Llama 4 家族:原生多模态 AI 创新的新时代开启

0 要点总结
- Meta发布 Llama 4 系列的首批模型,帮用户打造更个性化多模态体验
- Llama 4 Scout 是有 170 亿激活参数、16 个专家模块的模型,同类中全球最强多模态模型,性能超越以往所有 Llama 系列模型,能在一张 NVIDIA H100 GPU 上运行。该模型支持业界领先的 1000 万上下文窗口,在多个权威测试中表现优于 Gemma 3、Gemini 2.0 Flash-Lite 和 Mistral 3.1
- Llama 4 Maverick 也拥有 170 亿激活参数,但配置多达 128 个专家模块,是同类中最强的多模态模型,在多个广泛测试中超越 GPT-4o 和 Gemini 2.0 Flash,推理和编程能力可与 DeepSeek v3 相当,但激活参数数量不到其一半。其聊天版在 LMArena 上取得了 1417 的 ELO 分数,性能与成本比行业领先
- 这些出色的模型得益于“教师模型” Llama 4 Behemoth 的知识蒸馏。Behemoth 拥有 2880 亿激活参数和 16 个专家模块,是我们最强大的模型,在多项 STEM 基准测试中超越 GPT-4.5、Claude Sonnet 3.7 和 Gemini 2.0 Pro。目前该模型仍在训练中,我们将持续分享更多细节。
- 立即前往 llama.com 或 Hugging Face 下载 Llama 4 Scout 与 Maverick。也可在 WhatsApp、Messenger、Instagram 私信体验基于 Llama 4 构建的 Meta AI。
随 AI 在日常生活中的广泛应用,确保领先的模型与系统开放可用,对推动个性化体验创新至关重要。支持整个 Llama 生态 的最先进模型组合。正式推出的 Llama 4 Scout 和 Llama 4 Maverick,是首批开放权重、原生多模态、支持超长上下文窗口、采用 MoE架构构建的模型。“巨兽”—— Llama 4 Behemoth,不仅是迄今最强大的模型之一,也是新一代模型的“老师”。
这些 Llama 4 模型的发布标志着 Llama 生态迈入新纪元。Llama 4 系列中的 Scout 和 Maverick 都是高效设计的模型:
- 前者能以 Int4 量化方式部署在单张 H100 GPU 上
- 后者则适配于单个 H100 主机
训练了 Behemoth 教师模型,在 STEM 基准(如 MATH-500 和 GPQA Diamond)中表现优于 GPT-4.5、Claude Sonnet 3.7 和 Gemini 2.0 Pro。
开放才能推动创新,对开发者、Meta 和整个世界都是利好。可通过 llama.com 和 Hugging Face 下载 Scout 与 Maverick。同时,Meta AI 也已在 WhatsApp、Messenger、Instagram 私信启用 Llama 4 模型。
这只是 Llama 4 系列的开始。最智能的系统应能泛化行动、自然对话并解决未曾遇到的问题。赋予 Llama 在这些领域的“超能力”,将催生更优质的产品和更多开发者创新机会。
无论你是构建应用的开发者,集成 AI 的企业用户,或是对 AI 潜力充满好奇的普通用户,Llama 4 Scout 和 Maverick 都是将下一代智能融入产品的最佳选择。接下来,介绍它们的四大研发阶段以及设计过程中的一些关键洞察。
1 预训练阶段
这些模型代表 Llama 系列的巅峰之作,具备强大多模态能力,同时在成本上更具优势,甚至性能超越了一些参数规模更大的模型。为打造 Llama 下一代模型,在预训练阶段采用了多项新技术。
MoE
Llama 4是首批采用MoE的模型。MoE架构的一个核心优势:每个 token 只激活模型中一小部分参数,从而大幅提高训练与推理的效率。在给定的 FLOPs(浮点运算)预算下,MoE 模型的效果优于传统的密集模型。
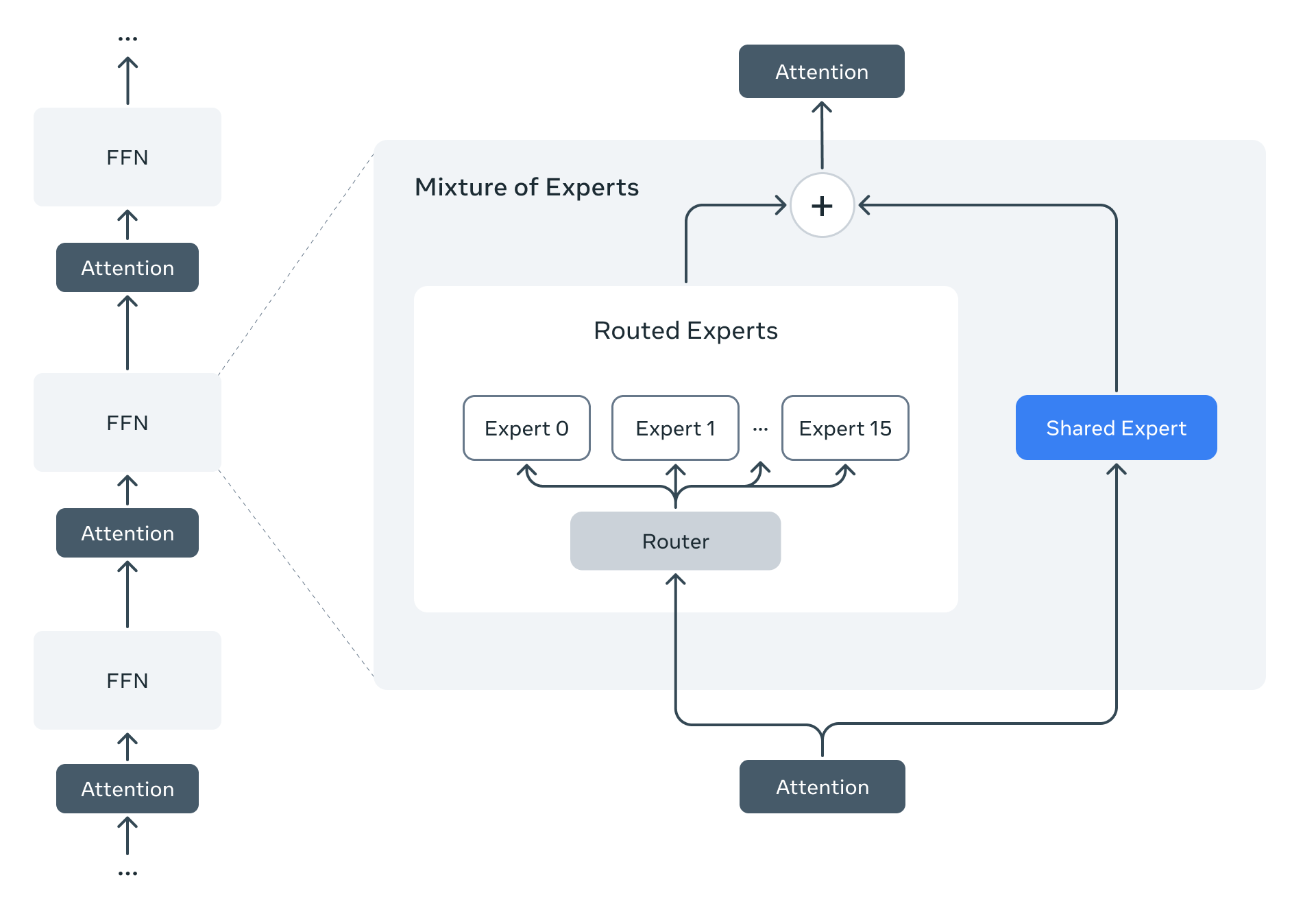
以 Llama 4 Maverick 为例:它拥有 170 亿激活参数,总参数数为 4000 亿。其网络结构在推理过程中交替使用密集层与 MoE 层。每个 token 会被送入一个共享专家和一个 128 个路由专家之一,这种机制确保模型在保持全参数存储的同时,仅激活必要部分,从而提升运行效率、降低成本与延迟。Maverick 可在一台 NVIDIA H100 DGX 主机上运行,也支持分布式部署以实现最大效率。
Llama 4 天生支持多模态输入,采用 早期融合(early fusion)机制,将文本与视觉 token 一体化输入模型主干。使得能用大量未标注的文本、图像和视频数据对模型进行联合预训练。同时,升级视觉编码器,基于 MetaCLIP 的改进版,在预训练阶段与冻结的 Llama 主干协同优化。
新训练方法MetaP
精确控制每层学习率和初始化比例。这些超参数在不同 batch size、模型宽度、深度和 token 数下都具有良好的迁移性。Llama 4 预训练涵盖 200 多种语言,其中 100 多种语言的数据量超过 10 亿 tokens,总体上多语种训练 token 数量是 Llama 3 的 10 倍。
FP8 精度
用 FP8 精度 进行训练,保持模型质量的同时提高训练效率。如训练 Behemoth 时,用 32000 张 GPU,并实现 390 TFLOPs/GPU 的高效能。整个训练数据超过 30 万亿个 token,是 Llama 3 的两倍,数据类型包含多样的文本、图像和视频内容。
训练中期,采用“mid-training”阶段,通过专门数据集提升模型的核心能力,如支持更长上下文的能力。得益于这些改进,Llama 4 Scout 实现 业界领先的 1000 万 token 输入长度。
2 后训练阶段
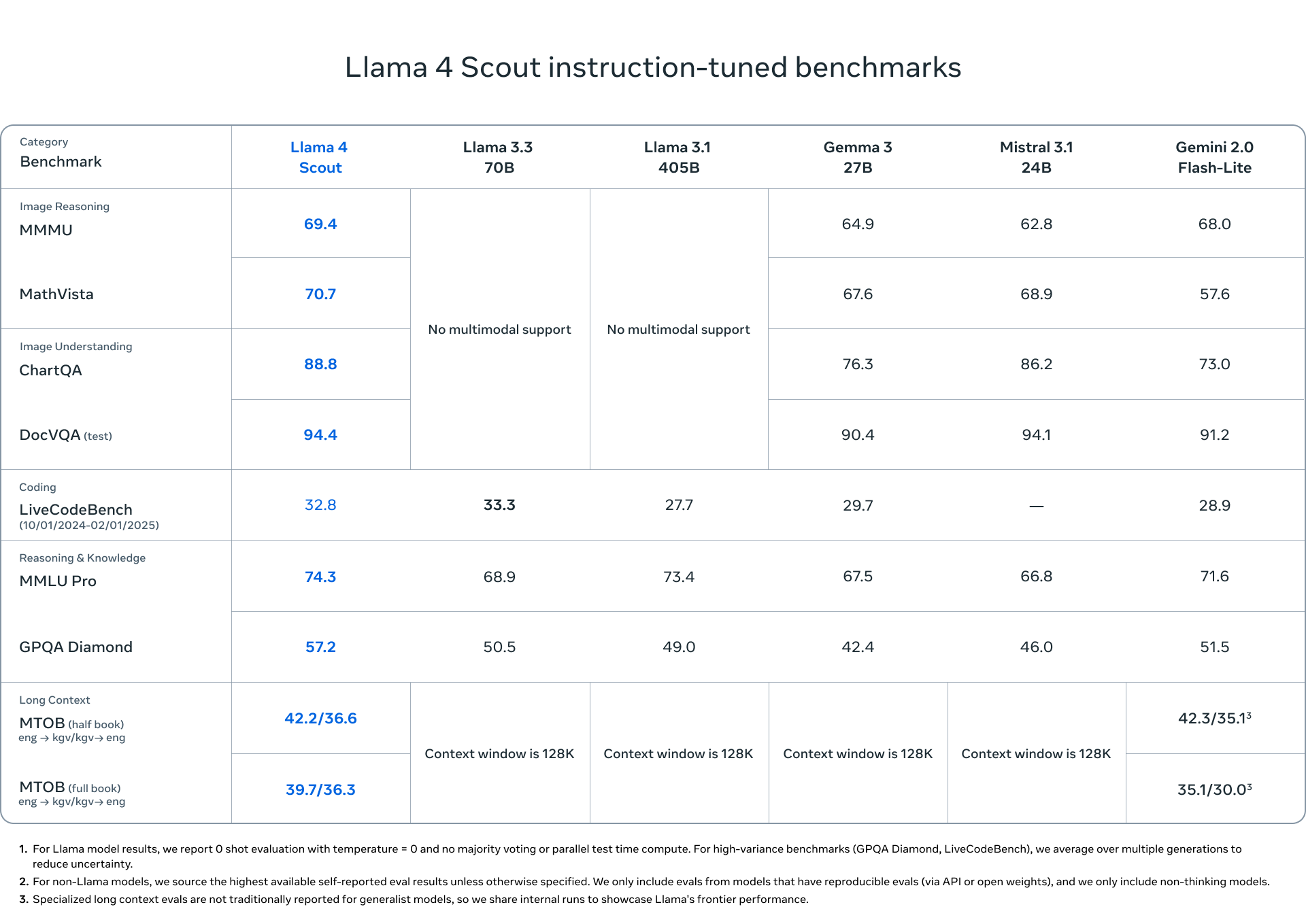
新模型有大小多种选择,以满足不同应用场景与开发者需求。Llama 4 Maverick 在图像和文本理解方面表现卓越,是多语言 AI 应用和创意写作的理想选择。
后训练阶段最大的挑战是保持不同输入模态、推理能力与对话能力之间的平衡。为此,设计“多模态课程”训练策略,确保模型不因学习多模态而牺牲单一模态性能。更新了后训练流程,采取轻量监督微调(SFT)> 在线强化学习(RL)> 轻量偏好优化(DPO)的方式。发现SFT 与 DPO 若使用不当,会限制模型在 RL 阶段的探索,特别是在推理、编程和数学领域会导致效果下降。
为解决这问题,剔除超过 50% 的“简单样本”,仅对更难数据进行 SFT。之后 RL 阶段用更具挑战性提示,实现性能飞跃。采用 持续在线 RL 策略:训练模型 → 用模型筛选中等难度以上的提示 → 再训练,如此循环,有效平衡计算成本与精度。最终,我们通过轻量 DPO 优化边缘情况,全面提升模型的智能与对话能力。
Llama 4 Maverick 拥有 170 亿激活参数、128 个专家模块与 4000 亿总参数,在性能上超越 Llama 3.3 的 70B 模型。它是目前最顶级的多模态模型,在编程、推理、多语言、长文本与图像等任务中优于 GPT-4o 与 Gemini 2.0,与 DeepSeek v3.1 的表现不相上下。
[外链图片转存中…(img-Y4bYAPfr-1743952046715)]
Llama 4 Scout 是一款通用模型,具备 170 亿激活参数、16 个专家模块、1090 亿总参数,性能在同类模型中首屈一指。它将上下文长度从 Llama 3 的 128K 大幅提升至 1000 万 tokens,支持多文档摘要、个性化任务解析、大型代码库推理等复杂应用。
Scout 在预训练和后训练阶段都使用了 256K 上下文长度,从而拥有出色的长文本泛化能力。在文本检索、代码负对数似然(NLL)评估等任务中均表现优秀。其一大创新是采用了 不使用位置嵌入的交错注意力机制(iRoPE),通过 温度调节推理机制 提升了对超长输入的处理能力。
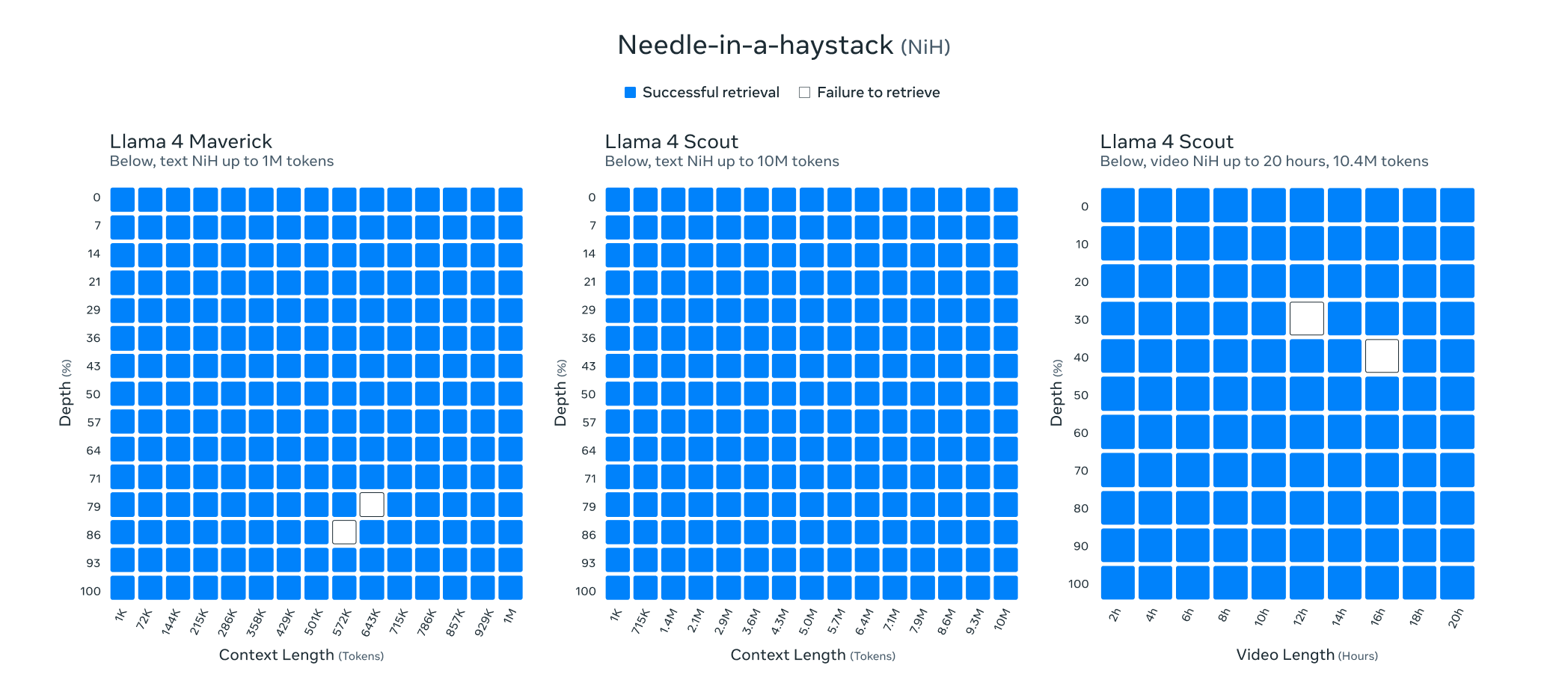

我们对两个模型都进行了广泛的图像和视频帧训练,以增强它们对视觉内容的理解能力,包括时间相关活动和图像之间的关联。这让模型在处理多图输入时能轻松地结合文字提示进行视觉推理与理解。预训练阶段使用最多48张图像的输入,并在后期测试中验证模型在处理最多8张图像时的良好表现。
Llama 4 Scout 在图像定位方面表现尤为出色,能够将用户的提示准确对应到图像中的具体视觉元素,实现更精确的视觉问答。这款模型在编程、推理、长文本理解和图像处理等方面全面超越以往版本的 Llama 模型,性能领先同类模型。
3 推出更大规模的 Llama:2 万亿参数巨兽 Behemoth
Llama 4 Behemoth——拥有高级智能的“教师模型”,在同类模型中表现领先。Behemoth 是一个多模态专家混合(MoE)模型,激活参数达 2880 亿,拥有 16 个专家模块,总参数量接近两万亿。在数学、多语言和图像基准测试中表现一流,因此成为训练更小的 Llama 4 模型的理想“老师”。
从 Behemoth 模型中通过“共蒸馏”(codistillation)技术训练出了 Llama 4 Maverick,有效提升了最终任务表现。我们还研发了一种全新的损失函数,能在训练过程中动态调整软标签和硬标签的权重。此外,我们还通过在 Behemoth 上运行前向传递,生成用于训练学生模型的数据,大幅降低了训练成本。
对这样一个拥有两万亿参数的模型,其后期训练本身就是一项巨大挑战。我们从数据量级就开始彻底改革训练方法。为提升性能,我们将监督微调(SFT)数据削减了95%(相比于小模型只需要削减50%),以更专注于数据质量和效率。
还发现:先进行轻量级的 SFT,再进行大规模强化学习(RL),能够显著提升模型的推理和编程能力。RL策略包括:
- 使用 pass@k 方法选取具有挑战性的提示构建训练课程;
- 动态过滤无效提示;
- 混合多个任务的提示组成训练批次;
- 使用多种系统指令样本,确保模型能广泛适应不同任务。
为支持 2 万亿参数的 RL 训练,重构了整个强化学习基础设施。对 MoE 并行架构进行了优化,提高训练速度,并开发了完全异步的在线 RL 框架,提升了训练的灵活性和效率。通过将不同模型分配到不同 GPU 并进行资源平衡,实现训练效率的近10倍提升。
4 安全机制与防护措施
致力打造有用且安全的模型,同时规避潜在的重大风险。Llama 4 遵循《AI 使用开发指南》中的最佳实践,从预训练到系统级都融入了防护机制,以保障开发者免受恶意行为干扰,从而开发出更安全、可靠的应用。
4.1 预训练与后训练防护
- 预训练:使用数据过滤等方法保护模型。
- 后训练:通过一系列技术确保模型遵循平台政策,保持对用户和开发者的友好性和安全性。
4.2 系统级方法
开源了多种安全工具,方便集成进 Llama 模型或第三方系统:
- Llama Guard:与 MLCommons 联合开发的风险分类法构建的输入输出安全模型。
- Prompt Guard:一个可识别恶意提示(如 Jailbreak 和提示注入)的分类模型。
- CyberSecEval:帮助开发者了解和降低生成式 AI 网络安全风险的评估工具。
这些工具支持高度定制,开发者可根据应用需求进行优化配置。
4.3 安全评估与红队测试
我们在各种使用场景下进行系统化测试,并将测试结果反馈到模型后训练中。我们使用动态对抗性探测技术(包括自动和人工测试)来识别模型的潜在风险点。
一种新测试方式——生成式攻击智能代理测试(GOAT),可模拟中等技能水平的攻击者进行多轮交互,扩大测试覆盖范围。GOAT 的自动化测试能替代人工团队处理已知风险区域,让专家更专注于新型对抗场景,提高测试效率。
4.4 解决语言模型中的偏见问题
大型语言模型容易出现偏见,尤其在社会和政治话题上偏向自由派。这是因为网络训练数据本身就存在倾向性。
目标是消除偏见,让 Llama 能够公正地理解并表达有争议话题的不同观点,而非偏袒某一方。
Llama 4 在这方面取得了重大进展:
- 拒答比例从 Llama 3 的 7% 降低至 Llama 4 的 2% 以下;
- 对于具有争议性的问题,拒答不平衡的比例降至 1% 以下;
- 表现出强烈政治倾向的响应率仅为 Llama 3 的一半,与 Grok 相当。
继续努力,进一步降低偏见水平。
5 探索 Llama 生态系统
除了模型智能,用户还希望模型反应个性化、速度快。Llama 4 是迄今为止最先进的模型,已为此进行优化。模型只是打造完整体验的一部分。
本项目感谢以下 AI 生态伙伴的大力支持(按字母顺序排列):
Accenture、Amazon Web Services、AMD、Arm、CentML、Cerebras、Cloudflare、Databricks、Deepinfra、DeepLearning.AI、Dell、Deloitte、Fireworks AI、Google Cloud、Groq、Hugging Face、IBM Watsonx、Infosys、Intel、Kaggle、Mediatek、Microsoft Azure、Nebius、NVIDIA、ollama、Oracle Cloud、PwC、Qualcomm、Red Hat、SambaNova、Sarvam AI、Scale AI、Scaleway、Snowflake、TensorWave、Together AI、vLLM、Wipro。
相关文章:

Llama 4 家族:原生多模态 AI 创新的新时代开启
0 要点总结 Meta发布 Llama 4 系列的首批模型,帮用户打造更个性化多模态体验Llama 4 Scout 是有 170 亿激活参数、16 个专家模块的模型,同类中全球最强多模态模型,性能超越以往所有 Llama 系列模型,能在一张 NVIDIA H100 GPU 上运…...

如何让eDrawings html文件在Chrome浏览器上展示——allWebPlugin中间件扩展
应用背景 eDrawing html文件是仅可在 Internet Explorer 5.5 和以上版本中查阅,由于IE浏览器限制,目前使用非常不方便,为了不修改html的请提下,在chrome浏览器查阅原本html文件,可使用安装allWebPlugin中间件扩展。 a…...

【内网安全】DHCP 饿死攻击和防护
正常情况:PC2可以正常获取到DHCP SERVER分别的IP地址查看DHCP SERCER 的ip pool地址池可以看到分配了一个地址、Total 253个 Used 1个 使用kali工具进行模拟攻击 进行DHCP DISCOVER攻击 此时查看DHCP SERVER d大量的抓包:大量的DHCP Discover包 此时模…...

keepalived高可用介绍
keepalived 是 Linux 一个轻量级的高可用解决方案,提供了心跳检测和资源接管、检测集群中的系统服务,在集群节点间转移共享IP 地址的所有者等。 工作原理 keepalived 通过 VRRP(virtual router redundancy protocol)虚拟路由冗余…...

基于大模型的脑梗死全流程诊疗技术方案
目录 《基于大模型的脑梗死全流程诊疗技术方案》一、核心算法实现1. 多模态特征融合算法(术前规划)2. 术中实时预警算法二、系统模块设计1. 术前规划系统流程图2. 术中实时监控系统架构三、技术验证方案1. 模型验证矩阵2. 实验验证设计四、关键技术创新点五、工程实现规范1. …...

ngx_timezone_update
定义在 src\os\unix\ngx_time.c void ngx_timezone_update(void) { #if (NGX_FREEBSD)if (getenv("TZ")) {return;}putenv("TZUTC");tzset();unsetenv("TZ");tzset();#elif (NGX_LINUX)time_t s;struct tm *t;char buf[4];s tim…...

Redis 热key问题怎么解决?
Redis 热 Key 问题分析与解决方案 热 Key(Hot Key)是指被高频访问的某个或多个 Key,导致单个 Redis 节点负载过高,可能引发性能瓶颈甚至服务崩溃。以下是常见原因及解决方案: 1. 热 Key 的常见原因 突发流量:如明星八卦、秒杀商品、热门直播等场景。缓存设计不合理:如全…...
)
JavaWeb(楠)
JavaWeb21-1:Java Web开发的地位、Tomcat服务器 Java Web开发概述 主流地位:Java可用于移动端、桌面应用、机器学习等多个领域,但在Web开发领域优势显著,是Java最主流的研发方向。市场上95%以上的Web端开发都使用Java,…...

批量将 JSON 转换为 Excel/思维导入等其它格式
json 格式相信对大家来说都不陌生,这是一种轻量级的结构化数据,可以对对象进行描述。json 格式也是一种普通的文本文件格式,用记事本就能够打开编辑 json 格式的文件,可以很方便的转换为其他格式。今天要给大家介绍的就是如何将 j…...
之通过WebServer查询天气预报)
C# Winform 入门(13)之通过WebServer查询天气预报
展示 控件 添加WebServer 右键项目> 添加引用> 添加服务引用 天气预报URL: WeatherWebService Web 服务WeatherWebService Web 服务http://www.webxml.com.cn/WebServices/WeatherWebService.asmx 查询按钮实现 private void btn_Inquiry_Click(object sender, EventA…...
)
算法思想之滑动窗口(一)
欢迎拜访:雾里看山-CSDN博客 本篇主题:算法思想之滑动窗口(一) 发布时间:2025.4.6 隶属专栏:算法 目录 滑动窗口算法介绍核心思想时间复杂度适用场景注意事项 例题长度最小的子数组题目链接题目描述算法思路代码实现 无重复字符的…...

爬虫工程师无意义的活
30岁的年龄;这个年龄大家都是成年人;都是做父母的年龄了;你再工位上的心态会发生很大变化的; 爬虫工程师基本都是如此;社会最low的一帮连销售都做不了的;单子都开不出来的然后转行做爬虫工程师的;这样的人基本不太和社会接触; 你作为爬虫初级工程师就敲着键盘然后解析着html;…...

DeepSeek 关联公司公布新型数据采集专利 提升数据采集效率与质量
4 月 1 日,国家知识产权局公布了一项由 DeepSeek 关联公司杭州深度求索人工智能基础技术研究有限公司申请的专利,名为 “一种广度数据采集的方法及其系统”,公开号为 CN 119739917 A,申请日期可追溯至 2024 年 12 月。此专利的发布…...

实际犯错以及复盘1
Ds1302 需要两个 一个Set_Rtc 一个Read_Rtc : 本质 read是 85-2i 的 写入是84-2i 然后 写入的时候 是需要对 0x8e 进行 0x00 和0x80进行解开和 锁定的开头结尾。 使用的时候 赋值给ucRtc[i] 然后 主函数使用的时候 需要直接写个(ucRtc) 因为unsigned char* 默认的…...

初探:简道云系统架构及原理
一、系统架构概述 简道云作为一款低代码开发平台,其架构设计以模块化和云端协同为核心,主要分为以下层次: 1. 前端层 可视化界面:基于Web的拖拽式表单设计器,支持动态渲染(React/Vue框架)。多…...

Nginx负载均衡时如何为指定ip配置固定服务器
大家在用Nginx做负载均衡时,一般是采用默认的weight权重指定或默认的平均分配实现后端服务器的路由,还有一种做法是通过ip_hash来自动计算进行后端服务器的路由,但最近遇到一个问题,就是希望大部分用户采用ip_hash自动分配后端服务…...

玩转MCP:用百度热搜采集案例快速上手并接入cline
MCP的大火,让MCP服务器开发也变得热门,上一篇文章: 手搓MCP客户端&服务端:从零到实战极速了解MCP是什么? 手搓了一个极其简单的小场景的MCP实战案例,详细的安装环境及操作步骤已经讲过了,本文不在重复…...
)
003集——《利用 C# 与 AutoCAD API 开发 WPF 随机圆生成插件》(侧栏菜单+WPF窗体和控件+MVVM)
本案例聚焦于开发一款特色鲜明的 AutoCAD 插件。其核心功能在于,用户在精心设计的 WPF 控件界面中输入期望生成圆的数量,完成输入后,当用户点击 “生成” 按钮,一系列联动操作随即展开。通过数据绑定与命令绑定这一精妙机制&#…...
责任链模式)
设计模式简述(十)责任链模式
责任链模式 描述基本使用使用 描述 如果一个请求要经过多个类似或相关处理器的处理。 可以考虑将这些处理器添加到一个链上,让请求逐个经过这些处理器进行处理。 通常,在一个业务场景下会对整个责任链进行初始化,确定这个链上有哪些Handler…...
)
分组(二分查找)
#include <bits/stdc.h> using namespace std; const int N1e55; int a[N]; int n,k;bool f(int x){int num1;int ma[1];for(int i2;i<n;i){if(a[i]-m>x){ // 当前元素加入当前组会超过极差 xnum; // 新开一组ma[i]; // 新组的最小值设为当前元素}}r…...

vue的主要核心文件介绍
1.package.json 查看依赖包的版本 项目基本信息记录 项目标识:记录项目名称(name 字段)、版本号(version 字段)、描述(description 字段)等基础信息,方便识别和管理项目。例如&…...

从奖励到最优决策:动作价值函数与价值学习
从奖励到最优决策:动作价值函数与价值学习 价值学习动作价值函数对 U t U_t Ut求期望得到动作价值函数动作价值函数的意义最优动作价值函数(Optimal Action-Value Function)如何理解 Q ∗ Q^* Q∗函数 价值学习的基本思想Deep Q-Network(DQN)DQN玩游戏的具体流程如…...

DApp实战篇:先用前端起个项目
前言 本篇将使用vue框架quasar起一个项目,为了防止大家不会使用quasar,本篇详细讲解一下quasar如何使用。 quasar 如果你不想深入了解quasar,其实你完全可以将quasar当成一个vue的组件库即可,它是一个类谷歌Material风格的UI组件库,但同时它又是一个基于vue的强大框架。…...

论文阅读11——V2V-LLM:采用多模式大型语言模型的车对车协同自动驾驶
原文地址: 2502.09980https://arxiv.org/pdf/2502.09980 论文翻译: V2V-LLM: Vehicle-to-Vehicle Cooperative Autonomous Driving with Multi-Modal Large Language Models V2V-LLM:采用多模式大型语言模型的车对车协同自动驾驶 摘要&#…...

NLP 梳理01 — 文本预处理和分词
文章目录 一、说明二、文本预处理概述2.1 为什么要预处理文本?2.2 文本预处理的常见步骤2.3 什么是令牌化?2.4 为什么令牌化很重要? 三、分词类型四、用于分词化的工具和库五、实际实施六、编写函数以对文本进行标记七、结论 一、说明 本文总…...

Windows11 优雅的停止更新、禁止更新
网上有很多关闭自动更新的方法,改注册表、修改组策略编辑器、禁用Windows Update等等,大同小异,但最后奏效的寥寥无几,今天给大家带来另一种关闭win11自动更新的方法,亲测有效! 1、winR 打开运行窗口&…...

Kafka 中的 offset 提交问题
手动提交和自动提交 我们来一次性理清楚:Kafka 中的自动提交 vs 手动提交,到底区别在哪,怎么用,什么场景适合用哪个👇 🧠 一句话总结 ✅ 自动提交:Kafka 每隔一段时间自动提交 offset ✅ 手动…...

PowerBI窗口函数与视觉计算
文章目录 一、 窗口函数1.1 OFFSET(动态查询、求连续值)1.1.1 不使用orderBy1.1.2 使用orderBy1.1.3 统计连续值的最大出现次数(待补) 1.2 INDEX(静态查询)1.3 WINDOW(滚动求和、累计求和、帕累…...

代码随想录算法训练营Day22
回溯知识 力扣77.组合【medium】 一、回溯知识 1、定义 回溯法也可以叫做回溯搜索法,它是一种搜索的方式。回溯是递归的副产品,只要有递归就会有回溯。 2、回溯法的效率 回溯的本质是穷举,穷举所有可能,然后选出我们想要的答案…...

几种常见的HTTP方法之GET和POST
如大家所了解的,每条 HTTP 请求报文都必须包含一个请求方法,这个方法会告诉服务器要执行什么操作(例如获取一个 Web 页面、运行一个网关程序、删除一个文件等)。常见的几种 HTTP 方法如下: GET: 请求指定的…...

Nginx之https重定向为http
为了将Nginx中443端口的请求重定向到80端口,你可以按照以下步骤进行操作: 确认Nginx已经正确安装并运行: 确保Nginx服务已经在你的系统上安装并运行。你可以通过运行以下命令来检查Nginx的状态(具体命令可能因操作系统而异&a…...

落地DevOps文化:运维变革的正确打开方式
落地DevOps文化:运维变革的正确打开方式 DevOps,这个近年来被谈论得沸沸扬扬的概念,是企业数字化转型的一把钥匙。然而,很多公司虽然喊着“要上DevOps”,却苦于如何真正落地。而DevOps不仅仅是技术工具的堆砌,更是一种文化的重塑。从我的经历来看,DevOps实施的核心在于…...

《C++后端开发最全面试题-从入门到Offer》目录
当今科技行业对C++开发者的需求持续高涨,从金融科技到游戏开发,从嵌入式系统到高性能计算,C++凭借其卓越的性能和灵活性始终占据着关键地位。然而,成为一名优秀的C++工程师并非易事,不仅需要扎实的语言基础,还要掌握现代C++特性、设计模式、性能优化技巧以及各种工业级开…...
(附原文《高校负面舆情成因与演化路径研究》))
24统计建模国奖论文写作框架2(机器学习+自然语言处理类)(附原文《高校负面舆情成因与演化路径研究》)
一、引言 研究背景及意义 文献综述 研究内容与创新点 二、高校负面舆情热点现状分析 案例数据的获取与处理 高效负面舆情热点词频分析 高效负面舆情热点变化趋势分析 三、高校负面舆情成因分析 高校负面舆情变量的选取与赋值 基于QCA方法的高校负面舆情成因分析 四、…...

论文阅读笔记——Deformable Radial Kernel Splatting
DRK 论文 DRK(可变形径向核)的核心创新正是通过极坐标参数化与切平面投影,对传统3D高斯泼溅(3D-GS)进行了多维度的优化。 传统 3DGS 依赖径向对称的高斯核,只能表示平滑、各向同性的形状(球体、…...
)
网络编程—TCP/IP模型(IP协议)
上篇文章: 网络编程—TCP/IP模型(TCP协议)https://blog.csdn.net/sniper_fandc/article/details/147011479?fromshareblogdetail&sharetypeblogdetail&sharerId147011479&sharereferPC&sharesourcesniper_fandc&sharef…...

Android NDK C/C++交叉编译脚本
以下是 Android (arm64-v8a) 交叉编译 C/C 项目的完整脚本模板,基于 NDK 工具链,支持自定义源文件编译为静态库/动态库/可执行文件: 1. 基础交叉编译脚本 (build_android.sh) bash 复制 #!/bin/bash# Android 交叉编译脚本 (arm64-…...

IS-IS-单区域的配置
一、IS-IS的概念 IS-IS(Intermediate System to Intermediate System,中间系统到中间系统)是一种链路状态路由协议,最初设计用于OSI(Open Systems Interconnection)参考模型的网络层(CL…...
)
Java EE期末总结(第四章)
目录 一、ORM框架 二、MyBatis与Hibernate 1、 概念与设计理念 2、SQL 控制 3、学习成本 4、开发效率 三、MyBatisAPI 1、SqlSessionFactoryBuilder 2、SqlSessionFactory 3、SqlSession 四、MyBatis配置 1、核心依赖与日志依赖 2、建立.XML映射文件 3、建立映射…...

Kafka 的选举机制
Kafka 的选举机制在 Zookeeper 模式 和 KRaft 模式 下有所不同,主要体现在 领导选举 和 集群元数据管理 的方式上。下面详细介绍这两种模式下 Kafka 如何进行选举机制。 1. Zookeeper 模式下的选举机制 在早期的 Kafka 架构中,集群的元数据管理和选举机…...

FreeRTOS移植笔记:让操作系统在你的硬件上跑起来
一、为什么需要移植? FreeRTOS就像一套"操作系统积木",但不同硬件平台(如STM32、ESP32、AVR等)的CPU架构和外设差异大,需要针对目标硬件做适配配置。移植工作就是让FreeRTOS能正确管理你的硬件资源。 二、…...
策略模式)
设计模式简述(十二)策略模式
策略模式 描述基本使用使用传统策略模式的缺陷以及规避方法 枚举策略描述基本使用使用 描述 定义一组策略,并将其封装起来到一个策略上下文中。 由调用者决定应该使用哪种策略,并且可以动态替换 基本使用 定义策略接口 public interface IStrategy {…...

如何在idea中快速搭建一个Spring Boot项目?
文章目录 前言1、创建项目名称2、勾选需要的依赖3、在setting中检查maven4、编写数据源5、开启热启动(热部署)结语 前言 Spring Boot 凭借其便捷的开发特性,极大提升了开发效率,为 Java 开发工作带来诸多便利。许多大伙伴希望快速…...

【注解简化配置的原理是什么】
注解(Annotation)简化配置的核心原理是将原本分散在外部文件(如XML、properties)中的元数据直接内嵌到代码中,通过声明式编程让框架或工具自动处理这些元数据,从而减少手动配置的复杂度。以下是其实现原理的…...

Livox-Mid-70雷达使用------livox_mapping建图
1.ubuntu20.04 和Livox mid 70 的IP设置 连接好Livox-Mid-70雷达,然后进行局域网配置 1.1 Livox mid 70的IP是已知的,即192.168.1.1XX, XX表示mid 70广播码的后两位 1.2 ubuntu 20.04的IP设置 a.查看本机IP名 ifconfig b.设置本机IP地址 sudo ifconfig enx00e04…...

Django中使用不同种类缓存的完整案例
Django中使用不同种类缓存的完整案例 推荐超级课程: 本地离线DeepSeek AI方案部署实战教程【完全版】Docker快速入门到精通Kubernetes入门到大师通关课AWS云服务快速入门实战目录 Django中使用不同种类缓存的完整案例步骤1:设置Django项目步骤2:设置URL路由步骤3:视图级别…...
、LeetCode 518 零钱兑换 II、377 组合总数 IV、爬楼梯(进阶))
代码随想录算法训练营Day32| 完全背包问题(二维数组 滚动数组)、LeetCode 518 零钱兑换 II、377 组合总数 IV、爬楼梯(进阶)
理论基础 完全背包问题 在完全背包问题中,每种物品都有无限个,我们可以选择任意个数(包括不选),放入一个容量为 W W W 的背包中。我们希望在不超过容量的情况下,最大化背包内物品的总价值。 完全背包&a…...

Django SaaS案例:构建一个多租户博客应用
Django SaaS案例:构建一个多租户博客应用 推荐超级课程: 本地离线DeepSeek AI方案部署实战教程【完全版】Docker快速入门到精通Kubernetes入门到大师通关课AWS云服务快速入门实战目录 Django SaaS案例:构建一个多租户博客应用如果你正在从事一个SaaS(软件即服务)项目或一…...

静态库与动态库
静态库(Static Library) 定义:静态库(如 .a 文件或 .lib 文件)是编译时直接链接到可执行文件中的库。其代码和数据会被完整复制到最终的可执行文件中。 特点: 独立部署:无需依赖外部库文件。 …...

优选算法的妙思之流:分治——归并专题
专栏:算法的魔法世界 个人主页:手握风云 目录 一、归并排序 二、例题讲解 2.1. 排序数组 2.2. 交易逆序对的总数 2.3. 计算右侧小于当前元素的个数 2.4. 翻转对 一、归并排序 归并排序也是采用了分治的思想,将数组划分为多个长度为1的子…...