CV - 目标检测
物体检测
目标检测和图片分类的区别:
图像分类(Image Classification)
目的:图像分类的目的是识别出图像中主要物体的类别。它试图回答“图像是什么?”的问题。
输出:通常输出是一个标签或一组概率值,表示图像属于各个预定义类别的可能性。例如,对于一张包含猫的图片,分类器可能会输出“猫”这个标签。
应用场景:适用于只需要了解图像整体内容的场景,如识别照片中的动物种类、区分不同的风景类型等。
目标检测(Object Detection)
目的:目标检测不仅需要识别图像中所有感兴趣物体的类别,还需要确定每个物体在图像中的具体位置。它试图回答“图像中有什么?它们在哪里?”的问题。
输出:除了给出物体的类别外,还会输出物体所在的边界框(bounding box),即用矩形框标记出每个物体的位置。例如,在自动驾驶场景下,系统不仅要能识别出行人、车辆等物体,还要精确地定位它们的位置以便做出安全决策。
应用场景:适合于需要知道图像内特定对象位置的情况,比如视频监控、自动驾驶汽车、医学影像分析等领域。
边缘框
- 一个边缘框可以通过 4 个数字定义
- (左上 x,左上 y,右下 x,右下 y)
- (左上 x,左上 y,宽,高)

目标检测数据集
- 每行表示一个物体
- 图片文件名,物体类别,边缘框
- COCO (cocodataset.org)
- 80 物体,330K 图片,1.5M 物体
总结
- 物体检测识别图片里的多个物体的类别和位置
- 位置通常用边缘框表示。
边缘框实现
%matplotlib inline
import torch
from d2l import torch as d2ld2l.set_figsize()
img = d2l.plt.imread('../img/catdog.jpg')
d2l.plt.imshow(img);

定义在这两种表示法之间进行转换的函数
#@save
def box_corner_to_center(boxes):"""从(左上,右下)转换到(中间,宽度,高度)"""x1, y1, x2, y2 = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]cx = (x1 + x2) / 2cy = (y1 + y2) / 2w = x2 - x1h = y2 - y1boxes = torch.stack((cx, cy, w, h), axis=-1)return boxes#@save
def box_center_to_corner(boxes):"""从(中间,宽度,高度)转换到(左上,右下)"""cx, cy, w, h = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]x1 = cx - 0.5 * wy1 = cy - 0.5 * hx2 = cx + 0.5 * wy2 = cy + 0.5 * hboxes = torch.stack((x1, y1, x2, y2), axis=-1)return boxes
定义图像中狗和猫的边界框
# bbox是边界框的英文缩写
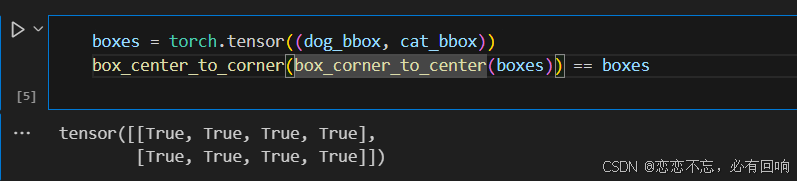
dog_bbox, cat_bbox = [60.0, 45.0, 378.0, 516.0], [400.0, 112.0, 655.0, 493.0]boxes = torch.tensor((dog_bbox, cat_bbox))
box_center_to_corner(box_corner_to_center(boxes)) == boxes
将边界框在图中画出
#@save
def bbox_to_rect(bbox, color):# 将边界框(左上x,左上y,右下x,右下y)格式转换成matplotlib格式:# ((左上x,左上y),宽,高)return d2l.plt.Rectangle(xy=(bbox[0], bbox[1]), width=bbox[2]-bbox[0], height=bbox[3]-bbox[1],fill=False, edgecolor=color, linewidth=2)fig = d2l.plt.imshow(img)
fig.axes.add_patch(bbox_to_rect(dog_bbox, 'blue'))
fig.axes.add_patch(bbox_to_rect(cat_bbox, 'red'));

数据集
李沐老师收集并标记了一个小型数据集,下面首先是下载该数据集:
%matplotlib inline
import os
import pandas as pd
import torch
import torchvision
from d2l import torch as d2l#@save
d2l.DATA_HUB['banana-detection'] = (d2l.DATA_URL + 'banana-detection.zip','5de26c8fce5ccdea9f91267273464dc968d20d72')
读取香蕉检测数据集
#@save
def read_data_bananas(is_train=True):"""读取香蕉检测数据集中的图像和标签"""data_dir = d2l.download_extract('banana-detection')csv_fname = os.path.join(data_dir, 'bananas_train' if is_trainelse 'bananas_val', 'label.csv')csv_data = pd.read_csv(csv_fname)csv_data = csv_data.set_index('img_name')images, targets = [], []for img_name, target in csv_data.iterrows():images.append(torchvision.io.read_image(os.path.join(data_dir, 'bananas_train' if is_train else'bananas_val', 'images', f'{img_name}')))# 这里的target包含(类别,左上角x,左上角y,右下角x,右下角y),# 其中所有图像都具有相同的香蕉类(索引为0)targets.append(list(target))return images, torch.tensor(targets).unsqueeze(1) / 256
创建一个自定义 Dataseet 实例:
#@save
class BananasDataset(torch.utils.data.Dataset):"""一个用于加载香蕉检测数据集的自定义数据集"""def __init__(self, is_train):self.features, self.labels = read_data_bananas(is_train)print('read ' + str(len(self.features)) + (f' training examples' ifis_train else f' validation examples'))def __getitem__(self, idx):return (self.features[idx].float(), self.labels[idx])def __len__(self):return len(self.features)
为训练集和测试集返回两个数据加载器实例
#@save
def load_data_bananas(batch_size):"""加载香蕉检测数据集"""train_iter = torch.utils.data.DataLoader(BananasDataset(is_train=True),batch_size, shuffle=True)val_iter = torch.utils.data.DataLoader(BananasDataset(is_train=False),batch_size)return train_iter, val_iter
读取一个小批量,并打印其中的图像和标签的形状
batch_size, edge_size = 32, 256
train_iter, _ = load_data_bananas(batch_size)
batch = next(iter(train_iter))
batch[0].shape, batch[1].shape

演示:
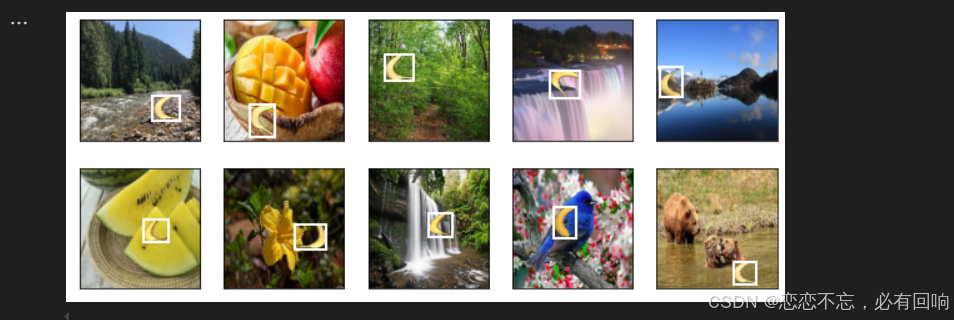
imgs = (batch[0][0:10].permute(0, 2, 3, 1)) / 255
axes = d2l.show_images(imgs, 2, 5, scale=2)
for ax, label in zip(axes, batch[1][0:10]):d2l.show_bboxes(ax, [label[0][1:5] * edge_size], colors=['w'])
QA 思考
Q1:如果在工业检测中数据集非常小(近百张),除了进行数据增强外,还有什么更好的方法吗?
A1:迁移学习:找一个非常好的,在一个比较大的目标检测数据集上训练的比较好的模型,然后拿过来进行微调。近百张其实也不算小的了,只是说模型训练出来不是很好。数据增强的话,对图像进行处理,对应的框也必须要相应的变化一下,这是比较麻烦的点。
后记
自己实现了一遍,然后也是使用的李沐老师在课件中提供的狗猫图片:
import torch
from matplotlib import pyplot as plt
from PIL import Imagedef set_image_display_size():plt.figure(figsize=(8, 6))def load_image(img_path):return Image.open(img_path)def show_single_image(img):plt.imshow(img)plt.axis('on') # 显示坐标轴plt.show()def box_corner_to_center(boxes):x1, y1, x2, y2 = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]cx = (x1 + x2) / 2cy = (y1 + y2) / 2w = x2 - x1h = y2 - y1boxes = torch.stack((cx, cy, w, h), axis=-1)return boxesdef box_center_to_corner(boxes):# 这里向左和向上都是减小的cx, cy, w, h = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]x1 = cx - 0.5 * wy1 = cy - 0.5 * hx2 = cx + 0.5 * wy2 = cy + 0.5 * hboxes = torch.stack((x1, y1, x2, y2), axis=-1)return boxesdef bbox_to_rect(bbox, color):# 将边界框(左上x, 左上y, 右下x, 右下y)格式转换成matplotlib格式:# ((左上x, 左上y), 宽, 高)return plt.Rectangle(xy=(bbox[0], bbox[1]), width=bbox[2] - bbox[0], height=bbox[3] - bbox[1],fill=False, edgecolor=color, linewidth=2)if __name__ == "__main__":# 设置图像显示大小set_image_display_size()# 加载图像img_path = '../image/catdog.jpg' # 确保路径正确img = load_image(img_path)show_single_image(img)# dog, cat 边界框dog_bbox, cat_bbox = [60.0, 45.0, 378.0, 516.0], [400.0, 112.0, 655.0, 493.0]# 转换为张量并测试转换函数是否正确boxes = torch.tensor((dog_bbox, cat_bbox))converted_boxes = box_center_to_corner(box_corner_to_center(boxes))# torch.allclose,判断两个张量是否在一定容差范围内相等。print("转换是否一致:", torch.allclose(converted_boxes, boxes))# 显示图像并绘制边界框,imshow 将 img 显示在画布上fig = plt.imshow(img)# add_patch 是 matplotlib 中用于在坐标轴上添加图形元素(如矩形、圆形等)的函数fig.axes.add_patch(bbox_to_rect(dog_bbox, 'blue')) # 狗的边界框fig.axes.add_patch(bbox_to_rect(cat_bbox, 'red')) # 猫的边界框plt.show()
我在colab上跑了一下下面的代码,发现可以,下载不了的可能需要一点 “魔法”
import hashlib
import os
import tarfile
import zipfile
import pandas as pd
import requests
import torch
import torchvisionfrom matplotlib import pyplot as plt"""这段代码本身并没有包含训练过程。它只是加载了已经标注好的香蕉检测数据集,并可视化了图像及其对应的边界框。这些边界框信息是预先标注好的(存储在 CSV 文件中),而不是通过模型训练得到的。read_data_bananas 函数读取数据集中的图像和标签:图像存储在文件夹中(如 bananas_train/images/)。标签存储在 CSV 文件中(如 bananas_train/label.csv)。每个标签包括图像名称、目标类别(香蕉类别的索引为 0)、以及边界框坐标。zip 结构类似如下:banana-detection/├── bananas_train/│ ├── images/│ │ ├── image1.jpg│ │ ├── image2.jpg│ │ └── ...│ └── label.csv # 包含每张图像的标注信息(即边界框和类别)└── bananas_val/├── images/│ ├── image1.jpg│ ├── image2.jpg│ └── ...└── label.csv
"""
DATA_HUB = dict()
DATA_URL = 'http://d2l-data.s3-accelerate.amazonaws.com/'DATA_HUB['banana-detection'] = (DATA_URL + 'banana-detection.zip','5de26c8fce5ccdea9f91267273464dc968d20d72')def download(name, cache_dir=os.path.join('..', 'data')):"""下载一个DATA_HUB中的文件,返回本地文件名"""# assert 条件, 错误信息assert name in DATA_HUB, f"{name} 不存在于 {DATA_HUB}""""url:文件的下载地址。 http://d2l-data.s3-accelerate.amazonaws.com/banana-detection.zipsha1_hash:文件内容的 SHA-1 校验值,用于验证文件完整性。5de26c8fce5ccdea9f91267273464dc968d20d72"""url, sha1_hash = DATA_HUB[name]"""递归创建目录:包括所有必要的父目录。避免重复创建导致的错误:如果目录已经存在,不会抛出异常。"""os.makedirs(cache_dir, exist_ok=True)"""url.split('/')[-1]:提取 URL 路径的最后一部分(通常是文件名)。os.path.join(cache_dir, ...):将缓存目录和文件名组合成完整的本地文件路径。"""fname = os.path.join(cache_dir, url.split('/')[-1]) # fname = ../data/banana-detection.zipif os.path.exists(fname): # 文件存在,进入校验流程# 创建一个 SHA-1 哈希对象,用于计算文件的哈希值。sha1 = hashlib.sha1()# 以二进制模式读取文件with open(fname, 'rb') as f:while True:# 每次读取 1MB 数据(1048576 字节),更新哈希对象。data = f.read(1048576)# 为空,退出循环if not data:break# 将读取的数据块逐步添加到哈希计算中sha1.update(data)"""计算哈希值:调用 sha1.hexdigest() 获取最终的 SHA-1 哈希值(40 个字符的十六进制字符串)。校验哈希值:将计算得到的哈希值与预期的哈希值 sha1_hash 进行比较。如果两者相等,说明文件完整且未被篡改,直接返回文件路径(命中缓存)。否则,继续执行下载逻辑。"""if sha1.hexdigest() == sha1_hash:return fname # 命中缓存print(f'正在从{url}下载{fname}...')"""使用 requests.get 方法发送 HTTP 请求,从远程服务器下载文件。参数说明:stream=True:以流式方式下载文件,避免一次性加载整个文件到内存中。verify=True:启用 SSL 证书验证,确保安全连接。"""r = requests.get(url, stream=True, verify=True)"""打开本地文件 fname,以二进制写入模式('wb')创建或覆盖文件。将下载的内容 r.content 写入文件。下载完成后,关闭文件。"""with open(fname, 'wb') as f:f.write(r.content)return fnamedef download_extract(name, folder=None):"""下载并解压zip/tar文件"""fname = download(name) # 下载文件的完整路径"""os.path.dirname(fname):提取文件所在的目录路径(即父目录)。例如,如果 fname 是 '../data/example.zip',则 base_dir 是 '../data'。os.path.splitext(fname):将文件路径拆分为文件名和扩展名。例如,如果 fname 是 '../data/example.zip',则 data_dir 是 '../data/example',ext 是 '.zip'。"""base_dir = os.path.dirname(fname)data_dir, ext = os.path.splitext(fname)if ext == '.zip':fp = zipfile.ZipFile(fname, 'r')elif ext in ('.tar', '.gz'):fp = tarfile.open(fname, 'r')else:assert False, '只有zip/tar/gz 文件可以被解压缩'# 解压文件到指定的目录 base_dirfp.extractall(base_dir)"""如果 folder 参数存在:返回 os.path.join(base_dir, folder),即解压后目录下的指定子目录。如果 folder 参数不存在:返回 data_dir,即解压后的默认目录。"""return os.path.join(base_dir, folder) if folder else data_dirdef read_data_bananas(is_train=True):"""读取香蕉检测数据集中的图像和标签"""data_dir = download_extract('banana-detection')"""根据 is_train 参数,确定加载训练集还是验证集的标注文件:如果 is_train=True,加载 'bananas_train/label.csv'。如果 is_train=False,加载 'bananas_val/label.csv'。使用 pandas 库的 read_csv 方法读取 CSV 文件内容。将 img_name 列设置为索引列(方便后续按图像名称访问数据)。"""csv_fname = os.path.join(data_dir, 'bananas_train' if is_trainelse 'bananas_val', 'label.csv') # for example: ../data/banana-detection/banana_train/label.csvcsv_data = pd.read_csv(csv_fname) # 读取 csv 文件# 将 img_name 列设置为索引列csv_data = csv_data.set_index('img_name')"""images:用于存储读取的图像数据。targets:用于存储每张图像对应的标注信息。"""images, targets = [], []"""img_name:当前行的索引值(即图像名称)。target:当前行的数据(即标注信息)。"""for img_name, target in csv_data.iterrows():images.append(torchvision.io.read_image(os.path.join(data_dir, 'bananas_train' if is_train else'bananas_val', 'images', f'{img_name}')))# 这里的target包含(类别,左上角x,左上角y,右下角x,右下角y),# 其中所有图像都具有相同的香蕉类(索引为0)targets.append(list(target))"""images:图像数据列表。torch.tensor(targets).unsqueeze(1) / 256:将 targets 转换为 PyTorch 张量。使用 unsqueeze(1) 在维度 1 上增加一个维度,使其形状变为 (N, 1, 5),其中 N 是样本数量,5 是每个标注信息的长度。所有边界框坐标除以 256,进行归一化处理(假设图像大小为 256x256)。"""return images, torch.tensor(targets).unsqueeze(1) / 256class BananasDataset(torch.utils.data.Dataset):"""一个用于加载香蕉检测数据集的自定义数据集"""def __init__(self, is_train):self.features, self.labels = read_data_bananas(is_train)print('read ' + str(len(self.features)) + (f' training examples' ifis_train else f' validation examples'))# such as : read 1000 training examplesdef __getitem__(self, idx):return self.features[idx].float(), self.labels[idx]def __len__(self):return len(self.features)def load_data_bananas(batch_size):"""加载香蕉检测数据集"""train_iter = torch.utils.data.DataLoader(BananasDataset(is_train=True),batch_size, shuffle=True)val_iter = torch.utils.data.DataLoader(BananasDataset(is_train=False),batch_size)return train_iter, val_iterdef show_images(imgs, num_rows, num_cols, titles=None, scale=1.5):figsize = (num_cols * scale, num_rows * scale)"""_:表示整个图形对象(这里用下划线忽略)axes:表示所有子图的数组"""_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)axes = axes.flatten()for i, (ax, img) in enumerate(zip(axes, imgs)):if torch.is_tensor(img):ax.imshow(img.numpy())else:ax.imshow(img)ax.axes.get_xaxis().set_visible(False)ax.axes.get_yaxis().set_visible(False)if titles:ax.set_title(titles[i])return axesdef bbox_to_rect(bbox, color):"""将边界框(左上x,左上y,右下x,右下y)格式转换成matplotlib格式:((左上x,左上y),宽,高)"""return plt.Rectangle(xy=(bbox[0], bbox[1]), width=bbox[2] - bbox[0], height=bbox[3] - bbox[1],fill=False, edgecolor=color, linewidth=2)# 定义一个名为 numpy 的函数,它能够将 PyTorch 张量转换为 NumPy 数组,并且自动处理张量的梯度信息
numpy = lambda x, *args, **kwargs: x.detach().numpy(*args, **kwargs)def show_bboxes(axes, bboxes, labels=None, colors=None):"""显示所有边界框""""""功能:将输入对象转换为列表形式。如果 obj 是 None,返回默认值 default_values。如果 obj 不是列表或元组,则将其包装成单元素列表。否则,直接返回 obj。作用:确保 labels 和 colors 参数始终是列表形式,以便后续迭代操作。"""def _make_list(obj, default_values=None):if obj is None:obj = default_valueselif not isinstance(obj, (list, tuple)):obj = [obj]return obj"""将 labels 转换为列表形式。如果未提供标签,则返回空列表。将 colors 转换为列表形式。如果未提供颜色,则使用默认颜色列表 ['b', 'g', 'r', 'm', 'c'](蓝色、绿色、红色、洋红色、青色)。"""labels = _make_list(labels)colors = _make_list(colors, ['b', 'g', 'r', 'm', 'c'])"""遍历 bboxes 列表中的每个边界框 bbox。根据索引 i,从 colors 列表中循环选择颜色(防止颜色不足时重复使用)。调用 bbox_to_rect 函数,将边界框坐标转换为 Matplotlib 的矩形对象。假设 bbox_to_rect 是一个已定义的函数,用于将边界框坐标转换为 matplotlib.patches.Rectangle 对象。numpy(bbox):将边界框数据转换为 NumPy 数组(假设 bbox 是 PyTorch 张量)。使用 axes.add_patch(rect) 将矩形添加到绘图区域中。"""for i, bbox in enumerate(bboxes):color = colors[i % len(colors)]rect = bbox_to_rect(numpy(bbox), color)axes.add_patch(rect)"""检查是否提供了标签,并且当前索引 i 在标签范围内。根据边界框颜色选择标签文字的颜色:如果边界框颜色为白色('w'),标签文字颜色为黑色('k')。否则,标签文字颜色为白色('w')。使用 axes.text 方法,在边界框的左上角位置添加标签文本。rect.xy[0] 和 rect.xy[1]:矩形左上角的 x 和 y 坐标。va='center' 和 ha='center':设置文本垂直和水平居中对齐。fontsize=9:设置字体大小为 9。color=text_color:设置文本颜色。bbox=dict(facecolor=color, lw=0):为文本添加背景框,背景颜色与边界框一致,边框宽度为 0。"""if labels and len(labels) > i:text_color = 'k' if color == 'w' else 'w'axes.text(rect.xy[0], rect.xy[1], labels[i],va='center', ha='center', fontsize=9, color=text_color,bbox=dict(facecolor=color, lw=0))if __name__ == "__main__":batch_size, edge_size = 32, 256train_iter, _ = load_data_bananas(batch_size)"""使用 iter(train_iter) 创建一个迭代器对象。调用 next() 获取迭代器的第一个批次的数据。"""batch = next(iter(train_iter))"""torch.Size([32, 3, 256, 256]):表示 32 张 RGB 图像,每张图像大小为 256x256。torch.Size([32, num_boxes, 5]):表示每张图像有 num_boxes 个边界框,每个边界框包含 5 个值(类别 + 坐标)。 """print(batch[0].shape, batch[1].shape)"""功能:batch[0][0:10]:从 batch[0] 中提取前 10 张图像。.permute(0, 2, 3, 1):调整张量的维度顺序,将 (N, C, H, W) 转换为 (N, H, W, C),即从 PyTorch 的默认格式转换为适合显示的格式。/ 255:将像素值归一化到 [0, 1] 范围(假设原始像素值范围是 [0, 255])。结果:imgs 是一个形状为 (10, 256, 256, 3) 的张量,表示 10 张归一化的 RGB 图像。"""imgs = (batch[0][0:10].permute(0, 2, 3, 1)) / 255axes = show_images(imgs, 2, 5, scale=2)for ax, label in zip(axes, batch[1][0:10]):"""label[0][1:5]:提取第一个边界框的坐标信息([x_min, y_min, x_max, y_max])。* edge_size:将归一化的坐标值还原为原始像素坐标。show_bboxes(ax, ...):在子图 ax 上绘制边界框,颜色为白色 ('w')。"""show_bboxes(ax, [label[0][1:5] * edge_size], colors=['w'])plt.show()
"""
归一化是为了模型训练:确保输入数据在合理的范围内,加速收敛并提高稳定性。
还原是为了可视化:将数据转换回原始范围,以便人类可以直观地理解图像和标注信息。
"""
相关文章:

CV - 目标检测
物体检测 目标检测和图片分类的区别: 图像分类(Image Classification) 目的:图像分类的目的是识别出图像中主要物体的类别。它试图回答“图像是什么?”的问题。 输出:通常输出是一个标签或一组概率值&am…...

linux提权 corn 提权
corn提权 corn的基本使用方法 corn的作用就是可以定时的完成一下任务(如备份一下log 或者清除一下日志文件 这些就是运维人员用的) 先找一下定时任务的工作表 cat /bin/corntab 这个是普通用户 我们直接看都看不了 说明什么说明这个 是root高权限执…...

1Panel安装失败 国内docker安装失败
本文仅针对学习交流,只为了帮助计算机相关专业大学生个人技能实操而记录 非学习目的严禁学习!!!否则后果自负 1、离线安装1Panel(不需要手动安装docker,离线安装包里包括了docker) 离线包下载地…...

Excel + VBA 实现“准实时“数据的方法
Excel 本身是静态数据处理工具,但结合 VBA(Visual Basic for Applications) 可以实现 准实时数据更新,不过严格意义上的 实时数据(如毫秒级刷新)仍然受限。以下是详细分析: 1. Excel + VBA 实现“准实时”数据的方法 (1) 定时刷新(Timer 或 Application.OnTime) Appl…...

请问你怎么看待测试,指导哪些测试的类型,有用过哪些测试方法?
作为深耕测试领域多年的博主,我始终认为测试是软件质量的守护者,更是推动研发流程优化的催化剂。以下从测试认知、分类体系到实战方法论,结合具体案例为你系统拆解: 一、测试的本质认知 测试≠找 Bug,而是通过系统性验证回答三个核心问题: 软件是否符合用户需求?系统在…...
)
详解 Redis repl_backlog_buffer(如何判断增量同步)
一、repl_backlog_buffer 复制积压缓冲区(Replication Backlog Buffer) 是一个环形内存区域(Ring Buffer),用于临时保存主节点最近写入的写命令,以支持从节点断线重连后的增量同步。 1.1 三个复制偏移量 …...

工业操作系统国产化替代的战略路径与挑战分析
一、政策背景与战略意义 工信部提出的 2027 年替换 80 万套工业操作系统计划,是中国制造业向智能化转型的核心举措。该政策旨在通过国产化替代,解决工业领域 “缺芯少魂” 的问题,构建自主可控的工业软件生态体系。当前,中国工业操…...

JMeter接口性能测试从入门到精通
前言: 本文主要介绍了如何利用jmter进行接口的性能测试 1.在测试计划中添加线程组 1.1.线程组界面中元素含义 如果点击循环次数为永远: 2.添加HTTP取样器 2.1.填写登录接口的各个参数 2.2.在线程组下面增加查看结果树 请求成功的情况: 请求…...
——RichTextBox控件详解)
WinForm真入门(9)——RichTextBox控件详解
WinForm中RichTextBox控件详解:从基础到高级应用 上一文中笔者重点介绍了TextBox控件的详细用法,忘记的 请点击WinForm真入门(8)——TextBox控件详解,那么本文中的RichTextBox与TextBox有什么区别吗,光看名字的话,多了…...

Linux : 内核中的信号捕捉
目录 一 前言 二 信号捕捉的方法 1.sigaction()编辑 2. sigaction() 使用 三 可重入函数 四 volatile 关键字 一 前言 如果信号的处理动作是用户自定义函数,在信号递达时就调用这个函数,这称为捕捉信号。在Linux: 进程信号初识-CSDN博客 这一篇中已经学习到了一种信号…...

Linux 字符串截取#与%
在Linux的Shell脚本中,#和%用于字符串截取,通过通配符模式匹配删除部分内容 批量修改文件名技巧:Linux下#、##、%、%%符号操作详解-CSDN博客 从左截取(# 和 ##) #:删除最短匹配左侧内容。 ##:…...

Android学习总结之自定义View实战篇
场景一:自定义进度条 在很多应用中,我们会看到一些独特样式的进度条,接下来就实现一个简单的圆形进度条。 实现思路 继承 View 类。重写 onDraw 方法,在该方法里使用 Canvas 和 Paint 来绘制圆形进度条。提供更新进度的方法。 …...

C++ STL 详解 ——list 的深度解析与实践指南
在 C 的标准模板库(STL)中,list作为一种重要的序列式容器,以其独特的双向链表结构和丰富的操作功能,在许多编程场景下发挥着关键作用。深入理解list的特性与使用方法,能帮助开发者编写出更高效、灵活的代码…...

open函数的概念和使用案例
open 是 Linux/Unix 系统中用于打开或创建文件的系统调用,返回一个文件描述符(File Descriptor),后续可通过该描述符进行文件读写等操作。以下是其核心概念和使用案例的详细说明: 1. 核心概念 作用:打开或…...

整理一些大模型部署相关的知识
不一定有什么用, 不经常用还会忘掉. 之前被人问到一次,脑子卡壳回答不出要点, 非常尴尬! 在此记录一下使用心得, 偶尔回来翻看! 一 并行方式 1.1 数据并行 (Data Parallelism) 主要用于模型训练阶段, 即将多个完整的模型副本分布到多个gpu上, 每个gpu运行一部分数据数据, 每个…...
 [第191~200题](持续更新))
算法刷题记录——LeetCode篇(2.10) [第191~200题](持续更新)
更新时间:2025-04-04 算法题解目录汇总:算法刷题记录——题解目录汇总技术博客总目录:计算机技术系列博客——目录页 优先整理热门100及面试150,不定期持续更新,欢迎关注! 198. 打家劫舍 你是一个专业的…...

蓝桥杯备赛 Day 19 加练dfs
是否需要回溯? 输入参数有哪几个(当前dfs和下一个dfs什么会变?)? 是否需要返回值? 一.1158: 八皇后 P1158 - 八皇后 - New Online Judge (ecustacm.cn) 学习: 1.dfs输入为层数,即行号i,因为是每行只放一个,下一个dfs就是i1 2…...

蓝桥杯-卡java排序
问题描述 本题是一道针对 Java 中 Arrays.sort 的题目,因此只有一个数据,该数据可以把 int 类型的数组在使用 Arrays.sort 后卡成 O(n2)O(n2)。 给定一个有 nn 个正整数的序列 aa,你需要将其升序排序后输出。 输入格式 第一行输入一个正整…...

内存管理模块
在 Linux 内核中,内存管理是一个复杂而关键的组成部分。内核空间的虚拟地址被划分为多个区域,每个区域有其特定的用途和映射机制。本文将详细介绍 直接映射区(Direct Mapping Area)、vmalloc 区、永久内核映射区(Perma…...

Spring RestTemplate修仙指南:从HTTP萌新到请求大能的终极奥义
各位在Spring生态摸爬滚打的道友们!今天要解锁的是Spring官方御用HTTP法宝——RestTemplate!这货堪称Java界的"御剑飞行术",虽然官方已推荐WebClient接棒,但江湖上仍有80%项目在用这员老将!准备好一键起飞了…...

cpp经典数论问题
题目如下 思路 代码如下...

Redis 线程模型:单线程也能快如闪电?
目录 一、核心思想:快刀斩乱麻的“单线程”高手 🦸♂️二、为什么是“单线程”?🤔三、单线程如何做到高性能?✨ “I/O 多路复用”是关键!四、真的一直都只有“一个线程”吗?并不完全是&#x…...

游戏引擎学习第208天
运行游戏并回顾我们的情况 今天,我们将继续完成之前中断的调试输出工作。最近的工作偏离了一些,展示了如何进行元编程的实践,主要涉及了一个小的解析器。尽管这个解析器本身是一个玩具,但它展示了如何完成一个完整的循环…...
(箭头函数不绑定自己的this,而是继承上下文的this;不能用于造函数)JavaScript =>)
JavaScript箭头函数介绍(=>)(箭头函数不绑定自己的this,而是继承上下文的this;不能用于造函数)JavaScript =>
文章目录 JavaScript箭头函数全解析箭头函数的基本语法简洁语法特性隐式返回值对象字面量返回 词法绑定的this不适用箭头函数的场景对象方法构造函数DOM事件处理 高级用法在数组方法中的应用链式调用柯里化函数 性能考量1. 作为回调函数时减少创建闭包的开销2. 简化代码结构&am…...

数据对象:DTO、DO、PO和 BO的区别和关系
在Java开发中,DTO(Data Transfer Object)、DO(Domain Object)、PO(Persistent Object)和BO(Business Object)是常用的数据对象概念,下面为你详细介绍并给出简…...

Java内存模型详解:堆、栈、方法区
1. 堆(Heap) 作用:存放所有对象实例及数组,是垃圾回收的主要区域。 结构: 新生代(Young Generation): Eden区:新创建的对象首先分配在此。 Survivor区(From…...

ubuntu 20.04 编译运行LeGo_LOAM 跑数据集 并且保存pcl文件
1.搭建文件目录,clone代码,编译 mkdir -p Lego_LOAM/src cd Lego_LOAM/src git clone https://github.com/RobustFieldAutonomyLab/LeGO-LOAM.git cd .. catkin_make -j1 错误1:: fatal error: opencv/cv.h: 没有那个文件或目录 13 | #include <opencv/cv.h…...

CMake使用教程
CMake是开源、跨平台的构建工具,可以让我们通过编写简单的配置文件去生成本地的Makefile,这个配置文件是独立于运行平台和编译器的,这样就不用亲自去编写Makefile了,而且配置文件可以直接拿到其它平台上使用,无需修改,非常方便。 使用命令行执行CMakeLists.txt,对文件进…...

快速上手Linux进程管理
一.理解进程和线程 1.1 什么是进程 它表示一个正在执行的程序实例。在操作系统中,进程是系统进行资源分配和调度的基本单位。每个进程都有自己独立的内存空间、代码、数据和系统资源,如打开的文件、使用的硬件设备等。 进程的主要特点包括:…...

pytorch框架实现cnn四种天气图片多分类问题-添加dropout和bn层
目录 1.导包 2.加载数据、拼接训练、测试文件夹 3. 查看当前目录下的所有文件名,以列表的形式输出 4.原数据集dataset中存在的数据的目标类别 5.创建train和test目录 及其需要分类的子文件夹 6.使用torchvision 的transforms进行数据预处理 6.1数据统一缩放resize、To…...

swift-11-init、deinit、可选链、协议、元类型
一、required 二、属性观察器 三、可失败初始化器 可以用init!定义隐式解包的可失败初始化器 可失败初始化器可以调用非可失败初始化器,非可失败初始化器调用可失败初始化器需要进行解包 如果初始化器调用一个可失败初始化器导致初始化失败 ,那么整个初…...
搜索插入位置)
【力扣hot100题】(062)搜索插入位置
感觉自己对二分法还是没有很好掌握,主要在于边界问题,只会基本的搜索,如果要搜索比目标值大的第一个索引或者比目标值小的最后一个索引(或者换一些花里胡哨的题目)就完全不会了。 class Solution { public:int search…...

TCPIP详解 卷1协议 三 链路层
3.1——以太网和IEEE802局域网/城域网标准 以太网这个术语通常指一套标准,由DEC,Intel公司和Xerox公司在1980年首次发布,并在1982年加以修订。第一个常见格式的以太网,目前被称为10Mb/s以太网或共享以太网。它被IEEE采纳为802.3标…...

以太网安全
前言: 端口隔离可实现同一VLAN内端口之间的隔离。用户只需要将端口加入到隔离组中,就可以实现隔离组内端口之间的二层数据的隔离端口安全是一种在交换机接入层实施的安全机制,旨在通过控制端口的MAC地址学习行为,确保仅授权设备能…...

linux如何查看当前系统的资源占用情况
在 Linux 系统中,有多个命令可以查看当前系统的资源占用情况。以下是一些常用的命令及其说明: 1. 查看内存使用情况:free free -h-h 参数表示以人类可读的格式显示(如 MB, GB)。输出示例: to…...
)
人脸识别系统(人脸识别、前后端交互、Python项目)
基于Flask、Face_Recognition的人脸识别系统 项目介绍 基于flask、face_recognition的人脸识别系统。 本项目采用Face_Recognition库内置的ResNet-34预训练模型,其已对LFW公开数据集进行预训练而得到的模型。利用ResNet-34预训练模型,可使用少量已知人…...
)
2025 ArkTS语言开发入门之前言(二)
2025 ArkTS语言开发入门之前言(二) 前言 在上一节,咱们学习了如何下载并安装ArkTS的集成开发环境,这时候有的臭宝会发现,左边的这些叽里咕噜的是什么?下面,我来带着臭宝们来学习一下这些是什么…...
)
VLAN(虚拟局域网)
一、vlan概述 VLAN(virtual local area network)是一种通过逻辑方式划分网络的技术,允许将一个物理网络划分为多个独立的虚拟网络。每一个vlan是一个广播域,不同vlan之间的通信需要通过路由器或三层交换机 [!注意] vlan是交换机独有的技术,P…...

2025.4.6总结
今日记录:今天玩的有些累,先是去护肤店护理了脸部,然后去汉口江滩那看了看美景,吹吹江风。节假日去玩,光是挤一个半小时地铁都感觉累。还好上下班期间不用挤地铁,不然还真受不了。 假期小结 1.消费&#…...

【清明折柳】写在扬马三周目后
黄绿之间,方寸之外。 文章目录 楔子解耦到离散螃蟹与毒药文本的力量朝花夕拾后记 楔子 “——就像物理学家通过演绎与归纳将宏微世界的运转规律浓缩到数学公式中时,如今的人工智能也在试图量化整个人类文明。” “——只是,使用的是昂贵、笨…...
)
P1258 小车问题(二分)
题目描述 甲、乙两人同时从 A 地出发要尽快同时赶到 B 地。出发时 A 地有一辆小车,可是这辆小车除了驾驶员外只能带一人。已知甲、乙两人的步行速度一样,且小于车的速度。问:怎样利用小车才能使两人尽快同时到达。 输入格式 仅一行&#x…...

一个基于ragflow的工业文档智能解析和问答系统
工业复杂文档解析系统 一个基于ragflow的工业文档智能解析和问答系统,支持多种文档格式的解析、知识库管理和智能问答功能。 系统功能 1. 文档管理 支持多种格式文档上传(PDF、Word、Excel、PPT、图片等)文档自动解析和分块处理实时处理进度显示文档解析结果预览批量文档…...

负指数二项式展开
转载:负指数二项式展开_二项式负数次幂的展开式-CSDN博客...

CentOS 7服务器上快速安装mamba函数库
本次预配置虚拟环境为cuda 11.8torch 2.2.2python 3.10 1. 创建conda虚拟环境:conda create -n mamba python3.10 激活环境:conda activate mamba 2. 安装Pytorch环境: conda install pytorch2.2.2 torchvision0.17.2 torchaudio2.2.2 py…...
:添加 CPCA通道先验卷积注意力机制)
ResNet改进(18):添加 CPCA通道先验卷积注意力机制
1. CPCA 模块 CPCA(Channel Prior Convolutional Attention)是一种结合通道先验信息的卷积注意力机制,旨在通过显式建模通道间关系来增强特征表示能力。 核心思想 CPCA的核心思想是将通道注意力机制与卷积操作相结合,同时引入通道先验知识,通过以下方式优化特征学习: 通…...

代码随想录算法训练营--打卡day6
一.四数相加 1.题目链接 454. 四数相加 II - 力扣(LeetCode) 2.思路 使用 HashSet 无法记录每种和出现的次数,当不同的 (nums1[i], nums2[j]) 组合得到相同的和时,会出现统计错误。这里应该使用 HashMap 来记录和以及其出现的…...

edge webview2 runtime跟Edge浏览器软件安装包双击无反应解决方法
软件安装报错问题有需要远程文章末尾获取联系方式,可以帮你远程处理各类安装报错。 一 、edge webview2 runtime跟Edge浏览器软件安装包双击无反应 在安装edge webview2 runtime跟Edge浏览器双击无反应没有出现安装界面。这个可能是 新版本的Edge WebView2 Runti…...

Xorg 内存上涨的根源探究
Xorg 内存上涨的根源探究 起因 在同一客户端进程内显示多股视频源,通过SDL创建窗口渲染,由于网络抖动视频源出现频繁断流现象导致,渲染任务反复重启,从而导致SDL渲染窗口反复创建释放,最后导致Xorg内存持续上涨 排查准备 Xorg是什么? Xorg(X.Org Server)是 X Wind…...

Neo4j基本命令使用
neo4j neo4j简介安装可视化管理后台登录 Cyphercreatematchmergecreate创建关系merge创建关系wheredelete sort命令字符串函数toUpper()函数toLower()函数substring()函数replace()函数 聚合函数count()函数max()函数min()函数sum()函数avg()函数索引index python 中使用neo4j …...

Python爬虫教程009:requests的基本使用以及get和post请求的使用
文章目录 5.1 基本使用5.2 get请求5.3 post请求5.1 基本使用 在 Python 爬虫开发中,requests 是一个非常流行、简单易用的 HTTP 库,用于发送网络请求。它可以让你方便地抓取网页内容、提交表单、上传文件等。 🔧安装: pip install requestsresponse的属性及类型: resp…...