【DLI】Generative AI with Diffusion Models通关秘籍
Generative AI with Diffusion Models,加载时间在20分钟左右,耐心等待。
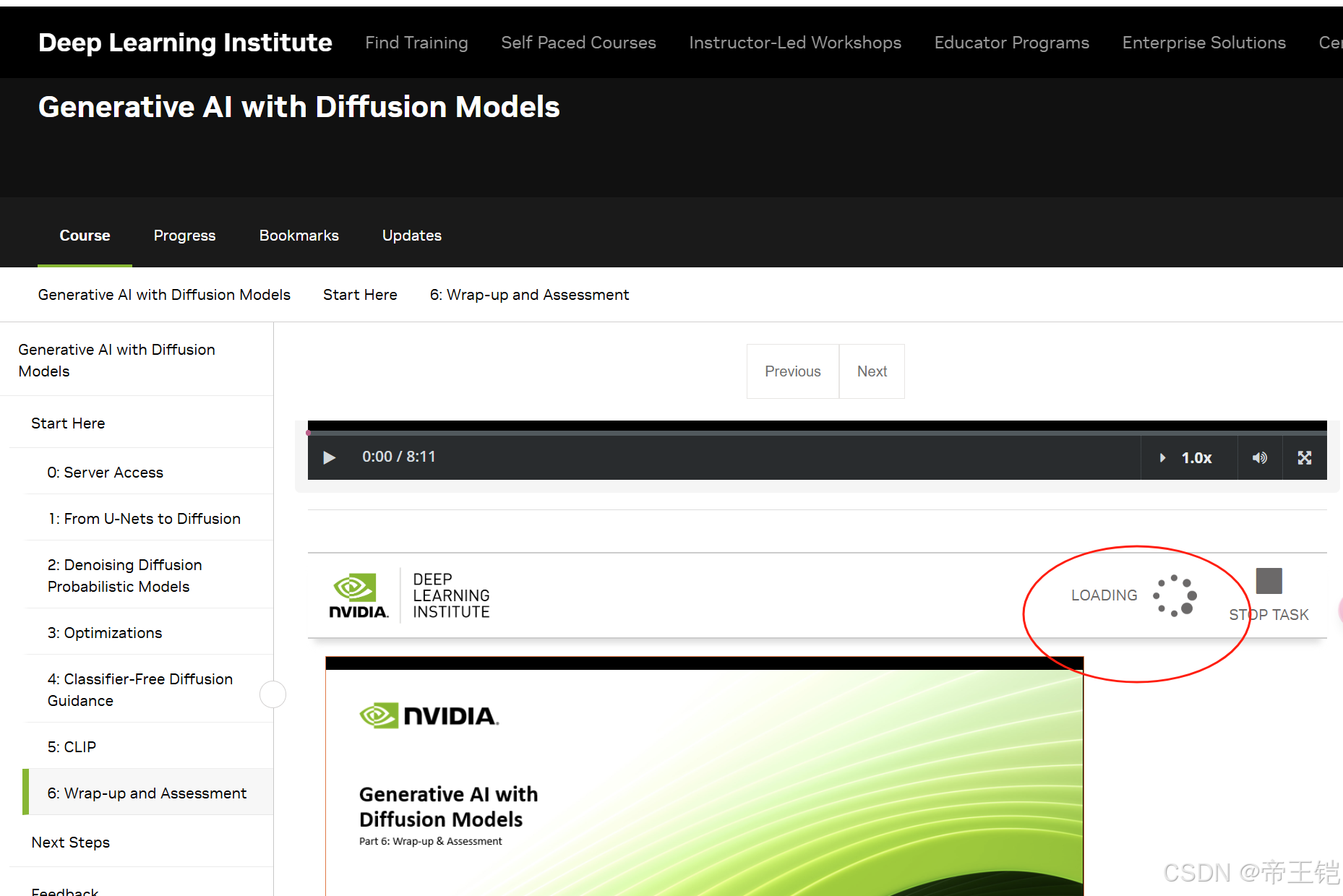

6.2TODO
这里是在设置扩散模型的参数,代码里的FIXME部分需要根据上下文进行替换。以下是各个FIXME的替换说明:
1.a_bar 是 a 的累积乘积,在 PyTorch 里可以用 torch.cumprod 实现。
2.sqrt_a_bar、sqrt_one_minus_a_bar 和 sqrt_a_inv 都是对输入张量求平方根,可使用 torch.sqrt 实现。
3.pred_noise_coeff 中的 FIXME(1 - a_bar) 同样是求平方根,用 torch.sqrt 即可。
以下是替换后的代码:
nrows = 10
ncols = 15T = nrows * ncols
B_start = 0.0001
B_end = 0.02
B = torch.linspace(B_start, B_end, T).to(device)a = 1.0 - B
a_bar = torch.cumprod(a, dim=0)
sqrt_a_bar = torch.sqrt(a_bar) # Mean Coefficient
sqrt_one_minus_a_bar = torch.sqrt(1 - a_bar) # St. Dev. Coefficient# Reverse diffusion variables
sqrt_a_inv = torch.sqrt(1 / a)
pred_noise_coeff = (1 - a) / torch.sqrt(1 - a_bar) # Predicted Noise Coefficient
在扩散模型里,正向扩散过程 q 函数是按照如下公式把原始图像 x_0 逐步添加噪声变成 x_t 的
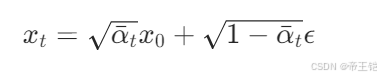
FIXME 部分应该分别用 sqrt_a_bar_t 和 sqrt_one_minus_a_bar_t 来替换。
在这个 q 函数中,按照扩散模型的正向过程公式,把原始图像 x_0 和随机噪声 noise 按一定比例组合,从而得到加噪后的图像 x_t。
def q(x_0, t):t = t.int()noise = torch.randn_like(x_0)sqrt_a_bar_t = sqrt_a_bar[t, None, None, None]sqrt_one_minus_a_bar_t = sqrt_one_minus_a_bar[t, None, None, None]x_t = sqrt_a_bar_t * x_0 + sqrt_one_minus_a_bar_t * noisereturn x_t, noise
在反向扩散过程中,我们要根据当前的潜在图像,当前时间步 , 以及预测的噪声 来恢复上一个时间步的图像。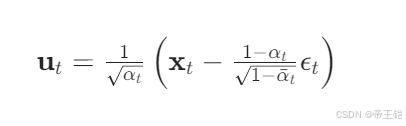
在这个 reverse_q 函数中,我们根据反向扩散过程的公式,从当前的潜在图像和预测的噪声中恢复上一个时间步的图像。如果当前时间步为 0,则表示反向扩散过程完成。否则,我们会添加一些噪声以模拟扩散过程。下面是对代码中 FIXME 部分的分析与替换:
@torch.no_grad()
def reverse_q(x_t, t, e_t):t = t.int()pred_noise_coeff_t = pred_noise_coeff[t]sqrt_a_inv_t = sqrt_a_inv[t]u_t = sqrt_a_inv_t * (x_t - pred_noise_coeff_t * e_t)if t[0] == 0: # All t values should be the samereturn u_t # Reverse diffusion complete!else:B_t = B[t - 1] # Apply noise from the previous timestepnew_noise = torch.randn_like(x_t)return u_t + torch.sqrt(B_t) * new_noise

6.3TODO
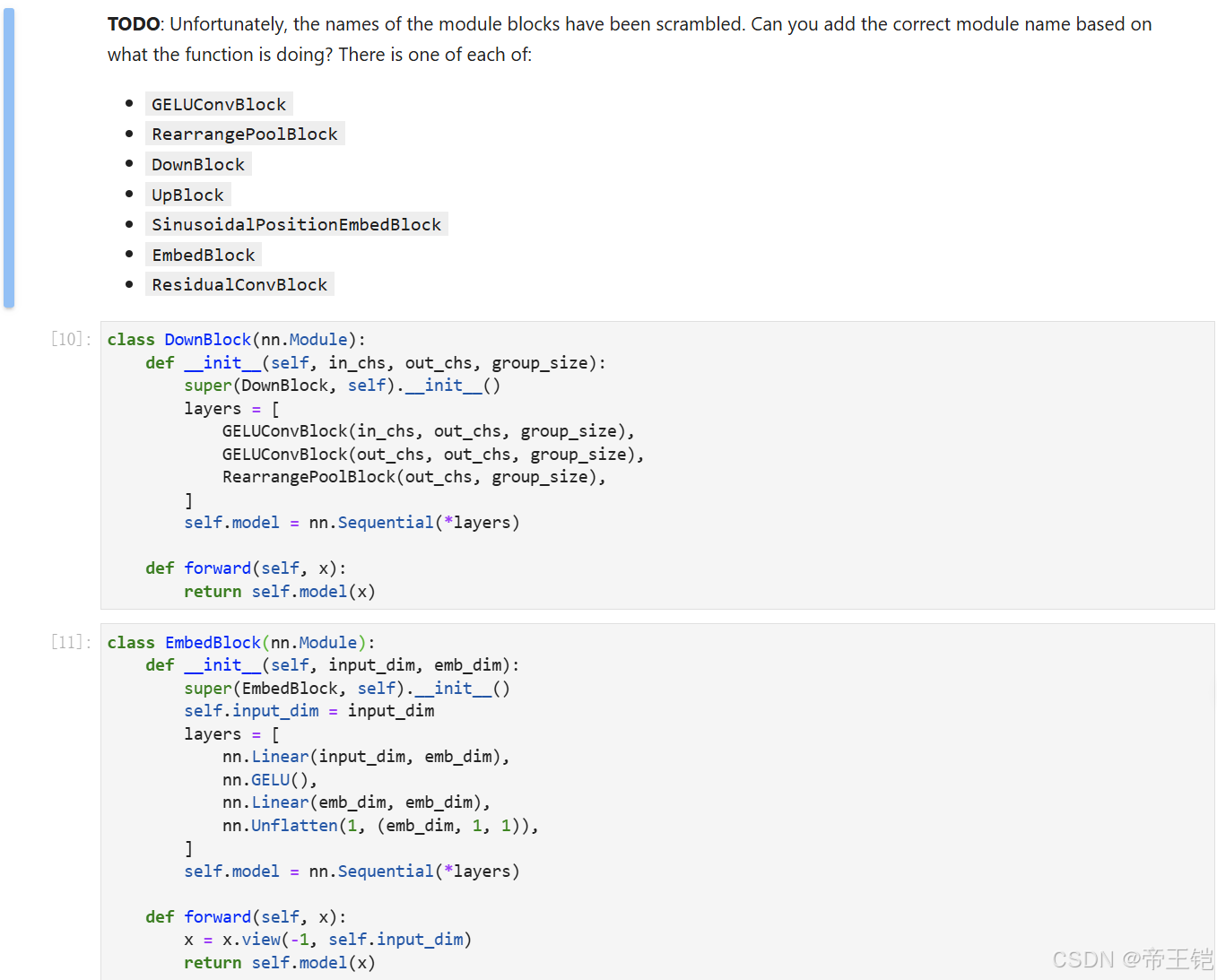
每个类的功能来添加正确模块名 依次改写FIXME 即可:
DownBlock进行下采样操作,包含卷积和池化相关的块
EmbedBlock将输入进行线性变换和激活
GELUConvBlock使用了卷积、组归一化和 GELU 激活函数,通常是一个卷积块
RearrangePoolBlock使用了 Rearrange 进行张量重排和卷积操作
ResidualConvBlock使用了两个卷积块并进行了残差连接
SinusoidalPositionEmbedBlock实现了正弦位置嵌入的功能
UpBlock上采样操作,包含转置卷积和卷积块
6.4TODO
在这个 get_context_mask 函数里,其目的是随机丢弃上下文信息。要实现随机丢弃,通常会使用 torch.bernoulli 函数。torch.bernoulli 函数会依据给定的概率来生成一个二进制掩码张量,其中每个元素为 1 的概率就是传入的概率值。
在这个函数中,我们希望以 drop_prob 的概率丢弃上下文,所以每个元素保留的概率是 1 - drop_prob。因此,FIXME 处应该填入 bernoulli。
def get_context_mask(c, drop_prob):c_hot = F.one_hot(c.to(torch.int64), num_classes=N_CLASSES).to(device)c_mask = torch.bernoulli(torch.ones_like(c_hot).float() * (1 - drop_prob)).to(device)return c_hot, c_mask
代码解释:
c_hot = F.one_hot(c.to(torch.int64), num_classes=N_CLASSES).to(device):将输入的 c 转换为独热编码向量,并且移动到指定的设备(如 GPU)上。
c_mask = torch.bernoulli(torch.ones_like(c_hot).float() * (1 - drop_prob)).to(device):生成一个与 c_hot 形状相同的二进制掩码张量,每个元素以 1 - drop_prob 的概率为 1,以 drop_prob 的概率为 0。
return c_hot, c_mask:返回独热编码向量和二进制掩码张量。
这样,你就可以使用这个函数来随机丢弃上下文信息了。

在扩散模型里,通常采用均方误差损失(Mean Squared Error Loss,MSE)来衡量预测噪声 noise_pred 和实际添加的噪声 noise 之间的差异。因为均方误差能够很好地衡量两个向量之间的平均平方误差,这对于扩散模型中预测噪声的准确性评估是很合适的。
在 PyTorch 中,nn.functional.mse_loss 函数可用于计算均方误差损失。所以 FIXME 处应填入 mse_loss。
def get_loss(model, x_0, t, *model_args):x_noisy, noise = q(x_0, t)noise_pred = model(x_noisy, t/T, *model_args)return F.mse_loss(noise, noise_pred)
代码解释
x_noisy, noise = q(x_0, t):调用 q 函数给原始图像 x_0 添加噪声,得到加噪后的图像 x_noisy 以及实际添加的噪声 noise。
noise_pred = model(x_noisy, t/T, *model_args):把加噪后的图像 x_noisy 和归一化后的时间步 t/T 输入到模型 model 中,得到模型预测的噪声 noise_pred。
return F.mse_loss(noise, noise_pred):使用 F.mse_loss 函数计算实际噪声 noise 和预测噪声 noise_pred 之间的均方误差损失并返回。
通过使用均方误差损失,模型能够学习到如何更准确地预测添加到图像中的噪声,从而在反向扩散过程中更好地恢复原始图像。
下一个 TODO
- c_drop_prob 的设置
c_drop_prob 是上下文丢弃概率,一般在训练过程中会采用线性衰减策略,也就是在训练初期以较高概率丢弃上下文,随着训练的推进逐渐降低丢弃概率。在代码中,我们可以简单地将其设置为一个随着训练轮数逐渐降低的值。 - get_context_mask 函数的输入
get_context_mask 函数需要一个上下文标签作为输入,在代码里这个标签应该从 batch 中获取。通常假设 batch 的第二个元素为上下文标签。
optimizer = Adam(model.parameters(), lr=0.001)
epochs = 5
preview_c = 0model.train()
for epoch in range(epochs):# 线性衰减上下文丢弃概率c_drop_prob = max(0.1, 1 - epoch / epochs) #这里我调整了顺序for step, batch in enumerate(dataloader):optimizer.zero_grad()t = torch.randint(0, T, (BATCH_SIZE,), device=device).float()x = batch[0].to(device)# 假设 batch 的第二个元素是上下文标签c = batch[1].to(device)c_hot, c_mask = get_context_mask(c, c_drop_prob)loss = get_loss(model, x, t, c_hot, c_mask)loss.backward()optimizer.step()if epoch % 1 == 0 and step % 100 == 0:print(f"Epoch {epoch} | Step {step:03d} | Loss: {loss.item()} | C: {preview_c}")c_drop_prob = 0 # Do not drop context for previewc_hot, c_mask = get_context_mask(torch.Tensor([preview_c]).to(device), c_drop_prob)sample_images(model, IMG_CH, IMG_SIZE, ncols, c_hot, c_mask)preview_c = (preview_c + 1) % N_CLASSES
代码解释
c_drop_prob 的设置:运用线性衰减策略,在训练初期 c_drop_prob 为 0.9,随着训练的推进逐渐降低到 0.1。
get_context_mask 函数的输入:假设 batch 的第二个元素是上下文标签,将其传入 get_context_mask 函数。
训练过程:在每个训练步骤中,先将梯度清零,接着计算损失,再进行反向传播和参数更新。每训练 100 个步骤,就打印一次损失信息并进行一次样本生成。
通过这些修改,代码就能正常运行,从而开始训练模型。
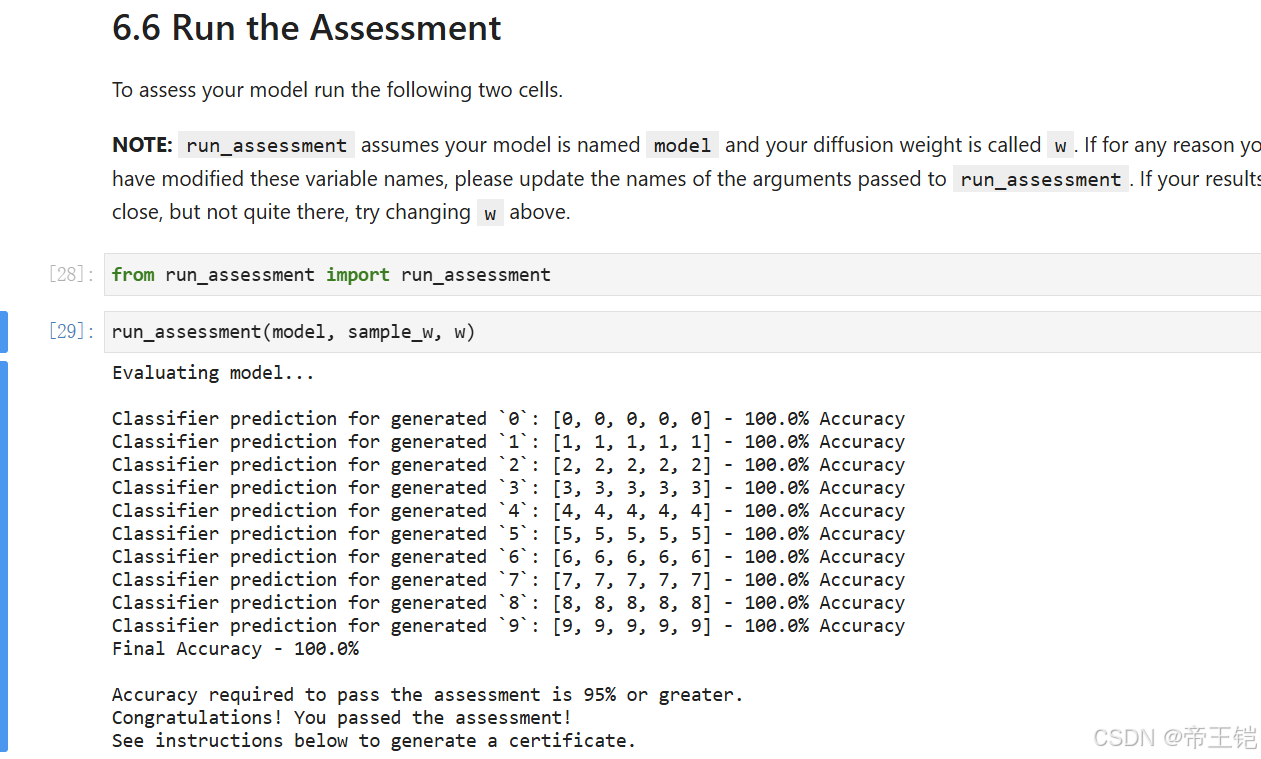
6.5TODO
在扩散模型的采样过程中,为了给扩散过程添加权重,一般会根据给定的权重 w 对保留上下文的预测噪声 e_t_keep_c 和丢弃上下文的预测噪声 e_t_drop_c 进行加权组合。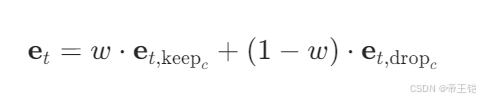
在代码中,FIXME 处应该根据上述公式进行计算,将 e_t_keep_c 和 e_t_drop_c 按照权重 w 进行组合。具体的代码如下:
def sample_w(model, c, w):input_size = (IMG_CH, IMG_SIZE, IMG_SIZE)n_samples = len(c)w = torch.tensor([w]).float()w = w[:, None, None, None].to(device) # Make w broadcastablex_t = torch.randn(n_samples, *input_size).to(device)# One c for each wc = c.repeat(len(w), 1)# Double the batchc = c.repeat(2, 1)# Don't drop context at test timec_mask = torch.ones_like(c).to(device)c_mask[n_samples:] = 0.0x_t_store = []for i in range(0, T)[::-1]:# Duplicate t for each samplet = torch.tensor([i]).to(device)t = t.repeat(n_samples, 1, 1, 1)# Double the batchx_t = x_t.repeat(2, 1, 1, 1)t = t.repeat(2, 1, 1, 1)# Find weighted noisee_t = model(x_t, t, c, c_mask)e_t_keep_c = e_t[:n_samples]e_t_drop_c = e_t[n_samples:]e_t = w * e_t_keep_c + (1 - w) * e_t_drop_c# Deduplicate batch for reverse diffusionx_t = x_t[:n_samples]t = t[:n_samples]x_t = reverse_q(x_t, t, e_t)return x_t
在扩散模型里,权重 w 可用于控制上下文信息在生成过程中的影响程度。w 值越接近 1,生成结果就越依赖上下文信息;w 值越接近 0,生成结果受上下文信息的影响就越小。若要让生成的数字能够被持续识别,你可以试着增大 w 的值,以此增强上下文信息对生成过程的影响。
下面是修改后的代码,你可以调整 w 的值来观察生成结果:
model.eval()
w = 5.0 # 可以尝试不同的值,通常大于 1 能增强上下文的影响
c = torch.arange(N_CLASSES).to(device)
c_drop_prob = 0
c_hot, c_mask = get_context_mask(c, c_drop_prob)x_0 = sample_w(model, c_hot, w)
other_utils.to_image(make_grid(x_0.cpu(), nrow=N_CLASSES))
代码解释
w = 5.0:把 w 的值设为 5.0,你可以根据实际情况调整这个值。通常,当 w 大于 1 时,上下文信息的影响会得到增强,这样生成的数字可能会更易于识别。
x_0 = sample_w(model, c_hot, w):调用 sample_w 函数生成图像,将 w 作为参数传入。
other_utils.to_image(make_grid(x_0.cpu(), nrow=N_CLASSES)):把生成的图像转换为可视化的形式。
你可以多次运行这段代码,并且调整 w 的值,直到生成的数字能够被稳定识别。
至此结束。
完整代码都在图片里
相关文章:

【DLI】Generative AI with Diffusion Models通关秘籍
Generative AI with Diffusion Models,加载时间在20分钟左右,耐心等待。 6.2TODO 这里是在设置扩散模型的参数,代码里的FIXME部分需要根据上下文进行替换。以下是各个FIXME的替换说明: 1.a_bar 是 a 的累积乘积,在 …...
方法时候报错Type is not supported)
TP6图片操作 Image::open 调用->save()方法时候报错Type is not supported
错误提示: { "code": 0, "msg": "Type is not supported", "data": { "code": 0, "line": 50, "file": "/www/wwwroot/ytems/vendor/topthink/framework/src/think…...

11_常用函数
文章目录 一、概述二、字符函数2.1、获取字符串所占字节数2.2、获取字符个数2.3、拼接字符串2.4、大小写转换2.5、获取子串2.6、获取子串第一次出现的索引2.7、去除字符串前后子字符串2.7.1、去掉左侧空格2.7.2、去掉右侧空格 2.8、左右填充2.9、字符串替换 三、数学函数3.1、四…...
》50+MOD整合包)
《inZOI(云族裔)》50+MOD整合包
载具 RebelCore - 年龄和时间 mod启动器 优化补丁 去除雾气 坦克模型 菜单 前置 跳过启动 更好性能 等 共计50MOD整合 在游戏的世界里,追求更丰富、更优质的体验是玩家们永恒的主题。RebelCore 这款游戏通过精心打造的 50MOD 整合,为玩家带来了前所未有的…...

【技术报告】GPT-4o 原生图像生成的应用与分析
【技术报告】GPT-4o 原生图像生成的应用与分析 1. GPT-4o 原生图像生成简介1.1 文本渲染能力1.2 多轮对话迭代1.3 指令遵循能力1.4 上下文学习能力1.5 跨模态知识调用1.6 逼真画质与多元风格1.7 局限性与安全性 2. GPT-4o 技术报告2.1 引言2.2 安全挑战、评估与缓解措施2.2.1 安…...

拼多多延迟发货解答2
三、延迟发货处理标准 延迟发货极大地影响了消费者的购物体验,平台对延迟发货行为也有相应的处理标准,因此各位商家一定不要以为延迟发货是小事儿。延迟发货处理标准具体可查看《拼多多发货规则》第3条。 商家发生延迟发货的,拼多多平台有权…...

RTOS基础 -- NXP M4小核的RPMsg-lite与端点机制回顾
一、RPMsg-lite与端点机制回顾 在RPMsg协议框架中: Endpoint(端点) 是一个逻辑通信端口,由本地地址(local addr)、远程地址(remote addr)和回调函数组成。每个消息都会发送到特定的…...

25.4.3学习总结【Java】
又是一道错题: 1. 班级活动https://www.lanqiao.cn/problems/17153/learning/?page1&first_category_id1&sortdifficulty&asc1&second_category_id3 问题描述 小明的老师准备组织一次班级活动。班上一共有 n 名 (n 为偶数) 同学,老师…...

市场交易策略优化与波动管理
市场交易策略优化与波动管理 在市场交易中,策略的优化和波动的管理至关重要。市场价格的变化受多种因素影响,交易者需要根据市场环境动态调整策略,以提高交易的稳定性,并有效规避市场风险。 一、市场交易策略的优化方法 趋势交易策…...

TypeScript 元数据操作 API 及示例
TypeScript 元数据操作 API 及示例 1. 配置环境 安装依赖 npm install reflect-metadatatsconfig.json 配置 {"compilerOptions": {"experimentalDecorators": true,"emitDecoratorMetadata": true,"target": "ES6"} }2…...
)
蓝桥杯刷题记录【并查集001】(2024)
主要内容:并查集 并查集 并查集的题目感觉大部分都是模板题,上板子!! class UnionFind:def __init__(self, n):self.pa list(range(n))self.size [1]*n self.cnt ndef find(self, x):if self.pa[x] ! x:self.pa[x] self.fi…...

搜广推校招面经六十六
高德推荐算法 一、介绍Transformer中的位置编码(Positional Encoding) 在 Transformer 结构中,由于模型没有内置的序列信息(不像 RNN 那样有时间步的顺序依赖),需要通过**位置编码(Positional…...

Java高频面试题2:集合框架
一、集合框架概述 1. 常见的集合框架有哪些? Collection:存储单个元素的集合。 List(有序、可重复):ArrayList(动态数组)、LinkedList(双向链表)。Set(无序…...

06-公寓租赁项目-后台管理-公寓管理篇
尚庭公寓项目/公寓管理模块 https://www.yuque.com/pkqzyh/qg2yge/5ba67653b51379d18df61b9c14c3e946 一、属性管理 属性管理页面包含公寓和房间各种可选的属性信息,其中包括房间的可选支付方式、房间的可选租期、房间的配套、公寓的配套等等。其所需接口如下 1.1…...

目前主流OCR/语义理解/ASR
OCR 基于多篇专业评测的结果,以下是目前免费开源OCR工具的推荐排名(侧重中文场景): 1. RapidOCR 优势:基于PaddleOCR优化,在印刷中文、自然场景文字识别中综合评分第一,支持180度旋转和低对比…...

Selenium 元素定位方法详解
Selenium 提供了多种元素定位方式,掌握这些方法是进行 Web 自动化测试的基础。以下是主要的元素定位方法及其使用示例: 1. 基本定位方法 1.1 通过 ID 定位 element driver.find_element(By.ID, "element_id") 1.2 通过 Name 定位 element …...
)
fastGPT—前端开发获取api密钥调用机器人对话接口(HTML实现)
官网文档链接:OpenAPI 介绍 | FastGPT 首先按照文档说明创建api密钥 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-sca…...
)
c语言数据结构--------拓扑排序和逆拓扑排序(Kahn算法和DFS算法实现)
#include <stdio.h> #include <string.h> #include <stdbool.h> #include <stdlib.h>//使用卡恩算法(Kahn)和深度优先算法(DFS)实现//拓扑排序和逆拓扑排序//拓扑排序和逆拓扑排序顶点顺序相反//图,邻接矩阵存储 #define MaxVertexNum 100 …...

日期类的实现
本文运用c类和对象中的构造函数, 析构函数 ,拷贝构造函数 , 赋值运算符重载等为大家模拟实现日期类的操作 #define _CRT_SECURE_NO_WARNINGS 1 #include"date.h" void Date:: showinfo() {cout << _year << "年&…...

3dgs通俗讲解
3d gaussian splatting:基于splatting和机器学习的三维重建方法。 特点: 无深度学习简单的机器学习大量的CG知识复杂的线性代数对GPU的高性能编程 一、什么是splatting 1、选择“雪球”; 为什么使用核(雪球) 各向…...

源码分析之Leaflet比例尺控件Control.Scale实现原理
概述 Control.Scale 是一个用于显示地图比例尺的控件,是 Leaflet 中实现比例尺控件的核心逻辑,用于在地图上动态显示公制(米/千米)和英制(英尺/英里)的比例尺。 源码分析 源码实现 Control.Scale的源码…...

【无标题 langsmith
【GPT入门】第32课 langsmith介绍与实战 1.lang smith作用2.lang smith配置方法3. 上手第一个lang smith3.1 可运行代码3.2 lang smith 官网,个人项目下 1.lang smith作用 LangSmith是由LangChain开发的一个平台,主要用于构建生产级LLM应用程序…...

智能建造新范式:装配式建筑 4.0 的数字化进阶
在全球数字化与可持续发展的浪潮中,建筑业正经历着第四次工业革命的深刻变革。装配式建筑4.0的出现,标志着建筑行业从传统的“钢筋水泥时代”迈向“数据驱动时代”,其核心在于通过技术融合重构建筑全生命周期的生产方式,实现从设计…...
)
从标准输入中读取所有内容sys.stdin.read()
sys.stdin.read().strip() 用于从标准输入中读取所有内容并去除首尾的空白字符。 1. sys.stdin.read() 作用:从标准输入流中读取所有内容,直到遇到文件结束符(EOF)。在命令行中,EOF 可以通过 CtrlD(Linux…...

网络:华为数通HCIA学习:静态路由基础
文章目录 前言静态路由基础静态路由应用场景 静态路由配置静态路由在串行网络的配置静态路由在以太网中的配置 负载分担配置验证 路由备份(浮动静态路由)配置验证 缺省路由配置验证 总结 华为HCIA 基础实验-静态路由 & eNSP静态路由 基础…...

DAY 35 leetcode 202--哈希表.快乐数
题号202 编写一个算法来判断一个数 n 是不是快乐数。 「快乐数」 定义为: 对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 1。如果这个过程 结果为 1&a…...

Linux Command nmap 网络扫描
tags: 网络 文章目录 简介原理端口状态选项基本扫描发现扫描禁用DNS名称解析无ping扫描 端口扫描版本检测防火墙规避技术故障排除和调试NMAP 脚本 简介 Nmap(“ Network Mapper ”)是一个用于网络探索和安全审计的开源工具。它旨在快速扫描大型网络&…...

根据源码分析vue中nextTick的实现原理
根据源码分析vue中nextTick的实现原理 一. 核心变量定义二. 异步策略选择(降级处理)1. 微任务优先2. 降级到 MutationObserver3. 降级到宏任务 三、回调执行逻辑四、 nextTick 函数实现五、 与 Vue 更新流程的结合六、关键设计…...

Linux内核TCP/IP协议栈中的设计模式:从面向对象到系统级软件的跨界实践
引言 设计模式(Design Patterns)自GoF(Gang of Four)在1994年提出以来,已成为软件工程领域的核心概念。尽管其经典定义基于面向对象编程(OOP),但设计模式的本质是解决复杂问题的经验总结,而非局限于特定编程范式。本文以Linux内核的TCP/IP协议栈为例,探讨设计模式在…...

风云可测:华为AI天气大模型将暴雨预测误差缩至3公里内
华为云正式发布全球首个气象专用人工智能大模型"盘古气象",实现台风路径24小时预测误差<30公里、暴雨落区72小时精度91%,较传统数值预报效率提升10000倍。本文基于对西北太平洋10个台风回溯测试、全国2360个气象站验证数据,解析…...

DeepSeek-R1 面试题汇总
Deepseek-r1 面试宝典 原文地址:https://articles.zsxq.com/id_91kirfu15qxw.html DeepSeek-R1 面试题汇总 DeepSeek-R1 面试题汇总 GRPO(Group Relative Policy Optimization)常见面试题汇总篇 DeepSeek-R1 DeepSeek-R1-Zero 常见面试题汇总…...

ASM1042A型CANFD芯片通信可靠性研究
摘要 本文旨在深入探讨ASM1042A型CAN-FD芯片在多节点通信中的可靠性表现。通过对芯片的电气特性、测试环境、多节点通信测试结果等多方面进行分析,结合实验数据与理论研究,全面评估其在复杂通信场景下的性能与可靠性。研究结果表明,ASM1042A…...
)
Java8 到 Java21 系列之 Stream API:数据处理的新方式(Java 8)
Java 8 到 Java 21 系列之 Stream API:数据处理的新方式(Java 8) 系列目录 Java8 到 Java21 系列之 Lambda 表达式:函数式编程的开端(Java 8)Java 8 到 Java 21 系列之 Stream API:数据处理的…...

【每日一个知识点】分布式数据湖与实时计算
在现代数据架构中,分布式数据湖(Distributed Data Lake) 结合 实时计算(Real-time Computing) 已成为大数据处理的核心模式。数据湖用于存储海量的结构化和非结构化数据,而实时计算则确保数据能够被迅速处理…...

接口自动化学习三:参数化parameterize
使用parametrize之前: def add(x,y):return xy class TestAddFunction(object):def test01(self):resadd(2,4)assert 6resdef test02(self):resadd(4,6)assert 10resparametrize参数化之后: import pytest def add(x,y):return xydata[(10,20,30),(200…...

呼叫中心系统压力测试文档
前期准备 用户需要准备两台配置相同的服务器,A服务器和B服务器。我们在这两台服务器上部署相同授权的程序。 配置流程 1. 创建话术 A服务器和B服务器都需要创建压力测试放音的话术,用于放音。按图操作: 2. 线路和线路组配置 A服务器&am…...
——第1章 简单的介绍一下ESP8266和他的编程指令)
从0开始的构建的天气预报小时钟(基于STM32F407ZGT6,ESP8266 + SSD1309)——第1章 简单的介绍一下ESP8266和他的编程指令
目录 ESP8266编程指令前导——三种工作模式 ESP8266编程指令 工作确认指令(用于非穿透模式下) 设置工作模式:ATCWMODEX 两个重要的复位 硬复位ATRESTORE 软复位ATRST 加入Wifi ATCWJAP 开始一次TCP通信 进入和退出穿透模式 进入 ES…...

Cadence Integrity 3D-IC的解密
Early System-Level Analysis and Signoff Flow 请看下期发布...

清晰易懂的 Flutter 开发环境搭建教程
Flutter 是 Google 推出的跨平台应用开发框架,支持 iOS/Android/Web/桌面应用开发。本教程将手把手教你完成 Windows/macOS/Linux 环境下的 Flutter 安装与配置,从零到运行第一个应用,全程避坑指南! 一、安装 Flutter SDK 1. 下载…...
)
NO.63十六届蓝桥杯备战|基础算法-⼆分答案|木材加工|砍树|跳石头(C++)
⼆分答案可以处理⼤部分「最⼤值最⼩」以及「最⼩值最⼤」的问题。如果「解空间」在从⼩到⼤的「变化」过程中,「判断」答案的结果出现「⼆段性」,此时我们就可以「⼆分」这个「解空间」,通过「判断」,找出最优解。 这个「⼆分答案…...

Python星球日记 - 第1天:欢迎来到Python星球
🌟引言: 上一篇:Python星球日记专栏介绍(持续更新ing) 名人说:莫听穿林打叶声,何妨吟啸且徐行。—— 苏轼《定风波莫听穿林打叶声》 创作者:Code_流苏(CSDN)(一个喜欢古诗…...
)
去中心化交易所(DEX)
核心概念与DEX类型 DEX vs CEX 中心化交易所(CEX)风险:资产托管风险(如2019年超2.9亿美元被盗)、隐私泄露(如50万用户信息泄漏)。 DEX优势:用户自持资产(非托管&#x…...

HTTP数据传输的几个关键字Header
本文着重针对http在传输数据时的几种封装方式进行描述。 1. Content-Type(描述body内容类型以及字符编码) HTTP的Content-Type用于定义数据传输的媒体类型(MIME类型),主要分为以下几类: (一)、基础文本类型 text/plain …...

Redis 的 Raft 选举协议
Redis 的 Raft 选举协议 主要用于 Redis Sentinel 和 Redis Cluster 的高可用实现中(尽管 Redis Cluster 默认使用类似 Gossip 的协议,但 Raft 的思想在 Sentinel 的领导者选举中有体现)。以下是关于 Raft 协议在 Redis 中的应用及脑裂问题的详细解析: 一、Redis 中的 Raft…...

sshd启动报错“Failed to start OpenSSH Server daemon”
“systemctl restart sshd”启动sshd服务异常,报错“Failed to start OpenSSH Server daemon”。 使用sshd -t命令检查sshd配置文件,返回关键信息gssapikexalgorithms相关错误。 解决方法 禁用 GSSAPI 相关的 KEX 算法 编辑sshd配置文件,注…...
)
MIT6.828 Lab3-2 Print a page table (easy)
实验内容 实现一个函数来打印页表的内容,帮助我们更好地理解 xv6 的三级页表结构。 修改内容 kernel/defs.h中添加函数声明,方便其它函数调用 void vmprint(pagetable_t);// lab3-2 Print a page tablekernel/vm.c中添加函数具体定义 采用…...

AI本地部署之ragflow
Ubunturagflowdeepseek本地部署目录 一、配置说明1. 软件配置说明2. 硬件配置说明 二、RagFlow安装和部署1. 前置条件2. 安装注:如果发现没有出现这个界面,可以进入ragflow/docker/ragflow-logs这个路径,查看ragflow_server.log文件中的内容&…...

源码分析之Leaflet属性控件Control.Attribution实现原理
概述 Control.Attribution 是一个 Leaflet 地图控件,用于显示地图的版权信息。它可以显示地图提供者的名称和链接,以及地图上的图层的版权信息。 源码分析 源码实现 Control.Attribution的源码实现如下 var ukrainianFlag <svg aria-hidden"…...
)
NO.62十六届蓝桥杯备战|基础算法-二分查找|查找元素的第一个和最后一个位置|牛可乐和魔法封印|A-B数对|烦恼的高考意愿(C++)
⼆分算法是我觉得在基础算法篇章中最难的算法。⼆分算法的原理以及模板其实是很简单的,主要的难点在于问题中的各种各样的细节问题。因此,⼤多数情况下,只是背会⼆分模板并不能解决题⽬,还要去处理各种乱七⼋糟的边界问题 34. 在…...

开源模型应用落地-Qwen2.5-Omni-7B模型-部署 “光速” 指南
一、前言 2025年3月,阿里巴巴通义千问团队开源的全模态大模型Qwen2.5-Omni-7B,犹如一记惊雷划破AI领域的长空。这个仅70亿参数的"小巧巨人",以端到端的架构实现了对文本、图像、音频、视频的全模态感知,更通过创新的Thinker-Talker双核架构,将人类"接收-思…...