Kafka的索引设计有什么亮点
想获取更多高质量的Java技术文章?欢迎访问Java技术小馆官网,持续更新优质内容,助力技术成长
Java技术小馆官网![]() https://www.yuque.com/jtostring
https://www.yuque.com/jtostring
Kafka的索引设计有什么亮点?
Kafka 之所以能在海量数据的传输和处理过程中保持高效的性能和低延迟,背后隐藏着众多精妙的设计,而索引设计便是其中的一个关键亮点。在消息系统中,索引的作用不可小觑,它直接影响到数据的快速定位和读取效率。尤其在 Kafka 中,如何通过合理的索引设计来优化磁盘 IO、减少数据查找的时间复杂度。
Kafka 的索引机制不仅仅是简单地记录消息在日志中的偏移量,它更结合了高效的日志分段策略、内存映射文件技术以及零拷贝等多种优化手段,使得消息的存储与检索更加高效。在 Kafka 的架构设计中,索引文件被分为 Offset 索引和 TimeIndex 索引,每种索引各司其职,分别针对消息的偏移量和时间戳进行管理,这种设计为 Kafka 提供了快速定位消息的能力。同时,Kafka 的索引系统采用了顺序写入和高效的磁盘寻址策略,极大地提升了读写性能。在实际的应用场景中,Kafka 通过这些索引设计,不仅实现了高效的数据存取,还能够在数据量剧增的情况下保持稳定的性能表现。
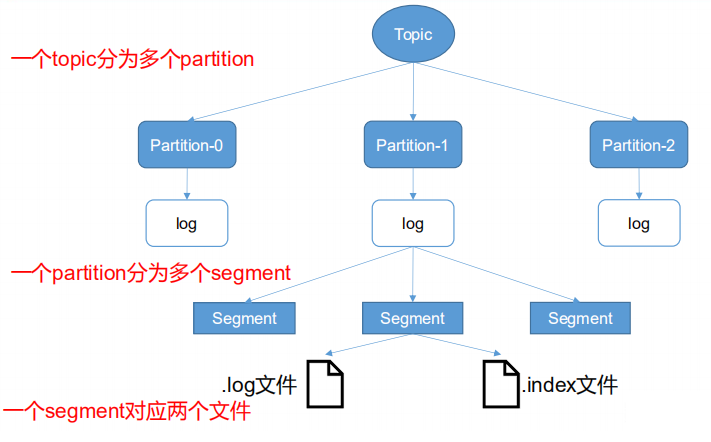
Kafka索引的基本概念
Kafka 将消息存储在称为主题(Topic)的逻辑实体中,每个主题又可以细分为多个分区(Partition)。每个分区实际上是一个有序的、不间断的日志文件,这些日志文件被存储在磁盘上。消息一旦被写入日志文件,就会被持久化,并分配一个唯一的偏移量(Offset),表示它在分区日志中的位置。
索引的基本概念
在 Kafka 中,索引的主要目的是为了提高消息检索的效率。随着时间的推移和数据量的增加,日志文件会变得非常庞大,如果没有索引,查找特定消息的操作将变得极其低效。Kafka 通过创建索引文件来快速定位和访问特定的消息,而无需遍历整个日志文件。Kafka 索引主要分为两种类型:
- Offset 索引:Offset 索引文件记录了每个消息的偏移量和该消息在日志文件中的物理位置(即字节偏移量)。Offset 索引是稀疏的,即它并不会为每条消息都建立索引,而是每隔一段距离(例如每隔若干条消息或若干字节)建立一个索引项。这种稀疏索引的设计大大减少了索引文件的大小,同时保持了良好的查找性能。当 Kafka 需要定位一条消息时,它首先通过二分查找快速定位到 Offset 索引项,然后从索引项中读取到接近该消息的物理偏移量,最后在实际的日志文件中进行一次顺序扫描,找到确切的消息。
- TimeIndex 索引:TimeIndex 索引文件记录了每个时间戳和该时间戳所对应的消息的物理位置(字节偏移量)。在实际应用场景中,许多消费者希望能够按时间范围消费消息,例如获取从某个时间点开始的所有消息。TimeIndex 索引使得 Kafka 可以通过时间戳快速查找对应的消息位置,而不需要遍历整个日志文件。同样,TimeIndex 索引也是稀疏的,进一步优化了存储和查找性能。
Kafka 索引文件的存储和管理
Kafka 将日志数据和索引数据分开存储。每个分区(Partition)的日志文件和索引文件在文件系统中分别管理,并且每个日志文件会对应多个索引文件。Kafka 使用分段日志(Segmented Log)机制,将每个分区的日志文件分成多个较小的段(Segment)。每个段都有其对应的索引文件。当一个段的大小达到设定的阈值或时间超过设定的上限时,Kafka 会创建一个新的段和对应的索引文件。通过这种分段机制,Kafka 避免了单个文件过大带来的管理和性能问题,同时简化了数据的归档和删除操作。
Kafka 索引的设计考量
Kafka 的索引设计旨在平衡性能和存储效率。通过稀疏索引和分段日志的结合,Kafka 能够在保持高效数据访问的同时,避免了索引文件过于庞大所带来的存储开销。此外,Kafka 采用顺序写入的方式来更新索引和日志文件,这样不仅提高了磁盘写入的效率,还充分利用了现代磁盘的顺序读写性能。Kafka 还使用了内存映射文件(Memory-Mapped Files)技术,将索引文件直接映射到内存中,这样在读写索引时,可以像访问内存一样高效。
Kafka的日志分段机制
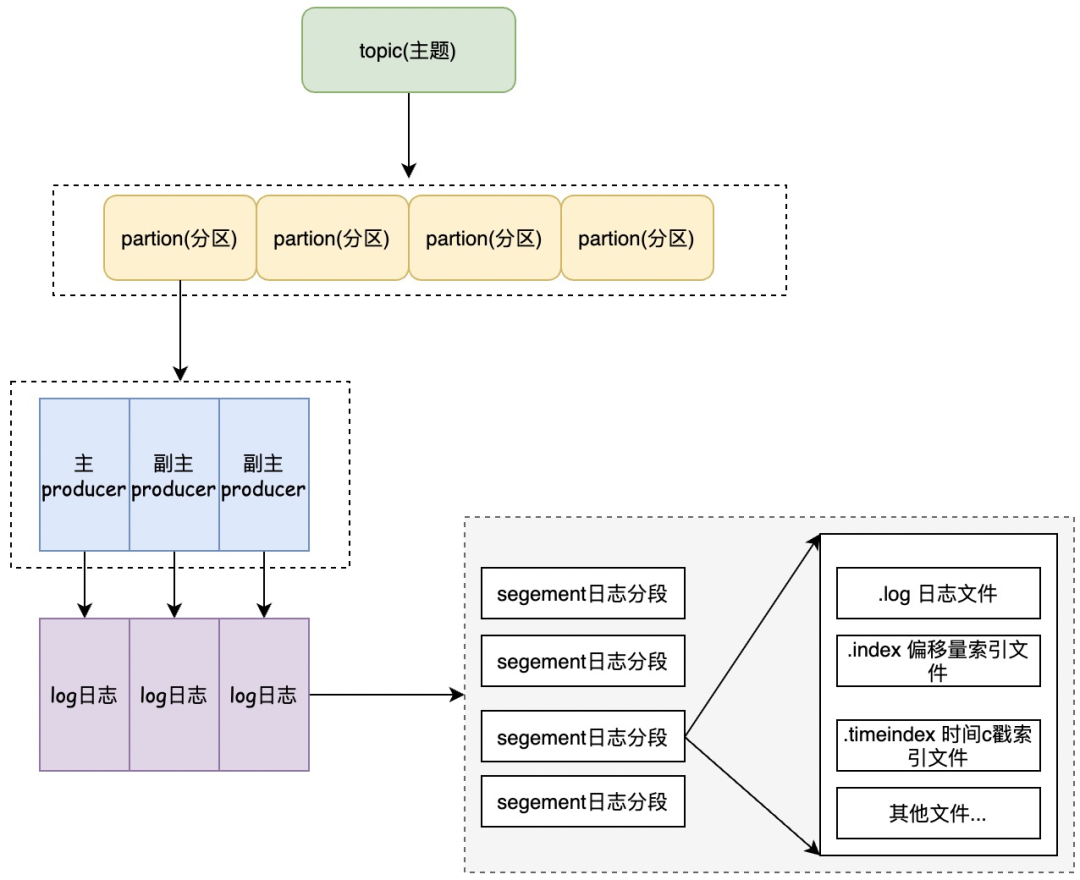
Kafka 的日志分段机制(Segmented Log)是其存储架构中非常重要的一部分,直接影响了消息的存储、检索效率和系统的整体性能。
1. Kafka 日志模型概述
在 Kafka 中,日志(Log)是消息存储的基本单位,每个主题(Topic)可以分为多个分区(Partition),每个分区实际上是一个有序的、不间断的日志文件。所有生产者发送的消息都会被追加到分区的末尾,并持久化到磁盘中,这些消息被分配一个唯一的偏移量(Offset),用于标识它在该分区中的位置。分区的这种设计使得 Kafka 能够提供非常高的吞吐量,因为每个分区都可以被单个消费者独占消费。
2. 为什么需要日志分段机制?
如果没有日志分段机制,Kafka 会将所有消息都保存在一个巨大的日志文件中,这样的设计会带来许多问题:
- 性能问题:随着时间的推移,日志文件会变得非常庞大。对这些庞大的日志文件进行操作(如查找、删除)会导致性能大幅下降。例如,如果没有分段机制,要删除旧的消息时,可能需要移动大量数据,这会严重影响性能。
- 存储管理问题:单个大文件的存储和管理也会变得更加复杂。文件系统对大文件的处理效率一般较低,且大文件在出现问题时恢复起来也更困难。
- 数据保留和删除策略:Kafka 允许为每个主题配置数据保留策略(如基于时间或大小),这要求系统能够高效地删除过期的数据。如果没有分段机制,删除旧消息将变得非常复杂和低效。
3. 日志分段的实现
Kafka 的日志分段机制将每个分区的日志文件拆分成若干个较小的段(Segment)。每个段都有自己的日志文件和对应的索引文件,Kafka 通过这些文件来管理和检索消息。每个分区的日志文件可以看作是由多个段组成的一个日志链表(Log Sequence)。
- 分段文件的组织方式:每个分段文件由两个部分组成:日志数据文件(.log)和索引文件(.index, .timeindex)。日志数据文件用于存储实际的消息数据,而索引文件用于加速消息的查找操作。分段文件的文件名通常是该段的起始偏移量(例如:
00000000000000000000.log),通过这个偏移量可以唯一确定一个段文件在分区日志中的位置。 - 分段大小的控制:Kafka 通过配置参数(如
log.segment.bytes和log.segment.ms)来控制每个段的大小或者寿命。当一个分段文件的大小达到配置的阈值,或当它的创建时间超过了指定的时间,Kafka 会自动滚动(Roll)到一个新的段。这种分段和滚动策略使得日志文件的大小和数量得以控制,从而有效地避免了单个大文件带来的问题。
4. 日志分段的优势
- 提高查找和删除效率:通过将日志文件分段,Kafka 能够在较小的文件范围内进行查找和删除操作,大大提升了操作效率。例如,在消息消费过程中,Kafka 只需在相应的段中查找消息,而不必遍历整个分区的所有数据。
- 优化磁盘 I/O:分段机制允许 Kafka 充分利用操作系统的文件系统缓存和磁盘的顺序 I/O 特性。由于日志数据文件和索引文件通常都比较小,Kafka 可以利用内存映射文件(Memory-Mapped Files)技术将它们直接映射到内存中,提高读写效率。
- 简化数据管理:分段机制使得 Kafka 可以更容易地实施数据保留策略。例如,对于基于时间的策略,Kafka 可以简单地删除过期的段文件,而无需逐条删除消息。这大大简化了数据管理和存储回收。
- 提高系统的可扩展性和容错性:通过分段,Kafka 可以更方便地在分布式环境中进行数据复制和备份。当一个分区需要迁移或复制时,Kafka 只需操作相应的段文件,而不必复制整个分区的数据。
5. Kafka 的日志分段管理
Kafka 自动管理分段文件的创建、滚动和删除。每当新的消息到达时,Kafka 会检查当前活跃段(Active Segment)的大小和寿命,决定是否需要创建一个新的段。在进行日志压缩(Log Compaction)或数据删除操作时,Kafka 还会定期扫描分段文件,执行必要的删除和压缩操作。
6. 日志分段与 Kafka 索引的协同工作
日志分段机制与 Kafka 的索引机制紧密协作,共同提升消息的存储与检索效率。每个段都有其自己的索引文件,存储着消息的偏移量与物理位置的映射关系。这使得 Kafka 能够通过索引快速定位消息,从而避免了顺序扫描整个日志的操作,进一步提升了性能。
Kafka的索引文件类型
Kafka的索引机制是其高性能和高吞吐量的关键组成部分,通过索引文件,Kafka能够在日志中快速定位和检索消息。Kafka的索引文件主要包括两种类型:偏移量索引文件(Offset Index)和时间戳索引文件(TimeIndex)。此外,Kafka还使用事务索引文件(Transaction Index)来支持事务性消息。
1. 偏移量索引文件(Offset Index)
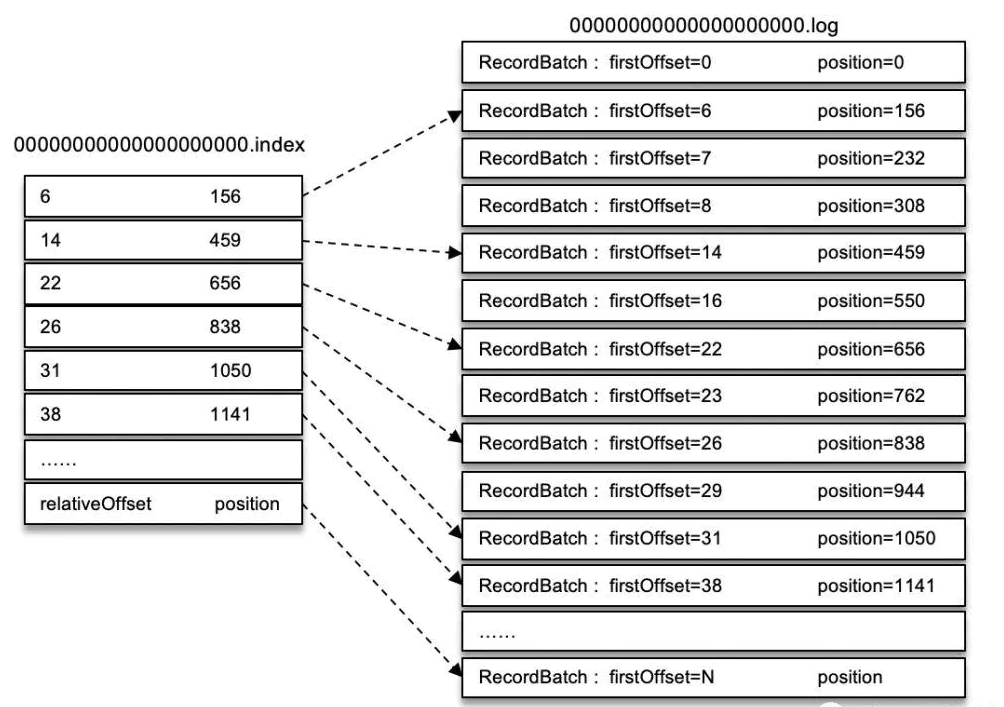
偏移量索引文件是Kafka最基础和最常用的索引文件类型之一。它记录了日志文件中每条消息的逻辑偏移量(Offset)和它在物理文件中的字节位置。由于每个分区是一个顺序写入的日志文件,偏移量索引允许Kafka在日志文件中快速查找到特定偏移量的消息,而无需顺序扫描整个日志文件。
- 工作原理:Offset Index是一个稀疏索引(Sparse Index),即它并不为每条消息创建索引,而是每隔一段距离创建一个索引项(Entry)。一个典型的Offset Index文件中,每个条目包括两个字段:逻辑偏移量和物理偏移量。例如,一个索引项可能表示“逻辑偏移量1000的消息从物理偏移量8000开始”。当Kafka需要查找偏移量为1500的消息时,它首先在索引文件中找到偏移量最接近的条目(例如1000),然后从该条目指定的物理位置开始顺序扫描日志文件,直到找到目标消息。
- 索引文件的大小:由于是稀疏索引,Offset Index文件相对于日志文件而言非常小。Kafka通常将索引文件映射到内存中(Memory-Mapped Files),这使得偏移量查找操作非常快速。Kafka允许配置每个索引文件的最大条目数(例如,
index.interval.bytes),从而控制索引的稀疏程度。 - 优势:Offset Index文件的稀疏设计使得它在减少存储空间的同时,仍然能够提供快速的查找性能。这种设计在处理非常大的日志文件时,显得尤为重要。
2. 时间戳索引文件(TimeIndex)
时间戳索引文件(TimeIndex)是Kafka中引入的一种增强型索引文件,用于支持按时间范围检索消息的操作。许多使用Kafka的应用程序需要根据时间戳检索消息,例如获取某个时间点之后的所有消息。TimeIndex的引入使得这种基于时间的查找操作变得更加高效。
- 工作原理:与Offset Index类似,TimeIndex也是一个稀疏索引。每个条目包括两个字段:时间戳(Timestamp)和物理偏移量(File Position)。这些条目按时间戳顺序排列。查找操作首先在时间戳索引文件中进行二分查找,找到最接近的时间戳条目,然后从该条目指定的物理偏移量开始顺序扫描日志文件,直到找到所需的消息。
- 时间戳管理:Kafka的每条消息都带有一个时间戳,时间戳可以由生产者设置,也可以由Kafka代理自动设置。Kafka提供了两种时间戳类型:创建时间(CreateTime)和日志时间(LogAppendTime)。时间戳索引基于这些时间戳来进行构建和查找。
- 优势:TimeIndex的主要优势在于它能大幅加速基于时间范围的消息查找操作,特别是在需要从大量历史数据中提取特定时间范围内的消息时。通过TimeIndex,Kafka不必扫描整个日志文件,而是可以快速定位到合适的时间戳位置,极大地减少了I/O操作。
3. 事务索引文件(Transaction Index)
事务索引文件(Transaction Index)是Kafka在引入事务性消息支持后新增的一种索引文件类型。它用于管理和跟踪事务性消息的状态,以便在故障恢复和消息消费过程中正确地处理事务。
- 工作原理:Transaction Index记录了事务的起始偏移量、结束偏移量以及事务的状态(如未提交、已提交、已中止等)。在Kafka中,一个事务可以跨越多个消息和多个分区,因此需要一种机制来记录这些事务的边界和状态。事务索引文件通过事务ID(Transaction ID)和偏移量来跟踪这些信息。
- 用途:当消费者在消费事务性消息时,它需要知道哪些消息属于已提交的事务,哪些消息需要忽略或回滚。事务索引文件提供了这种能力,使得消费者能够准确地处理事务边界,从而保证数据的一致性和可靠性。
- 优势:Transaction Index提高了Kafka在事务性消息处理方面的能力,使得Kafka能够支持更加复杂和严谨的数据一致性需求,例如在金融系统、订单管理系统等关键应用场景中应用。
4. Kafka索引文件的存储和管理
Kafka将日志数据和索引数据分开存储。每个分区(Partition)的日志文件和多个索引文件在文件系统中分别管理。Kafka使用分段日志(Segmented Log)机制,将每个分区的日志文件分成多个较小的段(Segment),每个段对应一个日志数据文件和多个索引文件。
- 文件命名和组织:每个索引文件都与其对应的日志段共享相同的基文件名,只是文件扩展名不同(例如,
00000000000000000000.index,00000000000000000000.timeindex)。 - 内存映射(Memory-Mapped Files):Kafka使用内存映射技术将索引文件直接映射到内存中。这种方式不仅提升了索引文件的读写效率,还减少了堆外内存的使用,从而提高了系统的性能。
Kafka索引的设计亮点
Kafka的索引设计是其高效数据管理和高性能消息处理能力的核心之一。Kafka的索引设计不仅旨在提供快速的数据检索能力,还充分考虑了存储效率、数据恢复、系统吞吐量以及数据一致性等方面。
1. 稀疏索引设计(Sparse Indexing)
Kafka的索引文件使用稀疏索引(Sparse Indexing)来优化存储空间和查找速度。稀疏索引意味着Kafka不会为日志中的每条消息创建一个索引条目,而是每隔一个固定的字节数(index.interval.bytes)创建一个索引条目。这样,Kafka能够在提供快速查找的同时,将索引文件的大小保持在较低水平。
- 优势:稀疏索引显著减少了索引文件的大小,降低了内存占用和磁盘I/O开销。因为索引文件较小,Kafka可以使用内存映射文件(Memory-Mapped Files)技术将整个索引文件加载到内存中,从而极大地加速了查找操作。
- 应用场景:在实际使用中,稀疏索引的优势在于它能够支持大规模数据的快速检索,尤其是在处理高吞吐量、高并发的消息流时,稀疏索引能够显著提升系统的整体性能。
2. 内存映射文件技术(Memory-Mapped Files)
Kafka的索引文件使用内存映射文件技术来提高读写性能。内存映射文件是一种将磁盘文件的内容直接映射到进程的地址空间中的技术,使得文件内容可以像访问内存一样被访问。
- 优势:内存映射文件技术大幅减少了文件I/O的开销,因为它避免了传统的读写系统调用和数据复制操作。这种技术能够快速访问索引文件,提升消息查找的效率。同时,使用内存映射还减少了对JVM堆内存的使用,避免了频繁的垃圾回收(GC)问题。
- 应用场景:在需要快速响应的场景下(例如实时数据处理和分析应用),内存映射文件技术可以确保低延迟和高性能。Kafka通过这种技术优化了索引文件的读写性能,尤其适合对延迟敏感的应用场景。
3. 分段日志机制(Segmented Log Mechanism)
Kafka使用分段日志机制(Segmented Log Mechanism)来管理分区中的日志文件,每个分区的日志被分割成多个较小的段(Segment)。每个段都有其对应的索引文件,这种设计使得Kafka可以在日志文件变得非常大的情况下仍然保持高效的索引和数据检索性能。
- 优势:分段日志机制不仅提高了日志的可管理性,还提高了索引的查找效率。通过将日志分段,Kafka可以快速丢弃过期的数据段,而不必扫描或修改索引文件。此外,分段日志机制还简化了数据恢复过程,在系统崩溃后,可以快速加载和恢复特定段的数据和索引。
- 应用场景:在高可用、高性能要求的场景下,分段日志机制为Kafka提供了灵活的数据管理能力,例如数据归档、过期数据的自动清除等,同时保证系统的性能不受影响。
4. 多种索引类型的支持(Multiple Index Types)
Kafka支持多种索引类型,包括偏移量索引(Offset Index)、时间戳索引(Time Index)和事务索引(Transaction Index),以满足不同的查找需求和使用场景。
- 偏移量索引(Offset Index):提供了快速根据偏移量查找消息的能力。偏移量索引是Kafka最基础的索引类型,用于大多数的消息检索场景,支持消费者快速查找到特定偏移量的消息。
- 时间戳索引(Time Index):支持基于时间范围的消息查找能力,允许消费者查找特定时间点之后的所有消息。时间戳索引提高了Kafka在日志分析、时间序列数据处理等应用场景下的检索效率。
- 事务索引(Transaction Index):用于管理和跟踪事务性消息的状态,确保在故障恢复和消费过程中正确处理事务边界。事务索引支持Kafka的事务性消息处理能力,确保数据一致性和可靠性。
- 优势:通过支持多种索引类型,Kafka能够根据不同的应用需求,提供灵活的消息检索和管理能力,确保在各种复杂场景下都能高效运行。
5. 高效的索引更新和压缩机制
Kafka在索引文件的更新和压缩方面也进行了优化设计,以减少系统的开销和提高性能。当消息被删除或段被压缩时,Kafka能够有效地更新或压缩索引文件,避免了频繁的重建索引操作。
- 优势:这种高效的索引更新和压缩机制不仅提高了Kafka的整体性能,还减少了磁盘空间的浪费。同时,Kafka在后台进行这些操作,不会阻塞正常的消息写入和读取,确保系统的高可用性。
- 应用场景:在需要处理大量数据并定期清理或压缩日志的应用中(例如日志收集和监控系统),Kafka的索引压缩和更新机制可以显著减少系统的开销和维护复杂度。
6. 动态索引管理(Dynamic Index Management)
Kafka允许动态调整索引的管理策略,例如修改索引文件的稀疏度(index.interval.bytes)和分段大小(segment.bytes),以适应不同的工作负载和性能需求。
- 优势:动态索引管理策略使Kafka能够根据系统负载和性能需求进行调整,确保系统在各种负载下都能高效运行。这种灵活性对于需要动态扩展和调整的分布式系统来说尤为重要。
- 应用场景:在云环境或弹性伸缩场景中,Kafka的动态索引管理能力可以帮助系统根据实时的负载情况进行调整,确保系统始终在最佳状态下运行。
Kafka索引的查找效率
Kafka的索引设计在消息系统中扮演着至关重要的角色,其查找效率直接影响到消息消费的速度和系统的整体性能。
1. 稀疏索引提升查找效率
Kafka采用了稀疏索引(Sparse Indexing)机制,在日志文件中并不是为每一条消息创建索引条目,而是每隔一段固定的字节数(由index.interval.bytes参数决定)才创建一个索引条目。稀疏索引的好处在于,它减少了索引文件的大小,这使得索引文件可以被高效地加载到内存中并通过内存映射文件(Memory-Mapped Files)技术进行快速访问。
- 查找过程:当消费者需要查找特定的消息时,首先通过稀疏索引定位到较接近的偏移量位置,然后通过顺序扫描查找到精确的消息位置。因为稀疏索引文件较小,可以全部载入内存,初步的索引查找可以在O(1)时间复杂度内完成。接下来的顺序扫描只需遍历相对较小的日志范围,极大地减少了I/O操作的次数。
- 效率提升:稀疏索引显著减少了磁盘I/O次数和内存占用,从而加速了消息的查找过程。它将内存用在更为关键的索引条目上,同时避免了过多的内存占用。这种设计非常适合大规模、高吞吐量的数据流处理场景,因为它在保证查找效率的同时,降低了系统资源的消耗。
2. 内存映射文件优化查找速度
Kafka使用内存映射文件(Memory-Mapped Files)技术来加快索引文件的读取和写入速度。内存映射文件将磁盘文件直接映射到进程的地址空间中,这样读写操作可以直接在内存中完成,而不需要经过操作系统的缓冲区。
- 查找过程:在进行消息查找时,Kafka通过内存映射文件技术可以直接从内存中读取索引信息,而无需进行磁盘I/O操作。这大大提升了索引查找的速度,因为内存访问的速度要远远快于磁盘访问。
- 效率提升:内存映射文件不仅减少了磁盘I/O,还减少了系统调用的开销。Kafka的索引查找因此能够以接近内存速度的效率完成,极大地减少了查找的延迟。对于实时性要求较高的应用(如金融数据流处理、实时监控系统等),这种优化是非常关键的。
3. 分段日志与多级索引结构
Kafka的日志文件被设计为分段结构(Segmented Logs),每个分区的日志被分割成多个小段(Segment),每个段有自己的索引文件。这种设计不仅优化了日志管理,还提升了索引查找的效率。
- 分段查找过程:当消费者请求一条消息时,Kafka首先通过分区的全局索引快速定位到可能包含该消息的段,然后再在该段的索引文件中进行查找。由于日志被分段,Kafka只需加载需要的段文件及其索引文件到内存中,减少了不必要的I/O操作和内存消耗。
- 多级索引结构:Kafka在处理查找请求时采用了多级索引结构。首先,通过分区的全局索引快速定位段,然后通过段索引进一步定位到精确的消息位置。这样分层查找大大提高了查找效率,尤其是在处理大规模数据时。
- 效率提升:分段日志与多级索引结构的组合使得Kafka能够在大数据量场景下仍然保持高效的查找能力。这种结构使得查找过程被精确限制在较小的段范围内,避免了全局范围的扫描,提高了查找效率。
4. 时间戳索引(Time Index)和偏移量索引(Offset Index)
Kafka同时支持时间戳索引和偏移量索引,分别用于不同的消息查找需求。偏移量索引是Kafka最常用的索引类型,用于快速定位特定偏移量的消息;时间戳索引则允许消费者根据时间戳查找消息。
- 查找过程:对于偏移量查找,Kafka使用偏移量索引快速定位偏移量所在的段,然后通过顺序扫描定位到具体的消息。对于时间戳查找,Kafka使用时间戳索引快速定位到最近的时间点,然后在相应的日志段中进行查找。
- 效率提升:时间戳索引和偏移量索引的组合使得Kafka在不同的应用场景下都能够提供高效的查找能力。偏移量索引优化了传统的消息消费模式,而时间戳索引则扩展了Kafka的应用场景,支持基于时间的查询需求,例如数据回溯、事件重放等。
5. 磁盘顺序读取优化
Kafka在设计时特别优化了磁盘顺序读取(Sequential Disk Read)能力。通过将日志和索引文件设计为分段存储,Kafka能够最大限度地利用磁盘顺序读取的高效性。顺序读取的性能远远优于随机读取,这对于日志系统的性能表现至关重要。
- 查找过程:当Kafka确定需要读取的日志段时,它能够通过顺序读取的方式快速加载段数据和对应的索引文件。磁盘顺序读取减少了磁盘寻道时间和I/O操作开销,大幅提高了数据加载速度。
- 效率提升:通过优化磁盘顺序读取,Kafka能够以非常高的吞吐量处理日志数据。对于需要快速处理和消费大规模数据流的应用(如大型电商网站、金融系统实时数据流处理等),这种优化确保了Kafka的高性能和低延迟。
索引与消息持久化策略
在Kafka中,索引与消息持久化策略是确保数据一致性、快速读取和高效存储的核心设计之一。Kafka的持久化策略是其能够处理大规模、高吞吐量数据流的关键特性,索引机制在其中起到了至关重要的作用。Kafka通过独特的日志存储设计和索引策略,使得消息的持久化和检索都能够高效、可靠地完成。
1. 消息持久化的基本策略
Kafka的消息持久化策略主要依赖于其基于磁盘的日志存储系统。所有消息一旦生产,都会首先写入磁盘日志文件中,这保证了消息的持久性和可靠性。在高吞吐量的数据处理场景中,磁盘的顺序写入性能远远优于随机写入,Kafka通过设计高效的日志结构,使得消息写入的开销最小化。
- 顺序写入:Kafka采用顺序写入的方式将消息写入磁盘,顺序写入的效率非常高,因为磁盘的顺序写入不需要频繁的磁盘寻道操作,能够充分利用磁盘的带宽。这种方式不仅提高了写入速度,还减少了写入过程中的I/O消耗。
- 日志分段(Segmented Log):Kafka将每个分区的日志拆分成多个较小的段(Segment),每个段有自己的日志文件和对应的索引文件。通过将日志划分为多个段,Kafka能够高效管理存储和持久化过程。段的切分使得日志文件不至于无限增大,从而避免了因单个文件过大导致的磁盘管理问题。同时,段切分也有助于日志的压缩和过期管理。
- 刷盘策略(Flush Policy):Kafka采用灵活的刷盘策略来控制日志的持久化频率。刷盘策略通常基于两种配置参数:
log.flush.interval.messages(消息数)和log.flush.interval.ms(时间间隔)。当达到这两个条件之一时,Kafka会将内存中的日志缓冲区强制刷新到磁盘。这种策略允许Kafka在写入性能和数据持久化安全性之间做出平衡。
2. 索引与持久化的协同设计
Kafka的索引设计与消息持久化策略紧密结合,旨在提高消息查找效率和系统吞吐量。Kafka采用了多种索引策略,以确保在任何持久化条件下,都能够快速定位和检索到所需的消息。
- 稀疏索引(Sparse Indexing):Kafka的日志文件使用稀疏索引,这意味着不是每条消息都在索引中记录。相反,索引每隔一定的字节偏移量才记录一个索引条目。这种稀疏索引策略大大减少了索引文件的大小,使得索引文件可以高效地存储和加载到内存中。稀疏索引的设计确保了索引操作的低开销,特别是在日志文件非常大的情况下,稀疏索引能够显著减少磁盘I/O和内存使用。
- 时间戳索引(Time Index):Kafka在日志段内维护了基于消息时间戳的索引,这允许消费者根据时间范围进行消息查找。时间戳索引与偏移量索引共同工作,提供了双重查找机制,使得Kafka在各种使用场景下都能够保持高效。时间戳索引的引入使得在数据恢复和时间窗口查询场景下,Kafka能够快速定位到目标消息段,大大提高了查找效率。
- 多级索引结构(Multi-level Index Structure):Kafka的索引机制是分层次的,第一层是稀疏索引,快速定位日志段,第二层是段内的详细索引,用于精确定位消息。多级索引结构结合了快速粗略定位和细粒度查找的优点,使得Kafka在查找大量数据时既能快速跳转又能精确查找。
3. 消息过期与删除策略
Kafka支持基于时间和大小的日志保留策略来管理消息的过期和删除。这些策略直接影响到消息的持久化方式和索引的有效性。
- 基于时间的保留策略:Kafka允许配置每个主题的日志段保留时间(
log.retention.hours),当日志段的存储时间超过设定的保留时间时,Kafka会自动删除这些段。此策略确保了磁盘空间的合理使用,同时也影响了索引的更新和重构。因为删除日志段意味着需要调整对应的索引条目,从而保持索引文件的最新状态。 - 基于大小的保留策略:Kafka还支持基于日志大小的保留策略(
log.retention.bytes)。当日志段的大小超过配置的阈值时,会触发日志段的删除。基于大小的策略对于控制磁盘使用和保证持久化存储的高效性非常有效。索引文件的设计与这种策略相配合,确保在删除操作中能够快速调整和更新索引。
4. 数据压缩与存储优化
Kafka在持久化过程中支持多种数据压缩方式,如GZIP、Snappy、LZ4等,以降低存储空间和网络传输成本。数据压缩策略直接影响到持久化文件的格式和大小,也影响到索引的组织形式。
- 压缩日志段:在Kafka的持久化策略中,压缩通常是基于整个日志段的。每个段被视为一个压缩单元,Kafka通过段的起始偏移量和压缩标识,快速解压和读取目标消息。这种段级压缩策略与Kafka的索引结构结合紧密,使得在保持压缩优势的同时,查找效率不受影响。
- 优化查找效率:压缩对索引的影响主要在于如何快速找到压缩数据中的偏移位置。Kafka的索引通过稀疏方式记录压缩数据的起始位置和偏移量,使得即使在压缩情况下,查找特定偏移量的消息也能保持高效。这种优化确保了在存储优化的同时,不牺牲性能。
5. 高效的副本同步机制
Kafka的高可用性和可靠性体现在其强大的副本同步机制中。每个分区有一个领导者和多个副本,消息持久化需要在领导者和副本之间进行数据同步。Kafka使用异步复制的方式将日志从领导者复制到副本,副本的数据同步与索引的更新是紧密关联的。
- 副本的索引同步:在副本数据同步过程中,索引文件需要同步更新以保持一致性。Kafka通过分段日志的设计,能够快速将已同步的数据段及其对应的索引应用到副本上。索引文件的同步效率与副本的恢复时间和可用性密切相关,因此Kafka的设计在这方面做了大量优化。
- 基于ISR(In-Sync Replica)机制的同步策略:Kafka的ISR机制确保只有完全同步的副本才能参与数据读取操作,这样保证了数据的一致性和可靠性。在副本的日志和索引文件同步完成后,ISR机制会更新已同步的副本状态,使其能够继续参与读取和消费。这种机制使得即使在高并发、高吞吐的场景下,Kafka也能够保持数据的高一致性和可靠性。
6. 索引与持久化策略的整体效益
Kafka的索引与消息持久化策略的设计体现了在大规模分布式消息系统中的多重平衡:性能与可靠性、存储效率与读取效率、灵活性与简洁性。通过将稀疏索引、时间戳索引、日志分段、多级索引结构、压缩、以及副本同步机制等技术结合起来,Kafka能够在各种复杂场景下都保持高效的性能和高可用性。
- 整体效率提升:Kafka的持久化策略和索引设计协同工作,极大地提升了消息的持久化效率和查找效率。无论是在高吞吐的数据写入场景下,还是在复杂的数据查找场景下,Kafka都能够提供可靠且高效的服务。
- 可靠性保障:Kafka的持久化策略保证了数据不丢失,并且能够在崩溃恢复时迅速恢复数据状态;其索引策略则保证了在数据完整性的基础上,能够快速、精准地查找到所需的数据。两者结合使得Kafka在面临高并发读写、海量数据存储等挑战时,仍然能够提供稳定且可靠的服务。
想获取更多高质量的Java技术文章?欢迎访问Java技术小馆官网,持续更新优质内容,助力技术成长
Java技术小馆官网![]() https://www.yuque.com/jtostring
https://www.yuque.com/jtostring
相关文章:

Kafka的索引设计有什么亮点
想获取更多高质量的Java技术文章?欢迎访问Java技术小馆官网,持续更新优质内容,助力技术成长 Java技术小馆官网https://www.yuque.com/jtostring Kafka的索引设计有什么亮点? Kafka 之所以能在海量数据的传输和处理过程中保持高…...

基于大模型的病态窦房结综合征预测及治疗方案研究报告
目录 一、引言 1.1 研究背景与目的 1.2 研究意义 二、病态窦房结综合征概述 2.1 定义与病因 2.2 临床表现与分型 2.3 诊断方法 三、大模型在病态窦房结综合征预测中的应用 3.1 大模型介绍 3.2 数据收集与预处理 3.3 模型训练与优化 四、术前预测与准备 4.1 风险预…...
——《RFC 3550》的附录A)
音视频入门基础:RTCP专题(5)——《RFC 3550》的附录A
一、引言 本文对应《RFC 3550》的附录A(Appendix A. Algorithms)。 二、Appendix A. Algorithms 根据《RFC 3550》第62页,《RFC 3550》提供了有关RTP发送方和接收方算法的C代码示例。在特定的运行环境下,可能还有其他更快或更有…...

qemu仿真调试esp32,以及安装版和vscode版配置区别
不得不说,乐鑫在官网的qemu介绍真的藏得很深 首先在首页的sdk的esp-idf页面里找找 然后页面拉倒最下面 入门指南 我这里选择esp32-s3 再点击api指南-》工具 才会看到qemu的介绍 QEMU 模拟器 - ESP32-C3 - — ESP-IDF 编程指南 latest 文档https://docs.espressi…...

协方差相关问题
为什么无偏估计用 ( n − 1 ) (n-1) (n−1) 而不是 n n n,区别是什么? 在统计学中,无偏估计是指估计量的期望值等于总体参数的真实值。当我们用样本数据估计总体方差或协方差时,分母使用 ( n − 1 ) (n-1) (n−1) 而不是 n n…...

Android OpenCV 人脸识别 识别人脸框 识别人脸控件自定义
先看效果 1.下载OpenCV 官网地址:opcv官网 找到Android 4.10.0版本下载 下载完毕 解压zip如图: 2.将OpenCV-android_sdk导入项目 我这里用的最新版的Android studio 如果是java开发 需要添加kotlin的支持。我用的studio比较新可以参考下,如果…...

深入解析Linux软硬链接:原理、区别与应用实践
Linux系列 文章目录 Linux系列前言一、软硬链接的概念引入1.1 硬链接1.2 软链接 二、软硬链接的使用场景2.1 软链接2.2 硬链接 三、总结 前言 上篇文章我们详细的介绍了文件系统的概念及底层实现原理,本篇我们就在此基础上探讨Linux系统中文件的软链接࿰…...
)
TDengine 与 taosAdapter 的结合(二)
五、开发实战步骤 (一)环境搭建 在开始 TDengine 与 taosAdapter 结合的 RESTful 接口开发之前,需要先完成相关环境的搭建,包括 TDengine 和 taosAdapter 的安装与配置,以及相关依赖的安装。 TDengine 安装…...
与可变码率(VBR)?)
OBS 中如何设置固定码率(CBR)与可变码率(VBR)?
在使用 OBS 进行录制或推流时,设置“码率控制模式”(Rate Control)是非常重要的一步。常见的控制模式包括: CBR(固定码率):保持恒定的输出码率,适合直播场景。 VBR(可变码率):在允许的范围内动态调整码率,适合本地录制、追求画质。 一、CBR vs. VBR 的差异 项目CBR…...

优艾智合人形机器人“巡霄”,开启具身多模态新时代
近日,优艾智合-西安交大具身智能机器人研究院公布人形机器人矩阵,其中轮式人形机器人“巡霄”首次亮相。 “巡霄”集成移动导航、操作控制与智能交互技术,具备跨场景泛化能,适用于家庭日常服务、电力设备巡检、半导体精密操作及仓…...
)
蓝桥杯小白打卡第七天(第十四届真题)
小蓝的金属冶炼转换率问题 小蓝有一个神奇的炉子用于将普通金属 (O) 冶炼成为一种特殊金属 (X) 。 这个炉子有一个称作转换率的属性 (V) ,(V) 是一个正整数,这意味着消耗 (V) 个普通金属 (O) 恰好可以冶炼出一个特殊金属 (X) ,当普通金属 (…...

excel经验
Q:我现在有一个excel,有一列数据,大概两千多行。如何在这一列中 筛选出具有关键字的内容,并输出到另外一列中。 A: 假设数据在A列(A1开始),关键字为“ABC”在相邻空白列(如B1)输入公…...

【Pandas】pandas DataFrame astype
Pandas2.2 DataFrame Conversion 方法描述DataFrame.astype(dtype[, copy, errors])用于将 DataFrame 中的数据转换为指定的数据类型 pandas.DataFrame.astype pandas.DataFrame.astype 是一个方法,用于将 DataFrame 中的数据转换为指定的数据类型。这个方法非常…...

【Netty4核心原理④】【简单实现 Tomcat 和 RPC框架功能】
文章目录 一、前言二、 基于 Netty 实现 Tomcat1. 基于传统 IO 重构 Tomcat1.1 创建 MyRequest 和 MyReponse 对象1.2 构建一个基础的 Servlet1.3 创建用户业务代码1.4 完成web.properties 配置1.5 创建 Tomcat 启动类 2. 基于 Netty 重构 Tomcat2.1 创建 NettyRequest和 Netty…...

4.6学习总结
包装类 包装类:基本数据类型对应的引用数据类型 JDK5以后新增了自动装箱,自动拆箱 以后获取包装类方法,不需要new,直接调用方法,直接赋值即可 //1.把整数转成二进制,十六进制 String str1 Integer.toBin…...

MySQL学习笔记五
第七章数据过滤 7.1组合WHERE子句 7.1.1AND操作符 输入: SELECT first_name, last_name, salary FROM employees WHERE salary < 4800 AND department_id 60; 输出: 说明:MySQL允许使用多个WHERE子句,可以以AND子句或OR…...

成为社交场的导演而非演员
一、情绪的本质:社交信号而非自我牢笼 进化功能:情绪是人类进化出的原始社交工具。愤怒触发群体保护机制,悲伤唤起同情支持,喜悦巩固联盟关系。它们如同可见光谱,快速传递生存需求信号。双刃剑效应:情绪的…...

怎么使用vue3实现一个优雅的不定高虚拟列表
前言 很多同学将虚拟列表当做亮点写在简历上面,但是却不知道如何手写,那么这个就不是加分项而是减分项了。实际项目中更多的是不定高虚拟列表,这篇文章来教你不定高如何实现。 什么是不定高虚拟列表 不定高的意思很简单,就是不…...

LemonSqueezy: 1靶场渗透
LemonSqueezy: 1 来自 <LemonSqueezy: 1 ~ VulnHub> 1,将两台虚拟机网络连接都改为NAT模式 2,攻击机上做namp局域网扫描发现靶机 nmap -sn 192.168.23.0/24 那么攻击机IP为192.168.23.182,靶场IP192.168.23.225 3,对靶机进…...

2025 年山东保安员职业资格考试要点梳理
山东作为人口大省,保安市场规模庞大。2025 年考试报考条件常规。报名通过山东省各市公安机关指定的培训机构或政务服务窗口,提交资料与其他地区类似。 理论考试注重对山东地域文化特色相关安保知识的考查,如在孔庙等文化圣地安保中&#x…...

ARM处理器内核全解析:从Cortex到Neoverse的架构与区别
ARM处理器内核全解析:从Cortex到Neoverse的架构与区别 ARM作为全球领先的处理器架构设计公司,其内核产品线覆盖了从高性能计算到低功耗嵌入式应用的广泛领域。本文将全面解析ARM处理器的内核分类、架构特点、性能差异以及应用场景,帮助读者深…...

网络缓冲区
网络缓冲区分为内核缓冲区和用户态网络缓冲区 我们重点要实现用户态网络缓冲区 1.设计用户态网络缓冲区的原因 ①.生产者和消费者的速度不匹配问题, 需要缓存数据。 ②.粘包处理问题, 不能确保一次系统调用读取或写入完整数据包。 2.代码实现(cha…...
)
数据仓库的核心架构与关键技术(数据仓库系列二)
目录 一、引言 二、数据仓库的核心架构 三、数据仓库的关键技术 1 数据集成与治理 2 查询优化与性能提升 3 数据共享服务 BI:以Tableau为例 SQL2API:以麦聪QuickAPI为例 4 实时数据处理 四、技术的协同作用 五、总结与展望 六、预告 一、引言…...

基于PyQt5与OpenCV的图像处理系统设计与实现
1. 系统概述 本系统是一个集成了多种经典图像处理算法的图形用户界面(GUI)应用程序,采用Python语言开发,基于PyQt5框架构建用户界面,利用OpenCV库实现核心图像处理功能。 系统支持11种图像处理操作,每种操作都提供参数实时调节功能,并具备原始图像与处理后图像的双视图对…...

如何根据设计稿进行移动端适配:全面详解
如何根据设计稿进行移动端适配:全面详解 文章目录 如何根据设计稿进行移动端适配:全面详解1. **理解设计稿**1.1 设计稿的尺寸1.2 设计稿的单位 2. **移动端适配的核心技术**2.1 使用 viewport 元标签2.1.1 代码示例2.1.2 参数说明 2.2 使用相对单位2.2.…...
?哪个大模型更好用?)
什么是大型语言模型(LLM)?哪个大模型更好用?
什么是 LLM? ChatGPT 是一种大型语言模型 (LLM),您可能对此并不陌生。它以非凡的能力而闻名,已证明能够出色地完成各种任务,例如通过考试、生成产品内容、解决问题,甚至在最少的输入提示下编写程序。 他们的实力现已…...

集合学习内容总结
集合简介 1、Scala 的集合有三大类:序列 Seq、集Set、映射 Map,所有的集合都扩展自 Iterable 特质。 2、对于几乎所有的集合类,Scala 都同时提供了可变和不可变的版本,分别位于以下两个包 不可变集合:scala.collect…...

使用typedef和不使用的区别
使用 typedef 定义的函数指针类型 typedef sensor_drv_params_t* (*load_sensor_drv_func)(); 不使用 typedef 的函数指针声明 sensor_drv_params_t* (*load_sensor_drv_func)(); 这两者看似相似,但在语义和用途上有显著区别。下面将详细解释这两种声明的区别、各…...

基于线性回归模型的汽车燃油效率预测
基于线性回归模型的汽车燃油效率预测 1.作者介绍2.线性回归介绍2.1 线性回归简介2.2 线性回归应用场景 3.基于线性回归模型的汽车燃油效率预测实验3.1 Auto MPG Data Set数据集3.2代码调试3.3完整代码3.4结果展示 4.问题分析 基于线性回归模型的汽车燃油效率预测 1.作者介绍 郝…...

Playwright之自定义浏览器目录访问出错:BrowserType.launch: Executable doesn‘t exist
Playwright之自定义浏览器目录访问出错:BrowserType.launch: Executable doesn’t exist 问题描述: 在使用playwright进行浏览器自动化的时候,配置了自定义的浏览器目录,当按照自定义的浏览器目录启动浏览器进行操作时,…...

如何拿到iframe中嵌入的游戏数据
在 iframe 中嵌入的游戏数据是否能被获取,取决于以下几个关键因素: 1. 同源策略 浏览器的同源策略是核心限制。如果父页面和 iframe 中的内容同源(即协议、域名和端口号完全相同),那么可以直接通过 JavaScript 访问 …...

优选算法第七讲:分治
优选算法第七讲:分治 1.分治_快排1.1颜色分类1.2排序数组1.3数组中第k个最大元素1.4库存管理II 2.分治_归并2.1排序数组2.2交易逆序对的总数2.3计算右侧小于当前元素的个数2.4翻转对 1.分治_快排 1.1颜色分类 1.2排序数组 1.3数组中第k个最大元素 1.4库存管理II 2.…...

OpenBMC:BmcWeb 处理http请求4 处理路由对象
OpenBMC:BmcWeb 处理http请求2 查找路由对象-CSDN博客 Router::handle通过findRoute获取了FindRouteResponse对象foundRoute void handle(const std::shared_ptr<Request>& req,const std::shared_ptr<bmcweb::AsyncResp>& asyncResp){FindRouteResponse …...

直流电能表计量解决方案适用于光伏储能充电桩基站等场景
多场景解决方案,准确测量 01 市场规模与增长动力 全球直流表市场预测: 2025年市场规模14亿美元,CAGR超15%。 驱动因素:充电桩、光伏/储能、基站、直流配电 市场增长引擎分析: 充电桩随新能源车迅猛增长ÿ…...

x-cmd install | Slumber - 告别繁琐,拥抱高效的终端 HTTP 客户端
目录 核心优势,一览无遗安装应用场景,无限可能示例告别 GUI,拥抱终端 还在为调试 API 接口,发送 HTTP 请求而苦恼吗?还在各种 GUI 工具之间切换,只为了发送一个简单的请求吗?现在,有…...

git修改已经push的commit的message
1.修改信息 2.修改message 3.强推...

STM32 基础2
STM32中断响应过程 1、中断源发出中断请求。 2、判断处理器是否允许中断,以及该中断源是否被屏蔽。 3、中断优先级排队。 4、处理器暂停当前程序,保护断点地址和处理器的当前状态,根据中断类型号,查找中断向量表,转到…...

【STL 之速通pair vector list stack queue set map 】
考list 的比较少 --双端的啦 pair 想下,程序是什么样的. 我是我们要带着自己的思考去学习DevangLic.. #include <iostream> #include <utility> #include <string>using namespace std;int main() {// 第一部分:创建并输出两个 pair …...

深度学习篇---LSTM+Attention模型
文章目录 前言1. LSTM深入原理剖析1.1 LSTM 架构的进化理解遗忘门简介数学表达式实际作用 输入门简介数学表达式后选候选值实际作用 输出门简介数学表达式最终输出实际作用 1.2 Attention 机制的动态特性内容感知位置无关可解释性数学本质 1.3 LSTM与Attention的协同效应组合优…...

React 多个 HOC 嵌套太深,会带来哪些隐患?
在 React 中,使用多个 高阶组件(HOC,Higher-Order Component) 可能会导致组件层级变深,这可能会带来以下几个影响: 一、带来的影响 1、调试困难 由于组件被多个 HOC 包裹,React 开发者工具&am…...

企业工厂生产线马达保护装置 功能参数介绍
安科瑞刘鸿鹏 摘要 工业生产中,电压暂降(晃电)是导致电动机停机、生产中断的主要原因之一,给企业带来巨大的经济损失。本文以安科瑞晃电再起动控制器为例,探讨抗晃电保护器在生产型企业工厂中的应用,分析…...

Redis 的五种数据类型面试回答
这里简单介绍一下面试回答、我之前有详细的去学习、但是一直都觉得太多内容了、太深入了 然后面试的时候不知道从哪里讲起、于是我写了这篇CSDN帮助大家面试回答、具体的深入解析下次再说 面试官你好 我来介绍一下Redis的五种基本数据类型 有String List Set ZSet Map 五种基…...
 - 3)
多线程代码案例(定时器) - 3
定时器,是我们日常开发所常用的组件工具,类似于闹钟,设定一个时间,当时间到了之后,定时器可以自动的去执行某个逻辑 目录 Timer 的基本使用 实现一个 Timer 通过这个类,来描述一个任务 通过这个类&…...

基于大模型的GCSE预测与治疗优化系统技术方案
目录 技术方案文档:基于大模型的GCSE预测与治疗优化系统1. 数据预处理模块功能:整合多模态数据(EEG、MRI、临床指标等),标准化并生成训练集。伪代码流程图2. 大模型架构(Transformer-GNN混合模型)功能:联合建模时序信号(EEG)与空间结构(脑网络)。伪代码流程图3. 术…...

IntelliJ IDEA 中 Continue 插件使用 DeepSeek-R1 模型指南
IntelliJ IDEA 中 Continue 插件使用 DeepSeek-R1 模型指南 Continue 是一款开源的 AI 编码助手插件,支持 IntelliJ IDEA 等 JetBrains 系列 IDE。它可以通过连接多种语言模型(如 DeepSeek-R1)提供实时代码生成、问题解答和单元测试生成等功…...

Valgrind——内存调试和性能分析工具
文章目录 一、Valgrind 介绍二、Valgrind 功能和使用1. 主要功能2. 基本用法2.1 常用选项2.2 内存泄漏检测2.3 详细报告2.4 性能分析2.5 多线程错误检测 三、在 Ubuntu 上安装 Valgrind四、示例1. 检测内存泄漏2. 使用未初始化的内存3. 内存读写越界4. 综合错误 五、工具集1. M…...

京东API智能风控引擎:基于行为分析识别恶意爬虫与异常调用
京东 API 智能风控引擎基于行为分析识别恶意爬虫与异常调用,主要通过以下几种方式实现: 行为特征分析 请求频率:正常用户对 API 的调用频率相对稳定,受到网络延迟、操作速度等因素限制。若发现某个 IP 地址或用户在短时间内对同一…...

Swift 解 LeetCode 250:搞懂同值子树,用递归写出权限系统检查器
文章目录 前言问题描述简单说:痛点分析:到底难在哪?1. 子树的概念搞不清楚2. 要不要“递归”?递归从哪开始?3. 怎么“边遍历边判断”?这套路不熟 后序遍历 全局计数器遍历过程解释一下:和实际场…...

Nginx搭建API网关服务教程-系统架构优化 API统一管理
超实用!用Nginx搭建API网关服务,让你的系统架构更稳更强大!🚀 亲们,今天来给大家种草一个超级实用的API网关搭建方案啦!👀 在如今的Web系统架构中,一个稳定、高性能、可扩展的API网…...

SQL2API是什么?SQL2API与BI为何对数据仓库至关重要?
目录 一、SQL2API是什么? 二、SQL2API的历史演变:从数据共享到服务化革命 1990年代:萌芽于数据仓库的数据共享需求 2010年代初:数据中台推动服务化浪潮 2022年左右:DaaS平台的兴起 2025年代:麦聪定义…...