【NLP 55、强化学习与NLP】
万事开头难,苦尽便是甜
—— 25.4.8
一、什么是强化学习
强化学习和有监督学习是机器学习中的两种不同的学习范式
强化学习:目标是让智能体通过与环境的交互,学习到一个最优策略以最大化长期累积奖励。
不告诉具体路线,首先去做,做了之后,由环境给你提供奖励,根据奖励的多少让模型进行学习,最终找到正确路线
例如:在机器人导航任务中,智能体需要学习如何在复杂环境中移动,以最快速度到达目标位置,同时避免碰撞障碍物,这个过程中智能体要不断尝试不同的行动序列来找到最优路径。
监督学习:旨在学习一个从输入特征到输出标签的映射函数,通常用于预测、分类和回归等任务。
给出标准答案,让模型朝着正确答案方向去进行学习
例如:根据历史数据预测股票价格走势,或者根据图像特征对图像中的物体进行分类,模型通过学习已知的输入输出对来对新的未知数据进行预测
二、强化学习的重要概念
1.智能体和环境
智能体是个很宽泛的概念,可以是一个深度学习模型,也可以是一个实体机器人
环境可能随智能体的动作发生变化,为智能体提供奖励
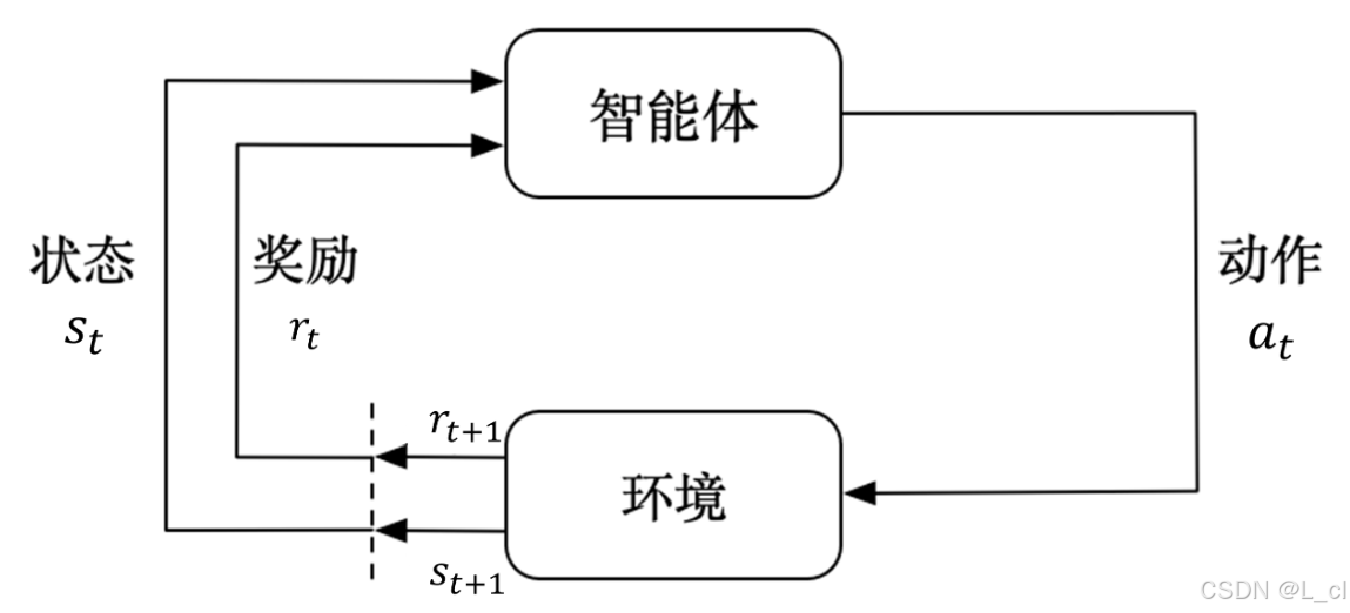
例:
以一个围棋智能体为例,围棋规则即是环境
状态(State):当前的盘面即是一种状态
行动(Action):接下来在棋盘中的下法是一种行动
奖励(Reward):输赢是一种由环境给出的奖励,奖励随每个动作逐个传递
奖励黑客(reward hacking):在强化学习(RL)中,智能体通过利用奖励函数中的漏洞或模糊性来获得高奖励,而没有真正完成预期任务的行为。
2.强化学习基础流程
智能体在状态 s_t 下,选择动作 a_t
环境根据动作 a_t 转移到新状态 s_t+1,并给出奖励 r_t
智能体根据奖励 r_t 和新状态 s_t+1 更新策略或价值函数
重复上述过程,直到达到终止条件
① 智能体与环境交互:智能体(Agent)在环境中执行动作(Action),环境根据智能体的动作给出反馈,即奖励(Reward),并转移到新的状态(State)
② 状态感知与动作选择:智能体根据当前的状态,依据某种策略(Policy)选择下一个动作。策略可以是确定性的,也可以是随机的
③ 奖励反馈:环境根据智能体的动作给予奖励,奖励可以是即时的,也可以是延迟的。智能体的目标是最大化累积奖励
④ 策略更新:智能体根据获得的奖励和新的状态,更新其策略或价值函数(Value Function),以优化未来的决策
⑤ 循环迭代:上述过程不断重复,智能体通过不断的试错和学习,逐步优化其策略,以达到最大化累积奖励的目标
强化学习的核心在于智能体通过与环境的交互,不断优化其策略,以实现长期奖励的最大化
2.策略(Policy)
智能体要学习的内容 —— 策略(Policy):用于根据当前状态,选择下一步的行动
以围棋来说,可以理解为在当前盘面下,下一步走每一格的概率
策略 π 是一个:输入状态(state) 和 输出动作(action) 的函数
![]()
或者是一个:输入为状态+动作,输出为概率的函数
有了策略之后,就可以不断在每个状态下,决定执行什么动作,进而进入下一个状态,依次类推完成整个任务
s1 -> a1 -> s2 -> a2 -> s3....基于前一个状态,产生下一个动作,这就是所谓的“马尔可夫决策过程” 【MDP】
强化学习有多种策略
3.价值函数(Value Function)【奖励】
智能体要学习的内容 —— 价值函数(Value Function):基于策略 π 得到的函数,具体分为两种:
① 状态价值函数 V(s)
最终未来的收益
表示从状态 s 开始,遵循策略 π 所能获得的长期累积奖励(r_t)的期望
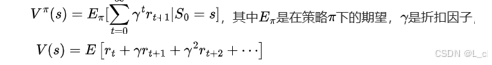
折扣因子 γ ∈ [0,1],反映对于未来奖励的重视程度,γ 越接近于1,表示模型越看重未来的奖励,γ 越接近于0,代表模型越看重当前的奖励
② 动作价值函数 Q(s, a)
下在某点时,未来的收益
表示在状态 s 下采取动作 a,遵循策略 π 所能获得的长期累积奖励的期望
![]()
状态价值函数评估的是当前环境局面怎么样
动作价值函数评估的是当前环境下采取某一个动作收益会怎么样
二者关系:![]()
在每一个状态下,执行每个动作得到的奖励乘以执行每个动作的概率,再求和,就等于当前状态下的状态价值函数,也就是所谓的全概率公式
4.优势估计函数
优化目标 —— 优势估计函数:类似于损失函数Loss,但区别在于我们需要最大化这个值,表示在当前状态下我应该选取的最好的动作
A(s, a) = Q(s, a) - V(s)
动作价值函数Q 和 状态价值函数V 都是基于策略 π 的函数,所以整个函数也是一个基于策略 π 的函数
策略 π 可以是一个神经网络,要优化这个网络的参数
训练过程中,通过最大化优势估计函数 A(s,a),来更新策略网络的参数
也就是说优势估计函数的作用类似于loss函数,是一个优化目标,可以通过梯度反传(梯度上升)来优化
这是强化学习中的一种方法,一般称为策略梯度算法
策略梯度算法 是强化学习中与NLP任务最有关的方法
三、强化学习 与 NLP
将文本生成过程看作一个序列决策过程
状态(state) = 已经生成的部分文本
动作(action) = 选择下一个要生成的token
强化学习适用于NLP 中的 推理任务 和 泛模型
做某种任务最终结果进行推理 ,不在乎中间结果,对泛化性要求较高,适合使用强化学习
先输入一个提示词(当前的状态),然后输出接下来的词,重点在于设计奖励

四、PPO算法
1.定义
PPO(Proximal Policy Optimization,近端策略优化)是OpenAI于2017年提出的一种策略梯度算法,旨在改进传统策略梯度方法的训练稳定性。其核心思想是通过限制策略更新幅度,避免因步长过大导致的性能崩溃,同时平衡探索与利用
2.核心机制
① 剪切(Clipping):通过截断新旧策略概率比(如设置阈值ε=0.2),限制策略突变。
② 重要性采样:利用历史数据调整梯度权重,提升样本效率。
③ Actor-Critic框架:策略网络(Actor)生成动作,价值网络(Critic)评估长期收益
3.训练目标
多阶段流程:奖励模型训练 → Critic网络预训练 → 策略迭代优化
动态优势估计:通过Critic网络预测状态价值,计算TD误差
稳定性控制:KL散度惩罚防止策略突变,熵奖励鼓励探索
4.核心公式
![]()
r_t(θ) = π_θ(a_t | s_t)/ π_old(a_t | s_t):策略更新比率
A_t:GAE(广义优势估计)
ξ:Clipping阈值(通常为0.1 ~ 0.2)
5.算法流程
第一个阶段:SFT,把模型从续写转换为问答,标准的有监督学习过程(收集数据,给一些提示词,由人来标注对应的希望的答案,让模型进行学习)
第二个阶段:训练一个所谓的奖励模型(给一个提示词到若干个模型,若干个模型会输出若干个结果,然后有一个标注人员将这些结果按照优劣进行排序,然后用一个专门的模型按排序的顺序学习结果的优劣,来进行排序比较谁比谁好)
第三个阶段:利用第二步训练的奖励模型函数policy,优化我们的语言模型,使用强化学习的方法(用一个新的提示词生成新的答案,计算其奖励数值,利用奖励模型计算奖励分数,然后用PPO算法优化选择的策略模型)
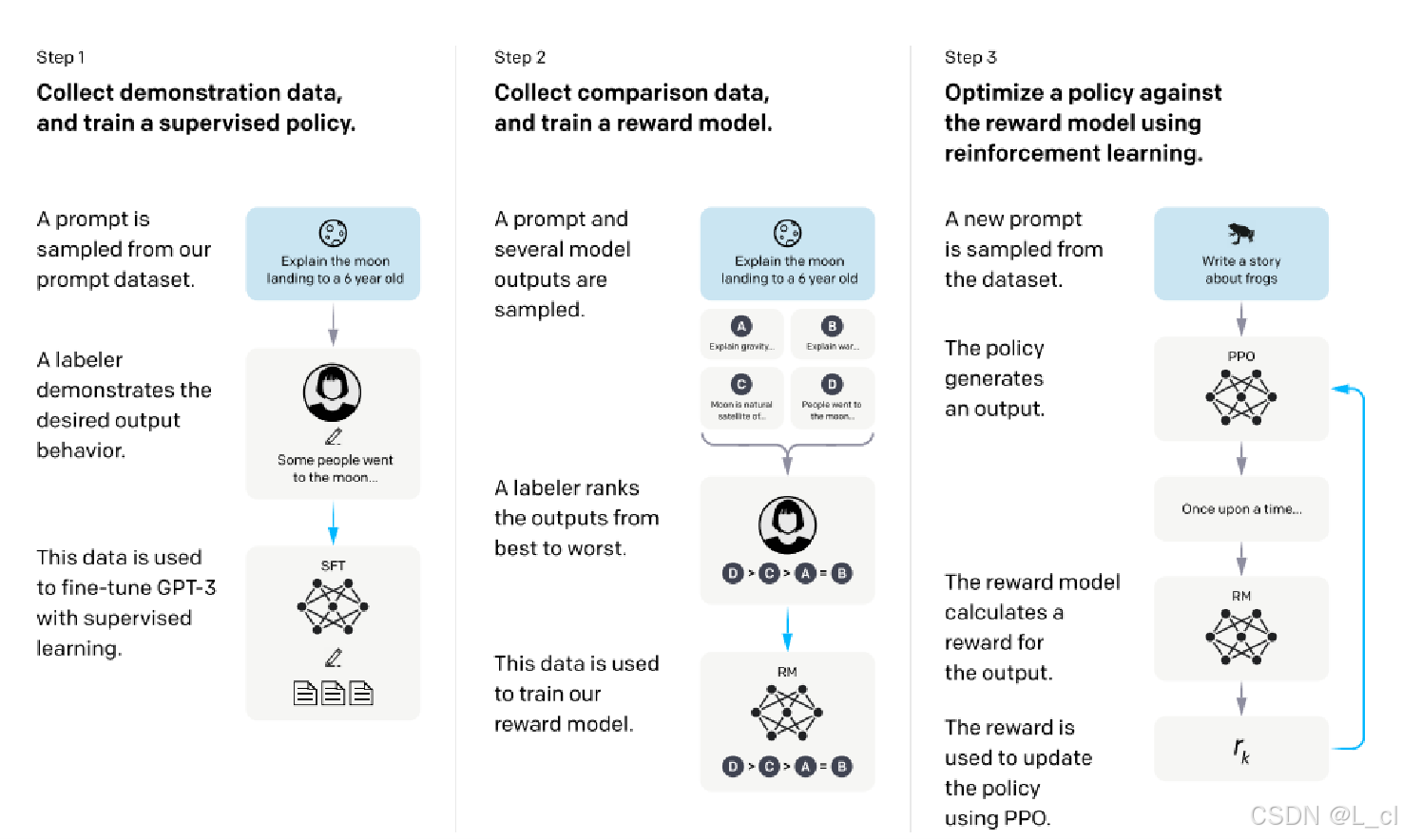
6.RW训练(奖励模型训练)
训练目标:训练一个奖励模型(Reward Model),将人类偏好或环境反馈映射为标量奖励。
输入:标注的偏好数据(如“答案A比答案B好”)或环境交互数据。
作用:为RL训练提供奖励信号,指导策略优化。
对于一个输入问题,获取若干可能的答案,由人工进行排序打分,两两一组进行Reward Model训练
Ⅰ、奖励公式
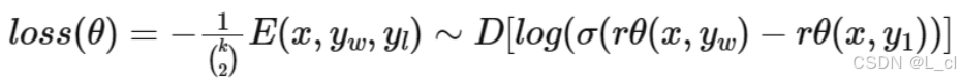
x:问题(prompt)
y_w:相对好的答案
y_l:相对差的答案
rθ:一个交互式文本匹配模型,输入为一个问答对(x,y),输出为标量(0 ~ 1),输出的 rθ分数 越接近于0,答案越不好;输出的 rθ分数 越接近于1,答案越好;rθ 也就是强化学习中的奖励模型
Ⅱ、如何判断是否是一个好的答案:
最大化 rθ(x, y_w) - rθ(x, y_l) 作为训练目标,最小化 -rθ(x, y_w) - rθ(x, y_l) 作为loss损失
训练好的 rθ分数 越接近于0,答案越不好;输出的 rθ分数 越接近于1,答案越好
示例: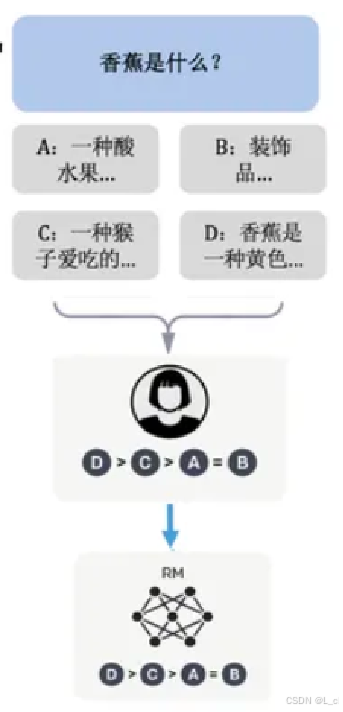
5.RL训练(强化学习训练)
目标:通过PPO算法优化策略模型(Actor),最大化累积奖励。
流程:
数据采样:当前策略生成交互数据(状态-动作-奖励)。
优势估计:使用GAE(广义优势估计)计算动作长期收益。
策略更新:通过剪切目标函数调整策略参数,限制KL散度。

RLHF训练目标
新旧两版模型,多关注二者的差异,少关注二者的共性

6.PPO加入约束


五、DPO算法
1.定义
DPO(Direct Preference Optimization,直接偏好优化)是一种替代PPO的轻量化RLHF(基于人类反馈的强化学习)方法,由斯坦福团队提出。其核心思想是跳过显式奖励模型训练reward model,直接利用偏好数据优化策略。
实际上DPO并不是严格意义上的强化学习,更适合叫对比学习
2.核心公式

β:温度系数,控制优化强度
σ:Sigmoid函数,将概率差映射为偏好得分
π_ref:参考策略(如SFT模型)
3.训练目标
单阶段优化:直接利用偏好对数据(y_w,y_l)训练,无需独立奖励模型
策略对齐:通过KL散度约束,确保新策略π_θ与参考策略π_ref不过度偏离
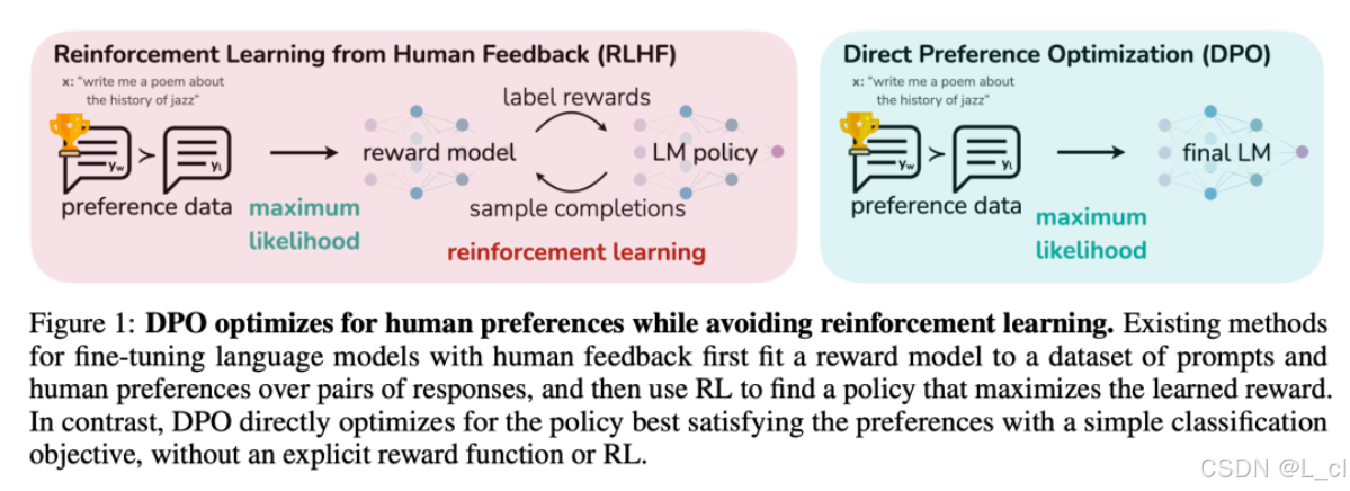
4.DPO 与 PPO的核心区别
| 维度 | PPO | DPO |
|---|---|---|
| 训练流程 | 需奖励模型(RM)+策略模型(Actor / Policy) | 仅策略模型Policy(直接优化偏好数据) |
| 数据依赖 | 环境交互数据 + 奖励模型标注 | 人类偏好对(无需奖励模型) |
| 计算复杂度 | 高(需多模型协同训练) | 低(单模型优化) |
| 适用场景 | 复杂任务(如游戏AI、机器人控制) | 对齐任务(如对话生成、文案优化) |
| 稳定性 | 依赖剪切机制和奖励模型设计 | 更稳定(避免奖励模型误差传递) |
| 多样性 | 支持多目标优化(如探索与利用) | 可能受限于偏好数据分布 |
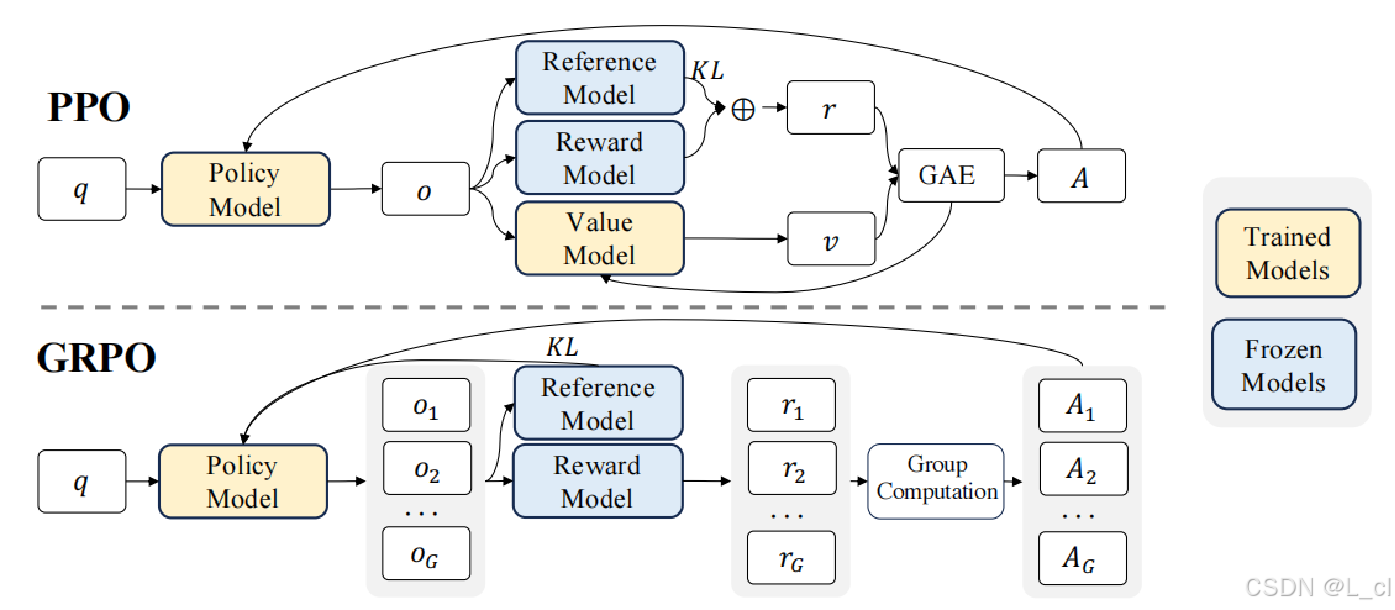
六、GRPO算法
1.定义
GRPO由DeepSeek提出,通过组内归一化优势估计替代Critic网络,核心优势在于:
多候选生成:同一提示生成多个响应(如G=8),计算组内相对奖励
动态基线计算:用组内均值和标准差归一化优势值,公式为:A_i = (r_i - μ_group) / σ_group
资源优化:省去Critic网络,显存占用降低50%
2.核心公式
![]()
3.PPO、GRPO算法目标对比
PPO算法:追求绝对奖励最大化,通过剪切机制和KL约束平衡探索与利用,适合复杂动态环境;
GRPO算法:聚焦组内相对优势优化,通过统计归一化和自对比降低计算成本,更适合资源受限的静态推理任务。
奖励(Reward model)可以是硬规则,如:
① 问题是否回答正确,正确为1,错误为0
② 生成代码是否可运行,可运行为1,不可运行为0
③ 回复格式是否符合要求,符合要求为1,不符合为0
④ 回复文本是否包含不同语种,不包含为1,包含为0
七、DeepSeek-R1

模型输出格式:
<think>
……
</think>
<answer>
……
</answer>
这种先输出一段think思考过程,再输出一段answer答案的模型现在我们称为Reasoning Model
如何得到R1模型
第一步:预训练 + SFT 得到DeepSeek - v3 - Base模型
第二步:通过一些带有长思维链的数据再做SFT
第三步:做强化学习得到R1模型
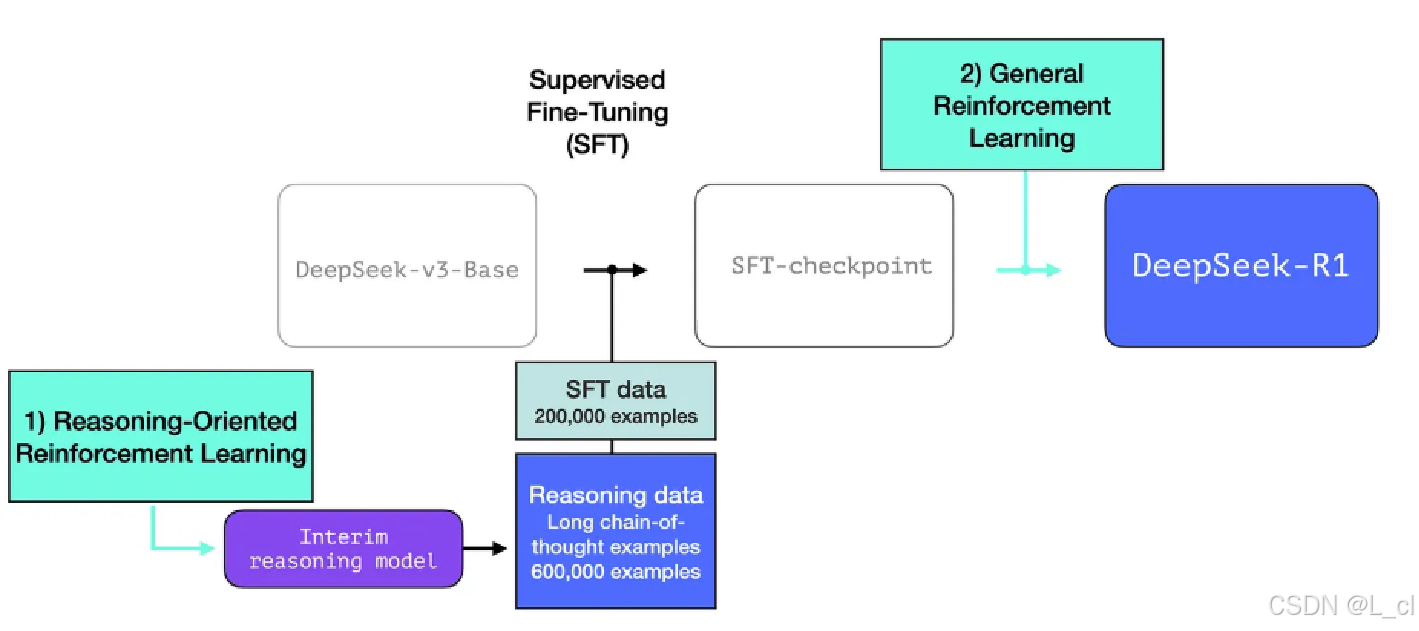
R1-zero
带有长思维链的数据从R1-zero模型训练得到
R1-zero:使用一个预训练模型,不做SFT,直接使用GRPO,用规则替换奖励,再进行强化学习,在训练过程中模型就可以自发直接得到R1-zero,这个模型可以自然得到长的推理链
使用GRPO + 规则奖励,直接从基础模型(无sft)进行强化学习得到 模型在回复中会产生思维链,包含反思,验证等逻辑 虽然直接回答问题效果有缺陷,但是可以用于生成带思维链的训练数据
相关文章:

【NLP 55、强化学习与NLP】
万事开头难,苦尽便是甜 —— 25.4.8 一、什么是强化学习 强化学习和有监督学习是机器学习中的两种不同的学习范式 强化学习:目标是让智能体通过与环境的交互,学习到一个最优策略以最大化长期累积奖励。 不告诉具体路线,首先去做…...

【Linux】单例模式及其在线程池中的应用
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...

Ansible的使用2
#### 一、Ansible变量 ##### facts变量 > facts组件是Ansible用于采集被控节点机器的设备信息,比如IP地址、操作系统、以太网设备、mac 地址、时间/日期相关数据,硬件信息等 - setup模块 - 用于获取所有facts信息 shell ## 常用参数 filter…...

十三届蓝桥杯省赛A组 扫描游戏
#算法/线段树 #算法/快读 参考题解: 题解参考 这题思路: 先将坐标进行极角排序,按照顺时针的先后顺序,如果出现两个坐标在一个象限中,我们就先判断这两个坐标是否在同一条直线上,如果在同一条直线上,我们按照离原点最近的长度进行排序 之后,我们通过线段树的方法,定义结点tr[i]…...
)
Python 序列构成的数组(list.sort方法和内置函数sorted)
list.sort方法和内置函数sorted list.sort 方法会就地排序列表,也就是说不会把原列表复制一份。这 也是这个方法的返回值是 None 的原因,提醒你本方法不会新建一个列 表。在这种情况下返回 None 其实是 Python 的一个惯例:如果一个函数 或者…...

C++类与对象进阶知识深度解析
目录 一、再谈构造函数 (一)构造函数体赋值 (二)初始化列表 (三)成员变量初始化顺序 (四)explicit关键字 二、static成员 (一)概念 (二&am…...

【机器学习案列】基于LightGBM算法的互联网防火墙异常行为检测:数据不平衡的解决方案
🧑 博主简介:曾任某智慧城市类企业算法总监,目前在美国市场的物流公司从事高级算法工程师一职,深耕人工智能领域,精通python数据挖掘、可视化、机器学习等,发表过AI相关的专利并多次在AI类比赛中获奖。CSDN…...

详解minio部署
MinIO 是一款高性能、开源的分布式对象存储解决方案,专为存储非结构化数据(如图片、视频、备份数据等)而设计。MinIO 在吞吐量和延迟上表现出高性能提供与 Amazon S3 完全兼容的 API,支持水平扩展,支持端到端加密、访问…...

校园AI体育:科技赋能教育,运动点亮未来
校园AI体育:科技赋能教育,运动点亮未来 在数字化浪潮的推动下,人工智能(AI)已经悄然走进校园,成为教育领域的一股创新力量。而在体育教育中,AI技术的引入更是为传统体育教学注入了新的活力。校…...
_35)
LeetCode算法题(Go语言实现)_35
题目 给你一棵根为 root 的二叉树,请你返回二叉树中好节点的数目。 「好节点」X 定义为:从根到该节点 X 所经过的节点中,没有任何节点的值大于 X 的值。 一、代码实现 func goodNodes(root *TreeNode) int {if root nil {return 0}return d…...
)
ROS2_control 对机器人控制(不完整,有时间再更新)
ROS2_control 对机器人控制 安装与介绍安装介绍 使用gz 中写法.yaml文件中写法type: joint_state_broadcaster/JointStateBroadcaster的来源 命令接口关节控制command_interfacetransmission CMakelist.txt与package.xml文件 gz_ros2_control与自定义插件例子描述自定义插件使用…...
技术全景解析)
SAP-ABAP:SAP Enterprise Services Repository(ESR)技术全景解析
以下是对SAP PO中Enterprise Services Repository(ESR)的深度技术解析,包含详细架构设计、开发实践及企业级应用方案: SAP Enterprise Services Repository(ESR)技术全景解析 一、ESR核心架构与组件关系 1. 技术堆栈定位 ┌─────────────────────…...

每日一道leetcode
2130. 链表最大孪生和 - 力扣(LeetCode) 题目 在一个大小为 n 且 n 为 偶数 的链表中,对于 0 < i < (n / 2) - 1 的 i ,第 i 个节点(下标从 0 开始)的孪生节点为第 (n-1-i) 个节点 。 比方说&…...

通过Aop实现限制修改删除指定账号的数据
1、需求 对于Teach账号创建的数据,其他用户仅仅只有查询的权限,而不能修改和删除。并且部分接口只允许Teach账号访问 2、实现思路 在删除和修改时往往需要传递数据的id,进而可以通过id查询该数据是否由Teach账号创建。当然我们可以在每个删…...

递归实现指数型枚举
我们以n2 为例 我们每次都有选和不选两种 方案,对于每个数字 核心代码 tatic void dfs(int u) { // u代表当前处理的数字if (u > n) { // 终止条件:处理完所有数字for (int i 1; i < n; i) { // 遍历所有数字if (nums[i]) {…...

无代码国产流程引擎 FlowLong 1.1.6 发布
无代码国产流程引擎 FlowLong 1.1.6 于 2025 年 4 月 7 日发布。 FlowLong 是一款纯血国产自研的工作流引擎,具有以下特点: 核心精简:引擎核心仅 8 张表实现逻辑数据存储,采用 json 数据格式存储模型,结构简洁直观。组…...

软考高项-考前冲刺资料-M 类【项目管理类】【光头张老师出品】
重点考点汇总 一、案例答题时需要注意: 1.条目写要清晰,要标注 1、2、3、4、… 2.关键字突出,关键字一定是专业词汇如 “监控”“控制成本”…等等,代替自己平时工作中的用此。 3.尽量多写几点,错了不扣分,但是避免重复写,避免写了一大段的内容,但是表达的是一个观点。…...

LLM Agents项目推荐:MetaGPT、AutoGen、AgentVerse详解
这一部分我们将深入介绍三大备受关注的LLM Agents项目:MetaGPT、AutoGen和AgentVerse,包括它们的背景、设计思路、主要功能、技术亮点以及典型应用场景。 1. MetaGPT:让AI像软件工程团队一样协作 项目背景 MetaGPT由Huang et al.于2023年提…...

win10家庭版安装Docker
win10家庭版本中成功安装Docker,亲测! 1、下载Docker 下载地址:http://mirrors.aliyun.com/docker-toolbox/windows/docker-toolbox/ Docker的有CE和EE版,CE为免费版,EE由公司支持的付费版,在此选择CE版本…...

mapbox基础,加载ESRI OpenStreetMap开放街景标准风格矢量图
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:mapbox 从入门到精通 文章目录 一、🍀前言1.1 ☘️mapboxgl.Map 地图对象1.1 ☘️mapboxgl.Map style属性二、🍀加载ESRI OpenStreetMap开放街景标准风…...

【网络安全 | 漏洞挖掘】通过分析JS文件实现接口未授权访问与账户接管
未经许可,不得转载。 文中所述漏洞均已修复,未经授权不得进行非法渗透测试。 文章目录 正文正文 大约一年前,我给我妈买了一辆 2023 款斯巴鲁 Impreza,前提是她得答应我,之后我可以借来做一次“白帽渗透测试”。过去几年我一直在研究其他车企的安全问题,但一直没有机会仔…...
新时代)
引领东方语言识别新风潮!Dolphin语音模型开创自动语音识别(ASR)新时代
引领东方语言识别新风潮!Dolphin语音模型开创自动语音识别(ASR)新时代 在全球语音识别技术领域,随着人工智能的飞速发展,许多技术巨头纷纷推出了多语言支持的语音识别系统,如Whisper等。然而,尽…...
)
运动规划实战案例 | 基于四叉树分解的路径规划(附ROS C++/Python仿真)
目录 1 为什么需要四叉树?2 基于四叉树的路径规划2.1 分层抽象2.2 路图搜索2.3 动态剪枝 3 算法仿真3.1 ROS C算法仿真3.2 Python算法仿真 1 为什么需要四叉树? 路径规划的本质是在给定环境中寻找从起点到终点的最优或可行路径,其核心挑战在…...

java设计模式-享元模式
享元模式 基本介绍 1、享元模式(flyweight Pattern),也叫作蝇量模式:运用在共享技术有效的支持大量细粒度的对象。 2、常用语系统底层开发,解决系统的性能问题。像 数据库连接,里面都是创建好的连接对象,在这些连接对…...
)
Java 大视界 -- Java 大数据在智慧水利水资源调度与水情预测中的应用创新(180)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...

自动驾驶---苹果又要造车了吗?
1 背景 巴菲特一直认为造车的企业是一个做 “苦生意” 的企业,可能苹果高层也意识到了这一点, 于是造车计划在去年被终止。 但2025年2月份,苹果公司署名发了一篇自动驾驶领域的论文《Robust Autonomy Emerges from Self-Play》,详…...

Redis主从复制:告别单身Redis!
目录 一、 为什么需要主从复制?🤔二、 如何搭建主从架构?前提条件✅步骤📁 创建工作目录📜 创建 Docker Compose 配置文件🚀 启动所有 Redis🔍 验证主从状态 💡 重要提示和后续改进 …...

PHP:将关联数组转换为索引数组的完整示例
处理之前的数据 头和行在一起显示 // 执行SQL查询后的原始数据(假设查询返回3条记录) $rawData [[wip_entity_name > JOB001,primary_item > ITEM001,primary_name > 主产品1,primary_desc > 主产品描述1,start_quantity > 100,quanti…...
)
27.[2019红帽杯]easyRE1(保姆教程)
收到文件,.elf 文件,ExeinfoPE查看一下基础信息。无壳,64bit。 把文件拖入IDA工具,查看一下。 点击关键字,ctrl x 交叉搜索一下位置,跟进,顺便菜单左侧 Edit --> Plugins--> findcrypt …...

【Redis】Redis实现分布式锁
1. 基于Redis 1.1 加锁 setnx lockKey uniqueValue1.2 解锁 基于Lua脚本保证解锁的原子性。Redis在执行Lua脚本时,可以以原子性的方式执行,确保原子性。 if redis.call("get", keys[1]) argv[1] then return redis.call("del", …...

AI大模型底层技术——Scaling Law
0. 定义 Scaling Law 是描述 AI 模型性能随关键因素(如参数量、数据量、计算量)增长而变化的数学规律,通常表现为幂律关系。 历史里程碑: **OpenAI 2020 年论文首次系统提出语言模型的缩放定律**DeepMind、Google 等机构后续发表…...
)
Spring MVC 国际化机制详解(MessageSource 接口体系)
Spring MVC 国际化机制详解(MessageSource 接口体系) 1. 核心接口与实现类详解 接口/类名描述功能特性适用场景MessageSource核心接口,定义消息解析能力支持参数化消息(如{0}占位符)所有国际化场景的基础接口Resource…...

java学习笔记13——IO流
File 类的使用 常用构造器 路径分隔符 常用方法 File类的获取功能和重命名功能 File 类的判断功能 File类的创建功能和删除功能 File 类的使用 总结: 1.File类的理解 > File类位于java.io包下,本章中涉及到的相关流也都声明在java.io包下 > File…...

防DDoS流量清洗核心机制解析
本文深度剖析DDoS流量清洗技术演进路径,揭示混合云清洗系统的四层过滤架构,结合2023年新型反射攻击案例,提出基于AI行为分析的动态防御策略。通过Gartner最新攻防效能数据与金融行业实战方案,阐明流量清洗系统在误判率、清洗延迟、…...

边缘计算革命:低功耗GPU在自动驾驶实时决策中的应用
边缘计算革命:低功耗GPU在自动驾驶实时决策中的应用 ——分析NVIDIA Jetson与华为昇腾的嵌入式方案差异 一、自动驾驶的实时决策挑战与边缘计算需求 自动驾驶系统需在30ms内完成环境感知、路径规划与车辆控制的全流程闭环。传统云端计算受限于网络延迟…...

ubuntu24.04-MyEclipse的项目导入到 IDEA中
用myeclipse创建的一个web项目, jdk1.7,tomcat7,mysql8.0,导入到idea项目中 1.导入现有项目 1.打开IDEA,选择“Import Project”进入下一步 2.选择所需要导入的项目,点击“OK” 3.点击创建一个新的项目,然后下一步 4.直接点…...

基于SpringBoot的律师事务所案件管理系统【附源码】
基于SpringBoot的律师事务所案件管理系统(源码L文说明文档) 目录 4 系统设计 4.1界面设计原则 4.2功能结构设计 4.3数据库设计 4.3.1属性图 4.3.2 数据库物理设计 5 系统实现 5.1客户信息管理 5.2 律师…...

电力网关:推动电力物联网及电力通信系统革新
在“双碳”目标与新型电力系统建设的背景下,电力行业正加速向数字化、智能化、绿色化转型。作为国内领先的电力物联网解决方案提供商,厦门计讯物联科技有限公司(以下简称“计讯物联”)依托自主研发的电力专用网关、边缘计算平台及…...

Android系统的Wi-Fi系统框架和详细启动流程
目录 一、前言 二、系统架构层次 1、应用层 2、Framework层 3、HAL层 4、驱动层 三、Wi-Fi 目录树结构 四、系统流程 1、应用层请求 2、Wi-Fi管理服务处理 3、硬件交互 4、数据处理与事件通知 5.连接管理 6.状态维护 五、WiFi启动流程及函数调用…...

Scala基础知识8
集合计算高级函数 包括过滤、转换或映射、扁平化、扁平化加映射、分组、简化(归约),折叠 过滤:遍历一个集合并从中获取满足指定条件的元素组成一个新的集合。 转换或映射:将原始集合中的元素映射到某个函数中。 扁平化:取消嵌套格式&…...
教程目录)
SwiftUI 本地推送(Local Notification)教程目录
1. 本地推送简介 1.1 什么是本地推送?1.2 本地推送的应用场景(提醒、定时任务、用户交互等)1.3 本地推送与远程推送的区别 2. 前提条件 2.1 开发环境要求(Xcode 13、iOS 15)2.2 需要的基础知识(SwiftUI …...

大数据技术与Scala
集合高级函数 过滤 通过条件筛选集合元素,返回新集合。 映射 对每个元素应用函数,生成新集集合 扁平化 将嵌套集合展平为单层集合。 扁平化映射 先映射后展平,常用于拆分字符串。 分组 按规则将元素分组为Map结构。 归约 …...

golang通过飞书邮件服务API发送邮件功能详解
一.需求 需要实现通过飞书邮件服务API发送邮件验证码功能:用户输入邮箱, 点击发送邮件,然后发送邮件验证码, 这里验证码有过期时间, 保存到redis缓存中 二.实现 实现的部分代码如下: 控制器部分代码 // 发送邮件控制器 func EmailSendController(userId uint64, m proto.Messa…...

BoostSearch搜索引擎项目 —— 测试用例设计 + web自动化测试代码
web自动化代码: https://gitee.com/chicken-c/boost-search/tree/master/AutoTest...

MySQL学习笔记集--触发器
触发器 MySQL触发器(Trigger)是一种特殊的存储过程,它在指定的数据库表上指定的事件(INSERT、UPDATE、DELETE)之前或之后自动执行。触发器可以用来强制执行复杂的业务逻辑、数据完整性规则、自动更新数据等。 触发器…...

算力驱动未来:从边缘计算到高阶AI的算力革命
算力驱动未来:从边缘计算到高阶AI的算力革命 摘要 本文深入探讨了不同算力水平(20TOPS至160TOPS)在人工智能领域的多样化应用场景。从边缘计算的实时目标检测到自动驾驶的多传感器融合,从自然语言处理的大模型应用到AI for Scie…...
)
4.8刷题记录(双指针)
今天刷的部分是代码随想录中的双指针专题代码随想录 由于里面包含的题目大部分之前刷过,并且用双指针做过。所以今天仅仅复习,不再进行代码的搬运。 1.19. 删除链表的倒数第 N 个结点 - 力扣(LeetCode) 分析:此题无…...

在shell脚本中,$@和$#的区别与联系
在 Shell 脚本里,$ 和 $* 都是用于表示传递给脚本或函数的所有参数,下面详细介绍它们的区别与联系。 联系 表示所有参数:二者都能够代表传递给脚本或者函数的全部参数。当你在执行脚本时带上了多个参数,$ 和 $* 都能把这些参数呈…...

IP节点详解及国内IP节点获取指南
获取国内IP节点通常涉及网络技术或数据资源的使用,IP地址作为网络设备的唯一标识,对于网络连接和通信至关重要。详细介绍几种修改网络IP地址的常用方法,无论是对于家庭用户还是企业用户,希望能找到适合自己的解决方案。以下是方法…...
)
Google Play上架:解决android studio缓存问题(内容清理不干净导致拒审)
在as打包中,经常会遇到改变工程参数或者对应文件参数的情况,比如 修改android gradle版本 快捷键:ctrl + alt + shift + s 修改SDK文件路径 快捷键:ctrl + alt + shift + s 修改Gradle存储下载文件的默认位置 快捷键:ctrl + alt + s 先打开设置 修改compile...