论文阅读11——V2V-LLM:采用多模式大型语言模型的车对车协同自动驾驶
原文地址:
论文翻译:
摘要:
当前的自动驾驶车辆主要依赖于其各个传感器来了解周围场景并规划未来的轨迹,而当传感器发生故障或被遮挡时,这可能是不可靠的。为了解决这个问题,人们提出了通过车对车(V2V)通信的协作感知方法,但它们往往专注于检测或跟踪等感知任务。这些方法如何有助于整体合作规划绩效仍然没有得到充分的研究。受到使用大型语言模型(LLM)构建自动驾驶系统的最新进展的启发,我们提出了一种新颖的问题设置,将多模式LLM集成到协作式自动驾驶中,并提出了车对车调度服务(V2V-QA)数据集和基准。我们还提出了我们的基线方法车对车多模式大型语言模型(V2V-LLM),该模型使用LLM来融合来自多个连接的自动驾驶车辆(CAB)的感知信息,并回答各种类型的驾驶相关问题:接地、显着物体识别和规划。实验结果表明,我们提出的V2V-LLM可以成为一种有前途的统一模型架构,用于在协作自动驾驶中执行各种任务,并且优于使用不同融合方法的其他基线方法。我们的工作还开辟了一个新的研究方向,可以提高未来自动驾驶系统的安全性。代码和数据将向公众发布,以促进该领域的开源研究。
1 介绍
由于深度学习算法、计算基础设施的发展以及大规模现实世界驾驶数据集和基准的发布,自动驾驶技术取得了显着进步[3,13,38]。然而,自动驾驶汽车的感知和规划系统在日常操作中,主要依靠当地的LiDAR传感器和相机来检测附近的显著物体并规划未来的轨迹。当传感器被附近的大型物体遮挡时,这种方法可能会遇到安全关键问题。在这种情况下,自动驾驶车辆无法准确地检测到附近所有值得注意的物体,使得后续的规划结果不可靠。
为了解决这个安全关键问题,最近的研究提出了通过车对车(V2 V)通信的合作感知算法[6,9,44,50-52]。在协作驾驶场景中,多个彼此附近行驶的互联自动驾驶汽车(CAB)通过V2 V通信共享其感知信息。然后,将从多个CV接收到的感知数据进行融合,以生成更好的整体检测或跟踪结果。许多协作自动驾驶数据集已向公众发布,包括模拟数据[10、24、51、52]和真实数据[48、53、59、60]。这些数据集还建立了评估合作感知算法性能的基准。然而,迄今为止,合作驾驶研究和数据集主要集中在感知任务上。这些最先进的合作感知模型如何与下游规划模型相连接以产生良好的合作规划结果仍然没有得到充分的探索。
最近的其他研究尝试使用基于LLM的方法来为个人自动驾驶车辆构建端到端感知和规划算法,因为它们具有来自大规模预训练数据的常识推理和概括能力。这些基于LLM的模型将原始传感器输入编码为视觉特征,然后执行视觉理解并回答各种与驾驶相关的感知和规划问题。这些方法已经显示出一些希望,但尚未探索合作感知和规划的好处。当单个车辆的感觉能力有限时,没有合作感知的基于LLM的驾驶算法也可能面临安全关键问题。
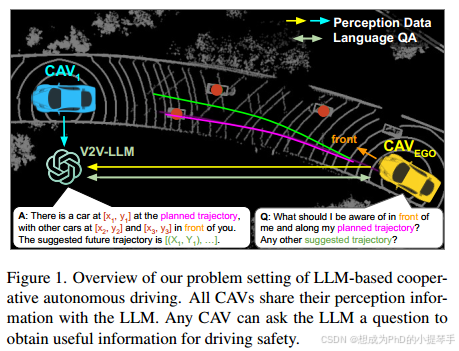
图1.概述我们基于LLM的协作自动驾驶的问题设置。所有CAB都与LLM共享他们的感知信息。任何卡韦都可以向LLM提出问题,以获取对驾驶安全有用的信息。
在本文中,我们提出并探索了一种新的问题设置,其中基于LLM的方法用于构建协作自动驾驶的端到端感知和规划算法,如图1所示。在这个问题设置中,我们假设有多个CAV和一个集中式LLM计算节点。所有CAV都与LLM共享其个人感知信息。任何CAV都可以用自然语言向LLM提出问题,以获得对驾驶安全有用的信息。为了研究这个问题,我们首先创建了V2V-QA数据集,该数据集基于V2V4 Real [53]和V2X-Real [48]用于自动驾驶的协作感知数据集。我们的V2 VQA包括接地(图图2a至图2c)、显著对象识别(图2d)和规划(图2 e)问答对。我们的新问题设置和其他现有的基于LLM的驾驶研究之间存在一些差异[4,33,35,37,39,43]。首先,我们的LLM可以融合来自不同卡韦的多个感知信息,并为任何卡韦的不同问题提供答案,而不仅仅为单个自动驾驶汽车提供服务。其次,我们的基础问题是专门设计的,旨在关注每个单独的卡韦的潜在遮挡区域。Tab1中总结了我们的V2V-QA与其他相关数据集之间的更多差异。
为了建立V2V-QA数据集的基准,我们首先提出了一种强基线方法:用于协作自动驾驶的车到车多模式大型语言模型(V2 V-LLM),如图3所示。每个卡韦提取自己的感知特征并与V2 V-LLM共享。V2 V-LLM融合场景级特征图和对象级特征载体,然后进行视觉和语言理解,为V2 V-QA中的输入驱动相关问题提供答案。我们还将V2V-LLM与对应于不同特征融合方法的其他基线方法进行比较:无融合、早期融合和中间融合[48,50-53]。结果表明,V2 V-LLM在更重要的显着物体识别和规划任务中实现了最佳性能,并在接地任务中实现了竞争性能,为整个自动驾驶系统实现了强劲的性能。
我们的贡献可以总结如下:
- 我们创建并引入V2V-QA数据集,以支持基于LLM的端到端协作自动驾驶方法的开发和评估。V2V-QA包括基础、显着对象识别和规划问答任务。
- 我们提出了一种用于协作自动驾驶的基线方法V2 V-LLM,为V2 V-QA提供初始基准。该方法融合了多个卡韦提供的场景级特征地图和对象级特征载体,回答不同卡韦与驾驶相关的问题。
- 我们为V2V-QA创建了一个基准,并表明V2V-LLM在显着物体识别和规划任务方面优于其他基线融合方法,并在接地任务方面实现了有竞争力的结果,这表明V2V-LLM有潜力成为协作自动驾驶的基础模型。
2 相关工作
2.1.自动驾驶中的合作感知
提出了合作感知算法来解决个人自主车辆中潜在的遮挡问题。开创性工作F-Cooper提出了第一种中间融合方法,该方法合并特征图以实现良好的协作检测性能。V2VNet构建用于合作感知的图神经网络。DiscoNet采用知识提炼方法。最近的工作Attendix、V2X-ViT和CoBEVT集成了基于注意力的模型来聚合特征。另一组作品的重点是开发有效的沟通方法。
从数据集的角度,模拟数据集OPV2V、V2X-Sim和V2 XSet首先是为合作感知研究而生成的。最近,收集了真实的数据集。V2V4Real是全球第一个具有感知基准的真实车对车合作感知数据集。V2X-Real、DAIR-V2X和TUMTraf-V2X还包括来自路边基础设施的传感器数据。
与这组研究不同的是,我们的问题设置和拟议的V2 V-QA数据集包括多个CAB的感知和规划问答任务。我们提出的V2 V-LLM还采用了一种新颖的基于LLM的融合方法。
2.2 基于LLM的自动驾驶
基于图像的规划模型首先将驾驶场景,物体检测结果,车辆自身状态转换为LLM的文本输入。然后LLM生成文本输出,包括建议的驾驶动作或计划的未来轨迹。最近的方法使用多模式大型语言模型(MLLM)将点云或图像编码为视觉特征。然后,将视觉特征投影到语言嵌入空间,供LLM执行视觉理解和问答任务。
从数据集的角度来看,几个基于LLM的自动驾驶数据集是在现有自动驾驶数据集的基础上构建的。例如,Talk 2Car [11]、NuPromote [47]、NuScenes-QA [35]、NuDirecct [49]和Reason 2Drive [34]基于NuScenes [3]数据集创建字幕、感知、预测和规划QA对。BDD-X [18]由BDD 100 K [58]扩展而来。DriveLM [37]采用NuScenes [3]的真实数据和CARLA [12]的模拟数据,以实现更大规模、更多样化的驾驶QA。独立策划的其他数据集专注于不同类型的QA任务。HAD [19]包含人与车辆的建议数据。戏剧[30]引入了联合风险定位和字幕。Lingo-QA [33]提出了反事实问答任务。MAPLMQA [4]强调地图和交通场景的理解。
与那些仅支持个人自动驾驶汽车的基于LLM的驾驶研究不同,我们的问题设置和拟议的V2 V-QA数据集是为具有多个CAE的协作驾驶场景而设计的。在我们的问题设置中,LLM可以聚合多个Cavv的感知特征,并为不同Cavv的问题提供答案。我们的V2 V-QA还旨在关注潜在的遮挡区域。此外,我们的V2VQA包含高速公路和城市合作驾驶场景,使我们的规划任务比之前基于NuScenes [3]数据集的作品更具挑战性。
3 V2V-QA数据集
为了在我们提出的新颖问题设置(基于LLM的协作自动驾驶)中进行研究,我们创建了车对车调度服务(V2VQA)数据集,以基准测试不同模型在融合感知信息和回答安全关键驾驶相关问题方面的性能。
3.1 问题设置
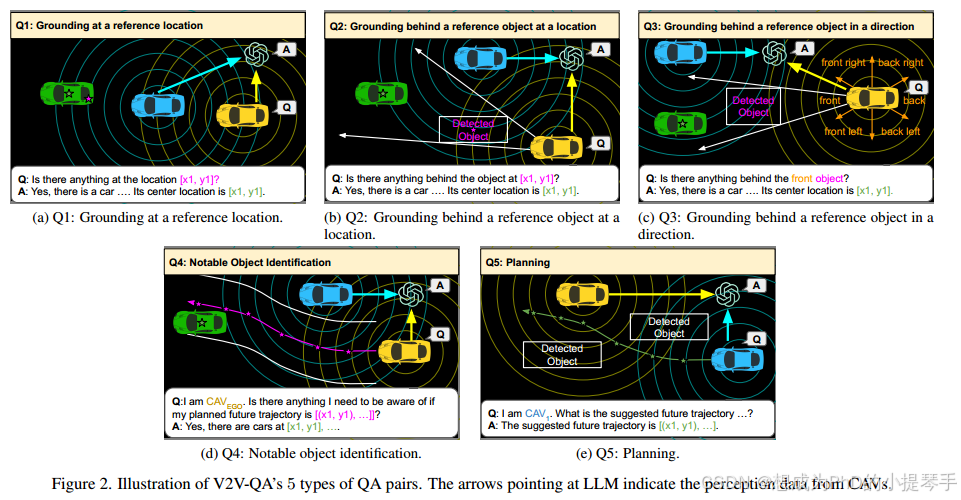
我们提出的具有LLM问题的V2V协作自动驾驶如图1所示。在此设置中,我们假设有多个互联自动驾驶车辆(Cavs)和一个集中式LLM计算节点。所有CAV都与集中式LLM共享其各自的感知信息,例如场景级或对象级特征。任何CAV都可以用自然语言向LLM提出问题,以获取驾驶安全信息。LLM汇总从多个CAE接收的感知信息,并为CAE问题提供自然语言答案。在这项研究中,问题和答案包括基础(Q1-3)、显着物体识别(Q4)和规划(Q5),如图2所示。
3.2 数据集细节
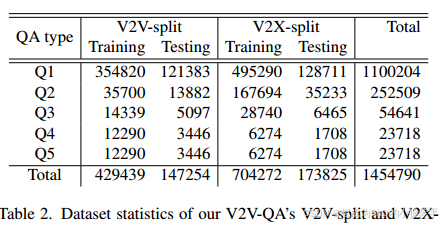
我们的V2 V-QA数据集包含两个拆分:V2 V-split和V2 X-split,它们分别构建在V2 V4 Real [53]和V2 X-Real [48]数据集之上。这些基本数据集是通过驾驶两辆配备LiDART传感器的车辆同时靠近彼此收集的。这些数据集还包括表2中其他对象的3D边界框注释我们的V2 V-QA的V2 V-split和V2 Xsplit的数据集统计。Q1:在参考位置接地。Q2:在某个位置的参考物体后面接地。Q3:以一个方向落在参考物体后面。Q4:著名物体识别。Q5:规划。驾驶场景。在V2 V4 Real [53]中,训练集具有32个驱动序列,每个卡韦总共有7105帧数据,测试集具有9个驱动序列,每个卡韦总共有1993帧数据。在V2X-Real [48]中,训练集有43个驱动序列,每个CAV总共有5772帧数据,测试集有9个驱动序列,每个CAV总共有1253帧数据。帧率为10 Hz。在V2X-Real [48]中,一些驾驶场景还提供来自路边基础设施的激光雷达点云。在我们的V2X分割中,我们还将它们作为LLM的感知输入,方法与使用CAV的激光雷达点云回答CAV的问题相同。在构建V2 V-split和V2Xsplit时,我们遵循V2 V4 Real [53]和V2X-Real [48]中相同的训练和测试设置。
表2总结了我们提出的V2 V-QA的V2 V-分裂和V2X-分裂中QA对的数量。我们总共有1.45 M QA对,平均每帧30.2 QA对。更多详情请参阅补充材料。
3.3 问答配对节目
对于V2 V4 Real [53]和V2X-Real [48]数据集的每个帧,我们创建了5种不同类型的QA对,包括3种类型的基础问题,1种类型的显着对象识别问题和1种类型的规划问题。这些QA是为合作驾驶场景而设计的。为了生成这些QA对的实例,我们使用V2 V4 Real [53]和V2X-Real [48]的地面实况边界框注释,每个CAV的地面实况轨迹和单个检测结果作为源信息。然后,我们使用不同的手动设计的规则的基础上,上述实体和文本模板之间的几何关系,以产生我们的QA对。文本模板可以在图1A和1B中看到。5和6.每个QA类型的生成规则如下所述。
Q1.在参考位置接地(图2a):在这种类型的问题中,我们要求LLM识别是否存在占据特定查询2D位置的对象。如果是,则LLM被期望提供对象的中心位置。否则,LLM应指示在参考位置处没有任何东西。我们使用地面真值框和每个卡韦的单个检测结果框的中心位置作为问题中的查询位置。通过这样做,我们可以更多地专注于评估每个模型对潜在假阳性和假阴性检测结果的合作基础能力。
Q2.在某个位置的参考物体后面接地(图2b):当卡韦的视野被附近检测到的大型物体遮挡时,该卡韦可能想要要求集中式LLM确定在遮挡的大型物体后面是否存在任何物体给定来自所有卡韦的融合感知信息。如果是这样,LLM预计将返回物体的位置,而提出请求的CAE可能需要更具防御性地驾驶或调整其规划。否则,LLM应该指示引用对象后面没有任何内容。我们使用每个检测结果框的中心位置作为这些问题中的查询位置。我们根据提出请求的卡韦和参考物体的相对姿态绘制一个扇形区域,并选择该区域中最近的地面真相物体作为答案。
Q3.以方向上的参考对象为基础(图2c):我们通过用参考方向关键字替换Q2的参考2D位置,进一步挑战LLM的语言和空间理解能力。我们首先获得作为参考对象的卡韦6个方向中每个方向上最接近的检测结果框。然后我们在第二季度遵循相同的方法,以获得相应部门区域中最近的地面真值框作为答案。
Q4. 显著物体识别(图 2d): 上述接地任务是自动驾驶流程中的中间任务。自动驾驶车辆更关键的能力包括识别计划未来轨迹附近的显著物体,以及调整未来规划以避免潜在碰撞。我们从未来 3 秒的地面实况轨迹中提取 6 个航点,作为问题中的未来参考航点。然后,我们最多会得到距离参考未来轨迹 10 米以内的 3 个最近的地面实况物体作为答案。
Q5. 规划(图 2e): 规划非常重要,因为自动驾驶车辆的最终目标是在复杂环境中安全导航,避免未来可能发生的任何碰撞。为了生成规划 QA,我们从每辆 CAV 的地面实况未来轨迹中提取了 6 个未来航点作为答案,这些航点在未来 3 秒内均匀分布。我们的 V2V-QA 规划任务比其他基于 NuScenes [3] 的 LLM 驾驶相关工作更具挑战性,原因有以下几点。首先,我们在合作驾驶场景中支持多辆 CAV。LLM 模型需要根据提出问题的 CAV 提供不同的答案,而之前的工作只需要为单个自动驾驶车辆生成规划结果。其次,我们的 V2VQA 地面实况规划轨迹更加多样化。V2V-QA 包含城市和高速公路两种驾驶场景,而 NuScenes [3] 仅包含城市驾驶场景。详细的数据集统计和比较见补充材料。
3.4 评估指标
我们沿用之前的研究成果 [39, 43] 来评估模型性能。对于接地问题(Q1、Q2、Q3)和显著物体识别问题(Q4),评价指标是 F1 分数、精确度和召回率。地面实况答案和模型输出包含对象的中心位置。如果地面实况答案与模型输出之间的中心距离小于阈值,则该输出被视为真阳性。我们将阈值设定为 4 米,这是车辆的典型长度。
对于规划问题(问题 5),评估指标是 L2 误差和碰撞率。地面实况答案和模型输出包含 6 个未来航点,因此我们计算这些航点的 L2 误差。在计算碰撞率时,我们假设每个 CAV 的边界框尺寸为长 4 米、宽 2 米、高 1.5 米。我们将每个 CAV 的边界框放置在模型输出的未来航点上,并计算这些未来帧中 CAV 边界框与每个地面实况对象注释边界框之间的 “联合交叉”(Intersection-over-Union,IOU)。如果 IOU 大于 0,则视为碰撞。
4 V2V-LLM
我们还针对这一基于 LLM 的协同驾驶问题提出了一个有竞争力的基准模型 V2VLLM,如图 3 所示。我们的模型是一种多模态 LLM(MLLM),它将每个 CAV 的单个感知特征作为视觉输入,将问题作为语言输入,并生成答案作为语言输出。
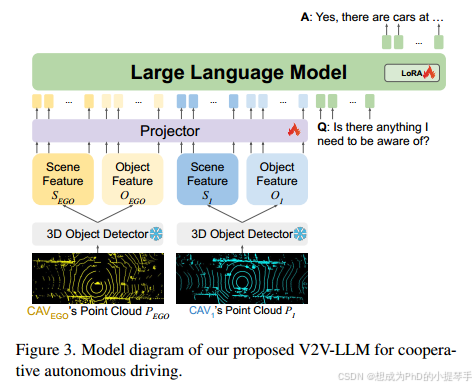
4.1 基于激光雷达的输入特征
为了提取感知输入特征,每个 CAV 都会对其各自的激光雷达点云应用三维物体检测模型: PEGO和P1。我们从三维物体检测模型中提取场景级特征图 SEGO 和 S1,并将三维物体检测结果转换为物体级特征向量 OEGO 和 O1。根据之前的 V2V4Real [53] 和 V2X-Real [48],我们使用 PointPillars [20] 作为三维物体检测器进行公平比较。
4.2. 基于激光雷达的多模态 LLM 模型架构
鉴于 LLaVA [25] 在视觉问题解答任务中的卓越表现,我们利用 LLaVA 开发了 MLLM。不过,由于我们合作驾驶任务的感知特征是基于激光雷达的,而不是 LLaVA [25] 使用的 RGB 图像,因此我们使用基于激光雷达的 3D 物体检测器作为点云特征编码器(如上一节所述),而不是 LLaVA [25] 的 CLIP [36] 图像特征编码器。然后,我们将得到的特征输入基于多层感知器的投影仪网络,进行从点云嵌入空间到语言嵌入空间的特征对齐。对齐后的感知特征就是 LLM 所消化的输入感知标记和问题中的输入语言标记。最后,LLM 会汇总来自所有 CAV 的感知信息,并根据问题返回答案。
训练:我们使用 8 个英伟达 A100-80GB GPU 训练模型。我们的 V2V-LLM 使用 LLaVA-v1.5-7b [25] 的 Vicuna [7] 作为 LLM 骨干。为了训练模型,我们通过加载预训练的 LLaVA-v1.5-7b [25] 的检查点来初始化模型。我们冻结 LLM 和点云特征编码器,并对模型的投影仪和 LoRA [14] 部分进行微调。在训练过程中,我们使用的批次大小为 32。采用 Adam 优化器进行训练,起始学习率为 2e-5,余弦学习率调度器的热身率为 3%。所有其他训练设置和超参数均沿用 LLaVA-v1.5-7b [25]。
5 实验
5.1 基线方法
我们沿用 V2V4Real [53] 和 V2X-Real [48],为我们提出的 V2V-QA 数据集建立基准,使用不同的融合方法对基线方法进行实验:无融合、早期融合、中期融合和我们提出的基线 LLM 融合(图 3)。基线方法也采用了与 V2V-LLM 相同的投影仪和 LLM 架构,但点云特征编码器不同,如图 4 所示。在 V2X-split 的一些驾驶序列中,如果有来自路边基础设施的点云,我们也将其作为感知输入,与使用 CAV 点云的方法相同。
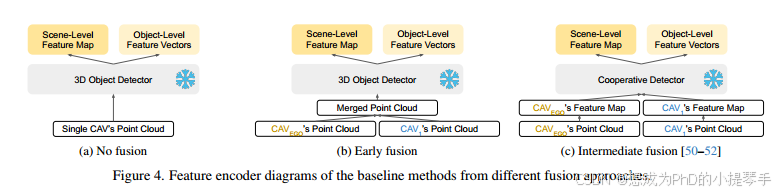
无融合: 只将单个 CAV 的激光雷达点云输入单个 3D 物体检测器,以提取场景级和物体级特征,作为 LLM 的视觉输入。预计这种方法的性能比所有其他合作感知方法都要差。
早期融合: 首先合并来自两个 CAV 的激光雷达点云。然后将合并后的点云作为三维物体检测器的输入,提取视觉特征作为 LLM 的视觉输入。这种方法需要更高的通信成本,在现实世界的自动驾驶车辆上部署不太实用。
中间融合: 先前的工作 CoBEVT [50]、V2XViT [51] 和 AttFuse [52]提出了合作检测模型,通过注意机制合并来自多个 CAV 的特征图。这些方法所需的通信成本较低,但仍能实现良好的性能。在我们的基准中,我们从这些合作检测模型中提取特征作为 LLM 的输入标记。
LLM 融合: 我们将所提出的 V2V-LLM 归类为一种新型融合方法--LLM 融合,即让每个 CAV 执行单独的 3D 物体检测,以提取场景级特征图和物体级特征向量,并使用多模式 LLM 融合多个 CAV 的特征。这种方法与传统的后期融合方法有关,后者先进行单独的三维物体检测,然后通过非最大抑制(NMS)对结果进行聚合。我们的方法不使用 NMS,而是采用 LLM 来执行更多任务,而不仅仅是检测。
5.2 实验结果
5.2.1 基础
V2V-LLM 和基线方法在 V2V-QA 的 3 种接地问题上的性能见表 3。表 3 分别列出了 V2V-split 和 V2X-split。V2X-split 的结果不包括 CoBEVT [50],因为 V2X-Real [48] 没有发布其 CoBEVT [50] 基线模型。平均而言,V2V-LLM 在 V2V-split 中取得了相似的性能,而在 V2X-split 中则优于所有其他基线方法。这些结果表明,我们的 V2VLLM 在融合多个 CAV 的感知特征来回答接地问题方面具有良好的能力。
5.2.2. 著名物体识别
表 3 显示了显著物体识别任务(Q4)的成绩。表 3 显示了在显著物体识别任务(Q4)上的性能。在 V2V 分路和 V2X 分路中,我们提出的 V2V-LLM 性能优于所有其他方法。与上述接地任务相比,这项值得注意的物体识别任务需要更强的空间理解能力,以识别靠近计划中未来航点的物体。对于这样的任务,我们的 V2V-LLM 让多模态 LLM 同时执行感知特征融合和问题解答,取得了最佳效果。
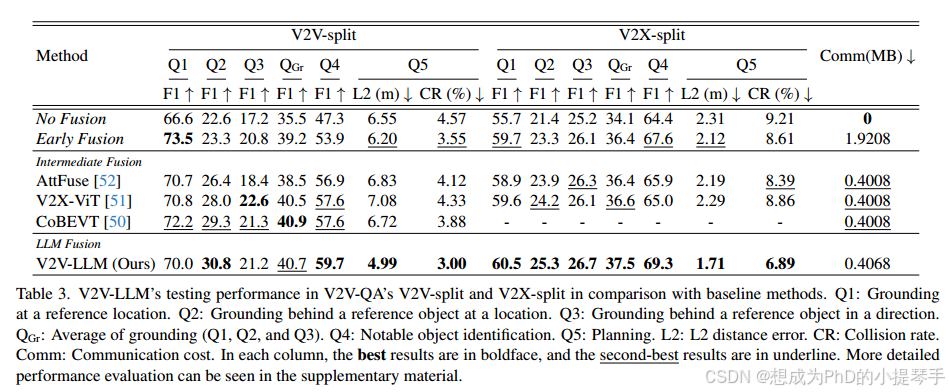
表 3. V2V-LLM 在 V2V-QA 的 V2V-split 和 V2X-split 测试中与基准方法的性能对比。Q1: 在参考位置接地。Q2: 在参考位置的参考物体后面接地。Q3:参考物体后方按方向接地。QGr: 接地(Q1、Q2 和 Q3)的平均值。Q4: 显著物体识别。Q5: 规划。L2: L2 距离误差。CR: 碰撞率Comm:通信 通信成本。每列中,最佳结果以黑体显示,次佳结果以下划线显示。更详细的性能评估见补充材料。
5.2.3. 规划
表 3 分别显示了 V2V 分路和 V2X 分路的规划任务(Q5)性能。表 3 分别显示了 V2V-split 和 V2X-split 的规划任务 (Q5) 的性能。我们提出的 V2VLLM 在这项对安全至关重要的任务中表现优于其他方法,它可以生成旨在避免潜在碰撞的未来轨迹。更多规划性能评估见补充材料。
5.2.4 通信成本和规模分析
在我们的集中式设置中,每个 CAV 在每个时间步向 LLM 计算节点发送一个场景级特征图(≤ 0.2MB)、一组单个物体检测结果参数(≤ 0.003MB)和一个问题(≤ 0.0002MB),并接收一个答案(≤ 0.0002MB)。如果有 Nv 个 CAV,每个 CAV 提出 Nq 个问题,则每个 CAV 的通信成本为 (0.2 + 0.003 + (0.0002 + 0.0002)Nq) = (0.203 + 0.0004Nq) MB,LLM 的成本为 (0.2 + 0.003 + (0.0002 + 0.0002)Nq)Nv = (0.203Nv + 0.0004NqNv) MB,如表 4 所示。4. 请注意,每个 CAV 在每个时间步只需向 LLM 计算节点发送一次相同的特征,因为 LLM 节点可以保存并重复使用这些特征,以便在同一时间步回答来自相同或不同 CAV 的多个问题。详细的缩放分析见补充材料。
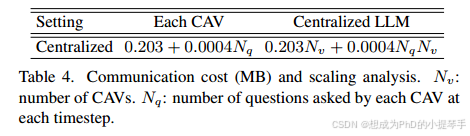
表 4. 通信成本(MB)和扩展分析。Nv:CAV 数量。Nq:每个 CAV 在每个时间步所提问题的数量。
5.2.5 结论
总体而言,V2V-LLM 在显著的物体识别和规划任务中取得了最佳效果,而这两项任务在自动驾驶应用中至关重要。V2V-LLM 在接地任务中还实现了有竞争力的结果。在通信成本方面,与其他中间融合基线方法相比,V2V-LLM 只增加了 1.5% 的通信成本。更详细的评估和分析见补充材料。
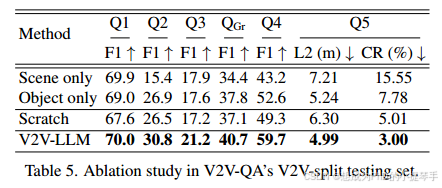
5.3 消融实验
输入特征: 我们对 V2VLLM 模型的变体进行了试验,将场景级特征图或物体级特征向量作为视觉输入。消融结果见表 5。5. 在所有质量保证任务中,这两种类型的特征都有助于提高最终性能。一般来说,纯对象级模型优于纯场景级模型。这意味着对象级特征更容易被 LLM 消化,这与之前使用 TOKEN 模型的研究结果一致[39]。
从零开始的培训:表 5 显示,从头开始训练的性能更差。表 5 显示,从头开始训练的性能更差,这意味着使用 LLaVA 的 VQA 任务进行预训练可以提高我们的 V2VLLM 在 V2V-QA 中的性能。更详细的消融结果见补充材料。
5.4 定量分析
图 5 显示了 V2V-LLM 的接地结果和 V2V-QA 测试集上的可视化地面实况。我们可以观察到,我们的 V2V-LLM 在 3 种类型的接地问题中都能根据所提供的参考信息找到对象。图 6 左侧显示了 V2V-LLM 的显著物体识别结果。V2V-LLM 展示了其在每个 CAV 的问题中指定的计划未来轨迹附近识别多个物体的能力。图 6 的右侧显示了 V2VLLM 的规划结果。我们的模型能够提出避免与附近物体发生潜在碰撞的未来轨迹。总体而言,在所有问题类型中,我们模型的输出结果都与地面实况的答案非常吻合,这表明我们的模型在合作式自动驾驶任务中具有很强的鲁棒性。

图 5. V2V-LLM 在 V2V-QA 测试集上的接地结果。洋红色 ◦:问题中的参考位置。黄色 +:模型输出位置。绿色 ◦:地面实况答案。
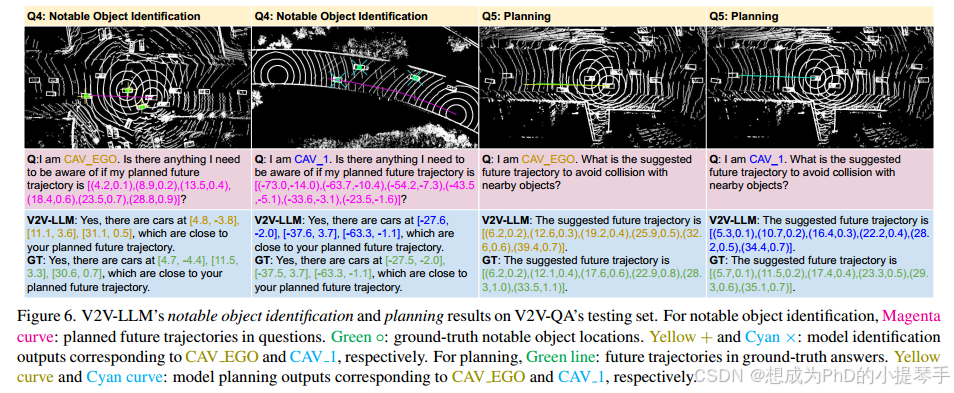
图 6. V2V-LLM 在 V2V-QA 测试集上的显著物体识别和规划结果。对于显著物体识别,洋红色曲线:问题中规划的未来轨迹。绿色 ◦:地面实况中的显著物体位置。黄色 + 和青色 ×:分别对应 CAV EGO 和 CAV 1 的模型识别输出。对于规划,绿线:地面实况答案中的未来轨迹。黄色曲线和青色曲线:分别对应 CAV EGO 和 CAV 1 的模型规划输出。
6 结论
在这项工作中,我们通过整合使用基于多模态 LLM 的方法,拓展了合作式自动驾驶的研究范围,旨在提高未来自动驾驶系统的安全性。我们提出了一个新的问题设置,并创建了一个新颖的 V2V-QA 数据集和基准,其中包括针对各种合作驾驶场景设计的接地、显著物体识别和规划问题解答任务。我们提出了一个基线模型 V2V-LLM,该模型可融合每辆 CAV 的单独感知信息,并执行视觉和语言理解,以回答来自任何 CAV 的与驾驶相关的问题。我们提出的 V2V-LLM 在显著的目标识别和规划任务中优于所有其他采用最先进合作感知算法的基线模型,并在接地任务中取得了具有竞争力的性能。这些实验结果表明,V2V-LLM 作为一种统一的多模式基础模型很有前途,它能有效地执行合作式自动驾驶的感知和规划任务。我们将公开发布我们的 V2V-QA 数据集和代码,以促进开源研究,并相信它将把合作驾驶研究带入下一个阶段。
相关文章:

论文阅读11——V2V-LLM:采用多模式大型语言模型的车对车协同自动驾驶
原文地址: 2502.09980https://arxiv.org/pdf/2502.09980 论文翻译: V2V-LLM: Vehicle-to-Vehicle Cooperative Autonomous Driving with Multi-Modal Large Language Models V2V-LLM:采用多模式大型语言模型的车对车协同自动驾驶 摘要&#…...

NLP 梳理01 — 文本预处理和分词
文章目录 一、说明二、文本预处理概述2.1 为什么要预处理文本?2.2 文本预处理的常见步骤2.3 什么是令牌化?2.4 为什么令牌化很重要? 三、分词类型四、用于分词化的工具和库五、实际实施六、编写函数以对文本进行标记七、结论 一、说明 本文总…...

Windows11 优雅的停止更新、禁止更新
网上有很多关闭自动更新的方法,改注册表、修改组策略编辑器、禁用Windows Update等等,大同小异,但最后奏效的寥寥无几,今天给大家带来另一种关闭win11自动更新的方法,亲测有效! 1、winR 打开运行窗口&…...

Kafka 中的 offset 提交问题
手动提交和自动提交 我们来一次性理清楚:Kafka 中的自动提交 vs 手动提交,到底区别在哪,怎么用,什么场景适合用哪个👇 🧠 一句话总结 ✅ 自动提交:Kafka 每隔一段时间自动提交 offset ✅ 手动…...

PowerBI窗口函数与视觉计算
文章目录 一、 窗口函数1.1 OFFSET(动态查询、求连续值)1.1.1 不使用orderBy1.1.2 使用orderBy1.1.3 统计连续值的最大出现次数(待补) 1.2 INDEX(静态查询)1.3 WINDOW(滚动求和、累计求和、帕累…...

代码随想录算法训练营Day22
回溯知识 力扣77.组合【medium】 一、回溯知识 1、定义 回溯法也可以叫做回溯搜索法,它是一种搜索的方式。回溯是递归的副产品,只要有递归就会有回溯。 2、回溯法的效率 回溯的本质是穷举,穷举所有可能,然后选出我们想要的答案…...

几种常见的HTTP方法之GET和POST
如大家所了解的,每条 HTTP 请求报文都必须包含一个请求方法,这个方法会告诉服务器要执行什么操作(例如获取一个 Web 页面、运行一个网关程序、删除一个文件等)。常见的几种 HTTP 方法如下: GET: 请求指定的…...

Nginx之https重定向为http
为了将Nginx中443端口的请求重定向到80端口,你可以按照以下步骤进行操作: 确认Nginx已经正确安装并运行: 确保Nginx服务已经在你的系统上安装并运行。你可以通过运行以下命令来检查Nginx的状态(具体命令可能因操作系统而异&a…...

落地DevOps文化:运维变革的正确打开方式
落地DevOps文化:运维变革的正确打开方式 DevOps,这个近年来被谈论得沸沸扬扬的概念,是企业数字化转型的一把钥匙。然而,很多公司虽然喊着“要上DevOps”,却苦于如何真正落地。而DevOps不仅仅是技术工具的堆砌,更是一种文化的重塑。从我的经历来看,DevOps实施的核心在于…...

《C++后端开发最全面试题-从入门到Offer》目录
当今科技行业对C++开发者的需求持续高涨,从金融科技到游戏开发,从嵌入式系统到高性能计算,C++凭借其卓越的性能和灵活性始终占据着关键地位。然而,成为一名优秀的C++工程师并非易事,不仅需要扎实的语言基础,还要掌握现代C++特性、设计模式、性能优化技巧以及各种工业级开…...
(附原文《高校负面舆情成因与演化路径研究》))
24统计建模国奖论文写作框架2(机器学习+自然语言处理类)(附原文《高校负面舆情成因与演化路径研究》)
一、引言 研究背景及意义 文献综述 研究内容与创新点 二、高校负面舆情热点现状分析 案例数据的获取与处理 高效负面舆情热点词频分析 高效负面舆情热点变化趋势分析 三、高校负面舆情成因分析 高校负面舆情变量的选取与赋值 基于QCA方法的高校负面舆情成因分析 四、…...

论文阅读笔记——Deformable Radial Kernel Splatting
DRK 论文 DRK(可变形径向核)的核心创新正是通过极坐标参数化与切平面投影,对传统3D高斯泼溅(3D-GS)进行了多维度的优化。 传统 3DGS 依赖径向对称的高斯核,只能表示平滑、各向同性的形状(球体、…...
)
网络编程—TCP/IP模型(IP协议)
上篇文章: 网络编程—TCP/IP模型(TCP协议)https://blog.csdn.net/sniper_fandc/article/details/147011479?fromshareblogdetail&sharetypeblogdetail&sharerId147011479&sharereferPC&sharesourcesniper_fandc&sharef…...

Android NDK C/C++交叉编译脚本
以下是 Android (arm64-v8a) 交叉编译 C/C 项目的完整脚本模板,基于 NDK 工具链,支持自定义源文件编译为静态库/动态库/可执行文件: 1. 基础交叉编译脚本 (build_android.sh) bash 复制 #!/bin/bash# Android 交叉编译脚本 (arm64-…...

IS-IS-单区域的配置
一、IS-IS的概念 IS-IS(Intermediate System to Intermediate System,中间系统到中间系统)是一种链路状态路由协议,最初设计用于OSI(Open Systems Interconnection)参考模型的网络层(CL…...
)
Java EE期末总结(第四章)
目录 一、ORM框架 二、MyBatis与Hibernate 1、 概念与设计理念 2、SQL 控制 3、学习成本 4、开发效率 三、MyBatisAPI 1、SqlSessionFactoryBuilder 2、SqlSessionFactory 3、SqlSession 四、MyBatis配置 1、核心依赖与日志依赖 2、建立.XML映射文件 3、建立映射…...

Kafka 的选举机制
Kafka 的选举机制在 Zookeeper 模式 和 KRaft 模式 下有所不同,主要体现在 领导选举 和 集群元数据管理 的方式上。下面详细介绍这两种模式下 Kafka 如何进行选举机制。 1. Zookeeper 模式下的选举机制 在早期的 Kafka 架构中,集群的元数据管理和选举机…...

FreeRTOS移植笔记:让操作系统在你的硬件上跑起来
一、为什么需要移植? FreeRTOS就像一套"操作系统积木",但不同硬件平台(如STM32、ESP32、AVR等)的CPU架构和外设差异大,需要针对目标硬件做适配配置。移植工作就是让FreeRTOS能正确管理你的硬件资源。 二、…...
策略模式)
设计模式简述(十二)策略模式
策略模式 描述基本使用使用传统策略模式的缺陷以及规避方法 枚举策略描述基本使用使用 描述 定义一组策略,并将其封装起来到一个策略上下文中。 由调用者决定应该使用哪种策略,并且可以动态替换 基本使用 定义策略接口 public interface IStrategy {…...

如何在idea中快速搭建一个Spring Boot项目?
文章目录 前言1、创建项目名称2、勾选需要的依赖3、在setting中检查maven4、编写数据源5、开启热启动(热部署)结语 前言 Spring Boot 凭借其便捷的开发特性,极大提升了开发效率,为 Java 开发工作带来诸多便利。许多大伙伴希望快速…...

【注解简化配置的原理是什么】
注解(Annotation)简化配置的核心原理是将原本分散在外部文件(如XML、properties)中的元数据直接内嵌到代码中,通过声明式编程让框架或工具自动处理这些元数据,从而减少手动配置的复杂度。以下是其实现原理的…...

Livox-Mid-70雷达使用------livox_mapping建图
1.ubuntu20.04 和Livox mid 70 的IP设置 连接好Livox-Mid-70雷达,然后进行局域网配置 1.1 Livox mid 70的IP是已知的,即192.168.1.1XX, XX表示mid 70广播码的后两位 1.2 ubuntu 20.04的IP设置 a.查看本机IP名 ifconfig b.设置本机IP地址 sudo ifconfig enx00e04…...

Django中使用不同种类缓存的完整案例
Django中使用不同种类缓存的完整案例 推荐超级课程: 本地离线DeepSeek AI方案部署实战教程【完全版】Docker快速入门到精通Kubernetes入门到大师通关课AWS云服务快速入门实战目录 Django中使用不同种类缓存的完整案例步骤1:设置Django项目步骤2:设置URL路由步骤3:视图级别…...
、LeetCode 518 零钱兑换 II、377 组合总数 IV、爬楼梯(进阶))
代码随想录算法训练营Day32| 完全背包问题(二维数组 滚动数组)、LeetCode 518 零钱兑换 II、377 组合总数 IV、爬楼梯(进阶)
理论基础 完全背包问题 在完全背包问题中,每种物品都有无限个,我们可以选择任意个数(包括不选),放入一个容量为 W W W 的背包中。我们希望在不超过容量的情况下,最大化背包内物品的总价值。 完全背包&a…...

Django SaaS案例:构建一个多租户博客应用
Django SaaS案例:构建一个多租户博客应用 推荐超级课程: 本地离线DeepSeek AI方案部署实战教程【完全版】Docker快速入门到精通Kubernetes入门到大师通关课AWS云服务快速入门实战目录 Django SaaS案例:构建一个多租户博客应用如果你正在从事一个SaaS(软件即服务)项目或一…...

静态库与动态库
静态库(Static Library) 定义:静态库(如 .a 文件或 .lib 文件)是编译时直接链接到可执行文件中的库。其代码和数据会被完整复制到最终的可执行文件中。 特点: 独立部署:无需依赖外部库文件。 …...

优选算法的妙思之流:分治——归并专题
专栏:算法的魔法世界 个人主页:手握风云 目录 一、归并排序 二、例题讲解 2.1. 排序数组 2.2. 交易逆序对的总数 2.3. 计算右侧小于当前元素的个数 2.4. 翻转对 一、归并排序 归并排序也是采用了分治的思想,将数组划分为多个长度为1的子…...

PDFBox渲染生成pdf文档
使用PDFBox可以渲染生成pdf文档,并且自定义程度高,只是比较麻烦,pdf的内容位置都需要手动设置x(横向)和y(纵向)绝对位置,但是每个企业的单据都是不一样的,一般来说都会设…...

flutter dio网络请求与json数据解析
在Flutter中,Dio 是一个功能强大且易于使用的网络请求库,用于处理HTTP请求和响应。与 http 包相比,Dio 提供了更多高级功能,例如拦截器、文件上传/下载、请求取消等。结合 json_serializable 或手动解析 JSON 数据,可以…...
的详细讲解)
7. RabbitMQ 消息队列——延时队列(Spring Boot + 安装message_exchange“延迟插件“ 的详细配置说明)的详细讲解
7. RabbitMQ 消息队列——延时队列(Spring Boot 安装message_exchange"延迟插件" 的详细配置说明)的详细讲解 文章目录 7. RabbitMQ 消息队列——延时队列(Spring Boot 安装message_exchange"延迟插件" 的详细配置说明)的详细讲解1. RabbitMQ 延时队列概…...

使用 MyBatis-Plus 实现高效的 Spring Boot 数据访问层
在开发 Spring Boot 应用时,数据访问是不可或缺的部分。为了提高开发效率并减少样板代码,MyBatis-Plus 提供了强大的功能,能够简化与数据库交互的操作。本文将详细介绍如何在 Spring Boot 中使用 MyBatis-Plus,并结合具体代码示例…...

Linux学习笔记——零基础详解:什么是Bootloader?U-Boot启动流程全解析!
零基础详解:什么是Bootloader?U-Boot启动流程全解析! 一、什么是Bootloader?📌 举个例子: 二、U-Boot 是什么?三、U-Boot启动过程:分为两个阶段🔹 第一阶段(汇…...

网络初识 - Java
网络发展史: 单机时代(独立模式) -> 局域网时代 -> 广域网时代 -> 移动互联网时代 网络互联:将多台计算机链接再一起,完成数据共享。 数据共享的本质是网络数据传输,即计算机之间通过网络来传输数…...
独立按键控制流水灯LED流向(独立按键教程)(LED使用教程))
(51单片机)独立按键控制流水灯LED流向(独立按键教程)(LED使用教程)
源代码 如上图将7个文放在Keli5 中即可,然后烧录在单片机中就行了 烧录软件用的是STC-ISP,不知道怎么安装的可以去看江科大的视频: 【51单片机入门教程-2020版 程序全程纯手打 从零开始入门】https://www.bilibili.com/video/BV1Mb411e7re?…...
)
QML输入控件: TextArea的应用(带行号的编辑器)
目录 引言📚 相关阅读🔨BUG修复实现思路代码解析主窗口代码自定义TextAreaItem组件行号显示部分文本编辑区域滚动同步 关键功能解析1. 动态更新行号2. 属性映射3. 外观定制 运行效果总结工程下载 引言 在开发Qt/QML应用程序时,文本编辑功能是…...

kafka 的存储文件结构
Kafka 的存储文件结构是其高吞吐量和高效性能的关键部分。Kafka 的存储结构是围绕 日志(Log) 的设计展开的,而每个 Kafka 分区(Partition) 都会以日志文件的形式存储。Kafka 采用了顺序写入、分段存储和索引文件的机制…...

FAISS原理深度剖析与LLM检索分割难题创新解决方案
一、FAISS核心技术解构:突破传统检索的次元壁 1.1 高维空间的降维艺术 FAISS(Facebook AI Similarity Search)通过独创的Product Quantization(乘积量化)技术,将高维向量空间切割为多个正交子空间。每个子…...
)
Windows操作系统安全配置(一)
1.操作系统和数据库系统管理用户身份标识应具有不易被冒用的特点,口令应有复杂度要求并定期更换 配置方法:运行“gpedit.msc”计算机配置->Windows设置->安全设置>帐户策略->密码策略: 密码必须符合复杂性要求->启用 密码长度最小值->…...

JavaScript promise实例——通过XHR获取省份列表
文章目录 需求和步骤代码示例效果 需求和步骤 代码示例 <!DOCTYPE html> <html lang"zh-CN"><head><meta charset"UTF-8"><!-- 确保IE浏览器使用最新的渲染引擎 --><meta http-equiv"X-UA-Compatible" conten…...
搜索旋转排序数组)
【力扣hot100题】(065)搜索旋转排序数组
难点在于情况真的很多需要逐一判断,画个走向图再写判断条件就行了。 还有处理边界条件也比较麻烦。 class Solution { public:int search(vector<int>& nums, int target) {int left0;int rightnums.size()-1;while(left<right){int mid(leftright)/…...

毕设论文的分类号与UDC查询的网站
毕业论文分类号 中图分类号查询链接 找到自己的细分类,一个一个点就好,然后就找到了 毕业论文UDC UDC查询...

pyqt5实现多个窗口互相调用
使用以下代码可以实现多窗口之间的相互调用: import sys from PyQt5.QtWidgets import QApplication, QMainWindow import win0, win1, win2, win3 # 分别包含 Ui_win0 和 Ui_win1class Win0Window(QMainWindow, win0.Ui_win0):def __init__(self, x, parentNone)…...
)
Python基于Django的企业it资产管理系统(附源码,文档说明)
博主介绍:✌IT徐师兄、7年大厂程序员经历。全网粉丝15W、csdn博客专家、掘金/华为云//InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇dz…...

浅谈在HTTP中GET与POST的区别
从 HTTP 报文来看: GET请求方式将请求信息放在 URL 后面,请求信息和 URL 之间以 ?隔开,请求信息的格式为键值对,这种请求方式将请求信息直接暴露在 URL 中,安全性比较低。另外从报文结构上来看,…...

计算机视觉5——运动估计和光流估计
一、运动估计 (一)运动场(Motion Field) 定义与物理意义 运动场是三维场景中物体或相机运动在二维图像平面上的投影,表现为图像中每个像素点的运动速度矢量。其本质是场景点三维运动(平移、旋转、缩放等&a…...

8. RabbitMQ 消息队列 + 结合配合 Spring Boot 框架实现 “发布确认” 的功能
8. RabbitMQ 消息队列 结合配合 Spring Boot 框架实现 “发布确认” 的功能 文章目录 8. RabbitMQ 消息队列 结合配合 Spring Boot 框架实现 “发布确认” 的功能1. RabbitMQ 消息队列 结合配合 Spring Boot 框架实现 “发布确认” 的功能1.1 回退消息 2.备用交换机3. API说…...

铰链损失函数 Hinge Loss和Keras 实现
一、说明 在为了了解 Keras 深度学习框架的来龙去脉,本文介绍铰链损失函数,然后使用 Keras 实现它们以进行练习并了解它们的行为方式。在这篇博客中,您将首先找到两个损失函数的简要介绍,以确保您在我们继续实现它们之前直观地理解…...

【Tips】Cloudflare用户与网站之间的中介
Cloudflare是一家提供多种网络服务的公司,旨在帮助网站和应用程序提高性能、安全性和可靠性。它为全球网站、应用程序和网络提供一系列网络安全、性能优化和可靠性服务。Cloudflare 的核心使命是让互联网更加安全、快速和可靠。 以下是其主要服务介绍:…...

PDF 转图片,一行代码搞定!批量支持已上线!
大家好,我是程序员晚枫。今天我要给大家带来一个超实用的功能——popdf 现在支持 PDF 转图片了,而且还能批量操作!是不是很激动?别急,我来手把手教你玩转这个功能。 1. 一行代码搞定单文件转换 popdf 的核心就是简单暴…...

可以使用费曼学习法阅读重要的书籍
书本上画了很多线,回头看等于没画出任何重点。 不是所有的触动都是有效的。就像你曾经看过很多好文章,当时被触动得一塌糊涂,还把它们放进了收藏夹,但一段时间之后,你就再也记不起来了。如果让你在一本书上画出令自己…...