# 深入理解GPT:架构、原理与应用示例
深入理解GPT:架构、原理与应用示例
一、引言
GPT(Generative Pre-trained Transformer)系列模型自2018年问世以来,凭借其强大的文本生成能力和多任务适应性,彻底改变了自然语言处理(NLP)领域。本文将从架构设计、训练方法到实际应用,结合代码示例与架构图,带您全面理解GPT的核心原理。
二、GPT的核心架构
1. 整体架构图(文字描述)
输入文本 → [词嵌入层] → [位置编码层] → ↓
多层Transformer解码器(仅Decoder):├─ Masked Self-Attention层(遮蔽未来信息)├─ 前馈神经网络(FFN)└─ 残差连接 + 层归一化↓
输出层 → Softmax生成概率分布 → 下一个词预测
GPT主要基于 Transformer 解码器(Decoder-only),整体架构如下:
GPT由词嵌入(Embedding)、多层Transformer解码器、输出层 组成:
1️⃣ 输入嵌入(Token Embeddings):
- 使用 Byte-Pair Encoding(BPE) 进行子词分词,将文本转换为 token。
- 通过 词嵌入矩阵 将 token 映射为固定维度的向量。
2️⃣ 位置编码(Positional Encoding):
- GPT 使用 可训练的位置嵌入(Learnable Positional Embeddings),不像 BERT 采用固定三角函数编码。
3️⃣ 多层 Transformer 解码器(Multi-layer Decoder):
- 由多个 自注意力(Self-Attention)、前馈神经网络(FFN)、残差连接(Residual Connections) 组成。
- Masked Self-Attention 机制,确保每个 token 只能看到 之前的 token,防止未来信息泄露。
4️⃣ 输出层(Output Layer):
- 经过线性变换 + Softmax计算概率分布,生成下一个token。
看三个语言模型的对比架构图, 中间的就是GPT:
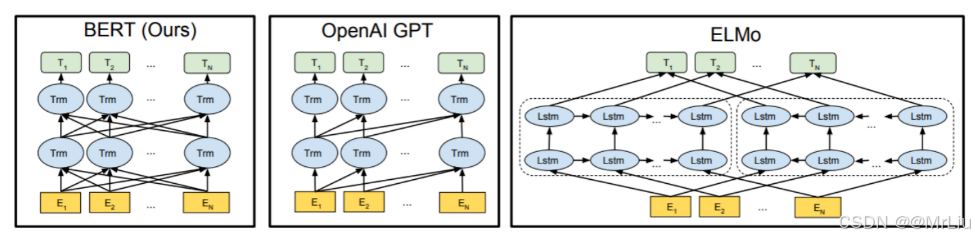
从上图可以很清楚的看到GPT采用的是单向Transformer模型, 例如给定一个句子[u1, u2, …, un], GPT在预测单词ui的时候只会利用[u1, u2, …, u(i-1)]的信息, 而BERT会同时利用上下文的信息[u1, u2, …, u(i-1), u(i+1), …, un]。
作为两大模型的直接对比, BERT采用了Transformer的Encoder模块, 而GPT采用了Transformer的Decoder模块。并且GPT的Decoder Block和经典Transformer Decoder Block还有所不同, 如下图所示:
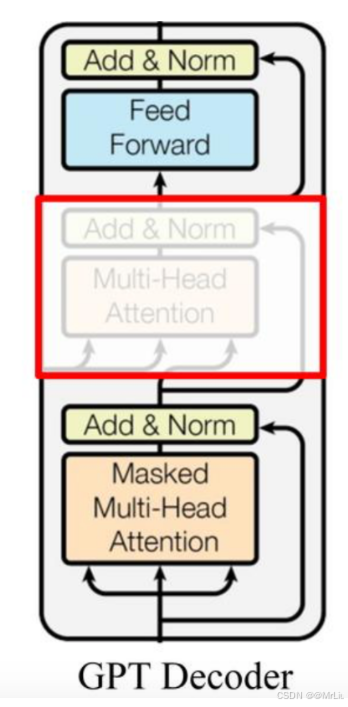
如上图所示, 经典的Transformer Decoder Block包含3个子层, 分别是Masked Multi-Head Attention层, encoder-decoder attention层, 以及Feed Forward层。但是在GPT中取消了第二个encoder-decoder attention子层, 只保留Masked Multi-Head Attention层, 和Feed Forward层。
作为单向Transformer Decoder模型, GPT利用句子序列信息预测下一个单词的时候, 要使用Masked Multi-Head Attention对单词的下文进行遮掩(look ahead mask), 来防止未来信息的提前泄露。例如给定一个句子包含4个单词[A, B, C, D], GPT需要用[A]预测B, 用[A, B]预测C, 用[A, B, C]预测D。很显然的就是当要预测B时, 需要将[B, C, D]遮掩起来。
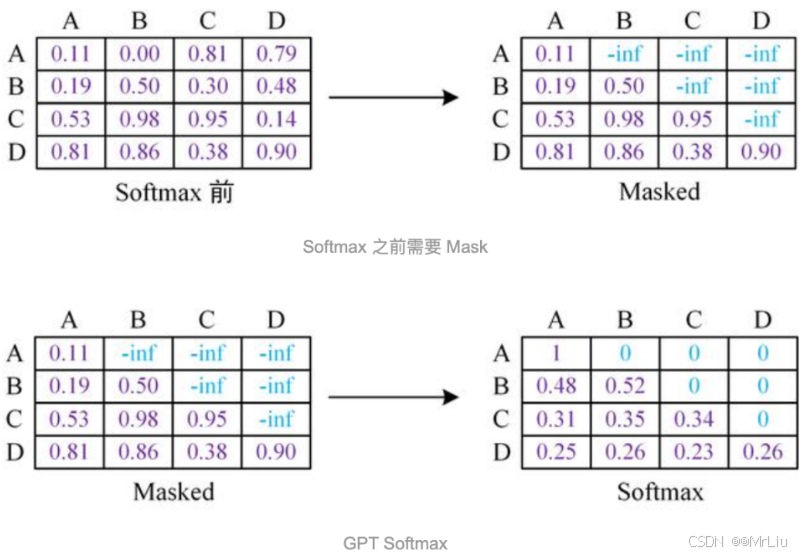
具体的遮掩操作是在slef-attention进行softmax之前进行的, 一般的实现是将MASK的位置用一个无穷小的数值-inf来替换, 替换后执行softmax计算得到新的结果矩阵,这样-inf的位置就变成了0。如上图所示, 最后的矩阵可以很方便的做到当利用A预测B的时候, 只能看到A的信息; 当利用[A, B]预测C的时候, 只能看到A, B的信息。
注意:对比于经典的Transformer架构, 解码器模块采用了6个Decoder Block; GPT的架构中采用了12个Decoder Block。
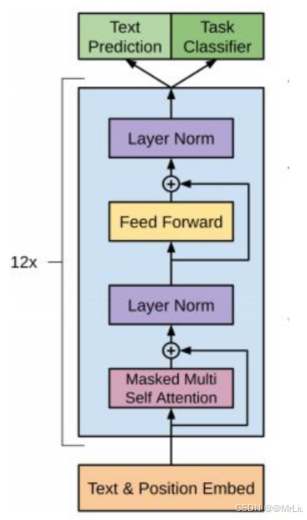
2. 关键组件详解
(1)词嵌入与位置编码
- 词嵌入:通过Byte-Pair Encoding(BPE)将文本切分为子词单元(如
"Transformer"→["Trans", "former"]),再映射为稠密向量。 - 位置编码:GPT使用可学习的位置嵌入(区别于BERT的固定三角函数编码),为模型注入序列顺序信息。
(2)Transformer解码器
GPT仅使用Transformer的解码器(Decoder)部分,核心组件包括:
-
- 自注意力层(Self-Attention Layer)
- 计算输入序列中每个词与其他词的相关性,动态分配权重。
- 公式:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V - Q Q Q(Query)、 K K K(Key)、 V V V(Value)为线性变换后的向量。
- d k d_k dk为缩放因子,防止内积过大。
-
- 前馈神经网络(Feed-Forward Network)
- 对每个词的表示进行非线性变换(如ReLU)。
-
- 残差连接与层归一化
- 每个子层后添加残差连接(Residual Connection)和层归一化(LayerNorm),缓解梯度消失。
- Masked Self-Attention:通过
look-ahead mask确保预测第i个词时只能看到前i-1个词。例如:# 遮蔽矩阵示例(4词序列) [[0, -inf, -inf, -inf],[0, 0, -inf, -inf],[0, 0, 0, -inf],[0, 0, 0, 0]] - 堆叠结构:GPT-3使用48-96层解码器,每层包含:
- 多头自注意力(16-32头)
- 前馈网络(ReLU激活)
- 残差连接与层归一化
三、训练方法与关键技术
1. 预训练流程
# 损失函数:最大化下一个词的对数似然
def pretrain_loss(logits, labels):return -tf.reduce_mean(tf.math.log(tf.nn.softmax(logits))[labels])
- 数据:互联网文本(网页、书籍等)
- 任务:预测被遮蔽的下一个词(自回归任务)
2. 微调策略
# 文本分类任务示例(添加分类头)
class GPTClassifier(tf.keras.Model):def __init__(self, base_model, num_classes):super().__init__()self.gpt = base_modelself.cls_head = tf.keras.layers.Dense(num_classes)def call(self, inputs):outputs = self.gpt(inputs)return self.cls_head(outputs[:, 0, :]) # 取[CLS]位置输出
3. 创新技术
- 上下文窗口扩展:GPT-4支持32768 token超长上下文
- 指令微调(Instruction Tuning):通过人类指令数据(如"请翻译这句话")对齐模型输出
四、代码示例:文本生成与问答
1. 文本生成(GPT-2)
from transformers import GPT2LMHeadModel, GPT2Tokenizermodel = GPT2LMHeadModel.from_pretrained("gpt2")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")input_text = "人工智能的未来发展趋势是"
inputs = tokenizer(input_text, return_tensors="pt")# 生成参数详解
outputs = model.generate(**inputs,max_length=50,temperature=0.7, # 控制随机性(0.0-确定性,1.0-随机)top_k=50, # 限制候选词数量do_sample=True # 启用采样策略
)print(tokenizer.decode(outputs[0]))
2. 问答任务(GPT-3风格)
input_text = "Q: 什么是Transformer模型?\nA:"
inputs = tokenizer(input_text, return_tensors="pt")outputs = model.generate(**inputs,max_length=100,num_beams=5, # 束搜索提升质量early_stopping=True
)print(tokenizer.decode(outputs[0]))
# 输出示例:"A: Transformer是一种基于自注意力机制的神经网络架构..."
五、架构对比与演进
| 版本 | 参数量 | 关键改进 | 应用场景 |
|---|---|---|---|
| GPT-1 | 1.17亿 | 基础Transformer解码器 | 基础文本生成 |
| GPT-2 | 15亿 | WebText预训练,Zero-shot | 多任务泛化 |
| GPT-3 | 1750亿 | Few-shot学习,API服务 | 代码生成、复杂推理 |
| GPT-4 | 未知 | 多模态支持,32K上下文 | 长文本分析、视觉推理 |
六、优缺点分析
优势
- 生成质量:可生成连贯的长文本(如小说章节)
- 上下文理解:捕捉跨句依赖(如代词消解)
- 任务泛化:通过提示词(Prompt)完成未见过的任务
局限
- 计算成本:GPT-3单次推理需约350W参数计算
- 事实幻觉:可能生成看似合理但错误的内容
- 单向性:传统GPT仅利用左侧上下文(GPT-3后引入双向注意力改进)
七、总结与展望
GPT通过预训练-微调范式与大规模Transformer架构,重新定义了NLP的边界。未来发展方向包括:
- 多模态融合:结合文本、图像、音频(如GPT-4V)
- 推理强化:通过RLHF(人类反馈强化学习)提升逻辑性
- 效率优化:稀疏注意力、模型蒸馏等技术降低计算成本
附录:架构图绘制建议
使用工具如draw.io或Mermaid绘制以下结构:
相关文章:

# 深入理解GPT:架构、原理与应用示例
深入理解GPT:架构、原理与应用示例 一、引言 GPT(Generative Pre-trained Transformer)系列模型自2018年问世以来,凭借其强大的文本生成能力和多任务适应性,彻底改变了自然语言处理(NLP)领域。…...

C语言递归
一、递归的核心原理 1. 递归的本质 自相似性:将问题分解为与原问题结构相同但规模更小的子问题(如树的遍历、分治算法)。 栈机制:每次递归调用都会在内存栈中创建一个新的函数栈帧,保存当前状态(参数、局…...

Jetpack Compose 基础组件学习2.0
文章目录 1、kotlin版本修改问题修改2、前言:参考知识点: 3、文字超链接的实现新版实现(Text AnnotatedString实现效果) 4、文字强调效果( Material3 的透明度方案)material依赖实现文字强调效果ÿ…...

MySQL SQL 优化的10个关键方向
1. 索引优化 合理创建索引:为高频查询条件、JOIN字段、排序字段创建索引 复合索引设计:遵循最左前缀原则,将选择性高的列放在前面 避免索引失效:防止索引列上使用函数、类型转换、OR条件不当使用 覆盖索引:尽量让查…...

babel-runtime 如何缩小打包体积
🤖 作者简介:水煮白菜王,一位前端劝退师 👻 👀 文章专栏: 前端专栏 ,记录一下平时在博客写作中,总结出的一些开发技巧和知识归纳总结✍。 感谢支持💕💕&#…...

VMware Fusion虚拟机Mac版安装CentOS Stream 9
VMware Fusion虚拟机Mac版安装CentOS Stream 9 文章目录 VMware Fusion虚拟机Mac版安装CentOS Stream 9一、介绍二、效果三、下载 一、介绍 CentOS Stream 9是CentOS Stream发行版的最新主要版本,旨在提供Red Hat Enterprise Linux(RHEL)的每…...
手搓多模态-05 transformer编码层
前情回顾 前面我们已经实现一个图像嵌入层和顶层的模型调度: class SiglipVisionTransformer(nn.Module): ##视觉模型的第二层,将模型的调用分为了图像嵌入模型和transformer编码器模型的调用def __init__(self, config:SiglipVisionConfig):super().__i…...

LightTrack + VOT2019 + Jetson 部署全流程指南【轻量级目标跟踪】
LightTrack VOT2019 Jetson 部署全流程指南【轻量级目标跟踪】 🔧 1. 环境准备(Jetson 平台)推荐配置:⚙️ 安装 Python 3.6 虚拟环境(Jetson 原生 Python 版本较新) 📥 2. 下载 LightTrack 源…...

【Easylive】视频删除方法详解:重点分析异步线程池使用
【Easylive】项目常见问题解答(自用&持续更新中…) 汇总版 方法整体功能 这个deleteVideo方法是一个综合性的视频删除操作,主要完成以下功能: 权限验证:检查视频是否存在及用户是否有权限删除核心数据删除&…...
循环单链表(数据结构)(指针)(循环列表教程))
(C语言)循环单链表(数据结构)(指针)(循环列表教程)
目录 源代码: 代码详解: 1. 头文件和宏定义 2. 类型定义 3. 初始化链表 4. 判断链表是否为空 5. 求链表的长度 6. 清空链表 7. 销毁链表 8. 链表的插入(头插法) 9. 链表的插入(尾插法) 10. 查看…...

Debian 12 服务器搭建Beego环境
一、Debian 12系统准备 1.更新系统 #apt update && apt upgrade -y 2.安装基础工具 #apt install -y git curl wget make gcc 二、安装Go环境 Go语言的镜像官网:https://golang.google.cn/ 1.下载go最新版 #cd /usr/local/src #wget -o https://golang.go…...
)
淘宝商品评论API接口概述及JSON数据参考(测试)
前言 一、淘宝商品评论API接口概述 淘宝商品评论API接口是淘宝开放平台提供的一项服务,允许开发者通过HTTP请求获取指定商品的评论数据。这些数据包括评论内容、评论者信息、评分、评论时间等,为开发者提供了丰富的商品评价信息,有助于分析…...

AI:决策树、决策森林与随机森林
决策树与随机森林:从原理到实战的全面解析(2025最新版) 引言 在机器学习的世界里,决策树和森林模型(包括随机森林)常常是数据科学家们常用的工具之一。无论是初学者还是资深从业者,理解这些模型的原理和应用,都能帮助你在数据分析和预测任务中获得更好的结果。本文将…...

图形化编程语言:低代码赛道的技术革命与范式突破
在 2024 年 Gartner 低代码平台魔力象限报告中,传统低代码厂商市场份额增速放缓至 12%,而图形化编程语言赛道融资额同比激增 370%。本文深度剖析低代码平台的技术瓶颈,系统阐释图形化编程语言的核心优势,揭示其如何重构软件开发范…...

EdgeInfinite: 用3B模型处理无限长的上下文
论文标题 EdgeInfinite: A Memory-Efficient Infinite-Context Transformer for Edge Devices 论文地址 https://arxiv.org/pdf/2503.22196 作者背景 vivo,浙江大学 代码 The code will be released after the official audit. 动机 self-attention的二次时…...

大模型论文:Improving Language Understanding by Generative Pre-Training
大模型论文:Improving Language Understanding by Generative Pre-Training OpenAI2018 文章地址:https://www.mikecaptain.com/resources/pdf/GPT-1.pdf 摘要 自然语言理解包括各种各样的任务,如文本蕴涵、问题回答、语义相似性评估和文…...

springboot 项目怎样开启https服务
要在Spring Boot项目中启用HTTPS服务,请按照以下步骤操作: 1. 生成SSL证书密钥库 使用keytool生成自签名证书 在终端或命令行工具中运行以下命令,生成一个PKCS12格式的密钥库文件: keytool -genkeypair -alias myapp -keyalg …...

R语言之mlr依赖包缺失警告之分析
因为本地没有网络,所有相关的依赖包都是手动下载,再使用脚本一键安装的。 在使用mlr包时,执行下面的代码时,总是报各种依赖缺失,也不知道咋看FAIL信息。 # 建模与调参 # 查阅线性回归、随机森林、xgboost和KNN四种模…...

如何记录日常笔记
关于用Obsidian记日常笔记这事儿,我的经验是别想得太复杂。刚开始用的时候总想着要搞个完美的分类系统,后来发现简单粗暴反而最实用。 文件夹分两类就够了——比如「工作记录」扔一个文件夹,「读书笔记」扔另一个,别分太细&#…...

Completablefuture的底层原理是什么
参考面试回答: 个人理解 CompletableFuture 是 Java 8 引入的一个类、它可以让我们在多线程环境中更加容易地处理异步任务。CompletableFuture 的底层原理是基于一个名为 FutureTask 的机制、结合了 监听器模式 和 等待-通知机制 来处理异步计算。 1.首先就是Com…...
 目录结构与路径描述:对比 Windows 系统差异(期末,期中复习笔记全))
Linux学习笔记(1) 目录结构与路径描述:对比 Windows 系统差异(期末,期中复习笔记全)
前言 一、Linux 的目录结构 二、Linux 路径的描述方式 三、总结 前言 在计算机操作系统的领域中,Linux 和 Windows 是两大主流系统。它们在目录结构和路径描述方式上存在显著不同,理解这些差异对于熟练掌握 Linux 系统至关重要。 一、Linux 的目录结构…...

《算法笔记》10.3小节——图算法专题->图的遍历 问题 A: 第一题
题目描述 该题的目的是要你统计图的连通分支数。 输入 每个输入文件包含若干行,每行两个整数i,j,表示节点i和j之间存在一条边。 输出 输出每个图的联通分支数。 样例输入 1 4 4 3 5 5样例输出 2 分析: 由于题目没给出范围࿰…...

【docker】
1.构建jar包 2.构建自定义的镜像dockerfile vim Dockerfile # 使用 OpenJDK 17 作为基础镜像,该镜像包含 JDK 17 环境 # 该镜像适用于需要编译或运行基于 JDK 17 的 Java 应用程序FROM openjdk:8-jdk-alpine# 设置容器中的工作目录为 /app # 所有后续操作…...
)
深度学习总结(1)
初识神经网络(helloworld) 要解决的问题是,将手写数字的灰度图像(28像素28像素)划分到10个类别中(从0到9)。我们将使用MNIST数据集。 在机器学习中,分类问题中的某个类别叫作类(class),数据点叫作样本(sample),与某个样本对应的类叫作标签(label)。…...

Java面试38-Dubbo是如何动态感知服务下线的?
首先,Dubbo默认采用Zookeeper实现服务注册与服务发现,就是多个Dubbo服务之间的通信地址,是使用Zookeeper来维护的。在Zookeeper上,会采用树形结构的方式来维护Dubbo服务提供端的协议地址,Dubbo服务消费端会从Zookeeper…...

企业数据分析何时该放弃Excel?
在企业数据分析中,Excel 的适用数据量范围取决于 数据复杂度、计算需求 和 硬件性能: 一、Excel 适合处理的数据量范围 数据规模适用场景限制与风险≤10万行- 日常报表 - 简单数据透视表 - 基础公式计算(如SUMIFS、VLOOKUP)处理流畅,无明显性能问题10万~50万行- 较复杂分析…...

单片机实现触摸按钮执行自定义任务组件
触摸按钮执行自定义任务组件 项目简介 本项目基于RT8H8K001开发板 RT6809CNN01开发板 TFT显示屏(1024x600) GT911触摸屏实现了一个多功能触摸按钮组件。系统具备按钮控制后执行任务的功能,可用于各类触摸屏人机交互场景。 硬件平台 MCU: STC8H8K64U࿰…...

深度学习与神经网络 | 邱锡鹏 | 第四章学习笔记 神经网络
四、神经网络 文章目录 四、神经网络4.1 神经元4.2 神经网络4.3 前馈神经网络4.4 反向传播算法4.5 计算图与自动微分4.6 优化问题 4.1 神经元 w表示每一维(其他神经元)的权重,b可以用来调控阈值,z 经过激活函数得到最后的值a来判…...

去产能、去库存、去杠杆、降成本、补短板的智慧工业开源了。
智慧工业视觉监控平台是一款功能强大且简单易用的实时算法视频监控系统。它的愿景是最底层打通各大芯片厂商相互间的壁垒,省去繁琐重复的适配流程,实现芯片、算法、应用的全流程组合,从而大大减少企业级应用约95%的开发成本。用户只需在界面上…...

【嵌入式系统设计师】知识点:第4章 嵌入式系统软件基础知识
提示:“软考通关秘籍” 专栏围绕软考展开,全面涵盖了如嵌入式系统设计师、数据库系统工程师、信息系统管理工程师等多个软考方向的知识点。从计算机体系结构、存储系统等基础知识,到程序语言概述、算法、数据库技术(包括关系数据库、非关系型数据库、SQL 语言、数据仓库等)…...

Scala基础知识
数组 不可变数组 第一种方式定义数组 定义:val arr1 new Array[Int](10) (1)new 是关键字 (2)[Int]是指定可以存放的数据类型,如果希望存放任意数据类型,则指定Any (3&#x…...
)
scala课后总结(7)
不可变数组与可变数组的转换 arr1.toBuffer :将不可变数组 arr1 转换为可变数组,原 arr1 不变,返回新的可变数组 。 arr2.toArray :把可变数组 arr2 转为不可变数组, arr2 本身不变,返回新的不可…...

【T2I】MIGC: Multi-Instance Generation Controller for Text-to-Image Synthesis
code:CVPR 2024 MIGC: Multi-Instance Generation Controller for Text-to-Image Synthesis [CVPR 2024] MIGC: Multi-Instance Generation Controller for Text-to-Image Synthesis - 知乎 Abstract 我们提出了一个多实例生成(Multi-Instance Generation, MIG)任务…...

MyBatis的第三天笔记
4. MyBatis核心配置文件详解 4.1 配置文件结构 MyBatis核心配置文件采用XML格式,主要用于配置数据库连接、事务管理、映射文件等信息。以下是一个基本的配置文件示例: <?xml version"1.0" encoding"UTF-8" ?> <!DOCTY…...

03_docker 部署 nginx 配置 HTTPS 并转发请求到后端服务
03_Docker 部署 Nginx 配置 HTTPS 并转发请求到后端服务 一、在 Docker 内部署 Nginx 拉取 Nginx 镜像 docker pull nginx:1.19.4 //如果能直接拉取使用这个命令 docker pull docker.xuanyuan.me/nginx:1.19.4 //不能直接拉取需要在前面加上镜像地址拉取成功后,创建…...

位运算题目:N 天后的牢房
文章目录 题目标题和出处难度题目描述要求示例数据范围 解法思路和算法代码复杂度分析 题目 标题和出处 标题:N 天后的牢房 出处:957. N 天后的牢房 难度 5 级 题目描述 要求 8 \texttt{8} 8 间牢房排成一排,每间牢房的状态是被占用或…...

OceanBase V4.3.5 上线全文索引功能,让数据检索更高效
近日,OceanBase 4.3.5 BP1 版本正式推出了企业级全文索引功能。该版本在中文分词、查询效率及混合检索能力上进行了全面提升。经过自然语言模式和布尔模式在不同场景下的对比测试,OceanBase 的全文索引性能明显优于 MySQL。 点击下载 OceanBase 社区版…...

【MySQL 数据库】数据表的操作
🔥博客主页🔥:【 坊钰_CSDN博客 】 欢迎各位点赞👍评论✍收藏⭐ 目录 1. 表的查看 1.1 语法 2. 表的创建 2.1 语法 2.2 练习 3. 查看表结构 3.1 语法 3.2 示例 4. 表的修改 4.1 语法 4.2 示例操作 4.2.1 向表中添加字段…...
Dart 中使用 Pub 包管理系统与 HTTP 请求教程)
(三十七)Dart 中使用 Pub 包管理系统与 HTTP 请求教程
Dart 中使用 Pub 包管理系统与 HTTP 请求教程 Pub 包管理系统简介 Pub 是 Dart 和 Flutter 的包管理系统,用于管理项目的依赖。通过 Pub,开发者可以轻松地添加、更新和管理第三方库。 使用 Pub 包管理系统 1. 找到需要的库 访问以下网址,…...

几款开源网盘的比较
开源网盘 1. Nextcloud2. Seafile3. ownCloud4. Syncthing5. FileBrowser6. Z-File7. kiftd总结对比推荐选择 1. Nextcloud 开发语言:PHP (后端) JavaScript (前端) 官网:https://nextcloud.com/ 特点: 功能全面(文件同步、共享…...

python中的in关键字查找的时间复杂度
列表(List) 对于列表来说, in 运算符的复杂度是 O(n),其中n是列表的长度。这意味着如果列表中有n个元素,那么执行 in 运算符需要遍历整个列表来查找目标元素。 以下是一个示例,演示了在列表中使用 in 运算…...

Windows注册鼠标钩子,获取用户选中的文本
注册鼠标钩子 // 注册鼠标钩子 HHOOK hMouseHook; hMouseHook SetWindowsHookEx(WH_MOUSE_LL, MouseProc, GetModuleHandle(NULL), 0);// 取消鼠标钩子 UnhookWindowsHookEx(hMouseHook); hMouseHook nullptr; 上述代码中MouseProc方法用于处理系统的鼠标消息 处理鼠标消息…...

UE5 蓝图里的反射
蓝图支持使用名字调用函数 使用SetTimerByFunctionName节点即可,该节点是指延后多少时间调用函数,注意时间不能是0也不能是负数,否者不会执行...

私有化视频会议系统,业务沟通协作安全不断线
BeeWorks Meet视频会议平台具备丰富而强大的功能,能够满足企业多样化的业务场景需求。其会议管理功能,让企业能够轻松安排和管理各类会议。 从创建会议、设置会议时间、邀请参会人员到会议提醒,一应俱全,确保会议的顺利进行。多人…...
-kafka详解)
大数据学习(100)-kafka详解
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一…...

unittest测试模块:Python 标准库中的单元测试利器
在当今的软件开发中,测试的必要性不言而喻。为了确保代码的质量和稳定性,开发者需要一种高效的方式去编写和运行单元测试。Python 提供了一个强大的工具——unittest。这是一个标准库模块,专为编写和运行测试而设计,帮助开发者减少…...

java后端对时间进行格式处理
时间格式处理 通过java后端,使用jackson库的注解JsonFormat(pattern "yyyy-MM-dd HH:mm:ss")进行格式化 package com.weiyu.pojo;import com.fasterxml.jackson.annotation.JsonFormat; import lombok.AllArgsConstructor; import lombok.Data; import …...

Spring的简单介绍
Spring的简单介绍 Spring 是一个开源的 Java 企业级应用开发框架,旨在简化企业应用的开发过程。它通过提供全面的基础设施支持,帮助开发人员构建可靠的、高效的、可扩展的企业级应用程序。Spring 提供了多种功能模块,支持开发不同类型的应用…...
)
Python基础知识点(函数2)
#需求 打印stu_info def show_info(name,age): print(f"姓名:{name},年龄:{age}") #1.必要参数 在调用函数的时候必须传值 show_info("tom",3) #注意!对于形参,除了个数要匹配,顺序也要匹配 …...

MySQL的左连接、右连接、内连接、外连接
一、前言 MySQL中的左连接、右连接、内连接和全外连接是用于多表关联查询的核心操作。 二、内连接(INNER JOIN) 定义:返回两个表中完全匹配的行,即只保留两个表连接字段值相等的行。示例场景:查询所有有选课记录的学…...