从零开始微调Embedding模型:基于BERT的实战教程
文章目录
- 背景
- 微调实战
- 装包
- 介绍
- 项目文件介绍
- 微调硬件配置要求
- debug 重要代码分析【选看】
- 资源分享
- 参考资料
背景
在理解与学会了Naive RAG的框架流程后,就很自然地关注到embedding模型,与问题相关的文本召回,也有很多论文在做这方面的创新。
以前一直不知道embedding模型是如何微调出来的,一直听说是微调BERT,但是不知道是怎么微调出来的。直到在B站上看到bge模型微调的视频[参考资料4]才理解。
于是便想着自己也微调出一个 embedding模型。涉及到下面三个阶段:
- 数据集制作
- 模型训练
- 评估
微调实战
装包
pip install -U FlagEmbedding[finetune]
项目基于 https://github.com/FlagOpen/FlagEmbedding,若遇到环境报错,可参考该项目的环境,完成python环境设置
FlagEmbedding论文:C-Pack: Packed Resources For General Chinese Embeddings , 也称 C-METB
介绍
你可以阅读参考资料[1]和[2],先尝试实现一次官方的微调教程。
官方微调的模型是BAAI/bge-large-en-v1.5,我选择直接微调BERT模型,这样感受微调的效果更明显。仅仅是出于学习的目的,我才选择微调BERT,如果大家打算用于生产环境,还是要选择微调现成的embedding模型。因为embedding模型也分为预训练与微调两个阶段,我们不做预训练。
embedding 模型需要通过encode方法把文本变成向量,而BERT模型没有encode方法。故要使用FlagEmbedding导入原生的BERT模型。
from FlagEmbedding.inference.embedder.encoder_only.base import BaseEmbedder# 省略数据集加载代码bert_embedding = BaseEmbedder("bert-base-uncased")
# get the embedding of the corpus
corpus_embeddings = bert_embedding.encode(corpus_dataset["text"])print("shape of the corpus embeddings:", corpus_embeddings.shape)
print("data type of the embeddings: ", corpus_embeddings.dtype)
可浏览:eval_raw_bert.ipynb
项目文件介绍
数据集构建:
-
build_train_dataset.ipynb: 构建训练集数据,随机采样负样本数据通过修改
neg_num的值,构架了training_neg_10.json和training_neg_50.json两个训练的数据集,比较增加负样本的数量是否能提高模型召回的效果(实验结果表明:这里的效果并不好,提升不明显)。 -
build_eval_dataset.ipynb: 构建测试集数据,评估大模型生成的效果。与FlagEmbedding数据集构建结构不同,我个人用这种数据集样式更方便,不需要像FlagEmbedding一样从下标读出正确的样本的数据。
模型训练:
finetune_neg10.shfinetune_neg50.sh
finetune_neg10.sh的代码如下:
torchrun --nproc_per_node=1 \-m FlagEmbedding.finetune.embedder.encoder_only.base \--model_name_or_path bert-base-uncased \--train_data ./ft_data/training_neg_10.json \--train_group_size 8 \--query_max_len 512 \--passage_max_len 512 \--pad_to_multiple_of 8 \--query_instruction_for_retrieval 'Represent this sentence for searching relevant passages: ' \--query_instruction_format '{}{}' \--output_dir ./output/bert-base-uncased_neg10 \--overwrite_output_dir \--learning_rate 1e-5 \--fp16 \--num_train_epochs 3 \--per_device_train_batch_size 4 \--warmup_ratio 0.1 \--logging_steps 200 \--save_steps 2000 \--temperature 0.02 \--sentence_pooling_method cls \--normalize_embeddings True \--kd_loss_type kl_div
bash finetune_neg10.sh > finetune_neg10.log 2>&1 & 把训练的日志保存到 finetune_neg10.log 日志文件中,训练用时6分钟。
neg10代表每条数据10个负样本,neg50代表每条数据50个负样本。
评估:
评估是在所有语料上完成的评估,并不是在指定的固定数量的负样本上完成的评估。
由于是在全部语料上完成召回,故使用到了faiss向量数据库。
eval_raw_bert.ipynb: 评估BERT原生模型eval_train_neg10.ipynb: 评估基于10条负样本微调后的模型eval_train_neg50.ipynb: 评估基于50条负样本微调后的模型eval_bge_m3.ipynb: 评估 BAAI 现在表现效果好的 BGE-M3 模型
结论:通过评估结果,可看出BERT经过微调后的提升明显,但依然达不到BGE-M3 模型的效果。
微调硬件配置要求
微调过程中GPU显存占用达到了9G左右
设备只有一台GPU
debug 重要代码分析【选看】
下述代码是旧版本的代码,不是最新的FlagEmbedding的代码:
- 视频教程,bge模型微调流程:https://www.bilibili.com/video/BV1eu4y1x7ix/
推荐使用23年10月份的代码进行debug,关注核心代码。新版的加了抽象类与继承,增加了很多额外的东西,使用早期版本debug起来更聚焦一些。
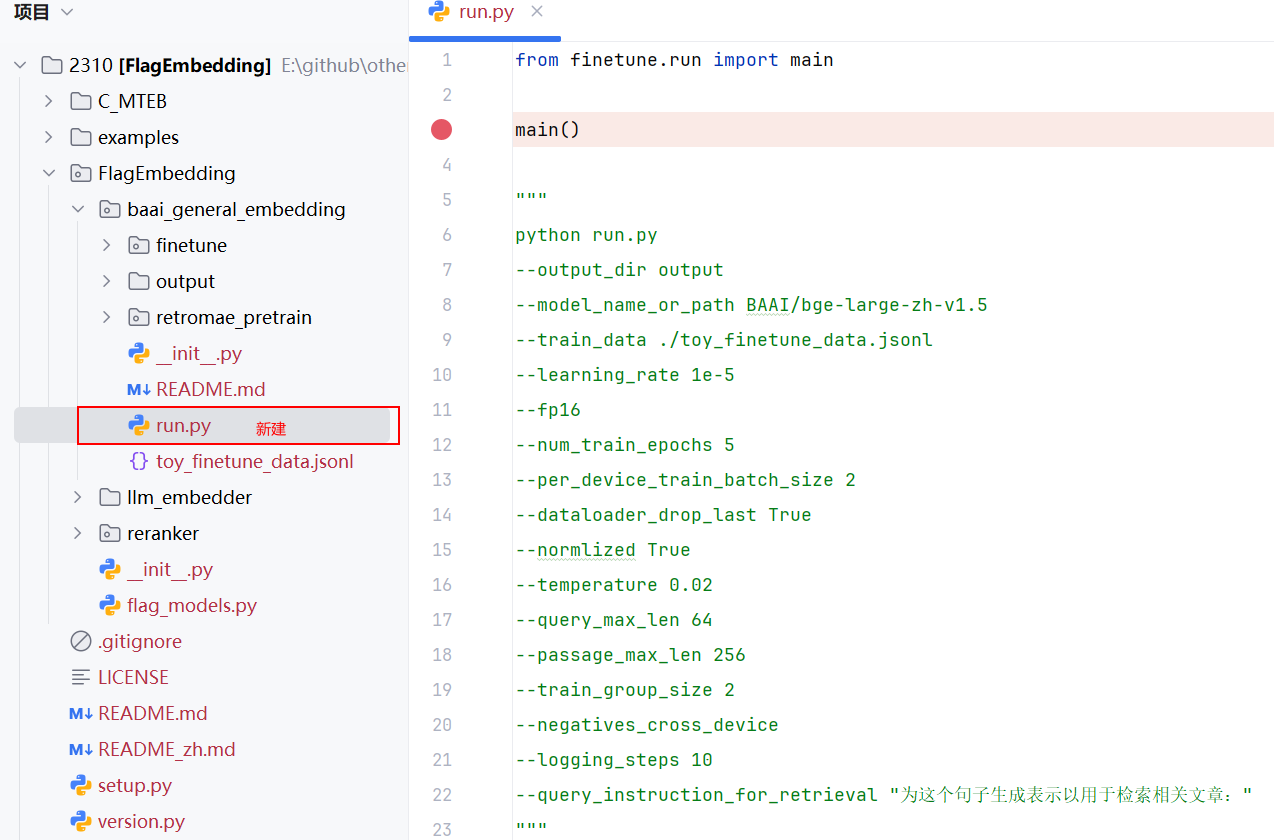
python run.py
--output_dir output
--model_name_or_path BAAI/bge-large-zh-v1.5
--train_data ./toy_finetune_data.jsonl
--learning_rate 1e-5
--fp16
--num_train_epochs 5
--per_device_train_batch_size 2
--dataloader_drop_last True
--normlized True
--temperature 0.02
--query_max_len 64
--passage_max_len 256
--train_group_size 2
--negatives_cross_device
--logging_steps 10
--query_instruction_for_retrieval "为这个句子生成表示以用于检索相关文章:"
由于需要传递参数再运行脚本,需要在pycharm配置一些与运行相关的参数:
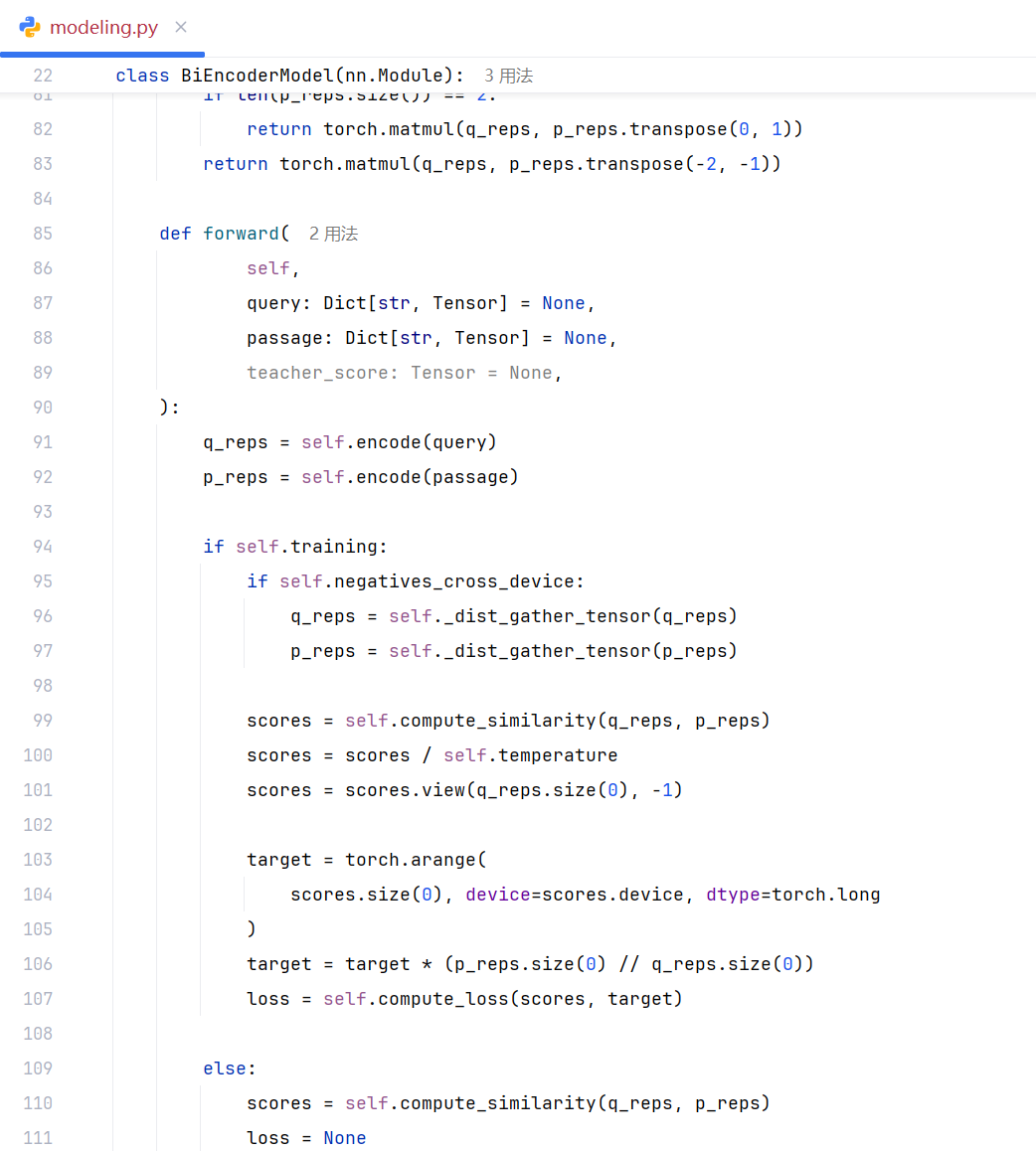
下述是embedding计算损失的核心代码,这里的query与passage都是batch_size数量的输入,如果只是一条query与passage,大家理解起来就容易很多。由于这里是batch_size数量的输入,代码中涉及到矩阵运算会给大家带来理解困难。
比较难理解的是下述代码,这里的target 其实就是label:
target = torch.arange(scores.size(0), device=scores.device, dtype=torch.long)
target = target * (p_reps.size(0) // q_reps.size(0))
p_reps 是相关文本矩阵, q_reps 是问题矩阵。每一个问题都对应固定数量的相关文本。p_reps.size(0) // q_reps.size(0) 是每个问题对应的相关文本的数量。下一行的target 乘以 相关文本的块数,得到query对应的 Gold Truth(也称 pos 文本)的下标,因为在每个相关文本中,第一个位置都是正确文本,其后是负样本,这些 Gold Truth 下标之间的距离是固定,通过乘法就可以计算出每个 Gold Truth 的下标。
额外补充【选看】:
在微调的过程中,不要错误的以为每个问题只和自己的相关文本计算score。真实的情况是,在batch_size的数据中,每个问题会与所有的相关文本计算score。根据上述代码可看出 target 最大的取值是:query的数量 x 相关文本数量,这也印证了每个问题会与所有的相关文本都计算score。故我们在随机采样负样本的时候,负样本数量设置的太小也不用太担心,因为在计算过程中负样本的数量会乘以 batch_size。
【注意】:query的数量 = batch_size
- 损失函数

def compute_loss(self, scores, target):return self.cross_entropy(scores, target)
C-METB 论文中,关于损失函数的介绍,公式看起来很复杂,本质就是cross_entropy。
资源分享
上述的代码开源在github平台,为了不增大github仓库的容量,数据集没有上传到github平台。若希望直接获得完整的项目文件夹,从下述提供的网盘分享链接进行下载:
-
github开源地址:https://github.com/JieShenAI/csdn/tree/main/25/04/embedding_finetune
-
通过网盘分享的文件:embedding_finetune.zip
链接: https://pan.baidu.com/s/1CDRpkkjS1-0jtmIBiTWx1A 提取码: free
最新的代码,请以 github 的链接为准,网盘分享的文件,本意只是为了存储数据,避免增加github仓库的容量
参考资料
[1] BAAI官方微调教程: https://github.com/FlagOpen/FlagEmbedding/blob/master/Tutorials/7_Fine-tuning/7.1.2_Fine-tune.ipynb
[2] BAAI官方评估教程:https://github.com/FlagOpen/FlagEmbedding/blob/master/Tutorials/4_Evaluation/4.1.1_Evaluation_MSMARCO.ipynb
[3] 多文档知识图谱问答:https://jieshen.blog.csdn.net/article/details/146390208
[4] bge模型微调流程:https://www.bilibili.com/video/BV1eu4y1x7ix/
[5] FlagEmbedding 旧版本可用于debug的代码:https://github.com/FlagOpen/FlagEmbedding/blob/9b6e521bcb7583ed907f044ca092daef0ee90431/FlagEmbedding/baai_general_embedding/finetune/run.py
相关文章:

从零开始微调Embedding模型:基于BERT的实战教程
文章目录 背景微调实战装包介绍 项目文件介绍微调硬件配置要求 debug 重要代码分析【选看】资源分享参考资料 背景 在理解与学会了Naive RAG的框架流程后,就很自然地关注到embedding模型,与问题相关的文本召回,也有很多论文在做这方面的创新…...
——个人理解篇5(梯度下降中遇到的问题))
机器学习(神经网络基础篇)——个人理解篇5(梯度下降中遇到的问题)
在神经网络训练中,计算参数的梯度是关键步骤。numerical_gradient 方法旨在通过数值微分(中心差分法)计算损失函数对网络参数的梯度。然而,该方法的实现存在一个关键问题,导致梯度计算错误。 1、错误代码示例…...
)
带label的3D饼图(threejs)
3D饼图 使用three.js实现,选择threejs的原因:label需要实际的显示在具体的饼对应的模块上 “three”: “^0.127.0”, <template><div><div ref"chartContainer" class"chart-container"></div><div clas…...

ragflow开启https访问:使用自签证书还是有不安全警告,如何解决
背景:在ragflow里的使用了自签证书来启动ragflow,在浏览器里访问还是不安全警告,如何解决 在方案2中,证书不会在访问网站时自动下载,需要你手动获取并安装证书文件。以下是具体操作步骤: 详细步骤:手动获取并安装自签名证书 第一步:获取证书文件 找到证书文件 证书文件位…...

条件变量核心要素
条件变量内部实现原理 原子性解锁阻塞机制: // pthread_cond_wait内部伪代码大致如下: int pthread_cond_wait(cond_t *cond, mutex_t *mutex) {atomic {unlock(mutex); // 原子操作中先释放互斥锁block_thread(); // 立即将线程加入等待队列…...

C语言求鞍点
我们先在第一行中找出最大的值,然后在该列中找出最小值看这两个是否相等。 若是相等,那么这个数就是鞍点跳出循环 若是不想等,则继续在下一行寻找,若是一直到整体的循环都结束了还是没有,那么不存在鞍点。 运行结果:…...

XELA机器人多种“形态和玩法”的Uskin磁性阵列式三轴触觉传感器,你使用过了吗?
XELA Robotics为机器人行业提供创新的磁性触觉传感技术,uSkin触觉传感器是一种高密度的三轴触觉传感器,因其轻薄、表面柔软耐用和布线少的结构设计,可以轻松集成到机器人本体,灵巧手,机器人夹爪等部位,使机…...

转换效率高达 96%,12V转5V同步降压WD5030
特点1 宽输入电压范围:能在 7V 至 30V 的宽输入电压范围内工作,可适应多种不同电压等级的供电环境,无论是工业设备中的较高电压输入,还是便携式设备经过初步升压后的电压,都能良好适配,极大地拓展了应用的…...

请你回答一下单元测试、集成测试、系统测试、验收测试、回归测试这几步中最重要的是哪一步?
在软件测试的不同阶段中,每个环节都有其不可替代的价值,但若从工程效率和缺陷防控的全局视角来看,单元测试(Unit Testing) 是质量金字塔的基石,其重要性最为关键。以下是分层解析: 一、从缺陷修复成本看优先级 美国国家标准与技术研究院(NIST)研究显示: 单元测试阶段…...

QML和C++交互
目录 1 QML与C交互基础1.1 全局属性1.2 属性私有化(提供接口访问) 2 QT与C交互(C创建自定义对象,qml文件直接访问)3 QT与C交互(qml直接访问C中的函数)4 QT与C交互(qml端发送信号 C端实现槽函数)…...
试题速浏、分类及浅析)
2021年-全国大学生数学建模竞赛(CUMCM)试题速浏、分类及浅析
2021年-全国大学生数学建模竞赛(CUMCM)试题速浏、分类及浅析 全国大学生数学建模竞赛(China Undergraduate Mathematical Contest in Modeling)是国家教委高教司和中国工业与应用数学学会共同主办的面向全国大学生的群众性科技活动,目的在于激励学生学习数学的积极性,提高学…...

mariadb使用docker compose方式安装
问题 本地mac m1上面的mysql和mariadb突然不用使用了,重新安装也不想,最近mac系统也更新了,brew也更新了,重新安装mariadb还是不能正常使用,现在我打算使用docker来安装本地的mariadb了。 默认配置文件my.cnf 从容器…...

Logo语言的死锁
Logo语言的死锁现象研究 引言 在计算机科学中,死锁是一个重要的研究课题,尤其是在并发编程中。它指的是两个或多个进程因争夺资源而造成的一种永久等待状态。在编程语言的设计与实现中,如何避免死锁成为了优化系统性能和提高程序可靠性的关…...
具身智能零碎知识点(一):深入解析Transformer位置编码
深入解析Transformer位置编码 Transformer位置编码完全解析:从公式到计算的终极指南一、位置编码的必要性演示二、位置编码公式深度拆解原始公式参数说明(以d_model4为例) 三、完整计算过程演示步骤1:计算频率因子步骤2࿱…...

0201概述-机器学习-人工智能
文章目录 1、概述1.1、示例1.2、概念 2、应用场景2.1、行业应用场景2.1.1、金融领域2.1.2、 医疗健康2.1.3、零售与电商2.1.4、 制造业2.1.5、自动驾驶 2.2、功能场景分类2.2.1、 预测类2.2.2、分类与识别类2.2.3、生成与优化类 2.3、机器学习适用场景的共同特征 3、实现机器学…...

金能电力工具柜:“五世同堂”演绎创新华章
在电力与工业领域的浩瀚星空中,金能电力如同一颗璀璨的星辰,其工具柜产品更是经历了五代更迭,如同家族中的“五世同堂”,每一代都承载着前人的智慧与后人的创新,共同谱写着传承与创新的交响曲。 初识平凡:普…...

蓝桥杯每日刷题c++
目录 P9240 [蓝桥杯 2023 省 B] 冶炼金属 - 洛谷 (luogu.com.cn) P8748 [蓝桥杯 2021 省 B] 时间显示 - 洛谷 (luogu.com.cn) P10900 [蓝桥杯 2024 省 C] 数字诗意 - 洛谷 (luogu.com.cn) P10424 [蓝桥杯 2024 省 B] 好数 - 洛谷 (luogu.com.cn) P8754 [蓝桥杯 2021 省 AB2…...

MySQL基础 [五] - 表的增删查改
目录 Create(insert) Retrieve(select) where条件 编辑 NULL的查询 结果排序(order by) 筛选分页结果 (limit) Update Delete 删除表 截断表(truncate) 插入查询结果(insertselect&…...

深入解析 MySQL 中的日期时间函数:DATE_FORMAT 与时间查询优化
深入解析 MySQL 中的日期时间函数:DATE_FORMAT 与时间查询优化 在数据库管理和应用开发中,日期和时间的处理是不可或缺的一部分。MySQL 提供了多种日期和时间函数来满足不同的需求,其中DATE_FORMAT函数以其强大的日期格式化能力,…...

GPU是什么? 与 FPGA 有何关联
前段时间,AMD 和英伟达相继接到通知将对我国断供高端 GPU 芯片,很多人这才意识到 GPU 的战略价值。那么 GPU 究竟是什么?它为何如此重要?今天就由 宸极教育 带大家一起了解 GPU 的核心地位,以及它与国产FPGA发展的关系…...

数据结构与算法:基础与进阶
🌟 各位看官好,我是maomi_9526! 🌍 种一棵树最好是十年前,其次是现在! 🚀 今天来学习C语言的相关知识。 👍 如果觉得这篇文章有帮助,欢迎您一键三连,分享给更…...

低配置云服务器网站的高效防御攻略
在网络环境日益复杂的当下,低配置云服务器网站常面临攻击威胁。不少站长疑惑,明明设置了 CC 防御,服务器却依旧不堪一击,这是怎么回事呢? 比如,在 CC 防御配置中,设定 10 秒内允许访问 50 次。但…...

使用 Lua 脚本高效查询 Redis 键的内存占用
使用 Lua 脚本高效查询 Redis 键的内存占用 在处理 Redis 数据时,我们常常需要了解某些键的内存占用情况,尤其是在优化内存使用或排查问题时。虽然 Redis 提供了MEMORY USAGE命令来查询单个键的内存占用,但如果需要批量查询多个键࿰…...

【Linux篇】基础IO - 揭秘重定向与缓冲区的管理机制
📌 个人主页: 孙同学_ 🔧 文章专栏:Liunx 💡 关注我,分享经验,助你少走弯路! 文章目录 一. 理解重定向1.1 理解重定向1.2 dup21.3 进一步理解重定向输出重定向:追加重定向…...

centos 8 启动Elasticsearch的时候报内存不足问题解决办法
centos 8 启动Elasticsearch 的时候报错,导致无法启动Elasticsearch 。 [root@CentOS-8 ~]# journalctl -xe Apr 07 18:25:56 CentOS-8.0 kernel: [ 8754] 0 8754 3180 63 69632 0 0 sh Apr 07 18:25:56 CentOS-8.0 kernel: [ 8755] 0 8755 3180 64 69632 0 0 sh Apr 07 18:25…...

深入剖析Java IO设计模式:从底层原理到实战应用
🔍 引言:设计模式与IO的完美交响 在软件开发的浩瀚星河中,设计模式犹如璀璨的导航星,而Java IO体系则是支撑数据流动的神经网络。 当我们以设计模式的视角重新审视Java IO库时,会发现这个看似平凡的IO世界实则暗藏着…...

阶段测试 【过程wp】
分享总结: 回顾起来,真的感慨很多呀。看着并不难啊,但难的是解题思维:如何判断该页面的关键点,快速地确定问题的核心,找到对应的解决方法。达到便捷、高效的得到结果。我们做了整整近七个半小时。在这个过程中,我发现自己的思维钝化,不太能自主高效地划分判断漏洞类型,…...

qml信号与槽函数
目录 信号与槽函数基础方法1-使用Connections方式2-使用connect(不常用) 自定义组件与信号槽使用 信号与槽函数基础 方法1-使用Connections main.qml import QtQuick 2.15 import QtQuick.Window 2.15 import QtQuick.Controls 2.15Window {id:windoww…...

ngx_palloc
定义在 src\core\ngx_palloc.c void * ngx_palloc(ngx_pool_t *pool, size_t size) { #if !(NGX_DEBUG_PALLOC)if (size < pool->max) {return ngx_palloc_small(pool, size, 1);} #endifreturn ngx_palloc_large(pool, size); } 判断 需要分配的内存大小 是否小于 poo…...
)
notepad++日常使用(每行开头、每行末尾增加字符串,每行中间去掉字符串)
1. 每行开头增加字符串 如果我们要给下面的数据每行的开头都增加相同的一些字符串{value: 这时候只需要使用notepad的语法,使用快捷键Crtl H 替换功能,每一行开头使用 ^ 符号,替换成自己想要的字符串 {value: 使用全部替换就会在每行数据…...

Java面试黄金宝典39
1. SNMP、SMTP 协议 SNMP(简单网络管理协议) 定义:SNMP 是一种应用层协议,用于在 IP 网络中管理网络节点(如服务器、路由器、交换机等)。它允许网络管理员监控网络设备的状态、收集性能数据、进行故障诊断等操作。SNMP 基于 UDP 协议,采用轮询和事件驱动相结合的方式来收…...
如何解决:http2: Transport received Server‘s graceful shutdown GOAWAY
有一次做压力测试,客户端经常出现如下错误: http2: Transport: cannot retry err [http2: Transport received Servers graceful shutdown GOAWAY] after Request.Body was written; define Request.GetBody to avoid this error是 Golang 中使用 HTTP/…...
(java)俄罗斯套娃信封问题)
贪心算法(16)(java)俄罗斯套娃信封问题
题目:给你一个二维整数数组 envelopes ,其中 envelopes[i] [wi, hi] ,表示第 i 个信封的宽度和高度。 当另一个信封的宽度和高度都比这个信封大的时候,这个信封就可以放进另一个信封里,如同俄罗斯套娃一样。 请计算…...

【DeepSeek原理学习2】MLA 多头隐变量注意力
解决的问题 Multi-Head Latent Attention,MLA——解决的问题:KV cache带来的计算效率低和内存需求大以及上下文长度扩展问题。 MLA原理 MLA原理:其核心思想是将键(Key)和值(Value)矩阵压缩到…...

2024年RAG大赛
2024 CCF国际AIOps挑战赛赛题与赛制解读-CSDN博客 自动化测评也比较有意思,分数为 关键字 语义相似度,分值比为6:4. 2024 CCF AIOPS国际挑战赛优秀奖方案分享 https://zhuanlan.zhihu.com/p/7444390758 【大模型RAG获奖方案分享】如何提高RAG系统在…...
的一些内置函数与求和函数)
2025-4-6-C++ 学习 有序数组、set()的一些内置函数与求和函数
C的学习必须更加精进一些,对于好多的函数和库的了解必须深入一些。 文章目录 3510. 移除最小数对使数组有序 II(有序数组)题目参考代码(1)auto it idx.lower_bound(i);功能解释可能的使用场景常见错误 (2&…...

Flutter:Flutter SDK版本控制,fvm安装使用
1、首先已经安装了Dart,cmd中执行 dart pub global activate fvm2、windows配置系统环境变量 fvm --version3、查看本地已安装的 Flutter 版本 fvm releases4、验证当前使用的 Flutter 版本: fvm flutter --version5、切换到特定版本的 Flutter fvm use …...

GPT-4o 的“图文合体”是怎么做到的
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

PyTorch教程:如何读写张量与模型参数
本文演示了PyTorch中张量(Tensor)和模型参数的保存与加载方法,并提供完整的代码示例及输出结果,帮助读者快速掌握数据持久化的核心操作。 1. 保存和加载单个张量 通过torch.save和torch.load可以直接保存和读取张量。 import to…...

MySQL8.0.31安装教程,附pdf资料和压缩包文件
参考资料:黑马程序员 一、下载 点开下面的链接:https://dev.mysql.com/downloads/mysql/ 点击Download 就可以下载对应的安装包了, 安装包如下: 我用夸克网盘分享了「mysql」,链接:https://pan.quark.cn/s/ab7b7acd572b 二、解…...
进行分区、格式化或挂载的操作)
Linux 系统中对存储设备(/dev/mmcblk、/dev/sd、/dev/nvme)进行分区、格式化或挂载的操作
在 Linux 系统中对存储设备(/dev/mmcblk、/dev/sd、/dev/nvme)进行分区、格式化或挂载的操作步骤如下: 一、确认设备信息 首先明确要操作的设备名称(如 /dev/sdb、/dev/nvme0n1),避免误操作导致数据丢失&a…...
)
【Kafka基础】topics命令行操作大全:高级命令解析(1)
1 创建压缩主题(Log Compaction) /export/home/kafka_zk/kafka_2.13-2.7.1/bin/kafka-topics.sh --create \--bootstrap-server 192.168.10.33:9092 \--topic comtopic \--partitions 3 \--replication-factor 2 \--config cleanup.policycompact \--con…...

springboot集成spring loadbalancer实现客户端负载均衡
在 Spring Boot 中实现负载均衡,通常需要结合 Spring Cloud 组件,比如 Spring Cloud LoadBalancer。Spring Cloud LoadBalancer 是一个客户端负载均衡器,可以与 Spring Boot 集成,实现微服务之间的负载均衡。 以下是一个简单的示…...
)
什么是 k8s Affinity(亲和性)
在 Kubernetes(K8s)中,Affinity(亲和性) 是一种 Pod 调度策略,它用于控制 Pod 在什么条件下可以被调度到特定的节点上。它比 Taints 和 Tolerations 更灵活,可以基于 节点属性 或 Pod 之间的关系…...

深度探索:策略学习与神经网络在强化学习中的应用
深度探索:策略学习与神经网络在强化学习中的应用 策略学习(Policy-Based Reinforcement Learning)一、策略函数1.1 策略函数输出的例子 二、使用神经网络来近似策略函数:Policy Network ,策略网络2.1 策略网络运行的例子2.2需要的几个概念2.3神经网络近似…...

用VAE作为标题显示标题过短,所以标题变成了这样
VAE (Variational Autoencoder / 变分自编码器) 基本概念: VAE 是一种生成模型 (Generative Model),属于自编码器 (Autoencoder) 家族。 它的目标是学习数据的潜在表示 (Latent Representation),并利用这个表示来生成新的、与原始数据相似的数据。 与标…...

【day27】测试策略升级方案:需求阶段介入与业务规则覆盖矩阵设计
测试策略升级方案:需求阶段介入与业务规则覆盖矩阵设计 一、需求评审阶段:主动识别业务逻辑问题 在需求评审时,测试团队应通过结构化提问提前暴露潜在风险,避免后期返工。以下为提问框架与示例: 1. 业务逻辑澄清提问模…...

AI烘焙大赛中的算法:理解PPO、GRPO与DPO的罪简单的方式
🧠 向所有学习者致敬! “学习不是装满一桶水,而是点燃一把火。” —— 叶芝 我的博客主页: https://lizheng.blog.csdn.net 🌐 欢迎点击加入AI人工智能社区! 🚀 让我们一起努力,共创…...

二分 —— 基本算法刷题路程
一、1.求阶乘 - 蓝桥云课 算法代码: #include <bits/stdc.h> using namespace std; #define ll long long ll check(ll n) {ll cnt0;while(n){cnt(n/5);}return cnt; }int main() {ll k;cin>>k;ll L0,R1e19;while(L<R){ll mid(LR)>>1;if(che…...

内存序问题排查
1 内存序 2 简介 std::memory_order 是 C11 引入的一个枚举类型,用于和 <atomic> 原子操作一起使用,控制多线程环境下内存的可见性和执行顺序。 它的主要作用是:告诉编译器和 CPU,在执行某个原子操作时,哪些内…...