针对Qwen-Agent框架的源码阅读与解析:FnCallAgent与ReActChat篇
在《针对Qwen-Agent框架的Function Call及ReAct的源码阅读与解析:Agent基类篇》中,我们已经了解了Agent基类的大体实现。这里我们就再详细学习一下FnCallAgent类和ReActChat的实现思路,从而对Agent的两条主流技术路径有更深刻的了解。同时,在前面的文章《基于Qwen-Agent框架的Function Call及ReAct方式调用自定义工具》中我们尝试了中英文提示词和并行调用工具,这里我们将追溯源码,看看它们的深层次实现以及失效的原因。
文章目录
- FnCallAgent类
- 初始化函数
- 执行函数
- 工具调用
- 关于中英文提示词的分析
- 模型初始化路径
- 模型推理路径
- 关于并行调用工具失效的分析
- ReActChat类
- 初始化函数
- 执行函数
- 与Function Call方法的区别
- 提示词处理
- 工具解析
- 关于中英文提示词的分析
- 关于并行调用工具失效的分析
🎉进入大模型应用与实战专栏 | 🚀查看更多专栏内容

FnCallAgent类
在Agent类的基础上,qwen_agent/agents/fncall_agent.py下的FnCallAgent类又重写了三个函数,接下来我们就分别来看一下它们的源码实现,并做对应的分析。
初始化函数
def __init__(self,function_list: Optional[List[Union[str, Dict, BaseTool]]] = None,llm: Optional[Union[Dict, BaseChatModel]] = None,system_message: Optional[str] = DEFAULT_SYSTEM_MESSAGE,name: Optional[str] = None,description: Optional[str] = None,files: Optional[List[str]] = None,**kwargs):"""Initialization the agent.Args:function_list: One list of tool name, tool configuration or Tool object,such as 'code_interpreter', {'name': 'code_interpreter', 'timeout': 10}, or CodeInterpreter().llm: The LLM model configuration or LLM model object.Set the configuration as {'model': '', 'api_key': '', 'model_server': ''}.system_message: The specified system message for LLM chat.name: The name of this agent.description: The description of this agent, which will be used for multi_agent.files: A file url list. The initialized files for the agent."""super().__init__(function_list=function_list,llm=llm,system_message=system_message,name=name,description=description)if not hasattr(self, 'mem'):# Default to use Memory to manage filesself.mem = Memory(llm=self.llm, files=files, **kwargs)
其实很简单,就是添加了Memory,用来完成文件相关的操作。
执行函数
def _run(self, messages: List[Message], lang: Literal['en', 'zh'] = 'en', **kwargs) -> Iterator[List[Message]]:messages = copy.deepcopy(messages)num_llm_calls_available = MAX_LLM_CALL_PER_RUNresponse = []while True and num_llm_calls_available > 0:num_llm_calls_available -= 1extra_generate_cfg = {'lang': lang}if kwargs.get('seed') is not None:extra_generate_cfg['seed'] = kwargs['seed']output_stream = self._call_llm(messages=messages,functions=[func.function for func in self.function_map.values()],extra_generate_cfg=extra_generate_cfg)output: List[Message] = []for output in output_stream:if output:yield response + outputif output:response.extend(output)messages.extend(output)used_any_tool = Falsefor out in output:use_tool, tool_name, tool_args, _ = self._detect_tool(out)if use_tool:tool_result = self._call_tool(tool_name, tool_args, messages=messages, **kwargs)fn_msg = Message(role=FUNCTION,name=tool_name,content=tool_result,)messages.append(fn_msg)response.append(fn_msg)yield responseused_any_tool = Trueif not used_any_tool:breakyield response
这是一个大模型推理和工具执行的核心方法,主要功能和特点如下:
- 输入与初始化
- 接收消息列表和语言参数
- 深拷贝输入消息
- 设置最大LLM调用次数限制(默认是8)
- 推理流程
- 循环调用语言模型
- 通过
_call_llm获取模型输出 - 逐步生成和扩展响应消息链
- 工具调用机制
- 检测模型输出中是否需要调用工具
- 使用
_call_tool执行工具 - 将工具调用结果作为函数消息追加到消息链
- 特殊设计
- 支持设置随机数种子
- 可配置语言(中/英)
- 实时流式输出响应
- 通过
yield返回中间结果
- 终止条件
- LLM调用次数耗尽
- 没有工具被调用时退出
核心逻辑:不断调用LLM,检测并执行工具,直到达到最大调用次数或无需调用工具。
工具调用
在上面的执行过程中,需要调用_call_tool方法完成工具的调用,其实该方法在基类中已有定义,代码中的super()._call_tool对应基类的方法。这里之所以要重写,主要是为了对file_access标记进行判断:
- 如果工具需要文件访问,则从消息和系统文件中提取文件
- 否则直接调用原始工具调用方法
这是一种针对特定工具需求的定制处理方案。
def _call_tool(self, tool_name: str, tool_args: Union[str, dict] = '{}', **kwargs) -> str:if tool_name not in self.function_map:return f'Tool {tool_name} does not exists.'# Temporary plan: Check if it is necessary to transfer files to the tool# Todo: This should be changed to parameter passing, and the file URL should be determined by the modelif self.function_map[tool_name].file_access:assert 'messages' in kwargsfiles = extract_files_from_messages(kwargs['messages'], include_images=True) + self.mem.system_filesreturn super()._call_tool(tool_name, tool_args, files=files, **kwargs)else:return super()._call_tool(tool_name, tool_args, **kwargs)
关于中英文提示词的分析
在上面的代码中,可以通过修改extra_generate_cfg = {'lang': lang}来设置模型推理时使用的语言,我们接下来就看看随着设置不同的语言类型,模型所采用的提示词会有哪些差异。为了更好地分析这一点,我们需要分别从模型初始化和模型推理这两个角度出发,查看并厘清FnCallAgent类的调用路径。
模型初始化路径
qwen_agent/agents/fncall_agent.py路径下FnCallAgent的 __init__函数→【执行】→super().__init__
qwen_agent/agent.py路径下Agent的 __init__函数→【执行】→self.llm = get_chat_model(llm)
qwen_agent/llm/__init__.py路径下的get_chat_model函数→【执行】→return LLM_REGISTRY[model_type](cfg)
这里还做了下面的判断,以openai的形式调用模型
if 'model_server' in cfg:if cfg['model_server'].strip().startswith('http'):model_type = 'oai'return LLM_REGISTRY[model_type](cfg)
而LLM_REGISTRY是一个字典,用于记录不同类型模型的初始化函数,其内容如下所示
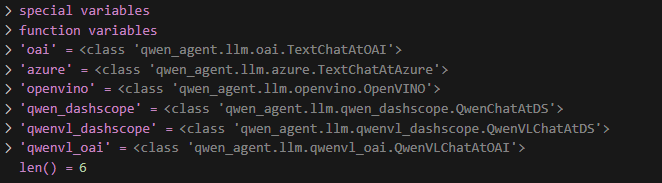
所以接下来的调用路径是这样的:
qwen_agent/llm/oai.py路径下TextChatAtOAI的 __init__函数→【执行】→super().__init__
又由于TextChatAtOAI继承自BaseFnCallModel,所以最终的初始化函数位于qwen_agent/llm/function_calling.py下的BaseFnCallModel,相关代码如下:
class BaseFnCallModel(BaseChatModel, ABC):def __init__(self, cfg: Optional[Dict] = None):super().__init__(cfg)fncall_prompt_type = self.generate_cfg.get('fncall_prompt_type', 'qwen')if fncall_prompt_type == 'qwen':from qwen_agent.llm.fncall_prompts.qwen_fncall_prompt import FN_STOP_WORDS, QwenFnCallPromptself.fncall_prompt = QwenFnCallPrompt()stop = self.generate_cfg.get('stop', [])self.generate_cfg['stop'] = stop + [x for x in FN_STOP_WORDS if x not in stop]else:raise NotImplementedError
这里的提示词self.fncall_prompt调用了QwenFnCallPrompt(),我们将在推理阶段分析里面的中英文提示设置。
模型推理路径
在推理阶段,首先进入qwen_agent/agents/fncall_agent.py路径下FnCallAgent的 _run函数→【执行下面代码】
output_stream = self._call_llm(messages=messages,functions=[func.function for func in self.function_map.values()],extra_generate_cfg=extra_generate_cfg)
接下来进入qwen_agent/agent.py路径下Agent的 _call_llm函数→【执行下面代码】
return self.llm.chat(messages=messages,functions=functions,stream=stream,extra_generate_cfg=merge_generate_cfgs(base_generate_cfg=self.extra_generate_cfg,new_generate_cfg=extra_generate_cfg,))
接下来进入qwen_agent/llm/base.py路径下BaseChatModel的 chat函数→【执行下面代码】
messages = self._preprocess_messages(messages, lang=lang, generate_cfg=generate_cfg, functions=functions)
最终进入qwen_agent/llm/function_calling.py下的BaseFnCallModel,执行_preprocess_messages
def _preprocess_messages(self,messages: List[Message],lang: Literal['en', 'zh'],generate_cfg: dict,functions: Optional[List[Dict]] = None,) -> List[Message]:messages = super()._preprocess_messages(messages, lang=lang, generate_cfg=generate_cfg)if (not functions) or (generate_cfg.get('function_choice', 'auto') == 'none'):messages = self._remove_fncall_messages(messages, lang=lang)else:validate_num_fncall_results(messages=messages,support_multimodal_input=self.support_multimodal_input,)messages = self.fncall_prompt.preprocess_fncall_messages(messages=messages,functions=functions,lang=lang,parallel_function_calls=generate_cfg.get('parallel_function_calls', False),function_choice=generate_cfg.get('function_choice', 'auto'),)return messages
其具体实现位于qwen_agent/llm/fncall_prompts/qwen_fncall_prompt.py下的QwenFnCallPrompt中的preprocess_fncall_messages函数
def preprocess_fncall_messages(messages: List[Message],functions: List[dict],lang: Literal['en', 'zh'],parallel_function_calls: bool = True,function_choice: Union[Literal['auto'], str] = 'auto',) -> List[Message]:ori_messages = messages# Change function_call responses to plaintext responses:messages = []for msg in copy.deepcopy(ori_messages):role, content = msg.role, msg.contentif role in (SYSTEM, USER):messages.append(msg)elif role == ASSISTANT:content = (content or [])fn_call = msg.function_callif fn_call:f_name = fn_call.namef_args = fn_call.argumentsif f_args.startswith('```'): # if code snippetf_args = '\n' + f_args # for markdown renderingfunc_content = '\n' if messages[-1].role == ASSISTANT else ''func_content += f'{FN_NAME}: {f_name}'func_content += f'\n{FN_ARGS}: {f_args}'content.append(ContentItem(text=func_content))if messages[-1].role == ASSISTANT:messages[-1].content += contentelse:messages.append(Message(role=role, content=content))elif role == FUNCTION:assert messages[-1].role == ASSISTANTassert isinstance(content, list)assert all(isinstance(item, ContentItem) for item in content)if content:f_result = copy.deepcopy(content)else:f_result = [ContentItem(text='')]f_exit = f'\n{FN_EXIT}: 'last_text_content = messages[-1].content[-1].textif last_text_content.endswith(f_exit):messages[-1].content[-1].text = last_text_content[:-len(f_exit)]f_result = [ContentItem(text=f'\n{FN_RESULT}: ')] + f_result + [ContentItem(text=f_exit)]messages[-1].content += f_resultelse:raise TypeError# Add a system prompt for function calling:tool_desc_template = FN_CALL_TEMPLATE[lang + ('_parallel' if parallel_function_calls else '')]tool_descs = '\n\n'.join(get_function_description(function, lang=lang) for function in functions)tool_names = ','.join(function.get('name_for_model', function.get('name', '')) for function in functions)tool_system = tool_desc_template.format(tool_descs=tool_descs, tool_names=tool_names)if messages[0].role == SYSTEM:messages[0].content.append(ContentItem(text='\n\n' + tool_system))else:messages = [Message(role=SYSTEM, content=[ContentItem(text=tool_system)])] + messages# Remove ': ' for continued generation of function calling,# because ': ' may form a single token with its following words:if messages[-1].role == ASSISTANT:last_msg = messages[-1].contentfor i in range(len(last_msg) - 1, -1, -1):item_type, item_text = last_msg[i].get_type_and_value()if item_type == 'text':if item_text.endswith(f'{FN_EXIT}: '):last_msg[i].text = item_text[:-2]break# Add the function_choice prefix:if function_choice not in ('auto', 'none'):if messages[-1].role == ASSISTANT:last_msg = messages[-1]if last_msg.content:if extract_text_from_message(last_msg, add_upload_info=False).endswith(FN_EXIT):last_msg.content.append(ContentItem(text=': \n'))else:last_msg.content.append(ContentItem(text='\n'))messages = messages[:-1]else:last_msg = Message(role=ASSISTANT, content=[])last_msg.content.append(ContentItem(text=f'{FN_NAME}: {function_choice}'))messages = messages + [last_msg]return messages
我们可以看到,与提示词直接相关的是这句话:
tool_desc_template = FN_CALL_TEMPLATE[lang + ('_parallel' if parallel_function_calls else '')]
而FN_CALL_TEMPLATE定义了以下四种提示词,包括了中英文及它们各自的并行版本
FN_CALL_TEMPLATE = {'zh': FN_CALL_TEMPLATE_INFO_ZH + '\n\n' + FN_CALL_TEMPLATE_FMT_ZH,'en': FN_CALL_TEMPLATE_INFO_EN + '\n\n' + FN_CALL_TEMPLATE_FMT_EN,'zh_parallel': FN_CALL_TEMPLATE_INFO_ZH + '\n\n' + FN_CALL_TEMPLATE_FMT_PARA_ZH,'en_parallel': FN_CALL_TEMPLATE_INFO_EN + '\n\n' + FN_CALL_TEMPLATE_FMT_PARA_EN,
}
列表记录一下它们的具体内容
- 中文
# 工具## 你拥有如下工具:{tool_descs}## 你可以在回复中插入零次、一次或多次以下命令以调用工具:✿FUNCTION✿: 工具名称,必须是[{tool_names}]之一。
✿ARGS✿: 工具输入
✿RESULT✿: 工具结果
✿RETURN✿: 根据工具结果进行回复,需将图片用渲染出来
- 英文
# Tools## You have access to the following tools:{tool_descs}## When you need to call a tool, please insert the following command in your reply, which can be called zero or multiple times according to your needs:✿FUNCTION✿: The tool to use, should be one of [{tool_names}]
✿ARGS✿: The input of the tool
✿RESULT✿: Tool results
✿RETURN✿: Reply based on tool results. Images need to be rendered as 
- 中文并行
# 工具## 你拥有如下工具:{tool_descs}## 你可以在回复中插入以下命令以并行调用N个工具:✿FUNCTION✿: 工具1的名称,必须是[{tool_names}]之一
✿ARGS✿: 工具1的输入
✿FUNCTION✿: 工具2的名称
✿ARGS✿: 工具2的输入
...
✿FUNCTION✿: 工具N的名称
✿ARGS✿: 工具N的输入
✿RESULT✿: 工具1的结果
✿RESULT✿: 工具2的结果
...
✿RESULT✿: 工具N的结果
✿RETURN✿: 根据工具结果进行回复,需将图片用渲染出来
- 英文并行
# Tools## You have access to the following tools:{tool_descs}## Insert the following command in your reply when you need to call N tools in parallel:✿FUNCTION✿: The name of tool 1, should be one of [{tool_names}]
✿ARGS✿: The input of tool 1
✿FUNCTION✿: The name of tool 2
✿ARGS✿: The input of tool 2
...
✿FUNCTION✿: The name of tool N
✿ARGS✿: The input of tool N
✿RESULT✿: The result of tool 1
✿RESULT✿: The result of tool 2
...
✿RESULT✿: The result of tool N
✿RETURN✿: Reply based on tool results. Images need to be rendered as 
在确定_preprocess_messages的提示词之后,我们跳回去看一下qwen_agent/llm/base.py下chat函数的关键执行逻辑
- 配置和语言处理
generate_cfg = merge_generate_cfgs(base_generate_cfg=self.generate_cfg, new_generate_cfg=extra_generate_cfg)
if 'seed' not in generate_cfg:generate_cfg['seed'] = random.randint(a=0, b=2**30)
if 'lang' in generate_cfg:lang: Literal['en', 'zh'] = generate_cfg.pop('lang')
else:lang: Literal['en', 'zh'] = 'zh' if has_chinese_messages(messages) else 'en'if messages[0].role != SYSTEM:messages = [Message(role=SYSTEM, content=DEFAULT_SYSTEM_MESSAGE)] + messages
这部分代码:
- 合并基本配置和额外配置
- 确保有一个随机种子(如果未提供)
- 确定语言(通过配置或自动检测中文)
- 如果第一条消息不是系统消息,添加默认系统消息
- 输入截断处理
max_input_tokens = generate_cfg.pop('max_input_tokens', DEFAULT_MAX_INPUT_TOKENS)
if max_input_tokens > 0:messages = _truncate_input_messages_roughly(messages=messages,max_tokens=max_input_tokens,)
根据最大输入令牌限制截断消息,避免超过模型的输入限制。注释指出这是一个粗略的估计,尤其对函数调用和多模态内容的令牌计数不精确。通过查看相关代码实现,截断逻辑事实上采用了"保留最新(采用从最新到最旧的方式截断,优先保留最近的对话)、完整轮次(按完整轮次(用户+助手)进行保留,不会截断单个轮次中间,至少保留最新的一轮用户-助手交互)、系统消息必留(无论令牌限制如何,系统消息始终保留)"的策略,尽可能保证在令牌限制内保留最有价值的对话内容。
- 函数调用模式处理
if functions:fncall_mode = True
else:fncall_mode = False
if 'function_choice' in generate_cfg:fn_choice = generate_cfg['function_choice']valid_fn_choices = [f.get('name', f.get('name_for_model', None)) for f in (functions or [])]valid_fn_choices = ['auto', 'none'] + [f for f in valid_fn_choices if f]if fn_choice not in valid_fn_choices:raise ValueError(f'The value of function_choice must be one of the following: {valid_fn_choices}. 'f'But function_choice="{fn_choice}" is received.')if fn_choice == 'none':fncall_mode = False
这段逻辑处理函数调用相关配置:
- 默认情况下,如果提供了functions参数则启用函数调用
- 验证function_choice参数是否有效
- 如果function_choice为’none’,则禁用函数调用
- 预处理和多模态处理
messages = self._preprocess_messages(messages, lang=lang, generate_cfg=generate_cfg, functions=functions)
if not self.support_multimodal_input:messages = [format_as_text_message(msg, add_upload_info=False) for msg in messages]
对消息进行预处理,并处理不支持多模态输入的模型情况,将消息格式化为纯文本。
- 模型服务调用逻辑
def _call_model_service():if fncall_mode:return self._chat_with_functions(messages=messages,functions=functions,stream=stream,delta_stream=delta_stream,generate_cfg=generate_cfg,lang=lang,)else:# TODO: Optimize code structureif messages[-1].role == ASSISTANT:assert not delta_stream, 'Continuation mode does not currently support `delta_stream`'return self._continue_assistant_response(messages, generate_cfg=generate_cfg, stream=stream)else:return self._chat(messages,stream=stream,delta_stream=delta_stream,generate_cfg=generate_cfg,)
这个内部函数根据不同情况调用不同的模型服务方法:
-
函数调用模式使用_chat_with_functions
-
如果最后一条消息是助手消息,使用_continue_assistant_response(续写模式)
续写模式本质上是一种"巧妙的欺骗":
- 它将用户的最新消息和助手的最新回复合并成一个新的"用户消息"
- 这让模型认为用户输入了一段已经包含部分回答的文本
- 模型会自然地继续这段文本,从而实现"续写"效果
- 从用户角度看,这就像是助手继续了之前的回复
-
这种方法的优点是不需要模型专门支持续写功能,通过重新构造输入就能实现。但它也有局限性,例如对函数调用不支持,且可能在某些复杂场景下效果不佳。
-
总结来说,续写模式通过将"已有对话"重新构造为"用户输入",让模型自然地延续之前的回复,实现了简单而有效的续写功能。
-
否则使用普通的_chat方法
- 重试和流式处理
if stream and delta_stream:# No retry for delta streamingoutput = _call_model_service()
elif stream and (not delta_stream):output = retry_model_service_iterator(_call_model_service, max_retries=self.max_retries)
else:output = retry_model_service(_call_model_service, max_retries=self.max_retries)
根据流式选项决定如何调用模型服务:
- delta_stream模式下不进行重试(已弃用)
- 普通流模式使用迭代器重试方法
- 非流模式使用普通重试方法
- 后处理和返回结果
非流式情况:
if isinstance(output, list):assert not streamlogger.debug(f'LLM Output:\n{pformat([_.model_dump() for _ in output], indent=2)}')output = self._postprocess_messages(output, fncall_mode=fncall_mode, generate_cfg=generate_cfg)if not self.support_multimodal_output:output = _format_as_text_messages(messages=output)if self.cache:self.cache.set(cache_key, json_dumps_compact(output))return self._convert_messages_to_target_type(output, _return_message_type)
流式情况:
else:assert streamif delta_stream:# Hack: To avoid potential errors during the postprocessing of stop words when delta_stream=True.# Man, we should never have implemented the support for `delta_stream=True` in the first place!generate_cfg = copy.deepcopy(generate_cfg) # copy to avoid conflicts with `_call_model_service`assert 'skip_stopword_postproc' not in generate_cfggenerate_cfg['skip_stopword_postproc'] = Trueoutput = self._postprocess_messages_iterator(output, fncall_mode=fncall_mode, generate_cfg=generate_cfg)def _format_and_cache() -> Iterator[List[Message]]:o = []for o in output:if o:if not self.support_multimodal_output:o = _format_as_text_messages(messages=o)yield oif o and (self.cache is not None):self.cache.set(cache_key, json_dumps_compact(o))return self._convert_messages_iterator_to_target_type(_format_and_cache(), _return_message_type)
这部分处理结果输出:
- 对输出进行后处理
- 处理不支持多模态输出的情况
- 根据需要缓存结果
- 将结果转换为原始输入类型(字典或Message对象)
- 流式输出使用迭代器,并在结束时缓存最终结果
总体流程图如下:
关于并行调用工具失效的分析
在上一章中,我们尝试通过在run函数中设置parallel_function_calls=True来实现工具的并行化调用,但并没有生效。经过分析资料和阅读源码,我发现真正的调用方法应该写成下面这种,即在extra_generate_cfg里面来设置
def _run(self, messages: List[Message], lang: Literal['en', 'zh'] = 'en', **kwargs) -> Iterator[List[Message]]:messages = copy.deepcopy(messages)num_llm_calls_available = MAX_LLM_CALL_PER_RUNresponse = []while True and num_llm_calls_available > 0:num_llm_calls_available -= 1extra_generate_cfg = {'lang': lang, 'parallel_function_calls': True}...
但即使是这样设,依然没有预期的并行调用的效果,所以我们再往深处瞧一瞧。
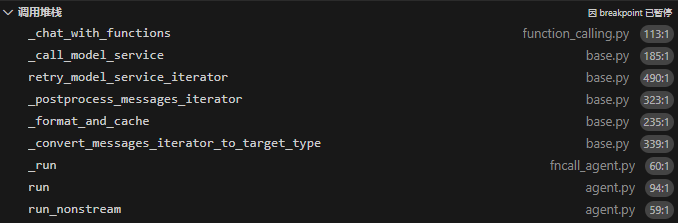
跟分析中英文提示词一样,从调用模型服务时的self._chat_with_functions追根溯源到qwen_agent/llm/function_calling.py,里面有这样一个神奇的函数:
def _chat_with_functions(self,messages: List[Message],functions: List[Dict],stream: bool,delta_stream: bool,generate_cfg: dict,lang: Literal['en', 'zh'],) -> Union[List[Message], Iterator[List[Message]]]:if delta_stream:raise NotImplementedError('Please use stream=True with delta_stream=False, because delta_stream=True'' is not implemented for function calling due to some technical reasons.')generate_cfg = copy.deepcopy(generate_cfg)for k in ['parallel_function_calls', 'function_choice']:if k in generate_cfg:del generate_cfg[k]return self._continue_assistant_response(messages, generate_cfg=generate_cfg, stream=stream)
在倒数第二行,它移除了配置字典中的并行函数调用parallel_function_calls和函数选择配置function_choice!!!所以你设了这两个参数也是白设!!!
所以并行函数调用唯一影响的地方只有提示词,而在我看来,似乎实际上并不会对调用并行有什么实际影响。
这个函数最后调用了_continue_assistant_response续写函数,有点奇怪,因为最后一句的角色不是assistant,等价于直接调用_chat函数。
ReActChat类
在FnCallAgent类的基础上,qwen_agent/agents/fncall_agent.py下的ReActChat类又重写了三个函数,接下来我们就分别来看一下它们的源码实现,并做对应的分析。
初始化函数
ReActChat 的初始化函数 __init__ 继承了 FnCallAgent 的初始化方法,并设置了特定的生成配置参数:
def __init__(self,function_list: Optional[List[Union[str, Dict, BaseTool]]] = None,llm: Optional[Union[Dict, BaseChatModel]] = None,system_message: Optional[str] = DEFAULT_SYSTEM_MESSAGE,name: Optional[str] = None,description: Optional[str] = None,files: Optional[List[str]] = None,**kwargs):super().__init__(function_list=function_list,llm=llm,system_message=system_message,name=name,description=description,files=files,**kwargs)self.extra_generate_cfg = merge_generate_cfgs(base_generate_cfg=self.extra_generate_cfg,new_generate_cfg={'stop': ['Observation:', 'Observation:\n']},)
这里的关键点是设置了 stop 序列为 ['Observation:', 'Observation:\n'],这是为了在生成过程中在观察结果之前停止生成,以便于后续处理中插入工具调用的结果。这种方式确保了 ReAct 格式(思考-行动-观察循环)的正确实现。
执行函数
_run 方法是实现 ReAct 推理过程的核心,接收消息列表并使用迭代器返回回复:
def _run(self, messages: List[Message], lang: Literal['en', 'zh'] = 'en', **kwargs) -> Iterator[List[Message]]:text_messages = self._prepend_react_prompt(messages, lang=lang)num_llm_calls_available = MAX_LLM_CALL_PER_RUNresponse: str = 'Thought: 'while num_llm_calls_available > 0:num_llm_calls_available -= 1# 显示流式响应output = []for output in self._call_llm(messages=text_messages):if output:yield [Message(role=ASSISTANT, content=response + output[-1].content)]# 累积当前响应if output:response += output[-1].contenthas_action, action, action_input, thought = self._detect_tool(output[-1].content)if not has_action:break# 添加工具调用结果observation = self._call_tool(action, action_input, messages=messages, **kwargs)observation = f'\nObservation: {observation}\nThought: 'response += observationyield [Message(role=ASSISTANT, content=response)]if (not text_messages[-1].content.endswith('\nThought: ')) and (not thought.startswith('\n')):# 在"Question:"和第一个"Thought:"之间添加换行符text_messages[-1].content += '\n'if action_input.startswith('```'):# 为代码块的正确渲染添加换行符action_input = '\n' + action_inputtext_messages[-1].content += thought + f'\nAction: {action}\nAction Input: {action_input}' + observation
这个函数实现了 ReAct 格式的核心流程:
- 首先调用
_prepend_react_prompt将 ReAct 提示词添加到消息中 - 使用计数器限制 LLM 调用次数,防止无限循环
- 开始响应总是以 "Thought: " 开头
- 在循环中:
- 调用 LLM 生成一段回复
- 使用
_detect_tool解析回复中的工具调用信息 - 如果没有检测到工具调用,则完成推理并结束循环
- 如果检测到工具调用,则执行工具并获取观察结果
- 将观察结果和新的 "Thought: " 提示添加到响应中
- 更新历史消息以包含完整的思考、行动和观察过程,为下一轮生成提供上下文
与Function Call方法的区别
注意在调用公共推理函数的时候,ReActChat的写法是self._call_llm(messages=text_messages),而FnCallAgent的写法是self._call_llm(messages=messages, functions=[func.function for func in self.function_map.values()],extra_generate_cfg=extra_generate_cfg),这是因为ReActChat已经把Function的信息和内容都汇聚到了文本中,因此它的Function为None,Function Call所调用的一系列与Function相关的处理与后处理都被跳过了。
提示词处理
_prepend_react_prompt 方法负责将 ReAct 格式的提示词添加到用户消息中:
def _prepend_react_prompt(self, messages: List[Message], lang: Literal['en', 'zh']) -> List[Message]:tool_descs = []for f in self.function_map.values():function = f.functionname = function.get('name', None)name_for_human = function.get('name_for_human', name)name_for_model = function.get('name_for_model', name)assert name_for_human and name_for_modelargs_format = function.get('args_format', '')tool_descs.append(TOOL_DESC.format(name_for_human=name_for_human,name_for_model=name_for_model,description_for_model=function['description'],parameters=json.dumps(function['parameters'], ensure_ascii=False),args_format=args_format).rstrip())tool_descs = '\n\n'.join(tool_descs)tool_names = ','.join(tool.name for tool in self.function_map.values())text_messages = [format_as_text_message(m, add_upload_info=True, lang=lang) for m in messages]text_messages[-1].content = PROMPT_REACT.format(tool_descs=tool_descs,tool_names=tool_names,query=text_messages[-1].content,)return text_messages
这个函数的主要工作:
- 为每个工具生成描述,包括名称、描述和参数信息
- 将所有工具描述合并为一个字符串
- 生成用于提示中的工具名称列表
- 将原始消息转换为文本格式
- 使用
PROMPT_REACT模板替换最后一条消息内容,并填入工具描述、工具名称和原始查询
这样确保了 LLM 在生成回复时遵循 ReAct 格式的思考、行动和观察循环。
工具解析
_detect_tool 方法负责从 LLM 回复中解析工具调用信息:
def _detect_tool(self, text: str) -> Tuple[bool, str, str, str]:special_func_token = '\nAction:'special_args_token = '\nAction Input:'special_obs_token = '\nObservation:'func_name, func_args = None, Nonei = text.rfind(special_func_token)j = text.rfind(special_args_token)k = text.rfind(special_obs_token)if 0 <= i < j: # 如果文本包含 `Action` 和 `Action input`if k < j: # 但不包含 `Observation`# 那么可能是 LLM 输出省略了停止词# 因为输出文本可能丢弃了停止词text = text.rstrip() + special_obs_token # 将其添加回去k = text.rfind(special_obs_token)func_name = text[i + len(special_func_token):j].strip()func_args = text[j + len(special_args_token):k].strip()text = text[:i] # 返回工具调用前的响应,即 `Thought`return (func_name is not None), func_name, func_args, text
这个函数通过查找特殊标记(Action、Action Input、Observation)来解析 LLM 输出中的工具调用信息:
- 查找最后出现的 “Action:”、“Action Input:” 和 “Observation:” 标记
- 如果找到了 Action 和 Action Input 但没有 Observation,则手动添加一个 Observation 标记
- 解析出工具名称(func_name)和工具参数(func_args)
- 返回一个元组,包含:
- 是否存在工具调用
- 工具名称
- 工具参数
- 思考部分的文本内容
这个函数确保了即使 LLM 的输出格式略有偏差,也能正确解析出工具调用信息,保证了 ReAct 过程的稳定执行。
关于中英文提示词的分析
在qwen_agent/agents/react_chat.py中,一开始就定义了英文提示词模板
TOOL_DESC = ('{name_for_model}: Call this tool to interact with the {name_for_human} API. ''What is the {name_for_human} API useful for? {description_for_model} Parameters: {parameters} {args_format}')PROMPT_REACT = """Answer the following questions as best you can. You have access to the following tools:{tool_descs}Use the following format:Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can be repeated zero or more times)
Thought: I now know the final answer
Final Answer: the final answer to the original input questionBegin!Question: {query}
Thought: """
其经_prepend_react_prompt 方法处理后的实例如下:
[Message({'role': 'user', 'content': 'Answer the following questions as best you can. You have access to the following tools:\n\nmultiply: Call this tool to interact with the multiply API. What is the multiply API useful for? 两个整数相乘 Parameters: [[{"name": "first_int", "type": "integer", "description": "第一个整数", "required": true}, {"name": "second_int", "type": "integer", "description": "第二个整数", "required": true}]] 此工具的输入应为JSON对象。\n\nadd: Call this tool to interact with the add API. What is the add API useful for? 两个整数相加 Parameters: [[{"name": "first_add", "type": "integer", "description": "第一个整数", "required": true}, {"name": "second_add", "type": "integer", "description": "第二个整数", "required": true}]] 此工具的输入应为JSON对象。\n\nUse the following format:\n\nQuestion: the input question you must answer\nThought: you should always think about what to do\nAction: the action to take, should be one of [multiply,add]\nAction Input: the input to the action\nObservation: the result of the action\n... (this Thought/Action/Action Input/Observation can be repeated zero or more times)\nThought: I now know the final answer\nFinal Answer: the final answer to the original input question\n\nBegin!\n\nQuestion: 3乘12的数值是多少?以及,11加49是多少?\nThought: '})]
那么中文体现在哪里呢,其实只在qwen_agent/utils/utils.py中的def format_as_multimodal_message( 下作了一些小小的翻译:
for f in [get_basename_from_url(f) for f in files]:if is_image(f):if has_zh:upload.append(f'')else:upload.append(f'')else:if has_zh:upload.append(f'[文件]({f})')else:upload.append(f'[file]({f})')
upload = ' '.join(upload)
if has_zh:upload = f'(上传了 {upload})\n\n'
else:upload = f'(Uploaded {upload})\n\n'
关于并行调用工具失效的分析
在上一章中,我们尝试通过在run函数中设置parallel_function_calls=True来实现工具的并行化调用,但并没有生效。事实上,由于工具都写在了提示词中,在qwen_agent/llm/base.py中的_call_model_service并没有调用self._chat_with_functions而是直接进入了self._chat。所以至少,这个参数如果你去设,它不会被人为删掉。
那么_chat的下一步是哪里呢?其实是qwen_agent/llm/oai.py中的_chat_complete_create函数
def _chat_complete_create(*args, **kwargs):# OpenAI API v1 does not allow the following args, must pass by extra_bodyextra_params = ['top_k', 'repetition_penalty']if any((k in kwargs) for k in extra_params):kwargs['extra_body'] = copy.deepcopy(kwargs.get('extra_body', {}))for k in extra_params:if k in kwargs:kwargs['extra_body'][k] = kwargs.pop(k)if 'request_timeout' in kwargs:kwargs['timeout'] = kwargs.pop('request_timeout')client = openai.OpenAI(**api_kwargs)return client.chat.completions.create(*args, **kwargs)
看起来好像没什么问题,试试看设置有没有用。

哈哈哈哈哈参数不正确,可以放心地死心了。
相关文章:

针对Qwen-Agent框架的源码阅读与解析:FnCallAgent与ReActChat篇
在《针对Qwen-Agent框架的Function Call及ReAct的源码阅读与解析:Agent基类篇》中,我们已经了解了Agent基类的大体实现。这里我们就再详细学习一下FnCallAgent类和ReActChat的实现思路,从而对Agent的两条主流技术路径有更深刻的了解。同时&am…...

在docker中安装RocketMQ
第一步你需要有镜像包,这个2023年的时候docker就不能用pull拉取镜像了,需要你自己找 第二步我用的是FinalShell,用别的可视化界面也用, 在你自己平时放镜像包的地方创建一个叫rocketmq的文件夹,放入镜像包后,创建一个…...

Spring Boot + Kafka 消息队列从零到落地
背景 依赖 <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> <version>2.8.1</version> </dependency> 发送消息 //示例: private final KafkaTemplate<St…...

《打破语言壁垒:bilingual_book_maker 让外文阅读更轻松》
在寻找心仪的外文电子书时,常常会因语言障碍而感到困扰。虽然可以将文本逐段复制到在线翻译工具中,但这一过程不仅繁琐,还会打断阅读的连贯性,让人难以沉浸其中。为了克服这一难题,我一直在寻找一种既能保留原文&#…...

JCR一区文章,壮丽细尾鹩莺算法Superb Fairy-wren Optimization-附Matlab免费代码
本文提出了一种新颖的基于群体智能的元启发式优化算法——壮丽细尾鹩优化算法(SFOA),SFOA从精湛的神仙莺的生活习性中汲取灵感。融合了精湛的神仙莺群体中幼鸟的发育、繁殖后鸟类喂养幼鸟的行为以及它们躲避捕食者的策略。通过模拟幼鸟生长、繁殖和摄食阶…...

Kafka 如何实现 Exactly Once
Kafka 中实现 Exactly Once Semantics(EOS,精确一次语义),是为了确保: 每条消息被处理一次且仅一次,既不会丢失,也不会重复消费。 这是一种在分布式消息系统中非常难实现的语义。Kafka 从 0.11 …...

在K8S中,内置的污点主要有哪些?
在Kubernetes (K8S)中,内置的污点(Taints)主要用于自动化的节点亲和性和反亲和性管理。当集群中的节点出现某种问题或满足特定条件时,kubelet会自动给这些节点添加内置污点。以下是一些常见的内置污点: node.kubernete…...
2.1 从零训练自己的大模型概述)
AI大模型:(二)2.1 从零训练自己的大模型概述
目录 1. 分词器训练 1.1 分词器概述 1.2 训练简述 2.预训练 2.1 预训练概述 2.2 预训练过程简介 3.微调训练 3.1 微调训练概述 3.2 微调过程简介 4.人类对齐 4.1 人类对齐概述 4.2 人类对齐训练过程简介 近年来,大语言模型(LLM)如GPT-4、Claude、LLaMA等…...
)
电动垂直起降飞行器(eVTOL)
电动垂直起降飞行器(eVTOL)的详细介绍,涵盖定义、技术路径、应用场景、市场前景及政策支持等核心内容: 一、定义与核心特性 eVTOL(Electric Vertical Take-off and Landing)即电动垂直起降飞行器…...

LM Studio本地部署大模型
现在的AI可谓是火的一塌糊涂, 看到使用LM Studio部署本地模型非常的方便, 于是我也想在自己的本地试试 LM Studio 简介 LM Studio 是一款专为本地运行大型语言模型(LLMs)设计的桌面应用程序,支持 Windows 和 macOS 系统。它允许用户在个人电…...
PyTorch 深度学习 || 6. Transformer | Ch6.1 Transformer 框架
1. Transformer 框架...

SLAM文献之-SLAMesh: Real-time LiDAR Simultaneous Localization and Meshing
SLAMesh 是一种基于 LiDAR 的实时同步定位与建图(SLAM)算法,其核心创新点在于将定位与稠密三维网格重建相结合,通过动态构建和优化多边形网格(Mesh)来实现高精度定位与环境建模。以下是其算法原理的详细解析…...

[Python] 位置相关的贪心算法-刷题+思路讲解版
位置贪心-题目目录 例题1 - 香蕉商人编程实现输入描述输出描述思路AC代码 例题2 - 分糖果编程实现输入描述输入样例输出样例思路AC代码 例题4 - 分糖果II编程实现输入描述输出描述输入样例思路AC代码 例题3 - 分糖果III编程实现输入描述输出描述输入样例输出样例思路AC代码 例题…...

练习题:125
目录 Python题目 题目 题目分析 需求理解 关键知识点 实现思路分析 代码实现 代码解释 导入 random 模块: 指定范围: 生成随机整数: 输出结果: 运行思路 结束语 Python题目 题目 生成一个指定范围内的随机整数。 …...

实战设计模式之迭代器模式
概述 与上一篇介绍的解释器模式一样,迭代器模式也是一种行为设计模式。它提供了一种方法来顺序访问一个聚合对象中的各个元素,而无需暴露该对象的内部表示。简而言之,迭代器模式允许我们遍历集合数据结构中的元素,而不必了解这些集…...
)
Spring-AOP详解(AOP概念,原理,动态代理,静态代理)
目录 什么是AOP:Spring AOP核心概念需要先引入AOP依赖:1.切点(Pointcut):2.连接点:3.通知(Advice):4.切面: 通知类型:Around:环绕通知,此注解标注的通知方法在目标方法前,…...

【dify应用】将新榜排行数据免费保存到飞书表格
新榜中导出数据是收费的,如何免费导出呢 接口分析 切换分类排行,数据是在这个接口中请求的 参数: {"rankType":1,"rankDate":"2025-04-05","type":["财富"],"size":25,"…...

【Linux】线程池详解及基本实现
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...
)
基于论文的大模型应用:基于SmartETL的arXiv论文数据接入与预处理(一)
1. 背景 arXiv简介(参考DeepSeek大模型生成内容): arXiv(发音同“archive”,/ˈɑːrkaɪv/)是一个开放的学术预印本平台,主要用于研究人员分享和获取尚未正式发表或已完成投稿的学术论文。创…...

Leetcode 3508. Implement Router
Leetcode 3508. Implement Router 1. 解题思路2. 代码实现 题目链接:3508. Implement Router 1. 解题思路 这一题就是按照题意写作一下对应的函数即可。 我们需要注意的是,这里,定义的类当中需要包含以下一些内容: 一个所有i…...
)
Nmap全脚本使用指南!NSE脚本全详细教程!Kali Linux教程!(六)
脚本类别 discovery(发现) sip-methods 已演示过。这里不再演示。 436. smb-enum-domains 尝试枚举系统上的域及其策略。这通常需要凭据,但 Windows 2000 除外。除了实际域之外,通常还会显示“内置”域。Windows 在域列表中返…...

了解适配器模式
目录 适配器模式定义 适配器模式角色 适配器模式的实现 适配器的应用场景 适配器模式定义 适配器模式,也叫包装模式。将一个类的接口,转换成客户期望的另一个接口,适配器让原本接口不兼容的类可以合作无间。 简单来说就是目标类不能直接…...

C语言:几种字符串常用的API
字符串的常用操作 C 语言的标准库 <string.h> 提供了很多用于处理字符串的函数。 1. strlen - 计算字符串长度 size_t strlen(const char *str);功能:计算字符串 str 的长度,不包含字符串结束符 \0。 2.strcpy - 复制字符串 char *strcpy(char…...

Django构建安全中间件实用示例
Django安全中间件实用指南 推荐超级课程: 本地离线DeepSeek AI方案部署实战教程【完全版】Docker快速入门到精通Kubernetes入门到大师通关课AWS云服务快速入门实战目录 Django安全中间件实用指南什么是Django中的中间件?Django中的安全中间件特性配置示例配置示例配置示例示…...
【泪光2929】)
排序算法(快速排序,选择排序......)【泪光2929】
hello,大家好!今天给大家分享一下各种排序: 1,选择排序 首先从原始数组中 选择最小的1个数据,将其和位于第1个位置的数据交换。接着从剩下的n-1个数据中选择次小的1个元素,将其和第2个位置的数据交换然后…...

UE5学习记录part14
第17节 enemy behavior 173 making enemies move: AI Pawn Navigation 按P查看体积 So its very important that our nav mesh bounds volume encompasses all of the area that wed like our 因此,我们的导航网格边界体积必须包含我们希望 AI to navigate in and …...

树莓派llama.cpp部署DeepSeek-R1-Distill-Qwen-1.5B
树莓派的性能太低了,我们需要对模型进行量化才能使用,所以现在的方案是,在windows上将模型格式和量化处理好,然后再将模型文件传输到树莓派上。而完成上面的操作就需要部署llama.cpp。 三、环境的准备 这里要求大家准备…...

Llama 4 最新发布模型分析
1. 引言 在2025年4月5日,Meta公司正式发布了最新一代大型语言模型Llama 4系列,包括Llama 4 Scout和Llama 4 Maverick。该模型添加了多模态支持,能够处理文本、图像、音频和视频数据,实现更加充分的AI功能应用。 2. 技术特性 2.1…...

Llama 4 家族:原生多模态 AI 创新的新时代开启
0 要点总结 Meta发布 Llama 4 系列的首批模型,帮用户打造更个性化多模态体验Llama 4 Scout 是有 170 亿激活参数、16 个专家模块的模型,同类中全球最强多模态模型,性能超越以往所有 Llama 系列模型,能在一张 NVIDIA H100 GPU 上运…...

如何让eDrawings html文件在Chrome浏览器上展示——allWebPlugin中间件扩展
应用背景 eDrawing html文件是仅可在 Internet Explorer 5.5 和以上版本中查阅,由于IE浏览器限制,目前使用非常不方便,为了不修改html的请提下,在chrome浏览器查阅原本html文件,可使用安装allWebPlugin中间件扩展。 a…...

【内网安全】DHCP 饿死攻击和防护
正常情况:PC2可以正常获取到DHCP SERVER分别的IP地址查看DHCP SERCER 的ip pool地址池可以看到分配了一个地址、Total 253个 Used 1个 使用kali工具进行模拟攻击 进行DHCP DISCOVER攻击 此时查看DHCP SERVER d大量的抓包:大量的DHCP Discover包 此时模…...

keepalived高可用介绍
keepalived 是 Linux 一个轻量级的高可用解决方案,提供了心跳检测和资源接管、检测集群中的系统服务,在集群节点间转移共享IP 地址的所有者等。 工作原理 keepalived 通过 VRRP(virtual router redundancy protocol)虚拟路由冗余…...

基于大模型的脑梗死全流程诊疗技术方案
目录 《基于大模型的脑梗死全流程诊疗技术方案》一、核心算法实现1. 多模态特征融合算法(术前规划)2. 术中实时预警算法二、系统模块设计1. 术前规划系统流程图2. 术中实时监控系统架构三、技术验证方案1. 模型验证矩阵2. 实验验证设计四、关键技术创新点五、工程实现规范1. …...

ngx_timezone_update
定义在 src\os\unix\ngx_time.c void ngx_timezone_update(void) { #if (NGX_FREEBSD)if (getenv("TZ")) {return;}putenv("TZUTC");tzset();unsetenv("TZ");tzset();#elif (NGX_LINUX)time_t s;struct tm *t;char buf[4];s tim…...

Redis 热key问题怎么解决?
Redis 热 Key 问题分析与解决方案 热 Key(Hot Key)是指被高频访问的某个或多个 Key,导致单个 Redis 节点负载过高,可能引发性能瓶颈甚至服务崩溃。以下是常见原因及解决方案: 1. 热 Key 的常见原因 突发流量:如明星八卦、秒杀商品、热门直播等场景。缓存设计不合理:如全…...
)
JavaWeb(楠)
JavaWeb21-1:Java Web开发的地位、Tomcat服务器 Java Web开发概述 主流地位:Java可用于移动端、桌面应用、机器学习等多个领域,但在Web开发领域优势显著,是Java最主流的研发方向。市场上95%以上的Web端开发都使用Java,…...

批量将 JSON 转换为 Excel/思维导入等其它格式
json 格式相信对大家来说都不陌生,这是一种轻量级的结构化数据,可以对对象进行描述。json 格式也是一种普通的文本文件格式,用记事本就能够打开编辑 json 格式的文件,可以很方便的转换为其他格式。今天要给大家介绍的就是如何将 j…...
之通过WebServer查询天气预报)
C# Winform 入门(13)之通过WebServer查询天气预报
展示 控件 添加WebServer 右键项目> 添加引用> 添加服务引用 天气预报URL: WeatherWebService Web 服务WeatherWebService Web 服务http://www.webxml.com.cn/WebServices/WeatherWebService.asmx 查询按钮实现 private void btn_Inquiry_Click(object sender, EventA…...
)
算法思想之滑动窗口(一)
欢迎拜访:雾里看山-CSDN博客 本篇主题:算法思想之滑动窗口(一) 发布时间:2025.4.6 隶属专栏:算法 目录 滑动窗口算法介绍核心思想时间复杂度适用场景注意事项 例题长度最小的子数组题目链接题目描述算法思路代码实现 无重复字符的…...

爬虫工程师无意义的活
30岁的年龄;这个年龄大家都是成年人;都是做父母的年龄了;你再工位上的心态会发生很大变化的; 爬虫工程师基本都是如此;社会最low的一帮连销售都做不了的;单子都开不出来的然后转行做爬虫工程师的;这样的人基本不太和社会接触; 你作为爬虫初级工程师就敲着键盘然后解析着html;…...

DeepSeek 关联公司公布新型数据采集专利 提升数据采集效率与质量
4 月 1 日,国家知识产权局公布了一项由 DeepSeek 关联公司杭州深度求索人工智能基础技术研究有限公司申请的专利,名为 “一种广度数据采集的方法及其系统”,公开号为 CN 119739917 A,申请日期可追溯至 2024 年 12 月。此专利的发布…...

实际犯错以及复盘1
Ds1302 需要两个 一个Set_Rtc 一个Read_Rtc : 本质 read是 85-2i 的 写入是84-2i 然后 写入的时候 是需要对 0x8e 进行 0x00 和0x80进行解开和 锁定的开头结尾。 使用的时候 赋值给ucRtc[i] 然后 主函数使用的时候 需要直接写个(ucRtc) 因为unsigned char* 默认的…...

初探:简道云系统架构及原理
一、系统架构概述 简道云作为一款低代码开发平台,其架构设计以模块化和云端协同为核心,主要分为以下层次: 1. 前端层 可视化界面:基于Web的拖拽式表单设计器,支持动态渲染(React/Vue框架)。多…...

Nginx负载均衡时如何为指定ip配置固定服务器
大家在用Nginx做负载均衡时,一般是采用默认的weight权重指定或默认的平均分配实现后端服务器的路由,还有一种做法是通过ip_hash来自动计算进行后端服务器的路由,但最近遇到一个问题,就是希望大部分用户采用ip_hash自动分配后端服务…...

玩转MCP:用百度热搜采集案例快速上手并接入cline
MCP的大火,让MCP服务器开发也变得热门,上一篇文章: 手搓MCP客户端&服务端:从零到实战极速了解MCP是什么? 手搓了一个极其简单的小场景的MCP实战案例,详细的安装环境及操作步骤已经讲过了,本文不在重复…...
)
003集——《利用 C# 与 AutoCAD API 开发 WPF 随机圆生成插件》(侧栏菜单+WPF窗体和控件+MVVM)
本案例聚焦于开发一款特色鲜明的 AutoCAD 插件。其核心功能在于,用户在精心设计的 WPF 控件界面中输入期望生成圆的数量,完成输入后,当用户点击 “生成” 按钮,一系列联动操作随即展开。通过数据绑定与命令绑定这一精妙机制&#…...
责任链模式)
设计模式简述(十)责任链模式
责任链模式 描述基本使用使用 描述 如果一个请求要经过多个类似或相关处理器的处理。 可以考虑将这些处理器添加到一个链上,让请求逐个经过这些处理器进行处理。 通常,在一个业务场景下会对整个责任链进行初始化,确定这个链上有哪些Handler…...
)
分组(二分查找)
#include <bits/stdc.h> using namespace std; const int N1e55; int a[N]; int n,k;bool f(int x){int num1;int ma[1];for(int i2;i<n;i){if(a[i]-m>x){ // 当前元素加入当前组会超过极差 xnum; // 新开一组ma[i]; // 新组的最小值设为当前元素}}r…...

vue的主要核心文件介绍
1.package.json 查看依赖包的版本 项目基本信息记录 项目标识:记录项目名称(name 字段)、版本号(version 字段)、描述(description 字段)等基础信息,方便识别和管理项目。例如&…...

从奖励到最优决策:动作价值函数与价值学习
从奖励到最优决策:动作价值函数与价值学习 价值学习动作价值函数对 U t U_t Ut求期望得到动作价值函数动作价值函数的意义最优动作价值函数(Optimal Action-Value Function)如何理解 Q ∗ Q^* Q∗函数 价值学习的基本思想Deep Q-Network(DQN)DQN玩游戏的具体流程如…...