3D点云配准RPM-Net模型解读(附论文+源码)
RPM-Net
- 总体流程
- 代码
- 数据预处理
- 模型
- 计算 α α α和 β β β
- 特征提取
- 变换矩阵
- 计算损失
论文链接:RPM-Net: Robust Point Matching using Learned Features
官方链接:RPMNet
老规矩,先看看效果。

看看论文里给的对比图

总体流程
在学之前得储备PointNet++的知识,因为RPM-Net是通过PointNet++提取输入特征的。因为之前讲过Pointnet++,所以这里不会重复讲PointNet++的内容。
RPMNet是一个用于点云配准的模型,基于传统算法RPM做的,而RPM是非常吃经验值 α α α和 β β β的,RPMNet通过神经网络来预测这两个值。
算法的总体框架如下图。
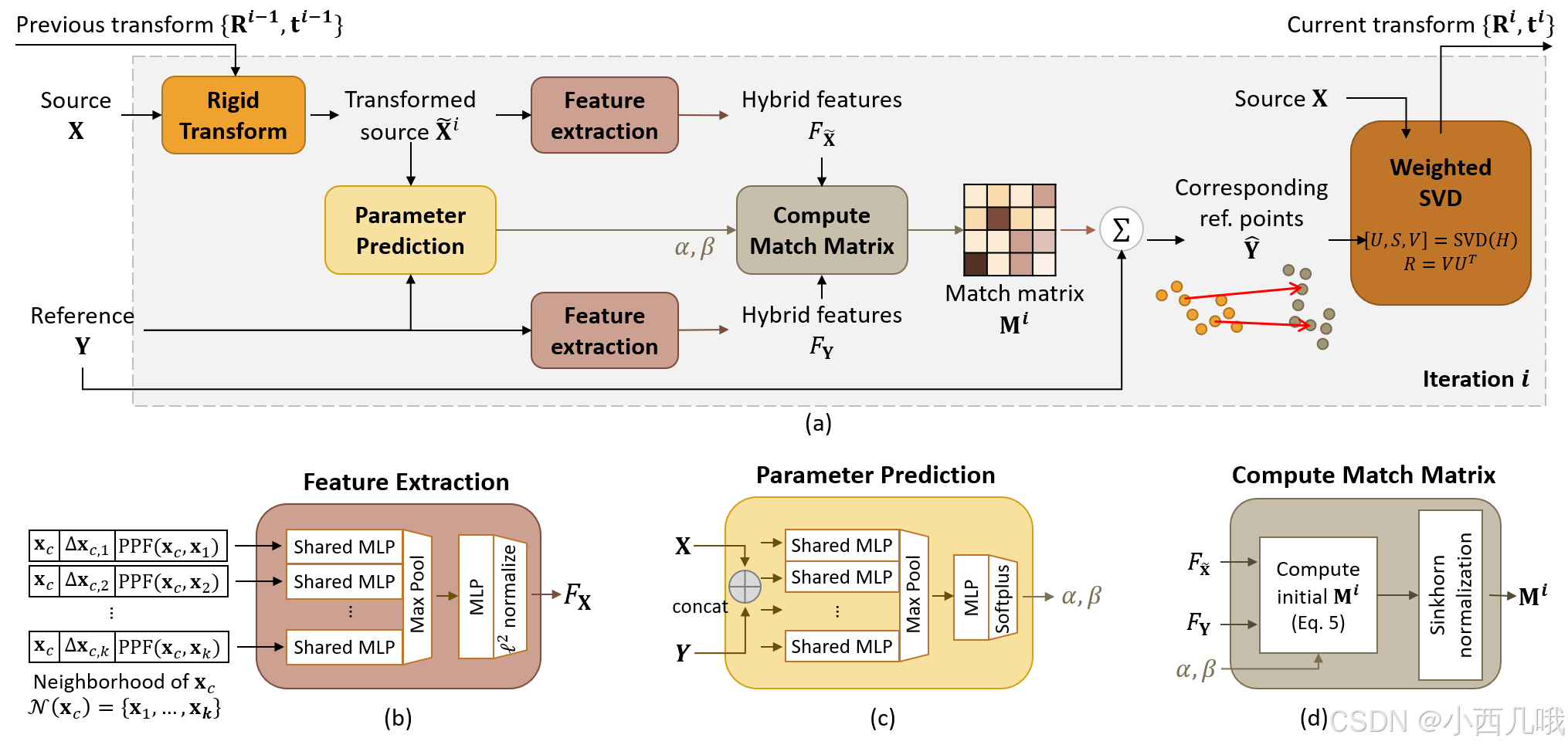
(b)这个特征提取模块和PointNet++是一样,不过这里有些不同的是,这里会提取10个特征。首先xyz、dxyz肯定是有的,然后还有4个就是这个PPF。PointNet++ 里不是有多簇嘛,每个簇里有很多个点,这些点与簇的关系是怎么样的呢?这就是PPF要干的事情,最后会得到4个关系特征。
(c)X,Y分别是原点云数据和参考点云数据(原点云数据仅是在原数据上采样了,或者裁剪了,位置什么的都没有变化。参考点云数据在采样裁剪的基础上还会有一些扰动,比如旋转平移之类的)。然后经过一系列的Conv1D卷积,maxpool,连几个MLP全连接层,最后激活输出 α α α和 β β β。
(d)这里输入的 F x F_x Fx和 F y F_y Fy是(b)的输出, α α α和 β β β是©的输出。最后我们得到啥?变换的矩阵啊。这个变换矩阵的的求解论文到没详细说,只是引用了两篇参考文献,表示照着这个人家这个做的,有兴趣的可以去看看这两篇文献[DeepICP,Deep Closest Point]。
代码
数据预处理
数据预处理这块很简单,在路径src/data_loader/datasets.py的方法get_train_datasets。
def get_train_datasets(args: argparse.Namespace):train_categories, val_categories = None, Noneif args.train_categoryfile: # 训练类别train_categories = [line.rstrip('\n') for line in open(args.train_categoryfile)]train_categories.sort()if args.val_categoryfile: # 验证类别val_categories = [line.rstrip('\n') for line in open(args.val_categoryfile)]val_categories.sort()# 根据指定的参数对数据进行变换train_transforms, val_transforms = get_transforms(args.noise_type, args.rot_mag, args.trans_mag,args.num_points, args.partial)_logger.info('Train transforms: {}'.format(', '.join([type(t).__name__ for t in train_transforms])))_logger.info('Val transforms: {}'.format(', '.join([type(t).__name__ for t in val_transforms])))train_transforms = torchvision.transforms.Compose(train_transforms)val_transforms = torchvision.transforms.Compose(val_transforms)if args.dataset_type == 'modelnet_hdf': # 从数据集中选择了部分数据train_data = ModelNetHdf(args.dataset_path, subset='train', categories=train_categories,transform=train_transforms)val_data = ModelNetHdf(args.dataset_path, subset='test', categories=val_categories,transform=val_transforms)else:raise NotImplementedErrorreturn train_data, val_data
步骤很简单吧,首先拿到数据的类别信息,然后根据参数对数据进行变换。数据集里并不是所有的数据都适合做这个任务的,所以作者选了一部分的数据来做。主要看看get_transforms吧,别的也没啥好说的。
def get_transforms(noise_type: str,rot_mag: float = 45.0, trans_mag: float = 0.5,num_points: int = 1024, partial_p_keep: List = None):partial_p_keep = partial_p_keep if partial_p_keep is not None else [0.7, 0.7] # 裁剪比例if noise_type == "clean":...elif noise_type == "jitter":...elif noise_type == "crop":# Both source and reference point clouds cropped, plus same noise in "jitter"train_transforms = [Transforms.SplitSourceRef(), # 复制一份 源点云和参考点云Transforms.RandomCrop(partial_p_keep), # 裁剪Transforms.RandomTransformSE3_euler(rot_mag=rot_mag, trans_mag=trans_mag), # 旋转 平移Transforms.Resampler(num_points), # 采样num_points个点Transforms.RandomJitter(), # 高斯噪声Transforms.ShufflePoints()] # 打乱点的顺序test_transforms = [Transforms.SetDeterministic(),Transforms.SplitSourceRef(),Transforms.RandomCrop(partial_p_keep),Transforms.RandomTransformSE3_euler(rot_mag=rot_mag, trans_mag=trans_mag),Transforms.Resampler(num_points),Transforms.RandomJitter(),Transforms.ShufflePoints()]else:raise NotImplementedErrorreturn train_transforms, test_transforms
因为clean和jitter的内容都包含在crop,我就直接说crop了。作者没有直接用transforms.Compose的方法哈,所有的变换都是自己写的,在路径src/data_loader/transforms.py下。我就不去transforms.py里细讲了,这个看名字也知道干啥了。SplitSourceRef()拷贝一份点云数据(源点云和参考点云)、RandomCrop()随机裁剪、RandomTransformSE3_euler()随机旋转和平移、Resampler()随机采样、RandomJitter()添加高斯噪声、ShufflePoints()随机打乱。
模型
主要来看看模型的前向传播是怎么搞的,在路径src/models/rpmnet.py里RPMNet的方法forward。
def forward(self, data, num_iter: int = 1):endpoints = {}xyz_ref, norm_ref = data['points_ref'][:, :, :3], data['points_ref'][:, :, 3:6]xyz_src, norm_src = data['points_src'][:, :, :3], data['points_src'][:, :, 3:6]xyz_src_t, norm_src_t = xyz_src, norm_src # (b,717,3) 717=1024*0.7transforms = []all_gamma, all_perm_matrices, all_weighted_ref = [], [], []all_beta, all_alpha = [], []for i in range(num_iter):beta, alpha = self.weights_net([xyz_src_t, xyz_ref])feat_src = self.feat_extractor(xyz_src_t, norm_src_t) # (b,717,96)feat_ref = self.feat_extractor(xyz_ref, norm_ref) # (b,717,96)feat_distance = match_features(feat_src, feat_ref) # 计算距离 (b,717,717)affinity = self.compute_affinity(beta, feat_distance, alpha=alpha) # (b,717,717)# Compute weighted coordinateslog_perm_matrix = sinkhorn(affinity, n_iters=self.num_sk_iter, slack=self.add_slack)perm_matrix = torch.exp(log_perm_matrix)weighted_ref = perm_matrix @ xyz_ref / (torch.sum(perm_matrix, dim=2, keepdim=True) + _EPS) # (b,717,3)# Compute transform and transform pointstransform = compute_rigid_transform(xyz_src, weighted_ref, weights=torch.sum(perm_matrix, dim=2)) # (b,3,4)xyz_src_t, norm_src_t = se3.transform(transform.detach(), xyz_src, norm_src)transforms.append(transform)all_gamma.append(torch.exp(affinity))all_perm_matrices.append(perm_matrix)all_weighted_ref.append(weighted_ref)all_beta.append(to_numpy(beta))all_alpha.append(to_numpy(alpha))endpoints['perm_matrices_init'] = all_gammaendpoints['perm_matrices'] = all_perm_matricesendpoints['weighted_ref'] = all_weighted_refendpoints['beta'] = np.stack(all_beta, axis=0)endpoints['alpha'] = np.stack(all_alpha, axis=0)return transforms, endpoints先将源点和参考点的xyz坐标与法向量坐标拿出来吗,方便后面做计算。好,直接看for循环。之前有说过传统算法RPM是非常吃经验值的, α α α和 β β β需要人为估计一个值。作者一想,好麻烦,直接使用神经网络来预测一个吧。来看看self.weights_net怎么做的。
计算 α α α和 β β β
在路径src/models/feature_nets.py里ParameterPredictionNet的方法forward。
def forward(self, x):src_padded = F.pad(x[0], (0, 1), mode='constant', value=0) # 多了一个标识符 src的为0ref_padded = F.pad(x[1], (0, 1), mode='constant', value=1) # ref的为1 (b,717,4) 4->xyz+标识符concatenated = torch.cat([src_padded, ref_padded], dim=1) # (b,1434,4)prepool_feat = self.prepool(concatenated.permute(0, 2, 1)) # (b,4,1434) -> (b,1024,1434)pooled = torch.flatten(self.pooling(prepool_feat), start_dim=-2) # (b,1024)raw_weights = self.postpool(pooled) # (b,2)beta = F.softplus(raw_weights[:, 0])alpha = F.softplus(raw_weights[:, 1])return beta, alpha
首先将源点云数据和参考点云数据拼接在一起,在此之前呢会给它们添个标识符,源的为0,参考的为1。
这里解释一下为什么经常使用permute来转变维度,因为pytorch里channel first,特征维度要放在第一位(也就是batch后的第一位)。正常特征图的维度是(c,h,w),但这里只有两个维度啊,2D卷积用不了,所以用的是一维卷积Conv1d。看一下self.prepool的结构。
self.prepool = nn.Sequential(nn.Conv1d(4, 64, 1),nn.GroupNorm(8, 64),nn.ReLU(),nn.Conv1d(64, 64, 1),nn.GroupNorm(8, 64),nn.ReLU(),nn.Conv1d(64, 64, 1),nn.GroupNorm(8, 64),nn.ReLU(),nn.Conv1d(64, 128, 1),nn.GroupNorm(8, 128),nn.ReLU(),nn.Conv1d(128, 1024, 1),nn.GroupNorm(16, 1024),nn.ReLU(),
)
self.prepool里有好几层Conv1d,可以看到channel的的变化,4->64->64->64->128->1024。这里的nn.GroupNorm也是一种归一化的方式,第一个参数是num_groups,表示将channel划分为num_groups组,比如第一层输出是(8, 64, 1434),会将64个channel划分为8组,每组8个channel。然后每个样本独立计算(不依赖 batch 统计信息),每个组共享均值和方差,然后归一化。(像常见的BN,会依赖batch size,因为它是计算整个 batch 维度的均值和方差)。
然后做一个maxpooling,将数据浓缩成精华。比如pooling之前,1434个点有1024个特征;pooling完之后,不是每个点有啥特征了,而是全局的一个特征是一个1024维向量。现在做完这些我们得有一个输出了,还记得我们初衷吗?预测 α α α和 β β β啊。看一下self.postpool的结构。
self.postpool = nn.Sequential(nn.Linear(1024, 512),nn.GroupNorm(16, 512),nn.ReLU(),nn.Linear(512, 256),nn.GroupNorm(16, 256),nn.ReLU(),nn.Linear(256, 2 + np.prod(weights_dim)),
)
连了几个全连接,可以看到维度的转变, 1024->512->256->2。输出的结果可以看到有正有负,不过 α α α和 β β β的值需要是正数,所以连个F.softplus,可以看做激活函数,最后输出。
=======================================================================
回到RPMNet的forward,现在需要对原点云数据和参考点云数据进行特征提取,来看看self.feat_extractor是怎么做的。
特征提取
在路径src/models/feature_nets.py里FeatExtractionEarlyFusion的方法forward。先展示部分。
def forward(self, xyz, normals):features = sample_and_group_multi(-1, self.radius, self.n_sample, xyz, normals)features['xyz'] = features['xyz'][:, :, None, :]
之前PointNet++里也有sample_and_group_multi,代码一模一样的,不过这里面添了个PPF,来看看怎么回事。
def sample_and_group_multi(npoint: int, radius: float, nsample: int, xyz: torch.Tensor, normals: torch.Tensor,returnfps: bool = False):B, N, C = xyz.shapeif npoint > 0:S = npointfps_idx = farthest_point_sample(xyz, npoint) # [B, npoint, C]new_xyz = index_points(xyz, fps_idx)nr = index_points(normals, fps_idx)[:, :, None, :]else:S = xyz.shape[1]fps_idx = torch.arange(0, xyz.shape[1])[None, ...].repeat(xyz.shape[0], 1).to(xyz.device)new_xyz = xyznr = normals[:, :, None, :] # (b,717,1,3)idx = query_ball_point(radius, nsample, xyz, new_xyz, fps_idx) # (B, npoint, nsample)grouped_xyz = index_points(xyz, idx) # (B, npoint, nsample, C) npoint个簇 每个簇nsample个点 每个点C个特征d = grouped_xyz - new_xyz.view(B, S, 1, C) # d = p_r - p_i (B, npoint, nsample, 3) 去均值(邻域点相对中心点的位置偏移量)ni = index_points(normals, idx)nr_d = angle(nr, d) # 中心点法向量与邻域点坐标偏移量的夹角 (b,717,64)ni_d = angle(ni, d) # 邻域点法向量与邻域点坐标偏移量的夹角 (b,717,64)nr_ni = angle(nr, ni) # 中心点法向量与邻域点法向量的夹角 (b,717,64)d_norm = torch.norm(d, dim=-1) # 邻域点相对中心点的距离 (b,717,64)xyz_feat = d # (B, npoint, n_sample, 3)ppf_feat = torch.stack([nr_d, ni_d, nr_ni, d_norm], dim=-1) # (B, npoint, n_sample, 4)if returnfps:return {'xyz': new_xyz, 'dxyz': xyz_feat, 'ppf': ppf_feat}, grouped_xyz, fps_idxelse:return {'xyz': new_xyz, 'dxyz': xyz_feat, 'ppf': ppf_feat}
这里输入的npoint为-1,表示每个点都作为中心点画圈采样。query_ball_point之前在PointNet++里面讲的很详细了,这里就不说了。得到的grouped_xyz的size为(B, 717, 64, 3),可以理解为:以所有点为中心画圈,圈成717个簇,每个簇64个点,每个点3个特征。
nr_d的size为(B,717,64),这个计算的是中心点法向量与邻域点坐标偏移量的夹角,可以理解为:每簇里有64个点,这64个点与对应簇的关系。同理,ni_d、nr_ni和d_norm你都可以这样理解,就是计算簇里的点与簇的关系,论文里也没解释为啥这样做。
=======================================================================
回到FeatExtractionEarlyFusion的forward中,继续往下看。
# Gate and concat
concat = []
for i in range(len(self.features)): # 为了将10个特征拼在一起f = self.features[i]expanded = (features[f]).expand(-1, -1, self.n_sample, -1)concat.append(expanded)
fused_input_feat = torch.cat(concat, -1) # (B,717,64,10)# Prepool_FC, pool, postpool-FC
new_feat = fused_input_feat.permute(0, 3, 2, 1) # [B, 10, n_sample, N]
new_feat = self.prepool(new_feat)pooled_feat = torch.max(new_feat, 2)[0] # Max pooling (B, C, N)post_feat = self.postpool(pooled_feat) # Post pooling dense layers
cluster_feat = post_feat.permute(0, 2, 1)
cluster_feat = cluster_feat / torch.norm(cluster_feat, dim=-1, keepdim=True)return cluster_feat # (B, N, C)
for循环是为了将xyz、dxyz和ppf的特征拼接在一起,得到fused_input_feat的size为(b,717,64,10)。ok。现在我们有3个维度了,可以做2D卷积了,来看看self.prepool的结构。
Sequential(nn.Conv2d(10, 96, 1),nn.GroupNorm(8, 96),nn.ReLU(),nn.Conv2d(96, 96, 1),nn.GroupNorm(8, 96),nn.ReLU(),nn.Conv2d(96, 192, 1),nn.GroupNorm(8, 192),nn.ReLU(),
)
可以看到维度的变化,10->96->96->192。然后接着Max pooling得到size为(b,192,717)。这下又只有两个维度了,只能用1D卷积了,来看一下self.postpool的结构。
Sequential(nn.Conv1d(192, 192, 1),nn.GroupNorm(8, 192),nn.ReLU(),nn.Conv1d(192, 96, 1),nn.GroupNorm(8, 96),nn.ReLU(),nn.Conv1d(96, 96, 1),
)
可以看到维度的变化,192->96。最后进行L2归一化,得到最终输出,size为(B,717,96)
。
=======================================================================
回到RPMNet的forward,继续往下看。现在要计算变换矩阵了。
变换矩阵
1、计算加权坐标
现在源点云数据和参考点云数据的特征都提取出来了,match_features来计算它俩之间的距离。每个源点与所有的参考点计算距离(相似度),构成一个J × K 的匹配矩阵(这里J、K是一样的),size为(b,717,717)。compute_affinity的解释是计算匹配矩阵值的对数, 看一下是怎么计算的。
def compute_affinity(self, beta, feat_distance, alpha=0.5):if isinstance(alpha, float):hybrid_affinity = -beta[:, None, None] * (feat_distance - alpha)else:hybrid_affinity = -beta[:, None, None] * (feat_distance - alpha[:, None, None])return hybrid_affinity
很简单啊,公式就是 β × ( 匹配矩阵 − α ) β×(匹配矩阵-α) β×(匹配矩阵−α),这个公式可以理解为,衡量每对点之间是否是对应点(源点-参考点 对应关系)。你要问我为什么这样就可以衡量?那我包支支吾吾的,应该涉及传统RPM算法的数学公式吧…。不过,很显然这里面也没计算对数啊,我看了一下在下面的sinkhorn计算了。
sinkhorn的解释是将输入矩阵归一化为近似的双重随机矩阵(每行、每列的和小于等于1)。就不跳进去看了,代码很简单。结果出来又进行了torch.exp,刚log完又exp回来,就理解为将刚刚的矩阵归一化了就行,得到源点和参考点的匹配关系。最后计算加权的参考点坐标,用刚刚的概率矩阵作为权重(因为归一化了嘛,就当概率矩阵看吧),与参考点进行加权求和,最终得到每个源点对应的加权参考点坐标,然后归一化。
(注:这里应该是涉及了一些数学公式的推导,但是论文里并没有详细说,就这么理解吧)
2、计算刚体变换矩阵和变换点
compute_rigid_transform是计算刚体变换的,即找到一个 旋转矩阵和平移向量 ,使得源点变换后最接近参考点。看一下compute_rigid_transform干了啥吧。
def compute_rigid_transform(a: torch.Tensor, b: torch.Tensor, weights: torch.Tensor):weights_normalized = weights[..., None] / (torch.sum(weights[..., None], dim=1, keepdim=True) + _EPS) # (b,717,1)centroid_a = torch.sum(a * weights_normalized, dim=1) # (b,3)centroid_b = torch.sum(b * weights_normalized, dim=1) # (b,3)a_centered = a - centroid_a[:, None, :] # 去中心化 (b,717,3)b_centered = b - centroid_b[:, None, :] # (b,717,3)cov = a_centered.transpose(-2, -1) @ (b_centered * weights_normalized) # (b,3,3)# Compute rotation using Kabsch algorithm. Will compute two copies with +/-V[:,:3]# and choose based on determinant to avoid flipsu, s, v = torch.svd(cov, some=False, compute_uv=True)rot_mat_pos = v @ u.transpose(-1, -2)v_neg = v.clone()v_neg[:, :, 2] *= -1rot_mat_neg = v_neg @ u.transpose(-1, -2)rot_mat = torch.where(torch.det(rot_mat_pos)[:, None, None] > 0, rot_mat_pos, rot_mat_neg)assert torch.all(torch.det(rot_mat) > 0)# Compute translation (uncenter centroid)translation = -rot_mat @ centroid_a[:, :, None] + centroid_b[:, :, None]transform = torch.cat((rot_mat, translation), dim=2)return transform
先将权重归一化,这个权重weights就是我刚刚说的概率矩阵的和。对源点坐标和参考点坐标进行去中心化,使其绕 (0,0,0) 旋转。然后计算它俩之间的协方差矩阵,…,woc下面全是数学公式,看得我头疼。
下面代码看不懂,看注释上写的是计算旋转矩阵、处理镜像翻转、计算平移向量,最终找到源点到参考点的最优刚体变换(旋转+平移)。返回的是刚体变换矩阵size为(b,3,4),3表示xyz,4:前三列是旋转矩阵,最后一列是平移向量。
======================================================================
回到RPMNet的forward,继续往下看。
这时候我们已经有变换矩阵了,那得看看这个矩阵效果怎么样啊。se3.transform将源点通过变换矩阵得到变换后的点,用于下一次迭代的特征提取和匹配。将每次循环的结果都存储起来,为后续损失计算做准备。
计算损失
来到路径src/train.py下看看compute_losses损失是什么计算的。
def compute_losses(data: Dict, pred_transforms: List, endpoints: Dict,loss_type: str = 'mae', reduction: str = 'mean') -> Dict:losses = {}num_iter = len(pred_transforms)# Compute lossesgt_src_transformed = se3.transform(data['transform_gt'], data['points_src'][..., :3]) # (b,717,3)if loss_type == 'mse':# MSE loss to the groundtruth (does not take into account possible symmetries)criterion = nn.MSELoss(reduction=reduction)for i in range(num_iter):pred_src_transformed = se3.transform(pred_transforms[i], data['points_src'][..., :3])if reduction.lower() == 'mean':losses['mse_{}'.format(i)] = criterion(pred_src_transformed, gt_src_transformed)elif reduction.lower() == 'none':losses['mse_{}'.format(i)] = torch.mean(criterion(pred_src_transformed, gt_src_transformed),dim=[-1, -2])elif loss_type == 'mae':# MSE loss to the groundtruth (does not take into account possible symmetries)criterion = nn.L1Loss(reduction=reduction)for i in range(num_iter):pred_src_transformed = se3.transform(pred_transforms[i], data['points_src'][..., :3])if reduction.lower() == 'mean':losses['mae_{}'.format(i)] = criterion(pred_src_transformed, gt_src_transformed)elif reduction.lower() == 'none':losses['mae_{}'.format(i)] = torch.mean(criterion(pred_src_transformed, gt_src_transformed),dim=[-1, -2])else:raise NotImplementedError# Penalize outliersfor i in range(num_iter):ref_outliers_strength = (1.0 - torch.sum(endpoints['perm_matrices'][i], dim=1)) * _args.wt_inlierssrc_outliers_strength = (1.0 - torch.sum(endpoints['perm_matrices'][i], dim=2)) * _args.wt_inliersif reduction.lower() == 'mean':losses['outlier_{}'.format(i)] = torch.mean(ref_outliers_strength) + torch.mean(src_outliers_strength)elif reduction.lower() == 'none':losses['outlier_{}'.format(i)] = torch.mean(ref_outliers_strength, dim=1) + \torch.mean(src_outliers_strength, dim=1)discount_factor = 0.5 # Early iterations will be discountedtotal_losses = []for k in losses:discount = discount_factor ** (num_iter - int(k[k.rfind('_')+1:]) - 1)total_losses.append(losses[k] * discount)losses['total'] = torch.sum(torch.stack(total_losses), dim=0)return losses
又看到se3.transform老朋友了,先将源点通过变换矩阵变换过来,这里用的都是真实值,是真货。判断一下用哪种损失函数,然后又看到se3.transform兄弟,这次还是源点通过变换矩阵变换过来,but,这次用的是我们预测出来的变换矩阵,是假货。ok,让我们来看看真货与假货之间的差异。
单单计算配准损失,不够不够,得再来点离群惩罚。上面说过,perm_matrices里存放的是源点与参考点的匹配概率,对行或列求和再取1-sum,就是匹配失败的程度。
之前在rpmnet里计算时,不是迭代的计算了几次,每次迭代的数据都被存储下来了。很显然,前面迭代的时候只是粗糙的计算了一下,后面再此基础上再微调,让其越来越准确。因此,需要加个权重discount ,前面迭代的结果损失轻点,但是到后面了,就不能一直这么碌碌无为了,得加重点。最终加权叠加所有损失返回结果。
相关文章:
)
3D点云配准RPM-Net模型解读(附论文+源码)
RPM-Net 总体流程代码数据预处理模型计算 α α α和 β β β特征提取变换矩阵计算损失 论文链接:RPM-Net: Robust Point Matching using Learned Features 官方链接:RPMNet 老规矩,先看看效果。 看看论文里给的对比图 总体流程 在学…...

23种设计模式-行为型模式-命令
文章目录 简介问题解决代码核心设计优势 总结 简介 命令是一种行为设计模式, 它能把请求转换为一个包含与请求相关的所有信息 的独立对象。这个转换能让你把请求方法参数化、延迟请求执行或把请求放在队列里,并且能实现可撤销操作。 问题 假如你正在开…...

ngx_cpystrn
定义在 src\core\ngx_string.c u_char * ngx_cpystrn(u_char *dst, u_char *src, size_t n) {if (n 0) {return dst;}while (--n) {*dst *src;if (*dst \0) {return dst;}dst;src;}*dst \0;return dst; } ngx_cpystrn 函数的作用是安全地将源字符串(src&#x…...

常用的国内镜像源
常见的 pip 镜像源 阿里云镜像:https://mirrors.aliyun.com/pypi/simple/ 清华大学镜像:https://pypi.tuna.tsinghua.edu.cn/simple 中国科学技术大学镜像:https://pypi.mirrors.ustc.edu.cn/simple/ 豆瓣镜像:https://pypi.doub…...
)
【小沐杂货铺】基于Three.JS绘制太阳系Solar System(GIS 、WebGL、vue、react)
🍺三维数字地球系列相关文章如下🍺:1【小沐学GIS】基于C绘制三维数字地球Earth(456:OpenGL、glfw、glut)第一期2【小沐学GIS】基于C绘制三维数字地球Earth(456:OpenGL、glfw、glut)第二期3【小沐…...
2025最详细图文教程安装手册)
Navicat17详细安装教程(附最新版本安装包和补丁)2025最详细图文教程安装手册
目录 前言:为什么选择Navicat 17? 一、下载Navicat17安装包 二、安装Navicat 1.运行安装程序 2.启动安装 3.同意“协议” 4.设置安装位置 5.创建桌面图标 6.开始安装 7.安装完成 三、安装补丁 1.解押补丁包 2.在解压后的补丁包目录下找到“w…...

记忆宫殿APP:全方位脑力与思维训练,助你提升记忆力,预防老年痴呆
记忆宫殿APP,一款专业的记忆训练软件,能去帮你提升自己的记忆能力,多样的训练项目创新的记忆方法,全方面帮你去提升你的记忆能力。 记忆宫殿APP有丰富的记忆训练项目,如瞬间记忆、短时记忆、机械记忆等,以…...

SpringBoot+Spring+MyBatis相关知识点
目录 一、相关概念 1.spring框架 2.springcloud 3.SpringBoot项目 4.注解 5.SpringBoot的文件结构 6.启动类原理 二、相关操作 1.Jar方式打包 2.自定义返回的业务状态码 3.Jackson 4.加载配置文件 5.异常处理 三、优化配置 1.简化sql语句 2.查询操作 复杂查询 一…...
岛屿数量)
【力扣hot100题】(050)岛屿数量
一开始还以为会很难很难(以为暴力搜索会时间超限要用别的办法),没想到并不难。 我最开始是用vector<vector<bool>>记录搜索过的地域,每次递归遍历周围所有地域。 class Solution { public:vector<vector<char…...

Opencv计算机视觉编程攻略-第九节 描述和匹配兴趣点
一般而言,如果一个物体在一幅图像中被检测到关键点,那么同一个物体在其他图像中也会检测到同一个关键点。图像匹配是关键点的常用功能之一,它的作用包括关联同一场景的两幅图像、检测图像中事物的发生地点等等。 1.局部模板匹配 凭单个像素就…...

pat学习笔记
two pointers 双指针 给定一个递增的正整数序列和一个正整数M,求序列中的两个不同位置的数a和b,使得它们的和恰好为M,输出所有满足条件的方案。例如给定序列{1,2,3,4,5,6}和正整数M 8,就存在268和358成立。 容易想到࿱…...
)
MoE Align Sort在医院AI医疗领域的前景分析(代码版)
MoE Align & Sort技术通过优化混合专家模型(MoE)的路由与计算流程,在医疗数据处理、模型推理效率及多模态任务协同中展现出显著优势,其技术价值与应用意义从以下三方面展开分析: 一、方向分析 1、提升医疗数据处理效率 在医疗场景中,多模态数据(如医学影像、文本…...

大数据概念介绍
这节课给大家讲一下大数据的生态架构, 大数据有很多的产品琳琅满目, 大家看到图上就知道产品很多, 那这些产品它们各自的功能是什么, 它们又是怎么样相互配合, 来完成一整套的数据存储, 包括分析计算这样的一些任务, 这节课就要给大家进行一个分析, 那我们按照数据处理…...
)
Linux(2025.3.15)
1、将/etc/passwd,/etc/shadow,/etc/group文件复制到/ceshi; 操作: (1)在根目录下创建ceshi目录; (2)复制; 结果: 2、找到/etc/ssh目录下ssh开头的所有文件并将其复制到…...

centosububntu设置开机自启动
一、centos 1.将脚本放到/etc/rc.d/init.d路径下 2.给脚本授权 sudo chmod -R 777 脚本名称 3.添加脚本至开机启动项中 sudo chkconfig --add 脚本名称 4.开启脚本 sudo chkconfig 脚本名称 on 5.查看开机启动项中是否包含该脚本 ls /etc/rc.d/rc*.d 二、ubuntu 1.在…...
)
基于大模型与动态接口调用的智能系统(知识库实现)
目录 引言 1、需求背景 2、实现原理 3、实现步骤 3.1 构建知识库接口调用提示模板 3.2 动态接口配置加载 3.3 智能参数提取链 3.4 接口智能路由 3.5 建议生成链 3.6 组合完整工作流 3.7 展示效果 总结 引言 在医疗信息化快速发展的今天,我们开发了一个智能问诊系…...

23种设计模式-行为型模式-迭代器
文章目录 简介问题解决代码设计关键点: 总结 简介 迭代器是一种行为设计模式,让你能在不暴露集合底层表现形式(列表、栈和树等)的情况下遍历集合中所有的元素。 问题 集合是编程中最常使用的数据类型之一。 大部分集合使用简单列表存储元素。但有些集…...

【Java集合】ArrayList源码深度分析
参考笔记: java ArrayList源码分析(深度讲解)-CSDN博客 【源码篇】ArrayList源码解析-CSDN博客 目录 1.前言 2. ArrayList简介 3. ArrayList类的底层实现 4. ArrayList的源码Debug 4.1 使用空参构造 (1)开始De…...

ISIS单区域抓包分析
一、通用头部报文 Intra Domain Routing Protocol Discriminator:域内路由选择协议鉴别符:这里是ISIS System ID Length:NSAP地址或NET中System ID区域的长度。值为0时,表示System ID区域的长度为6字节。值为255时,表…...

关键业务数据如何保持一致?主数据管理的最佳实践!
随着业务规模的扩大和系统复杂性的增加,如何确保关键业务数据的一致性成为许多企业面临的重大挑战。数据不一致可能导致决策失误、运营效率低下,甚至影响客户体验。因此,主数据管理(Master Data Management,简称MDM&am…...

ISIS单区域配置
一、什么是ISIS单区域 ISIS(Intermediate System to Intermediate System,中间系统到中间系统)单区域是指使用ISIS路由协议时,所有路由器都位于同一个区域(Area)内的网络配置。 二、实验拓扑 三、实验目的…...

Visual Basic语言的物联网
Visual Basic语言在物联网中的应用 引言 物联网(IoT)作为一种新兴的技术趋势,正在深刻地改变我们的生活方式与工业制造过程。在众多编程语言中,Visual Basic(VB)凭借其简单易用的特性,逐渐成为…...
)
【小沐杂货铺】基于Three.JS绘制三维数字地球Earth(GIS 、WebGL、vue、react)
🍺三维数字地球系列相关文章如下🍺:1【小沐学GIS】基于C绘制三维数字地球Earth(456:OpenGL、glfw、glut)第一期2【小沐学GIS】基于C绘制三维数字地球Earth(456:OpenGL、glfw、glut)第二期3【小沐…...

Vite环境下解决跨域问题
在 Vite 开发环境中,可以通过配置代理来解决跨域问题。以下是具体步骤: 在项目根目录下找到 vite.config.js 文件:如果没有,则需要创建一个。配置代理:在 vite.config.js 文件中,使用 server.proxy 选项来…...

嵌入式Linux开发环境搭建,三种方式:虚拟机、物理机、WSL
目录 总结写前面一、Linux虚拟机1 安装VMware、ubuntu18.042 换源3 改中文4 中文输入法5 永不息屏6 设置 root 密码7 安装 terminator8 安装 htop(升级版top)9 安装 Vim10 静态IP-虚拟机ubuntu11 安装 ssh12 安装 MobaXterm (SSH)…...

React项目在ts文件中使用router实现跳转
前言: 默认你已经进行了router的安装,目前到了配置http请求的步骤,在配置token失效或其他原因,需要实现路由跳转。在普通的 TypeScript 文件中无法直接使用Router的 useNavigate Hook。Hook 只能在 React 组件或自定义 Hook 中调用…...

Java中的正则表达式Lambda表达式
正则表达式&&Lambda表达式 正则表达式和Lambda表达式是Java编程中两个非常实用的特性。正则表达式用于字符串匹配与处理,而Lambda表达式则让函数式编程在Java中变得更加简洁。本文将介绍它们的基本用法,并结合示例代码帮助理解。同时要注意&…...

【idea设置文件头模板】
概述 设置模板,在创建java类时,统一添加内容(作者、描述、创建时间等等自定义内容),给java类添加格式统一的备注信息。 1、在settings 中找到File and Code Templates 选择File Header 2、模板内容示例 /*** Author hweiyu* Descriptio…...

我与数学建模之顺遂!
下面一段时期是我一段真正走进数模竞赛的时期。 在大二上学期结束之后,就开始张罗队友一起报名参加美赛,然后同时开始学LaTeX和Matlab,当时就是买了本Matlab的书,把书上的例题还有课后题全部做完了,然后用latex将书上…...

【Python使用】嘿马推荐系统全知识和项目开发教程第2篇:1.4 案例--基于协同过滤的电影推荐,1.5 推荐系统评估【附代码
教程总体简介:1.1 推荐系统简介 学习目标 1 推荐系统概念及产生背景 2 推荐系统的工作原理及作用 3 推荐系统和Web项目的区别 1.3 推荐算法 1 推荐模型构建流程 2 最经典的推荐算法:协同过滤推荐算法(Collaborative Filtering) 3 …...

Linux makefile的一些语法
一、定义变量 1. 变量的基本语法 在 makefile 中,变量的定义和使用非常类似于编程语言中的变量。变量的定义格式(最好不要写空格)如下: VARIABLE_NAMEvalue 或者 VARIABLE_NAME:value 表示延迟赋值,变量的值在引…...
(A-D))
Educational Codeforces Round 177 (Rated for Div. 2)(A-D)
题目链接:Dashboard - Educational Codeforces Round 177 (Rated for Div. 2) - Codeforces A. Cloudberry Jam 思路 小数学推导问题,直接输出n*2即可 代码 void solve(){int n;cin>>n;cout<<n*2<<"\n"; } B. Large A…...

第十八节课:Python编程基础复习
课程复习 前三周核心内容回顾 第一周:Python基本语法元素 基础语法:缩进、注释、变量命名、保留字数据类型:字符串、整数、浮点数、列表程序结构:赋值语句、分支语句(if)、函数输入输出:inpu…...

动物多导生理信号采集分析系统技术简析
一 技术参数 通道数:通道数量决定了系统能够同时采集的生理信号数量。如中南大学湘雅医学院的生物信号采集系统可达 128 通道,OmniPlex 多导神经信号采集分析系统支持 16、32、64、128 通道在体记录。不过,这个也要看具体的应用场景ÿ…...

Linux——Linux系统调用函数练习
一、实验名称 Linux系统调用函数练习 二、实验环境 阿里云服务器树莓派 三、实验内容 1. 远程登录阿里云服务器 2. 创建目录 操作步骤: mkdir ~/xmtest2 cd ~/xmtest2结果: 成功创建并进入homework目录。 3. 编写C代码 操作步骤: …...

列表与列表项
认识列表和列表项 FreeRTOS 中的 列表(List) 和 列表项(ListItem)是其内核实现的核心数据结构,广泛用于任务调度、队列管理、事件组、信号量等模块。它们通过双向链表实现,支持高效的元素插入、删除和遍历…...
手动初始化)
mofish软件(MacOS版本)手动初始化
mofish软件手动初始化MacOS 第一步,打开终端 command空格键唤起搜索页面,输入终端,点击打开终端 第二步,进入mofish配置目录,删除初始化配置文件 在第一步打开的终端中输入如下命令后按回车键,删除mofish配置文件 …...
)
基于javaweb的SpringBoot图片管理系统图片相册系统设计与实现(源码+文档+部署讲解)
技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文…...

密码学基础——DES算法
前面的密码学基础——密码学文章中介绍了密码学相关的概念,其中简要地对称密码体制(也叫单钥密码体制、秘密密钥体制)进行了解释,我们可以知道单钥体制的加密密钥和解密密钥相同,单钥密码分为流密码和分组密码。 流密码࿰…...

我与数学建模之波折
我知道人生是起起伏伏,但没想到是起起伏伏伏伏伏伏 因为简单讲讲,所以我没讲很多生活上的细节,其实在7月我和l学长一起在外面租房子备赛。这个时间节点其实我不太愿意讲,但是逃不了,那段时间因其他事情导致我那段时间…...
)
离线部署kubesphere(已有k8s和私有harbor的基础上)
前言说明:本文是在已有k8s集群和私有仓库harbor上进行离线安装kubesphere;官网的离线教程写都很详细,但是在部署部份把搭建集群和搭建仓库也写一起了,跟着做踩了点坑,这里就记录下来希望可以帮助到需要的xdm。 1.根据官…...

量子计算入门:Qiskit实战量子门电路设计
引言:量子计算的编程基石 量子门是量子计算的基本操作单元,其通过操控量子比特的叠加与纠缠实现并行计算。IBM开发的Qiskit框架为量子算法设计与模拟提供了强大工具。本文将从量子门基础、Qiskit实战、量子隐形传态案例三个维度,结合代码解析…...

AIGC8——大模型生态与开源协作:技术竞逐与普惠化浪潮
引言:大模型发展的分水岭时刻 2024年成为AI大模型发展的关键转折点:OpenAI的GPT-4o实现多模态实时交互,中国DeepSeek-MoE-16b模型以1/8成本达到同类90%性能,而开源社区如Mistral、LLama 3持续降低技术门槛。这场"闭源商业巨…...

FPGA练习
文章目录 一、状态机思想写一个 LED流水灯的FPGA代码二、 CPLD和FPGA芯片的主要技术区别是什么? 它们各适用于什么场合?1、CPLD适用场景2、FPGA适用场景 三、 在hdlbitsFPGA教程网站上进行学习1、练习题12、练习题2练习题3练习题4练习题5 一、状态机思想…...

阿里云服务器遭遇DDoS攻击有争议?
近年来,阿里云服务器频繁遭遇DDoS攻击的事件引发广泛争议。一方面,用户质疑其防御能力不足,导致服务中断甚至被迫进入“黑洞”(清洗攻击流量的隔离机制),轻则中断半小时,重则长达24小时…...

leetcode-代码随想录-哈希表-有效的字母异位词
题目 题目链接:242. 有效的字母异位词 - 力扣(LeetCode) 给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的 字母异位词。 输入: s "anagram", t "nagaram" 输出: true输入: s "rat",…...

kotlin中主构造函数是什么
一 Kotlin 中的主构造函数 主构造函数(Primary Constructor)是 Kotlin 类声明的一部分,用于在 创建对象时初始化类的属性。它不像 Java 那样是一个函数体,而是紧跟在类名后面。 主构造函数的基本定义 class Person(val name: S…...

Julia语言的测试覆盖率
Julia语言的测试覆盖率探讨 引言 在现代软件开发中,测试是确保软件质量的重要环节。随着软件的复杂度不断增加,测试覆盖率作为衡量测试质量的一个重要指标,受到了越来越多开发者的关注。Julia语言作为一种高性能的动态编程语言,…...
)
Apache httpclient okhttp(2)
学习链接 Apache httpclient & okhttp(1) Apache httpclient & okhttp(2) okhttp github okhttp官方使用文档 okhttp官方示例代码 OkHttp使用介绍 OkHttp使用进阶 译自OkHttp Github官方教程 SpringBoot 整合okHttp…...
)
BUUCTF-web刷题篇(10)
19.EasyMD5 md5相关内容总结: ①string md5(&str,raw) $str:需要计算的字符串; raw:指定十六进制或二进制输出格式。计算成功,返回md5值,计算失败,返回false。 raw参数为true:16个字符的二进制格式&…...