预测分析(四):面向预测分析的神经网络简介
文章目录
- 面向预测分析的神经网络简介
- 神经网络模型
- 1. 基本概念
- 2. 前馈神经网络
- 3. 常见激活函数
- 4. 循环神经网络(RNN)
- 5. 卷积神经网络(CNN)
- MPL
- 结构
- 工作原理
- 激活函数
- 训练方法
- 基于神经网络的回归——以钻石为例
- 构建预测钻石价格的MLP
- 训练 M L P MLP MLP
- 基于神经网络的分类
面向预测分析的神经网络简介
神经网络模型
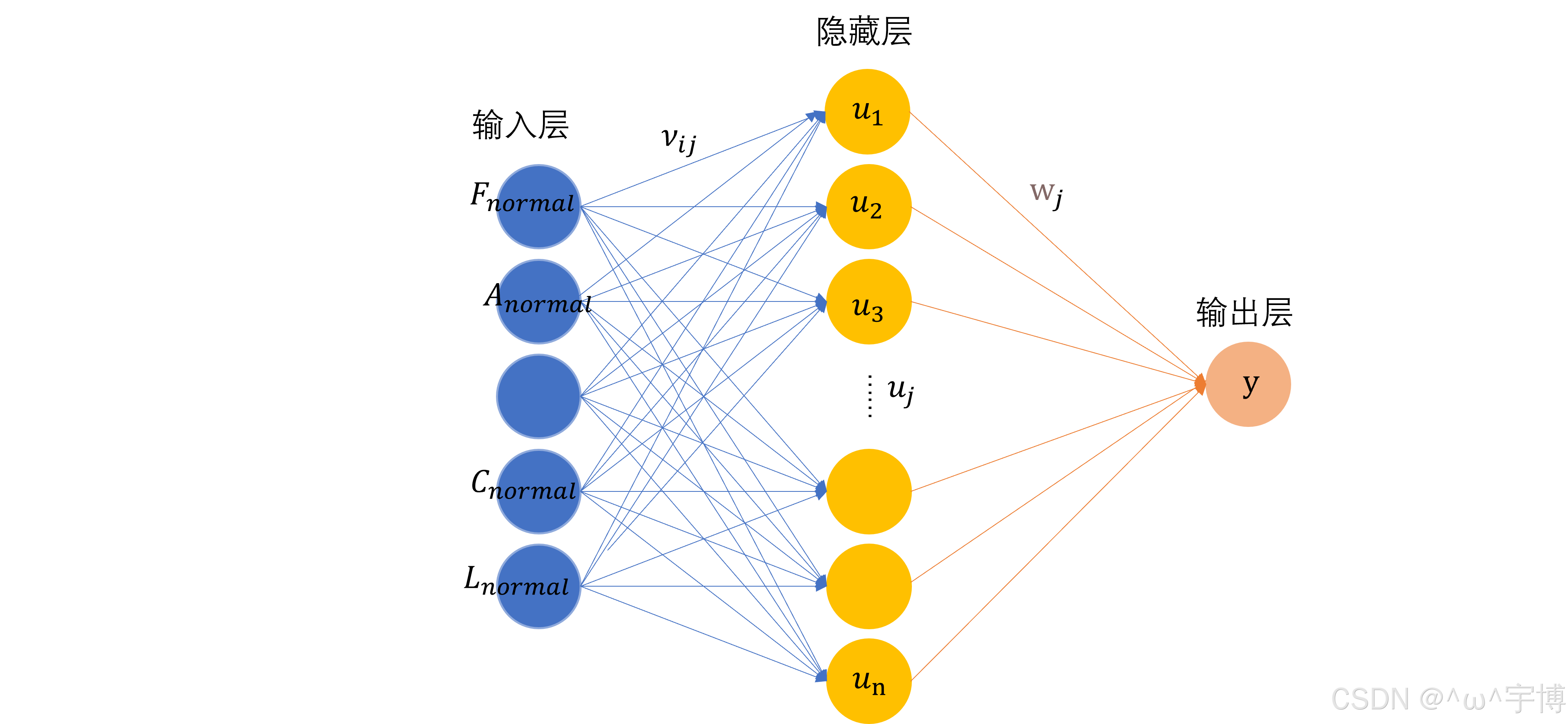
神经网络(Neural Network),也被称为人工神经网络(Artificial Neural Network,ANN),是一种模仿人类神经系统的计算模型,在机器学习和深度学习领域应用广泛。
1. 基本概念
- 神经元:神经网络的基本计算单元,接收多个输入信号,通过激活函数对输入进行非线性变换后输出结果。一个简单的神经元可以表示为 y = f ( ∑ i = 1 n w i x i + b ) y = f(\sum_{i = 1}^{n}w_{i}x_{i}+b) y=f(∑i=1nwixi+b),其中 x i x_i xi 是输入, w i w_i wi 是对应的权重, b b b 是偏置, f f f激活函数。
- 层:多个神经元组成一层,常见的层包括输入层、隐藏层和输出层。输入层接收原始数据;隐藏层对输入数据进行特征提取和转换;输出层给出最终的预测结果。
- 网络结构:不同层之间相互连接形成神经网络的结构,常见的有前馈神经网络(Feed - Forward Neural Network),信息只能从输入层依次向前传递到输出层;还有循环神经网络(Recurrent Neural Network,RNN),它允许信息在网络中循环流动,适合处理序列数据。
2. 前馈神经网络
- 工作原理:输入数据从输入层进入,经过隐藏层的一系列计算和变换,最终在输出层得到预测结果。每一层的神经元将上一层的输出作为输入,通过加权求和和激活函数处理后传递给下一层。
- 训练过程
- 定义损失函数:用于衡量预测结果与真实标签之间的差异,常见的损失函数有均方误差(Mean Squared Error,MSE)用于回归问题,交叉熵损失(Cross - Entropy Loss)用于分类问题。
- 前向传播:将输入数据传入网络,计算得到预测结果。
- 反向传播:根据损失函数的梯度,从输出层开始反向计算每个参数(权重和偏置)的梯度,以确定如何调整参数来减小损失。
- 参数更新:使用优化算法(如随机梯度下降,SGD)根据计算得到的梯度更新网络中的参数。
3. 常见激活函数
- Sigmoid函数:
f ( x ) = 1 1 + e − x f(x)=\frac{1}{1 + e^{-x}} f(x)=1+e−x1
将输入值映射到 (0, 1) 区间,常用于二分类问题的输出层。但它存在梯度消失问题,即当输入值过大或过小时,梯度趋近于 0,导致训练速度变慢。
- ReLU函数:
f ( x ) = max ( 0 , x ) f(x)=\max(0,x) f(x)=max(0,x)
计算简单,能有效缓解梯度消失问题,在隐藏层中应用广泛。
- Softmax函数:
常用于多分类问题的输出层,将输入值转换为概率分布,所有输出值之和为 1。
4. 循环神经网络(RNN)
- 特点:RNN 引入了循环结构,允许信息在不同时间步之间传递,因此能够处理序列数据,如自然语言处理中的文本序列、时间序列分析中的股票价格数据等。
- 局限性:传统的 RNN 存在长期依赖问题,即难以捕捉序列中相隔较远的信息之间的关系。为了解决这个问题,出现了长短期记忆网络(LSTM)和门控循环单元(GRU)等改进模型。
5. 卷积神经网络(CNN)
- 原理:CNN 主要用于处理具有网格结构的数据,如图像。它通过卷积层、池化层和全连接层组成。卷积层使用卷积核在输入数据上滑动进行卷积操作,提取局部特征;池化层用于降低特征图的维度,减少计算量;全连接层将卷积和池化得到的特征进行整合,输出最终的预测结果。
- 优势:CNN 具有参数共享和局部连接的特点,大大减少了模型的参数数量,降低了计算复杂度,同时提高了模型的泛化能力。
MPL
MLP通常指多层感知机(Multilayer Perceptron),它是一种基础且经典的人工神经网络模型,下面从结构、工作原理、激活函数、训练方法、优缺点和应用场景等方面为你详细介绍:
结构
MLP由输入层、一个或多个隐藏层以及输出层组成。
- 输入层:负责接收原始数据,神经元的数量通常等于输入特征的数量。
- 隐藏层:可以有一层或多层,每一层包含多个神经元。隐藏层通过非线性变换对输入数据进行特征提取和转换,是MLP学习复杂模式的关键部分。
- 输出层:输出模型的预测结果,神经元的数量根据具体的任务而定。例如,在二分类问题中,输出层可能只有一个神经元;在多分类问题中,输出层的神经元数量等于类别数。
工作原理
MLP的工作过程分为前向传播和反向传播。
- 前向传播:输入数据从输入层传入,依次经过各个隐藏层,最终到达输出层。在每一层中,神经元会对输入进行加权求和,并通过激活函数进行非线性变换,将结果传递给下一层。
- 反向传播:根据输出层的预测结果与真实标签之间的误差,计算误差关于每个神经元权重的梯度,然后使用优化算法(如梯度下降法)更新权重,以减小误差。
激活函数
激活函数为MLP引入非线性特性,使其能够学习复杂的非线性关系。常见的激活函数有:
- Sigmoid函数:将输入映射到(0, 1)区间,常用于二分类问题的输出层。
- ReLU函数:当输入大于0时,输出等于输入;当输入小于等于0时,输出为0。它计算简单,能有效缓解梯度消失问题,是隐藏层中常用的激活函数。
- Softmax函数:常用于多分类问题的输出层,将输出转换为概率分布。
训练方法
MLP通常使用误差反向传播算法(Backpropagation)进行训练,具体步骤如下:
- 初始化权重:随机初始化MLP中所有神经元之间的连接权重。
- 前向传播:将输入数据传入网络,计算输出结果。
- 计算误差:根据输出结果与真实标签之间的差异,计算损失函数的值。
- 反向传播:计算误差关于每个权重的梯度。
- 更新权重:使用优化算法(如随机梯度下降、Adam等)根据梯度更新权重。
- 重复步骤2 - 5:直到损失函数收敛或达到预设的训练轮数。
基于神经网络的回归——以钻石为例
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import os
%matplotlib inlineDATA_DIR = '../data'
FILE_NAME = 'diamonds.csv'
data_path = os.path.join(DATA_DIR, FILE_NAME)
diamonds = pd.read_csv(data_path)# 数据预处理
diamonds = diamonds.loc[(diamonds['x'] > 0) | (diamonds['y'] > 0)]
diamonds.loc[11182, 'x'] = diamonds['x'].median()
diamonds.loc[11182, 'z'] = diamonds['z'].median()
diamonds = diamonds.loc[~((diamonds['y'] > 30) | (diamonds['z'] > 30))]
diamonds = pd.concat([diamonds, pd.get_dummies(diamonds['cut'], prefix='cut', drop_first=True)], axis=1)
diamonds = pd.concat([diamonds, pd.get_dummies(diamonds['color'], prefix='color', drop_first=True)], axis=1)
diamonds = pd.concat([diamonds, pd.get_dummies(diamonds['clarity'], prefix='clarity', drop_first=True)], axis=1)# 分割数据集
X = diamonds.drop(['cut', 'color', 'clarity', 'price'], axis=1)
y = diamonds['price']from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=123)# PCA降维
from sklearn.decomposition import PCA
pca = PCA(n_components=1, random_state=123)
pca.fit(X_train[['x', 'y', 'z']])
X_train['dim_index'] = pca.transform(X_train[['x', 'y', 'z']]).flatten()
X_train.drop(['x', 'y', 'z'], axis=1, inplace=True)# 标准化数值特征
numerical_features = ['carat', 'depth', 'table', 'dim_index']
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train[numerical_features])
X_train.loc[:, numerical_features] = scaler.transform(X_train[numerical_features])
现在我们完成了神经网络的建模工作。
构建预测钻石价格的MLP
如前面所述,神经网络模型由一系列的层组成,因此Keras有一个类称为Sequential这个类可以用来实例化神经网络模型:
from keras.models import Sequential
nn_reg = Sequential()
现在需要为它添加层——奖使用的层名为全连接层或者稠密层:
from keras.layers import Dense
接下来添加第一层:
n_input=X_train.shape[1]
n_hidden1=32
# 增加第一个隐藏层
nn_reg.add(Dense(units=n_hidden1,activation='relu',input_shape=(n_input,)))
units:这是层中神经元的个数activation:这是每个神经元的激活函数,这里选用:ReLuinput_shape:这是网络接受的输入个数,其值等于数据集合中预测特征的个数。
接下来我们可以添加更多的隐藏层:
n_hidden2=16
n_hidden3=8
nn_reg.add(Dense(units=n_hidden2,activation='relu'))
nn_reg.add(Dense(units=n_hidden3,activation='relu'))
......
注意:这里使用各层的单元个数以 2 2 2的乘方逐次减少。
我们现在还需要添加一个最终层——输出层。对于每个样本来说,这是一个回归问题,需要的结果只有一个。因此添加最后一层:
nn_reg.add(Dense(units=1,activation=None))
接下来就要训练 M L P MLP MLP了,修正这些随机的权重和偏置。
训练 M L P MLP MLP
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import os
from sklearn.model_selection import train_test_split
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from sklearn.neural_network import MLPRegressor
from sklearn.metrics import mean_squared_error, r2_score# 假设之前的数据预处理代码已经执行,这里接着进行模型训练
# ...之前的数据预处理代码...# 训练MLP模型
mlp = MLPRegressor(hidden_layer_sizes=(100, 50), # 两个隐藏层,分别有100和50个神经元activation='relu', # 使用ReLU激活函数solver='adam', # 使用Adam优化器random_state=123,max_iter=500) # 最大迭代次数mlp.fit(X_train, y_train)# 对测试集进行预测
X_test['dim_index'] = pca.transform(X_test[['x', 'y', 'z']]).flatten()
X_test.drop(['x', 'y', 'z'], axis=1, inplace=True)
X_test.loc[:, numerical_features] = scaler.transform(X_test[numerical_features])
y_pred = mlp.predict(X_test)# 评估模型
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)print(f"均方误差 (MSE): {mse}")
print(f"决定系数 (R²): {r2}")all
import numpy as np
import pandas as pd
import os
from sklearn.model_selection import train_test_split
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.metrics import mean_squared_error, r2_score# 假设之前的数据预处理代码已经执行,这里接着进行模型训练
# ...之前的数据预处理代码...# 创建Sequential模型
nn_reg = Sequential()# 获取输入特征的数量
n_input = X_train.shape[1]
n_hidden1 = 32
# 增加第一个隐藏层
nn_reg.add(Dense(units=n_hidden1, activation='relu', input_shape=(n_input,)))# 添加更多的隐藏层
n_hidden2 = 16
n_hidden3 = 8
nn_reg.add(Dense(units=n_hidden2, activation='relu'))
nn_reg.add(Dense(units=n_hidden3, activation='relu'))# 添加输出层
nn_reg.add(Dense(units=1, activation=None))# 编译模型
nn_reg.compile(optimizer='adam', # 使用Adam优化器loss='mse', # 使用均方误差作为损失函数metrics=['mse']) # 监控均方误差# 训练模型
history = nn_reg.fit(X_train, y_train,epochs=50, # 训练的轮数batch_size=32, # 每个批次的样本数validation_split=0.1, # 用于验证集的比例verbose=1)# 对测试集进行预测
X_test['dim_index'] = pca.transform(X_test[['x', 'y', 'z']]).flatten()
X_test.drop(['x', 'y', 'z'], axis=1, inplace=True)
X_test.loc[:, numerical_features] = scaler.transform(X_test[numerical_features])
y_pred = nn_reg.predict(X_test)# 评估模型
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)print(f"均方误差 (MSE): {mse}")
print(f"决定系数 (R²): {r2}")# 绘制训练和验证损失曲线
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()基于神经网络的分类
类似的,这里先水一下:
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam
from sklearn.metrics import accuracy_score# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target# 数据预处理
# 数据标准化
scaler = StandardScaler()
X = scaler.fit_transform(X)# 标签编码
encoder = OneHotEncoder(sparse_output=False)
y = encoder.fit_transform(y.reshape(-1, 1))# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 构建模型
model = Sequential()
model.add(Dense(16, activation='relu', input_shape=(X_train.shape[1],)))
model.add(Dense(8, activation='relu'))
model.add(Dense(3, activation='softmax'))# 编译模型
model.compile(optimizer=Adam(learning_rate=0.001),loss='categorical_crossentropy',metrics=['accuracy'])# 训练模型
model.fit(X_train, y_train, epochs=50, batch_size=16, validation_split=0.1)# 评估模型
y_pred = model.predict(X_test)
y_pred_classes = np.argmax(y_pred, axis=1)
y_test_classes = np.argmax(y_test, axis=1)
accuracy = accuracy_score(y_test_classes, y_pred_classes)
print(f"模型准确率: {accuracy}")相关文章:
:面向预测分析的神经网络简介)
预测分析(四):面向预测分析的神经网络简介
文章目录 面向预测分析的神经网络简介神经网络模型1. 基本概念2. 前馈神经网络3. 常见激活函数4. 循环神经网络(RNN)5. 卷积神经网络(CNN) MPL结构工作原理激活函数训练方法 基于神经网络的回归——以钻石为例构建预测钻石价格的M…...

实战交易策略 篇十四:江南神鹰捕捉热点和熊市生存交易策略
文章目录 系列文章捕捉热点是股市最大的掘金术市场温度不低于50是热点产生的必要条件题材的大小和新颖程度决定热点的持续时间和涨幅炒作热点的3个阶段捕捉热点的方法与步骤操作实战案例熊市生存术“熊市最好的做法是离开股市”的说法是一句空话熊市盈利模式:不轻言底部,超跌…...
)
去中心化衍生品(以Synthetix为例)
去中心化衍生品(以Synthetix为例) 核心概念 合成资产(Synths): 定义:链上追踪现实资产价值的代币化合约(如sXAU追踪黄金,iBTC反向追踪比特币)。 类型: 正…...

JavaScript重难点突破:事件循环
想了解事件循环,首先要了解js中线程的概念。 宿主环境 在浏览器环境中,js实际上包含了三个部分ECMAScript、DOM(文档对象模型)、BOM(浏览器对象模型),我们最熟悉的js代码指的是ECMAScript这一…...
)
Python每日一题(15)
Python每日一题2025.4.4 一、题目题目描述输入格式输出格式输入输出样例 #1输入 #1输出 #1 二、分析三、源代码四、deepseek 一、题目 题目描述 您需要写一种数据结构,来维护一些数(都是绝对值 1 0 9 10^9 109 以内的数)的集合,…...
关于 sequence 和 property 的区别和联系)
#SVA语法滴水穿石# (003)关于 sequence 和 property 的区别和联系
在 SystemVerilog Assertions (SVA) 中,sequence 和 property 是两个核心概念,它们既有区别又紧密相关。对于初学者,可能不需要过多理解;但是要想写出复杂精美的断言,深刻理解两者十分重要。今天,我们汇总和学习一下该知识点。 1. 区别 特性sequenceproperty定义描述一系…...

有人DTU使用MQTT协议控制Modbus协议的下位机-含数据库
本文为备忘录,不做太多解释。 DTU型号:G780 服务器:win2018 一。DTU设置 正确设置波特率,进入配置状态,获取当前参数,修改参数,设置并保存所有参数。 1.通道1设置 2.Modbus轮询设置 二&am…...

Smart Link 技术全面解析
1.1 网络冗余技术的演进与需求 1.2 Smart Link 的核心价值与本文目标 第一章 Smart Link 技术概述 2.1 Smart Link 的应用场景与背景 2.2 Smart Link 的基本概念与组网角色 2.3 Smart Link 与传统技术的对比 第二章 Smart Link 工作原理 3.1 Smart Link 组的构成与运行机…...
)
【学Rust写CAD】30 Alpha256结构体补充方法(alpha256.rs)
源码 impl Alpha256 {#[inline]pub fn alpha_mul(&self, x: u32) -> u32 {let mask 0xFF00FF;let src_rb ((x & mask) * self.0) >> 8;let src_ag ((x >> 8) & mask) * self.0;(src_rb & mask) | (src_ag & !mask)} }代码分析 功能 输…...

提升 Web 性能:使用响应式图片优化体验
在现代 Web 开发中,图片通常占据页面加载的大部分带宽,如何高效管理图片资源直接影响用户体验和性能得分。Google 的 Lighthouse 工具在性能审计中特别强调“使用响应式图片”(Uses Responsive Images),旨在确保图片在…...

基于K8s的演示用单机ML服务部署
这是仅用一台机器(比如一台MacBook)模拟在k8s上部署一个机器学习服务的演示用实例。 项目地址:https://github.com/HarmoniaLeo/Local-K8s-ML-Demo 该实例分为以下几个部分: 使用KerasTensorflow搭建并训练神经网络,…...

强化中小学人工智能教育:塑造未来社会的科技基石
在数字化浪潮席卷全球的今天,人工智能(AI)已成为推动社会进步与经济发展的核心力量。面对这一不可逆转的趋势,如何培养具备AI素养与创新能力的下一代,成为各国教育改革的重中之重。辽宁省教育厅近日发布的《关于加强中小学人工智能教育的实施方案》,无疑为我国中小学人工…...
)
音视频基础(视频的主要概念)
文章目录 **1. 视频码率(Bitrate)****概念****分类****码率对比** **2. 视频帧率(Frame Rate, FPS)****概念****常见帧率****帧率 vs. 观感** **3. 视频分辨率(Resolution)****概念****常见分辨率****分辨率…...
)
JWT与Session的实战选择-杂谈(1)
JWT与Session的实战选择:从原理到踩坑心得 作为在金融科技领域经历过多次认证方案迭代的开发者,我想分享一些实战经验。这两种方案适用场景各异,选型需慎重考量。 一、本质差异:状态管理方式 Session机制:服务端维护…...

SQL Server安装后 Reporting Services 配置失败
问题现象: 完成 SQL Server 2022 安装后,尝试配置 Reporting Services (SSRS) 时失败,错误提示 “报表服务器数据库配置无效” 或 “无法启动 Reporting Services 服务”(错误代码 0x80070005)。 快速诊断 检查服务状态…...
)
操作系统面经(一)
部分参考来自小林coding 线程、进程、协程 进程是操作系统分配资源(内存、文件等)的基本单位,每个进程独立运行,互相隔离,稳定性高但开销大;线程是CPU调度的基本单位,属于同一进程的多个线程共…...

Qt 中 findChild和findChildren绑定自定义控件
在 Qt 中,findChild 和 findChildren 是两个非常实用的方法,用于在对象树中查找特定类型的子对象。这两个方法是 QObject 类的成员函数,因此所有继承自 QObject 的类都可以使用它们。当您需要查找并绑定自定义控件时,可以按照以下…...

对模板方法模式的理解
对模板方法模式的理解 一、场景1、题目【[来源](https://kamacoder.com/problempage.php?pid1087)】1.1 题目描述1.2 输入描述1.3 输出描述1.4 输入示例1.5 输出示例 二、不采用模板方法模式1、代码2、问题 三、采用模板方法模式1、代码 四、总结 一、场景 1、题目【来源】 …...

SpringMVC+Spring+MyBatis知识点
目录 一、相关概念 1.关系 2.网页 3.架构 4.URL 5.http 6.https 7.服务器 8.Tomcat 9.Servelet 10.Javaweb作用域对象 11.JSP 二、相关操作 1.RequestDispatcher 2.sendRedirect 3.cookie 4.Session 5.Filter过滤器 6.Listener监听器 7.MVC模型 8.JDBC连接…...
:系统架构与广告反作弊深度剖析)
程序化广告行业(58/89):系统架构与广告反作弊深度剖析
程序化广告行业(58/89):系统架构与广告反作弊深度剖析 大家好!在程序化广告这个充满挑战与机遇的领域,不断学习和探索是保持竞争力的关键。今天,我希望和大家一起学习进步,深入了解程序化广告行…...

一周学会Pandas2 Python数据处理与分析-NumPy简介
锋哥原创的Pandas2 Python数据处理与分析 视频教程: 2025版 Pandas2 Python数据处理与分析 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili NumPy(Numerical Python)是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩…...

第二十七章:Python-Aquarel库与多种主题库结合实现Matplotlib美化
资源绑定附上完整资料供读者参考学习! 一、库介绍与安装 1.1 Aquarel库 Aquarel是一个轻量级的Python库,用于简化Matplotlib的样式配置,使数据可视化更加美观和高效。 1.2 Catppuccin库 Catppuccin是一个社区驱动的粉彩主题库࿰…...

leetcode155.最小栈
思路源自 【力扣hot100】【LeetCode 155】最小栈 为了让检索时间达到o(1),采用空间换时间,维护两个栈,第一个栈实现正常的push、pop、top,另一个栈的栈顶每次都只放以一个栈中最小的元素 class MinStack …...

Mysql 中的 MyISAM 引擎
🧱 什么是 MyISAM? MyISAM 是 MySQL 早期的默认存储引擎,特点是结构简单、读取速度快,但不支持事务和行级锁。 它适合那些 读多写少、对事务安全要求不高 的场景,比如旧版博客系统、数据仓库等。 📦 MyISA…...

操作系统、虚拟化技术与云原生及云原生AI简述
目录 操作系统基础 操作系统定义 操作系统的组成 操作系统的分类 Linux操作系统特性 虚拟化技术 概述 CPU虚拟化 内存虚拟化 I/O虚拟化 虚拟化技术 虚拟化平台管理工具 容器 容器与云原生:详细介绍 容器的特点 什么是云原生? 云原生的特点 容器与云原生的…...
)
Java EE期末总结(第二章)
目录 一、JSP页面里的page指令 二、JSP脚本元素 1、全局声明<%!……%> 2、表达式<%……%> 3、脚本程序段<%……%> 三、文件包含指令include 四、引入标签库指令taglib 五、JSP动作标签 1、包含文件动作标签 2、请求转发动作标签 3、JavaBean动作标签 …...

FreeRTOS任务查询和信息统计API
下面例举几个常见的任务查询API(其余可参考FreeRTOS开发手册): UBaseType_t Priority; Priority uxTaskPriorityGet(QUERYTask_Handler); printf("Task Pri %d \r\n",Priority); TaskStatus_t * TaskStatusArray; UBaseType_t …...
:一款面向信创应用开发者的数据库开发和管理工具)
SQLark(百灵连接):一款面向信创应用开发者的数据库开发和管理工具
SQLark(百灵连接)是一款面向信创应用开发者的数据库开发和管理工具,用于快速查询、创建和管理不同类型的数据库系统。 目前可以支持达梦数据库、Oracle 以及 MySQL。 SQL 智能编辑器 基于语法语义解析实现代码补全能力,为你提供…...
)
Linux | 安装超级终端串口软件连接i.MX6ULL开发板(8)
01 它的安装步骤也非常简单,安装语言选择中文简体,点击确定,如下图所示。 点击下一步,如下图所示。 02...

Qt 事件系统负载测试:深入理解 Qt 事件处理机制
Qt 事件系统负载测试:深入理解 Qt 事件处理机制 文章目录 Qt 事件系统负载测试:深入理解 Qt 事件处理机制摘要引言实现原理1. 自定义事件类型2. 事件队列管理3. 性能指标监控4. 事件发送机制 性能监控实现1. 负载计算2. 内存监控3. 延迟计算 使用效果优化…...

如何评价Manus?
Manus是由Monica公司发布的全球首款通用型AI Agent产品,定位于一个性能强大的通用型助手,能够独立思考、规划并执行复杂任务,直接交付完整的任务成果。 Manus 这个名字灵感来源于拉丁格言 “Mens et Manus”(意为“头脑与双手”),寓意它既能动脑也能动手。 Manus的核…...

AI浪潮下的IT职业转型:医药流通行业传统IT顾问的深度思考
AI浪潮下的IT职业转型:医药流通行业传统IT顾问的深度思考 一、AI重构IT行业的技术逻辑与实践路径 1.1 医药流通领域的智能办公革命 在医药批发企业的日常运营中,传统IT工具正经历颠覆性变革。以订单处理系统为例,某医药集团引入AI智能客服…...

2011-2019年各省地方财政国土资源气象等事务支出决策数数据
2011-2019年各省地方财政国土资源气象等事务支出决策数数据 1、时间:2007-2019年 2、来源:国家统计局、统计年鉴 3、指标:行政区划代码、地区、年份、地方财政国土资源气象等事务支出决策数 4、范围:31省 5、指标说明&#x…...

《微服务概念进阶》精简版
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 什么是微服务(进阶精简版&#x…...

免费送源码:Java+SSM+Android Studio 基于Android Studio游戏搜索app的设计与实现 计算机毕业设计原创定制
摘要 本文旨在探讨基于SSM框架和Android Studio的游戏搜索App的设计与实现。首先,我们详细介绍了SSM框架,这是一种经典的Java Web开发框架,由Spring、SpringMVC和MyBatis三个开源项目整合而成,为开发企业级应用提供了高效、灵活、…...

栈回溯和离线断点
栈回溯和离线断点 栈回溯(Stack Backtrace) 栈回溯是一种重建函数调用链的技术,对于分析栈溢出的根本原因非常有价值。 实现方式 // 简单的栈回溯实现示例(ARM Cortex-M架构) void stack_backtrace(void) {uint32_…...

探索轻量高性能的 Rust HTTP 服务器框架 —— Hyperlane
探索轻量高性能的 Rust HTTP 服务器框架 —— Hyperlane 随着互联网应用对性能和实时性要求的不断提升,选择一个高效且易于扩展的 HTTP 服务器框架变得尤为重要。今天,我们将介绍一个专为 Rust 开发者设计的框架 —— Hyperlane。该框架不仅支持 HTTP 请…...
- 表单验证)
第四章 表单(3)- 表单验证
在Blazor中,表单的验证可以通过两种方式实现,一种是使用Blazor所提供表单验证特性,另一种是使用ValidationMessageStore进行验证。 表单验证的基础使用(内置特性) 一、内置特性表单验证的开启 Blazor中,使用表单组件<EditFo…...

手撕AVL树
引入:为何要有AVL树,二次搜索树有什么不足? 二叉搜索树有其自身的缺陷,假如往树中插入的元素有序或者接近有序,二叉搜索树就会退化成单支树,时间复杂度会退化成O(N),因此产生了AVL树,…...

Linux驱动开发练习案例
1 开发目标 1.1 架构图 操作系统:基于Linux5.10.10源码和STM32MP157开发板,完成tf-a(FSBL)、u-boot(SSBL)、uImage、dtbs的裁剪; 驱动层:为每个外设配置DTS并且单独封装外设驱动模块。其中电压ADC测试,采用linux内核…...

Redis 下载 — Ubuntu22.04稳定版,配置
官方文档 : https://redis.io/docs/latest/operate/oss_and_stack/install/install-redis/ Nano学习 : 【Linux环境下最先应该掌握的文本编辑器nano】https://www.bilibili.com/video/BV1p8411z7dJ?vd_source5ce003da2a16f44ea73ec9bbc30389e4 Redis配置…...

有没有可以帮助理解高数的视频或者书籍资料?
高数的学习是一个入门很高,但是一旦入门之后,就会变得比较简单的科目。 可是,我们应该怎么入门高数呢?在当年刚开始学习高数的时候,我也有过这样的困惑。 但是,后来我发现,我总是可以在经历一…...

了解拦截器
目录 什么是拦截器 拦截器的基本使用 拦截器的使用步骤 拦截器路径设置 拦截器执行流程 一、什么是拦截器 拦截器是Spring框架提供的核心功能之一,主要用来拦截用户的请求,在指定方法前后,根据业务需要执行预先设定的代码。 开发人员可以…...

Linux / Windows 下 Mamba / Vim / Vmamba 安装教程及安装包索引
目录 背景0. 前期环境查询/需求分析1. Linux 平台1.1 Mamba1.2 Vim1.3 Vmamba 2. Windows 平台2.1 Mamba2.1.1 Mamba 12.1.2 Mamba 2- 治标不治本- 终极版- 高算力版 2.2 Vim- 治标不治本- 终极版- 高算力版 2.3 Vmamba- 治标不治本- 终极版- 高算力版 3. Linux / Windows 双平…...

prism WPF 对话框
项目结构 1.创建对话框 用户控件 Views \ DialogView.xaml <UserControl x:Class"PrismWpfApp.Views.DialogView"xmlns"http://schemas.microsoft.com/winfx/2006/xaml/presentation"xmlns:x"http://schemas.microsoft.com/winfx/2006/xaml"…...

eventEmitter实现
没有做任何异常处理,简单模拟实现 事件对象的每一个事件都对应一个数组 /*__events {"事件1":[cb1,cb2],"事件2":[cb3,cb4],"事件3":[...],"事件4":[...],};*/class E{__events {};constructor(){}//注册监听回调on(type , callbac…...

Koordinator-NodeInfoCollector
Run 每秒执行一次 func (n *nodeInfoCollector) Run(stopCh <-chan struct{}) {go wait.Until(n.collectNodeInfo, n.collectInterval, stopCh) }collectNodeInfo() 采集node cpu信息采集node numa信息func (n *nodeInfoCollector) collectNodeInfo() {started := time.No…...

洛谷题单3-P5724 【深基4.习5】求极差 最大跨度值 最大值和最小值的差-python-流程图重构
题目描述 给出 n n n 和 n n n 个整数 a i a_i ai,求这 n n n 个整数中的极差是什么。极差的意思是一组数中的最大值减去最小值的差。 输入格式 第一行输入一个正整数 n n n,表示整数个数。 第二行输入 n n n 个整数 a 1 , a 2 … a n a_1,…...

SignalR给特定User发送消息
1、背景 官网上SignalR的demo很详细,但是有个特别的问题,就是没有详细阐述如何给指定的用户发送消息。 2、解决思路 网上整体解决思路有三个: 1、最简单的方案,客户端连接SignalR的Hub时,只是简单的连接,…...

新浪财经股票每天10点自动爬取
老规矩还是先分好三步,获取数据,解析数据,存储数据 因为股票是实时的,所以要加个cookie值,最好分线程或者爬取数据时等待爬取,不然会封ip 废话不多数,直接上代码 import matplotlib import r…...