如何对LLM大型语言模型进行评估与基准测试

基础概念
这几年,随着生成式 AI 和大型语言模型(LLMs)的兴起,AI 领域整体迎来了一波大爆发。
随着各种基于 LLM 的应用程序在企业里落地,人们开始需要评估不同推理部署方案的性价比。
LLM 应用的部署成本,主要取决于它每秒能处理多少请求,同时还能保证对用户来说够快、回答也够准确。
这篇文章,主要聚焦在 LLM 吞吐量(throughput)和延迟(latency)的测量,这也是评估 LLM 应用成本的一部分。
评估 LLM 性能可以用各种工具来实现。市面上常用的这些客户端测试工具,虽然都能测 LLM 的性能指标,但每个工具对指标的定义、测量方式、计算公式都有点不一样。
这就导致,不同工具的测试结果,很难直接拿来互相比对。
所以这篇文章,会澄清常见的一些指标定义,以及流行测试工具在这些指标上的细微差别。同时,还会聊聊做基准测试时需要注意的一些重要参数。
负载测试 vs 性能基准测试
负载测试和性能基准测试,其实是两种不同的测试方法。
- 负载测试,是模拟一大批用户同时访问模型,测试模型在高并发、真实使用场景下的表现。
主要是找出服务器容量、自动扩容策略、网络延迟、资源使用这些方面的问题。 - 性能基准测试,则是专注于测模型本身,比如它的吞吐量、响应延迟、每个 Token 的处理速度等等。
这主要用来发现模型效率、优化效果、以及配置合理性方面的问题。
简单讲,负载测试关心“顶得住多少人用”,性能基准测试关心“跑得有多快”。
两种测试配合着做,能让开发者更全面了解自己 LLM 部署的能力,找到需要优化的地方。
LLM 推理是怎么回事
在开始讲具体测试指标之前,先搞懂 LLM 推理流程和相关术语。
一个 LLM 应用,在推理时一般分四步:
- Prompt(提示):用户输入问题或者指令
- 排队(Queuing):请求进入处理队列
- 预填(Prefill):模型处理输入内容,为生成做好准备
- 生成(Generation):模型一个 Token 一个 Token 地生成回答
这里要特别讲一下 Token ——这是 LLM 中的一个核心概念。
Token 是 LLM 处理自然语言时使用的最小单位,相当于“词片段”或“字串”。
每个模型都有自己的 Tokenizer,会根据训练数据学出来,专门把文本切成 Token,以便更高效地处理。
大致来说,常见英文 LLM 里,一个 Token 差不多等于 0.75 个英文单词。
还有一些跟 Token 长度相关的重要概念:
- 输入序列长度(ISL):送进模型的总 Token 数,包含用户的问题、系统提示、历史对话、链式推理内容(Chain-of-Thought)、以及检索增强(RAG)返回的文档等。
- 输出序列长度(OSL):模型生成的 Token 数。
- 上下文长度(Context Length):生成过程当前已处理过的所有 Token 数(包含输入和已经生成的部分)。
每个 LLM 都有个固定的最大上下文长度,输入+输出的 Token 总数不能超过这个上限。
另外,**流式输出(Streaming)**是一种让模型边生成边返回的模式。
比如在聊天机器人里,这样能让用户尽快看到初步回复,同时后台继续生成后面的内容。
如果不开启流式模式,就得等模型一口气把全部回答生成完,再一次性返回。
LLM 推理性能指标
这一部分,我们来解释一些业界常用的推理性能指标,比如“首 Token 时间”(Time to First Token,简称 TTFT)和“Token 间延迟”(Intertoken Latency,简称 ITL)。虽然这些指标听起来挺直观,但不同测试工具在定义和测量方式上,其实有一些细微但重要的差别。
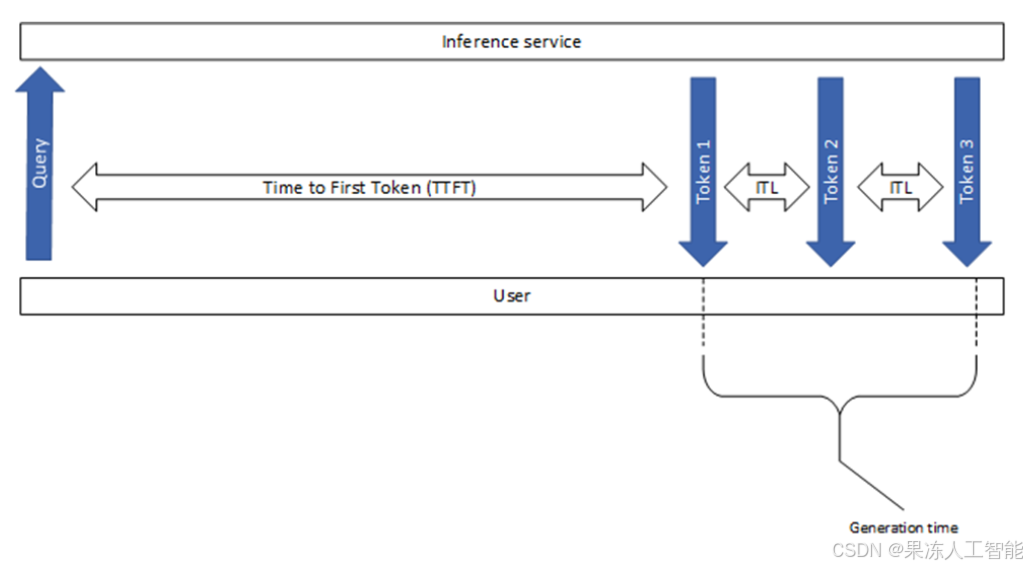
图 1:LLM 推理性能指标
首 Token 时间(Time to First Token,TTFT)
TTFT 指的是:从用户发出请求,到模型生成第一个Token所花的时间。
也就是说,用户输入问题后,要等多久才能看到模型给出的第一个字或者词。
需要注意的是,不同的基准测试工具(比如 GenAI-Perf 和 LLMPerf)在测 TTFT 时,通常会忽略那些“无内容”的初始响应,比如返回了空字符串或者没有生成任何 Token 的情况。这是因为,如果第一条返回的内容是空的,TTFT这个指标就没什么参考价值了。
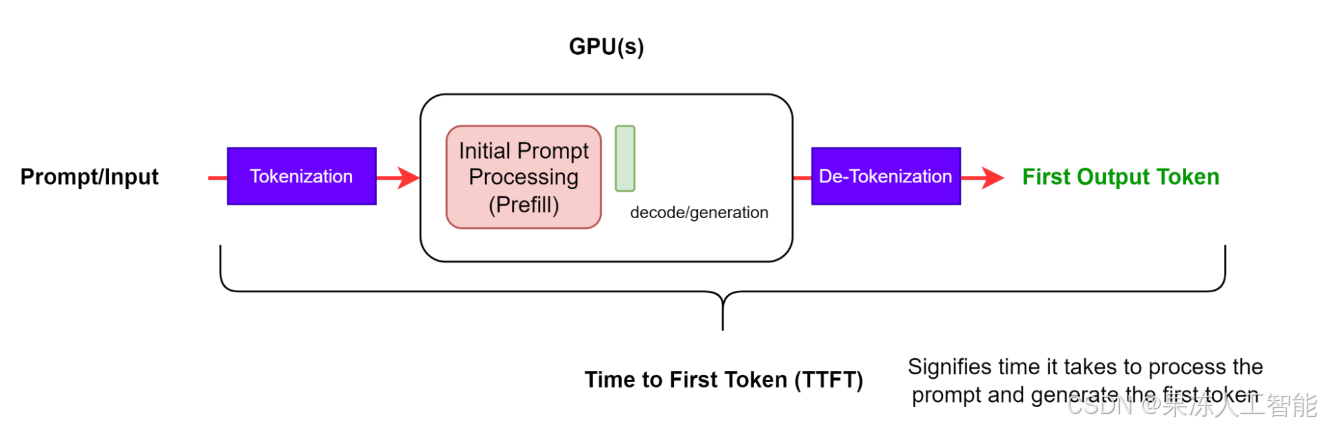
图 2:生成第一个 Token 的过程
一般来说,TTFT 包含了几个阶段的耗时:
- 请求排队的时间
- 预填处理(Prefill)阶段的时间
- 网络传输延迟
而且,Prompt 越长,TTFT 通常也越高。
因为注意力机制(Attention)需要处理整个输入序列,构建所谓的 Key-Value(KV)缓存,才好进入后续的逐 Token 生成循环。
另外,真实生产环境里,通常会同时处理多个请求,所以有可能一个请求还在 Prefill,另一个请求已经开始 Generation。两者可能会互相叠加,影响整体响应时间。
端到端请求延迟(End-to-End Request Latency)
端到端延迟(简称 e2e_latency)指的是:从发出请求,到收到完整回复之间的总耗时。
它包括了排队时间、批处理(Batching)时间,以及网络延迟等因素。
在流式(Streaming)模式下,因为中途可以部分返回 Token,所以在收到最终完整响应之前,可能已经经历了多次中间 detokenization(反 Token 化)处理。
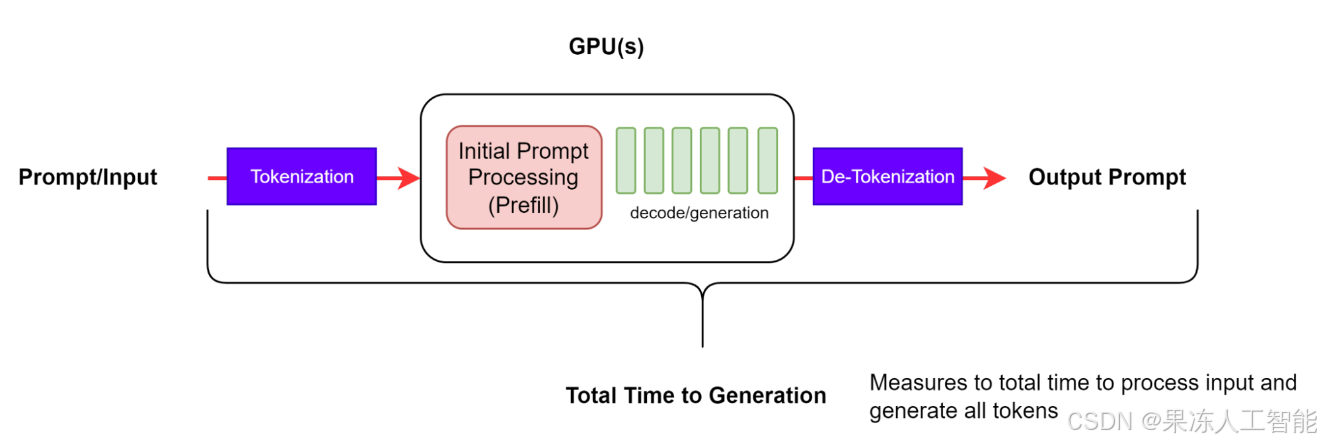
图 3:端到端请求延迟
对于单个请求来说,端到端延迟就是从请求发出到最后一个 Token 返回的时间差。
![]()
需要注意的是,生成阶段的持续时间(generation_time)是从收到第一个 Token 到最后一个 Token 的时间跨度。同时,一些测试工具(比如 GenAI-Perf)会过滤掉最后的完成信号或者空白响应,不把这些算进 e2e_latency 里。
Token 间延迟(Intertoken Latency,ITL)
Token 间延迟,指的是连续两个 Token 生成之间的平均耗时。
有时候也叫每输出一个 Token 的时间(Time Per Output Token,TPOT)。
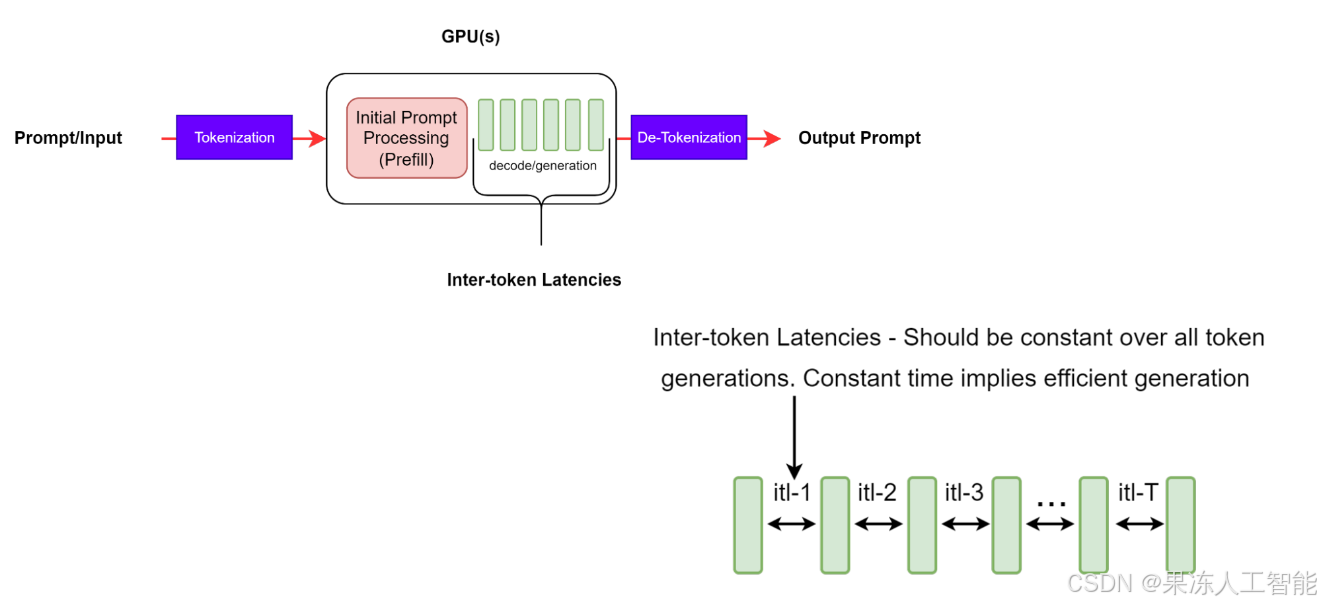
图 4:ITL ——连续生成 Token 之间的平均时间
虽然定义听着简单,不同工具在测量时还是有差别的。
比如说:
- GenAI-Perf:在计算 ITL 的时候不包含首 Token 时间(TTFT)
- LLMPerf:则是包含首 Token 时间在内
GenAI-Perf 的 ITL 公式大致是:
![]()
平均 Token 时间 = (收到最后一个 Token 的时间 - 收到第一个 Token 的时间) / (总 Token 数 - 1)
这里减 1,是为了把首 Token 排除掉,让 ITL 更准确地反映真正的解码(Decoding)阶段性能。
另外,随着输出 Token 数量增加,KV Cache 也会逐渐变大。
每生成一个新 Token,注意力机制的计算量也线性增长。不过通常,这个阶段不会是计算瓶颈。
如果 ITL 保持稳定,说明内存管理和带宽利用都做得不错,Attention 机制也处理得高效。
每秒生成 Token 数(Tokens Per Second,TPS)
TPS 是系统整体每秒生成多少个 Token 的量。
一开始,随着并发请求数增加,系统的 TPS 也会跟着增加,直到 GPU 资源被用满,TPS 就会趋于饱和,甚至可能开始下降。
比如,在一次完整的基准测试中,可以这么理解时间轴上的事件:
- Li:第 i 个请求的端到端延迟
- T_start:基准测试开始时间
- Tx:第一个请求发出的时间
- Ty:最后一个响应完成的时间
- T_end:基准测试结束时间

图 5:一次基准测试运行中的时间线
GenAI-Perf 将 TPS 定义为:总生成 Token 数除以第一个请求和最后一个请求的最后一个响应之间的端到端延迟时间:
![]()
LLMPerf 将 TPS 定义为:总生成 Token 数除以整个基准测试持续时间:
![]()
因此,LLMPerf 计算 TPS 时,还额外包含了以下开销:
- 输入 Prompt 的生成时间
- 请求准备时间
- 响应保存时间
根据我们的观察,在单并发(single concurrency)场景下,这些开销有时候可以占到整个基准测试持续时间的 33% 左右。
需要注意的是,TPS 的计算是批量(batch)完成的,不是实时(live)动态变化的指标。
另外,GenAI-Perf 使用了滑动窗口技术(sliding window technique)来寻找稳定的测量区间。
这意味着,最终统计的结果是基于一部分已经完成的代表性请求子集得出的,
也就是说,在计算时,会排除掉刚开始预热(warming up)和最后收尾阶段(cooling down)的请求。
每个用户的 TPS(TPS per user)表示从单个用户角度测量的吞吐量,定义为:
![]()
这个定义适用于单个用户的每次请求。
当输出序列长度不断增加时,TPS per user 的值会逐渐趋近于 1/ITL(即每个 Token 的平均生成时间的倒数)。
需要注意的是,随着系统中并发请求数的增加:
- 系统整体的总 TPS 会增加,
- 但单个用户的 TPS(TPS per user)会随着延迟增加而下降。
每秒请求数(Requests Per Second,RPS)
RPS 表示系统平均每秒能成功完成多少个请求。
它的计算方式比较简单,就是:
![]()
虽然 RPS 这个指标比 TPS 粗一些,但也很重要,尤其是对应用服务器层面的性能评估来说。
基准测试参数和最佳实践
这一节,我们来聊聊在做 LLM 性能测试时,一些非常重要的参数设定,以及它们应该怎么调。合理的测试设置,才能保证测试结果既靠谱,又能真正反映系统性能。
应用场景对 LLM 性能的影响
不同的应用场景,对输入(ISL)和输出(OSL)Token 数量的要求是完全不一样的。
而这些 Token 数的变化,直接影响系统消化输入、构建 KV 缓存、生成输出的速度。
一般来说:
- 输入序列越长,预填阶段(Prefill)需要的显存就越多,首 Token 时间(TTFT)就越高;
- 输出序列越长,生成阶段(Generation)对显存带宽和容量的要求也越高,Token 间延迟(ITL)就越大。
所以,在部署 LLM 时,一定要搞清楚自己应用场景里,输入和输出的长度分布情况。
这样才能更好地规划硬件资源,做到最优利用。
常见应用场景和它们的 ISL / OSL 特征举例:
- 翻译:
包括语言翻译和代码翻译。特点是输入输出长度差不多,都在 500~2000 个 Token 左右。 - 内容生成:
比如生成代码、故事、邮件正文或者通过检索生成一般性内容。
特点是输出很长(大概 1000 Token 量级),而输入通常很短(大概 100 Token 量级)。 - 摘要总结:
包括检索、链式思考提示(CoT prompting)、多轮对话等场景。
特点是输入很长(大约 1000 Token 以上),输出很短(大约 100 Token)。 - 推理(Reasoning):
最近的新型推理模型,比如做复杂推理、代码生成、数学题、逻辑谜题时,经常需要非常详细的链式思考、反思验证等。
特点是输入短(大概 100 Token),但输出超级长(1000 到 10000 Token 级别)。
负载控制参数(Load Control Parameters)
这里讲一些专门用来“施加负载”的参数。
- 并发数(Concurrency N):
同时活跃的请求数,也可以理解为有多少个用户在同时发请求。
每当一个用户的请求完成,就立刻发起下一个请求,保证系统里随时有 N 个活跃请求。
通常,描述 LLM 推理负载最常用的就是并发数。 - 最大批处理大小(Max Batch Size):
指推理引擎一次能同时处理的最多请求数。
这可能是并发请求的一个子集。
如果并发数超过了最大批处理大小 × 活跃副本数,多余的请求就得排队,等待后面有空位再处理。
这种情况下,TTFT(首 Token 时间)也会因为排队而变长。 - 请求速率(Request Rate):
控制新请求发送频率的另一种方式。- 恒定速率(Constant Rate):每 1/r 秒发 1 个请求
- 泊松分布速率(Poisson Rate):请求之间的间隔时间是随机的,但平均速率固定
不同测试工具支持的负载控制方式也不太一样,有的更倾向用并发数,有的支持两种。
一般建议优先用并发控制,因为如果只控制发送速率,而系统处理不过来,未完成请求数可能会无限堆积。
小技巧:在设定测试参数时,可以从并发数 1 开始,逐步增加到略高于最大批处理大小的范围。
因为通常,在并发数接近最大批处理时,系统吞吐量会达到饱和,而延迟会继续上升。
其他重要参数
除了负载相关的,还有一些其他设置也会影响推理性能,或者影响测试准确性:
- 是否忽略 EOS(ignore_eos 参数):
大多数 LLM 都有一个特别的“结束符”(EOS Token),表示生成结束。
正常推理时,模型遇到 EOS 就会停止生成。但在性能测试时,为了测到指定长度、保证每次输出长度一致,通常会设置忽略 EOS,让模型继续生成直到达到最大 Token 数。 - 采样策略(Sampling Parameters):
不同的采样策略,比如:- Greedy(每次选得分最高的 Token)
- Top-p(按累积概率筛选)
- Top-k(按最高 k 个概率选)
- Temperature(调整随机性)
都会影响生成速度。
比如 Greedy 策略最快,因为不用排序、归一化概率分布,直接拿最高分的 Token 就行了。
做基准测试时,不管选哪个采样方法,都要在整个测试过程中保持一致,避免引入额外干扰。
小结
LLM 性能基准测试,是确保模型既快又省钱、能支撑大规模部署的重要一步。
这篇文章讲了在基准测试时,最核心的性能指标、参数设定,以及一些好用的实践建议。
开始行动
给 LLM 做性能基准测试,是保证模型既能跑得快、又能在大规模部署时省钱、省资源的关键一步。
本文已经讲解了在进行 LLM 推理基准测试时,最重要的一些性能指标和参数设置。
如果你想更深入了解,可以参考这些方向:
- AI 推理:平衡成本、延迟和性能
(讲怎么在推理系统里做到又快又省) - 五分钟部署 LLM 微服务指南
(介绍快速部署小型推理微服务的方法) - 简单上手指南:用微服务部署生成式 AI
(手把手教你怎么搭一套生成式 AI 系统)
相关文章:

如何对LLM大型语言模型进行评估与基准测试
基础概念 这几年,随着生成式 AI 和大型语言模型(LLMs)的兴起,AI 领域整体迎来了一波大爆发。 随着各种基于 LLM 的应用程序在企业里落地,人们开始需要评估不同推理部署方案的性价比。 LLM 应用的部署成本,…...

C语言内存函数和数据在内存的存储
一、内存操作函数深度解析 函数名原型核心特性典型应用场景注意事项memcpyvoid* memcpy(void* dest, const void* src, size_t num)内存块无重叠复制,性能高数组拷贝、结构体复制1. 必须确保目标空间足够 2. 不支持重叠内存(用memmove替代) …...

ChatGPT之智能驾驶问题讨论
ChatGPT之智能驾驶问题讨论 1. 源由2. 问题:2.1 智能驾驶级别定义🚗 L2(部分自动化,Partial Automation)🤖 L3(有条件自动化,Conditional Automation)🛸 L4&a…...

【PalladiumZ2 使用专栏 1 -- 波形 trigger 抓取详细介绍】
文章目录 Palladium Z2 OverviewPalladium 波形抓取Palladium 波形存放文件创建Palladium Trigger 断点设置Palladium 加探针并 dumpPalladium 波形查看 Palladium Z2 Overview Cadence Palladium Z2 是 Cadence 推出的企业级硬件仿真加速平台,旨在应对复杂 SoC 设…...

elasticsearch 8设置验证登录查询
最近总是困扰于9200网络勒索,老是在捣乱,动不动给我清理了index,实在是费劲,今天研究了下config配置,设置ca验证。 以下是完整的步骤和配置,确保生成的证书文件与elasticsearch.yml的配置一致: 1. 生成CA证书 运行以下命令生成CA证书:让输入账号或密码请直接回车。 …...

为什么使用了CDN源服务器需要关闭防火墙?
在网站运营过程中,不少站长会遇到这样的困惑:当使用 CDN 源服务器时,好像就得关闭源服务器的防火墙,不然就状况百出。这背后究竟是什么原因呢? 当你在浏览网页时,要是看到 “502 - 服务暂时不可用” 的提…...

Android 学习之 Navigation导航
1. Navigation 介绍 Navigation 组件 是 Android Jetpack 的一部分,用于简化应用内导航逻辑,支持 Fragment、Activity 和 Compose 之间的跳转。核心优势: 单 Activity 架构:减少 Activity 冗余,通过 Fragment 或 Com…...

初识 Three.js:开启你的 Web 3D 世界 ✨
3D 技术已经不再是游戏引擎的专属,随着浏览器技术的发展,我们完全可以在网页上实现令人惊艳的 3D 效果。而 Three.js,作为 WebGL 的封装库,让 Web 3D 的大门向更多开发者敞开了。 这是我开启这个 Three.js 专栏的第一篇文章&…...

PyTorch 笔记
简介与安装 PyTorch 是一个开源的 Python 机器学习库,基于 Torch 库,底层由C实现,应用于人工智能领域,如计算机视觉和自然语言处理。 PyTorch 最初由 Meta Platforms 的人工智能研究团队开发,现在属 于Linux 基金会的…...

day24学习Pandas库
文章目录 三、Pandas库4.函数计算3遍历3.1.遍历Series对象3.2.遍历DataFrame对象 4排序4.1 sort_index4.2 sort_values 5.去重drop_duplicates6.先分组在计算6.1 groupby6.2 filter过滤 7.合并未完待续.. 三、Pandas库 4.函数计算 3遍历 3.1.遍历Series对象 在讲解Series部…...

AI日报 - 2025年4月8日
AI日报 - 2025年4月8日 🌟 今日概览(60秒速览) ▎🤖 模型进展 | Llama 4发布引爆讨论 (性能、应用、部署、训练争议),OpenAI保持高速迭代,香港大学推Dream 7B扩散模型。 Meta Llama 4 Scout & Maveric…...
 命令基础:从概念到实践(期末,期中复习笔记全))
Linux学习笔记(2) 命令基础:从概念到实践(期末,期中复习笔记全)
前言 一、认识命令行与命令 二、Linux 命令的基础格式 三、命令示例解析 (1)ls -l /home/itheima (2)cp -r test1 test2 四结语 前言 在 Linux 系统的世界里,命令行是与系统交互的重要方式。熟练掌握 Linux 命令…...
)
langgraph简单Demo4(checkpoint检查点)
在 langgraph 里,检查点(checkpoint)是一项重要的功能,它能够记录工作流在执行过程中的中间状态。当工作流因某些原因中断时,可以从检查点恢复继续执行,避免从头开始,提升效率。 示例ÿ…...

【题解】AtCoder AT_abc400_c 2^a b^2
题目大意 我们定义满足下面条件的整数 X X X 为“好整数”: 存在一个 正整数 对 ( a , b ) (a,b) (a,b) 使得 X 2 a ⋅ b 2 X2^a\cdot b^2 X2a⋅b2。 给定一个正整数 N N N( 1 ≤ N ≤ 1 0 18 1\le N\le 10^{18} 1≤N≤1018)ÿ…...

七种驱动器综合对比——《器件手册--驱动器》
目录 九、驱动器 概述 定义 功能 分类 1. 按负载类型分类 2. 按功能特性分类 工作原理 优势 应用领域 详尽阐述 1 隔离式栅极驱动器 定义 工作原理 应用场景 优势 2 变压器驱动器 定义 工作原理 应用场景 优势 设计注意事项 3 LED驱动 定义 功能与作用 应用场景 设计…...
:GStreamer介绍,在windows平台部署安装,打开usb摄像头对比测试)
GStreamer开发笔记(一):GStreamer介绍,在windows平台部署安装,打开usb摄像头对比测试
若该文为原创文章,转载请注明原文出处 本文章博客地址:https://blog.csdn.net/qq21497936/article/details/147049923 长沙红胖子Qt(长沙创微智科)博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、O…...

西湖大学团队开源SaProt等多款蛋白质语言模型,覆盖结构功能预测/跨模态信息搜索/氨基酸序列设计等
2025 年 3 月 22—23 日,上海交通大学「AI 蛋白质设计峰会」正式举行。 本次峰会汇聚了来自清华大学、北京大学、复旦大学、浙江大学、厦门大学等知名高校的 300 多位专家学者,以及 200 余位行业领军企业代表和技术研发人员,深入探讨了 AI 在…...

ansible+docker+docker-compose快速部署4节点高可用minio集群
目录 github项目地址 示例服务器列表 安装前 修改变量文件group_vars/all.yml 修改ansible主机清单 修改setup.sh安装脚本 用法演示 安装后验证 github项目地址 https://github.com/sulibao/ansible_minio_cluster.git 示例服务器列表 安装前 修改变量文件group_var…...

说话人分离中的聚类方法:深入解析Agglomerative聚类、KMeans聚类和Oracle聚类
说话人分离(Speaker Diarization)是将音频流根据说话人身份划分为同质片段的过程。这一过程中的关键步骤是聚类,即将说话人嵌入(embeddings)分组为不同的簇,每个簇代表一个独特的说话人。在pyannote.audio管…...

蓝桥杯真题——前缀总分、遗迹
蓝桥杯2024年第十五届省赛真题-前缀总分 题目描述 给定 n 个由小写英文字母组成的字符串 s1, s2, , sn ,定义前缀总分为V ∑i<j P(si, sj) ,其中 P(si, sj) 表示 si, sj 的最长公共前缀的长度。 小蓝可以选择其中一个字符串,并修改其…...

性能比拼: MySQL vs PostgreSQL
本内容是对知名性能评测博主 Anton Putra MySQL vs PostgreSQL Performance Benchmark (Latency - Throughput - Saturation) 内容的翻译与整理, 有适当删减, 相关指标和结论以原作为准 MySQL vs PostgreSQL 数据库性能对比** 在本内容中,我们将对比 MySQL 和 Pos…...

TypeScript 中的 infer 关键字用途
infer 是 TypeScript 中的高级类型关键字,主要用于条件类型中推断类型。它允许我们在条件类型的 extends 子句中声明一个类型变量,然后在该条件类型的 true 分支中使用这个推断出的类型。 1. 基本语法 type SomeType<T> T extends infer U ? U…...

关于Spring MVC中@RequestParam注解的详细说明,用于在前后端参数名称不一致时实现参数映射。包含代码示例和总结表格
以下是关于Spring MVC中RequestParam注解的详细说明,用于在前后端参数名称不一致时实现参数映射。包含代码示例和总结表格: 1. 核心作用 RequestParam用于显式绑定HTTP请求参数到方法参数,支持以下场景: 参数名不一致࿱…...

Spring Boot中Spring MVC相关配置的详细描述及表格总结
以下是Spring Boot中Spring MVC相关配置的详细描述及表格总结: Spring MVC 配置项详解 1. 异步请求配置 spring.mvc.async.request-timeout 描述:设置异步请求的超时时间(单位:毫秒)。默认值:未设置&…...

Shell脚本编程之正则表达式
一、概念 在 Shell 脚本中,正则表达式是一种强大且常用的文本处理工具,它可以用来匹配、搜索、替换和截取字符串。 正则表达式是由一些字符去描述规则,在正则表达式中有两类字符 (1)元字符(Meta Character):Shell 环境中具有特殊含…...

spring-ai-openai调用Xinference1.4.1报错
1、Xinference 报错logs 此处是调用 /v1/chat/completions 接口 2025-04-06 15:48:51 xinference | return await dependant.call(**values) 2025-04-06 15:48:51 xinference | File "/usr/local/lib/python3.10/dist-packages/xinference/api/restful_api.py", …...

XC7K160T-2FFG676I Kintex‑7系列 Xilinx 赛灵思 FPGA 详细技术规格
XC7K160T-1FFG676I XC7K160T-1FFG676C XC7K160T-2FFG676C 1. 基本概述 XC7K160T-2FFG676I 属于 Xilinx Kintex‑7 系列 FPGA,该系列芯片采用 28nm (HKMG)工艺制造,旨在提供高性能与低功耗的平衡。该芯片主要面向对高速数据处理、…...

C++学习之udp通信
1.UDP特点 c /* udp 传输层协议, 和tcp是一样的 特点: 面向无连接的, 不安全的, 报式传输协议 1. 无连接: udp通信的时候不需要connect 1). 通信不需要建立连接 2). 如果想给对方发送数据, 只需要指定对方的IP和端口 2. udp会丢包 1). 数…...
试题速浏、分类及浅析)
2020年-全国大学生数学建模竞赛(CUMCM)试题速浏、分类及浅析
2020年-全国大学生数学建模竞赛(CUMCM)试题速浏、分类及浅析 全国大学生数学建模竞赛(China Undergraduate Mathematical Contest in Modeling)是国家教委高教司和中国工业与应用数学学会共同主办的面向全国大学生的群众性科技活动,目的在于激励学生学习数学的积极性,提高学…...

【数据标准】数据标准化实施流程与方法-保障机制篇
导读:1、数据标准化保障机制(组织架构、协作流程)是战略落地的基石,确保责权分明与资源协同;2、数据标准化制度建设(政策、标准、工具)构建了统一治理框架,规范数据…...

ZLMediaKit部署与配置
ZLMediaKit编译 # 安装编译器 sudo apt install build-essential cmake# 其它依赖库 sudo apt-get install libssl-dev libsdl-dev libavcodec-dev libavutil-dev ffmpeg git cd /usr/local/srcgit clone --depth 1 https://gitee.com/xia-chu/ZLMediaKit.git cd ZLMediaKit# …...
)
38、web前端开发之Vue3保姆教程(二)
三、Vue3语法详解 1、组件 1 什么是组件? 组件是 Vue.js 中最重要的概念之一。它是一种可复用的 Vue 实例,允许我们将 UI 拆分为独立的、可复用的部分。组件可以提高代码的组织性和可维护性。 2 创建组件 在 Vue 3 中,组件通常使用单文件组件(SFC)编写,其包含三个主…...

知识中台如何重构企业信息生态?关键要素解析
在信息化快速发展的时代,企业面临着如何高效整合和管理知识资源的挑战。知识中台作为企业信息管理的核心工具,正在帮助企业提升运营效率和创新力。本文将探讨知识中台如何重构企业信息生态,并解析其关键要素。 一、什么是知识中台?…...
)
蓝桥杯python组备赛(记录个人模板)
文章目录 栈队列堆递归装饰器并查集树状数组线段树最近公共祖先LCAST表字典树KMPmanacher跳表(代替C STL的set)dijkstra总结 栈 用list代替 队列 用deque双端队列替代 堆 用heapq 递归装饰器 众所周知,python的递归深度只有1000,根本满足不了大部…...

C++的多态 - 下
目录 多态的原理 虚函数表 1.计算包含虚函数类的大小 2.虚函数表介绍 多态底层原理 1.父类引用调用 2.父类指针调用 3.动态绑定与静态绑定 单继承和多继承关系的虚函数表 函数指针 1.函数指针变量 (1)函数指针变量创建 (2)函数指针变量的使用 (3)两段有趣的代码 …...
)
XSS(跨站脚本攻击)
什么是 XSS 攻击? XSS 攻击(Cross-Site Scripting)是一种常见的网络攻击手段,攻击者通过在网站上注入恶意的 JavaScript 代码,让网站在用户的浏览器中执行这些恶意代码,进而达到 窃取信息、篡改网页内容 或…...

LLM Agents的历史、现状与未来趋势
引言 大型语言模型(Large Language Model, LLM)近年在人工智能领域掀起革命,它们具备了出色的语言理解与生成能力。然而,单纯的LLM更像是被动的“回答者”,只能根据输入给出回复。为了让LLM真正“行动”起来ÿ…...

最简rnn_lstm模型python源码
1.源码 GitCode - 全球开发者的开源社区,开源代码托管平台 不到120行代码,参考了《深度学习与交通大数据实战》3.2节。注意这本书只能在京东等在线商城网购,才能拿到相应的数据集和源码。我的是在当地新华书店买的——买清华出版社,记得这个…...
,源码可白嫖!)
基于Android的图书借阅和占座系统(源码+lw+部署文档+讲解),源码可白嫖!
摘要 基于Android的图书借阅和占座系统设计的目的是为用户提供图书信息、图书馆、图书资讯等内容,用户可以进行图书借阅、预约选座等操作。 与PC端应用程序相比,图书借阅和占座系统的设计主要面向于广大用户,旨在为用户提供一个图书借阅及占…...

vue3+element-plus动态与静态表格数据渲染
一、表格组件: <template> <el-table ref"myTable" :data"tableData" :header-cell-style"headerCellStyle" header-row-class-name"my-table-header" cell-class-name"my-td-cell" :row-style"r…...

数据库50个练习
数据表介绍 --1.学生表 Student(SId,Sname,Sage,Ssex) --SId 学生编号,Sname 学生姓名,Sage 出生年月,Ssex 学生性别 --2.课程表 Course(CId,Cname,TId) --CId 课程编号,Cname 课程名称,TId 教师编号 --3.教师表 Teacher(TId,Tname) --TId 教师编号,Tname 教师姓名 --4.成绩…...
)
Open CASCADE学习|读取点集拟合样条曲线(续)
问题 上一篇文章已经实现了样条曲线拟合,但是仍存在问题,Tolerance过大拟合成直线了,Tolerance过大头尾波浪形。 正确改进方案 1️⃣ 核心参数优化 通过调整以下参数控制曲线平滑度: Standard_Integer DegMin 3; // 最低阶…...

HTML基础教程:创建双十一购物狂欢节网页
页面概况: 在这篇技术博客中,我将详细讲解如何使用HTML基础标签创建一个简单而美观的双十一购物狂欢节主题网页。我们将逐步分析代码结构,了解每个HTML元素的作用,以及如何通过HTML属性控制页面布局和样式。 页面整体结构 首先&…...

ES6 新增特性 箭头函数
简述: ECMAScript 6(简称ES6)是于2015年6月正式发布的JavaScript语言的标准,正式名为ECMAScript 2015(ES2015)。它的目标是使得JavaScript语言可以用来编写复杂的大型应用程序,成为企业级开发语…...

【C++算法】49.分治_归并_计算右侧小于当前元素的个数
文章目录 题目链接:题目描述:解法C 算法代码:图解 题目链接: 315. 计算右侧小于当前元素的个数 题目描述: 解法 归并排序(分治) 当前元素的后面,有多少个比我小。(降序&…...

Multi-class N-pair Loss论文理解
一、N-pair loss 对比 Triplet loss 对于N-pair loss来说,当N2时,与triplet loss是很相似的。对anchor-positive pair,都只有一个negative sample。而且,N-pair loss(N2时)为triplet loss的平滑近似Softpl…...

uniapp微信小程序地图marker自定义气泡 customCallout偶尔显示不全解决办法
这个天坑问题,在微信开发工具上是不会显示出来的,只有在真机上才会偶尔出现随机样式偏移/裁剪/宽长偏移,询问社区也只是让你提交代码片段,并无解决办法。 一开始我怀疑是地图组件加载出现了问题,于是给地图加了一个v-if"reL…...

蓝桥杯嵌入式总结
1.lcd显示和led引脚冲突 在lcd使用到的函数中加入两行代码 uint16_t temp GPIOC->ODR; GPIOC->ODR temp; 2.关于PA15,PB4pwm波输入捕获 首先pwm输入捕获中断 使用 HAL_TIM_IC_Start_IT(&htim2,TIM_CHANNEL_1); 再在输入捕获中断回调函数中使用 void HAL…...

C#的反射机制
C#反射机制详解 什么是反射? 反射(Reflection)是C#中的一项强大功能,它允许程序在运行时动态获取类型信息、访问和操作对象成员。简单来说,反射使程序可以在不预先知道类型的情况下,查看、使用和修改程序集中的代码。 常见反射…...

Java并发编程高频面试题
一、基础概念 1. 并行与并发的区别? 并行:多个任务在多个CPU核心上同时执行(物理上同时)。并发:多个任务在单CPU核心上交替执行(逻辑上同时)。类比:并行是多个窗口同时服务&#x…...