MySQL基础 [五] - 表的增删查改
目录
Create(insert)
Retrieve(select)
where条件
编辑 NULL的查询
结果排序(order by)
筛选分页结果 (limit)
Update
Delete
删除表
截断表(truncate)
插入查询结果(insert+select)
聚合函数
分组聚合统计(group by)
CRUD : Create(创建), Retrieve(读取),Update(更新),Delete(删除)
Create(insert)
语法:
[ ]内的是可以省略的
INSERT [INTO] table_name[(column [, column] ...)]VALUES (value_list) [, (value_list)] ...value_list: value, [, value] ...使用:创建一个学生表

单行数据 + 指定列插入
value_list 数量必须和定义表的列的数量及顺序一致。value的左右两边必须值对应,类型也对应

可以不用指定id,因为mysql会用默认的值进行自增
单行数据 + 全列插入
全列插入可以省略values左侧的列属性
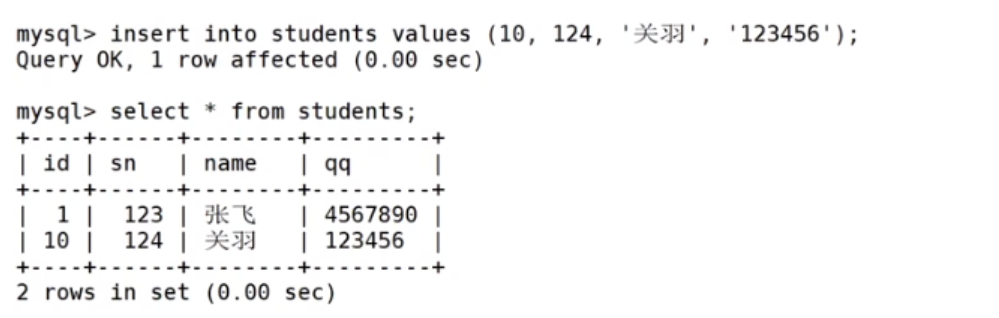
多行数据 + 全列插入
多行数据用逗号隔开

多行数据 + 指定列插入
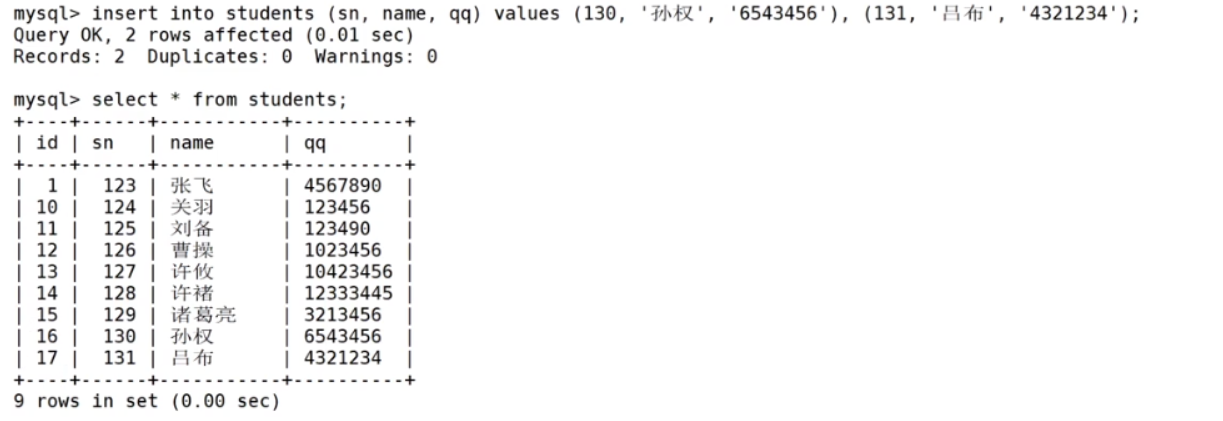
插入是否更新
可能会出现由于主键或者唯一键对应的值已经存在而导致插入失败的情况

这时候我们希望能够进行可以选择性的进行同步更新操作而不是直接报错
INSERT ... ON DUPLICATE KEY UPDATE column = value [, column = value] ... 举个例子

第一个错误是因为主键冲突,第二个错误是因为我们尝试更新的数据和其他行数据也冲突了
相当于是多做一次尝试,如果语句冲突了,就把insert操作改成updata操作
需要注意的是你也要保证更新的数据不要和其他行数据的主键发生冲突!!
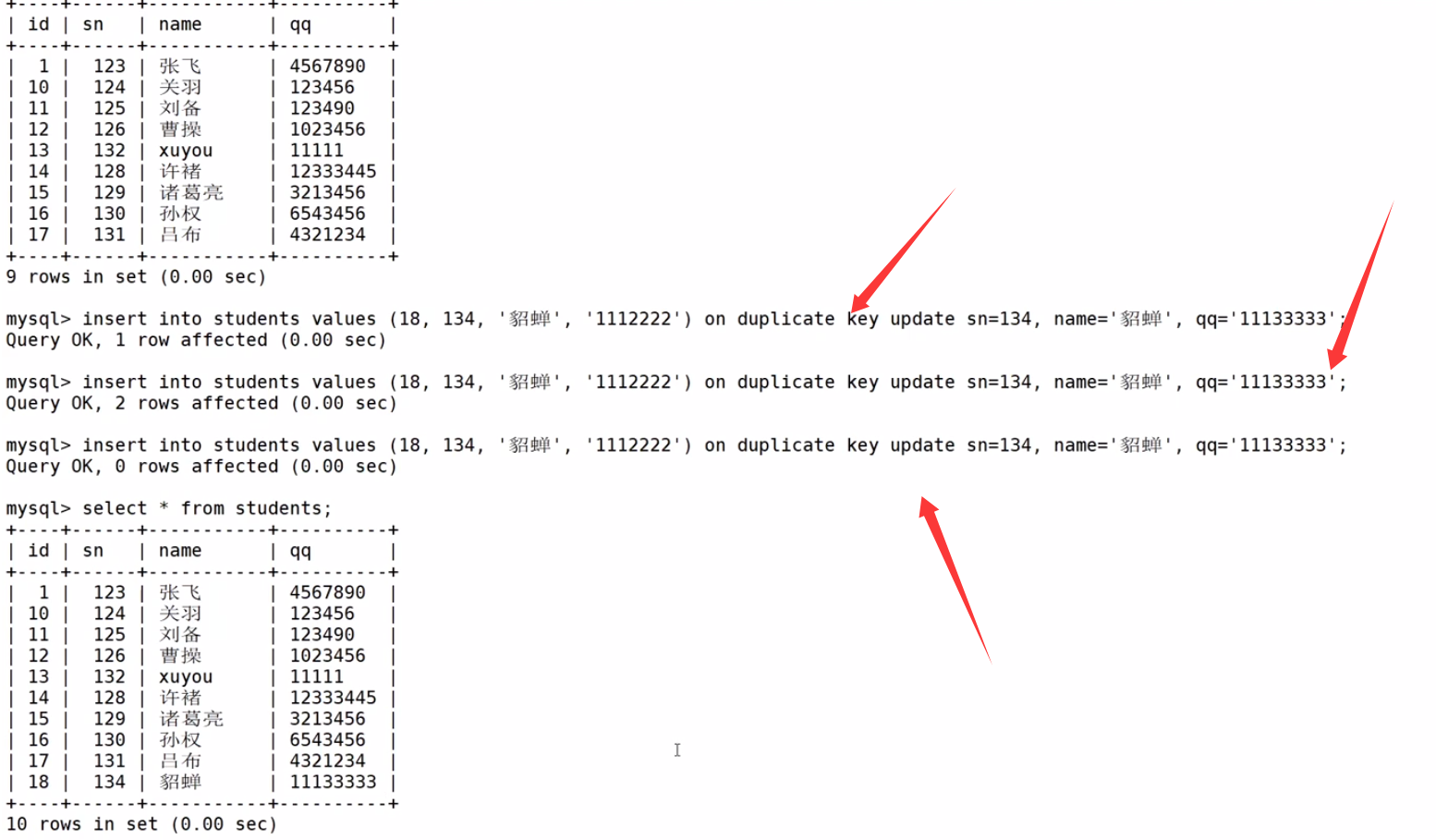
- 0 row affected: 表中有冲突数据,但冲突数据的值和 update 的值相等
- 1 row affected: 表中没有冲突数据,数据被插入
- 2 row affected: 表中有冲突数据,并且数据已经被更新
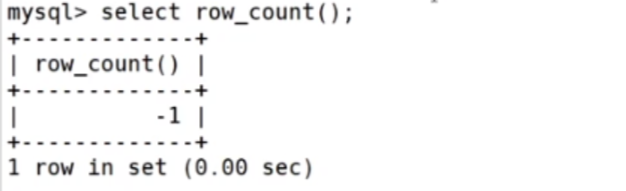
也可通过 MySQL row_count()函数获取受到影响的数据行数 (-1表示没有)
replace
- 主键 或者唯一键 没有冲突,则直接插入;
- 主键 或者 唯一键 如果冲突,则删除后再插入
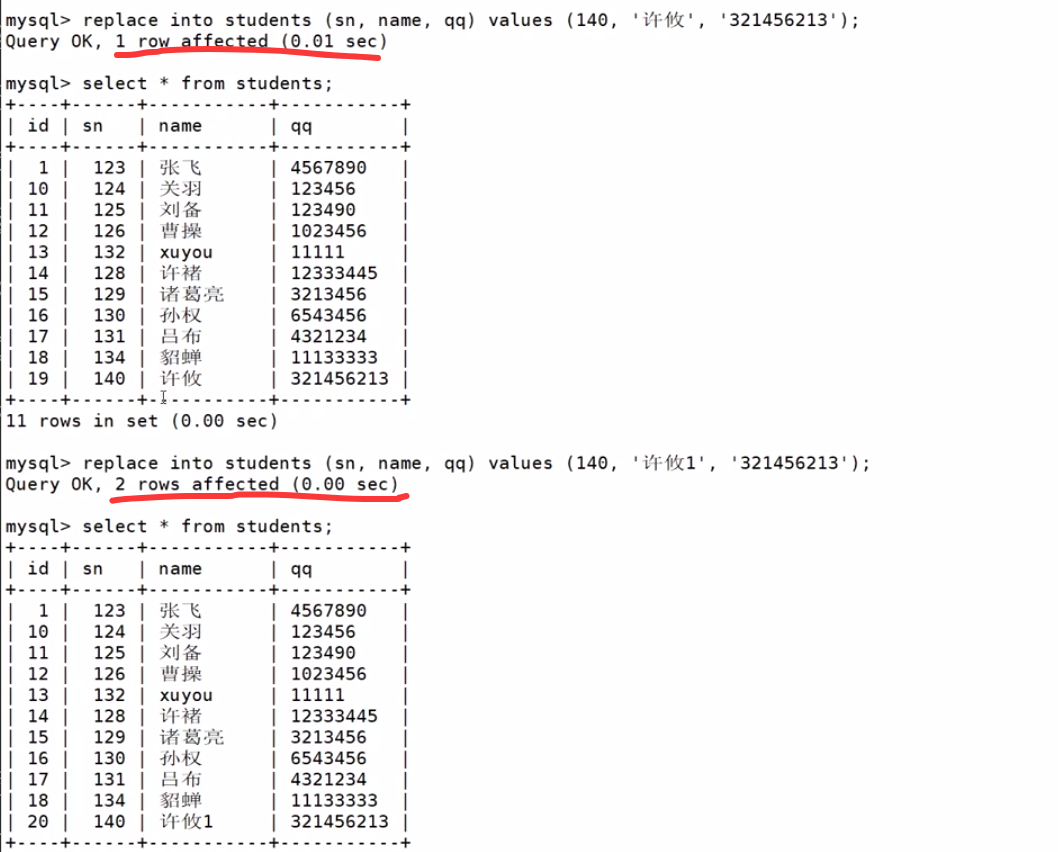
1 row affected: 表中没有冲突数据,数据被插入
2 row affected: 表中有冲突数据,删除后重新插入
Retrieve(select)
语法
SELECT [DISTINCT]//去重 {* | {column [, column] ...} [FROM table_name] //从某个表里去提取[WHERE ...] //筛选条件[ORDER BY column [ASC | DESC], ...] //排序LIMIT ... //限定筛选出来的结果条数创建表结构 并插入数据
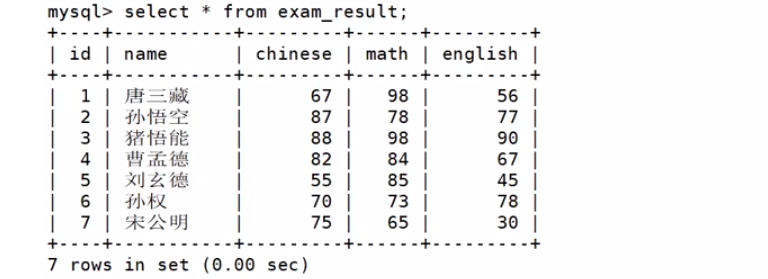
CREATE TABLE exam_result ( id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT, name VARCHAR(20) NOT NULL COMMENT '同学姓名', chinese float DEFAULT 0.0 COMMENT '语文成绩', math float DEFAULT 0.0 COMMENT '数学成绩', english float DEFAULT 0.0 COMMENT '英语成绩'
); INSERT INTO exam_result (name, chinese, math, english) VALUES ('唐三藏', 67, 98, 56), ('孙悟空', 87, 78, 77), ('猪悟能', 88, 98, 90), ('曹孟德', 82, 84, 67), ('刘玄德', 55, 85, 45), ('孙权', 70, 73, 78), ('宋公明', 75, 65, 30);
Query OK, 7 rows affected (0.00 sec)
Records: 7 Duplicates: 0 Warnings: 0 全列查询(*)
通常情况下不建议使用*进行全列查询
- 查询的列越多,意味着需要传输的数据量越大(线性遍历);
- 可能会影响到索引的使用 。
指定列查询
是将表中所有的数据拿出来,然后要什么再显示什么,指定列的顺序不需要按定义表的顺序来

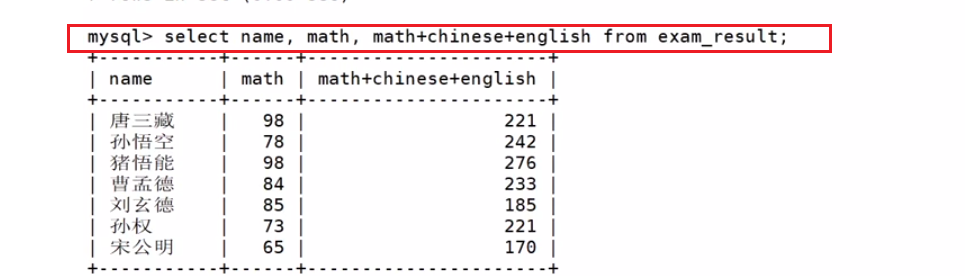
查询字段为表达式
表达式不包含字段

表达式包含一个字段

表达式包含多个字段
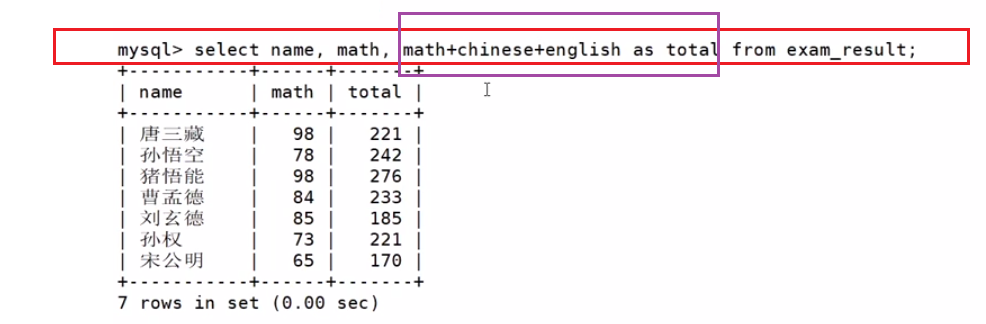
为查询结果指定别名(as)
SELECT column [AS] alias_name [...] FROM table_name;
起多个别名
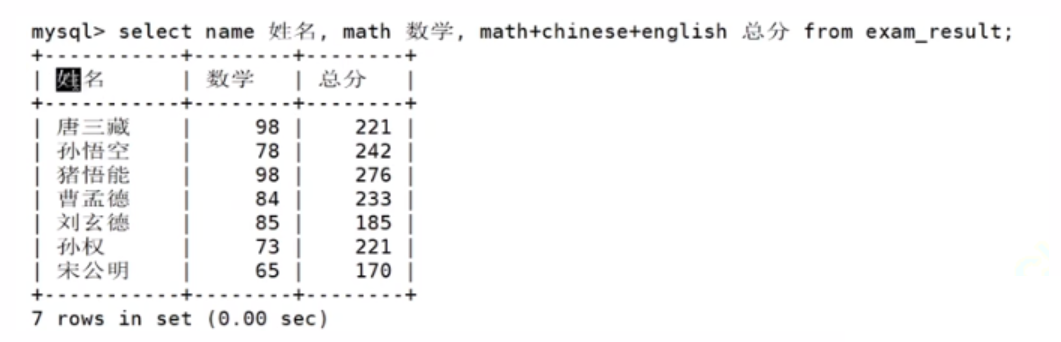
结果筛选并去重
我们发现98分重复了

SELECT DISTINCT column [...] FROM table_name; 
where条件
比较运算符

逻辑运算符
英语不及格的同学即英语成绩 ( < 60 )
SELECT name, english FROM exam_result WHERE english < 60;
语文成绩在 [80, 90] 分的同学及语文成绩
使用 AND 进行条件连接
SELECT name, chinese FROM exam_result WHERE chinese >= 80 AND chinese <= 90;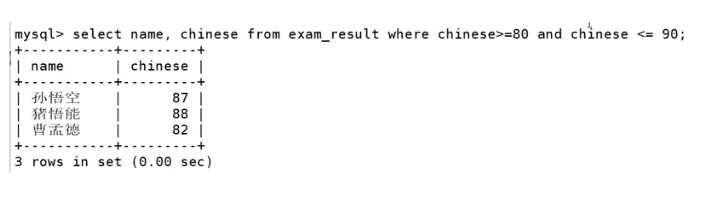
使用 BETWEEN ... AND ... 条件
SELECT name, chinese FROM exam_result WHERE chinese BETWEEN 80 AND 90; 
数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩
使用 OR 进行条件连接
SELECT name, math FROM exam_result WHERE math = 58 OR math = 59 OR math = 98 OR math = 99; 
使用 IN 条件
SELECT name, math FROM exam_result WHERE math IN (58, 59, 98, 99);
_ 匹配严格的一个任意字符
SELECT name FROM exam_result WHERE name LIKE '孙_';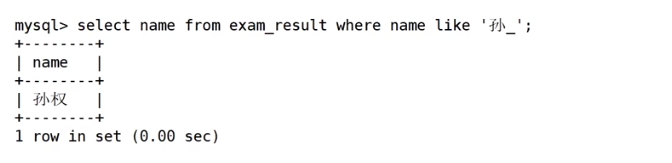
语文成绩好于英语成绩的同学
WHERE 条件中比较运算符两侧都是字段
SELECT name, chinese, english FROM exam_result WHERE chinese > english;
总分在 200 分以下的同学
SELECT name, chinese + math + english 总分 FROM exam_result WHERE chinese + math + english < 200; 
能用别名进行查找吗?

上述代码的执行顺序:先 from exam_result 再 where total < 200 最后 chinese+english+math total;
根据上图我们会发现如果直接在筛选条件那里重命名也是不可以的!!因为对列做重命名已经是属于显示范畴了,相当于是已经把数据拿完了,然后在最后把列名字起别名,这一步是最后一步了!所以语法上不允许的!!
孙某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80
综合性查询
SELECT name, chinese, math, english, chinese + math + english 总分
FROM exam_result
WHERE name LIKE '孙_' OR ( chinese + math + english > 200 AND chinese < math AND english > 80
);  NULL的查询
NULL的查询
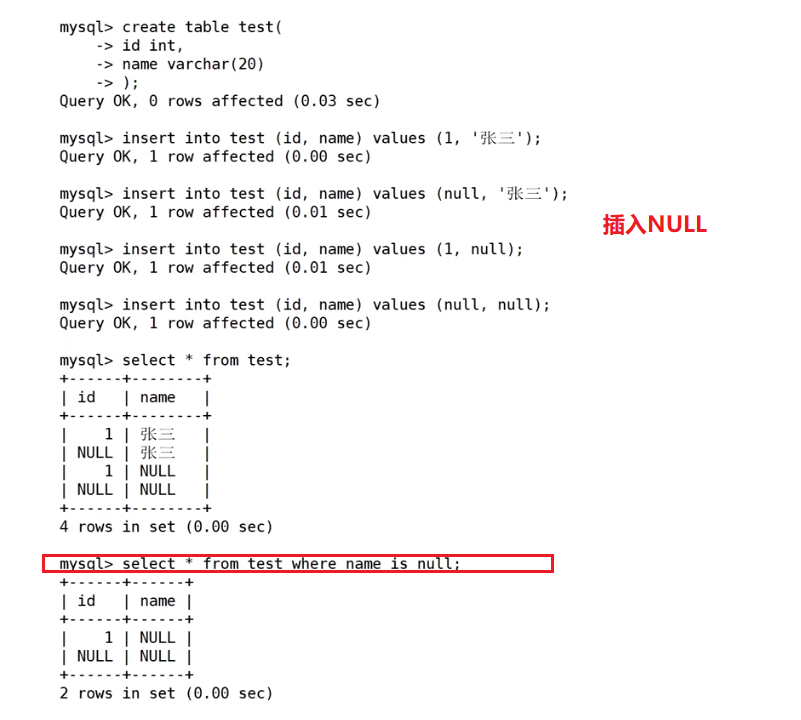
‘ ’ 和NULL没有关系!!

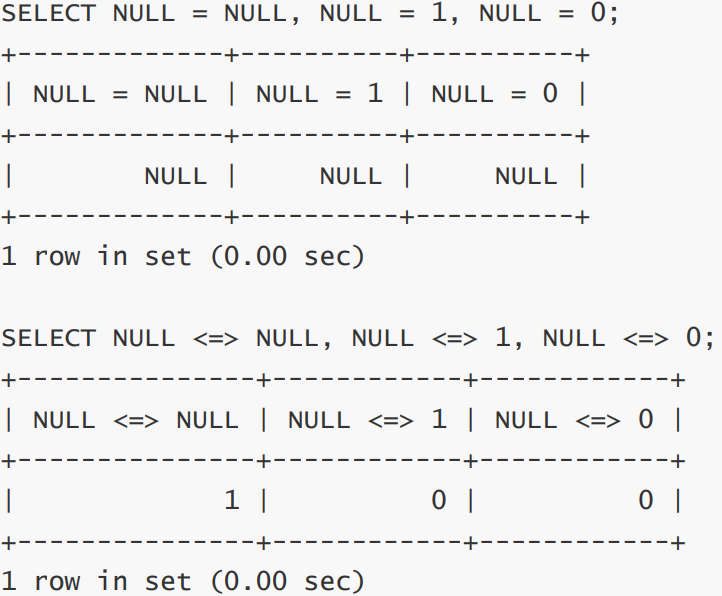
-- NULL 和 NULL 的比较,= 和 的区别
结果排序(order by)
语法:
SELECT ... FROM table_name [WHERE ...] ORDER BY column [ASC|DESC], [...]; //依据哪一列做排序- ASC 为升序(从小到大) //ascending order
- DESC 为降序(从大到小) //descending order
- 默认为 ASC
注意:没有 ORDER BY 子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序
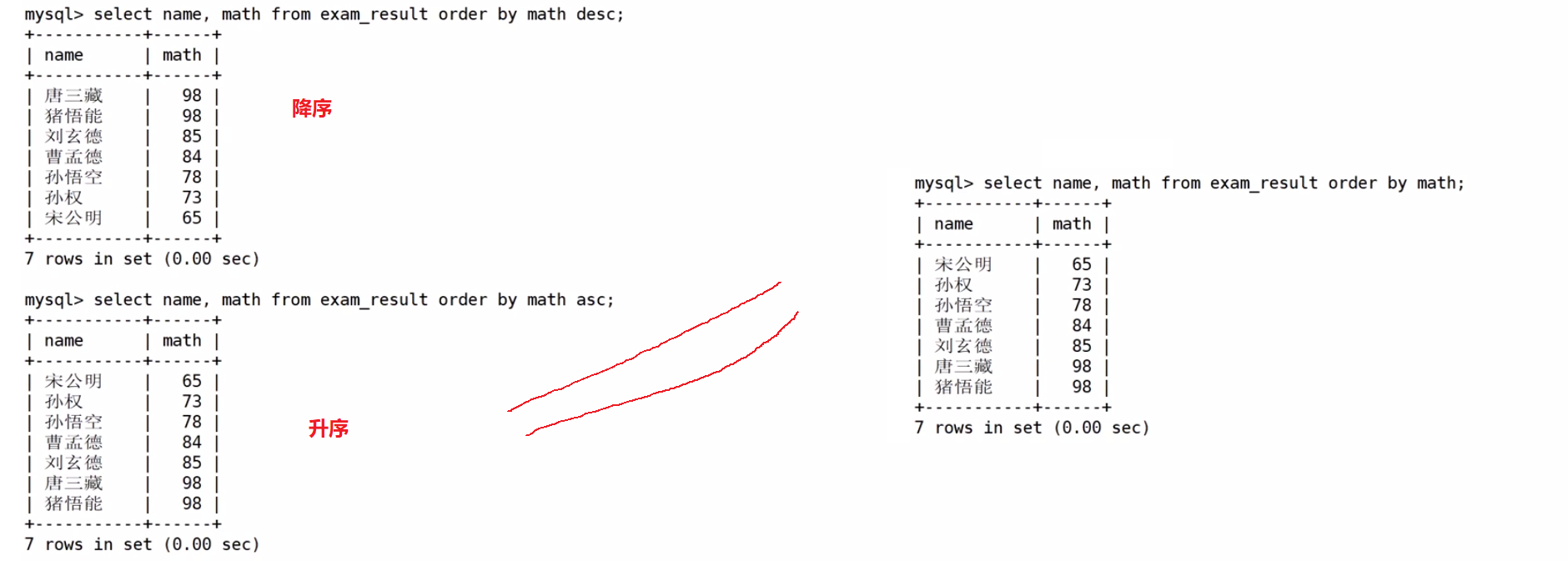
同学及数学成绩,按数学成绩升序显示

同学及qq号,按姓名排序显示
NULL视为比任何值都小,升序出现在最上面。降序在最下面
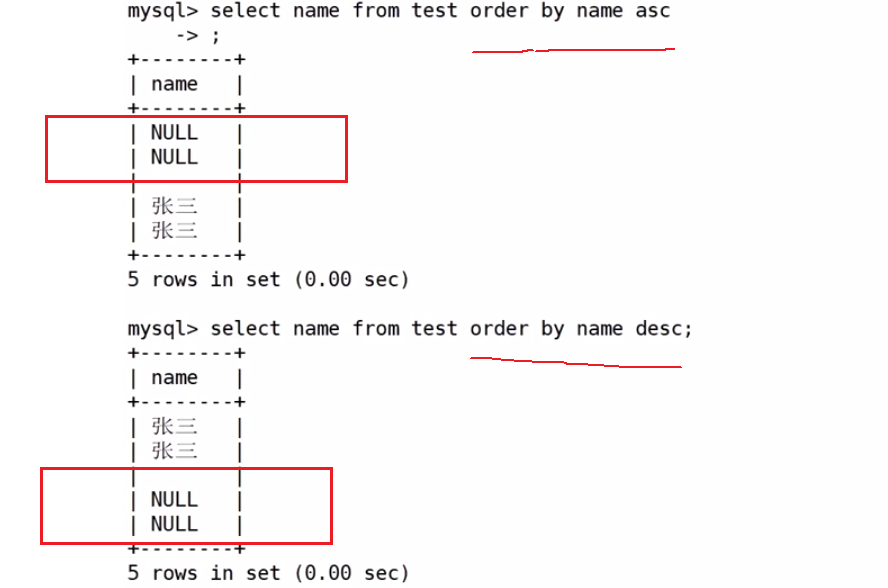
默认是按照升序来排序
查询同学各门成绩,依次按数学降序,英语升序,语文升序的方式显示
多字段排序,排序优先级随书写顺序
也就是说先比较第一个顺序,然后当两个或者多个数据第一个顺序相同时,再比较第二个数据,第三个数据,以此类推

查询同学及总分,由高到低
- ORDER BY中可以使用表达式
- ORDER BY子句中可以使用列别名

为什么这里用别名进行排序呢?上次我们将where的时候不是不能用别名吗?
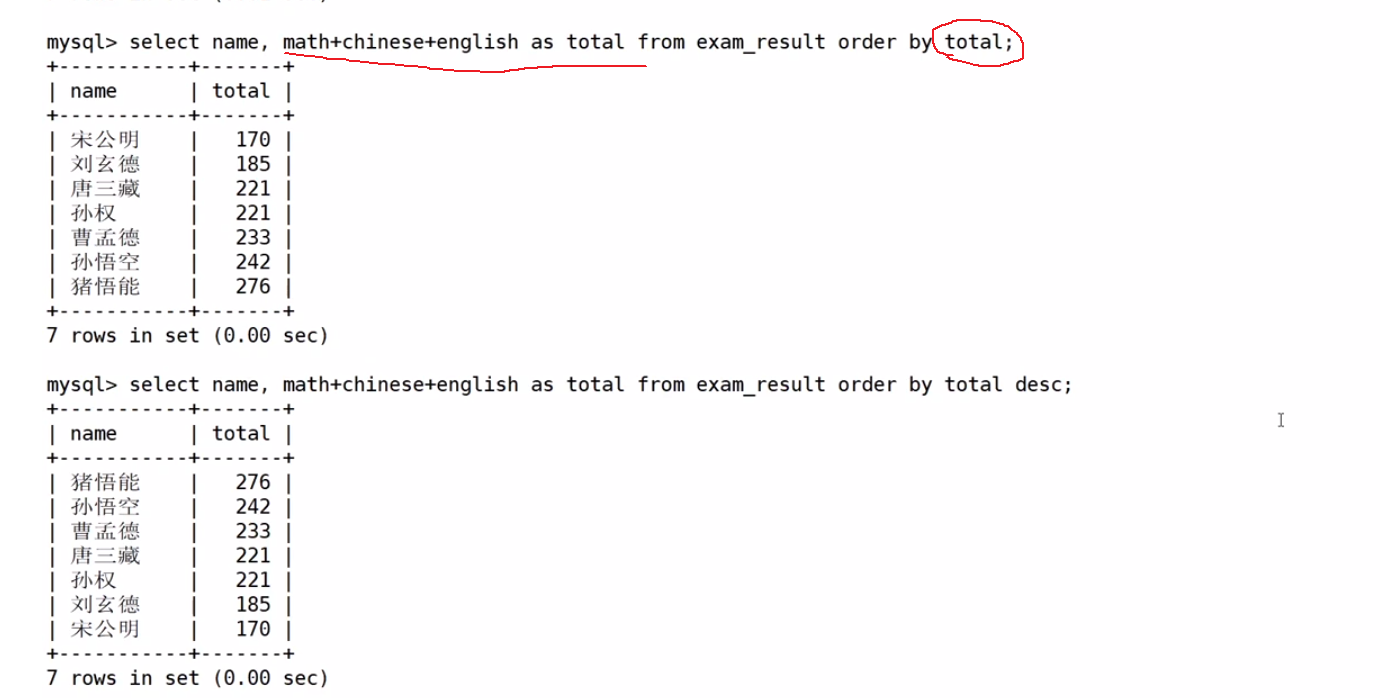
因为这个排序是第四步,也就是晚于下面的任何一步

所以也就是起别名之后再进行order by操作,故而是可以用别名来进行排序的。能不能用起的别名,完全取决与使用的顺序,如果你使用的时候别名还没起呢,那肯定用不了,如果已经起过了,那就可以用了
查询姓孙的同学或者姓曹的同学数学成绩,结果按数学成绩由高到低显示
结合 WHERE 子句 和 ORDER BY 子句

筛选分页结果 (limit)


对于limit而言,也可以使用别名的原因

排序是需要现有数据的
只有数据准备好了,你才能显示,而limit的本质功能就是"显示" ,而不是筛选,所以limit的执行顺序会更靠后,比排序还靠后。所以也可以使用别名。
Update
语法
UPDATE table_name SET column = expr [, column = expr ...] [WHERE ...] [ORDER BY ...] [LIMIT ...]对查询到的结果进行列值更新(一般要加where条件否则会全部被更新)
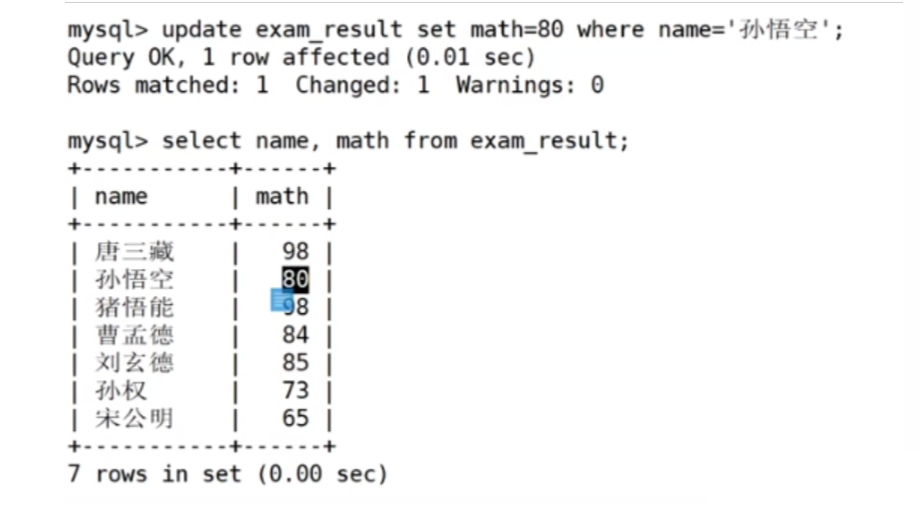
将孙悟空同学的数学成绩变更为80分
更新值为具体值
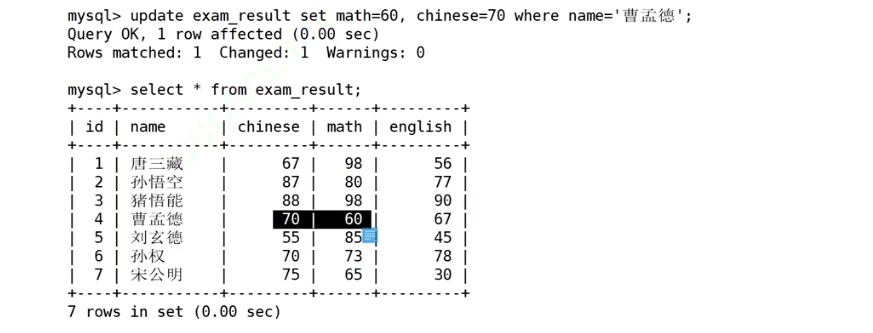
将曹孟德同学的数学成绩变更为60分,语文成绩变更为70分
一次更新多个列
将总成绩倒数前三的3位同学的数学成绩加上30分
数据更新,不支持math+=30这种语法 要用math = math+30这种写法
update exam_result set math=math+30 order by chinese+english+math asc limit 3;
将所有同学的语文成绩更新为原来的2倍
注意:更新全表的语句慎用!--没有WHERE子句,则更新全表
update exam_result set chinese=chinese*2;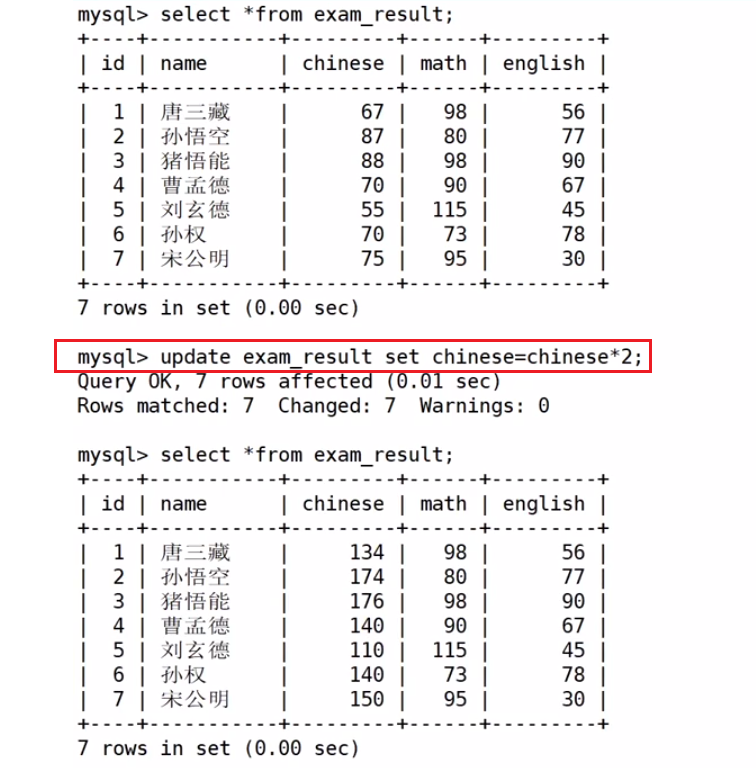
Delete
删除表
语法
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]删除孙悟空同学的考试成绩
delete from exam_result where name='孙悟空';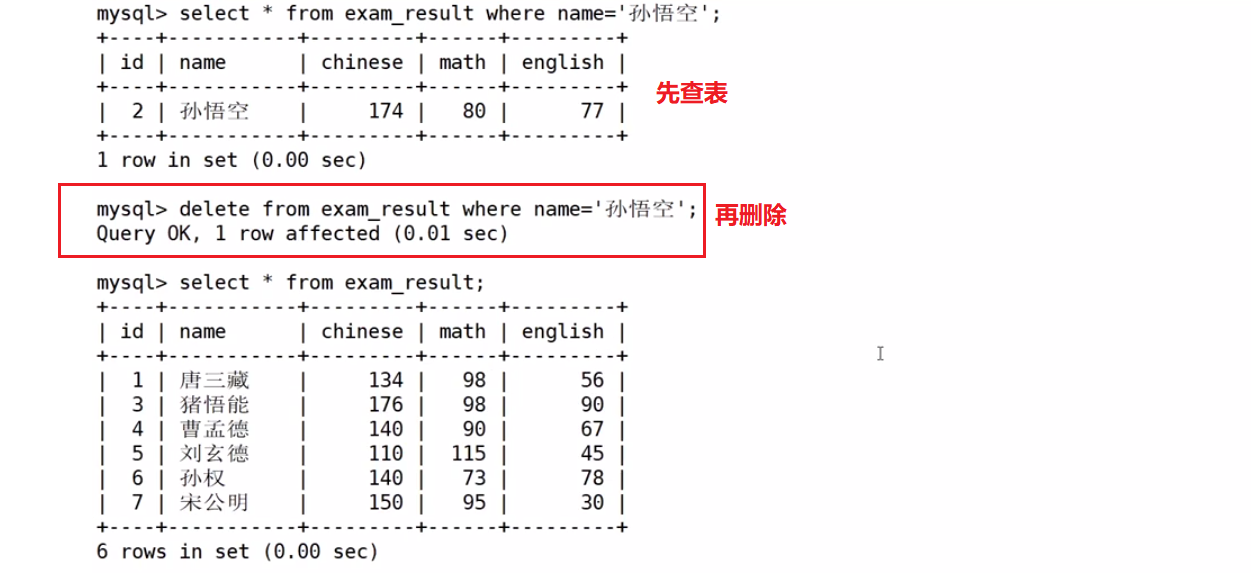
去掉班级的倒数第一名
delete from exam_result order by english+math+chinese asc limit 1;
删除整张表数据
delete只是删表数据,不删表结构。表结构是由alter来管理的
先新建表,并插入一点数据
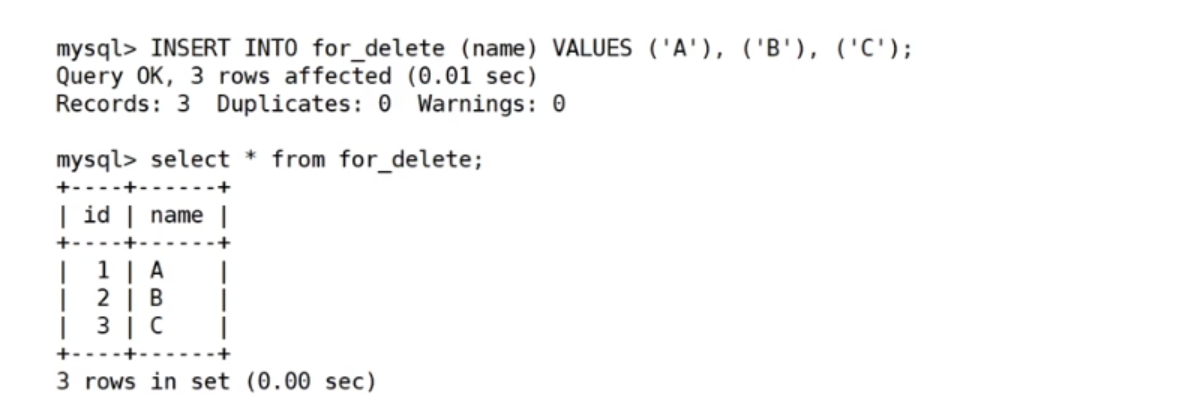
再查表的结构,然后再进行删除操作
 我们会发现我们只是把表数据给删除了,但是表的结构还在!!计数器没有变
我们会发现我们只是把表数据给删除了,但是表的结构还在!!计数器没有变
截断表(truncate)
语法
TRUNCATE [TABLE] table_name我们还按照刚才的例子重新测试下
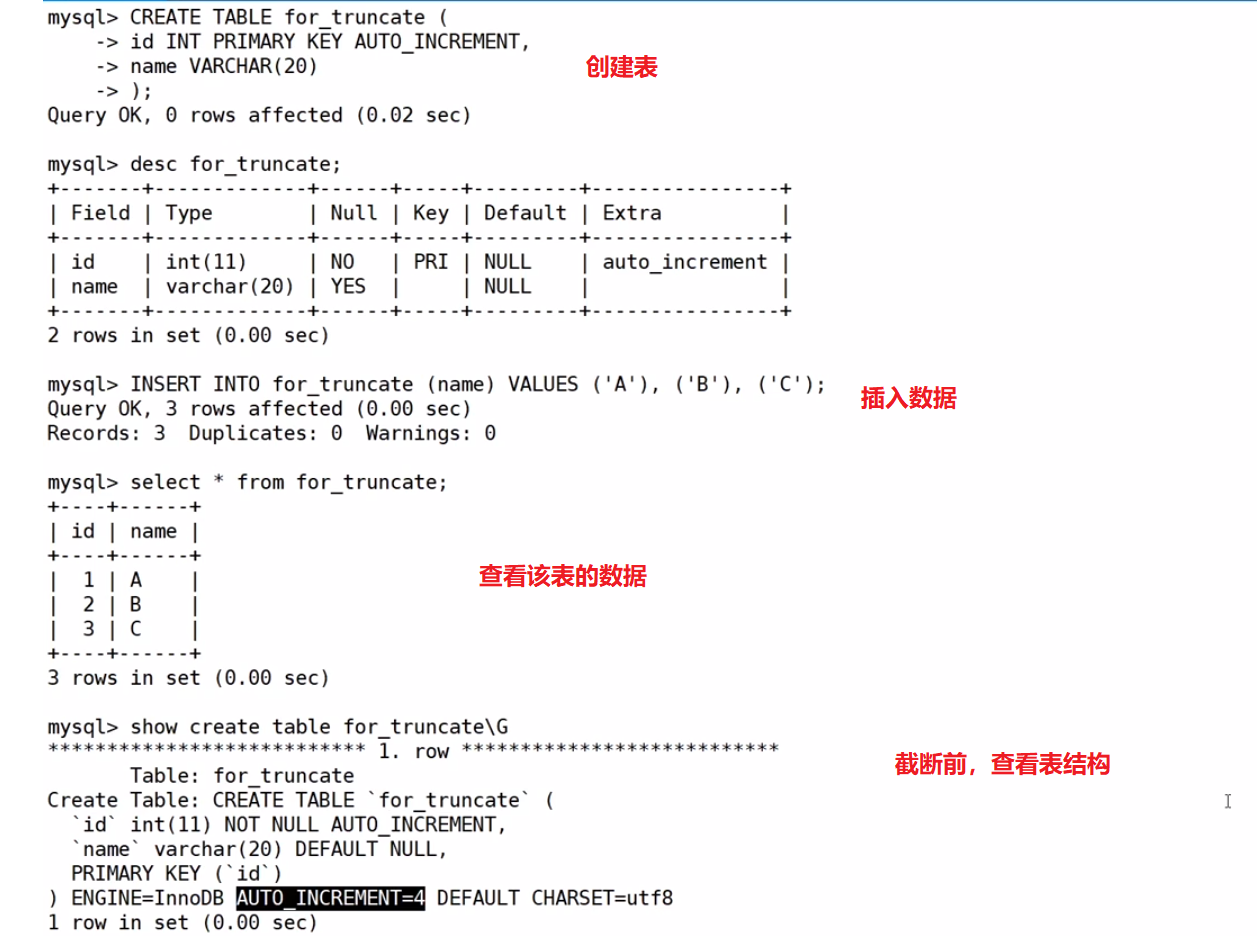
然后开始截断,并再次查看表数据和表结构

注意:这个操作慎用
只能对整表操作,不能像DELETE一样针对部分数据操作;
实际上MySQL 不对数据操作,所以比DELETE更快,但是TRUNCATE在删除数据的时候,并不经过真正的事务(不会被记录到日志里),所以无法回滚
会重置AUTO_INCREMENT项
三种日志:
bin log: 历史上操作过的sql语句优化之后保留下来——方便主从同步、备份、恢复
redo log:确保宕机、断电的时候数据不丢失(因为数据可能在内存中存着)——保证崩溃安全
undo log:做事务回滚、事务的隔离性
插入查询结果(insert+select)
INSERT INTO table_name [(column [, column ...])] SELECT ...
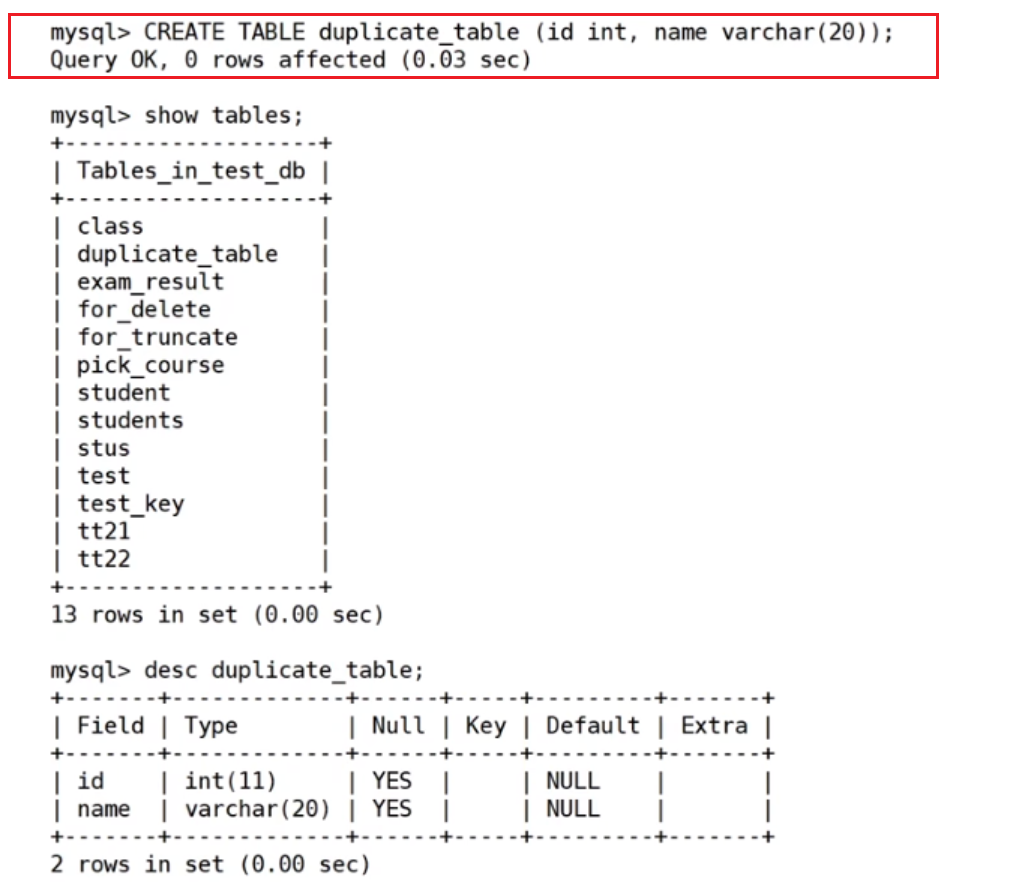
删除表中的重复记录,重复的数据只能有一份
建表
 插入测试数据
插入测试数据
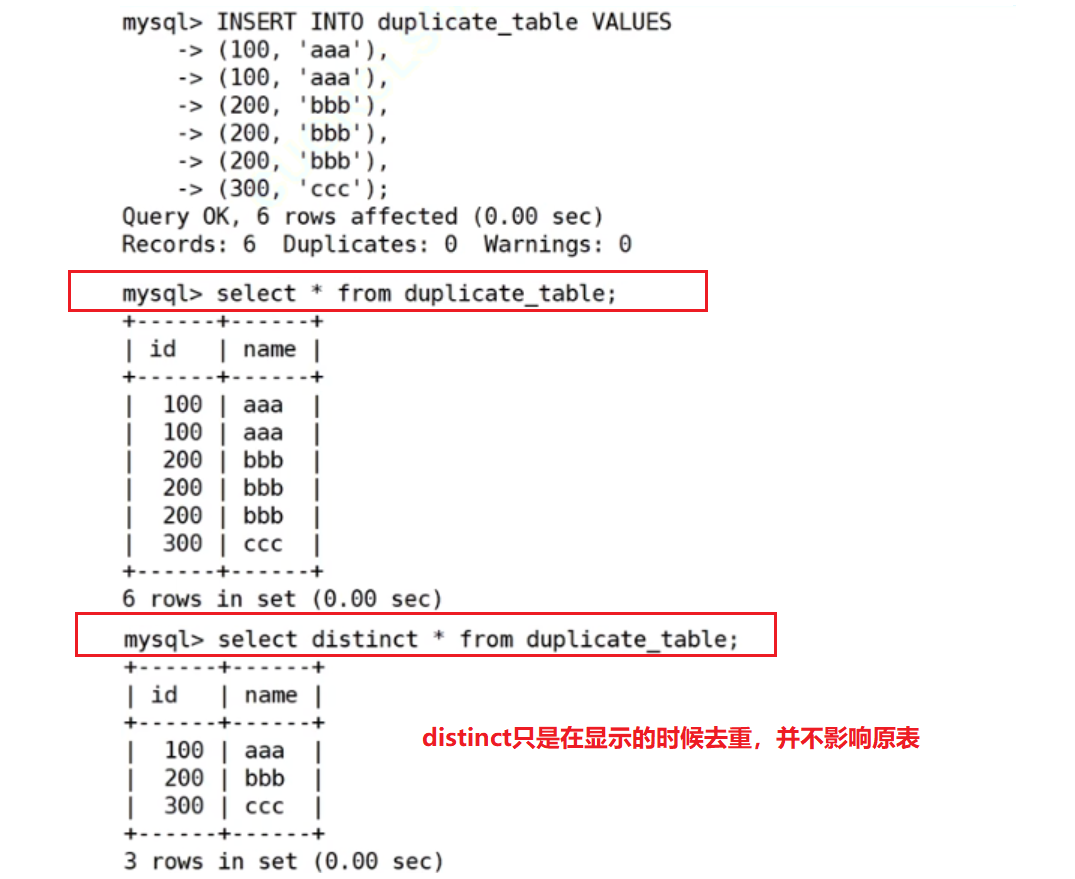
不能用distinct去重,因为它不影响原表的数据,而是修改的显示的数据
但是我们可以将insert和select结合起来用,将distinct筛选出来的数据插入到空表中!!然后再改一下表的名字!!
第一步:create table no_duplicate_table like duplicate_table;建立一张和原表结构相同的空表
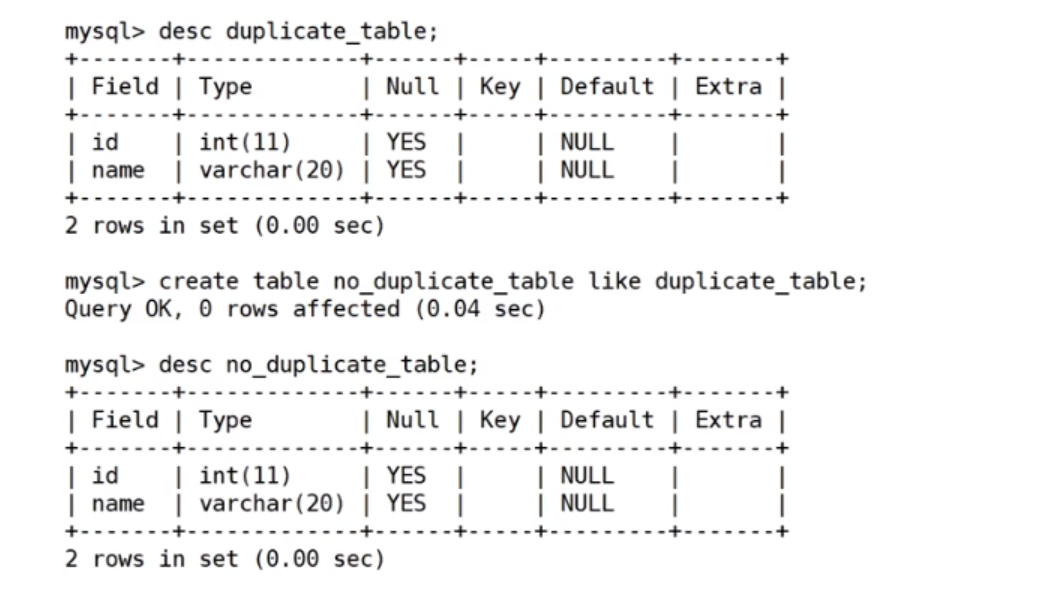
第二步:insert into no_duplicate_table select distinct * from duplicate_table; 查询原表去重后的结果然后插入到新表中

第三步:rename table duplicate_table to old_duplicate_table,no_duplicate_table to duplicate_table;将原表重命名备份一下,然后再把新表的名字改成原表的名字
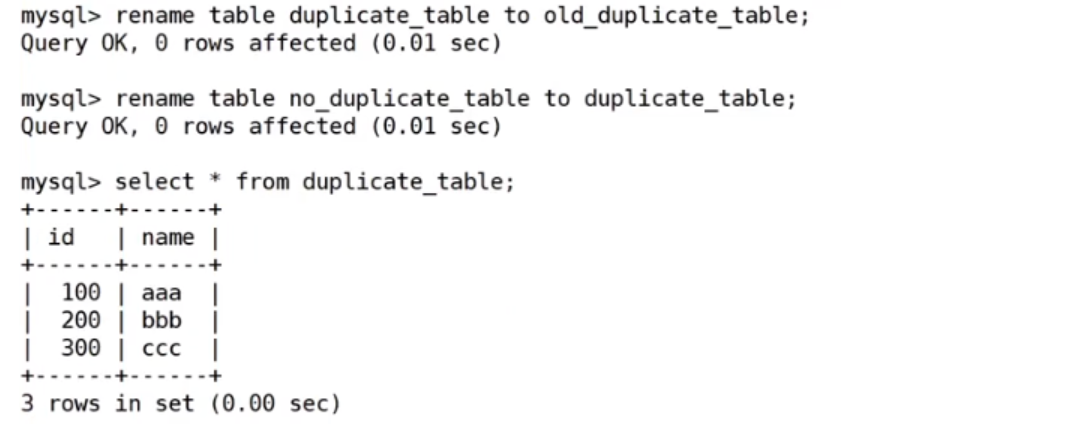
为什么最后是通过rename的方式进行的?
创建一个数据库其实就是创建一个文件夹,创建一张表其实就是创建一个文件,对应的系统调用就是mkdir和touch,而rename背后的也是类似rename这样的系统调用,平时我们用的move指令重命名也是类似的,如果我今天想把一个文件上传到linux下,可能上传得很慢,我想等这个文件上传好之后,把这个文件放到某个目录下,我希望他放入的过程是原子的,所以我们一定不能直接把这个文件直接上传到对应的目录下,因为上传的过程一直在写入,一定不是原子的,所以一般我们喜欢把这个要上传的文件上传到一个临时的目录下,等全都上传完成之后,再把整个文件move到特定的目录下,这个move是原子的。
所以总的来说,用rename单纯就是相等一切都就绪了,然后统一放入、更新、生效等。因为我们的move操作和重命名操作实际上就是在文件系统里就是改这个文件所在的目录里面文件名和inode的映射关系,他相较于冗长地向表中插入和冗长的上传行为比起来非常轻。很有可能我这个目录有很多文件包括正在操作的这个文件正在被外部的网站或者各种语言正在访问,所以我们不能着急动这个表而是应该先把这个表先传到临时目录然后再统一move过去,这是一种比较推荐的做法
聚合函数
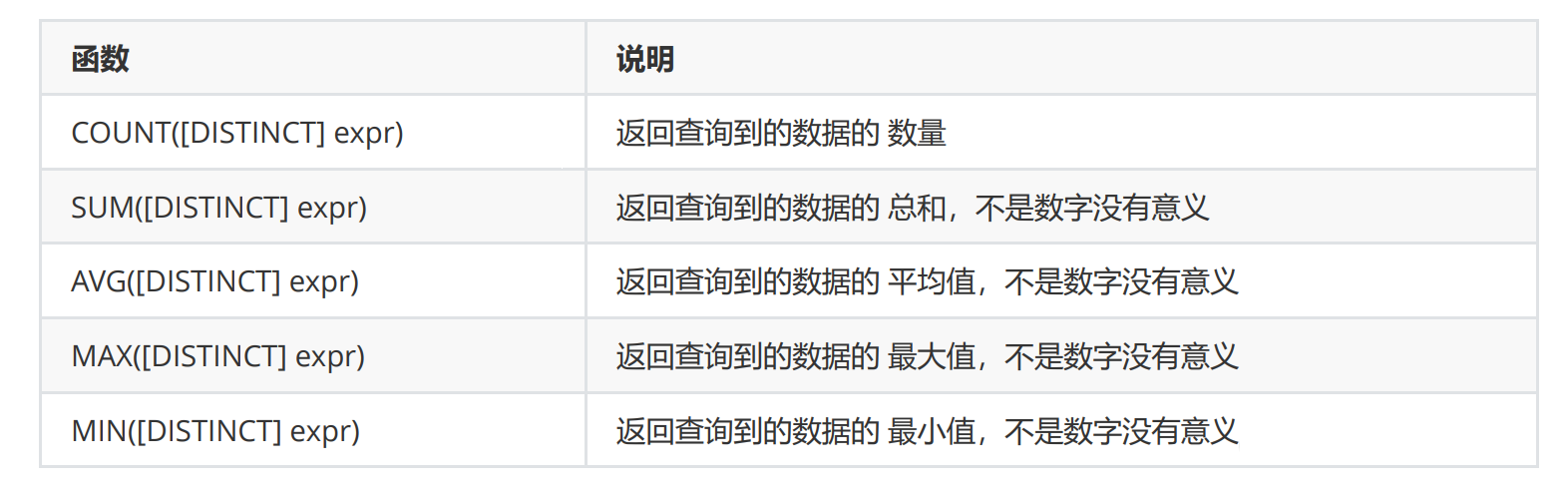
统计班级共有多少同学
使用 * 做统计,不受 NULL 影响
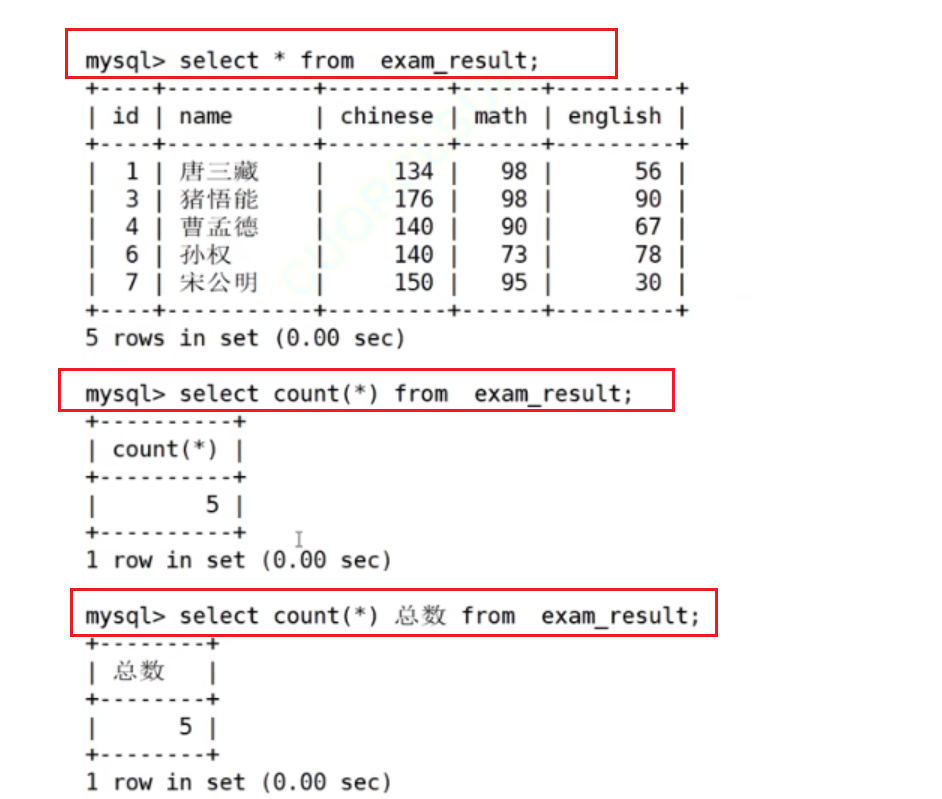
统计本次考试的数学成绩分数个数
NULL 不会计入结果
COUNT(math) 统计的是全部成绩

COUNT(DISTINCT math) 统计的是去重成绩数量

统计数学成绩总分

统计数学的平均分
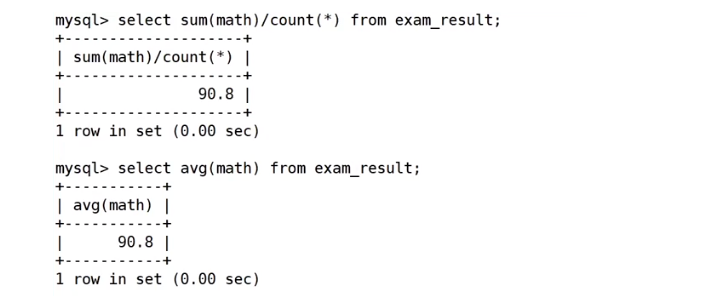
数学不及格的人有多少

统计平均总分

返回英语最高分
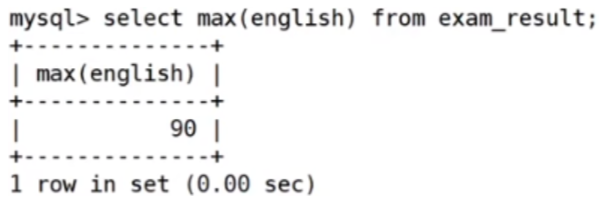
返回 > 70 分以上的数学最低分

聚合函数:1、在应用层上更多的是在未来进行某种程度上的数据统计,是有自己的现实需求的2、大部分聚合都是简单的场景,还有一部分场景需要对信息做完分组之后做聚合
分组聚合统计(group by)
分组的目的是为了方便后面的聚合统计 (比如说分成男生女生然后分别做统计)
在select中使用group by 子句可以对指定列进行分组查询
select column1, column2, .. from table group by column;案例:准备工作,创建一个雇员信息表(来自oracle 9i的经典测试表)
1、EMP员工表
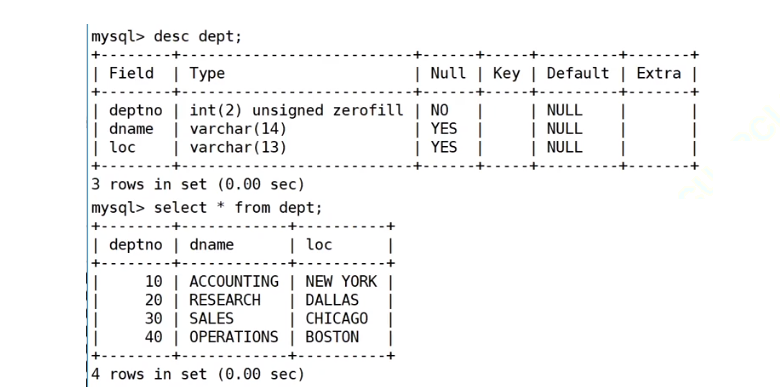
2、DEPT部门表
3、SALGRADE工资等级表
//利用source将该备份文件恢复到数据库中
DROP database IF EXISTS `scott`;//如果曾经有这个名字是数据库就删掉
CREATE database IF NOT EXISTS `scott` DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;//创建这个数据库USE `scott`;//使用这个数据库DROP TABLE IF EXISTS `dept`;//如果有这个名字的部门表叫把他删掉
CREATE TABLE `dept` (//创建部门表`deptno` int(2) unsigned zerofill NOT NULL COMMENT '部门编号',`dname` varchar(14) DEFAULT NULL COMMENT '部门名称',`loc` varchar(13) DEFAULT NULL COMMENT '部门所在地点'
);DROP TABLE IF EXISTS `emp`;//如果有这个名字的部门表叫把他删掉
CREATE TABLE `emp` (//创建员工表`empno` int(6) unsigned zerofill NOT NULL COMMENT '雇员编号',`ename` varchar(10) DEFAULT NULL COMMENT '雇员姓名',`job` varchar(9) DEFAULT NULL COMMENT '雇员职位',`mgr` int(4) unsigned zerofill DEFAULT NULL COMMENT '雇员领导编号',`hiredate` datetime DEFAULT NULL COMMENT '雇佣时间',`sal` decimal(7,2) DEFAULT NULL COMMENT '工资月薪',//外键`comm` decimal(7,2) DEFAULT NULL COMMENT '奖金',`deptno` int(2) unsigned zerofill DEFAULT NULL COMMENT '部门编号'//外键
);DROP TABLE IF EXISTS `salgrade`;//如果有这个名字的部门表叫把他删掉
CREATE TABLE `salgrade` (//薪资表 可以客观反应这个员工在公司的重要程度`grade` int(11) DEFAULT NULL COMMENT '等级',`losal` int(11) DEFAULT NULL COMMENT '此等级最低工资',`hisal` int(11) DEFAULT NULL COMMENT '此等级最高工资'
);//插入部门
insert into dept (deptno, dname, loc)
values (10, 'ACCOUNTING', 'NEW YORK');//核算部门
insert into dept (deptno, dname, loc)
values (20, 'RESEARCH', 'DALLAS');//搜索部门
insert into dept (deptno, dname, loc)
values (30, 'SALES', 'CHICAGO');//销售部门
insert into dept (deptno, dname, loc)
values (40, 'OPERATIONS', 'BOSTON');//运营部门//插入员工
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7369, 'SMITH', 'CLERK', 7902, '1980-12-17', 800, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7499, 'ALLEN', 'SALESMAN', 7698, '1981-02-20', 1600, 300, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7521, 'WARD', 'SALESMAN', 7698, '1981-02-22', 1250, 500, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7566, 'JONES', 'MANAGER', 7839, '1981-04-02', 2975, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7654, 'MARTIN', 'SALESMAN', 7698, '1981-09-28', 1250, 1400, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7698, 'BLAKE', 'MANAGER', 7839, '1981-05-01', 2850, null, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7782, 'CLARK', 'MANAGER', 7839, '1981-06-09', 2450, null, 10);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7788, 'SCOTT', 'ANALYST', 7566, '1987-04-19', 3000, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7839, 'KING', 'PRESIDENT', null, '1981-11-17', 5000, null, 10);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7844, 'TURNER', 'SALESMAN', 7698,'1981-09-08', 1500, 0, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7876, 'ADAMS', 'CLERK', 7788, '1987-05-23', 1100, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7900, 'JAMES', 'CLERK', 7698, '1981-12-03', 950, null, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7902, 'FORD', 'ANALYST', 7566, '1981-12-03', 3000, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7934, 'MILLER', 'CLERK', 7782, '1982-01-23', 1300, null, 10);//插入不同等级的薪资
insert into salgrade (grade, losal, hisal) values (1, 700, 1200);
insert into salgrade (grade, losal, hisal) values (2, 1201, 1400);
insert into salgrade (grade, losal, hisal) values (3, 1401, 2000);
insert into salgrade (grade, losal, hisal) values (4, 2001, 3000);
insert into salgrade (grade, losal, hisal) values (5, 3001, 9999);该数据库的表结构
表emp
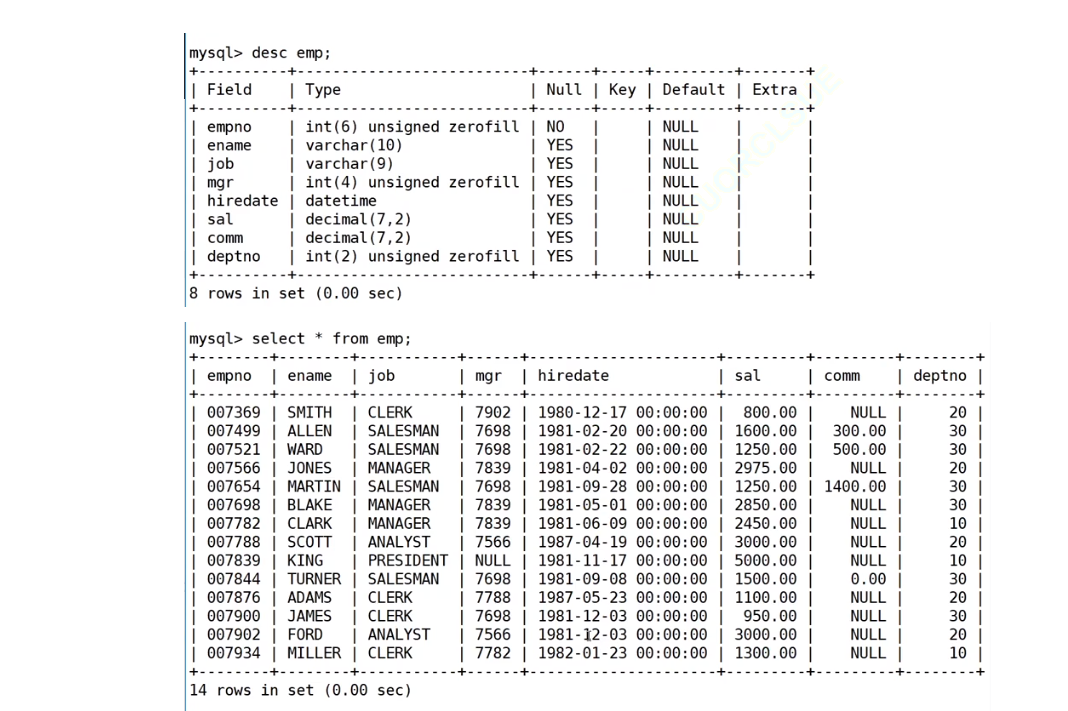
表 dept
表salgrade 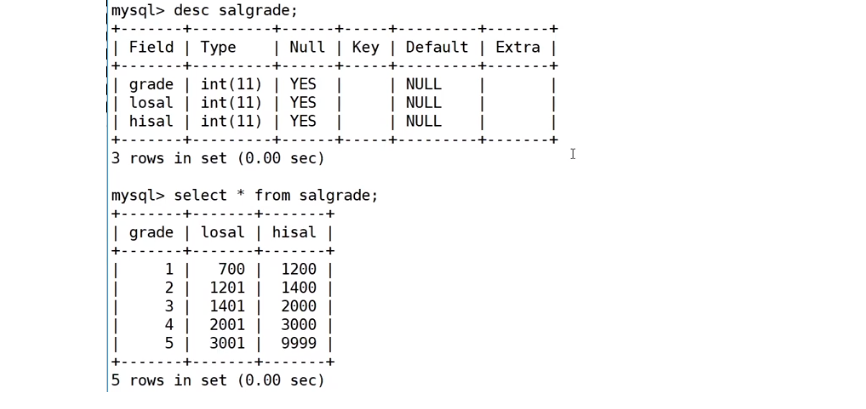
显示每个部分的平均工资和最高工资
select deptno,max(sal) 最高,avg(sal) 平均 from EMP group by deptno; from emp:- 从 emp(员工)表中查询数据
group by deptno:- 按部门编号(deptno)将员工数据分组
- 意味着所有具有相同部门编号的员工会被归类到同一个组
select部分:deptno:显示部门编号max(sal) 最高:计算每个部门的最高工资avg(sal) 平均:计算每个部门的平均工资
这个查询的具体含义是:
- 按部门编号(deptno)将员工表(emp)分组
- 对每个部门计算:
- 最高工资(max(sal))
- 平均工资(avg(sal))

groupby的宏观理解
让我们进行分组聚合统计的。分组指定列名,实际分组是用该列的不同的行数据
比如说你按照deptno进行分组,那它就会把deptno列中,相同的数据成为一组,也就是可以被聚合压缩。
分组,就是把一组按照条件拆成了多个组,然后进行各自组内的统计。
分组也就是把一张表按照条件在逻辑上拆成了多个子表,然后分别对各自的子表进行聚合统计
显示每个部门的每种岗位的平均工资和最低工资
也就是说不仅要按照部门分组,也要按照岗位分组
用,来进行区分不同的组
select deptno,job from EMP group by deptno, job; 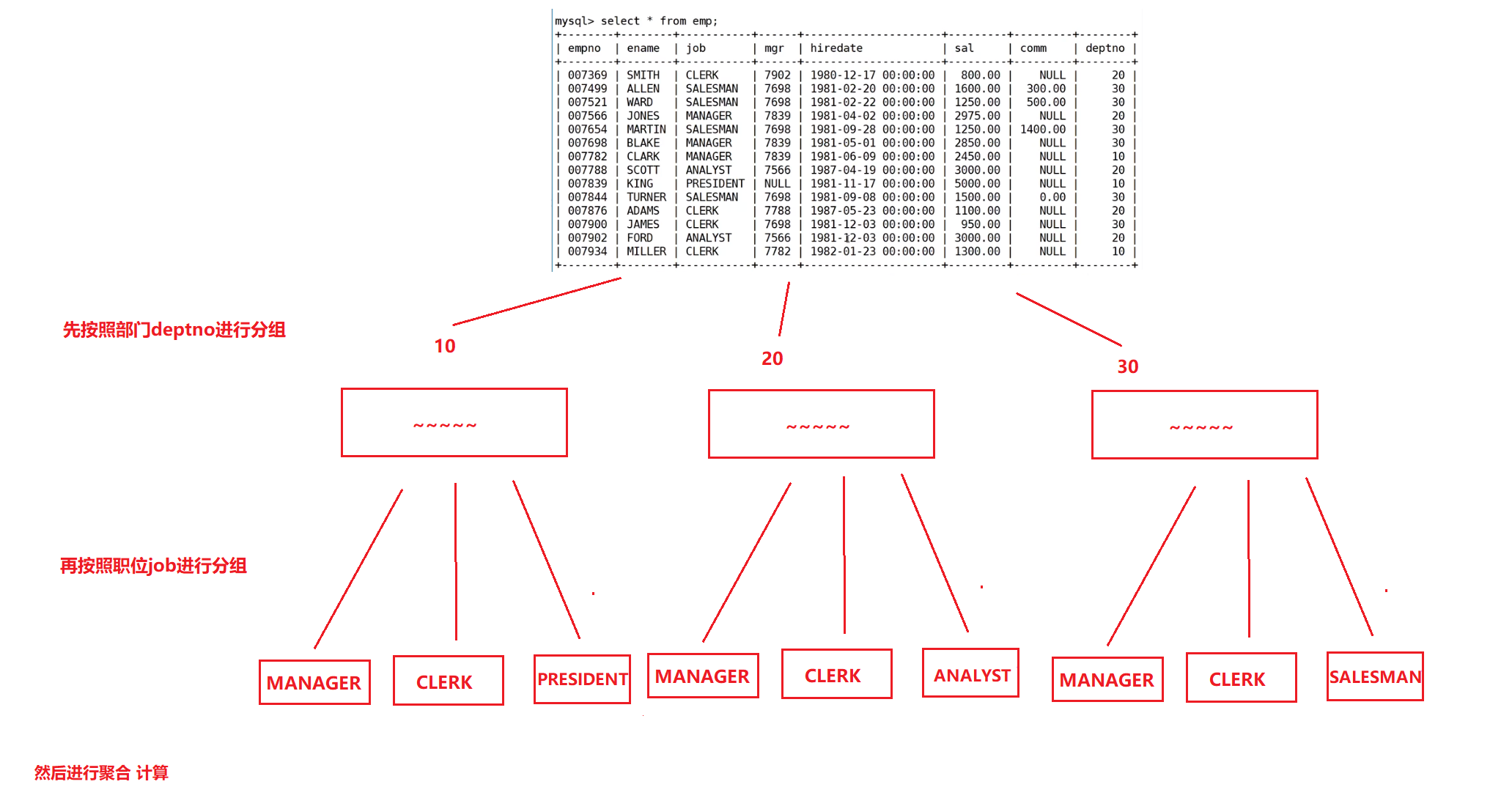
再聚合,也就是进行计算所需要的数据
select deptno,job,avg(sal) 平均,min(sal) 最低 from EMP group by deptno, job; 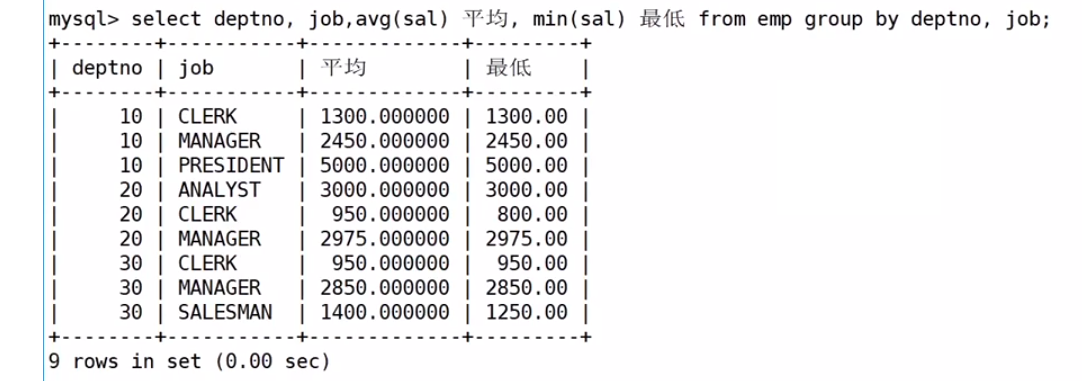
为啥进行员工名字ename分组的时候不行呢?

原因是ename没有在分组条件中出现,不属于分组条件,所以无法进行聚合和压缩。也就是说,select后面要想能出现,必须在group by后进行添加。
显示平均工资低于2000的部门和它的平均工资
第一步,先统计出来每一个部门的平均工资,然后在进行对比,也就是说先把结果聚合出来
select deptno,avg(sal) deptavg from EMP group by deptno;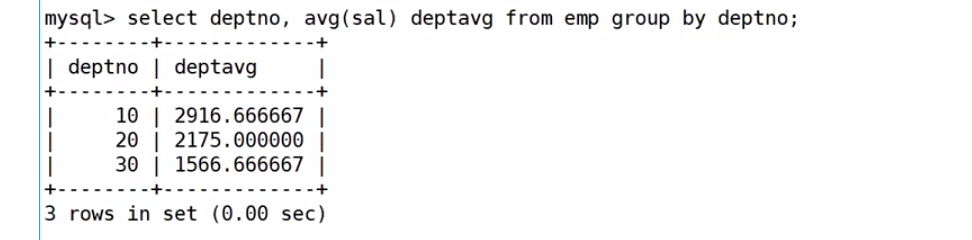
第二步,再进行判断。就是对聚合的结果进行判断
select deptno,avg(sal) deptavg from EMP group by deptno having deptavg<2000;
那怎么对聚合的结果进行判断呢?
having和group by配合使用,对group by结果进行过滤
having经常和group by搭配使用,作用是对聚合后的统计数据进行条件筛选,作用有些像where。
hvaing和where的区别理解是什么呢?

- 执行顺序不同:
- WHERE在分组和聚合函数计算之前执行
- HAVING在分组和聚合函数计算之后执行
- 作用对象不同:
- WHERE作用于表中的列/字段,筛选原始数据
- HAVING作用于分组后的结果集,可以使用聚合函数
不要单纯的认为,只有磁盘上表结构导入到mysql,真实存在的表才叫做表。中间筛选出来的,包括最终结果,全部都是逻辑上的表!“MySQL一切皆表”。也就是说未来只要我们处理好单表的CURD,所有的sql场景我们全部都能用统一的方式进行
面试题:SQL查询中各个关键字的执行先后顺序 from > on> join > where > group by > with > having > select > distinct > order by > limit
相关文章:

MySQL基础 [五] - 表的增删查改
目录 Create(insert) Retrieve(select) where条件 编辑 NULL的查询 结果排序(order by) 筛选分页结果 (limit) Update Delete 删除表 截断表(truncate) 插入查询结果(insertselect&…...

深入解析 MySQL 中的日期时间函数:DATE_FORMAT 与时间查询优化
深入解析 MySQL 中的日期时间函数:DATE_FORMAT 与时间查询优化 在数据库管理和应用开发中,日期和时间的处理是不可或缺的一部分。MySQL 提供了多种日期和时间函数来满足不同的需求,其中DATE_FORMAT函数以其强大的日期格式化能力,…...

GPU是什么? 与 FPGA 有何关联
前段时间,AMD 和英伟达相继接到通知将对我国断供高端 GPU 芯片,很多人这才意识到 GPU 的战略价值。那么 GPU 究竟是什么?它为何如此重要?今天就由 宸极教育 带大家一起了解 GPU 的核心地位,以及它与国产FPGA发展的关系…...

数据结构与算法:基础与进阶
🌟 各位看官好,我是maomi_9526! 🌍 种一棵树最好是十年前,其次是现在! 🚀 今天来学习C语言的相关知识。 👍 如果觉得这篇文章有帮助,欢迎您一键三连,分享给更…...

低配置云服务器网站的高效防御攻略
在网络环境日益复杂的当下,低配置云服务器网站常面临攻击威胁。不少站长疑惑,明明设置了 CC 防御,服务器却依旧不堪一击,这是怎么回事呢? 比如,在 CC 防御配置中,设定 10 秒内允许访问 50 次。但…...

使用 Lua 脚本高效查询 Redis 键的内存占用
使用 Lua 脚本高效查询 Redis 键的内存占用 在处理 Redis 数据时,我们常常需要了解某些键的内存占用情况,尤其是在优化内存使用或排查问题时。虽然 Redis 提供了MEMORY USAGE命令来查询单个键的内存占用,但如果需要批量查询多个键࿰…...

【Linux篇】基础IO - 揭秘重定向与缓冲区的管理机制
📌 个人主页: 孙同学_ 🔧 文章专栏:Liunx 💡 关注我,分享经验,助你少走弯路! 文章目录 一. 理解重定向1.1 理解重定向1.2 dup21.3 进一步理解重定向输出重定向:追加重定向…...

centos 8 启动Elasticsearch的时候报内存不足问题解决办法
centos 8 启动Elasticsearch 的时候报错,导致无法启动Elasticsearch 。 [root@CentOS-8 ~]# journalctl -xe Apr 07 18:25:56 CentOS-8.0 kernel: [ 8754] 0 8754 3180 63 69632 0 0 sh Apr 07 18:25:56 CentOS-8.0 kernel: [ 8755] 0 8755 3180 64 69632 0 0 sh Apr 07 18:25…...

深入剖析Java IO设计模式:从底层原理到实战应用
🔍 引言:设计模式与IO的完美交响 在软件开发的浩瀚星河中,设计模式犹如璀璨的导航星,而Java IO体系则是支撑数据流动的神经网络。 当我们以设计模式的视角重新审视Java IO库时,会发现这个看似平凡的IO世界实则暗藏着…...

阶段测试 【过程wp】
分享总结: 回顾起来,真的感慨很多呀。看着并不难啊,但难的是解题思维:如何判断该页面的关键点,快速地确定问题的核心,找到对应的解决方法。达到便捷、高效的得到结果。我们做了整整近七个半小时。在这个过程中,我发现自己的思维钝化,不太能自主高效地划分判断漏洞类型,…...

qml信号与槽函数
目录 信号与槽函数基础方法1-使用Connections方式2-使用connect(不常用) 自定义组件与信号槽使用 信号与槽函数基础 方法1-使用Connections main.qml import QtQuick 2.15 import QtQuick.Window 2.15 import QtQuick.Controls 2.15Window {id:windoww…...

ngx_palloc
定义在 src\core\ngx_palloc.c void * ngx_palloc(ngx_pool_t *pool, size_t size) { #if !(NGX_DEBUG_PALLOC)if (size < pool->max) {return ngx_palloc_small(pool, size, 1);} #endifreturn ngx_palloc_large(pool, size); } 判断 需要分配的内存大小 是否小于 poo…...
)
notepad++日常使用(每行开头、每行末尾增加字符串,每行中间去掉字符串)
1. 每行开头增加字符串 如果我们要给下面的数据每行的开头都增加相同的一些字符串{value: 这时候只需要使用notepad的语法,使用快捷键Crtl H 替换功能,每一行开头使用 ^ 符号,替换成自己想要的字符串 {value: 使用全部替换就会在每行数据…...

Java面试黄金宝典39
1. SNMP、SMTP 协议 SNMP(简单网络管理协议) 定义:SNMP 是一种应用层协议,用于在 IP 网络中管理网络节点(如服务器、路由器、交换机等)。它允许网络管理员监控网络设备的状态、收集性能数据、进行故障诊断等操作。SNMP 基于 UDP 协议,采用轮询和事件驱动相结合的方式来收…...
如何解决:http2: Transport received Server‘s graceful shutdown GOAWAY
有一次做压力测试,客户端经常出现如下错误: http2: Transport: cannot retry err [http2: Transport received Servers graceful shutdown GOAWAY] after Request.Body was written; define Request.GetBody to avoid this error是 Golang 中使用 HTTP/…...
(java)俄罗斯套娃信封问题)
贪心算法(16)(java)俄罗斯套娃信封问题
题目:给你一个二维整数数组 envelopes ,其中 envelopes[i] [wi, hi] ,表示第 i 个信封的宽度和高度。 当另一个信封的宽度和高度都比这个信封大的时候,这个信封就可以放进另一个信封里,如同俄罗斯套娃一样。 请计算…...

【DeepSeek原理学习2】MLA 多头隐变量注意力
解决的问题 Multi-Head Latent Attention,MLA——解决的问题:KV cache带来的计算效率低和内存需求大以及上下文长度扩展问题。 MLA原理 MLA原理:其核心思想是将键(Key)和值(Value)矩阵压缩到…...

2024年RAG大赛
2024 CCF国际AIOps挑战赛赛题与赛制解读-CSDN博客 自动化测评也比较有意思,分数为 关键字 语义相似度,分值比为6:4. 2024 CCF AIOPS国际挑战赛优秀奖方案分享 https://zhuanlan.zhihu.com/p/7444390758 【大模型RAG获奖方案分享】如何提高RAG系统在…...
的一些内置函数与求和函数)
2025-4-6-C++ 学习 有序数组、set()的一些内置函数与求和函数
C的学习必须更加精进一些,对于好多的函数和库的了解必须深入一些。 文章目录 3510. 移除最小数对使数组有序 II(有序数组)题目参考代码(1)auto it idx.lower_bound(i);功能解释可能的使用场景常见错误 (2&…...

Flutter:Flutter SDK版本控制,fvm安装使用
1、首先已经安装了Dart,cmd中执行 dart pub global activate fvm2、windows配置系统环境变量 fvm --version3、查看本地已安装的 Flutter 版本 fvm releases4、验证当前使用的 Flutter 版本: fvm flutter --version5、切换到特定版本的 Flutter fvm use …...

GPT-4o 的“图文合体”是怎么做到的
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

PyTorch教程:如何读写张量与模型参数
本文演示了PyTorch中张量(Tensor)和模型参数的保存与加载方法,并提供完整的代码示例及输出结果,帮助读者快速掌握数据持久化的核心操作。 1. 保存和加载单个张量 通过torch.save和torch.load可以直接保存和读取张量。 import to…...

MySQL8.0.31安装教程,附pdf资料和压缩包文件
参考资料:黑马程序员 一、下载 点开下面的链接:https://dev.mysql.com/downloads/mysql/ 点击Download 就可以下载对应的安装包了, 安装包如下: 我用夸克网盘分享了「mysql」,链接:https://pan.quark.cn/s/ab7b7acd572b 二、解…...
进行分区、格式化或挂载的操作)
Linux 系统中对存储设备(/dev/mmcblk、/dev/sd、/dev/nvme)进行分区、格式化或挂载的操作
在 Linux 系统中对存储设备(/dev/mmcblk、/dev/sd、/dev/nvme)进行分区、格式化或挂载的操作步骤如下: 一、确认设备信息 首先明确要操作的设备名称(如 /dev/sdb、/dev/nvme0n1),避免误操作导致数据丢失&a…...
)
【Kafka基础】topics命令行操作大全:高级命令解析(1)
1 创建压缩主题(Log Compaction) /export/home/kafka_zk/kafka_2.13-2.7.1/bin/kafka-topics.sh --create \--bootstrap-server 192.168.10.33:9092 \--topic comtopic \--partitions 3 \--replication-factor 2 \--config cleanup.policycompact \--con…...

springboot集成spring loadbalancer实现客户端负载均衡
在 Spring Boot 中实现负载均衡,通常需要结合 Spring Cloud 组件,比如 Spring Cloud LoadBalancer。Spring Cloud LoadBalancer 是一个客户端负载均衡器,可以与 Spring Boot 集成,实现微服务之间的负载均衡。 以下是一个简单的示…...
)
什么是 k8s Affinity(亲和性)
在 Kubernetes(K8s)中,Affinity(亲和性) 是一种 Pod 调度策略,它用于控制 Pod 在什么条件下可以被调度到特定的节点上。它比 Taints 和 Tolerations 更灵活,可以基于 节点属性 或 Pod 之间的关系…...

深度探索:策略学习与神经网络在强化学习中的应用
深度探索:策略学习与神经网络在强化学习中的应用 策略学习(Policy-Based Reinforcement Learning)一、策略函数1.1 策略函数输出的例子 二、使用神经网络来近似策略函数:Policy Network ,策略网络2.1 策略网络运行的例子2.2需要的几个概念2.3神经网络近似…...

用VAE作为标题显示标题过短,所以标题变成了这样
VAE (Variational Autoencoder / 变分自编码器) 基本概念: VAE 是一种生成模型 (Generative Model),属于自编码器 (Autoencoder) 家族。 它的目标是学习数据的潜在表示 (Latent Representation),并利用这个表示来生成新的、与原始数据相似的数据。 与标…...

【day27】测试策略升级方案:需求阶段介入与业务规则覆盖矩阵设计
测试策略升级方案:需求阶段介入与业务规则覆盖矩阵设计 一、需求评审阶段:主动识别业务逻辑问题 在需求评审时,测试团队应通过结构化提问提前暴露潜在风险,避免后期返工。以下为提问框架与示例: 1. 业务逻辑澄清提问模…...

AI烘焙大赛中的算法:理解PPO、GRPO与DPO的罪简单的方式
🧠 向所有学习者致敬! “学习不是装满一桶水,而是点燃一把火。” —— 叶芝 我的博客主页: https://lizheng.blog.csdn.net 🌐 欢迎点击加入AI人工智能社区! 🚀 让我们一起努力,共创…...

二分 —— 基本算法刷题路程
一、1.求阶乘 - 蓝桥云课 算法代码: #include <bits/stdc.h> using namespace std; #define ll long long ll check(ll n) {ll cnt0;while(n){cnt(n/5);}return cnt; }int main() {ll k;cin>>k;ll L0,R1e19;while(L<R){ll mid(LR)>>1;if(che…...

内存序问题排查
1 内存序 2 简介 std::memory_order 是 C11 引入的一个枚举类型,用于和 <atomic> 原子操作一起使用,控制多线程环境下内存的可见性和执行顺序。 它的主要作用是:告诉编译器和 CPU,在执行某个原子操作时,哪些内…...
——Chainswap20210711)
历年跨链合约恶意交易详解(四)——Chainswap20210711
漏洞合约函数 function receive(uint256 fromChainId, address to, uint256 nonce, uint256 volume, Signature[] memory signatures) virtual external payable {_chargeFee();require(received[fromChainId][to][nonce] 0, withdrawn already);uint N signatures.length;r…...

Johnson
理论 全源最短路算法 Floyd 算法,时间复杂度为 O(n)跑 n 次 Bellman - Ford 算法,时间复杂度是 O(nm)跑 n 次 Heap - Dijkstra 算法,时间复杂度是 O(nmlogm) 第 3 种算法被 Johnson 做了改造,可以求解带负权边的全源最短路。 J…...

spring boot + Prometheus + Grafana 实现项目监控
一、引入依赖 <dependencies><!-- Spring Boot Starter Actuator --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><!-- Micrometer Reg…...

Mythical Beings:第八季即将回归,探索新的神话传承
Mythical Beings是由Tarasca Art & Games开发的、基于Ignis区块链的卡牌收集游戏。自发布以来,这款游戏以其独特的玩法和深厚的神话背景吸引了大量玩家的关注。每张卡牌不仅代表着独特的游戏属性,还融合了丰富的文化和神话故事,使玩家不仅…...

Linux中查看占用端口号的进程信息的方法
在 Linux 中查看占用 ** 端口(eg:1717)**的进程号(PID),可以通过以下命令实现: 方法 1:使用 netstat 命令 sudo netstat -tulnp | grep :1717参数解释: -t:查看 TCP 端口…...

批量将 txt/html/json/xml/csv 等文本拆分成多个文件
我们的文本文件太大的时候,我们通常需要对文本文件进行拆分,比如按多少行一个文件将一个大的文本文件拆分成多个小的文本文件。这样我们在打开或者传输的时候都比较方便。今天就给大家介绍一种同时对多个文本文件进行批量拆分的方法,可以快速…...

爱普生高精度车规晶振助力激光雷达自动驾驶
在自动驾驶技术快速落地的今天,激光雷达作为车辆的“智慧之眼”,其测距精度与可靠性直接决定了自动驾驶系统的安全上限。而在这双“眼睛”的核心,爱普生(EPSON)的高精度车规晶振以卓越性能成为激光雷达实现毫米级感知的…...
)
Spring Boot 自定义 Redis Starter 开发指南(附动态 TTL 实现)
一、功能概述 本 Starter 基于 Spring Boot 2.7 实现以下核心能力: Redis 增强:标准化 RedisTemplate 配置(JSON 序列化 LocalDateTime 支持)缓存扩展:支持 Cacheable(value “key#60s”) 语法动态设置 TTL配置集中…...

区分CRI、OCI、containerd、Docker、CRI-O、runc等名词概念
这些概念可以分为: 一、容器运行时Container Runtimes a、规范OCI (Open Container Initiative) 定义:OCI 是一个开放标准,用于定义容器格式和运行时的规范。它旨在确保容器镜像的格式和容器运行时的操作方式在不同的实现之间保持兼容性。 •…...

#关于process.env.NODE_ENV 与 import.meta.env 相关了解
process.env.NODE_ENV 在前端 Vue 项目中非常重要,但它其实是个“假象”,在前端它并不是原生就有的变量。下面我从多个角度来给你通俗讲明白它的由来和使用方式 👇 🌐 一、process.env.NODE_ENV 是干嘛用的? 这是 一个…...

R语言赋能气象水文科研:从多维数据处理到学术级可视化
全球气候变化加剧了极端天气与水文事件的复杂性,气象卫星、雷达、地面观测站及水文传感器每天产生TB级时空异质数据。传统研究常面临四大瓶颈: 数据清洗低效:缺失值、异常值处理耗时;时空分析模型构建复杂࿱…...
)
MySQL 约束(入门版)
目录 一、约束的基本概念 二、约束演示 三、外键约束 (一)介绍 (二)外键约束语法 (三)删除/更新行为 一、约束的基本概念 1、概念:约束是作用于表中字段上的规则,用于限制存储…...

【go】类型断言
接口-类型断言 Type Assertion Type Assertion(中文名叫:类型断言),通过它可以做到以下几件事情 检查 i 是否为 nil(是nil直接抛出panic)检查 i 存储的值是否为某个类型 具体的使用方式有两种ÿ…...
CExercise_06_1指针和数组_2 给定一个double数组,求平均值,并且返回)
(复看)CExercise_06_1指针和数组_2 给定一个double数组,求平均值,并且返回
题目: 求平均值,给定一个double数组,求平均值,并且返回。 要求使用while循环遍历数组,然后配合"*p"的语法实现。 函数的声明如下: double get_ave(double *arr, int len); 关键点 分析࿱…...

Ubuntu 服务器上运行相关命令,关闭终端就停止服务,怎么才能启动后在后台运行?
环境: Ubuntu 20.04 LTS 问题描述: Ubuntu 服务器上运行相关命令,关闭终端就停止服务,怎么才能启动后在后台运行? bash docker/entrypoint.sh解决方案: bash docker/entrypoint.sh 脚本在后台运行&…...

ffmpeg提取字幕
使用ffmpeg -i test.mkv 获取视频文件的字幕流信息如下 Stream #0:4(chi): Subtitle: subrip (srt) (default) Metadata: title : chs Stream #0:5(chi): Subtitle: subrip (srt) Metadata: title : cht Stream #0:6(jpn)…...

深入理解Socket编程:构建简单的计算器服务器
一、Socket通信基础 1. Socket通信基本流程 服务器端流程: 创建Socket (socket()) 绑定地址和端口 (bind()) 监听连接 (listen()) 接受连接 (accept()) 数据通信 (read()/write()) 关闭连接 (close()) 客户端流程: 创建Socket (socket()) 连接…...