【从0到1学MybatisPlus】MybatisPlus入门
Mybatis-Plus
使用场景
大家在日常开发中应该能发现,单表的CRUD功能代码重复度很高,也没有什么难度。而这部分代码量往往比较大,开发起来比较费时。
因此,目前企业中都会使用一些组件来简化或省略单表的CRUD开发工作。目前在国内使用较多的一个组件就是MybatisPlus.
快速入门
Mybatis-Plus官方网站
导入依赖
<dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.3.1</version>
</dependency>
定义Mapper
为了简化单表CRUD,MybatisPlus提供了一个基础的BaseMapper接口,其中已经实现了单表的CRUD:
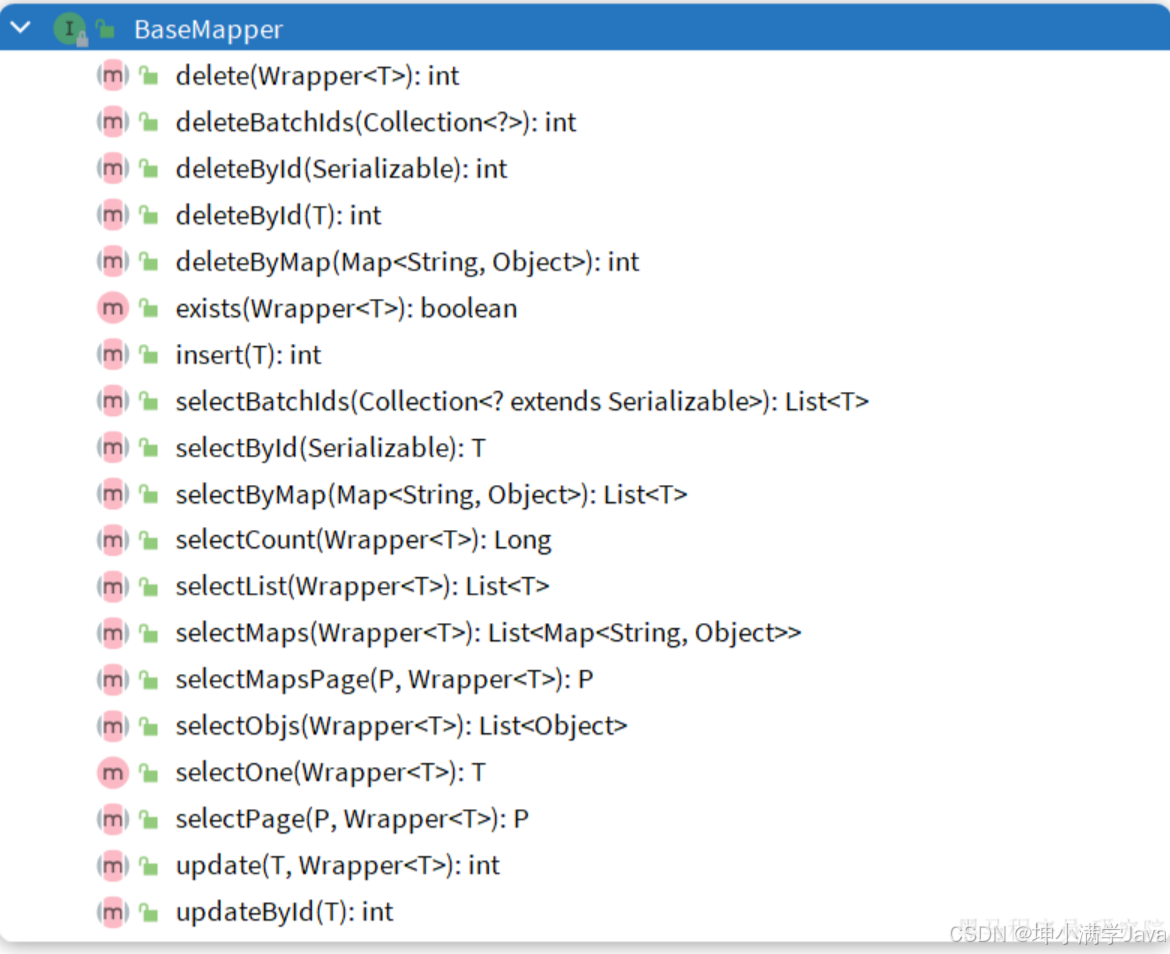
因此我们自定义的Mapper只要实现了这个BaseMapper,就无需自己实现单表CRUD了。
修改mp-demo中的com.itheima.mp.mapper包下的UserMapper接口,让其继承BaseMapper:
package com.itheima.mp.mapper;import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.itheima.mp.domain.po.User;public interface UserMapper extends BaseMapper<User> {
}
测试
package com.itheima.mp.mapper;import com.itheima.mp.domain.po.User;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;import java.time.LocalDateTime;
import java.util.List;@SpringBootTest
class UserMapperTest {@Autowiredprivate UserMapper userMapper;@Testvoid testInsert() {User user = new User();user.setId(5L);user.setUsername("Lucy");user.setPassword("123");user.setPhone("18688990011");user.setBalance(200);user.setInfo("{\"age\": 24, \"intro\": \"英文老师\", \"gender\": \"female\"}");user.setCreateTime(LocalDateTime.now());user.setUpdateTime(LocalDateTime.now());userMapper.insert(user);}@Testvoid testSelectById() {User user = userMapper.selectById(5L);System.out.println("user = " + user);}@Testvoid testSelectByIds() {List<User> users = userMapper.selectBatchIds(List.of(1L, 2L, 3L, 4L, 5L));users.forEach(System.out::println);}@Testvoid testUpdateById() {User user = new User();user.setId(5L);user.setBalance(20000);userMapper.updateById(user);}@Testvoid testDelete() {userMapper.deleteById(5L);}
}
常见注解
@TableName
- 描述:表名注解,标识实体类对应的表
- 使用位置:实体类
@TableName("user")
public class User {private Long id;private String name;
}
| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
|---|---|---|---|---|
| value | String | 否 | “” | 表名 |
| schema | String | 否 | “” | schema |
| keepGlobalPrefix | boolean | 否 | false | 是否保持使用全局的 tablePrefix 的值(当全局 tablePrefix 生效时) |
| resultMap | String | 否 | “” | xml 中 resultMap 的 id(用于满足特定类型的实体类对象绑定) |
| autoResultMap | boolean | 否 | false | 是否自动构建 resultMap 并使用(如果设置 resultMap 则不会进行 resultMap 的自动构建与注入) |
| excludeProperty | String[] | 否 | {} | 需要排除的属性名 @since 3.3.1 |
@TableId
- 描述:主键注解,标识实体类中的主键字段
- 使用位置:实体类的主键字段
@TableName("user")
public class User {@TableIdprivate Long id;private String name;
}
TableId注解支持两个属性:
| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
|---|---|---|---|---|
| value | String | 否 | “” | 表名 |
| type | Enum | 否 | IdType.NONE | 指定主键类型 |
IdType支持的类型有:
| 值 | 描述 |
|---|---|
| AUTO | 数据库 ID 自增 |
| NONE | 无状态,该类型为未设置主键类型(注解里等于跟随全局,全局里约等于 INPUT) |
| INPUT | insert 前自行 set 主键值 |
| ASSIGN_ID | 分配 ID(主键类型为 Number(Long 和 Integer)或 String)(since 3.3.0),使用接口IdentifierGenerator的方法nextId(默认实现类为DefaultIdentifierGenerator雪花算法) |
| ASSIGN_UUID | 分配 UUID,主键类型为 String(since 3.3.0),使用接口IdentifierGenerator的方法nextUUID(默认 default 方法) |
| ID_WORKER | 分布式全局唯一 ID 长整型类型(please use ASSIGN_ID) |
| UUID | 32 位 UUID 字符串(please use ASSIGN_UUID) |
| ID_WORKER_STR | 分布式全局唯一 ID 字符串类型(please use ASSIGN_ID) |
这里比较常见的有三种:
AUTO:利用数据库的id自增长INPUT:手动生成idASSIGN_ID:雪花算法生成Long类型的全局唯一id,这是默认的ID策略
@TableField
@TableName("user")
public class User {@TableIdprivate Long id;private String name;private Integer age;@TableField(is_married")private Boolean isMarried;@TableField("`concat`")private String concat;
}
一般情况下我们并不需要给字段添加@TableField注解,一些特殊情况除外:
- 成员变量名与数据库字段名不一致
- 成员变量是以isXXX命名,按照JavaBean的规范,MybatisPlus识别字段时会把is去除,这就导致与数据库不符。
成员变量名与数据库一致,但是与数据库的关键字冲突。使用@TableField注解给字段名添加转义字符:``
| 属性 | 类型 | 必填 | 默认值 | 描述 |
|---|---|---|---|---|
| value | String | 否 | “” | 数据库字段名 |
| exist | boolean | 否 | true | 是否为数据库表字段 |
| condition | String | 否 | “” | 字段 where 实体查询比较条件,有值设置则按设置的值为准,没有则为默认全局的 %s=#{%s},参考(opens new window) |
| update | String | 否 | “” | 字段 update set 部分注入,例如:当在version字段上注解update=“%s+1” 表示更新时会 set version=version+1 (该属性优先级高于 el 属性) |
| insertStrategy | Enum | 否 | FieldStrategy.DEFAULT | 举例:NOT_NULL insert into table_a(column) values (#{columnProperty}) |
| updateStrategy | Enum | 否 | FieldStrategy.DEFAULT | 举例:IGNORED update table_a set column=#{columnProperty} |
| whereStrategy | Enum | 否 | FieldStrategy.DEFAULT | 举例:NOT_EMPTY where column=#{columnProperty} |
| fill | Enum | 否 | FieldFill.DEFAULT | 字段自动填充策略 |
| select | boolean | 否 | true | 是否进行 select 查询 |
| keepGlobalFormat | boolean | 否 | false | 是否保持使用全局的 format 进行处理 |
| jdbcType | JdbcType | 否 | JdbcType.UNDEFINED | JDBC 类型 (该默认值不代表会按照该值生效) |
| typeHandler | TypeHander | 否 | 类型处理器 (该默认值不代表会按照该值生效) | |
| numericScale | String | 否 | “” | 指定小数点后保留的位数 |
核心功能
条件构造器
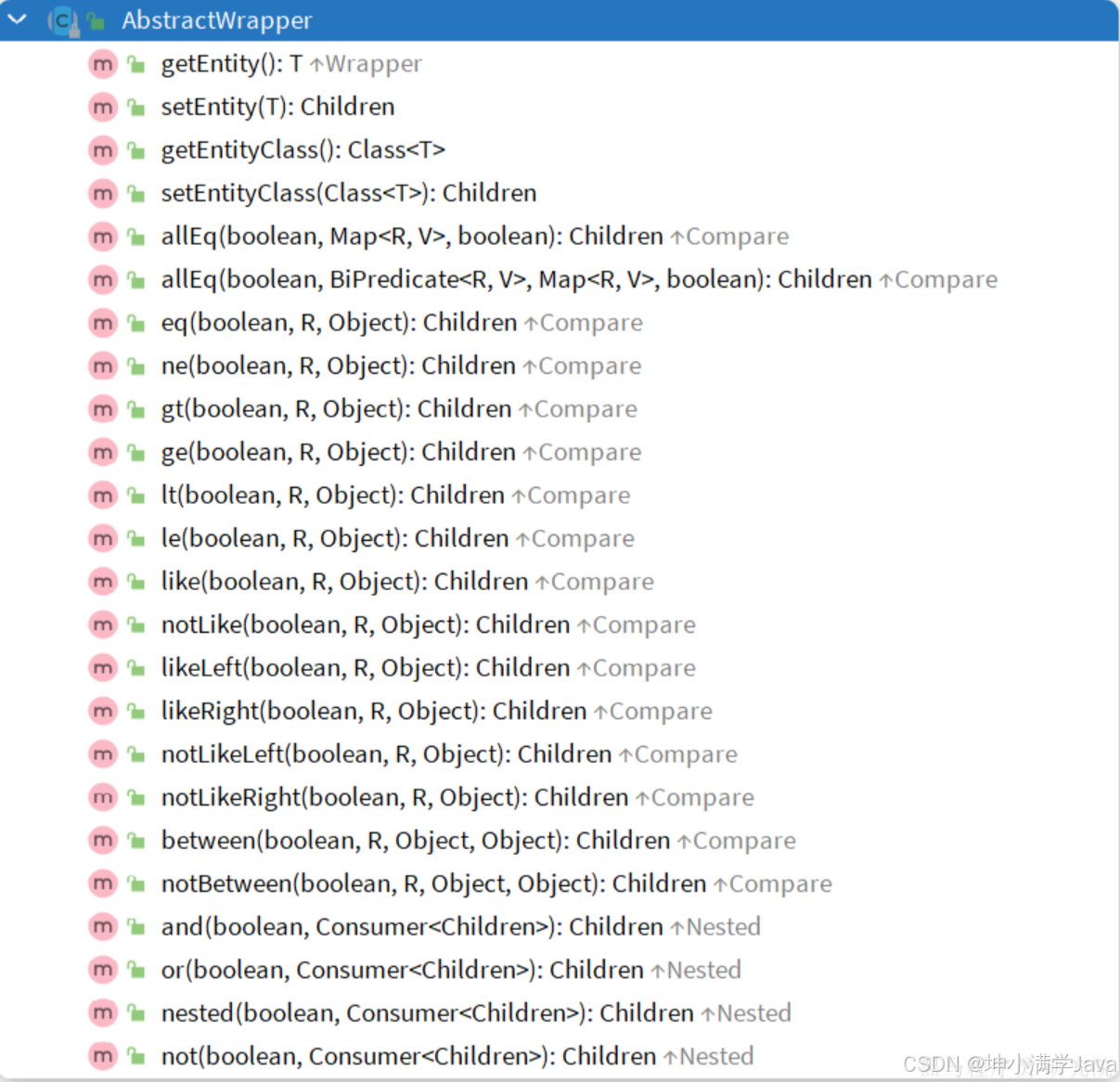
除了新增以外,修改、删除、查询的SQL语句都需要指定where条件。因此BaseMapper中提供的相关方法除了以id作为where条件以外,还支持更加复杂的where条件。

Wrapper的子类AbstractWrapper提供了where中包含的所有条件构造方法:
QueryWrapper
无论是修改、删除、查询,都可以使用QueryWrapper来构建查询条件。接下来看一些例子:
查询:查询出名字中带o的,存款大于等于1000元的人。代码如下:
@Test
void testQueryWrapper() {// 1.构建查询条件 where name like "%o%" AND balance >= 1000QueryWrapper<User> wrapper = new QueryWrapper<User>().select("id", "username", "info", "balance").like("username", "o").ge("balance", 1000);// 2.查询数据List<User> users = userMapper.selectList(wrapper);users.forEach(System.out::println);
}
更新:更新用户名为jack的用户的余额为2000,代码如下:
@Test
void testUpdateByQueryWrapper() {// 1.构建查询条件 where name = "Jack"QueryWrapper<User> wrapper = new QueryWrapper<User>().eq("username", "Jack");// 2.更新数据,user中非null字段都会作为set语句User user = new User();user.setBalance(2000);userMapper.update(user, wrapper);
}
UpdateWrapper
基于BaseMapper中的update方法更新时只能直接赋值,对于一些复杂的需求就难以实现。
例如:更新id为1,2,4的用户的余额,扣200,对应的SQL应该是:
UPDATE user SET balance = balance - 200 WHERE id in (1, 2, 4)
SET的赋值结果是基于字段现有值的,这个时候就要利用UpdateWrapper中的setSql功能了:
@Test
void testUpdateWrapper() {List<Long> ids = List.of(1L, 2L, 4L);// 1.生成SQLUpdateWrapper<User> wrapper = new UpdateWrapper<User>().setSql("balance = balance - 200") // SET balance = balance - 200.in("id", ids); // WHERE id in (1, 2, 4)// 2.更新,注意第一个参数可以给null,也就是不填更新字段和数据,// 而是基于UpdateWrapper中的setSQL来更新userMapper.update(null, wrapper);
}
LambdaQueryWrapper
无论是QueryWrapper还是UpdateWrapper在构造条件的时候都需要写死字段名称,会出现字符串魔法值。这在编程规范中显然是不推荐的。
那怎么样才能不写字段名,又能知道字段名呢?
其中一种办法是基于变量的gettter方法结合反射技术。因此我们只要将条件对应的字段的getter方法传递给MybatisPlus,它就能计算出对应的变量名了。而传递方法可以使用JDK8中的方法引用和Lambda表达式。
因此MybatisPlus又提供了一套基于Lambda的Wrapper,包含两个:
- LambdaQueryWrapper
- LambdaUpdateWrapper
分别对应QueryWrapper和UpdateWrapper
@Test
void testLambdaQueryWrapper() {// 1.构建条件 WHERE username LIKE "%o%" AND balance >= 1000QueryWrapper<User> wrapper = new QueryWrapper<>();wrapper.lambda().select(User::getId, User::getUsername, User::getInfo, User::getBalance).like(User::getUsername, "o").ge(User::getBalance, 1000);// 2.查询List<User> users = userMapper.selectList(wrapper);users.forEach(System.out::println);
}
自定义SQL

这种写法在某些企业也是不允许的,因为SQL语句最好都维护在持久层,而不是业务层。就当前案例来说,由于条件是in语句,只能将SQL写在Mapper.xml文件,利用foreach来生成动态SQL。
这实在是太麻烦了。假如查询条件更复杂,动态SQL的编写也会更加复杂。
基本用法
@Test
void testCustomWrapper() {// 1.准备自定义查询条件List<Long> ids = List.of(1L, 2L, 4L);QueryWrapper<User> wrapper = new QueryWrapper<User>().in("id", ids);// 2.调用mapper的自定义方法,直接传递WrapperuserMapper.deductBalanceByIds(200, wrapper);
}
package com.itheima.mp.mapper;import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.itheima.mp.domain.po.User;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Update;
import org.apache.ibatis.annotations.Param;public interface UserMapper extends BaseMapper<User> {@Select("UPDATE user SET balance = balance - #{money} ${ew.customSqlSegment}")void deductBalanceByIds(@Param("money") int money, @Param("ew") QueryWrapper<User> wrapper);
}
我们可以吧自定义的条件以参数的方式传递下去
Service接口
MybatisPlus不仅提供了BaseMapper,还提供了通用的Service接口及默认实现,封装了一些常用的service模板方法。
通用接口为IService,默认实现为ServiceImpl,其中封装的方法可以分为以下几类:
- save:新增
- remove:删除
- update:更新
- get:查询单个结果
- list:查询集合结果
- count:计数
- page:分页查询
CRUD
新增
- save是新增单个元素
- saveBatch是批量新增
- saveOrUpdate是根据id判断,如果数据存在就更新,不存在则新增
- saveOrUpdateBatch是批量的新增或修改

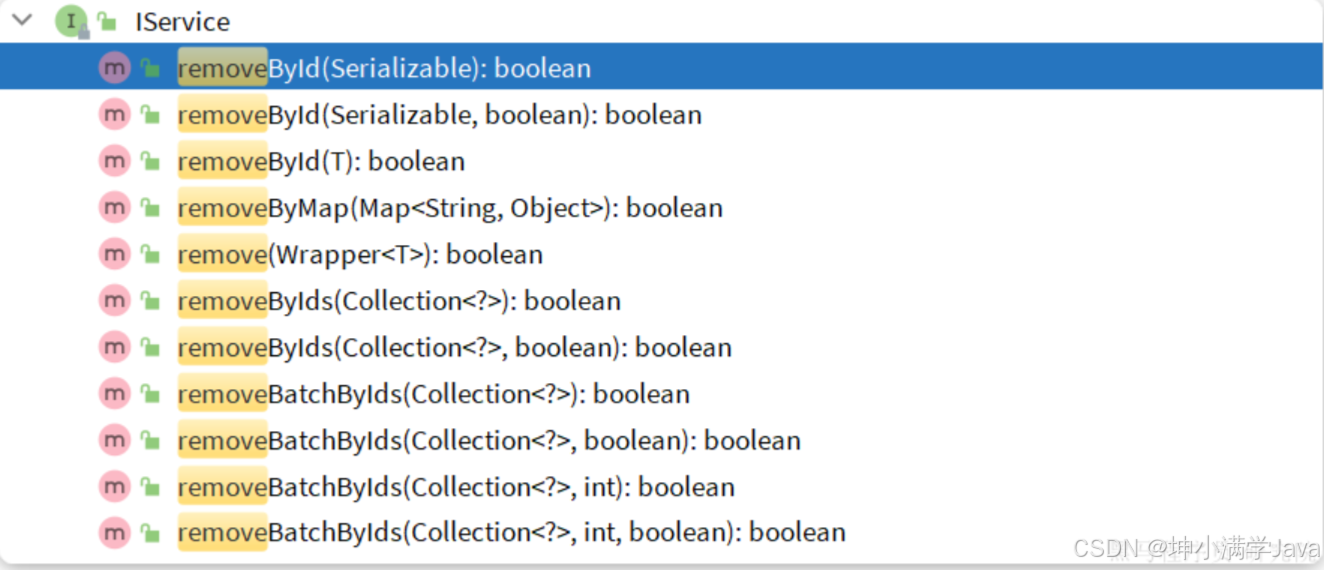
删除
- removeById:根据id删除
- removeByIds:根据id批量删除
- removeByMap:根据Map中的键值对为条件删除
- remove(Wrapper):根据Wrapper条件删除
removeBatchByIds:暂不支持
修改
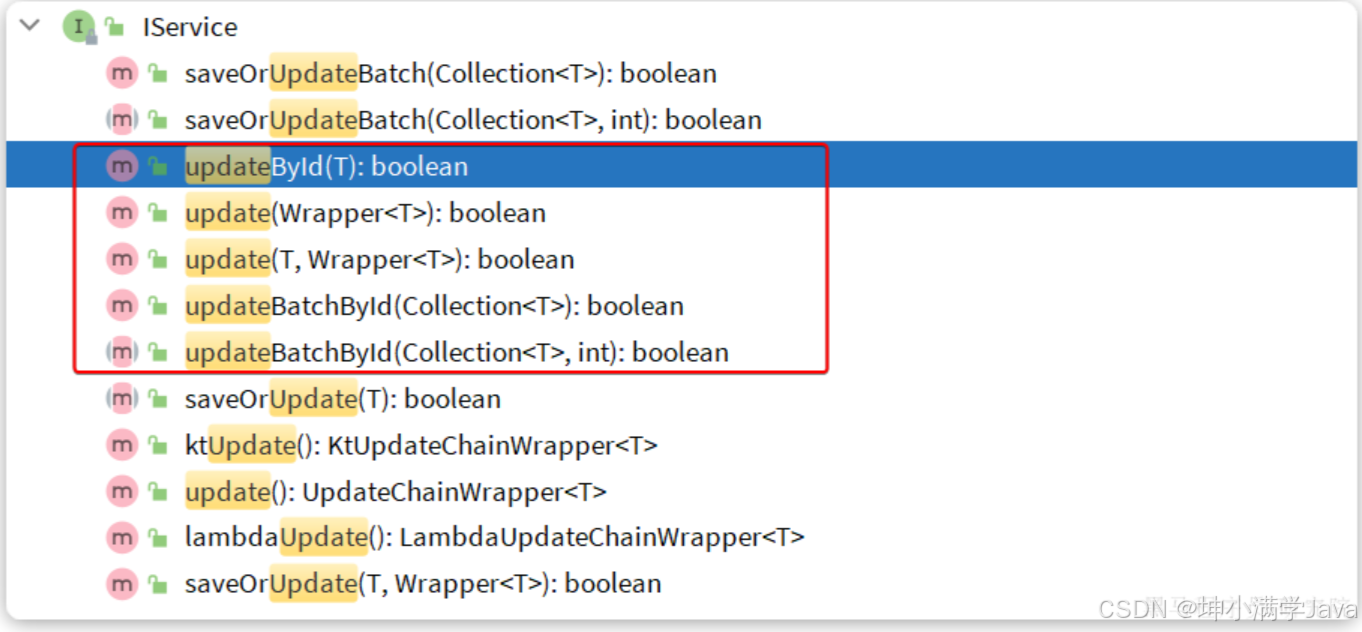
- updateById:根据id修改
- update(Wrapper):根据UpdateWrapper修改,Wrapper中包含set和where部分
- update(T,Wrapper):按照T内的数据修改与Wrapper匹配到的数据
- updateBatchById:根据id批量修改
Get:
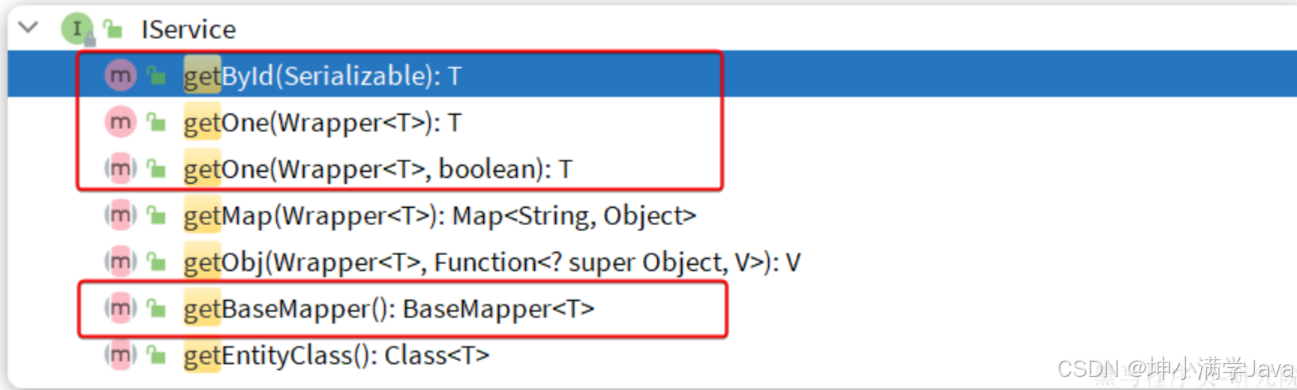
- getById:根据id查询1条数据
- getOne(Wrapper):根据Wrapper查询1条数据
- getBaseMapper:获取Service内的BaseMapper实现,某些时候需要直接调用Mapper内的自定义SQL时可以用这个方法获取到Mapper
List:
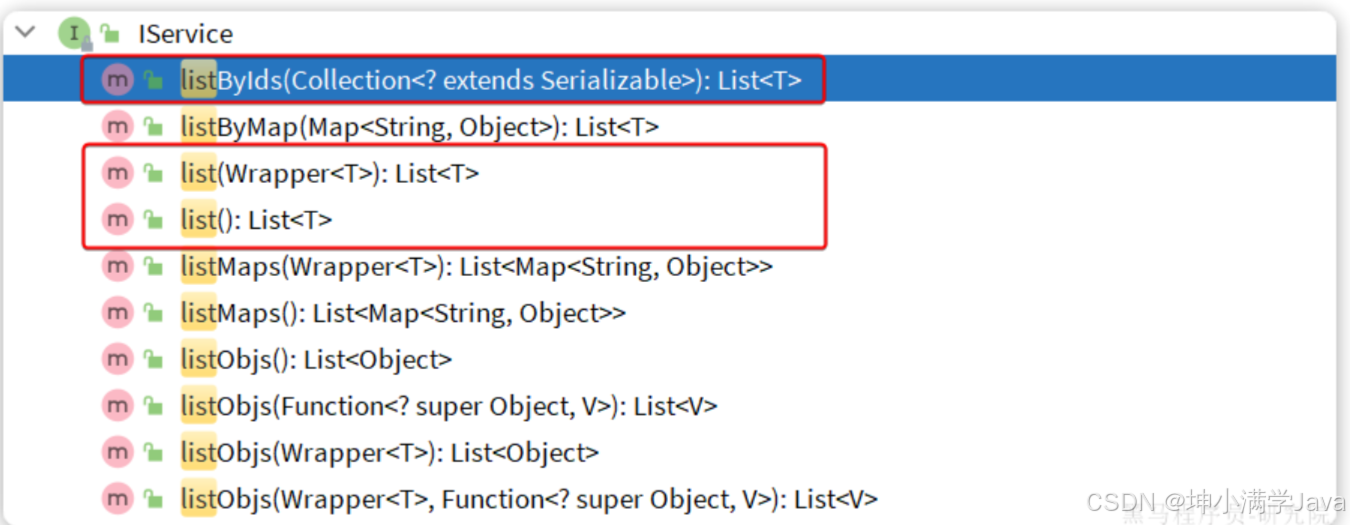
- listByIds:根据id批量查询
- list(Wrapper):根据Wrapper条件查询多条数据
- list():查询所有
Count:

- count():统计所有数量
- count(Wrapper):统计符合Wrapper条件的数据数量
getBaseMapper:
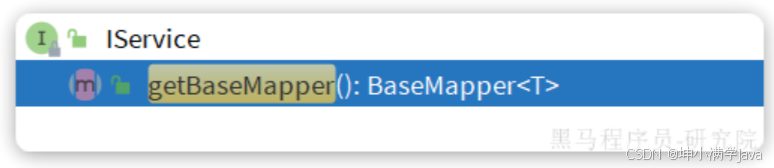
当我们在service中要调用Mapper中自定义SQL时,就必须获取service对应的Mapper,就可以通过这个方法:
基本用法
由于Service中经常需要定义与业务有关的自定义方法,因此我们不能直接使用IService,而是自定义Service接口,然后继承IService以拓展方法。同时,让自定义的Service实现类继承ServiceImpl,这样就不用自己实现IService中的接口了。
首先,定义IUserService,继承IService:
package com.itheima.mp.service;import com.baomidou.mybatisplus.extension.service.IService;
import com.itheima.mp.domain.po.User;public interface IUserService extends IService<User> {// 拓展自定义方法
}
package com.itheima.mp.service.impl;import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.itheima.mp.domain.po.User;
import com.itheima.mp.domain.po.service.IUserService;
import com.itheima.mp.mapper.UserMapper;
import org.springframework.stereotype.Service;@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User>implements IUserService {
}
Lambda
IService中还提供了Lambda功能来简化我们的复杂查询及更新功能。
@GetMapping("/list")
@ApiOperation("根据id集合查询用户")
public List<UserVO> queryUsers(UserQuery query){// 1.组织条件String username = query.getName();Integer status = query.getStatus();Integer minBalance = query.getMinBalance();Integer maxBalance = query.getMaxBalance();LambdaQueryWrapper<User> wrapper = new QueryWrapper<User>().lambda().like(username != null, User::getUsername, username).eq(status != null, User::getStatus, status).ge(minBalance != null, User::getBalance, minBalance).le(maxBalance != null, User::getBalance, maxBalance);// 2.查询用户List<User> users = userService.list(wrapper);// 3.处理voreturn BeanUtil.copyToList(users, UserVO.class);
}
在组织查询条件的时候,我们加入了 username != null 这样的参数,意思就是当条件成立时才会添加这个查询条件,类似Mybatis的mapper.xml文件中的标签。这样就实现了动态查询条件效果了。
不过,上述条件构建的代码太麻烦了。
因此Service中对LambdaQueryWrapper和LambdaUpdateWrapper的用法进一步做了简化。我们无需自己通过new的方式来创建Wrapper,而是直接调用lambdaQuery和lambdaUpdate方法:
@GetMapping("/list")
@ApiOperation("根据id集合查询用户")
public List<UserVO> queryUsers(UserQuery query){// 1.组织条件String username = query.getName();Integer status = query.getStatus();Integer minBalance = query.getMinBalance();Integer maxBalance = query.getMaxBalance();// 2.查询用户List<User> users = userService.lambdaQuery().like(username != null, User::getUsername, username).eq(status != null, User::getStatus, status).ge(minBalance != null, User::getBalance, minBalance).le(maxBalance != null, User::getBalance, maxBalance).list();// 3.处理voreturn BeanUtil.copyToList(users, UserVO.class);
}
- .one():最多1个结果
- .list():返回集合结果
- .count():返回计数结果
@Override
@Transactional
public void deductBalance(Long id, Integer money) {// 1.查询用户User user = getById(id);// 2.校验用户状态if (user == null || user.getStatus() == 2) {throw new RuntimeException("用户状态异常!");}// 3.校验余额是否充足if (user.getBalance() < money) {throw new RuntimeException("用户余额不足!");}// 4.扣减余额 update tb_user set balance = balance - ?int remainBalance = user.getBalance() - money;lambdaUpdate().set(User::getBalance, remainBalance) // 更新余额.set(remainBalance == 0, User::getStatus, 2) // 动态判断,是否更新status.eq(User::getId, id).eq(User::getBalance, user.getBalance()) // 乐观锁.update();
}
上面代码我们看到在对余额进行更新的时候,我们对用户余额进行判断,也就是说我们在扣减用户余额时,如果发现剩余余额为0,则应该将status修改为2,这就是说update语句的set部分是动态的。
批量新增
首先我们用逐条加入数据来测试
@Test
void testSaveOneByOne() {long b = System.currentTimeMillis();for (int i = 1; i <= 100000; i++) {userService.save(buildUser(i));}long e = System.currentTimeMillis();System.out.println("耗时:" + (e - b));
}private User buildUser(int i) {User user = new User();user.setUsername("user_" + i);user.setPassword("123");user.setPhone("" + (18688190000L + i));user.setBalance(2000);user.setInfo("{\"age\": 24, \"intro\": \"英文老师\", \"gender\": \"female\"}");user.setCreateTime(LocalDateTime.now());user.setUpdateTime(user.getCreateTime());return user;
}
通过执行时长我们看到,耗时非常长达到了20多秒
然后再试试MybatisPlus的批处理:
@Test
void testSaveBatch() {// 准备10万条数据List<User> list = new ArrayList<>(1000);long b = System.currentTimeMillis();for (int i = 1; i <= 100000; i++) {list.add(buildUser(i));// 每1000条批量插入一次if (i % 1000 == 0) {userService.saveBatch(list);list.clear();}}long e = System.currentTimeMillis();System.out.println("耗时:" + (e - b));
}
速度比之前快了快十倍左右,我们继续看MybatisPlus源码
@Transactional(rollbackFor = Exception.class)
@Override
public boolean saveBatch(Collection<T> entityList, int batchSize) {String sqlStatement = getSqlStatement(SqlMethod.INSERT_ONE);return executeBatch(entityList, batchSize, (sqlSession, entity) -> sqlSession.insert(sqlStatement, entity));
}
// ...SqlHelper
public static <E> boolean executeBatch(Class<?> entityClass, Log log, Collection<E> list, int batchSize, BiConsumer<SqlSession, E> consumer) {Assert.isFalse(batchSize < 1, "batchSize must not be less than one");return !CollectionUtils.isEmpty(list) && executeBatch(entityClass, log, sqlSession -> {int size = list.size();int idxLimit = Math.min(batchSize, size);int i = 1;for (E element : list) {consumer.accept(sqlSession, element);if (i == idxLimit) {sqlSession.flushStatements();idxLimit = Math.min(idxLimit + batchSize, size);}i++;}});
}
可以发现其实MybatisPlus的批处理是基于PrepareStatement的预编译模式,然后批量提交,最终在数据库执行时还是会有多条insert语句,逐条插入数据。SQL类似这样:
Preparing: INSERT INTO user ( username, password, phone, info, balance, create_time, update_time ) VALUES ( ?, ?, ?, ?, ?, ?, ? )
Parameters: user_1, 123, 18688190001, "", 2000, 2023-07-01, 2023-07-01
Parameters: user_2, 123, 18688190002, "", 2000, 2023-07-01, 2023-07-01
Parameters: user_3, 123, 18688190003, "", 2000, 2023-07-01, 2023-07-01
那么如果想要得到很好的性能,我们最好把Sql编为一句
INSERT INTO user ( username, password, phone, info, balance, create_time, update_time )
VALUES
(user_1, 123, 18688190001, "", 2000, 2023-07-01, 2023-07-01),
(user_2, 123, 18688190002, "", 2000, 2023-07-01, 2023-07-01),
(user_3, 123, 18688190003, "", 2000, 2023-07-01, 2023-07-01),
(user_4, 123, 18688190004, "", 2000, 2023-07-01, 2023-07-01);
该怎么做呢?
MySQL的客户端连接参数中有这样的一个参数:rewriteBatchedStatements。顾名思义,就是重写批处理的statement语句。参考文档:文档
这个参数的默认值是false,我们需要修改连接参数,将其配置为true
修改项目中的application.yml文件,在jdbc的url后面添加参数&rewriteBatchedStatements=true:
spring:datasource:url: jdbc:mysql://127.0.0.1:3306/mp?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=truedriver-class-name: com.mysql.cj.jdbc.Driverusername: rootpassword: MySQL123
拓展功能
代码生成
在使用MybatisPlus以后,基础的Mapper、Service、PO代码相对固定,重复编写也比较麻烦。因此MybatisPlus官方提供了代码生成器根据数据库表结构生成PO、Mapper、Service等相关代码。只不过代码生成器同样要编码使用,也很麻烦。
安装插件
使用

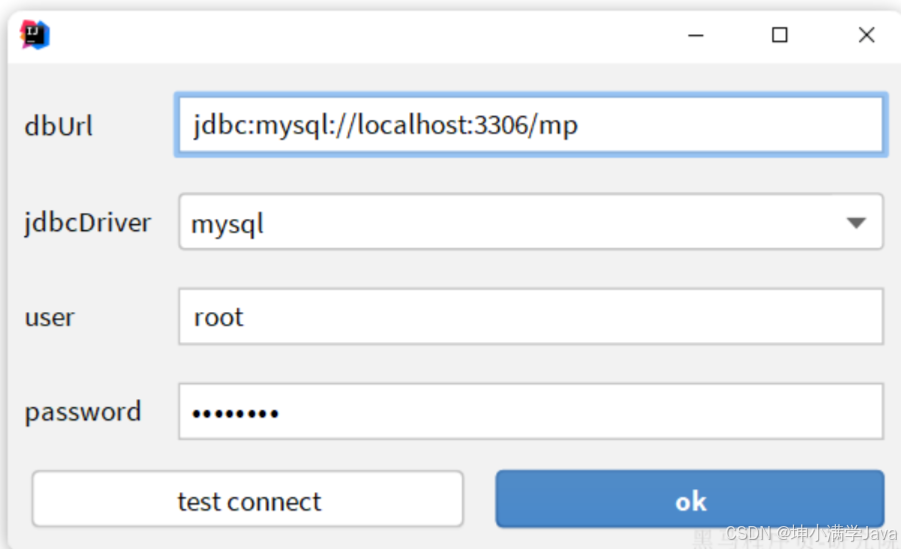
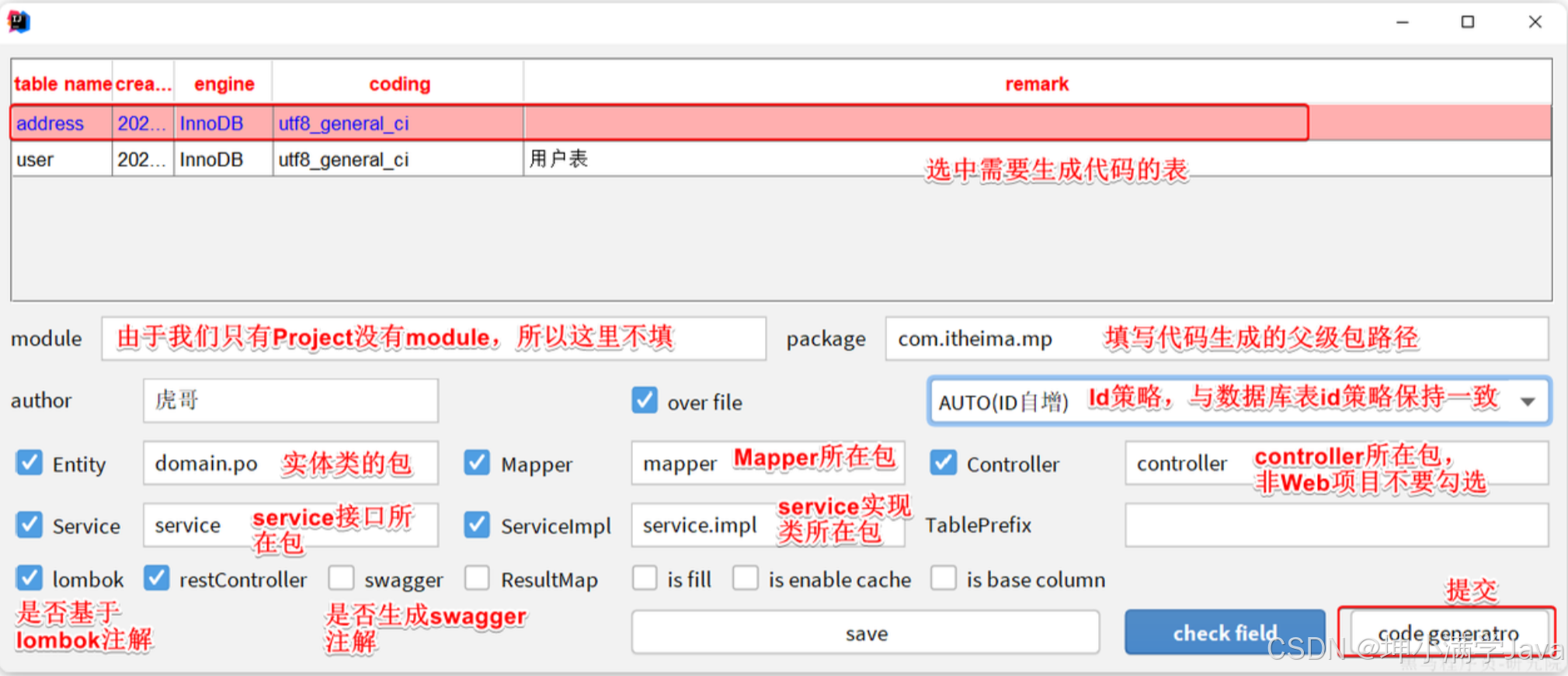
然后再次点击Idea顶部菜单中的other,然后选择Code Generator:

静态工具
有的时候Service之间也会相互调用,为了避免出现循环依赖问题,MybatisPlus提供一个静态工具类:Db,其中的一些静态方法与IService中方法签名基本一致,也可以帮助我们实现CRUD功能:

demo
@Test
void testDbGet() {User user = Db.getById(1L, User.class);System.out.println(user);
}@Test
void testDbList() {// 利用Db实现复杂条件查询List<User> list = Db.lambdaQuery(User.class).like(User::getUsername, "o").ge(User::getBalance, 1000).list();list.forEach(System.out::println);
}@Test
void testDbUpdate() {Db.lambdaUpdate(User.class).set(User::getBalance, 2000).eq(User::getUsername, "Rose");
}
逻辑删除
对于一些比较重要的数据,我们往往会采用逻辑删除的方案,即:
- 在表中添加一个字段标记数据是否被删除
- 当删除数据时把标记置为true
- 查询时过滤掉标记为true的数据
一旦采用了逻辑删除,所有的查询和删除逻辑都要跟着变化,非常麻烦。
为了解决这个问题,MybatisPlus就添加了对逻辑删除的支持。

配置
mybatis-plus:global-config:db-config:logic-delete-field: deleted # 全局逻辑删除的实体字段名(since 3.3.0,配置后可以忽略不配置步骤2)logic-delete-value: 1 # 逻辑已删除值(默认为 1)logic-not-delete-value: 0 # 逻辑未删除值(默认为 0)
通用枚举
我们定义一个枚举类
package com.itheima.mp.enums;import com.baomidou.mybatisplus.annotation.EnumValue;
import lombok.Getter;@Getter
public enum UserStatus {NORMAL(1, "正常"),FREEZE(2, "冻结");private final int value;private final String desc;UserStatus(int value, String desc) {this.value = value;this.desc = desc;}
}
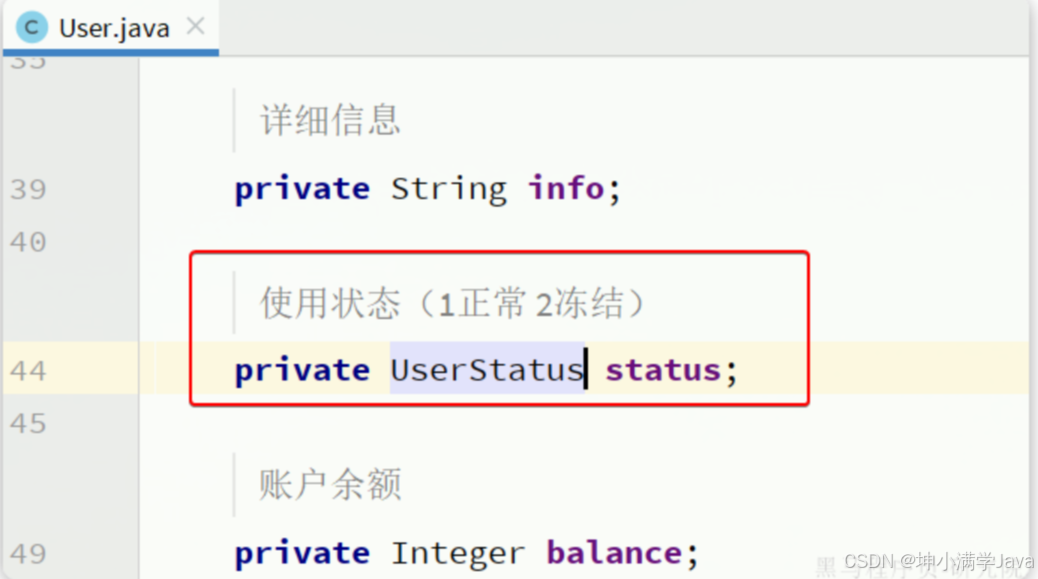
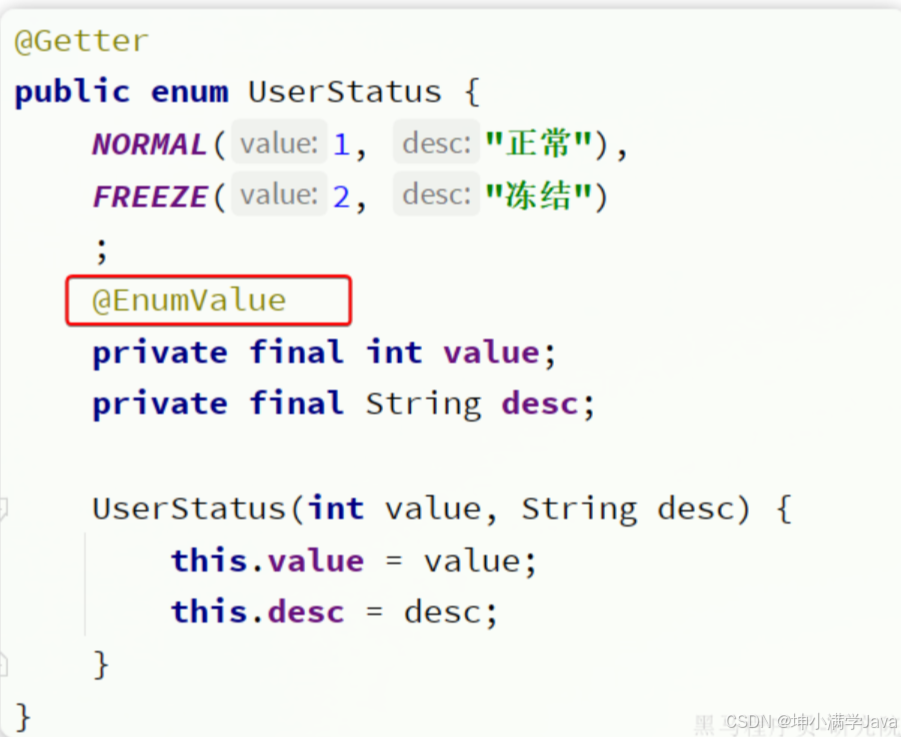
要让MybatisPlus处理枚举与数据库类型自动转换,我们必须告诉MybatisPlus,枚举中的哪个字段的值作为数据库值。
MybatisPlus提供了@EnumValue注解来标记枚举属性:
配置枚举处理器
mybatis-plus:configuration:default-enum-type-handler: com.baomidou.mybatisplus.core.handlers.MybatisEnumTypeHandler
JSON类型处理器
数据库有一个字段是JSON类型的,但是在Java当中我们没有JSON类型的类,目前我们只能用JSON来处理
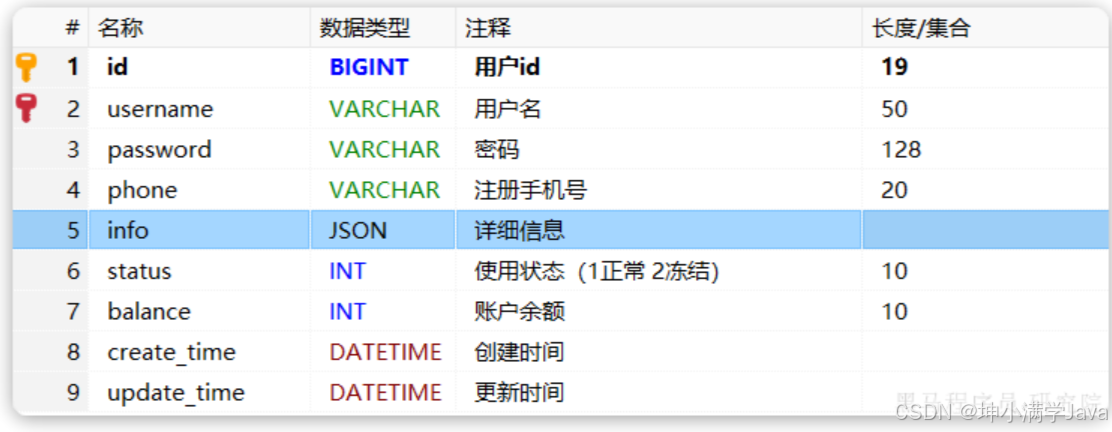
这样一来,我们要读取info中的属性时就非常不方便。如果要方便获取,info的类型最好是一个Map或者实体类。
而一旦我们把info改为对象类型,就需要在写入数据库时手动转为String,再读取数据库时,手动转换为对象,这会非常麻烦。
因此MybatisPlus提供了很多特殊类型字段的类型处理器,解决特殊字段类型与数据库类型转换的问题。例如处理JSON就可以使用JacksonTypeHandler处理器。
我们先定义一个与Json格式相同的实体类
package com.itheima.mp.domain.po;import lombok.Data;@Data
public class UserInfo {private Integer age;private String intro;private String gender;
}
接下来,将User类的info字段修改为UserInfo类型,并声明类型处理器:
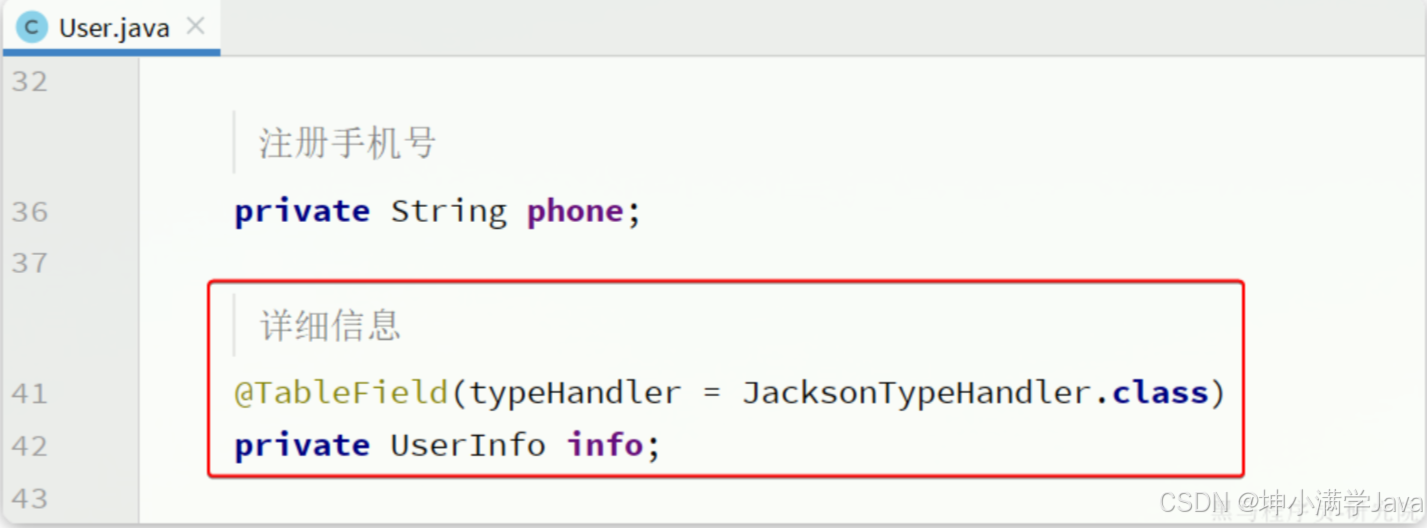
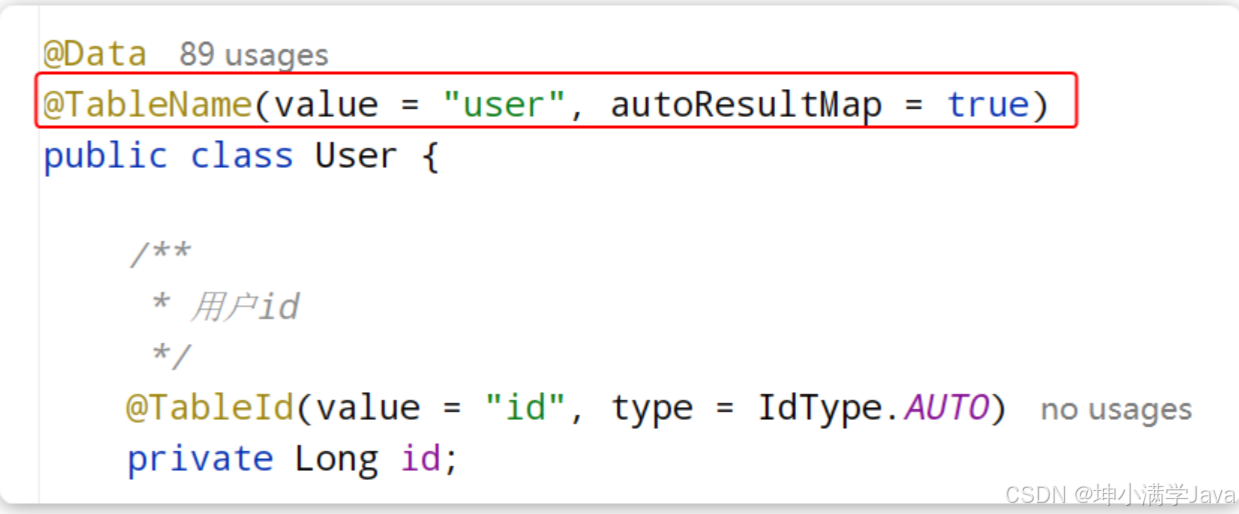
同时,在User类上添加一个注解,声明自动映射:
分页插件
配置分页插件
创建一个配置类
package com.itheima.mp.config;import com.baomidou.mybatisplus.annotation.DbType;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class MybatisConfig {@Beanpublic MybatisPlusInterceptor mybatisPlusInterceptor() {// 初始化核心插件MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();// 添加分页插件interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));return interceptor;}
}
使用
@Test
void testPageQuery() {// 1.分页查询,new Page()的两个参数分别是:页码、每页大小Page<User> p = userService.page(new Page<>(2, 2));// 2.总条数System.out.println("total = " + p.getTotal());// 3.总页数System.out.println("pages = " + p.getPages());// 4.数据List<User> records = p.getRecords();records.forEach(System.out::println);
}
指定排序规则
int pageNo = 1, pageSize = 5;
// 分页参数
Page<User> page = Page.of(pageNo, pageSize);
// 排序参数, 通过OrderItem来指定
page.addOrder(new OrderItem("balance", false));userService.page(page);
简化实体类
从上面开发我们可以看到,从Query到Page是非常麻烦的
package com.itheima.mp.domain.query;import com.baomidou.mybatisplus.core.metadata.OrderItem;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import lombok.Data;@Data
public class PageQuery {private Integer pageNo;private Integer pageSize;private String sortBy;private Boolean isAsc;public <T> Page<T> toMpPage(OrderItem ... orders){// 1.分页条件Page<T> p = Page.of(pageNo, pageSize);// 2.排序条件// 2.1.先看前端有没有传排序字段if (sortBy != null) {p.addOrder(new OrderItem(sortBy, isAsc));return p;}// 2.2.再看有没有手动指定排序字段if(orders != null){p.addOrder(orders);}return p;}public <T> Page<T> toMpPage(String defaultSortBy, boolean isAsc){return this.toMpPage(new OrderItem(defaultSortBy, isAsc));}public <T> Page<T> toMpPageDefaultSortByCreateTimeDesc() {return toMpPage("create_time", false);}public <T> Page<T> toMpPageDefaultSortByUpdateTimeDesc() {return toMpPage("update_time", false);}
}
那么我们就可以在里面添加一些方法,简化转化
在查询出分页结果后,数据的非空校验,数据的vo转换都是模板代码,编写起来很麻烦。
我们完全可以将其封装到PageDTO的工具方法中,简化整个过程:
package com.itheima.mp.domain.dto;import cn.hutool.core.bean.BeanUtil;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;import java.util.Collections;
import java.util.List;
import java.util.function.Function;
import java.util.stream.Collectors;@Data
@NoArgsConstructor
@AllArgsConstructor
public class PageDTO<V> {private Long total;private Long pages;private List<V> list;/*** 返回空分页结果* @param p MybatisPlus的分页结果* @param <V> 目标VO类型* @param <P> 原始PO类型* @return VO的分页对象*/public static <V, P> PageDTO<V> empty(Page<P> p){return new PageDTO<>(p.getTotal(), p.getPages(), Collections.emptyList());}/*** 将MybatisPlus分页结果转为 VO分页结果* @param p MybatisPlus的分页结果* @param voClass 目标VO类型的字节码* @param <V> 目标VO类型* @param <P> 原始PO类型* @return VO的分页对象*/public static <V, P> PageDTO<V> of(Page<P> p, Class<V> voClass) {// 1.非空校验List<P> records = p.getRecords();if (records == null || records.size() <= 0) {// 无数据,返回空结果return empty(p);}// 2.数据转换List<V> vos = BeanUtil.copyToList(records, voClass);// 3.封装返回return new PageDTO<>(p.getTotal(), p.getPages(), vos);}/*** 将MybatisPlus分页结果转为 VO分页结果,允许用户自定义PO到VO的转换方式* @param p MybatisPlus的分页结果* @param convertor PO到VO的转换函数* @param <V> 目标VO类型* @param <P> 原始PO类型* @return VO的分页对象*/public static <V, P> PageDTO<V> of(Page<P> p, Function<P, V> convertor) {// 1.非空校验List<P> records = p.getRecords();if (records == null || records.size() <= 0) {// 无数据,返回空结果return empty(p);}// 2.数据转换List<V> vos = records.stream().map(convertor).collect(Collectors.toList());// 3.封装返回return new PageDTO<>(p.getTotal(), p.getPages(), vos);}
}
相关文章:

【从0到1学MybatisPlus】MybatisPlus入门
Mybatis-Plus 使用场景 大家在日常开发中应该能发现,单表的CRUD功能代码重复度很高,也没有什么难度。而这部分代码量往往比较大,开发起来比较费时。 因此,目前企业中都会使用一些组件来简化或省略单表的CRUD开发工作。目前在国…...

【S32M244 RTD200P04 LLD篇8】S32M244 PWM ADC LLD demo
【S32M244 RTD200P04 LLD篇8】S32M244 PWM ADC LLD demo 一,文档简介二,PWMTRGMUXPDBADC 2ch 软件配置与实现2.1 软硬件版本平台2.2 Demo CT 模块配置2.2.1 引脚配置2.2.2 时钟配置2.2.3 外设配置 2.3主程序调用情况 三, 测试结果 一…...
动态规划蓝桥杯竞赛指南:动态规划解决最少钞票数问题(超详细解析+代码实现))
(蓝桥杯)动态规划蓝桥杯竞赛指南:动态规划解决最少钞票数问题(超详细解析+代码实现)
问题描述 近期,黄开的银行新发行了一种面额为 4 的钞票,使得钞票种类增至 5 种:20、10、5、4 和 1 元。银行在发钞时十分“节俭”,当有客户取钱时,需要以最少的钞票数来满足取款金额。 问题要求: 对于给定…...

深度:善用人工智能推动高等教育学习、教学与治理的深层变革
在人工智能技术与教育深度融合的当下,高等教育正经历着前所未有的范式转型。从学习方式的革新到教学模式的重构,再到治理体系的升级,人工智能已不再仅仅是辅助工具,而是成为重塑高等教育生态的核心驱动力。这一变革浪潮中,生成式人工智能(Generative AI)作为技术前沿的代…...

python全栈-JavaScript
python全栈-js 文章目录 js基础变量与常量JavaScript引入到HTML文件中JavaScript注释与常见输出方式 数据类型typeof 显示数据类型算数运算符之加法运算符运算符之算术运算符运算符之赋值运算符运算符之比较运算符运算符之布尔运算符运算符之位运算符运算符优先级类型转换 控制…...

Django信号使用完全指南示例
推荐超级课程: 本地离线DeepSeek AI方案部署实战教程【完全版】Docker快速入门到精通Kubernetes入门到大师通关课AWS云服务快速入门实战目录 **引言:****先决条件:****目录:****1. 什么是Django信号?****2:设置你的Django项目****2.1. 安装Django**2.2. 创建一个Django项…...

# 深入理解GPT:架构、原理与应用示例
深入理解GPT:架构、原理与应用示例 一、引言 GPT(Generative Pre-trained Transformer)系列模型自2018年问世以来,凭借其强大的文本生成能力和多任务适应性,彻底改变了自然语言处理(NLP)领域。…...

C语言递归
一、递归的核心原理 1. 递归的本质 自相似性:将问题分解为与原问题结构相同但规模更小的子问题(如树的遍历、分治算法)。 栈机制:每次递归调用都会在内存栈中创建一个新的函数栈帧,保存当前状态(参数、局…...

Jetpack Compose 基础组件学习2.0
文章目录 1、kotlin版本修改问题修改2、前言:参考知识点: 3、文字超链接的实现新版实现(Text AnnotatedString实现效果) 4、文字强调效果( Material3 的透明度方案)material依赖实现文字强调效果ÿ…...

MySQL SQL 优化的10个关键方向
1. 索引优化 合理创建索引:为高频查询条件、JOIN字段、排序字段创建索引 复合索引设计:遵循最左前缀原则,将选择性高的列放在前面 避免索引失效:防止索引列上使用函数、类型转换、OR条件不当使用 覆盖索引:尽量让查…...

babel-runtime 如何缩小打包体积
🤖 作者简介:水煮白菜王,一位前端劝退师 👻 👀 文章专栏: 前端专栏 ,记录一下平时在博客写作中,总结出的一些开发技巧和知识归纳总结✍。 感谢支持💕💕&#…...

VMware Fusion虚拟机Mac版安装CentOS Stream 9
VMware Fusion虚拟机Mac版安装CentOS Stream 9 文章目录 VMware Fusion虚拟机Mac版安装CentOS Stream 9一、介绍二、效果三、下载 一、介绍 CentOS Stream 9是CentOS Stream发行版的最新主要版本,旨在提供Red Hat Enterprise Linux(RHEL)的每…...
手搓多模态-05 transformer编码层
前情回顾 前面我们已经实现一个图像嵌入层和顶层的模型调度: class SiglipVisionTransformer(nn.Module): ##视觉模型的第二层,将模型的调用分为了图像嵌入模型和transformer编码器模型的调用def __init__(self, config:SiglipVisionConfig):super().__i…...

LightTrack + VOT2019 + Jetson 部署全流程指南【轻量级目标跟踪】
LightTrack VOT2019 Jetson 部署全流程指南【轻量级目标跟踪】 🔧 1. 环境准备(Jetson 平台)推荐配置:⚙️ 安装 Python 3.6 虚拟环境(Jetson 原生 Python 版本较新) 📥 2. 下载 LightTrack 源…...

【Easylive】视频删除方法详解:重点分析异步线程池使用
【Easylive】项目常见问题解答(自用&持续更新中…) 汇总版 方法整体功能 这个deleteVideo方法是一个综合性的视频删除操作,主要完成以下功能: 权限验证:检查视频是否存在及用户是否有权限删除核心数据删除&…...
循环单链表(数据结构)(指针)(循环列表教程))
(C语言)循环单链表(数据结构)(指针)(循环列表教程)
目录 源代码: 代码详解: 1. 头文件和宏定义 2. 类型定义 3. 初始化链表 4. 判断链表是否为空 5. 求链表的长度 6. 清空链表 7. 销毁链表 8. 链表的插入(头插法) 9. 链表的插入(尾插法) 10. 查看…...

Debian 12 服务器搭建Beego环境
一、Debian 12系统准备 1.更新系统 #apt update && apt upgrade -y 2.安装基础工具 #apt install -y git curl wget make gcc 二、安装Go环境 Go语言的镜像官网:https://golang.google.cn/ 1.下载go最新版 #cd /usr/local/src #wget -o https://golang.go…...
)
淘宝商品评论API接口概述及JSON数据参考(测试)
前言 一、淘宝商品评论API接口概述 淘宝商品评论API接口是淘宝开放平台提供的一项服务,允许开发者通过HTTP请求获取指定商品的评论数据。这些数据包括评论内容、评论者信息、评分、评论时间等,为开发者提供了丰富的商品评价信息,有助于分析…...

AI:决策树、决策森林与随机森林
决策树与随机森林:从原理到实战的全面解析(2025最新版) 引言 在机器学习的世界里,决策树和森林模型(包括随机森林)常常是数据科学家们常用的工具之一。无论是初学者还是资深从业者,理解这些模型的原理和应用,都能帮助你在数据分析和预测任务中获得更好的结果。本文将…...

图形化编程语言:低代码赛道的技术革命与范式突破
在 2024 年 Gartner 低代码平台魔力象限报告中,传统低代码厂商市场份额增速放缓至 12%,而图形化编程语言赛道融资额同比激增 370%。本文深度剖析低代码平台的技术瓶颈,系统阐释图形化编程语言的核心优势,揭示其如何重构软件开发范…...

EdgeInfinite: 用3B模型处理无限长的上下文
论文标题 EdgeInfinite: A Memory-Efficient Infinite-Context Transformer for Edge Devices 论文地址 https://arxiv.org/pdf/2503.22196 作者背景 vivo,浙江大学 代码 The code will be released after the official audit. 动机 self-attention的二次时…...

大模型论文:Improving Language Understanding by Generative Pre-Training
大模型论文:Improving Language Understanding by Generative Pre-Training OpenAI2018 文章地址:https://www.mikecaptain.com/resources/pdf/GPT-1.pdf 摘要 自然语言理解包括各种各样的任务,如文本蕴涵、问题回答、语义相似性评估和文…...

springboot 项目怎样开启https服务
要在Spring Boot项目中启用HTTPS服务,请按照以下步骤操作: 1. 生成SSL证书密钥库 使用keytool生成自签名证书 在终端或命令行工具中运行以下命令,生成一个PKCS12格式的密钥库文件: keytool -genkeypair -alias myapp -keyalg …...

R语言之mlr依赖包缺失警告之分析
因为本地没有网络,所有相关的依赖包都是手动下载,再使用脚本一键安装的。 在使用mlr包时,执行下面的代码时,总是报各种依赖缺失,也不知道咋看FAIL信息。 # 建模与调参 # 查阅线性回归、随机森林、xgboost和KNN四种模…...

如何记录日常笔记
关于用Obsidian记日常笔记这事儿,我的经验是别想得太复杂。刚开始用的时候总想着要搞个完美的分类系统,后来发现简单粗暴反而最实用。 文件夹分两类就够了——比如「工作记录」扔一个文件夹,「读书笔记」扔另一个,别分太细&#…...

Completablefuture的底层原理是什么
参考面试回答: 个人理解 CompletableFuture 是 Java 8 引入的一个类、它可以让我们在多线程环境中更加容易地处理异步任务。CompletableFuture 的底层原理是基于一个名为 FutureTask 的机制、结合了 监听器模式 和 等待-通知机制 来处理异步计算。 1.首先就是Com…...
 目录结构与路径描述:对比 Windows 系统差异(期末,期中复习笔记全))
Linux学习笔记(1) 目录结构与路径描述:对比 Windows 系统差异(期末,期中复习笔记全)
前言 一、Linux 的目录结构 二、Linux 路径的描述方式 三、总结 前言 在计算机操作系统的领域中,Linux 和 Windows 是两大主流系统。它们在目录结构和路径描述方式上存在显著不同,理解这些差异对于熟练掌握 Linux 系统至关重要。 一、Linux 的目录结构…...

《算法笔记》10.3小节——图算法专题->图的遍历 问题 A: 第一题
题目描述 该题的目的是要你统计图的连通分支数。 输入 每个输入文件包含若干行,每行两个整数i,j,表示节点i和j之间存在一条边。 输出 输出每个图的联通分支数。 样例输入 1 4 4 3 5 5样例输出 2 分析: 由于题目没给出范围࿰…...

【docker】
1.构建jar包 2.构建自定义的镜像dockerfile vim Dockerfile # 使用 OpenJDK 17 作为基础镜像,该镜像包含 JDK 17 环境 # 该镜像适用于需要编译或运行基于 JDK 17 的 Java 应用程序FROM openjdk:8-jdk-alpine# 设置容器中的工作目录为 /app # 所有后续操作…...
)
深度学习总结(1)
初识神经网络(helloworld) 要解决的问题是,将手写数字的灰度图像(28像素28像素)划分到10个类别中(从0到9)。我们将使用MNIST数据集。 在机器学习中,分类问题中的某个类别叫作类(class),数据点叫作样本(sample),与某个样本对应的类叫作标签(label)。…...

Java面试38-Dubbo是如何动态感知服务下线的?
首先,Dubbo默认采用Zookeeper实现服务注册与服务发现,就是多个Dubbo服务之间的通信地址,是使用Zookeeper来维护的。在Zookeeper上,会采用树形结构的方式来维护Dubbo服务提供端的协议地址,Dubbo服务消费端会从Zookeeper…...

企业数据分析何时该放弃Excel?
在企业数据分析中,Excel 的适用数据量范围取决于 数据复杂度、计算需求 和 硬件性能: 一、Excel 适合处理的数据量范围 数据规模适用场景限制与风险≤10万行- 日常报表 - 简单数据透视表 - 基础公式计算(如SUMIFS、VLOOKUP)处理流畅,无明显性能问题10万~50万行- 较复杂分析…...

单片机实现触摸按钮执行自定义任务组件
触摸按钮执行自定义任务组件 项目简介 本项目基于RT8H8K001开发板 RT6809CNN01开发板 TFT显示屏(1024x600) GT911触摸屏实现了一个多功能触摸按钮组件。系统具备按钮控制后执行任务的功能,可用于各类触摸屏人机交互场景。 硬件平台 MCU: STC8H8K64U࿰…...

深度学习与神经网络 | 邱锡鹏 | 第四章学习笔记 神经网络
四、神经网络 文章目录 四、神经网络4.1 神经元4.2 神经网络4.3 前馈神经网络4.4 反向传播算法4.5 计算图与自动微分4.6 优化问题 4.1 神经元 w表示每一维(其他神经元)的权重,b可以用来调控阈值,z 经过激活函数得到最后的值a来判…...

去产能、去库存、去杠杆、降成本、补短板的智慧工业开源了。
智慧工业视觉监控平台是一款功能强大且简单易用的实时算法视频监控系统。它的愿景是最底层打通各大芯片厂商相互间的壁垒,省去繁琐重复的适配流程,实现芯片、算法、应用的全流程组合,从而大大减少企业级应用约95%的开发成本。用户只需在界面上…...

【嵌入式系统设计师】知识点:第4章 嵌入式系统软件基础知识
提示:“软考通关秘籍” 专栏围绕软考展开,全面涵盖了如嵌入式系统设计师、数据库系统工程师、信息系统管理工程师等多个软考方向的知识点。从计算机体系结构、存储系统等基础知识,到程序语言概述、算法、数据库技术(包括关系数据库、非关系型数据库、SQL 语言、数据仓库等)…...

Scala基础知识
数组 不可变数组 第一种方式定义数组 定义:val arr1 new Array[Int](10) (1)new 是关键字 (2)[Int]是指定可以存放的数据类型,如果希望存放任意数据类型,则指定Any (3&#x…...
)
scala课后总结(7)
不可变数组与可变数组的转换 arr1.toBuffer :将不可变数组 arr1 转换为可变数组,原 arr1 不变,返回新的可变数组 。 arr2.toArray :把可变数组 arr2 转为不可变数组, arr2 本身不变,返回新的不可…...

【T2I】MIGC: Multi-Instance Generation Controller for Text-to-Image Synthesis
code:CVPR 2024 MIGC: Multi-Instance Generation Controller for Text-to-Image Synthesis [CVPR 2024] MIGC: Multi-Instance Generation Controller for Text-to-Image Synthesis - 知乎 Abstract 我们提出了一个多实例生成(Multi-Instance Generation, MIG)任务…...

MyBatis的第三天笔记
4. MyBatis核心配置文件详解 4.1 配置文件结构 MyBatis核心配置文件采用XML格式,主要用于配置数据库连接、事务管理、映射文件等信息。以下是一个基本的配置文件示例: <?xml version"1.0" encoding"UTF-8" ?> <!DOCTY…...

03_docker 部署 nginx 配置 HTTPS 并转发请求到后端服务
03_Docker 部署 Nginx 配置 HTTPS 并转发请求到后端服务 一、在 Docker 内部署 Nginx 拉取 Nginx 镜像 docker pull nginx:1.19.4 //如果能直接拉取使用这个命令 docker pull docker.xuanyuan.me/nginx:1.19.4 //不能直接拉取需要在前面加上镜像地址拉取成功后,创建…...

位运算题目:N 天后的牢房
文章目录 题目标题和出处难度题目描述要求示例数据范围 解法思路和算法代码复杂度分析 题目 标题和出处 标题:N 天后的牢房 出处:957. N 天后的牢房 难度 5 级 题目描述 要求 8 \texttt{8} 8 间牢房排成一排,每间牢房的状态是被占用或…...

OceanBase V4.3.5 上线全文索引功能,让数据检索更高效
近日,OceanBase 4.3.5 BP1 版本正式推出了企业级全文索引功能。该版本在中文分词、查询效率及混合检索能力上进行了全面提升。经过自然语言模式和布尔模式在不同场景下的对比测试,OceanBase 的全文索引性能明显优于 MySQL。 点击下载 OceanBase 社区版…...

【MySQL 数据库】数据表的操作
🔥博客主页🔥:【 坊钰_CSDN博客 】 欢迎各位点赞👍评论✍收藏⭐ 目录 1. 表的查看 1.1 语法 2. 表的创建 2.1 语法 2.2 练习 3. 查看表结构 3.1 语法 3.2 示例 4. 表的修改 4.1 语法 4.2 示例操作 4.2.1 向表中添加字段…...
Dart 中使用 Pub 包管理系统与 HTTP 请求教程)
(三十七)Dart 中使用 Pub 包管理系统与 HTTP 请求教程
Dart 中使用 Pub 包管理系统与 HTTP 请求教程 Pub 包管理系统简介 Pub 是 Dart 和 Flutter 的包管理系统,用于管理项目的依赖。通过 Pub,开发者可以轻松地添加、更新和管理第三方库。 使用 Pub 包管理系统 1. 找到需要的库 访问以下网址,…...

几款开源网盘的比较
开源网盘 1. Nextcloud2. Seafile3. ownCloud4. Syncthing5. FileBrowser6. Z-File7. kiftd总结对比推荐选择 1. Nextcloud 开发语言:PHP (后端) JavaScript (前端) 官网:https://nextcloud.com/ 特点: 功能全面(文件同步、共享…...

python中的in关键字查找的时间复杂度
列表(List) 对于列表来说, in 运算符的复杂度是 O(n),其中n是列表的长度。这意味着如果列表中有n个元素,那么执行 in 运算符需要遍历整个列表来查找目标元素。 以下是一个示例,演示了在列表中使用 in 运算…...

Windows注册鼠标钩子,获取用户选中的文本
注册鼠标钩子 // 注册鼠标钩子 HHOOK hMouseHook; hMouseHook SetWindowsHookEx(WH_MOUSE_LL, MouseProc, GetModuleHandle(NULL), 0);// 取消鼠标钩子 UnhookWindowsHookEx(hMouseHook); hMouseHook nullptr; 上述代码中MouseProc方法用于处理系统的鼠标消息 处理鼠标消息…...

UE5 蓝图里的反射
蓝图支持使用名字调用函数 使用SetTimerByFunctionName节点即可,该节点是指延后多少时间调用函数,注意时间不能是0也不能是负数,否者不会执行...

私有化视频会议系统,业务沟通协作安全不断线
BeeWorks Meet视频会议平台具备丰富而强大的功能,能够满足企业多样化的业务场景需求。其会议管理功能,让企业能够轻松安排和管理各类会议。 从创建会议、设置会议时间、邀请参会人员到会议提醒,一应俱全,确保会议的顺利进行。多人…...