Java8 到 Java21 系列之 Stream API:数据处理的新方式(Java 8)
Java 8 到 Java 21 系列之 Stream API:数据处理的新方式(Java 8)
系列目录
- Java8 到 Java21 系列之 Lambda 表达式:函数式编程的开端(Java 8)
- Java 8 到 Java 21 系列之 Stream API:数据处理的新方式(Java 8)
- Java 8 到 Java 21 系列之 Optional 类型:优雅地处理空值(Java 8)
- Java 8 到 Java 21 系列之 新日期时间 API:精确的时间管理(Java 8) 更新中
- Java 8 到 Java 21 系列之 模块化系统:构建模块化的 Java 应用(Java 9) 更新中
- Java 8 到 Java 21 系列之 JShell:即时运行 Java 代码(Java 9) 更新中
- Java 8 到 Java 21 系列之 局部变量类型推断:var 关键字的妙用(Java 10) 更新中
- Java 8 到 Java 21 系列之 HTTP Client API:现代网络通信的基础(Java 11) 更新中
- Java 8 到 Java 21 系列之 ZGC:低延迟垃圾收集器的秘密(Java 11) 更新中
- Java 8 到 Java 21 系列之 Switch 表达式的进化(Java 12) 更新中
- Java 8 到 Java 21 系列之 文本块:轻松管理多行字符串(Java 13) 更新中
- Java 8 到 Java 21 系列之 instanceof 模式匹配:简化类型检查(Java 14) 更新中
- Java 8 到 Java 21 系列之 Records:数据类的全新体验(Java 14) 更新中
- Java 8 到 Java 21 系列之 密封类:限制继承的艺术(Java 15) 更新中
- Java 8 到 Java 21 系列之 外部函数与内存 API:无缝集成本地代码(Java 17) 更新中
- Java 8 到 Java 21 系列之 Sealed Classes 正式登场:增强类型安全性(Java 17) 更新中
- Java 8 到 Java 21 系列之 强封装 JDK 内部 API:保护你的应用程序(Java 17) 更新中
- Java 8 到 Java 21 系列之 增强的伪随机数生成器:更高质量的随机数(Java 17) 更新中
- Java 8 到 Java 21 系列之 虚拟线程:并发编程的新纪元(Java 21) 更新中
- Java 8 到 Java 21 系列之 分代 ZGC 优化:迈向更高性能(Java 21) 更新中
- Java 8 到 Java 21 系列之 序列集合 API:简化集合操作(Java 21) 更新中
摘要与引言
随着Java 8的到来,Stream API作为一项革命性的特性被引入,它为Java开发者提供了一种全新的、声明式的方式来处理集合数据。通过Stream API,我们可以轻松地执行过滤、映射、排序和聚合等操作,同时还能享受到并行处理带来的性能提升。本文将深入探讨Stream API的核心概念、常用操作以及一些实际应用案例,帮助你快速上手这一强大的工具。
Stream API简介
在Java 8中,Stream是一种用于处理元素序列的数据结构抽象,它可以高效地进行各种数据处理任务。Stream不是一种数据存储机制,而是一个从源(如集合、数组)获取数据并进行处理的管道。
Stream的特点
- 惰性求值:中间操作不会立即执行,只有当遇到终端操作时才会触发。
- 不可重复消费:流只能被消费一次,一旦流开始计算,就不能再次使用。
- 支持并行:利用多核处理器的能力,可以轻松实现并行处理。
1 传统方法 vs Stream API
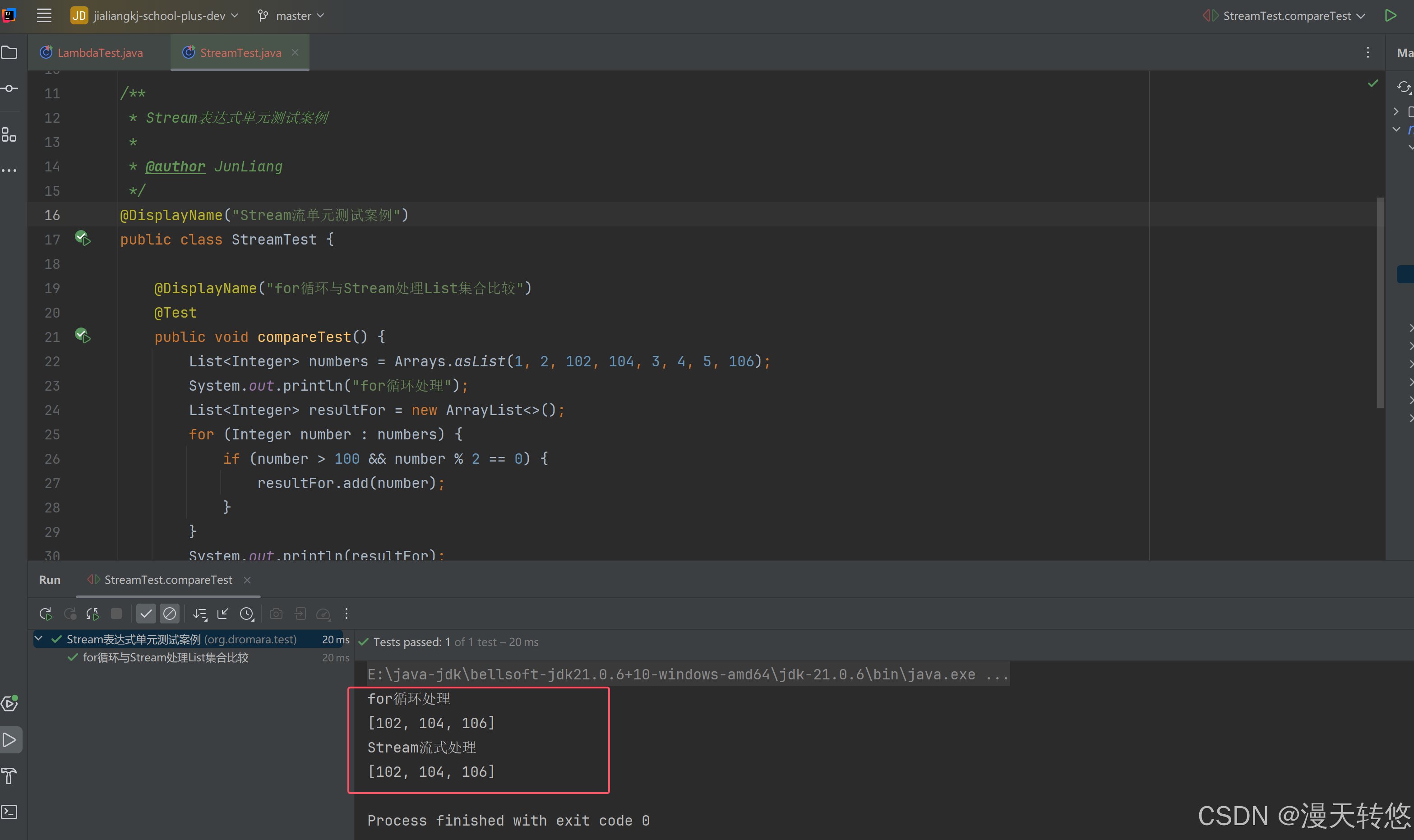
在Java 8之前,对集合的操作通常需要手动编写循环和条件语句,首先附上一个最常用的List集合遍历处理案例。例如,假设我们有一个整数列表,并希望找出其中所有大于100的偶数:
分别使用for循环与Stream流对List集合进行遍历
/*** Stream表达式单元测试案例** @author JunLiang*/
@DisplayName("Stream流单元测试案例")
public class StreamTest {@DisplayName("for循环与Stream处理List集合比较")@Testpublic void compareTest() {List<Integer> numbers = Arrays.asList(1, 2, 102, 104, 3, 4, 5, 106);System.out.println("for循环处理");List<Integer> resultFor = new ArrayList<>();for (Integer number : numbers) {if (number > 100 && number % 2 == 0) {resultFor.add(number);}}System.out.println(resultFor);System.out.println("Stream流式处理");List<Integer> resultStream = numbers.stream().filter(n -> n > 100).filter(n -> n % 2 == 0).collect(Collectors.toList());System.out.println(resultStream);}
}
处理显示结果一致
传统方法
List<Integer> numbers = Arrays.asList(1, 2, 102, 104, 3, 4, 5, 106);
List<Integer> result = new ArrayList<>();
for (Integer number : numbers) {if (number > 100 && number % 2 == 0) {result.add(number);}
}
Stream API 方法
List<Integer> numbers = Arrays.asList(1, 2, 102, 104, 3, 4, 5, 106);
List<Integer> result = numbers.stream().filter(n -> n > 100).filter(n -> n % 2 == 0).collect(Collectors.toList());
从上述例子可以看出,使用Stream API可以使代码更加简洁和易读。
2 顺序流和并行流
好了,现在我们大概知道Stream流式处理是什么了,在这其中还有分为顺序流和并行流,下面将进行逐一解释。
2.1 Java 8中的顺序流和并行流介绍
顺序流(Sequential Stream)
在Java 8中,顺序流是指按照元素在源集合中的出现顺序逐一处理每个元素的流。顺序流的操作是在单个线程上按顺序执行的,这意味着每一个操作都必须等待前一个操作完成后才能开始。顺序流非常适合那些不需要考虑并发性的小规模数据集或需要保持处理顺序的情况。
示例代码:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
numbers.stream() // 创建顺序流.filter(n -> n % 2 == 0) // 过滤偶数.map(n -> n * 2) // 将每个数字乘以2.forEach(System.out::println); // 输出结果
并行流(Parallel Stream)
并行流则是利用多线程技术同时处理多个元素的流。通过将任务分解为多个子任务并在多个线程上并行执行,可以显著提高处理速度,尤其是在多核处理器上。并行流适合于大规模数据集或者CPU密集型任务。
示例代码:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
numbers.parallelStream() // 创建并行流.filter(n -> n % 2 == 0).map(n -> n * 2).forEach(System.out::println);
2.2 原理解析
2.2.1 顺序流原理
顺序流内部使用了链表结构来组织中间操作(如filter, map等),这些操作形成一个链条。当触发终端操作(如forEach, collect等)时,会从头到尾遍历这个链条,对每个元素依次应用所有的中间操作。
2.2.2 并行流原理
并行流基于Fork/Join框架实现。当你创建一个并行流时,实际上是在创建一系列可以在多个线程上并行执行的任务。这些任务被分配给不同的线程,然后由各个线程独立执行。完成之后,结果会被合并起来,形成最终的结果。并行流还采用了工作窃取算法(work-stealing),即空闲线程可以从其他忙碌线程的任务队列尾部“偷取”任务来执行,从而提高了资源利用率。
2.3 性能对比
下面是一个简化的性能对比表格,展示了不同大小的数据集上顺序流和并行流的处理时间(以毫秒为单位)。请注意,实际性能可能会根据硬件配置、JVM版本等因素有所不同。
| 数据集大小 | 顺序流处理时间(ms) | 并行流处理时间(ms) |
|---|---|---|
| 1,000 | 5 | 3 |
| 10,000 | 50 | 15 |
| 100,000 | 500 | 70 |
| 1,000,000 | 5,000 | 500 |
2.4 在实际项目开发中的选择
在实际项目开发中选择顺序流还是并行流应考虑以下几个因素:
-
数据量大小:对于小数据集,顺序流通常更高效,因为启动并行流带来的额外开销可能超过性能提升。对于大数据集,并行流能显著减少处理时间。
-
任务类型:如果任务是CPU密集型且各任务间相互独立,那么并行流可能提供更好的性能。如果是I/O密集型任务,顺序流可能更为合适。
-
线程安全:尽管并行流自身是线程安全的,在涉及共享可变状态时仍需注意同步问题。
-
性能测试:在决定采用哪种方式之前,应该进行性能测试,确保所选方式确实带来预期的性能增益。
例如,如果你正在处理一个包含数百万条记录的大文件,那么并行流可能是加速处理过程的好选择;然而,如果你的工作负载主要是网络请求或者数据库查询等I/O受限的任务,那么顺序流可能更适合,因为它不需要额外的线程管理开销。此外,对于那些依赖于元素处理顺序的应用场景,也需要特别注意,因为并行流并不保证处理顺序。在这种情况下,可能需要使用forEachOrdered()方法来确保顺序输出,但这可能会牺牲一些性能优势。
3 Stream流常见用法
Java 8 中的 Stream API 提供了丰富的操作集合数据的方法,可以极大地简化代码并提高开发效率。以下是一些常用的 Stream 流用法及示例代码,并简要介绍了它们在实际项目中的使用场景。
3.1 创建流
3.1.1 从集合创建流
List<String> list = Arrays.asList("apple", "banana", "cherry");
Stream<String> streamFromList = list.stream();
3.1.2 从数组创建流
String[] array = {"apple", "banana", "cherry"};
Stream<String> streamFromArray = Arrays.stream(array);
3.1.3 使用 Stream.builder创建流
Stream<String> streamFromBuilder = Stream.<String>builder().add("apple").add("banana").build();
3.1.4 无限流
// 使用 generate 创建无限流
Stream<Integer> infiniteStream = Stream.generate(() -> 1).limit(10); // 生成10个1// 使用 iterate 创建无限流
Stream<Integer> infiniteNumberStream = Stream.iterate(0, n -> n + 2).limit(10); // 生成0到18的偶数
使用场景:当你需要处理列表、集或其他实现了Collection接口的集合时,这是最常用的方式。
3.2 中间操作
3.2.1 过滤(filter)
stream.filter(s -> s.startsWith("a")); // 筛选出以'a'开头的字符串
使用场景:用于筛选出符合条件的数据,如过滤掉无效用户或不符合条件的商品等。
3.2.2 映射(map)
stream.map(String::toUpperCase); // 将所有字符串转换为大写
使用场景:将一种类型的对象转换为另一种类型,例如将用户的ID映射到完整的User对象。
3.2.3 扁平化映射(flatMap)
List<List<Integer>> listOfLists = Arrays.asList(Arrays.asList(1, 2), Arrays.asList(3, 4));
listOfLists.stream().flatMap(Collection::stream).forEach(System.out::println); // 输出: 1 2 3 4
使用场景:当你的数据结构是嵌套的集合时,使用flatMap来扁平化处理。
3.2.4 去重(distinct)
stream.distinct(); // 去除重复元素
使用场景:移除集合中的重复项,比如获取唯一用户ID列表。
3.2.5 排序(sorted)
stream.sorted(); // 自然排序
stream.sorted((s1, s2) -> s2.compareTo(s1)); // 定制排序
使用场景:对数据进行排序,例如按价格降序排列商品列表。
3.3 终端操作
3.3.1 遍历(forEach)
stream.forEach(System.out::println); // 对每个元素执行动作
使用场景:打印输出或者对每个元素执行某些操作。
3.3.2 收集结果(collect)
List<String> result = stream.collect(Collectors.toList()); // 转换为列表
Set<String> resultSet = stream.collect(Collectors.toSet()); // 转换为集合
Map<String, Integer> resultMap = stream.collect(Collectors.toMap(Function.identity(), String::length)); // 转换为映射
使用场景:将流中的元素收集到集合中,如构建报告时汇总数据。
3.3.3 统计(count, min, max)
long count = stream.count(); // 统计元素数量
Optional<String> min = stream.min(String::compareTo); // 获取最小值
Optional<String> max = stream.max(String::compareTo); // 获取最大值
使用场景:统计分析数据,如计算销售额总和或找出最高/最低价格。
3.3.4 归约(reduce)
Optional<String> reduced = stream.reduce((s1, s2) -> s1 + "," + s2); // 字符串连接
int sum = IntStream.range(1, 5).reduce(0, (a, b) -> a + b); // 数字求和
使用场景:对流中的元素进行累积运算,如计算购物车中商品总价。
3.3.5 匹配(anyMatch, allMatch, noneMatch)
boolean anyMatch = stream.anyMatch(s -> s.contains("a")); // 是否有任何一个元素包含'a'
boolean allMatch = stream.allMatch(s -> s.length() == 1); // 是否所有元素长度都是1
boolean noneMatch = stream.noneMatch(s -> s.isEmpty()); // 是否没有空字符串
使用场景:验证数据是否符合特定条件,如检查是否有未完成的任务。
3.3.6 Map集合的操作
3.3.6.1 将Map的值转换为新格式
Map<String, Integer> scores = new HashMap<>();
scores.put("Alice", 85);
scores.put("Bob", 90);Map<String, Integer> updatedScores = scores.entrySet().stream().collect(Collectors.toMap(Map.Entry::getKey,entry -> entry.getValue() + 10));
3.3.6.2 根据值排序Map
Map<String, Integer> sortedByValue = scores.entrySet().stream().sorted(Map.Entry.<String, Integer>comparingByValue().reversed()).collect(Collectors.toMap(Map.Entry::getKey,Map.Entry::getValue,(e1, e2) -> e1,LinkedHashMap::new));
3.3.7 分组(Collectors.groupingBy)
分组操作允许根据特定条件对元素进行分组。
Map<Integer, List<String>> groupByLength = Stream.of("a", "bb", "ccc", "dddd").collect(Collectors.groupingBy(String::length)); // 按字符串长度分组
3.3.8 分区(Collectors.partitioningBy)
分区是分组的一个特例,它根据布尔表达式的结果将元素分为两组。
Map<Boolean, List<String>> partitionedByLength = Stream.of("a", "bb", "ccc", "dddd").collect(Collectors.partitioningBy(s -> s.length() > 2)); // 根据长度是否大于2进行分区
3.3.9 自定义Collector
有时候内置的Collector不能满足需求,可以通过Collector.of()创建自定义的Collector。
Collector<Person, ?, Map<String, List<Person>>> personByCity = Collector.of(HashMap::new,(map, person) -> map.computeIfAbsent(person.getCity(), k -> new ArrayList<>()).add(person),(map1, map2) -> {map2.forEach((city, persons) -> map1.merge(city, persons, (existing, toAdd) -> {existing.addAll(toAdd);return existing;}));return map1;}
);
3.4 注意事项
- 惰性求值:Stream的中间操作不会立即执行,只有在终端操作时才会触发计算。
- 短路操作:像
findFirst这样的短路操作可以在找到所需元素后立即停止遍历,节省资源。 - 避免不必要的对象创建:在循环中创建新的对象可能会导致性能下降,尽量复用对象或使用原始类型流(如
IntStream)。
这些只是Stream API的一部分功能,它还包括更多复杂的操作,如分组、分区等。在实际项目中,Stream API可以用于任何需要高效地处理大量数据的情况,尤其是在处理集合时,能够显著减少样板代码的数量,同时提高了代码的可读性和维护性。例如,在电子商务系统中,可以使用Stream API来过滤产品列表,根据用户偏好推荐商品;在金融系统中,可以用它来处理交易记录,进行数据分析等。
总结
通过以上文章内容,你应该可以大概了解和掌握Stream流的基本概念和用法。
相关文章:
)
Java8 到 Java21 系列之 Stream API:数据处理的新方式(Java 8)
Java 8 到 Java 21 系列之 Stream API:数据处理的新方式(Java 8) 系列目录 Java8 到 Java21 系列之 Lambda 表达式:函数式编程的开端(Java 8)Java 8 到 Java 21 系列之 Stream API:数据处理的…...

【每日一个知识点】分布式数据湖与实时计算
在现代数据架构中,分布式数据湖(Distributed Data Lake) 结合 实时计算(Real-time Computing) 已成为大数据处理的核心模式。数据湖用于存储海量的结构化和非结构化数据,而实时计算则确保数据能够被迅速处理…...

接口自动化学习三:参数化parameterize
使用parametrize之前: def add(x,y):return xy class TestAddFunction(object):def test01(self):resadd(2,4)assert 6resdef test02(self):resadd(4,6)assert 10resparametrize参数化之后: import pytest def add(x,y):return xydata[(10,20,30),(200…...

呼叫中心系统压力测试文档
前期准备 用户需要准备两台配置相同的服务器,A服务器和B服务器。我们在这两台服务器上部署相同授权的程序。 配置流程 1. 创建话术 A服务器和B服务器都需要创建压力测试放音的话术,用于放音。按图操作: 2. 线路和线路组配置 A服务器&am…...
——第1章 简单的介绍一下ESP8266和他的编程指令)
从0开始的构建的天气预报小时钟(基于STM32F407ZGT6,ESP8266 + SSD1309)——第1章 简单的介绍一下ESP8266和他的编程指令
目录 ESP8266编程指令前导——三种工作模式 ESP8266编程指令 工作确认指令(用于非穿透模式下) 设置工作模式:ATCWMODEX 两个重要的复位 硬复位ATRESTORE 软复位ATRST 加入Wifi ATCWJAP 开始一次TCP通信 进入和退出穿透模式 进入 ES…...

Cadence Integrity 3D-IC的解密
Early System-Level Analysis and Signoff Flow 请看下期发布...

清晰易懂的 Flutter 开发环境搭建教程
Flutter 是 Google 推出的跨平台应用开发框架,支持 iOS/Android/Web/桌面应用开发。本教程将手把手教你完成 Windows/macOS/Linux 环境下的 Flutter 安装与配置,从零到运行第一个应用,全程避坑指南! 一、安装 Flutter SDK 1. 下载…...
)
NO.63十六届蓝桥杯备战|基础算法-⼆分答案|木材加工|砍树|跳石头(C++)
⼆分答案可以处理⼤部分「最⼤值最⼩」以及「最⼩值最⼤」的问题。如果「解空间」在从⼩到⼤的「变化」过程中,「判断」答案的结果出现「⼆段性」,此时我们就可以「⼆分」这个「解空间」,通过「判断」,找出最优解。 这个「⼆分答案…...

Python星球日记 - 第1天:欢迎来到Python星球
🌟引言: 上一篇:Python星球日记专栏介绍(持续更新ing) 名人说:莫听穿林打叶声,何妨吟啸且徐行。—— 苏轼《定风波莫听穿林打叶声》 创作者:Code_流苏(CSDN)(一个喜欢古诗…...
)
去中心化交易所(DEX)
核心概念与DEX类型 DEX vs CEX 中心化交易所(CEX)风险:资产托管风险(如2019年超2.9亿美元被盗)、隐私泄露(如50万用户信息泄漏)。 DEX优势:用户自持资产(非托管&#x…...

HTTP数据传输的几个关键字Header
本文着重针对http在传输数据时的几种封装方式进行描述。 1. Content-Type(描述body内容类型以及字符编码) HTTP的Content-Type用于定义数据传输的媒体类型(MIME类型),主要分为以下几类: (一)、基础文本类型 text/plain …...

Redis 的 Raft 选举协议
Redis 的 Raft 选举协议 主要用于 Redis Sentinel 和 Redis Cluster 的高可用实现中(尽管 Redis Cluster 默认使用类似 Gossip 的协议,但 Raft 的思想在 Sentinel 的领导者选举中有体现)。以下是关于 Raft 协议在 Redis 中的应用及脑裂问题的详细解析: 一、Redis 中的 Raft…...

sshd启动报错“Failed to start OpenSSH Server daemon”
“systemctl restart sshd”启动sshd服务异常,报错“Failed to start OpenSSH Server daemon”。 使用sshd -t命令检查sshd配置文件,返回关键信息gssapikexalgorithms相关错误。 解决方法 禁用 GSSAPI 相关的 KEX 算法 编辑sshd配置文件,注…...
)
MIT6.828 Lab3-2 Print a page table (easy)
实验内容 实现一个函数来打印页表的内容,帮助我们更好地理解 xv6 的三级页表结构。 修改内容 kernel/defs.h中添加函数声明,方便其它函数调用 void vmprint(pagetable_t);// lab3-2 Print a page tablekernel/vm.c中添加函数具体定义 采用…...

AI本地部署之ragflow
Ubunturagflowdeepseek本地部署目录 一、配置说明1. 软件配置说明2. 硬件配置说明 二、RagFlow安装和部署1. 前置条件2. 安装注:如果发现没有出现这个界面,可以进入ragflow/docker/ragflow-logs这个路径,查看ragflow_server.log文件中的内容&…...

源码分析之Leaflet属性控件Control.Attribution实现原理
概述 Control.Attribution 是一个 Leaflet 地图控件,用于显示地图的版权信息。它可以显示地图提供者的名称和链接,以及地图上的图层的版权信息。 源码分析 源码实现 Control.Attribution的源码实现如下 var ukrainianFlag <svg aria-hidden"…...
)
NO.62十六届蓝桥杯备战|基础算法-二分查找|查找元素的第一个和最后一个位置|牛可乐和魔法封印|A-B数对|烦恼的高考意愿(C++)
⼆分算法是我觉得在基础算法篇章中最难的算法。⼆分算法的原理以及模板其实是很简单的,主要的难点在于问题中的各种各样的细节问题。因此,⼤多数情况下,只是背会⼆分模板并不能解决题⽬,还要去处理各种乱七⼋糟的边界问题 34. 在…...

开源模型应用落地-Qwen2.5-Omni-7B模型-部署 “光速” 指南
一、前言 2025年3月,阿里巴巴通义千问团队开源的全模态大模型Qwen2.5-Omni-7B,犹如一记惊雷划破AI领域的长空。这个仅70亿参数的"小巧巨人",以端到端的架构实现了对文本、图像、音频、视频的全模态感知,更通过创新的Thinker-Talker双核架构,将人类"接收-思…...

顺序容器 -forward list单链表
forward list单链表是C11加入到STL的。 使用forward list,必须包含头文件<forward_list> #include <forward_list> 这个头文件被定义在命名空间std内。 namespace std {template <typename T,typename Allocator allocator<T> >class …...

C++:算术运算符
程序员Amin 🙈作者简介:练习时长两年半,全栈up主 🙉个人主页:程序员Amin 🙊 P S : 点赞是免费的,却可以让写博客的作者开心好久好久😎 📚系列专栏:Java全…...

缺页异常导致的iowait打印出相关文件的绝对路径
一、背景 在之前的博客 增加等IO状态的唤醒堆栈打印及缺页异常导致iowait分析-CSDN博客 里,我们进一步优化了D状态和等IO状态的事件的堆栈打印,补充了唤醒堆栈打印,也分析了一种比较典型的缺页异常filemap_fault导致的iowait的情况。 在这篇…...

【Centos】centos7内核升级-亲测有效
相关资源 通过网盘分享的文件:脚本升级 链接: https://pan.baidu.com/s/1yrCnflT-xWhAPVQRx8_YUg?pwd52xy 提取码: 52xy –来自百度网盘超级会员v5的分享 使用教程 将脚本文件上传到服务器的一个目录 执行更新命令 yum install -y linux-firmware执行脚本即可 …...

多模态模型:专栏概要与内容目录
文章目录 多模态模型📚 核心内容模块Stable Diffusion基础教程Stable Diffusion原理深度解析部署与环境配置其他多模态模型实践 多模态模型 🔥 专栏简介 | 解锁AI绘画与多模态模型的技术奥秘 探索多模态AI技术,掌握Stable Diffusion等流行框…...

1. 购物车
1. 购物车 咱们购物车基于 V2 装饰器进行开发,底气来源于 自定义组件混用场景指导 1.1. 素材整合 observedv2和Trace 数据模型和页面 // 其他略 // 购物车 export interface CartGoods {count: number;id: string;name: string;picture: string;price: number;…...
)
frp 让服务器远程调用本地的服务(比如你的java 8080项目)
1、服务器上安装frp 2、本地安装frp 服务器上 frps.toml 配置信息: bindPort 30000auth.token "密码" # 客户端连接密码vhostHTTPPort 8082 本地 frpc.toml serverAddr "服务器ip" serverPort 30000 auth.token "服务器上设置的…...

《AI大模型应知应会100篇》第56篇:LangChain快速入门与应用示例
第56篇:LangChain快速入门与应用示例 前言 最近最火的肯定非Manus和OpenManus莫属,因为与传统AI工具仅提供信息不同,Manus能完成端到端的任务闭环。例如用户发送“筛选本月抖音爆款视频”,它会自动完成: 爬取平台数据…...

大模型——如何在本地部署微软的OmniParser V2
微软的 OmniParser V2 是一款尖端的人工智能屏幕解析器,可通过分析屏幕截图从图形用户界面中提取结构化数据,使人工智能代理能够与屏幕元素进行无缝交互。该工具是构建自主图形用户界面代理的完美选择,它改变了自动化和工作流程优化的游戏规则。在本指南中,我们将介绍如何在…...
:DML触发器)
Oracle触发器使用(一):DML触发器
Oracle触发器使用(一):DML触发器 DML触发器条件谓词触发器INSTEAD OF DML触发器复合DML触发器Oracle数据库中的触发器(Trigger)本质上也是PL/SQL代码,触发器可以被Enable或者Disable,但是不能像存储过程那样被直接调用执行。 触发器不能独立存在,而是定义在表、视图、…...

智慧园区大屏如何实现全局监测:监测意义、内容、方式
智慧园区的价值不容小觑呀,可以说园区的大部分数据都在这个大屏上,监测数据越多,那么大屏的价值就越大。很多小伙伴拿到需求后感觉无从下手,本文在这里智慧园区大屏可以监测哪些内容、监测的意义、监测的方式等,欢迎点…...
)
LeetCode 解题思路 31(Hot 100)
解题思路: 递归参数: 字符串 s、结果集 result、当前路径 path、回文子串数组 dp、开始位置 start。递归过程: 当当前路径 path 的长度等于 s.length() 时,说明已经分割完成,加入结果集。若当前起止位置满足回文条件…...

fastAPI详细介绍以及使用方法
FastAPI是一个现代的Python web框架,它提供快速构建API的能力。它具有高性能、易用性和文档自动生成的特点,使得开发者能够快速开发高效的API服务。 以下是一些FastAPI的主要特点和优势: 快速:FastAPI基于Python 3.6的异步框架St…...

数字人训练数据修正和查看 不需要GPU也能运行的DH_live-加载自己训练-
自己训练模pth报错 le "D:\ai\dh_live\app.py", line 42, in demo_mini interface_mini(asset_path, wav_path, output_video_name) File "D:\ai\dh_live\demo_mini.py", line 21, in interface_mini renderModel_mini.loadModel("checkpoi…...
)
WGAN-GP 原理及实现(pytorch版)
WGAN-GP 原理及实现 一、WGAN-GP 原理1.1 WGAN-GP 核心原理1.2 WGAN-GP 实现步骤1.3 总结二、WGAN-GP 实现2.1 导包2.2 数据加载和处理2.3 构建生成器2.4 构建判别器2.5 训练和保存模型2.6 图片转GIF一、WGAN-GP 原理 Wasserstein GAN with Gradient Penalty (WGAN-GP) 是对原…...

chromium魔改——navigator.webdriver 检测
chromium源码官网 https://source.chromium.org/chromium/chromium/src 说下修改的chromium源码思路: 首先在修改源码过检测之前,我们要知道它是怎么检测的,找到他通过哪个JS的API来做的检测,只有知道了如何检测,我们…...

Sentinel[超详细讲解]-7 -之 -熔断降级[异常比例阈值]
📖 主要讲解熔断降级之 --- 异常比例阈值 🚀 1️⃣ 背景 Sentinel 以流量作为切入点,提供了很多的丰富的功能,例如🤗: 流量控制,熔断降级等,它能够有效的适用各个复杂的业务场景&am…...
:S2S对接与第三方广告监测全解析)
程序化广告行业(56/89):S2S对接与第三方广告监测全解析
程序化广告行业(56/89):S2S对接与第三方广告监测全解析 大家好!在前面的博客中,我们一起深入学习了程序化广告的人群标签、用户标签生成、Look Alike原理,以及DMP与DSP对接和数据统计原理等内容。今天&…...

C++进阶知识复习 31~38
目的 写这一系列文章的目的主要是为了秋招时候应对计算机基础问题能够流畅的回答出来 (如果不整理下 磕磕绊绊的回答会被认为是不熟悉) 本文章题目的主要来源来自于 面试鸭 部分面试鸭上没有而牛客网上有的博主会进行查缺补漏 题目编号按照面试鸭官网…...

Spring Boot 整合mybatis
2025/4/3 向全栈工程师迈进!!! 配置文件在实际开发中如何使用呢,接下去将通过Spring Boot整合mybatis来看配置文件如何在实际开发中被使用。 一、引入mybatis起步依赖 在pom.xml中引入mybatis的起步依赖,如下。 在这…...

新能源汽车测试中的信号调理模块:从原理到实战应用
摘要 信号调理模块(Signal Conditioning Module, SCM)是新能源汽车(NEV)测试系统中的关键环节,直接影响数据采集的精度与可靠性。本文面向HIL测试工程师、电机测试工程师及整车动力经济性测试工程师,系统性…...

一篇关于Netty相关的梳理总结
一篇关于Netty的梳理总结 一、Netty1.1 什么是netty?为什么要用netty1.2 Netty是什么? 二、Netty关于网络基础2.1 线程池2.2 线程池线程的生命周期和状态2.3 为什么要使用线程池2.4 简述线程池原理,FixedThreadPool用的阻塞队列是什么2.5 并发…...

纺织车间数字化转型:降本增效新路径
在纺织行业竞争日益激烈的当下,如何提升生产效率、降低成本成为企业关注的焦点。某纺织车间通过创新引入明达技术MBox20网关并部署IOT 平台,成功接入千台设备,实现了生产模式的重大变革。 以往,纺织车间生产犹如黑箱,…...

递归典例---汉诺塔
https://ybt.ssoier.cn/problem_show.php?pid1205 #include<bits/stdc.h> #define endl \n #define pii pair<int,int>using namespace std; using ll long long;void move(int n,char a,char b,char c) // n 个盘子,通过 b,从 a 移动到 …...

Unity2D:从零开始制作一款跑酷游戏!
目录 成品展示 美术资源 制作步骤 场景预布设: 实现人物基础功能: 移动背景——横向卷轴: 生成障碍物: 生成敌人与攻击逻辑: UI制作与重新开始: 导出游戏: 小结 大家小时候都玩过《…...

维拉工时自定义字段:赋能项目数据的深度洞察 | 上新预告
原文链接:维拉工时自定义字段:赋能项目数据的深度洞察 | 上新预告 在项目管理实践中,每个企业都有独特的数据统计与分析需求。为了帮助用户实现个性化数据建模,从而更精准地衡量项目进度和预算投入,维拉工时全新升级的…...
)
C++ | 文件读写(ofstream/ifstream/fstream)
一、C文件操作核心类 C标准库通过<fstream>提供了强大的文件操作支持,主要包含三个关键类: 类名描述典型用途ofstream输出文件流(Output File Stream)文件写入操作ifstream输入文件流(Input File Stream&#…...

flux文生图部署笔记
目录 依赖库: 文生图推理代码cpu: cuda版推理: 依赖库: tensorrt安装: pip install nvidia-pyindex # 添加NVIDIA仓库索引 pip install tensorrt 文生图推理代码cpu: import torch from diffusers import FluxPipelinemodel_id = "black-forest-labs/FLUX.1-s…...
如何学习英语)
二语习得理论(Second Language Acquisition, SLA)如何学习英语
二语习得理论(Second Language Acquisition, SLA)是研究学习者如何在成人或青少年阶段学习第二语言(L2)的理论框架。该理论主要关注语言习得过程中的认知、社会和文化因素,解释了学习者如何从初学者逐渐变得流利并能够…...

策略模式实际用处,改吧改吧直接用,两种方式
controller RestController RequestMapping("admin/test") RequiredArgsConstructor(onConstructor __(Autowired)) public class TestController {Autowiredprivate VideoFactory VideoFactory;GetMapping("getList")public R getList(){// 第一种方式T…...

计算机网络-TCP的流量控制
内容来源:小林coding 本文是对小林coding的TPC流量控制的精简总结 什么是流量控制 发送方不能无脑的发数据给接收方,要考虑接收方处理能力 如果一直无脑的发数据给对方,但对方处理不过来,那么就会导致触发重发机制 从而导致网…...

搬砖--贪心+排序的背包
a在上面b在下面->a.v-M-b.m>b.v-M-a.m->剩余率大 所以我先遍历a,让a在上面 这就是要考虑贪心排序的01背包 因为它有放的限制条件 #include<bits/stdc.h> using namespace std; #define N 100011 typedef long long ll; typedef pair<ll,int>…...