animals_classification动物分类
数据获取
深度学习训练中第一个是获取数据集,数据集的质量很重要,我们这里做的是动物分类,大致会选择几个动物,来做一个简单的多分类问题,数据获取的方法,鼠鼠我这里选择使用爬虫的方式来对数据进行爬取,目标网站为Hippopx - beautiful free stock photos
代码如下
# -*- coding: utf-8 -*-
import json
import os
import requests
from lxml import etreeimage_number = 1def get_image(folder_name, page):global image_numberheaders = {"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7","accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6","priority": "u=0, i","referer": "https://www.hippopx.com/zh/search?q=%E5%B0%8F%E7%8B%97","sec-ch-ua": "\"Microsoft Edge\";v=\"129\", \"Not=A?Brand\";v=\"8\", \"Chromium\";v=\"129\"","sec-ch-ua-mobile": "?0","sec-ch-ua-platform": "\"Windows\"","sec-fetch-dest": "document","sec-fetch-mode": "navigate","sec-fetch-site": "same-origin","sec-fetch-user": "?1","upgrade-insecure-requests": "1","user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36 Edg/129.0.0.0"}url = "https://www.hippopx.com/zh/search"params = {"q": folder_name,"page": page}response = requests.get(url, headers=headers, params=params)html = etree.HTML(response.text)data_list = html.xpath('//ul[@class="main_list"]/li//a/img')for data in data_list:src = data.xpath('string(./@src)')folder_path = f"dataset/{folder_name}"if not os.path.exists(folder_path):os.makedirs(folder_path)print(f"文件夹 '{folder_path}' 已创建。")response = requests.get(src)if response.status_code == 200:# 打开一个文件以二进制写入模式with open(f"{folder_path}/{image_number}.jpg", "wb") as file:file.write(response.content)print(f"{image_number}保存成功")else:print("请求失败,状态码:", response.status_code)image_number += 1if __name__ == '__main__':folder_name = str(input("请输入你要爬取的动物名称:"))for page in range(1, 3): # 爬取两页的图片数据get_image(folder_name=folder_name, page=str(page))
计算图像均值和方差
代码如下
# -*- coding: utf-8 -*-
from torchvision.datasets import ImageFolder
import torch
from torchvision import transforms as T
from tqdm import tqdmtransform = T.Compose([T.RandomResizedCrop(224), T.ToTensor(), ])def getStat(train_data):"""computer mean and variance for training data:param train_data: 自定义类Dataset:return: (mean,std)"""print('Compute mean and variance for training data.')print(len(train_data))train_loader = torch.utils.data.DataLoader(train_data, batch_size=1, shuffle=False, num_workers=0,pin_memory=True)mean = torch.zeros(3)std = torch.zeros(3)for x, _ in tqdm(train_loader):for d in range(3):mean[d] += x[:, d, :, :].mean()std[d] += x[:, d, :, :].std()mean.div_(len(train_data))std.div_(len(train_data))return list(mean.numpy()), list(std.numpy())if __name__ == '__main__':train_dataset = ImageFolder(root=r'./dataset', transform=transform)mean, std = getStat(train_dataset)print(f"mean={mean},std={std}") # mean=[0.5045225, 0.4722667, 0.39059258],std=[0.20998387, 0.20583159, 0.20718254]

代码详解
from torchvision.datasets import ImageFolder
可以自动加载一个文件夹中的图像文件。它假设文件夹的结构是按照类别组织的,即每个子文件夹代表一个类别,子文件夹中的图像文件属于该类别。
是一个简单而强大的工具,适用于加载和处理图像数据集。它能够自动加载图像文件、标注类别,并支持数据增强和与 PyTorch 数据加载器的集成,极大地简化了图像数据集的准备工作。
transform = T.Compose([T.RandomResizedCrop(224), T.ToTensor(), ])
使用了 torchvision.transforms 模块(通常简称为 T)的 Compose 方法来组合多个图像变换操作
T.RandomResizedCrop(224)
随机裁剪图像,并将其大小调整为 224×224 像素。
T.ToTensor()
将图像从 PIL 图像格式或 NumPy 数组格式转换为 PyTorch 的 Tensor 格式。
具体实现:
-
将像素值从 [0, 255] 范围归一化到 [0.0, 1.0] 范围。
-
将图像的通道顺序从 H×W×C(高度×宽度×通道)转换为 C×H×W(通道×高度×宽度),以符合 PyTorch 的张量格式要求。
train_dataset = ImageFolder(root=r'./dataset', transform=transform)
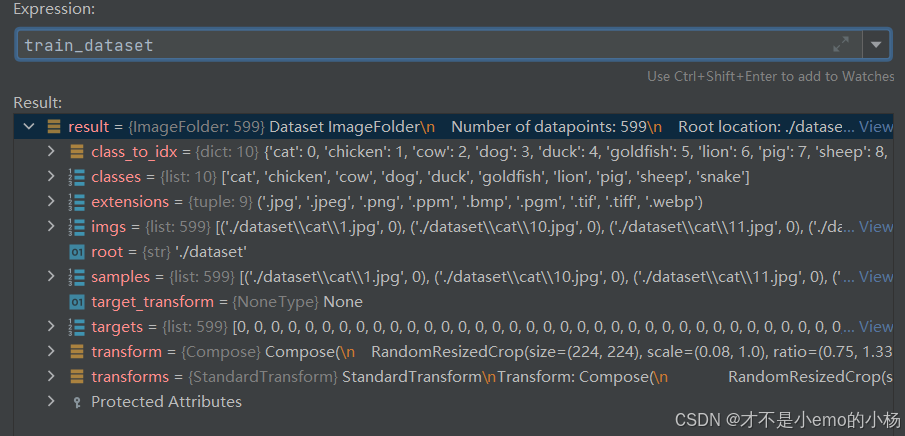
train_loader = torch.utils.data.DataLoader(
train_data, batch_size=1, shuffle=False, num_workers=0,
pin_memory=True)
pin_memory=True
pin_memory=True 的作用是将数据加载到 Pinned Memory(固定内存) 中。在使用 GPU 进行训练时,pin_memory=True 可以显著提高数据传输的效率,减少数据加载的延迟,从而提高整体的训练速度。
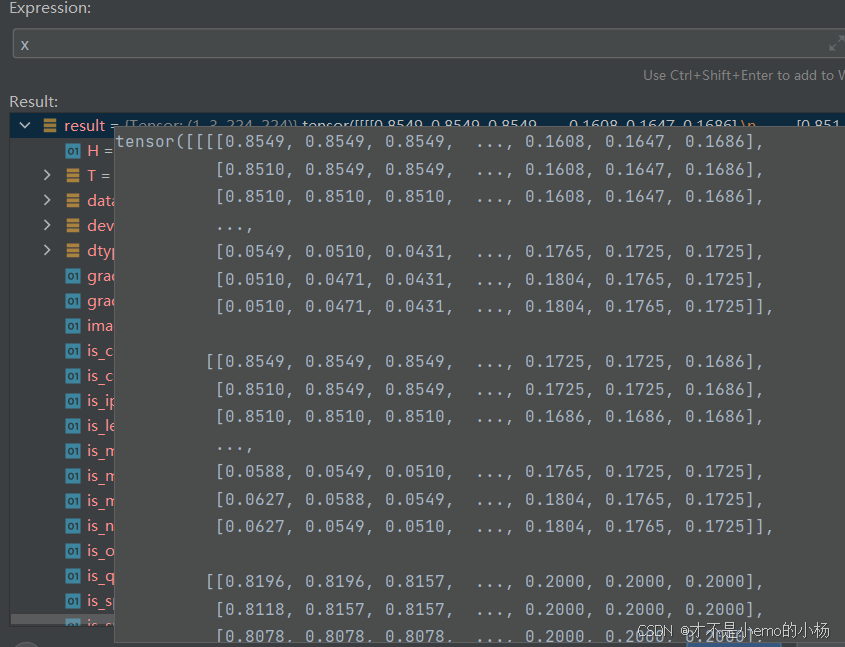
for x, _ in tqdm(train_loader)
x的结果
_的值为,标签值转化为tensor格式
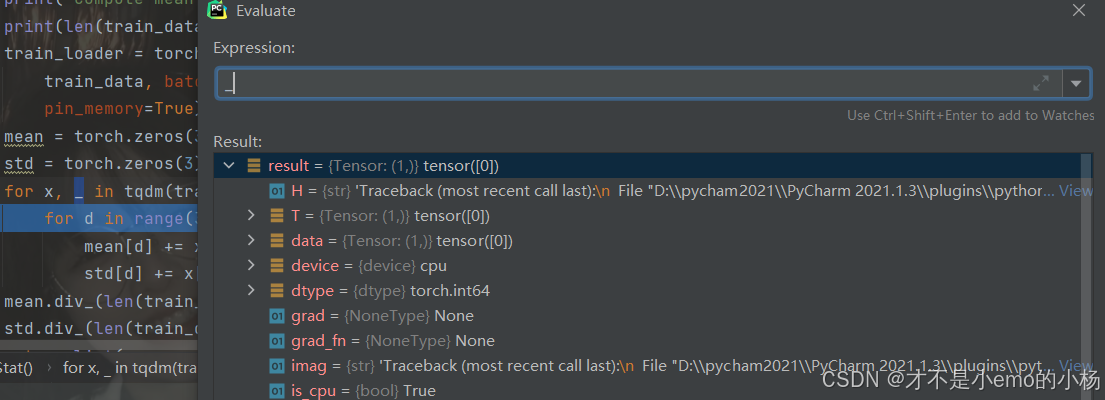
mean.div_(len(train_data))
这段代码的作用是对一个张量(mean)进行原地除法操作,将其每个元素除以 train_data 的长度(即数据集的大小)。这里的 div_ 是 PyTorch 中的原地操作(in-place operation),表示直接在原张量上修改值,而不是创建一个新的张量。
CreateDataset
# -*- coding: utf-8 -*-
"""
生成训练集和测试集,保存到txt文件中
"""
import os
import randomdef CreateTrainingSet(rootdata, train_ratio):train_list, test_list = [], [] # 读取里面每一类的类别data_list = []# 生产train.txt和test.txtclass_flag = -1for a, b, c in os.walk(rootdata):print(a)for i in range(len(c)):data_list.append(os.path.join(a, c[i]))for i in range(0, int(len(c) * train_ratio)):train_data = os.path.join(a, c[i]) + '\t' + str(class_flag) + '\n'train_list.append(train_data)for i in range(int(len(c) * train_ratio), len(c)):test_data = os.path.join(a, c[i]) + '\t' + str(class_flag) + '\n'test_list.append(test_data)class_flag += 1print(train_list)random.shuffle(train_list) # 打乱次序random.shuffle(test_list)with open('train.txt', 'w', encoding='UTF-8') as f:for train_img in train_list:f.write(train_img)with open('text.txt', 'w', encoding='UTF-8') as f:for test_img in test_list:f.write(test_img)if __name__ == '__main__':rootdata = r"./dataset"train_ratio = 0.8CreateTrainingSet(rootdata, train_ratio)

代码详解
os.walk
os.walk 会返回一个生成器,每次迭代返回一个三元组 (a, b, c):
-
a:表示当前正在遍历的目录路径(字符串)。 -
b:表示当前目录下的子目录列表(列表,包含子目录的名称)。 -
c:表示当前目录下的文件列表(列表,包含文件的名称)。
其他没有什么好讲的了
MYDataset
# -*- coding: utf-8 -*-
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader
import cv2 as cvclass MyDataset(Dataset):def __init__(self, txt_path, img_size=224, train_flag=True):self.imgs_info = self.get_images(txt_path)self.train_flag = train_flag# 图片标准化transform_BZ = transforms.Normalize(mean=[0.5045225, 0.4722667, 0.39059258],std=[0.20998387, 0.20583159, 0.20718254])self.train_tf = transforms.Compose([transforms.ToPILImage(), # 将numpy数组转换位PIL图像transforms.Resize((img_size, img_size)), # 将图片压缩成224*224的大小transforms.RandomHorizontalFlip(), # 对图片进行随机的水平翻转transforms.RandomVerticalFlip(), # 随机的垂直翻转transforms.ToTensor(), # 把图片改成Tensor格式transform_BZ # 图片表转化的步骤])self.val_tf = transforms.Compose([ ##简单把图片压缩了变成Tensor模式transforms.ToPILImage(), # 将 numpy数组转换为PIL图像transforms.Resize((img_size, img_size)),transforms.ToTensor(),transform_BZ # 标准化操作])def get_images(self, txt_path):with open(txt_path, 'r', encoding='utf-8') as f:imgs_info = f.readlines()imgs_info = list(map(lambda x: x.strip().split('\t'), imgs_info))return imgs_info # 返回图片信息def __getitem__(self, index): # 返回真正想返回的东西img_path, label = self.imgs_info[index]img = cv.imread(img_path)img = cv.cvtColor(img, cv.COLOR_BGR2RGB) # 将图片从BGR转换为RGB格式if self.train_flag:img = self.train_tf(img)else:img = self.val_tf(img)label = int(label)return img, labeldef __len__(self):return len(self.imgs_info)if __name__ == '__main__':my_dataset_train = MyDataset("train.txt", train_flag=True)my_dataloader_train = DataLoader(my_dataset_train, batch_size=10, shuffle=True)# 尝试拂去训练集数据print("读取训练集数据")for x, y in my_dataloader_train:print(x.type(), x.shape, y)my_dataset_test = MyDataset("test.txt", train_flag=False)my_dataloader_test = DataLoader(my_dataset_test, batch_size=10, shuffle=False)# 尝试读取训练集数据print("读取测试集数据")for x, y in my_dataloader_test:print(x.shape, y)
list(map(lambda x:x.strip().split('\t'), imgs_info))
-
map是 Python 的内置函数,用于对一个可迭代对象(如列表)中的每个元素应用一个函数,并返回一个新的可迭代对象。
结果为
transform_BZ = transforms.Normalize(
mean=[0.5045225, 0.4722667, 0.39059258],
std=[0.20998387, 0.20583159, 0.20718254]
)
这段代码的作用是定义一个归一化操作,将输入图像的每个通道的像素值减去指定的均值并除以指定的标准差。这种归一化处理有助于提高模型的训练效率和泛化能力。
其他的就没什么好讲的了
MyModel
from torchsummary import summary
import torch.nn as nn
import torch.nn.functional as F# 定义模型
class NeuralNetwork(nn.Module):def __init__(self):super().__init__()self.flatten = nn.Flatten()self.linear_relu_stack = nn.Sequential(nn.Linear(28 * 28, 512),nn.ReLU(),nn.Linear(512, 512),nn.ReLU(),nn.Linear(512, 10))def forward(self, x):x = self.flatten(x)logits = self.linear_relu_stack(x)return logitsclass SimpleCNN(nn.Module):def __init__(self):super(SimpleCNN, self).__init__()self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1)self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)self.conv3 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)self.fc1 = nn.Linear(128 * 28 * 28, 512)self.fc2 = nn.Linear(512, 128)self.fc3 = nn.Linear(128, 10)def forward(self, x):# Convolutional layers with ReLU and MaxPoolx = self.pool(F.relu(self.conv1(x)))x = self.pool(F.relu(self.conv2(x)))x = self.pool(F.relu(self.conv3(x)))# Flatten the output for the fully connected layersx = x.view(-1, 128 * 28 * 28)# Fully connected layers with ReLUx = F.relu(self.fc1(x))x = F.relu(self.fc2(x))# Output layerx = self.fc3(x)return xif __name__ == '__main__':# Create an instance of the networkmodel = SimpleCNN().cuda()print(model)summary(model, (3, 224, 224))
main函数
# -*- coding: utf-8 -*-
import torch
from torch import nn
from torch.utils.data import DataLoader
from tqdm import tqdm # pip install tqdm
import matplotlib.pyplot as plt
import os
from torchsummary import summaryfrom torch.utils.tensorboard import SummaryWriterimport wandb
import datetimefrom MyModel import SimpleCNN
from MYDataset import MyDataset# # 定义训练函数
def train(dataloader, model, loss_fn, optimizer):# 初始化训练数据集的大小和批次数量size = len(dataloader.dataset)num_batches = len(dataloader)# 设置模型为训练模式model.train()# 初始化总损失和正确预测数量loss_total = 0correct = 0# 遍历数据加载器中的所有数据批次for X, y in tqdm(dataloader):# 将数据和标签移动到指定设备(例如GPU)X, y = X.to(device), y.to(device)# 使用模型进行预测pred = model(X)# 计算正确预测的数量correct += (pred.argmax(1) == y).type(torch.float).sum().item()# 计算预测结果和真实结果之间的损失loss = loss_fn(pred, y)# 累加总损失loss_total += loss.item()# 执行反向传播,计算梯度loss.backward()# 更新模型参数optimizer.step()# 清除梯度信息optimizer.zero_grad()# 计算平均损失和准确率loss_avg = loss_total / num_batchescorrect /= size# 返回准确率和平均损失,保留三位小数return round(correct, 3), round(loss_avg, 3)# 定义测试函数
def test(dataloader, model, loss_fn):# 初始化测试数据集的大小和批次数量size = len(dataloader.dataset)num_batches = len(dataloader)# 设置模型为评估模式model.eval()# 初始化测试损失和正确预测数量test_loss, correct = 0, 0# 不计算梯度,以提高计算效率并减少内存使用with torch.no_grad():# 遍历数据加载器中的所有数据批次for X, y in tqdm(dataloader):# 将数据和标签移动到指定设备(例如GPU)X, y = X.to(device), y.to(device)# 使用模型进行预测pred = model(X)# 累加预测损失test_loss += loss_fn(pred, y).item()# 累加正确预测的数量correct += (pred.argmax(1) == y).type(torch.float).sum().item()# 计算平均测试损失和准确率test_loss /= num_batchescorrect /= size# 返回准确率和平均测试损失,保留三位小数return round(correct, 3), round(test_loss, 3)def writedata(txt_log_name, tensorboard_writer, epoch, train_accuracy, train_loss, test_accuracy, test_loss):# 保存到文档with open(txt_log_name, "a+") as f:f.write(f"Epoch:{epoch}\ttrain_accuracy:{train_accuracy}\ttrain_loss:{train_loss}\ttest_accuracy:{test_accuracy}\ttest_loss:{test_loss}\n")# 保存到tensorboard# 记录全连接层参数for name, param in model.named_parameters():tensorboard_writer.add_histogram(name, param.clone().cpu().data.numpy(), global_step=epoch)tensorboard_writer.add_scalar('Accuracy/train', train_accuracy, epoch)tensorboard_writer.add_scalar('Loss/train', train_loss, epoch)tensorboard_writer.add_scalar('Accuracy/test', test_accuracy, epoch)tensorboard_writer.add_scalar('Loss/test', test_loss, epoch)wandb.log({"Accuracy/train": train_accuracy,"Loss/train": train_loss,"Accuracy/test": test_accuracy,"Loss/test": test_loss})def plot_txt(log_txt_loc):with open(log_txt_loc, 'r') as f:log_data = f.read()# 解析日志数据epochs = []train_accuracies = []train_losses = []test_accuracies = []test_losses = []for line in log_data.strip().split('\n'):epoch, train_acc, train_loss, test_acc, test_loss = line.split('\t')epochs.append(int(epoch.split(':')[1]))train_accuracies.append(float(train_acc.split(':')[1]))train_losses.append(float(train_loss.split(':')[1]))test_accuracies.append(float(test_acc.split(':')[1]))test_losses.append(float(test_loss.split(':')[1]))# 创建折线图plt.figure(figsize=(10, 5))# 训练数据plt.subplot(1, 2, 1)plt.plot(epochs, train_accuracies, label='Train Accuracy')plt.plot(epochs, test_accuracies, label='Test Accuracy')plt.title('Training Metrics')plt.xlabel('Epoch')plt.ylabel('Value')plt.legend()# 设置横坐标刻度为整数plt.xticks(range(min(epochs), max(epochs) + 1))# 测试数据plt.subplot(1, 2, 2)plt.plot(epochs, train_losses, label='Train Loss')plt.plot(epochs, test_losses, label='Test Loss')plt.title('Testing Metrics')plt.xlabel('Epoch')plt.ylabel('Value')plt.legend()# 设置横坐标刻度为整数plt.xticks(range(min(epochs), max(epochs) + 1))plt.tight_layout()plt.show()if __name__ == '__main__':batch_size = 64init_lr = 1e-3epochs = 5log_root = "logs"log_txt_loc = os.path.join(log_root, "log.txt")# 指定TensorBoard数据的保存地址tensorboard_writer = SummaryWriter(log_root)# WandB信息保存地址run_time = datetime.datetime.now().strftime("%Y-%m-%d-%H-%M-%S")wandb.init(dir=log_root,project='Flower Classify',name=f"run-{run_time}",config={"learning_rate": init_lr,"batch_size": batch_size,"model": "SimpleCNN","dataset": "Flower10","epochs": epochs,})if os.path.isdir(log_root):passelse:os.mkdir(log_root)train_data = MyDataset("train.txt", train_flag=True)test_data = MyDataset("test.txt", train_flag=False)# 创建数据加载器train_dataloader = DataLoader(train_data, batch_size=batch_size)test_dataloader = DataLoader(test_data, batch_size=batch_size)for X, y in test_dataloader:print(f"Shape of X [N, C, H, W]: {X.shape}")print(f"Shape of y: {y.shape} {y.dtype}")break# 指定设备device = "cuda" if torch.cuda.is_available() else "cpu"print(f"Using {device} device")model = SimpleCNN().to(device)print(model)summary(model, (3, 224, 224))# 模拟输入,大小和输入相同即可init_img = torch.zeros((1, 3, 224, 224), device=device)tensorboard_writer.add_graph(model, init_img)# 添加wandb的模型记录wandb.watch(model, log='all', log_graph=True)# 定义损失函数loss_fn = nn.CrossEntropyLoss()# 定义优化器optimizer = torch.optim.SGD(model.parameters(), lr=init_lr)best_acc = 0# 定义循环次数,每次循环里面,先训练,再测试for t in range(epochs):print(f"Epoch {t + 1}\n-------------------------------")train_acc, train_loss = train(train_dataloader, model, loss_fn, optimizer)test_acc, test_loss = test(test_dataloader, model, loss_fn)writedata(log_txt_loc, tensorboard_writer, t, train_acc, train_loss, test_acc, test_loss)# 保存最佳模型if test_acc > best_acc:best_acc = test_acctorch.save(model.state_dict(), os.path.join(log_root, "best.pth"))torch.save(model.state_dict(), os.path.join(log_root, "last.pth"))print("Done!")plot_txt(log_txt_loc)tensorboard_writer.close()wandb.finish()
导出数据集的全部预测结果
'''1.单幅图片验证2.多幅图片验证
'''
import torch
from torch.utils.data import DataLoader
from MYDataset import MyDataset
from MyModel import SimpleCNN
import pandas as pd
from tqdm import tqdm
import osdef eval(dataloader, model):pred_list = []model.eval()with torch.no_grad():# 加载数据加载器,得到里面的X(图片数据)和y(真实标签)for X, y in tqdm(dataloader, desc="Model is predicting, please wait"):# 将数据转到GPUX = X.to(device)# 将图片传入到模型当中就,得到预测的值predpred = model(X)pred_softmax = torch.softmax(pred,1).cpu().numpy()pred_list.append(pred_softmax.tolist()[0])return pred_listif __name__ == "__main__":'''加载预训练模型'''# 1. 导入模型结构device = "cuda" if torch.cuda.is_available() else "cpu"# 2. 加载模型参数model = SimpleCNN()model_state_loc = r"logs/best.pth"torch_data = torch.load(model_state_loc, map_location=torch.device(device))model.load_state_dict(torch_data)model = model.to(device)'''加载需要预测的图片'''valid_data = MyDataset("test.txt", train_flag=False)test_dataloader = DataLoader(dataset=valid_data, num_workers=4,pin_memory=True, batch_size=1)'''获取结果'''# 获取模型输出pred = eval(test_dataloader, model)dir_names = []for root,dirs,files in os.walk("dataset"):if dirs:dir_names = dirs# 将输出保存到exel中,方便后续分析label_names = dir_names # 可以把标签写在这里print(label_names)df_pred = pd.DataFrame(data=pred, columns=label_names)df_pred.to_csv('pred_result.csv', encoding='gbk', index=False)print("Done!")图像分类评价指标
- 混淆矩阵
- 准确率
- 查准率
- 查全率
- F1-分数
混淆矩阵
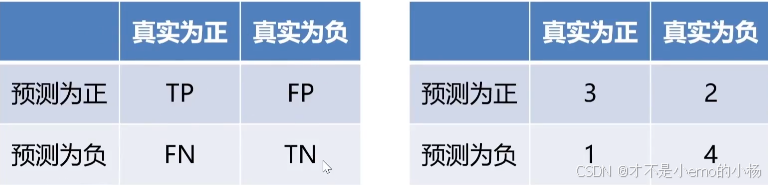
True:正确的 False:错误的 Positive :正例 Negative:反例
准确率
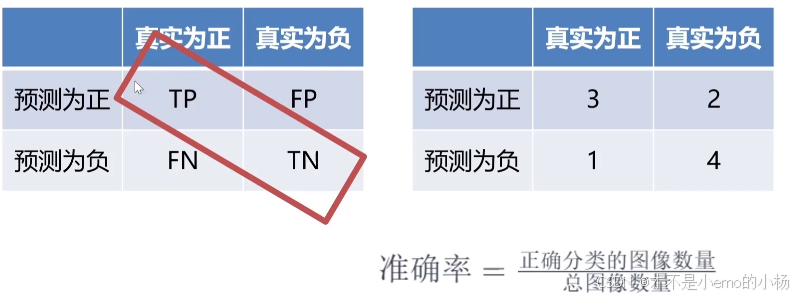
查准率
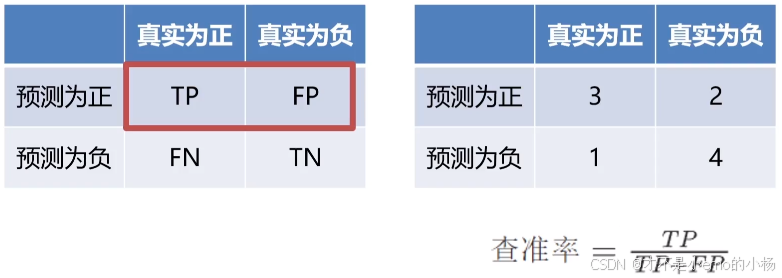
查全率
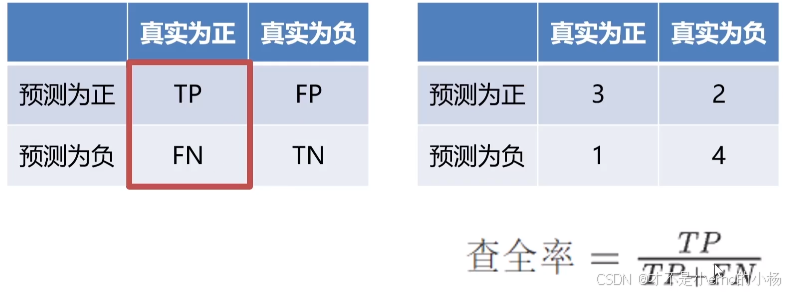
F1-分数
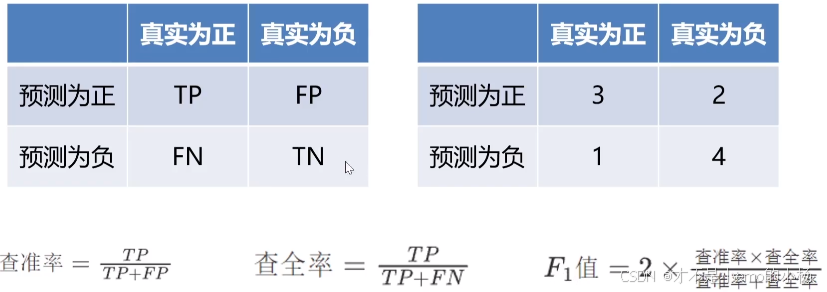
对比实验结果
'''模型性能度量
'''
from sklearn.metrics import * # pip install scikit-learn
import matplotlib.pyplot as plt # pip install matplotlib
import pandas as pd # pip install pandas
import matplotlib
'''
读取数据需要读取模型输出的标签(predict_label)以及原本的标签(true_label)'''matplotlib.rcParams['font.sans-serif']=['SimHei'] # 用黑体显示中文
matplotlib.rcParams['axes.unicode_minus']=False # 正常显示负号target_loc = "test.txt" # 真实标签所在的文件
target_data = pd.read_csv(target_loc, sep="\t", names=["loc","type"])
true_label = [i for i in target_data["type"]]# print(true_label)predict_loc = "pred_result.csv" # 3.ModelEvaluate.py生成的文件
predict_data = pd.read_csv(predict_loc, encoding='gbk')#,index_col=0)
predict_label = predict_data.to_numpy().argmax(axis=1)
# predict_score = predict_data.to_numpy().max(axis=1)'''常用指标:精度,查准率,召回率,F1-Score
'''
report = classification_report(true_label, predict_label)
print("分类报告:\n",report)# 精度,准确率, 预测正确的占所有样本种的比例
accuracy = accuracy_score(true_label, predict_label)
print("精度: ",accuracy)# 查准率P(准确率),precision(查准率)=TP/(TP+FP)
precision = precision_score(true_label, predict_label, labels=None, pos_label=1, average='macro') # 'micro', 'macro', 'weighted'
print("查准率P: ",precision)# 查全率R(召回率),原本为对的,预测正确的比例;recall(查全率)=TP/(TP+FN)
recall = recall_score(true_label, predict_label, average='macro') # 'micro', 'macro', 'weighted'
print("召回率: ",recall)# F1-Score
f1 = f1_score(true_label, predict_label, average='macro') # 'micro', 'macro', 'weighted'
print("F1 Score: ",f1)'''
混淆矩阵
'''
# label_names = ["猫", "鸡", "牛", "狗", "鸭子","金鱼","狮子","猪","绵羊","蛇"]
import os
dir_names = []
for root,dirs,files in os.walk("dataset"):if dirs:dir_names = dirs
# 将输出保存到exel中,方便后续分析
label_names = dir_names # 可以把标签写在这里confusion = confusion_matrix(true_label, predict_label, labels=[i for i in range(len(label_names))])plt.matshow(confusion, cmap=plt.cm.Oranges) # Greens, Blues, Oranges, Reds
plt.colorbar()
for i in range(len(confusion)):for j in range(len(confusion)):plt.annotate(confusion[j,i], xy=(i, j), horizontalalignment='center', verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.xticks(range(len(label_names)), label_names)
plt.yticks(range(len(label_names)), label_names)
plt.title("Confusion Matrix")
plt.show()相关文章:

animals_classification动物分类
数据获取 深度学习训练中第一个是获取数据集,数据集的质量很重要,我们这里做的是动物分类,大致会选择几个动物,来做一个简单的多分类问题,数据获取的方法,鼠鼠我这里选择使用爬虫的方式来对数据进行爬取&a…...

15.QT窗口:主窗口、浮动窗口、对话框
0. 概述 Qt窗口是通过 QMainWindow类 来实现的。 QMainWindow 是一个为用户提供主窗口程序的类,继承自QWidget类,并且提供了一个预定义的布局。QMainWindow包含一个菜单栏(menu bar)、多个工具栏(tool barsÿ…...

nginx中地理位置访问控制模块geo
1.安装 GeoIP2 模块 Ubuntu/Debian 系统: sudo apt-get update sudo apt-get install nginx-module-geoip2 sudo apt-get install libnginx-mod-http-geoip2CentOS/RHEL 系统: sudo yum install nginx-module-geoip22.下载 GeoIP2 数据库 下载 GeoIP2 …...
)
基于SpringBoot酒店管理系统设计和实现(源码+文档+部署讲解)
技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文…...

蓝桥杯嵌入式第十四届模拟二
一.LED 先配置LED的八个引脚为GPIO_OutPut,锁存器PD2也是,然后都设置为起始高电平,生成代码时还要去解决引脚冲突问题 二.按键 按键配置,由原理图按键所对引脚要GPIO_Input 生成代码,在文件夹中添加code文件夹,code中添加fun.c、fun.h、headfile.h文件,去资源包中把lc…...

【前端】Node.js一本通
近两天更新完毕,建议关注收藏点赞。 目录 复习Node.js概述使用fs文件系统模块path路径模块http模块模块化 复习 为什么JS可以在浏览器中执行 原理:待执行的JS代码->JS解析引擎 不同的浏览器使用不同的 JavaScript 解析引擎:其中…...

Groovy
一:了解 1:groovy保留字 2: 标识符 二:数据类型 1:字符串(1) 1: java.lang.string 定义的字符串是不能改变的 2: groovy.lang.GString 定义的字符串的值是不能改变的 2: 总结 三:数值类型 1: Groovy的数值型包括整数型(integer)…...
)
【并发编程 | 第七篇】深入学习线程池(一)
什么是线程池? 线程池是用来管理和复用线程的⼯具,它可以减少线程的创建和销毁开销。 在 Java 中,ThreadPoolExecutor 是线程池的核⼼实现,它通过核⼼线程数、最⼤线程数、任务队列和拒绝策略来 控制线程的创建和执⾏。 举个栗…...
字符串并转换为数字)
C++ 获取一整行(一行)字符串并转换为数字
代码很简单,主要是自己总是忘记,记录一下: #include <iostream> #include <cstdlib> #include <cstring>#include <string> #include <vector> #include <sstream>using namespace std;void print_int_…...

初探:简道云平台架构及原理
一、系统架构概述 简道云作为一款低代码开发平台,其架构设计以模块化和云端协同为核心,主要分为以下层次: 1. 前端层 可视化界面:基于Web的拖拽式表单设计器,支持动态渲染(React/Vue框架)。多…...

鸿蒙Arkts开发飞机大战小游戏,包含无敌模式,自动射弹,暂停和继续
飞机大战可以把飞机改成图片,目前包含无敌模式,自动射弹,暂停和继续的功能 代码如下: // 定义位置类 class GamePosition {x: numbery: numberconstructor(x: number, y: number) {this.x xthis.y y} }Entry Component struct…...

使用`sklearn`中的逻辑回归模型进行股票的情感分析,以及按日期统计积极和消极评论数量的功能
以下是完成上述任务的Python代码,可在Jupyter Notebook中运行。此代码包含了使用sklearn中的逻辑回归模型进行情感分析,以及按日期统计积极和消极评论数量的功能。 import pandas as pd from sklearn.feature_extraction.text import TfidfVectorizer f…...

简洁的 PlantUML 入门教程
评论中太多朋友在问,我的文章中图例如何完成的。 我一直用plantUML,也推荐大家用,下面给出一个简洁的PlantUML教程。 🌱 什么是 PlantUML? PlantUML 是一个用纯文本语言画图的工具,支持流程图、时序图、用例图、类图、…...
)
Python 面向对象 - 依赖倒置原则 (DIP)
1. 核心概念 依赖倒置原则(Dependency Inversion Principle, DIP) 是SOLID原则中的"D",包含两个关键点: 高层模块不应依赖低层模块,二者都应依赖抽象抽象不应依赖细节,细节应依赖抽象 2. 使用场景 典型应用场景 系…...
--分层自动化测试)
自动化框架及其设计搭建浅谈(二)--分层自动化测试
目录 测试金字塔模型 分层自动化测试的模型 分层自动化测试的最佳实践 自动化分层测试的误区 自动化框架的设计与自动化分层 自动化测试的设计建议 分层自动化测试,顾名思义,就是分层的自动化测试,那么自动化测试为什么要分层呢&#x…...
:基于PyTorch的ResNet改进方案详解:Mish激活+SPP模块+MixUp数据增强)
ResNet改进(19):基于PyTorch的ResNet改进方案详解:Mish激活+SPP模块+MixUp数据增强
1. 前言 ResNet作为深度学习领域里程碑式的网络架构,在图像分类等计算机视觉任务中表现出色。然而,随着研究的深入和技术的发展,原始的ResNet架构仍有改进空间。本文将详细介绍一种基于PyTorch的ResNet改进方案,该方案融合了Mish激活函数、SPP模块和MixUp数据增强等先进技…...
命令模式)
设计模式简述(九)命令模式
命令模式 描述基本使用使用 描述 命令模式是一种体现高内聚的行为模式。 将整个请求封装成一个命令对象,由这个命令对象完成所需业务调用。 命令对象封装了该命令需要的所有逻辑,不需要调用方关注内部细节。 基本使用 定义抽象命令(所有命…...

Codecademy—— 交互式编程学习的乐园
一、网站概述 Codecademy 是一家美国在线学习编程知识的网站,它为编程学习者提供了一种全新的学习方式。在如今众多的编程学习平台中,Codecademy 凭借其独特的优势脱颖而出,吸引了全球数百万用户。其目标是帮助更多人轻松学习编程࿰…...

分布式数据库HBase
1.概述 1.1从BigTable 说起 BigTable是一个分布式存储系统,BigTable起初用于解决典型的互联网搜索问题。 BigTable是一个分布式存储系统利用谷歌提出的MapReduce分布式并行计算模型来处理海量数据使用谷歌分布式文件系统GFS作为底层数据存储采用Chubby提供协同服…...
)
Linux进程地址空间(12)
文章目录 前言一、进程空间地址基本概念代码分析 二、如何理解地址空间三、进一步理解页表和写实拷贝对虚拟地址的进一步深入fork() 的两个返回值? 总结 前言 融会贯通! 本篇会让你再次对计算机世界里面的大智慧感到汗颜! 本篇研究环境基…...

鸿蒙开发04界面渲染
文章目录 前言一、条件渲染1.1 if/else1.2 属性控制1.3 可见性 二、循环渲染三、滚动渲染3.1 下拉刷新3.2 上拉加载 前言 在声明式描述语句中开发者除了使用系统组件外,还可以使用渲染控制语句来辅助UI的构建,这些渲染控制语句包括控制组件是否显示的条…...

CANoe CAPL——Ethernet CAPL函数
CANoe CAPL——CAN CAPL函数 事件过程(Event Procedures) 函数名简要描述on ethernetErrorPacket收到错误的以太网数据包时调用。on ethernetMacsecStatus当物理端口的以太网 MACsec 连接状态变化时调用。on ethernetPacket接收到以太网数据包后调用。…...
;)
语法: setup_lcd (mode, prescale, [segments]);
SETUP_LCD( ) 语法: setup_lcd (mode, prescale, [segments]); 参数: mode可能是来自devices.h头文件如下常数: LCD_DISABLED, LCD_STATIC, LCD_MUX12, LCD_MUX13, LCD_MUX14 下面的参数:STOP_ON_SLEEP, USE_TIMER_1可同上面的LCD_DISABLED, LCD_STATIC, LCD_MUX12, LCD…...

微前端随笔
✨ single-spa: js-entry 通过es-module 或 umd 动态插入 js 脚本 ,在主应用中发送请求,来获取子应用的包, 该子应用的包 singleSpa.registerApplication({name: app1,app: () > import(http://localhost:8080/app1.js),active…...
Linux)
实操(不可重入函数、volatile、SIGCHLD、线程)Linux
1 不可重入函数 为什么会导致节点丢失内存泄露?main函数在执行insert,但是没执行完就被信号中断了,又进了这个函数里,所以这个insert函数在不同的执行流中,同一个函数被重复进入,如果没有问题,…...

如何在Linux系统上通过命令调用AI大模型?
如何在Linux系统上通过命令调用AI大模型? 文章目录 如何在Linux系统上通过命令调用AI大模型?一、准备工作二、编写API调用脚本三、配置命令行工具 使用AI命令帮我做一个文档总结提问技术问题编写简单的shell脚本帮我写一个docker-compose 在这个AI技术飞…...

数据分析-Excel-学习笔记Day1
Day1 复现报表聚合函数:日期联动快速定位区域SUMIF函数SUMIFS函数环比、同比计算IFERROR函数混合引用单元格格式总结汇报 拿到一个Excel表格,首先要看这个表格的构成(包含了哪些数据),几行几列,每一列的名称…...

负载均衡是什么,Kubernetes如何自动实现负载均衡
负载均衡是什么? 负载均衡(Load Balancing) 是一种网络技术,用于将网络流量(如 HTTP 请求、TCP 连接等)分发到多个服务器或服务实例上,以避免单个服务器过载,提高系统的可用性、可扩…...

洞察 Linux 进程管理
一、进程和线程的概念 1.进程 (1)概念 进程是程序在操作系统中的一次执行过程,是系统进行资源分配和调度的基本单位。进程是程序的执行实例,拥有独立的资源(如内存、文件描述符等)。每个进程在创建时会被…...

http协议版本的区别 -- 2和3
目录 http2和http3的区别 传输层协议 QUIC协议 介绍 连接建立与握手 建立安全连接的过程 RTT 建连为什么需要两个过程 原因 解决 QUIC协议的1-RTT 建连 必要性 连接过程 第一次握手(Client Hello) 版本号 key_share 其他 第二次握手 介绍 Server Hello 身…...

Vue2-实现elementUI的select全选功能
文章目录 使用 Element UI 的全选功能自定义选项来模拟全选 在使用 Element UI 的 el-select组件时,实现“全选”功能,通常有两种方式:一种是使用内置的全选功能,另一种是通过自定义选项来模拟全选。 使用 Element UI 的全选功能…...
)
Spring Boot 与 TDengine 的深度集成实践(四)
优化与扩展 批量插入数据 在实际应用中,当需要插入大量数据时,逐条插入会导致性能低下,因为每次插入都需要建立数据库连接、解析 SQL 语句等操作,这些操作会带来额外的开销 。为了提高数据插入效率,我们可以采用批量…...

2025年【山东省安全员C证】考试题及山东省安全员C证考试内容
在当今建筑行业蓬勃发展的背景下,安全生产已成为企业生存与发展的基石。安全员作为施工现场安全管理的直接责任人,其专业能力和资质认证显得尤为重要。山东省安全员C证作为衡量安全员专业水平的重要标准,不仅关乎个人职业发展,更直…...

提升Spring Boot开发效率的Idea插件:Spring Boot Helper
一、Spring Boot Helper插件介绍 Spring Boot Helper是一款专为Spring Boot开发者设计的IntelliJ IDEA插件,它提供了丰富的功能来简化和加速Spring Boot应用程序的开发过程。 该插件能够智能识别Spring Boot项目结构,提供专属的代码生成、配置辅助和运…...

【USTC 计算机网络】第三章:传输层 - 面向连接的传输:TCP
本文介绍了面向连接的传输协议:TCP,首先介绍 TCP 报文段的结构以及如何设置超时定时器,接着介绍 TCP 如何实现可靠数据传输以及流量控制,最后介绍 TCP 中最重要的三次握手与四次挥手的连接建立与关闭过程。 1. TCP 概述与段结构 …...

Linux主要开发工具之gcc、gdb与make
此系列还有两篇,大家想完整掌握可以阅读另外两篇 Linux文本编辑与shell程序设计-CSDN博客 Linux基础知识详解与命令大全(超详细)-CSDN博客 1.gcc编译系统 1.1 文件名后缀 文件名后缀 文 件 类 型 文件名后缀 文 件 类 型 .c C源…...

23种设计模式-行为型模式-观察者
文章目录 简介问题解决代码关键实现说明 总结 简介 观察者是一种行为设计模式, 允许你定义一种订阅通知机制, 可在事件发生时通知多个“观察/订阅”该对象的其他对象。 问题 假如你有两种类型的对象: 顾客和商店。顾客对某个新品非常感兴趣࿰…...

去中心化预测市场
去中心化预测市场 核心概念 预测市场类型: 类别型市场:二元结果(YES/NO),例如“BTC在2024年突破10万美元?” 多选型市场:多个选项(如总统候选人),赔付基于…...

springboot-ai接入DeepSeek
1、引入pom依赖 <dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-model-openai</artifactId> </dependency><dependencyManagement><dependencies><dependency><groupId>o…...
)
【C语言】数据在内存中的储存(整形)
目录 前言: 预备知识 整数在内存中的储存 原码 反码 补码 总结: 前言: 在上两章中讲解了五大内存函数,其中memchr函数,这个函数考察到数据内存的存储。 接下来为大家讲解整数在内存中的储存。 预备知识 认识…...
)
PCL 树木树干粗提取(地基数据,TLS)
文章目录 一、简介二、实现代码三、实现效果参考资料一、简介 主要的思路如下: 1、首先,使用之前的CSF算法提取点云的地面点,在提取的过程中我们可以得到一个布料结构(地面模型)。 2、在得到这个布料结构之后,我们也就可以得到整个地面模型的高度了,之后我们只需要遍历每…...

Spring 中的 IOC
🌱 一、什么是 IOC? 📖 定义(通俗理解): IOC(Inversion of Control,控制反转) 是一种设计思想:对象不再由你自己创建和管理,而是交给 Spring 容器…...

尚硅谷2019版Java集合和泛型
第十一章 Java集合框架 集合框架全景图 mindmaproot((Java集合))Collection单列List有序可重复ArrayListLinkedListVectorSet无序唯一HashSetLinkedHashSetTreeSetMap双列HashMapLinkedHashMapTreeMapHashtablePropertiesToolsCollectionsArrays三大核心接口对比 特性ListSe…...

车载诊断架构 --- 整车重启先后顺序带来的思考
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 周末洗了一个澡,换了一身衣服,出了门却不知道去哪儿,不知道去找谁,漫无目的走着,大概这就是成年人最深的孤独吧! 旧人不知我近况,新人不知我过…...

华为eNSP:实验 配置单区域集成ISIS
单区域集成ISIS是一种基于中间系统到中间系统(IS-IS)协议的网络架构优化方案,主要用于简化网络设计并提升数据传输效率。其核心特点包括: 单一区域部署 ISIS协议在单一逻辑区域内运行,消除多区域间的分层复杂性&am…...
----中间件IIS6)
常见框架漏洞(五)----中间件IIS6
一、【PUT漏洞】 漏洞描述:IIS Server 在 Web 服务扩展中开启了 WebDAV ,配置了可以写⼊的权限,造成任意⽂件上传。 版本:IIS 6.0 1. 环境 fofa搜素环境:"IIS-6.0" 或者环境搭建:本地搭建2003…...

leetcode221.最大正方形
class Solution {public int maximalSquare(char[][] matrix) {int result 0; // 记录正方形边长int m matrix.length, n matrix[0].length;int[][] dp new int[m 1][n 1];// 动态规划for (int i 1; i < m; i) {for (int j 1; j < n; j) {if (matrix[i - 1][j - …...

C++实现AVL树
一 AVL树的概念 上上节我们学习了二叉搜索树,他的理想查找的时间复杂度是o(log n),但是如果是下面这种情况,那么它的时间复杂度就会变成o(n). 这种情况就是出现一边高的那种,它的个数和它的高度相差不大。 那么这样就会把二叉搜索…...

Linux系统安全及应用
目录 一.账号安全措施 1.1系统账号清理 1.1.1将非登录用户的shell设为无法登录 1.1.2删除无用用户 userdel 1.1.3锁定账号文件 1.1.4锁定长期不使用的账号 1.2密码安全控制 1.2.1 对新建用户 1.2.2对已有用户 1.3命令历史限制 1.3.1临时清除历史命令 1.3.2限制命令…...
:Spring2)
JAVA反序列化深入学习(十三):Spring2
让我们回到Spring Spring2 在 Spring1 的触发链上有所变换: 替换了 spring-beans 的 ObjectFactoryDelegatingInvocationHandler使用了 spring-aop 的 JdkDynamicAopProxy ,并完成了后续触发 TemplatesImpl 的流程 简而言之,换了一个chain&am…...