MySQL中的索引
explain关键字,
MySQL索引特性
索引的概念
MySQL 索引是一种用于提高数据库查询效率的数据结构
- 数据库表中存储的数据都是以记录为单位的,如果在查询数据时直接一条条遍历表中的数据记录,那么查询的时间复杂度将会是 O ( N )。
- 索引的价值在于提高海量数据的检索速度,只要执行了正确的创建索引的操作,查询速度就可能提高成百上千倍。当一张表创建索引后,在数据库底层就会为表中的数据记录构建特定的数据结构,后续在查询表中数据时就能通过查询该数据结构快速定位到目标数据。
- 索引虽然提高了数据的查询速度,但在一定程度上也会降低数据增删改的效率,因为这时在对表中的数据进行增删改操作时,除了需要进行对应的增删改操作之外,可能还需要对底层建立的数据结构进行调整维护。
常见的索引分为:
- 主键索引(primary key)。
- 唯一索引(unique)。
- 普通索引(index)。
- 全文索引(fulltext)。ouce
source xxx.sql
定位扇区时采用CHS寻址方式:
- 磁头(Heads): 每个盘面都有一个对应的磁头,因此确定了磁头也就确定了数据在哪一个盘面。
- 柱面(Cylinder): 所有盘面中半径相同的同心磁道构成柱面,因此在确定了数据在哪一个盘面的基础上,再确定柱面也就确定了数据在该盘面上的哪一个磁道。
- 扇区(Sector): 每个磁道被划分成若干个扇区,因此在确定了数据在哪一个磁道的基础上,再确定扇区也就确定了数据在该磁道上的哪个扇区。
简单来说,CHS寻址方式就是先通过H确定数据所在的盘面,再通过C确定数据所在的磁道,最后通过S定位到目标扇区。
- CHS寻址方式是磁盘定位扇区的方式,但实际CHS寻址方式对磁盘以外的设备来说没什么作用,因此系统软件在定位磁盘上的数据时采用的是LBA(Logical Block Address,逻辑区块地址)。
- LBA是描述计算机存储设备上数据所在区块的通用机制,LBA和CHS之间可以通过计算公式进行相互转换,LBA存在的意义就是对底层逻辑器件进行虚拟化,让系统软件可以不用关心底层硬件具体的寻址方式,而实际底层硬件采用的还是CHS寻址方式。
操作系统与磁盘交互的基本单位
操作系统与磁盘进行IO交互的基本单位是4KB,而不是扇区的大小512字节,原因如下:
- 物理内存实际是被划分成一个个4KB大小的页框的,磁盘上的数据也会被划分成一个个4KB大小的页帧,因此操作系统与磁盘以4KB为单位进行IO交互,就能提高数据加载和保存的效率。
- 操作系统与磁盘进行IO交互时,如果直接以扇区的大小作为IO的基本单位,那么这时系统的IO代码和硬件就是强相关的,将来当硬件的扇区大小发生变化时就需要对应修改操作系统的IO代码。
- 此外,以扇区的大小作为IO的基本单位太小了,这就意味着读取同样的数据内容,需要进行更多次的磁盘访问,而磁盘的效率是比较低的,这样IO效率就降低了。
因此操作系统与磁盘以4KB作为IO交互的基本单位,一方面是为了提高IO效率,另一方面是为了实现硬件和系统的解耦。
随机访问与连续访问
- 随机访问: 本次IO所给出的扇区地址与上次IO给出的扇区地址不连续,磁头在两次IO操作之间需要做比较大的移动动作才能找到目标扇区进行IO。
- 连续访问: 本次IO所给出的扇区地址与上次IO给出的扇区地址是连续的,磁头很快就能找到目标扇区进行IO。
MySQL与磁盘交互的基本单位
MySQL作为一款应用软件,可以想象成是一种特殊的文件系统,它有着更高频的IO场景,因此为了提高基本的IO效率,MySQL与磁盘交互的基本单位是16KB,这个基本数据单元在MySQL这里也叫做Page。
通过show命令查看系统中的全局变量,可以看到InnoDB存储引擎交互的基本单位是16KB。如下
- 在MySQL中进行的各种CRUD操作时,都需要先通过计算找到对应的操作位置,只要涉及计算就需要CPU参与,而冯诺依曼体系结构决定了CPU只能和内存打交道,因此为了便于CPU参与,就需要先将数据加载到内存当中。
- 所以在特定的时间内,MySQL中的数据一定是同时存在于磁盘和内存中的,当操作完内存数据后,再以特定的刷新策略将内存中的数据刷新到磁盘当中,这时MySQL和磁盘进行数据交互的基本单位就是Page。
- 为了更好的支持上述操作,MySQL服务器在启动的时候会预先申请一块内存空间来进行各种缓存,这块内存空间叫做Buffer Pool,后续磁盘中加载的数据就会保存在Buffer Pool中,刷新数据时也就是将Buffer Pool中的数据刷新到磁盘。
- 由于内核中是有内核缓冲区的,因此MySQL从磁盘读取数据时,需要先将数据从磁盘读取到内核缓冲区,再将数据从内核缓冲区读取到Buffer Pool,MySQL将数据刷新到磁盘时,同样需要先将数据从Buffer Pool刷新到内核缓冲区,再将数据从内核缓冲区刷新到磁盘。

因此所谓的操作系统和磁盘交互的基本单位是4KB,就是指内核缓冲区与磁盘之间是以4KB为单位进行交互的。而MySQL的Buffer Pool和磁盘实际并不是直接交互的,因此所谓的MySQL与磁盘交互的基本单位是16KB,指的是MySQL的Buffer Pool与内核缓冲区之间是以16KB为单位进行交互的。只不过在说的时候更关注的是MySQL和磁盘之间的关系,所以直接说的是MySQL与磁盘交互的基本单位是16KB,相当于忽略了中间的内核缓冲区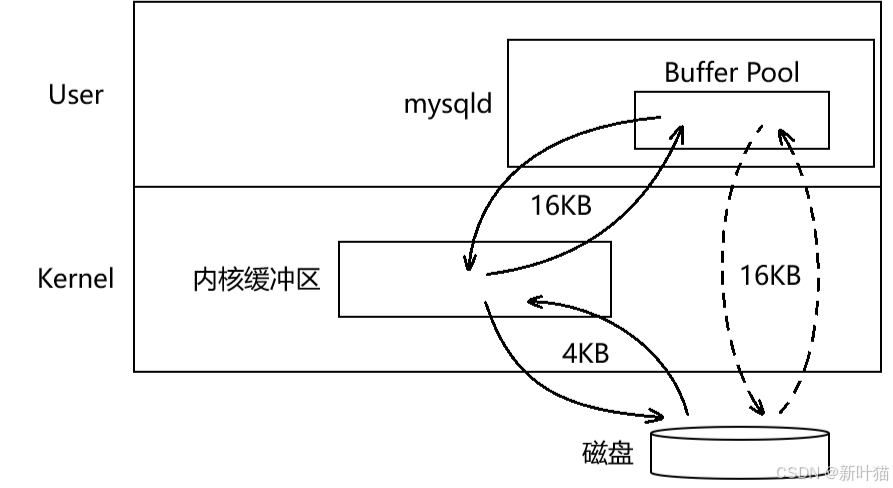
为什么MySQL与磁盘交互的基本单位是Page
MySQL与磁盘进行交互时为什么不是按需交互,而是以Page为基本单位进行交互的?
- 当我们查询表中的某一条记录时,如果MySQL只从磁盘中将这一条记录加载到内存当中,那么当我们继续查询表中的其他记录时,MySQL就一定需要再次与磁盘进行IO交互。
- 而如果当我们查询表中的某一条记录时,MySQL直接将这条记录所在的整个Page都加载到内存当中,那么当我们继续查询表中的其他记录时,MySQL很可能就不再需要与磁盘进行IO交互了,因为这条记录很可能也在被加载进来的Page当中,这时直接在内存中进行查询即可,大大减少了IO的次数。
- 当然,我们不能保证用户下一次要访问的数据一定就在本次加载进来的Page当中,但是根据统计学原理,当一个数据正在被访问时,那么下一次有很大可能会访问其周围的数据(局部性原理),因此我们有较大概率保证用户下一次要访问的数据和本次访问的数据在同一个Page当中,如果局部性原理没有起作用,那就再把对应的Page加载到内存当中即可。
也就是说,MySQL与磁盘进行交互时以Page为基本单位,可以减少与磁盘IO交互的次数,进而提高IO的效率。
推导主键索引结构的构建:
单个Page:
- MySQL中要管理很多数据文件,在运行期间一定有大量的Page需要被换入换出,因此MySQL一定需要将内存中大量的Page管理起来。
- MySQL将内存中的每一个Page都用一个结构体描述起来,然后再将各个结构体以双链表的形式组织起来,因此一个Page结构体内部既包含数据字段,也包含属性字段。
- 此外,为了方便后续数据的插入和删除,每个Page结构体内部存储的数据记录会以单链表的形式组织起来,并且各个记录之间会按照主键进行排序。

说明一下:
- 每个Page结构体内部的数据会按照主键进行排序,目的是为了优化数据查询的效率,因为单链表在查找的时候是顺序查找的,有序就意味着在查找的过程中有机会提前结束查询过程。
- 这也就是前面所说的,只要设置了主键,即便向表中插入的数据是乱序的,MySQL底层也会自动按照主键对插入的数据进行排序,因此查询得到的数据是按照主键进行有序排序的。
多个Page
- 随着数据量不断增大,单个Page中无法存下所有数据,这时就需要用多个Page来存储数据。
- 这时在查询数据时就需要,先遍历Page双链表确定目标数据在哪一个Page,然后再在该Page内部找到目标数据
Page之上创建页目录
- 虽然在单个Page内部能够通过页内目录来快速定位数据,但在遍历Page双链表寻找目标Page时本质进行的还是线性遍历。
- 这时可以给各个Page结构体也建立页目录,页目录中的每个目录项都指向一个Page,而这个目录项存放的就是其指向的Page中存放的最小数据的键值。
- 在给各个Page结构体建立页目录后,在查询数据时就可以先通过遍历页目录找到目标数据所在的Page,然后再在该Page内部找到目标数据。
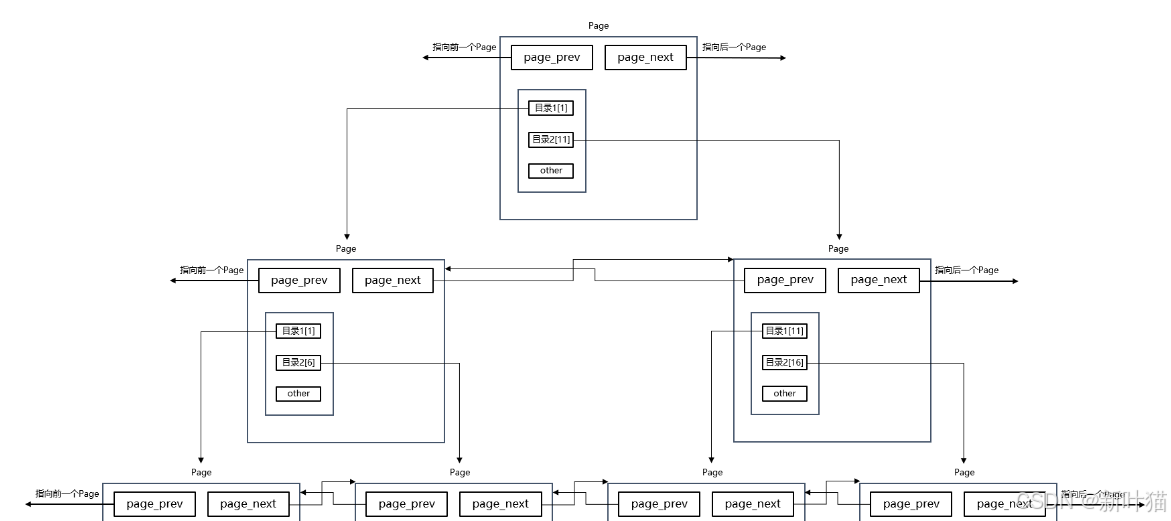
- 最终构建出来的实际就是一棵B+树,这棵B+树就是InnoDB的索引结构,其中每一层Page的作用就是加速它的下一层的查找效率。
- 如果我们创建表时设置了主键,那么MySQL在底层就会自动将这张表中的的数据以B+树的形式组织起来,保存在Buffer Pool当中,当我们查询数据时就可以通过查询这棵B+树来提高查询效率。
- MySQL中可能同时有大量的表正在被处理,因此Buffer Pool中可能会存在多个索引结构,也就是同时存在多个B+树结构,当我们查询表时访问的就是这张表对应的B+树结构
B+树中的Page结点是否需要全量加入到Buffer Pool中?
- 当对MySQL中的某张表进行增删查改操作时,不需要将其对应B+树的所有结点全量加入到Buffer Pool中,甚至在刚开始时只需要将B+树的根结点加入到Buffer Pool中。
- 当后续访问表中的数据时,再将该数据对应路径上的结点加入到Buffer Pool中即可,对于其他不需要的结点根本不用加入到Buffer Pool中,这一点和操作系统中的页表是很像的。
- 此外,在刷新数据时也不需要将B+树中所有的结点都进行刷新,在Page结构体中有一个标记位用来标记当前Page是否被修改过,如果被修改过则说明这是一个脏数据,在刷新数据时只有脏数据才需要被刷新到磁盘上。
- 由于B+树中的结点都是16KB大小的Page,因此无论是刷新数据到磁盘函数从磁盘加载数据到Buffer Pool,都是以Page为单位进行的,这也就是所谓的MySQL与磁盘交互的基本单位是Page。
如果把这棵B+树逆时针旋转90度,就会发现这其实就是操作系统中的页表结构,本质操作系统中的页表也是B+树结构。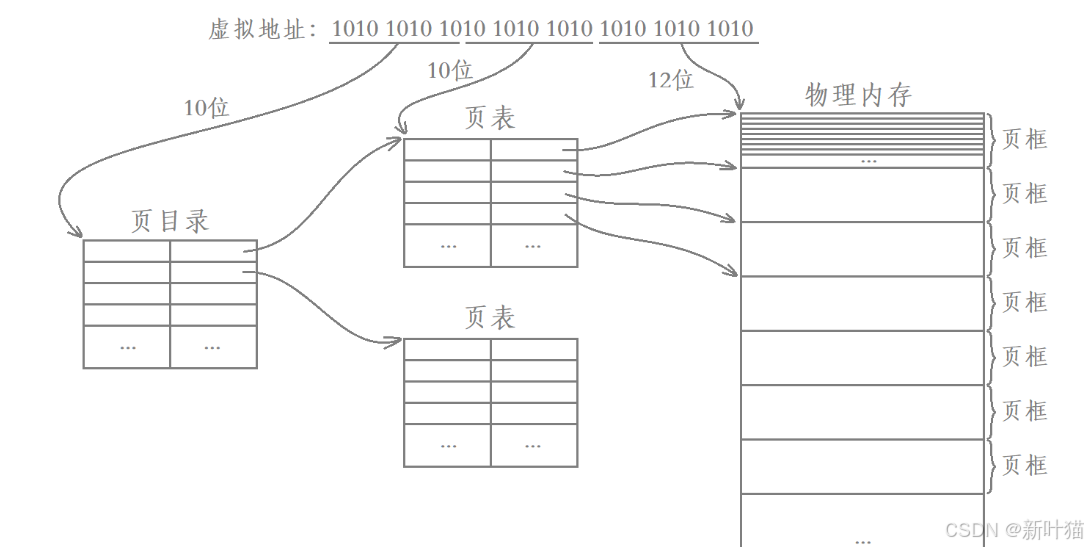
以32位平台为例,页表将一个虚拟地址转换成物理地址的过程如下:
- 选择虚拟地址的前10个比特位在页目录当中进行查找,找到对应的页表。
- 再继续选择虚拟地址后续的10个比特位在对应的页表当中进行查找,找到物理内存中对应页框的起始地址。
- 最后选择虚拟地址中剩下的12个比特位作为偏移量,从对应页框的起始地址处向后进行偏移,最终得到的就是转换后的物理地址
说明一下:
12个比特位有 2^12种取值,字节对应就是4KB,所以物理内存中一个页框的大小就是4KB,这也就是为什么操作系统与磁盘交互的基本单位是4KB的原因。
此外,页表中的各个B+树结点也不需要全量加入到内存中,而只需要加入访问到的结点即可,所以页表占用的内存大小实际是可控的,这也就是为什么二级页表可行的原因。
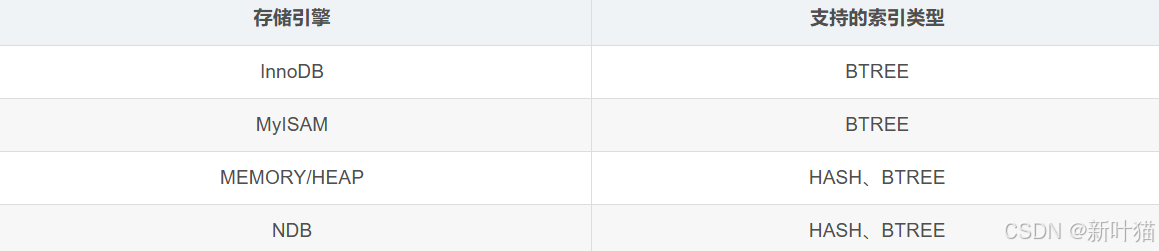
索引结构可以采用哪些数据结构
索引结构可以采用哪些数据结构
除了InnoDB存储引擎所采用的B+树结构,索引结构还可以采用哪些数据结构呢?

 B树 VS B+树
B树 VS B+树
B+树是B树的一种变形结构,那为什么我们没有采用普通的B树作为索引结构呢?
- 首先,普通B树中的所有结点中都同时包括索引信息和数据信息,由于一个Page的大小是固定的,因此非叶子结点中如果包含了数据信息,那么这些结点中能够存储的索引信息一定会变少,这时这棵树形结构一定会变得更高更瘦,当查询数据时就可能需要与磁盘进行更多次的IO操作。
- 其次,普通B树中的各个叶子结点之间没有连接起来,这将不利于进行数据的范围查找,而B+树的各个叶子结点之间是连接起来的,当我们进行范围查找时,直接先找到第一个数据然后继续向后遍历找到之后的数据即可,因此将各个叶子结点连接起来更有利于进行数据的范围查找。
聚簇索引 VS 非聚簇索引
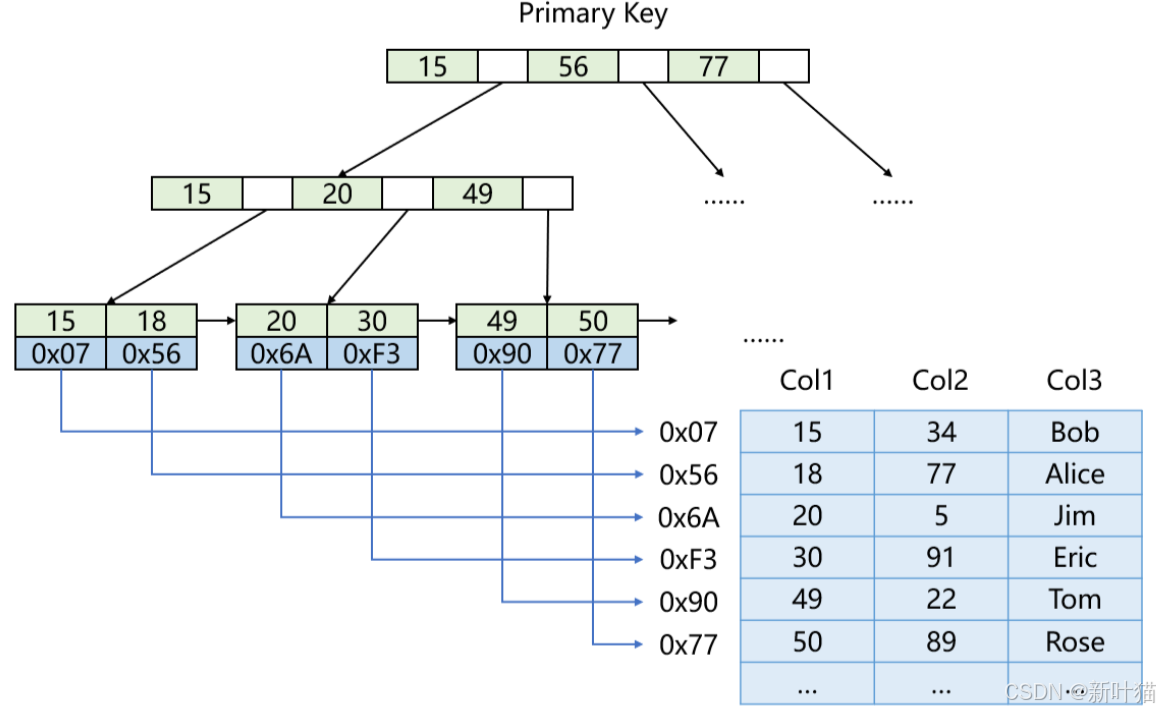
MyISAM存储引擎 - 主键索引结构
之前推导的主键索引结构是InnoDB存储引擎的主键索引结构,而MyISAM存储引擎同样采用B+树作为索引的基本数据结构。
与InnoDB存储引擎的B+树不同的是,MyISAM存储引擎的B+树的叶子结点存放的不是数据记录,而是数据记录对应的地址。
- 聚簇索引: 像InnoDB存储引擎这种,将数据记录与索引结构放在一起的索引方案,叫做聚簇索引。
- 非聚簇索引: 像MyISAM存储引擎这种,将数据记录与索引结构分离的索引方案,叫做非聚簇索引。
MyISAM存储引擎的主键索引结构
MyISAM存储引擎 - 普通索引结构
MyISAM存储引擎的普通索引采用的也是B+树结构,与主键索引唯一不同的地方就是普通索引的B+树中的键值可以重复。
因此一张表可能会同时存在多个B+树结构,但由于MyISAM存储引擎的B+树叶子结点中,存储的是对应的数据记录的地址,因此有效数据只会存储一份。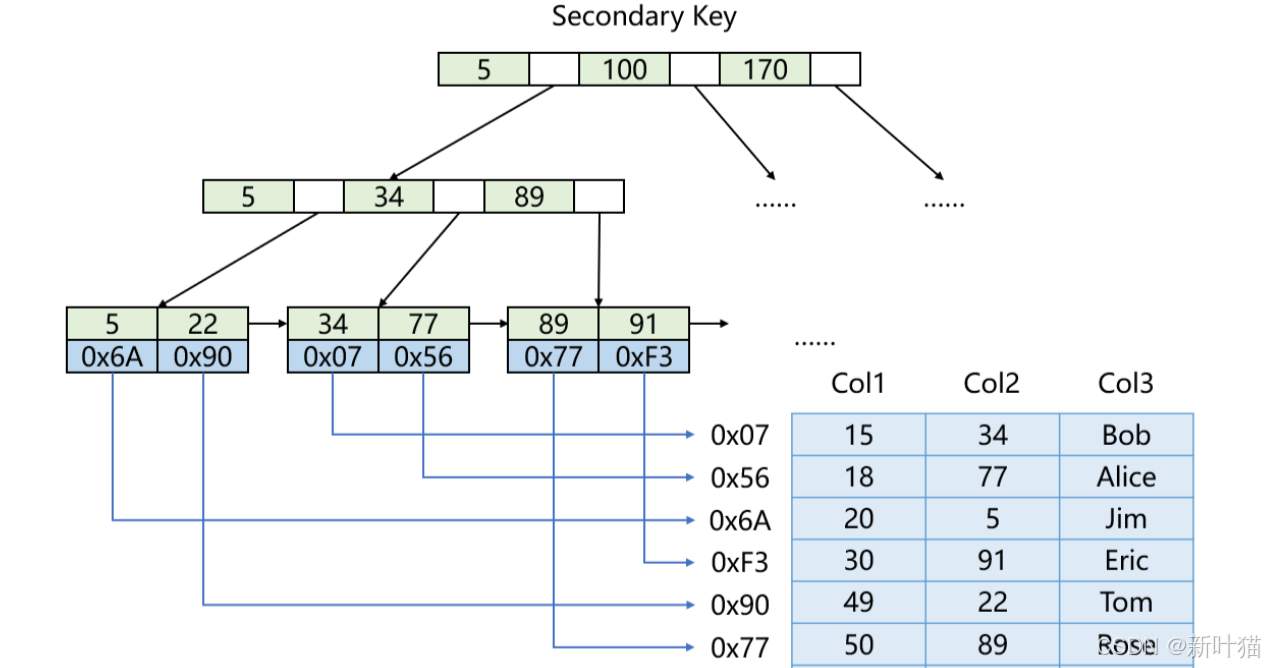
InnoDB存储引擎 - 普通索引结构
InnoDB存储引擎的普通索引采用的也是B+树结构,但普通索引的B+树中的键值可以重复,并且B+树的叶子结点中存储的不是数据记录,而是对应数据记录的主键值。
当根据普通索引查询数据时,会先查找普通索引对应的B+树找到目标记录的主键值,然后再查找主键索引对应的B+树找到目标记录,这个过程就叫做回表查询
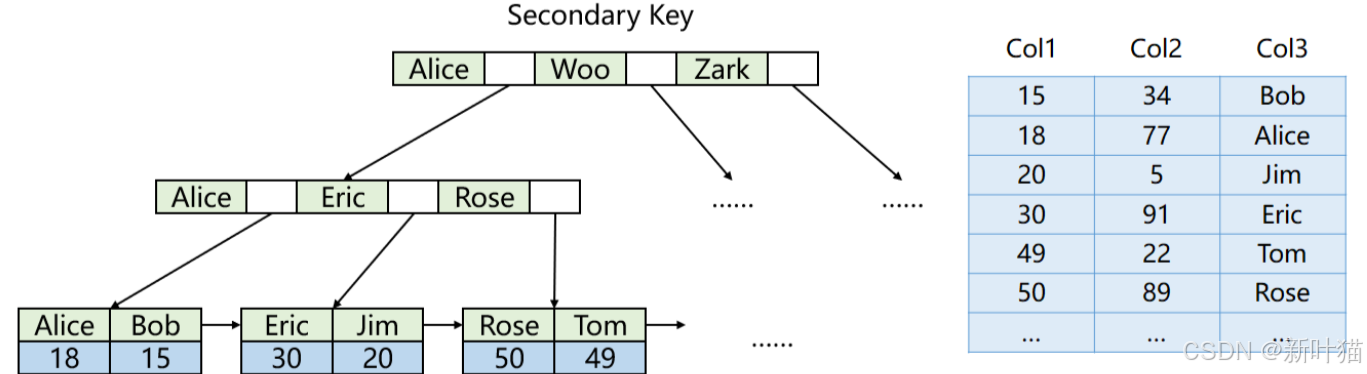
说明一下:
- InnoDB存储引擎的普通索引的B+树叶子结点中没有保存整条数据记录,是为了节省空间,因为同一张表可能会创建多个普通索引,每个普通索引的B+树中都保存一份数据会造成数据冗余,所以通过回表查询主键索引对应的B+来获取整个数据记录,该做法本质一种以时间换取空间的做法。
- 当根据普通索引查询数据时,其实也不一定需要进行回表查询,因为有可能我们要查询的就是这条记录对应的主键值,因此查询完普通索引对应B+树后即可完成查询。
- 采用InnoDB存储引擎建立的每张表都会有一个主键,就算用户没有设置,InnoDB也会自动帮你创建一个不可见的主键,因为完整数据记录只会存储在主键索引对应的B+树中的,因此采用InnoDB存储引擎建立的表必须有主键
当采用InnoDB存储引擎创建表时,在数据库对应的目录下会新增两个文件。如下:
当采用MyISAM存储引擎创建表时,在数据库对应的目录下会新增三个文件。如下:
说明一下:
- 采用InnoDB和MyISAM存储引擎创建表时都会生成xxx.frm文件,该文件中存储的是表结构相关的信息。
- 采用InnoDB存储引擎创建表时会生成一个xxx.ibd文件,该文件中存储的是索引和数据相关的信息,这就是所谓的聚簇索引,索引和数据是存储在同一个文件中的。
- 采用MyISAM存储引擎创建表时会生成一个xxx.MYD文件和一个xxx.MYI文件,其中xxx.MYD文件中存储的是数据相关的信息,而xxx.MYI文件中存储的是索引相关的信息,这就是所谓的非聚簇索引,索引和数据是分开存储的。
MySQL创建主键索引的所有方法
1. 在创建表时定义主键
在创建表时,可以直接在列定义后面使用 PRIMARY KEY 关键字来指定某列为主键,也可以在表定义的最后使用 PRIMARY KEY 关键字来指定多列组合为主键。
单字段主键
CREATE TABLE students (student_id INT NOT NULL,name VARCHAR(50),age INT,PRIMARY KEY (student_id)
);
多字段组合主键
CREATE TABLE enrollments (student_id INT NOT NULL,course_id INT NOT NULL,enrollment_date DATE,PRIMARY KEY (student_id, course_id)
);
2. 使用 ALTER TABLE 语句添加主键
如果表已经存在,并且没有主键,可以使用 ALTER TABLE 语句来添加主键。
为单字段添加主键
-- 创建一个没有主键的表
CREATE TABLE employees (employee_id INT NOT NULL,first_name VARCHAR(50),last_name VARCHAR(50)
);-- 使用 ALTER TABLE 语句添加主键
ALTER TABLE employees
ADD PRIMARY KEY (employee_id);
为多字段添加组合主键
-- 创建一个没有主键的表
CREATE TABLE order_items (order_id INT NOT NULL,product_id INT NOT NULL,quantity INT
);-- 使用 ALTER TABLE 语句添加组合主键
ALTER TABLE order_items
ADD PRIMARY KEY (order_id, product_id);
3. 在创建表时使用 AUTO_INCREMENT 属性创建主键
当主键字段的值需要自动递增时,可以使用 AUTO_INCREMENT 属性。通常,该属性与 INT 类型的列一起使用。
CREATE TABLE products (product_id INT AUTO_INCREMENT PRIMARY KEY,product_name VARCHAR(100),price DECIMAL(10, 2)
);
唯一索引
unique_key,操作与上类似
唯一索引
index,操作与上类似
全文索引
fulltext给title和body,操作与上类似
如果要通过全文索引来查询,需要使用match against进行搜索
在这条SQL语句前面加上explain,可以看到key对应的值为title,表示这条SQL在执行过程中用到了索引名为title的索引
使用全文索引进行搜索
MySQL 提供了 MATCH...AGAINST 函数来使用全文索引进行搜索。
SELECT * FROM articles
WHERE MATCH (title, content) AGAINST '搜索的内容';
自然语言搜索模式
自然语言搜索模式是最常用的模式,它会将搜索字符串作为自然语言进行处理。
SELECT * FROM articles
WHERE MATCH (title, content) AGAINST ('MySQL 全文索引' IN NATURAL LANGUAGE MODE);
上述代码会在 articles 表的 title 和 content 列中搜索包含 “MySQL 全文索引” 的记录。
布尔搜索模式
布尔搜索模式允许使用特殊的运算符来构建更复杂的搜索条件。
SELECT * FROM articles
WHERE MATCH (title, content) AGAINST ('+MySQL -数据库' IN BOOLEAN MODE);
这里的 + 表示必须包含该词,- 表示必须不包含该词,所以上述查询会搜索 title 和 content 列中包含 “MySQL” 但不包含 “数据库” 的记录。
查询扩展搜索模式
查询扩展搜索模式会先进行一次初始搜索,然后根据搜索结果中的相关词进行二次搜索,以扩大搜索范围。
SELECT * FROM articles
WHERE MATCH (title, content) AGAINST ('MySQL 全文索引' WITH QUERY EXPANSION);
首先,MySQL 会找到标题和内容中直接包含 “MySQL 全文索引” 的文章。假设这些文章中还经常提到 “索引优化”“全文搜索算法” 等词汇,那么 MySQL 会将这些词汇添加到查询中,再次搜索,可能会找到一些虽然没有直接提及 “MySQL 全文索引”,但与索引优化或全文搜索算法相关的文章,从而扩大了搜索范围,提高了找到相关文档的可能性3. 全文索引的限制和注意事项
- 支持的存储引擎:目前只有
InnoDB和MyISAM存储引擎支持全文索引。 - 最小和最大词长:全文索引会忽略一些长度小于最小词长或大于最大词长的词,这些长度可以通过
ft_min_word_len和ft_max_word_len系统变量进行配置。 - 停用词:全文索引会忽略一些常用的停用词,如 “the”、“and”、“or” 等,你可以通过修改
ft_stopword_file系统变量来调整停用词列表。 - 更新和维护:当表中的数据发生变化时,全文索引会自动更新,但大量的数据更新可能会影响性能。在进行批量数据更新时,可以考虑先禁用全文索引,更新完成后再重新启用。
说明一下:
- MyISAM存储引擎是支持全文索引的,而InnoDB存储引擎是在5.6以后才开始支持全文索引的。
- 同时使用title和body建立全文索引时,相当于建立了一个复合索引,默认会选择fulltext中的第一个列名作为这个复合索引的索引名,所以这里explain中key对应的索引名为title。
- 由于是title和body共同建立的全文索引,所以如果文章当中没有出现关键字,但文章名称中出现了关键字则也会被筛选出来(当前示例没有体现出来)。
索引创建的原则如下:
- 比较频繁作为查询条件的字段应该创建索引。
- 唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件。
- 更新非常频繁的字段不适合创建索引。
- 不会出现在where子句中的字段不应该创建索引。
MySQL删除主键索引的所有方法
1. 一般表删除主键索引
当表结构比较常规时,可以直接使用 ALTER TABLE 语句并结合 DROP PRIMARY KEY 子句来删除主键索引。
-- 创建一个带有主键的表
CREATE TABLE students (student_id INT NOT NULL,name VARCHAR(50),age INT,PRIMARY KEY (student_id)
);-- 删除主键索引
ALTER TABLE students
DROP PRIMARY KEY;
在上述示例中,首先创建了一个名为 students 的表,其中 student_id 列被指定为主键。然后使用 ALTER TABLE 语句和 DROP PRIMARY KEY 子句将该表的主键索引删除。
2. 包含自增列的表删除主键索引
如果表中包含自增列(使用了 AUTO_INCREMENT 属性),并且该自增列是主键的一部分,那么在删除主键索引之前,需要先将自增属性移除。
-- 创建一个包含自增列作为主键的表
CREATE TABLE products (product_id INT AUTO_INCREMENT PRIMARY KEY,product_name VARCHAR(100),price DECIMAL(10, 2)
);-- 移除自增属性
ALTER TABLE products
MODIFY product_id INT;-- 删除主键索引
ALTER TABLE products
DROP PRIMARY KEY;
在这个例子中,先创建了一个 products 表,product_id 列是自增的主键。接着使用 MODIFY 子句将 product_id 列的自增属性移除,最后再使用 DROP PRIMARY KEY 子句删除主键索引。
相关文章:

MySQL中的索引
explain关键字, MySQL索引特性 索引的概念 MySQL 索引是一种用于提高数据库查询效率的数据结构 数据库表中存储的数据都是以记录为单位的,如果在查询数据时直接一条条遍历表中的数据记录,那么查询的时间复杂度将会是 O ( N )。索引的价值在…...

AI小白:JavaPython开发环境双轨制搭建指南
文章目录 1 Python深度学习环境配置1.1 Anaconda生态体系建设1.2 JupyterLab高效工作流魔法命令与可视化调试扩展插件配置指南 2 Java深度学习方案:DL4J实战2.1 企业级部署架构设计2.2 集成传统Java系统Spring Boot微服务封装模型性能优化技巧 1 Python深度学习环境…...

《比特城的机密邮件:加密、签名与防篡改的守护之战》
点击下面图片带您领略全新的嵌入式学习路线 🔥爆款热榜 88万阅读 1.6万收藏 第一章:风暴前的密令 比特城的议会大厅内,首席长老艾德文握着一卷足有半人高的羊皮纸,眉头紧锁。纸上是即将颁布的《新纪元法典》——这份文件不仅内…...

Redis之布隆过滤器
面试场景切入 针对于电话号码问题的痛点 布隆过滤器是什么? 由一个初值都为0的bit数组和多个哈希函数构成,用来快速判断集合中是否存在某个元素。 设计思想 本质就是判断具体数据是否存在于一个大的集合中。布隆过滤器是一种类似Set的数据结构&#…...

这是一份简单优雅的Prompt Engineering教程
Prompt Engineering(提示工程)是通过精心设计输入文本(prompt)来引导大型语言模型(LLM)生成更准确、相关且符合预期的输出的技术。其核心在于通过调整提问的措辞、结构、上下文和附加信息,优化模…...

Java基础 4.6
1.成员方法练习 //编写类A:判断一个数是奇数还是偶数,返回boolean //根据行、列、字符打印对应行数和列数的字符,比如:行4 列4 字符# 则打印相应的效果 public class MethodExercise01 {public static void main(String[] args) …...

DApp实战篇:前端技术栈一览
前言 在前面一系列内容中,我们由浅入深地了解了DApp的组成,从本小节开始我将带领大家如何完成一个完整的DApp。 本小节则先从前端开始。 前端技术栈 在前端开发者速入:DApp中的前端要干些什么?文中我说过,即便是在…...
函数实现)
C++中如何比较两个字符串的大小--compare()函数实现
一、现在有一个问题描述:有两个字符串,要按照字典顺序比较它们的大小(注意所有的小写字母都大于所有的大写字母 )。 二、代码 #include <bits/stdc.h> using namespace std;int main() {string str1 "apple";…...

c++中的auto关键字
在 C 中,auto 是一个类型推断关键字(C11 引入),允许编译器根据变量的初始化表达式自动推导其类型。它极大地简化了代码编写,尤其在涉及复杂类型或模板的场景中。以下是 auto 的详细说明: 1. 基本用法 1.1 …...

zk源码—1.数据节点与Watcher机制及权限二
大纲 1.ZooKeeper的数据模型、节点类型与应用 (1)数据模型之树形结构 (2)节点类型与特性(持久 临时 顺序 ) (3)节点的状态结构(各种zxid 各种version) (4)节点的版本(version cversion aversion) (5)使用ZooKeeper实现锁(悲观锁 乐观锁) 2.发布订阅模式࿱…...

交换机和集线器的区别
集线器(Hub)—— 大喇叭广播站 工作原理: 集线器像村里的“大喇叭”,收到任何消息都会广播给所有人。 比如A对B说“你好”,全村人(C、D、E)都能听到,但只有B会回…...

微服务系统记录
记录下曾经工作涉及到微服务的相关知识。 1. 架构设计与服务划分 关键内容 领域驱动设计(DDD): 利用领域模型和限界上下文(Bounded Context)拆分业务,明确服务边界。通过事件风暴(Event Storm…...

同花顺客户端公司财报抓取分析
目标客户端下载地址:https://ft.51ifind.com/index.php?c=index&a=download PC版本 主要难点在登陆,获取token中的 jgbsessid (每次重新登录这个字段都会立即失效,且有效期应该是15天的) 抓取jgbsessid 主要通过安装mitmproxy 使用 mitmdump + 下边的脚本实现监听接口…...

二叉树与红黑树核心知识点及面试重点
二叉树与红黑树核心知识点及面试重点 一、二叉树 (Binary Tree) 1. 基础概念 定义:每个节点最多有两个子节点(左子节点和右子节点) 术语: 根节点:最顶层的节点 叶子节点:没有子节点的节点 深度…...

Rocket-JWT鉴权
目录 一、概述 二、相关依赖 三、环境准备 3.1 创建项目 3.2 读取私钥信息 3.3 token数据负载 3.4 生成token 四、Web鉴权 4.1 验证载体 4.2 接收请求 五、总结 Welcome to Code Blocks blog 本篇文章主要介绍了 [Rocket-JWT鉴权] ❤博主广交技术好友,喜…...

2025 年网络安全终极指南
我们生活在一个科技已成为日常生活不可分割的一部分的时代。对数字世界的依赖性日益增强的也带来了更大的网络风险。 网络安全并不是IT专家的专属特权,而是所有用户的共同责任。通过简单的行动,我们可以保护我们的数据、隐私和财务,降低成为…...

横扫SQL面试——PV、UV问题
📊 横扫SQL面试:UV/PV问题 🌟 什么是UV/PV? 在数据领域,UV(Unique Visitor,独立访客) 和 PV(Page View,页面访问量) 是最基础也最重要的指标&…...

ctf-show-杂项签到题
下载文件,解压需要密码,用010打开没看出什么 然后用Advanced Archive Password Recovery暴力破解,发现没用 怀疑是伪解密,解压出来发现加密受损用随波逐流修复加密文件 打开修复的加密文件直接得flag flag:flag{79d…...

对解释器模式的理解
对解释器模式的理解 一、场景1、题目【[来源](https://kamacoder.com/problempage.php?pid1096)】1.1 题目描述1.2 输入描述1.3 输出描述1.4 输入示例1.5 输出示例 二、不采用解释器模式1、代码2、“缺点” 三、采用解释器模式1、代码2、“优点” 四、思考1、解释器模式的意义…...
基本总结回顾64)
高频面试题(含笔试高频算法整理)基本总结回顾64
干货分享,感谢您的阅读! (暂存篇---后续会删除,完整版和持续更新见高频面试题基本总结回顾(含笔试高频算法整理)) 备注:引用请标注出处,同时存在的问题请在相关博客留言…...

python入门之从安装python及vscode开始
本篇将解决三个问题: 1. 如何下载及安装官方python? 2. 如何下载及安装vscode? 3. 如何配置vscode的python环境? 一、python下载及安装 1.搜索python,找到官网并打开 2.找到download,按需选择版本下载 …...
)
OpenGL学习笔记(模型材质、光照贴图)
目录 光照与材质光照贴图漫反射贴图采样镜面光贴图 GitHub主页:https://github.com/sdpyy OpenGL学习仓库:https://github.com/sdpyy1/CppLearn/tree/main/OpenGLtree/main/OpenGL):https://github.com/sdpyy1/CppLearn/tree/main/OpenGL 光照与材质 在现实世界里&…...
视觉_transform
visual_transform 图像分块 (Patch Embedding) 假设输入图像为 x ∈ R ∗ H ∗ ∗ W ∗ ∗ C ∗ x∈R^{*H**W**C*} x∈R∗H∗∗W∗∗C∗ C 是图像的通道数(例如,RGB图像的 C3) 将图像分割成N个大小为P*CP的patch,每个patch的大…...

Redis的安装及通用命令
二. Redis 的安装及通用命令 1. Ubuntu 安装 Redis (1) 切换到 root 用户: su root(2) 搜索 Redis 软件包 apt search redis(3) 安装 Redis apt install redis(4) 查看 Redis netstat -anp | grep redis(5) 切换到 Redis 目录下 cd /etc/redis/(6) 修改 Redis 配置文件:…...
)
Python 实现的运筹优化系统代码详解(0-1规划背包问题)
一、引言 在数学建模与实际决策场景的交织领域中,诸多复杂问题亟待高效且精准的解决方案。0-1 规划作为一种特殊且极为重要的优化方法,宛如一把万能钥匙,能够巧妙开启众多棘手问题的解决之门。它专注于处理决策变量仅能取 0 或 1 这两种极端状…...

护网蓝初面试题
《网安面试指南》https://mp.weixin.qq.com/s/RIVYDmxI9g_TgGrpbdDKtA?token1860256701&langzh_CN 5000篇网安资料库https://mp.weixin.qq.com/s?__bizMzkwNjY1Mzc0Nw&mid2247486065&idx2&snb30ade8200e842743339d428f414475e&chksmc0e4732df793fa3bf39…...
:VP8和VP9)
音视频学习(三十二):VP8和VP9
VP8 简介 全称:Video Processing 8发布者:原 On2 Technologies(2010 被 Google 收购)定位:开源视频压缩标准,主要竞争对手是 H.264应用: WebRTC 视频通信HTML5 <video> 标签(…...

美国mlb与韩国mlb的关系·棒球9号位
MLB(Major League Baseball,美国职业棒球大联盟)作为全球最高水平的职业棒球联赛,与韩国市场流行的“MLB”时尚品牌之间存在着授权合作关系,但两者在业务范畴和品牌定位上存在显著差异。 一、品牌授权背景:…...

免费在线PUA测试工具:识别情感操控,守护情感健康
免费在线PUA测试工具:识别情感操控,守护情感健康 你是否曾经在感情中感到困惑、不安,甚至怀疑自己?今天为大家推荐一个专业的PUA测试工具,帮助你识别是否正在经历情感操控。 测试工具链接:PUA测试工具 什么…...

nginx中的try_files指令
try_files 是 Nginx 中一个非常有用的指令,用于按顺序检查文件是否存在,并返回第一个找到的文件。如果所有指定的文件都不存在,则执行回退逻辑,如重定向到一个指定的 URI 或返回一个错误代码。 作用 文件查找:按顺序检…...

[特殊字符] 驱动开发硬核特训 · Day 4
主题:从硬件总线到驱动控制 —— I2C 协议与传感器驱动开发全解析 I2C(Inter-Integrated Circuit)总线是一种广泛用于嵌入式设备的串行通信协议,因其低成本、简单布线和多从设备支持,成为连接各种传感器(温…...

Python 实现玻璃期货数据处理、入库与分析:从代码到应用
Python 实现期货数据处理与分析:从代码到应用 引言 在金融市场中,期货数据的处理和分析对于投资者和分析师来说至关重要。Python 凭借其丰富的库和简洁的语法,成为了处理和分析期货数据的强大工具。本文将详细解读一段用于处理期货持仓和行…...

神经网络之损失函数
引言:损失函数 (Loss Function)是机器学习和深度学习中非常重要的一个概念。用于衡量模型的预测值与真实值之间的差异,从而指导模型优化其参数以最小化这种差异。 一、损失函数作用 量化误差:损失函数是将预测值和真实…...
)
在Ubuntu内网环境中为Gogs配置HTTPS访问(通过Apache反向代理使用IP地址)
一、准备工作 确保已安装Gogs并运行在HTTP模式(默认端口3000) 确认服务器内网IP地址(如192.168.1.100) 二、安装Apache和必要模块 sudo apt update sudo apt install apache2 -y sudo a2enmod ssl proxy proxy_http rewrite headers 三、创建SSL证书 1. 创建证书存储目录…...

printf
printf() 是 C 和 C 标准库中的一个输出函数,位于 <cstdio> 头文件中。下面为你详细介绍它的相关知识点。 1. 基本使用 printf() 函数的作用是按照指定格式将数据输出到标准输出设备(通常是控制台)。其基本语法如下: cpp …...

Leetcode 311 Sparse Matrix Multiplication 稀疏矩阵相乘
Problem Given two sparse matrices A and B, return the result of AB. You may assume that A’s column number is equal to B’s row number. Example: A [[ 1, 0, 0],[-1, 0, 3] ]B [[ 7, 0, 0 ],[ 0, 0, 0 ],[ 0, 0, 1 ] ]| 1 0 0 | | 7 0 0 | | 7 0 0 | AB …...

mysql和sqlite关于data数据的识别问题
<input type"date" name"birthday" value""> # 表单传入的日期 birthday request.form.get(birthday) # 获取日期 birthday Column(birthday, Date, comment出生日期, nullableTrue) # 数据库的数据字段模型 birthday_str request…...

2024 天梯赛——工业园区建设题解
思路 将点 i i i 视为固定点, 点 j j j 视为灵活点,其中 s i 1 s_{i} 1 si1, s j 0 s_{j} 0 sj0。维护四个队列,其中 q 0 q_{0} q0 和 q 1 q_{1} q1 分别维护还没有被选用的固定点 和 灵活点, Q 0 Q…...

亚马逊AI新功能上线:5大亮点解锁精准消费预测
在人工智能技术不断重塑跨境电商生态之际,全球电商巨头亚马逊(Amazon)再次迈出关键一步。近日,亚马逊正式对其卖家中心推出一系列基于AI的新功能,聚焦于消费数据预测、用户行为洞察、库存智能管理与个性化营销服务等方…...

opus+ffmpeg+c++实现录音
说明: opusffmpegc实现录音 效果图: step1:C:\Users\wangrusheng\source\repos\WindowsProject1\WindowsProject1\WindowsProject1.cpp // WindowsProject1.cpp : 定义应用程序的入口点。 //#include "framework.h" #include "Windows…...

ComfyUI的本地私有化部署使用Stable Diffusion文生图
什么是ComfyUI ? ComfyUI是一个基于节点流程的Stable Diffusion操作界面。以下是关于它的详细介绍: 特点与优势 高度可定制:提供丰富的节点类型,涵盖文本处理、图像处理、模型推理等功能。用户可根据需求自由组合节点࿰…...

【学习笔记17】Windows环境下安装RabbitMQ
一. 下载RabbitMQ( 需要按照 Erlang/OTP 环境的版本依赖来下载) (1) 先去 RabbitMQ 官网,查看 RabbitMQ 需要的 Erlang 支持:https://www.rabbitmq.com/ 进入官网,在 Docs -> Install and Upgrade -> Erlang V…...
(Go语言版))
【LeetCode 热题100】55:跳跃游戏(详细解析)(Go语言版)
🚀 LeetCode 热题 55:跳跃游戏(Jump Game)完整解析 📌 题目描述 给定一个非负整数数组 nums,你最初位于数组的第一个下标。 数组中的每个元素代表你在该位置可以跳跃的最大长度。 判断你是否能够到达最后一…...

OpenCV轮廓检测全面解析:从基础到高级应用
一、概述 轮廓检测是计算机视觉中的基础技术,用于识别和提取图像中物体的边界。与边缘检测不同,轮廓检测更关注将边缘像素连接成有意义的整体,形成封闭的边界。 轮廓检测的核心价值 - 物体识别:通过轮廓可以识别图像中的独立物体…...

微服务入门:Spring Boot 初学者指南
大家好,这里是架构资源栈!点击上方关注,添加“星标”,一起学习大厂前沿架构! 微服务因其灵活性、可扩展性和易于维护性而成为现代软件架构的重要组成部分。在本博客中,我们将探讨如何使用 Spring Boot 构建…...

Windows环境下开发pyspark程序
Windows环境下开发pyspark程序 一、环境准备 1.1. Anaconda/Miniconda(Python环境) 如果不怕包的版本管理混乱,可以直接使用已有的Python环境。 需要安装anaconda/miniconda(python3.8版本以上):Anaconda…...

嵌入式学习笔记——大小端及跳转到绝对地址
大小端以及跳转到绝对地址 0x100000 嵌入式编程中的大小端详解一、大端模式与小端模式二、判断当前系统是大端还是小端方法一:指针强制类型转换方法二:使用联合体(union) 三、结构体位段和大小端的影响四、大小端影响内存的 memc…...

eprime相嵌模式实验设计
一、含义与模型结构 该模式的实验设计至少 由两个存储不同实验材料及 属性的List和一个核心实验 过程CEP组成。子list1和 list2相嵌在父List中,CEP 可以调用List中的材料,也 可以调用list1和list2中的材 料。 二、相嵌模式的应用 应用于解决“多重随…...

编译uboot的Makefile编写
make ARCHarm CROSS_COMPILEarm-linux-gnueabihf- distcleanmake ARCHarm CROSS_COMPILEarm-linux-gnueabihf- mx6ull_14x14_ddr512_emmc_defconfigmake V1 ARCHarm CROSS_COMPILEarm-linux-gnueabihf- -j12 这三条命令中 ARCHarm 设置目标为 arm 架构, CROSS_COMP…...

Go语言常用算法实现
以下是Go语言中常用的算法实现,涵盖排序、搜索、数据结构操作等核心算法。 一、排序算法 1. 快速排序 func QuickSort(arr []int) []int {if len(arr) < 1 {return arr}pivot : arr[0]var left, right []intfor i : 1; i < len(arr); i {if arr[i] < pi…...