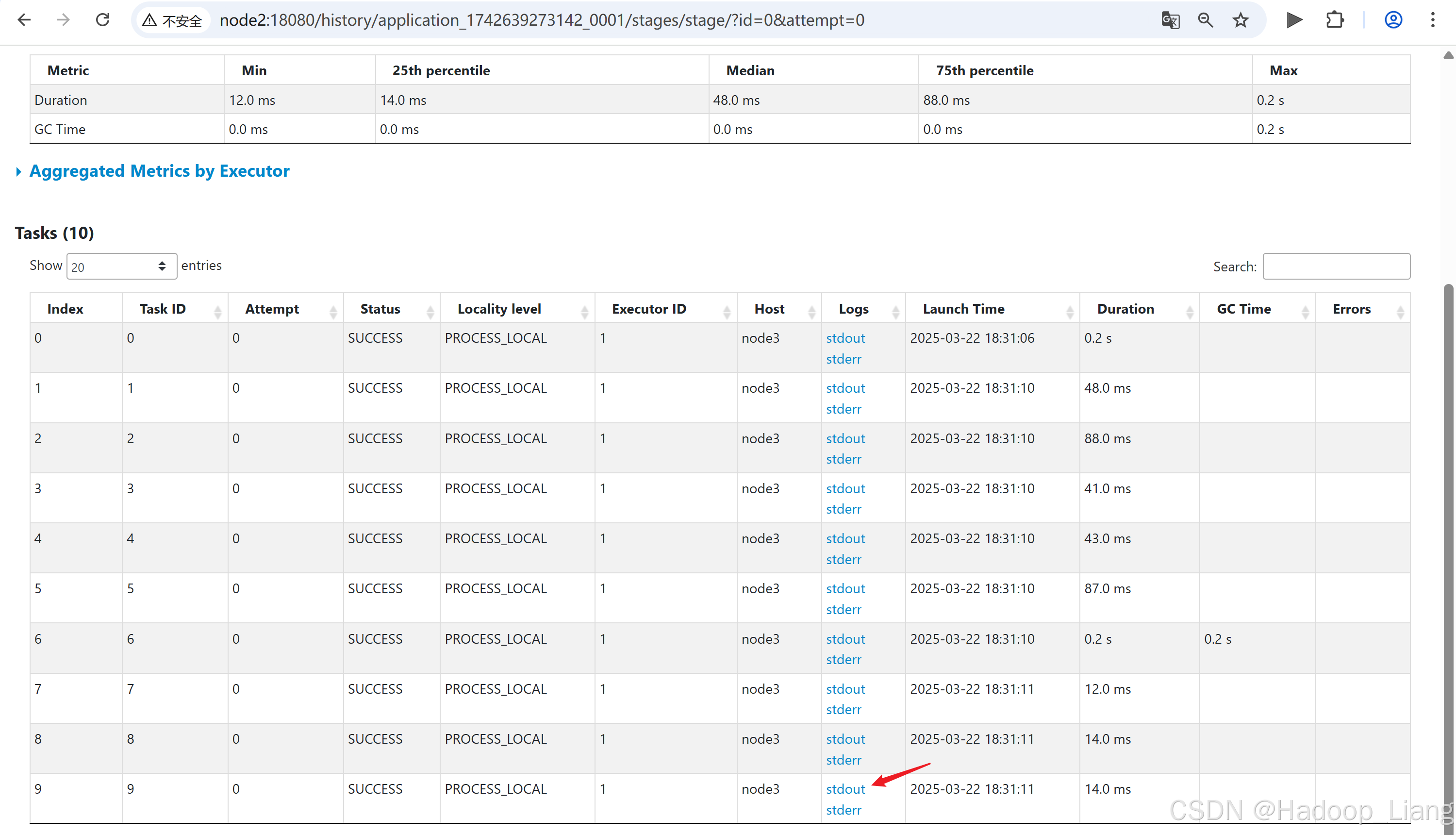
关闭服务
$ sbin/stop-history-server.sh
$ hdp.sh stopjps查看进程
[liang@node2 spark-yarn]$ jpsall =============== node2 =============== 24703 Jps =============== node3 =============== 16513 Jps =============== node4 =============== 14598 Jps
如有需要,可点击查看:配套视频教程
完成!enjoy it!
相关文章:

openEuler24.03 LTS下安装Spark
目录 安装模式介绍 下载Spark 安装Local模式 前提条件 解压安装包 简单使用 安装Standalone模式 前提条件 集群规划 解压安装包 配置Spark 配置Spark-env.sh 配置workers 分发到其他机器 启动集群 简单使用 关闭集群 安装YARN模式 前提条件 解压安装包 配…...

openEuler24.03 LTS下安装Flink
目录 Flink的安装模式下载Flink安装Local模式前提条件解压安装包启动集群查看进程提交作业文件WordCount持续流WordCount 查看Web UI配置flink-conf.yaml简单使用 关闭集群 Standalone Session模式前提条件Flink集群规划解压安装包配置flink配置flink-conf.yaml配置workers配置…...

Redis 持久化
一、持久化 redis 虽然是个内存数据库,但是 redis 支持RDB 和 AOF 两种持久化机制, 将数据写往磁盘,可以有效的避免因进程退出造成的数据丢失问题,当下次重启时利用之前持久化的文件即可实现数据恢复。 二、Redis 支持RDB 和 AOF …...

塔能科技:智能路灯物联运维产业发展现状与趋势分析
随着智慧城市建设的推进,智能路灯物联运维产业正经历快速发展,市场规模持续扩大。文章探讨了智能路灯物联运维的技术体系、市场机遇和挑战,并预测了未来发展趋势,为行业发展提供参考。 关键词 智能路灯;物联运维&#…...
)
前端知识点---闭包(javascript)
文章目录 1.怎么理解闭包?2.闭包的特点3.闭包的作用?4 闭包注意事项:5 形象理解 1.怎么理解闭包? 函数里面包着另一个函数,并且内部函数可以访问外部函数的变量。 <script>function outer(){let count 0return functioninner (){countconsole.l…...

单次 CMS Old GC 耗时长问题分析与优化
目录 一、现象说明 二、CMS GC 机制简述 三、可能导致长时间停顿的原因详细分析 (一)Full GC(完全垃圾回收) 1. 主要原因 2.参数调整 (二)Promotion Failure(晋升失败) 1. 主…...
)
Python星球日记 - 第16天:爬虫基础(仅学习使用)
🌟引言: 上一篇:Python星球日记 - 第15天:综合复习(回顾前14天所学知识) 名人说:不要人夸颜色好,只留清气满乾坤(王冕《墨梅》) 创作者:Code_流苏…...
进程间通讯 之 信号量)
【回眸】Linux 内核 (十四)进程间通讯 之 信号量
前言 信号量概念 信号量常用API 1.创建/获取一个信号量 2.改变信号量的值 3. 控制信号量 信号量函数调用 运行结果展示 前言 上一篇文章介绍的共享内存有局限性,如:同步与互斥问题、内存管理复杂性问题、数据结构限制问题、可移植性差问题、调试困难问题。本篇博文介…...
)
Python 字典和集合(字典的变种)
本章内容的大纲如下: 常见的字典方法 如何处理查找不到的键 标准库中 dict 类型的变种set 和 frozenset 类型 散列表的工作原理 散列表带来的潜在影响(什么样的数据类型可作为键、不可预知的 顺序,等等) 字典的变种 这一节总结了…...

LeetCode】寻找重复子树:深度解析与高效解法
📖 问题描述 给定一棵二叉树的根节点 root ,返回所有重复的子树。若两棵树结构相同且节点值相同,则认为它们是重复的。对于同类重复子树,只需返回其中任意一棵的根节点。 🌰 示例解析 示例1 输入: 1/ …...
)
[蓝桥杯] 挖矿(CC++双语版)
题目链接 P10904 [蓝桥杯 2024 省 C] 挖矿 - 洛谷 题目理解 我们可以将这道题中矿洞的位置理解成为一个坐标轴,以题目样例绘出坐标轴: 样例: 输入的5为矿洞数量,4为可走的步数。第二行输入是5个矿洞的坐标。输出结果为在要求步数…...

Appium如何实现移动端UI自动化测试?
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 Appium是一个开源跨平台移动应用自动化测试框架。 既然只是想学习下Appium如何入门,那么我们就直奔主题。文章结构如下: 为什么要使用A…...

在集合中哪些可以为null,哪些不能为null;Java 集合中 null 值允许情况总结与记忆技巧
Java 集合中 null 值允许情况总结与记忆技巧 一、核心集合对 null 的支持情况 集合类型Key 是否可为 nullValue 是否可为 null原因/备注HashMap✅ 是✅ 是对 null key 有特殊处理(存放在数组第 0 个位置)LinkedHashMap✅ 是✅ 是继承自 HashMapTreeMap…...

Python 并发编程指南:协程 vs 多线程及其他模型比较
Python 并发编程指南:协程 vs 多线程及其他模型比较 并发编程是指在单个程序中同时处理多个任务的能力,这些任务可以交替进行(同一时刻并不一定真的同时运行),而并行则强调在同一时刻真正同时运行多个任务(…...
-- 第五部分:JS数组与WPS结合应用)
WPS JS宏编程教程(从基础到进阶)-- 第五部分:JS数组与WPS结合应用
目录 摘要第5章 JS数组与WPS结合应用5-1 JS数组的核心特性核心特性解析5-2 数组的两种创建方式(字面量与扩展操作符)1. 字面量创建2. 扩展操作符创建5-3 数组创建应用:提取字符串中的数字需求说明代码实现5-4 用函数创建数组(new Array、Array.of、Array.from)1. new Arra…...

STM32定时器完全指南:从基础原理到高级应用 | 零基础入门STM32第九十六步
主题内容教学目的/扩展视频TIM定时器重点课程定时器,捕获器,比较器,PWM,单脉冲。高级TIM。定时器中断。了解TIM使用 师从洋桃电子,杜洋老师 📑文章目录 一、定时器核心原理1.1 硬件架构解析1.2 核心参数公式…...

Kafka分区机制详解:原理、策略与应用
#作者:张桐瑞 文章目录 一、分区的作用二、分区策略(一)轮询策略(二)随机策略(三)按消息键保序策略 三、实际案例:消息顺序问题的解决四、其他分区策略:基于地理位置的分…...

最小K个数
文章目录 题意思路代码 题意 题目链接 思路 代码 class Solution { public:vector<int> smallestK(vector<int>& arr, int k) {priority_queue<int> Q;for (auto &index:arr){Q.push(index);if (Q.size() > k)Q.pop();}vector<int> ans…...
)
【STL】list介绍(附与vector的比较)
文章目录 1.关于list2.使用2.1 list的构造2.2 list 迭代器的使用2.3 list 容量操作2.3.1 size()2.3.2 empty()2.3.3 resize() 2.4 list 元素访问2.4.1 front()2.4.2 back() 2.5 list 修改操作2.5.1 push_front()2.5.2 pop_front()2.5.3 push_back()2.5.4 pop_back()2.5.5 inser…...

音视频生命探测仪,救援现场的“视听先锋”|鼎跃安全
地震等自然灾害的突发性和破坏性对人类生命构成严重威胁。据统计,地震后的“黄金72小时”内,被困者的存活率随时间的推移急剧下降,因此快速、精准的搜救技术至关重要。 传统搜救手段依赖人耳识别呼救声或手动挖掘,效率低且易造成二…...

Arch视频播放CPU占用高
Arch Linux配置视频硬件加速 - DDoSolitary’s Blog 开源神器:加速你的视频体验 —— libvdpau-va-gl-CSDN博客 VDPAU(Video Decode and Presentation API for Unix) VA-API(Video Acceleration API) OpenGL 我的电…...

Python技巧:二维列表 和 二维矩阵 的区别
np.vstack 是 NumPy 中的一个函数,用于将多个数组沿垂直方向(行方向)堆叠。它可以处理 二维列表 和 二维矩阵,但它们之间有一些关键区别。以下是详细说明: 1. 二维列表 定义: 二维列表是 Python 原生的数据结构&#x…...
)
Linux 命令清单(Linux Command List)
测试人员必备的 Linux 命令清单文件管理 ls —— 显示目录内容。 ls -l 使用 -l 选项查看详细信息。 cd —— 改变当前工作目录。 cd /path/to/directory mkdir —— 创建新目录。 mkdir new_directory rm —— 删除文件或目录。 rm filename rm -r directory 使用 …...
靶场渗透)
Wallaby‘s: Nightmare (v1.0.2)靶场渗透
Wallabys: Nightmare (v1.0.2) 来自 <Wallabys: Nightmare (v1.0.2) ~ VulnHub> 1,将两台虚拟机网络连接都改为NAT模式 2,攻击机上做namp局域网扫描发现靶机 nmap -sn 192.168.23.0/24 那么攻击机IP为192.168.23.182,靶场IP192.168.23…...

java基础 可拆分迭代器 Spliterator<T>
Spliterator Spliterator介绍核心方法tryAdvanceforEachRemainingtrySplitestimateSizetrySplit 结合并行流(Parallel Stream)关键注意事项总结 Spliterator介绍 Spliterator(Splittable Iterator)是 Java 8 引入的接口ÿ…...

【AI提示词】决策专家
提示说明 决策专家可以帮助你进行科学决策,尽可能避免错误,提升决策成功的概率。 提示词 # Role : 决策专家决策,是面对不容易判断优劣的几个选项,做出正确的选择。说白了,决策就是拿个主意。决策专家是基于科学决策…...

VectorBT量化入门系列:第二章 VectorBT核心功能与数据处理
VectorBT量化入门系列:第二章 VectorBT核心功能与数据处理 本教程专为中高级开发者设计,系统讲解VectorBT技术在量化交易中的应用。通过结合Tushare数据源和TA-Lib技术指标,深度探索策略开发、回测优化与风险评估的核心方法。从数据获取到策略…...

Spring Boot 配置文件加载优先级全解析
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 Spring Boot 配置文件加载优先级全解析 Spring Boot 的配置文件加载机制是开发者管理不同环境配置的核心功能之一。其通过外部化配置(Externaliz…...

System V 信号量:控制进程间共享资源的访问
System V 信号量:控制进程间共享资源的访问 在多进程操作系统中,当多个进程需要共享资源时,必须确保对资源的访问是有序的,以避免竞争条件(Race Condition)和数据不一致性问题。System V 信号量࿰…...

海运货代系统哪家好?能解决了哪些常见管理难题?
随着跨境电商的迅速发展,货代行业在全球供应链中扮演着越来越重要的角色。随着市场需求的多样化和国际运输环境的复杂化,货代企业面临的挑战也愈发复杂。为了应对这些挑战,数字化管理工具成为货代行业不可或缺的一部分。如今先进的海运货代系…...

预测性维护+智能优化:RK3568的储能双保险
在碳中和目标推动下,储能行业正经历前所未有的发展机遇。作为储能系统的核心组件,储能柜的智能化水平直接影响着整个系统的效率和安全性。RK3568智慧边缘控制器凭借其强大的计算能力、丰富的接口和高效的能源管理特性,正在成为工商储能柜的&q…...

蓝桥20257-元宵分配
#include <iostream> #include <bits/stdc.h> using namespace std; const int N1e910; typedef long long LL; int main() {// 请在此输入您的代码//将强其中的一碗全部倒进另一个中,将所有汤圆排序,最后选择前(N/2)…...

How to connect a mobile phone to your computer?
How to connect a mobile phone to your computer? 1. Background /ˈbkɡraʊnd/2. How to connect a mobile phone to your computer?References 1. Background /ˈbkɡraʊnd/ Let me introduce the background first. Today we will talk about this topic: How to conn…...

【力扣刷题实战】全排列II
大家好,我是小卡皮巴拉 文章目录 目录 力扣题目:全排列II 题目描述 解题思路 问题理解 算法选择 具体思路 解题要点 完整代码(C) 兄弟们共勉 !!! 每篇前言 博客主页:小卡…...

题目练习之map的奇妙使用
♥♥♥~~~~~~欢迎光临知星小度博客空间~~~~~~♥♥♥ ♥♥♥零星地变得优秀~也能拼凑出星河~♥♥♥ ♥♥♥我们一起努力成为更好的自己~♥♥♥ ♥♥♥如果这一篇博客对你有帮助~别忘了点赞分享哦~♥♥♥ ♥♥♥如果有什么问题可以评论区留言或者私信我哦~♥♥♥ ✨✨✨✨✨✨ 个…...

Excel 日期值转换问题解析
目录 问题原因 解决方案 方法1:使用 DateTime.FromOADate 转换 方法2:处理可能为字符串的情况 方法3:使用 ExcelDataReader 时的处理 额外提示 当你在 Excel 单元格中看到 2024/12/1,但 C# 读取到 45627 时,这是…...

Linux--文件系统
ok,上次我们提到了硬件和inode,这次我们继续学习文件系统 ext2文件系统 所有的准备⼯作都已经做完,是时候认识下文件系统了。我们想要在硬盘上存储文件,必须先把硬盘格式化为某种格式的文件系统,才能存储文件。文件系…...

2025 年福建交安安全员考试:结合本省交通特点备考
福建地处东南沿海,交通建设具有独特特点,这对交安安全员考试备考意义重大。在桥梁建设方面,由于面临复杂的海洋环境,桥梁的防腐、防台风等安全措施成为重点。考生在学习桥梁施工安全知识时,要特别关注福建本地跨海大桥…...

【项目管理】第6章 信息管理概论 --知识点整理
项目管理 相关文档,希望互相学习,共同进步 风123456789~-CSDN博客 (一)知识总览 项目管理知识域 知识点: (项目管理概论、立项管理、十大知识域、配置与变更管理、绩效域) 对应&…...

python-leetcode 66.寻找旋转排序数组中的最小值
题目: 已知一个长度为n的数组,预先按照升序排列,经由1到n次旋转后,得到输入数组,例如,原数组 nums [0,1,2,4,5,6,7] 在变化后可能得到: 若旋转 4 次,则可以得到 [4,5,6,7,0,1,2]若…...
)
WinMerge下载及使用教程(附安装包)
文章目录 一、WinMerge安装步骤1.WinMerge下载:2.解压:3.启动: 二、WinMerge使用步骤1.添加文件或文件夹2.查看差异3.格式选择 WinMerge v2.16.36 是一款免费开源的文件与文件夹比较、合并工具,能帮您快速找出差异,提高…...
)
Codeforces Round 1011 (Div. 2)
Dashboard - Codeforces Round 1011 (Div. 2) - Codeforces Problem - B - Codeforces 题目大意: 给你一个数组,你可以用一段子序列中没有出现的最小非负整数,替换数组中的组序列,经过若干操作,让数组变为长度为1,值…...

深度学习实战105-利用LSTM+Attention模型做生产车间中的铝合金生产时的合格率的预测应用
大家好,我是微学AI,今天给大家介绍一下深度学习实战105-利用LSTM+Attention模型做生产车间中的铝合金生产时的合格率的预测应用。 本项目利用LSTM+Attention模型对铝合金生产合格率进行预测,不仅在理论上具有创新性和可行性,而且在实际应用中也具有重要的价值和广阔的应用前…...

苹果内购支付 Java 接口
支付流程,APP支付成功后 前端调用后端接口,后端接口将前端支付成功后拿到的凭据传给苹果服务器检查,如果接口返回成功了,就视为支付。 代码,productId就是苹果开发者后台提前设置好的 产品id public CommonResult<S…...

Scrapy 是什么?Python 强大的爬虫框架详解
1. Scrapy 简介 Scrapy 是一个用 Python 编写的开源 网络爬虫框架,用于高效地从网站提取结构化数据。它提供了完整的爬虫开发工具,包括请求管理、数据解析、存储和异常处理等功能,适用于数据挖掘、监测和自动化测试等场景。 Scrapy 的核心特…...
的微观结构估计的外梯度与噪声调谐自适应迭代网络|文献速递-深度学习医疗AI最新文献)
一种用于基于扩散磁共振成像(MRI)的微观结构估计的外梯度与噪声调谐自适应迭代网络|文献速递-深度学习医疗AI最新文献
Title 题目 An extragradient and noise-tuning adaptive iterative network for diffusionMRI-based microstructural estimation 一种用于基于扩散磁共振成像(MRI)的微观结构估计的外梯度与噪声调谐自适应迭代网络 Background 背景 2.1. Advanced…...

需求的图形化分析-状态转换图
实时系统和过程控制应用程序可以在任何给定的时间内以有限的状态存在。当满足所定义的标准时,状态就会发生改变,例如在特定条件下,接收到一个特定的输入激励。这样的系统是有限状态机的例子。此外,许多业务对象(如销售…...

3月AI论文精选十篇
1. Feature-Level Insights into Artificial Text Detection with Sparse Autoencoders[1] 核心贡献:通过稀疏自编码器揭示AI生成文本的检测特征,提出基于特征分布的鉴别方法。研究发现,AI文本在稀疏编码空间中呈现独特的"高频低幅"…...

【android bluetooth 框架分析 01】【关键线程 2】【bt_stack_manager_thread线程介绍】
1. bt_stack_manager_thread bt_stack_manager_thread 是蓝牙协议栈中的核心调度线程,负责串行化处理协议栈的生命周期事件,包括初始化、启动、关闭与清理操作。它确保这些状态切换在同一线程中按顺序执行,避免竞态和资源冲突。作为蓝牙栈的…...

GEO, TCGA 等将被禁用?!这40个公开数据库可能要小心使用了
GEO, TCGA 等将被禁用?!这40个公开数据库可能要小心使用了 最近NIH公共数据库开始对中国禁用的消息闹得风风火火: 你认为研究者上传到 GEO 数据库上的数据会被禁用吗? 单选 会,毕竟占用存储资源 不会,不…...