用Scala玩转Flink:从零构建实时处理系统
大家好!欢迎来到 Flink 的奇妙世界!如果你正对实时数据处理充满好奇,或者已经厌倦了传统批处理的漫长等待,那么你找对地方了。本系列文章将带你使用优雅的 Scala 语言,一步步掌握强大的流处理引擎——Apache Flink。
今天,我们先来打个前站,深入浅出地了解 Flink 的基本概念和核心优势,为后续的实战打下坚实的基础。
目录
一、Flink 简介
二、流处理 vs 批处理:数据世界的“实时”与“离线”
三、Flink 的架构:幕后英雄的协作
四、有状态流处理的核心优势:让你的数据流拥有“记忆”
五、案例演示
六、总结
一、Flink 简介
Apache Flink 是一个开源的流处理引擎,最早诞生于批处理系统演进而来,但它的核心设计目标是解决实时流数据处理问题。Flink 能够高效地处理无界数据流,同时也支持批处理任务。其高吞吐、低延迟、可扩展性和容错能力使其在实时数据处理、事件驱动应用和复杂事件处理等场景中得到了广泛应用。
简单来说,Apache Flink 是一个 分布式、高性能、始终可用、且准确的流处理和批处理框架。你没看错,它不仅擅长处理源源不断到来的实时数据流,也能高效地处理存储在文件系统或数据库中的静态数据。
你可以把 Flink 想象成一家“数据工厂”,它能接收各种各样的数据“原材料”,然后按照你设定的“生产线”进行加工处理,最终产出你需要的“产品”——比如实时的业务指标、异常告警、个性化推荐等等。

二、流处理 vs 批处理:数据世界的“实时”与“离线”
在深入 Flink 之前,我们先来区分一下两种主要的数据处理模式:流处理和批处理。
批处理 (Batch Processing)
-
场景: 想象一下你每天晚上下班后,需要统计今天所有的销售数据,生成一份日报表。你需要收集齐所有的数据,然后一次性进行分析计算。
-
特点:
-
处理的数据是静态的、有界的 (Bounded)。 所有数据都事先收集好,形成一个“批次”。
-
处理过程通常有明确的开始和结束。
-
延迟较高。 你只能在整个批次处理完成后才能看到结果。
-
典型代表: Hadoop MapReduce、Spark Batch。
-
流处理 (Stream Processing)
-
场景: 想象一下一个电商平台的实时监控系统,需要实时监测用户下单、支付、浏览等行为,一旦发现异常操作(比如短时间内大量异地登录),立即发出警报。
-
特点:
-
处理的数据是动态的、无界的 (Unbounded)。 数据源源不断地到来,没有明确的结束。
-
处理是持续进行的。 一旦有新数据到达,就会被立即处理。
-
延迟极低。 可以实现毫秒级的实时响应。
-
典型代表: Apache Flink、Apache Kafka Streams、Apache Storm。
-
可以用一个简单的生活例子来理解:
批处理: 像整理你一学期的照片,你需要等所有照片都拍完才能开始整理、分类。
流处理: 像观看一场直播,画面和声音是实时传输和播放的,你不需要等待所有内容结束后再观看。
让我们用一张图来更形象地展示它们的区别
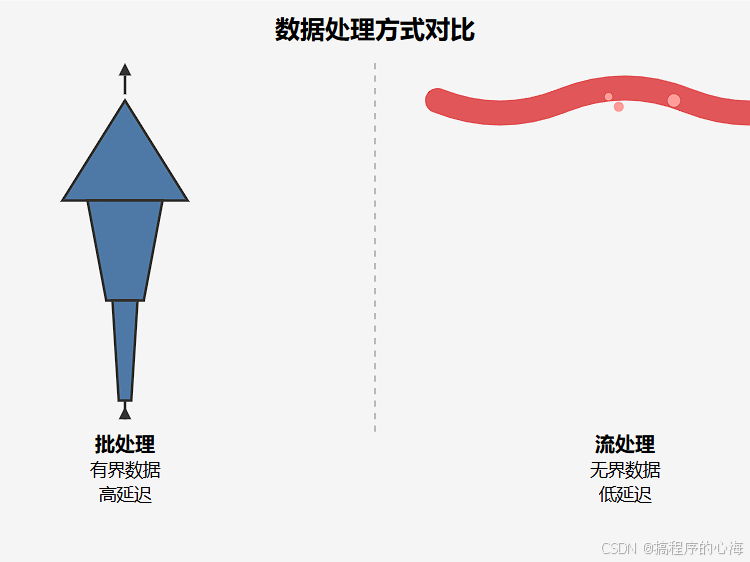
虽然批处理在历史上有其重要性,但在很多现代应用场景下,我们更需要实时地响应数据变化,这就凸显了流处理的重要性。而 Flink,正是流处理领域的佼佼者。
三、Flink 的架构:幕后英雄的协作
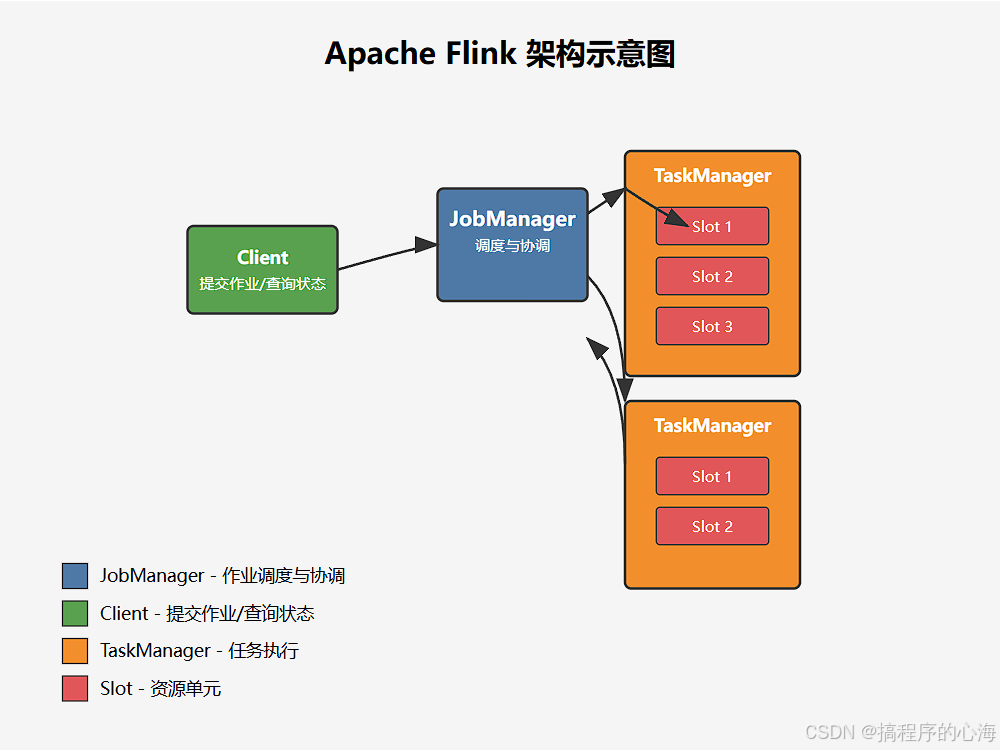
Flink 的强大功能背后,是一套精心设计的分布式架构。理解其主要组件及其职责,能帮助我们更好地理解 Flink 的工作原理。Flink 的主要组件包括:
-
JobManager:集群的大脑
JobManager 是 Flink 集群的协调者,负责接收用户提交的作业 (Job),并将作业分解成多个任务 (Task),然后将这些任务分配给 TaskManager 执行。它还负责作业的生命周期管理、资源管理、以及维护整个集群的状态信息。
你可以把 JobManager 想象成一家工厂的“总指挥部”,它接收生产订单(用户提交的作业),然后将订单拆解成具体的生产步骤(任务),并安排给不同的“生产线”(TaskManager)去执行。
-
TaskManager:干活的工人
TaskManager 是 Flink 集群中真正执行任务的工作节点。它接收来自 JobManager 的任务,并负责在自己的 slots (资源槽) 中执行这些任务。每个 TaskManager 可以管理多个 slots,每个 slot 可以运行一个 Task 的一部分或者一个完整的 Task。
继续上面的比喻,TaskManager 就是工厂里的“生产线”,它接收 JobManager 分配的任务,利用自己的“工人”(slots)来完成具体的生产工作。
-
Client:与集群的交互入口
Client 是用户与 Flink 集群交互的接口。用户可以通过 Client 提交作业给 JobManager,也可以查询作业的状态和集群的信息。Client 本身不是 Flink 集群运行的一部分,它可以在任何可以访问 Flink 集群的地方运行。
Client 就像是工厂的“客户服务中心”,用户通过它下达生产指令(提交作业)或查询生产进度(查看作业状态)。
让我们用一张图来展示 Flink 的基本架构:
四、有状态流处理的核心优势:让你的数据流拥有“记忆”
传统的数据处理往往是无状态的,这意味着每次处理数据都像是一个全新的开始,不记得之前发生过什么。但在很多实际应用中,我们需要记住过去的状态,才能做出更准确的判断和决策。
Flink 提供了强大的有状态流处理能力,这正是其核心优势之一。
什么是状态 (State)?
在流处理中,状态是指应用程序在处理数据流的过程中需要记住的信息。它可以是简单的计数器、最近的事件、聚合的结果,甚至是更复杂的数据结构。
为什么有状态流处理如此重要?
考虑以下几个场景:
-
实时统计: 计算过去 5 分钟内每个用户的点击次数。这需要记录每个用户的点击计数状态,并在新的点击事件到来时更新。
-
复杂事件处理 (CEP): 检测符合特定模式的事件序列。例如,连续三次登录失败后尝试支付,这需要记住之前的登录状态和支付尝试状态。
-
会话分析: 分析用户的会话行为,例如用户在网站上的点击路径和停留时间。这需要维护每个用户的会话状态。
-
Exactly-Once 语义: 在数据处理过程中,保证每条数据都被精确地处理一次,不多不少。这在很大程度上依赖于 Flink 强大的状态管理和容错机制。
Flink 如何管理状态?
Flink 提供了一套完善的状态管理机制,包括:
-
不同的状态后端 (State Backends): Flink 支持将状态存储在不同的后端,例如内存、文件系统、RocksDB 等,以满足不同规模和性能要求的应用。
-
Keyed State 和 Operator State:
-
Keyed State: 顾名思义,这种状态是与特定的 key 关联的。在进行有状态操作时,Flink 会根据 key 将具有相同 key 的数据路由到同一个 TaskManager 的同一个 Task 实例进行处理,从而保证了状态的局部性和一致性。这就像是按照用户 ID 来分别记录每个用户的浏览历史。
-
Operator State: 这种状态是与一个 Task 实例相关联的,而不是与特定的 key。例如,Kafka Consumer 连接器的 offset 信息就可以作为 Operator State 来管理。
-
五、案例演示
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Timeobject WindowedCount {def main(args: Array[String]): Unit = {// 创建流处理执行环境val env = StreamExecutionEnvironment.getExecutionEnvironment// 模拟数据源:每隔一秒生成一个随机整数val stream = env.socketTextStream("localhost", 9999).map(_.toInt)// 按时间窗口进行聚合(例如:每5秒统计一次总和)val aggregatedStream = stream.timeWindowAll(Time.seconds(5)).reduce(_ + _)// 输出结果aggregatedStream.print()// 启动任务env.execute("Scala Flink Windowed Count")}
}
代码解析
创建执行环境:通过
StreamExecutionEnvironment.getExecutionEnvironment获取流处理环境。数据源定义:这里使用 socket 作为数据源,开发者可以替换为 Kafka 或其他数据源。
窗口聚合:
timeWindowAll(Time.seconds(5))定义了一个5秒的滚动窗口,通过reduce方法对窗口内数据进行聚合计算。任务启动:调用
env.execute启动 Flink 作业。
六、总结
本文通过对 Flink 的基本概念、流处理与批处理的对比、架构组成和有状态流处理的优势进行了详细讲解,并配合了图示和 Scala 代码示例。希望这篇文章能帮助我们快速入门 Flink 编程,并激发我们在实时数据处理领域的探索热情。
接下来,我们可以进一步学习如何构建更加复杂的 Flink 应用,如结合 Kafka 进行实时流数据处理、利用 CEP(复杂事件处理)实现异常检测等。无论我们是初学者还是有一定基础的开发者,都能在 Flink 的生态系统中找到适合自己的解决方案。
如果这篇文章对你有所启发,期待你的点赞关注!

相关文章:

用Scala玩转Flink:从零构建实时处理系统
大家好!欢迎来到 Flink 的奇妙世界!如果你正对实时数据处理充满好奇,或者已经厌倦了传统批处理的漫长等待,那么你找对地方了。本系列文章将带你使用优雅的 Scala 语言,一步步掌握强大的流处理引擎——Apache Flink。 今…...

【LeetCode】算法详解#3 ---最大子数组和
1.题目介绍 给定一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。 子数组是数组中的一个连续部分。 1 < nums.length < 105-104 < nums[i] < 104 2.解决思路 要求出…...

基于Python的心衰疾病数据可视化分析系统
【Python】基于Python的心衰疾病数据可视化分析系统 (完整系统源码开发笔记详细部署教程)✅ 目录 一、项目简介二、项目界面展示三、项目视频展示 一、项目简介 本项目基于Python开发,重点针对5000条心衰疾病患者的数据进行可视化分析&#…...

oracle批量删除分区
为了清理数据,往往需要删除一些分区 简单查看当前分区 附件 --创建测试表 -- drop table test_part purge;CREATE TABLE test_part (sales_id NUMBER,sale_date DATE,amount NUMBER ) PARTITION BY RANGE (sale_date) INTERVAL (INTERVAL 1 MONTH) -- 每个月创建…...

Android Compose入门和基本使用
文章目录 一、Jetpack Compose 介绍Jetpack Compose是什么Composable 函数命令式和声明式UI组合和继承 二、状态管理什么是状态Stateremember状态提升 三、自定义布局Layout ModifierLayout Composable固有特性测量使用内置组件固有特性测量自定义固有特性测量 四、项目中使用J…...

xLua的Lua调用C#的2,3,4
使用Lua在Unity中创建游戏对象,组件: 相关代码如下: Lua --Lua实例化类 --C# Npc objnew Npc() --通过调用构造函数创建对象 local objCS.Npc() obj.HP100 print(obj.HP) local obj1CS.Npc("admin") print(obj1.Name)--表方法希…...

使用 Python 连接 PostgreSQL 数据库,从 `mimic - III` 数据库中筛选数据并导出特定的数据图表
要使用 Python 连接 PostgreSQL 数据库,从 mimic - III 数据库中筛选数据并导出特定的数据图表,你可以按照以下步骤操作: 安装所需的库:psycopg2 用于连接 PostgreSQL 数据库,pandas 用于数据处理,matplot…...
 [第151~160题](持续更新))
算法刷题记录——LeetCode篇(2.6) [第151~160题](持续更新)
更新时间:2025-04-06 算法题解目录汇总:算法刷题记录——题解目录汇总技术博客总目录:计算机技术系列博客——目录页 优先整理热门100及面试150,不定期持续更新,欢迎关注! 152. 乘积最大子数组 给你一个…...
)
Dijkstra求最短路径问题(优先队列优化模板java)
首先 1. 主类定义与全局变量 public class Main {static int N 100010; // 最大节点数static int INF Integer.MAX_VALUE; // 无穷大static ArrayList<Pair>[] G new ArrayList[N]; // 邻接表存储图static int[] dis new int[N]; // 存储每个节点的最短…...

【软件测试】性能测试 —— 基础概念篇
🥰🥰🥰来都来了,不妨点个关注叭! 👉博客主页:欢迎各位大佬!👈 本期内容主要介绍性能测试相关知识,首先我们需要了解性能测试是什么,本期内容主要介绍性能测试…...

Jmeter脚本使用要点记录
一,使用Bean shell获取请求响应的数据 byte[] result prev.getResponseData(); String str new String(result); System.out.println(str);其中,prev是jmeter的内置变量,直接使用即可。 二,不同的流程中传参数 vars.put(&quo…...

HTML5
HTML5是对HTML标准的第5次修订 HTML是超文本标记语言的简称,是为【网页创建和其它可在网页浏览器中所看到信息】而设计的一种标记性语言。 H5优点:跨平台使用将互联网语义化,更好地被人类与机器所理解降低了对浏览器的依赖,更好地…...

算法—博弈问题
1.博弈问题 1.前提:每一步都是最优解的情况下,先手的那个人已经确定了胜负 用dp数组记录每一步操作后的结果,如果下一步会出现必输结果,那么说明执行这步操作的人必胜,因为必输结果的下一步操作后都是必胜的结果,所以在…...
)
vector模拟实现(2)
1.构造函数 2.拷贝构造 我们利用push_back和reserve来实现拷贝构造。 3.迭代器的实现 由于底层是一段连续的空间,所以我们选择用指针来实现迭代器。 4.swap 这里的swap函数是有两种方法,一种是开辟一段新的空间,然后memcpy来把原来的数据拷…...

【嵌入式系统设计师】知识点:第3章 嵌入式硬件设计
提示:“软考通关秘籍” 专栏围绕软考展开,全面涵盖了如嵌入式系统设计师、数据库系统工程师、信息系统管理工程师等多个软考方向的知识点。从计算机体系结构、存储系统等基础知识,到程序语言概述、算法、数据库技术(包括关系数据库、非关系型数据库、SQL 语言、数据仓库等)…...

输入框输入数字且保持精度
在项目中如果涉及到金额等需要数字输入且保持精度的情况下,由于输入框是可以随意输入文本的,所以一般情况下可能需要监听输入框的change事件,然后通过正则表达式去替换掉不匹配的文本部分。 由于每次文本改变都会被监听,包括替换…...

Vue3中的Inject用法全解析
大家好呀~今天给大家带来一个超级实用的Vue3技巧:如何使用inject进行组件间的通信!如果你对组件间的数据传递、事件触发感兴趣,那一定不要错过这篇文章哦!话不多说,直接开整~ 🌟 什么…...

FPGA同步复位、异步复位、异步复位同步释放仿真
FPGA同步复位、异步复位、异步复位同步释放仿真 xilinx VIVADO仿真 行为仿真 综合后功能仿真,综合后时序仿真 实现后功能仿真,实现后时序仿真 目录 前言 一、同步复位 二、异步复位 三、异步复位同步释放 总结 前言 本文将详细介绍FPGA同步复位、异…...

深度解析需求分析:理论、流程与实践
深度解析需求分析:理论、流程与实践 一、需求分析的目标(一)准确捕捉用户诉求(二)为开发提供清晰指引 二、需求分析流程(一)需求获取(二)需求整理(三…...

QT学习笔记4--事件
1. 鼠标事件 1.1 鼠标按下 QObject中的mousePressEvent()方法 在子类中重写该方法,就可以处理鼠标按下 void myLabel::mousePressEvent(QMouseEvent *ev) {if (ev->button() Qt::LeftButton) {QString str QString("mouse press x %1, y %2").…...

AnimateCC基础教学:json数据结构的测试
一.核心代码: const user1String {"name": "张三", "age": 30, "gender": "男"}; const user1Obj JSON.parse(user1String); console.log("测试1:", user1Obj.name, user1Obj.age, user1Obj.gender);/*const u…...

针对Qwen-Agent框架的源码阅读与解析:FnCallAgent与ReActChat篇
在《针对Qwen-Agent框架的Function Call及ReAct的源码阅读与解析:Agent基类篇》中,我们已经了解了Agent基类的大体实现。这里我们就再详细学习一下FnCallAgent类和ReActChat的实现思路,从而对Agent的两条主流技术路径有更深刻的了解。同时&am…...

在docker中安装RocketMQ
第一步你需要有镜像包,这个2023年的时候docker就不能用pull拉取镜像了,需要你自己找 第二步我用的是FinalShell,用别的可视化界面也用, 在你自己平时放镜像包的地方创建一个叫rocketmq的文件夹,放入镜像包后,创建一个…...

Spring Boot + Kafka 消息队列从零到落地
背景 依赖 <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> <version>2.8.1</version> </dependency> 发送消息 //示例: private final KafkaTemplate<St…...

《打破语言壁垒:bilingual_book_maker 让外文阅读更轻松》
在寻找心仪的外文电子书时,常常会因语言障碍而感到困扰。虽然可以将文本逐段复制到在线翻译工具中,但这一过程不仅繁琐,还会打断阅读的连贯性,让人难以沉浸其中。为了克服这一难题,我一直在寻找一种既能保留原文&#…...

JCR一区文章,壮丽细尾鹩莺算法Superb Fairy-wren Optimization-附Matlab免费代码
本文提出了一种新颖的基于群体智能的元启发式优化算法——壮丽细尾鹩优化算法(SFOA),SFOA从精湛的神仙莺的生活习性中汲取灵感。融合了精湛的神仙莺群体中幼鸟的发育、繁殖后鸟类喂养幼鸟的行为以及它们躲避捕食者的策略。通过模拟幼鸟生长、繁殖和摄食阶…...

Kafka 如何实现 Exactly Once
Kafka 中实现 Exactly Once Semantics(EOS,精确一次语义),是为了确保: 每条消息被处理一次且仅一次,既不会丢失,也不会重复消费。 这是一种在分布式消息系统中非常难实现的语义。Kafka 从 0.11 …...

在K8S中,内置的污点主要有哪些?
在Kubernetes (K8S)中,内置的污点(Taints)主要用于自动化的节点亲和性和反亲和性管理。当集群中的节点出现某种问题或满足特定条件时,kubelet会自动给这些节点添加内置污点。以下是一些常见的内置污点: node.kubernete…...
2.1 从零训练自己的大模型概述)
AI大模型:(二)2.1 从零训练自己的大模型概述
目录 1. 分词器训练 1.1 分词器概述 1.2 训练简述 2.预训练 2.1 预训练概述 2.2 预训练过程简介 3.微调训练 3.1 微调训练概述 3.2 微调过程简介 4.人类对齐 4.1 人类对齐概述 4.2 人类对齐训练过程简介 近年来,大语言模型(LLM)如GPT-4、Claude、LLaMA等…...
)
电动垂直起降飞行器(eVTOL)
电动垂直起降飞行器(eVTOL)的详细介绍,涵盖定义、技术路径、应用场景、市场前景及政策支持等核心内容: 一、定义与核心特性 eVTOL(Electric Vertical Take-off and Landing)即电动垂直起降飞行器…...

LM Studio本地部署大模型
现在的AI可谓是火的一塌糊涂, 看到使用LM Studio部署本地模型非常的方便, 于是我也想在自己的本地试试 LM Studio 简介 LM Studio 是一款专为本地运行大型语言模型(LLMs)设计的桌面应用程序,支持 Windows 和 macOS 系统。它允许用户在个人电…...
PyTorch 深度学习 || 6. Transformer | Ch6.1 Transformer 框架
1. Transformer 框架...

SLAM文献之-SLAMesh: Real-time LiDAR Simultaneous Localization and Meshing
SLAMesh 是一种基于 LiDAR 的实时同步定位与建图(SLAM)算法,其核心创新点在于将定位与稠密三维网格重建相结合,通过动态构建和优化多边形网格(Mesh)来实现高精度定位与环境建模。以下是其算法原理的详细解析…...

[Python] 位置相关的贪心算法-刷题+思路讲解版
位置贪心-题目目录 例题1 - 香蕉商人编程实现输入描述输出描述思路AC代码 例题2 - 分糖果编程实现输入描述输入样例输出样例思路AC代码 例题4 - 分糖果II编程实现输入描述输出描述输入样例思路AC代码 例题3 - 分糖果III编程实现输入描述输出描述输入样例输出样例思路AC代码 例题…...

练习题:125
目录 Python题目 题目 题目分析 需求理解 关键知识点 实现思路分析 代码实现 代码解释 导入 random 模块: 指定范围: 生成随机整数: 输出结果: 运行思路 结束语 Python题目 题目 生成一个指定范围内的随机整数。 …...

实战设计模式之迭代器模式
概述 与上一篇介绍的解释器模式一样,迭代器模式也是一种行为设计模式。它提供了一种方法来顺序访问一个聚合对象中的各个元素,而无需暴露该对象的内部表示。简而言之,迭代器模式允许我们遍历集合数据结构中的元素,而不必了解这些集…...
)
Spring-AOP详解(AOP概念,原理,动态代理,静态代理)
目录 什么是AOP:Spring AOP核心概念需要先引入AOP依赖:1.切点(Pointcut):2.连接点:3.通知(Advice):4.切面: 通知类型:Around:环绕通知,此注解标注的通知方法在目标方法前,…...

【dify应用】将新榜排行数据免费保存到飞书表格
新榜中导出数据是收费的,如何免费导出呢 接口分析 切换分类排行,数据是在这个接口中请求的 参数: {"rankType":1,"rankDate":"2025-04-05","type":["财富"],"size":25,"…...

【Linux】线程池详解及基本实现
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...
)
基于论文的大模型应用:基于SmartETL的arXiv论文数据接入与预处理(一)
1. 背景 arXiv简介(参考DeepSeek大模型生成内容): arXiv(发音同“archive”,/ˈɑːrkaɪv/)是一个开放的学术预印本平台,主要用于研究人员分享和获取尚未正式发表或已完成投稿的学术论文。创…...

Leetcode 3508. Implement Router
Leetcode 3508. Implement Router 1. 解题思路2. 代码实现 题目链接:3508. Implement Router 1. 解题思路 这一题就是按照题意写作一下对应的函数即可。 我们需要注意的是,这里,定义的类当中需要包含以下一些内容: 一个所有i…...
)
Nmap全脚本使用指南!NSE脚本全详细教程!Kali Linux教程!(六)
脚本类别 discovery(发现) sip-methods 已演示过。这里不再演示。 436. smb-enum-domains 尝试枚举系统上的域及其策略。这通常需要凭据,但 Windows 2000 除外。除了实际域之外,通常还会显示“内置”域。Windows 在域列表中返…...

了解适配器模式
目录 适配器模式定义 适配器模式角色 适配器模式的实现 适配器的应用场景 适配器模式定义 适配器模式,也叫包装模式。将一个类的接口,转换成客户期望的另一个接口,适配器让原本接口不兼容的类可以合作无间。 简单来说就是目标类不能直接…...

C语言:几种字符串常用的API
字符串的常用操作 C 语言的标准库 <string.h> 提供了很多用于处理字符串的函数。 1. strlen - 计算字符串长度 size_t strlen(const char *str);功能:计算字符串 str 的长度,不包含字符串结束符 \0。 2.strcpy - 复制字符串 char *strcpy(char…...

Django构建安全中间件实用示例
Django安全中间件实用指南 推荐超级课程: 本地离线DeepSeek AI方案部署实战教程【完全版】Docker快速入门到精通Kubernetes入门到大师通关课AWS云服务快速入门实战目录 Django安全中间件实用指南什么是Django中的中间件?Django中的安全中间件特性配置示例配置示例配置示例示…...
【泪光2929】)
排序算法(快速排序,选择排序......)【泪光2929】
hello,大家好!今天给大家分享一下各种排序: 1,选择排序 首先从原始数组中 选择最小的1个数据,将其和位于第1个位置的数据交换。接着从剩下的n-1个数据中选择次小的1个元素,将其和第2个位置的数据交换然后…...

UE5学习记录part14
第17节 enemy behavior 173 making enemies move: AI Pawn Navigation 按P查看体积 So its very important that our nav mesh bounds volume encompasses all of the area that wed like our 因此,我们的导航网格边界体积必须包含我们希望 AI to navigate in and …...

树莓派llama.cpp部署DeepSeek-R1-Distill-Qwen-1.5B
树莓派的性能太低了,我们需要对模型进行量化才能使用,所以现在的方案是,在windows上将模型格式和量化处理好,然后再将模型文件传输到树莓派上。而完成上面的操作就需要部署llama.cpp。 三、环境的准备 这里要求大家准备…...

Llama 4 最新发布模型分析
1. 引言 在2025年4月5日,Meta公司正式发布了最新一代大型语言模型Llama 4系列,包括Llama 4 Scout和Llama 4 Maverick。该模型添加了多模态支持,能够处理文本、图像、音频和视频数据,实现更加充分的AI功能应用。 2. 技术特性 2.1…...

Llama 4 家族:原生多模态 AI 创新的新时代开启
0 要点总结 Meta发布 Llama 4 系列的首批模型,帮用户打造更个性化多模态体验Llama 4 Scout 是有 170 亿激活参数、16 个专家模块的模型,同类中全球最强多模态模型,性能超越以往所有 Llama 系列模型,能在一张 NVIDIA H100 GPU 上运…...